5.1 The core idea: From single-token to multi-token prediction
The entire training process for the language models we’ve discussed so far has been based on a single, simple objective: Next-Token Prediction. In the standard approach, we give the model a sequence of input tokens. These tokens are processed through a series of Transformer blocks (the “Shared Transformer Trunk”), and for each input token, the model’s goal is to predict the single token that immediately follows it.
Figure 5.2 The standard single-token prediction process. For a given sequence of input tokens, the model predicts only the single immediate next token for each position.
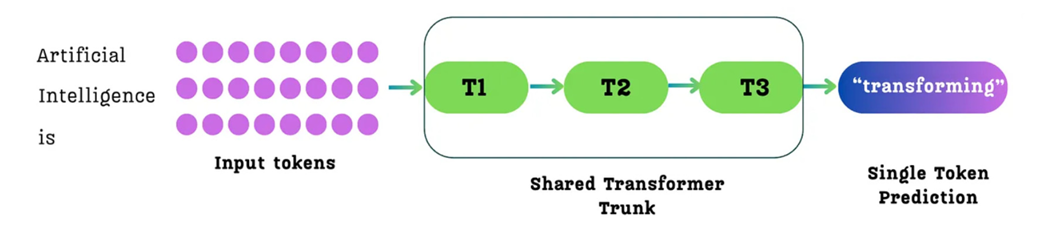
As shown in figure 5.2, for an input like “Artificial Intelligence is,” the model processes these three tokens. For the token “is,” its primary training goal is to predict the single next token, “transforming.” While it also makes predictions for the other tokens (e.g., predicting “Intelligence” after “Artificial”), the learning signal at each position is focused on a horizon of just one step into the future.
Multi-Token Prediction, as the name suggests, changes this fundamental objective. Instead of predicting only the single next token, the model is trained to predict multiple future tokens at once.
Figure 5.3 The Multi-Token Prediction (MTP) process. For a given sequence of input tokens, the model is trained to predict multiple future tokens simultaneously from each position. For example, from the input token “is,” it might predict the sequence “transforming,” “the,” “world.”
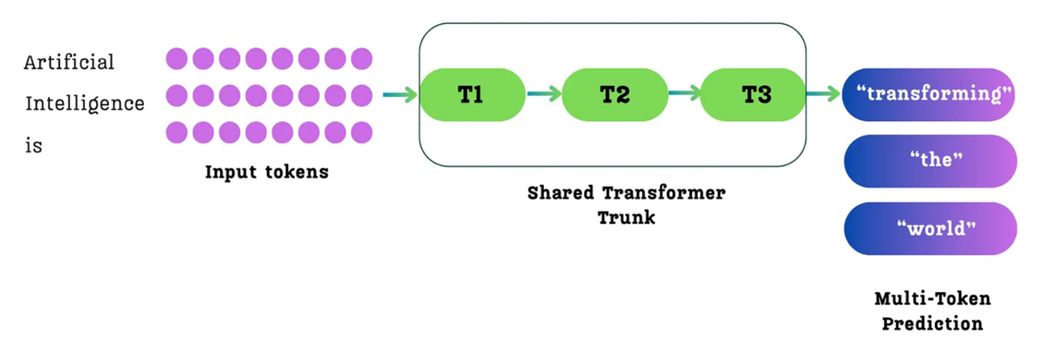
As illustrated in figure 5.3, when the model processes the input “Artificial Intelligence is,” it makes predictions from each token. In the standard single-token approach (figure 5.2), the primary goal for the token “is” would be to predict only the next token, “transforming.”
With MTP, the task is expanded. From the position of the token “is,” the model is now tasked with predicting a whole sequence of future tokens: “transforming,” “the,” and “world.” The loss is then calculated based on how well it predicted this entire future sequence from that position.
This seemingly simple change from predicting one token to predicting many has profound implications for the model’s training process and its final capabilities. It was not invented by DeepSeek but was explored in a paper from Meta AI researchers titled “Better and faster large language models via multi-token prediction.” (https://arxiv.org/pdf/2404.19737) DeepSeek took this powerful idea and integrated it with their own unique architectural innovations.