4.1 The intuition behind mixture of experts
To understand Mixture of Experts, we must first look at the component it replaces within the standard Transformer block: the Feed-Forward Network (FFN). The FFN acts as the primary processing unit within each Transformer layer, a dense neural network that accounts for the majority of the model’s parameters and its computational workload. This change marks a genuine revolution in design. Instead of relying on one massive, all-purpose neural network, we now substitute it with a diverse number of smaller, specialized neural networks each an “expert” in its own right. MoE allows models to grow far larger and more knowledgeable without a proportional increase in computational cost.
4.1.1 The problem with dense FFNs in transformer: High parameter count and computational cost
As we know following the multi-head attention layer and layer norm, the resulting context vectors are processed by a Feed-Forward Network (FFN), the architecture of which is depicted in Figure 4.2. The FFN consists of a two-layer neural network that implements an “expansion-contraction” sequence. As Figure 4.2 illustrates, the first linear layer expands the embedding dimension (e.g., by a factor of 4), while the second linear layer contracts it back to its original size. This design is critical for the model’s performance, as the expanded intermediate layer provides a richer, higher-dimensional space for the model to capture complex patterns before the output is passed to the subsequent block.
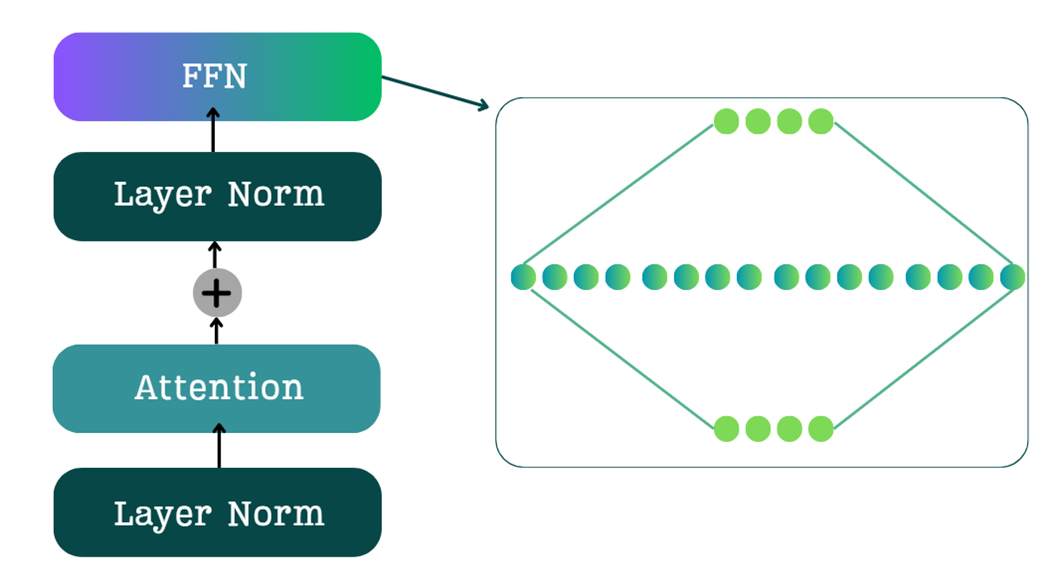
However, this FFN is dense. This means that for every single input token, all of the millions of parameters in the FFN are activated and used in the computation. This has two major consequences:
- High Training Cost: The large number of parameters in the FFNs across all Transformer blocks accounts for a significant portion of the model’s total training time.
- High Inference Cost: Similarly, during inference, these dense computations contribute significantly to the latency of generating each new token.
4.1.2 The sparsity solution: Activating only a subset of experts per token
The core idea of Mixture of Experts is to replace the single, large, dense FFN with a collection of multiple, smaller FFNs, which we call “experts.” The traditional FFN is a single, dense network. In an MoE architecture, this single block is replaced by a set of parallel expert networks, as shown in Figure 4.3.
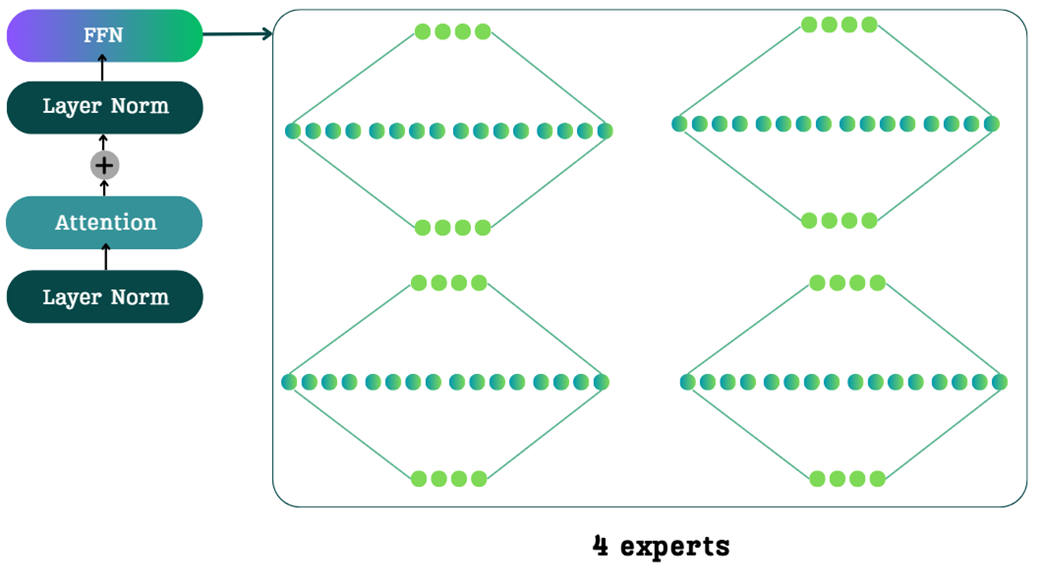
You might think that replacing one network with four would quadruple the computational cost, but this is where the magic of MoE comes in, driven by a single concept: sparsity.
Sparsity: In an MoE model, for any given input token, only a small subset of the total experts is activated. The rest remain dormant or inactive.
For example, in the 4-expert model shown in Figure 4.3, a token might be routed to only one or two of them. The other experts are not used for that specific token, meaning their parameters are not loaded and their computations are not performed.
This is the source of MoE’s incredible efficiency. We get the benefit of having a huge number of total parameters (the sum of all experts), but the computational cost for any single token is very low, as we only activate a small fraction of them. This allows us to build models that are vastly more knowledgeable (more total parameters) without a proportional increase in the cost of training or inference.
4.1.3 Expert specialization: The “why” behind sparsity
The concept of sparsity activating only a few experts per token is what makes MoE efficient. But why does this work? Why can we get away with ignoring most of the experts? The answer lies in expert specialization.
During the massive pre-training process, each expert network learns to become highly specialized in handling specific types of information or performing particular tasks. Instead of one giant, generalist FFN that must know how to do everything, we have a committee of specialists.
This specialization was proven quantitatively in the 2022 paper “ST-MoE: Designing Stable and Transferable Sparse Expert Models,” (https://arxiv.org/pdf/2202.08906) which analyzed what different experts in a trained model had learned to do. The results were fascinating and provided a clear window into the mind of an MoE model.
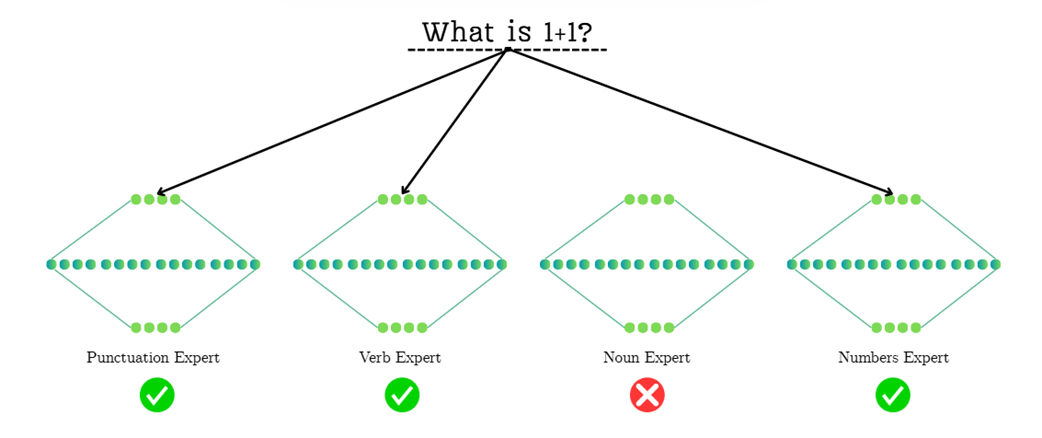
To make this concrete, let’s trace how the model might process the simple question “What is 1+1?”, as illustrated in Figure 4.4. The routing network must look at the incoming tokens and select the most appropriate specialists from its available committee:
- Punctuation Expert: The router first encounters the question mark (?). Having learned to recognize punctuation, it activates the Punctuation Expert. This expert is highly specialized in understanding the role of punctuation marks and how they influence the meaning and structure of a sequence.
- Verb Expert: The token is a common verb. The router, recognizing this, sends the token to the Verb Expert. This specialist has learned the grammatical and semantic patterns associated with actions and states of being, and it is best equipped to handle this part of the input.
- Dormant Experts (e.g., Noun Expert): Notice that the Noun Expert is not activated. Since the query contains no significant nouns, the router intelligently saves computation by keeping this expert dormant. The same would apply to a Proper Noun Expert; since there are no names like “Martin” or “DeepSeek,” that specialist is not needed.
- Domain-Specific Experts: This is where the process becomes even more granular. You might expect the Numbers Expert to be the most critical for handling “1+1”. However, as the diagram shows, the router might have learned that the signals from the question mark and the verb are stronger or more immediately recognizable. In this case, it prioritizes the grammatical experts, leaving the mathematical ones dormant. This highlights the complex and sometimes non-obvious decisions the routing mechanism makes, activating only the experts it deems most relevant for a given token based on its training.
This is the beauty of the MoE design. When an input token arrives, the model doesn’t need to consult its entire knowledge base. It uses a small, efficient routing network (which we will build later) to ask, “Who is the specialist expert for this type of token?” It then sends the token only to the relevant experts.
A token representing a comma does not need to activate the expert that specializes in mathematical verbs. By routing the token only to the punctuation expert, the model saves an enormous amount of computation.