5.2 The four key advantages of MTP
Changing the training objective from predicting one token to predicting many is more than just a minor tweak; it fundamentally alters what the model learns and how efficiently it learns it. Four major benefits arise from this architectural shift, as demonstrated in the original MTP paper and leveraged by DeepSeek.
5.2.1 Densification of training signals
The first and most important advantage is that MTP provides much richer and denser training signals than single-token prediction. In traditional training, for each token, the model receives a gradient signal based on its ability to predict just one step ahead. It learns about immediate, local dependencies very well (e.g., that “Intelligence” is likely to follow “Artificial”).
With MTP, the learning signal is far more comprehensive. When the model processes the token “Artificial,” it’s not just getting feedback on its prediction of “Intelligence.” It’s also getting feedback on its ability to foresee “is,” “transforming,” “the,” and “world.”
This means that from a single training example, the model is forced to learn about longer-range structure, grammar, and coherence. It sees and learns the relationships across multiple future steps simultaneously. This richer gradient information guides the model’s internal representations towards better planning and forecasting of sequences. The training process becomes more efficient because every single training sample now contains much more information for the model to learn from.
5.2.2 Improved data efficiency
This densification of training signals leads directly to the second benefit: improved data efficiency. Since each training sample is now more informative, the model can achieve a higher level of performance with the same amount of training data.
This isn’t just a theoretical benefit; it has been proven quantitatively. The original MTP paper demonstrated this on standard coding benchmarks like MBPP (Mostly Basic Python Problems) and HumanEval, as shown in figure 5.4.
Figure 5.4 Performance improvement of MTP over single-token prediction on coding benchmarks. Positive bars indicate MTP is better. (Source: Gloeckle et al., 2024)
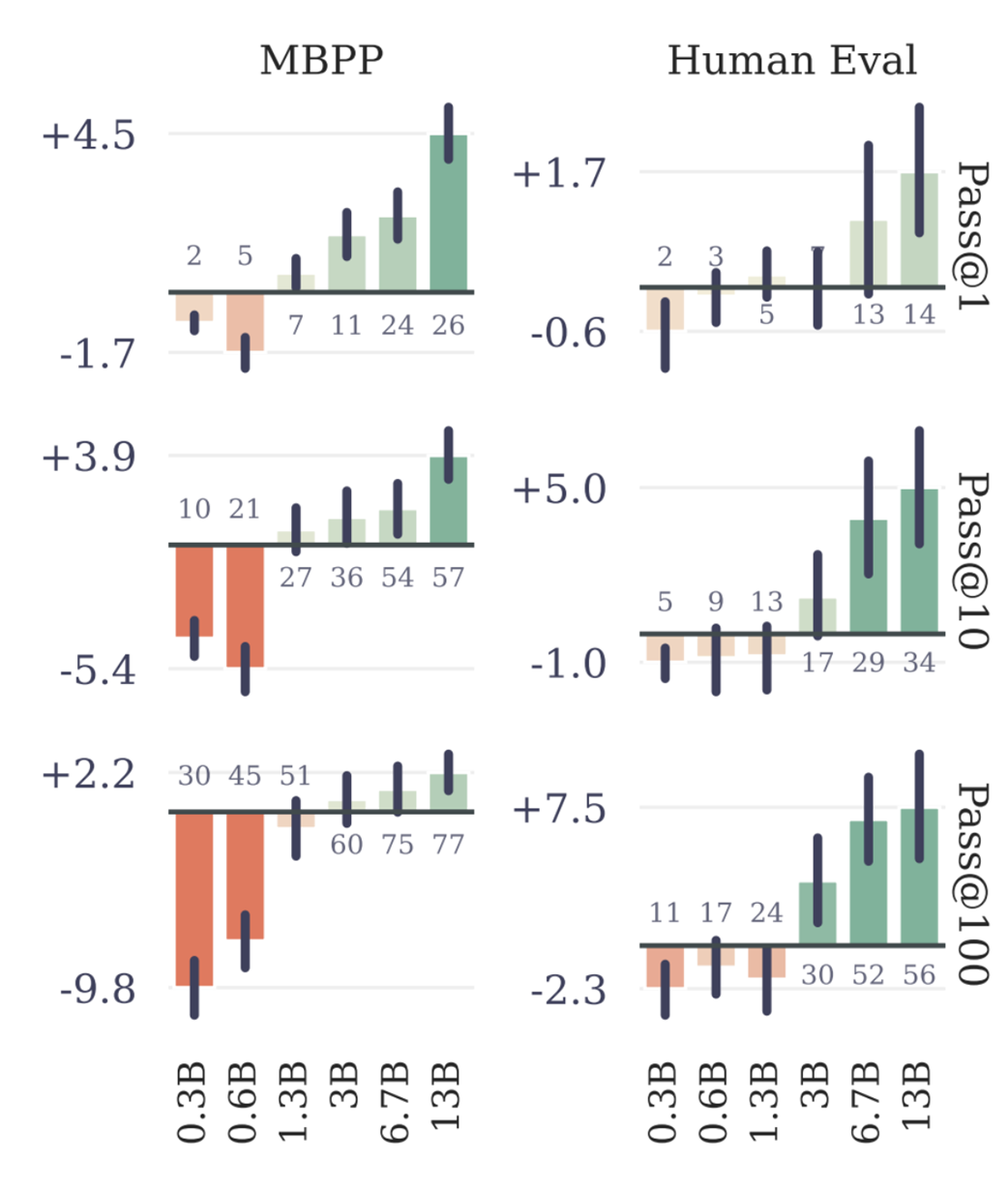
The data clearly shows that as models scale (from 0.3B to 13B parameters), the performance advantage of MTP becomes more pronounced and consistent. This establishes that MTP is a powerful technique for improving data efficiency. However, this raises a new question: if predicting multiple tokens is good, how many should we predict? The same study explored this by varying the number of predicted future tokens, denoted by n.
Figure 5.5 The effect of increasing the number of predicted future tokens (n) on benchmark performance. (Source: Gloeckle et al., 2024)
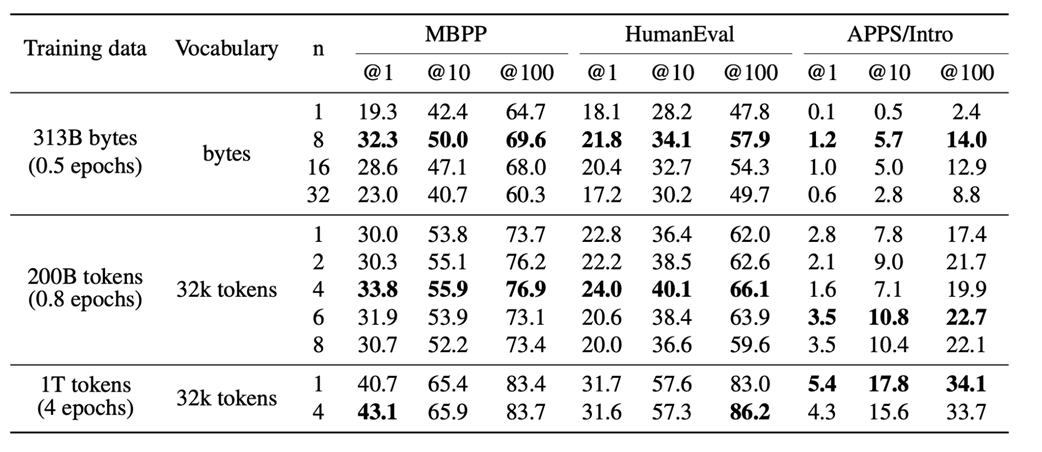
These results show two clear trends:
- As shown in figure 5.4, while MTP can sometimes perform worse on very small models, as the model size increases, it consistently and significantly outperforms the single-token baseline.
- As shown in figure 5.5, for a fixed amount of training data, increasing the number of predicted future tokens (n) generally leads to better performance on these benchmarks, up to a certain point.
This provides strong evidence that MTP allows the model to learn more effectively from the same data, a crucial advantage when training on massive, expensive datasets.
5.2.3 Better planning by prioritizing “choice points”
The third advantage of MTP is more subtle but incredibly powerful: it implicitly teaches the model to be better at planning by forcing it to pay more attention to the most important tokens in a sequence.
To understand this, we need to introduce the concept of a “choice point.” A choice point is a key token in a sequence that significantly influences the future outcome. Most transitions are simple and predictable (e.g., 1 -> 2, 2 -> 3), but some transitions represent a major shift in context (e.g., transitioning from numbers to letters).
Figure 5.6 MTP implicitly assigns higher weights to consequential “choice point” tokens. (Source: Gloeckle et al., 2024)
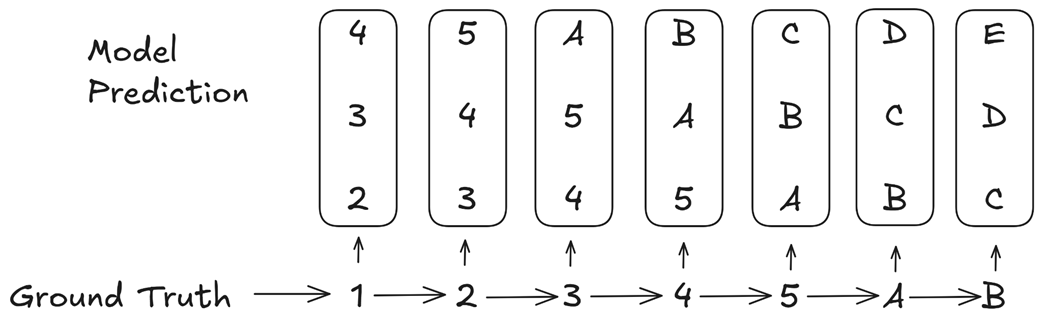
Let’s analyze the example in figure 5.6. The ground truth sequence is 1 -> 2 -> 3 -> 4 -> 5 -> A -> B. The transition from 5 -> A is the critical “choice point” where the pattern changes from numbers to letters.
Now, consider how the MTP loss is calculated. When the model sees the input token 3, it is trained to predict the next three tokens: 4, 5, A. The error associated with predicting A is part of the loss calculation for the input 3.
When the model sees the input 4, it is trained to predict 5, A, B. The error for A is part of the loss again. When it sees 5, it is trained to predict A, B, C, and the error for A is part of the loss a third time.
The errors related to predicting the consequential token A appear repeatedly in the overall loss calculation, far more often than the errors for the simple, inconsequential transitions. This means the multi-token prediction loss implicitly assigns a higher weight to these critical choice points.
The training process, therefore, naturally prioritizes getting these crucial, pattern-shifting tokens correct. This forces the model to develop better internal representations for planning and forecasting sequences, as it learns to recognize and correctly handle the most important decision points in the text.
5.2.4 Higher inference speed via speculative decoding
The fourth and final advantage is that MTP can lead to significantly faster inference, with observed speedups of up to 3x on certain tasks. This is achieved through a technique called speculative decoding. In standard autoregressive generation, we run the full, large language model once for every single token. This is slow.
Speculative decoding works differently:
- Drafting: A small, fast “draft” model (or an MTP head) generates a chunk of several candidate tokens at once.
- Verification: The main, large language model then processes this entire chunk in a single forward pass to verify which of the drafted tokens are correct.
Because a single forward pass over a chunk of tokens is much faster than multiple, sequential forward passes, this can dramatically speed up generation. MTP is a natural fit for this process, as the MTP heads can serve as the “draft” model, predicting multiple future tokens that the main model can then verify.
It’s important to note, as mentioned in the DeepSeek V3 paper, that they used MTP’s benefits primarily during pre-training to get the advantages of denser signals and better planning. For their public release, the inference was done using standard single-token prediction, discarding the MTP modules. However, they explicitly state that the MTP modules can be repurposed for speculative decoding to accelerate inference, highlighting the dual benefit of this powerful technique.