Meningkatkan Kecerdasan
- Yang akan kita pelajari pada bab ini:
- 4.1.1 Masalah pada FFN yang Padat: Jumlah parameter dan biaya komputer yang tinggi
- 4.1.2 Solusi Sistem Renggang (Sparsity): Hanya mengaktifkan sebagian kecil ahli untuk setiap kata
- 4.1.3 Spesialisasi Ahli: Alasan “Mengapa” kerenggangan ini berhasil
- 4.2.1 Tujuannya: Menggabungkan hasil dari beberapa ahli menjadi satu
- 4.2.2 Sistem Renggang Beraksi: Pemilihan Top-K (K-Terbaik)
- 4.2.3 Mekanisme Rute: Dari masukan menuju skor ahli
- 4.2.4 Dari skor menjadi bobot: Pemilihan Top-K dan Softmax
- 4.2.5 Hasil Akhir: Penjumlahan Tertimbang
- 4.3.1 Percobaan #1: Hukuman Tambahan (Auxiliary Loss)
- 4.3.2 Percobaan #2: Kerugian Penyeimbangan Beban (Load Balancing Loss)
- 4.4.1 Inovasi #1: Pemecahan Ahli Secara Detail (Fine-grained)
- 4.2.2 Inovasi #2: Mengasingkan Ahli Pengetahuan Umum (Shared Expert Isolation)
- 4.4.3 Inovasi #3: Menyeimbangkan Beban Tanpa Hukuman (Auxiliary-loss-free load balancing)
- 4.6.1 Batasan dan kelemahan MoE dalam mencari pengetahuan statis (fakta pasti)
- 4.6.2 Memperkenalkan Engram: Memodernisasi ingatan N-gram untuk Pencarian Kilat O(1)
- 4.6.3 Hukum Pembagian Kerenggangan: Menyeimbangkan ahli MoE dan memori Engram
- 4.6.4 Efisiensi Sistem Komputer: Memisahkan memori dan prosesor dengan memindahkannya ke CPU Biasa (Host CPU Offloading)
Bab 4 Meningkatkan Kecerdasan: Campuran Para Ahli (Mixture-of-Experts / MoE) & Memori Bersyarat (Engram)
Yang akan kita pelajari pada bab ini:
- Konsep Mixture of Experts (MoE) dan bagaimana sistem kerja renggang (sparsity) memungkinkan kita memperbesar AI dengan efisien.
- Panduan praktik dan matematika langkah demi langkah dari lapisan otak DeepSeekMoE.
- Solusi canggih DeepSeek untuk menyeimbangkan beban kerja tanpa mengganggu proses belajar AI (tanpa auxiliary loss).
- (Baru) Batasan dan kelemahan MoE dalam mencari fakta dan pengetahuan pasti (statis).
- (Baru) Memperkenalkan Engram: Sebuah cara kerja renggang yang baru melalui sistem pencarian kilat O(1) hash lookup.
Pada Bab 3, kita telah menyelesaikan masalah kecepatan komputer dan kemacetan memori dengan cara memampatkan (mengompres) sistem attention (perhatian). Akan tetapi, saat kita ingin membangun model AI yang benar-benar cerdas—yang mampu menulis kode program, menalar soal matematika, dan mengingat banyak sekali pengetahuan dunia—kita menghadapi masalah baru: kapasitas model.
Untuk membuat model AI menjadi lebih pintar, secara umum Anda harus membuatnya lebih besar dengan menambahkan lebih banyak parameter (jaringan saraf buatan). Namun, dalam arsitektur AI Transformer standar yang padat, setiap sel saraf tersebut harus menyala dan melakukan perhitungan matematika untuk setiap kata yang dibaca. Memperbesar model yang padat ini akan menyebabkan ledakan biaya perhitungan komputer (disebut FLOPs), yang membuat proses pelatihan dan penggunaannya menjadi sangat lambat dan sangat mahal.
Hal ini membawa kita ke Tahap 2 dari peta jalan kita (Gambar 4.1): Meningkatkan Kapasitas (Scaling Capacity).
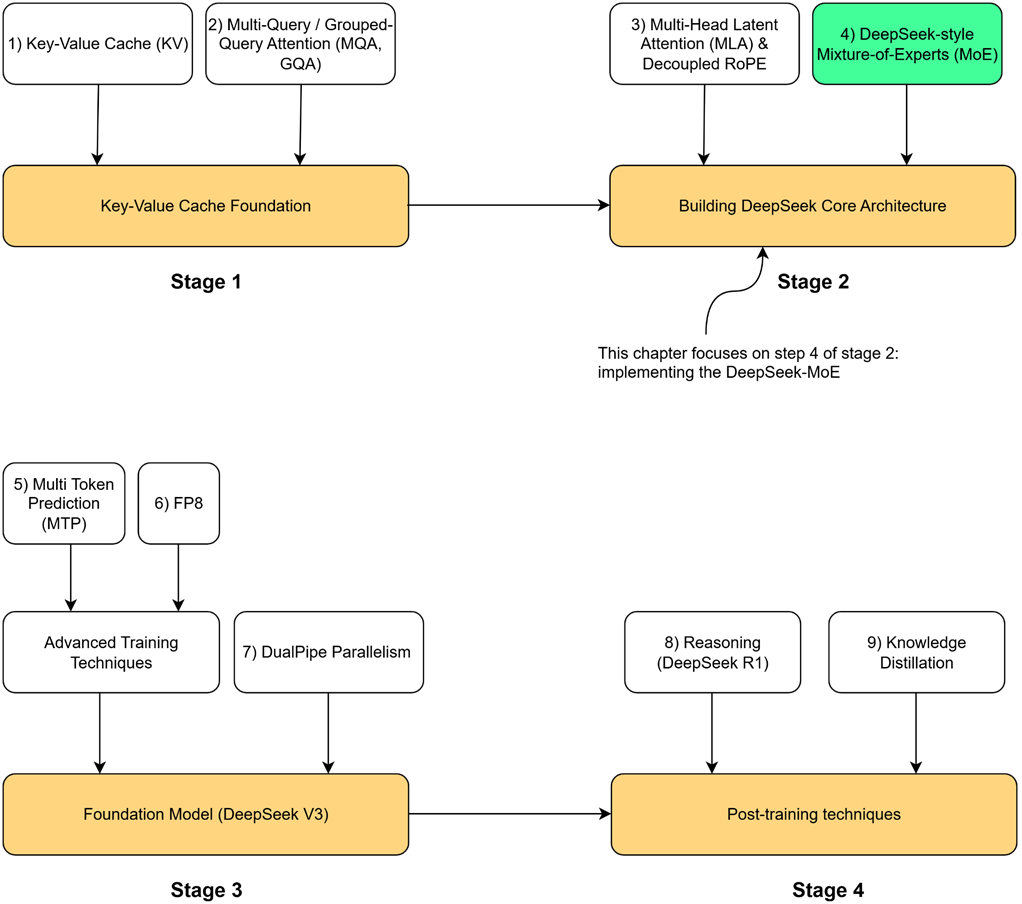
Bagaimana cara kita membangun model yang sangat besar dan berpengetahuan luas tanpa membuat biaya komputernya ikut membengkak? Jawabannya terletak pada Sparsity (Sistem Kerja Renggang/Efisien).
Pada bab ini, kita akan menjelajahi dua jenis sistem kerja renggang yang berbeda. Pertama, kita akan membongkar rahasia dari Mixture-of-Experts (MoE) / Campuran Para Ahli, yaitu sebuah mekanisme yang digunakan DeepSeek untuk meningkatkan kemampuan penalaran logika mereka. Kita akan membedah matematikanya, menjelajahi inovasi khusus DeepSeek (seperti Shared Experts dan penyeimbangan Auxiliary-Loss-Free), serta menulis kode lapisan MoE yang berfungsi penuh di bahasa pemrograman PyTorch.
Namun, MoE memiliki sebuah cacat tersembunyi: ia sangat tidak efisien untuk mengambil kembali fakta-fakta pasti yang bersifat ingatan statis. Oleh karena itu, di paruh kedua bab ini, kita akan menjelajahi batas paling mutakhir dari arsitektur DeepSeek dengan memperkenalkan Engram (Memori Bersyarat). Dengan menghidupkan kembali teknik N-gram klasik menggunakan sistem hashing modern, Engram memperkenalkan jenis kerenggangan yang sama sekali baru, memungkinkan model AI untuk memisahkan ruang penyimpanan pengetahuan yang besar dari otak tempat ia berpikir.
Mari kita mulai dengan memahami logika dasar di balik MoE.
4.1 Logika Dasar di Balik Campuran Para Ahli (MoE)
Untuk memahami Mixture of Experts, pertama-tama kita harus melihat komponen yang digantikannya di dalam blok Transformer standar, yaitu: Feed-Forward Network (FFN) atau Jaringan Umpan-Maju.
FFN bertindak sebagai unit pemrosesan utama di dalam setiap lapisan Transformer. FFN adalah jaringan saraf yang padat dan merupakan tempat di mana sebagian besar parameter (sel saraf) model AI serta beban kerja komputernya berada.
4.1.1 Masalah pada FFN yang Padat: Jumlah parameter dan biaya komputer yang tinggi
Setelah melewati lapisan multi-head attention (lapisan yang memahami hubungan antarkata), data vektor konteks yang dihasilkan akan diproses oleh FFN, seperti yang digambarkan pada Gambar 4.2. FFN terdiri dari jaringan saraf dua lapis yang melakukan urutan “perluasan lalu penyusutan”. Lapisan linier pertama memperluas ukuran data (misalnya, diperbesar 4 kali lipat), sedangkan lapisan linier kedua menyusutkannya kembali ke ukuran aslinya. Ruang perantara yang diperluas ini memberikan area yang lebih luas dan kaya bagi model untuk menangkap pola-pola bahasa yang rumit.
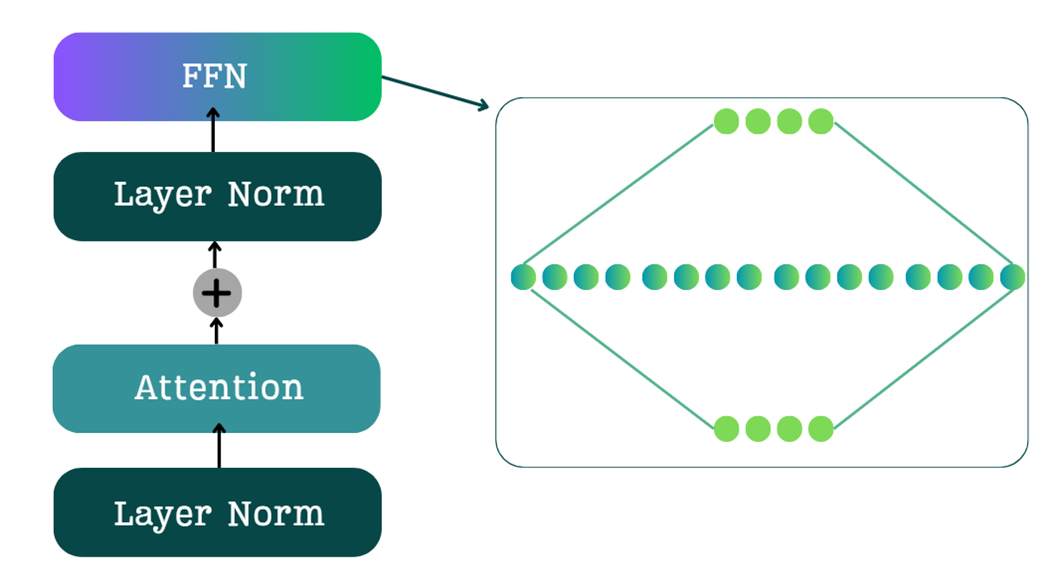
Namun, FFN ini bersifat padat. Untuk setiap satu kata masukan, jutaan parameter di dalam FFN ini semuanya harus diaktifkan dan dikalikan secara matematika. Hal ini menimbulkan dua akibat besar:
- Biaya Pelatihan Tinggi: Parameter di dalam FFN memakan sebagian besar dari total waktu pelatihan model dan tenaga komputer (FLOPs).
- Biaya Penggunaan (Inferensi) Tinggi: Saat AI digunakan, perhitungan yang padat ini membuat AI menjadi lambat dalam memunculkan setiap kata baru. Jika Anda memperbesar model padat hingga memiliki 600 Miliar parameter, komputer Anda harus melakukan 600 Miliar perkalian matematika untuk setiap satu kata.
4.1.2 Solusi Sistem Renggang (Sparsity): Hanya mengaktifkan sebagian kecil ahli untuk setiap kata
Ide inti dari Mixture of Experts adalah mengganti satu FFN besar yang padat dengan sekumpulan FFN kecil yang jumlahnya banyak, yang kita sebut sebagai “Para Ahli” (Experts).
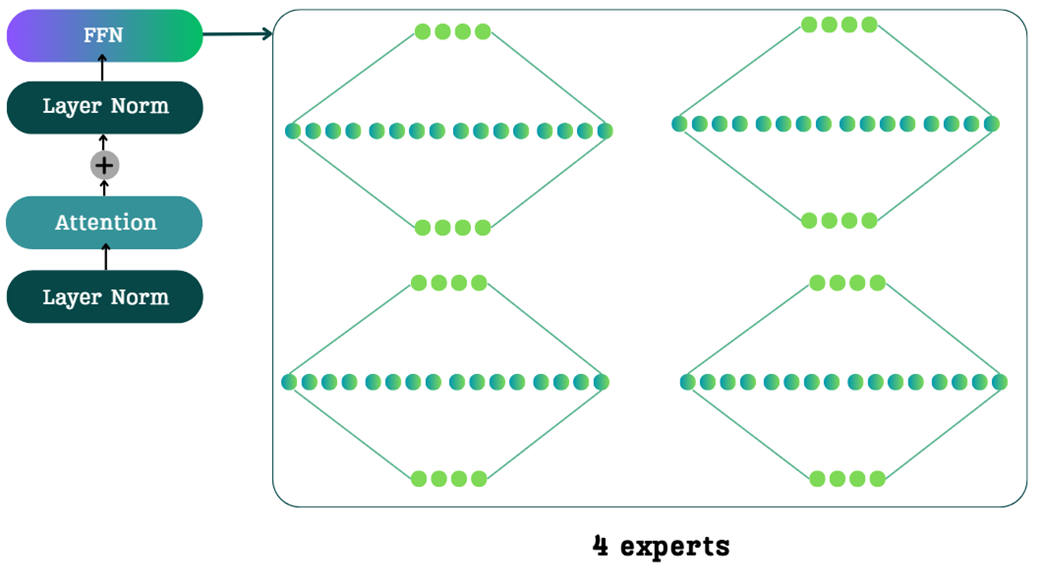
Anda mungkin mengira bahwa mengganti satu jaringan dengan empat jaringan akan membuat beban kerja komputer menjadi empat kali lipat. Di sinilah letak keajaiban MoE, yang didorong oleh satu konsep tunggal: Kerenggangan (Sparsity).
Dalam model MoE, untuk setiap kata masukan apa pun, hanya sebagian kecil dari total para ahli yang dinyalakan. Sisanya dibiarkan tertidur lelap. Misalnya, dalam sebuah model yang memiliki 64 ahli, sebuah kata mungkin hanya dikirimkan kepada 2 ahli saja. Ke-62 ahli lainnya diabaikan; parameter mereka tidak dimuat ke dalam memori komputer, dan perhitungannya dilewati sepenuhnya.
Inilah sumber efisiensi MoE yang luar biasa. Kita mendapatkan keuntungan dari kumpulan pengetahuan yang sangat besar (gabungan dari semua ahli), tetapi biaya perhitungan komputer untuk satu kata tunggal tetap sangat rendah.
4.1.3 Spesialisasi Ahli: Alasan “Mengapa” kerenggangan ini berhasil
Mengapa sistem renggang ini bisa bekerja? Mengapa kita bisa mengabaikan sebagian besar jaringan otak untuk sebuah kata tertentu? Jawabannya terletak pada spesialisasi para ahli.
Selama proses pelatihan AI yang sangat besar, setiap jaringan ahli belajar untuk menjadi sangat ahli (spesialis) dalam menangani jenis informasi tertentu. Daripada memiliki satu FFN raksasa yang serba bisa yang harus tahu cara melakukan segalanya, kita membangun sebuah komite berisi dokter-dokter spesialis.
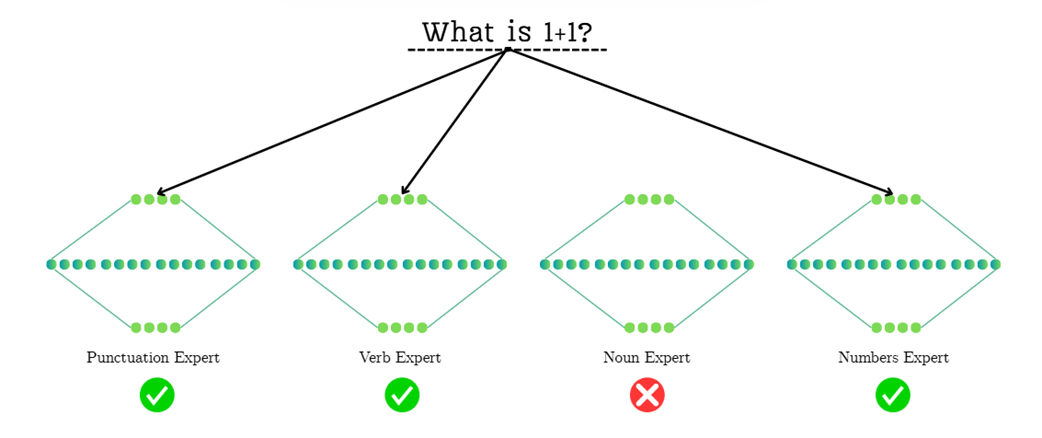
Mari kita telusuri bagaimana model memproses kalimat pertanyaan: “What is 1+1?” (Apa itu 1+1?) seperti pada Gambar 4.4. Jaringan pengatur rute (router) harus melihat kata-kata yang masuk dan memilih spesialis yang paling tepat:
- Ahli Tanda Baca: Router melihat tanda tanya (
?). Karena sudah belajar mengenali tanda baca, ia mengaktifkan Ahli Tanda Baca, dan melewati ahli yang lain. - Ahli Kata Kerja: Kata
"is"(adalah) adalah kata kerja yang umum. Router mengirim kata tersebut ke Ahli Kata Kerja, yang memang bertugas menangani tata bahasa tersebut. - Ahli yang Tertidur: Perhatikan bahwa Ahli Kata Benda tidak diaktifkan. Karena pertanyaan tersebut tidak mengandung kata benda yang penting, router secara cerdas menghemat tenaga komputer dengan membiarkan ahli ini tetap tertidur.
Ketika sebuah kata masukan tiba, model tidak perlu berkonsultasi dengan seluruh basis pengetahuannya. Ia menggunakan jaringan pengatur rute yang kecil dan sangat efisien untuk bertanya, “Siapa ahli yang tepat untuk jenis kata ini?” Dengan hanya mengirim kata tersebut kepada ahli yang relevan, model AI menghemat sejumlah besar perhitungan komputer.
4.2 Cara Kerja MoE: Panduan Matematika Langkah demi Langkah
Sekarang setelah kita memahami logikanya, mari kita buka kotak rahasianya. Kita akan melacak perjalanan sekumpulan kata langkah demi langkah, dari awal hingga akhir. Kita akan menggunakan contoh kalimat “The next day is.”
4.2.1 Tujuannya: Menggabungkan hasil dari beberapa ahli menjadi satu
Kita memiliki sebuah matriks masukan (tabel data) berukuran (4, 8), yang mewakili empat kata ("The", "next", "day", "is"), di mana masing-masing kata diubah menjadi 8 angka dimensi yang berasal dari lapisan perhatian (attention) sebelumnya.
Asumsikan lapisan MoE kita berisi tiga jaringan ahli yang terpisah ($E_1, E_2, E_3$). Jika kita memasukkan matriks masukan kita melewati ketiganya, kita akan mendapatkan tiga matriks keluaran terpisah yang masing-masing berukuran (4, 8).
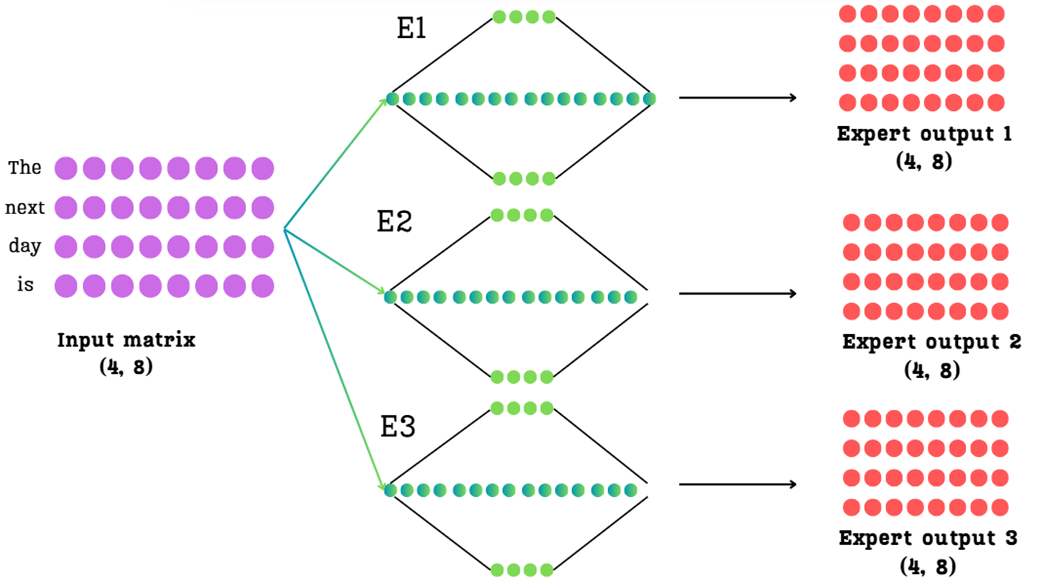
Aturan bangunan Transformer mengharuskan kita hanya mengirimkan satu matriks tunggal ke lapisan berikutnya. Tugas kita adalah menggabungkan ketiga matriks hasil ini secara cerdas menjadi satu matriks keluaran akhir.
4.2.2 Sistem Renggang Beraksi: Pemilihan Top-K (K-Terbaik)
Kita memaksakan sistem kerja renggang dengan membuat keputusan penting: untuk setiap kata, kita hanya akan memilih ahli-ahli terbaik sebanyak $k$. Kita akan menetapkan nilai $k=2$. Dari tiga ahli yang tersedia, hanya dua yang akan dinyalakan untuk setiap kata.
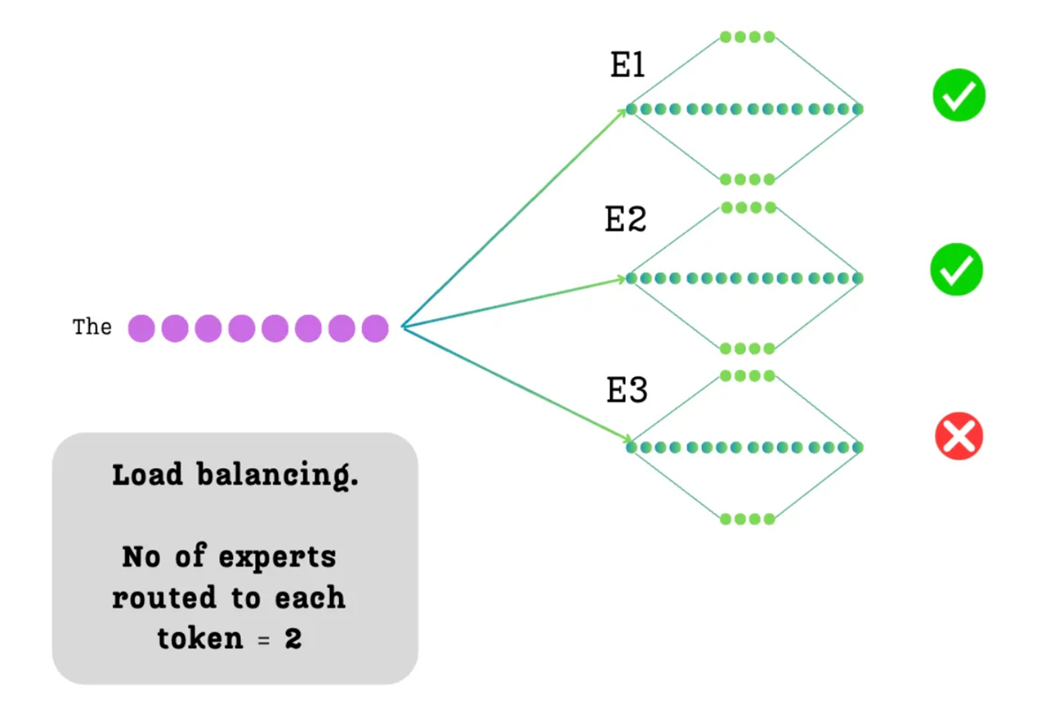
Lalu, bagaimana model AI memutuskan dua ahli mana yang harus dipilih, dan seberapa besar pengaruh yang akan diberikan pada hasil jawaban mereka? Ini adalah tugas dari router (mesin pengatur rute).
4.2.3 Mekanisme Rute: Dari masukan menuju skor ahli
Router adalah sebuah lapisan linier yang sederhana. Kita mengalikan Matriks Masukan (4, 8) dengan Matriks Rute yang telah dipelajari oleh AI berukuran (8, 3).

Hasilnya adalah Matriks Pemilih Ahli berukuran (4, 3) yang berisi skor mentah belum diolah (disebut logits). Skor ini menunjukkan seberapa cocok setiap ahli untuk setiap kata. Misalnya, baris 1 kolom 2 adalah skor kesesuaian jika kita mengirim kata "The" kepada Ahli nomor 2.
4.2.4 Dari skor menjadi bobot: Pemilihan Top-K dan Softmax
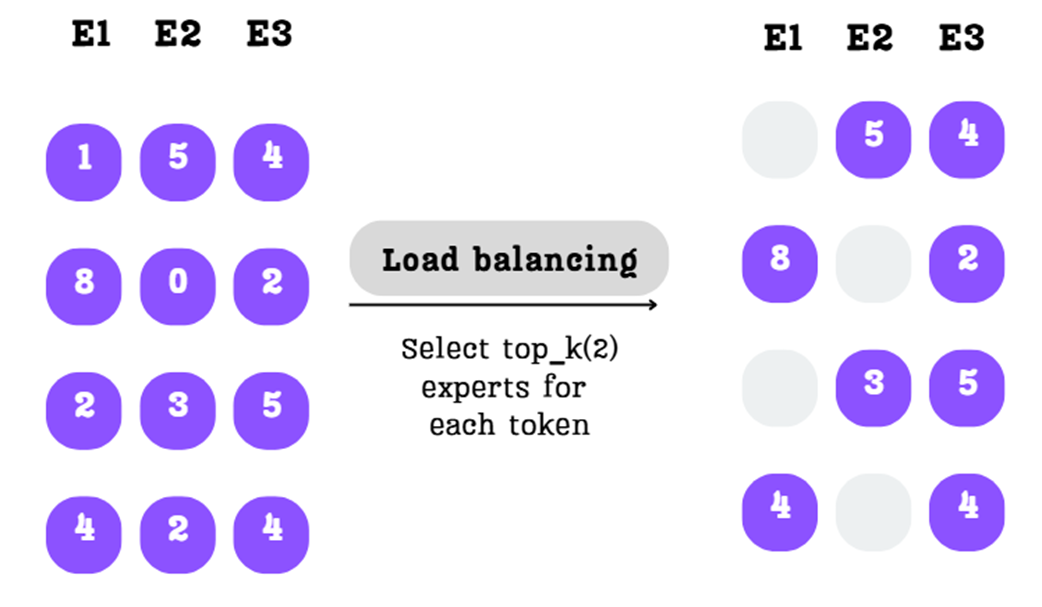
Kita harus mengubah skor mentah ini menjadi pembagian bobot yang dinormalkan (persentase), sambil tetap menegakkan aturan batas $k$-terbaik kita.
Langkah A: Pilih Para Ahli Top-K Untuk setiap baris (kata), kita mencari nilai skor tertinggi sebanyak $k=2$.
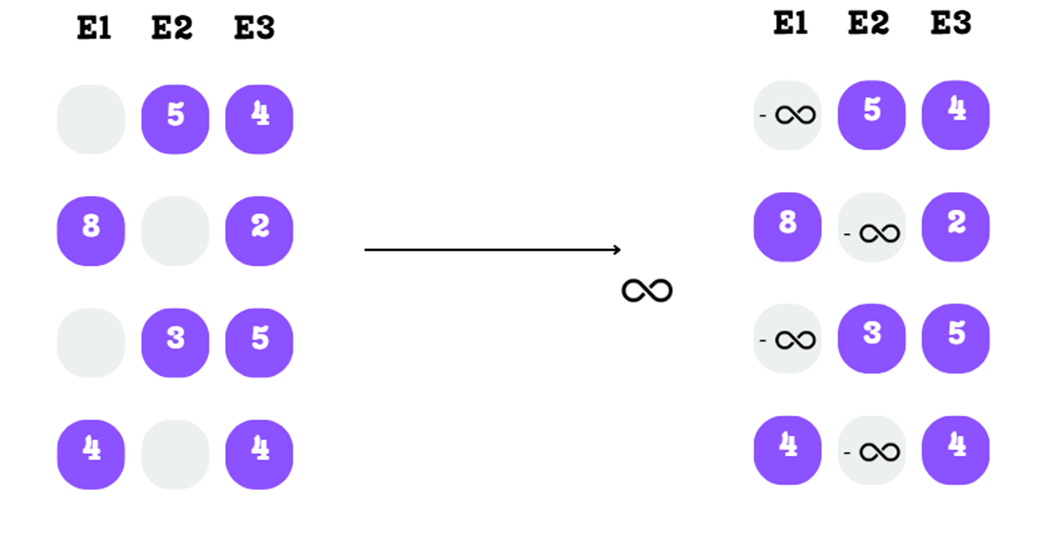
Langkah B: Menutupi (Masking) dengan Minus Tak Terhingga Kita mengganti nilai skor milik ahli yang tidak terpilih dengan angka minus tak terhingga ($-\infty$).
Langkah C: Menerapkan Softmax
Kita menerapkan fungsi matematika softmax ke setiap baris. Sifat matematika dari $e^{-\infty}$ adalah $0$. Oleh karena itu, para ahli yang ditutupi tadi akan menerima bobot persis bernilai nol (0%). Sementara itu, 2 ahli terbaik yang terpilih diubah menjadi bobot peluang (persentase) yang jika dijumlahkan hasilnya pasti 1 (100%).
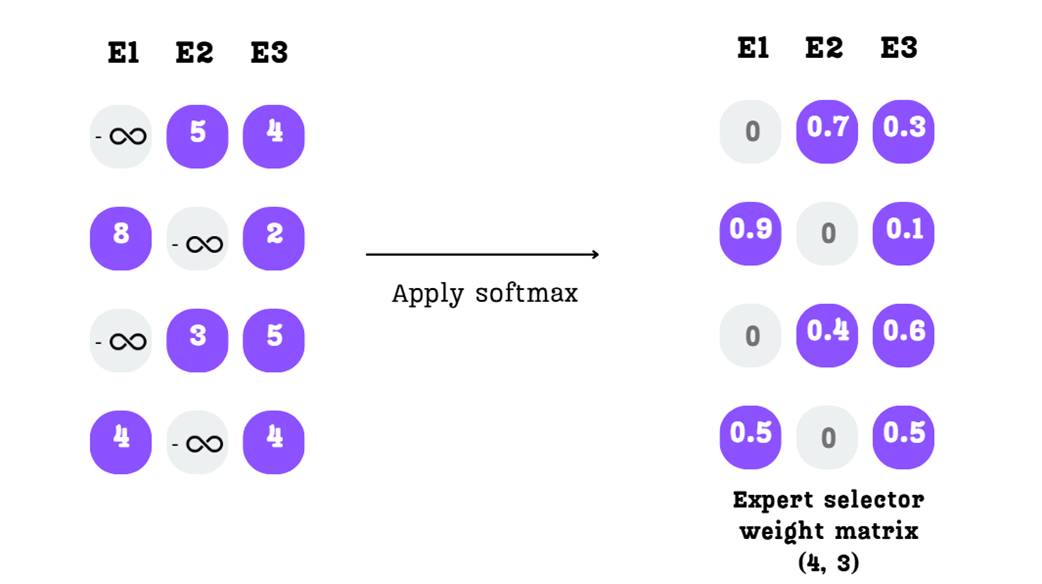
Hasil akhirnya adalah Matriks Bobot Pemilih Ahli kita. Untuk kata "The", matriks ini memberitahu kita: “Abaikan Ahli 1, berikan 60% kekuatan kepada jawaban Ahli 2, dan berikan 40% kekuatan kepada jawaban Ahli 3.”
4.2.5 Hasil Akhir: Penjumlahan Tertimbang
Untuk setiap kata, kita mengalikan hasil jawaban dari ahli yang dipilih dengan bobot persentase yang sudah ditugaskan tadi, lalu menjumlahkannya menjadi satu.
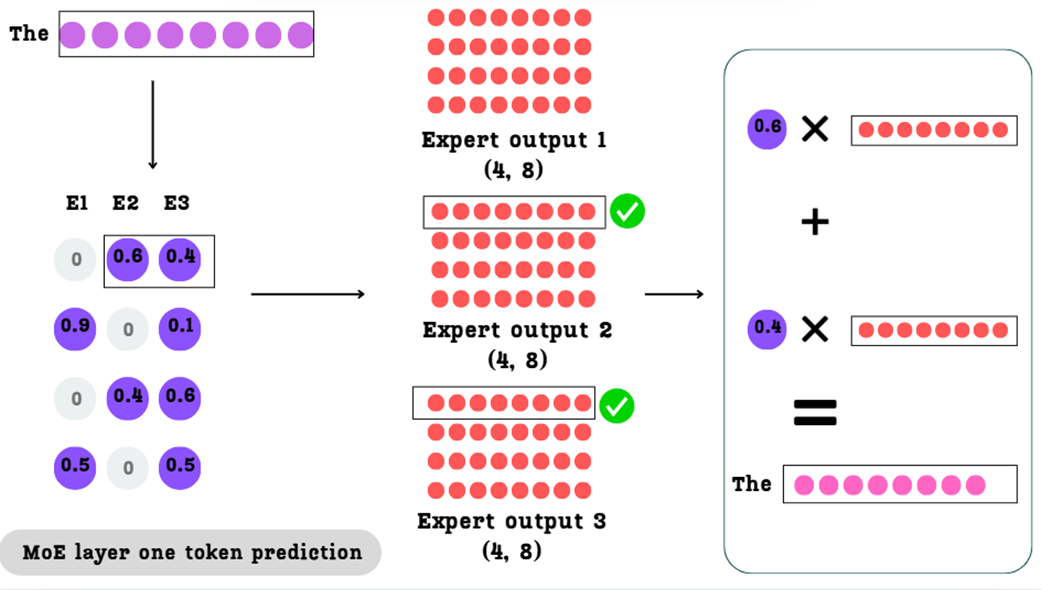
Hasil Akhir_"The" = (0.6 * Hasil_"The"_Ahli2) + (0.4 * Hasil_"The"_Ahli3)
Kita melakukan proses ini secara bersamaan (paralel) untuk setiap kata.
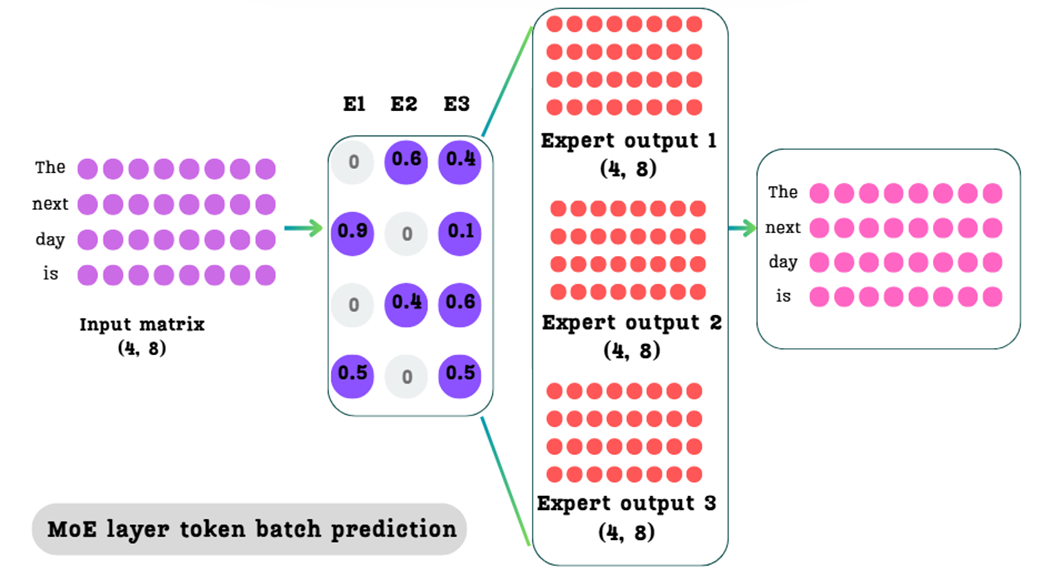
Hasil paling akhirnya adalah sebuah matriks tunggal dengan ukuran yang sama persis seperti ukuran aslinya yaitu (4, 8). Kita telah berhasil mengganti FFN padat yang berat dengan sistem ahli campuran (MoE) renggang yang sangat efisien bagi komputer.
4.3 Tantangan Keseimbangan: Memastikan Semua Ahli Bekerja Sama Rata
Walaupun arsitektur ini sangat efisien, ada sebuah masalah tak terlihat yang muncul: pengaturan rute yang tidak seimbang.
Jika jaringan pengatur rute (router) sejak awal masa pelatihan AI secara tidak sengaja terbiasa memfavoritkan (lebih sering memilih) ahli-ahli tertentu, maka ahli tersebut akan menerima lebih banyak kata. Akibatnya, ahli itu belajar lebih cepat, dan akhirnya menjadi semakin difavoritkan lagi. Siklus yang berulang ini menciptakan “ahli yang terlalu sibuk” (sehingga membuat komputer macet antre) dan “ahli yang mati” (yang tidak pernah dipilih sehingga membuang-buang memori).
Kita menginginkan model MoE yang seimbang, di mana semua ahli digunakan secara merata.
4.3.1 Percobaan #1: Hukuman Tambahan (Auxiliary Loss)
Metode tradisional yang dulu dipakai adalah menambahkan nilai hukuman (penalti) ke dalam angka kegagalan latihan model AI. Ini disebut auxiliary loss (kerugian tambahan).
Kita menghitung seberapa “penting” setiap ahli dengan menjumlahkan nilai persentase peluangnya dari atas ke bawah pada setiap kolom di dalam Matriks Bobot Pemilih Ahli.
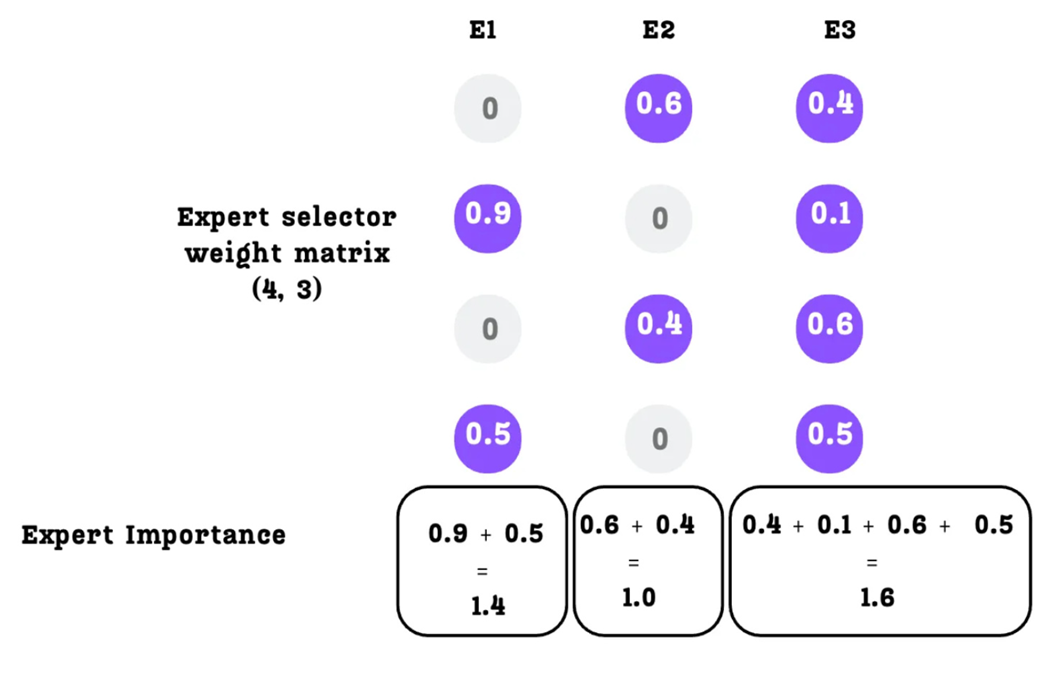
Jika ada perbedaan (variasi) yang sangat besar di antara skor kepentingan ini (ada yang sangat besar dan ada yang sangat kecil), kita akan menghukum model AI tersebut menggunakan rumus Koefisien Variasi (Coefficient of Variation / CV).
\[\text{AuxLoss} = \lambda \cdot CV(\text{SkorKepentingan})^2\]Hukuman ini memaksa mesin router untuk membagi persentase peluangnya lebih merata ke semua ahli. Akan tetapi, cara ini memiliki sebuah kelemahan terselubung.
4.3.2 Percobaan #2: Kerugian Penyeimbangan Beban (Load Balancing Loss)
Memberikan nilai penting (peluang persentase) yang sama rata ternyata tidak menjamin bahwa jumlah beban kerja kata yang diterima oleh masing-masing ahli akan sama rata.
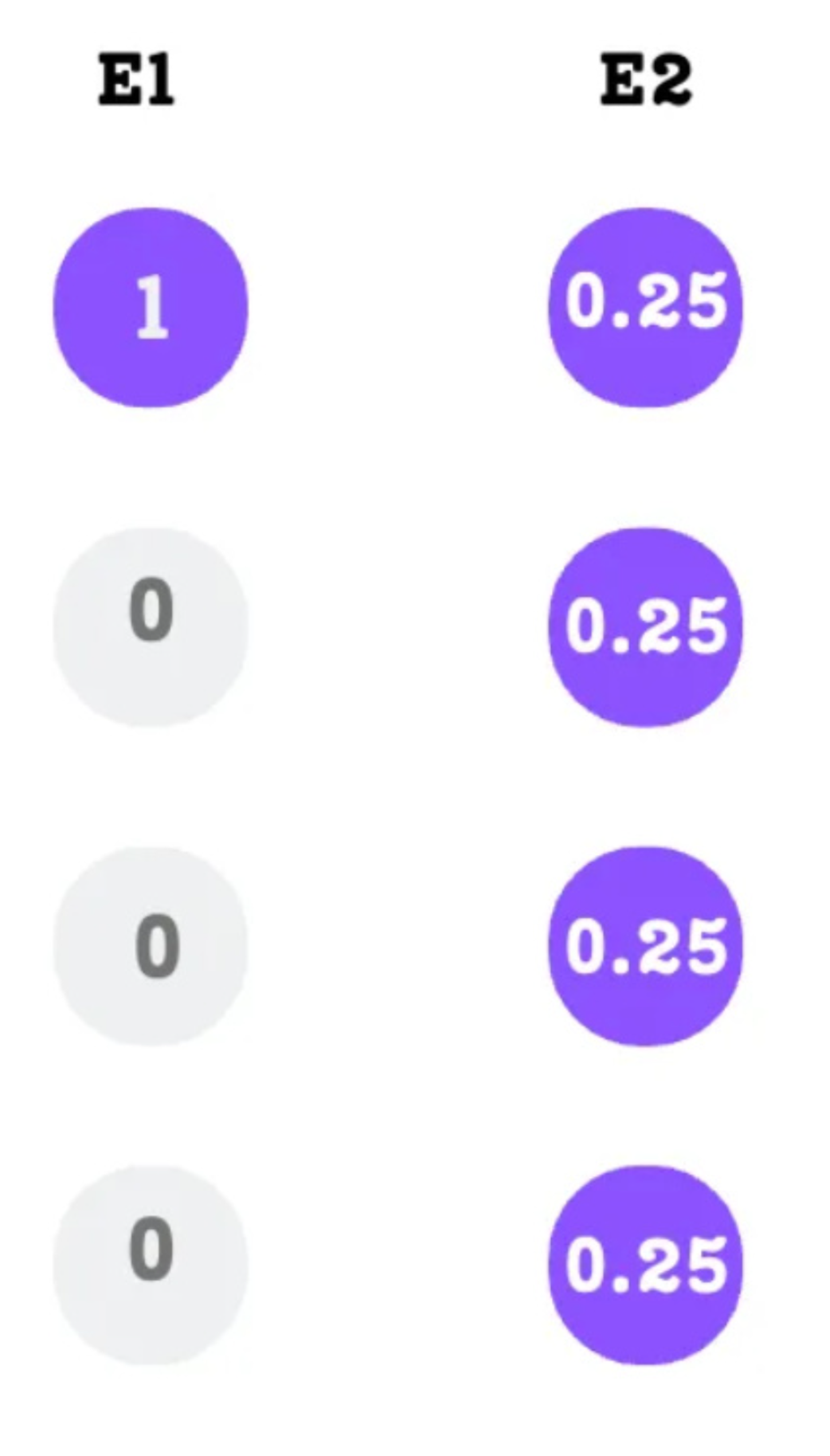
Pada Gambar 4.16, Ahli 1 menerima 1 kata dengan peluang 100%. Sedangkan Ahli 2 menerima 4 kata dengan peluang masing-masing 25%. Jika dijumlahkan, keduanya sama-sama memiliki skor kepentingan total 1.0 (100%), tetapi kenyataannya Ahli 2 harus bekerja 4 kali lipat lebih berat secara fisik!
Untuk mengatasi hal ini, kita menggunakan rumus Load Balancing Loss (Kerugian Penyeimbangan Beban), yang mempertimbangkan tidak hanya nilai peluang router ($p_i$), tetapi juga persentase jumlah kata yang benar-benar dikirimkan secara fisik ($f_i$):
\[\text{LoadBalancingLoss} = \lambda \cdot N \cdot \sum_{i=1}^{N} (f_i \cdot p_i)\]Dengan menekan hasil perkalian rumus ini sekecil mungkin, kita bisa menjamin bahwa sebaran persentase peluang sekaligus beban kerja fisik pada mesin komputer (hardware) akan tetap seimbang dan adil di seluruh ahli.
4.4 Inovasi DeepSeek-MoE: Menuju Ahli Spesialis Tingkat Tinggi
Tim peneliti DeepSeek mengidentifikasi dua masalah mendasar yang menghambat arsitektur MoE tradisional untuk mencapai kemampuan maksimalnya, yaitu: Knowledge Hybridity (Pengetahuan Campur Aduk) dan Knowledge Redundancy (Pengetahuan Berulang).
4.4.1 Inovasi #1: Pemecahan Ahli Secara Detail (Fine-grained)
Ketika sebuah model AI hanya memiliki beberapa ahli berukuran besar (misalnya, hanya 8 atau 16 ahli), setiap ahli terpaksa harus menjadi ahli serba bisa (generalis). Satu ahli yang sama mungkin dipaksa bertugas untuk membaca bahasa pemrograman Python, kontrak hukum, dan sekaligus sejarah dunia. Ini menyebabkan Knowledge Hybridity (Pengetahuan Campur Aduk): parameter sarafnya berubah menjadi kompromi yang membingungkan, sehingga mencegah ahli tersebut mendalami suatu bidang secara spesifik.
Solusi dari DeepSeek adalah Fine-Grained Expert Segmentation (Pemecahan Ahli Secara Detail): gunakan jumlah ahli yang sangat banyak, tetapi ukurannya jauh lebih kecil.
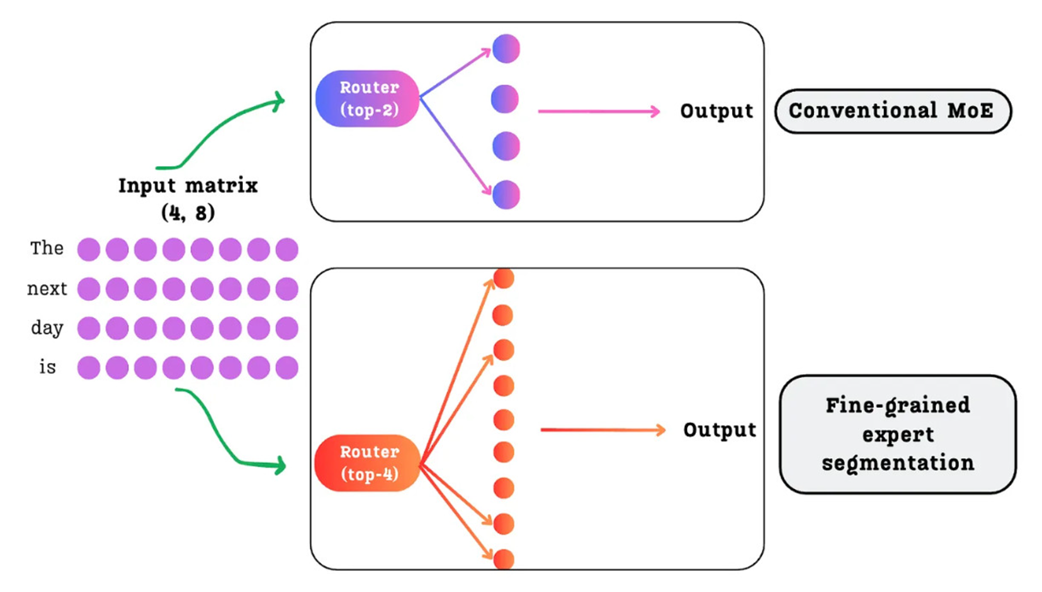
Daripada menggunakan 16 ahli raksasa, DeepSeek menggunakan 64 (atau pada versi terbarunya, 256) ahli berukuran kecil. Kapasitas total dan beban komputernya tetap sama persis, namun ruang pengetahuannya dipecah menjadi wadah yang lebih tajam dan fokus. Sekarang, router bisa mengirim kata kepada ahli yang sangat spesifik, misalnya ahli yang khusus menangani kesalahan penulisan (sintaks) pada kode Python saja.
4.2.2 Inovasi #2: Mengasingkan Ahli Pengetahuan Umum (Shared Expert Isolation)
Bahkan ahli yang sangat spesifik sekalipun (seperti ahli Python dan ahli makalah Kedokteran) keduanya tetap harus mempelajari dasar tata bahasa Inggris agar bisa berfungsi. Pada sistem MoE tradisional, kedua ahli ini akan membuang-buang memori parameter mereka untuk menghafal aturan dasar bahasa Inggris yang sama persis. Inilah yang disebut Knowledge Redundancy (Pengetahuan Berulang yang Sia-sia).
DeepSeek memperkenalkan Shared Expert Isolation (Pengasingan Ahli Pengetahuan Umum). Mereka membagi lapisan MoE menjadi dua kelompok yang berbeda tugas:
- Routed Experts (Ahli Jalur Khusus): Ini adalah kumpulan besar para ahli spesialis. Mereka hanya diaktifkan sesekali (secara renggang) oleh router.
- Shared Experts (Ahli Pengetahuan Umum): Ini adalah kelompok kecil berisi para ahli serba bisa. Mereka diaktifkan secara padat dan terus-menerus untuk setiap kata yang lewat.
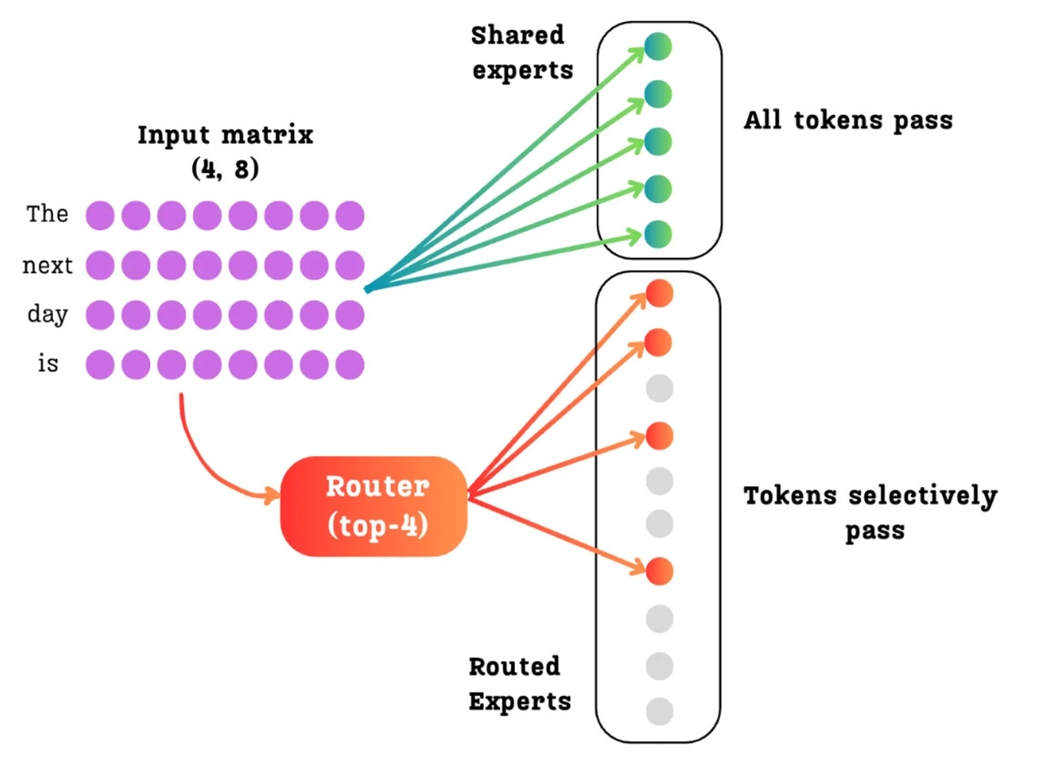
Karena Ahli Pengetahuan Umum selalu melihat setiap kata yang masuk, mereka secara alami akan menghafal pengetahuan dasar yang umum. Hal ini membebaskan para Ahli Khusus dari tugas menghafal hal-hal mendasar, sehingga mereka dapat mendedikasikan 100% parameter memori mereka untuk tugas-tugas yang super spesifik.
4.4.3 Inovasi #3: Menyeimbangkan Beban Tanpa Hukuman (Auxiliary-loss-free load balancing)
Rumus kerugian penyeimbang tradisional yang tadi kita bahas (Auxiliary Loss dan Load Balancing Loss) memiliki satu kelemahan besar: mereka mengganggu tujuan utama model AI dalam belajar. Jika nilai hukuman keseimbangannya ($\lambda$) terlalu besar, model AI tersebut akan berhenti belajar bahasa dan malah menghabiskan waktunya hanya untuk menyeimbangkan antrean para ahli.
DeepSeek memecahkan hal ini dengan membuang seluruh rumus hukuman tersebut. Mereka memperkenalkan Auxiliary-Loss-Free Load Balancing (Penyeimbangan Tanpa Hukuman) melalui sistem nilai bias (bonus poin) yang dapat berubah-ubah (dinamis).
Logikanya adalah menggunakan sistem yang bisa mengoreksi dirinya sendiri:
- Di setiap akhir sesi latihan, AI akan memeriksa ahli mana saja yang kelebihan beban atau yang kekurangan beban.
- AI akan mengubah sebuah nilai bias ($b_i$) milik setiap ahli. Jika ada ahli yang menganggur, nilai bonus biasnya dinaikkan; jika ada ahli yang terlalu sibuk, nilai biasnya diturunkan.
- Pada sesi tebakan selanjutnya, AI akan menambahkan nilai bonus bias ini ke dalam skor mentah milik router sebelum masuk ke tahap pemilihan Top-K.
Jika ada ahli yang kurang dimanfaatkan (menganggur), nilai biasnya akan meningkat. Hal ini secara otomatis menaikkan skor kesesuaiannya, sehingga router akan lebih tertarik untuk memilihnya. Sistem ini melepaskan urusan antrean ahli dari urusan pembelajaran utama. Dengan demikian, model AI bisa 100% fokus belajar tata bahasa, sementara nilai bias tadi yang akan diam-diam mengatur keseimbangan antrean di mesin komputer secara halus.
4.5 Membangun Model Bahasa DeepSeek-MoE Lengkap dari Nol
Mari kita gabungkan semua konsep hebat ini ke dalam modul kode bahasa pemrograman PyTorch yang bisa berfungsi nyata. Kode lengkapnya juga tersedia di penyimpanan GitHub resmi: https://github.com/VizuaraAI/DeepSeek-From-Scratch/tree/main/ch04.
Langkah 1: Membuat Jaringan FFN Ahli Setiap ahli adalah jaringan saraf dua lapis (MLP) sederhana dengan proses perluasan-penyusutan, ditambah sebuah saklar pengaktifan matematika (GELU).
Kode Program 4.1 Modul ExpertFFN
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class ExpertFFN(nn.Module):
def __init__(self, d_model: int, hidden: int, dropout: float = 0.0):
super().__init__()
self.fc1 = nn.Linear(d_model, hidden, bias=False)
self.fc2 = nn.Linear(hidden, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Pendekatan rumus Gelu
gelu = 0.5 * x * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
return self.fc2(self.dropout(gelu))
Langkah 2: Menyiapkan Lapisan Awal MoE
Kita akan membuat daftar untuk para Ahli Umum (Shared) dan Ahli Khusus (Routed), lalu membuat matriks router (centroids), dan menyiapkan tempat untuk nilai bias dinamis yang tidak ikut dilatih (untuk penyeimbang tanpa hukuman).
Kode Program 4.2 Metode Langkah Awal __init__ DeepSeekMoE
class DeepSeekMoE(nn.Module):
def __init__(self, d_model, n_routed_exp, n_shared_exp=1, top_k=8, routed_hidden=2048):
super().__init__()
self.d_model = d_model
self.n_routed = n_routed_exp
self.top_k = top_k
self.bias_lr = 0.01
# A) Kumpulan ahli khusus yang hanya aktif sesekali (sparse).
self.routed = nn.ModuleList([ExpertFFN(d_model, routed_hidden) for _ in range(n_routed_exp)])
# B) Ahli umum yang aktif terus-menerus untuk setiap kata.
self.shared = nn.ModuleList([ExpertFFN(d_model, routed_hidden) for _ in range(n_shared_exp)])
# C) Matriks pengaturan rute (Router)
self.register_parameter("centroids", nn.Parameter(torch.empty(n_routed_exp, d_model)))
nn.init.normal_(self.centroids, std=d_model ** -0.5)
# D) Nilai bonus bias dinamis untuk penyeimbang beban tanpa hukuman.
self.register_buffer("bias", torch.zeros(n_routed_exp))
Langkah 3 & 4: Langkah Maju (Jalur Ahli Umum dan Khusus)
Kode Program 4.3 & 4.4 Langkah Maju (Forward Pass)
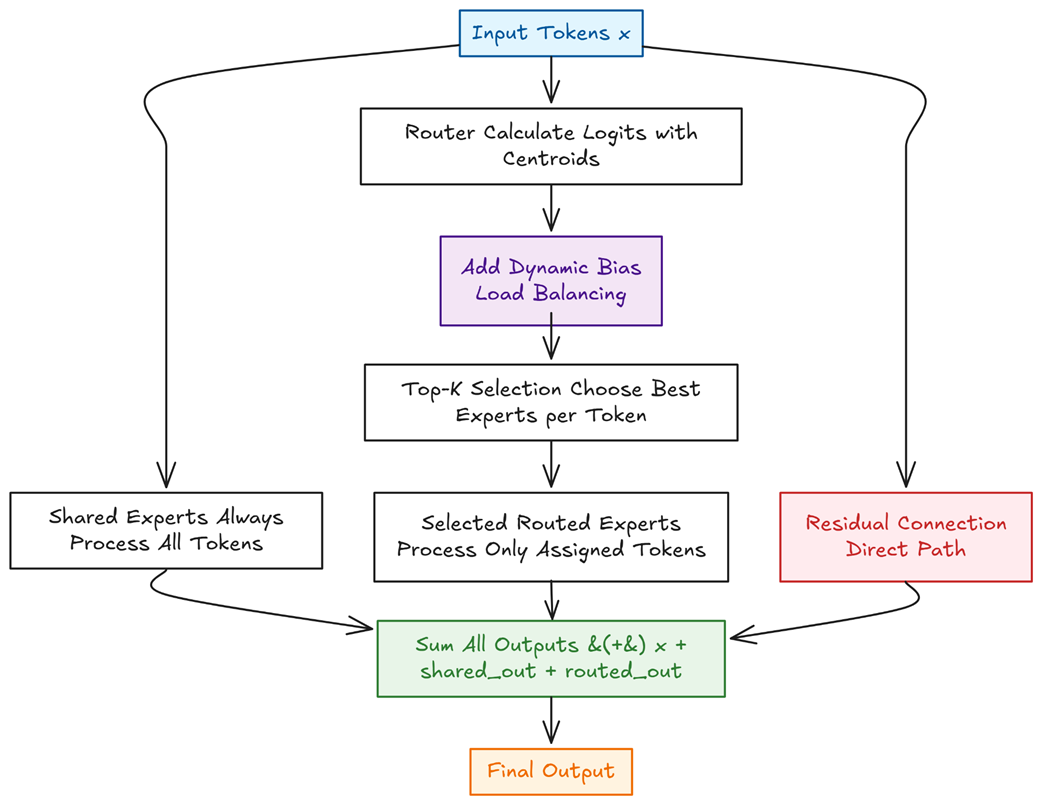
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, S, D = x.shape
x_flat = x.reshape(-1, D)
# 1) Jalur Ahli Umum (Padat / Aktif Semua)
shared_out = torch.zeros_like(x_flat)
for exp in self.shared:
shared_out += exp(x_flat)
# 2) Skor Router (Logits) + Bonus Bias Dinamis
logits = F.linear(x_flat, self.centroids)
logits = logits + self.bias.to(logits.dtype)
# 3) Pemilihan Pintu Gerbang Top-K
topk_logits, topk_idx = torch.topk(logits, self.top_k, dim=-1)
gate = F.softmax(topk_logits, dim=-1, dtype=x.dtype)
# 4) Pengiriman Renggang (Hanya ke ahli yang terpilih)
routed_out = torch.zeros_like(x_flat)
for i in range(self.n_routed):
# Mencari kata-kata mana saja yang ditujukan ke ahli nomor 'i'
mask = (topk_idx == i)
row_idx, which_k = mask.nonzero(as_tuple=True)
if row_idx.numel() == 0: continue
# Memproses kata dan mengalikannya dengan bobot persentasenya
exp_in = x_flat.index_select(0, row_idx)
out = self.routed[i](exp_in)
w = gate[row_idx, which_k].unsqueeze(-1)
routed_out.index_add_(0, row_idx, out * w)
# 5) Menggabungkan semua jalur menjadi satu
return x + shared_out.view(B, S, D) + routed_out.view(B, S, D)
Langkah 5: Metode Pembaruan Nilai Bias
Kode Program 4.5 Metode update_bias
@torch.no_grad()
def update_bias(self, x: torch.Tensor):
logits = F.linear(x.reshape(-1, self.d_model), self.centroids) + self.bias
_, idx = torch.topk(logits, self.top_k, dim=-1)
# Menghitung jumlah kata yang diterima oleh masing-masing ahli
counts = torch.bincount(idx.flatten(), minlength=self.n_routed).float()
avg = counts.sum() / max(1, self.n_routed)
# Menghitung tingkat pelanggaran (Angka Positif = kurang kerjaan / menganggur)
violation = (avg - counts) / (avg + 1e-6)
# Menerapkan penyesuaian nilai bonus secara halus
self.bias.add_(self.bias_lr * torch.tanh(violation))
4.6 Sistem Kerja Renggang Jenis Baru: Memori Bersyarat Melalui Pencarian Kilat (Engram)
Sampai titik ini di dalam bab ini, kita telah menyelesaikan masalah memperbesar kapasitas AI menggunakan Mixture-of-Experts (MoE). Dengan hanya menyalakan sebagian kecil jaringan saraf (renggang), kita berhasil meningkatkan kemampuan menalar dan logika AI secara besar-besaran tanpa membuat tenaga komputer (FLOPs) meledak.
Akan tetapi, MoE ternyata memiliki sebuah kelemahan bawaan pada struktur aslinya.
4.6.1 Batasan dan kelemahan MoE dalam mencari pengetahuan statis (fakta pasti)
Pemrosesan bahasa pada AI melibatkan dua tugas yang sifatnya sangat berbeda:
- Penalaran Komposisional: Ini adalah ilmu berpikir logika yang rumit dan dinamis (misalnya, memecahkan persamaan matematika atau menulis naskah pemrograman Python). MoE sangat ahli dan luar biasa dalam tugas ini.
- Pencarian Pengetahuan: Ini adalah tugas mengingat fakta-fakta yang pasti, baku, dan statis (misalnya, mengingat bahwa ibu kota negara Prancis adalah Paris, atau mengenali nama tokoh
"Diana, Putri Wales").
Model Transformer standar (termasuk arsitektur MoE) tidak memiliki alat bantu bawaan untuk langsung mencari tahu sebuah fakta pasti. Jika Anda bertanya kepada AI tentang suatu fakta, model tersebut terpaksa harus berpura-pura mencari dengan cara melakukan perhitungan matematika panjang. Model ini harus menggunakan berlapis-lapis jaringan attention dan jaringan MoE yang berat untuk secara bertahap menyusun ciri-ciri kata, yang mana hal ini sama saja dengan membangun ulang sebuah buku kamus dari awal pada saat ia ditanya.
Hal ini sungguh sangat tidak efisien. Mengapa kita harus memaksa otak jaringan saraf yang mahal untuk menghitung matematika demi mencari fakta pasti, padahal di dunia ilmu komputer biasa hal ini bisa diselesaikan dengan mudah menggunakan tabel pemetaan langsung (hash map)?
4.6.2 Memperkenalkan Engram: Memodernisasi ingatan N-gram untuk Pencarian Kilat O(1)
Agar arsitektur model AI bisa cocok dengan dua sifat tugas bahasa ini, tim DeepSeek (bersama para peneliti dari Universitas Peking) memperkenalkan metode kerenggangan yang sama sekali baru: Conditional Memory via Engram (Memori Bersyarat melalui Engram).
Jika MoE menggunakan metode perhitungan bersyarat untuk memproses logika yang berubah-ubah, maka Engram menggunakan metode memori bersyarat untuk mengambil fakta-fakta pasti melalui operasi pencarian yang instan, langsung ketemu di langkah pertama yang secara matematika disebut rumus pencarian $O(1)$.
Modul Engram ini didasari pada struktur bahasa N-gram klasik (metode mencocokkan kata berurutan) namun telah diperbarui untuk era LLM modern. Daripada sibuk menghitung ciri-ciri kata, Engram menggunakan beberapa teks kata terakhir sebagai kunci (key) untuk mencari langsung ke dalam sebuah tabel kamus memori raksasa berisi miliaran parameter, guna menemukan isi (value)-nya secara instan.
Alur Kerja Arsitektur Engram:
- Kompresi Pemecah Kata (Tokenizer Compression): Untuk mencegah ada dua kata yang kodenya sama, kode-kode angka kata diubah ke dalam sebuah peta ruang ID dasar, sehingga memperkecil jumlah ukuran kamus secara efektif.
- Hashing Multi-Kepala (Multi-Head Hashing): Konteks kalimat (misalnya, 3 kata terakhir yang baru dibaca) diubah menjadi sebuah kode sandi indeks acak (ID) menggunakan fungsi matematika XOR yang pasti.
- Pengambilan Renggang (Sparse Retrieval): Model AI kemudian menggunakan ID sandi ini untuk melakukan pencarian instan $O(1)$ di dalam sebuah tabel memori terpisah yang sangat besar, langsung menarik keluar sebuah “vektor ingatan” yang statis (pasti).
- Pintu Gerbang Penyesuai Konteks (Context-Aware Gating): Karena ingatan pasti kadang bisa punya makna ganda (polisemi), ada sebuah mekanisme gerbang (mirip seperti attention) yang akan membandingkan ingatan ini dengan konteks kalimat yang sedang dipikirkan oleh jaringan saraf. Jika ingatan yang diambil tadi ternyata bertentangan dengan konteks kalimat, pintu gerbang ini akan menekan dan membuang memori yang salah tersebut menjadi nol.
Modul Engram ini dimasukkan sebagai sambungan di lapisan-lapisan awal jaringan otak AI: H = H + Gated_Engram_Memory (Data = Data + Memori Engram Terfilter).
Dengan cara menyuntikkan fakta secara langsung ke dalam otak AI melalui jalur pencarian instan, Engram berhasil membebaskan lapisan-lapisan awal otak Transformer dari beban tugas menghafal dan menyusun ulang fakta-fakta pasti.
4.6.3 Hukum Pembagian Kerenggangan: Menyeimbangkan ahli MoE dan memori Engram
Jika Anda memiliki batasan jumlah parameter memori (misalnya, total hanya boleh 27 Miliar parameter), bagaimana cara Anda membaginya? Apakah Anda akan membuat model murni berisi MoE dengan ratusan ahli? Atau apakah Anda akan memberikan jatah parameter itu untuk tabel memori Engram?
Para peneliti DeepSeek merumuskan masalah Alokasi Kerenggangan (Sparsity Allocation) ini dan menemukan sebuah Hukum Skala berbentuk huruf-U yang sangat jelas.
Mereka menemukan bahwa model yang “Murni 100% MoE” itu tidaklah bagus. Jika Anda tidak memiliki ruang memori khusus, otak AI akan membuang-buang kemampuannya hanya untuk menghafal. Sebaliknya, model yang “Murni 100% Engram” akan kehilangan kemampuannya untuk melakukan penalaran dan berpikir logika.
Arsitektur yang paling hebat membutuhkan alokasi campuran (hybrid). Dalam sebuah uji coba menggunakan 27 Miliar parameter, mereka berhasil mencapai performa terbaik di dunia (state-of-the-art) dengan cara mengambil sebagian parameter dari ahli MoE dan memindahkannya ke dalam sebuah tabel memori Engram sebesar 5,7 Miliar parameter.
Secara mengejutkan, menambahkan sistem Engram ternyata tidak hanya meningkatkan nilai pada ujian tentang hafalan pengetahuan (seperti ujian TriviaQA). Dengan membebaskan sistem attention dari tugas menghafal, Engram juga membiarkan kepala-kepala attention tersebut untuk fokus 100% pada pemahaman logika panjang tingkat tinggi. Hal ini sukses meningkatkan nilai ujian AI secara drastis dalam hal Matematika, Pemrograman Coding, dan tes membaca dokumen raksasa sepanjang 100.000 kata (tes Needle-In-A-Haystack / Mencari Jarum di Tumpukan Jerami).
4.6.4 Efisiensi Sistem Komputer: Memisahkan memori dan prosesor dengan memindahkannya ke CPU Biasa (Host CPU Offloading)
Mungkin keunggulan paling menakjubkan dari Engram dibandingkan MoE adalah efisiensi pada sistem komputernya.
MoE bergantung pada pengaturan rute dinamis—di mana Anda tidak akan tahu ahli mana yang Anda butuhkan sampai jaringan saraf AI tersebut selesai menghitung kata yang masuk. Karena itulah, semua ahli MoE secara wajib harus selalu siap sedia di dalam ruang memori kartu grafis (GPU VRAM) yang harganya sangat mahal.
Di sisi lain, Engram bertumpu pada pencarian hashing yang sudah pasti. Karena nomor kode pencarian (ID) dibuat murni berdasarkan teks kata masukan yang sudah kita ketahui sejak awal, maka sistem komputer sudah tahu persis blok memori mana saja yang akan ia butuhkan bahkan sebelum proses perhitungan matematika AI itu dimulai.
Karena sifatnya yang bisa diprediksi ini, Tabel memori Engram tidak perlu disimpan di dalam GPU yang mahal. DeepSeek merancang sebuah sistem di mana tabel Engram yang berukuran raksasa (hingga 100 Miliar parameter) dipindahkan dan disimpan ke dalam RAM CPU Komputer biasa yang jauh lebih murah (atau bahkan bisa disimpan di hardisk NVMe SSD). Jadi, sementara GPU sibuk menghitung pikiran awal AI, ia bisa sambil diam-diam menyedot dan mengambil memori Engram yang dibutuhkan lewat kabel data di dalam komputer (PCIe).
Hal ini memungkinkan model AI untuk memperluas kapasitas pengetahuannya hingga ratusan miliar parameter tanpa menambah beban perhitungan komputer (nol FLOPs tambahan), dan hanya memberi efek keterlambatan (loading) di bawah 3%. Memori bersyarat kini telah membuka batas kemajuan yang sama sekali baru dan super besar untuk dunia arsitektur AI sumber terbuka (Open-Source).
4.7 Ringkasan
- Jaringan Umpan-Maju (FFN) yang padat menciptakan masalah kemacetan pada komputer, karena semua parameternya harus dinyalakan untuk setiap kata yang masuk.
- Mixture of Experts (MoE) / Campuran Para Ahli menggantikan FFN padat tersebut dengan komite renggang yang berisi banyak jaringan spesialis. Ia hanya akan mengaktifkan sejumlah kecil (Top-K) ahli terbaik saja untuk setiap katanya.
- DeepSeek-MoE berhasil mengatasi kelemahan MoE gaya lama menggunakan Pemecahan Secara Detail (Fine-Grained Segmentation) (membuat ahli kecil yang banyak) untuk mencegah Pengetahuan Campur Aduk, dan menggunakan Pengasingan Ahli Pengetahuan Umum (Shared Expert Isolation) (membuat sedikit ahli yang selalu aktif) untuk mencegah Pengetahuan Berulang.
- Metode Penyeimbangan Tanpa Hukuman (Auxiliary-Loss-Free Balancing) milik DeepSeek menggunakan nilai bonus bias dinamis untuk meratakan beban kerja komputer tanpa merusak dan mengganggu proses belajar tata bahasa utama dari model AI tersebut.
- MoE sangat kesulitan untuk melakukan pencarian pengetahuan fakta pasti, yang mana memaksa otak AI yang mahal untuk berpura-pura mencari fakta melalui proses berhitung.
- Engram (Memori Bersyarat) memperkenalkan cara kerja renggang dari sudut pandang baru. Engram menggunakan kode pencarian N-gram yang pasti untuk melakukan pencarian instan $O(1)$ ke dalam tabel memori raksasa.
- Dengan meringankan otak AI dari tugas menghafal, Engram secara tak langsung “memperdalam” kemampuan AI tersebut, sehingga meningkatkan kemampuan penalaran logika yang rumit serta pemahaman teks yang sangat panjang.
- Karena pencarian Engram sangat bisa diprediksi dari awal, tabel pengetahuan yang masif bisa dipindahkan pengelolaannya ke memori CPU Komputer biasa. Hal ini memungkinkan model AI membesar hingga ratusan miliar parameter tanpa menambah beban hitung komputer (nol FLOPs) dan tanpa membuat AI menjadi lambat.