2.1 The LLM inference loop: Generating text one token at a time
The first and most important concept to grasp is that the KV cache is only relevant during the inference stage of a language model. This distinction is critical, so let’s clarify the two main phases of an LLM’s life.
2.1.1 Distinguishing pre-training from inference
Every large language model, from GPT-2 to DeepSeek-V3, goes through two distinct phases:
- Training: This is the massive, computationally expensive learning phase. The model is trained on a vast dataset (trillions of tokens) to learn grammar, facts, reasoning patterns, and the statistical relationships between words. During this phase, its parameters (or weights) are adjusted. Once pre-training is complete, the model’s parameters are fixed, resulting in a pre-trained LLM.
- Inference: This is the “usage” phase. The pre-trained model, with its fixed parameters, is now used to perform tasks. When you interact with ChatGPT or use an API to ask a model to “make a travel plan for Italy,” you are performing inference. The model isn’t learning anymore; it’s using its learned knowledge to predict the next token in a sequence.
The entire discussion in this chapter applies exclusively to the inference stage. We assume we have a fully trained model, and our goal is simply to use it to generate text.
2.1.2 The autoregressive process: Appending tokens to build context
During inference, a language model generates text one token at a time. While a user interface like ChatGPT might make it look like the entire response appears at once, underneath the hood, a methodical, step-by-step process is unfolding. This is called autoregressive generation.
The core idea is simple but powerful: each new token the model generates is immediately added back to the input sequence, becoming part of the context for generating the next token. This creates a feedback loop that allows the model to build coherent and contextually relevant text.
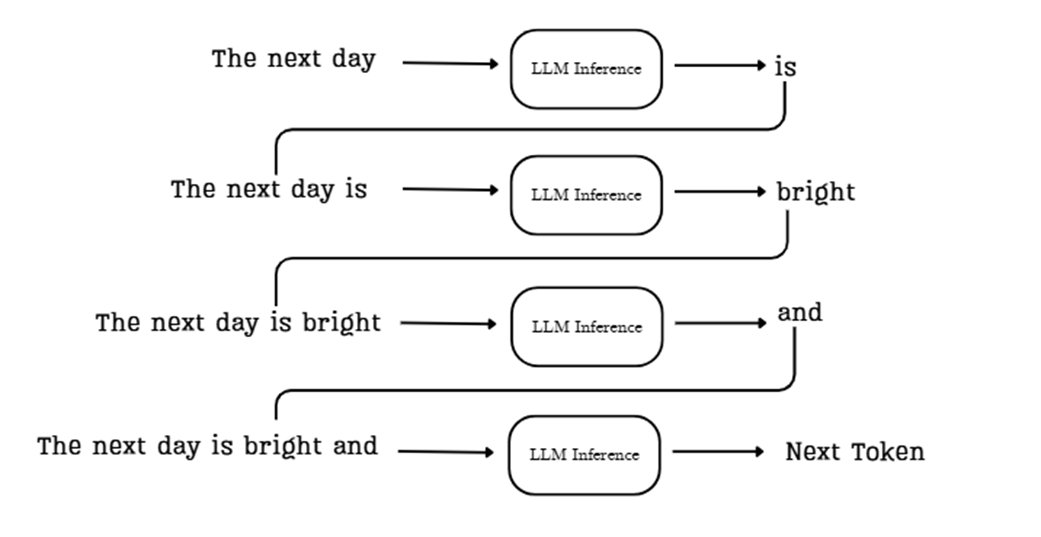
Let’s trace the flow shown in the diagram:
Sidebar “The next day.”.
The model’s task is to predict the most likely token to follow this sequence. Here’s how the process works:
- Initial Context: We start by providing the model with an initial prompt, such as “The next day.”
- First Prediction: This sequence is fed into the LLM inference pipeline, which processes the context and predicts the most probable next token, in this case, “is.”
- Append and Repeat: The new token, “is,” is appended to the sequence. The input for the next step is now the expanded context: “The next day is.” This new, longer sequence is fed back into the model.
- Second Prediction: The model now processes “The next day is” and predicts the next token, “bright.” This process continues, with the context growing one token at a time.
This loop continues, with each newly generated token being added back to the input sequence for the next prediction step. The process stops when the model generates a special end-of-sequence token or reaches a predefined limit on the number of new tokens to generate.
This iterative, feedback-driven process is fundamental to how autoregressive LLMs like the transformer construct coherent and contextually relevant text. Keep this flow in mind, as it’s the key to understanding why the KV cache is both necessary and problematic within this architectural paradigm.
2.1.3 Visualizing autoregressive generation with GPT-2
The following listing demonstrates the autoregressive loop in action using the pre-trained GPT-2 model. The code starts with an initial prompt and then enters a loop. Inside this loop, it performs the core task: it passes the current sequence to the model, gets the prediction for the very next token, and immediately appends that new token to the sequence for the next iteration. This simple visualization makes it clear that the model is performing a full computational pass for every single new token it generates.
You can find this code, along with other code listings in this book, in the official GitHub repository: https://github.com/VizuaraAI/DeepSeek-From-Scratch.
Listing 2.1 Visualizing autoregressive generation with GPT-2
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
prompt = "The next day is bright"
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs.input_ids
print(f"Prompt: '{prompt}'", end="")
for _ in range(20):
# The model processes the entire current sequence of tokens on every pass.
outputs = model(input_ids)
logits = outputs.logits
# We only use the logits from the very last token to predict the next one.
next_token_logits = logits[:, -1, :]
next_token_id = next_token_logits.argmax(dim=-1).unsqueeze(-1)
# The newly predicted token is appended to the input sequence,
# which is then fed back into the model in the next loop.
# This is the core of the autoregressive process.
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
new_token = tokenizer.decode(next_token_id[0])
print(new_token, end="", flush=True)
print("\n")
Running this code produces the following output, where the text after the initial prompt is generated token by token:
‘The next day is bright and sunny, and the sun is shining. The sun is shining, and the moon is shining.
This simple demonstration makes a crucial point clear: the model is performing a full computational pass through its architecture for every single new token it generates.
This is evident because the call to outputs = model(input_ids) happens inside the for loop, and the input_ids tensor, which contains the entire sequence so far, is passed to the model on every single iteration. This observation leads us to a critical question: what exactly is happening inside that computation, and is all of it truly necessary?