Mengatasi Masalah Kemacetan Kinerja
Mengatasi Masalah Kemacetan Kinerja Menggunakan Memori Penyimpanan Sementara (Key-Value Cache)
Yang akan kita pelajari pada bab ini:
- Ketidakefisienan mendasar dari cara kerja AI yang menebak kata demi kata (inferensi autoregresif).
- Key-Value (KV) Cache (Memori Kunci-Nilai): sebuah solusi cerdas yang sayangnya memakan biaya memori sangat besar.
- Multi-Query Attention (MQA) dan Grouped-Query Attention (GQA): Solusi generasi pertama untuk mengatasi batas memori pada KV Cache.
Untuk benar-benar memahami inovasi luar biasa di dalam rancangan bangunan (arsitektur) DeepSeek, kita harus mulai dengan masalah teknis terberat yang sengaja mereka pecahkan. Perjalanan kita mengikuti peta jalan empat tahap yang telah dijelaskan di awal buku ini, dan bab ini didedikasikan sepenuhnya untuk Tahap 1: Fondasi Key-Value Cache.
Tahap ini membahas rintangan paling mendasar dalam penggunaan (inferensi) LLM modern: masalah mentoknya memori dan kemampuan komputer. Sebelum kita bisa mengagumi lompatan teknologi canggih seperti Multi-Head Latent Attention (MLA) atau DeepSeek Sparse Attention (DSA) buatan DeepSeek di Tahap 2, kita harus menguasai dulu mekanisme dasar dari mana teknologi tersebut berasal.
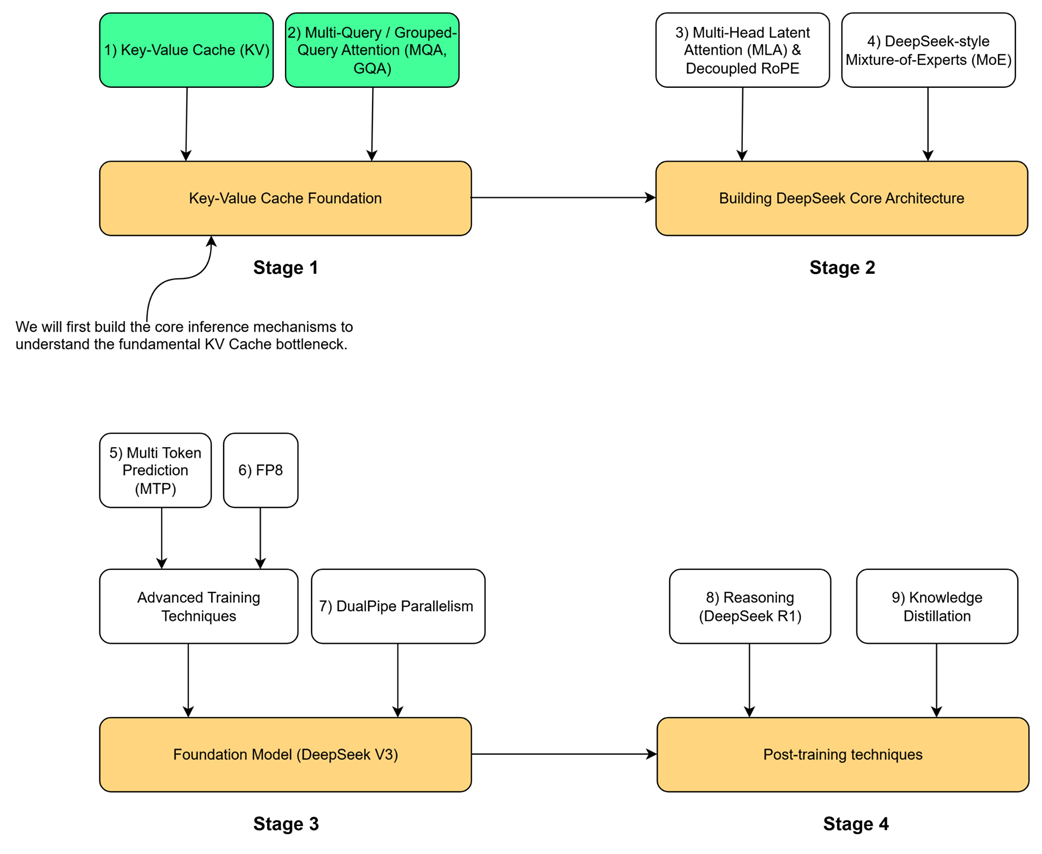
Seperti yang ditunjukkan pada peta jalan di atas, fondasi ini dibangun di atas dua konsep utama: Key-Value (KV) Cache itu sendiri, dan cara pengoptimalan generasi pertamanya, yaitu Multi-Query Attention (MQA) dan Grouped-Query Attention (GQA). Teknik-teknik ini membentuk dasar di mana arsitektur yang lebih canggih dibangun. Tahap 2 dari peta jalan kita nanti akan memperkenalkan inovasi inti dari DeepSeek (seperti MLA, Decoupled RoPE, dan Mixture-of-Experts). Namun sebelum membahas itu, kita akan membagi bab ini menjadi tiga bagian untuk membangun pemahaman dasar kita dari nol:
Pertama, kita akan membangun putaran (loop) pembuatan teks secara utuh. Kita akan melihat langsung bagaimana model bahasa menghasilkan teks satu per satu kata (token). Praktik langsung ini akan membuat kita melihat sendiri betapa tidak efisiennya cara kerja komputer pada pendekatan tradisional ini.
Kedua, kita akan membuat kode untuk KV Cache. Ini adalah solusi cerdas yang memecahkan masalah kelambatan awal tadi. Melalui kode kita, kita akan menunjukkan betapa drastisnya peningkatan kecepatannya. Namun, kita juga akan mengungkap “sisi gelapnya”: biaya memori yang sangat besar yang menciptakan masalah kemacetan baru, terutama jika AI harus membaca teks sepanjang 1 juta kata.
Terakhir, kita akan membangun lapisan kode PyTorch yang berfungsi untuk MQA dan GQA. Ini adalah arsitektur solusi generasi pertama di industri AI yang dirancang untuk mengurangi masalah memori pada KV Cache. Sangat penting untuk dipahami bahwa solusi ini tidaklah gratis; baik MQA maupun GQA secara sadar mengorbankan kualitas dan kecerdasan model demi menghemat memori komputer. MQA adalah bentuk paling ekstrem, yang mengutamakan penghematan memori di atas segalanya. Sementara itu, GQA menawarkan jalan tengah yang lebih seimbang. Dengan membangun teknik-teknik ini dan memahami kelemahannya, kita akan memiliki dasar pengetahuan yang tepat untuk memahami inovasi unik DeepSeek di bab-bab selanjutnya, yang bertujuan untuk mendapatkan yang terbaik dari kedua sisi tanpa ada yang dikorbankan.
2.1 Putaran penggunaan LLM: Menghasilkan teks satu per satu kata
Konsep pertama dan paling penting untuk dipahami adalah bahwa KV cache hanya berlaku selama tahap inferensi (tahap penggunaan) dari sebuah model bahasa. Perbedaan ini sangat penting, jadi mari kita perjelas dua fase utama dalam siklus hidup sebuah LLM.
2.1.1 Membedakan masa pelatihan (pre-training) dari masa penggunaan (inference)
Setiap model bahasa besar, dari GPT-2 versi awal hingga DeepSeek-V4, melewati dua fase yang sangat berbeda:
- Pelatihan (Pra-pelatihan & Pasca-pelatihan): Ini adalah fase belajar yang sangat besar dan memakan biaya komputer yang sangat mahal. Model dilatih menggunakan sekumpulan data yang sangat luas (triliunan kata) untuk mempelajari tata bahasa, fakta, pola logika, dan hubungan antar kata. Selama fase ini, miliaran parameternya (bobot/jaringan sarafnya) secara aktif diubah dan disesuaikan. Setelah pelatihan selesai, parameter model tersebut dikunci (tidak berubah lagi).
- Inferensi (Penggunaan): Ini adalah fase “pemakaian”. Model yang sudah dilatih dan dikunci tadi sekarang digunakan untuk melakukan tugas. Saat Anda mengobrol dengan ChatGPT atau meminta AI untuk “menulis kode Python,” Anda sedang melakukan inferensi. Model tersebut tidak lagi belajar; ia murni menggunakan pengetahuannya yang sudah dikunci untuk menebak kata apa yang akan muncul selanjutnya dalam sebuah kalimat.
Seluruh pembahasan dalam bab ini—dan masalah kemacetan memori yang ingin kita pecahkan—berlaku secara eksklusif (khusus) untuk tahap inferensi. Kita mengasumsikan kita sudah memiliki model yang sudah selesai dilatih, dan tujuan kita adalah menggunakannya untuk menghasilkan teks secepat dan seefisien mungkin.
2.1.2 Proses autoregresif: Menambahkan kata untuk membangun konteks
Selama tahap penggunaan, sebuah model bahasa menghasilkan teks tepat satu per satu kata (token). Meskipun tampilan layar di HP atau komputer Anda mungkin membuatnya terlihat seolah-olah seluruh paragraf muncul sekaligus, di balik layar, ada sebuah proses langkah demi langkah yang sedang berlangsung. Ini disebut pembuatan teks autoregresif.
Ide intinya sederhana tetapi sangat menguras tenaga komputer: setiap kata baru yang dihasilkan oleh model akan langsung dimasukkan kembali ke dalam kalimat awal, menjadi bagian dari konteks untuk menebak kata berikutnya. Hal ini menciptakan sebuah putaran yang terus berulang.
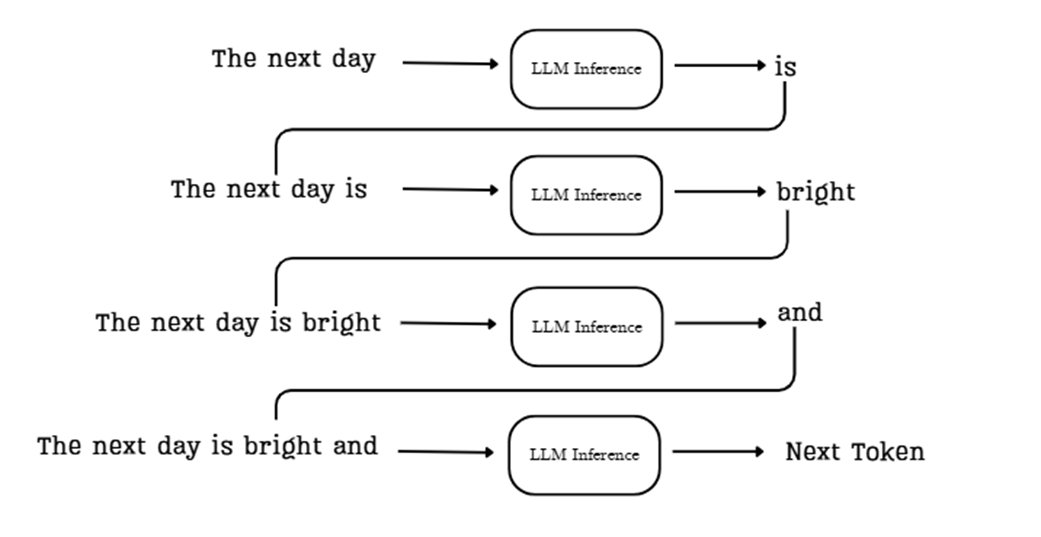
Mari kita telusuri alur yang ditunjukkan dalam diagram di atas menggunakan sebuah kalimat pancingan (prompt) sederhana: “The next day” (Keesokan harinya).
Tugas model AI adalah menebak kata apa yang paling mungkin muncul setelah kalimat ini. Berikut adalah urutan kejadiannya:
- Konteks Awal: Kita mulai dengan memberikan pancingan awal kepada model: “The next day.”
- Tebakan Pertama: Seluruh kalimat ini dimasukkan ke dalam pipa saluran inferensi LLM. Model memproses kalimat tersebut dan menebak kata selanjutnya yang paling mungkin. Dalam hal ini, model menebak kata “is” (adalah).
- Tambahkan dan Ulangi: Kata baru tersebut, “is,” ditambahkan ke bagian belakang kalimat. Masukan untuk langkah selanjutnya sekarang menjadi kalimat yang lebih panjang: “The next day is.” Kalimat baru yang lebih panjang ini dimasukkan kembali ke dalam model dari awal.
- Tebakan Kedua: Model sekarang memproses “The next day is” dan menebak kata selanjutnya: “bright” (cerah). Proses ini terus berlanjut, dengan kalimat yang terus bertambah satu kata pada setiap langkahnya.
Putaran ini terus berlanjut sampai model menghasilkan sebuah tanda khusus bernama end-of-sequence (<EOS> / akhir dari kalimat) atau mencapai batas jumlah kata yang sudah ditentukan. Proses yang berulang dan saling menyambung ini adalah prinsip dasar tentang bagaimana LLM menyusun teks yang masuk akal. Ingatlah alur ini dengan baik, karena ini adalah kunci untuk memahami mengapa KV cache itu sangat diperlukan sekaligus sangat bermasalah.
2.1.3 Memvisualisasikan pembuatan autoregresif dengan GPT-2
Kode pemrograman berikut ini mendemonstrasikan putaran autoregresif yang sedang bekerja menggunakan model GPT-2 yang sudah dilatih sebelumnya. Kode dimulai dengan kalimat pancingan awal dan masuk ke dalam sebuah putaran for. Di dalam putaran ini, kode melakukan tugas utamanya: ia mengirim kalimat saat ini ke model, mendapatkan tebakan untuk kata berikutnya, dan langsung menambahkan kata baru tersebut ke dalam kalimat untuk putaran selanjutnya.
Visualisasi sederhana ini memperjelas kenyataan yang menyakitkan: model komputer harus memproses ulang dan membaca seluruh kalimat dari awal untuk setiap satu kata baru yang ia hasilkan.
(Catatan: Anda dapat menemukan kode ini, beserta kode pemrograman lainnya dalam buku ini, di penyimpanan GitHub resmi: https://github.com/VizuaraAI/DeepSeek-From-Scratch.)
Kode Pemrograman 2.1 Memvisualisasikan pembuatan autoregresif dengan GPT-2
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
prompt = "The next day is bright"
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs.input_ids
print(f"Prompt: '{prompt}'", end="")
for _ in range(20):
# Model memproses seluruh rangkaian kata saat ini pada setiap putaran.
outputs = model(input_ids)
logits = outputs.logits
# Kita hanya menggunakan skor (logits) dari kata yang paling terakhir
# untuk menebak kata berikutnya.
next_token_logits = logits[:, -1, :]
next_token_id = next_token_logits.argmax(dim=-1).unsqueeze(-1)
# Kata yang baru ditebak kemudian ditambahkan ke kalimat masukan,
# yang kemudian dimasukkan kembali ke dalam model di putaran berikutnya.
# Ini adalah inti dari proses autoregresif.
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
new_token = tokenizer.decode(next_token_id[0])
print(new_token, end="", flush=True)
print("\n")
Menjalankan kode ini akan menghasilkan teks berikut, di mana teks yang muncul setelah kalimat pancingan awal dibuat satu per satu kata:
Prompt: ‘The next day is bright’ and sunny, and the sun is shining. The sun is shining, and the moon is shining.
Demonstrasi ini memperjelas satu poin yang sangat penting: model komputer melakukan proses matematika penuh melalui seluruh arsitektur besarnya untuk setiap satu kata baru. Kita tahu hal ini terjadi karena perintah pemanggilan outputs = model(input_ids) berada di dalam kurung putaran for, dan data input_ids (yang berisi seluruh sejarah teks kalimat tersebut) dikirimkan ke model secara utuh pada setiap putarannya.
Pengamatan ini membawa kita pada sebuah pertanyaan kritis: apa yang sebenarnya terjadi di dalam perhitungan matematika tersebut, dan apakah menghitung ulang seluruh kalimat dari awal itu benar-benar diperlukan?
2.2 Tugas Inti: Menebak kata berikutnya
Untuk memahami perhitungan apa saja yang mungkin kita ulang-ulang secara sia-sia selama proses inferensi, kita harus mengupas lapisan-lapisan arsitektur AI dan melihat ke bagian paling tengah dari blok Transformer: mekanisme Multi-Head Attention (Perhatian Banyak-Kepala).
Diagram di bawah ini memberikan gambaran umum dari perjalanan ini. Diagram ini menunjukkan bagaimana contoh kalimat kita, “The next day is bright,” mengalir melewati komponen-komponen utama. Ingatlah gambar ini karena ini mewakili seluruh proses yang akan kita bedah sebentar lagi.
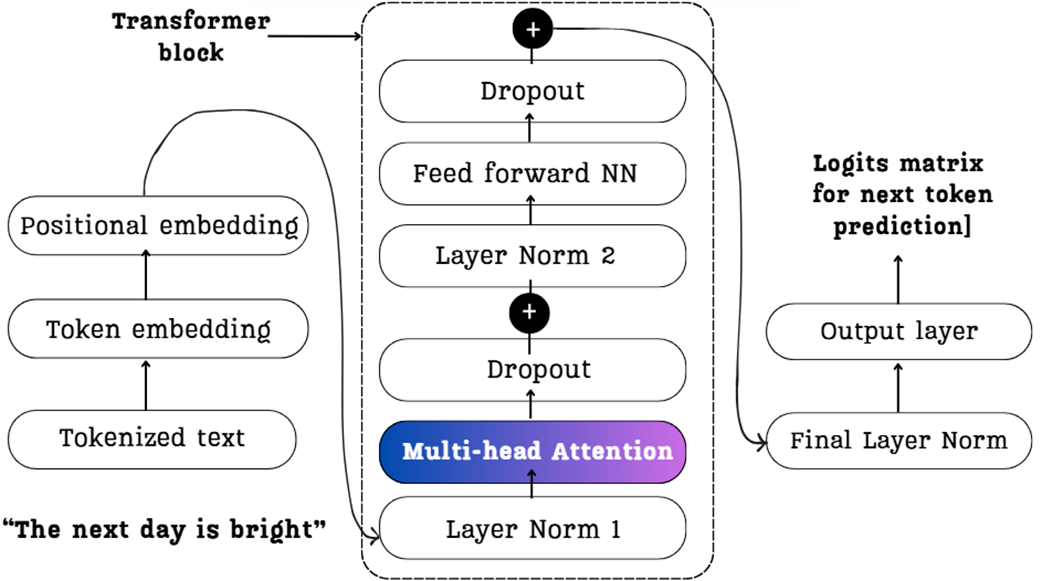
2.2.1 Dari Embedding Masukan hingga Vektor Konteks: Penjelasan Matematika
Mari kita telusuri jalur kalimat masukan kita, “The next day is,” melalui satu perhitungan Attention (Perhatian) untuk melihat apa yang sebenarnya terjadi di dalam mesin komputer.
Langkah 1: Mengubah Masukan Menjadi Query, Key, dan Value
Setelah teks dipecah menjadi kata (tokenisasi) dan diubah menjadi angka (embedding), masukan kita diubah menjadi sebuah tabel angka matematika (matriks), yang akan kita sebut X. Untuk penjelasan ini, kita akan menggunakan ukuran tabel yang disederhanakan agar matematikanya mudah diikuti. Mari kita asumsikan tabel X kita memiliki ukuran (4, 8). Artinya, ada 4 kata, dan masing-masing kata diwakili oleh 8 angka (dimensi embedding). Pada model AI sungguhan, dimensi embedding ini jauh lebih besar (misalnya, berukuran 7168 pada DeepSeek-V3), tetapi rumus matematika dasarnya sama persis.
Langkah pertama yang dilakukan di dalam blok attention adalah memproyeksikan (mengubah) tabel masukan ini menjadi tiga tabel perwakilan yang berbeda: Tabel Query (Q / Pertanyaan), Key (K / Kunci), dan Value (V / Nilai). Hal ini dilakukan dengan mengalikan tabel X dengan tiga tabel bobot pelajaran AI yang terpisah: $W_q$, $W_k$, dan $W_v$.
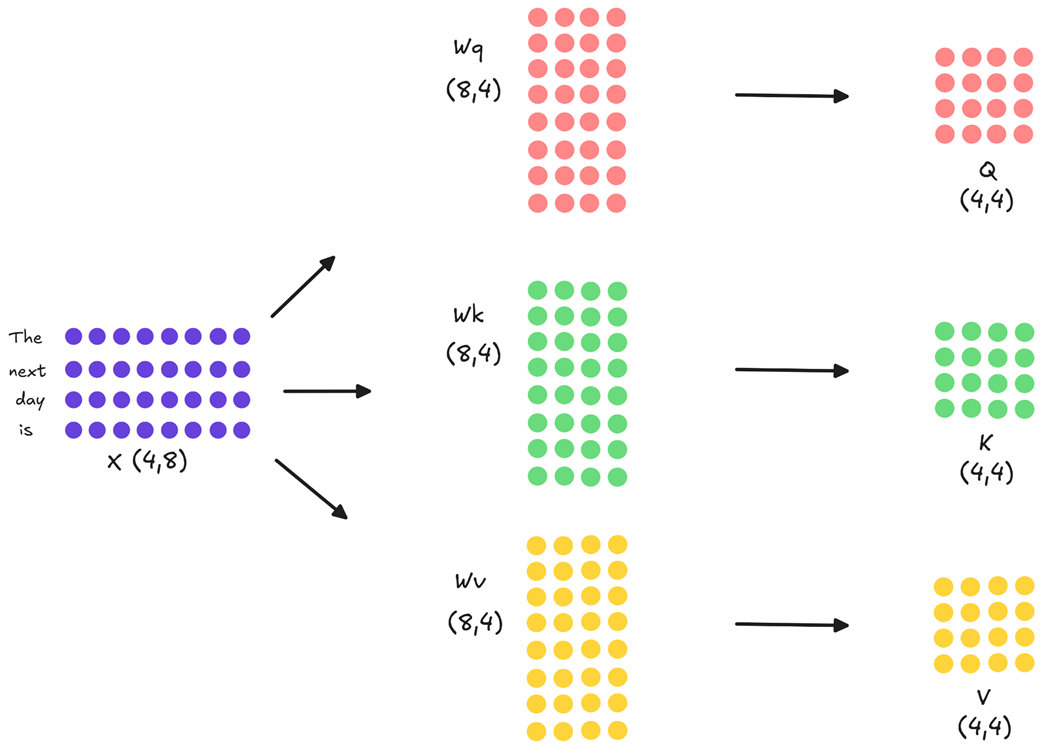
Seperti yang diilustrasikan pada diagram:
- Masukan X (ukuran 4x8) dikalikan dengan $W_q$ (ukuran 8x4) untuk menghasilkan matriks Query (ukuran 4x4).
- Masukan X (ukuran 4x8) dikalikan dengan $W_k$ (ukuran 8x4) untuk menghasilkan matriks Key (ukuran 4x4).
- Masukan X (ukuran 4x8) dikalikan dengan $W_v$ (ukuran 8x4) untuk menghasilkan matriks Value (ukuran 4x4).
Anggaplah ketiga matriks ini sebagai peran. Matriks Query (Pertanyaan) mewakili apa yang sedang “dicari” oleh setiap kata. Sedangkan matriks Key (Kunci) dan Value (Nilai/Isi) mewakili apa yang “ditawarkan” oleh setiap kata kepada kata-kata lain di sekitarnya.
Langkah 2: Menghitung Skor Perhatian (Attention Scores)
Selanjutnya, model AI harus menentukan seberapa penting hubungan antara satu kata dengan semua kata lainnya. Kita mengambil matriks Query dan melakukan perkalian matriks (disebut dot product) dengan kebalikan posisi dari matriks Key ($Q \times K^T$).

Matriks Skor Perhatian yang dihasilkan (berukuran 4x4) mengukur hubungan antara setiap pasangan kata. Misalnya, angka yang berada di baris keempat dan kolom kedua mewakili seberapa besar kata “is” harus memberikan perhatian (fokus) kepada kata “next.”
Langkah 3: Dari Skor Menjadi Vektor Konteks
Skor mentah ini kemudian diskalakan (diperkecil) agar proses pelatihannya stabil, lalu sebuah topeng kausal (causal mask) diterapkan. Karena proses pembuatan bahasa selalu bergerak maju ke depan, sebuah kata hanya bisa mengumpulkan informasi dari kata-kata sebelumnya. Topeng ini mencegah model untuk “mencontek” dengan melihat kata di masa depan. Caranya adalah dengan mengubah nilai pada segitiga bagian atas matriks skor perhatian menjadi nol. Terakhir, sebuah fungsi matematika bernama softmax mengubah skor-skor tersebut menjadi Bobot Perhatian (attention weights)—yaitu sekumpulan angka peluang/probabilitas yang jika dijumlahkan per baris hasilnya adalah 1.
Bobot perhatian akhir ini kemudian dikalikan dengan matriks Value (Nilai).
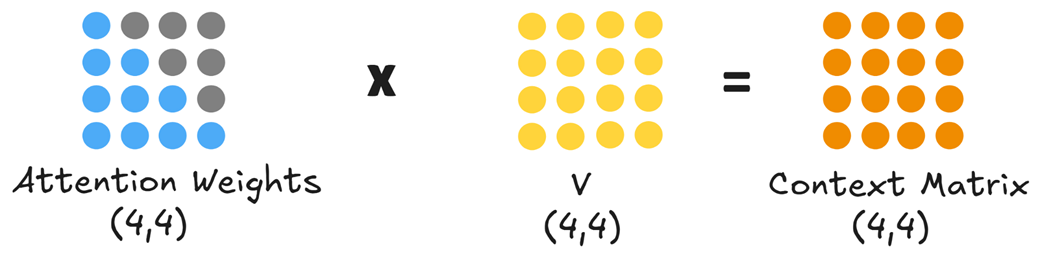
Perkalian terakhir ini menghasilkan Matriks Konteks (ukuran 4x4). Setiap baris dalam matriks ini adalah baris angka (vektor) baru yang sangat kaya akan informasi. Angka konteks untuk kata “is,” misalnya, kini merupakan jumlah gabungan dari semua angka Value (Nilai) kata-kata yang muncul sebelumnya, dan mengandung informasi makna yang sangat kaya tentang seluruh kejadian di kalimat sebelumnya.
Langkah 4: Memperbesar menjadi Multi-Head Attention (Perhatian Banyak Kepala)
Proses yang dijelaskan di atas baru menangani satu buah perhitungan perhatian tunggal. Namun, bahasa manusia itu rumit. Sebuah model AI perlu melacak aturan tata bahasa (apakah subjek dan kata kerjanya cocok) dan hubungan makna kata (semantik) secara bersamaan.
Di sinilah Multi-Head Attention (MHA) berperan. Daripada menggunakan satu set matriks perhitungan yang sangat besar, model ini menggunakan banyak set matriks yang lebih kecil dan bekerja secara mandiri—masing-masing disebut “kepala” (head).
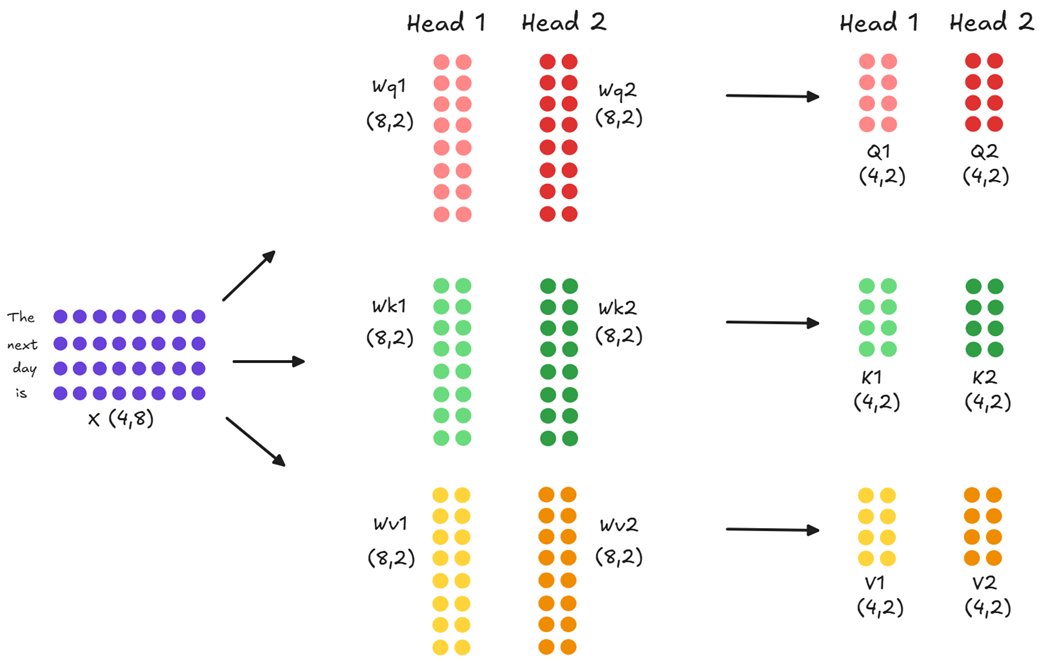
Seperti yang ditunjukkan pada Gambar 2.7, jika model kita memiliki dua kepala, masukan awal (ukuran 4, 8) diproyeksikan secara bersamaan (paralel) menjadi enam matriks berukuran kecil (4, 2): $Q_1$, $K_1$, $V_1$ untuk Kepala 1, dan $Q_2$, $K_2$, $V_2$ untuk Kepala 2.
Setiap kepala kemudian menghitung skor perhatiannya sendiri secara sepenuhnya mandiri tanpa melihat kepala yang lain.
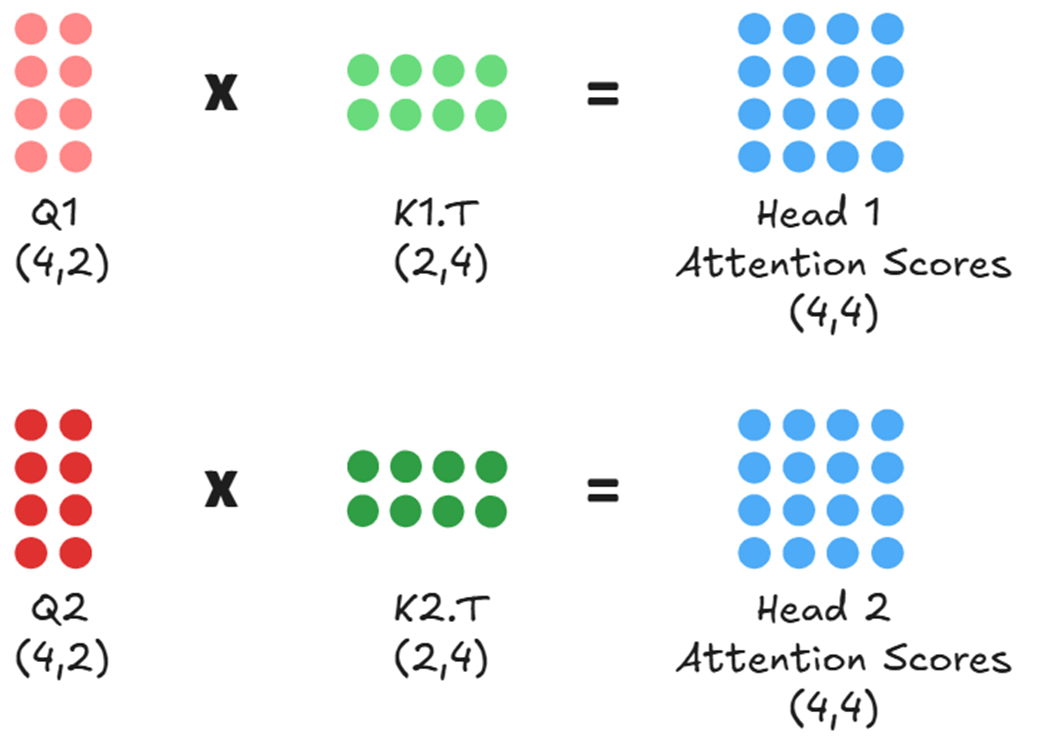
Proses paralel (bekerja bersama-sama) inilah yang menjadi rahasia kekuatan Transformer. Karena setiap kepala memiliki angka acak awal yang unik, mereka belajar untuk melihat kalimat masukan dari sudut pandang yang berbeda. Kepala 1 mungkin menjadi ahli tata bahasa, sementara Kepala 2 menjadi ahli makna kalimat.
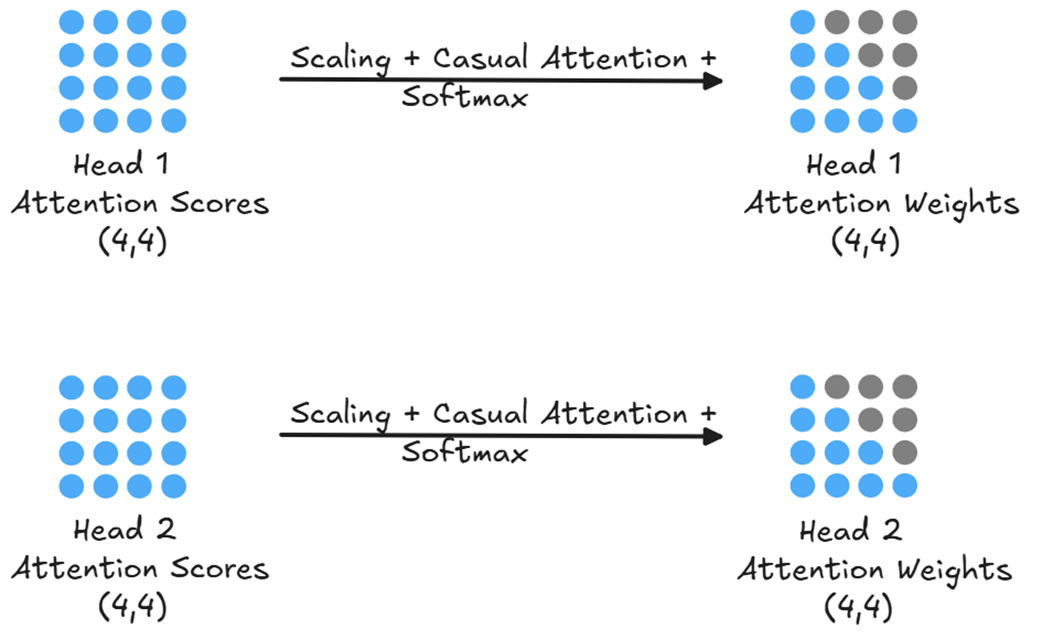
Sama seperti kasus kepala tunggal sebelumnya, skor mentah dari setiap kepala diskalakan, ditutupi topeng, dan diubah menjadi angka peluang (probabilitas) melalui rumus softmax. Terakhir, setiap kepala mengalikan bobotnya sendiri dengan matriks Value miliknya sendiri untuk menghasilkan Matriks Konteks masing-masing.
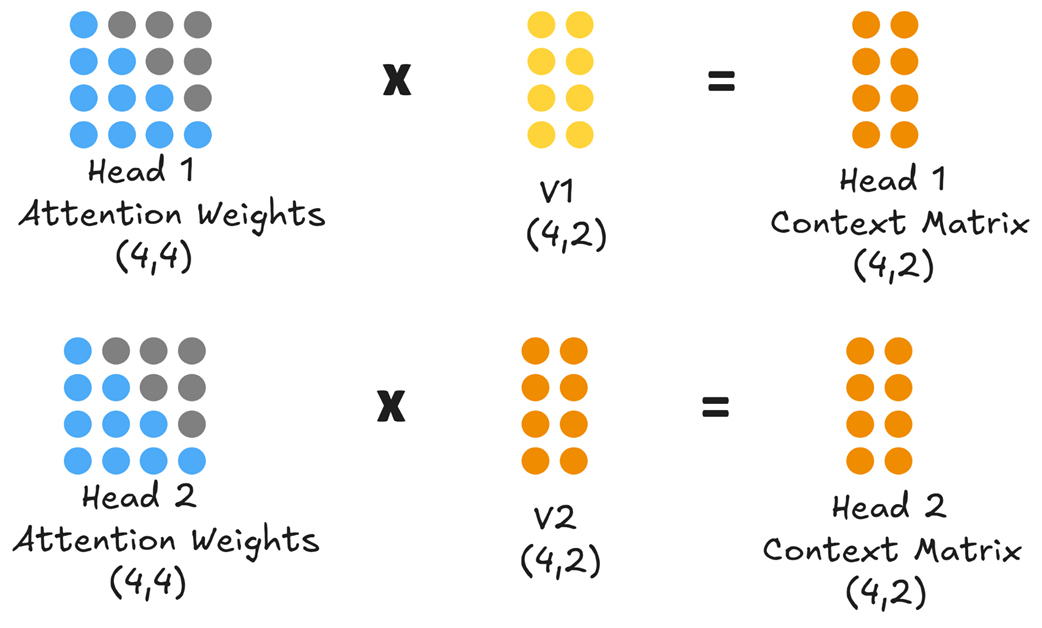
Pada titik ini, kita memiliki dua Matriks Konteks (ukuran 4, 2) yang terpisah. Untuk meneruskan data ini ke lapisan otak AI berikutnya, kita harus menyatukan kembali aliran yang terpisah ini.

Pertama, kita menyambung (menggabungkan/concatenate) matriks-matriks tersebut di bagian ujungnya, mengubah dua matriks (4, 2) milik kita kembali menjadi satu matriks gabungan (4, 4). Kedua, matriks gabungan ini dilewatkan melalui sebuah lapisan proyeksi keluaran (sebuah lapisan matematika linier dengan bobot yang sudah dipelajari) yang berfungsi mencampurkan pemahaman dari berbagai kepala tersebut kembali ke dalam bentuk yang dapat dibaca oleh otak utama AI.
2.2.2 Dari Vektor Konteks menuju Logits
Mekanisme Perhatian (Attention) kita telah berhasil menghasilkan Matriks Konteks yang kaya informasi. Untuk kalimat masukan kita “The next day is,” kita memiliki matriks (4, 4) di mana setiap baris mencerminkan pemahaman yang mendalam tentang kata tersebut beserta konteks sekitarnya. Sekarang, matriks ini harus melewati sisa blok Transformer untuk menghasilkan tebakan akhir.
Langkah 1: Jaringan Feed-Forward (FFN) Matriks Konteks melewati Jaringan Feed-Forward (FFN). Berbeda dengan sistem attention (yang membandingkan satu kata dengan kata lainnya), FFN memproses data angka setiap kata secara mandiri dan sendirian. FFN bertindak sebagai pencocok pola yang rumit, menerapkan perubahan matematika tingkat lanjut tanpa mengubah ukuran matriksnya.
Langkah 2: Mengulang Melalui Blok-Blok Transformer Hasil keluarannya melewati proses Normalisasi Lapisan dan sebuah sambungan sisa (menambahkan data masukan awal blok ke data keluaran akhirnya). Seluruh blok utuh ini (Attention + FFN + Normalisasi) kemudian diulang. Datanya mengalir ke blok berikutnya, mengulangi siklus tersebut sebanyak jumlah lapisan yang dimiliki oleh model AI.
Langkah 3: Proyeksi Akhir Menjadi Logits Setelah keluar dari blok Transformer terakhir, matriks tersebut melewati Lapisan Keluaran (Output Layer). Lapisan linier ini mengubah kumpulan angka konteks kita menjadi ruang yang sangat luas sebesar jumlah total kosakata yang diketahui model AI tersebut.
Definisi: Apa itu Logits? Logit adalah skor mentah yang belum diubah menjadi persentase pasti. Untuk setiap posisi kata dalam sebuah kalimat, model menghasilkan angka logit untuk setiap kata yang ada dalam kamusnya. Logit tertinggi sesuai dengan kata berikutnya yang paling mungkin muncul.

Seperti yang ditunjukkan pada Gambar 2.12, setiap dari 4 baris dalam Matriks Konteks kita diubah menjadi barisan angka dengan panjang 50.257 (yaitu jumlah ukuran kosakata kamus milik model GPT-2). Hal ini menghasilkan sebuah Matriks Logits raksasa yang berukuran (4, 50257). Baris pertama berisi tebakan untuk kata apa yang muncul setelah “The”, baris kedua untuk apa yang muncul setelah “next”, dan seterusnya.
2.2.3 Fakta terpenting: Mengapa hanya baris terakhir yang berguna
Kita sekarang memiliki Matriks Logits (4, 50257) yang sangat besar berisi tebakan untuk setiap posisi kata. Akan tetapi, tujuan asli kita sangatlah spesifik: kita hanya ingin menebak satu kata tunggal yang muncul setelah keseluruhan kalimat masukan kita, “The next day is.”
Ini berarti kita bisa membuang hampir seluruh informasi yang ada di dalam Matriks Logits tersebut.
- Baris 1 (tebakan kata setelah “The”) tidak berguna bagi kita saat ini.
- Baris 2 (tebakan kata setelah “next”) tidak berguna.
- Baris 3 (tebakan kata setelah “day”) tidak berguna.
Satu-satunya baris yang kita pedulikan hanyalah baris paling akhir: baris logit yang berhubungan dengan kata “is.”
Ini adalah fakta yang paling penting dan krusial dalam proses inferensi LLM: Karena kita hanya menggunakan baris terakhir untuk membuat tebakan, maka menghitung ulang skor logits untuk semua baris sebelumnya pada setiap putaran pembuatan kata adalah tindakan yang sangat membuang-buang tenaga komputer.
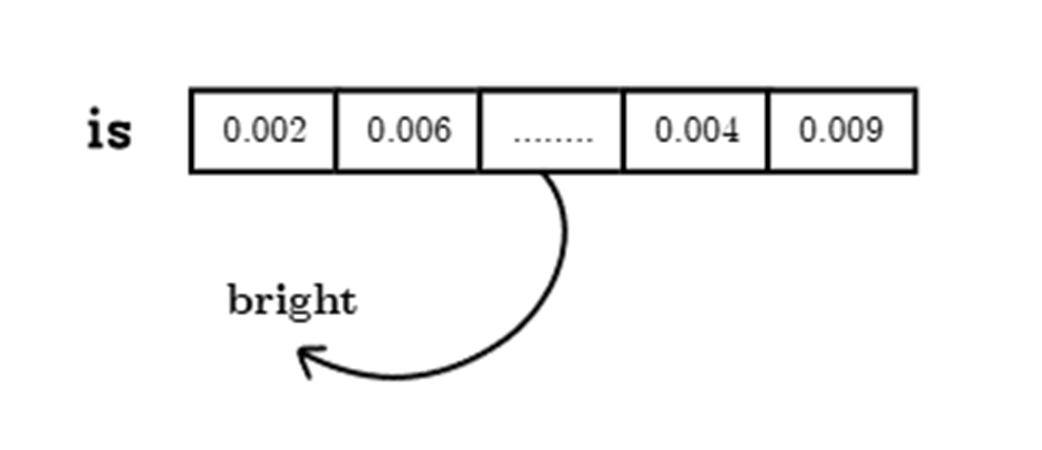
Untuk memilih kata berikutnya, kita melakukan hal berikut:
- Pisahkan Barisan Logits Terakhir: Kita potong bagian baris paling bawah saja (ukurannya menjadi 1, 50257).
- Terapkan Softmax: Kita mengubah skor mentah ini menjadi pembagian persentase (probabilitas) yang jika dijumlahkan hasilnya pasti 1 (100%).
- Pilih Katanya: Kita melakukan operasi komputer bernama
argmaxuntuk mencari skor persentase yang paling tinggi, yang akhirnya mengungkapkan kata tebakan kita (misalnya, “bright”).
Seluruh jalur perhitungan yang rumit ini dijalankan untuk setiap satu kata. Menyadari bahwa tebakan akhir hanya bergantung pada vektor kata terakhir (yang di dalamnya sudah berisi ringkasan dari kata-kata masa lalu berkat self-attention), seharusnya segera menjadi tanda bahaya bagi kita. Jika kita terus-menerus mengirimkan kalimat yang semakin panjang kembali ke dalam model, apakah kita sedang melakukan perhitungan matematika tak berguna dalam jumlah yang sangat tidak masuk akal di blok attention?
Jawabannya adalah: Ya, sangat.
2.3 Masalah perhitungan yang berulang-ulang (redundan)
Kita telah menetapkan dua fakta penting:
- Model menghasilkan teks secara autoregresif, yaitu dengan mengirimkan teks hasil keluarannya sendiri kembali ke dalam sebagai masukan baru.
- Untuk menebak kata berikutnya, model tersebut hanya memerlukan hasil matematika dari kata yang posisinya paling terakhir di dalam kalimat tersebut.
Jika model terus-menerus memproses ulang kalimat yang semakin panjang hanya untuk mengambil data dari kata terakhir saja, pemborosan tenaga yang terjadi sangatlah mengejutkan.
2.3.1 Intuisi Logika: Apakah kita sedang menghitung hal yang sama berulang kali?
Bayangkan proses ini seperti Anda sedang membaca buku.
- Langkah 1: Untuk memahami Bab 1, Anda membaca Bab 1.
- Langkah 2: Untuk memahami Bab 2, Anda membaca ulang Bab 1 dari awal, lalu membaca Bab 2.
- Langkah 3: Untuk memahami Bab 3, Anda membaca ulang Bab 1, membaca ulang Bab 2, lalu membaca Bab 3.
Jika membaca satu bab membutuhkan waktu yang pasti (tetap), maka membaca sampai bab ke-$n$ akan membutuhkan tenaga sebanyak $1 + 2 + 3 … + n$ unit pekerjaan. Secara matematika, hal ini berkembang secara kuadrat, yang disimbolkan sebagai $O(n^2)$.
Mari kita lihat data yang mengalir ke dalam model AI kita:
- Waktu T=3: Masukannya adalah “The next day”. Hasil tebakannya adalah “is”.
- Waktu T=4: Masukannya adalah “The next day is”. Hasil tebakannya adalah “bright”.
- Waktu T=5: Masukannya adalah “The next day is bright”. Hasil tebakannya adalah “and”.
Pada Langkah 4, kita memproses ulang kata “The”, “next”, dan “day” dari nol. Pada Langkah 5, kita memproses ulang semuanya lagi dari nol. Setiap kata baru yang dibuat akan memaksa komputer (GPU) untuk memproses data berlipat ganda secara eksponensial. Ini membuat pembuatan kalimat yang panjang menjadi sangat lambat dan menyiksa. Mari kita buktikan hal ini secara matematis.
2.3.2 Bukti matematis: Melihat perhitungan yang diulang
Mari kita lihat lebih dekat dua langkah yang berurutan di dalam mekanisme attention untuk membuktikan bahwa kita sedang melakukan perhitungan matematika yang sama persis dua kali.
Langkah A: Penggunaan di Waktu T=4 (Masukan: “The next day is”)
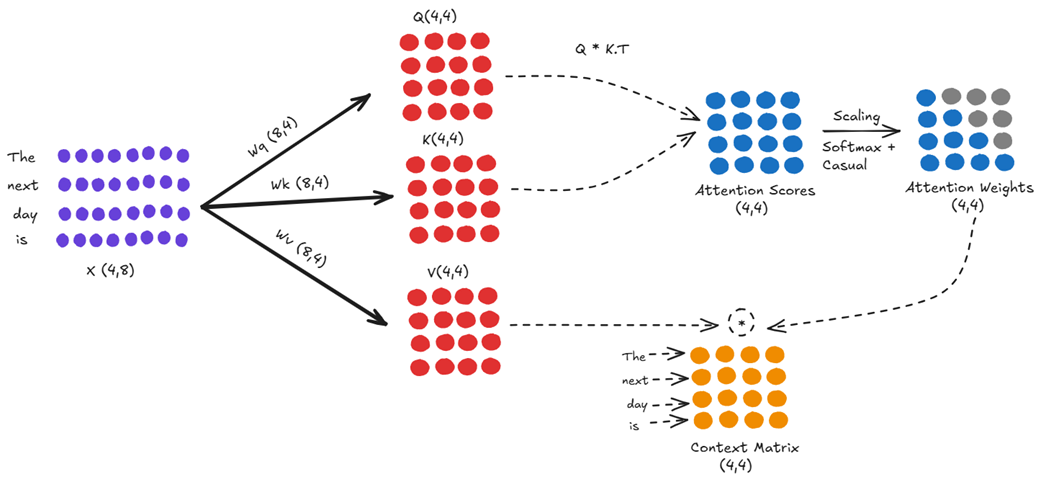
Lacak aliran pada Gambar 2.14: Matriks masukan X (4, 8) diproyeksikan menjadi Q, K, V berukuran (4, 4). Kita menghitung Skor Perhatian $4 \times 4$, menerapkan topeng batas dan softmax, lalu mengalikannya dengan matriks V untuk mendapatkan Matriks Konteks berukuran (4, 4) kita. Kita menggunakan baris terakhirnya saja untuk menebak kata “bright”.
Langkah B: Penggunaan di Waktu T=5 (Masukan: “The next day is bright”)
Kita menambahkan kata “bright” ke belakang, dan mengirim kalimat 5 kata yang baru ini kembali ke dalam.
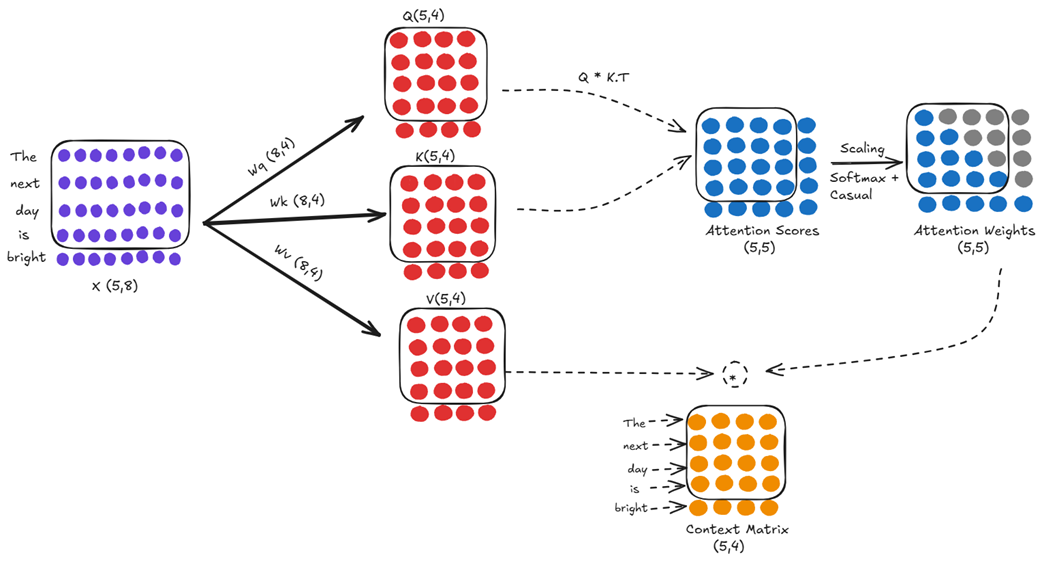
Lihat baik-baik pada Gambar 2.15. Empat baris pertama dari matriks masukan X (5, 8) kita yang baru ini ternyata sama persis dengan seluruh matriks masukan dari langkah sebelumnya. Karena matriks bobot ($W_q, W_k, W_v$) miliki AI selalu dikunci secara kaku selama tahap penggunaan, maka empat baris pertama dari matriks Query, Key, dan Value kita yang baru ini hasilnya sama persis dengan matriks yang baru saja kita hitung sepersekian milidetik yang lalu.
Pengulangan sia-sia ini mengalir terus secara beruntun sampai ke matriks Skor Perhatian. Skor pada posisi baris ke-$j$ dan kolom ke-$i$ adalah hasil kali dari pertanyaan (Query) $j$ dan kunci (Key) $i$. Karena empat pertanyaan dan kunci pertama belum berubah sama sekali, maka seluruh kotak berukuran $4 \times 4$ di bagian kiri atas dari matriks Skor Perhatian berukuran $5 \times 5$ kita yang baru ini adalah hasil menghitung ulang angka-angka yang sama persis.
Kita sedang sibuk menghitung ulang seluruh sejarah masa lalu hanya untuk menghitung satu baris baru di bagian bawahnya, dan kemudian kita membuang semua baris masa lalu yang sudah dihitung tersebut.
2.3.3 Dampak terhadap performa komputer: Dari rumit kuadrat menjadi ringan lurus (linier)
Tanpa ada pengoptimalan, mekanisme perhitungan inti attention ini bersifat kuadratik: disimbolkan $O(n^2)$. Semakin panjang teks ($n$), jumlah perhitungannya melonjak secara kuadrat.
- Untuk 4 kata: Kita harus menghitung kotak matriks $4 \times 4$ (16 skor).
- Untuk 5 kata: Kita harus menghitung kotak matriks $5 \times 5$ (25 skor).
- Untuk 100.000 kata: Kita harus menghitung kotak matriks $100.000 \times 100.000$ (10 miliar skor).
Seiring panjang kalimat ($n$) bertambah, jumlah pekerjaan komputer meledak. Setiap kata baru butuh waktu yang semakin lama untuk dibuat oleh AI.
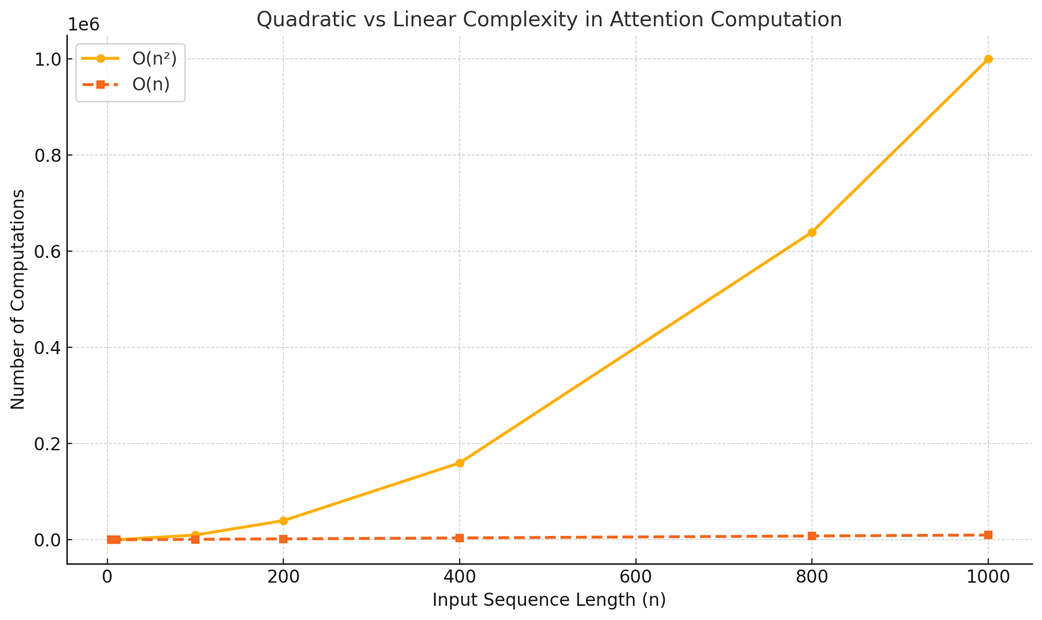
Tujuan para insinyur yang merancang AI adalah untuk mengubah proses $O(n^2)$ yang meledak ini menjadi proses $O(n)$ yang linier (lurus bersahabat). Jika kita bisa mencapai perhitungan linier, maka kalau panjang teks berlipat ganda, pekerjaan komputer hanya bertambah dua kali lipat saja, sehingga mencegah kelambatan yang parah.
Hal inilah yang bisa dicapai dengan metode caching (membuat memori simpanan). Jika kita menyimpan hasil rumus matematika dari kata-kata masa lalu, maka satu-satunya perhitungan baru yang diperlukan oleh komputer hanyalah untuk menghitung kata yang paling baru. Dengan begitu, menghasilkan kata yang ke-1.000 akan memakan waktu yang kira-kira sama cepatnya dengan menghasilkan kata yang ke-10.