lmvr-12
- 12.1. Pengantar Pelatihan yang Efisien
- 12.2. Paralelisme dan Konkurensi di Rust
- 12.3. Teknik Pelatihan Terdistribusi
- 12.4. Akselerasi Perangkat Keras dan Optimalisasi
- 12.5. Algoritma Optimasi untuk Pelatihan yang Efisien
- 12.6. Profiling dan Pemantauan Kinerja Pelatihan
- 12.7. Studi Kasus dan Aplikasi
- 12.8. Kesimpulan
Bab 12: Teknik Pelatihan yang Efisien
“Efisiensi dalam pelatihan AI bukan hanya tentang komputasi yang lebih cepat—ini tentang algoritma yang lebih cerdas, manajemen sumber daya yang lebih baik, dan optimalisasi inovatif yang mendorong batas-batas dari apa yang mungkin dilakukan.” — Andrew Ng
Bab 12 dari LMVR menggali teknik dan strategi untuk melatih model bahasa besar secara efisien menggunakan Rust. Bab ini dimulai dengan menekankan pentingnya pemanfaatan sumber daya, waktu, dan biaya dalam proses pelatihan, memperkenalkan konsep-konsep kunci seperti paralelisme, pelatihan terdistribusi, dan akselerasi perangkat keras. Ini mencakup implementasi paralelisme dan konkurensi di Rust, mengeksplorasi strategi pelatihan terdistribusi, dan mendiskusikan optimalisasi khusus perangkat keras, termasuk integrasi GPU dan TPU. Bab ini juga memeriksa peran algoritma optimasi, profiling, dan pemantauan waktu nyata dalam meningkatkan efisiensi pelatihan. Melalui implementasi praktis dan studi kasus, bab ini memberikan panduan komprehensif untuk memanfaatkan fitur-fitur Rust demi pelatihan LLM yang skalabel dan efisien.
12.1. Pengantar Pelatihan yang Efisien
Pelatihan yang efisien dari model bahasa besar (LLM) sangat penting untuk mengoptimalkan pemanfaatan sumber daya, mengurangi biaya, dan meminimalkan waktu pelatihan. Seiring bertambahnya ukuran dan kompleksitas LLM, sumber daya yang dibutuhkan untuk pelatihan, termasuk perangkat keras, waktu, dan energi, meningkat secara eksponensial. Praktik pelatihan yang efisien memastikan bahwa sumber daya ini digunakan secara strategis, menyeimbangkan tuntutan komputasi dengan batasan anggaran dan waktu. Bab ini memperkenalkan konsep efisiensi kritis seperti paralelisme, pelatihan terdistribusi, dan akselerasi perangkat keras, yang masing-masing memainkan peran penting dalam mempercepat proses pelatihan tanpa mengorbankan kinerja model. Dalam konteks Rust, yang dioptimalkan untuk kecepatan dan efisiensi memori, penerapan teknik-teknik ini sangat berdampak, karena kontrol tingkat rendah Rust memungkinkan pengembang untuk memaksimalkan kemampuan perangkat keras dari GPU, TPU, atau bahkan CPU multi-core, menjadikannya sangat cocok untuk lingkungan pelatihan berkinerja tinggi.
 Gambar 1: Optimalisasi pelatihan LLM.
Gambar 1: Optimalisasi pelatihan LLM.
Melatih LLM membutuhkan penanganan dataset yang sangat besar dan arsitektur model yang rumit yang intensif secara komputasi dan menuntut skalabilitas tinggi. Paralelisme, misalnya, sangat penting dalam memecah beban kerja pelatihan di beberapa prosesor, memungkinkan model dilatih pada subset data yang berbeda atau bagian dari arsitektur model secara bersamaan. Dalam paralelisme data, model yang sama dilatih pada batch data yang terpisah di beberapa perangkat, menyinkronkan gradien setelah setiap langkah untuk memastikan konsistensi. Sebaliknya, paralelisme model membagi model itu sendiri di berbagai perangkat, sehingga layak untuk melatih model yang melebihi kapasitas memori satu perangkat. Pelatihan terdistribusi melangkah lebih jauh, menskalakan di seluruh kluster perangkat atau node, yang penting untuk melatih LLM terbesar dengan miliaran parameter. Manajemen memori dan dukungan konkurensi Rust memberikan keunggulan dalam menerapkan teknik-teknik ini, karena memastikan komunikasi latensi rendah yang andal antar perangkat dan alokasi memori yang efisien untuk paralelisme data dan partisi model.
Terdapat trade-off yang inheren antara kecepatan pelatihan dan akurasi model. Mengurangi waktu yang dibutuhkan untuk pelatihan sering kali melibatkan penyesuaian seperti ukuran batch yang lebih kecil atau format presisi yang lebih rendah, yang dapat menimbulkan tantangan dalam konvergensi model atau menurunkan akurasi. Namun, teknik optimasi yang efisien dapat membantu menjaga keseimbangan, memungkinkan pelatihan kecepatan tinggi tanpa mengorbankan kinerja. Teknik-teknik seperti pelatihan presisi campuran (mixed-precision training), yang menggunakan format data presisi tinggi dan rendah, mengurangi kebutuhan memori dan meningkatkan kecepatan pemrosesan. Selain itu, teknik akumulasi gradien tingkat lanjut memungkinkan pelatihan batch besar yang efektif tanpa memerlukan memori yang luas. Dengan memahami trade-off ini, pengembang dapat menyesuaikan proses pelatihan untuk memenuhi persyaratan khusus mereka, mengoptimalkan kecepatan, akurasi, atau keseimbangan keduanya.
Optimalisasi yang sadar perangkat keras (hardware-aware optimization) juga penting dalam pelatihan yang efisien, terutama untuk memanfaatkan GPU dan TPU. Prosesor ini dioptimalkan untuk komputasi paralel, yang esensial untuk operasi matriks yang mendasari pelatihan LLM. Kompatibilitas Rust dengan CUDA untuk GPU dan XLA (Accelerated Linear Algebra) untuk TPU menyediakan kerangka kerja untuk memanfaatkan akselerasi perangkat keras ini secara efektif. Dengan menyesuaikan kode untuk bekerja dalam kekuatan arsitektural GPU dan TPU, pengembang dapat memastikan bahwa setiap operasi berjalan seefisien mungkin. Pendekatan sadar perangkat keras ini sangat berharga untuk LLM, di mana operasi floating-point yang ekstensif dapat memperoleh manfaat dari eksekusi yang diparalelkan dan inti pemrosesan data khusus pada GPU dan TPU. Kemampuan Rust yang berkinerja tinggi memungkinkan komputasi ini berjalan lancar, mengurangi waktu pelatihan keseluruhan dan meningkatkan throughput.
Menyiapkan lingkungan yang dioptimalkan untuk pelatihan LLM yang efisien melibatkan pemilihan pustaka tertentu dan konfigurasi toolchain untuk performa. Kode Python berikut mendemonstrasikan loop pelatihan jaringan saraf sederhana menggunakan PyTorch, yang setara dengan penggunaan tch-rs di Rust.
Contoh Python: Loop Pelatihan Sederhana (PyTorch)
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# Model Sederhana
class SimpleModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(SimpleModel, self).__init__()
self.weight = nn.Parameter(torch.randn(input_dim, output_dim))
def forward(self, x):
# Operasi perkalian matriks
return torch.matmul(x, self.weight)
# Dataset Sintetis
class SyntheticDataset:
def __init__(self, num_samples, input_dim, target_dim):
self.num_samples = num_samples
self.input_dim = input_dim
self.target_dim = target_dim
def get_batch(self, batch_size):
for _ in range(self.num_samples // batch_size):
inputs = torch.randn(batch_size, self.input_dim)
targets = torch.randn(batch_size, self.target_dim)
yield inputs, targets
def main():
input_dim = 10
target_dim = 10
model = SimpleModel(input_dim, target_dim)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.MSELoss()
dataset = SyntheticDataset(1000, input_dim, target_dim)
# Pelatihan dengan pemrosesan batch
for epoch in range(10):
for inputs, targets in dataset.get_batch(32):
# Forward pass
predictions = model(inputs)
loss = criterion(predictions, targets)
# Backward pass dan optimasi
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch} selesai")
if __name__ == "__main__":
main()
Mengidentifikasi hambatan (bottlenecks) dalam proses pelatihan sangat penting untuk optimalisasi. Dalam Rust, pengembang dapat memanfaatkan alat profiling untuk mengidentifikasi area di mana pemrosesan melambat, seperti alokasi memori yang tidak efisien, penundaan I/O, atau overhead komunikasi CPU-GPU. Kontrol memori Rust memungkinkan pengembang untuk menyetel transfer data dan sinkronisasi perangkat secara halus, merampingkan pipeline pelatihan dan memastikan throughput yang konsisten di seluruh perangkat keras.
Penggunaan efisien dari teknik pelatihan di berbagai sektor seperti kesehatan dan keuangan menunjukkan dampak nyata dari metode ini. Misalnya, perusahaan yang mengembangkan sistem rekomendasi berbasis bahasa dapat memperoleh manfaat dari pelatihan yang dipercepat untuk menyertakan preferensi pengguna terbaru. Tren pelatihan yang efisien menekankan pada penggunaan presisi campuran dan paralelisme terdistribusi, yang didukung dengan baik oleh pustaka berkinerja tinggi.
Sebagai kesimpulan, pelatihan LLM yang efisien melibatkan pendekatan strategis yang menyeimbangkan pemanfaatan sumber daya, akurasi, dan skalabilitas. Kontrol tingkat rendah Rust menjadikannya unik untuk mengembangkan lingkungan pelatihan berkinerja tinggi yang skalabel.
12.2. Paralelisme dan Konkurensi di Rust
Paralelisme dan konkurensi sangat penting dalam mempercepat pelatihan model besar dengan memungkinkan beberapa komputasi diproses secara bersamaan. Paralelisme dalam pelatihan model melibatkan pemisahan data atau struktur model di beberapa unit pemrosesan. Konkurensi mengacu pada pengelolaan beberapa tugas dalam jangka waktu yang sama menggunakan operasi asinkron. Model konkurensi Rust, termasuk dukungannya untuk thread, sintaks async/await, dan iterator paralel, sangat cocok untuk tugas-tugas tersebut karena penekanannya pada keamanan dan performa.
Rust menyediakan berbagai alat seperti thread dan library seperti rayon dan tokio. Crate rayon menyederhanakan pemrosesan paralel dengan menawarkan iterator paralel yang memungkinkan distribusi pemrosesan batch yang efisien. Sementara itu, tokio menyediakan kerangka kerja yang kuat untuk tugas asinkron, yang sangat bermanfaat saat mengelola proses pelatihan terdistribusi.
Dalam paralelisme data, beberapa salinan dari model yang sama didistribusikan ke berbagai perangkat, dan masing-masing memproses batch data yang berbeda. Jika sebuah model $M$ dilatih pada data $D$, paralelisme data mendistribusikan batch $D_1, D_2, \ldots, D_n$ ke $n$ perangkat, di mana setiap perangkat menghitung gradien secara independen sebagai $\nabla M(D_i)$. Sebaliknya, paralelisme model membagi model itu sendiri di beberapa perangkat, yang berguna untuk melatih model yang melebihi kapasitas memori satu perangkat tunggal.
Berikut adalah contoh Python menggunakan multiprocessing untuk mensimulasikan paralelisme data, yang setara dengan penggunaan rayon di Rust.
Contoh Python: Pelatihan Paralel Sederhana (Multiprocessing)
import numpy as np
from multiprocessing import Pool
import time
# Parameter
INPUT_SIZE = 10
HIDDEN_SIZE = 5
BATCH_SIZE = 64
LEARNING_RATE = 0.01
EPOCHS = 10
class NeuralNetwork:
def __init__(self):
self.w1 = np.random.uniform(-1, 1, (INPUT_SIZE, HIDDEN_SIZE))
self.w2 = np.random.uniform(HIDDEN_SIZE, 1, (HIDDEN_SIZE, 1))
def train_batch(self, batch):
x_batch, y_batch = batch
# Forward pass (sederhana)
hidden = np.maximum(0, np.dot(x_batch, self.w1))
output = np.dot(hidden, self.w2)
# Simulasi kalkulasi gradien dan update (untuk tujuan demo)
error = output - y_batch
loss = np.mean(error**2)
return loss
def generate_data(n):
x = np.random.uniform(-1, 1, (n, INPUT_SIZE))
y = np.sum(x, axis=1, keepdims=True)
return x, y
def main():
x_train, y_train = generate_data(1000)
nn = NeuralNetwork()
# Menyiapkan batch
batches = []
for i in range(0, len(x_train), BATCH_SIZE):
batches.append((x_train[i:i+BATCH_SIZE], y_train[i:i+BATCH_SIZE]))
# Pelatihan Sekuensial
start = time.time()
for _ in range(EPOCHS):
for b in batches:
nn.train_batch(b)
print(f"Pelatihan sekuensial selesai dalam: {time.time() - start:.4f} detik")
# Pelatihan Paralel (Simulasi dengan Pool)
start = time.time()
with Pool(processes=4) as pool:
for _ in range(EPOCHS):
pool.map(nn.train_batch, batches)
print(f"Pelatihan paralel selesai dalam: {time.time() - start:.4f} detik")
if __name__ == "__main__":
main()
Paralelisme model adalah pendekatan esensial untuk melatih jaringan saraf besar yang tidak dapat masuk seluruhnya ke dalam satu perangkat. Dalam Python, kita bisa menggunakan threading untuk mensimulasikan pembagian beban kerja antar lapisan model secara paralel.
Contoh Python: Paralelisme Model (Manual Threading)
import torch
import threading
import time
def forward_layer_1(input_data, results, idx):
# Simulasi beban kerja Layer 1
time.sleep(0.01)
results[idx] = input_data * 2
def forward_layer_2(input_data, results, idx):
# Simulasi beban kerja Layer 2
time.sleep(0.01)
results[idx] = input_data + 5
def main():
data = torch.randn(10)
results = [None, None]
start = time.time()
# Menjalankan dua "bagian model" secara paralel
t1 = threading.Thread(target=forward_layer_1, args=(data, results, 0))
t2 = threading.Thread(target=forward_layer_2, args=(data, results, 1))
t1.start()
t2.start()
t1.join()
t2.join()
print(f"Hasil paralel: {results}")
print(f"Waktu eksekusi: {time.time() - start:.4f} detik")
if __name__ == "__main__":
main()
Penerapan paralelisme secara langsung berdampak pada waktu pelatihan dan pemanfaatan sumber daya. Dengan mendistribusikan data dan komponen model, proses pelatihan dapat selesai lebih cepat.
12.3. Teknik Pelatihan Terdistribusi
Pelatihan terdistribusi telah menjadi landasan untuk penskalaan LLM guna menangani dataset luas dan arsitektur yang sangat kompleks. Strategi utama meliputi paralelisme data, paralelisme model, dan paralelisme pipeline. Paralelisme data membagi dataset di berbagai node di mana setiap node memegang replika model. Paralelisme model membagi model itu sendiri. Paralelisme pipeline merantai bagian-bagian model di berbagai node, memproses data secara berurutan dalam mode pipeline.
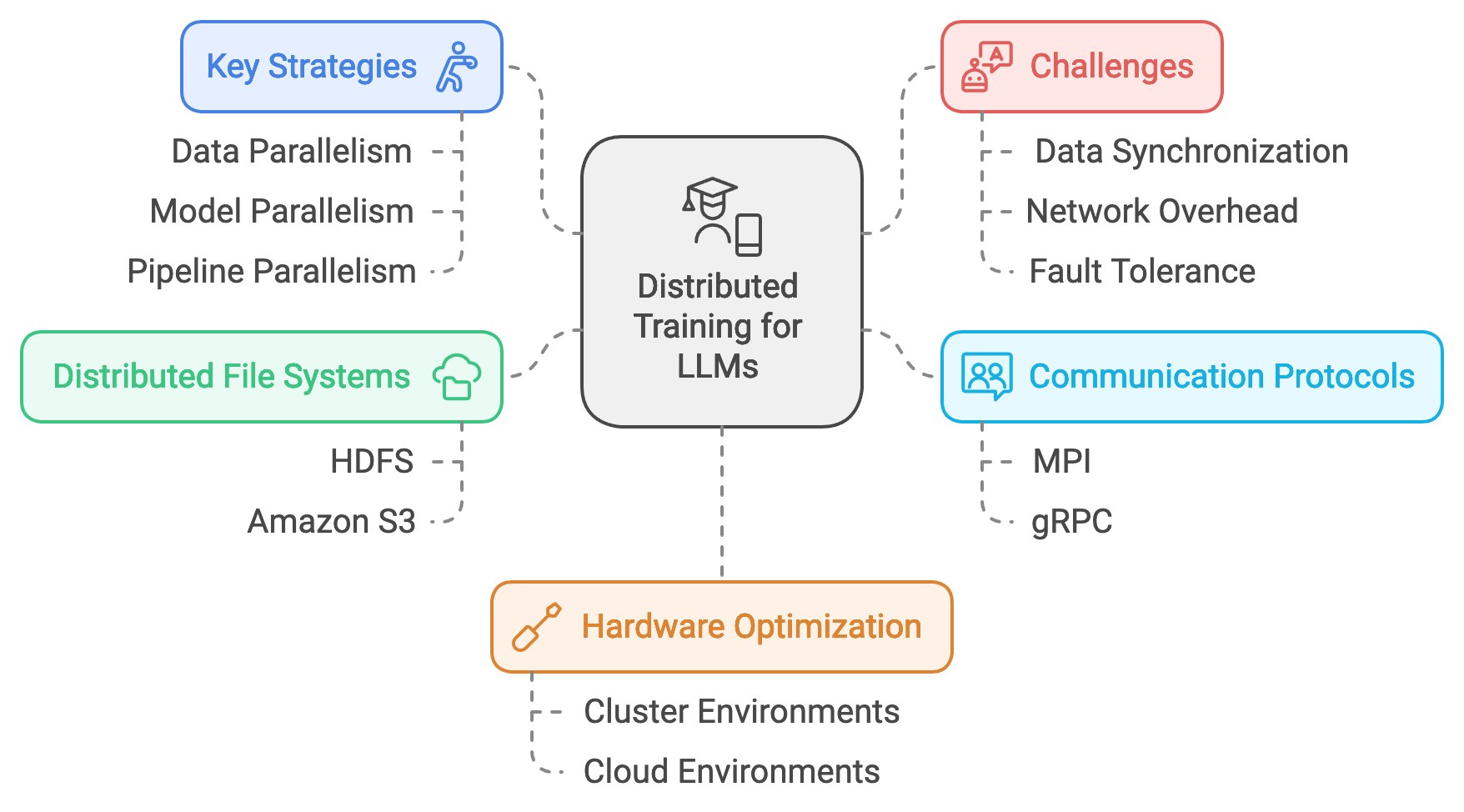 Gambar 2: Strategi pelatihan terdistribusi untuk LLM.
Gambar 2: Strategi pelatihan terdistribusi untuk LLM.
Protokol komunikasi seperti MPI (Message Passing Interface) dan gRPC (Google Remote Procedure Call) sangat penting untuk menyinkronkan data dan gradien antar node. Tantangan dalam pelatihan terdistribusi meliputi sinkronisasi data, overhead komunikasi jaringan, dan toleransi kesalahan (fault tolerance). Sistem file terdistribusi seperti HDFS atau Amazon S3 menyediakan solusi penyimpanan skalabel untuk akses data konkuren.
Berikut adalah simulasi sederhana pembagian parameter model di Python menggunakan pendekatan paralelisme model dasar.
Contoh Python: Simulasi Paralelisme Model dengan Gradien
import torch
import torch.nn as nn
import torch.optim as optim
# Anggap kita punya dua perangkat (CPU dalam simulasi ini)
class DistributedModel(nn.Module):
def __init__(self):
super().__init__()
# Layer 1 berada di "perangkat 1"
self.layer1 = nn.Linear(10, 64)
# Layer 2 berada di "perangkat 2"
self.layer2 = nn.Linear(64, 1)
def forward(self, x):
h = torch.tanh(self.layer1(x))
return self.layer2(h)
def main():
model = DistributedModel()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Simulasi data
inputs = torch.randn(32, 10)
targets = torch.randn(32, 1)
# Pelatihan satu langkah
outputs = model(inputs)
loss = nn.MSELoss()(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Loss pelatihan: {loss.item():.4f}")
if __name__ == "__main__":
main()
Menerapkan setup pelatihan terdistribusi pada kluster berbasis cloud memungkinkan skalabilitas dan evaluasi dalam lingkungan produksi. Tren saat ini fokus pada paralelisme hibrida, menggabungkan data, model, dan paralelisme pipeline untuk mengoptimalkan penggunaan sumber daya.
12.4. Akselerasi Perangkat Keras dan Optimalisasi
Akselerasi perangkat keras memainkan peran esensial dalam melatih LLM, di mana GPU, TPU, dan akselerator kustom menyediakan kekuatan komputasi untuk operasi matriks intensif. Teknik optimalisasi sadar perangkat keras seperti penggabungan kernel (kernel fusion), pelatihan presisi campuran, dan manajemen memori diterapkan untuk memaksimalkan pemanfaatan sumber daya.
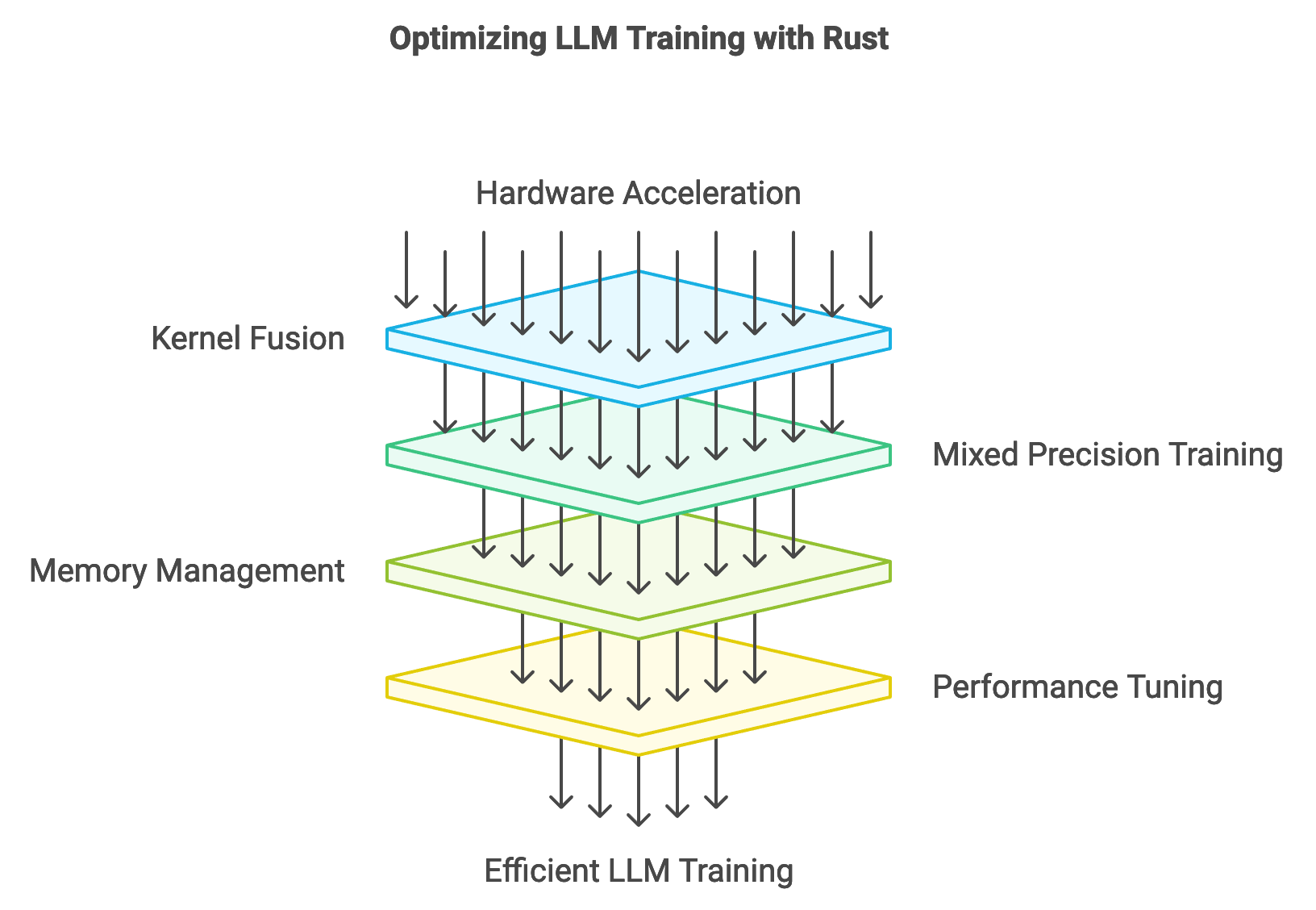 Gambar 3: Strategi akselerasi perangkat keras untuk pelatihan LLM.
Gambar 3: Strategi akselerasi perangkat keras untuk pelatihan LLM.
Kernel fusion menggabungkan beberapa langkah komputasi menjadi satu kernel tunggal untuk mengurangi latensi akses memori. Mixed precision training mengurangi penggunaan sumber daya dengan menggabungkan tipe data presisi rendah (FP16) dengan tipe presisi tinggi (FP32).
Pelatihan presisi campuran memanfaatkan operasi FP16 untuk pass maju guna mengoptimalkan memori dan kecepatan, sementara pass mundur (kalkulasi gradien) tetap dalam FP32 untuk menjaga stabilitas numerik. Berikut adalah cara mengimplementasikannya di Python menggunakan modul amp dari PyTorch.
Contoh Python: Pelatihan Presisi Campuran (Automatic Mixed Precision)
import torch
import torch.nn as nn
from torch.cuda.amp import autocast, GradScaler
def train_mixed_precision():
# Pastikan GPU tersedia
device = "cuda" if torch.cuda.is_available() else "cpu"
model = nn.Linear(128, 10).to(device)
optimizer = torch.optim.Adam(model.parameters())
scaler = GradScaler() # Menangani loss scaling
inputs = torch.randn(64, 128).to(device)
targets = torch.randn(64, 10).to(device)
for epoch in range(10):
optimizer.zero_grad()
# Forward pass dengan autocast
with autocast():
outputs = model(inputs)
loss = nn.MSELoss()(outputs, targets)
# Backward pass dengan scaler
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
print("Pelatihan presisi campuran selesai.")
if __name__ == "__main__":
# train_mixed_precision()
pass
Optimalisasi ini tidak hanya meningkatkan performa tetapi juga berkontribusi pada adopsi bahasa sistem dalam pembelajaran mesin, memposisikannya sebagai pilihan kompetitif untuk pengembangan AI yang efisien.
12.5. Algoritma Optimasi untuk Pelatihan yang Efisien
Algoritma optimasi sangat penting untuk melatih LLM guna menyesuaikan parameter model secara iteratif dan meminimalkan loss. Algoritma populer meliputi SGD, Adam, RMSprop, dan LAMB.
- Adam (Adaptive Moment Estimation): Menggabungkan momentum dan laju pembelajaran adaptif, sangat kuat untuk LLM.
- LAMB (Layer-wise Adaptive Moments for Batch Training): Dirancang untuk melatih model dengan batch yang sangat besar dengan menskalakan laju pembelajaran secara proporsional dengan norma lapisan.
Efisiensi juga dicapai melalui Learning Rate Schedules (seperti peluruhan eksponensial) dan Warm Restarts. Berikut adalah implementasi algoritma Adam dari nol di Python menggunakan NumPy.
Contoh Python: Implementasi Adam Optimizer (Dari Nol)
import numpy as np
class AdamOptimizer:
def __init__(self, params, lr=0.01, beta1=0.9, beta2=0.999, epsilon=1e-8):
self.params = params
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.m = {k: np.zeros_like(v) for k, v in params.items()}
self.v = {k: np.zeros_like(v) for k, v in params.items()}
self.t = 0
def step(self, grads):
self.t += 1
for k in self.params.keys():
self.m[k] = self.beta1 * self.m[k] + (1 - self.beta1) * grads[k]
self.v[k] = self.beta2 * self.v[k] + (1 - self.beta2) * (grads[k]**2)
m_hat = self.m[k] / (1 - self.beta1**self.t)
v_hat = self.v[k] / (1 - self.beta2**self.t)
self.params[k] -= self.lr * m_hat / (np.sqrt(v_hat) + self.epsilon)
# Contoh penggunaan
params = {'w': np.random.randn(10, 1)}
grads = {'w': np.random.randn(10, 1)}
opt = AdamOptimizer(params)
opt.step(grads)
LAMB (Layer-wise Adaptive Moments for Batch training) adalah algoritma optimasi tingkat lanjut yang sangat berguna untuk melatih LLM di mana ukuran batch melebihi batas tradisional, meningkatkan konvergensi dalam pelatihan terdistribusi.
Contoh Python: Logika LAMB Sederhana (PyTorch)
import torch
def lamb_step(param, grad, m, v, t, lr, beta1, beta2, eps, wd):
t += 1
# Update moment
m = beta1 * m + (1 - beta1) * grad
v = beta2 * v + (1 - beta2) * grad.pow(2)
m_hat = m / (1 - beta1**t)
v_hat = v / (1 - beta2**t)
# Kalkulasi update
update = m_hat / (torch.sqrt(v_hat) + eps) + wd * param
# Layer-wise adaptation
w_norm = torch.norm(param)
u_norm = torch.norm(update)
trust_ratio = 1.0
if w_norm > 0 and u_norm > 0:
trust_ratio = w_norm / u_norm
param.data -= lr * trust_ratio * update
return m, v, t
Sebagai kesimpulan, algoritma optimasi adalah bagian integral dari pelatihan LLM yang efisien. Dengan menyeimbangkan kecepatan konvergensi, akurasi, dan efisiensi sumber daya, LLM dapat dilatih secara optimal untuk aplikasi industri.
12.6. Profiling dan Pemantauan Kinerja Pelatihan
Profiling dan pemantauan adalah komponen penting untuk mengidentifikasi hambatan dan mengoptimalkan pipeline pelatihan. Dengan mengamati metrik seperti penggunaan memori, utilisasi CPU/GPU, dan kinerja I/O, pengembang dapat membuat keputusan berbasis data.
Profiling memori sangat penting untuk LLM. Permintaan memori total $M_{total}$ dapat dinyatakan sebagai jumlah kebutuhan lapisan individu $M_i$: \(M_{total} = \sum_{i=1}^n M_i\)
Alat seperti visualisasi flamegraph membantu menunjukkan fungsi mana yang paling banyak mengonsumsi sumber daya. Pemantauan waktu nyata (real-time monitoring) melengkapi hal ini dengan menyediakan pembaruan berkelanjutan tentang kemajuan pelatihan, memperingatkan pengembang tentang masalah seperti lonjakan loss atau penggunaan memori berlebih.
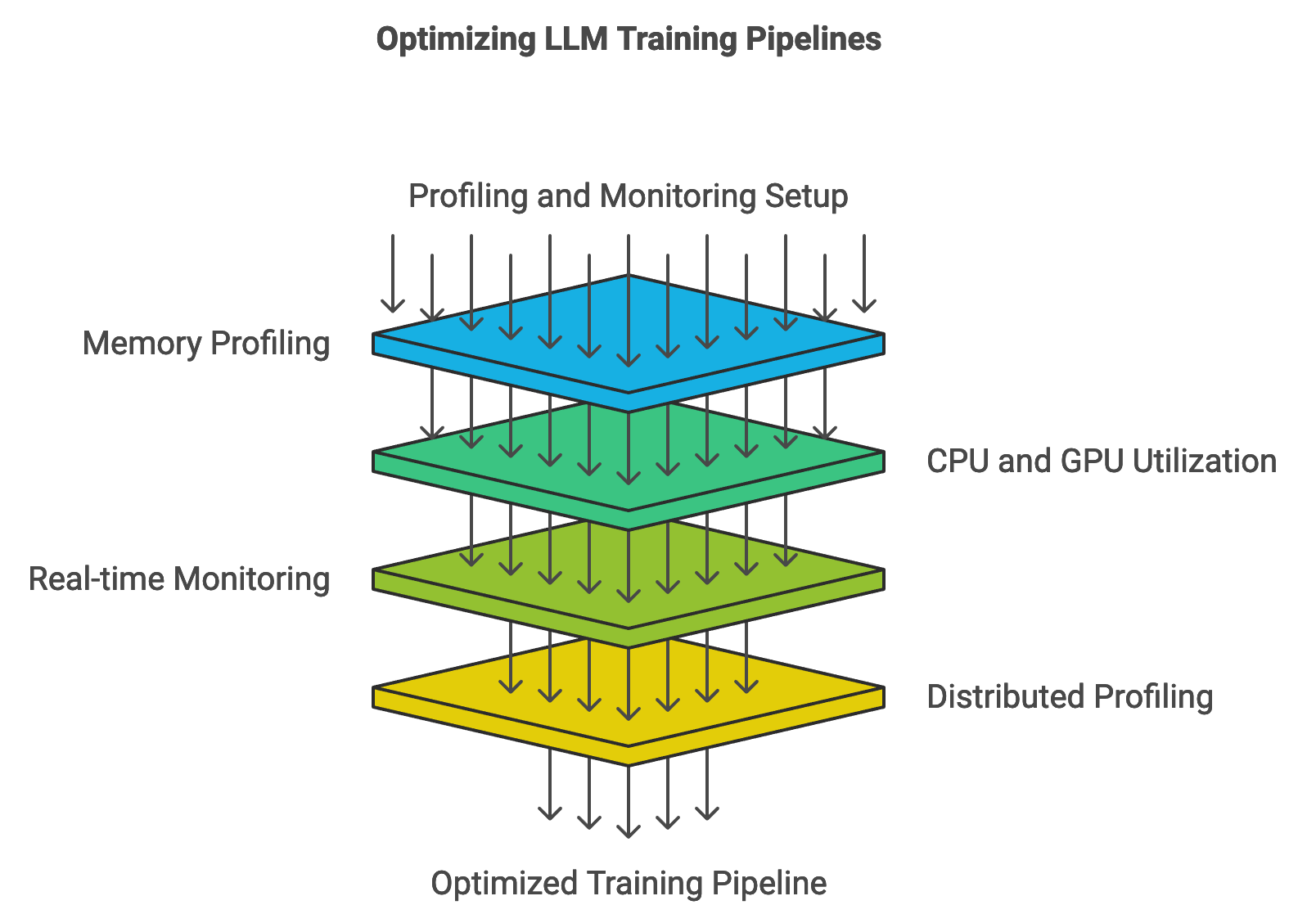 Gambar 4: Strategi optimalisasi untuk pelatihan LLM.
Gambar 4: Strategi optimalisasi untuk pelatihan LLM.
Berikut adalah kode Python yang menggunakan logger untuk melacak metrik selama pelatihan.
Contoh Python: Pemantauan Pelatihan dengan Logging
import logging
import time
import torch
# Konfigurasi logging
logging.basicConfig(level=logging.INFO, format='%(message)s')
logger = logging.getLogger()
def train_with_monitoring(epochs):
model = torch.nn.Linear(10, 1)
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(epochs):
start_time = time.time()
# Simulasi data
inputs = torch.randn(32, 10)
targets = torch.randn(32, 1)
optimizer.zero_grad()
outputs = model(inputs)
loss = torch.nn.functional.mse_loss(outputs, targets)
loss.backward()
optimizer.step()
duration = time.time() - start_time
# Log metrik secara real-time
logger.info(f"Epoch: {epoch}, Loss: {loss.item():.4f}, Durasi: {duration:.4f}s")
if __name__ == "__main__":
train_with_monitoring(5)
Pemantauan membantu mendeteksi model drift atau ketidakstabilan gradien lebih awal. Dashboard seperti Grafana dapat digunakan untuk memvisualisasikan log ini, menawarkan pandangan komprehensif tentang kesehatan pelatihan.
12.7. Studi Kasus dan Aplikasi
Eksplorasi teknik pelatihan yang efisien telah memungkinkan terobosan dalam penyebaran LLM di berbagai sektor:
- Kesehatan: Pelatihan model diagnostik pada dataset pasien yang besar menggunakan paralelisme data dan presisi campuran untuk memenuhi persyaratan latensi dan privasi yang ketat.
- Keuangan: Penerapan model rekomendasi waktu nyata untuk analisis stok. Teknik kernel fusion dan pre-alokasi memori meningkatkan utilisasi GPU, menghasilkan pengurangan waktu transfer data sebesar 40%.
Studi kasus ini mengungkapkan bahwa pemilihan teknik optimasi yang tepat sangat bergantung pada persyaratan spesifik domain. Kekuatan kolaboratif dari komunitas sumber terbuka sangat penting dalam memajukan aplikasi ini, memungkinkan tim pengembang untuk fokus pada penyetelan halus alih-alih infrastruktur dasar.
Aplikasi masa depan dari metode ini dapat meluas ke bidang manufaktur, di mana pemantauan waktu nyata dan kontrol kualitas sangat penting untuk mendeteksi cacat produk secara cepat.
12.8. Kesimpulan
Bab 12 membekali pembaca dengan pengetahuan dan alat untuk mengoptimalkan pelatihan model bahasa besar. Dengan menguasai teknik pelatihan yang efisien ini, pembaca dapat secara signifikan meningkatkan skalabilitas, kecepatan, dan efektivitas biaya dari proyek AI mereka, memposisikan diri di garis depan pengembangan AI.
12.8.1. Pembelajaran Lebih Lanjut dengan GenAI
- Jelaskan pentingnya pelatihan yang efisien dalam konteks LLM dan tantangan utamanya.
- Deskripsikan proses penyiapan lingkungan yang dioptimalkan untuk pelatihan efisien.
- Diskusikan perbedaan antara paralelisme dan konkurensi serta cara memanfaatkannya.
- Jelajahi peran paralelisme data dan model dalam mengoptimalkan pelatihan.
- Analisis tantangan pelatihan terdistribusi (sinkronisasi data, overhead jaringan).
- Diskusikan pentingnya akselerasi perangkat keras (GPU, TPU).
- Jelaskan konsep pelatihan presisi campuran dan manfaatnya.
- Jelajahi peran algoritma optimasi seperti SGD, Adam, dan LAMB.
- Diskusikan signifikansi jadwal laju pembelajaran dan laju pembelajaran adaptif.
- Analisis trade-off antara teknik regularisasi yang berbeda (L2, dropout).
- Jelajahi tantangan profiling dan pemantauan kinerja pelatihan.
- Diskusikan metrik kunci yang harus dipantau selama pelatihan LLM.
- Jelaskan proses pengaturan pipeline pelatihan terdistribusi di cloud.
- Diskusikan peran protokol komunikasi seperti MPI dan gRPC.
- Analisis manfaat penggunaan model konkurensi untuk mengurangi waktu pelatihan.
- Jelajahi tantangan integrasi akselerator perangkat keras.
- Diskusikan peran kernel fusion dalam optimalisasi perangkat keras.
- Jelaskan proses implementasi gradient clipping dan weight decay.
- Analisis dampak pemantauan dan logging waktu nyata pada stabilitas pipeline.
- Diskusikan implikasi luas dari teknik pelatihan efisien untuk masa depan pengembangan LLM.
12.8.2. Latihan Praktis
Latihan Mandiri 12.1: Mengimplementasikan Paralelisme Data
Tujuan: Mendapatkan pengalaman praktis dalam membagi dataset di berbagai thread untuk mengoptimalkan proses pelatihan.
Latihan Mandiri 12.2: Penyetelan Halus Pipeline Pelatihan Terdistribusi
Tujuan: Membangun setup pelatihan yang dikoordinasikan di beberapa node menggunakan protokol gRPC.
Latihan Mandiri 12.3: Profiling dan Optimalisasi Kinerja
Tujuan: Menggunakan alat profiling untuk mengidentifikasi hambatan memori dan I/O, kemudian menerapkan perbaikan berdasarkan data tersebut.
Latihan Mandiri 12.4: Implementasi Pelatihan Presisi Campuran
Tujuan: Melatih LLM menggunakan aritmatika presisi rendah pada GPU dan menganalisis dampaknya terhadap penggunaan memori dan akurasi.
Latihan Mandiri 12.5: Mengembangkan Sistem Pemantauan Waktu Nyata
Tujuan: Merancang framework pemantauan yang melacak metrik utilisasi dan kerugian pelatihan, serta menyiapkan sistem peringatan otomatis.