Terobosan Hebat DeepSeek
- Yang akan kita pelajari pada bab ini:
- 3.1 MLA: Mendapatkan yang Terbaik dari Keduanya
- 3.2 Arsitektur MLA: Panduan Visual Langkah demi Langkah
- 3.3 Keajaiban Matematika: Bagaimana Matriks Laten Membantu
- 3.4 Putaran Cara Kerja Baru dengan MLA
- 3.5 Menghitung Keuntungannya: Rumus KV Cache yang Baru
- 3.6 Membangun Modul MLA dari Awal
- 3.7 Evolusi Pengenalan Posisi Kata: Dari Angka Utuh menuju RoPE
- 3.8 Teknologi Puncak Masa Kini: Rotary Positional Encoding (RoPE)
- 3.9 Masalah Ketidakcocokan: Mengapa MLA dan RoPE Standar Tidak Bisa Bekerja Sama
- 3.10 Solusi DeepSeek: Memisahkan Posisi RoPE (Decoupled RoPE)
- 3.11 Menerobos Batasan Baru (Model V3.2): DeepSeek Sparse Attention (DSA)
- 3.12 Menuju 1 Juta Kata (Model V4): Arsitektur Hybrid Attention (Perhatian Campuran)
- 3.13 Ringkasan
Bab 3: Terobosan Hebat DeepSeek: Dari MLA hingga Perhatian Renggang (Sparse Attention) yang Super Efisien
Yang akan kita pelajari pada bab ini:
- Cara memampatkan (mengompres) Memori Komputer (KV Cache) menggunakan teknologi Multi-Head Latent Attention (MLA).
- Cara menyuntikkan kesadaran letak kata menggunakan teknologi Rotary Positional Encoding (RoPE).
- Cara menggabungkan MLA dan RoPE dengan arsitektur yang dipisah (Decoupled).
- (Baru) Memperluas kemampuan membaca hingga 128.000 kata dengan DeepSeek Sparse Attention (DSA).
- (Baru) Mencapai batas membaca hingga 1 Juta kata melalui Hybrid Attention (Perhatian Campuran) milik model V4.
Pada bab sebelumnya, kita telah menyelesaikan Tahap 1 dari perjalanan kita dengan membangun fondasi yang kuat tentang cara kerja AI agar hemat tenaga komputer. Kita mulai dengan masalah perhitungan yang selalu diulang-ulang, yang kemudian kita selesaikan menggunakan KV Cache (Memori Penyimpanan Sementara). Namun, kita kemudian menemukan sisi gelap dari KV Cache: memori ini memakan kapasitas yang sangat besar. Kita telah melihat solusi generasi pertama, yaitu Multi-Query Attention (MQA) dan Grouped-Query Attention (GQA). Sayangnya, solusi ini memaksa kita melakukan pengorbanan yang menyakitkan: memori memang jadi hemat, tapi kecerdasan AI menurun. Hal ini menyisakan masalah besar antara kecepatan komputer dan kecerdasan AI yang belum terselesaikan.
Gambar 3.1 Perjalanan empat tahap kita untuk membangun model DeepSeek. Setelah menyelesaikan Fondasi Key-Value Cache (Tahap 1), kita sekarang memulai Tahap 2. Bab ini berfokus pada komponen yang disorot: Multi-Head Latent Attention (MLA), Decoupled RoPE, dan Sparse Attention tingkat lanjut.
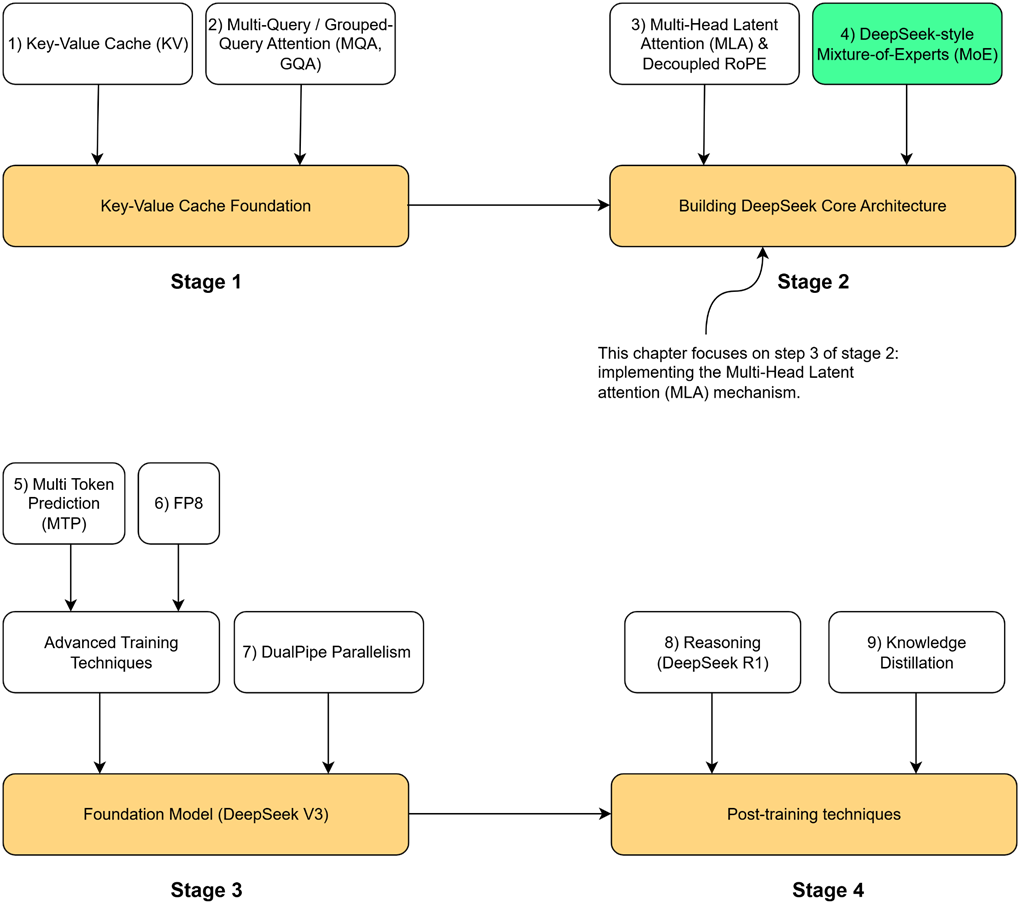
Seperti yang terlihat pada peta jalan kita (Gambar 3.1), bangunan arsitektur utama pertama yang akan kita buat adalah Multi-Head Latent Attention (MLA). Ini adalah inovasi inti yang diciptakan oleh model DeepSeek-V2 untuk menghancurkan batasan antara kecerdasan tinggi dan memori komputer yang terbatas. Akan tetapi, memecahkan masalah memori hanyalah separuh jalan. Agar bisa benar-benar memahami bahasa, model AI kita juga harus tahu di mana posisi sebuah kata berada di dalam kalimat. Kita akan memberikan kemampuan ini menggunakan teknologi paling canggih bernama Rotary Positional Encoding (RoPE).
Hal ini membawa kita pada tantangan utama: teknologi RoPE standar ternyata secara rumus matematika tidak bisa digabungkan dengan sistem kompresi memori milik MLA. Untuk mengatasi bentrokan ini, kita akan membangun sebuah blok utuh dari nol yang menerapkan arsitektur Decoupled RoPE (RoPE yang dipisah jalurnya) milik DeepSeek.
Terakhir, kita akan menjelajahi batas kemampuan tertinggi. Meskipun MLA sangat efisien, memperluas kemampuan AI untuk membaca 128.000 kata bahkan 1 Juta kata sekaligus membutuhkan teknologi yang lebih dari sekadar sistem perhatian (attention) biasa. Kita akan menutup bab ini dengan menjelajahi terobosan DeepSeek-V3.2 dan V4: DeepSeek Sparse Attention (DSA) dan Hybrid Attention (Perhatian Campuran), membuktikan bagaimana DeepSeek mempertahankan efisiensi yang luar biasa pada ukuran yang sangat raksasa.
3.1 MLA: Mendapatkan yang Terbaik dari Keduanya
Sebelum inovasi DeepSeek muncul, para insinyur komputer harus memilih satu dari dua pilihan yang sulit: di satu sisi ada sistem MHA yang sangat cerdas tetapi membuat memori komputer mati kutu; di sisi lain ada MQA yang hemat memori tetapi kecerdasannya menurun.
Tim DeepSeek menanyakan sebuah pertanyaan yang sangat mendalam: Bisakah kita menghancurkan aturan pengorbanan ini?
Apakah mungkin merancang sebuah mekanisme perhatian (attention) yang bisa memberikan:
- Ukuran Memori yang Kecil: Menghemat memori seukuran MQA atau GQA yang sangat irit.
- Kecerdasan Tinggi: Memiliki kekuatan penuh seperti MHA, di mana setiap “kepala” AI memiliki sudut pandang yang unik dan ahli.
Pada pandangan pertama, ini terdengar mustahil. Bagaimana mungkin kita memiliki isi ingatan (Key dan Value) yang berbeda-beda untuk setiap kepala AI, tanpa harus menyimpan semuanya di dalam memori?
Jawabannya terletak pada sebuah trik matematika yang indah. Inovasi inti dari MLA mengubah fokus kita dari mengurangi jumlah kepala AI, menjadi memampatkan (mengompres) informasi di dalam kepala-kepala tersebut.
Idenya begini: bagaimana jika kita tidak usah menyimpan tabel matriks Key (Kunci) dan Value (Isi) secara terpisah? Bagaimana jika kalimat yang dimasukkan itu kita ubah dulu menjadi satu tabel gabungan yang ukurannya jauh lebih kecil—sebuah matriks laten (tersembunyi)—dan kita hanya menyimpan matriks kecil itu saja ke dalam memori?
Alih-alih menyimpan dua buku besar ke dalam rak memori (buku $K$ dan $V$), MLA hanya menyimpan satu buku ringkasan yang sangat tipis (buku $cKV$). Matriks ringkasan tunggal ini menjadi memori cache baru kita yang sangat efisien. Nanti, ketika AI sedang butuh buku Key dan Value utuh untuk berhitung, kita tinggal menyulap (mengembalikan) ringkasan kecil tadi menjadi buku-buku ukuran penuh untuk setiap kepala AI.
- Untuk Penyimpanan: Kita hanya menyimpan satu matriks yang kecil dan sudah dikompres.
- Untuk Perhitungan: Kita mengembangkan kembali matriks tersebut menjadi matriks Key dan Value berukuran penuh dan unik untuk setiap kepala.
Pendekatan ini memberikan yang terbaik dari dua pilihan tersebut. Caranya adalah dengan membagi proses pembuatan Key dan Value menjadi dua tahap yang cerdas: tahap memampatkan data ke dalam ruang laten (ringkas), lalu diikuti dengan tahap mengembalikannya ke ruang dimensi penuh.
3.2 Arsitektur MLA: Panduan Visual Langkah demi Langkah
Untuk mewujudkan strategi “kompres saat disimpan, kembangkan saat digunakan” ini, MLA memperkenalkan lapisan pengubah (proyeksi) baru dan memodifikasi aliran data di dalam blok otak AI.
Mari kita periksa seluruh alur kerjanya, seperti yang digambarkan pada Gambar 3.2.
Gambar 3.2 Alur data arsitektur lengkap dari Multi-Head Latent Attention (MLA).
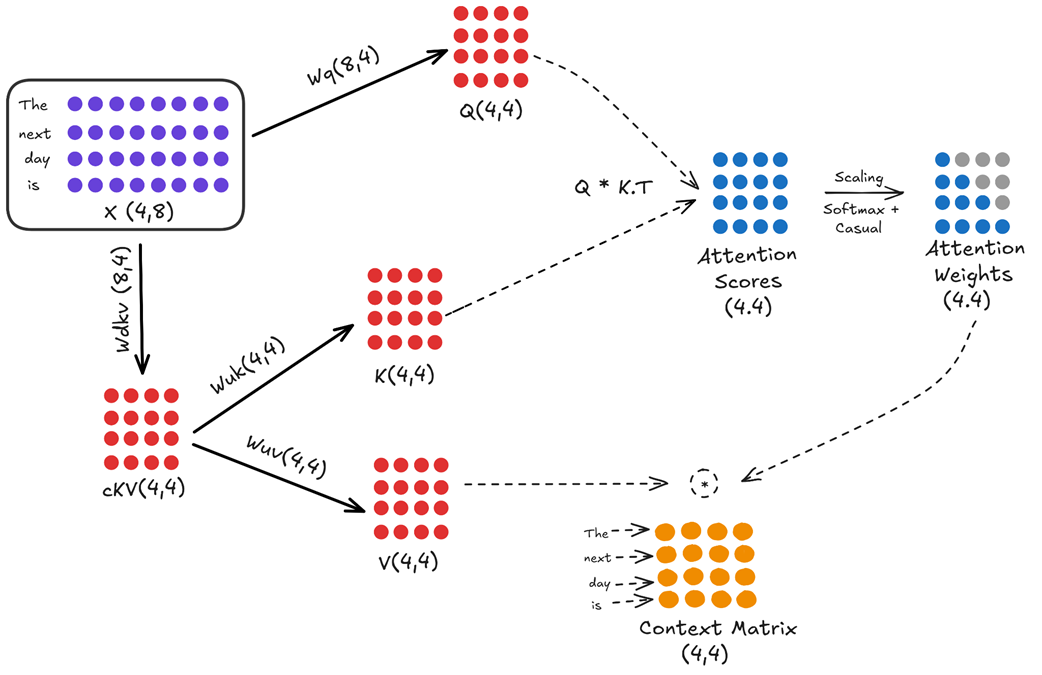
Diagram ini terbagi menjadi dua jalur utama: jalur pertanyaan (query) dan jalur kunci/isi (key/value).
3.2.1 Jalur pertanyaan / Query path (tidak berubah)
Jalur query pada versi MLA yang disederhanakan ini tetap sama seperti pada Multi-Head Attention standar. Tujuannya adalah membuat matriks pertanyaan ukuran penuh yang bisa “menanyakan” konteks kepada kalimat.
- Tabel angka masukan $X$ (ukuran baris 4, kolom 8) dikalikan dengan tabel bobot $W_q$ (ukuran 8, 4).
- Hal ini menghasilkan matriks
Queryakhir yaitu $Q$ (ukuran 4, 4), yang siap digunakan untuk proses perhitungan attention.
(Catatan: Pada versi MLA tingkat lanjut seperti DeepSeek-V3, bagian query juga dikompres untuk menghemat memori. Tetapi untuk memudahkan pemahaman inti dari inovasi ini, kita anggap jalur query berjalan standar).
3.2.2 Jalur kunci dan isi / Key/Value path (Inovasi utamanya)
Di sinilah letak keajaibannya. Alih-alih memisahkan perubahan untuk kunci dan isi, kita menggunakan proses dua tahap yang melibatkan sebuah matriks perantara berukuran ringkas (laten).
Tahap 1: Memperkecil ke ruang laten (Down-projection) Tabel angka masukan $X$ pertama-tama dikalikan dengan matriks bobot baru yang harus dipelajari AI, yang disebut KV Down-Projector ($W_{dkv}$).
- $X$ (ukuran 4, 8) dikalikan dengan $W_{dkv}$ (ukuran 8, 4).
- Hal ini menghasilkan satu buah matriks tunggal yang lebih kecil dan padat bernama Latent KV Matrix ($cKV$), dengan ukuran (4, 4).
Catatan Tentang Ukuran: Pada contoh kita, ukuran laten (4) kebetulan sama dengan jumlah kata (4). Ini murni agar diagram mudah dipahami. Di dunia nyata, ukuran ini berbeda jauh. Untuk model seperti DeepSeek-V3, ukuran model aslinya adalah 7168 sedangkan ukuran latennya hanya 512. Lapisan Down-Projector ini berhasil mengecilkan deretan angka sepanjang 7168 menjadi hanya 512 saja.
Matriks $cKV$ ini adalah satu-satunya hal yang disimpan ke dalam memori selama AI sedang digunakan. Perhatikan dua keuntungan instan dari hal ini:
- Kita menyimpan satu matriks, bukan dua.
- Ukuran matriks ini jauh lebih kecil dibandingkan ukuran matriks Key dan Value jika digabungkan.
Tahap 2: Memperbesar dari ruang laten (Up-projection) Sekarang, setelah kita memiliki matriks $cKV$ yang padat, kita bisa menyusun ulang matriks Key dan Value ukuran penuh menggunakan dua matriks baru yang disebut Up-Projection:
- $cKV$ (ukuran 4, 4) dikalikan dengan Key Up-Projector ($W_{uk}$) untuk menghasilkan matriks Key penuh yaitu $K$ (ukuran 4, 4).
- $cKV$ (ukuran 4, 4) dikalikan dengan Value Up-Projector ($W_{uv}$) untuk menghasilkan matriks Value penuh yaitu $V$ (ukuran 4, 4).
Setelah proses dua tahap ini selesai, kita mendapatkan tiga matriks yang kita butuhkan: $Q$, $K$, dan $V$. Dari titik ini, sisa dari perhitungan attention berjalan sama persis seperti pada MHA standar.
Lalu, bagaimana mungkin menambahkan langkah pengecilan dan pembesaran ini bisa membuat proses kerja komputer menjadi lebih efisien dan hemat tenaga? Jawabannya ditemukan dalam sebuah penerapan khusus dari ilmu perkalian matriks matematika: “trik penyerapan” (the absorption trick).
3.3 Keajaiban Matematika: Bagaimana Matriks Laten Membantu
Mungkin awalnya kita berpikir, memasukkan matriks $cKV$ perantara dan menambah langkah proyeksi justru membuat kerja AI semakin rumit. Namun, jawabannya terletak pada hukum Aljabar Linier yang berhasil dimanfaatkan oleh tim DeepSeek. Dengan mengatur ulang rumus perhitungannya secara cerdas, kita bisa membuktikan bahwa matriks laten kecil itulah satu-satunya informasi masa lalu yang perlu kita simpan di memori.
3.3.1 Penurunan Rumus Q, K, dan V secara Bertahap di MLA
Mari kita ubah diagram arsitektur tadi ke dalam bahasa matematika.
Gambar 3.3 Penurunan matematika langkah demi langkah untuk matriks Query, Key, dan Value di dalam arsitektur MLA.
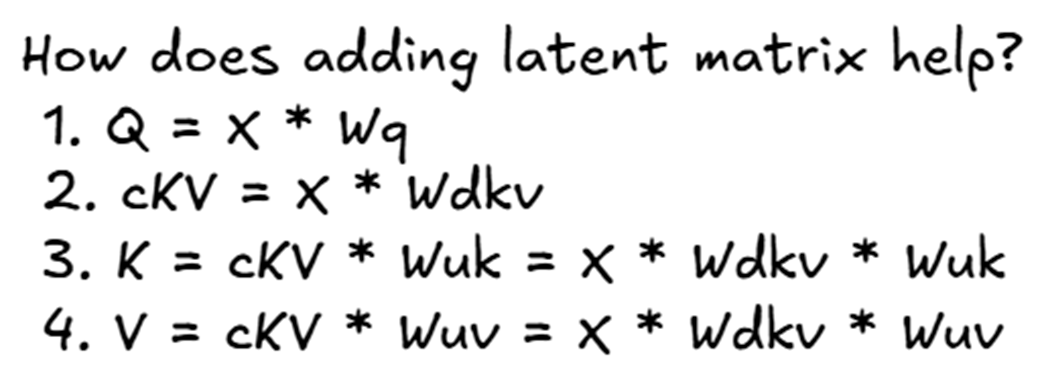
- Matriks Query ($Q$): $Q = X \cdot W_q$
- Matriks Latent KV ($cKV$): $cKV = X \cdot W_{dkv}$
- Matriks Key ($K$): $K = cKV \cdot W_{uk}$. Jika kita masukkan langkah 2 ke sini, rumusnya menjadi: \(K = (X \cdot W_{dkv}) \cdot W_{uk}\)
- Matriks Value ($V$): $V = cKV \cdot W_{uv}$. Jika kita masukkan langkah 2 ke sini, rumusnya menjadi: \(V = (X \cdot W_{dkv}) \cdot W_{uv}\)
3.3.2 Trik Penyerapan: Bagaimana Skor Perhatian Dihitung
Mari kita masukkan definisi rumus-rumus baru ini ke dalam rumus utama perhitungan skor (Scores $= Q \cdot K^T$):
\[Scores = (X \cdot W_q) \cdot ((X \cdot W_{dkv}) \cdot W_{uk})^T\]Menggunakan aturan pembalikan matriks dalam matematika yaitu $(AB)^T = B^T A^T$, kita dapat memecah bagian yang ada tanda $T$ (transpose) menjadi:
\[Scores = (X \cdot W_q) \cdot (W_{uk}^T \cdot (X \cdot W_{dkv})^T)\]Karena perkalian matriks bersifat asosiatif (boleh dikelompokkan bebas seperti $A \times B \times C = A \times (B \times C)$), kita bisa mengelompokkan ulang bagian-bagiannya:
Gambar 3.4 Pengaturan ulang matematika untuk rumus perhitungan skor di MLA.

Mari kita analisa rumus yang sudah disusun ulang ini:
- Matriks Bobot yang Diserap: $(W_q \cdot W_{uk}^T)$. Karena bobot $W_q$ dan $W_{uk}$ nilainya selalu tetap (tidak berubah) saat AI sedang digunakan, maka hasil perkalian keduanya pasti selalu menghasilkan sebuah matriks tunggal yang nilainya juga tetap. Kita cukup menghitung perkalian ini satu kali saja di awal.
- Matriks yang Disimpan (Cache): $(X \cdot W_{dkv})^T$. Rumus ini tidak lain dan tidak bukan adalah rumus persis dari matriks ringkasan kita, yaitu matriks laten $cKV$.
Inilah yang dinamakan “trik penyerapan”. Matriks pembesar kunci ($W_{uk}$) telah diserap masuk secara matematika ke dalam matriks pembuat pertanyaan ($W_q$). Rumus asli $Q \cdot K^T$ kini secara ajaib berubah menjadi:
\[Scores = Pertanyaan\_Yang\_Diserap \cdot cKV\_Cache^T\]Seiring bertambah panjangnya kalimat yang kita masukkan, matriks kecil $cKV$ yang merangkum sejarah kata-kata tersebut cukup diperluas dengan menambahkan data laten kata yang baru di bagian belakangnya. Kita telah berhasil mengubah rumus yang berat menjadi sangat ringan, karena AI kini hanya bergantung pada satu buah matriks kecil yang disimpan di memori.
3.3.3 Langkah Terakhir: Menghitung Vektor Konteks
Apakah penghematan efisiensi ini juga berlaku pada langkah terakhir: yaitu menciptakan Matriks Vektor Konteks? Rumus standar untuk ini adalah:
Mari kita masukkan rumus kita untuk nilai $V$:
\[Context = Bobot\_Perhatian \cdot ((X \cdot W_{dkv}) \cdot W_{uv})\]Gambar 3.5 Pengaturan ulang matematika untuk menghitung hasil keluaran akhir di MLA.

Sebelum data konteks ini dikeluarkan dari lapisan otak AI, ia harus menabrak lapisan proyeksi keluaran terakhir (disebut $W_o$):
\[Output = (Bobot\_Perhatian \cdot (cKV \cdot W_{uv})) \cdot W_o\]Dengan menggunakan prinsip matematika asosiatif (pengelompokan) lagi, nilai $W_{uv}$ bisa “diserap” masuk ke dalam lapisan proyeksi $W_o$. Hasil perkalian $(W_{uv} \cdot W_o)$ hanyalah menjadi sebuah matriks baku tunggal lain yang sudah dihitung di awal.
Hal ini secara mutlak membuktikan teori utama kita: kita memang hanya perlu menyimpan matriks laten kecil $cKV$ saja di dalam memori komputer.
3.4 Putaran Cara Kerja Baru dengan MLA
Mari kita telusuri perjalanan sebuah kata baru, yaitu "bright" (cerah), dengan asumsi AI tersebut sebelumnya sudah membaca dan memproses kalimat "The next day is" dan telah menyimpan ringkasannya ke dalam memori cache $cKV$.
3.4.1 Apa yang terjadi saat kata baru masuk?
Saat kata "bright" tiba, model AI melakukan jumlah perhitungan yang paling minimal:
- Menghitung Pertanyaan (Query): $Query_{bright} = X_{bright} \cdot W_q$
- Menghitung Laten KV (cKV): $cKV_{bright} = X_{bright} \cdot W_{dkv}$
Hanya dua perhitungan proyeksi inilah yang perlu dilakukan. Kita sama sekali tidak menghitung secara penuh vektor Key dan Value langsung dari input kata tersebut.
3.4.2 Menyimpan vektor laten: Satu-satunya hal yang kita simpan
Kita lalu menambahkan vektor laten yang baru kita buat tadi ke dalam memori cache lama yang sudah ada.
Gambar 3.8 Memperbarui Memori (Cache) Laten KV.
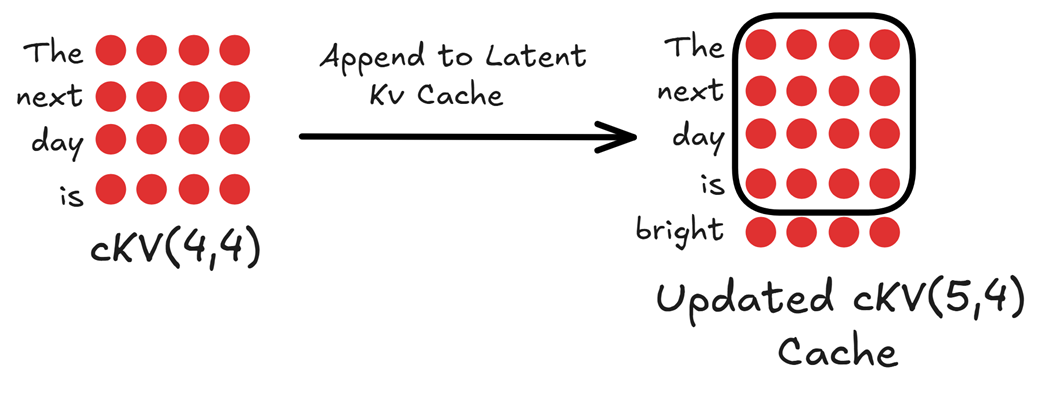
Jika memori $cKV$ lama kita memiliki ukuran (4, 4), maka dengan menambahkan vektor kata baru yang berukuran (1, 4), matriks laten di dalam memori kita sekarang diperbarui menjadi ukuran (5, 4). Matriks tunggal yang sangat kecil inilah satu-satunya catatan sejarah masa lalu yang kita simpan di dalam kartu grafis komputer (GPU).
3.4.3 Mengembangkan (dekompres) cache dan menghitung perhatian
Untuk melakukan perhitungan attention agar AI paham konteks kalimat, kita “mengembangkan ulang” memori laten kita dalam sekejap mata:
Gambar 3.9 Mengembangkan (dekompres) memori laten yang telah diperbarui menjadi matriks Key dan Value berukuran utuh.
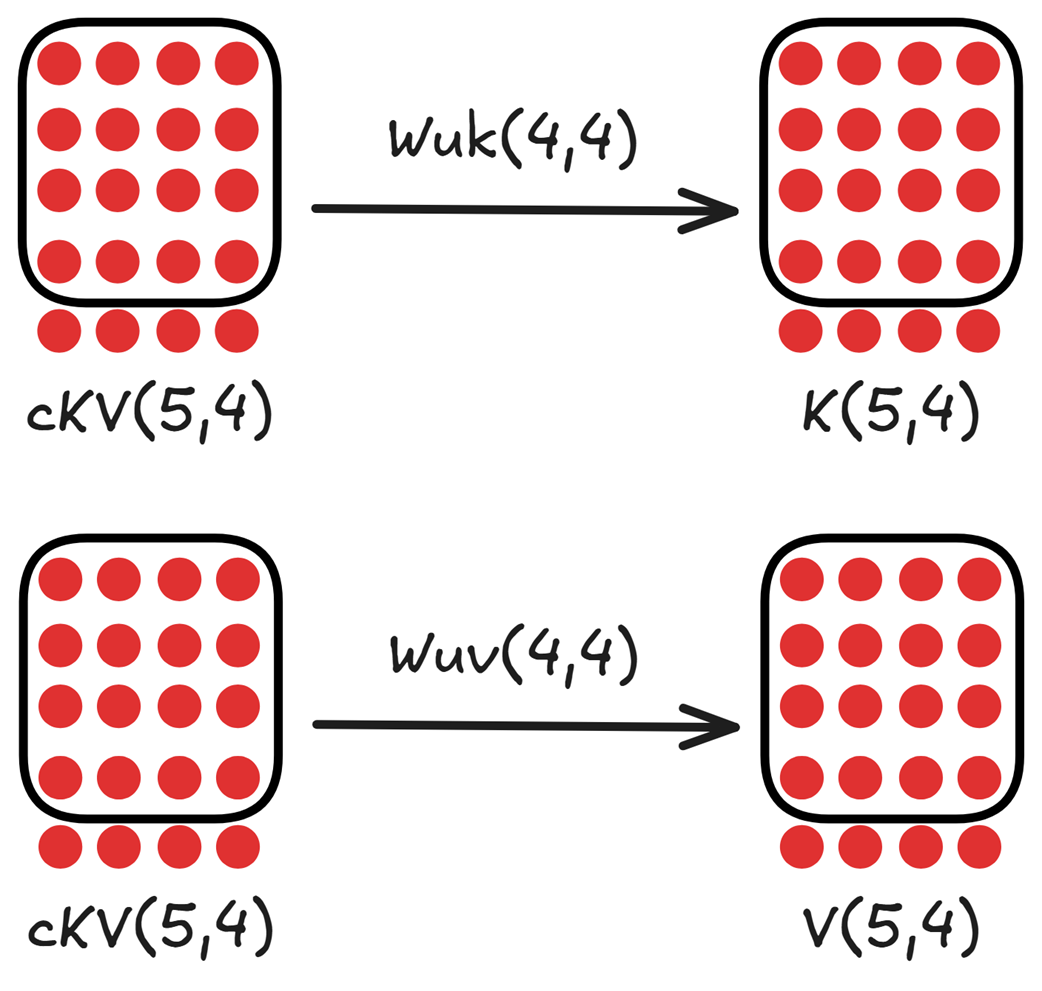
- $cKV_{diperbarui} \cdot W_{uk} \rightarrow Matriks_Key_Penuh (K)$
- $cKV_{diperbarui} \cdot W_{uv} \rightarrow Matriks_Value_Penuh (V)$
Dengan vektor Query milik kata baru dan matriks $K$ dan $V$ yang baru saja dikembangkan penuh, kita menghitung Bobot Perhatian, lalu mengalikannya dengan $V$ untuk mendapatkan Vektor Konteks akhir khusus untuk kata "bright". Setelah itu, model akan menebak apa kata berikutnya.
3.5 Menghitung Keuntungannya: Rumus KV Cache yang Baru
Mari kita hitung menggunakan angka nyata seberapa besar penghematan memori ini. Rumus memori KV cache pada sistem MHA standar adalah:
\[Size_{MHA} = 2 \times (n \times h) \times layers \times batch \times length \times 2_{bytes}\]Dengan menggunakan MLA, kita tidak lagi menyimpan dua jenis memori (Key dan Value), dan dimensi (ukurannya) jauh lebih kecil yaitu sebesar dimensi laten ($d_{latent}$). Rumusnya kini berubah menjadi:
\[Size_{MLA} = d_{latent} \times layers \times batch \times length \times 2_{bytes}\]Bagi sebuah model AI sekelas DeepSeek-V3 (dengan jumlah kepala $n=128$, ukuran kepala $h=128$, dan ukuran laten $d_{latent}=512$):
- Dimensi Memori pada MHA Standar: $2 \times (128 \times 128) = 32.768$
- Dimensi Memori pada MLA: $512$
Pengurangan ukuran data yang harus disimpan adalah sebesar $32.768 / 512 = \mathbf{64 \text{ kali lipat}}$. Sebuah memori yang secara teori membutuhkan ruang komputer raksasa sebesar 400 Gigabyte (GB), kini menyusut drastis menjadi ukuran wajar, yaitu sekitar 7 GB saja.
Lebih hebatnya lagi, karena matriks pembesar (up-projection $W_{uk}$ dan $W_{uv}$) terdiri dari banyak “kepala” AI, maka ketika kita mengembangkan $cKV$, masing-masing dari ke-128 kepala tersebut akan membangun ulang matriks Key dan Value-nya sendiri secara unik tanpa saling mencontek. Kita berhasil mempertahankan keberagaman sudut pandang dan tingkat kecerdasan luar biasa dari sistem kepala ganda (Multi-Head).
3.6 Membangun Modul MLA dari Awal
Mari kita buat kode program menggunakan PyTorch yang merangkum logika inti dari sistem MLA ini.
Kode Program 3.1 Membangun MLA dari Awal
import torch
import torch.nn as nn
class MultiHeadLatentAttention(nn.Module):
def __init__(self, d_model, num_heads, d_latent, dropout=0.0):
super().__init__()
assert d_model % num_heads == 0, \
"d_model harus bisa dibagi secara rata dengan num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_head = d_model // num_heads
self.d_latent = d_latent
self.W_q = nn.Linear(d_model, d_model)
self.W_dkv = nn.Linear(d_model, d_latent) # Ini lapisan untuk mengecilkan memori
self.W_uk = nn.Linear(d_latent, d_model) # Ini lapisan untuk memperbesar Keys
self.W_uv = nn.Linear(d_latent, d_model) # Ini lapisan untuk memperbesar Values
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(
1, 1, 1024, 1024), diagonal=1).bool())
def forward(self, x):
batch_size, seq_len, _ = x.shape
# 1. Jalur Pertanyaan (Query Path)
q = self.W_q(x).view(
batch_size, seq_len, self.num_heads, self.d_head
).transpose(1, 2)
# 2. Jalur Key/Value (Di sinilah Inovasi MLA terjadi)
# Turunkan ukurannya menuju ruang laten (Kompresi data)
c_kv = self.W_dkv(x)
# Naikkan kembali ukurannya dari ruang laten ke K dan V utuh (Dekompresi)
k = self.W_uk(c_kv).view(
batch_size, seq_len, self.num_heads, self.d_head
).transpose(1, 2)
v = self.W_uv(c_kv).view(
batch_size, seq_len, self.num_heads, self.d_head
).transpose(1, 2)
# 3. Proses Perhitungan Attention Standar
attn_scores = (q @ k.transpose(-2, -1)) / (self.d_head ** 0.5)
attn_scores = attn_scores.masked_fill(
self.mask[:, :, :seq_len, :seq_len], float('-inf'))
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vector = (attn_weights @ v).transpose(1, 2) \
.contiguous().view(batch_size, seq_len, self.d_model)
# 4. Proyeksi Hasil Keluaran Akhir
output = self.W_o(context_vector)
return output
Meski MLA ini sangat luar biasa dalam menghemat memori, sistem otaknya secara dasar masih “buta posisi”. Otak AI memperlakukan kalimat hanya seperti “sekarung kata-kata yang dikumpulkan jadi satu”. Agar paham maksud sebenarnya, model AI butuh kesadaran tentang letak dan posisi kata tersebut dalam sebuah kalimat.
3.7 Evolusi Pengenalan Posisi Kata: Dari Angka Utuh menuju RoPE
Tanpa informasi posisi, otak mesin akan melihat kalimat “anjing itu mengejar kucing” dan “kucing itu mengejar anjing” sebagai kalimat yang sama persis maknanya. Atau jika kita punya kalimat “Anjing itu mengejar anjing lain”, nilai kode angka untuk kedua kata “anjing” akan bernilai sama persis sehingga membingungkan AI.
Untuk mengatasi hal ini, kita harus menyuntikkan informasi posisi ke dalam setiap kata. Seiring berjalannya tahun, teknik penyuntikan posisi ini berkembang pesat.
3.7.1 Percobaan #1 & #2: Angka Biasa dan Angka Biner (Ternyata Cacat)
Percobaan #1: Kode Angka Biasa (Integer)
Ide paling gampang adalah dengan menjumlahkan posisi kata tersebut secara langsung ke dalam angka kode kata tersebut (misalnya, menambahkan angka [5, 5, 5...] kepada kata urutan ke-5).
- Kelemahannya: Angka asli dari sebuah kata itu biasanya sangat kecil dan halus (misalnya 0,1 atau -0,2). Jika kita menjumlahkannya dengan angka urutan kata yang besar seperti posisi ke-1000 (
[1000, 1000...]), maka angka besarnya akan menelan habis angka kecil aslinya. Kita sama saja merusak dan menghilangkan makna asli dari kata tersebut.
Percobaan #2: Kode Biner
Untuk memperbaiki masalah angka besar tadi, para insinyur menggunakan angka biner komputer (misalnya posisi kata ke-200 diubah menjadi [1, 1, 0, 0, 1, 0, 0, 0]). Menjumlahkan dengan angka 1 dan 0 mencegah meledaknya nilai angka aslinya.
Selain itu, posisi biner punya pola unik: angka paling belakang bergerak cepat (0, 1, 0, 1) memberikan info jarak posisi jarak dekat, sementara angka di depannya bergerak lambat, memberikan info jarak jauh.
- Kelemahannya: Nilai biner melompat secara tajam, murni dari angka 0 langsung ke 1. Padahal jaringan otak buatan komputer (AI) belajar dari sebuah kurva kelandaian yang halus. Lompatan kotak yang tajam ini membuat otak komputer kesulitan mempelajari hubungan posisi antarkata.
3.7.2 Percobaan #3: Kode Posisi Gelombang Sinusoidal
Diperkenalkan dalam jurnal ilmiah terkenal berjudul Attention Is All You Need, pendekatan ini membuang lompatan kasar 0 dan 1, lalu menggantinya dengan gelombang lembut tanpa putus menggunakan fungsi matematika sinus dan cosinus.
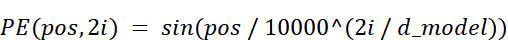
Rumus yang sangat brilian ini meniru pola bolak-balik dari sistem biner (angka kecil berayun cepat; angka besar berayun lambat) tetapi menghaluskan kurvanya dengan sempurna sehingga otak komputer mudah belajar. Terlebih lagi, berkat keajaiban trigonometri, kode posisi untuk posisi ke-($p+k$) hanyalah sebuah pergeseran linear dari posisi awal ke-$p$.
- Kelemahan Tersisanya: Angka kode posisi gelombang sinus ini tetap saja dijumlahkan secara langsung dengan nilai awal kata di bagian paling awal proses AI. Meskipun angkanya sudah dibatasi kecil antara -1 dan 1, proses matematika penjumlahannya akan sedikit mengubah nilai asli dari kata tersebut, sehingga mengurangi kemurnian makna kata aslinya.
3.8 Teknologi Puncak Masa Kini: Rotary Positional Encoding (RoPE)
Teknologi Rotary Positional Encoding (RoPE) mengambil ide terbaik dari gelombang sinus tadi, namun memecahkan masalah rusaknya makna asli kata melalui dua ide cemerlang:
1. Menyuntikkan posisi secara langsung ke dalam rumus Attention. Daripada mengotori nilai kata di tahap paling awal, RoPE secara pintar menyuntikkan informasi posisi langsung ke dalam vektor Query (Pertanyaan) dan Key (Kunci) sesaat sebelum mereka saling bertemu.
2. Gunakan Putaran Rotasi, bukan Penjumlahan. Jika kita menambahkan sebuah angka pada vektor, panjang ukurannya akan berubah. Namun, jika kita memutar (seperti memutar jarum jam) vektor tersebut di ruang 2 Dimensi, kita hanya mengubah arah posisinya saja. Panjang vektor tersebut sama sekali tidak tersentuh dan tidak berubah. Dengan demikian, kemurnian makna asli kata tersebut dipertahankan seratus persen.
RoPE bekerja dengan mengambil deretan vektor panjang dari Query dan Key, lalu mengelompokkannya menjadi pasangan 2 Dimensi (misalnya, deretan vektor 128 angka dipisah menjadi 64 pasang vektor berukuran 2 Dimensi).
Gambar 3.25 Setiap pasangan dimensi diperlakukan sebagai panah vektor 2D, lalu diputar sebesar sudut tertentu yaitu θ (theta) yang mewakili posisi kata.
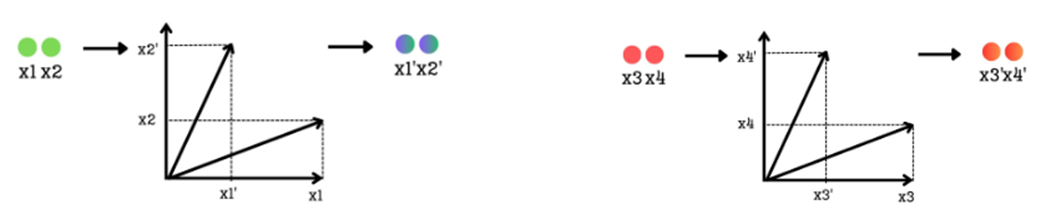
Setiap pasangan angka tersebut diputar sejauh sudut $\theta$ yang besarnya ditentukan dari posisi mutlak kata tersebut di dalam kalimat (namun tetap menjaga pola ayunan frekuensinya). Terakhir, pasangan 2D yang sudah diputar-putar itu dirakit kembali menjadi vektor panjang asli yang kini sudah mengandung kesadaran posisinya.
3.9 Masalah Ketidakcocokan: Mengapa MLA dan RoPE Standar Tidak Bisa Bekerja Sama
Kita sekarang memiliki dua inovasi yang sungguh luar biasa: MLA yang mampu sangat menghemat memori komputer, dan RoPE yang memberikan kesadaran posisi kata tanpa merusak artinya. Langkah yang paling masuk akal adalah menggabungkan keduanya. Namun celakanya, secara matematika mereka sangat bertolak belakang dan tidak cocok.
Mari kita ingat kembali “trik penyerapan” yang membuat MLA sangat efisien: \(Scores = X \cdot (W_q \cdot W_{uk}^T) \cdot (X \cdot W_{dkv})^T\)
Trik penyerapan rumus matematika ini seratus persen sangat bergantung pada fakta bahwa matriks $W_q$ dan $W_{uk}$ tidak mempedulikan posisi kata (artinya nilainya tetap/statis).
Sayangnya, sifat dasar RoPE adalah selalu berubah sesuai dengan posisi kata. Jika kita memaksakan rumus fungsi RoPE() ke dalam Query dan Key sebelum kita melakukan perkalian matematika, rumusnya akan hancur menjadi:
Fungsi posisi RoPE() yang selalu berubah-ubah ini bertindak sebagai sebuah dinding beton yang tebal. Kita tidak bisa lagi secara matematika mencampur aduk dan menghitung rumus di dalam kurung $W_q$ dan $W_{uk}^T$ di awal waktu (pra-komputasi). Trik penyerapan memori itu benar-benar rusak total. Tanpa trik penyerapan tersebut, kita terpaksa harus menghitung ulang matriks Key yang sudah diputar secara penuh untuk seluruh sejarah masa lalu pada setiap langkah penciptaan kata. Hal ini akan mematikan seluruh fungsi kehebatan hemat memori dari MLA.
3.10 Solusi DeepSeek: Memisahkan Posisi RoPE (Decoupled RoPE)
Untuk menyelesaikan bentrokan maut ini, tim DeepSeek memikirkan solusi yang sangat anggun: Decoupled Rotary Position Embedding (Memisahkan Jalurnya). Jika memasukkan informasi posisi dapat merusak trik penyerapan memori, kita buang saja sistem letak posisi itu dari jalur utamanya.
Arsitektur baru ini memecah perhitungan attention menjadi dua jalur jalan raya yang sejajar (paralel):
- Jalur Isi Kalimat (Jalur Utama): Ini murni menggunakan MLA saja tanpa membawa informasi posisi letak kata sama sekali. Dengan begitu, trik penyerapan rumus matematika tetap berfungsi seratus persen.
- Jalur Posisi Kata: Ini merupakan seperangkat jalur kecil khusus di mana proses RoPE dibiarkan berjalan bebas melakukan tugasnya mengatur posisi.
Skor perhatian akhir dari otak AI hanyalah hasil penjumlahan matematis dari kedua jalur jalan raya yang berdiri sendiri-sendiri tersebut.
3.10.1 Arsitektur Baru: Menyelam dalam Visual dan Matematika
A. Jalur Isi Kalimat (Tanpa RoPE) Angka kata masukan $X$ diperkecil untuk menciptakan query laten $cQ$ dan key-value laten $cKV$. Matriks kecil ini kemudian diperbesar lagi menjadi $Q_c, K_c, V_c$. Karena jalur ini bebas dari campur tangan putaran RoPE, maka trik penyerapan hemat memori ($Q_c \cdot K_c^T$) dapat bekerja dengan sempurna. Matriks kecil $cKV$ lalu disimpan di memori.
B. Jalur Posisi (Menggunakan RoPE) Berjalan di waktu yang bersamaan, jalur kedua ini sibuk menghitung Key posisi ($K_r$) dan Query posisi ($Q_r$).
- Masukan $X$ dikalikan dengan $W_{kr}$, dan putaran RoPE diterapkan. (Hasil $K_r$ ini dibagikan ke semua kepala AI untuk menghemat sedikit memori, lalu disimpan).
- Masukan $X$ lalu diperkecil ke $cQ$, diperbesar lagi via $W_{qr}$, lalu putaran RoPE diterapkan untuk menciptakan vektor posisi $Q_r$.
Gambar 3.30 Perhitungan skor perhatian akhir. Hasil akhirnya adalah penjumlahan dari skor di jalur isi dan skor di jalur posisi.
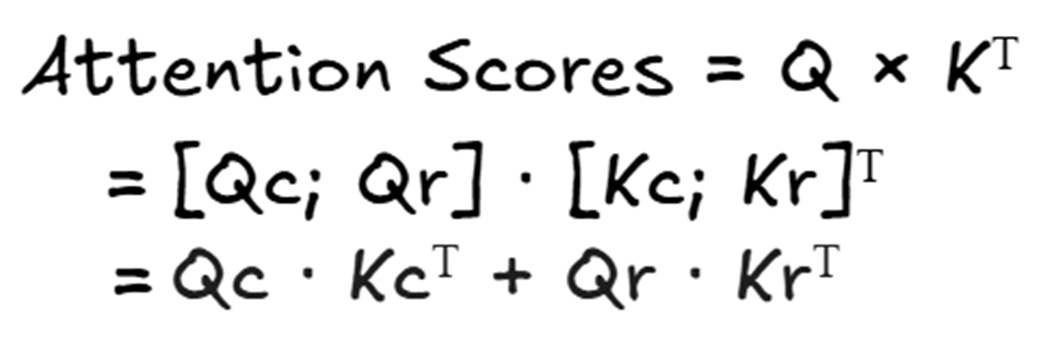
Desain yang sangat anggun ini secara sengaja mengorbankan sedikit sekali tambahan tenaga prosesor komputer (untuk menjalankan jalur kedua tadi) demi menghemat jumlah memori RAM GPU yang sangat luar biasa besar. Pengorbanan yang sangat menguntungkan di dunia nyata.
3.10.2 Membangun MLA yang digabung RoPE Terpisah dari Nol
Mari kita tuangkan rancangan pintar ini ke dalam bahasa pemrograman PyTorch. Kita akan merangkai modul otak DeepSeekAttention menggunakan sebuah alat bantu (modul) RotaryPositionalEncoding tambahan.
Kode Program 3.2 Modul Alat Bantu RotaryPositionalEncoding
import torch
import torch.nn as nn
class RotaryPositionalEncoding(nn.Module):
def __init__(self, d_head, max_seq_len=2048):
super().__init__()
theta = 1.0 / (10000 ** (
torch.arange(0, d_head, 2).float() / d_head))
self.register_buffer('theta', theta)
positions = torch.arange(max_seq_len).unsqueeze(1)
freqs = positions * self.theta.unsqueeze(0)
self.register_buffer('freqs_cis',
torch.polar(torch.ones_like(freqs), freqs))
def forward(self, x):
seq_len = x.shape[2]
x_complex = x.float().reshape(*x.shape[:-1], -1, 2)
x_complex = torch.view_as_complex(x_complex)
freqs_cis = self.freqs_cis[:seq_len, :].unsqueeze(0).unsqueeze(0)
# Menerapkan putaran melalui perkalian angka kompleks
x_rotated = x_complex * freqs_cis
x_rotated = torch.view_as_real(x_rotated).flatten(3)
return x_rotated.type_as(x)
Sekarang, kita tulis modul utamanya. Perhatikan dua jalur terpisah di dalam langkah __init__ dan langkah forward.
Kode Program 3.3 & 3.4 Modul DeepSeekAttention dengan Jalur yang Dipisah (Decoupled)
class DeepSeekAttention(nn.Module):
def __init__(self, d_model, num_heads, d_latent, d_rope, dropout=0.0):
super().__init__()
self.d_rope = d_rope
self.num_heads = num_heads
self.d_head = d_model // num_heads
self.d_model = d_model
# --- Jalur Isi Kalimat (Pure MLA) ---
self.W_q_content = nn.Linear(d_model, d_model)
self.W_dkv_content = nn.Linear(d_model, d_latent)
self.W_uk_content = nn.Linear(d_latent, d_model)
self.W_uv_content = nn.Linear(d_latent, d_model)
# --- Jalur Posisi (RoPE Diterapkan di Sini) ---
self.W_k_pos = nn.Linear(d_model, d_rope * num_heads)
self.W_q_pos = nn.Linear(d_model, d_rope * num_heads)
self.rope = RotaryPositionalEncoding(d_rope)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(1, 1, 1024, 1024), diagonal=1).bool())
def forward(self, x):
batch_size, seq_len, _ = x.shape
# --- Proses Perhitungan di Jalur Isi Kalimat ---
q_c = self.W_q_content(x).view(batch_size, seq_len, self.num_heads, self.d_head).transpose(1, 2)
c_kv = self.W_dkv_content(x)
k_c = self.W_uk_content(c_kv).view(batch_size, seq_len, self.num_heads, self.d_head).transpose(1, 2)
v_c = self.W_uv_content(c_kv).view(batch_size, seq_len, self.num_heads, self.d_head).transpose(1, 2)
# --- Proses Perhitungan di Jalur Posisi ---
q_r_unrotated = self.W_q_pos(x).view(batch_size, seq_len, self.num_heads, self.d_rope).transpose(1, 2)
k_r_unrotated = self.W_k_pos(x).view(batch_size, seq_len, self.num_heads, self.d_rope).transpose(1, 2)
# Terapkan RoPE pada jalur ini
q_r = self.rope(q_r_unrotated)
k_r = self.rope(k_r_unrotated)
# --- Menggabungkan Kedua Jalur ---
content_scores = (q_c @ k_c.transpose(-2, -1)) / (self.d_head ** 0.5)
position_scores = (q_r @ k_r.transpose(-2, -1)) / (self.d_rope ** 0.5)
attn_scores = content_scores + position_scores
attn_scores = attn_scores.masked_fill(self.mask[:, :, :seq_len, :seq_len], float('-inf'))
attn_weights = self.dropout(torch.softmax(attn_scores, dim=-1))
context_vector = (attn_weights @ v_c).transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
return self.W_o(context_vector)
Untuk membuktikan secara ilmiah apakah desain rancangan ini sungguh bekerja, kami telah melatih empat model AI (model MHA, MQA, GQA, dan MLA) yang masing-masing diberikan porsi otak parameter yang sama persis (~17 Juta parameter) dan diujikan untuk membaca kumpulan data cerita anak-anak (TinyStories dataset).
Tabel 3.2 Perbandingan berbagai tipe sistem perhatian (attention)
| Tipe Attention | Nilai Kehilangan Akurasi (Validasi) | Ukuran Memori KV Cache (MB) | Nilai Kebingungan AI (Perplexity - Makin Kecil Makin Bagus) |
|---|---|---|---|
| MHA | 2.3721 | 48.00 | 10.72 |
| MQA | 2.4080 | 6.00 | 11.11 |
| GQA | 2.3776 | 24.00 | 10.78 |
| MLA | 2.3089 | 12.00 | 10.06 |
Sesuai yang ditunjukkan pada Tabel 3.2, MLA secara meyakinkan terbukti mampu meniru kecerdasan tingkat atas milik sistem MHA yang boros (bahkan MLA sukses mendapatkan nilai kebingungan / perplexity yang paling rendah, yaitu angka 10.06), di saat yang bersamaan ia hanya memakan memori 4 kali lebih hemat pada percobaan berukuran kecil ini (yaitu hanya memakan memori 12 MB dibandingkan MHA yang rakus memakan 48 MB).
3.11 Menerobos Batasan Baru (Model V3.2): DeepSeek Sparse Attention (DSA)
Teknologi MLA memang sukses luar biasa dalam mengurangi masalah kemacetan memori berkat metode memampatkan data. Akan tetapi, ketika kita memaksanya membaca buku setebal 128.000 kata sekaligus, hal ini memunculkan masalah kelemahan jenis baru: kerumitan hitungan komputer. Sekalipun memori ukuran datanya sudah dikompres sangat kecil, menyuruh otak komputer menghitung kecocokan kata baru dengan 128.000 riwayat kata lama di belakangnya, membutuhkan proses matematika yang terlalu melelahkan.
Untuk memecahkan kebuntuan ini, DeepSeek-V3.2 memperkenalkan teknologi DeepSeek Sparse Attention (DSA) / Perhatian Renggang DeepSeek. Ide intinya sederhana saja: sebuah kata baru yang masuk tidak usah mengecek satu per satu semua sejarah kata lama. Ia cukup menengok dan fokus pada kata-kata yang paling berkaitan saja.
3.11.1 Pengindeks Kilat (The Lightning Indexer)
Bagaimana AI tahu mana kata lama yang berkaitan tanpa harus menghitung secara detail? Untuk menjawabnya, DSA menggunakan sebuah alat bernama Lightning Indexer (Pengindeks Kilat). Pengindeks ini bertindak sebagai sebuah saringan (filter) super cepat. Saringan ini bertugas menghitung skor kasaran sementara ($I_{t,s}$) antara kata baru yang ditanyakan ($h_t$) dengan kata-kata lama sebelumnya ($h_s$):
\[I_{t,s} = \sum_{h=1}^{H^I} w_{t,j}^I \cdot \text{ReLU} \left( q_{t,j}^I \cdot k_{s}^I \right)\]Karena si Pengindeks Kilat ini bekerja dengan menggunakan jumlah “kepala” yang sangat sedikit ($H^I$) serta dirancang untuk berlari di pengaturan komputer FP8 (format angka kecil) yang super ngebut, ia bisa menyapu bersih sejarah 128.000 kata tadi dengan kecepatan dan efisiensi tenaga komputer yang luar biasa mengagumkan.
3.11.2 Seleksi kata secara cermat di bawah teknologi MLA
Begitu si Pengindeks selesai memberi skor cepat ke semua kata lama, langkah selanjutnya adalah mekanisme seleksi kata secara cermat. Mekanisme ini hanya memanggil atau mengambil isi Key-Value (${c_s}$) yang benar-benar berhasil masuk ke dalam daftar “Top-K” (Beberapa Peringkat Teratas) dari skor kilat tadi. Perhitungan matematika penuh yang berat baru akan diizinkan jalan dan hanya dikerjakan pada beberapa kelompok kecil kata yang punya kaitan kuat saja (secara renggang).
Karena DeepSeek-V3.2 masih berpijak langsung di atas arsitektur MLA yang tadi kita kerjakan, maka DSA diterapkan di dalam pengaturan Multi-Query Attention (MQA) milik MLA. Berkat meminjam secara masal memori Key-Value terkompresi yang digabungkan, proses pemilihan Top-K bisa bersinergi lincah dengan memori MLA. Si Pengindeks Kilat ini dilatih sedemikian rupa lewat “Tahap Pemanasan Padat” agar ia sanggup meniru distribusi perhatian kata standar di awal, sebelum akhirnya dilepas total ke dalam “Tahap Pelatihan Renggang”.
3.12 Menuju 1 Juta Kata (Model V4): Arsitektur Hybrid Attention (Perhatian Campuran)
DeepSeek-V3.2 telah berhasil membaca 128.000 kata dengan sangat irit. Akan tetapi, demi menjebol batasan gaib 1 juta kata (1-million-token), dunia AI membutuhkan pemikiran yang benar-benar beda dan gila. Pada DeepSeek-V4, para periset mulai sadar bahwa ketika panjang halaman bacaan meroket ke skala jutaan, sistem “Perhatian Renggang” (Sparse Attention) saja lama-kelamaan akan menyerah dan menjadi berat bagi komputer.
Guna melahap 1.000.000 kata dengan lancar, DeepSeek-V4 membuang pola arsitektur seragam dan mengenalkan sebuah Hybrid Attention Architecture (Arsitektur Perhatian Campuran) yang menampilkan dua senjata ekstrem sekaligus:
3.12.1 Compressed Sparse Attention (CSA / Perhatian Renggang Terkompresi)
CSA menggabungkan cara kerja memampatkan kata dengan seleksi renggang. Ketimbang mengecek 1 juta kata satu per satu, CSA langsung menggabungkan beberapa kata yang berdekatan ($m$) dan memadatkannya menjadi satu blok (batu bata) tunggal. Sesudah perampingan yang drastis ini, barulah ia menyuruh Pengindeks Kilat DSA tadi untuk mengecek dan memilih blok Top-K mana saja yang mau dihitung.
3.12.2 Heavily Compressed Attention (HCA / Perhatian yang Sangat Sangat Terkompresi)
HCA membawa ide kompresi ke level paling ekstrem dan paling sadis. Ia menggabungkan riwayat kata lama secara sangat kasar ($m’$, di mana $m’$ angkanya lebih besar dari $m$) menjadi cuma sebuah blok tunggal kecil. Lantaran saking kecilnya panjang riwayat akibat dikompres ugal-ugalan ini, HCA sudah tidak perlu lagi trik seleksi renggang; ia langsung menggunakan metode penghitungan penuh (padat) untuk menatap langsung blok-blok semantik (makna) super padat tersebut.
Model DeepSeek-V4 ini meletakkan dan menyusun CSA dan HCA secara berselang-seling layaknya kue lapis di dalam arsitektur blok Transformernya.
3.12.3 Mengelola Memori KV Cache Campuran (Heterogen)
Berkat penggunaan berbagai tingkat kompresi ukuran data ($m$ dan $m’$) berdampingan dengan sistem perhatian jendela geser (Sliding Window Attention / SWA), memori di dalam kartu grafis (KV cache) tidak lagi tersusun rapi atau sama besar. DeepSeek-V4 dengan cerdas memecah isi perut memori menjadi dua kamar yang berbeda tugas:
- State Cache (Memori Keadaan): Ruang tunggu yang ukurannya dipatok pasti, bertugas menyimpan data kata-kata masa kini yang masih segar (belum sempat dikompres), dan kata di bagian ekor yang menunggu antrean untuk dijepit jadi balok kompres.
- Classical KV Cache (Memori Klasik): Bertugas menampung bata-bata blok kompresi masa lalu milik lapisan CSA dan HCA.
3.12.4 Penyimpanan KV Cache di dalam Diska Nyata (On-Disk)
Melayani pertanyaan dengan referensi teks atau sandi kode 1 juta kata memakan begitu banyak tempat. Demi mensiasatinya, DeepSeek-V4 memindahkan paksa sebagian blok memori CSA/HCA langsung ke dalam bongkahan “hardisk/SSD” fisik biasa di komputer (On-Disk). Lantaran kata-kata tadi ukurannya sangat mungil berkat mesin kompresi sakti AI, membacanya langsung lewat kabel penghubung di dalam komputer (PCIe) menjadi sesuatu yang mungkin dan super cepat. Trik ini sama saja “membobol” dan membebaskan diri dari sempitnya penjara memori kartu grafis (VRAM GPU), sehingga AI bisa mengerjakan hal-hal besar secara leluasa.
Melalui tumpukan taktik mulai dari MLA, DSA, hingga Kompresi Campuran (Hybrid), model DeepSeek masa kini meraih status menakjubkan: melakukan inferensi bacaan sejuta kata (1-million token inference) hanya menyerap 27% tenaga matematika komputer (FLOPs) dan hanya menghabiskan 10% memori KV Cache bila dibandingkan dari total yang dipakai pada generasi sebelumnya.
3.13 Ringkasan
- Multi-Head Latent Attention (MLA) sukses menghancurkan dilema “AI Pintar vs Boros Memori” dengan cara menyimpan versi ringkasan matriks laten yang terkompresi ($cKV$) dari nilai Kunci dan Isi. Ringkasan mungil ini akan langsung disulap (didekompres) menjadi matriks ukuran besar seutuhnya secara sekejap tepat pada saat setiap kepala AI mau melakukan perhitungan.
- Rotary Positional Encoding (RoPE) menuntaskan masalah “Makna yang Ternoda” dengan cara memutar vektor kata Pertanyaan dan Kunci. Putaran jarum jam di ruang 2D ini mengizinkan penyuntikan letak posisi kata tanpa menabrak atau merusak makna murni kata bawaannya.
- Kedahsyatan efisiensi MLA bersandar seratus persen pada rumus ajaib yang bernama “Trik Penyerapan Matematika”. Sayangnya, trik sakti ini secara harfiah mati kutu jika dipakai bareng rumus RoPE standar yang angkanya berubah-ubah tiap beda kata.
- Arsitektur Decoupled RoPE (RoPE Terpisah) hadir melerai perkelahian sistemik itu dengan membelah jalurnya. AI dibagi ke dalam jalur hemat memori bernama Jalur Isi Kalimat (murni MLA), dan jalan kecil khusus Jalur Posisi (murni RoPE), lalu menjumlahkan hasil keduanya secara damai di langkah terakhir.
- Pada model DeepSeek-V3.2, teknik DeepSeek Sparse Attention (DSA / Perhatian Renggang) menggunakan sebuah Pengindeks Kilat FP8 untuk menyeleksi kata-kata (riwayat) lama yang nilainya menempati urutan peringkat atas (Top-K) secara super cepat. Cara ini memangkas luar biasa energi prosesor komputer walau teks memanjang jadi 128.000 kata.
- Pada DeepSeek-V4, fitur raksasa bacaan 1-Juta kata dipecahkan lewat racikan Hybrid Attention. Formula ini menggabungkan sekaligus dua alat pemampat data yakni Compressed Sparse Attention (CSA) dan Heavily Compressed Attention (HCA), meremas puluhan ribu kata jadi sekepal bata padat, serta berhasil menyimpannya di Hardisk biasa secara lincah.