Solusi Kemacetan Kinerja
- Yang akan kita pelajari pada bab ini:
- 2.4 Solusi: Caching (Memori Simpanan) untuk efisiensi
- 2.5 Sisi gelap dari KV cache: Biaya memori komputer
- 2.6 Pendekatan yang mengutamakan hemat memori: Multi-Query Attention (MQA)
- 2.7 Mencari jalan tengah: Grouped-Query Attention (GQA)
- 2.8 Pengorbanan antara kecerdasan dan memori komputer
- 2.9 Ringkasan
Solusi Kemacetan Kinerja
Yang akan kita pelajari pada bab ini:
- Multi-Query Attention (MQA) dan Grouped-Query Attention (GQA)
- Solusi generasi pertama untuk mengatasi batas memori pada KV Cache.
2.4 Solusi: Caching (Memori Simpanan) untuk efisiensi
Jika kita menyadari bahwa kita berulang kali menghitung nilai yang sama persis untuk kata-kata di masa lalu, seharusnya kita menghitungnya cukup sekali saja lalu menyimpannya di memori komputer. Inilah yang dinamakan Key-Value (KV) Cache. Dengan memutus siklus kerja kuadratik yang melelahkan tersebut, teknologi ini membuat LLM modern akhirnya bisa digunakan oleh publik.
2.4.1 Apa saja yang harus disimpan ke memori? Penjelasan langkah demi langkah
Untuk memahami secara pasti data apa saja yang perlu dimasukkan ke dalam memori cache, kita perlu mundur selangkah dari tujuan akhir kita: kita hanya menginginkan vektor konteks akhir untuk satu kata terbaru kita, yaitu “bright.”
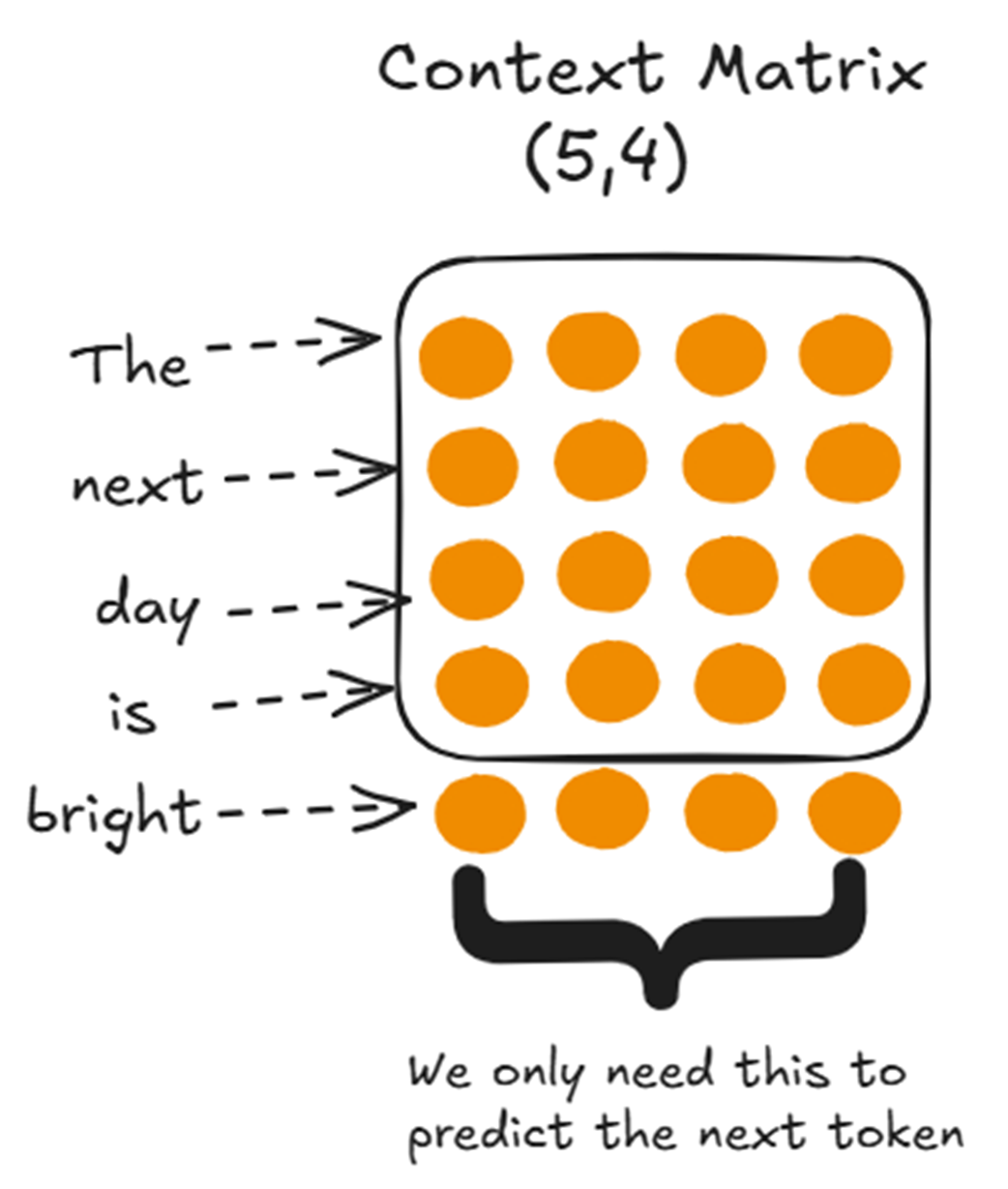
Untuk mendapatkan vektor konteks khusus untuk “bright”, kita harus mengalikan barisan bobot perhatian (attention weights) milik “bright” dengan keseluruhan matriks Value (Nilai).
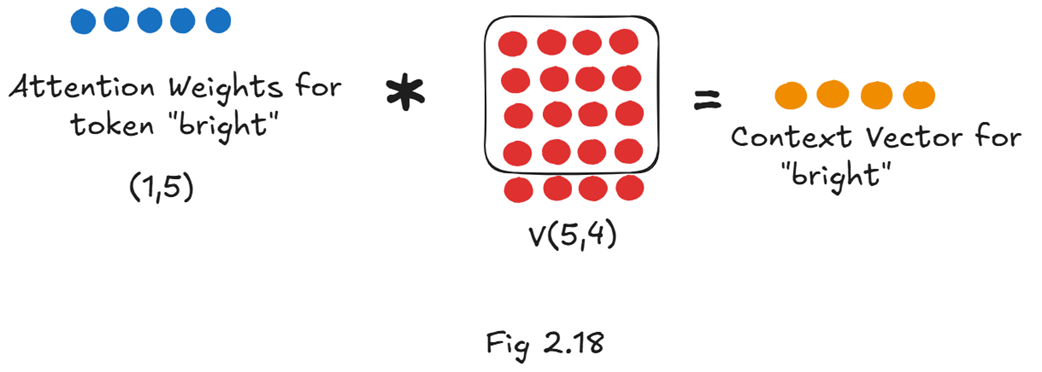
Oleh karena itu, benda-benda yang kita butuhkan adalah:
- Baris Bobot Perhatian khusus untuk “bright” (sebuah vektor berukuran $1 \times 5$).
- Matriks Value utuh (V) yang berisi isi/makna untuk kelima kata dalam kalimat.
Lalu bagaimana cara kita mendapatkan Bobot Perhatian untuk “bright”? Kita menghitungnya dari perkalian vektor matriks Query milik “bright” dengan kebalikan dari matriks Key yang utuh.
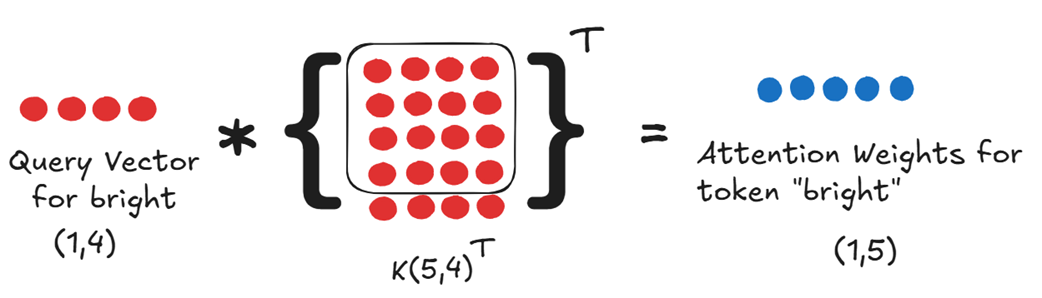
Jadi, hal minimal mutlak yang harus kita miliki untuk menebak kata selanjutnya adalah:
- Vektor Query khusus untuk kata “bright”.
- Matriks Key (K) secara utuh untuk semua kata di kalimat itu.
- Matriks Value (V) secara utuh untuk semua kata di kalimat itu.
Ketika kata “bright” yang baru ini masuk, kita segera mengubah angkanya (memproyeksikannya) menjadi vektor Query, Key, dan Value-nya sendiri.

Sekarang pertanyaannya, bagaimana dengan Key dan Value untuk semua kata-kata yang lama (“The next day is”?) Pada cara awal yang bodoh tadi, kita menghitung ulangnya dari awal. Pada cara yang sudah dioptimalkan, kita cukup mengambil data masa lalu itu dari dalam KV Cache (Memori).
Kita tidak menyimpan Query ke dalam memori. Kenapa? Karena vektor Query hanya digunakan sesekali untuk mengajukan pertanyaan mewakili kata yang saat ini sedang aktif. Begitu kata “bright” selesai menemukan konteksnya, vektor Query miliknya tidak akan pernah dibutuhkan lagi untuk menebak kata-kata di masa depan. Sebaliknya, Key (identitas) dan Value (isi) bertindak sebagai perpustakaan sejarah bagi model AI, sehingga mereka harus disimpan di memori selama mungkin.
2.4.2 Putaran penggunaan baru yang lebih cepat dengan KV caching
Putaran pembuatan kata (autoregresif) sekarang menjadi sangat dioptimalkan:
- Menerima Kata: Model komputer menerima satu buah kata (token) baru.
- Menghitung Perubahan: Komputer melakukan perhitungan matriks untuk mendapatkan vektor Q, K, dan V hanya khusus untuk satu kata baru ini saja.
- Mengambil Data Lama: Komputer memuat/mengambil matriks K dan V masa lalu dari KV Cache.
- Menyambung Data: Komputer menggabungkan vektor K dan V yang baru dengan matriks yang baru saja diambil dari memori.
- Menghitung Perhatian (Attention): Komputer mengalikan vektor Q baru dengan matriks K yang sudah digabungkan.
- Menghitung Konteks: Komputer mengalikan hasil bobot perhatian tadi dengan matriks V yang sudah digabungkan.
- Menebak: Komputer menghasilkan skor (logits) untuk menebak kata berikutnya.
- Memperbarui Memori: Komputer menyimpan matriks K dan V yang sudah ditambahkan kata baru ini kembali ke dalam memori kartu grafis (GPU).
Perhitungan perkalian angka matriks yang berat untuk kata-kata masa lalu kini hanya dilakukan tepat satu kali saja, tidak diulang lagi.
2.4.3 Mendemonstrasikan peningkatan kecepatan dari KV caching
Kita bisa membuktikan peningkatan kecepatan ini menggunakan kode pemrograman transformers dari Hugging Face, yang memungkinkan kita menyalakan atau mematikan tombol sistem memori use_cache.
Kode Pemrograman 2.2 Mendemonstrasikan Peningkatan Kecepatan KV Caching
prompt = "The next day is bright"
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs.input_ids
attention_mask = inputs.attention_mask
# Menghitung waktu TANPA KV cache (memaksa komputer berhitung
# dari awal secara O(n^2))
start_time_without_cache = time.time()
output_without_cache = model.generate(input_ids,
max_new_tokens=100,
use_cache=False,
attention_mask=attention_mask)
duration_without_cache = time.time() - start_time_without_cache
print(f"Waktu tanpa KV Cache: {duration_without_cache:.4f} detik")
# Menghitung waktu DENGAN KV cache (beroperasi secara cepat dan
# ringan secara linier O(n))
start_time_with_cache = time.time()
output_with_cache = model.generate(input_ids,
max_new_tokens=100,
use_cache=True,
attention_mask=attention_mask)
duration_with_cache = time.time() - start_time_with_cache
print(f"Waktu dengan KV Cache: {duration_with_cache:.4f} detik")
speedup = duration_without_cache / duration_with_cache
print(f"\nPeningkatan Kecepatan KV Cache: {speedup:.2f}x")
Menjalankan kode ini pada perangkat komputer standar akan memberikan hasil sebagai berikut:
Waktu tanpa KV Cache: 30.9818 detik
Waktu dengan KV Cache: 6.1630 detik
Peningkatan Kecepatan KV Cache: 5.03x
Dengan menghilangkan perhitungan berulang yang sia-sia, kita bisa membuat komputer bekerja 5 kali lebih cepat hanya untuk menghasilkan 100 kata. Untuk dokumen teks yang sangat panjang, peningkatan kecepatan ini bisa mencapai ratusan kali lebih cepat. Akan tetapi, mukjizat kecepatan ini datang dengan hukuman yang sangat parah.
2.5 Sisi gelap dari KV cache: Biaya memori komputer
Kita telah berhasil memecahkan masalah kemacetan beban kerja prosesor, tetapi sebagai gantinya, kita menciptakan kemacetan memori yang parah.
Untuk menggunakan KV cache, matriks Key dan Value yang ukurannya sangat raksasa ini harus disimpan secara fisik di dalam Memori Berkecepatan Tinggi (HBM) pada kartu grafis (GPU), dan memori ini harus terus-menerus dipindahkan bolak-balik ke inti komputernya. Penggunaan LLM dengan cepat berubah dari sebelumnya terbatas oleh seberapa kuat otak komputernya, menjadi terbatas oleh seberapa besar kapasitas memorinya. Kita pada dasarnya sedang menukar ruang VRAM fisik komputer demi menghemat waktu proses.
2.5.1 Rumus KV cache: Membedah ukuran memori
Kita bisa menghitung secara matematika ukuran VRAM (memori kartu grafis) yang pasti untuk menampung KV cache ini.
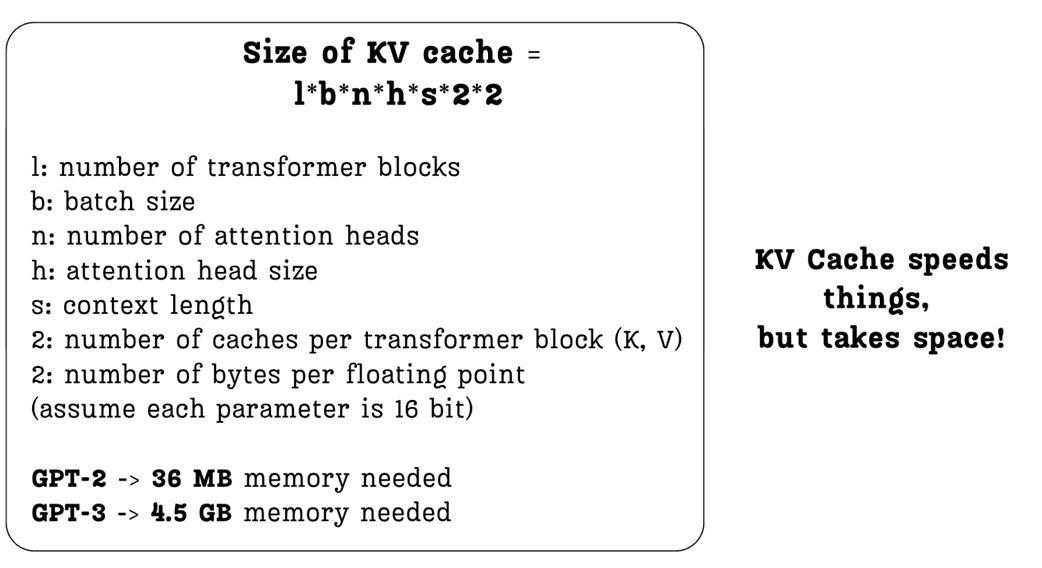
Rumusnya adalah:
\[\text{Ukuran KV Cache (Byte)} = 2 \times 2 \times l \times u \times n \times b \times z\]- l (layers / lapisan): Jumlah total blok Transformer.
- u (batch size / pengguna): Jumlah tugas/kalimat yang diproses dalam waktu bersamaan.
- n (heads / kepala): Jumlah kepala perhatian (attention heads) per lapisan.
- b (head size / ukuran kepala): Ukuran/dimensi dari vektor K dan V.
- z (sequence length / panjang teks): Jumlah kata/token yang sedang dibaca.
- Angka 2 pertama: Karena kita menyimpan dua jenis matriks (Key dan Value).
- Angka 2 kedua: Untuk presisi angka. Angka desimal 16-bit (FP16/BF16) memakan 2 byte memori.
Seiring berjalannya waktu, model AI dibuat semakin canggih dengan lapisan ($l$) dan kepala ($n$) yang semakin banyak. Selain itu, pengguna internet juga meminta AI mampu membaca teks cerita yang sangat panjang ($z$). Akibatnya, hasil hitungan dari rumus ini meledak tak terkendali.
2.5.2 Masalah ukuran di dunia nyata
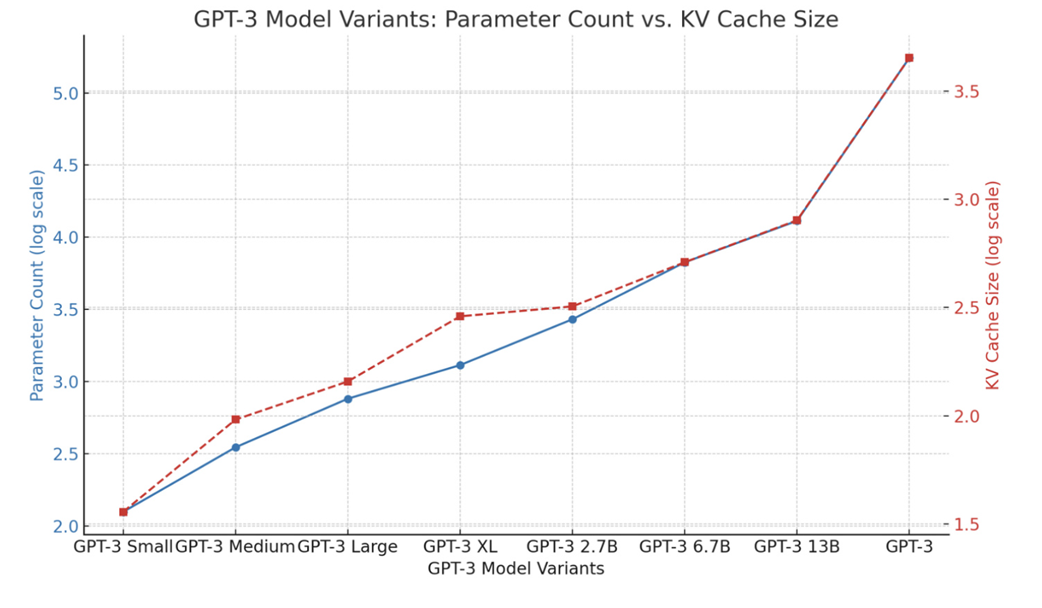
Coba bayangkan sebuah arsitektur AI modern seperti DeepSeek-V3 atau V4, yang memiliki 61 lapisan, 128 kepala (dengan ukuran per kepalanya 128), dan kemampuan membaca teks panjang hingga 1.000.000 kata (token).
Jika kita menerapkan sistem caching Multi-Head Attention standar ke urutan 1 juta kata untuk hanya melayani satu orang pengguna saja, maka KV cache ini sendirian akan menghabiskan memori VRAM lebih dari 3,8 Terabyte. Padahal, satu keping kartu grafis kelas dunia yaitu NVIDIA H100 GPU yang sangat mahal hanya memiliki memori 80GB. Untuk melayani satu pertanyaan dari pengguna saja, Anda akan membutuhkan satu rak server berisi 48 kartu grafis tersebut hanya untuk menampung memori cache-nya saja.
Inilah fakta pahit dalam pemasangan AI modern. Tekanan pada memori membuat teknik attention standar menjadi mustahil secara fisik untuk digunakan pada teks yang sangat panjang. Krisis kelangsungan hidup inilah yang memaksa perusahaan pembuat AI untuk menciptakan jalan pintas pada rancangan AI mereka, yang melahirkan: Multi-Query Attention dan Grouped-Query Attention.
2.6 Pendekatan yang mengutamakan hemat memori: Multi-Query Attention (MQA)
Apa cara paling ekstrem (brutal) untuk memotong rumus KV Cache tadi? Jawabannya adalah Multi-Query Attention (MQA). MQA mengusulkan perubahan desain AI yang sangat radikal: bagaimana jika semua kepala ahli (attention heads) yang berbeda-beda tadi dipaksa untuk berbagi satu buah matriks Key dan Value yang sama persis?
2.6.1 Ide intinya: Berbagi satu Kunci dan Nilai
Pada sistem standar Multi-Head Attention (MHA), setiap kepala bertindak sebagai seorang ahli yang mandiri dengan otak matriks $W_k$ dan $W_v$ miliknya sendiri-sendiri.
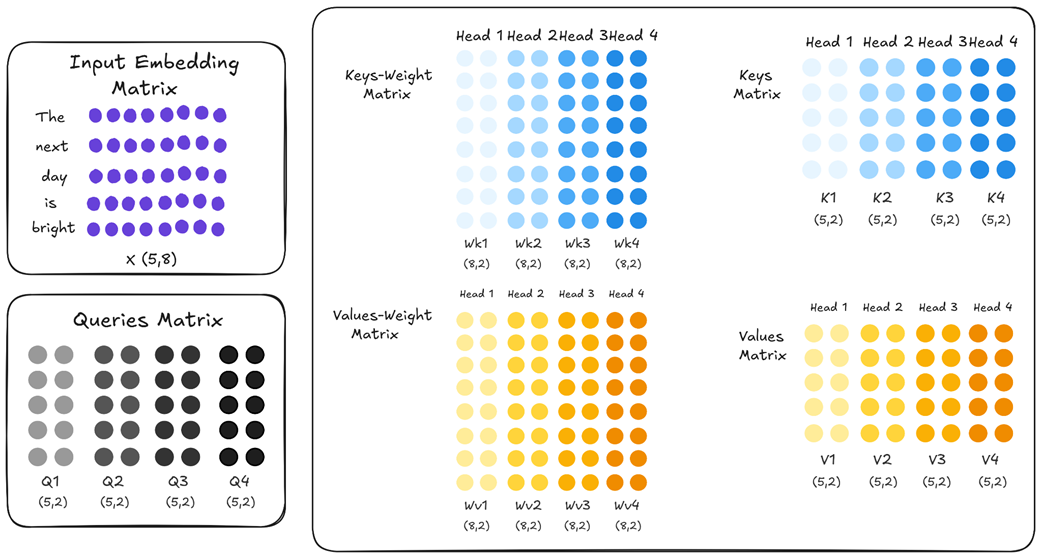
MQA menyederhanakan hal ini secara paksa. Meskipun setiap kepala masih boleh menyimpan proyeksi Query-nya masing-masing (sehingga setiap kepala masih bisa mengajukan pertanyaan yang berbeda), semua kepala tersebut dipaksa untuk meminjam dan memakai satu set matriks Key dan Value yang sama secara bersama-sama.
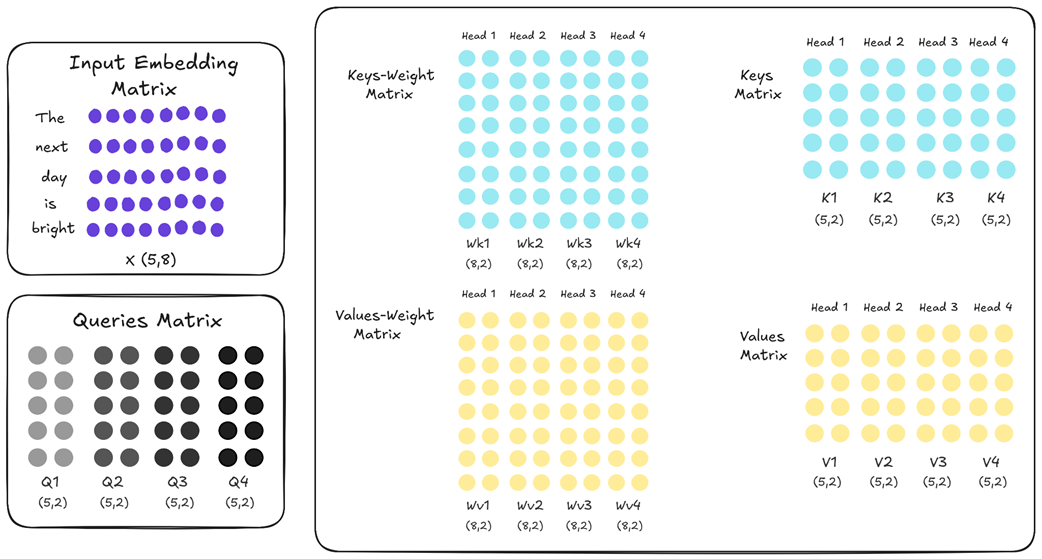
Pada Gambar 2.24, $K_1, K_2, K_3,$ dan $K_4$ sebenarnya adalah salinan matematik dari satu hal yang sama persis. Dampak dari hal ini sangatlah besar: alih-alih kita menyimpan salinan matriks Key/Value sebanyak $n$ (jumlah kepala) ke memori, sekarang kita hanya perlu menyimpan satu buah saja.
2.6.2 Dampaknya terhadap rumus KV cache
Dengan memaksa semua kepala berbagi satu pasangan K/V tunggal, variabel $n$ (jumlah kepala) di rumus kita yang sebelumnya besar, secara efektif langsung berubah menjadi angka 1.
\[\text{Ukuran KV Cache MQA} = 2 \times 2 \times l \times u \times \mathbf{1} \times b \times z\]Bagi sebuah model AI yang memiliki 128 kepala, MQA mengurangi ukuran KV Cache hingga 128 kali lipat. Ukuran memori komputer yang secara teori butuh 3,8 Terabyte tadi, kini menyusut drastis menjadi sekitar 30GB saja—sehingga muat dengan lega di dalam satu buah kartu grafis (GPU) standar.
2.6.3 Harga yang harus dibayar: Hilangnya kecerdasan bahasa
Penghematan memori besar-besaran ini harus dibayar dengan harga yang mahal: kecerdasan dan kemampuan AI memahami bahasa yang rumit jadi menurun drastis. Pertimbangkan kalimat ambigu (bermakna ganda) ini: “The artist painted the portrait of a woman with a brush.” (Seniman itu melukis potret seorang wanita dengan kuas).
- Makna A: Seniman menggunakan kuas untuk melukis.
- Makna B: Wanita di dalam lukisan tersebut sedang memegang kuas.
Sistem MHA standar dapat menangani makna ganda ini dengan sangat indah. Kepala 1 (si ahli tata bahasa) menggunakan matriks K/V unik miliknya untuk menghubungkan kata “painted” (melukis) dan “brush” (kuas). Kepala 2 (si ahli makna kalimat) menggunakan matriks K/V unik miliknya yang berbeda untuk menghubungkan kata “woman” (wanita) dan “brush” (kuas). Kedua makna tersebut bisa dipahami oleh AI secara bersamaan tanpa tertukar.
Sedangkan pada MQA, karena AI hanya memiliki satu matriks Key tunggal untuk semua kepala, matriks itu harus bertindak sebagai alat serba guna yang generik. Ketika Kepala 1 dan Kepala 2 mengirimkan pertanyaan (Query), mereka hanya bisa melihat ke jawaban (Key) yang sama dan generik tentang kata “brush”. Akibatnya, model AI ini akan kesulitan untuk menyandikan kedua makna halus tersebut secara bersamaan. Kemampuan menalar dan pemahaman bahasanya akan menurun. MQA murni merupakan solusi kompromi yang hanya memikirkan “memori yang penting hemat”.
2.6.4 Membangun lapisan MQA dari nol melalui kode
Menulis kode MQA di bahasa pemrograman PyTorch cukup mudah. Kita cukup membuat satu perhitungan untuk K dan V, lalu menggunakan perintah .repeat() (ulang) untuk membagikannya ke semua kepala tanpa harus menggandakan datanya di memori komputer.
Kode Pemrograman 2.3 Membangun lapisan MQA dari nol
import torch
import torch.nn as nn
class MultiQueryAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.0):
super().__init__()
assert d_model % num_heads == 0, \
"d_model harus bisa dibagi rata dengan num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_head = d_model // num_heads # Catatan: Pembagian bulat
# untuk PyTorch
self.W_q = nn.Linear(d_model, d_model)
# Lapisan Key dan Value sekarang hanya dibuat satu kali (tunggal).
# Inilah perubahan rancangan utama yang sangat menghemat memori
# KV cache.
self.W_k = nn.Linear(d_model, self.d_head)
self.W_v = nn.Linear(d_model, self.d_head)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(
torch.ones(1, 1, 1024, 1024), diagonal=1))
def forward(self, x):
batch_size, seq_len, _ = x.shape
q = self.W_q(x).view(batch_size, seq_len, self.num_heads,
self.d_head).transpose(1, 2)
k = self.W_k(x).view(batch_size, seq_len, 1,
self.d_head).transpose(1, 2)
v = self.W_v(x).view(batch_size, seq_len, 1,
self.d_head).transpose(1, 2)
# Tensor K dan V tunggal tadi "diulang" agar jumlahnya cocok
# dengan kepala Query.
# Ini menciptakan ilusi salinan tanpa harus membuang memori
# untuk menggandakan data secara sungguhan.
k = k.repeat(1, self.num_heads, 1, 1)
v = v.repeat(1, self.num_heads, 1, 1)
attn_scores = (q @ k.transpose(-2, -1)) / (self.d_head ** 0.5)
attn_scores = attn_scores.masked_fill(
self.mask[:,:,:seq_len,:seq_len] == 0, float('-inf'))
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
context_vector = (attn_weights @ v).transpose(1, 2) \
.contiguous().view(batch_size, seq_len, self.d_model)
output = self.W_o(context_vector)
return output
2.7 Mencari jalan tengah: Grouped-Query Attention (GQA)
Untuk mengurangi kebodohan bahasa yang terjadi pada MQA, para peneliti mengembangkan Grouped-Query Attention (GQA). GQA memberikan kompromi yang masuk akal dan bisa diatur di antara kedua sisi. Ia berusaha mencari keseimbangan antara AI yang sangat pintar pada MHA, dan AI yang super hemat memori pada MQA.
2.7.1 Ide intinya: Berbagi kunci dan nilai di dalam kelompok kecil
Alih-alih memaksa semua kepala untuk miskin dan berbagi satu pasangan K/V, GQA menciptakan kelompok-kelompok kecil.
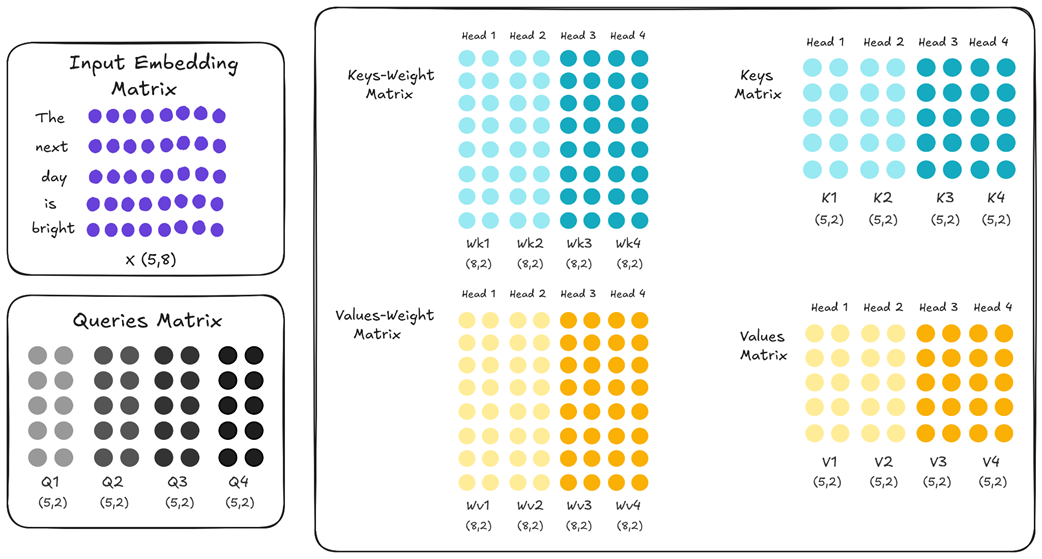
Pada Gambar 2.25, Kepala 1 dan 2 (Kelompok 1) berbagi satu pasangan K/V. Sementara itu, Kepala 3 dan 4 (Kelompok 2) berbagi pasangan K/V lain yang beda rumus matematikanya. Sistem pembagian kelompok ini memungkinkan kelompok kepala tertentu untuk memfokuskan keahliannya di bidang tertentu (mengembalikan sebagian kecerdasan AI yang hilang), namun tetap mampu menghemat memori karena jumlah matriks yang disimpan jauh lebih sedikit daripada MHA asli.
2.7.2 Tombol pengatur: Menyeimbangkan memori dan kecerdasan
GQA memperkenalkan variabel baru yaitu $g$ (jumlah kelompok / grup) ke dalam rumus cache kita:
\[Size_{GQA} = 2 \times 2 \times l \times u \times \mathbf{g} \times b \times z\]- Jika angka $g$ sama besarnya dengan jumlah seluruh kepala ($n$), maka GQA akan menjadi MHA asli (Kecerdasan AI maksimal, tapi memori boros maksimal).
- Jika angka $g$ diubah menjadi angka 1, maka GQA berubah kembali menjadi MQA (Kecerdasan AI jatuh minimal, tapi memori sangat hemat).
- Dengan mengatur $g$ ke angka pecahan tengah dari $n$ (contohnya, model AI bernama Llama 3 menggunakan 8 kelompok untuk 32 kepalanya), kita berhasil mencapai keseimbangan pengurangan memori yang pas.
2.7.3 Membangun lapisan GQA dari nol melalui kode
Di bahasa pemrograman PyTorch, kita menggunakan perintah repeat_interleave untuk membagikan jatah K/V kelompok kepada anggota kepala Query yang ditugaskan ke kelompok tersebut.
Kode Pemrograman 2.4 Membangun lapisan GQA dari nol
import torch
import torch.nn as nn
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, num_heads, num_groups,
dropout=0.0, max_seq_len: int = 0):
super().__init__()
assert d_model % num_heads == 0, \
"d_model harus bisa dibagi rata oleh num_heads"
assert num_heads % num_groups == 0, \
"num_heads harus bisa dibagi rata oleh num_groups"
self.d_model = d_model
self.num_heads = num_heads
self.num_groups = num_groups
self.d_head = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
# Kita membuat sejumlah 'num_groups' (kelompok).
# Ini adalah tombol putar yang bisa kita sesuaikan.
self.W_k = nn.Linear(d_model, self.num_groups * self.d_head)
self.W_v = nn.Linear(d_model, self.num_groups * self.d_head)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self._register_mask_buffer(max_seq_len)
def forward(self, x):
B, T, _ = x.shape
q = self.W_q(x).view(B, T, self.num_heads,
self.d_head).transpose(1, 2)
# Diproyeksikan ke sejumlah grup Key dan Value yang berbeda-beda
# sesuai jumlah num_groups.
k = self.W_k(x).view(B, T, self.num_groups,
self.d_head).transpose(1, 2)
v = self.W_v(x).view(B, T, self.num_groups,
self.d_head).transpose(1, 2)
heads_per_group = self.num_heads // self.num_groups
# perintah repeat_interleave akan menyiarkan jatah grup K/V
# ke kepala-kepala anggota di bawahnya.
k = k.repeat_interleave(heads_per_group, dim=1)
v = v.repeat_interleave(heads_per_group, dim=1)
attn_scores = (q @ k.transpose(-2, -1)) * (self.d_head**-0.5)
causal_mask = self._get_causal_mask(T, x.device)
attn_scores = attn_scores.masked_fill(causal_mask, float("-inf"))
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
context = (attn_weights @ v).transpose(1, 2).contiguous() \
.view(B, T, self.d_model)
return self.W_o(context)
def _register_mask_buffer(self, max_seq_len):
if max_seq_len > 0:
mask = torch.triu(torch.ones(1, 1, max_seq_len, max_seq_len,
dtype=torch.bool), diagonal=1)
self.register_buffer("causal_mask", mask, persistent=False)
else:
self.causal_mask = None
def _get_causal_mask(self, seq_len, device):
if self.causal_mask is not None and \
self.causal_mask.size(-1) >= seq_len:
return self.causal_mask[:, :, :seq_len, :seq_len]
return torch.triu(torch.ones(1, 1, seq_len, seq_len,
dtype=torch.bool, device=device), diagonal=1)
2.8 Pengorbanan antara kecerdasan dan memori komputer
Kita telah menjelajahi solusi generasi pertama terhadap masalah krisis penuhnya KV Cache. Akan tetapi, harus disadari bahwa baik MQA maupun GQA sebenarnya berjalan di atas satu bentuk kompromi yang sama: kedua solusi ini menghemat memori komputer dengan cara menghapus data Key dan Value yang unik, dan sebagai gantinya mereka mengorbankan kecerdasan model AI tersebut.
Ketegangan yang belum terselesaikan inilah yang membuat arsitektur DeepSeek menjadi sangat penting secara historis di dunia AI. Insinyur DeepSeek mengajukan pertanyaan yang sama sekali berbeda: daripada kita menghapus kepala AI dan menghilangkan kecerdasannya, bisakah kita memampatkan (meng-kompresi) informasi matematika di dalam KV Cache itu sendiri secara mendasar tanpa ada yang dibuang?
Perubahan pola pikir dari “menghapus kepala AI” menjadi “memampatkan data” ini mengarah langsung pada penemuan Multi-Head Latent Attention (MLA), dan pada akhirnya menciptakan teknologi yang sangat luar biasa hemat bernama DeepSeek Sparse Attention (DSA) dan Hybrid Attention yang dapat kita lihat pada model versi V3.2 dan V4. Di Bab 3, kita akan membedah secara rinci bagaimana model DeepSeek berhasil mempertahankan kecerdasan penuh seperti MHA yang asli, tetapi di saat bersamaan berhasil melakukan penghematan memori yang membuat membaca teks 1 juta kata menjadi kenyataan.
2.9 Ringkasan
- Pola pembuatan kata demi kata (autoregresif) menyebabkan model AI naif memproses seluruh sejarah teks secara berulang dari awal setiap saat. Hal ini menciptakan kemacetan kerja komputer dengan rumus kuadrat $O(n^2)$.
- Key-Value (KV) Cache memecahkan masalah ini dengan menyimpan matriks Key dan Value masa lalu di dalam memori, mengubah proses tebakan menjadi sangat efisien dan ringan secara linier $O(n)$.
- Namun, KV Cache menciptakan masalah kemacetan baru berupa kepenuhan memori komputer, yang membengkak setiap kali panjang teks bertambah. Pada pembacaan teks yang super panjang, ukuran memori AI ini melampaui kemampuan kartu grafis (VRAM GPU) paling mahal sekalipun.
- Multi-Query Attention (MQA) mengurangi ukuran memori cache dengan cara memaksa semua kepala AI berbagi satu pasang K/V saja. Kelemahannya, ini sangat merusak kemampuan AI dalam memahami bahasa ambigu yang rumit.
- Grouped-Query Attention (GQA) menawarkan kompromi jalan tengah yang dapat diatur sesuka hati. Sayangnya, sistem ini pada dasarnya tetap mengorbankan tingkat kecerdasan demi menghemat memori.