Menebak Banyak Kata Sekaligus
- 5.1 Ide inti: Dari menebak satu kata menjadi menebak banyak kata (Multi-Token)
- 5.4 Empat keuntungan utama MTP
- 5.3 Arsitektur MTP DeepSeek: Panduan Visual dan Matematika
- 5.4 Membangun program tebakan banyak kata (MTP) berantai dari nol
- 5.5 Kuantisasi (Pengecilan Ukuran): Mengorbankan Presisi demi Kecepatan dan Memori
- 5.5.1 Apa itu Kuantisasi (Pengecilan Ukuran Data)?
- 5.5.2 Mengapa harus dikuantisasi? Biaya memori raksasa dari angka akurat
- 5.5.3 Memahami format angka matematika: Batu bata dasar kuantisasi
- 5.5.4 Mekanisme dasar: Penskalaan (Scaling)
- 5.5.5 Lima Pilar Utama Sistem Pelatihan FP8 DeepSeek
- 5.5.6 Pilar 1: Kerangka Kerja Presisi Campuran
- 5.5.7 Pilar 2: Kuantisasi Sebagian-Sebagian secara Detail (Fine-Grained)
- 5.5.8 Pilar 3: Meningkatkan Presisi Penjumlahan (Accumulation) Angka
- 5.5.9 Pilar 4: Mengutamakan Detail Nilai (Mantissa) daripada Pangkat (Exponents)
- 5.5.10 Pilar 5: Kuantisasi Langsung Seketika (Online Quantization)
- 5.6 Mendobrak Kemustahilan Baru (DeepSeek-V4): Pelatihan Sadar-Kuantisasi (QAT) Memakai Kotak Mungil FP4
- 5.7 Ringkasan
Bab 5: Menebak Banyak Kata Sekaligus (MTP) dan Pengecilan Ukuran Data Tingkat Ekstrem (Kuantisasi FP8 hingga FP4)
Yang akan kita pelajari pada bab ini:
- Multi-Token Prediction (Menebak banyak kata sekaligus) untuk memberikan sinyal belajar yang lebih kuat pada AI.
- Cara membangun arsitektur tebakan berantai (kausal) dari nol.
- Menggunakan kuantisasi (pengecilan ukuran data) FP8 untuk membuat proses pelatihan menjadi sangat efisien dan irit komputer.
- (Baru) Menembus batas kemustahilan baru dengan pelatihan sadar-kuantisasi (QAT) menggunakan ukuran super kecil FP4.
Kita telah berhasil membangun pilar-pilar utama arsitektur otak model DeepSeek: Multi-Head Latent Attention (Perhatian untuk memahami kalimat), Mixture-of-Experts (Campuran Para Ahli), dan Engram (Memori Bersyarat). Inovasi-inovasi ini menentukan apa yang dihitung oleh model tersebut. Sekarang, kita akan beralih ke topik yang sama pentingnya, yang menentukan bagaimana perhitungan tersebut dilakukan dengan tingkat efisiensi yang luar biasa.
Bab ini akan membahas dua teknik utama yang menjadi pusat dari cara DeepSeek melatih modelnya: Multi-Token Prediction (MTP) dan Kuantisasi Ekstrem. Meskipun metode mengecilkan ukuran data (seperti format FP8) sudah mulai digunakan oleh perusahaan lain untuk mempercepat penggunaan AI, inovasi terbesar DeepSeek adalah membuktikan bahwa metode ini bisa digunakan secara stabil dan sukses untuk proses pelatihan AI skala raksasa yang jauh lebih rumit. Bahkan, pada DeepSeek-V4, mereka mendorong batasan ini lebih jauh lagi hingga ke ukuran FP4 yang sangat mungil.
Bab ini dibagi menjadi tiga bagian utama. Pertama, kita akan menyelami MTP. Kita akan memahami alasannya, keuntungannya, dan bagaimana tepatnya DeepSeek merancang versi tebakan berantai (kausal) mereka yang canggih. Anda tidak hanya akan belajar teorinya, tetapi juga cara membuat program MTP yang benar-benar berfungsi, dan melihat langsung bagaimana menyuruh AI menebak masa depan dapat memperkuat kemampuannya dalam menyusun rencana.
Setelah menguasai MTP, kita akan masuk ke bagian kedua, yaitu membedah kerangka kerja Kuantisasi FP8 yang memungkinkan model raksasa ini dilatih dengan kecepatan dan penghematan memori yang luar biasa. Terakhir, kita akan menjelajahi batas paling mutakhir yang diperkenalkan pada DeepSeek-V4: Pelatihan Sadar-Kuantisasi (QAT) FP4. Ini membuktikan bahwa kita bisa memampatkan memori otak AI menjadi lebih kecil lagi tanpa membuatnya menjadi bodoh.
Sekarang mari kita lihat peta jalan dari mekanisme ini. Seperti yang ditunjukkan pada Gambar 5.1, peta jalan kita menyoroti komponen-komponen yang akan kita bangun di bab ini.
Gambar 5.1 Perjalanan empat tahap kita untuk membangun model DeepSeek. Bab ini berfokus pada komponen yang disorot, yaitu Prediksi Multi-Token (MTP) dan Kuantisasi FP8/FP4, yang merupakan inovasi besar dalam jalur pelatihan tingkat lanjut.
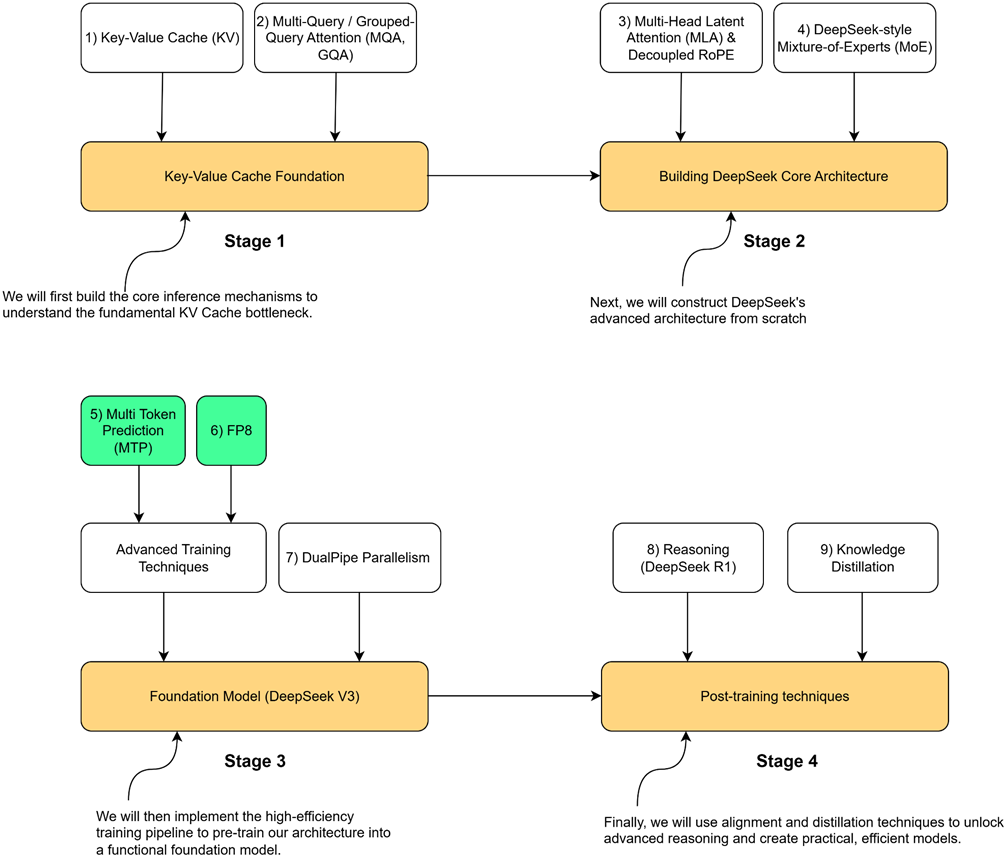
Bab ini mengakhiri Tahap 3 dari perjalanan kita. Dengan menerapkan teknik-teknik pelatihan berefisiensi tinggi ini, Anda akan mendapatkan pemahaman nyata tentang bagaimana model bahasa besar (LLM) modern dilatih pada ukuran yang raksasa. Pengetahuan ini bukan sekadar teori; ini memberikan alat terakhir yang kita butuhkan untuk melatih model dasar AI, sekaligus menyiapkan panggung untuk teknik penyelarasan dan penyulingan ilmu yang akan kita bahas di bagian akhir buku ini.
Mari kita mulai dengan menjelajahi ide hebat tentang menebak lebih dari satu kata dalam satu waktu.
5.1 Ide inti: Dari menebak satu kata menjadi menebak banyak kata (Multi-Token)
Seluruh proses pelatihan untuk model bahasa yang telah kita bahas sejauh ini didasarkan pada satu tujuan tunggal yang sederhana: Next-Token Prediction (Menebak Satu Kata Berikutnya). Pada cara standar, kita memberikan AI sebuah kalimat. Kata-kata ini diproses melalui serangkaian blok saraf Transformer (yang disebut “Batang Utama Transformer”). Lalu, untuk setiap kata yang dibaca, tujuan AI adalah menebak tepat satu kata yang muncul setelahnya.
Gambar 5.2 Proses standar menebak satu kata tunggal. Dari sebuah kalimat yang diberikan, model AI hanya menebak tepat satu kata berikutnya secara langsung untuk setiap posisi kata.
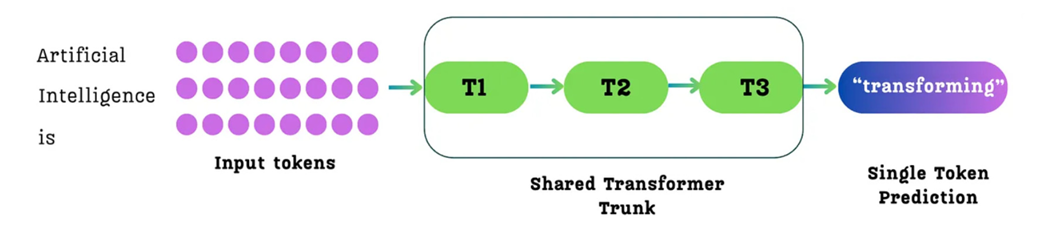
Seperti yang ditunjukkan pada Gambar 5.2, untuk masukan kalimat seperti “Artificial Intelligence is” (Kecerdasan Buatan itu), model memproses ketiga kata ini. Untuk kata “is” (itu), tujuan utama AI adalah menebak satu kata setelahnya, yaitu “transforming” (mengubah). Meskipun AI juga membuat tebakan untuk kata-kata lain (misalnya, menebak kata “Intelligence” setelah membaca “Artificial”), sinyal pelajaran yang didapat AI hanya difokuskan pada satu langkah saja ke masa depan.
Multi-Token Prediction (MTP), seperti namanya, mengubah tujuan dasar ini. Alih-alih hanya menebak satu kata berikutnya, model AI dilatih untuk menebak beberapa kata masa depan sekaligus secara bersamaan.
Gambar 5.3 Proses Prediksi Multi-Token (MTP). Dari kalimat masukan yang diberikan, model dilatih untuk menebak beberapa kata masa depan sekaligus dari setiap posisi kata. Misalnya, dari kata “is”, AI mungkin langsung menebak urutan kata “transforming”, “the”, “world”.
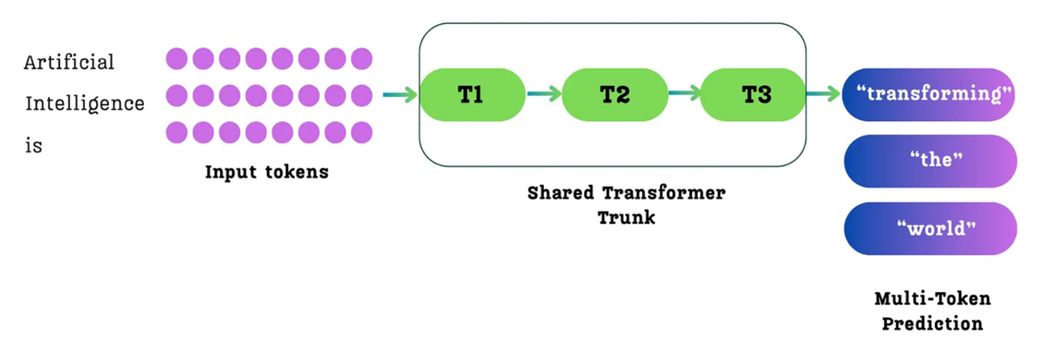
Seperti yang diilustrasikan pada Gambar 5.3, ketika model memproses kalimat “Artificial Intelligence is”, ia membuat tebakan dari setiap kata. Pada cara standar (Gambar 5.2), tujuan utama untuk kata “is” hanyalah menebak satu kata, “transforming”.
Dengan MTP, tugas AI diperluas. Dari posisi kata “is”, model kini ditugaskan untuk menebak seluruh rangkaian kata di masa depan: “transforming”, “the”, dan “world” (Kecerdasan Buatan itu / mengubah / di / dunia). Nilai kesalahan (koreksi) untuk AI kemudian dihitung berdasarkan seberapa pintar ia menebak seluruh rangkaian masa depan tersebut dari posisinya saat ini.
Perubahan yang tampaknya sederhana dari menebak satu kata menjadi menebak banyak kata ini memiliki dampak yang luar biasa terhadap proses belajar AI dan kemampuan akhirnya. Ide ini tidak diciptakan oleh DeepSeek, melainkan pertama kali diteliti dalam makalah dari ilmuwan Meta AI yang berjudul “Better and faster large language models via multi-token prediction” (Model bahasa besar yang lebih baik dan lebih cepat melalui prediksi multi-token). DeepSeek mengambil ide canggih ini dan menggabungkannya dengan inovasi arsitektur mereka sendiri.
5.4 Empat keuntungan utama MTP
Mengubah tujuan latihan dari menebak satu kata menjadi menebak banyak kata bukanlah sekadar perubahan kecil; hal ini secara mendasar mengubah apa yang dipelajari model dan seberapa cepat ia mempelajarinya. Ada empat manfaat besar yang muncul dari perubahan arsitektur ini, seperti yang dibuktikan dalam makalah MTP asli dan dimanfaatkan oleh DeepSeek.
5.2.1 Pemadatan Sinyal Pelatihan (Densification of training signals)
Keuntungan pertama dan paling penting adalah MTP memberikan sinyal belajar yang jauh lebih kaya dan lebih padat daripada tebakan satu kata. Pada pelatihan biasa, untuk setiap kata, model menerima nilai perbaikan (koreksi) berdasarkan kemampuannya menebak hanya selangkah ke depan. Model sangat hebat dalam mempelajari hubungan jarak dekat (misalnya, bahwa kata “Intelligence” kemungkinan besar akan mengikuti kata “Artificial”).
Dengan MTP, sinyal pembelajarannya jauh lebih lengkap. Ketika model memproses kata “Artificial”, ia tidak hanya mendapat koreksi atas tebakannya tentang kata “Intelligence”. Ia juga mendapat nilai koreksi atas kemampuannya meramalkan kata “is”, “transforming”, “the”, dan “world”.
Artinya, hanya dari satu contoh kalimat latihan saja, model AI dipaksa untuk mempelajari struktur bahasa jarak jauh, tata bahasa, dan keterkaitan makna kalimat yang lebih panjang. Model melihat dan mempelajari hubungan di berbagai langkah masa depan secara bersamaan. Informasi nilai perbaikan yang lebih kaya ini menuntun otak AI menuju kemampuan perencanaan dan peramalan kalimat yang lebih baik. Proses pelatihannya menjadi lebih efisien karena setiap contoh kalimat kini mengandung lebih banyak ilmu untuk diserap oleh AI.
5.2.2 Efisiensi data yang lebih baik
Sinyal pelatihan yang padat ini membawa kita langsung pada manfaat kedua: efisiensi data yang lebih baik. Karena setiap contoh latihan kini lebih padat informasi, model dapat mencapai tingkat kepintaran yang lebih tinggi dengan jumlah data latihan (buku/artikel) yang sama.
Ini bukan sekadar keuntungan teori; hal ini telah dibuktikan dengan angka. Makalah MTP asli mendemonstrasikannya pada ujian menulis kode pemrograman standar seperti MBPP (Masalah Python Dasar) dan HumanEval, seperti yang ditunjukkan pada Gambar 5.4.
Gambar 5.4 Peningkatan performa MTP dibandingkan tebakan satu kata pada ujian pemrograman. Diagram batang yang positif (ke atas) menunjukkan bahwa MTP lebih baik. (Sumber: Gloeckle dkk., 2024)
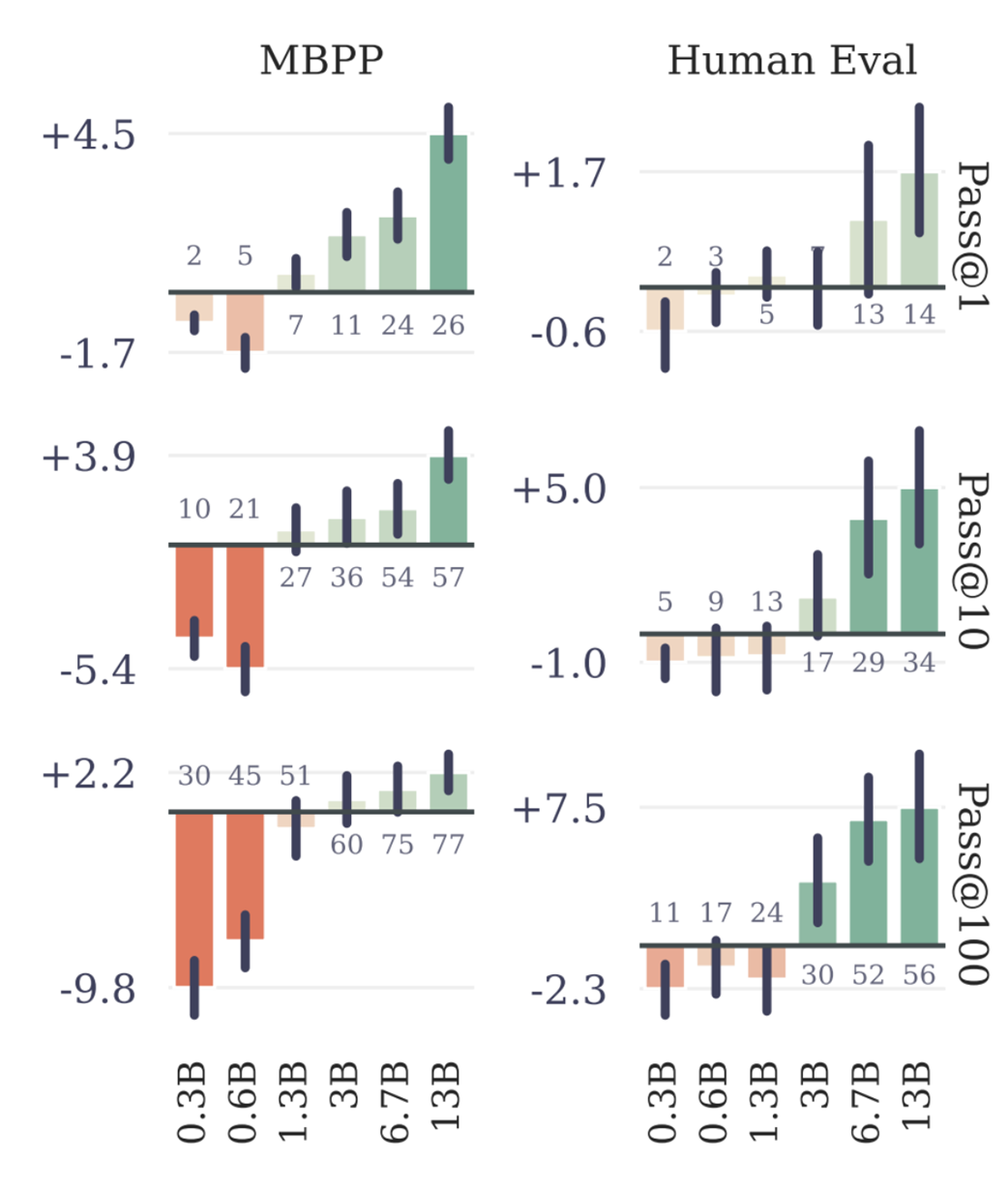
Data tersebut dengan jelas menunjukkan bahwa ketika model AI diperbesar (dari ukuran 0,3 Miliar hingga 13 Miliar parameter otak), keunggulan performa MTP menjadi semakin nyata dan konsisten. Hal ini menetapkan bahwa MTP adalah teknik yang ampuh untuk meningkatkan efisiensi data. Namun, hal ini memunculkan pertanyaan baru: jika menebak banyak kata itu bagus, seberapa banyak kata yang harus kita tebak? Penelitian yang sama juga menguji hal ini dengan mengubah jumlah tebakan kata masa depan, yang disimbolkan dengan huruf n.
Gambar 5.5 Efek peningkatan jumlah tebakan kata masa depan (n) terhadap performa ujian. (Sumber: Gloeckle dkk., 2024)
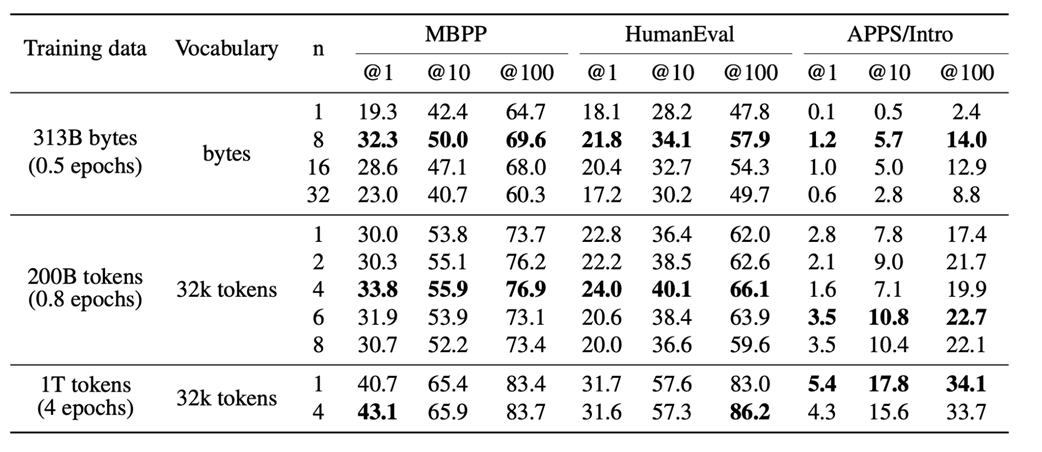
Hasil ini menunjukkan dua tren yang sangat jelas:
- Seperti yang ditunjukkan pada Gambar 5.4, meskipun MTP terkadang berkinerja lebih buruk pada model AI yang ukurannya sangat kecil, namun ketika ukuran model diperbesar, ia secara konsisten dan meyakinkan mengalahkan AI yang hanya menebak satu kata.
- Seperti yang ditunjukkan pada Gambar 5.5, untuk jumlah data latihan yang sama, meningkatkan jumlah tebakan kata masa depan (n) secara umum menghasilkan performa yang lebih baik pada ujian-ujian tersebut, hingga batas jumlah tertentu.
Hal ini memberikan bukti kuat bahwa MTP memungkinkan model belajar dengan jauh lebih efektif dari data yang sama. Ini adalah keuntungan penting saat kita harus melatih AI menggunakan sekumpulan data raksasa yang sangat mahal.
5.2.3 Perencanaan kalimat yang lebih baik dengan mengutamakan “Titik Penentuan” (Choice points)
Keuntungan ketiga dari MTP sedikit lebih rumit tetapi luar biasa kuat: MTP secara diam-diam melatih model untuk menjadi perencana kalimat yang lebih baik. Caranya adalah dengan memaksa AI untuk lebih memperhatikan kata-kata paling penting (krusial) dalam sebuah kalimat.
Untuk memahaminya, kita perlu memperkenalkan konsep “Titik Penentuan” (Choice Point). Titik penentuan adalah sebuah kata kunci dalam kalimat yang secara drastis mengubah arah kelanjutan kalimat tersebut. Kebanyakan perpindahan kata itu sederhana dan mudah ditebak (misalnya, angka 1 -> 2, 2 -> 3), tetapi beberapa perpindahan mewakili perubahan besar pada jalan ceritanya (misalnya, tiba-tiba berubah dari urutan angka menjadi urutan huruf).
Gambar 5.6 MTP secara diam-diam memberikan bobot nilai yang lebih tinggi pada kata “titik penentuan” yang membawa perubahan besar. (Sumber: Gloeckle dkk., 2024)
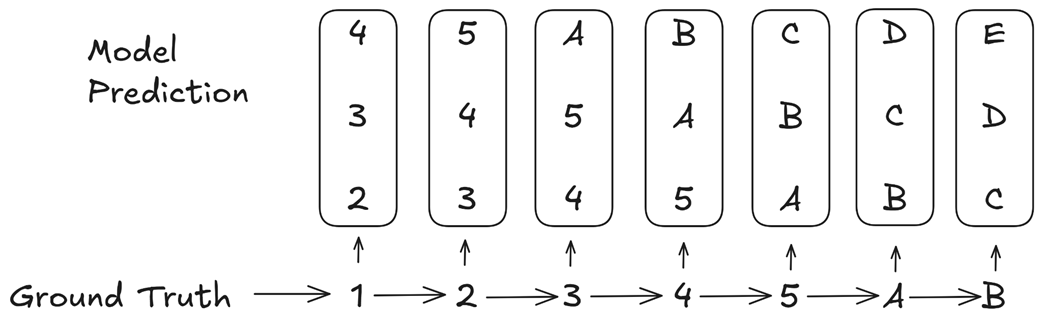
Mari kita analisa contoh pada Gambar 5.6. Urutan kalimat aslinya adalah 1 -> 2 -> 3 -> 4 -> 5 -> A -> B. Perpindahan dari angka 5 -> menuju huruf A adalah “titik penentuan” yang sangat penting di mana pola berubah dari angka menjadi huruf.
Sekarang, mari kita lihat bagaimana nilai kesalahan (hukuman/loss) MTP dihitung. Ketika model melihat kata masukan 3, ia dilatih untuk menebak tiga kata berikutnya: 4, 5, A. Kesalahan model dalam menebak datangnya huruf A akan dicatat sebagai bagian dari hukuman untuk langkah ke-3 ini.
Ketika model bergeser melihat masukan 4, ia dilatih menebak 5, A, B. Kesalahan dalam menebak datangnya huruf A kembali dihitung sebagai hukuman. Ketika ia melihat angka 5, ia dilatih menebak A, B, C, dan kesalahan menebak huruf A dicatat lagi sebagai hukuman untuk ketiga kalinya.
Nilai kesalahan yang berkaitan dengan kata penting A ini muncul berulang kali di dalam total perhitungan hukuman AI. Jumlahnya jauh lebih sering muncul dibandingkan kesalahan pada perpindahan biasa yang tidak penting. Ini berarti sistem hukuman MTP secara otomatis memberikan bobot pelajaran yang jauh lebih berat pada titik-titik perubahan yang kritis ini.
Oleh karena itu, proses pelatihan secara alami akan mengutamakan agar AI berhasil menjawab kata-kata pengubah pola kalimat yang sangat penting ini dengan benar. Hal ini memaksa model untuk mengembangkan pemahaman internal yang lebih baik dalam merencanakan dan memprediksi urutan cerita, karena ia belajar untuk mengenali dan menangani titik-titik penentuan terpenting dalam sebuah teks.
5.2.4 Kecepatan penggunaan yang lebih tinggi melalui tebakan spekulatif (Speculative decoding)
Keuntungan keempat dan terakhir adalah bahwa MTP dapat membuat kecepatan penggunaan AI (saat menjawab pengguna) menjadi jauh lebih cepat, dengan pengamatan peningkatan kecepatan hingga 3 kali lipat pada tugas-tugas tertentu. Ini dicapai melalui teknik yang disebut speculative decoding (pembacaan spekulatif/tebakan). Pada cara pembuatan kata standar, kita harus menjalankan seluruh mesin otak bahasa yang besar itu hanya untuk menghasilkan satu kata demi satu kata. Ini sangat lambat.
Pembacaan spekulatif bekerja dengan cara yang berbeda:
- Pembuatan Draf (Rancangan): Sebuah model AI kecil yang cepat (atau disebut kepala MTP) menebak dan menghasilkan serangkaian kandidat kata sekaligus secara instan.
- Pemeriksaan (Verifikasi): Model bahasa utama yang raksasa kemudian membaca seluruh rangkaian draf ini dalam satu kali proses saja untuk memeriksa dan memastikan mana tebakan kata draf yang benar dan mana yang salah.
Karena satu kali proses membaca sebuah kelompok kata jauh lebih cepat daripada berkali-kali proses untuk satu kata, hal ini dapat secara drastis mempercepat pembuatan jawaban AI. MTP sangat cocok untuk proses ini, karena kepala MTP dapat bertugas sebagai model “pembuat draf”, yang menebak beberapa kata masa depan yang nantinya tinggal dikoreksi (diverifikasi) oleh model utama.
Penting untuk dicatat, seperti yang disebutkan dalam makalah DeepSeek V3, bahwa mereka menggunakan manfaat MTP ini terutama selama masa pelatihan AI (pre-training) untuk mendapatkan keuntungan dari sinyal belajar yang padat dan kemampuan perencanaan kalimat. Namun, untuk rilis publik yang dipakai masyarakat, mereka menjawab pengguna menggunakan cara satu kata standar dan menonaktifkan modul MTP-nya. Walaupun begitu, mereka secara tegas menyatakan bahwa modul MTP dapat dihidupkan ulang untuk melakukan pembacaan spekulatif demi mempercepat tebakan, yang mana ini membuktikan manfaat ganda dari teknik yang hebat ini.
5.3 Arsitektur MTP DeepSeek: Panduan Visual dan Matematika
Meskipun makalah penelitian MTP asli dari Meta telah membuktikan kehebatan konsep ini, mereka melakukannya dengan membiarkan kepala-kepala AI menebak kata-kata masa depan secara mandiri dan tidak saling terkait. Artinya, tebakan untuk kata masa depan kedua dilakukan tanpa meminta informasi apa pun dari hasil tebakan kata pertama.
DeepSeek melihat ada peluang besar untuk menyempurnakannya. Sistem buatan mereka dirancang untuk menebak kata-kata tambahan secara berurutan dan menjaga rantai sebab-akibat (kausalitas) secara utuh pada setiap kedalaman tebakannya. Ini berarti tebakan untuk kata masa depan di posisi t + 2 akan diinformasikan dan dipengaruhi oleh hasil tebakan dari kata t + 1. Hal ini menciptakan mekanisme peramalan kalimat yang jauh lebih koheren (masuk akal) dan kuat. Mari kita bedah arsitektur mereka langkah demi langkah, dimulai dari titik masuk awal ke seluruh proses MTP ini.
5.3.1 Titik Awal: Batang Utama Transformer yang Dipakai Bersama
Proses Prediksi Multi-Token tidak dimulai langsung dari kata mentah yang kita ketik. Sebaliknya, proses ini baru dimulai setelah tubuh utama dari jaringan saraf Transformer selesai memproses kalimat masukan tersebut.
Sebuah kalimat (misalnya, “Artificial Intelligence is”) pertama-tama dilewatkan ke dalam apa yang disebut makalah MTP asli sebagai “Batang Utama Transformer yang Dipakai Bersama” (Shared Transformer Trunk). Ini hanyalah tumpukan standar dari blok-blok Transformer yang sudah kita kenal (misalnya, 61 blok pada DeepSeek-V3).
Gambar 5.7 Langkah awal dari proses Prediksi Multi-Token. Kata-kata masukan dilewatkan melalui “Batang Utama Transformer”, yang terdiri dari banyak blok Transformer. Hasil keluarannya adalah matriks awal berisi kondisi tersembunyi (disimbolkan sebagai h⁰ atau z), yang bertindak sebagai titik awal / garis start bagi modul-modul MTP.
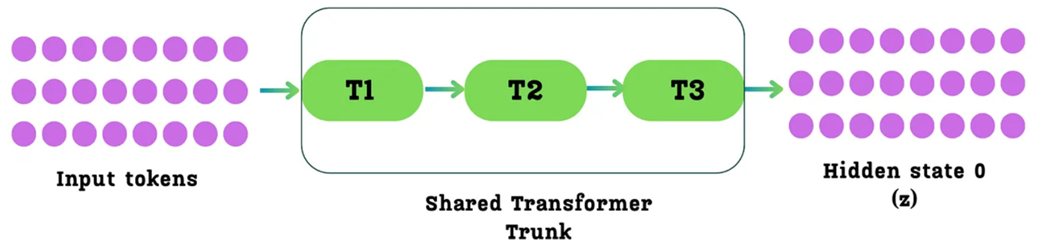
Seperti yang ditunjukkan pada Gambar 5.7, keluaran dari batang utama ini adalah sebuah matriks (tabel matematika) berisi Kondisi Tersembunyi (Hidden States). Mari kita artikan istilah ini dengan tepat:
Apa itu Kondisi Tersembunyi (Hidden State)?
Kondisi Tersembunyi adalah nama lain dari vektor konteks yang dikeluarkan oleh sebuah blok Transformer. Ini adalah sebuah data matematika kaya informasi yang merangkum makna suatu kata setelah ia diproses dan mengumpulkan informasi dari kata-kata tetangganya melalui mekanisme attention (perhatian).
Keluaran dari blok Transformer paling akhir di batang utama ini adalah sebuah matriks dari kondisi-kondisi tersembunyi tersebut, satu untuk setiap kata masukan. Untuk keperluan MTP, kita akan menyebut matriks awal ini sebagai Kondisi Tersembunyi 0, atau h⁰, mengikuti lambang rumus dalam makalah DeepSeek.
Matriks h⁰ inilah yang menjadi garis start untuk seluruh proses MTP. Ia bisa dibayangkan sebagai setumpuk baris data, satu baris untuk setiap kata dalam kalimat masukan. Untuk setiap satu kata, baris data h⁰ miliknya akan dimasukkan ke dalam rantai gerbong MTP untuk mulai meramal masa depan kata tersebut.
5.3.2 Modul MTP: Rantai Tebakan yang Berurutan
Alih-alih menggunakan satu kepala tebakan untuk menebak satu kata, arsitektur DeepSeek menggunakan serangkaian Modul MTP (gerbong MTP), di mana satu gerbong bertugas menebak satu kata di masa depan. Jika kita ingin AI mampu meramal 3 kata ke depan (kedalaman tebakan D=3), kita akan merangkai 3 modul MTP menjadi satu rantai panjang.
Inovasi kuncinya di sini bukan sekadar bahwa gerbong-gerbong ini saling bergantung, melainkan bagaimana struktur ketergantungannya. Berbeda dengan pendekatan sebelumnya yang menebak sendiri-sendiri, modul DeepSeek membentuk sebuah rantai kausal (sebab-akibat). Kondisi tersembunyi yang sudah disaring dari satu gerbong akan menjadi bahan masukan untuk gerbong berikutnya. Hal ini memungkinkan AI untuk terus mempertajam tebakannya secara berurutan di setiap langkah masa depan. Arsitektur “penyaringan data tersembunyi yang mengalir bagai air terjun” inilah yang membuat mekanisme ramalan DeepSeek begitu kuat dan masuk akal.
Gambar 5.8 Arsitektur berurutan dari modul MTP DeepSeek. Kondisi tersembunyi dari satu modul dikirim sebagai masukan untuk modul berikutnya, membentuk sebuah rantai sebab-akibat (kausal).
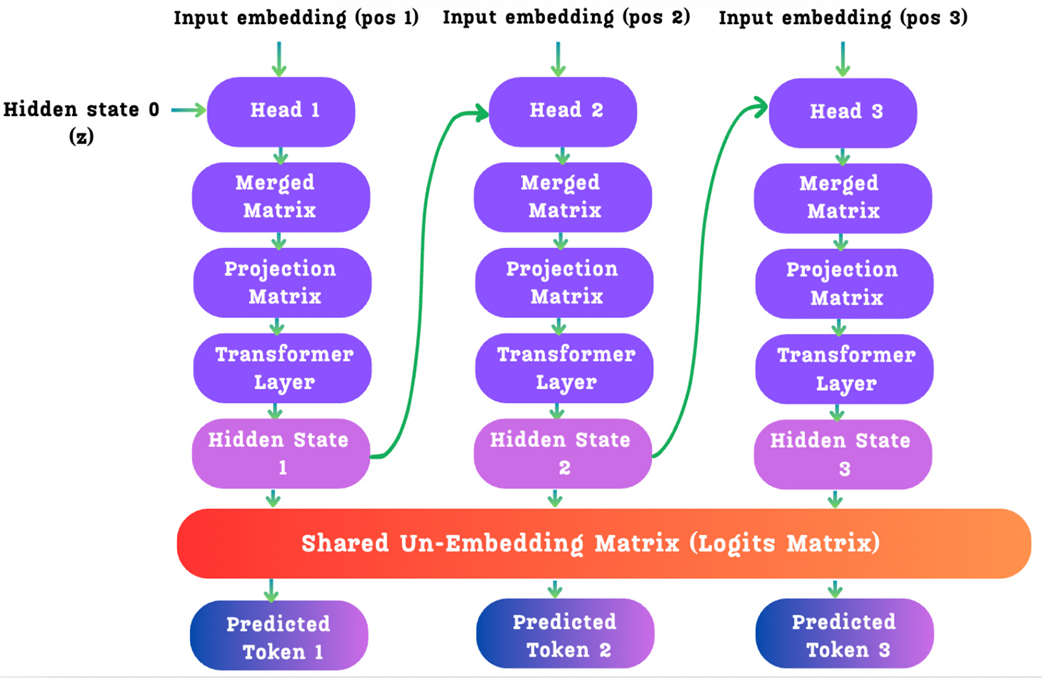
Diagram ini adalah kunci untuk memahami inovasi DeepSeek. Mari kita telusuri perjalanan data h⁰ milik satu kata masukan saat ia memasuki rantai ini. Kita akan fokus pada operasi-operasi yang terjadi di dalam satu modul MTP saja, misalnya modul pertama, yang akan kita sebut Kepala 1 (atau kedalaman k=1).
Setiap kepala MTP adalah sepotong mesin canggih yang dirancang untuk melakukan dua pekerjaan sekaligus:
- Menebak satu kata di masa depan.
- Menciptakan kondisi tersembunyi yang baru dan lebih tajam, untuk dikirimkan ke kepala berikutnya di dalam rantai tersebut.
Mari kita lihat ke dalam satu kepala untuk melihat bagaimana ia melakukan ini.
Gambar 5.9 Operasi internal (di dalam) dari satu kepala MTP.
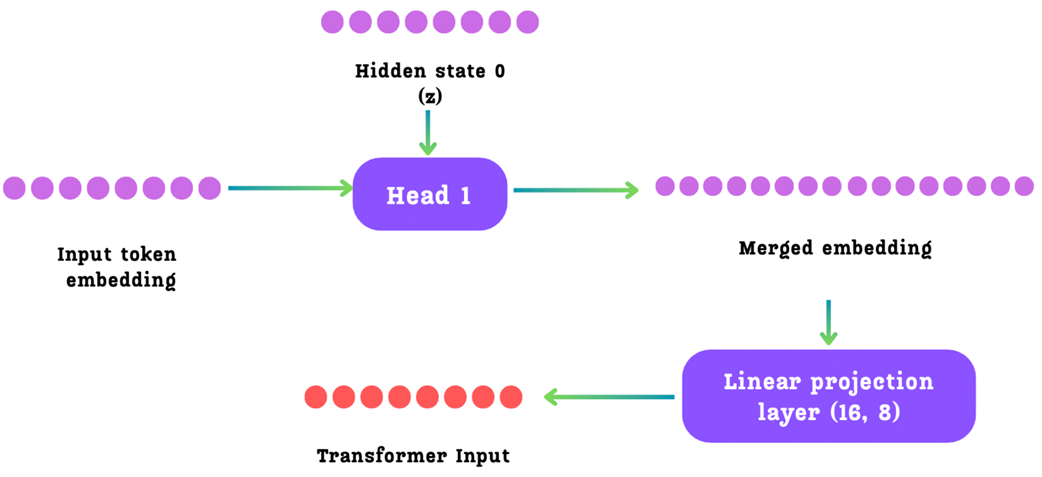
Operasi di dalam setiap kepala (k) dapat dirinci menjadi langkah-langkah berikut:
Langkah 1: Mengumpulkan Bahan Masukan
Setiap kepala k mengambil dua jenis bahan masukan yang berbeda:
- Kondisi Tersembunyi (
hᵏ⁻¹) dari kepala sebelumnya. Untuk Kepala 1, bahan ini adalahh⁰awal yang berasal dari batang utama Transformer. - Kode Angka (Embedding) Masukan (
Emb(tᵢ₊ₖ)) untuk kata masa depan yang sedang berusaha ia tebak. (Catatan: Selama masa pelatihan, bahan ini mengambil langsung kode angka asli dari kata jawaban masa depan yang ada di buku pelajaran AI). Untuk Kepala 1 (yang bertugas menebak kata di posisit+1), ia menggunakan kode angka dari katat+1.
Langkah 2: Menggabungkan dan Menyesuaikan Ukuran (Proyeksi)
Kedua vektor (barisan angka) masukan ini pertama-tama dilewatkan melalui sebuah lapisan penstabil matematika RMS Norm secara terpisah, lalu disatukan (disambung berjejer) untuk membentuk sebuah Data Gabungan. Data gabungan ini kini berisi informasi konteks sejarah dari masa lalu (dari langkah sebelumnya) sekaligus informasi makna dari kata masa depan yang akan ditebak.
Data gabungan ini, yang sekarang ukurannya menjadi dua kali lipat lebih panjang (2d), kemudian dimasukkan melalui sebuah Lapisan Proyeksi Linier (disimbolkan dengan Mₖ dalam makalah mereka). Tujuannya adalah untuk memampatkan kembali ukurannya menjadi ukuran standar milik model AI (d). Keluaran dari langkah pemampatan ini adalah “Bahan Masukan Transformer”.
Seluruh proses ini dirangkum dalam Persamaan 21 dari makalah DeepSeek V3.
Persamaan 5.1 \(h_{i}'^{k} = M_k[RMSNorm(h_i^{k-1}) ; RMSNorm(Emb(t_{i+k}))]\)
Rumus matematika ini dengan tepat menjabarkan proses tersebut: bahan masukan baru [h'] untuk blok Transformer di dalam modul MTP, diciptakan dengan cara memproyeksikan/memampatkan (Mₖ) hasil penyambungan jejeran data [ ; ] dari kondisi tersembunyi masa lalu yang telah dinormalkan, dengan kode kata masa depan yang juga telah dinormalkan.
Langkah 3: Blok Transformer MTP
Vektor yang sudah diproyeksikan (dimampatkan) [h'] ini sekarang bertindak sebagai bahan masukan ke dalam sebuah Blok Transformer khusus (TRMₖ) yang ada di dalam modul MTP tersebut.
Gambar 5.10 Blok Transformer di dalam sebuah modul MTP tunggal. Blok ini menerima vektor gabungan yang sudah diproyeksikan (gabungan antara kondisi tersembunyi dari masa lalu dan kode kata masa depan) sebagai bahan masukannya. Kemudian, blok ini akan melakukan perhitungan rumus Transformer secara penuh untuk menghasilkan kondisi tersembunyi yang baru dan lebih tajam, guna dikirim ke langkah berikutnya dalam rantai berantai tersebut.

Ini adalah langkah yang krusial. Ini bukan sekadar perubahan matematika linier sederhana; ini adalah perhitungan komputasi yang dalam dan menyeluruh, yang melibatkan sistem multi-head attention dan jaringan saraf umpan-maju. Hal ini memungkinkan model AI untuk melakukan proses nalar (berpikir) yang rumit mengenai gabungan antara masa lalu dan masa depan ini. AI seolah-olah sedang bertanya pada dirinya sendiri, “Berdasarkan pemahaman cerita saya sejauh ini (hᵢᵏ⁻¹), dan dengan mengetahui bahwa kata berikutnya adalah tᵢ₊ₖ, maka seperti apakah bentuk pemahaman saya yang baru dan sudah di-update?”
Hasil pemikiran dari blok Transformer ini adalah sebuah kondisi tersembunyi yang baru dan lebih tajam, yaitu hᵢᵏ. Proses ini dijabarkan oleh Persamaan 22 dari makalah mereka.
Gambar 5.11 Persamaan 22 dari makalah DeepSeek V3.
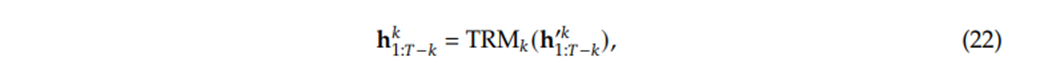
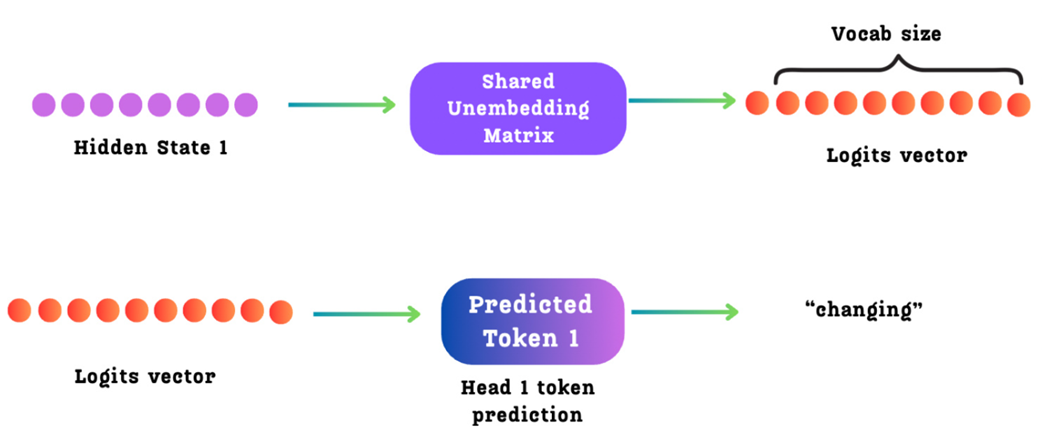
Langkah 4: Menghasilkan Jawaban Keluaran
Kondisi tersembunyi yang baru (hᵢᵏ) ini, kini melayani dua tujuan untuk menyelesaikan putaran tugasnya:
- Ia dikirim sebagai bahan masukan ke gerbong Modul MTP berikutnya. Hasil
h¹dari Kepala 1 akan menjadi bahan masukan untuk Kepala 2. Hasilh²dari Kepala 2 akan menjadi bahan masukan untuk Kepala 3, dan begitu seterusnya. Rantai inilah yang menghubungkan dan membuat implementasi MTP DeepSeek menjadi sangat kuat. Yang terpenting, dengan mengirimkan seluruh data kondisi tersembunyi tersebut (bukan sekadar mengirim hasil tebakan satu kata), AI telah mewariskan rangkuman cerita yang sangat kaya akan konteks ke gerbong berikutnya. Inilah letak keunggulan utama MTP kausal milik DeepSeek, karena memungkinkan setiap gerbong di belakangnya untuk membuat ramalan berdasarkan pemahaman cerita yang jauh lebih dalam. - Data ini juga dikirimkan ke Matriks Penerjemah Bahasa (Shared Un-Embedding Matrix) yang dipakai bersama. Matriks ini adalah lapisan yang sama persis dengan yang digunakan oleh batang utama AI untuk mengubah data komputer kembali menjadi bahasa manusia. Lapisan ini memproyeksikan data angka menjadi skor (logits) untuk menebak kata masa depan ke-
ktersebut.
Gambar 5.12 Langkah tebakan akhir di dalam sebuah modul MTP. Kondisi tersembunyi baru yang dihasilkan oleh blok Transformer MTP dikirim ke sebuah “Matriks Penerjemah Bahasa”. Matriks ini mengubah kondisi tersembunyi ke dalam ruang kamus kosakata AI untuk menghasilkan barisan skor (logits), yang mana dari skor inilah kata terakhir untuk langkah tersebut akan dipilih.
Proses ini dijabarkan oleh Persamaan 23 dari makalah mereka.
Gambar 5.13 Persamaan 23 dari makalah DeepSeek V3.
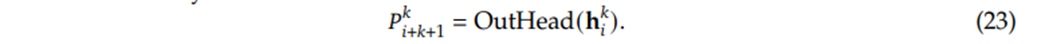
Rumus ini menyatakan bahwa distribusi peluang kebenaran P untuk tebakan kata masa depan ke-k dihasilkan dengan cara melewatkan data tersembunyi h dari Modul MTP ke-k melewati kepala penerjemah bahasa (LitHead).
5.3.3 Menghitung Kesalahan (Loss) Akhir Pelatihan
Seluruh proses berantai ini dilakukan untuk setiap jumlah kedalaman masa depan D yang ingin kita tebak. Pada akhirnya, untuk satu kata masukan tunggal tᵢ, kita akan mendapatkan D buah tebakan kata yang berbeda-beda. Selama AI sedang dilatih, kita akan membandingkan D buah tebakan AI ini dengan D buah kata kunci jawaban asli (ground-truth) yang ada di dalam buku panduan teks aslinya.
Gambar 5.14 Total kesalahan (Loss) untuk sebuah kata masukan tunggal adalah jumlah gabungan dari nilai kesalahan masing-masing tebakan pada setiap langkah masa depan.
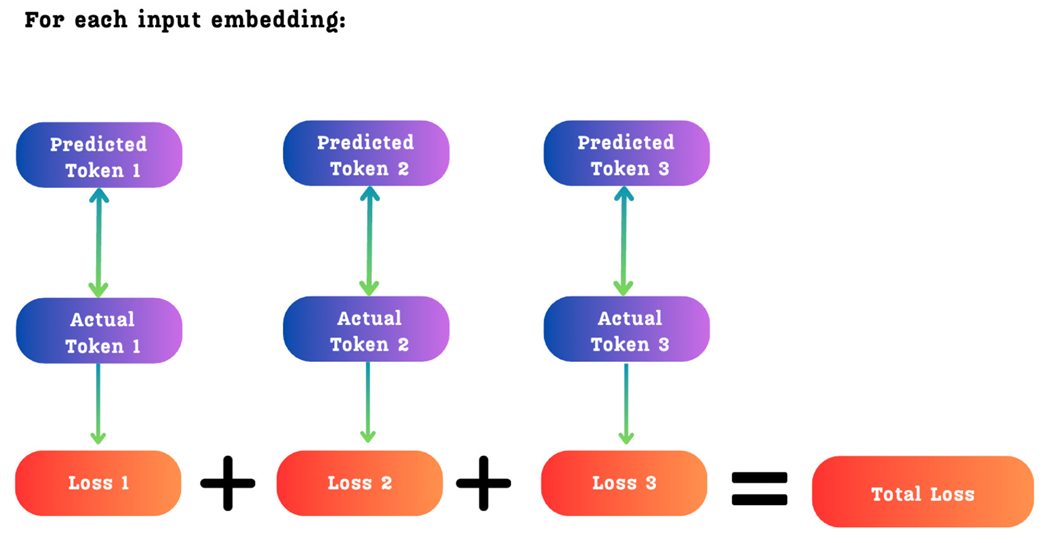
Seperti yang ditunjukkan pada Gambar 5.14, total kesalahan hanyalah penjumlahan sederhana dari masing-masing kesalahan (dinamakan cross-entropy loss) pada setiap kedalaman masa depan. Ini berarti model AI menerima sinyal rapor perbaikan (gradien) yang sangat kaya dan dari berbagai sisi, yang mendorongnya untuk menjadi lebih pintar tidak hanya dalam menebak kata yang tepat ada di depannya, tetapi juga mahir dalam meramalkan kelanjutan kalimat untuk jangka panjang.
5.4 Membangun program tebakan banyak kata (MTP) berantai dari nol
Kita telah menjelajahi teori di balik Multi-Token Prediction, mulai dari keuntungan intinya hingga spesifikasi arsitektur berantai canggih milik DeepSeek. Walaupun program skala penuh dari sistem ini sangatlah rumit dan tertanam dalam di kerangka kerja pelatihan raksasa mereka, kita bisa memantapkan pemahaman kita dengan cara membangun versi mini dari mekanisme ini di dalam bahasa pemrograman PyTorch.
Pendekatan praktik langsung ini akan mengubah diagram dan rumus matematika yang baru saja kita pelajari menjadi kode pemrograman nyata. Kita akan membangun seluruh sistem MTP ini dalam beberapa tahap:
- Modul MTP: Komponen inti mesin yang memproses satu langkah dalam rantai ramalan masa depan.
- Model Utama: Kelas rumah utama yang membungkus dan menggabungkan Batang Utama Transformer dengan rantai gerbong MTP.
- Proses Maju & Perhitungan Kesalahan: Logika lengkap untuk membuat tebakan berurutan dan menghitung total hukumannya (loss).
Mari kita mulai dengan komponen baru yang paling penting: Modul MTP itu sendiri. Kode kelas program ini merupakan wujud langsung dari logika yang ditunjukkan pada Gambar 5.9 hingga 5.13. Modul ini menerima data tersembunyi masa lalu dan kode angka kata masa depan, lalu memprosesnya untuk menghasilkan data tersembunyi yang baru dan tajam serta sebuah tebakan kata.
Pertama, kita akan mendefinisikan dua alat bantu. Kita akan mengimplementasikan fungsi RMSNorm, sebuah lapisan penstabil angka yang secara khusus digunakan di seluruh arsitektur DeepSeek. Ini adalah alat bantu dasar yang memastikan angka-angka matematika di dalam komputer tidak meledak tak terkendali selama proses pelatihan. Anda dapat menemukan semua modul impor dan alat bantu lainnya di penyimpanan GitHub resmi bab ini.
Jangan khawatir jika kode ini terlihat rumit, yang penting kita memahami alur pemikirannya!
Kode Pemrograman 5.1 Membangun Modul Prediksi Multi-Token dari Nol
class RMSNorm(nn.Module):
"""
Mengimplementasikan Root Mean Square Layer Normalization.
(Fungsi penstabil angka agar matematika komputer tidak kacau)
"""
def __init__(self, d_model: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Menghitung akar kuadrat terbalik dari rata-rata kuadrat
norm_x = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
# Menerapkan bobot yang bisa dipelajari AI
return self.weight * norm_x
Selanjutnya, kita akan membangun jantung dari arsitektur MTP: modul DeepSeekMTPModule. Modul ini berisi satu buah blok Transformer khusus beserta lapisan pemampatannya (proyeksi). Tujuannya adalah untuk menerima data masa lalu dan kata masa depan, lalu meraciknya menjadi pemahaman cerita yang lebih tajam untuk dikirim ke gerbong MTP berikutnya.
Kode Pemrograman 5.2 Modul MTP Berantai (Kausal)
class DeepSeekMTPModule(nn.Module):
def __init__(self, d_model: int, nhead: int, dim_feedforward: int, dropout: float = 0.0):
super().__init__()
self.d_model = d_model
self.projection_matrix = nn.Linear(2 * d_model, d_model, bias=False) # Bagian A
self.transformer_block = nn.TransformerEncoderLayer( # Bagian B
d_model=d_model,
nhead=nhead,
dim_feedforward=dim_feedforward,
dropout=dropout,
activation='gelu',
batch_first=True,
norm_first=True
)
self.norm_hidden = RMSNorm(d_model) # Bagian C
self.norm_embed = RMSNorm(d_model)
def forward(self, h_prev: torch.Tensor, future_token_embeds: torch.Tensor) -> torch.Tensor:
h_normed = self.norm_hidden(h_prev)
embed_normed = self.norm_embed(future_token_embeds)
concatenated = torch.cat([h_normed, embed_normed], dim=-1) # Bagian D
h_prime = self.projection_matrix(concatenated)
h_output = self.transformer_block(h_prime) # Bagian E
return h_output
- Bagian A: Matriks penyesuai ukuran
M_k, yang memampatkan kembali vektor data yang berukuran ganda menjadi ukuran standar milik model (D). - Bagian B: Sebuah blok Transformer (
TRM_k) utuh dan khusus untuk kedalaman langkah MTP ini. - Bagian C: Lapisan penstabil
RMSNormyang terpisah untuk menyetabilkan angka sejarah masa lalu dan angka kata masa depan, sesuai dengan rumus aslinya. - Bagian D: Kedua bahan masukan yang sudah stabil ini kemudian disambung berjejeran (dijejerkan/concatenated).
- Bagian E: Vektor yang sudah dimampatkan kemudian dimasukkan ke dalam blok Transformer untuk dipikirkan matang-matang guna menghasilkan pemahaman kondisi cerita yang baru dan lebih tajam.
Sekarang kita sudah memiliki batu bata fondasi berupa DeepSeekMTPModule, mari kita merakit rumah model AI secara utuh. Kode program di bawah ini menunjukkan proses perakitan (inisialisasi) dari kelas rumah DeepSeekV3WithMTP.
Perhatikan baik-baik bagaimana komponen-komponen yang berbeda ini disusun. Rumah AI ini tidak hanya berisi satu gerbong, tetapi memiliki sebuah daftar panjang berisi modules_m, satu gerbong untuk setiap langkah masa depan. Rumah ini juga menetapkan lapisan pembaca kamus bahasa yang akan dipakai bersama-sama oleh si Batang Utama Transformer dan oleh semua modul MTP. Ini adalah kunci rahasia mengapa arsitektur ini sangat efisien.
Kode Pemrograman 5.3 Merakit Rumah Arsitektur Model MTP Secara Utuh
class DeepSeekV3WithMTP(nn.Module):
def __init__(
self,
vocab_size: int,
d_model: int,
num_layers: int,
nhead: int,
num_mtp_heads: int, # D (Jumlah seberapa jauh masa depan yang mau ditebak) # Bagian A
dim_feedforward: int,
dropout: float = 0.0,
mtp_loss_weight: float = 0.1
):
super().__init__()
# ... (menyimpan pengaturan) ...
# Komponen yang dipakai bersama di seluruh bagian AI
self.shared_embed = nn.Embedding(vocab_size, d_model) # Bagian B
self.shared_lm_head = nn.Linear(d_model, vocab_size, bias=False) # Bagian C
# Tulang punggung utama AI (Batang Utama Transformer)
self.blocks = nn.ModuleList([ # Bagian D
nn.TransformerEncoderLayer(
d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward,
dropout=dropout, activation='gelu', batch_first=True,
norm_first=True
)
for _ in range(num_layers)
])
self.norm_f = RMSNorm(d_model)
# Menyatukan bobot antara kamus masukan dan kamus penerjemah keluaran
self.shared_lm_head.weight = self.shared_embed.weight
# Rantai gerbong modul MTP
self.mtp_modules = nn.ModuleList([ # Bagian E
DeepSeekMTPModule(d_model, nhead, dim_feedforward, dropout)
for _ in range(num_mtp_heads)
])
# ... (proses maju 'forward' ada di bawah) ...
- Bagian A: Parameter
num_mtp_headsmelambangkan hurufD, yaitu jumlah kata di masa depan yang ingin ditebak oleh AI. - Bagian B: Lapisan kamus bahasa tunggal (embedding layer) yang dipakai bersama.
- Bagian C: Lapisan penerjemah akhir tunggal (un-embedding layer) yang dipakai bersama untuk mengubah angka mesin menjadi skor tebakan kata manusia.
- Bagian D: Tumpukan blok-blok Transformer utama, yang kita sebut sebagai “Batang Utama Transformer yang Dipakai Bersama”.
- Bagian E: Sebuah daftar berisi modul-modul
DeepSeekMTPModule, yang dirangkai membentuk rantai berantai (sebab-akibat) MTP.
Dengan selesainya perakitan struktur model, kita sekarang dapat menjalankan metode forward (proses AI berjalan maju/berpikir). Di sinilah seluruh proses rantai MTP dihidupkan. Logikanya mengikuti urutan yang sangat jelas:
- Kata-kata masukan pertama kali akan dilewatkan melalui Batang Utama Transformer untuk menghasilkan kondisi pemahaman awal, yaitu
main_h. - Model AI kemudian memasuki mode putaran berulang (loop) yang akan berjalan menembus setiap gerbong modul MTP secara berurutan.
- Di dalam putaran loop ini, pada setiap langkah ke-
k, gerbong tersebut akan mengambil pemahaman dari langkah sebelumnya (prev_h) dan mengambil bocoran jawaban kata dari buku teks masa depan, lalu memprosesnya untuk menciptakan pemahaman cerita yang lebih baru lagi, yaitucurr_h. - Tebakan skor (logits) untuk kata masa depan ke-
ktersebut dihasilkan dan diterjemahkan dari pemahamancurr_htersebut. - Terakhir, total nilai kesalahan AI (rapor buruk) dihitung dengan cara menjumlahkan nilai kesalahan di batang utama (saat menebak kata terdekat) ditambah dengan rata-rata total kesalahan dari seluruh gerbong MTP.
Kode Pemrograman 5.4 Proses Jalan Maju MTP dan Perhitungan Total Kesalahan
# ... (masih di dalam kelas DeepSeekV3WithMTP) ...
def forward(self, input_ids: torch.Tensor, targets: Optional[torch.Tensor] = None):
B, S = input_ids.shape
# ... (persiapan lainnya) ...
# --- Proses jalan maju untuk Batang Utama AI ---
x = self.get_embedding(input_ids)
# ... (melewati tumpukan blok utama self.blocks) ...
h_main = self.norm_f(x)
logits_main = self.get_output_logits(h_main)
all_logits = [logits_main]
h_prev = h_main # Bagian A
# --- Rantai MTP: Menebak kata masa depan secara berurutan ---
for depth_k in range(1, self.num_mtp_heads + 1):
L = S - depth_k # Bagian B
if L <= 0: break
h_prev_sliced = h_prev[:, :L, :] # Bagian C
future_token_ids = input_ids[:, depth_k:depth_k + L]
future_token_embeds = self.get_embedding(future_token_ids) # Bagian D
h_curr = self.mtp_modules[depth_k - 1](h_prev_sliced, future_token_embeds) # Bagian E
logits_k = self.get_output_logits(h_curr)
all_logits.append(logits_k)
h_prev = h_curr # Bagian F
# --- Perhitungan nilai kesalahan (Loss) ---
loss = None
if targets is not None:
# ... (logika perhitungan kerugian) ...
total_loss = # ... Nilai kesalahan model Batang Utama ...
for k, logits_k in enumerate(all_logits[1:], start=1):
# ... (menghitung nilai kesalahan untuk kedalaman MTP ke-k) ...
mtp_loss_sum += loss_mtp_k
# Rumus Akhir Kesalahan: L = L_main + (λ/D) * Σ(L_MTP^k)
if self.num_mtp_heads > 0 and mtp_loss_sum > 0:
mtp_loss_weighted = (self.mtp_loss_weight / self.num_mtp_heads) * mtp_loss_sum # Bagian G
total_loss += mtp_loss_weighted
loss = total_loss
return {"logits_all": all_logits, "loss": loss}
- Bagian A: Keluaran dari batang utama bertugas menjadi titik start (garis awal) bagi rantai MTP.
- Bagian B: Panjang kalimat (
L) akan menyusut di setiap langkahk, karena sisa kata masa depan yang bisa ditebak akan semakin sedikit (habis di ujung kalimat). - Bagian C: Memotong (slicing) data pemahaman masa lalu agar panjangnya sesuai dengan sisa kalimat saat ini.
- Bagian D: Mengambil kunci jawaban bocoran untuk kata-kata masa depan pada langkah ke-
ksaat ini (untuk keperluan latihan). - Bagian E: Langkah MTP Utama: memanggil gerbong ke-(
k-1) untuk mengolah data dan menghasilkan kondisi pemahaman yang lebih baru. - Bagian F: Menyambung rantai: hasil keluaran dari gerbong ini ditetapkan sebagai bahan masukan awal untuk putaran gerbong selanjutnya.
- Bagian G: Menerapkan rumus akhir perhitungan kesalahan, mencari nilai rata-rata kesalahan MTP lalu menskalakannya dengan bobot
λ(lambda).
Kode Pemrograman 5.5 Menguji Coba Program MTP Berantai
def verify_deepseek_v3_mtp():
# --- Pengaturan Model AI ---
vocab_size = 1000
d_model = 128
num_layers = 6
nhead = 8
num_mtp_heads = 3 # D=3 (Disuruh menebak 3 kata ke depan) # Bagian A
dim_feedforward = 512
mtp_loss_weight = 0.1
model = DeepSeekV3WithMTP(
vocab_size=vocab_size, d_model=d_model, num_layers=num_layers,
nhead=nhead, num_mtp_heads=num_mtp_heads,
dim_feedforward=dim_feedforward, mtp_loss_weight=mtp_loss_weight
)
print(f"Model berhasil diciptakan dengan jumlah sel saraf {sum(p.numel() for p in model.parameters())/1e6:.2f}M params")
# --- Membuat Data Ujian Bohongan ---
batch_size = 2
seq_len = 20
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len)) # Bagian B
# --- Jalankan AI dan Periksa Hasilnya ---
outputs = model(input_ids, targets=input_ids)
all_logits = outputs['logits_all']
loss = outputs['loss']
print("\nBentuk ukuran hasil tebakan (Logits):")
for i, logits in enumerate(all_logits): # Bagian C
pred_type = "Batang Utama" if i == 0 else f"Gerbong MTP k={i}"
print(f" {pred_type:15}: {list(logits.shape)}")
print(f"\nTotal Nilai Kesalahan (Loss): {loss.item():.4f}") # Bagian D
- Bagian A: Kita mengatur jumlah kepala MTP (seberapa jauh AI meramal) sebanyak 3 langkah ke depan.
- Bagian B: Membuat data masukan (teks bohongan) dengan panjang kalimat 20 kata.
- Bagian C: Membuka hasil tebakan satu per satu dan mencetak bentuk/ukurannya ke layar.
- Bagian D: Mencetak nilai akhir dari total kesalahan AI (nilai loss).
Menjalankan program kecil ini akan menghasilkan teks berikut. Perhatikan baik-baik bagaimana panjang kalimat (angka di dimensi tengah) terus menyusut (dikurangi satu) pada setiap langkahnya. Hal ini membuktikan bahwa program tebakan berantai kausal kita telah berfungsi dengan tepat dan masuk akal.
Model berhasil diciptakan dengan jumlah sel saraf 2.01M params
Bentuk ukuran hasil tebakan (Logits):
Batang Utama : [2, 20, 1000]
Gerbong MTP k=1: [2, 19, 1000]
Gerbong MTP k=2: [2, 18, 1000]
Gerbong MTP k=3: [2, 17, 1000]
Total Nilai Kesalahan (Loss): 109.1470
Dengan ini, kita telah berhasil membangun logika inti dari arsitektur Prediksi Multi-Token milik DeepSeek. Kita telah melihat langsung bagaimana sebuah rantai gerbong yang berisi blok-blok Transformer khusus dapat dipakai untuk meramalkan rentetan masa depan, memberikan sinyal belajar yang sangat kaya bagi AI, dan menjadikannya sebuah mesin yang sangat jago dalam merencanakan masa depan sebuah kalimat.
5.5 Kuantisasi (Pengecilan Ukuran): Mengorbankan Presisi demi Kecepatan dan Memori
Kita sekarang telah menyelesaikan pembahasan tentang pilar-pilar utama bangunan (arsitektur) tingkat tinggi dari model DeepSeek: Multi-Head Latent Attention, Mixture of Experts, dan Multi-Token Prediction. Inovasi-inovasi ini bertugas menentukan apa yang dihitung oleh AI. Kini, kita akan beralih ke topik yang tidak kalah penting yang menentukan bagaimana perhitungan tersebut dilakukan dengan efisiensi yang nyaris mustahil: Kuantisasi FP8 (Metode Pengecilan Ukuran Data).
Topik ini adalah kunci rahasia terakhir untuk memahami bagaimana DeepSeek bisa melatih dan menjalankan model raksasa berukuran 671 miliar sel saraf (parameter), hanya dengan sebagian kecil dari biaya yang dikeluarkan oleh perusahaan pesaingnya. Pendekatan kuantisasi mereka bukanlah satu teknik sederhana, melainkan sebuah strategi rumit berlapis-lapis yang mendorong batas maksimal dari pelatihan berukuran presisi-rendah. Meskipun kata “presisi rendah” terdengar seperti penurunan kualitas, ini adalah harga yang sangat sepadan yang membuka gerbang penghematan memori dan peningkatan kecepatan yang luar biasa. Inilah yang membuat pelatihan AI raksasa menjadi mungkin dilakukan di dunia nyata.
Kita akan mulai dengan membangun dasar pemahaman yang kuat, yaitu memahami apa itu Kuantisasi dan mengapa ia sangat penting. Setelah itu, kita akan membedah lima inovasi besar yang menyusun kerangka kerja pelatihan FP8 milik DeepSeek.
5.5.1 Apa itu Kuantisasi (Pengecilan Ukuran Data)?
Pada dasarnya, setiap parameter (sel saraf) di dalam sebuah model bahasa besar—setiap bobot, dan setiap angka di semua lapisannya—hanyalah sebuah angka matematika. Secara umum, komputer secara otomatis menyimpan angka-angka ini dengan tingkat keakuratan (presisi) yang sangat tinggi, biasanya menggunakan format ukuran komputer yang disebut 32-bit floating-point (FP32).
Gambar 5.15 Perbandingan visual antara sebuah angka yang disimpan dalam kotak FP32 (32-bit) versus FP16 (16-bit). Diagram ini mengilustrasikan bagaimana mengurangi jumlah tempat (bit) yang disediakan untuk pangkat (eksponen) dan nilai angka aslinya (mantissa), akan menghasilkan angka yang lebih tidak akurat (kurang presisi) tetapi kotak memorinya menjadi jauh lebih kecil.
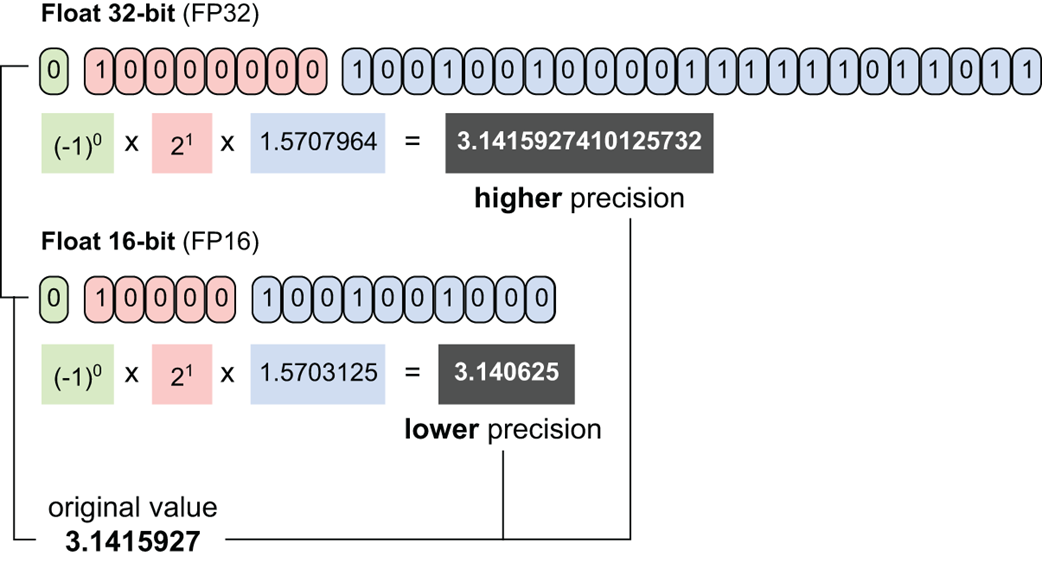
Seperti yang ditunjukkan pada Gambar 5.15, sebuah angka FP32 memakan ruang memori sebanyak 32 bit hanya untuk menyimpan satu nilai saja. Kotak yang besar ini memungkinkan komputer menyimpan angka yang sangat akurat (dengan sangat banyak angka di belakang koma) dan rentang yang sangat luas (mampu menyimpan angka miliaran maupun angka pecahan yang sangat kecil mendekati nol).
Kuantisasi adalah proses mengurangi keakuratan (presisi) ini secara sengaja. Ini adalah teknik untuk mengubah parameter otak AI dari kotak ukuran memori yang besar ke kotak ukuran yang lebih kecil. Misalnya, kita mengecilkan (mengkuantisasi) model dari FP32 ke FP16, yang berarti setiap angka yang tadinya memakan ruang 32 bit kini dipaksa masuk ke dalam kotak berukuran 16 bit.
Logika di balik pemaksaan ini paling mudah dipahami melalui sebuah perumpamaan gambar.
Gambar 5.16 Gambar yang telah dikuantisasi (dikecilkan resolusinya) menggunakan warna yang jauh lebih sedikit, tetapi kita tetap bisa mengenali gambar aslinya dengan jelas.

Seperti yang digambarkan pada Gambar 5.16, foto asli yang berkualitas tinggi menggunakan jutaan campuran warna untuk menampilkan setiap titik secara sempurna. Gambar yang sudah dikuantisasi hanya menggunakan kotak palet kecil berisi 8 warna dasar saja. Jika kita memperbesarnya, memang akan terlihat penurunan kualitas yang pecah-pecah (piksel kotak), namun secara keseluruhan, gambar itu masih sangat mudah untuk dikenali mata kita.
Kuantisasi melakukan hal yang sama persis terhadap otak jaringan AI. Ia mengurangi “palet warna angka” yang boleh digunakan oleh AI. Meskipun pemotongan ini mengakibatkan sedikit kehilangan akurasi pada masing-masing angka, otak AI secara keseluruhan ternyata masih bisa berfungsi dengan sangat cerdas dan luar biasa tahan banting.
5.5.2 Mengapa harus dikuantisasi? Biaya memori raksasa dari angka akurat
Alasan utama melakukan kuantisasi adalah untuk memecahkan masalah mahalnya biaya komputer dan rakusnya konsumsi memori akibat penggunaan model bahasa yang sangat besar (LLM). Menyimpan miliaran parameter dalam kotak berpresisi tinggi (FP32) itu luar biasa mahal.
Gambar 5.17 Penghematan memori dari metode kuantisasi pada sebuah model berisi 70 Miliar parameter. Perhitungan ini membuktikan bagaimana dengan menurunkan ketelitian angka dari 64-bit menjadi 32-bit, dan menurunkannya lagi jadi 16-bit, maka kita dapat secara dramatis memotong jumlah total memori yang dibutuhkan untuk sekadar menampung otak model AI tersebut.
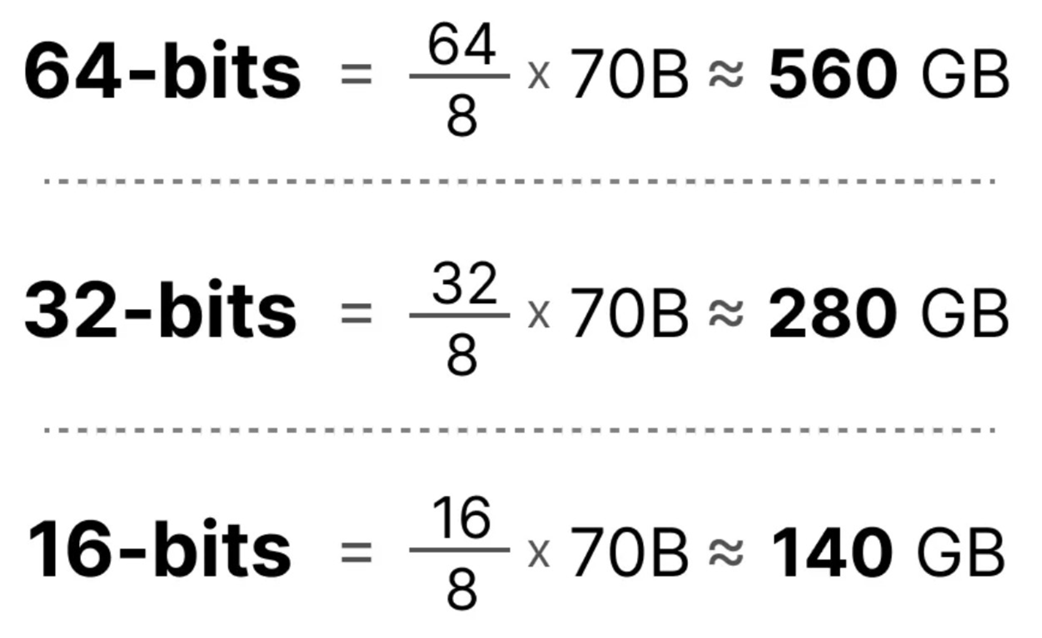
Seperti yang ditunjukkan pada Gambar 5.17, jumlah memori yang berhasil diselamatkan sangatlah sensasional. Dengan memampatkan model 70 Miliar dari ukuran 32-bit ke 16-bit, kita memotong setengah dari kebutuhan memorinya, yang awalnya memakan ukuran raksasa 280 GB turun menjadi 140 GB saja, yang mana ukuran ini lebih mudah dikelola. Pemotongan ukuran memori ini memberikan dua keuntungan langsung:
- Pelatihan dan Penggunaan AI yang Lebih Cepat: Parameter otak yang berukuran lebih kecil berarti beban data yang harus diangkut oleh kabel dari ruang memori (RAM) ke mesin pemroses (Cores) di dalam GPU menjadi jauh lebih ringan, yang secara drastis mempercepat seluruh proses hitung matematika.
- Lebih Merakyat dan Mudah Diakses: Hal ini memungkinkan model AI kelas berat bisa dijalankan di komputer yang lebih murah dengan memori yang lebih sedikit.
Inilah pertukaran (barter) utama dalam metode kuantisasi: kita rela menukar sedikit akurasi angka demi mendapatkan lonjakan efisiensi memori dan kecepatan komputer yang luar biasa besar.
5.5.3 Memahami format angka matematika: Batu bata dasar kuantisasi
Untuk bisa memahami kehebatan kerangka kerja milik DeepSeek, pertama-tama kita harus mengenali berbagai “palet angka”, atau format angka matematika, yang sering digunakan di dunia AI (Deep Learning). Setiap format angka pecahan disimpan di memori komputer dengan membaginya ke dalam tiga bagian:
- Tanda (Sign - 1 bit): Bagian paling sederhana. Satu bit ini hanya bertugas menentukan apakah angkanya positif (0) atau negatif (1).
- Pangkat (Exponent): Bit-bit di bagian ini bertugas menentukan seberapa besar atau kecil skala angka tersebut. Ini mirip seperti menentukan di mana letak koma pada angkanya. Semakin banyak kotak bit yang diberikan untuk pangkat, semakin luas rentang angka yang bisa ditampung (misalnya, dari 0,000001 hingga jutaan).
- Nilai Asli (Mantissa / Significand): Bit-bit di bagian ini menentukan tingkat keakuratan (detail/presisi) dari angka tersebut. Semakin banyak kotak bit untuk mantissa, semakin banyak angka di belakang koma yang bisa disimpan, yang berarti angkanya sangat akurat dan mulus.
Mari kita lihat bagaimana ketiga bagian ini dibagi-bagi porsinya pada berbagai ukuran kotak yang paling umum.
FP32 (32-bit Floating-Point - Sangat Presisi)
Ini adalah standar kotak presisi tingkat dewa kita. Ia menggunakan 1 bit untuk Tanda, 8 bit untuk Pangkat, dan 23 bit untuk Nilai Asli (Mantissa). Karena bit mantissanya sangat banyak (23 bit), angka ini sangatlah akurat. Pangkatnya yang berjumlah 8 bit juga memberikan kemampuan jangkauan (rentang) angka yang sangat besar.
FP16 (16-bit Floating-Point - Setengah Presisi)
Ini adalah salah satu format awal yang populer dipakai untuk menghemat memori. Ia menggunakan 1 bit untuk Tanda, 5 bit untuk Pangkat, dan 10 bit untuk Nilai Asli (Mantissa).
Gambar 5.18 Perbandingan antara FP32 dan FP16.
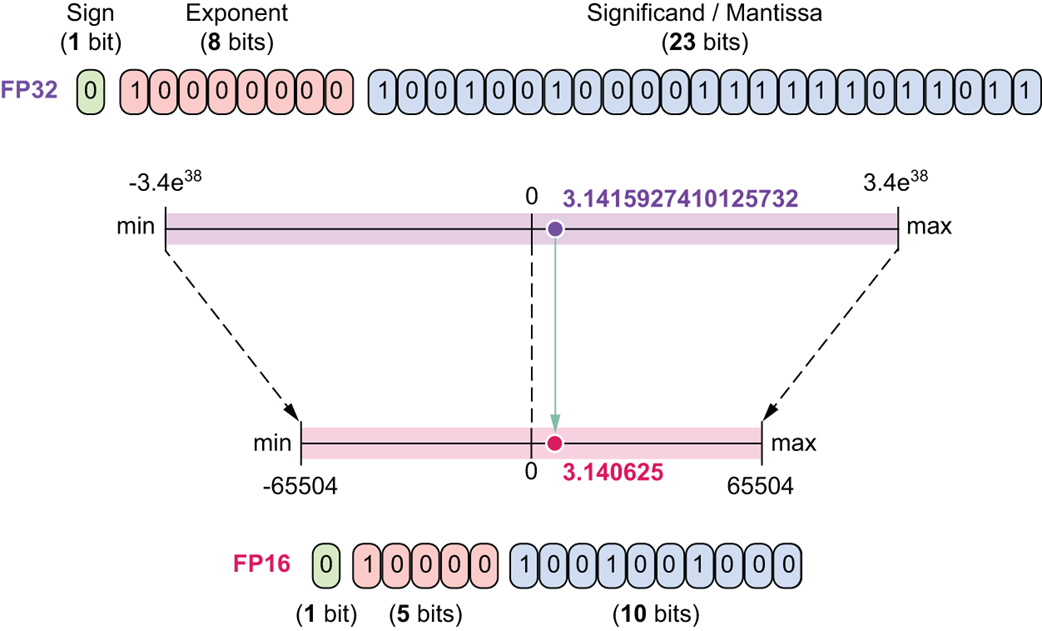
Seperti yang ditunjukkan Gambar 5.18, kotak FP16 ini sangat memangkas jumlah tempat untuk pangkat dan nilai asli. Akibatnya, baik jangkauan batas angkanya maupun keakuratannya jauh merosot dibandingkan FP32. Walau sangat irit memori, format ini punya penyakit: ia rentan mengalami overflow (angka aslinya meledak kepenuhan melebihi kotak pangkat) atau underflow (angkanya terlalu kecil sehingga dianggap nol dan detailnya hilang lenyap).
BF16 (16-bit “Brain Float” - Format Otak)
Ini adalah format cerdas yang diciptakan oleh Google untuk mendapatkan yang terbaik dari kedua sisi demi keperluan melatih AI. Ia menggunakan 1 bit Tanda, 8 bit Pangkat, dan hanya 7 bit untuk Nilai Asli.
Gambar 5.19 Perbandingan FP32 dan BFloat16.
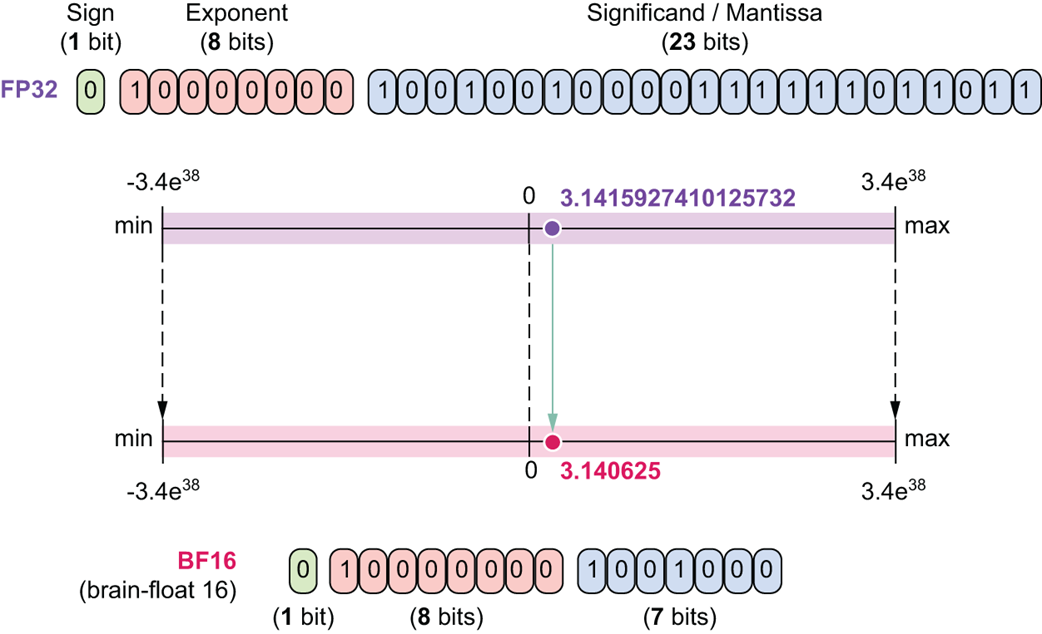
Sesuai dengan Gambar 5.19, BF16 secara cerdas memakai 8 bit penuh untuk Pangkat persis seperti milik FP32. Artinya, ia sanggup menampung angka raksasa tanpa takut kepenuhan. Ia menghemat ruang memori dengan cara memotong habis tempat untuk Nilai Aslinya menjadi cuma 7 bit, yang berarti BF16 ini bahkan jauh lebih tidak akurat (angka komanya sedikit) dibandingkan FP16. Tapi anehnya, format ini sangat luar biasa disukai untuk melatih AI, karena jangkauan angkanya yang super besar tadi menjamin komputer tidak mudah error (kepenuhan/overflow).
INT8 (8-bit Integer - Angka Bulat)
Ini adalah teknik pemotongan yang jauh lebih sadis. Ia hanya menggunakan 1 bit Tanda dan 7 bit nilai bulat, tanpa ada kemampuan menyimpan angka pecahan (koma) sama sekali.
Gambar 5.20 Perbandingan FP32 dan INT8.
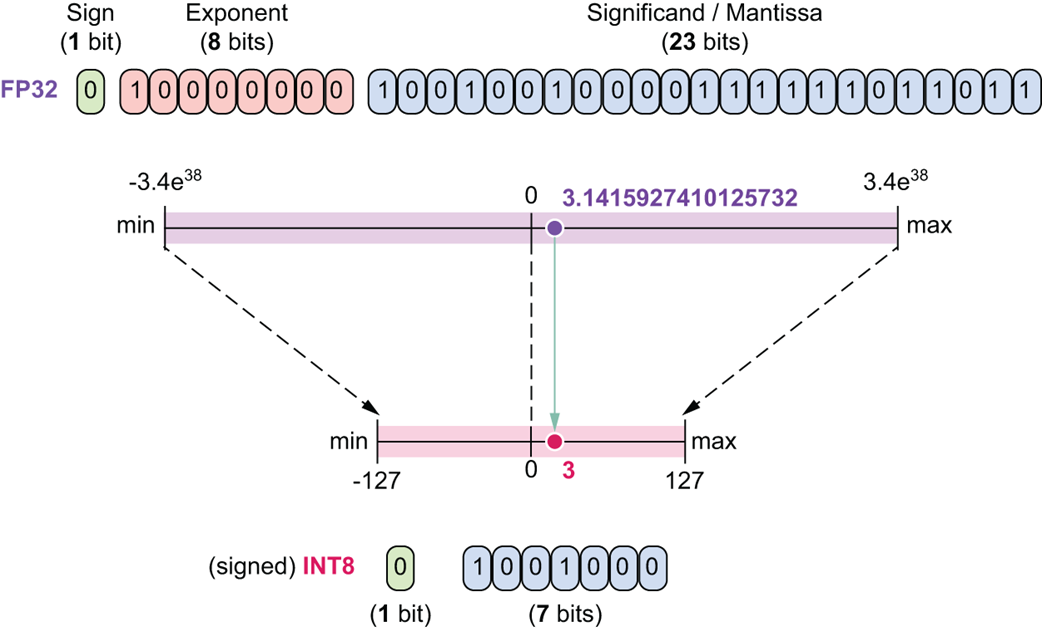
Seperti yang ditunjukkan Gambar 5.20, batas maksimal tampungan angkanya sangat mengenaskan dan sempit, yaitu mentok di angka -127 hingga 127 saja. Meskipun sangat amat cepat, memaksakan angka AI ke dalam kotak INT8 ini bisa merusak total informasi otak AI jika kebetulan angka aslinya terlalu bervariasi (terlalu besar atau terlalu kecil).
FP8 (8-bit Floating-Point - Kotak Idaman DeepSeek)
Terakhir, format yang menjadi andalan dan rahasia utama DeepSeek adalah FP8. Ini adalah kotak 8-bit yang, tidak seperti INT8, masih mengizinkan adanya sistem Tanda, Pangkat, dan Nilai Asli (Misalnya varian E4M3 yang membagi tempat jadi 4 bit Pangkat dan 3 bit Nilai Asli/Mantissa). FP8 menawarkan jalan tengah yang sangat cantik antara INT8 yang super ekstrem dan format angka pecahan lainnya yang masih fleksibel.
5.5.4 Mekanisme dasar: Penskalaan (Scaling)
Lalu, bagaimana sebenarnya cara memeras sebuah deretan angka besar FP32 ke dalam format kotak mungil seperti INT8? Proses ini disebut Penskalaan (Scaling). Ide dasarnya sederhana: kita memetakan (mengecilkan dengan perbandingan/skala) angka-angka asli kita agar masuk ke dalam rentang batas kotak baru yang kecil itu, tanpa merusak urutan besar-kecil angka tersebut.
Gambar 5.21 Proses penskalaan saat melakukan kuantisasi. Batasan jangkauan asli dari tensor angka FP32 dipetakan (disusutkan) agar pas dengan batasan format INT8 yang kecil.
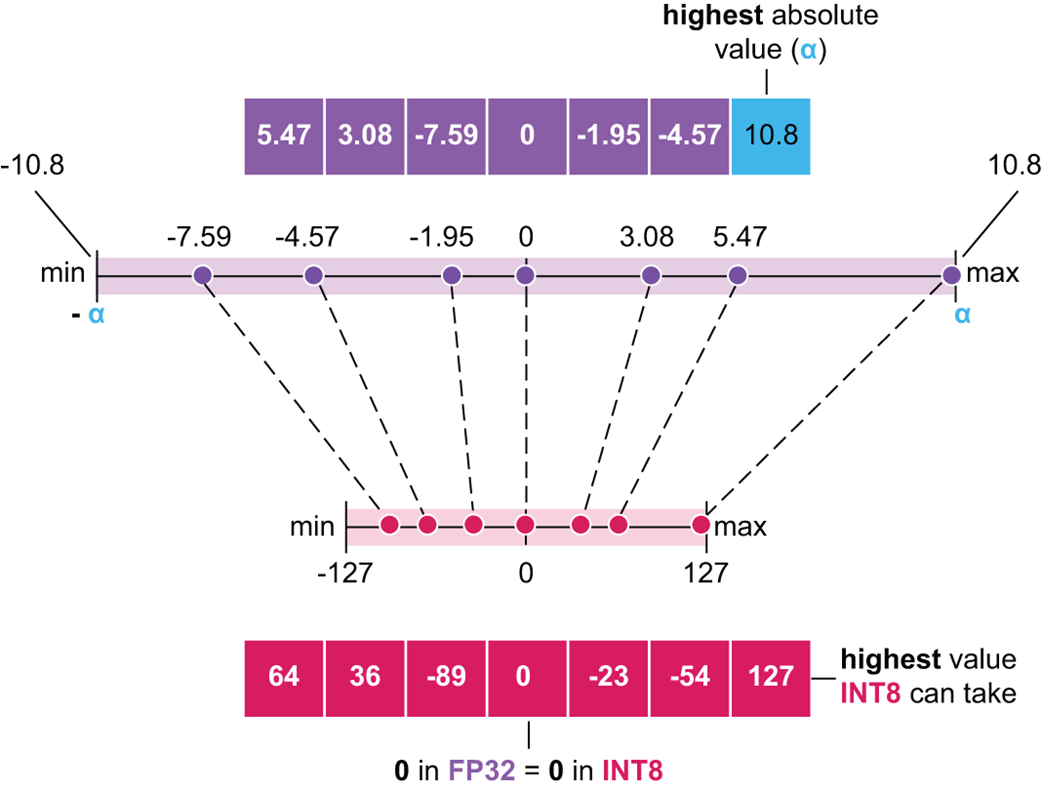
Seperti diilustrasikan pada Gambar 5.21, proses pengecilan ini melibatkan langkah-langkah yang cukup sederhana:
- Mencari Angka Tertinggi (Nilai Mutlak Terbesar / α): Pertama-tama, kita memindai (scan) seluruh deretan angka (disebut tensor) dan mencari satu angka yang memiliki nilai paling besar (tidak peduli itu minus atau plus). Pada contoh gambar, angka itu adalah 10.8. Angka maksimal ini, yang disimbolkan dengan
α(alpha), menjadi batas pagar atas dan bawah dari deretan angka kita (dari -α hingga +α). - Menghitung Angka Skala Pengecil (Scaling Factor): Kita ingin memasukkan deretan angka dari rentang [-10.8 hingga 10.8] ke dalam kotak baru format INT8 yang rentang batasnya sangat kecil, yaitu [-127 hingga 127]. Rumus skala pengecilnya hanyalah membagi batas kotak baru dengan batas asli (
batas_baru_max / batas_asli_max), yang hasilnya adalah127 / 10.8. - Mengecilkan (Kuantisasi): Kita mengalikan setiap angka dalam deretan asli dengan angka skala pengecil ini, lalu membulatkannya agar pas jadi angka biasa. Misalnya, angka
-7.59berubah menjadipembulatan( -7.59 * (127 / 10.8) ), yang menghasilkan angka-89. Angka bilangan bulat yang baru inilah yang menjadi perwakilan kecil dari angka aslinya. - Mengembalikan Ukuran (Dequantisasi): Jika komputer nanti ingin memakai angka ini untuk dihitung kembali menjadi ukuran normal (meski akurasinya sudah agak pudar), komputer tinggal memutarbalikkan prosesnya: yaitu membagi angka kecil tadi dengan angka skala yang sama. Misalnya,
-89 / (127 / 10.8)akan memberikan kembali angka sekitar-7.59.
Konsep mencari angka skala pengecil dari nilai tertinggi (maksimal) ini adalah syarat mutlak yang paling penting untuk dipahami sebelum kita bisa mengerti teknik rahasia tingkat tinggi DeepSeek. Sebagaimana yang akan kita lihat nanti, inovasi besar pertama mereka (Kuantisasi Sebagian-Sebagian) adalah sebuah cara jenius yang memodifikasi prinsip dasar penskalaan ini.
5.5.5 Lima Pilar Utama Sistem Pelatihan FP8 DeepSeek
Setelah kita memiliki dasar pemahaman yang kuat tentang apa itu kuantisasi dan berbagai bentuk kotaknya, kita siap untuk membedah bagaimana tepatnya DeepSeek menggunakannya. Pendekatan mereka bukanlah sebuah trik tunggal, melainkan sebuah strategi luar biasa canggih yang terdiri dari lima inovasi besar (Pilar). Kelima pilar ini bekerja bergotong-royong untuk memastikan AI bisa dilatih secara stabil dan ngebut meskipun hanya memakai otak berukuran sangat kecil (FP8).
Kelima pilar tersebut adalah:
- Kerangka Kerja Presisi Campuran (Mixed Precision Framework)
- Kuantisasi Sebagian-Sebagian secara Detail (Fine-Grained Quantization)
- Meningkatkan Presisi Penjumlahan Angka (Increasing Accumulation Precision)
- Mengutamakan Detail Nilai daripada Pangkat (Mantissa Over Exponents)
- Kuantisasi Langsung Seketika (Online Quantization)
Mari kita bongkar satu per satu pilar-pilar sakti ini, menjelaskan masalah apa yang mereka atasi dan bagaimana cara bekerjanya, baik melalui gambar maupun rumus matematika.
5.5.6 Pilar 1: Kerangka Kerja Presisi Campuran
Pilar pertama dan paling mendasar dari strategi DeepSeek adalah Kerangka Kerja Presisi Campuran.
Ide Intinya: Tidak Semua Angka Diciptakan Setara
Fakta utama yang mendasari ide ini adalah bahwa tidak semua proses perkalian atau semua data yang disimpan di dalam otak AI itu menuntut tingkat akurasi (presisi) yang sama tinggi. Sangat membuang-buang energi jika kita menggunakan angka mahal 32-bit (dengan belasan angka di belakang koma) hanya untuk proses sepele. Begitu juga, adalah sebuah kesalahan fatal jika kita menggunakan angka murah (kotak kecil) untuk menjaga nilai-nilai inti yang sangat mudah rusak jika diganggu.
Oleh karena itu, kerangka kerja presisi campuran adalah sebuah sistem ahli strategi yang membagi-bagi pemakaian ukuran kotak angka untuk berbagai tahapan proses AI. Tujuannya adalah meraup semua keuntungan:
- Gunakan ukuran murah (seperti FP8) untuk melakukan perhitungan kuli (seperti mengalikan jutaan angka secara masal) demi mencapai kecepatan maksimal dan menghemat ruang mesin.
- Gunakan ukuran mahal (seperti FP32) untuk menyimpan data-data yang sangat sensitif dan krusial (seperti menyimpan nilai ilmu permanen sang model AI) agar proses pembelajarannya tidak goyah dan tetap pintar.
Kerangka kerja DeepSeek adalah contoh mahakarya dalam menyeimbangkan pengorbanan ini dengan cerdas. Mari kita telusuri bagaimana mereka mengatur jenis ukuran angka saat AI membaca (maju) dan saat AI mengoreksi diri (mundur).
Gambar 5.22 Kerangka kerja presisi campuran yang memanfaatkan format data FP8 pada bagian operator Linier. Diagram ini melacak arus lalu lintas data melalui lapisan linier, memperlihatkan kapan bahan masukan dan bobot AI disulap menjadi ukuran FP8 yang cepat, dan kapan data penting seperti bobot otak utama (master) serta angka hukuman (gradien) harus dipertahankan dalam wujud FP32 yang utuh demi menjaga kewarasannya.
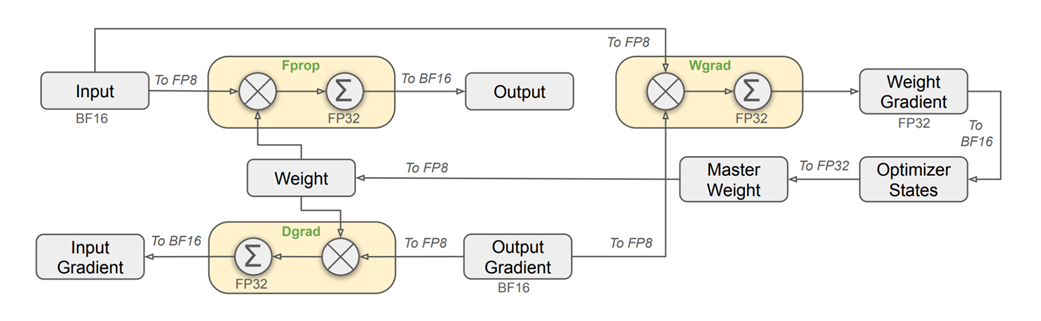
Gambar ini kelihatannya memang rumit, tetapi ia sekadar menggambarkan bagaimana lalu lintas angka mengalir melewati empat pos satpam dalam proses perhitungan matematika. Mari kita bedah tiap posnya.
A. Gerak Maju (Forward Propagation / Fprop)
Proses gerak maju adalah proses di mana AI bekerja menebak kata, di mana rumusnya adalah Keluaran = Bobot x Masukan. Ini adalah perhitungan utama yang terjadi saat AI sedang menjawab pertanyaan Anda.
Gambar 5.23 Alur data dan pilihan ukuran kotak angka untuk proses gerak maju.
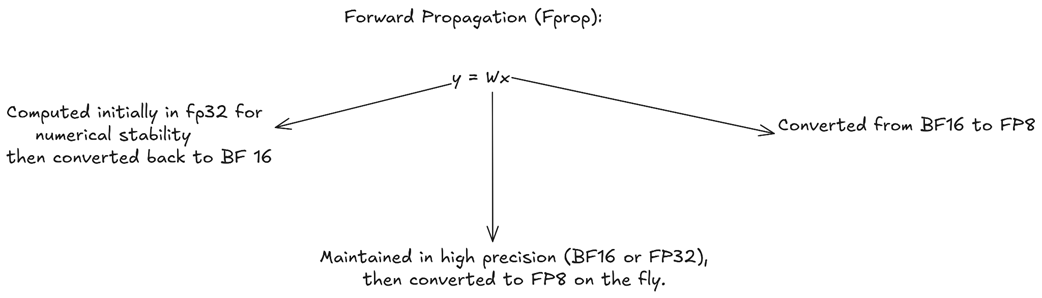
Seperti yang terlihat pada Gambar 5.23, campuran strategi digunakan di sini:
- Bahan Masukan (x): Data kata yang dikirim dari lapisan saraf sebelumnya biasanya dibungkus di dalam kotak BF16. Namun sesaat sebelum dikalikan, angka ini secara ajaib langsung dikecilkan (dikuantisasi) secara otomatis menjadi kotak FP8 yang super cepat.
- Bobot Pengetahuan (W): Kumpulan pengetahuan “Master (Tuan)” milik AI dijaga ketat agar selalu utuh dalam kotak mahal FP32 (atau BF16). Namun saat ingin ikut dikalikan, salinan bobot ini dikecilkan juga menjadi FP8 secara langsung di tempat.
- Keluaran (y): Hasil perkalian dari
FP8 x FP8ini akan dijumlahkan dan ditampung ke dalam wadah besar FP32. Hal ini wajib dilakukan agar angkanya tidak kacau atau luber. Setelah aman tertampung di FP32, hasil akhirnya segera dikecilkan lagi sedikit menjadi kotak BF16 untuk disetorkan ke ruang memori.
Mengapa repot-repot dicampur seperti ini? Jawabannya: Proses matematika beratnya (perkalian masal) dikerjakan menggunakan ukuran paling kecil dan paling ngebut (FP8). Namun hasil perkaliannya ditampung dan disimpan menggunakan ukuran yang cukup besar, agar informasi cerdasnya tidak bocor atau hilang.
B. Gerak Mundur Mengoreksi Diri: Nilai Kesalahan Terhadap Bahan Masukan (Dgrad)
Setelah proses gerak maju selesai dan AI memberikan tebakannya, model akan memeriksa apakah ia salah, dan proses belajar pun dimulai (Backpropagation). Proses gerak mundur melibatkan perhitungan angka hukuman (gradien) yang bertugas memberi tahu setiap sel saraf bagaimana cara memperbaiki diri. Proses ini menghitung dua jenis hukuman utama: hukuman pada bahan masukan (dgrad) dan hukuman pada pengetahuan/bobot (wgrad).
Gambar 5.24 Alur data untuk perhitungan hukuman masukan (Dgrad).
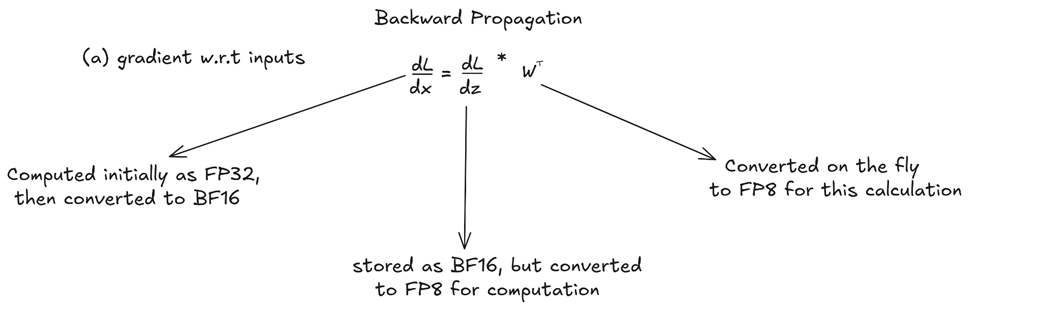
Angka hukuman terhadap bahan masukan (dL/dx) ini diperlukan untuk menularkan hukuman ke lapisan-lapisan awal di belakangnya. Rumusnya adalah dengan menggunakan Aturan Rantai (Chain Rule):
Di mana dL/dz adalah angka hukuman teguran yang datang dari lapisan depannya, dan W^T adalah posisi matriks bobot yang dibalik (ditranspose). DeepSeek menerapkan trik campuran yang serupa di sini:
- Teguran yang datang (
dL/dy), yang bentuknya BF16, disulap jadi FP8 sebelum dikalikan. - Matriks pengetahuan asli (
W), yang masih besar dan akurat, juga disulap sesaat menjadi FP8 untuk dihajar ke dalam rumus. - Hasil teguran yang akan ditularkan (
dL/dx), ditampung di dalam wadah besar FP32 lalu dikecilkan sedikit menjadi BF16 agar bisa dikirim mundur ke lapisan selanjutnya.
Perhatikan kemiripan polanya dengan saat gerak maju tadi: operasi inti selalu menggunakan tenaga kuli FP8 demi kecepatan maksimal, tetapi hasil yang akan diturunkan (diwariskan) selalu disimpan dalam wujud BF16 yang lebih tahan banting.
C. Gerak Mundur Mengoreksi Diri: Nilai Kesalahan Terhadap Bobot Pengetahuan (Wgrad)
Gambar 5.25 Alur data untuk perhitungan hukuman pada pengetahuan (Wgrad).
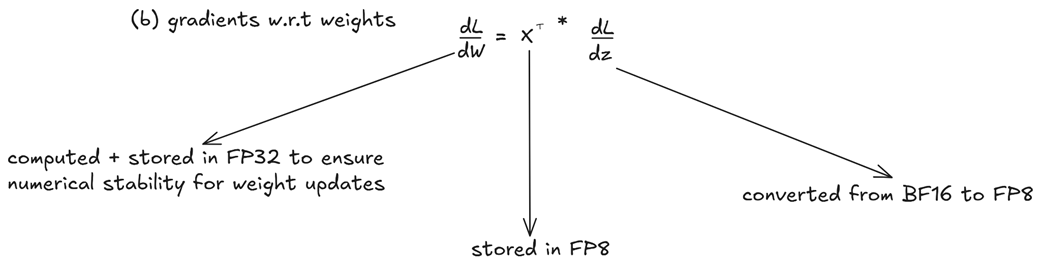
Nah, ini adalah bagian proses hukuman yang paling genting dan berbahaya, karena inilah yang menentukan apakah model AI kita tambah pintar atau malah tambah bodoh. Teguran dL/dW ini memberi tahu model bagaimana cara ia harus mengubah isi otaknya. Rumusnya adalah:
Di titik inilah strategi campuran DeepSeek bergeser dan mengutamakan keakuratan di atas segalanya. Teguran bobot yang cacat atau berantakan dapat menghancurkan dan meruntuhkan kepintaran AI yang sudah dibangun susah payah. Oleh sebab itu, DeepSeek membuat keputusan yang sangat penting:
- Bahan masukan (
x), yang tadinya sudah sempat dijadikan FP8 di langkah sebelumnya, dipakai lagi di sini. - Teguran yang masuk (
dL/dy) dikecilkan dari BF16 menjadi FP8. - Akan tetapi, hasil teguran akhirnya (
dL/dW), dihitung dan, yang paling penting, disimpan secara utuh di dalam brankas FP32 dengan keakuratan paling maksimal.
Inilah bukti sejati dari kata “campuran” di strategi ini. Meskipun jenis hukuman lain boleh disimpan di kotak BF16, hukuman yang bertugas merombak otak AI ini wajib dikawal dengan pengamanan resolusi tertinggi (FP32), memastikan isi otak AI di-update dengan sangat presisi tanpa ada kesalahan hitung satu koma pun.
D. Pembaruan Pengetahuan (The Weight Update)
Gambar 5.26 Proses pembaruan otak dilakukan sepenuhnya di ruangan elit berpresisi tinggi FP32.
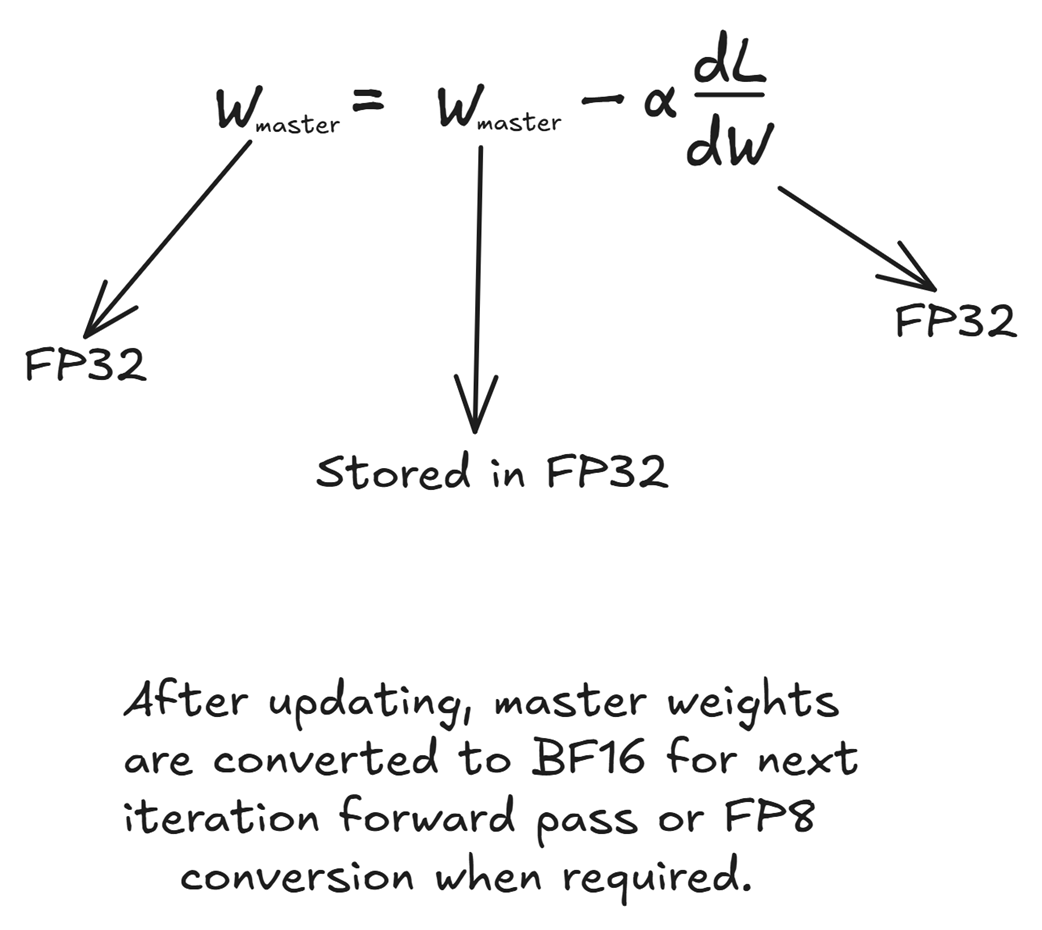
Sebagai penutup yang mendebarkan, sang Pengoptimal (Optimizer) akan menggunakan angka teguran (hukuman) FP32 tadi untuk mengutak-atik pengetahuan inti sang AI.
\[Bobot\_Master\_Baru = Bobot\_Master\_Lama - Tingkat\_Belajar * (dL/dW)\]Karena langkah ini menggoreskan ingatan permanen secara langsung pada memori model AI, kehati-hatian adalah hal yang mutlak. Maka dari itu, seluruh komponen di dalam ruangan ini murni hanya menggunakan FP32:
- Bobot Master (Otak Utama AI) bersemayam di dalam brankas FP32.
- Angka Teguran (
dL/dW) juga berwujud FP32. - Catatan memori milik sang Pengoptimal (seperti catatan AdamW) juga menggunakan kertas kerja FP32.
Pembaruan dilakukan dengan kemewahan akurasi tingkat tinggi. Setelah Bobot_Master_Baru selesai dihitung, ia disimpan dengan takzim dalam balutan FP32. Pada putaran latihan AI berikutnya, bobot-bobot master yang berharga ini akan disulap secara sementara lagi ke wujud buruh FP8, dan siklus pun kembali berulang.
Dengan menggunakan pasukan FP8 untuk mengurusi semua urusan perkalian kuli yang berat (Fprop, Dgrad, Wgrad), DeepSeek memaksimalkan kapasitas saluran data dan memeras habis kecepatan komputer modern. Taktik ini memberikan lonjakan kecepatan komputer (throughput) hingga 2 kali lipat dibandingkan sekadar memakai format BF16 konvensional.
Mereka telah mengidentifikasi secara cerdik bagian mana saja yang tidak boleh diganggu. Bobot Master dan catatan Pengoptimal dijaga suci dalam wujud FP32 agar AI terhindar dari penyakit pelupa akibat error pembulatan, sehingga ia bisa terus belajar secara stabil. Sementara itu, lalu lintas antar-lapisan dititipkan dalam wujud BF16 yang lebih membumi, menjadi jembatan yang lebih hemat tempat ketimbang FP32 namun jauh lebih aman ketimbang si mungil FP8.
Tim DeepSeek bahkan bertindak lebih cermat lagi. Mereka menemukan bahwa ada beberapa alat saraf tertentu di dalam arsitektur Transformer yang sangat sensitif (mudah alergi) terhadap pengecilan angka, dan mudah berantakan jika dikompres. Sebagai gantinya, mereka melindungi alat-alat ini agar selamanya tetap berada dalam format yang lebih lega (BF16), dan melarang sama sekali aturan pengecilan FP8 masuk ke area ini. Alat-alat sensitif tersebut adalah:
- Modul Kamus Angka / Embedding (baik untuk menerjemahkan kata maupun mengatur posisi kata)
- Kepala Keluaran Akhir (yang bertugas mengubah pikiran AI menjadi bahasa manusia)
- Pintu Gerbang Pengatur Ahli pada sistem Mixture-of-Experts (MoE)
- Lapisan Penstabil Angka (seperti RMSNorm)
- Operator Perhatian / Attention (khususnya untuk bagian rumus softmax dan perhitungan vektor konteks)
Keseimbangan antara memakai mesin berhitung kuli kecepatan tinggi (FP8) dengan perlindungan ruang arsip super aman (FP32/BF16) inilah rahasia utama mengapa DeepSeek mampu melatih model raksasa jauh lebih cepat tanpa perlu takut mesin AI tersebut “kesurupan” dan rusak karena error angka, sebuah momok yang sering menghantui para periset amatir saat mencoba mengecilkan angka secara sembarangan. Pilar pertama inilah lantai dasar tempat keempat pilar lainnya akan didirikan.
5.5.7 Pilar 2: Kuantisasi Sebagian-Sebagian secara Detail (Fine-Grained)
Jika Pilar 1 menceritakan “Kotak mana yang harus dipakai”, maka Pilar 2 menceritakan “Bagaimana cara memeras angkanya ke dalam kotak kecil (FP8) tersebut agar rapi dan informasinya tidak tumpah”.
Seperti yang kita pelajari di bagian 5.5.4, senjata utama untuk memeras angka adalah “Penskalaan” (Scaling). Kita mencari satu angka raksasa dari kumpulan angka yang ada, lalu memakainya sebagai alat pemotong (pembagi) untuk mengecilkan jutaan angka lainnya agar muat ke kotak mungil. Akan tetapi, ternyata cara bodoh ini menimbulkan bencana tersendiri.
Bencana akibat angka pencilan (outlier) dalam penskalaan standar
Pendekatan standar yang mengecilkan seluruh baris data menggunakan satu buah rumus skala memiliki satu kelemahan fatal: ia sangat lemah terhadap keberadaan “angka pencilan” (angka aneh yang tiba-tiba sangat besar sendirian). Sedikit saja ada satu angka raksasa yang menyelinap, maka keakuratan jutaan angka kecil lainnya akan hancur lebur.
Mari kita buktikan dengan contoh angka yang nyata. Bayangkan kita punya sebaris kecil data yang ingin kita gencet ke dalam format kotak 8-bit Integer (batasnya hanya -127 hingga 127): Angkanya adalah [2.0, 3.0, 500.0]. Kehadiran angka monster pencilan 500.0 ini akan memusnahkan semua arti dari angka lainnya:
- Cari Nilai Mutlak Terbesar (α): Angka paling besar secara absolut adalah
α = 500.0. - Hitung Rumus Pengecil (s): Untuk mengecilkan skala
[-500 hingga 500]agar muat ke[-127 hingga 127], rumus pengalinya adalahs = 127 / 500 = 0.254. - Mulai Menggencet (Kuantisasi): Kita kalikan setiap angka asli kita dengan nilai
stadi lalu kita bulatkan agar angkanya pas tanpa koma:pembulatan(2.0 * 0.254)=pembulatan(0.508)=1pembulatan(3.0 * 0.254)=pembulatan(0.762)=1pembulatan(500.0 * 0.254)=pembulatan(127.0)=127- Hasil angka yang sudah berhasil tergencet adalah
[1, 1, 127]. Bencana telah terjadi! Perbedaan penting antara angka2.0dan3.0telah hancur dihapus karena sama-sama berubah menjadi angka1.
- Mengembalikan Ukuran (De-quantize): Ketika kita membagi balik dengan nilai
suntuk mengembalikan ukuran, kita mendapatkan[1/0.254, 1/0.254, 127/0.254], yang mana kira-kira bernilai[3.94, 3.94, 500.0].
Error kecacatan pada dua angka pertama sangatlah parah (nilainya cacat hingga 97% dan 31%), sementara angka si monster pencilan justru kembali utuh tanpa cela. Ini adalah masalah kiamat di dunia Model Bahasa Besar (LLM), di mana jangkauan angka saat komputer bekerja bisa melompat dari yang sangat kerdil ke yang sangat raksasa secara tak terduga.
Solusi Jenius DeepSeek: Memotong data jadi grup kecil untuk diskala sendiri-sendiri
Untuk menghindari kiamat ini, DeepSeek memprakarsai teknik bernama Fine-Grained Quantization (Kuantisasi Sebagian-Sebagian secara Detail). Idenya ternyata brilian sekaligus sangat simpel: Jika membuat satu rumus skala besar merugikan banyak pihak, mengapa kita tidak memotong-motong data tersebut menjadi kelompok-kelompok kecil (blok/grup) dan membiarkan setiap grup menghitung dan memiliki rumus skalanya masing-masing?
Alih-alih cuma mencari satu angka nilai tertinggi untuk seluruh barisan data yang panjangnya ribuan, DeepSeek memotong-motong (mempartisi) barisan tersebut menjadi gerbong-gerbong yang jauh lebih kecil, dan mencari rumus skala yang mandiri untuk setiap gerbong kecil tersebut. Strategi potong memotong ini diterapkan dengan cara berbeda antara data yang masuk (aktivasi) dan data otak murni (bobot).
Memotong secara detail untuk data masukan (aktivasi)
Pertama, mari kita tinjau data aktivasi (data masukan dari lapisan sebelumnya). Sebuah barisan vektor aktivasi di dalam model besar bisa sangat panjang merentang (misalnya, panjang barisnya mencapai 7168 titik angka pada DeepSeek-V3). Untuk menggencetnya, DeepSeek memutilasi barisan panjang ini menjadi gerbong-gerbong (grup) pendek yang berurutan.
Gambar 5.27 Pengecilan sebagian-sebagian untuk sebuah baris vektor. Barisan panjang tersebut dipotong-potong menjadi grup yang lebih kecil. Setiap grup memiliki rumus skala pengalinya sendiri berdasarkan angka terbesar yang hanya ada di dalam grup itu sendiri, sehingga menyelamatkan keakuratan angka di grup yang tidak kebetulan memiliki angka monster pencilan.
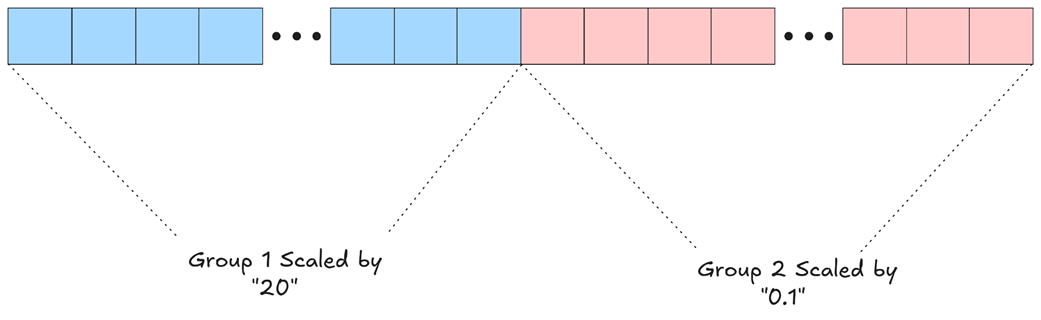
Seperti yang diilustrasikan pada Gambar 5.27, jika sebuah angka monster muncul di satu grup, ia tidak akan lagi meneror grup yang lainnya. Katakanlah Grup 1 kebetulan memiliki angka tertinggi yaitu “20”, sementara Grup 2 lebih damai dan angka terbesarnya hanya “0.1”. Dengan taktik ini:
- Semua anggota di Grup 1 akan ditindas (diskala) dengan batas
20. - Semua anggota di Grup 2 hanya akan diskala dengan batas
0.1.
Angka-angka kecil penghuni Grup 2 kini bisa bernapas lega dan dikuantisasi dengan adil. Detail selisih kecil di antara mereka tetap utuh terjaga tanpa takut “terinjak” atau tergencet hingga rata menjadi nol oleh si monster dari Grup 1. Penskalaan secara komplotan kecil ini menjadi kunci menyelamatkan keutuhan nalar representasi pemikiran model AI. Dalam praktiknya, DeepSeek mematok ukuran Grup (Ng) sebesar 128 titik data. Artinya, setiap potongan 128 data akan punya rumus skala pengecil privatnya sendiri-sendiri.
Memotong secara detail untuk Bobot (otak asli)
Aturan yang sama juga diterapkan pada otak asli AI (matriks Bobot), namun disesuaikan untuk bentuknya yang menyerupai selembar papan catur dua dimensi. Matriks papan bobot yang luas tidak dibiarkan sebagai satu hamparan tak bertuan. Sebaliknya, papan itu digaris dan dibagi-bagi menjadi kotak-kotak ubin yang lebih kecil (seperti ubin keramik).
Gambar 5.28 Pengecilan sebagian-sebagian untuk sebuah matriks bobot. Papan matriks tersebut digaris menjadi ubin yang lebih kecil (misal: W₁₁, W₁₂, dll.), dan setiap ubin dieksekusi mengecil dengan rumus skalanya sendiri yang unik.
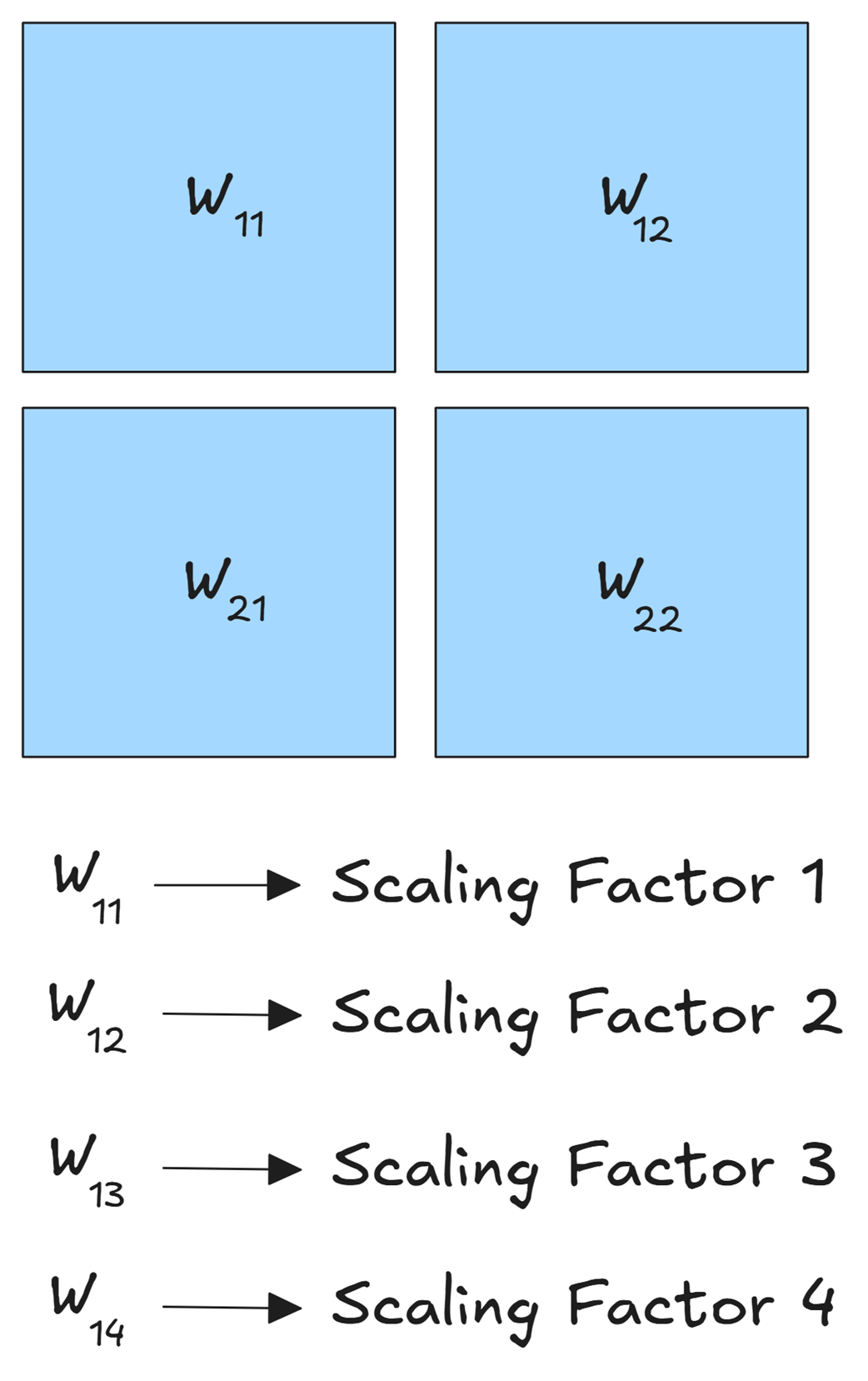
Sebagaimana terlihat pada Gambar 5.28, sebuah papan matriks W (Weight) mungkin akan dibelah jadi empat ubin: W₁₁, W₂₁, W₁₂, dan W₂₂. Setiap ubin kecil ini akan digencet (dikuantisasi) secara sepihak tanpa mempedulikan tetangganya:
- Ubin
W₁₁akan dikecilkan memakai Rumus Skala 1, yang dihitung cuma dari angka mutlak terbesar yang ada di dalam ubinnya saja. - Ubin
W₂₁akan dikecilkan memakai Rumus Skala 2, yang dihitung dari angka mutlak terbesar yang ada di area dia saja. - …dan begitu seterusnya untuk semua ubin.
Metode ubin ini mengamankan nasib otak AI; jika ada sekumpulan sel otak di satu pojok ubin yang tiba-tiba berteriak sangat keras (nilainya ekstrem/outlier), maka teriakan mereka tidak akan merusak kehalusan dan kepintaran jutaan sel saraf lain yang menetap di ubin-ubin yang tenang. Untuk kerangka kerja FP8 mereka, DeepSeek mencetak ukuran standar ubinnya sebesar area 128x128 sel.
Menyatukan semua prosesnya menjadi satu
Sekarang, kita siap untuk mencerna diagram alur lengkap yang dipresentasikan oleh tim DeepSeek. Diagram ini memamerkan bagaimana kedua metode pemotongan data (masukan dan bobot) bersatu padu di medan perang.
Gambar 5.29 Alur kerja Kuantisasi Sebagian-Sebagian (Fine-Grained Quantization) yang utuh.
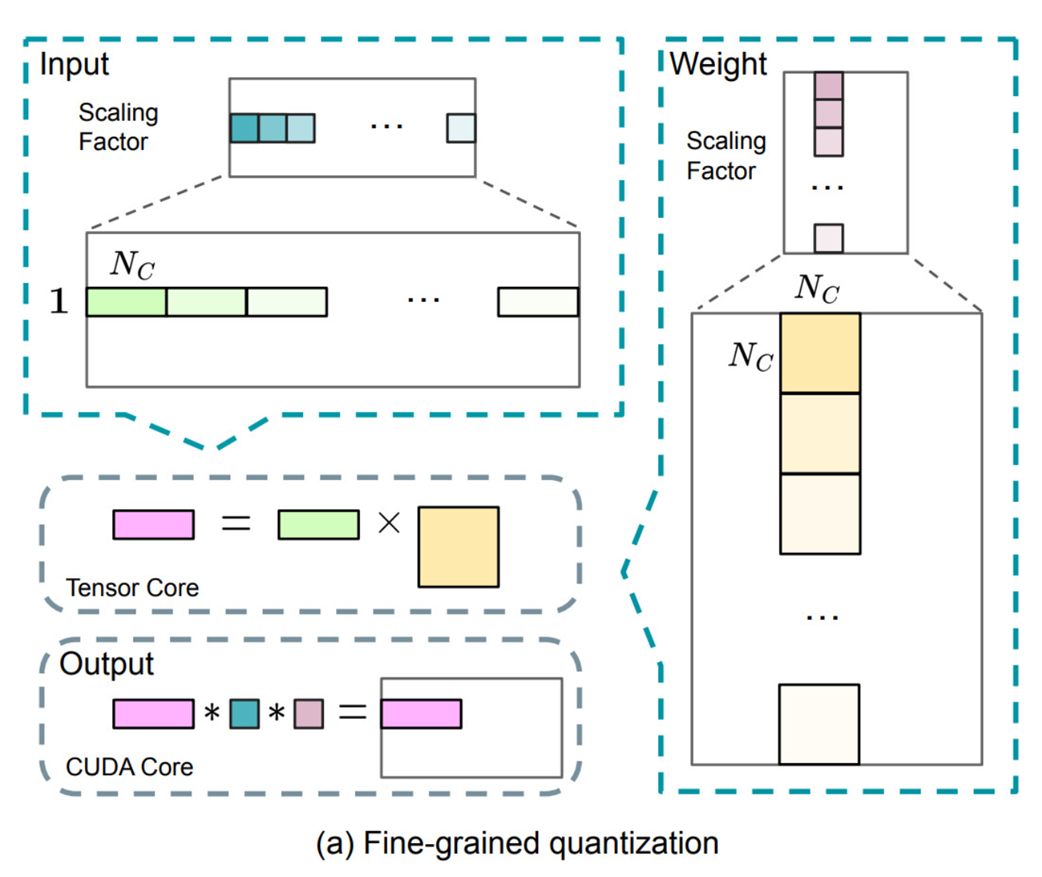
- Bahan Masukan (Aktivasi): Digambarkan di kiri atas. Ia digergaji menjadi potongan-potongan seukuran
Ks. Masing-masing potongan dihadiahi sebuah Rumus Skala (Scaling Factor) unik milik mereka sendiri (ditunjukkan lewat warna hijau yang berbeda-beda). - Otak Asli (Bobot): Digambarkan di kanan atas. Papan ini dipecah-pecah jadi ubin berukuran
Ks(yaitu ubinKs x Ks). Setiap ubin kebagian satu Rumus Skalanya sendiri-sendiri juga (ditunjukkan warna pink/ungu). - Proses di Pabrik Cepat (Tensor Core): Proses perkalian utama (
Keluaran = Masukan x Bobot) diserahkan kepada unit mesin khusus di GPU yang super ngebut bernamaTensor Cores. Mesin gila ini menelan masuk angka-angka yang sudah memar digencet (format FP8) lalu memuntahkan hasil sementara yang ukurannya juga masih buram dan rendah presisi (kotak warna pink polos). - Dikembalikan Utuh di Pabrik Pelan (CUDA Core): Nah, langkah terakhir ini dilakukan di unit umum GPU yang kerjanya lebih santai tapi teliti, yaitu
CUDA Cores. Hasil buram dari Tensor Core ditangkap. Kemudian, ia akan dibesarkan kembali ke dunia nyata (Dequantisasi). Caranya adalah dengan mengalikan hasil buram itu dengan warna hijau (Rumus Skala Masukan) DAN warna ungu (Rumus Skala Ubin) yang sempat disimpan tadi. Berkat pertolongan dua rumus skala ini, angka yang tadinya kecil berhasil ditarik membesar mendekati angka normal aslinya (walaupun tetap ada sedikit baret akibat dikompres). Hasil keluaran yang akhirnya utuh dan berpresisi tinggi ini sekarang siap untuk dikirim ke gerbong pemrosesan saraf berikutnya.
Dengan meruntuhkan proses kompresi raksasa menjadi potongan-potongan dan ubin kecil yang diurus secara mandiri, DeepSeek sanggup menjamin bahwa kualitas nalar angka AI tetap terjaga hingga ke detail paling kecil (level lokal). Inilah yang membuat proses pelatihan raksasa mereka sangat anti-badai dan kebal terhadap kejutan angka lonjakan yang sangat umum terjadi pada proses belajar LLM. Strategi “Pecah belah dan taklukkan” yang tampak sederhana ini adalah satu dari sekian banyak pahlawan di balik keberhasilan AI dilatih hanya dengan menggunakan komputer kelas FP8.
5.5.8 Pilar 3: Meningkatkan Presisi Penjumlahan (Accumulation) Angka
Pilar ketiga datang untuk menambal kelemahan dan cacat tersembunyi dari perangkat keras kartu grafis (GPU) masa kini. Meskipun GPU merupakan dewa dalam urusan mengalikan angka-angka miskin akurasi (misal FP8 dikali FP8) dengan sangat cepat, rupanya mesin ini punya keterbatasan konyol dalam menyediakan ruang memori tampungan sementara pada saat mesinnya sedang asyik menjumlahkan semua hasil perkalian tersebut.
Akar masalah: Angkanya luber dan hilang saat sedang asyik ditambahkan
Mari kita lihat ulang proses rumus perkalian matriks kita Y = W * X. Untuk memproduksi satu buah titik tebakan (hasil) Y, mesin harus mengerjakan operasi “Dot Product”: yaitu ia harus mengambil sederet angka (baris) dari papan W, mengambil sejejer angka turun (kolom) dari papan X, mengalikan mereka satu-satu secara berpasangan, dan terakhir menjumlahkan (mengumpulkan / accumulate) semua hasil perkalian satu per satu itu ke dalam sebuah ember kosong.
Ketika W dan X sama-sama memakai baju FP8, masing-masing proses perkalian tunggal (misal W_ik * X_kj) diselesaikan dengan cepat. Unit perangkat keras GPU yang bertugas melakukan ini disebut Tensor Cores. Mesin ini sekarang harus menjumlahkan semua kepingan hasil perkalian tersebut. Ruang buku catatan kecil di dalam mesin yang bertugas mencatat hasil penjumlahan angka sementara ini disebut sebagai Accumulator (Ember Penjumlah).
Petakanya adalah, pada mesin sekelas NVIDIA H800 GPU pun, Ember Penjumlah internal milik si Tensor Core ini ukuran catatannya sangatlah sempit (misalnya cuma mentok sekitar ruang presisi 14 bit), dan kemampuannya jauh di bawah standar kemewahan ukuran utuh 32-bit (FP32). Jika rantai antrean angka yang mau ditambahkan (k) itu sangat panjang (misal antre 4096 biji perkalian, suatu hal yang wajar di dalam LLM), maka kita sebenarnya sedang menyuruh mesin itu mencatat ribuan kepingan angka kecil. Jika Ember Penjumlahnya tidak punya tingkat keakuratan yang mewah, kita akan dihajar penyakit underflow (angkanya terlalu kecil sehingga tidak muat diukir di memori lalu dianggap hilang jadi nol), dan nilai hasil gabungan akhirnya nanti bisa mengalami kerusakan hitungan matematis (error) hingga menembus angka 2%. Kerusakan hitung ini benar-benar bisa membuat AI menjadi idiot dan menurunkan kualitas kebenarannya.
Jawaban Elegan DeepSeek: Kirim laporannya ke Pos CUDA Cores secara berkala (Promotion to CUDA Cores)
Untuk melumpuhkan penyakit ini, DeepSeek menciptakan manuver yang dinamakan Promotion to CUDA Cores (Mutasi laporan ke Pos CUDA Cores). Ide utamanya adalah memaksimalkan penggunaan dua jenis ras pekerja komputasi yang memang ada di dalam tubuh sebuah GPU. Ras pertama adalah si Tensor Cores, mesin spesialis bertenaga monster yang cuma bisa mengalikan dengan sangat cepat tapi akurasinya rabun (rendah presisi). Ras kedua adalah si CUDA Cores, pekerja serba guna yang kerjanya lebih selow namun mampu memberikan tingkat akurasi hitungan tingkat dewa yang sempurna.
Strategi DeepSeek adalah secara berkala menculik paksa hasil penjumlahan sementara yang masih setengah matang dari tangan si ngebut Tensor Cores, dan menyerahkan laporan setengah matang itu ke ruang kantor CUDA Cores yang bisa santai melakukan penjumlahan tahap akhir menggunakan perhitungan akurasi kelas atas (FP32) yang aman dan presisi.
Gambar 5.30 Taktik inti untuk menyelamatkan presisi penjumlahan: Hasil hitungan yang masih setengah matang diekspor secara berkala dari ruang kerja keras berpresisi-rendah (Tensor Cores) dan dipindahkan ke ruang kerja elit berpresisi-tinggi (CUDA Cores).

Untuk benar-benar meresapi cara mesin ini membengkokkan hukum alam komputer, kita harus melirik langsung ke onderdil perangkat keras yang dipakai. Operasi dimulai di perut Tensor Core, yang tengah menggila melakukan perkalian presisi-rendah yang dipecah-pecah ke dalam siklus-siklus kecil. Instruksi GPU yang membombardir tugas ini dinamai MMA (Matrix-Multiply-Accumulate / Matriks-Dikali-Dijumlahkan).
Di setiap detik siklus MMA, angka hasil perkalian sementara akan disetor ke ember memori murahan yang berlabel “Low Prec Acc” (Ember Penjumlah Presisi Rendah) pada Gambar 5.30. Seperti yang sudah kita ketahui, ember ini rawan bocor jika kepenuhan. Terobosan ajaib dari DeepSeek adalah dengan memerintahkan sistem untuk jangan pernah menunggu mesin itu selesai menghitung seluruh rantainya. Sebaliknya, pada setiap putaran waktu yang ditentukan (Interval Nc), angka setengah jalan yang ada di dalam “Low Prec Acc” tersebut akan segera dibajak dan “dipromosikan” (dipindahkan) secara paksa ke markas umum CUDA Core.
Si CUDA Core ini lantas menangkap angka setengah matang itu dan menyemplungkannya ke dalam “FP32 Register” (Brankas Register FP32), yaitu sebuah kotak penyimpanan mewah beresolusi super presisi. Karena tahap akhir penyatuan angka ini dilakukan di dalam Brankas beresolusi tinggi, maka DeepSeek secara ajaib menekan risiko tumpahnya (underflow) angka, sebuah momok abadi yang sering menggentayangi metode kalkulasi FP8 biasa.
Gambar 5.31 Membedah detail operasi Meningkatkan Presisi Penjumlahan (Increasing Accumulation Precision). Penambahan sementara dengan presisi ala kadarnya dilakukan bertahap di Tensor Core, lalu angkanya secara rutin ditarik keluar dan disetorkan ke brankas mewah (FP32) milik CUDA Core untuk digabungkan secara presisi.
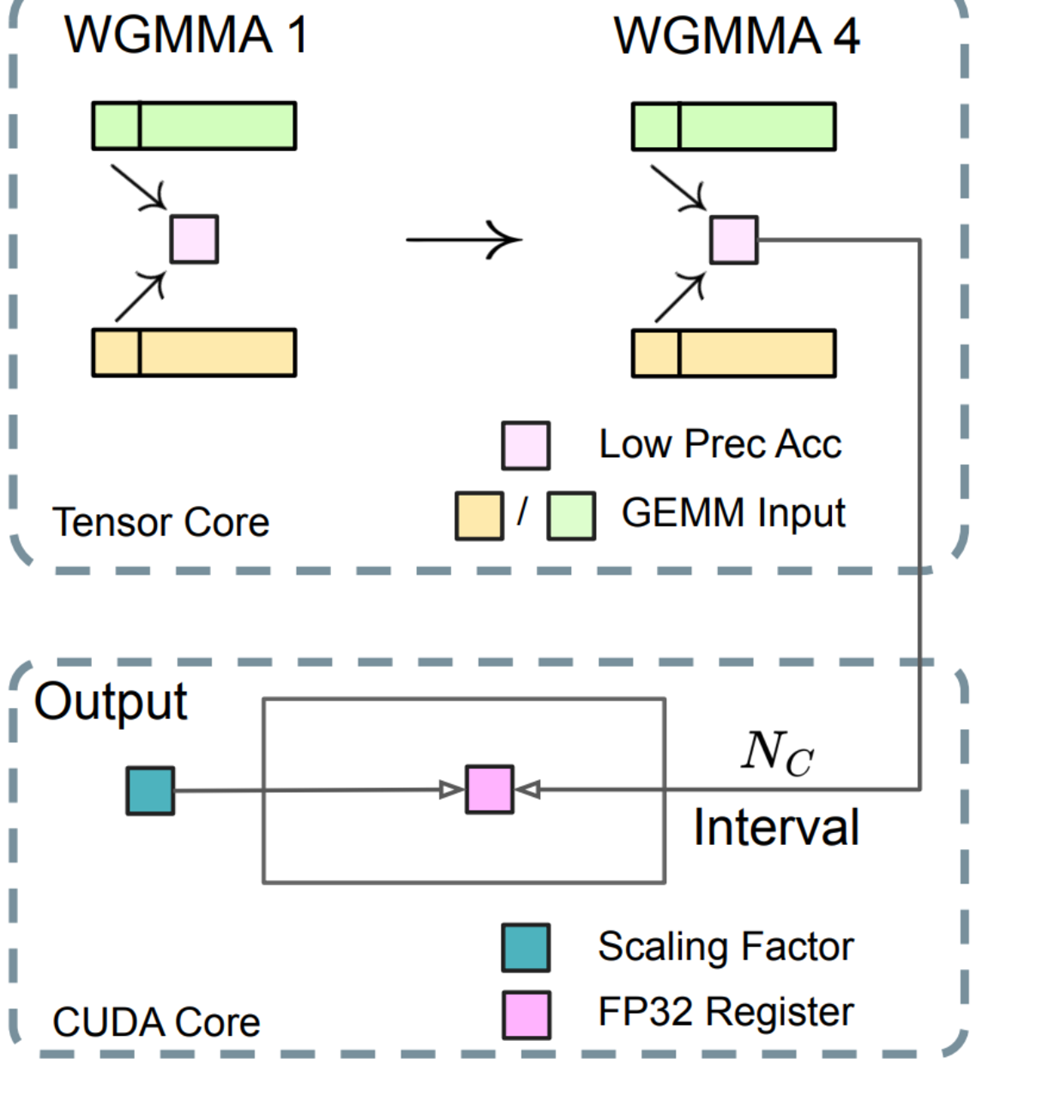
Mari kita ikuti petualangan sepotong data menyusuri labirin diagram ini tahap demi tahap:
Tahap 1: Markas Tensor Core - Di Sini Kecepatan Adalah Raja, Akurasi Bisa Belakangan
Bagian paling atas di Gambar 5.31 yang berlabel “Tensor Core”, adalah arena di mana otot kasar mesin diperah dan jutaan angka dikalikan secara membabi buta.
- Bahan Baku GEMM (GEMM Inputs): Terdapat dua balok memanjang di area langit-langit gambar yang berperan sebagai masukan dari rumus
y = Wx. Balok satu adalah rombongan angka data (Aktivasi yang sudah dipotong detail/Fine-Grained), sedangkan balok di sebelahnya adalah para Bobot AI. Hebatnya, mereka berdua saat ini sudah dipakaikan seragam FP8 siap tempur yang super ngebut. - Mesin Giling MMA (Matrix-Multiply-Accumulate): Ini adalah sebuah instruksi tingkat terendah rahasia milik mesin NVIDIA yang meneriakkan perintah kepada rombongan benang-benang prosesor (dipanggil gerombolan “warp”) untuk segera mengunyah perkalian matriks. Anda boleh memvisualisasikan tulisan
MMA 1sampaiMMA 4sebagai ketukan langkah mesin giling. Pada langkahMMA 1, mesin mungkin bertugas menggiling 32 angka awal dari seribu antrean di rumusY_ijkita tadi. - Low Prec Acc (Ember Murahan): Ini adalah kotak persegi kecil bertuliskan “Low Prec Acc”. Wujud aslinya adalah sebuah memori sementara tertanam tepat di jantung mesin Tensor Core. Saat mesin menyelesaikan langkah
MMA 1, hasil sisa kunyahannya disemburkan ke dalam kotak ini. Pada irama ketukanMMA 2, hasil kunyahan kedua juga akan dicampurkan lagi ke ember yang sama. Tapi kita semua tahu, ukuran ember ini terlalu sempit (cuma sekitar 14 bit).
Tahap 2: Operasi Pembajakan - Promosi Berkala ke Lantai Presisi Tinggi
Di sinilah letak revolusi otak DeepSeek: yaitu panah melengkung yang menghubungkan area Tensor Core ke arah area CUDA Core. Ini bukanlah penyerahan hasil akhir saat pabrik mau tutup; ini adalah sebuah operasi penculikan data di tengah jalan (promosi berkala).
Selang Waktu Nc (Interval Nc): DeepSeek tidak mau berjudi menunggu mesin kuli MMA menyelesaikan total gilingannya hingga ujung. Sebagai pencegahan, begitu mesin sudah berdetak sebanyak putaran Nc kali (di mana dokumen resmi menyebut Nc = 128), mesin disuruh menahan napas. Hasil gilingan setengah jadi yang tergeletak di dalam ember “Low Prec Acc” tersebut akan dibajak dan diselundupkan keluar dari arena Tensor Core.
Tahap 3: Markas CUDA Core - Pelan, Namun Akurasinya Tak Tertandingi
Setengah halaman terbawah dari diagram ini, dengan papan nama “CUDA Core”, adalah wilayah operasi senyap dan aman, tempat penyempurnaan matematika dilakukan. Pos CUDA Cores ini sanggup mengeksekusi perhitungan akurasi kelas sultan (FP32).
Register FP32 (Kotak Persegi Biru Muda): Laporan setengah matang yang dibajak dari Tensor Core akan mendarat dengan empuk ke dalam sebuah brankas “Register” yang luasnya berukuran 32-bit (FP32). Karena ruangannya sangat melimpah ruah, Brankas Register ini dapat menelan hasil ribuan angka kecil yang dijumlahkan secara rakus, tanpa ada satu pun angka di belakang koma yang tertolak ataupun tumpah. Begitu paket-paket kiriman baru (Nc) terus berdatangan dari atas, mereka semua akan disatukan dengan presisi tingkat dewa ke dalam catatan saldo yang utuh.
Penerjemah Skala (Kotak Warna Hijau/Teal): Dalam tempo yang sama, unit CUDA Core juga dengan gesit menyelesaikan pekerjaan “mengembalikan ukuran asli” (Dequantisasi). Ia segera mencabut buku catatan “Rumus Skala” (Scaling Factor) peninggalan dari teknik pemotongan detail (Pilar 2) tadi, lalu ia kalikan rumus skala itu dengan saldo raksasa yang berada di brankas tingginya.
Hasil Puncak (Output): Apa yang keluar di ujung pipa adalah sebuah angka yang berhasil dipulihkan skalanya, dengan jaminan mutu akurasi dewa yang kebal terhadap penyakit error numerik. Angka paripurna ini kemudian dipakaikan seragam BF16, siap untuk melenggang masuk ke tugas lapisan otak AI berikutnya.
Perkawinan paksa yang jenius ini benar-benar mencerminkan prinsip “Mendapatkan yang terbaik dari dua dunia”. Taktik ini menunjuk alat berat yang tepat untuk pekerjaan yang tepat pula: menyerahkan siksaan perkalian gila-gilaan ke unit spesialis balap (Tensor Cores), namun mendelegasikan tugas menjahit saldo akhir dan mengembalikan wujud angka kepada tangan-tangan dingin pengrajin CUDA Cores dengan akurasi presisi tinggi (FP32). Berkat perkawinan taktis ini, DeepSeek bisa menikmati betapa ngebutnya balapan komputer FP8 tanpa harus mengorbankan setetes pun kewarasan matematika sistem AI mereka.
5.5.9 Pilar 4: Mengutamakan Detail Nilai (Mantissa) daripada Pangkat (Exponents)
Seperti yang telah kita kupas pada Bagian 5.5.3, memilih format ukuran memori kotak (Floating Point) pada dasarnya adalah seni tebak-tebakan dan kompromi antara memanjangkan tempat untuk Pangkat (yang memberikan jangkauan angka luas) melawan memperbanyak tempat untuk Nilai Asli/Mantissa (yang memberikan keakuratan/presisi detail pada nilai komanya).
Di dunia pengecilan kotak berukuran 8-bit (FP8) ini, terdapat dua kubu aliran utama yang menguasai industri:
- Aliran E5M2: Memberikan jatah 5 bit untuk Pangkat (Exponent), dan 2 bit sisanya untuk Nilai Asli (Mantissa). Aliran ini menyukai bentangan jangkauan nilai yang membentang sangat luas dari angka raksasa ke kerdil, tapi sayangnya ia sangat kasar dan miskin keakuratan nilai koma di belakangnya.
- Aliran E4M3: Memberikan porsi 4 bit untuk Pangkat, dan 3 bit untuk Nilai Asli (Mantissa). Aliran ini lebih cepat menabrak tembok jangkauan (angka tidak bisa terlalu besar), tapi ia sangat tajam, presisi, dan menyimpan detail angka yang kaya.
Strategi Kompromi Zaman Dulu (Pendekatan Konvensional)
Jauh sebelum DeepSeek angkat bicara, perusahaan AI lain biasanya mencari aman dengan bermain di dua kaki:
- Menggunakan format detail yang tajam (E4M3) saat AI sedang berjalan menembak/menebak kata (Fprop), karena aliran angkanya cenderung jinak dan gampang diawasi.
- Panik lalu segera ganti seragam memakai format berjangkauan sangat luas (E5M2) saat proses mundur (Dgrad dan Wgrad) yang tugasnya menghukum AI (menyampaikan teguran gradien). Pasalnya, teguran dari jaringan ini sering kali berisi angka-angka monster (pencilan) yang luar biasa besar yang akan langsung meledakkan (overflow) kapasitas kotak sempit milik E4M3.
Inovasi DeepSeek: Seragam Penuh E4M3 (Detail Koma Adalah Segalanya)
Pasukan periset DeepSeek membantah kebiasaan ini. Mereka berteori bahwa cara “bermain aman ganti seragam” itu adalah sebuah upaya sia-sia untuk menutupi sebuah masalah yang sebenarnya sudah terlanjur mereka atasi secara tuntas di area lain. Berkat temuan senjata pamungkas mereka di Pilar 2 (Kuantisasi Sebagian-Sebagian / Fine-Grained Quantization), kemunculan monster pencilan (outlier) bukan lagi sebuah bencana.
Mengingat mereka sudah rajin memotong dan memutilasi data (serta memutilasi bobot otak) menjadi gerbong-gerbong kecil yang dihitung secara independen mandiri, maka kalaupun ada satu monster liar yang teriak di sebuah gerbong, ia cuma akan merusak gerbongnya sendiri dan tidak akan membakar kota gerbong lain di sebelahnya. Taktik ubin-ubin kecil ini telah menundukkan fluktuasi liar dari dinamika angka-angka dengan sangat elegan secara lokal per area.
Keyakinan baja inilah yang memberikan DeepSeek keberanian untuk mengambil manuver pemangkasan masalah: Mereka memutuskan untuk memaksa seluruh operasional proses, baik saat berjalan maju menebak maupun saat proses mundur menghukum AI, untuk mengenakan satu seragam berpresisi detail tajam yaitu E4M3.
Karena mereka percaya diri dan memasrahkan urusan dinamika angka monster kepada si tameng “Pilar 2” (Fine-Grained), DeepSeek dengan tenangnya bisa memperkaya kotak Mantissa (presisi nilai di belakang koma) milik AI di seluruh tahap pelatihan modelnya secara konsisten. Makalah resmi dari DeepSeek pun mengklaim:
“Dengan mengoperasikan proses kami pada kelompok komponen (gerbong) yang lebih kecil, metode yang kami usung ini sukses mendistribusikan manfaat bit Pangkat kepada seluruh elemen yang terkurung di dalam setiap grup kecil tersebut, yang mana strategi ini terbukti menumpulkan dampak buruk dari sempitnya rentang dinamika (dynamic range).”
Ini mungkin terdengar seperti inovasi yang remeh, tetapi ini adalah kemajuan yang sangat esensial. Ini merupakan kesaksian bagaimana kelima teknik gila dari DeepSeek ini ternyata menyusun sebuah mesin “puzle” besar yang saling mendukung dan mengisi kelemahan satu sama lain. Tameng Pilar 2 lah yang telah memberi mereka rasa aman (ruang bernapas) untuk bermanuver lebih agresif membela ketajaman nilai presisi data, di mana tingkat ketajaman data inilah yang menjadi tiang utama penyangga kewarasan dari pelatihan irit berbasis FP8 milik mereka.
5.5.10 Pilar 5: Kuantisasi Langsung Seketika (Online Quantization)
Kepingan misteri terakhir dari teka-teki Kuantisasi DeepSeek ini menyasar pada satu pertanyaan kapan waktu yang tepat untuk menghitung rumus skala pengubahnya. Seperti yang sudah dipelajari, rumus angka skala didapat dari mencari siapa penguasa angka “mutlak terbesar” di dalam jejeran sebuah baris data. Pertanyaannya: Baris data mana yang dipakai? Apakah kita mengintip angka raksasa dari data kemarin, atau kita hitung berdasarkan data yang saat ini tergeletak di atas meja potong?
Cara Jadul: Kuantisasi Kadaluwarsa (Delayed Quantization)
Kebanyakan kerangka pemampat otak AI zaman dulu menggunakan kebiasaan buruk yang dinamakan Kuantisasi Tertunda. Pada taktik usang ini, rumus rasio penyusutan (skala) yang dipakai untuk menggencet data saat ini dicontek murni dari catatan buku memori tentang siapa pemegang rekor angka maksimum pada putaran waktu sebelumnya. Cara jadul ini sekadar merekam catatan historis dari nilai masa lalu lalu menebak-nebak dan menggunakannya untuk tugas sekarang.
Penyakit kronis dari taktik dukun tebak-tebakan ini adalah bahwa data pikiran sang AI dapat bergolak liar secara drastis dalam hitungan kedipan mata pada saat ia sedang giat berlatih. Sangat mungkin jika penguasa angka paling tinggi dari data putaran saat ini nilainya ternyata jauh bertolak belakang dari catatan historis rekor minggu lalunya.
- Misalnya saja puncak angka hari ini wujudnya 100 kali lebih membengkak dibanding rekor masa lalu; maka apabila kita masih memakai rumus penyusutan lawas yang terlampau kecil, mesin akan mendadak kepenuhan muatan (overflow), di mana nilai barunya meloncat keluar dari saku penampungan kotak 8-bit.
- Sebaliknya, bila rentang angka hari ini sangat sunyi dan kerdil dibandingkan rekor bising masa lalu; menggunakan alat pemotong gergaji raksasa sisa kemarin akan meremukkan (underflow) angka lemah hari ini. Akibatnya segala macam rincian halus dari data hari ini akan tergencet konyol rata menjadi tanah (nilai nol), alias penyakit yang sempat kita kaji sebelumnya.
Obat Kuat ala DeepSeek: Kuantisasi Secara Online (Langsung Hitung di Tempat)
Untuk mengatasi dan meludahi penyakit fatal tersebut, DeepSeek memaksa mesin untuk melakukan Kuantisasi Secara Online. Jalan pikirannya sangat primitif namun kebal peluru: Pukul mundur kebiasaan hitung masa lalu, dan mulailah hitung ukuran alat skala saat itu juga secara langsung tepat waktu berdasarkan darah segar (data murni) yang tergeletak di atas meja.
Daripada pasrah disetir pada coretan kuno masa lalu, prosedur perangnya adalah:
- Tepat pada kedatangan data aktivasi atau data bobot kloter terbaru hari ini, lakukan pemindaian cepat (scan kilat) menyusuri seluruh lorong jejeran untuk menangkap satu saja sang penguasa angka paling tinggi di dalam kloter spesifik hari ini.
- Gunakan nilai perawan “online” ini guna langsung menelurkan angka pembagi (Rumus Skala).
- Jatuhi hukuman kompresi (Kuantisasi) menggunakan rumus skala yang masih hangat dan telah ditakar secara akurat ini langsung ke data di atas meja.
Taktik menghitung spontan (dadakan) di lapangan ini menjanjikan secara jaminan mutlak bahwa angka pembagi (skala) tersebut selamanya presisi layaknya penjahit kemeja jas yang mengukur sesuai dengan badan pemakai yang diukur hari itu juga. Praktik ini mutlak mengenyahkan segala bayang-bayang kengerian underflow maupun overflow yang lahir dari kesalahan pakai rumus kadaluwarsa.
Memang harus diakui, kegiatan mengabsen “mencari sang jawara tertinggi” sebelum mulai menggencet memakan jatah tenaga CPU ekstra. Tetapi tunggu dulu, ketahuilah bahwa sekadar aktivitas celingak-celinguk meronda barisan untuk mencari angka terbesar itu kecepatannya sungguh bagaikan kilat dibandingkan derita yang harus dilalui AI ketika harus melangsungkan ribuan operasi perkalian matriks (yang merupakan tulang punggung porsi operasi AI). Sehingga ongkos kompensasi ganti rugi (dalam bentuk penjagaan ketat agar hasil akurasi model AI tidak tiba-tiba amnesia dan idiot) yang mereka kantongi, sangat-sangat melimpah ruah dan keuntungannya menutupi ongkos pajaknya. Komitmen kaku untuk selalu menuhankan data “Real-Time” (terbaru yang aktual dan valid) meski ditebus dengan keringat secuil ekstra di depan ini, adalah pola dan ritme DNA asli dari DeepSeek. Ini jugalah penopang kerasulan (jaminan mutu tertinggi) dari arsitektur ketangguhan Kuantisasi format FP8 yang telah lama diagung-agungkan di sepanjang bab ini.
5.6 Mendobrak Kemustahilan Baru (DeepSeek-V4): Pelatihan Sadar-Kuantisasi (QAT) Memakai Kotak Mungil FP4
Meskipun model DeepSeek-V3 sukses menorehkan tinta emas dan menasbihkan kotak 8-bit (FP8) sebagai standar suci dalam efisiensi industri pelatih AI, rupanya ambisi ukuran tak wajar dari penerus model AI masa depan kembali berteriak meminta hal yang lebih brutal. Dalam peluncuran DeepSeek-V4, tim peneliti China ini kembali menghajar dinding batas keiritan memori dengan secara paksa memampatkan ruang kuantisasi AI melorot drastis jauh di bawah standar nalar sehat manusia: yaitu menggeretnya ke level yang mustahil: angka pemecah 4-bit (FP4).
Kita tahu bahwa usaha menyodorkan diklat/pelatihan bagi model berotak triliunan sel saraf sangatlah disiksa oleh keterbatasan memori fisik (RAM hardware) semata yang diperlukan cuma untuk sekadar menaruh dan menitipkan sisa-sisa ampas pikiran (parameter) di kumpulan rak besi GPU. Demi membuka jalur bebas hambatan kecepatan dan irit tempat saat modelnya sudah mau dilepas untuk dipakai publik, DeepSeek melahirkan satu teknik sesat yang disucikan bernama Quantization-Aware Training (QAT) atau Pelatihan yang Sadar Akan Adanya Kuantisasi, yang dilancarkan tepat saat masa pasca-pelatihan (post-training), khusus membidik kotak memori berlevel FP4 (yang mereka cap dengan format MXFP4).
5.6.1 Menyiksa Memori FP4 Khusus pada Bobot Ahli (MoE) dan Saluran Jalur QK
DeepSeek-V4 sama sekali tidak gegabah dan membabi-buta menggunting seluruh komponen otak AI dan memaksanya dipenjara ke ukuran FP4. Seperti ajaran leluhur yang kita imani di Pilar 1 mengenai Presisi Campuran, mereka bak prajurit elit sniper yang hanya secara sadis memutilasi kompartemen-kompartemen memori AI yang disinyalir sebagai sarang parasit pemakan kuota memori paling rakus, tanpa sedikit pun menggores atau menyentuh pangkalan rahasia pusat akurasi pikiran yang sensitif.
Secara beringas mereka menyasar dua target mangsa terbesar di mana pemampatan FP4 diterapkan secara sepihak:
- Bobot Otak Para Ahli (MoE): Sesuai wasiat pada Bab 4, jaringan Campuran Para Ahli (MoE) adalah penyumbang dominan pembengkakan memori GPU sekaligus biang kerok dari populasi ratusan miliar parameter yang dimiliki sang model. Melumat habis miliaran bobot sel otot MoE ini dari FP8 ke jurang neraka FP4 setara dengan kita membabat ludes secara efektif setengah dari raksasa jejak memori bangunan asli model tersebut.
- Lintasan Saluran QK (Query-Key) pada Pengindeks Kilat: Sesuai kitab pada Bab 3, kita disuguhi tontonan alat sakti Pengindeks Kilat yang mengabdi pada dewa Perhatian Renggang DeepSeek (Sparse Attention). Pada era kebangkitan V4 ini, data letupan (aktivasi)
Query-Key (QK)ini disimpan (cache), dituang keluar (loaded), hingga dikalikan satu sama lain seutuhnya dan murni terjadi mutlak di arena yang sempit berukuran FP4. Efek gaibnya? Perhitungan skor attention ini melesat gila-gilaan tak terkendali pada saat model diwajibkan mengurai atau membaca lautan bacaan yang super panjang sejuta-kata sekalipun.
5.6.2 Mukjizat Mekanisme Mengembangkan Ulang FP4-kembali-ke-FP8 Tanpa Kehilangan Sekecil Apapun (Lossless)
Logika sehat mana pun pasti akan berteriak mempertanyakan; bagaimana mungkin sebuah otak mesin yang pikirannya dicacah paksa hingga sisa 4 bit mampu belajar layaknya profesor? Misteri dan kunci mukjizat ini terletak tersembunyi bersemayam pada rancangan desain ilahi dari sifat matematika format 4-bit (E2M1) yang mereka utus, ditambah racikan rahasia dari doktrin “Pelatihan Sadar Kuantisasi” (QAT) tersebut.
Dalam periode sekte aliran QAT ini, sang otak AI dididik (disiksa mentalnya) dari dini untuk berlatih memaklumi dan terbiasa secara ikhlas serta beradaptasi terhadap segala cacat (kebodohan/degradasi akurasi) yang dilahirkan akibat sempitnya kotak kuantisasi. Beginilah kronologi tatanan cara aliran itu dipraktikkan:
- Sang Master Tertinggi ber-Takhta di Singgasana Mewah: Bobot utama sang “Master” yang diasuh oleh tangan tuhan (Sang Optimizer) wajib dibiarkan tak tersentuh menetap di kursi mahligai tahta akurasi mutlak,
FP32. - Siksaan Kuantisasi Halusinasi (Simulated): Namun di saat mesin disuruh berlari untuk berpikir (forward pass), takhta suci FP32 Master itu disambar guntur dan angkanya disusut-paksa menjadi balok sangat miskin yaitu format memori
FP4. - Penggelembungan Palsu saat Perang Pecah: Sebelum angka-angka super pelit FP4 ini dipersilahkan menabrak mesin cacah giling (Tensor Core), wujud menyedihkan dari nilai-nilai FP4 ini secara dadakan disentuh dan digelembungkan (didekuantisasi) meledak seketika menjadi angka utuh berukuran besar ke dalam saku
FP8.
Lalu, mengapa para petinggi menyebut sulap tipu daya pengembalian data ini bersifat Lossless (Aman tidak ada yang hilang tertinggal setetes pun)? Jawabannya bersarang merdu di dalam relung keutamaan angka bit-nya. Format FP8 (E4M3) milik panji armada DeepSeek secara legal dikaruniai kemewahan berupa 4 bit kotak jatah Pangkat. Bandingkan secara sepihak dengan kotak format FP4 (E2M1) yang malang, yang mana pangkatnya dipancung menyisakan cuma porsi 2 bit Pangkat semata. Hal ganjil inilah yang menjadi juru selamat: oleh karena FP8 terlahir sudah membawa keunggulan ekstra turunan genetik sebanyak 2 tambahan kotak bit pangkat, alhasil daya jangkauan muat (dynamic range) perut si FP8 ini tak ubahnya lautan tak bertepi jika disandingkan dengan FP4.
Oleh konklusi matematis luhur tersebut, manuver perombakan (dekuantisasi) angka dari status FP4-ditarik-mulur-menjadi-FP8 bersifat absolut dan paripurna tanpa cacat kerugian sedikit pun (Lossless). Asalkan jarak (rasio kesenjangan) antara angka kompresi ekstrem paling jumbo dengan angka yang paling cebol dari rombongan blok tile mungil (sebesar keramik ubin 1 x 32) milik penghuni saku FP4 saat mau disisipkan masuk diselundupkan ke dalam kotak koper induk (skala kuantisasi balok FP8 raksasa berukuran tile 128 x 128), tidak berani menabrak rambu ukur (batas ambang matematika) yang dihalalkan, niscaya kehalusan rincian presisi mikro dari jiwa data FP4 ini akan disedot dan diserap seutuhnya dengan sangat presisi, absolut serta direpresentasikan sempurna tanpa lecet segores pun oleh perut si besar nan luas milik jangkauan dinamis sang FP8.
Ritual Pembelajaran Mundur Serta Titik Puncak Penggunaan Praktik (Inference)
Selagi gelaran ritual amukan pembalasan mundur (Backward Pass), angka tuntutan teguran (Gradients) akan dicetak berpatokan pada tingkah dosa laku bobot FP8 tiruan (yang beraksi di sesi maju). Rapor cacat teguran ini secara serampangan lalu disetor merambat balik guna memberikan cambukan tuntutan revisi lurus langsung menghujam raga suci dari si Bobot Sang Master (FP32). Ritual ini secara keilmuan matematika menyamai gelar jurus keramat “Straight-Through Estimator” (STE) / Estimator Tembus Langsung yang mana ilmunya secara mistis menerabas batas lorong dimensi operasi pengecilan (kuantisasi), demi menghindari kepanikan harus menimang dan merakit-kalkulasi ulang teka-teki memutar-balik matriks wujud siluman dari bobot yang baru dikerucutkan.
Dan pada ujung garis penantian persembahan produk jadi (Inference and Deployment), yakni tatkala AI dipakai wujud utuh di alam nyata yang bebas dari kegiatan proses mundur evaluasi (Backward pass), maka model AI ini sungguh-sungguh dipersenjatai mutlak menggunakan senapan matriks murni cetakan mesin dari Bobot Kuantisasi FP4 tulen (tidak lagi mensimulasikan kepalsuan FP4 ala QAT tadi). Praktek nekat bin brilian ini secara jantan mengunci bahwa pola sifat/tingkah gila AI tersebut tatkala bersimulasi dan disiksa di padepokan latihan, 100% presisi identik sama perawakannya ketika sang AI telah diterjunkan terjun langsung menghirup atmosfer alam pemakaian nyata secara live, sambil merengkuh lonjakan angka balapan porsi daya asupan yang maha dahsyat dalam bentuk pemakasan irit bujet kepingan GPU RAM Hardware yang diwajibkan dalam menerbangkan proyek Frontir AI dunia!
5.7 Ringkasan
- Menebak Multi-Token/Banyak Kata Sekaligus (MTP): Sangat meningkatkan kehebatan penyedotan ilmu/data pelatihan (efisiensi data) dengan mengajari otak untuk menebak lautan rentetan angka masa depan dalam satu tembakan bersama, merestui sinyal siraman gradien (koreksi error) yang jauh lebih meresap padat agar AI paham koherensi masa depan.
- Garis objektif sistem hukuman MTP diam-diam memprioritaskan ajaran bagi AI untuk berani dan jeli mewaspadai “Titik Penentuan Pilihan” (Choice points), yakni pergeseran fatal di mana pola kata berubah tajam dalam narasi cerita, memuluskan pembentukan intuisi perencanaan matang murni pada insting si robot.
- Bentuk kreasi Rantai MTP DeepSeek ini membimbing asah ketajaman wawasan masa lalu (Hidden state) AI kita secara estafet (Kausal). Di sini, tebakan nasib kata satu ke depan dijadikan fondasi wahyu penerawangan langkah berikutnya, sehingga memancarkan sebuah aura mantra alat peramal berantai masa depan yang sukar dipatahkan.
- Kuantisasi (Pengkerdilan Ukuran Data): Adalah ritual pengorbanan yang sifatnya fardhu ain/wajib bagi kegiatan meracik otak (pelatihan AI skala raksasa). Caranya dengan memberangus serakahnya porsi kuota makan ruang giga memori maupun mengiris harga tarif komputasi, yang dicapai dengan cara memeras dan mengkompres serangkaian deret angka berbobot ber-presisi tajam menyusut rontok menuju saku-saku format kelas presisi paling rendahan (Kotak kecil misal 8-bit).
- Kerangka pondasi agung taktik FP8 DeepSeek, dibangun dan disusun menyatu menggunakan taktik Presisi Campuran: memperalat budak rendahan (Low Precision) untuk menggali semua kerjaan kasar berhitung kalkulasi gila-gilaan, selagi di satu waktu ia menjebloskan jajaran penguasa ringkih elit yang super sensitifnya selangit—seperti arsip bobot para sang Guru Besar/Master atau manuskrip hitungan mesin Pemandu Sang Optimizer—ke perlindungan benteng pertahanan Presisi kelas sultan tingkat tertinggi (FP32) agar sistem pikiran AI tetap tidak sinting selama diguncang krisis.
- Kuantisasi Pengecilan Potongan Detail Sebagian (Fine-Grained): Untuk meringankan penderitaan jatuhnya korban kemurnian angka presisi karena digencet nilai Pencilan (Outlier/Monster besar), DeepSeek menyicil secara parsial dengan membuat patokan Rumus Angka Skala sendiri-sendiri, dikhususkan untuk potongan-potongan ubin kelompok gerbong terkecil dari deretan nilai input (Aktivasi) dan papan Bobot. Strategi sakti ini menjaga kualitas dan sumbangsih integritas detail setiap angka sekecil pun agar aman terpelihara tetap tajam terukir hingga lapis area sempit nan di batas pojokan tingkat selurahan lokal RT/RW-nya.
- Mendongkrak Akurasi Penjumlahan (Increasing Accumulation): Sistem AI buatan China ini memaksa memboyong para produk tebakan berhitung paruh waktu (intermediate results) untuk dimutasi kabur secepat kilat meninggalkan rawa-rawa penuh genangan lumpur unit pemroses tak bermutu Tensor Cores, lalu menjinjing mereka dipindahtugaskan untuk dieksekusi dengan kesucian martabat absolut oleh jenderal penghitung super mewah (CUDA Cores). Semua total rekap sisa penjumlahan akan ditambahkan sempurna memakai fasilitas bak mandi perak Presisi Penuh, tanpa satu angka koma debu pecahan tercecil pun dibuang terbuang sia-sia masuk ke selokan jurang Underflow.
- Lebih Sayang ke Nilai Rincian (Mantissa) Melampaui Batas Kemampuan Jangkauan Pangkat (Exponents): Karena mesin Fine-Grained (Pilar ke-2) telah menihilkan kutukan nilai Pencilan Monster secara lokal area, DeepSeek berani mati berseragam menggunakan secara tunggal Format
E4M3yang dikenal paling pelit batasan kemampuannya—namun teramat pelit sekaligus amat mulia merawat rincian nilai di balik angka komanya. Format detail langka ini digenjot terus saat roda mobil AI digas untuk maju (Forward) atau disiksa ditabrak di-rem ketika disuruh Mundur (Backward), secara merata tak pandang bulu di seluruh kancah pelatihan tanpa ganti kostum. - Pengecilan Dadakan Spontan (Online Quantization): Mesin giling pembuat angka Skala dari DeepSeek dihitung segar meronta hidup-hidup (Dadakan real-time / Online) berbasis rekap daftar data porsi di jam tersebut juga. DeepSeek muntah dan pantang memakai contek menyontek nilai usang rekor sejarah kloter kemarin. Aturan gila spontan dadakan inilah tameng yang diandalkan menjauhkan mereka dari amarah dan goncangan turbulensi kehancuran sistem memori tak-proporsional gara-gara berhalusinasi salah pakai referensi Skala Jadul.
- QAT (Pelatihan Sadar Dikuantisasi) menggunakan kerdil sakti FP4: Pada seri mutakhir generasi V4 mereka, ambang sakral tembok pembatas memori ditembus dipalu hancur lebur lebih biadab lagi dengan cara mengecilkan bobot otak pakar/ahli (
MoE Expert Weights) secara diskriminatif beserta dengan perampasan aset lintasanQK Attention Renggangsupaya ditekan dan diperbudak turun merosot menuju titik absolut kemiskinan4-bit (FP4). Inovasi murtad tapi sangat ajaib ini memanfaat-gunakan pesona mutlak tanpa kehilangan serpihan nyawa data sedebu pun dari taktik mukjizat transisi dekode “FP4-ditarik-balik-ke-FP8” (lossless FP4-to-FP8 dequantization trick) yang seutuhnya berdiri murni beralaskan landasan celah teori Hukum Jarak Jangkauan Dinamis Angka (Dynamic Range).