DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
- Abstract
- 2.1 DeepSeek Sparse Attention
- 2.2 Parity Evaluation
- 2.3 Inference Costs
- 3.1 Scaling GRPO
- 3.2 Thinking in Tool-Use
- 4.1 Main Results
- 4.2 Results of DeepSeek-V3.2-Speciale
- 4.3 Synthesis Agentic Tasks
- 4.4 Context Management of Search Agent
- Appendix A: MHA and MQA Modes of MLA
- Appendix B: Cold Start Template
- Appendix C: Non-thinking DeepSeek-V3.2 Agentic Evaluation
- Appendix D: Evaluation Method
- Appendix E: Author List
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI research@deepseek.com
Abstract
We introduce DeepSeek-V3.2, a model that harmonizes high computational efficiency with superior reasoning and agent performance. The key technical breakthroughs of DeepSeek-V3.2 are as follows: (1) DeepSeek Sparse Attention (DSA): We introduce DSA, an efficient attention mechanism that substantially reduces computational complexity while preserving model performance in long-context scenarios. (2) Scalable Reinforcement Learning Framework: By implementing a robust reinforcement learning protocol and scaling post-training compute, DeepSeek-V3.2 performs comparably to GPT-5. Notably, our high-compute variant, DeepSeek-V3.2-Speciale, surpasses GPT-5 and exhibits reasoning proficiency on par with Gemini-3.0-Pro, achieving gold-medal performance in both the 2025 International Mathematical Olympiad (IMO) and the International Olympiad in Informatics (IOI). (3) Large-Scale Agentic Task Synthesis Pipeline: To integrate reasoning into tool-use scenarios, we developed a novel synthesis pipeline that systematically generates training data at scale. This methodology facilitates scalable agentic post-training, yielding substantial improvements in generalization and instruction-following robustness within complex, interactive environments.
 Figure 1: Benchmark of DeepSeek-V3.2 and its counterparts. For HMMT 2025, we report the February competition, consistent with the baselines. For HLE, we report the text-only subset.
Figure 1: Benchmark of DeepSeek-V3.2 and its counterparts. For HMMT 2025, we report the February competition, consistent with the baselines. For HLE, we report the text-only subset.
1 Introduction
The release of reasoning models (o1; deepseekr1) marked a pivotal moment in the evolution of Large Language Models (LLMs), catalyzing a substantial leap in overall performance across the verifiable fields. Since this milestone, the capabilities of LLMs have advanced rapidly. However, a distinct divergence has emerged in the past months. While the open-source community continues to make strides, the performance trajectory of closed-source proprietary models (gpt-5; sonnet-4.5; comanici2025gemini) has accelerated at a significantly steeper rate. Consequently, rather than converging, the performance gap between closed-source and open-source models appears to be widening, with proprietary systems demonstrating increasingly superior capabilities in complex tasks.
Through our analysis, we identify three critical deficiencies that limit the capability of open-source models in complex tasks. First, architecturally, the predominant reliance on vanilla attention mechanisms severely constrains efficiency for long sequences. This inefficiency poses a substantial obstacle to both scalable deployment and effective post-training. Second, regarding resource allocation, open-source models suffer from insufficient computational investment during the post-training phase, limiting their performance on hard tasks. Finally, in the context of AI agents, open-source models demonstrate a marked lag in generalization and instruction-following capabilities compared to their proprietary counterparts, hindering their effectiveness in real deployment.
To address these critical limitations, we first introduce DSA, a highly efficient attention mechanism designed to substantially reduce computational complexity. This architecture effectively addresses the efficiency bottleneck, preserving model performance even in long-context scenarios. Second, we develop a stable and scalable RL protocol that allows for significant computational expansion during the post-training phase. Notably, this framework allocates a post-training computational budget exceeding 10% of the pre-training cost, unlocking advanced capabilities. Thirdly, we propose a novel pipeline to foster generalizable reasoning in tool-use scenarios. First, we implement a cold-start phase utilizing the DeepSeek-V3 methodology to unify reasoning and tool-use within single trajectories. Subsequently, we advance to large-scale agentic task synthesis, where we generate over 1,800 distinct environments and 85,000 complex prompts. This extensive synthesized data drives the RL process, significantly enhancing the model’s generalization and instruction-following capability in the agent context.
DeepSeek-V3.2 achieves similar performance with Kimi-k2-thinking and GPT-5 across multiple reasoning benchmarks. Furthermore, DeepSeek-V3.2 significantly advances the agentic capabilities of open models, demonstrating exceptional proficiency on the long-tail agent tasks. DeepSeek-V3.2 emerges as a highly cost-efficient alternative in agent scenarios, significantly narrowing the performance gap between open and frontier proprietary models while incurring substantially lower costs. Notably, with the aim of pushing the boundaries of open models in the reasoning domain, we relaxed the length constraints to develop DeepSeek-V3.2-Speciale. As a result, DeepSeek-V3.2-Speciale achieves performance parity with the leading closed-source system, Gemini-3.0-Pro. It shows gold-medal performance in the IOI 2025, ICPC World Final 2025, IMO 2025, and CMO 2025.
2 DeepSeek-V3.2 Architecture
2.1 DeepSeek Sparse Attention
DeepSeek-V3.2 uses exactly the same architecture as DeepSeek-V3.2-Exp. Compared with DeepSeek-V3.1-Terminus, the last version of DeepSeek-V3.1, the only architectural modification of DeepSeek-V3.2 is the introduction of DeepSeek Sparse Attention (DSA) through continued training.
Prototype of DSA.
The prototype of DSA primarily consists of two components: a lightning indexer and a fine-grained token selection mechanism.
The lightning indexer computes the index score $I_{t,s}$ between the query token $\mathbf{h}{t}\in\mathbb{R}^{d}$ and a preceding token $\mathbf{h}{s}\in\mathbb{R}^{d}$, determining which tokens to be selected by the query token:
\[I_{t,s}=\sum_{j=1}^{H^{I}}w_{t,j}^{I}\cdot\text{ReLU}\left(\mathbf{q}^{I}_{t,j}\cdot\mathbf{k}^{I}_{s}\right), \quad (1)\]where $H^{I}$ denotes the number of indexer heads; $\mathbf{q}^{I}{t,j}\in\mathbb{R}^{d^{I}}$ and $w{t,j}^{I}\in\mathbb{R}$ are derived from the query token $\mathbf{h}{t}$; and $\mathbf{k}^{I}{s}\in\mathbb{R}^{d^{I}}$ is derived from the preceding token $\mathbf{h}_{s}$. We choose ReLU as the activation function for throughput consideration. Given that the lightning indexer has a small number of heads and can be implemented in FP8, its computational efficiency is remarkable.
Given the index scores ${I_{t,s}}$ for each query token $\mathbf{h}{t}$, our fine-grained token selection mechanism retrieves only the key-value entries ${\mathbf{c}{s}}$ corresponding to the top-k index scores. Then, the attention output $\mathbf{u}{t}$ is computed by applying the attention mechanism between the query token $\mathbf{h}{t}$ and the sparsely selected key-value entries ${\mathbf{c}_{s}}$:
\[\mathbf{u}_{t}=\text{Attn}\left(\mathbf{h}_{t},\{\mathbf{c}_{s} \mid I_{t,s}\in\text{Top-k}(I_{t,:})\}\right). \quad (2)\] Figure 2: Attention architecture of DeepSeek-V3.2, where DSA is instantiated under MLA. The green part illustrates how DSA selects the top-k key-value entries according to the indexer.
Figure 2: Attention architecture of DeepSeek-V3.2, where DSA is instantiated under MLA. The green part illustrates how DSA selects the top-k key-value entries according to the indexer.
Instantiate DSA Under MLA.
For the consideration of continued training from DeepSeek-V3.1-Terminus, we instantiate DSA based on MLA for DeepSeek-V3.2. At the kernel level, each key-value entry must be shared across multiple queries for computational efficiency. Therefore, we implement DSA based on the MQA mode of MLA, where each latent vector (the key-value entry of MLA) will be shared across all query heads of the query token. The DSA architecture based on MLA is illustrated in Figure 2. We also provide an open-source implementation of DeepSeek-V3.2.
2.1.1 Continued Pre-Training
Starting from a base checkpoint of DeepSeek-V3.1-Terminus, whose context length has been extended to 128K, we perform continued pre-training followed by post-training to create DeepSeek-V3.2.
The continued pre-training of DeepSeek-V3.2 consists of two training stages. For both stages, the distribution of training data is totally aligned with the 128K long context extension data used for DeepSeek-V3.1-Terminus.
Dense Warm-up Stage.
We first use a short warm-up stage to initialize the lightning indexer. In this stage, we keep dense attention and freeze all model parameters except for the lightning indexer. To align the indexer outputs with the main attention distribution, for the $t$-th query token, we first aggregate the main attention scores by summing across all attention heads. This sum is then L1-normalized along the sequence dimension to produce a target distribution $p_{t,:}\in\mathbb{R}^{t}$. Based on $p_{t,:}$, we set a KL-divergence loss as the training objective of the indexer:
\[\mathcal{L}^{I}=\sum_{t}\mathbb{D}_{\mathrm{KL}}\left(p_{t,:} \parallel \text{Softmax}(I_{t,:})\right). \quad (3)\]For warm-up, we use a learning rate of $10^{-3}$. We train the indexer for only 1000 steps, with each step consisting of 16 sequences of 128K tokens, resulting in a total of 2.1B tokens.
Sparse Training Stage.
Following indexer warm-up, we introduce the fine-grained token selection mechanism and optimize all model parameters to adapt the model to the sparse pattern of DSA. In this stage, we also keep aligning the indexer outputs to the main attention distribution, but considering only the selected token set $\mathcal{S}{t}={s \mid I{t,s}\in\text{Top-k}(I_{t,:})}$:
\[\mathcal{L}^{I}=\sum_{t}\mathbb{D}_{\mathrm{KL}}\left(p_{t,\mathcal{S}_{t}} \parallel \text{Softmax}(I_{t,\mathcal{S}_{t}})\right). \quad (4)\]It is worth noting that we detach the indexer input from the computational graph for separate optimization. The training signal of the indexer is from only $\mathcal{L}^{I}$, while the optimization of the main model is according to only the language modeling loss. In this sparse training stage, we use a learning rate of $7.3\times 10^{-6}$, and select 2048 key-value tokens for each query token. We train both the main model and the indexer for $15000$ steps, with each step consisting of 480 sequences of 128K tokens, resulting in a total of 943.7B tokens.
2.2 Parity Evaluation
Standard Benchmark
In September 2025, we evaluate DeepSeek-V3.2-Exp on a suite of benchmarks, which focus on diverse capabilities, and compare it with DeepSeek-V3.1-Terminus showing similar performance. While DeepSeek V3.2 Exp significantly improves computational efficiency on long sequences, we do not observe substantial performance degradation compared with DeepSeek-V3.1-Terminus, on both short- and long-context tasks.
Human Preference
Given that direct human preference assessments are inherently susceptible to bias, we employ ChatbotArena as an indirect evaluation framework to approximate user preferences for the newly developed base models. Both DeepSeek‑V3.1‑Terminus and DeepSeek‑V3.2‑Exp share an identical post‑training strategy, and their Elo scores, obtained from evaluations conducted on 10 November 2025, are closely matched. These results suggest that the new base model achieves performance on par with the previous iteration, despite incorporating a sparse attention mechanism.
Long Context Eval
Following the release of DeepSeek‑V3.2‑Exp, several independent long‑context evaluations were conducted using previously unseen test sets. A representative benchmark is AA‑LCR, in which DeepSeek‑V3.2‑Exp scores four points higher than DeepSeek-V3.1-Terminus in reasoning mode. In the Fiction.liveBench evaluation, DeepSeek‑V3.2‑Exp consistently outperforms DeepSeek-V3.1-Terminus across multiple metrics. This evidence indicates the base checkpoint of DeepSeek‑V3.2‑Exp does not regress on long context tasks.
2.3 Inference Costs
DSA reduces the core attention complexity of the main model from $O(L^2)$ to $O(Lk)$, where $k$ ($\ll L$) is the number of selected tokens. Although the lightning indexer still has a complexity of $O(L^2)$, it requires much less computation compared with MLA in DeepSeek-V3.1-Terminus. Combined with our optimized implementation, DSA achieves a significant end-to-end speedup in long-context scenarios. Figure 3 presents how token costs of DeepSeek-V3.1-Terminus and DeepSeek-V3.2 vary with the token position in the sequence. These costs are estimated from benchmarking the actual service deployed on H800 GPUs, at a rental price of 2 USD per GPU hour. Note that for short-sequence prefilling, we specially implement a masked MHA mode to simulate DSA, which can achieve higher efficiency under short-context conditions.
 Figure 3: Inference costs of DeepSeek-V3.1-Terminus and DeepSeek-V3.2 on H800 clusters. (a) Prefilling (b) Decoding.
Figure 3: Inference costs of DeepSeek-V3.1-Terminus and DeepSeek-V3.2 on H800 clusters. (a) Prefilling (b) Decoding.
3 Post-Training
After continued pre-training, we perform post-training to create the final DeepSeek-V3.2. The post-training of DeepSeek-V3.2 also employs sparse attention in the same way as the sparse continued pre-training stage. For DeepSeek-V3.2, we maintain the same post-training pipeline as in DeepSeek-V3.2-Exp, which includes specialist distillation and mixed RL training.
Specialist Distillation
For each task, we initially develop a specialized model dedicated exclusively to that particular domain, with all specialist models being fine-tuned from the same pre-trained DeepSeek-V3.2 base checkpoint. In addition to writing tasks and general question-answering, our framework encompasses six specialized domains: mathematics, programming, general logical reasoning, general agentic tasks, agentic coding, and agentic search, with all the domains supporting both thinking and non-thinking modes. Each specialist is trained with large-scale Reinforcement Learning (RL) computing. Furthermore, we employ different models to generate training data for long chain-of-thought reasoning (thinking mode) and direct response generation (non-thinking mode). Once the specialist models are prepared, they are used to produce the domain-specific data for the final checkpoint. Experimental results demonstrate that models trained on the distilled data achieve performance levels only marginally below those of domain-specific specialists, with the performance gap being effectively eliminated through subsequent RL training.
Mixed RL Training
For DeepSeek-V3.2, we still adopt Group Relative Policy Optimization (GRPO) as the RL training algorithm. As DeepSeek-V3.2-Exp, we merge reasoning, agent, and human alignment training into one RL stage. This approach effectively balances performance across diverse domains while circumventing the catastrophic forgetting issues commonly associated with multi-stage training paradigms. For reasoning and agent tasks, we employ rule-based outcome reward, length penalty, and language consistency reward. For general tasks, we employ a generative reward model where each prompt has its own rubrics for evaluation.
DeepSeek-V3.2 and DeepSeek-V3.2-Speciale
DeepSeek-V3.2 integrates reasoning, agent, and human alignment data distilled from specialists, undergoing thousands of steps of continued RL training to reach the final checkpoints. To investigate the potential of extended thinking, we also developed an experimental variant, DeepSeek-V3.2-Speciale. This model was trained exclusively on reasoning data with a reduced length penalty during RL. Additionally, we incorporated the dataset and reward method from DeepSeekMath-V2 to enhance capabilities in mathematical proofs.
3.1 Scaling GRPO
We first review the objective of GRPO. GRPO optimizes the policy model $\pi_{\theta}$ by maximizing the following objective on a group of responses ${o_{1},\cdots,o_{G}}$ sampled from the old policy $\pi_{\mathrm{old}}$ given each question $q$:
\(\mathcal{J}_{\mathrm{GRPO}}(\theta)=\mathbb{E}_{q\sim P(Q),\{o_{i}\}_{i=1}^{G}\sim\pi_{\mathrm{old}}(\cdot|q)}\left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|o_{i}|}\sum_{t=1}^{|o_{i}|} \right.\) \(\left.\min\left(r_{i,t}(\theta)\hat{A}_{i,t},\text{clip}\left(r_{i,t}(\theta),1-\varepsilon,1+\varepsilon\right)\hat{A}_{i,t}\right)-\beta\mathbb{D}_{\mathrm{KL}}\left(\pi_{\theta}(o_{i,t}) \parallel \pi_{\mathrm{ref}}(o_{i,t})\right)\right], \quad (5)\)
where \(r_{i,t}(\theta)=\frac{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}{\pi_{\mathrm{old}}(o_{i,t}|q,o_{i,<t})} \quad (6)\)
is the importance sampling ratio between the current and old policy. $\varepsilon$ and $\beta$ are hyper-parameters controlling the clipping range and KL penalty strength, respectively. $\hat{A}{i,t}$ is the advantage of $o{i,t}$ which is estimated by normalizing the outcome reward within each group. Specifically, a set of reward models are used to score an outcome reward $R_{i}$ for each output $o_{i}$ in the group, yielding $G$ rewards $\boldsymbol{R}={R_{1},\cdots,R_{G}}$ respectively. The advantage of $o_{i,t}$ is calculated by subtracting the average reward of the group from the reward of output $o_{i}$, i.e., $\hat{A}{i,t}=R{i}-\text{mean}(\boldsymbol{R})$.
In the following, we outline additional strategies that stabilize RL scaling, directly building on the GRPO algorithm.
Unbiased KL Estimate
Given $o_{i,t}$ is sampled from the old policy $\pi_{\mathrm{old}}(\cdot|q,o_{i,<t})$, we correct the K3 estimator to obtain an unbiased KL estimate using the importance-sampling ratio between the current policy $\pi_{\theta}$ and the old policy $\pi_{\mathrm{old}}$.
\[\mathbb{D}_{\mathrm{KL}}\left(\pi_{\theta}(o_{i,t}) \parallel \pi_{\mathrm{ref}}(o_{i,t})\right)=\frac{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}{\pi_{\mathrm{old}}(o_{i,t}|q,o_{i,<t})}\left(\frac{\pi_{\mathrm{ref}}(o_{i,t}|q,o_{i,<t})}{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}-\log\frac{\pi_{\mathrm{ref}}(o_{i,t}|q,o_{i,<t})}{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}-1\right). \quad (7)\]As a direct result of this adjustment, the gradient of this KL estimator becomes unbiased, which eliminates systematic estimation errors, thereby facilitating stable convergence. This contrasts sharply with the original K3 estimator, particularly when the sampled tokens have substantially lower probabilities under the current policy than the reference policy, i.e., $\pi_{\theta}\ll\pi_{\mathrm{ref}}$.
Off-Policy Sequence Masking
To improve the efficiency of RL systems, we typically generate a large batch of rollout data, which is subsequently split into multiple mini-batches for several gradient update steps. This practice inherently introduces off-policy behavior. To stabilize training and improve tolerance for off-policy updates, we mask negative sequences that introduce significant policy divergence, as measured by the KL divergence between the data-sampling policy $\pi_{\mathrm{old}}$ and the current policy $\pi_{\theta}$. More specifically, we introduce a binary mask $M$ into the GRPO loss:
\(\mathcal{J}_{\mathrm{GRPO}}(\theta)=\mathbb{E}_{q\sim P(Q),\{o_{i}\}_{i=1}^{G}\sim\pi_{\mathrm{old}}(\cdot|q)}\left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|o_{i}|}\sum_{t=1}^{|o_{i}|} \right.\) \(\left.\min\left(r_{i,t}(\theta)\hat{A}_{i,t},\text{clip}\left(r_{i,t}(\theta),1-\varepsilon,1+\varepsilon\right)\hat{A}_{i,t}\right)M_{i,t}-\beta\mathbb{D}_{\mathrm{KL}}\left(\pi_{\theta}(o_{i,t}) \parallel \pi_{\mathrm{ref}}(o_{i,t})\right)\right], \quad (8)\)
where
\[M_{i,t}=\begin{cases}0 & \hat{A}_{i,t}<0,\frac{1}{|o_{i}|}\sum_{t=1}^{|o_{i}|}\log\frac{\pi_{\mathrm{old}}(o_{i,t}|q,o_{i,<t})}{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}>\delta \\ 1 & \text{otherwise,}\end{cases} \quad (9)\]and $\delta$ is a hyper-parameter that controls the threshold of policy divergence.
Keep Routing
Mixture-of-Experts (MoE) models improve computational efficiency by activating only a subset of expert modules during inference. To mitigate routing path shifts between inference and training, we preserve the expert routing paths used during sampling in the inference framework and enforce the same routing paths during training.
Keep Sampling Mask
Top-p and top-k sampling are used to enhance response quality. To address the mismatch between the action spaces of $\pi_{\mathrm{old}}$ and $\pi_{\theta}$ caused by truncation, we preserve the truncation masks during sampling from $\pi_{\mathrm{old}}$ and apply them to $\pi_{\theta}$ during training.
3.2 Thinking in Tool-Use
3.2.1 Thinking Context Management
DeepSeek-R1 demonstrated that thinking processes enhance complex problem-solving. We integrated this into tool-calling scenarios. We developed a context management system tailored for tool-calling:
- Historical reasoning content is discarded only when a new user message is introduced. If only tool outputs are appended, reasoning content is retained.
- When reasoning traces are removed, the history of tool calls and results remains preserved.
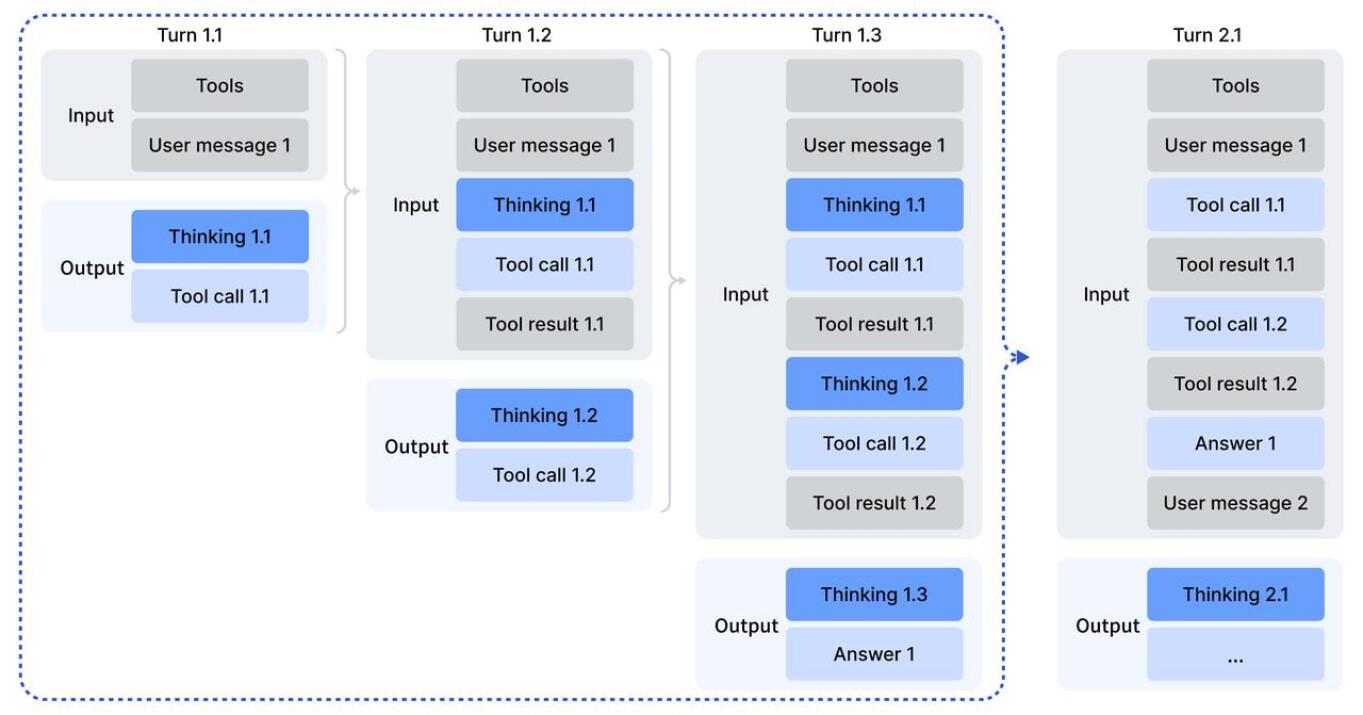 Figure 4: Thinking retention mechanism in tool-calling scenarios.
Figure 4: Thinking retention mechanism in tool-calling scenarios.
3.2.2 Cold-Start
We use carefully designed prompting to integrate reasoning and agentic capabilities. We designed system prompts that ask the model to reason before tool calls using the <think></think> tags. This enables the model to generate initial trajectories for subsequent reinforcement learning.
3.2.3 Large-Scale Agentic Tasks
A diverse set of RL tasks is crucial for robustness. We used real-world tools (search APIs, Jupyter) and synthetic environments.
| Task | number of tasks | environment | prompt |
|---|---|---|---|
| code agent | 24667 | real | extracted |
| search agent | 50275 | real | synthesized |
| general agent | 4417 | synthesized | synthesized |
| code interpreter | 5908 | real | extracted |
Table 1: The description of different agent tasks, including the number of tasks, environment type (real or synthesized), and prompt source (extracted or synthesized).
Search Agent
We used a multi-agent pipeline to generate QA pairs from web corpora, validated them with verification agents, and scored them using a generative reward model for factual reliability.
Code Agent
We constructed environments from GitHub issue-PR pairs. An automated agent powered by DeepSeek-V3.2 builds executable environments, resolving dependencies and ensuring gold patches fix issues while passing tests.
Code Interpreter Agent
We curate problems in math, logic, and data science that require Jupyter Notebook execution for solutions.
General Agent
We synthesized 1,827 task-oriented environments (e.g., trip planning). The workflow involves sandbox data retrieval, tool function synthesis, and iterative task difficulty scaling with verification functions.
An Example of Synthesized Task: Trip Planning I’m planning a three-day trip starting from Hangzhou, and I need help creating an itinerary from October 1st to October 3rd, 2025. A few important requirements: I don’t want to repeat any cities, hotels, attractions, or restaurants during the entire trip… (Full constraints omitted for brevity).
Tool Set for Trip Planning
get_all_attractions_by_city(city): Get all attractions for given city.get_all_cities(): Get all cities from the database.get_all_hotels_by_city(city): Get all hotels for given city.-
(Additional tools for transport, weather, etc.)
4 Evaluation
4.1 Main Results
We evaluate models across a broad range of benchmarks including MMLU-Pro, GPQA Diamond, Human Last Exam (HLE), LiveCodeBench, etc.
| Benchmark (Metric) | Claude-4.5-Sonnet | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | MiniMax M2 | DeepSeek-V3.2 Thinking |
|---|---|---|---|---|---|---|
| MMLU-Pro (EM) | 88.2 | 87.5 | 90.1 | 84.6 | 82.0 | 85.0 |
| GPQA Diamond (P@1) | 83.4 | 85.7 | 91.9 | 84.5 | 77.7 | 82.4 |
| HLE (Pass@1) | 13.7 | 26.3 | 37.7 | 23.9 | 12.5 | 25.1 |
| LiveCodeBench | 64.0 | 84.5 | 90.7 | 82.6 | 83.0 | 83.3 |
| AIME 2025 | 87.0 | 94.6 | 95.0 | 94.5 | 78.3 | 93.1 |
| SWE Verified | 77.2 | 74.9 | 76.2 | 71.3 | 69.4 | 73.1 |
| BrowseComp | 24.1 | 54.9 | - | -/60.2* | 44.0 | 51.4/67.6* |
| $\tau^2$-Bench | 84.7 | 80.2 | 85.4 | 74.3 | 76.9 | 80.3 |
Table 2: Comparison between DeepSeek-V3.2 and closed/open models. Numbers in bold represent best scores in class.
DeepSeek-V3.2 achieves similar performance with GPT-5-high on reasoning tasks but is slightly worse than Gemini-3.0-Pro. In code agent evaluations, it significantly outperforms other open-source models.
4.2 Results of DeepSeek-V3.2-Speciale
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| CodeForces | 2537 (29k) | 2708 (22k) | - | 2386 (42k) | 2701 (77k) |
Table 3: Benchmark performance and efficiency of reasoning models. Cells show accuracy and output token count.
| Competition | P1 | P2 | P3 | P4 | P5 | P6 | Overall | Medal |
|---|---|---|---|---|---|---|---|---|
| IMO 2025 | 7 | 7 | 7 | 7 | 7 | 0 | 35/42 | Gold |
| CMO 2025 | 18 | 18 | 9 | 21 | 18 | 18 | 102/126 | Gold |
| IOI 2025 | 100 | 82 | 72 | 100 | 55 | 83 | 492/600 | Gold |
Table 4: Performance of DeepSeek-V3.2-Speciale in top-tier competitions. Gold-medal level performance achieved.
4.3 Synthesis Agentic Tasks
Synthetic tasks are challenging; frontier models reach at most 62% on these tasks. RL on synthetic data yields substantial improvements on Tau2Bench and MCP benchmarks compared to SFT-only checkpoints.
4.4 Context Management of Search Agent
To address context window limits (128k), we use strategies like Summary, Discard-75%, and Discard-all. Discard-all achieves a score of 67.6 on BrowseComp, comparable to parallel scaling but more efficient.
 Figure 6: Accuracy of Browsecomp with different test-time compute expansion strategies.
Figure 6: Accuracy of Browsecomp with different test-time compute expansion strategies.
5 Conclusion, Limitation, and Future Work
DeepSeek-V3.2 bridges the gap between efficiency and reasoning. DSA addresses complexity, while increased RL budget allows GPT-5 level reasoning. Limitations include a world knowledge gap due to pre-training FLOPs and lower token efficiency compared to Gemini-3.0-Pro. Future work will focus on scaling pre-training and optimizing reasoning intelligence density.
Appendices
Appendix A: MHA and MQA Modes of MLA

Appendix B: Cold Start Template
(Detailed system prompts for reasoning and agentic modes provided in tables 6-8 of the original document).
Appendix C: Non-thinking DeepSeek-V3.2 Agentic Evaluation
Non-thinking mode remains competitive though slightly lower than thinking mode (e.g., 72.1% on SWE Verified vs 73.1% in thinking mode).
Appendix D: Evaluation Method
Standard competition rules were followed. IOI utilized a 50-submission strategy. IMO/CMO used a generate-verify-refine loop.
Appendix E: Author List
(Extensive list of researchers across Research & Engineering, Data Annotation, and Business & Compliance teams).