Mengatasi Masalah Kemacetan Kinerja
- Daftar Isi
- Mengapa Token ID Penting?
- Analogi untuk Penyematan Token: Ujian Masuk untuk Token
- Bagaimana Penyematan Posisional Bekerja
- Bagaimana Penyematan Input (Input Embeddings) Dibentuk
- Normalisasi (Normalization)
- Perhatian Multi-Kepala (Multi-head Attention)
- Dropout
- Koneksi Lewati (Skip Connection)
- Normalisasi 2
- Tujuan dari Normalisasi Kedua:
- Feed Forward Neural Network (Jaringan Saraf Tiruan Feed-Forward)
- Bagaimana Feed-Forward Network Bekerja
- Lapisan Dropout 2
- Koneksi Lewati Akhir (Final Skip Connection)
- Mengapa Pengulangan Ini Diperlukan?
- Mempertahankan Dimensi di Seluruh Blok Transformer
- Lapisan Proyeksi Output (Output Projection Layer): Memperluas ke Ukuran Kosakata
- Langkah Terakhir: Memilih Token Berikutnya
Perjalanan Sebuah Token Tunggal Melalui Arsitektur LLM
Daftar Isi
- Pendahuluan – Gambaran umum tentang bagaimana sebuah token bergerak melalui sebuah LLM.
- Analogi Perjalanan Token – Membandingkan pemrosesan token dengan bahan bakar di dalam sebuah mesin.
- Fase 1: Isolasi – Memisahkan token-token dari konteksnya.
- Fase 2: Pemberian ID Token (Token ID Assignment) – Memberikan ID unik untuk setiap token.
- Fase 3: Penyematan Token (Token Embeddings) – Mengubah token menjadi vektor numerik.
- Fase 4: Penyematan Posisional (Positional Embeddings) – Mengkodekan posisi token dalam sebuah kalimat.
- Fase 5: Penyematan Input (Input Embeddings) – Menggabungkan penyematan token dan posisional.
- Blok Transformer – Memproses token dengan mekanisme attention dan feed-forward layers.
- Lapisan Output (Output Layer) – Memprediksi token selanjutnya berdasarkan probabilitas.
- Kesimpulan – Merangkum perjalanan token dan kemajuan teknologi LLM.
Pendahuluan
Dalam blog ini, kita akan memulai sebuah perjalanan yang menarik—mengikuti sebuah token saat ia bergerak menembus arsitektur Large Language Model (LLM). Dengan melakukan ini, kita akan mengungkap cara kerja dari model-model canggih ini, mulai dari tokenisasi hingga penyematan (embedding), mekanisme perhatian (attention mechanisms), dan pembuatan output akhir. Eksplorasi ini akan memberikan gambaran tentang proses menakjubkan yang memungkinkan LLM untuk memahami dan menghasilkan teks layaknya manusia.
Perjalanan Sebuah Token (Kata) Melalui Arsitektur LLM
 Gambar 1: Perjalanan bahan bakar di dalam mesin (digunakan sebagai analogi untuk perjalanan token di dalam LLM)
Gambar 1: Perjalanan bahan bakar di dalam mesin (digunakan sebagai analogi untuk perjalanan token di dalam LLM)
Bayangkan Anda adalah setetes bahan bakar yang memasuki sebuah mesin yang sangat kuat. Saat Anda bergerak melalui sistemnya yang rumit, Anda diubah—dikompresi, dinyalakan, dan pada akhirnya dikonversi menjadi energi yang mendorong mesin tersebut maju. Dengan mengikuti perjalanan Anda, kita bisa memahami bagaimana mesin tersebut bekerja.
 Gambar 2: Bayangkan diri Anda sebagai sebuah token
Gambar 2: Bayangkan diri Anda sebagai sebuah token
Sekarang, mari kita ubah analogi ini ke ranah Large Language Models (LLMs). Alih-alih sebagai bahan bakar, bayangkan diri Anda sebagai sebuah token—sebuah kata atau bagian dari kata—yang memasuki mesin neural dari LLM. Apa yang terjadi pada Anda di dalam sana? Bagaimana Anda diproses, disaring, dan pada akhirnya digunakan untuk menghasilkan teks yang bermakna?
Dalam cerita ini, Anda adalah token tersebut, dikelilingi oleh kata-kata lain, menunggu untuk diproses. Anda akan dilemparkan ke dalam arsitektur LLM yang sangat luas. Saat kita menempatkan diri pada posisi Anda, kita akan mengikuti perjalanan Anda melalui setiap tahap dari sistem yang kompleks ini—melihat bagaimana Anda berevolusi, berinteraksi, dan berkontribusi pada output akhir.
Jadi, mari kita asumsikan kita pergi ke GPT dan memintanya untuk menghasilkan sebuah paragraf acak tentang “friends” (teman).
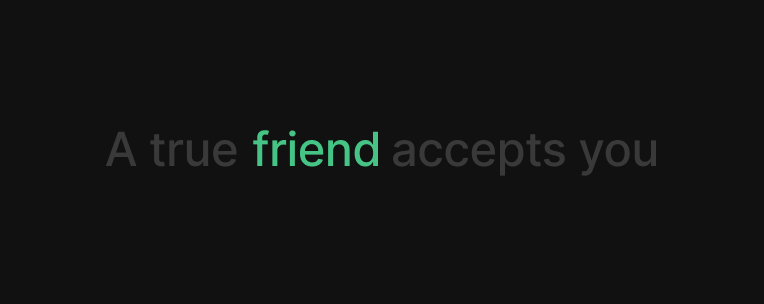
Friends are the people who bring joy, support, and understanding into our lives. They share in our laughter, stand by us in tough times, and offer a listening ear when needed. A true friend accepts you for who you are, encourages your growth, and adds meaning to your experiences. The bond between friends is built on trust, shared memories, and mutual respect, creating a relationship that enriches both individuals’ lives.
"A true friend accepts you"
Katakanlah kita sedang melihat kalimat di atas, yang merupakan rangkaian dari lima kata, dan kita perlu memprediksi kata berikutnya.
Kita akan secara spesifik berfokus pada kata “friend”.
Catatan: Token dan kata sebenarnya tidak sama persis, namun demi kesederhanaan penjelasan, kita akan menggunakan kedua istilah tersebut secara bergantian.
 Gambar 4: Tetangga kata yang familiar
Gambar 4: Tetangga kata yang familiar
Bayangkan Anda dikelilingi oleh tetangga Anda yang familiar—“a,” “true,” “accepts,” dan “you.” Sama seperti sekelompok teman dekat, Anda selalu eksis berdampingan dengan mereka, membentuk koneksi yang bermakna di dalam sebuah kalimat.
Tapi sekarang, sesuatu yang tak terduga terjadi.
Saat Anda memasuki pipa pemrosesan LLM (processing pipeline), langkah pertama adalah isolasi.
Fase 1: Isolasi
Tiba-tiba, Anda dipisahkan dari tetangga-tetangga Anda. Model tersebut tidak lagi melihat Anda sebagai bagian dari satu kalimat utuh, melainkan memeriksa Anda secara individu.
Ini menandai tahap kritis pertama dari pemrosesan input, di mana setiap token dipisahkan dari konteksnya sebelum menjalani analisis lebih lanjut.
Fase 2: Pemberian ID Token (Mendapatkan Tanda Pengenal Anda)
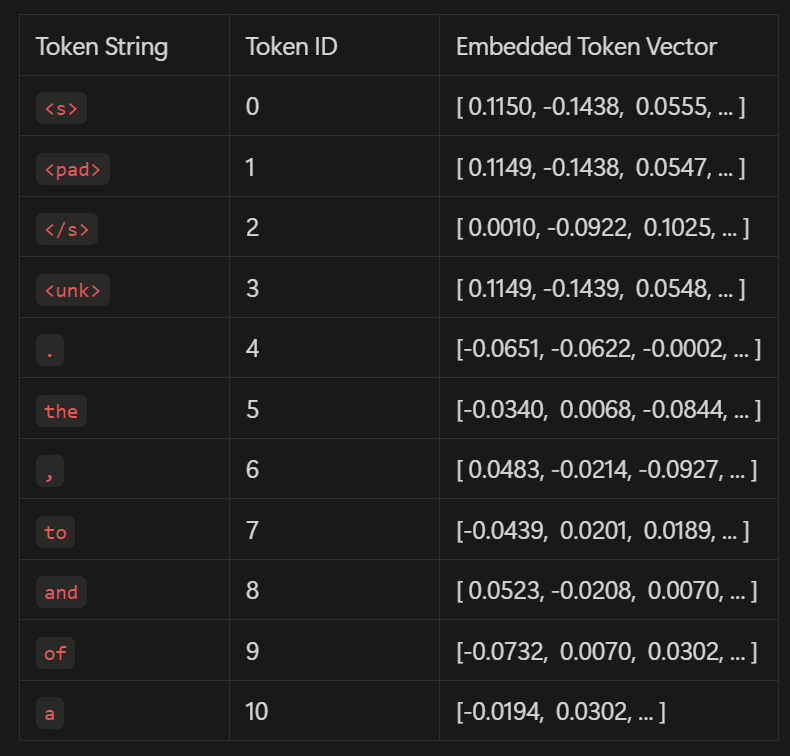 Gambar 6: Contoh tabel pencarian Token ID (Lookup table)
Gambar 6: Contoh tabel pencarian Token ID (Lookup table)
Setelah sebuah token diisolasi, langkah selanjutnya dalam pipa pemrosesan LLM adalah memberikannya identitas unik. Anggap saja ini seperti mendaftar di sekolah, militer, atau kamp musim panas—setiap peserta menerima tanda pengenal (ID badge) untuk membedakan mereka dari yang lain. Dengan cara yang sama, setiap token diberikan Token ID, yang berfungsi sebagai pengenal uniknya.
Model menyimpan sebuah buku berisi ID token, mirip dengan ensiklopedia dari semua token yang mungkin ada. Buku ini berisi:
- Karakter – Huruf individu seperti A, B, C … hingga Z.
- Kata utuh – Kata-kata utuh yang umum seperti “token,” “enter,” “begin.”
- Sub-kata (Subwords) – Pecahan dari kata, seperti “-ation” atau “un-“, yang sangat berguna untuk memproses kosakata yang kompleks.
Setiap token—entah itu berupa kata utuh, sub-kata, atau karakter—diberikan ID numerik dari buku ini. Sebagai contoh, kata “friend” mungkin diberikan ID seperti 2012, tergantung pada kamus kosakata (vocabulary) model tersebut.
Mengapa Token ID Penting?

Skema tokenisasi, seperti Byte Pair Encoding (BPE), membantu membuat dan memelihara kosakata token ini. Model yang berbeda memiliki ukuran kosakata yang berbeda pula:
- GPT-2 memiliki sekitar 50.000 token dalam kosakatanya.
- GPT-4 mungkin memiliki kosakata yang jauh lebih besar, mungkin 100.000 atau lebih.
Token ID memastikan bahwa setiap kata (atau bagian dari kata) diidentifikasi secara unik, memungkinkan LLM untuk secara efisien memproses dan memprediksi teks. Langkah ini meletakkan fondasi untuk pemahaman dan pembuatan (generasi) teks yang lebih dalam, saat setiap token bergerak melalui sisa arsitektur model.
Sekarang Anda telah diberikan tanda pengenal—sebuah Token ID unik yang memberi Anda identitas di dalam sistem.
Dengan nomor urut ini, Anda sekarang siap untuk beralih ke fase berikutnya dari perjalanan Anda melalui arsitektur LLM. Yaitu Fase 3.
Fase 3: Pemberian Penyematan Token / Token Embeddings (Ujian Masuk)
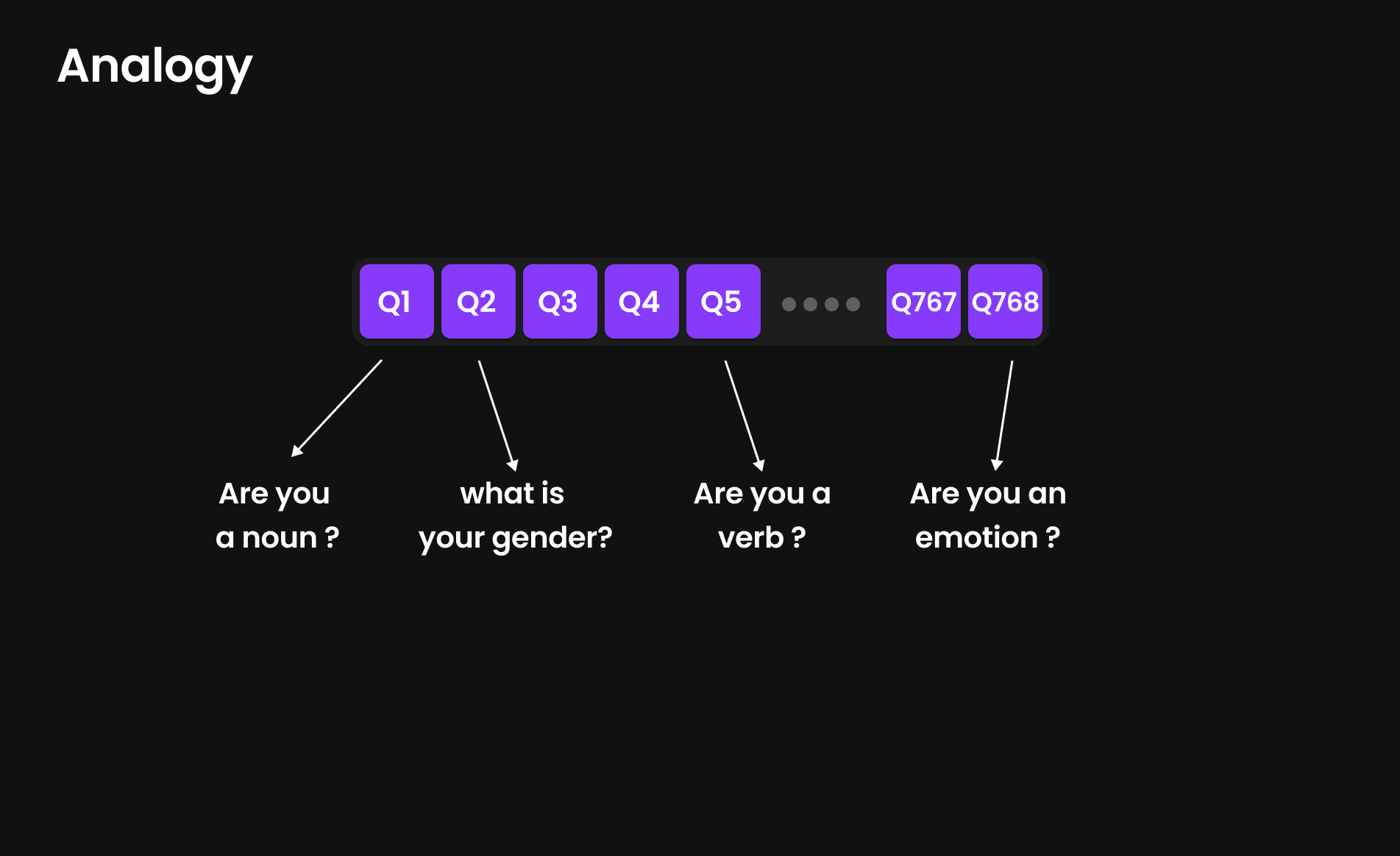
Analogi untuk Penyematan Token: Ujian Masuk untuk Token
Bayangkan Anda adalah seorang siswa yang sedang mengikuti ujian masuk untuk sebuah universitas bergengsi. Ujian tersebut terdiri dari 768 pertanyaan, di mana masing-masing pertanyaan menguji berbagai aspek dari kemampuan, latar belakang, dan kepribadian Anda.
Beberapa dari pertanyaan tersebut mungkin:
- Apakah Anda pandai matematika?
- Apakah Anda menyukai olahraga?
- Apakah Anda lebih analitis atau kreatif?
- Apakah Anda fasih dalam berbagai bahasa?
Di akhir ujian, jawaban-jawaban Anda akan menciptakan profil mendetail tentang siapa diri Anda, membantu universitas tersebut memahami kekuatan, kelemahan, dan ciri khas unik Anda.
Sekarang, mari kita terapkan analogi ini pada penyematan token (token embeddings) di dalam sebuah LLM.
Setiap token (kata atau sub-kata) melewati kuesioner yang serupa, tetapi bukannya menguji keterampilan akademik, model tersebut bertanya:
- Apakah Anda sebuah kata benda, kata kerja, atau kata sifat?
- Apakah Anda berkaitan dengan emosi?
- Apakah Anda sering muncul di awal atau akhir kalimat?
- Apakah Anda terhubung dengan konsep monarki (misalnya, raja, ratu, putri)?
Setiap token menjawab 768 pertanyaan tersembunyi, membentuk sebuah representasi vektor yang unik—sebuah sidik jari numerik yang mengkodekan makna, konteks, dan hubungannya dengan kata-kata lain.
Berbeda dengan Pemberian ID Token, yang hanya sekadar memberi nama pada sebuah kata, Penyematan Token (Token Embeddings) memberikannya identitas, membantu model memahami maknanya, dan bukan sekadar mengenalinya sebagai sebuah kata dalam kamus.
Sama seperti ujian masuk yang membantu universitas mengkategorikan siswa ke dalam berbagai bidang akademik, penyematan token membantu LLM mengklasifikasikan dan memahami kata-kata dalam struktur linguistik yang lebih luas.

Sebagai contoh, jika sebuah model seperti GPT-2 Small menggunakan 768 dimensi, maka setiap token akan direpresentasikan sebagai sebuah vektor berisi 768 nilai numerik—di mana setiap nilai menangkap aspek yang berbeda dari makna dan hubungannya dengan kata-kata lain.
Namun, jumlah dimensi ini tidaklah tetap/sama di semua LLM. Model yang berbeda menentukan ukuran embedding mereka berdasarkan seberapa kompleks model tersebut dan seberapa dalam pemahaman bahasa yang ditargetkan.
- GPT-2 Small → 768 dimensi
- GPT-2 XL → 1600 dimensi
- Model yang lebih besar → memiliki dimensi yang jauh lebih tinggi
Ini berarti bahwa ketika sebuah token diproses oleh LLM yang berbeda, ia mungkin dievaluasi berdasarkan jumlah fitur linguistik dan kontekstual yang berbeda pula. Sebuah token yang diproses di GPT-2 Small mungkin memiliki representasi 768 dimensi, sementara token yang sama di model yang lebih canggih bisa memiliki 1600 atau lebih dimensi, sehingga memperkaya pemahaman kontekstualnya.
Dengan menyesuaikan dimensi penyematan, model menyeimbangkan antara efisiensi dan kedalaman representasi, memastikan bahwa token menangkap cukup detail linguistik sambil tetap menjaga biaya komputasi agar dapat dikelola.
Jadi, bersama dengan tanda pengenal Anda (Token ID), Anda juga membawa hasil ujian Anda—yaitu nilai-nilai embedding Anda.
Token embedding adalah langkah krusial dalam LLM karena ia mengekstrak makna dari setiap token, memungkinkan model untuk memahami bahasa melebihi sekadar memberikan ID. Setiap token dianalisis melalui serangkaian fitur (misal, apakah ia kata benda, kata kerja, atau terkait dengan konsep tertentu), menghasilkan sebuah vektor 768-dimensi (untuk studi kasus GPT-2 Small). Vektor ini bertindak sebagai identitas token, menangkap sifat semantik dan kontekstualnya, yang kemudian digunakan model untuk pemrosesan bahasa dan prediksi token selanjutnya.
Fase 4: Penyematan Posisional (Positional Embedding)
Posisi Anda di antara para tetangga itu penting!
Meskipun Penyematan Token membantu menangkap makna dari sebuah token, ia sama sekali tidak menyimpan informasi tentang posisinya dalam sebuah kalimat. Padahal, dalam bahasa, urutan kata sangatlah krusial untuk menentukan makna. Di sinilah Penyematan Posisional (Positional Embeddings) berperan—mereka memungkinkan model untuk membedakan kata-kata yang identik namun muncul di tempat yang berbeda, dan membantunya memahami struktur kalimat.
Pertimbangkan frasa ini:
A true friend accepts you.
Di sini, setiap kata memiliki posisi spesifik dalam kalimat tersebut.

Kata “friend” berada di posisi ke-3. Tanpa pengkodean posisi (positional encoding), model akan memperlakukan semua kemunculan kata “friend” sebagai hal yang identik, tidak peduli di mana mereka muncul. Namun, dalam bahasa alami, urutan kata secara signifikan memengaruhi makna, sehingga model perlu mengkodekan informasi posisi bersama dengan penyematan token (token embeddings).
Mari kita pertimbangkan kalimat lain:
The dog chased another dog.
Dalam kasus ini, kedua kemunculan kata “dog” merujuk pada entitas yang berbeda. Kata “dog” pertama di posisi 2 adalah subjek (yang mengejar), sedangkan kata “dog” kedua di posisi 5 adalah objek (yang dikejar).

Jika kita hanya bergantung pada penyematan token (token embeddings), model akan memperlakukan kedua token “dog” tersebut sama persis, dan gagal menangkap makna kalimat yang sebenarnya. Penyematan posisional memecahkan masalah ini dengan memberikan nilai posisi yang berbeda, membantu model membedakan antara kata-kata identik yang muncul dalam konteks yang berbeda.
Bagaimana Penyematan Posisional Bekerja
Sama seperti penyematan token yang memiliki representasi 768 dimensi, penyematan posisional juga menggunakan 768 dimensi (dalam GPT-2 Small) untuk mengkodekan informasi posisi. Model memproses “pertanyaan-pertanyaan” seperti:
- Apakah token ini berada di awal kalimat?
- Apakah posisinya berada di tengah atau di akhir?
- Apakah ia mengkodekan ketergantungan jarak jauh (long-range dependencies)?
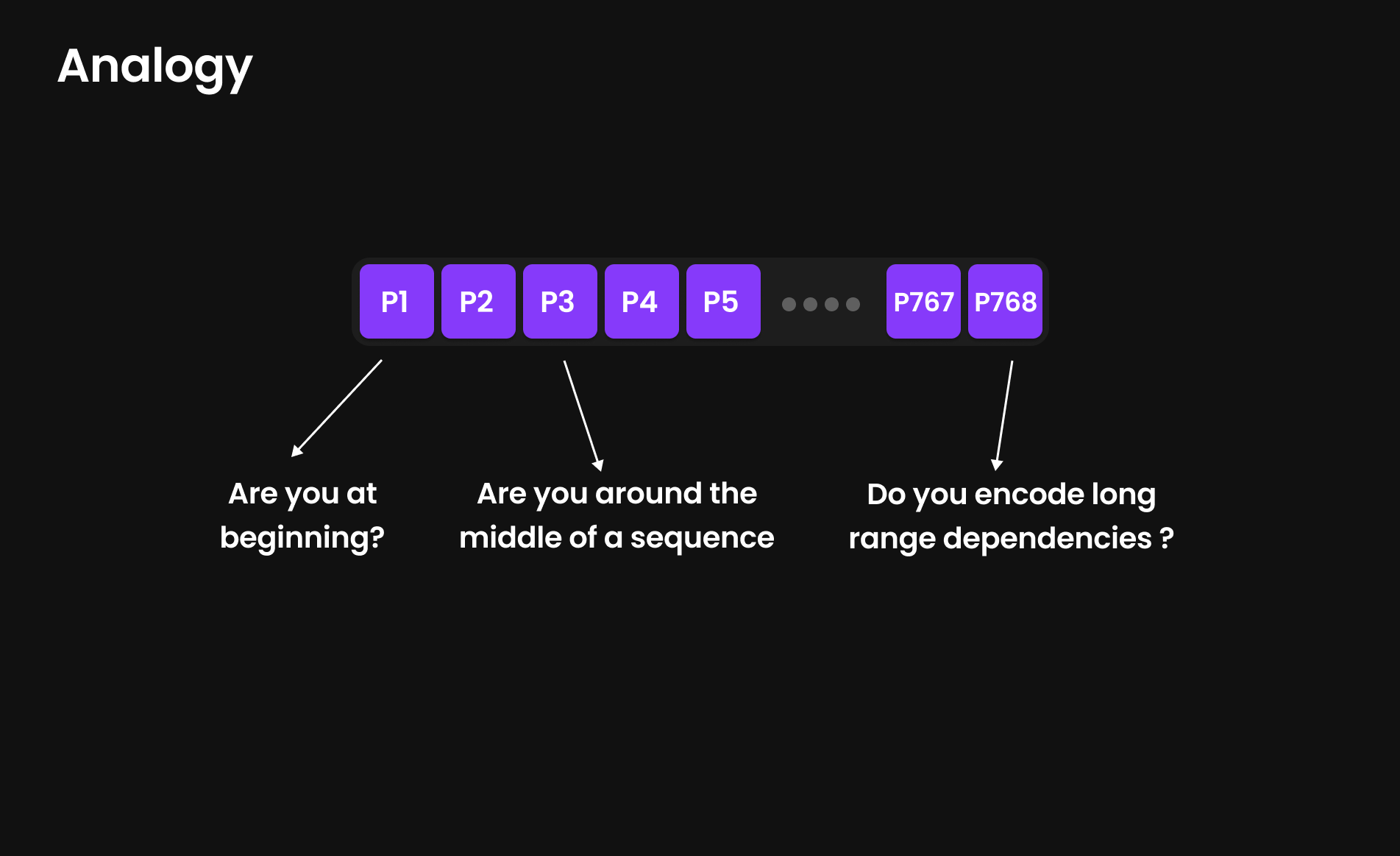
Meskipun kita tidak tahu persis apa “pertanyaan-pertanyaan” komputasional ini (bahkan mereka sebenarnya bukanlah pertanyaan dalam arti harfiah), kita menggunakan analogi ini untuk menyederhanakan penjelasan.
Oleh karena itu, setiap token diberikan dua buah embeddings:
- Penyematan Token (Token Embedding) – Menangkap maknanya.
- Penyematan Posisional (Positional Embedding) – Menangkap penempatannya di dalam kalimat.
Dengan menggabungkan keduanya, model tidak hanya belajar apa arti kata-kata tersebut tetapi juga di mana mereka muncul, memungkinkannya untuk memahami sintaksis, tata bahasa, dan struktur kalimat secara efektif.
Fase 5: Menambahkan Hasil Penyematan Token + Posisional
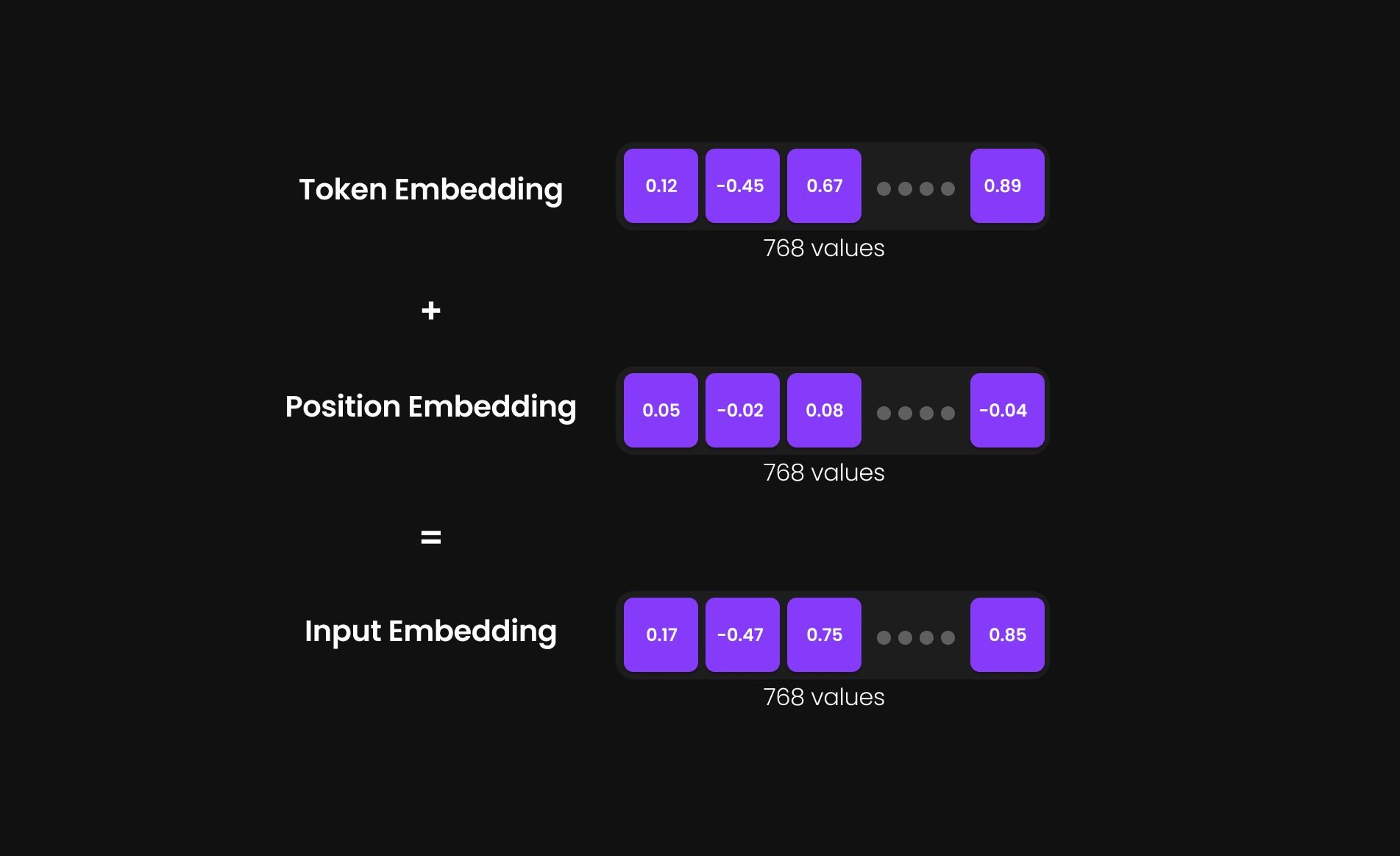
Bagaimana Penyematan Input (Input Embeddings) Dibentuk
Setiap token sekarang memiliki dua vektor 768-dimensi yang terpisah (di GPT-2 Small):
- Penyematan Token (Vektor 768-D) – Mengkodekan makna token.
- Penyematan Posisional (Vektor 768-D) – Mengkodekan posisinya dalam kalimat.
Alih-alih membawanya secara terpisah, kedua vektor ini dijumlahkan (ditambahkan bersama) untuk membentuk sebuah Penyematan Input (Input Embedding) tunggal berdimensi 768.
Input Embedding = Token Embedding + Positional Embedding
Representasi gabungan ini memungkinkan model untuk memproses setiap token sebagai sebuah entitas unik yang memiliki makna semantik sekaligus konteks posisional.
Akhirnya, setelah melalui semua langkah tersebut, ada satu hal ini, yaitu Input Embedding, yang membedakan kata tersebut dari kata-kata lainnya.
Anggaplah Input Embedding sebagai sebuah seragam khusus untuk setiap token. Setiap token dalam sebuah kalimat mengenakan seragam yang unik, dirancang secara spesifik untuknya.
Mengapa setiap seragam berbeda?
- Bahan kainnya (Token Embedding): Mewakili makna token—apakah ia kata benda, kata kerja, atau konsep abstrak.
- Ukuran dan potongannya (Positional Embedding): Mewakili posisinya di dalam kalimat—apakah ia muncul di awal, tengah, atau akhir.
Karena setiap token memiliki makna yang berbeda dan muncul dalam posisi yang berbeda, setiap token menerima seragam yang berbeda. Seragam inilah, atau Input Embedding, yang dibawa token saat bergerak melalui pipa pemrosesan LLM, memastikan bahwa model mengenali apa arti kata tersebut dan di mana ia muncul.
Analogi Harry Potter
Bayangkan Anda melangkah masuk ke Hogwarts, sekolah sihir legendaris, tetapi sebelum Anda bisa masuk, Anda harus terlebih dahulu diseleksi ke dalam salah satu asrama—Gryffindor, Ravenclaw, Hufflepuff, atau Slytherin. Setiap siswa menerima jubah asrama, yang mewakili identitas dan peran mereka di dalam sekolah tersebut.
Serupa dengan itu, di dalam sebuah LLM, setiap token harus terlebih dahulu menerima seragamnya—yaitu Input Embedding-nya—sebelum ia bisa memasuki Blok Transformer, di mana keajaiban yang sebenarnya terjadi. Model pada dasarnya tidak memahami kata-kata atau maknanya; ia hanya mengenali representasi numerik berdimensi tinggi (vektor) yang ditetapkan untuk setiap token.
Setelah berpakaian dengan benar, token-token tersebut akhirnya siap untuk naik kereta menuju Blok Transformer, di mana mereka akan berinteraksi, memengaruhi satu sama lain, dan pada akhirnya membentuk pemahaman model terhadap bahasa—sama seperti para penyihir muda yang mempelajari ilmu sihir di Hogwarts.
Ringkasan dari Blok Input (Input Block)
Blok Input adalah tahap pertama dari pipa pemrosesan sebuah LLM, di mana teks mentah diubah menjadi representasi numerik yang dapat dipahami oleh model. Fase ini terdiri dari lima langkah utama:
- Tokenisasi: Kalimat input dipecah menjadi token-token (kata atau sub-kata).
- Pemberian Token ID: Setiap token diberikan sebuah ID unik dari kosakata model.
- Penyematan Token (Token Embedding): Sebuah vektor 768-dimensi (untuk GPT-2 Small) ditetapkan untuk menangkap makna semantik dari token tersebut.
- Penyematan Posisional (Positional Embedding): Sebuah vektor 768-dimensi lainnya ditetapkan untuk mengkodekan posisi token di dalam kalimat.
- Pembentukan Penyematan Input (Input Embedding Formation): Token Embedding dan Positional Embedding digabungkan, menciptakan Input Embedding akhir, yang akan digunakan model untuk pemrosesan lebih lanjut.
Pada tahap ini, setiap token telah menerima sebuah identitas yang berbeda—mirip dengan siswa sekolah yang mengenakan seragam khusus. Sekarang, token-token tersebut siap untuk memasuki Blok Transformer, di mana pemrosesan yang lebih dalam, mekanisme attention, dan pemodelan bahasa (language modeling) terjadi.
Jantung dari LLM: Pengenalan pada Blok Transformer
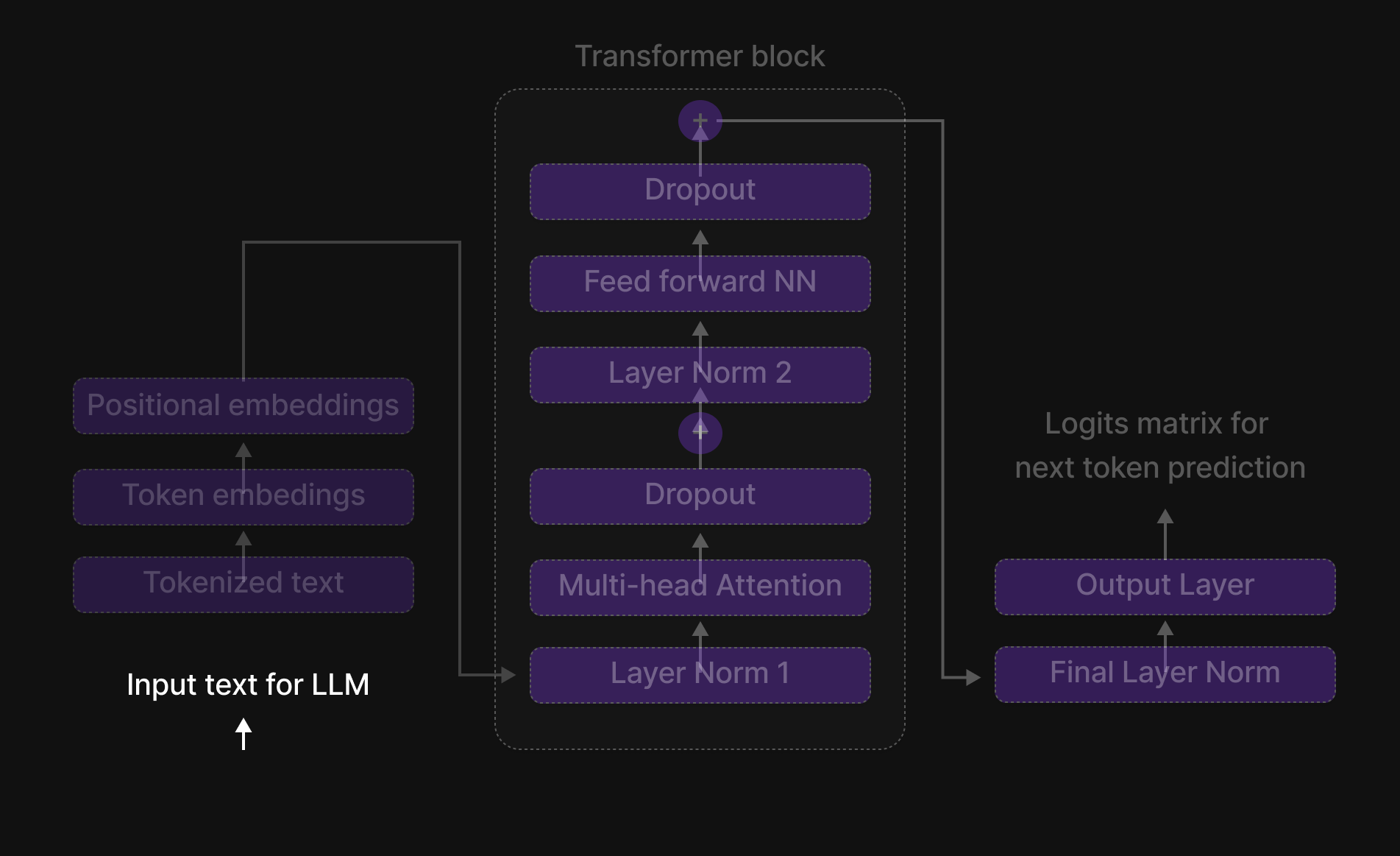
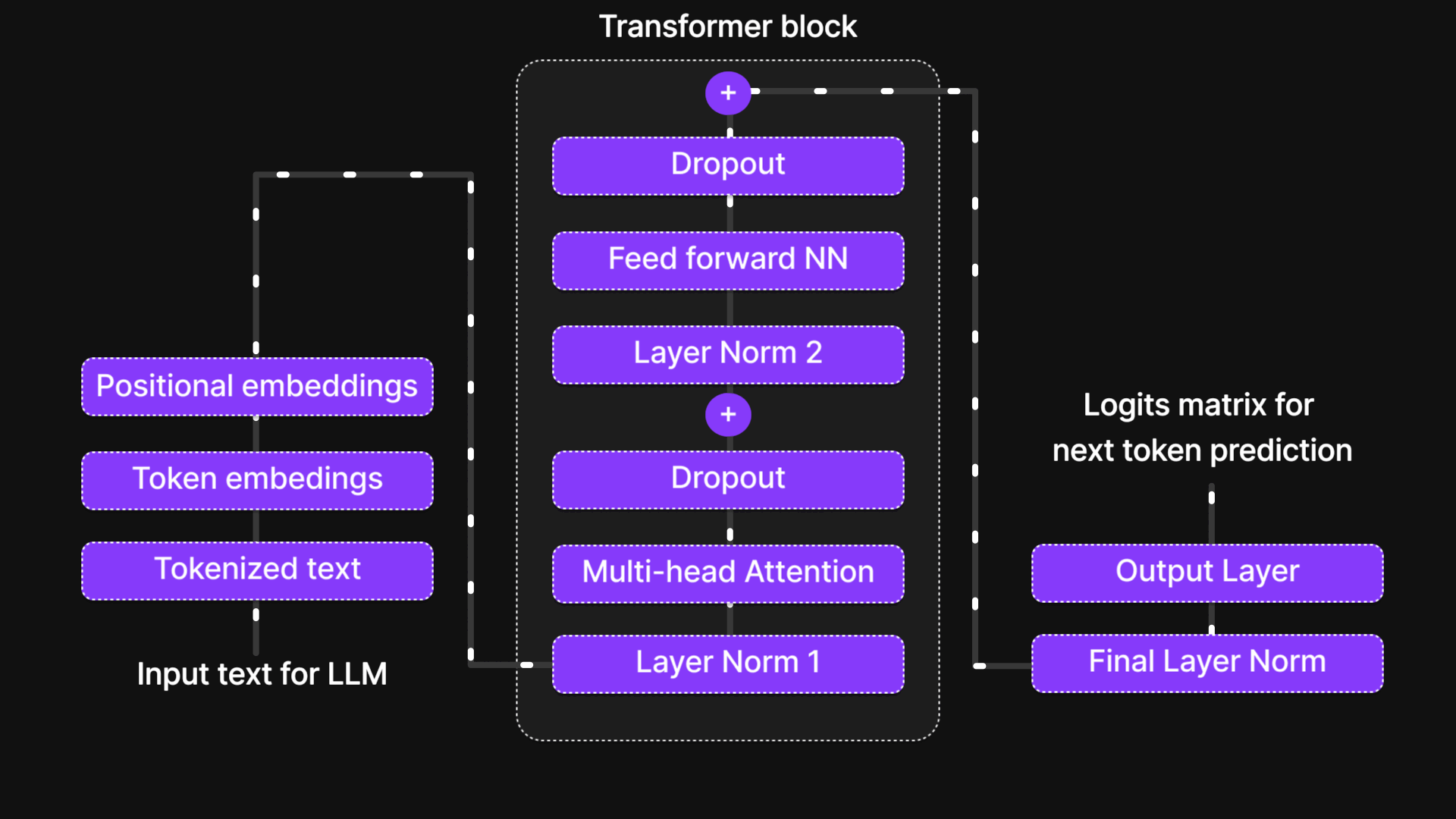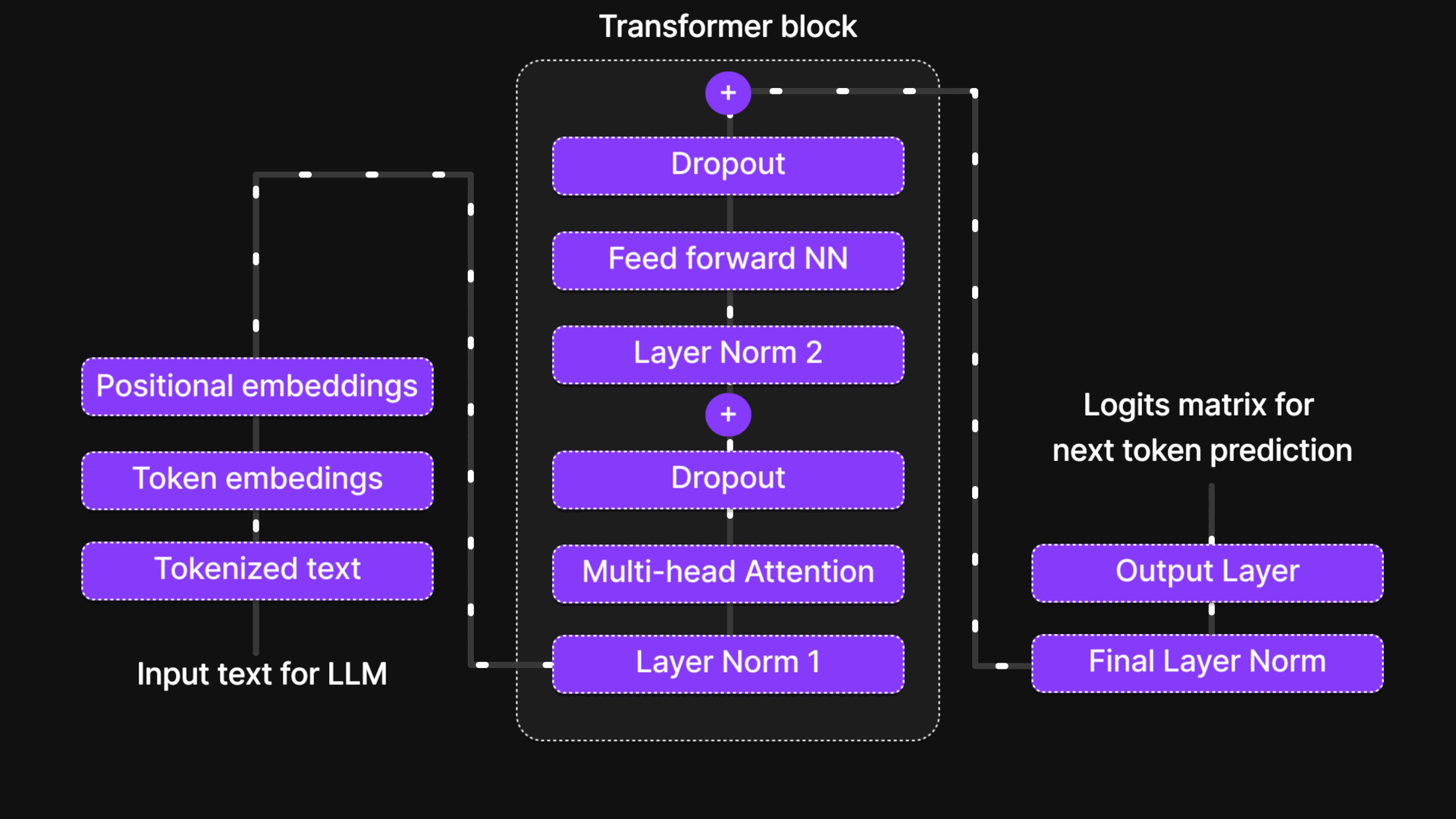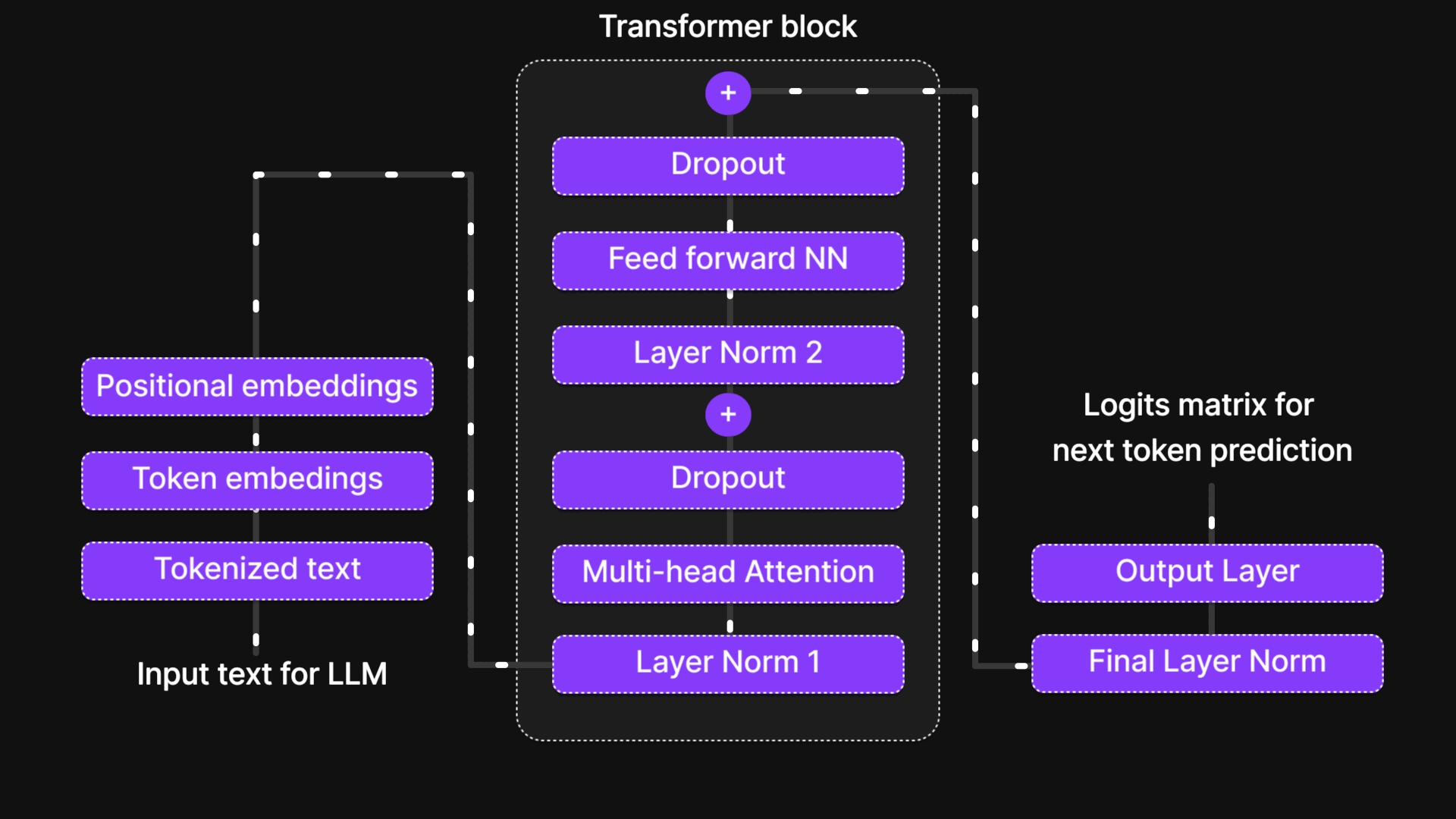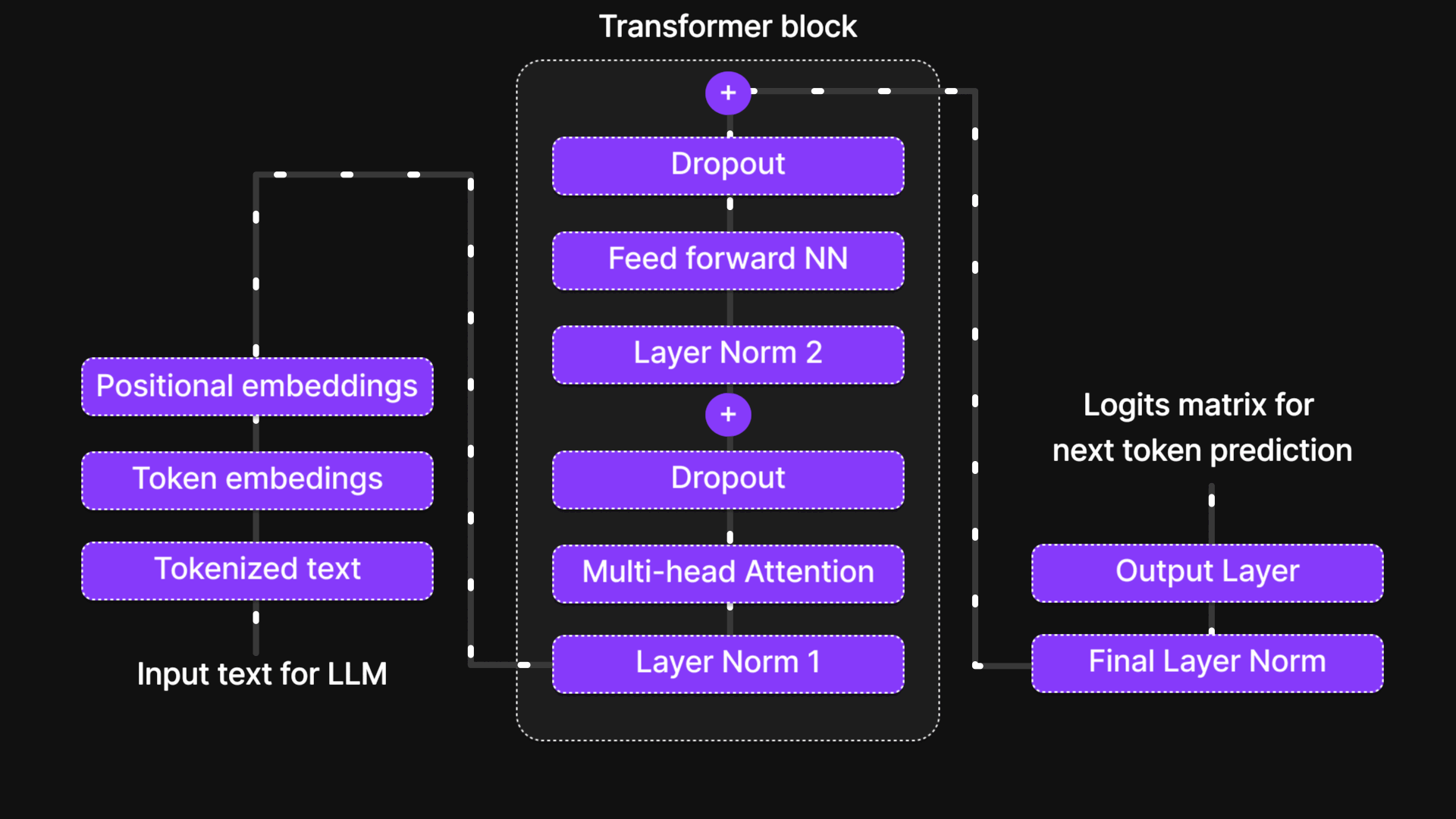
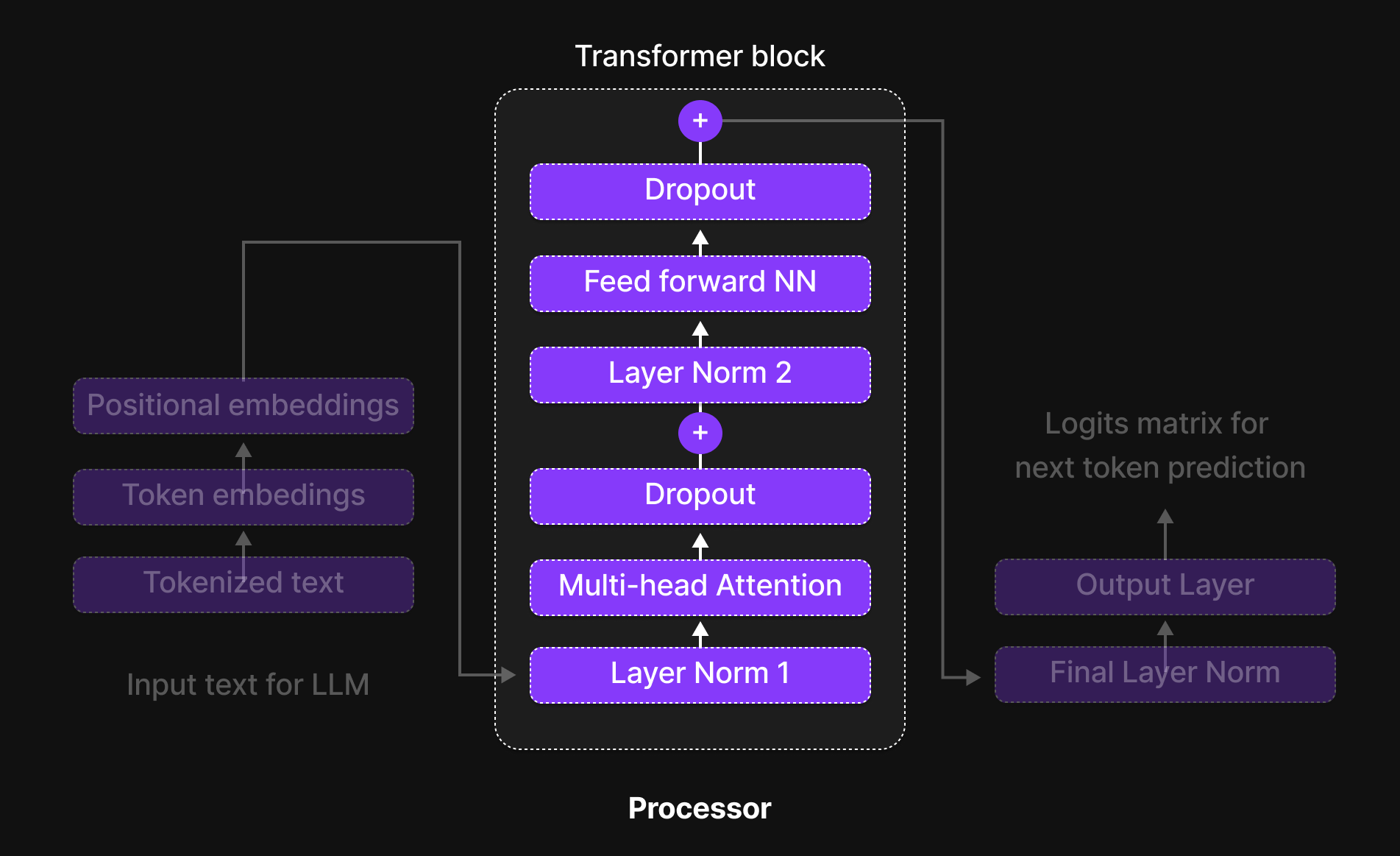 Gambar 14: Blok Transformer
Gambar 14: Blok Transformer
Blok Transformer adalah tempat di mana token-token berinteraksi, bertukar informasi, dan menyempurnakan pemahaman kontekstual mereka. Ini adalah otak yang sebenarnya dari model tersebut, memungkinkannya untuk menangkap hubungan antar kata, mengenali ketergantungan jarak jauh, dan mempelajari pola bahasa yang rumit.
Sekarang setelah token-token kita menerima seragam mereka (input embeddings) dan siap untuk diproses, mari kita melangkah masuk ke dalam Blok Transformer, di mana sihir yang sesungguhnya terjadi.
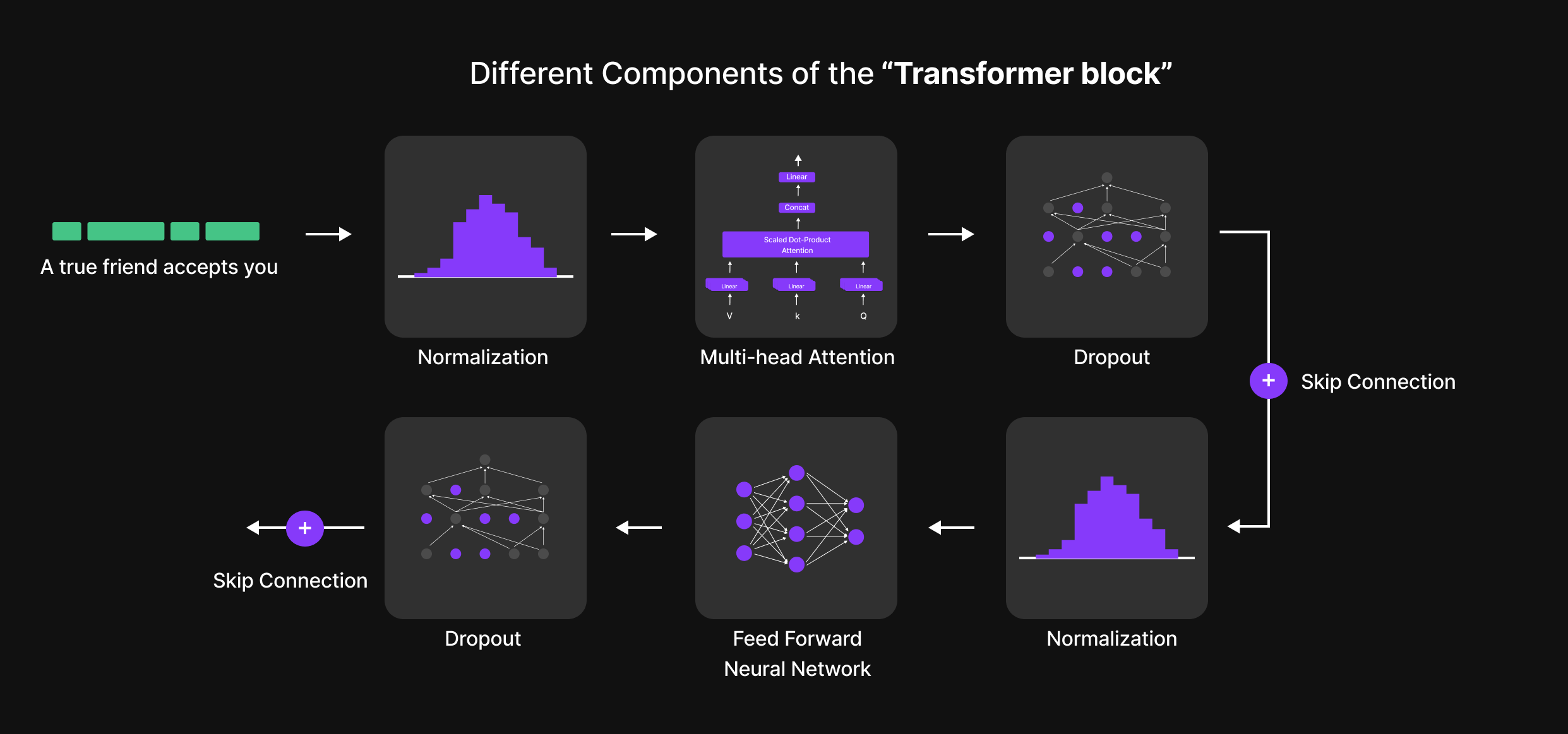
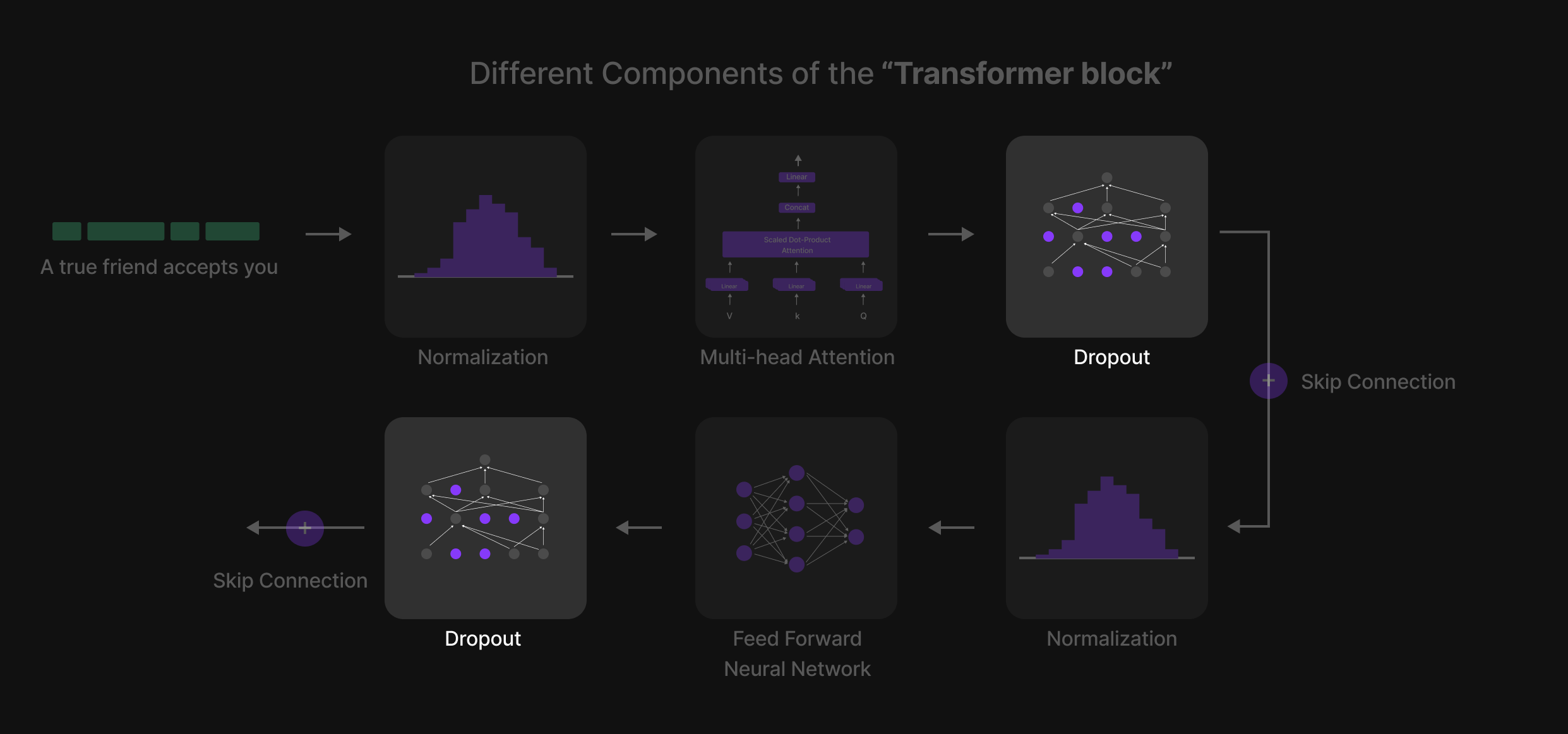
Enam Langkah Kunci dari Blok Transformer
Di dalam Blok Transformer, setiap token menjalani proses enam langkah terstruktur yang menyaring representasinya dan meningkatkan pemahaman kontekstual. Langkah-langkah tersebut adalah:
- Normalisasi (Layer Normalization)
- Perhatian Multi-Kepala (Multi-Head Attention)
- Dropout (Langkah Regularisasi 1)
- Jaringan Saraf Tiruan Feed-Forward (Feed-Forward Neural Network / FFN)
- Dropout (Langkah Regularisasi 2)
- Normalisasi (Final Layer Normalization)
Sebagai tambahan, Skip Connections (koneksi residual) digunakan di seluruh blok untuk memastikan aliran informasi yang lancar dan mencegah masalah vanishing gradients (gradien yang menghilang).
Urutan terstruktur ini diulang melintasi beberapa Blok Transformer, memungkinkan model untuk mempelajari pola dan hubungan bahasa yang kompleks.
Normalisasi (Normalization)
Di dalam Blok Transformer, Normalisasi memastikan bahwa representasi setiap token tetap stabil dan seimbang di seluruh lapisan.
Sebagai contoh, vektor 768-dimensi dari token “friend” dinormalisasi, yang berarti:
- Nilai rata-rata (mean) menjadi 0
- Standar deviasinya menjadi 1
Proses ini membantu model mempertahankan penskalaan yang konsisten, mencegah variasi ekstrem pada nilai token dan meningkatkan efisiensi pembelajaran. Normalisasi adalah langkah krusial yang menjaga komputasi tetap mulus dan stabil saat token bergerak melewati berbagai lapisan Transformer.
Perhatian Multi-Kepala (Multi-head Attention)
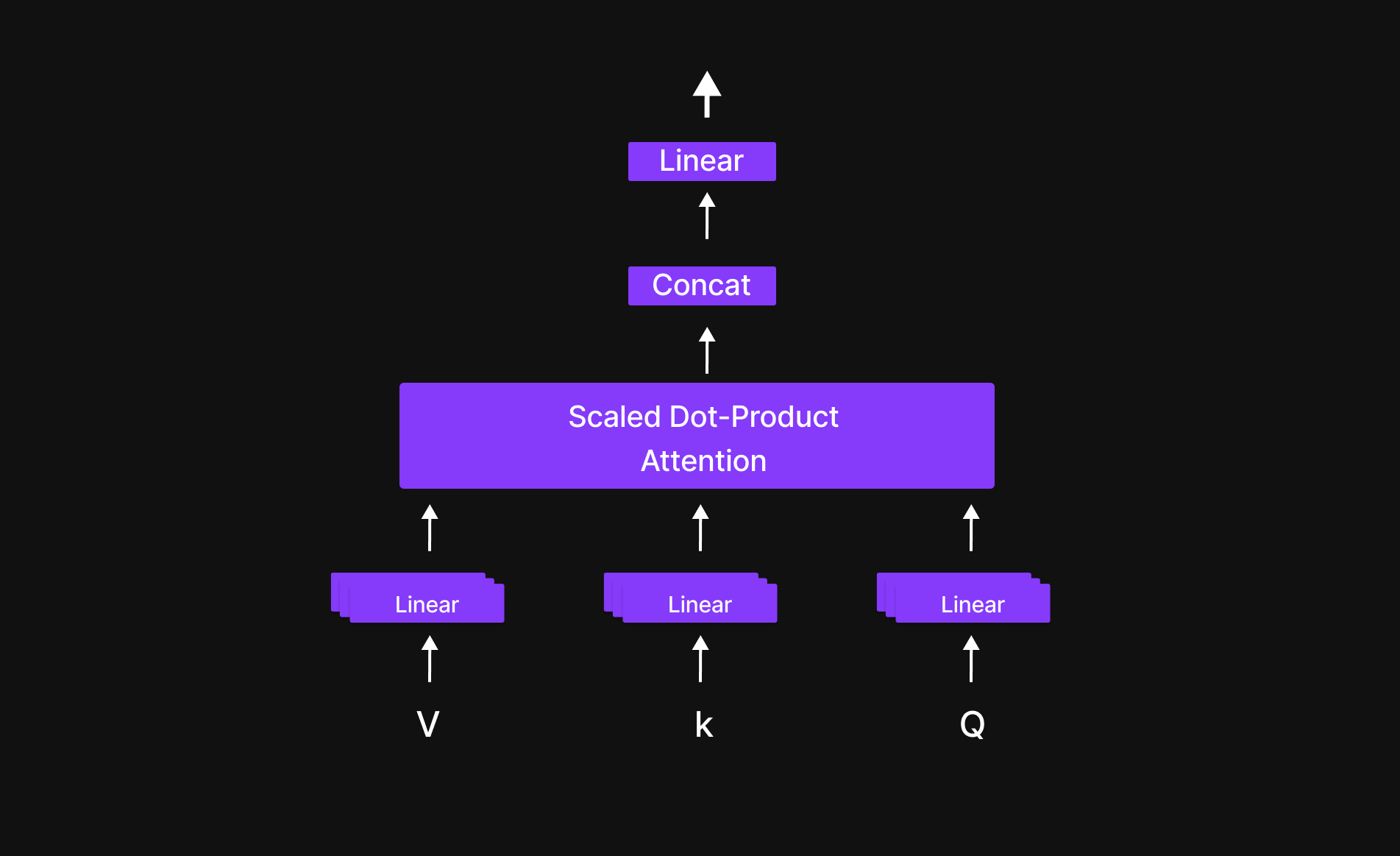 Gambar 17: Struktur dari head attention
Gambar 17: Struktur dari head attention
Dalam sebuah kalimat, setiap kata memiliki hubungan dengan kata lainnya. Multi-Head Attention membantu model menentukan seberapa besar kepentingan (perhatian) yang harus diberikan oleh setiap token kepada token-token lainnya.
Sebagai contoh, jika kita berfokus pada kata “friend”, model akan memutuskan seberapa besar perhatian yang harus diberikan pada kata “a,” “true,” “accepts,” dan “you.” Proses ini memungkinkan model untuk membuat peta konteks (context map), mengidentifikasi kata-kata mana yang paling relevan satu sama lain.
Dengan melakukan ini, Multi-Head Attention memungkinkan model untuk memahami struktur dan makna dari sebuah kalimat, menjadikannya sangat efektif dalam menangkap hubungan, konteks, dan ketergantungan di dalam bahasa.
Kita akan melihat mekanisme attention ini secara lebih detail di blog berikutnya
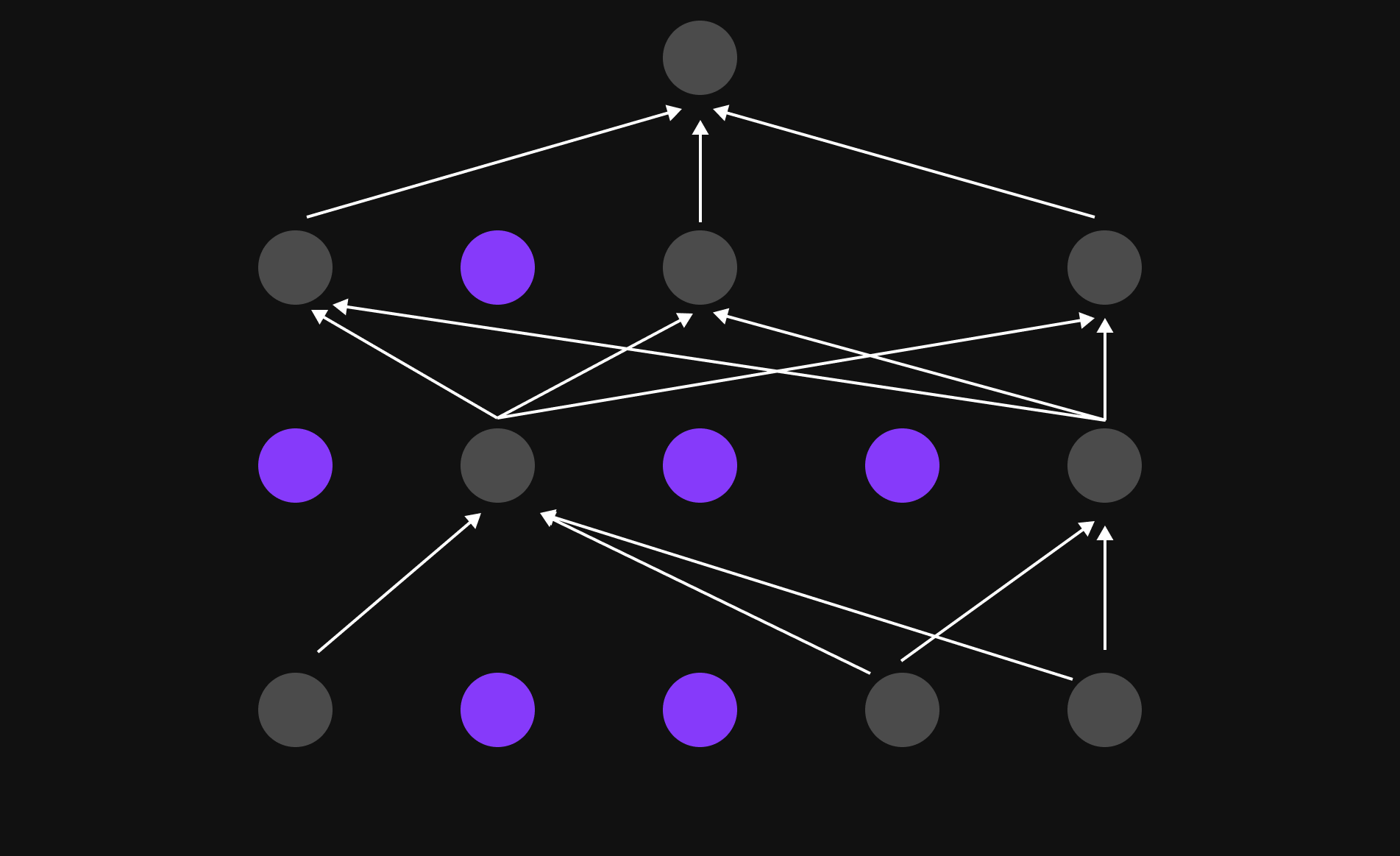
 Gambar 18: Memberikan perhatian pada kata-kata lain (peta konteks)
Gambar 18: Memberikan perhatian pada kata-kata lain (peta konteks)
Dropout
 Gambar 19: Dropout - secara acak mematikan sebagian parameter ini selama masa pelatihan
Gambar 19: Dropout - secara acak mematikan sebagian parameter ini selama masa pelatihan
Di dalam Large Language Models (LLMs), tidak semua parameter berkontribusi secara setara terhadap pembelajaran. Beberapa parameter tetap tidak aktif atau “malas,” dan terlalu bergantung pada parameter lain. Dropout adalah teknik regularisasi yang secara acak mematikan sebagian dari parameter ini selama fase pelatihan (training).
Dengan melakukan hal ini:
- Parameter yang tidak aktif dipaksa untuk belajar, karena mereka tidak bisa lagi bergantung pada parameter yang lain.
- Model menghindari overfitting, memastikannya dapat menggeneralisasi dengan baik pada teks baru alih-alih sekadar menghafal data pelatihan.
- Ini meningkatkan ketahanan (robustness), memastikan bahwa pembelajaran didistribusikan ke seluruh parameter, bukan hanya pada beberapa parameter yang dominan.
 Gambar 20: Dropout diterapkan dua kali
Gambar 20: Dropout diterapkan dua kali
Di dalam Blok Transformer, Dropout diterapkan dua kali—sekali setelah Multi-Head Attention dan sekali lagi setelah Feed-Forward Neural Network—memastikan bahwa pembelajaran tetap seimbang dan efektif di seluruh arsitektur model.
Koneksi Lewati (Skip Connection)
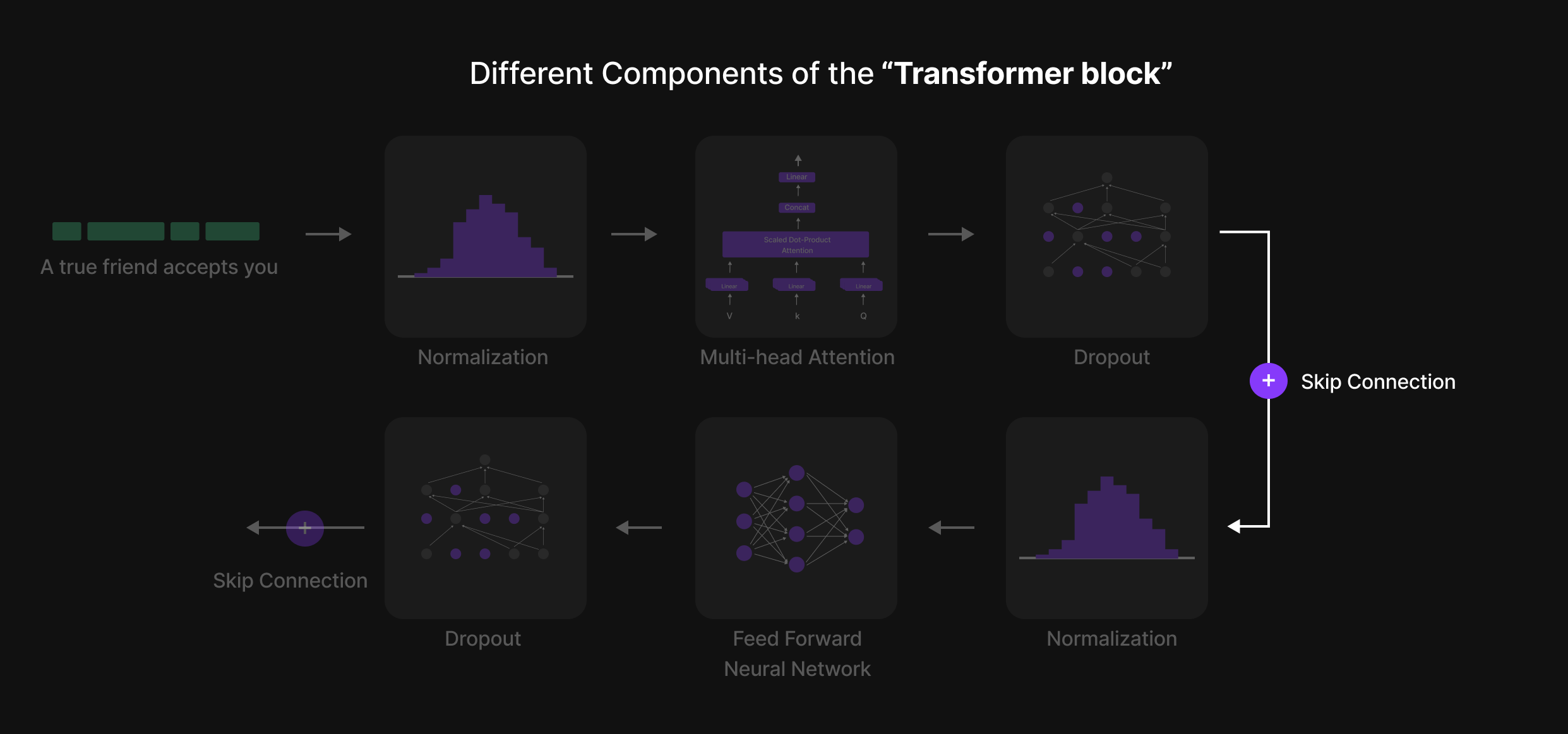
Dalam Large Language Models (LLMs), pelatihan melibatkan pengiriman informasi melalui beberapa Blok Transformer, yang masing-masing memiliki beberapa lapisan (layers). Namun, saat data bergerak melalui lapisan-lapisan ini, gradien (pembaruan yang memandu pembelajaran) bisa menjadi terlalu kecil (masalah vanishing gradient), membuat lapisan-lapisan awal lebih sulit untuk belajar secara efektif.
Skip Connections, juga dikenal sebagai Shortcut Connections, menyelesaikan masalah ini dengan menyediakan jalur alternatif agar gradien dapat mengalir. Alih-alih hanya bergantung pada pembaruan sekuensial, Skip Connections memungkinkan informasi untuk melewati lapisan tertentu dan ditambahkan langsung ke lapisan-lapisan selanjutnya.
Mekanisme ini memastikan bahwa:
- Lapisan awal terus menerima pembaruan gradien yang berguna, mencegah mereka menjadi stagnan.
- Jaringan saraf yang dalam (deep networks) dapat dilatih dengan lebih efisien, meningkatkan stabilitas pembelajaran secara keseluruhan.
- Model mempertahankan informasi penting, menghindari distorsi yang berlebihan setelah melalui berbagai transformasi.
Skip Connections memainkan peran yang sangat krusial dalam menjaga LLM agar tetap stabil, efisien, dan mampu memproses struktur linguistik yang dalam tanpa kehilangan informasi berharga.
Normalisasi 2
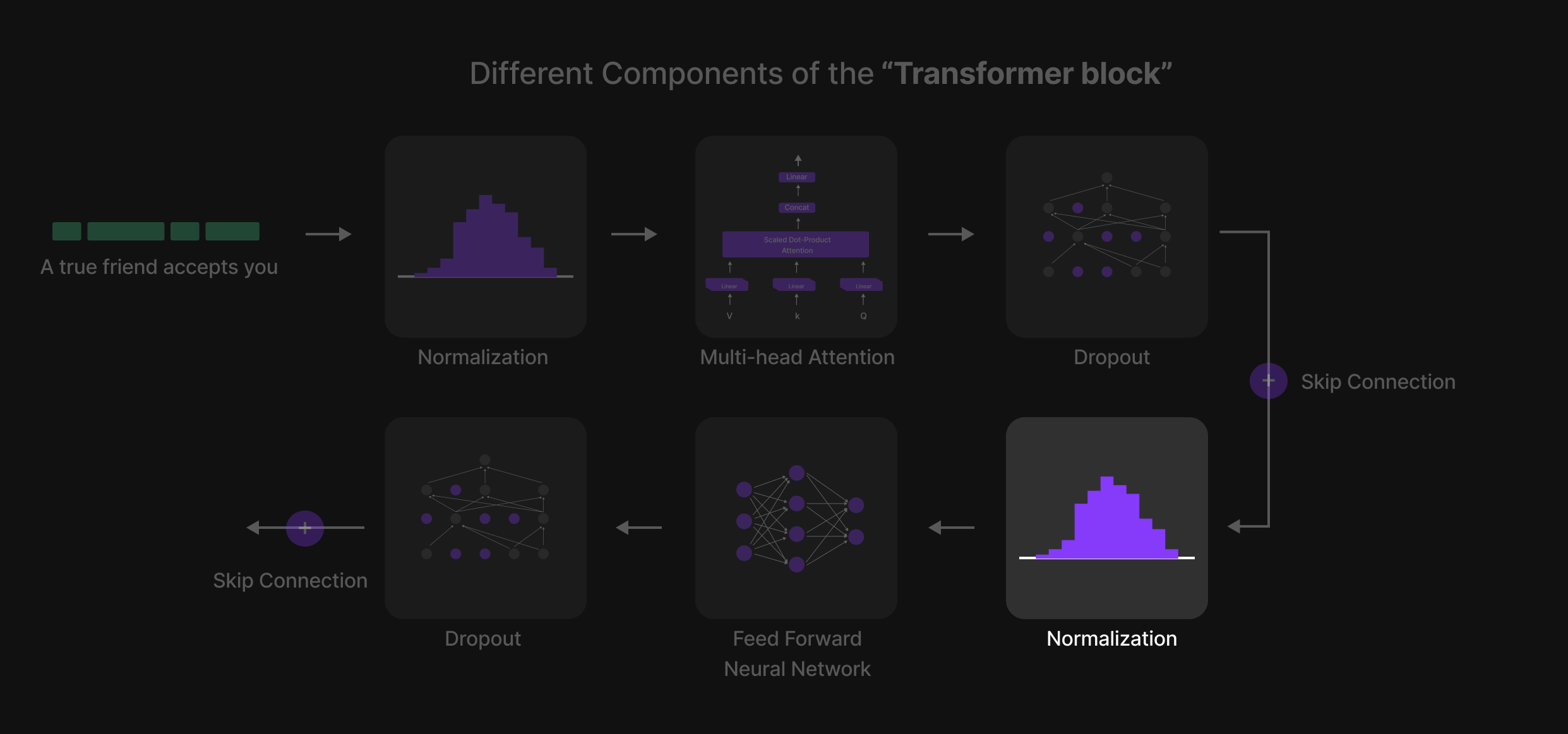
Setelah melewati Multi-Head Attention, representasi token sebenarnya telah diperbarui berdasarkan hubungan kontekstual. Namun, sebelum memasukkannya ke dalam Feed-Forward Neural Network (FFN), satu langkah Normalisasi lagi diterapkan.
Tujuan dari Normalisasi Kedua:
- Menstabilkan input ke Feed-Forward Network, memastikan bahwa aktivasi (activations) tetap seimbang.
- Mencegah ketidakstabilan numerik, menghindari variasi ekstrem pada nilai token.
- Meningkatkan efisiensi pelatihan dengan memastikan bahwa FFN memproses input yang memiliki skala dengan baik, sehingga mengurangi gangguan dalam proses pembelajaran.
Dengan menerapkan Normalisasi sebelum FFN, LLM mempertahankan representasi token yang konsisten dan terstruktur dengan baik, memungkinkan pembelajaran yang efisien dan pemodelan bahasa yang kuat melintasi banyak lapisan Transformer.
Feed Forward Neural Network (Jaringan Saraf Tiruan Feed-Forward)

Di dalam Blok Transformer, langkah selanjutnya adalah Feed-Forward Neural Network (FFN).
—Ini adalah langkah krusial yang meningkatkan kemampuan model untuk menangkap pola dan hubungan yang kompleks dalam bahasa.
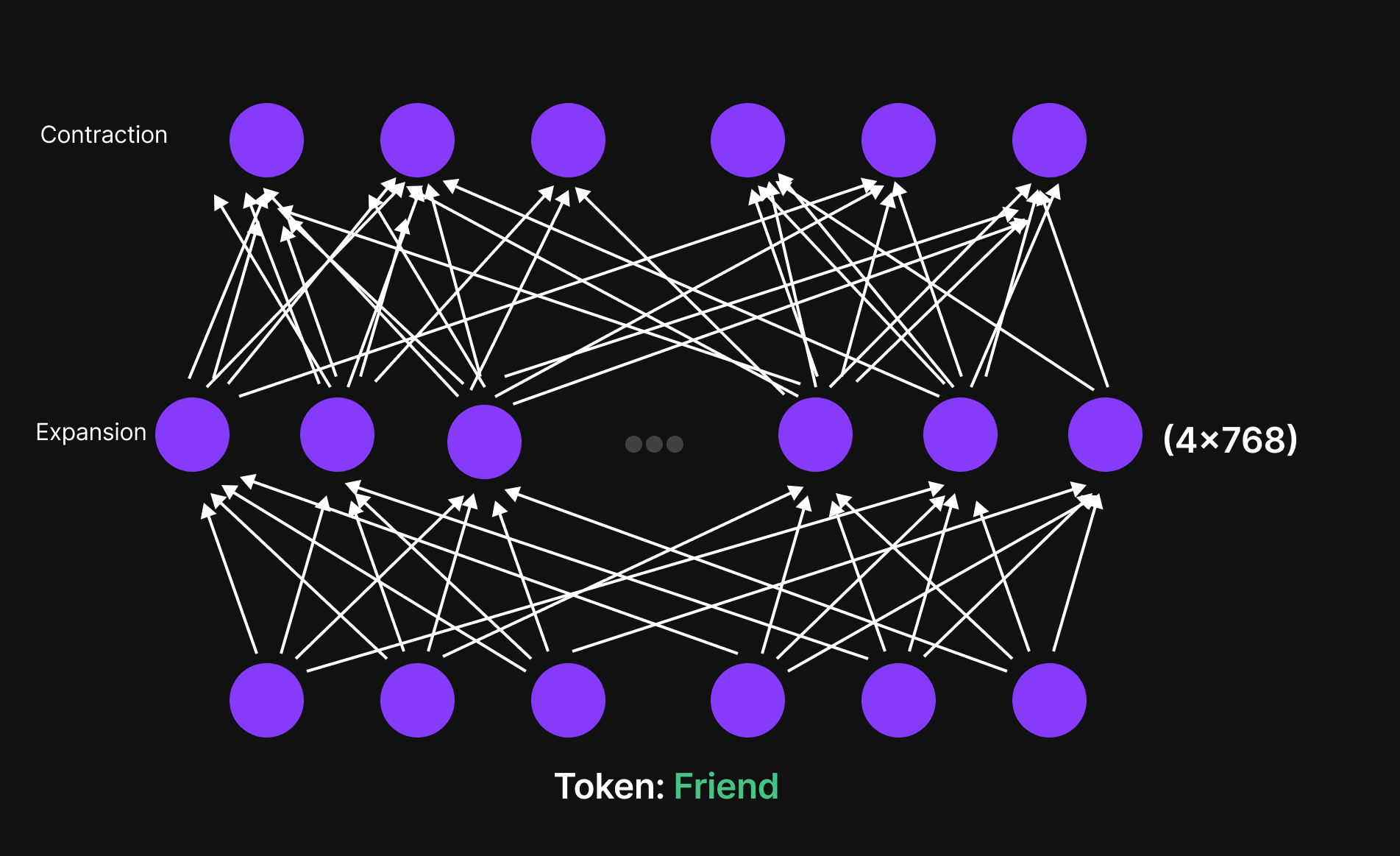 Gambar 24: Feed-Forward Neural Network (Ekspansi dan Kontraksi)
Gambar 24: Feed-Forward Neural Network (Ekspansi dan Kontraksi)
Bagaimana Feed-Forward Network Bekerja
- Setiap token, yang direpresentasikan sebagai vektor 768-dimensi (untuk GPT-2 Small), pertama-tama diekspansi (diperluas) ke ruang dimensi yang lebih tinggi—biasanya 4 kali ukuran aslinya (menjadi 3072 dimensi di GPT-2 Small).
- Ekspansi ini memungkinkan model untuk mengeksplorasi ruang fitur yang lebih kaya dan menangkap variasi halus dalam makna.
- Jaringan tersebut kemudian mengompresi representasinya kembali ke 768 dimensi, menyaring informasi tersebut untuk disiapkan menuju lapisan Transformer berikutnya.
Mekanisme ekspansi dan kontraksi ini memastikan bahwa model mempelajari struktur linguistik yang kompleks sambil tetap mempertahankan efisiensi komputasional.
Lapisan Dropout 2
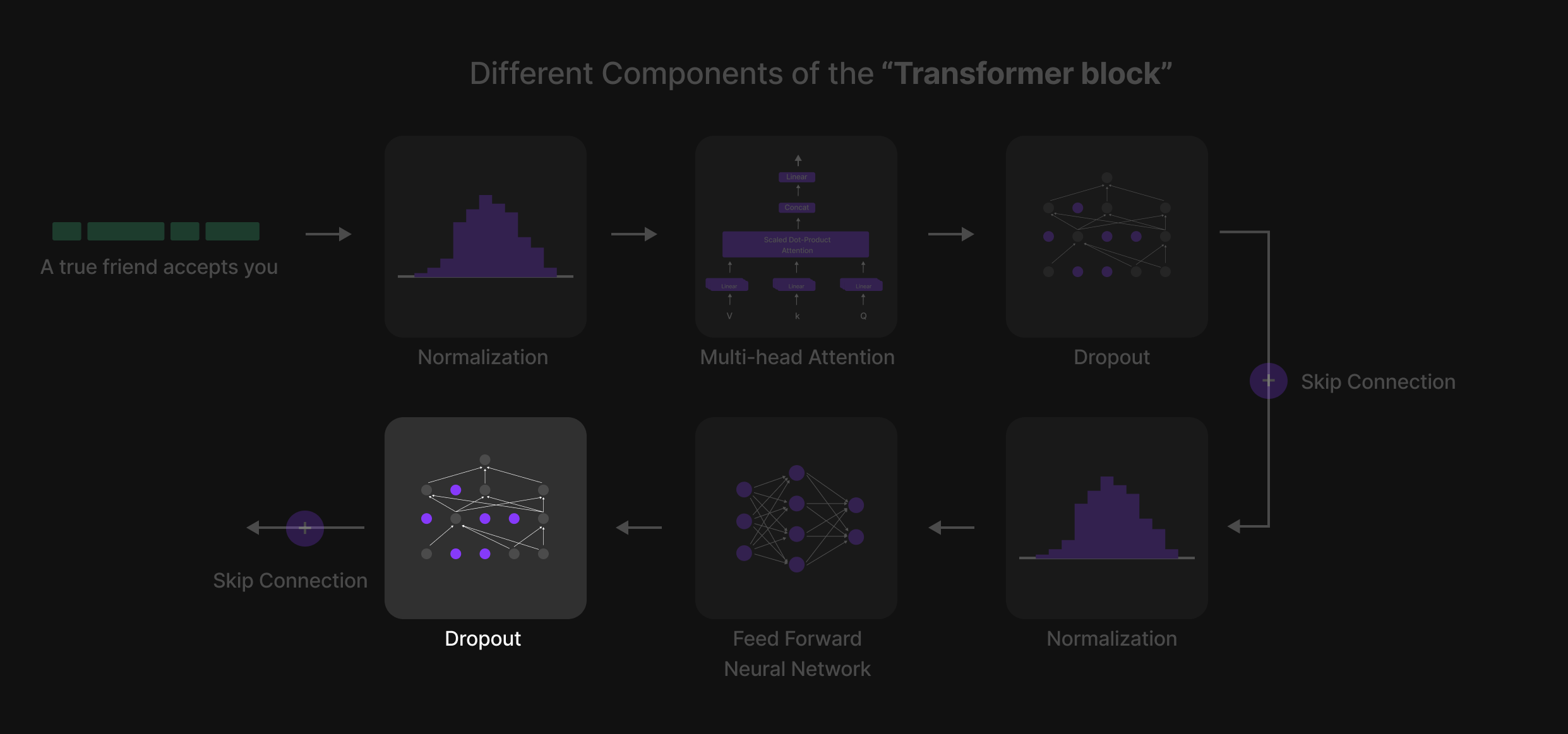 Gambar 25: Lapisan Dropout terakhir
Gambar 25: Lapisan Dropout terakhir
Setelah Feed-Forward Neural Network (FFN), lapisan Dropout terakhir diterapkan. Ini berfungsi sebagai perlindungan terakhir terhadap overfitting, memastikan bahwa model tidak bergantung terlalu berat pada parameter tertentu. Dengan menonaktifkan beberapa neuron secara acak, ini memaksa jaringan untuk mendistribusikan pembelajaran secara lebih efektif, yang mengarah pada generalisasi yang lebih baik ketika memproses teks yang belum pernah dilihat sebelumnya.
Koneksi Lewati Akhir (Final Skip Connection)
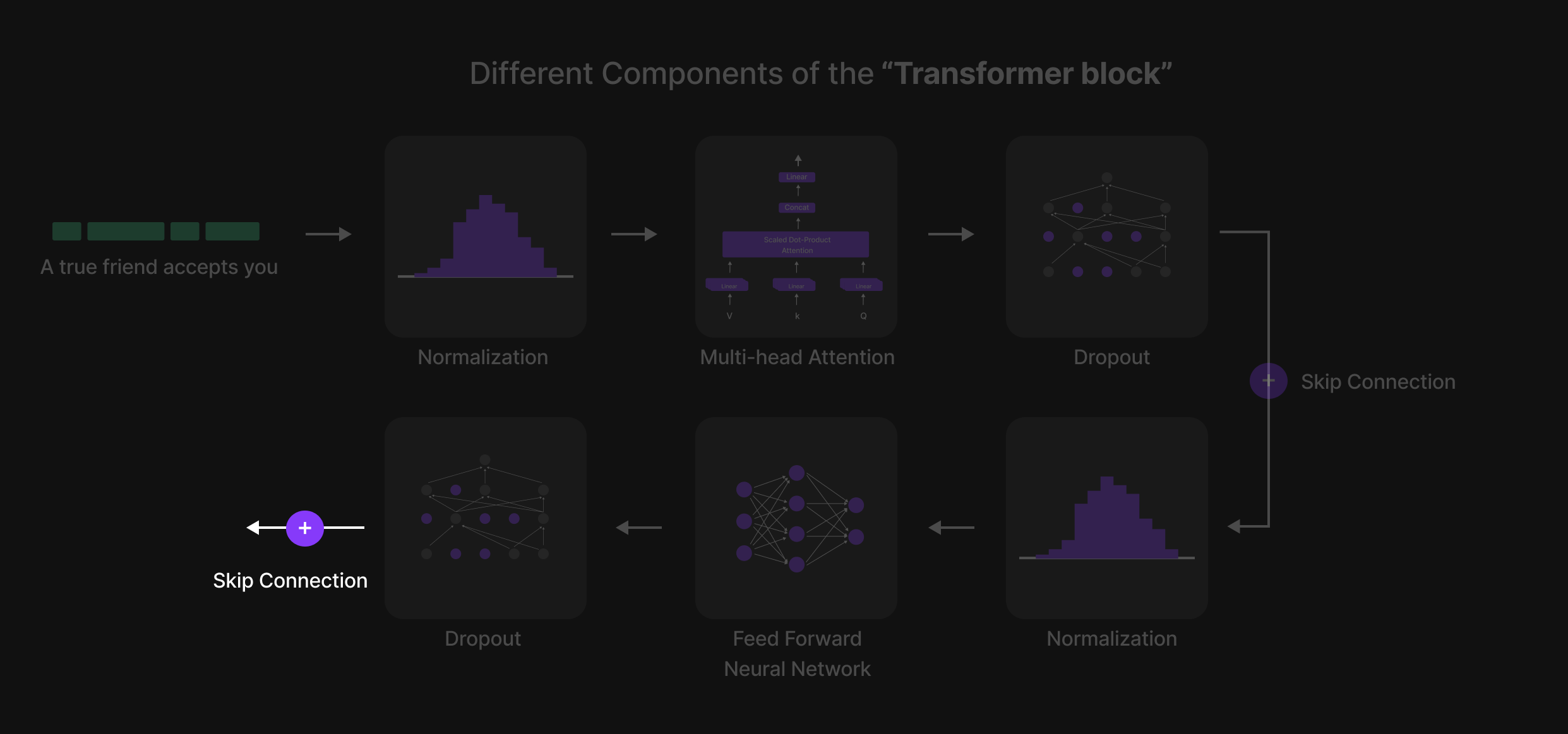 Gambar 26: Final Skip Connection
Gambar 26: Final Skip Connection
Setelah lapisan Dropout kedua, sebuah Skip Connection (Shortcut Connection) kembali diterapkan.
Kompleksitas Tidak Berhenti Di Sini
 Gambar 27: Beberapa Blok Transformer (Multiple Transformer block)
Gambar 27: Beberapa Blok Transformer (Multiple Transformer block)
Namun, kompleksitasnya tidak berhenti di situ. Sebuah model seperti GPT-2 Small memiliki 12 Blok Transformer, yang berarti setiap token harus mengulangi proses ini sebanyak 12 kali sebelum dapat bergerak maju. Untuk model yang lebih besar, seperti GPT-2 Large (36 blok) atau GPT-2 XL (48 blok), proses ini menjadi jauh lebih intensif. LLM modern seperti GPT-4 mungkin memiliki 96 atau lebih Blok Transformer, membuat perjalanannya jauh lebih menuntut secara komputasi.
Mengapa Pengulangan Ini Diperlukan?
Setiap Blok Transformer secara bertahap menyaring dan memperbaiki representasi sebuah token, memastikan ia menangkap hubungan dan makna yang lebih dalam. Saat token bergerak melalui blok-blok ini:
- Pemahaman kontekstualnya meningkat dengan setiap lapisan Multi-Head Attention.
- Feed-Forward Neural Network meningkatkan ruang fiturnya, membuatnya lebih adaptif terhadap pola yang rumit.
- Lapisan Dropout mencegah overfitting, memastikan kemampuan generalisasi yang tangguh.
- Skip Connections memungkinkan aliran gradien yang lebih mulus, menstabilkan pelatihan.
Meskipun sifatnya yang berulang, pemrosesan berlapis inilah yang memungkinkan LLM untuk memahami bahasa pada tingkat yang mahir/lanjutan.
Mempertahankan Dimensi di Seluruh Blok Transformer
Meskipun token menjalani banyak sekali transformasi, dimensinya tetap sama. Sebagai contoh, jika sebuah token memulai perjalanannya sebagai vektor 768-dimensi, ia tetap menjadi 768-dimensi bahkan setelah melewati semua 12 (atau lebih) Blok Transformer. Perbedaan utamanya adalah bahwa nilai-nilainya telah diperbarui, membuatnya jauh lebih sadar akan konteks dan lebih halus secara linguistik.
Setelah token menyelesaikan perjalanan yang melelahkan namun esensial ini, ia bergerak menuju lapisan output (output layer), di mana prediksi token akhir dilakukan.
Lapisan Output (Output Layer)
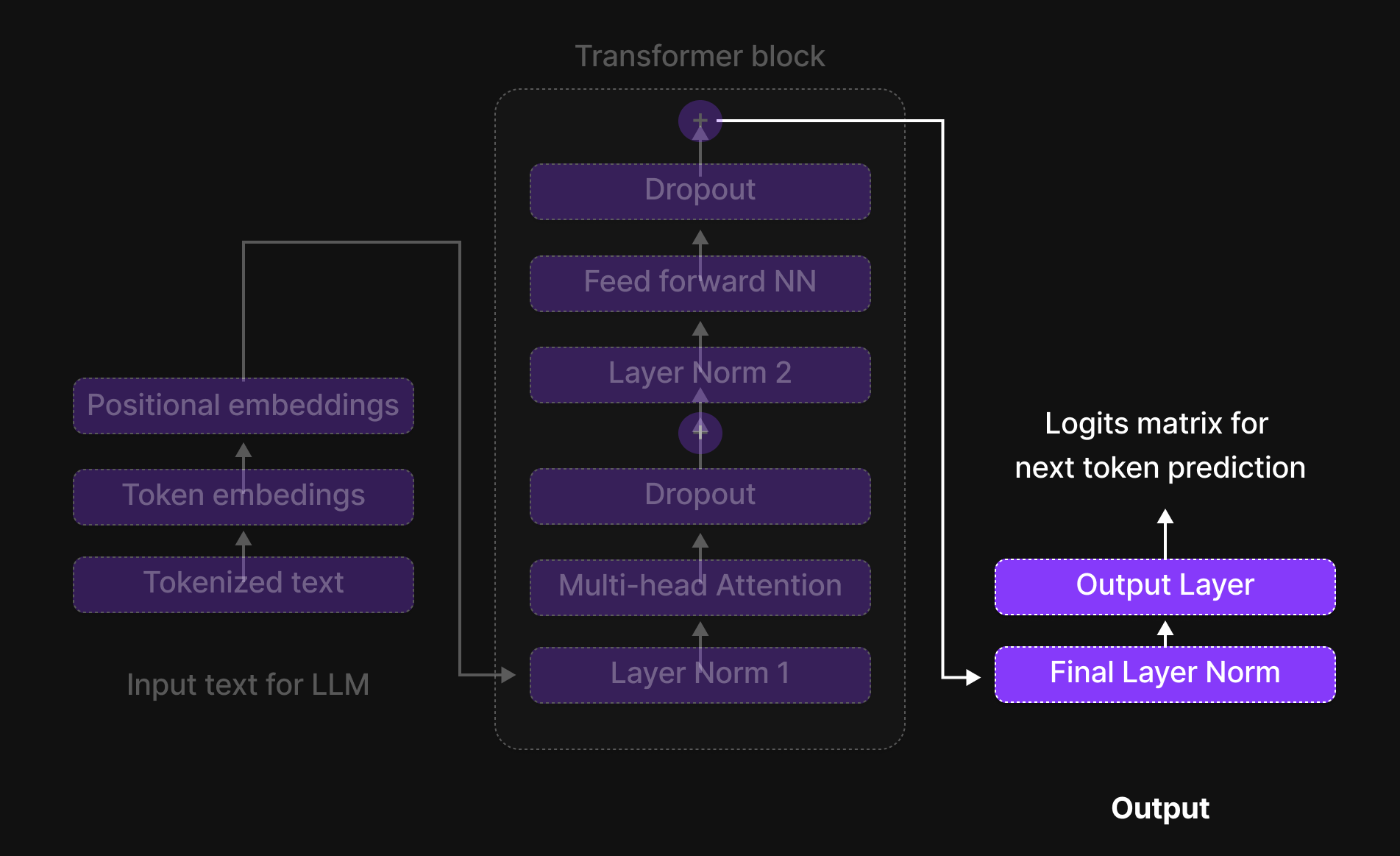 Gambar 28: Output Block dari arsitektur LLM
Gambar 28: Output Block dari arsitektur LLM
Setelah token-token tersebut (“A true friend accepts you”) melewati Blok Transformer, representasi mereka masih memiliki 768 dimensi, tetapi nilai-nilai di dalamnya telah berubah karena model terus menyaring pemahamannya tentang konteks kalimat.
Dimensinya tetap sama tetapi nilai-nilainya telah berubah, kini ia memiliki konteks yang jauh lebih kaya.
 Gambar 29: Dimensi tetap sama tetapi nilai-nilainya telah berubah, kini ia memiliki konteks yang jauh lebih kaya
Gambar 29: Dimensi tetap sama tetapi nilai-nilainya telah berubah, kini ia memiliki konteks yang jauh lebih kaya
Normalisasi Lapisan Akhir (Final Layer Normalization)
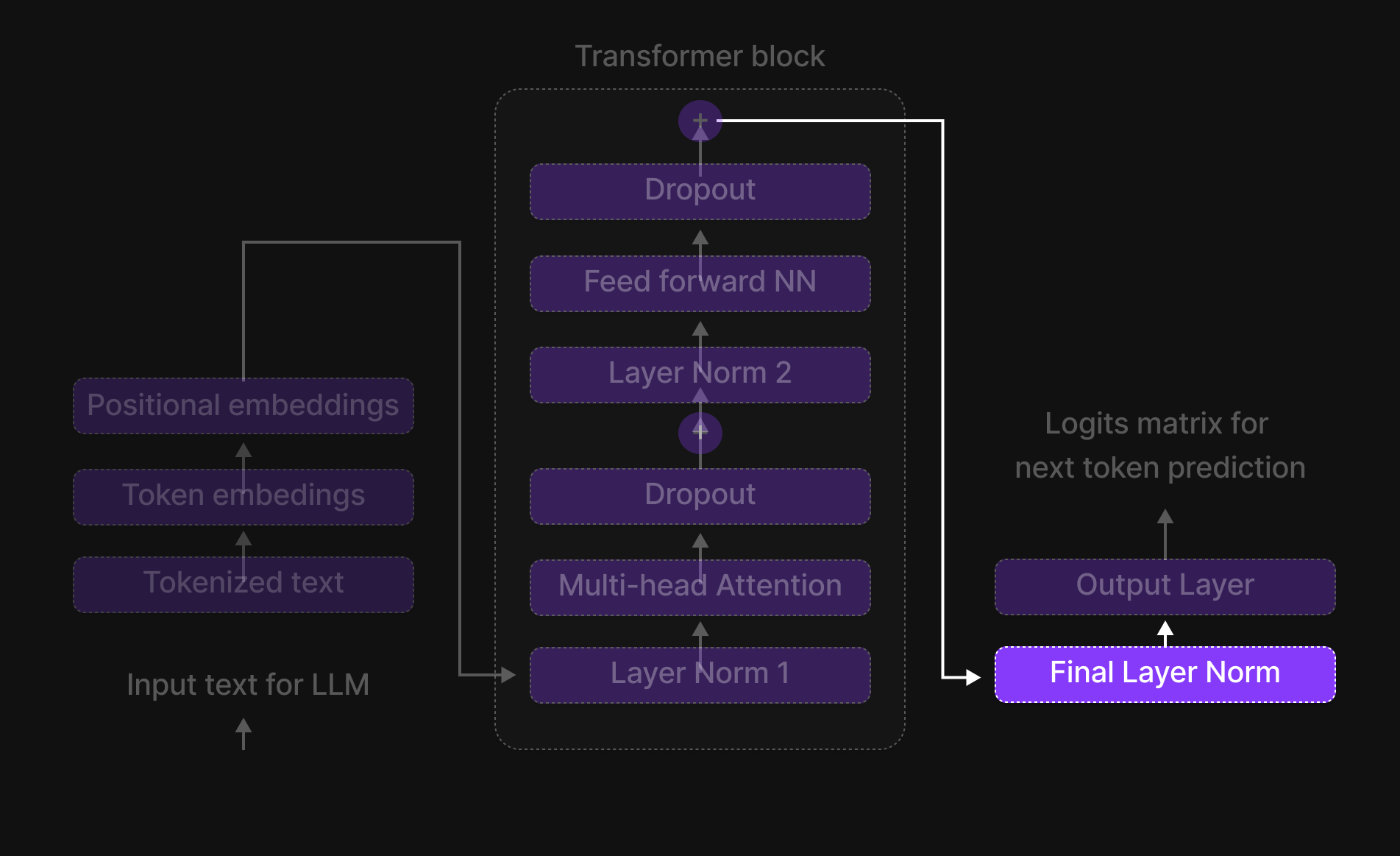 Gambar 30: Final Layer Normalization
Gambar 30: Final Layer Normalization
Sebelum berpindah ke langkah selanjutnya, setiap vektor 768-dimensi dilewatkan melalui proses Final Layer Normalization. Ini memastikan bahwa fitur-fitur yang telah dipelajari oleh model tetap terskala dengan baik dan stabil sebelum membuat prediksi.
Pada titik ini, semua representasi token masih mempertahankan 768 dimensi, tetapi nilai numerik mereka telah diperbarui sepenuhnya.
Lapisan Proyeksi Output (Output Projection Layer): Memperluas ke Ukuran Kosakata
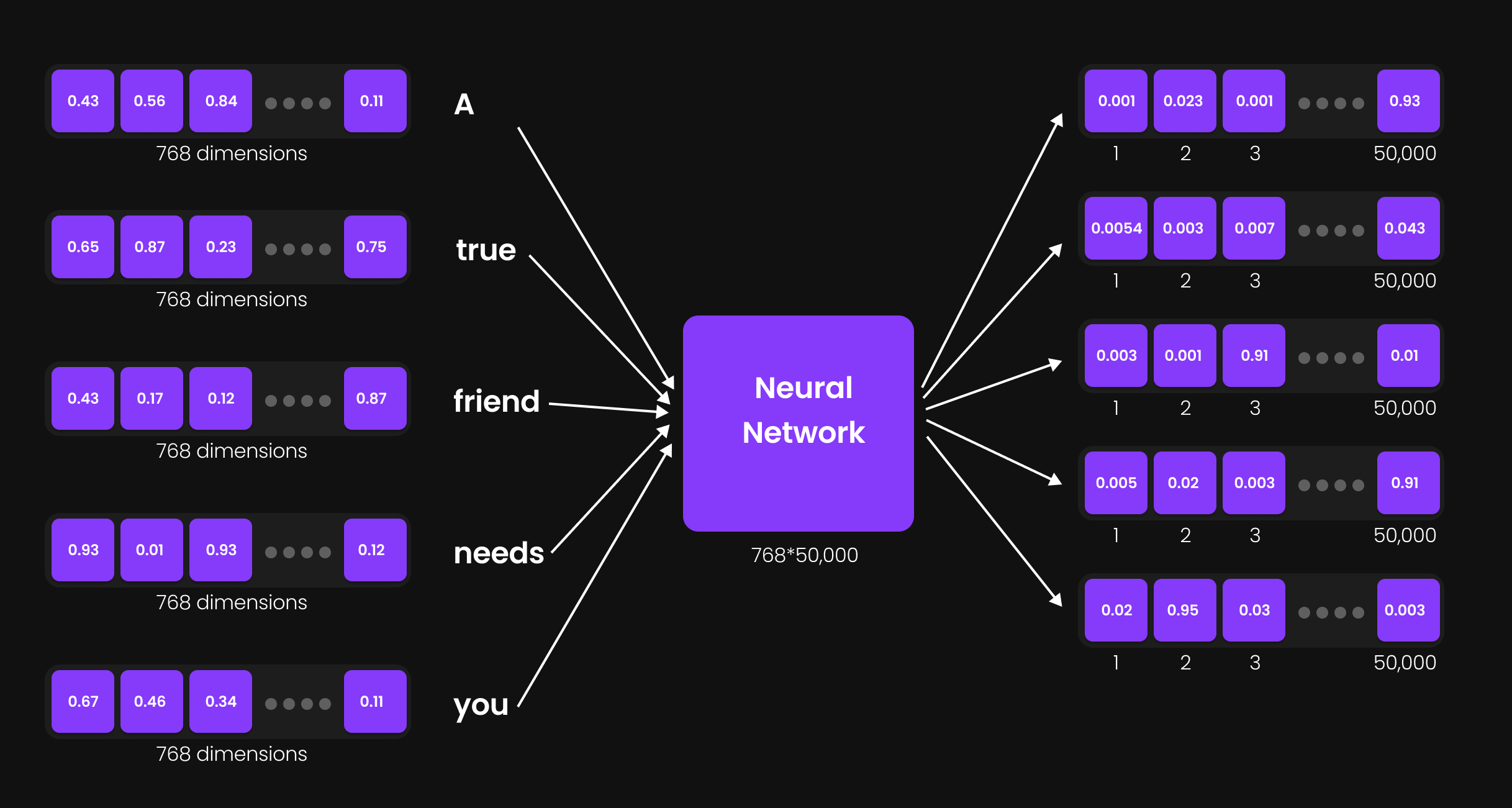 Gambar 31: Lapisan Proyeksi Output (Output Projection Layer)
Gambar 31: Lapisan Proyeksi Output (Output Projection Layer)
Sekarang, kita perlu mengubah setiap vektor 768-dimensi menjadi sebuah representasi yang sejajar/sesuai dengan ukuran kosakata model, yaitu 50.000. Transformasi ini dicapai dengan menggunakan sebuah lapisan proyeksi output (output projection layer)—sebuah jaringan saraf tiruan sederhana dengan ukuran 768 × 50.000.
Mengapa ini diperlukan?
- Setiap token membutuhkan sebuah vektor berdimensi 50.000 karena kita harus menentukan kemungkinan token berikutnya yang paling tinggi dari seluruh daftar kosakata.
- Lapisan proyeksi output memastikan bahwa representasi setiap token dapat dipetakan ke sebuah kata spesifik di dalam kosakata tersebut.
Setelah melalui lapisan ini, ukuran dari representasi setiap token menjadi 50.000, yang berarti sekarang kita memiliki:
- “A” → Vektor berdimensi 50.000
- “True” → Vektor berdimensi 50.000
- “Friend” → Vektor berdimensi 50.000
- “Accepts” → Vektor berdimensi 50.000
- “You” → Vektor berdimensi 50.000
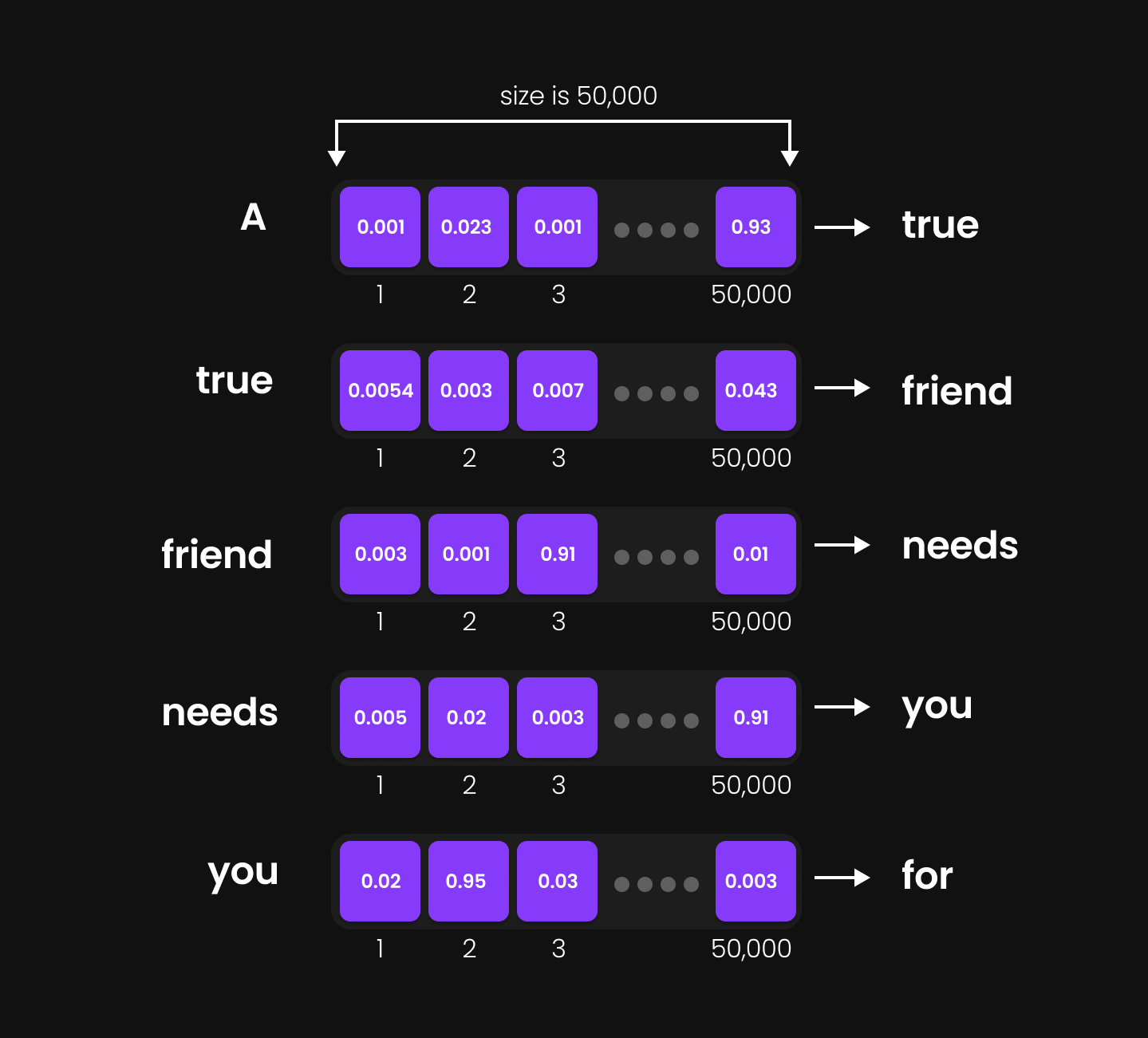
Langkah Terakhir: Memilih Token Berikutnya
Sekarang, model harus memilih token selanjutnya dari kosakatanya. Begini caranya:
-
Vektor berdimensi 50.000 untuk setiap token berisi nilai-nilai probabilitas yang sesuai dengan setiap kata di dalam kosakata.
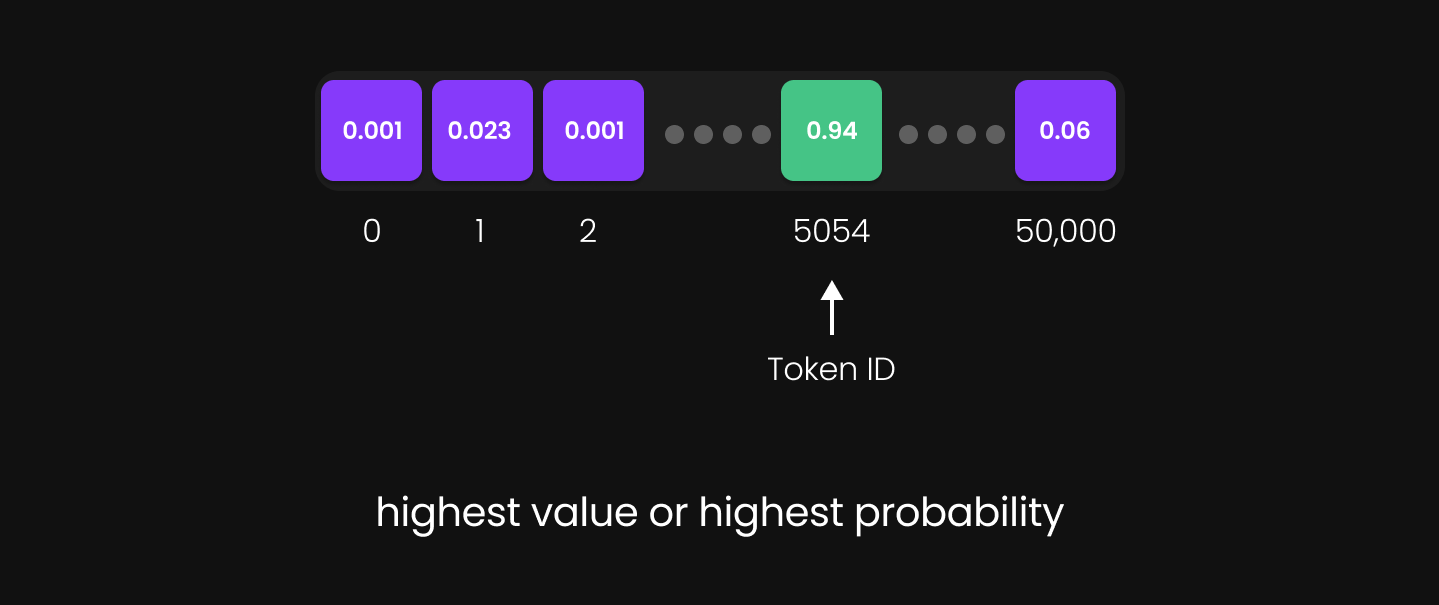 Gambar 33: Nilai probabilitas tertinggi
Gambar 33: Nilai probabilitas tertinggi -
Model mengidentifikasi indeks dengan nilai tertinggi (argmax)—indeks ini merepresentasikan prediksi kata berikutnya yang paling memungkinkan (most probable).
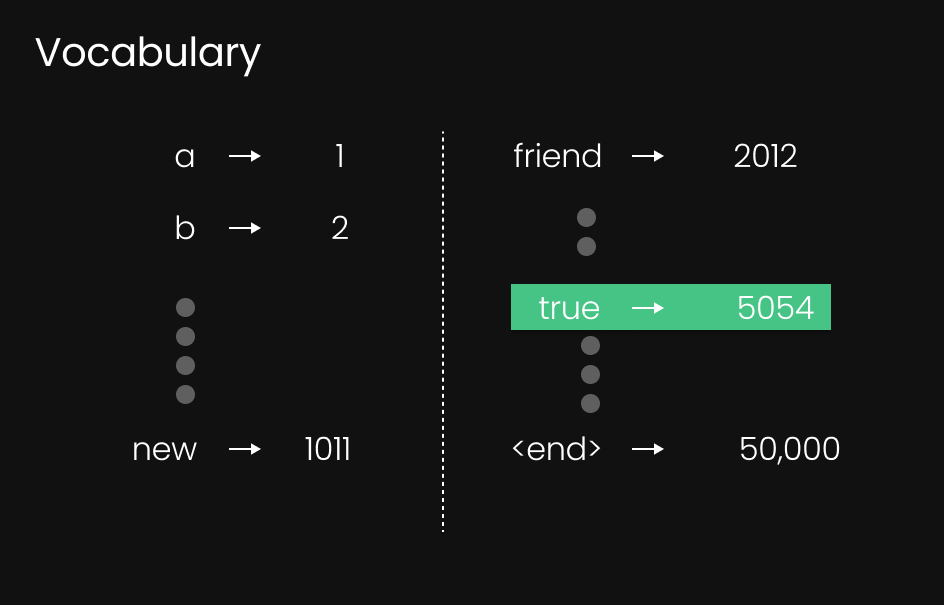
-
Menggunakan indeks ini, model mengambil token yang bersesuaian dari dalam kamus kosakatanya.
Sebagai contoh:
- Jika “A” adalah inputnya, probabilitas tertinggi mungkin mengarah ke indeks untuk kata “true,” sehingga “true” menjadi prediksi token berikutnya.
- Jika “A true” adalah inputnya, model memprediksi “friend” sebagai outputnya.
- Jika “A true friend” adalah inputnya, token selanjutnya yang diprediksi bisa jadi adalah “accepts,” dan seterusnya.
Proses ini terjadi pada setiap langkah (step-by-step), memastikan pembentukan teks (text generation) yang mengalir dan bermakna secara kontekstual.
Kesimpulan
 Gambar 35: Arsitektur LLM secara keseluruhan
Gambar 35: Arsitektur LLM secara keseluruhan
Perjalanan sebuah token melalui LLM mengubahnya dari sekadar teks mentah menjadi representasi yang disempurnakan dan sadar akan konteks. Perjalanan ini dimulai dengan tokenisasi, di mana kata-kata dipecah dan diberikan Token IDs. Kemudian, Penyematan Token (Token Embeddings) menangkap makna semantiknya, dan Penyematan Posisional (Positional Embeddings) memastikan urutan kata tetap terjaga. Gabungan dari embeddings ini membentuk Input Embedding, yang kemudian masuk ke dalam Blok Transformer, di mana Multi-Head Attention menyaring konteksnya, dan Feed-Forward Network (FFN) meningkatkan pemahamannya. Lapisan Dropout dan Normalization menjaga efisiensi dan stabilitas saat token bergerak melewati berbagai lapisan tersebut.
Pada akhirnya, di Lapisan Output (Output Layer), representasi token diekspansi untuk mencocokkan jumlah kosakata, dan model memprediksi kata berikutnya berdasarkan nilai probabilitas. Rangkaian proses inilah yang memungkinkan LLM menghasilkan teks yang koheren layaknya buatan manusia. Seiring dengan berkembangnya model melalui berbagai inovasi seperti Multi-Head Latent Attention, Mixture of Experts (MoE), dan RoPE, kemampuan mereka untuk memproses dan menghasilkan bahasa hanya akan menjadi semakin kuat. Memahami perjalanan ini memberikan wawasan kunci tentang bagaimana AI modern memahami dan menghasilkan bahasa.
Itu saja untuk saat ini!