Matematika pada Algoritma AI
- Pengantar Matematika pada Algoritma AI
- Matematika dalam Computer Vision (CV)
- Matematika dalam Computer Vision (CV): Apa Itu Computer Vision?
- Matematika dalam Computer Vision (CV): Memahami Citra sebagai Data Numerik
- Matematika dalam Computer Vision (CV): Analisis Fitur Citra Berbasis Statistik
- Matematika dalam Natural Language Processing (NLP)
- Matematika dalam Natural Language Processing (NLP): Pengenalan
- Matematika dalam Natural Language Processing (NLP): Visualisasi Distribusi Kata dengan WordCloud
- Matematika dalam Natural Language Processing (NLP): Representasi Frekuensi Kata (Bag-of-Words)
- Matematika dalam Natural Language Processing (NLP): TF-IDF: Memberi Bobot Kata
- Matematika dalam Natural Language Processing (NLP): Word Embedding
- Matematika dalam Natural Language Processing (NLP): Cosine Similarity
- Matematika dalam Time Series
- Matematika dalam Time Series: Komponen Statistik Time Series
- Matematika dalam Time Series: Stasioneritas: Asumsi Kritis untuk Inferensi
- Matematika dalam Time Series: Mengenal ACF & PACF
- Matematika dalam Time Series: Komponen Model ARIMA
- Matematika dalam Time Series: Membangun Model ARIMA
- Rangkuman Matematika pada Algoritma AI
Pengantar Matematika pada Algoritma AI
Sampai di titik ini, Anda sudah mempelajari banyak hal:
- mempelajari struktur dan karakteristik data–baik univariat maupun multivariat–beserta ukuran pemusatan dan penyebarannya dalam materi Data Univariat dan Multivariat;
- kemudian memahami konsep dasar probabilitas hingga Teorema Bayes yang esensial untuk mengukur ketidakpastian dalam materi Dasar-Dasar Probabilitas;
- lalu belajar berbagai jenis distribusi probabilitas dan penerapannya untuk memodelkan perilaku data dalam materi Distribusi Probabilitas;
- menaklukkan statistik inferensial, jembatan krusial yang memungkinkan kita menarik kesimpulan valid dari sampel menuju populasi;
- serta melakukan A/B testing untuk dapat memberikan rekomendasi strategi bisnis yang paling sesuai berdasarkan interpretasi hasil analisis data dan pengujian hipotesis dalam materi Studi Kasus A/B Testing dengan Python.
Sekarang, dengan fondasi matematika yang kokoh di tangan Anda, saatnya kita melangkah lebih jauh menuju inti dari sistem cerdas yang mengubah dunia: algoritma AI.
Sering kali, AI dipandang sebagai bidang yang murni komputasional atau hanya tentang “belajar” dari data secara ajaib. Namun, anggapan itu berbeda dengan kenyataan yang akan kita pelajari.
Bayangkan Anda ingin membangun sebuah sistem yang dapat mengenali wajah dari gambar, atau memahami makna dari kalimat yang diucapkan, atau bahkan memprediksi tren harga saham di masa depan. Algoritma di balik semua kemampuan luar biasa ini tidak lain adalah aplikasi canggih dari prinsip-prinsip matematika yang telah Anda pelajari.
- Bagaimana sistem mengukur tingkat keyakinannya terhadap suatu prediksi? Itu adalah probabilitas.
- Bagaimana sistem menangani variasi dan ketidakpastian? Itu adalah konsep distribusi.
- Bagaimana sebuah sistem “belajar” pola dalam data? Itu adalah proses estimasi statistik.
Pada materi ini, kita akan membongkar “kotak hitam” AI dan melihat bahwa statistika menjadi bahasa universal yang menjelaskan dan memandu setiap operasinya.
Kita akan secara spesifik menelaah hal berikut.
- Computer Vision (Metode Filtering): Filter gambar, yang esensial untuk mendeteksi tepi atau mengurangi noise, secara fundamental adalah operasi statistik yang menganalisis perubahan distribusi intensitas piksel dan variansi lokal.
- Natural Language Processing (Metode Ekstraksi Fitur): Representasi bahwa teks seperti TF-IDF dan Word Embeddings bukan sekadar kode angka, melainkan cerminan cerdas dari probabilitas kemunculan kata, korelasi kontekstual, serta analisis statistik frekuensi.
- Time Series (ARIMA): Model prediksi deret waktu seperti ARIMA sepenuhnya dibangun di atas konsep proses stokastik, autokorelasi, dan inferensi statistik untuk memahami serta memproyeksikan pola data yang bergantung pada waktu.
Jadi, bersiaplah untuk memperdalam pemahaman Anda, tidak hanya tentang hal yang dilakukan algoritma AI, tetapi yang lebih penting: alasan dan cara statistika untuk melakukannya.
Ini akan memberdayakan Anda untuk tidak hanya menjadi pengguna AI, tetapi juga seorang data scientist yang dapat mengerti, berinovasi, dan bahkan mengembangkan algoritma AI dengan landasan statistik yang kuat.
Matematika dalam Computer Vision (CV)
Kita telah menuntaskan pembahasan fundamental statistika–sebagai salah satu cabang matematika–pada materi-materi sebelumnya, mulai dari struktur data univariat dan multivariat, memahami konsep dasar probabilitas yang membentuk dasar ketidakpastian, menyelami berbagai distribusi probabilitas untuk memodelkan fenomena data, hingga menguasai statistik inferensial yang krusial dalam menarik kesimpulan dari sampel ke populasi. Semua pengetahuan ini adalah fondasi esensial kita.
Sekarang, ayo kita coba aplikasikan pemahaman statistika tersebut pada salah satu domain kunci dalam AI: computer vision.

Sebuah gambar digital, yang kita lihat sebagai representasi visual, pada dasarnya adalah matriks besar berisi data numerik atau berupa kumpulan piksel dengan nilai intensitas atau warna tertentu. Data ini, layaknya data numerik lainnya, sering kali memerlukan pemrosesan untuk menghilangkan gangguan atau menonjolkan fitur penting agar dapat dianalisis secara efektif oleh mesin. Di sinilah metode filtering dalam pemrosesan citra memegang peranan krusial.
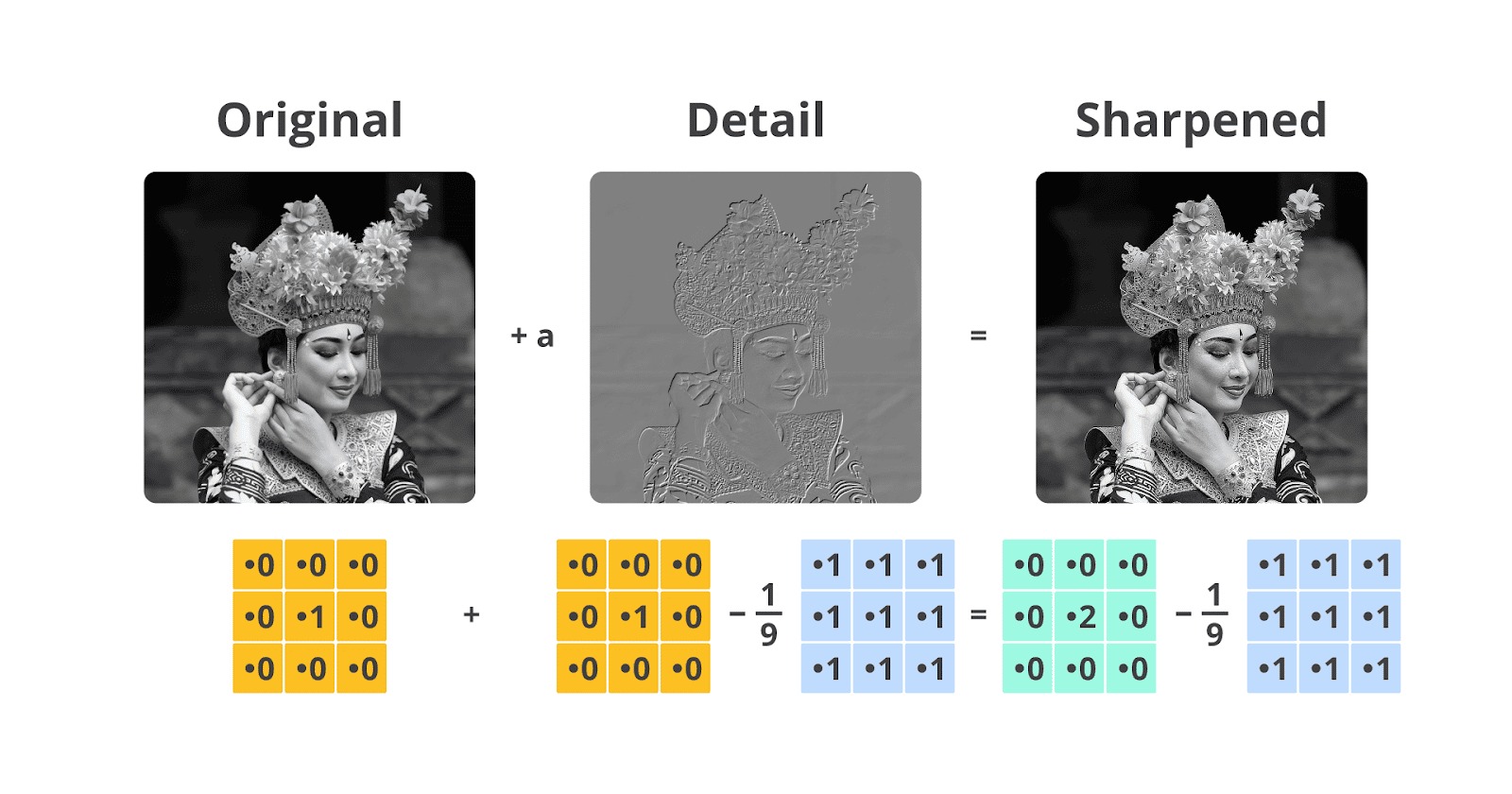
Anda mungkin telah familier dengan efek filter dalam aplikasi pengolahan gambar. Namun, apakah Anda memahami prinsip matematika yang mendasari operasi tersebut?
Tahukah Anda?
- Filter mampu menghaluskan noise dan secara presisi mendeteksi tepi objek melalui mekanisme pemrosesan spasial pada intensitas piksel.
- Setiap piksel dalam gambar dapat dimodelkan sebagai sampel acak dari suatu distribusi, sementara noise bisa direpresentasikan secara probabilistik sebagai penyimpangan dari distribusi tersebut.
- Operasi inti seperti konvolusi adalah bentuk rata-rata tertimbang atau pengukuran terhadap perbedaan statistik lokal antar piksel.
- Filter penghalus bekerja dengan cara mengurangi variansi lokal pada intensitas piksel, menyerupai pendekatan smoothing data dalam analisis statistik.
- Filter deteksi tepi mengestimasi gradien atau perubahan signifikan dalam distribusi intensitas piksel dengan menggunakan konsep turunan diskret yang merepresentasikan laju perubahan secara statistik.
Tenang, kita akan bedah istilah-istilah di atas dalam materi ini. Bersiaplah untuk melihat gambar bukan sebatas representasi visual, melainkan sebagai kumpulan data yang dapat diolah dan diinterpretasi melalui lensa statistik untuk mengungkap informasi tersembunyi.
Mari kita mulai eksplorasi.
Matematika dalam Computer Vision (CV): Apa Itu Computer Vision?
Computer vision (CV) adalah cabang dari bidang ilmu artificial intelligence (AI) untuk melatih komputer agar mampu “melihat” serta “memahami” dunia dari gambar dan video sebagaimana manusia melakukannya.
Tujuan utamanya bukan sekadar menampilkan gambar, melainkan untuk menginterpretasikan dan mengekstraksi informasi yang bermakna dari data visual tersebut.
Bayangkan saja kemampuan mata dan otak kita: mengenali wajah orang yang kita kenal, membaca tulisan pada papan reklame, membedakan berbagai jenis hewan, atau bahkan mengukur jarak benda dari kita. Computer vision berupaya mereplikasi kemampuan luar biasa tersebut pada lingkungan mesin.

Berbeda dengan data tekstual atau numerik biasa, CV bekerja dengan piksel. Setiap gambar atau frame video tersusun dari jutaan piksel, yakni masing-masing piksel memiliki nilai intensitas (untuk gambar hitam-putih) atau nilai warna (untuk gambar berwarna, misalnya red-green-blue atau RGB).
Dengan menganalisis pola, warna, bentuk, dan gerakan dari kumpulan piksel-piksel ini, komputer dapat “belajar” serta “memahami” hal yang sebenarnya terkandung dalam sebuah visual. Proses ini melibatkan banyak sekali perhitungan statistik untuk mengidentifikasi pola, mengukur kesamaan, dan membuat keputusan.
Implementasi computer vision mungkin terdengar rumit, tetapi faktanya, teknologi ini sudah meresap dalam berbagai aspek kehidupan kita sehari-hari, sering kali tanpa kita sadari.
- Pengenalan Wajah (Face Recognition)
Ini adalah salah satu aplikasi CV yang paling populer dan banyak digunakan. Contoh implementasinya sebagai berikut.- Membuka Kunci Smartphone: Anda cukup menatap layar ponsel dan dalam sepersekian detik, ponsel Anda terbuka. Sistem CV menganalisis fitur unik wajah Anda untuk memverifikasi identitas.
- Verifikasi Keamanan: Di bandara, stasiun, dan kantor; sistem CV dapat membandingkan wajah seseorang dengan database untuk memverifikasi identitas mereka.
- Tagging Otomatis pada Media Sosial: Ketika Anda mengunggah foto ke platform media sosial, sistem secara otomatis memberikan tag nama teman-teman Anda dalam foto.
- Mobil Otonom (Self-Driving Cars)
Computer vision bertindak sebagai “mata” utama bagi mobil tanpa pengemudi. Contoh implementasinya adalah berikut.- Deteksi Objek: Kamera pada mobil terus-menerus memindai lingkungan dan CV bertugas mendeteksi objek-objek penting, seperti mobil lain, pejalan kaki, pesepeda, serta hewan.
- Pengenalan Rambu Lalu Lintas dan Marka Jalan: CV membaca rambu “STOP”, “Belok Kiri”, atau mengenali garis putus-putus dan garis solid di jalan.
- Pelacakan Gerakan: Sistem melacak gerakan objek lain di sekitar mobil untuk memprediksi perilakunya dan mencegah tabrakan.
- Filter Media Sosial (Social Media Filters)
Pernah menambahkan telinga anjing, kacamata lucu, atau efek riasan virtual ke wajah Anda di Instagram, Snapchat, atau TikTok? Contoh implementasinya berikut.- CV mendeteksi dan melacak fitur-fitur penting pada wajah Anda secara real-time (misalnya, posisi mata, hidung, mulut, dan garis rahang).
- Setelah fitur-fitur ini terdeteksi, filter dapat menempatkan objek virtual dengan presisi tinggi, membuatnya terlihat menyatu dengan wajah Anda.
Pertanyaan menariknya, “Bagaimana computer vision bisa melakukan itu semua?”
Matematika dalam Computer Vision (CV): Memahami Citra sebagai Data Numerik
Kita telah melihat cara computer vision memungkinkan komputer “melihat” dan “memahami” dunia visual. Namun, bagaimana sebenarnya komputer melakukan itu?
Kuncinya terletak pada cara komputer memandang sebuah gambar: bukan sebagai representasi visual semata, melainkan sebagai kumpulan data numerik. Di sinilah statistika memegang peranan krusial dalam computer vision.
Setiap gambar digital yang kita lihat, dari foto dalam ponsel hingga frame video, pada dasarnya adalah kumpulan angka-angka (piksel). Bayangkan sebuah gambar sebagai lembaran kotak-kotak kecil yang sangat banyak. Setiap kotak kecil ini disebut piksel dan masing-masing piksel menyimpan nilai numerik yang mewakili intensitas cahaya atau warnanya.
- Pada citra grayscale (hitam-putih), setiap piksel memiliki satu nilai intensitas, biasanya dari 0 (hitam pekat) hingga 255 (putih terang).
- Untuk citra berwarna, seperti yang kita lihat sehari-hari, setiap piksel sebenarnya terdiri dari kombinasi tiga saluran warna dasar: merah (red), hijau (green), dan biru (blue), sering disebut RGB. Masing-masing saluran ini juga memiliki nilai intensitasnya sendiri (misalnya, dari 0 hingga 255) dan kombinasi ketiganya menghasilkan spektrum warna yang luas.
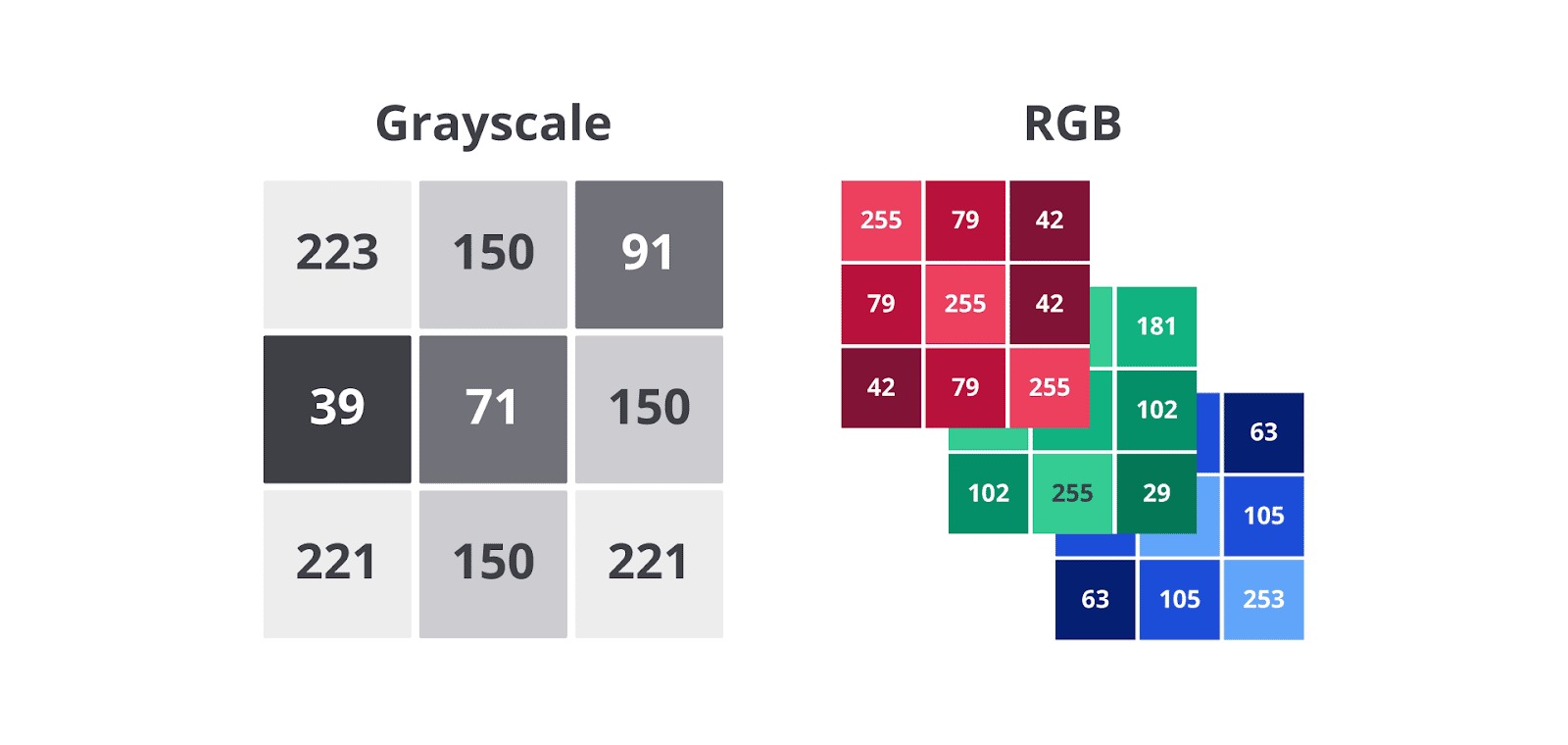
Karena sebuah gambar adalah kumpulan angka, semua alat dan konsep statistika yang telah kita pelajari menjadi sangat relevan. Kita dapat menggunakan statistika untuk hal-hal berikut.
- Menganalisis distribusi kecerahan atau warna dalam suatu area gambar. Misalnya, dengan menghitung rata-rata nilai piksel di sebuah area, kita bisa mengetahui seberapa terang area tersebut secara keseluruhan. Median bisa memberikan gambaran kecerahan yang lebih robust terhadap noise ekstrem, sementara modus bisa menunjukkan warna atau intensitas yang paling sering muncul.
- Menginterpretasi pola-pola yang tersembunyi dalam data piksel. Apakah ada area yang sangat bervariasi (memiliki variansi tinggi) yang menunjukkan adanya tepi atau tekstur? Atau apakah area tersebut sangat seragam?
- Mengekstrak informasi penting dari data citra. Statistik membantu kita mengidentifikasi fitur-fitur seperti tepi objek, tekstur permukaan, atau bahkan mengenali wajah, dengan mengukur dan memodelkan properti numerik dari kelompok piksel.
Dengan demikian, peran statistika sangat fundamental. Ia menyediakan kerangka kerja untuk menganalisis, menginterpretasi, dan mengekstrak informasi bermakna dari kumpulan data piksel, mengubahnya dari sekadar visual menjadi “pemahaman” yang dapat diolah mesin.
Matematika dalam Computer Vision (CV): Analisis Fitur Citra Berbasis Statistik
Setelah kita memahami bahwa setiap gambar adalah sekumpulan data numerik yang terdiri dari piksel, pertanyaan berikutnya adalah “Bagaimana kita bisa mendapatkan gambaran statistik secara menyeluruh dari miliaran piksel ini?” Lalu, “Bagaimana kita bisa ‘membaca’ data ini untuk memahami karakteristik visual sebuah gambar tanpa harus memeriksa setiap piksel satu per satu?”
Jawabannya ada pada histogram citra.
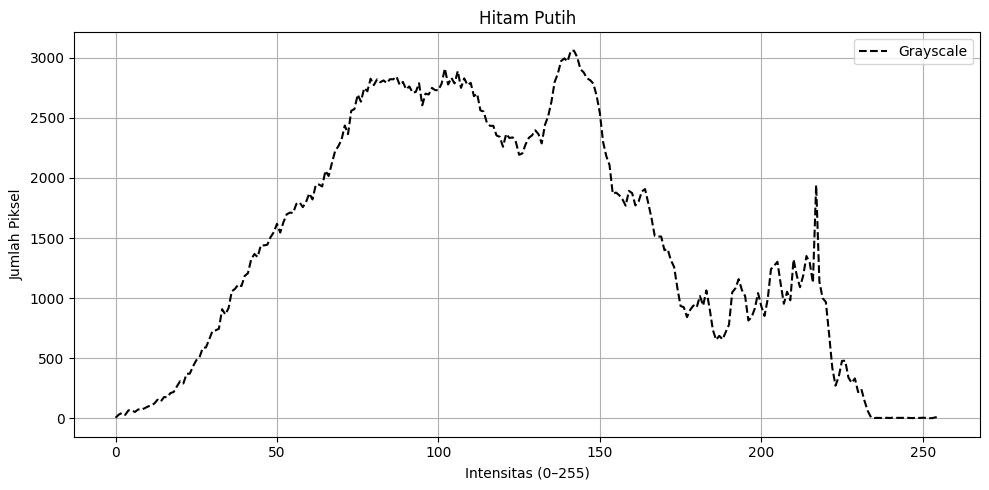
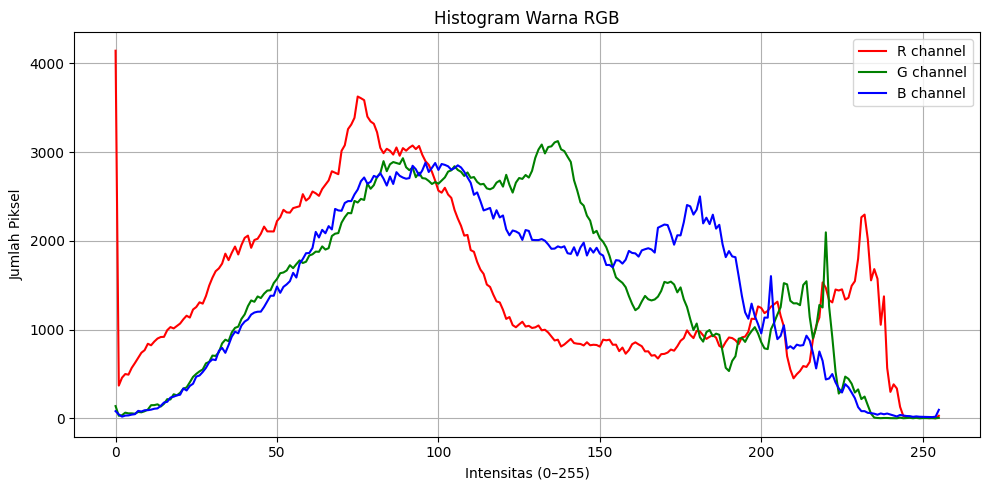
Histogram Citra: Distribusi Intensitas Piksel
Secara fundamental, histogram citra adalah representasi grafis dari distribusi frekuensi nilai intensitas piksel dalam sebuah gambar. Bayangkan seperti sensus mini yang dilakukan pada setiap piksel: Anda menghitung jumlah piksel yang memiliki nilai intensitas 0 (hitam pekat), yang memiliki nilai 1, yang memiliki nilai 2, dan seterusnya hingga nilai maksimal 255 (putih terang).
Histogram kemudian memvisualisasikan hasil penghitungan ini dalam bentuk grafik yang menunjukkan hubungan antara nilai intensitas (sumbu horizontal) dan jumlah piksel yang memiliki intensitas tersebut (sumbu vertikal). Dengan demikian, histogram membantu kita memahami sebaran kecerahan dalam sebuah gambar.
Berikut adalah penjelasan dari grafik histogram di atas.
- Sumbu horizontal (X-axis) mewakili rentang nilai intensitas piksel yang mungkin muncul dalam gambar, biasanya dari 0 hingga 255. Nilai 0 di ujung kiri menunjukkan piksel yang paling gelap, sedangkan nilai 255 di ujung kanan menunjukkan piksel yang paling terang.
- Sumbu vertikal (Y-axis) menunjukkan frekuensi, yaitu jumlah piksel yang memiliki nilai intensitas tertentu. Semakin tinggi nilai pada sumbu ini, semakin banyak piksel dalam gambar yang memiliki intensitas tersebut.
Jadi, dengan sekali pandang pada histogram, kita bisa langsung melihat “kecerahan” atau “warna” sebuah gambar terdistribusi secara statistik.
Statistik Spasial: Hubungan Antar Piksel Tetangga
Setelah kita menganalisis distribusi keseluruhan piksel dalam sebuah gambar menggunakan histogram, kini saatnya masuk lebih dalam pada hubungan antar piksel secara lokal. Ingat bahwa gambar bukan hanya sekumpulan piksel terisolasi; setiap piksel memiliki “tetangga” yang memengaruhi dan dipengaruhi olehnya.
Statistik spasial dalam computer vision berfokus pada analisis pola dan hubungan antar piksel yang berdekatan ini. Kemampuan untuk memahami hubungan lokal antar piksel adalah kunci bagi komputer untuk mengenali bentuk, tekstur, dan tepi objek.
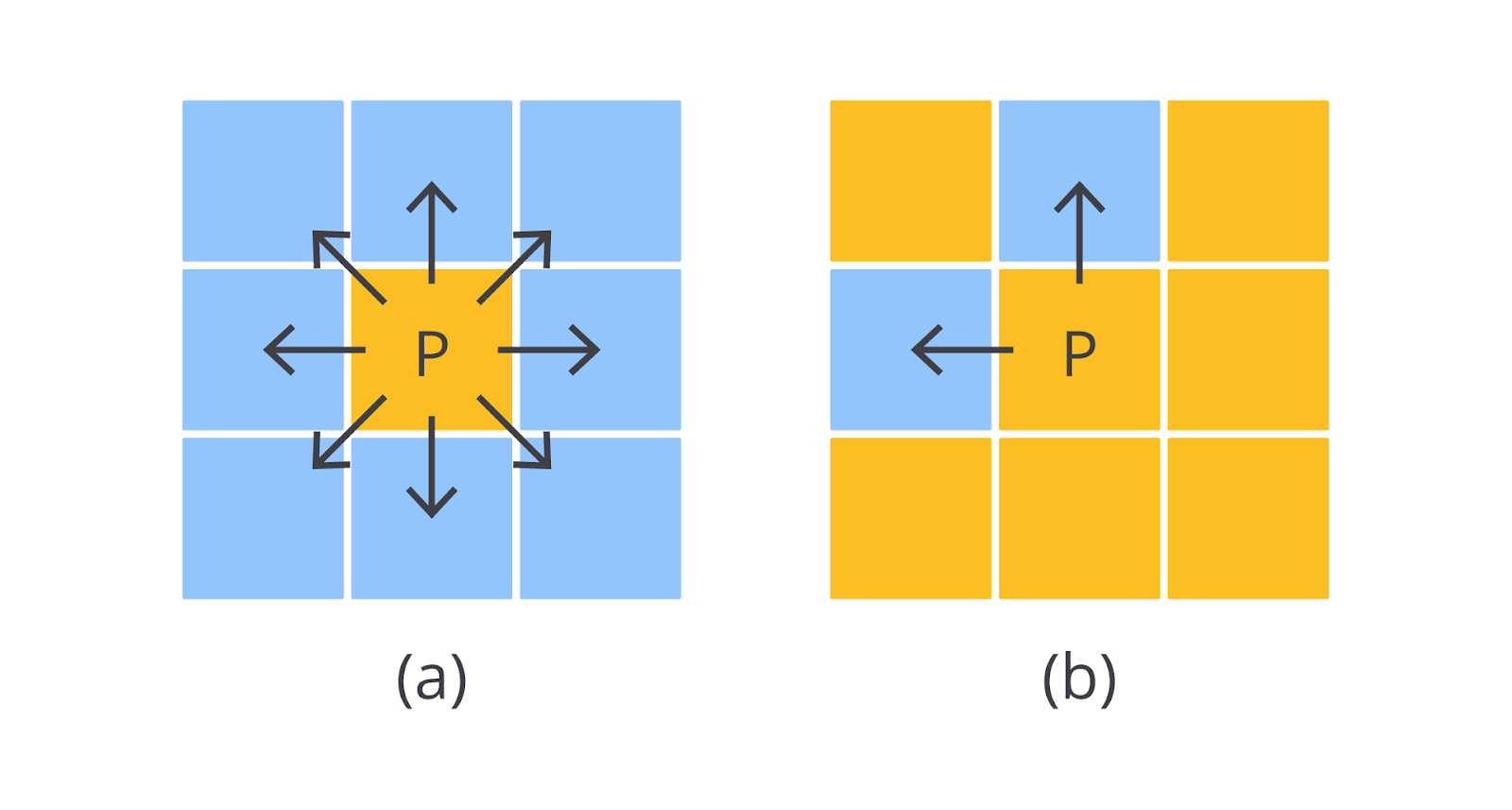
Hubungan antar piksel ini biasanya dianalisis melalui jendela kecil (disebut sebagai filter) yang mengelilingi suatu piksel pusat—misalnya area 3 × 3 atau 5 × 5 piksel. Dalam jendela tersebut, nilai intensitas piksel tetangga digunakan untuk menghitung karakteristik lokal, seperti rata-rata, variansi, atau gradien. Teknik ini memungkinkan kita menangkap pola-pola mikro yang tidak terlihat hanya dari histogram global. Kita bahas lebih lanjut nanti.
Intinya, statistik spasial menjadi landasan bagi banyak operasi dalam pemrosesan citra digital, seperti filtering, edge detection, dan feature extraction. Misalnya, filter deteksi tepi, seperti Sobel atau Laplacian bekerja dengan mengukur perubahan intensitas antar piksel tetangga untuk menemukan batas objek. Dengan kata lain, statistik spasial memungkinkan algoritma mengenali struktur lokal yang penting bagi pemahaman visual oleh komputer.
Konvolusi: Jendela Berjalan yang Membaca Pola Lokal
Inti dari banyak operasi statistik spasial dalam computer vision adalah konvolusi. Mungkin terdengar rumit, tapi secara intuitif, konvolusi bisa dibayangkan sebagai sebuah “jendela” kecil (disebut kernel atau filter) yang bergerak secara sistematis di atas seluruh gambar.
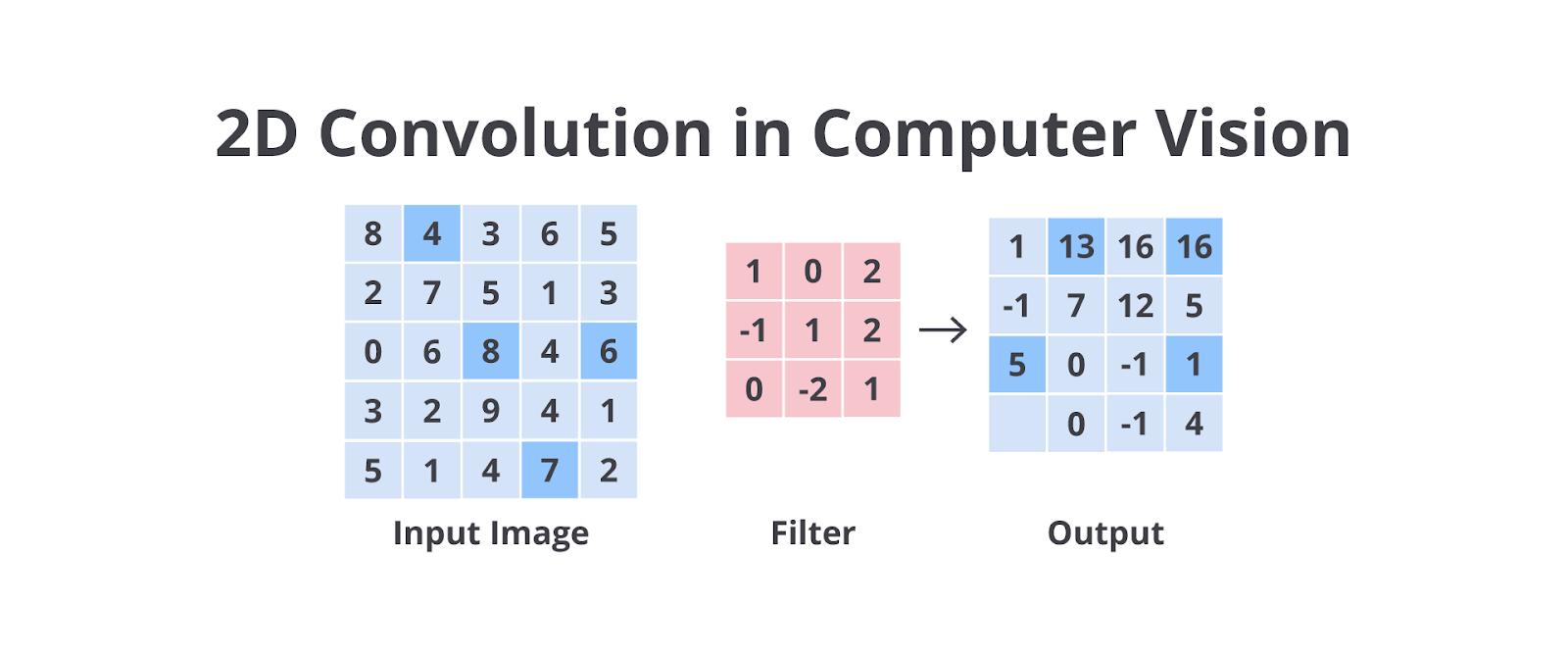
Bayangkan seperti ini.
- Jendela yang dimaksud ini berukuran kecil, biasanya 3 × 3 atau 5 × 5 piksel.
- Dalam jendela tersebut ada serangkaian angka (bobot) yang telah ditentukan.
- Jendela ini akan bergeser dari satu area gambar ke area lainnya, piksel demi piksel.
- Untuk setiap posisi jendela, komputer akan mengalikan nilai piksel di bawah jendela dengan bobot yang sesuai dalam jendela, lalu menjumlahkan semua hasil perkalian tersebut.
- Hasil penjumlahan ini kemudian menjadi nilai piksel baru untuk posisi tengah jendela pada gambar output.
Jadi, konvolusi pada dasarnya adalah proses “rata-rata tertimbang” atau “pengukuran perbedaan statistik lokal” antar piksel tetangga. Angka-angka dalam jendela (kernel) menentukan jenis “rata-rata” atau “perbedaan” yang sedang dihitung. Dengan mengubah angka-angka dalam kernel, kita bisa menciptakan berbagai efek filtering yang menyoroti karakteristik statistik spasial tertentu dari gambar.
Setelah kita tahu bahwa komputer bisa “membaca” gambar sebagai angka, langkah selanjutnya adalah cara kita bisa memerintahkan komputer untuk melakukan sesuatu yang berguna dengan angka-angka ini, misalnya membuat gambar jadi lebih halus atau menemukan batas-batas objek di dalamnya.
Mari kita lihat dua contoh umum berikut.
-
Filter Penghalus (Smoothing Filter): Menghilangkan Bintik-Bintik (Noise) dengan Efek Blur
Pernah melihat foto yang tampak memiliki bintik-bintik atau noise kecil yang mengganggu? Filter penghalus adalah salah satu solusi paling umum dalam pengolahan citra untuk mengatasi masalah ini.Filter ini bekerja dengan prinsip sederhana: meratakan nilai-nilai piksel di area lokal untuk menghasilkan tampilan yang lebih halus.
Dalam praktiknya, filter penghalus sering disebut juga sebagai blur filter karena memang efek visual yang dihasilkan adalah blur, yaitu gambar tampak lebih lembut dan tidak terlalu tajam. Efek ini terjadi karena variasi ekstrem antar piksel dikurangi sehingga transisi antar area menjadi lebih mulus.
Salah satu bentuk paling sederhana adalah mean filter atau box blur, yang menggunakan kernel berisi angka-angka seragam (misalnya semua 1). Ketika jendela filter bergerak di atas gambar, ia akan menghitung rata-rata nilai intensitas dari piksel-piksel dalam jendela tersebut, lalu mengganti nilai piksel pusat dengan rata-rata itu.
Apa artinya secara statistik? Piksel yang nilainya sangat berbeda dengan tetangganya— misalnya, terlalu terang di tengah piksel gelap—akan ditarik mendekati nilai rata-rata di sekitarnya. Hal ini efektif untuk mengurangi noise atau detail ekstrem yang tidak konsisten, mirip seperti kita menghitung rata-rata nilai ujian untuk memahami performa keseluruhan siswa, bukan hanya satu nilai ekstrem.
Hasilnya, gambar akan terlihat lebih halus (smooth), noise visual berkurang, serta detail halus dan tepi objek menjadi kurang tajam. Contohnya bisa Anda lihat pada perbandingan berikut: gambar asli vs. gambar setelah diterapkan filter penghalus (blur). Perhatikan detail arsitektur menjadi lebih lembut dan tekstur kasar menjadi rata.

-
Filter Deteksi Tepi: Menemukan Batasan Objek dengan Mengukur Perubahan Drastis
Sekarang, bayangkan Anda ingin komputer dapat mengenali garis-garis batas antara objek dalam sebuah gambar—misalnya tepi meja, batas bangunan, atau garis pada pakaian. Di sinilah filter deteksi tepi digunakan.Berbeda dari filter penghalus yang merata-ratakan nilai, filter deteksi tepi dirancang untuk mencari perbedaan nilai piksel yang signifikan. Kernel pada filter ini tidak diisi angka-angka seragam; biasanya berisi kombinasi nilai negatif dan positif untuk menyoroti perubahan intensitas antar piksel.
Ketika jendela filter ini bergerak di atas gambar, ia tidak lagi menghitung rata-rata, tetapi mengukur seberapa besar perubahan intensitas piksel dari satu sisi ke sisi lain. Bayangkan Anda sedang berjalan di permukaan datar, lalu tiba-tiba menghadapi tebing curam—perubahan drastis itulah yang coba dideteksi oleh filter ini.
Dalam konteks gambar, jika terjadi transisi tajam dari piksel gelap ke terang (atau sebaliknya), filter akan menghasilkan nilai intensitas tinggi, yang mengindikasikan adanya tepi. Area yang warnanya seragam atau perubahan intensitasnya halus tidak akan menghasilkan respons besar dari filter.
 Dengan kata lain, filter deteksi tepi bekerja seperti “sensor perubahan”—ia sangat sensitif terhadap lonjakan atau penurunan tajam dalam distribusi nilai piksel. Ini mirip dengan cara ahli statistik mencari “anomali” atau “peristiwa penting” dalam data numerik.
Dengan kata lain, filter deteksi tepi bekerja seperti “sensor perubahan”—ia sangat sensitif terhadap lonjakan atau penurunan tajam dalam distribusi nilai piksel. Ini mirip dengan cara ahli statistik mencari “anomali” atau “peristiwa penting” dalam data numerik.Filter deteksi tepi membantu komputer “melihat” struktur dan bentuk dalam gambar, menjadikannya komponen penting dalam tugas-tugas seperti segmentasi objek, pelacakan (tracking), dan pengenalan pola (pattern recognition).
Ekstraksi Fitur Statistik dari Area Citra
Setelah memahami cara filter sederhana dapat digunakan untuk menghaluskan gambar atau mendeteksi tepi, kini saatnya membahas pendekatan yang lebih canggih dalam “membaca” isi gambar, yaitu ekstraksi fitur statistik dari area citra. Pendekatan ini tidak lagi berfokus pada piksel secara individual, tetapi menganalisis kelompok piksel secara kolektif untuk mengenali pola yang lebih kompleks, seperti tekstur.
Tekstur merupakan salah satu ciri visual penting yang dapat membedakan antara permukaan kasar dan halus, membedakan kayu dari kain, atau bahkan membedakan dua objek yang memiliki warna serupa. Untuk mengenali tekstur, sistem computer vision menggunakan berbagai ukuran statistik—tidak hanya berdasarkan nilai rata-rata, tetapi juga memperhitungkan penyebaran, variasi, dan keteraturan intensitas piksel dalam suatu area.
Mengidentifikasi Tekstur dengan Variansi dan Standar Deviasi Lokal
Salah satu cara paling dasar untuk mengenali tekstur dalam citra adalah dengan mengukur variansi atau standar deviasi intensitas piksel pada area-area kecil yang bergerak melintasi gambar. Pendekatan ini mirip dengan operasi konvolusi—tapi alih-alih menghitung rata-rata, kita menilai seberapa besar sebaran nilai piksel dari nilai tengahnya, baik melalui variansi maupun akar kuadrat dari variansi tersebut (yaitu standar deviasi).
Bayangkan sebuah jendela kecil (misalnya 3 × 3 piksel) yang berjalan di atas gambar. Pada setiap posisi, kita menghitung seberapa bervariasi nilai-nilai piksel dalam jendela tersebut.
Daerah dengan variansi atau standar deviasi lokal tinggi menunjukkan adanya perubahan intensitas yang tajam dan tidak merata, yang merupakan ciri khas dari tekstur kasar atau detail tinggi—seperti permukaan batu, anyaman kain, atau helai daun.
Sebaliknya, area yang halus atau homogen—seperti langit, dinding polos, atau permukaan air—akan memiliki nilai yang rendah karena piksel-pikselnya cenderung seragam.
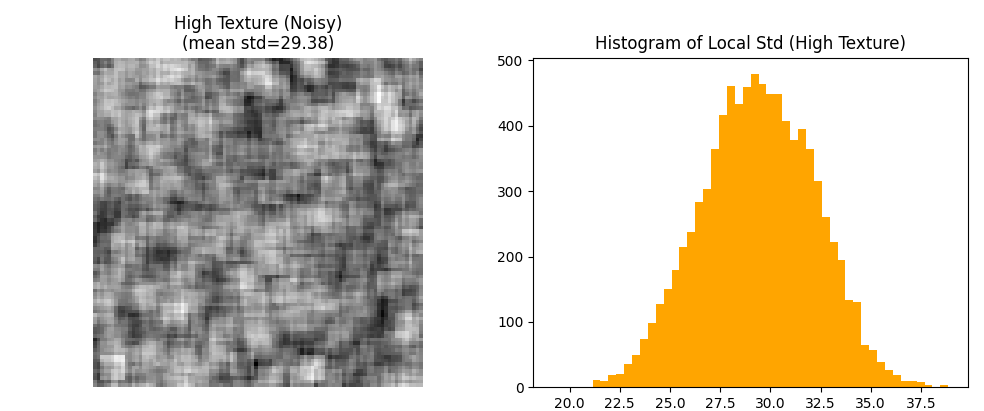
Untuk mempermudah pemahaman, perhatikan gambar visualisasi dari simulasi berikut.
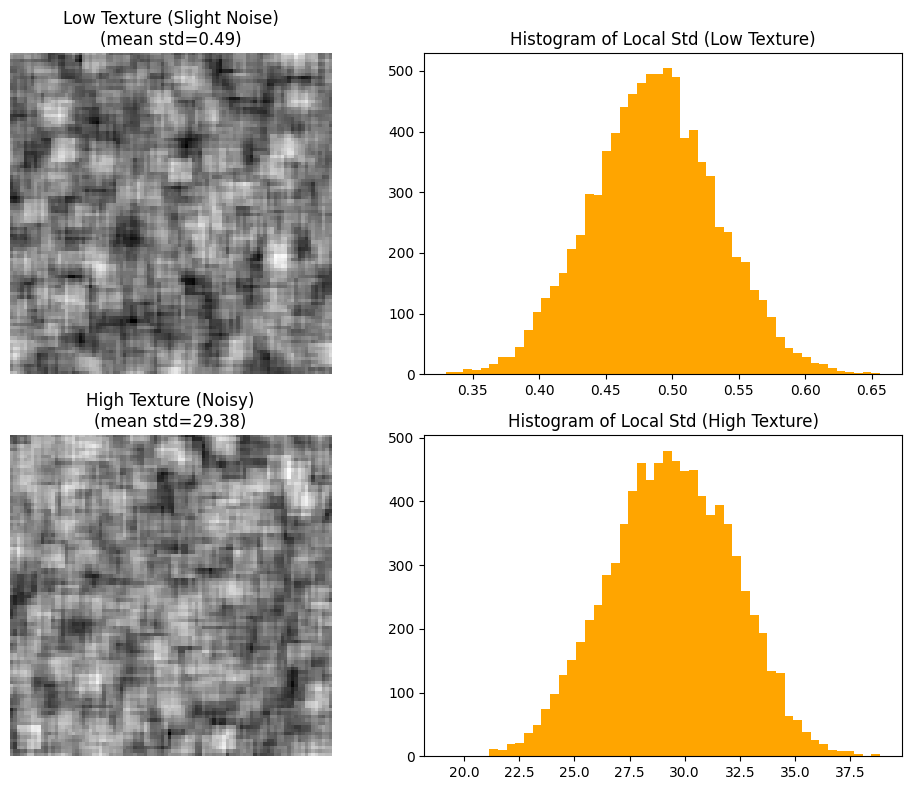
Visualisasi di atas memperlihatkan dua contoh.
- Citra dengan tekstur rendah (sedikit noise) menghasilkan histogram lokal standar deviasi yang sempit dan berpusat pada nilai rendah (mean std ≈ 0.49).
- Citra dengan tekstur tinggi (noisy) memiliki sebaran standar deviasi yang jauh lebih besar (mean std ≈ 29.38), menandakan tingkat keberagaman intensitas yang tinggi.
Dengan pendekatan ini, komputer dapat membedakan area bertekstur dari area datar hanya melalui analisis statistik lokal. Ini mirip dengan mengukur “keberagaman” nilai piksel di suatu wilayah—semakin tinggi keberagamannya, semakin bertekstur area tersebut.
Anda bisa mencoba simulasi di atas dengan menjalankan kode Python berikut pada Google Colab.
- import numpy as np
- import matplotlib.pyplot as plt
-
from numpy.lib.stride_tricks import sliding_window_view
- # Generate two synthetic images (100x100)
- np.random.seed(0)
- # Smooth image now with slight noise (low texture but non-zero std)
- img_smooth = np.random.normal(loc=128, scale=0.5, size=(100, 100))
- # Noisy image (high texture)
-
img_noisy = np.random.normal(loc=128, scale=30, size=(100, 100))
- # Compute local standard deviation with a 7x7 window
- window_size = 7
- def local_std(img):
- w = sliding_window_view(img, (window_size, window_size))
-
return w.std(axis=(2, 3))
- std_smooth = local_std(img_smooth)
-
std_noisy = local_std(img_noisy)
- # Mean std for titles
- mean_s = std_smooth.mean()
-
mean_n = std_noisy.mean()
- # Plotting
-
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
- # Smooth local std map and histogram
- axes[0, 0].imshow(std_smooth, cmap=‘gray’)
- axes[0, 0].set_title(f”Low Texture (Slight Noise)\n(mean std={mean_s:.2f})”)
-
axes[0, 0].axis(‘off’)
- axes[0, 1].hist(std_smooth.flatten(), bins=50, color=‘orange’)
-
axes[0, 1].set_title(“Histogram of Local Std (Low Texture)”)
- # Noisy local std map and histogram
- axes[1, 0].imshow(std_noisy, cmap=‘gray’)
- axes[1, 0].set_title(f”High Texture (Noisy)\n(mean std={mean_n:.2f})”)
-
axes[1, 0].axis(‘off’)
- axes[1, 1].hist(std_noisy.flatten(), bins=50, color=‘orange’)
-
axes[1, 1].set_title(“Histogram of Local Std (High Texture)”)
- plt.tight_layout()
- plt.show()
Kode di atas untuk mengidentifikasi dan membandingkan tekstur dalam citra menggunakan standar deviasi lokal sebagai ukuran statistik penyebaran intensitas piksel di area-area kecil. Mari kita bedah esensi kodenya.
Pembuatan Citra Sintetik
- img_smooth = np.random.normal(loc=128, scale=0.5, size=(100, 100))
- img_noisy = np.random.normal(loc=128, scale=30, size=(100, 100))
img_smooth: citra dengan tekstur rendah (sedikit noise), dibuat dari distribusi normal dengan standar deviasi kecil (scale=0.5).img_noisy: citra dengan tekstur tinggi (banyak noise), dibuat dari distribusi normal dengan standar deviasi besar (scale=30).
Kedua citra berukuran 100 × 100 piksel dan memiliki nilai intensitas pusat di sekitar 128 (abu-abu netral).
Menghitung Standar Deviasi Lokal
- window_size = 7
- def local_std(img):
- w = sliding_window_view(img, (window_size, window_size))
- return w.std(axis=(2, 3))
Fungsi local_std() menggunakan sliding window 7 × 7 untuk setiap piksel (tanpa padding). Untuk setiap jendela, kode menghitung standar deviasi nilai-nilai piksel dalam jendela tersebut. Ini memberi kita peta (map) yang menunjukkan seberapa besar variasi lokal di setiap wilayah gambar.
Visualisasi Citra dan Histogram
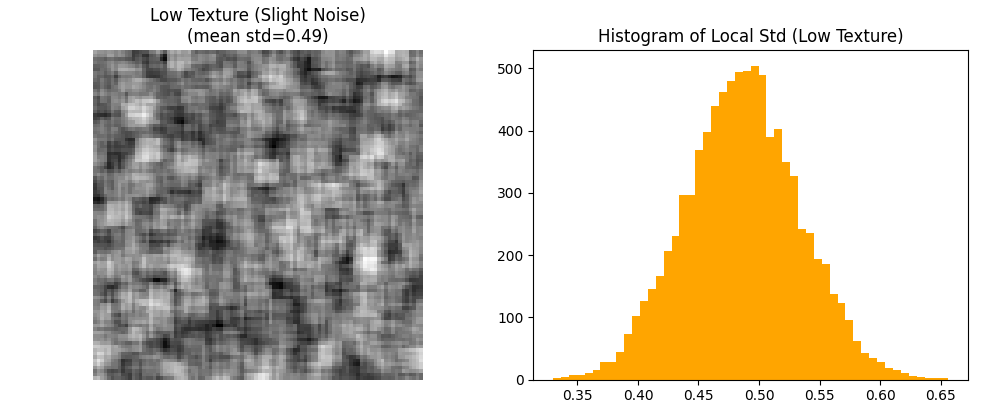
- axes[0, 0].imshow(std_smooth, cmap=‘gray’)
- axes[0, 1].hist(std_smooth.flatten(), bins=50, color=‘orange’)
Gambar kiri menunjukkan peta standar deviasi lokal dari citra dengan tekstur rendah. Gambar kanan adalah histogram distribusi nilai standar deviasi—sebagian besar nilainya rendah, mencerminkan area yang seragam.
- axes[1, 0].imshow(std_noisy, cmap=‘gray’)
- axes[1, 1].hist(std_noisy.flatten(), bins=50, color=‘orange’)
Gambar kiri menampilkan peta standar deviasi lokal untuk citra dengan tekstur tinggi. Histogramnya tersebar lebih luas dan memiliki nilai rata-rata lebih tinggi, menandakan keragaman piksel yang besar, tipikal dari tekstur kasar atau noisy.
Mendeskripsikan Bentuk Distribusi Intensitas dengan Skewness dan Kurtosis
Untuk mendeskripsikan tekstur secara lebih rinci, kita bisa melangkah lebih jauh dari sekadar variansi dan mulai memperhatikan bentuk distribusi intensitas piksel dalam suatu area menggunakan ukuran statistik, seperti skewness dan kurtosis.
Skewness (Kemiringan Distribusi)
Skewness mengukur seberapa asimetris distribusi nilai intensitas piksel di suatu area. Nilai skewness memberikan informasi tentang kecenderungan distribusi: apakah sebagian besar piksel berada dalam nilai rendah, tinggi, atau seimbang.
- Positive skew (skew > 0): Distribusi condong ke kiri. Artinya, sebagian besar piksel bernilai gelap dengan sedikit piksel terang. Histogram berpuncak di sisi kiri dan memiliki ekor panjang ke kanan.
- Negative skew (skew < 0): Distribusi condong ke kanan. Sebagian besar piksel bernilai terang dengan sedikit piksel gelap. Histogram berpuncak di kanan dan memiliki ekor ke kiri.
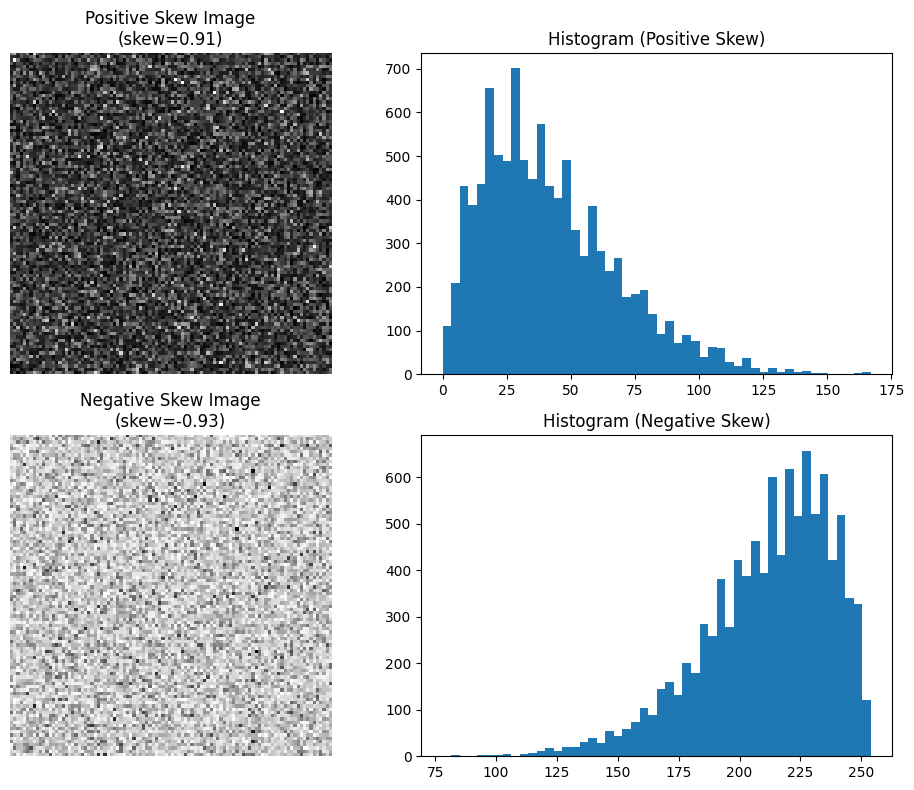
Metode ini membantu komputer membedakan tekstur atau pola pencahayaan berdasarkan persebaran intensitas terang-gelap di permukaan suatu objek.
Untuk melakukan simulasi di atas, Anda dapat menjalankan kode berikut pada Google Colab.
- import numpy as np
- import matplotlib.pyplot as plt
-
from scipy.stats import skew
- # Generate two synthetic images (100x100)
- # Positive skew: many dark pixels, few bright
- np.random.seed(0)
-
image_pos = (np.random.beta(a=2, b=10, size=(100, 100)) * 255).astype(int)
- # Negative skew: many bright pixels, few dark
-
image_neg = (np.random.beta(a=10, b=2, size=(100, 100)) * 255).astype(int)
- # Compute skewness
- skew_pos = skew(image_pos.flatten())
-
skew_neg = skew(image_neg.flatten())
- # Plotting
-
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
- # Positive skew image and histogram
- axes[0, 0].imshow(image_pos, cmap=‘gray’)
- axes[0, 0].set_title(f”Positive Skew Image\n(skew={skew_pos:.2f})”)
-
axes[0, 0].axis(‘off’)
- axes[0, 1].hist(image_pos.flatten(), bins=50)
-
axes[0, 1].set_title(“Histogram (Positive Skew)”)
- # Negative skew image and histogram
- axes[1, 0].imshow(image_neg, cmap=‘gray’)
- axes[1, 0].set_title(f”Negative Skew Image\n(skew={skew_neg:.2f})”)
-
axes[1, 0].axis(‘off’)
- axes[1, 1].hist(image_neg.flatten(), bins=50)
-
axes[1, 1].set_title(“Histogram (Negative Skew)”)
- plt.tight_layout()
- plt.show()
Kode di atas membuat dua citra sintetis (100 × 100).
- Positive skew image dihasilkan dari distribusi beta(2, 10), menunjukkan ekor panjang ke kanan.
- Negative skew image menggunakan beta(10, 2) sehingga distribusi terbalik.
Setiap baris subplot menampilkan hal berikut.
- Citra dalam skala abu-abu.
- Histogram frekuensi piksel (memperlihatkan kemiringan distribusi).
- Nilai skewness tercetak di judul citra, memudahkan interpretasi.
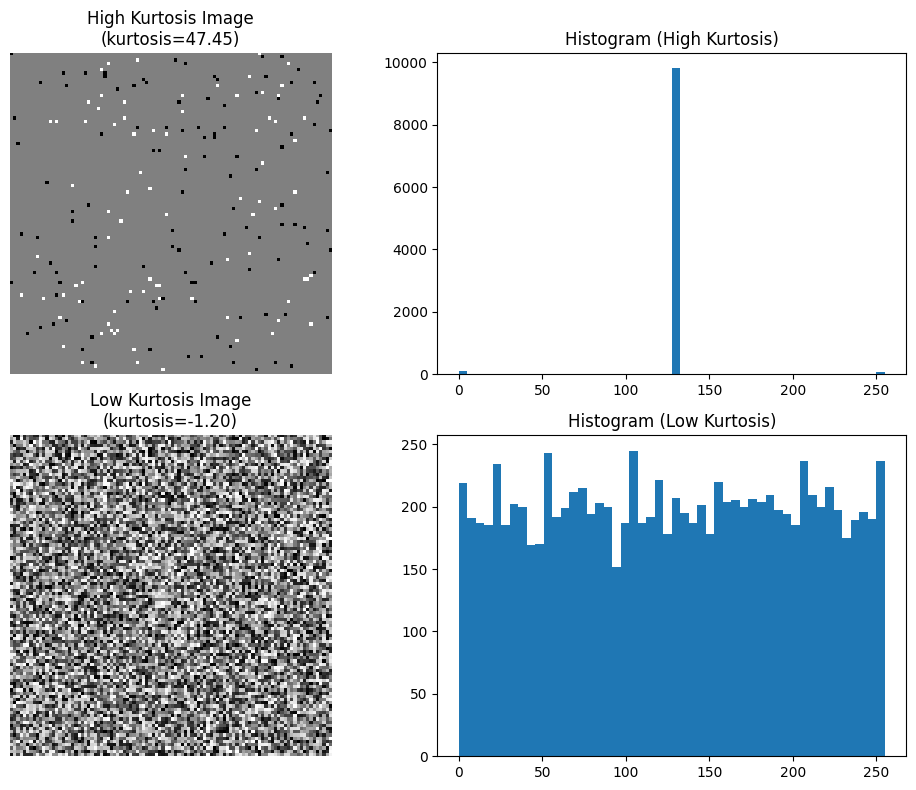
Kurtosis (Keruncingan Distribusi)
Kurtosis mengukur “puncak” atau “kerataan” distribusi nilai piksel di area tertentu. Area dengan kurtosis tinggi (“leptokurtic”) menampilkan distribusi yang sangat runcing—banyak piksel terpusat pada nilai intensitas tertentu dengan beberapa outlier (misal area seragam dengan beberapa bintik kontras tinggi).
Sebaliknya, area dengan kurtosis rendah (“platykurtic”) memiliki distribusi yang lebih datar, yakni saat nilai piksel tersebar merata dalam rentang nilai.
Untuk melakukan simulasi di atas, Anda dapat menjalankan kode berikut pada Google Colab.
- import numpy as np
- import matplotlib.pyplot as plt
-
from scipy.stats import kurtosis
- # Generate two synthetic images (100x100)
-
np.random.seed(1)
- # High kurtosis: mostly constant with few extreme spots
- base = np.full((100, 100), 128, dtype=int)
- num_spots = 200
- coords = (np.random.randint(0, 100, num_spots), np.random.randint(0, 100, num_spots))
-
base[coords] = np.random.choice([0, 255], size=num_spots)
- # Low kurtosis: uniform distribution across range
-
uniform_img = np.random.randint(0, 256, (100, 100))
- # Compute kurtosis
- kurt_high = kurtosis(base.flatten(), fisher=True)
-
kurt_low = kurtosis(uniform_img.flatten(), fisher=True)
- # Plotting
-
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
- # High kurtosis image and histogram
- axes[0, 0].imshow(base, cmap=‘gray’)
- axes[0, 0].set_title(f”High Kurtosis Image\n(kurtosis={kurt_high:.2f})”)
-
axes[0, 0].axis(‘off’)
- axes[0, 1].hist(base.flatten(), bins=50)
-
axes[0, 1].set_title(“Histogram (High Kurtosis)”)
- # Low kurtosis image and histogram
- axes[1, 0].imshow(uniform_img, cmap=‘gray’)
- axes[1, 0].set_title(f”Low Kurtosis Image\n(kurtosis={kurt_low:.2f})”)
-
axes[1, 0].axis(‘off’)
- axes[1, 1].hist(uniform_img.flatten(), bins=50)
-
axes[1, 1].set_title(“Histogram (Low Kurtosis)”)
- plt.tight_layout()
- plt.show()
Kode di atas menghasilkan dua citra sintetis (100 × 100).
- High Kurtosis Image: mayoritas piksel bernilai 128 dengan sedikit titik ekstrem pada nilai 0 atau 255 sehingga histogramnya sangat terpusat dan “runcing” (kurtosis ≈ 47.45).
- Low Kurtosis Image: piksel mengikuti distribusi uniform 0–255, menghasilkan histogram datar (kurtosis ≈ –1.20).
Dengan skewness dan kurtosis, kita mendapatkan gambaran statistik yang lebih kaya tentang cara intensitas piksel terdistribusi dan memberikan petunjuk lebih lanjut tentang karakteristik tekstur.
Mengekstraksi Pola Tekstur Kompleks dengan Fitur Haralick dan Matriks GLCM
Untuk mengenali tekstur kompleks dan memiliki pola berulang, metode yang lebih canggih sering digunakan, salah satunya adalah Fitur Haralick. Konsep dasar dari pendekatan ini adalah penggunaan Gray-Level Co-occurrence Matrix (GLCM).
GLCM adalah sebuah tabel statistik yang mencatat seberapa sering pasangan nilai intensitas piksel tertentu muncul bersama dalam citra dengan mempertimbangkan jarak dan arah tertentu.
Misalnya, secara konseptual, kita bisa membayangkan pertanyaan seperti berikut.
- “Berapa kali piksel dengan nilai 100 muncul tepat di sebelah kanan piksel bernilai 150?”
- “Berapa kali piksel bernilai 50 muncul dua langkah di bawah piksel bernilai 200?”
Pertanyaan-pertanyaan ini membantu kita memahami bahwa GLCM menangkap pola kemunculan lokal antar piksel yang membentuk tekstur.
Dari GLCM ini, berbagai fitur statistik yang dikenal sebagai Fitur Haralick dapat dihitung. Ada sekitar 14 fitur standar, masing-masing merepresentasikan karakteristik berbeda dari pola tekstur. Beberapa fitur utamanya berikut.
- Contrast: Mengukur perbedaan intensitas antara piksel-piksel yang berdekatan. Contoh: Tekstur kasar menghasilkan nilai kontras tinggi.
- Homogeneity: Mengukur seberapa dekat nilai-nilai GLCM terhadap diagonal utama. Contoh: Tekstur halus menghasilkan nilai homogenitas tinggi.
- Energy/Angular Second Moment: Mengukur tingkat keseragaman atau keteraturan dalam tekstur. Contoh: Area yang seragam memiliki energi tinggi.
Selain itu masih banyak lagi, yakni Correlation, Entropy, Dissimilarity, dll. Masing-masing menangkap aspek statistik yang berbeda dari pola distribusi piksel dalam ruang.
Fitur Haralick ini banyak digunakan dalam aplikasi nyata, seperti klasifikasi tekstur (misalnya, jenis kain, permukaan logam), deteksi anomali (pada citra medis atau satelit), dan segmentasi citra berbasis pola.
Berikut adalah contoh kode untuk melakukan simulasi dari penggunaan Fitur Haralick. Anda bisa menjalankan kode ini pada Google Colab (Anda perlu menginstal library scikit-image terlebih dahulu).
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
-
from skimage.feature import graycomatrix, graycoprops
- # Define larger (8x8) example matrices
- matrix1 = np.array([
- [0, 0, 0, 0, 10, 10, 10, 10],
- [0, 0, 0, 0, 10, 10, 10, 10],
- [0, 0, 0, 0, 10, 10, 10, 10],
- [0, 0, 0, 0, 10, 10, 10, 10],
- [100, 100, 100, 100, 200, 200, 200, 200],
- [100, 100, 100, 100, 200, 200, 200, 200],
- [100, 100, 100, 100, 200, 200, 200, 200],
- [100, 100, 100, 100, 200, 200, 200, 200]
-
], dtype=np.uint8)
-
matrix2 = np.linspace(0, 255, 64, dtype=np.uint8).reshape((8, 8))
- # Compute Haralick features
- def compute_haralick(mat, distances=[1], angles=[0]):
- glcm = graycomatrix(mat, distances=distances, angles=angles, levels=256, symmetric=True, normed=True)
- return {
- ’contrast’: graycoprops(glcm, ’contrast’)[0,0],
- ’homogeneity’: graycoprops(glcm, ’homogeneity’)[0,0],
- ’energy’: graycoprops(glcm, ’energy’)[0,0],
- ’correlation’: graycoprops(glcm, ’correlation’)[0,0],
- ’dissimilarity’: graycoprops(glcm, ’dissimilarity’)[0,0]
-
}
- feat1 = compute_haralick(matrix1)
-
feat2 = compute_haralick(matrix2)
- # Plot heatmaps
- fig, axs = plt.subplots(1, 2, figsize=(10, 5))
- axs[0].imshow(matrix1, interpolation=‘nearest’)
- axs[0].set_title(“Matrix 1 (8×8)”)
-
axs[0].axis(‘off’)
- axs[1].imshow(matrix2, interpolation=‘nearest’)
- axs[1].set_title(“Matrix 2 (8×8)”)
-
axs[1].axis(‘off’)
- plt.tight_layout()
-
plt.show()
- # Compute features
- feat1 = compute_haralick(matrix1)
-
feat2 = compute_haralick(matrix2)
- # Print results in a table format
- print(f”{‘Feature’:<15} {‘Matrix1’:>10} {‘Matrix2’:>10}”)
- print(‘-‘ * 37)
- for key in feat1:
- print(f”{key:<15} {feat1[key]:>10.4f} {feat2[key]:>10.4f}”)
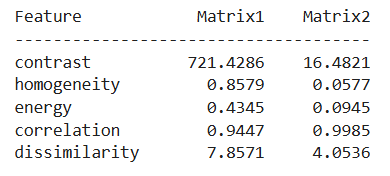
Kode di atas digunakan untuk membandingkan dua pola tekstur dengan menggunakan fitur Haralick, yang dihitung dari Gray-Level Co-occurrence Matrix (GLCM).
Pertama, dua buah matriks 8 × 8 dibuat seperti berikut.
matrix1terdiri dari dua blok homogen yang berbeda nilai. Empat baris pertama berisi nilai rendah (0–10) dan empat baris berikutnya berisi nilai tinggi (100–200). Matriks ini menampilkan perubahan tajam antar blok yang menyerupai tekstur kasar.matrix2adalah gradien linier dari 0 hingga 255 yang tersebar merata. Ini merepresentasikan tekstur halus tanpa batas blok yang jelas.
Fungsi compute_haralick() kemudian melakukan hal berikut.
- Menghitung GLCM pada jarak 1 piksel dalam arah horizontal (
angle = 0) dengan nilai piksel berada dalam rentang 0–255 (levels=256). - Menormalisasi GLCM.
- Mengekstraksi lima metrik Haralick utama.
contrast– perbedaan intensitas antar piksel bertetangga.homogeneity– seberapa dekat nilai GLCM terhadap diagonal utama.energy– tingkat keseragaman tekstur.correlation– hubungan linier antar nilai piksel.dissimilarity– perbedaan absolut antar nilai piksel tetangga.
Visualisasi dua matriks ditampilkan sebagai heatmap, sedangkan hasil perhitungan fitur ditampilkan dalam bentuk tabel agar mudah dibandingkan. Hasilnya menunjukkan hal berikut.
- Struktur blok yang tajam pada matrix1 menghasilkan kontras dan dissimilarity yang tinggi, serta homogeneity yang rendah.
- Gradien halus pada matrix2 cenderung menghasilkan nilai fitur lebih seimbang dan menggambarkan perubahan tekstur yang lebih lembut.
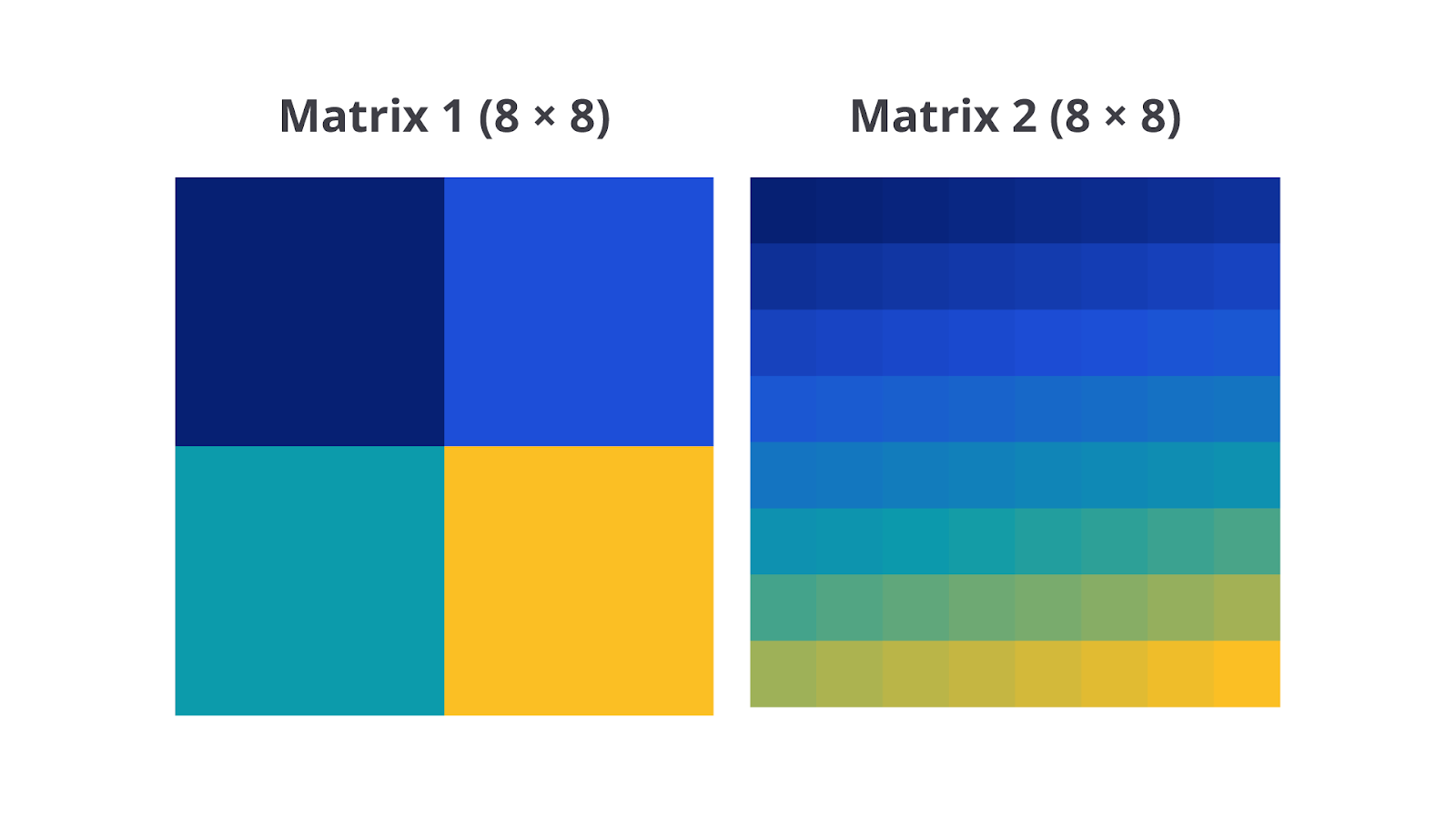
Akhirnya, nilai-nilai Fitur Haralick dari masing-masing matriks dicetak dalam bentuk tabel ringkas. Dengan membandingkan hasilnya, kita dapat langsung melihat bahwa struktur blok tajam pada matrix1 menghasilkan nilai kontras serta dissimilarity yang tinggi, sementara gradasi lembut pada matrix2 menghasilkan fitur lebih rendah dan homogen. Hal ini menunjukkan bahwa perbedaan visual dalam pola tekstur dapat diukur secara objektif menggunakan statistik dari GLCM.
Fitur Haralick memungkinkan computer vision untuk mengenali pola tekstur yang kompleks, berulang, dan tidak teratur—sesuatu yang tidak dapat ditangkap hanya dengan statistik dasar, seperti variansi, skewness, atau histogram piksel.
Dengan pendekatan ini, komputer dapat membedakan berbagai jenis permukaan yang tampak serupa secara warna, tapi berbeda secara pola, seperti berikut.
- Serat kayu yang memiliki arah dan ketebalan tertentu.
- Pola batu bata yang bersifat periodik dan kontras.
- Tekstur kulit yang acak, tapi khas.
Melalui pendekatan ini, kita dapat menghitung pola tekstur secara statistik dan memahami perbedaan visual dalam citra tecermin pada nilai-nilai Fitur Haralick.
Anda bisa akses kode lengkap yang dijelaskan dalam topik computer vision pada link berikut: Modul 6 - Computer Vision.ipynb
Matematika dalam Natural Language Processing (NLP)
Setelah memahami bahwa data numerik dianalisis secara statistik, kini saatnya kita berhadapan dengan jenis data yang lain, yang lebih kompleks, tapi juga sangat menarik, yaitu teks.
Anda mungkin bertanya-tanya, bagaimana mungkin mesin bisa memahami bahasa manusia yang penuh makna, nuansa, dan konteks? Kita saja sebagai manusia kadang harus bertanya dua kali untuk memahami maksud seseorang. Jadi, bagaimana caranya mesin bisa “mengerti”?
Ternyata, mesin tidak benar-benar “mengerti” seperti manusia. Namun, mereka bisa belajar dari pola dan caranya belajar adalah dengan menghitung. Statistik menjadi alat utama bagi sistem untuk memahami teks, bukan lewat arti kata dalam kamus, melainkan dari seberapa sering kata itu muncul, pada konteks apa, dan hubungannya dengan kata-kata lain.
Dalam materi ini, kita akan menyelami cara-cara sistem komputer mengekstrak fitur dari teks, mulai yang paling sederhana, seperti menghitung kemunculan kata, hingga metode yang bisa menangkap hubungan semantik yang lebih halus, seperti TF-IDF dan Word Embeddings.
Hal yang menarik, semua itu berpijak pada prinsip-prinsip statistik yang sudah Anda kenal.
Matematika dalam Natural Language Processing (NLP): Pengenalan
Natural language processing (NLP) adalah sebuah cabang menarik dari artificial intelligence (AI) yang berfokus pada cara komputer dapat memahami, menginterpretasi, dan bahkan menghasilkan bahasa manusia, baik itu teks tertulis maupun ucapan.
Tujuan utama NLP adalah menjembatani kesenjangan antara cara manusia berkomunikasi secara alami dengan cara komputer memproses informasi. Bayangkan komputer Anda bisa membaca sebuah berita, meringkasnya, lalu menjawab pertanyaan tentang isinya. Atau bisa mendengarkan perintah suara Anda, memahami maksudnya, dan melaksanakannya.
Inilah inti dari NLP: memberikan kemampuan “berbahasa” kepada mesin. Bahasa manusia itu rumit—penuh dengan ambiguitas, metafora, dan aturan yang fleksibel. NLP berupaya mengajarkan komputer untuk mengatasi kerumitan ini sehingga memungkinkannya berinteraksi dengan manusia secara lebih intuitif dan cerdas.

Sebelum sebuah sistem bisa memahami bahasa manusia, ia perlu tahu dulu cara “membaca” teks sebagai data. Namun, tidak seperti manusia yang bisa memahami makna kata berdasarkan pengalaman dan intuisi, komputer tidak punya kemampuan itu. Ia buta terhadap makna, nada, emosi, atau konteks. Hal yang bisa komputer lakukan hanyalah menghitung dan justru dari proses menghitung inilah muncul kemampuan dasar untuk “memahami” bahasa secara statistik.
Langkah awal ini penting karena dari sinilah semua proses lanjutan dibangun. Sebelum bisa berbicara tentang semantik, konteks, atau prediksi, kita harus mulai dari mengenali bahwa kata adalah bagian terkecil dari informasi dalam teks dan kemunculan kata bisa dihitung serta dijadikan dasar untuk mengenali pola.
Matematika dalam Natural Language Processing (NLP): Visualisasi Distribusi Kata dengan WordCloud
Distribusi kata mengacu pada cara kata-kata tertentu muncul dalam teks atau koleksi dokumen. Dengan memvisualisasikan distribusi kata, kita dapat dengan mudah memahami kata-kata yang sering muncul dalam teks dan yang jarang digunakan. Salah satu cara yang paling efektif untuk menggambarkan distribusi kata dalam teks adalah melalui WordCloud.
Apa itu WordCloud?
WordCloud adalah representasi grafis dari teks bahwa kata-kata yang lebih sering muncul dalam teks akan ditampilkan dengan ukuran lebih besar. Sebaliknya, kata-kata yang jarang muncul akan memiliki ukuran font lebih kecil.

WordCloud adalah salah satu teknik visualisasi yang sangat berguna dalam natural language processing (NLP) untuk memberikan gambaran umum tentang frekuensi kata pada sebuah teks atau kumpulan dokumen.
WordCloud sering digunakan dalam berbagai aplikasi seperti berikut.
- Analisis Sentimen: Untuk memvisualisasikan kata-kata yang sering digunakan dalam teks dengan sentimen positif atau negatif.
- Pencarian Informasi: Untuk mengetahui kata-kata kunci atau topik dominan dalam koleksi dokumen.
- Penyajian Data Teks: Membantu dalam presentasi data teks dengan cara yang mudah dipahami dan menarik.
Bagaimana WordCloud Mencerminkan Distribusi Kata?
Distribusi kata merujuk pada frekuensi kemunculan kata dalam sebuah teks atau koleksi teks. Dalam visualisasi WordCloud, distribusi kata ini digambarkan melalui ukuran font kata. Kata-kata yang sering muncul dalam teks akan memiliki font lebih besar, sementara kata-kata yang muncul lebih jarang akan tampil dengan ukuran font lebih kecil.
Berikut adalah proses visualisasi distribusi kata menggunakan WordCloud.
- Menghitung frekuensi kata: Setiap kata dalam dokumen dihitung dengan seberapa sering muncul.
- Memetakan frekuensi ke ukuran font: Kata dengan frekuensi tinggi akan diberi ukuran font besar, sedangkan kata dengan frekuensi rendah akan diberi ukuran kecil.
- Menampilkan visualisasi: WordCloud akan menampilkan kata-kata dalam bentuk gambar, yaitu kata-kata yang lebih sering muncul akan lebih dominan secara visual.
Manfaat Penggunaan WordCloud
Visualisasi distribusi kata dengan WordCloud memiliki banyak manfaat dalam konteks NLP, terutama untuk eksplorasi data dan analisis teks, antara lain berikut.
- Pengenalan Kata Kunci
WordCloud dapat memberikan gambaran sekilas tentang kata-kata kunci dalam teks atau dokumen. Kata-kata yang muncul dengan ukuran besar adalah kata-kata yang dianggap paling penting atau dominan dalam teks tersebut. - Identifikasi Tema atau Topik Dominan
Dengan menganalisis WordCloud, kita dapat dengan mudah mengidentifikasi tema atau topik yang sering dibicarakan dalam kumpulan dokumen. Misalnya, dalam koleksi artikel berita, kata-kata yang sering muncul akan memberikan petunjuk tentang topik utama dalam berita tersebut. - Memudahkan Eksplorasi Teks
WordCloud adalah alat yang sangat berguna untuk eksplorasi data teks secara cepat dan mudah dipahami. Ini memungkinkan kita untuk melihat pola atau hubungan antara kata-kata yang mungkin sulit dilihat hanya dengan analisis numerik atau statistik. - Memvisualisasikan Perubahan dalam Data Teks
WordCloud juga dapat digunakan untuk memvisualisasikan perubahan dalam distribusi kata dari waktu ke waktu. Misalnya, jika memiliki koleksi dokumen atau tweet yang terorganisasi berdasarkan waktu, kita dapat membuat WordCloud untuk setiap periode waktu dan melihat kata-kata yang lebih menonjol.
Membuat WordCloud dengan Python
Setelah memahami pengertian, cara kerja, dan manfaat dari penggunaan WordCloud, sekarang kita coba praktikkan pembuatan WordCloud dalam bahasa pemrograman Python. Anda bisa ikuti dengan menjalankan kode pada Google Colab.
Berikut adalah langkah-langkah untuk membuat WordCloud dengan Python.
Langkah 1: Impor Library
Hal pertama yang perlu dilakukan adalah mengimpor library yang dibutuhkan. Untuk membuat WordCloud dengan Python, kita dapat menggunakan library Matplotlib dan WordCloud.
- import matplotlib.pyplot as plt
- from wordcloud import WordCloud
Langkah 2: Menyiapkan Data Teks
Anda bisa menggunakan teks dari dokumen atau kumpulan ulasan, berita, atau sentimen. Kita akan gunakan contoh data statis berupa daftar ulasan pembelajaran matematika dari siswa seperti berikut.
- # Daftar ulasan
- reviews = [
- ”Saya suka belajar Matematika.”,
- ”Belajar matematika menyenangkan.”,
- ”Matematika itu menyenangkan.”,
- ”Belajar matematika sangat penting.”,
- ”Matematika adalah ilmu dasar.”
- ]
Kumpulan kalimat disimpan dalam list reviews. Kalimat-kalimat ini merepresentasikan opini atau pernyataan pengguna tentang topik tertentu (dalam hal ini: matematika).
Langkah 3: Menggabungkan Kalimat Menjadi Satu String
Untuk membuat WordCloud, semua teks digabungkan menjadi satu string panjang.
- # Gabungkan semua ulasan menjadi satu string untuk WordCloud
- combined_reviews = “ “.join(reviews)
Metode .join() menggabungkan elemen list reviews dengan spasi sebagai pemisah antar kalimat.
Langkah 4: Membuat WordCloud
Setelah datanya siap, sekarang saatnya kita generate WordCloud dengan kode berikut.
- # Membuat WordCloud
- wordcloud = WordCloud(width=800, height=400, background_color=‘white’).generate(combined_reviews)
Berikut detail penjelasannya.
WordCloud()adalah objek dari librarywordcloudyang digunakan untuk menghasilkan visualisasi.- Parameter
widthdanheightmenentukan ukuran kanvas gambar. background_color='white'menjadikan latar belakang Word Cloud berwarna putih..generate(combined_reviews)membuat visualisasi berdasarkan string gabungan yang sudah disiapkan.
Langkah 5: Menampilkan WordCloud
Langkah terakhir adalah bagian yang menyenangkan, yakni saatnya kita menampilkan visualisasi dari WordCloud yang tadi dibuat.
- # Menampilkan WordCloud
- plt.figure(figsize=(10, 5))
- plt.imshow(wordcloud, interpolation=‘bilinear’)
- plt.axis(‘off’) # Menyembunyikan axis
- plt.show()
Berikut detail penjelasannya.
plt.figure()menentukan ukuran figur tampilan.plt.imshow()menampilkan gambar WordCloud.interpolation='bilinear'memperhalus tampilan visual.plt.axis('off')menyembunyikan sumbu agar hasil tampak lebih bersih.plt.show()menampilkan hasil akhir pada layar.
Inilah tampilan visualisasi dari WordCloud yang kita buat.

Kita bisa lihat bahwa dalam contoh ini, kata “Matematika”, “Belajar”, dan “menyenangkan” tampil lebih besar karena sering muncul pada ulasan.
Dengan memperhitungkan frekuensi kata dalam sebuah dokumen atau kumpulan dokumen, WordCloud memungkinkan kita untuk melihat secara langsung kata-kata yang lebih dominan atau penting. Ini sangat berguna dalam eksplorasi data, analisis sentimen, pencarian informasi, dan aplikasi NLP lainnya.
Dengan menggunakan WordCloud, kita dapat mengidentifikasi kata kunci atau topik utama dalam kumpulan teks, serta melihat perubahan distribusi kata dari waktu ke waktu atau antar dokumen. Teknik visualisasi ini memungkinkan kita untuk lebih mudah memahami pola-pola dalam data teks besar.
Matematika dalam Natural Language Processing (NLP): Representasi Frekuensi Kata (Bag-of-Words)
Dalam dunia natural language processing (NLP), salah satu tantangan terbesar adalah membuat komputer memahami bahasa manusia.
Komputer, pada dasarnya, hanya mengerti angka. Jadi, jika ingin komputer menganalisis ulasan pelanggan, email, atau berita, kita harus mengubah teks-teks itu menjadi format numerik yang bisa diolah.
Di sinilah teknik Bag of Words (BoW) berperan sebagai salah satu metode paling sederhana dan paling awal untuk melakukan “terjemahan” ini.
Apa itu Bag of Words?
Bayangkan Bag of Words ini seperti sebuah tas belanja. Ketika Anda memasukkan bahan-bahan makanan ke tas, Anda mungkin tidak peduli dengan urutan memasukkannya. Hal yang penting adalah bahan dalam tas itu dan jumlah dari setiap jenis bahan yang Anda punya.

Konsep yang sama berlaku untuk BoW: kita hanya peduli kata dalam sebuah dokumen teks dan jumlah kemunculan masing-masing kata itu, tanpa memedulikan urutan atau konteks gramatikalnya.
Oleh karena itu, metode ini disebut “Bag of Words” karena mirip seperti kita melihat isi tas—kita hanya peduli tentang “apa” yang ada di dalamnya, bukan “bagaimana” urutannya.
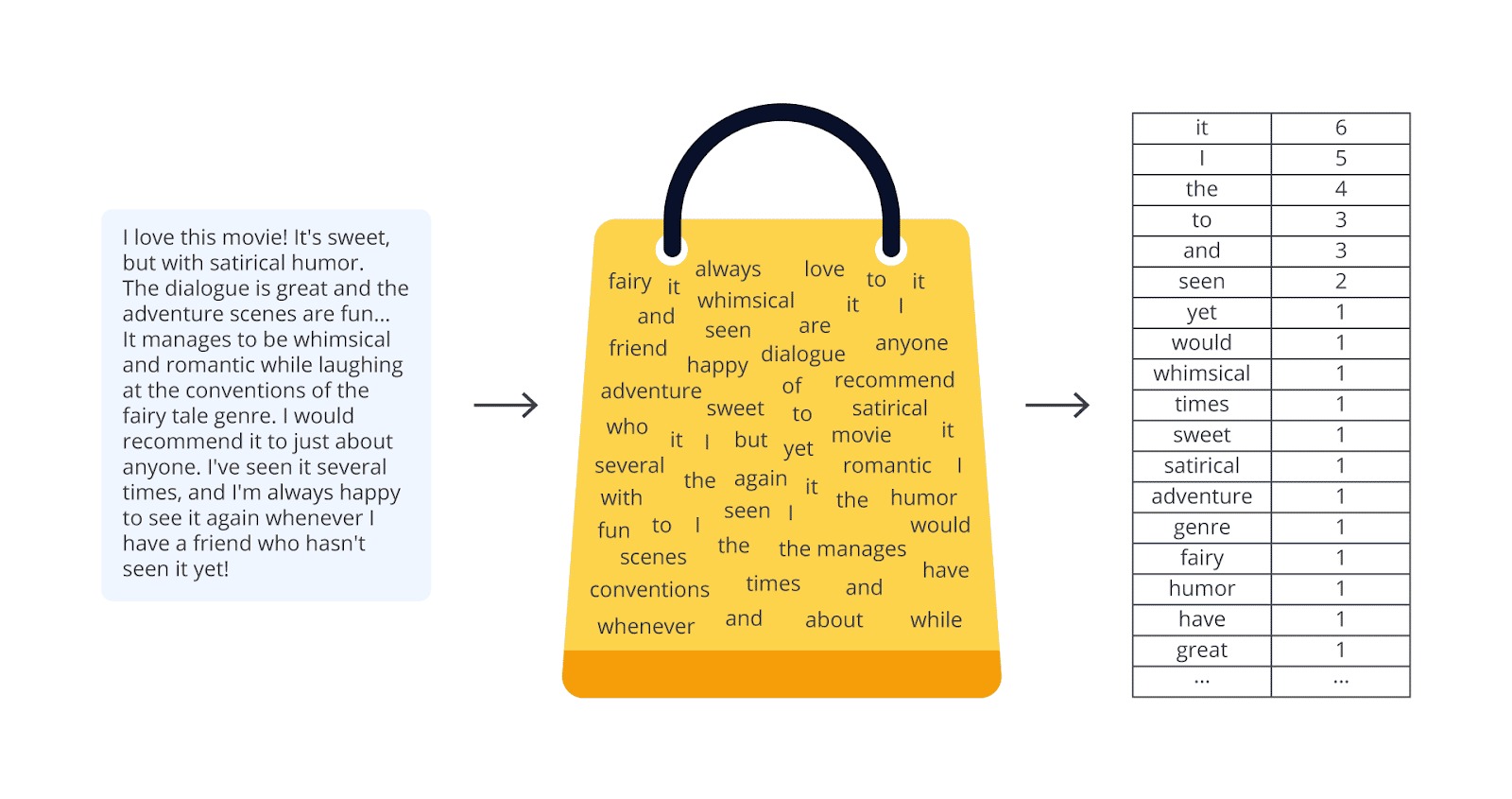
Bag of Words adalah pendekatan sederhana untuk merepresentasikan teks sebagai vektor angka berdasarkan frekuensi kemunculan kata dalam kumpulan dokumen.
Dalam konteks ini, setiap kata unik yang muncul pada semua ulasan disebut sebagai fitur (feature). Setiap teks diubah menjadi sebuah vektor yang menyatakan jumlah setiap kata muncul dalam ulasan tersebut.
Metode ini disebut “bag” karena struktur kalimat diabaikan dan urutan kata tidak diperhatikan; yang penting hanyalah keberadaan serta frekuensi kata.
Tujuan utama BoW adalah menghasilkan fitur numerik dari dokumen teks sehingga teks tersebut dapat diaplikasikan pada berbagai algoritma machine learning. Algoritma seperti Naïve Bayes, support vector machine (SVM), atau decision tree tidak bisa langsung bekerja dengan teks mentah. Mereka butuh angka.
Dalam metode BoW, setiap kata unik yang ditemukan dalam seluruh koleksi dokumen (sering disebut korpus) akan dianggap sebagai fitur tersendiri. Kemudian, untuk setiap dokumen, kita akan menghitung frekuensi (berapa kali) setiap kata unik tersebut muncul.
Hasilnya, setiap dokumen akan direpresentasikan sebagai sebuah vektor (barisan angka), yakni setiap elemen pada vektor tersebut menunjukkan frekuensi kemunculan kata tertentu dalam dokumen itu.
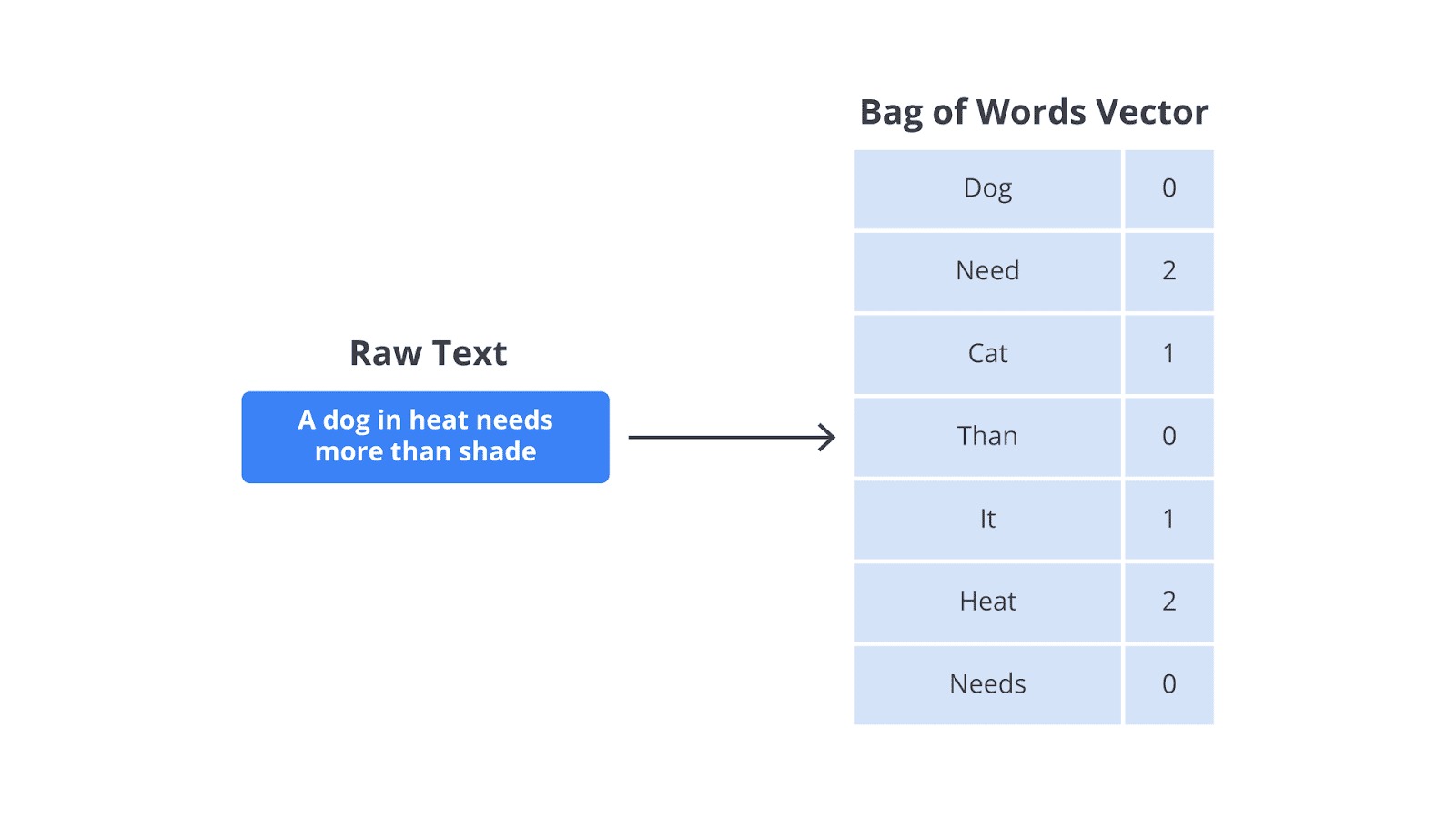
Metode ini sangat sering digunakan dalam tugas-tugas seperti klasifikasi teks, contohnya untuk menentukan jika sebuah ulasan bersifat positif atau negatif, atau lainnya untuk mengetahui bahwa sebuah email adalah spam atau bukan.
Cara Kerja Bag of Word
Untuk memahami cara kerja metode bag of words, mari kita mulai dengan sebuah contoh sederhana dan relevan. Bayangkan Anda adalah seorang analis yang ingin mengklasifikasikan ulasan siswa tentang pembelajaran matematika dalam dua kategori: “positif” atau “negatif” berdasarkan isi teks ulasannya.
Berikut adalah beberapa contoh ulasan yang berhasil dikumpulkan.
- Ulasan 1: “Saya suka belajar Matematika.”
- Ulasan 2: “Belajar matematika menyenangkan.”
- Ulasan 3: “Matematika itu menyenangkan.”
- Ulasan 4: “Belajar matematika sangat penting.”
- Ulasan 5: “Matematika adalah ilmu dasar.”
Namun, agar dapat dianalisis oleh komputer—terutama oleh algoritma machine learning—teks harus diubah dalam format numerik karena komputer tidak memahami makna bahasa seperti manusia. Di sinilah metode Bag of Words (BoW) berperan.
Untuk menerapkan metode Bag of Words, kita perlu melalui beberapa tahapan penting. Mari kita uraikan langkah-langkahnya berdasarkan contoh ulasan yang sudah dikumpulkan sebelumnya.
Menyusun Kosakata Unik (Vocabulary)
Langkah pertama adalah menyusun daftar kosakata unik yang muncul dalam seluruh kumpulan ulasan. Disebut “unik” karena setiap kata hanya dicatat satu kali meskipun muncul pada beberapa ulasan atau berulang kali dalam satu dokumen.
Dari lima ulasan yang dimiliki, kita memperoleh 11 kata unik, yaitu berikut.
‘adalah’, ‘belajar’, ‘dasar’, ‘ilmu’, ‘itu’, ‘matematika’, ‘menyenangkan’, ‘penting’, ‘sangat’, ‘saya’, ‘suka’
Kosakata ini akan menjadi fitur-fitur (kolom) dalam tabel representasi numerik.
Menghitung Frekuensi Kemunculan Kata per Dokumen
Setelah memiliki kosakata, kita menghitung jumlah setiap kata muncul dalam masing-masing ulasan.
- Jika sebuah kata muncul, kita beri nilai sesuai dengan frekuensinya (contohnya: 1 jika muncul satu kali).
- Jika tidak muncul, nilainya adalah 0.
Dengan cara ini, kita memperoleh tabel representasi dokumen, seperti gambar berikut.

Setiap baris mewakili satu ulasan dan setiap kolom merepresentasikan sebuah kata dari kosakata. Misalnya berikut.
Ulasan ke-1 (“Saya suka belajar matematika”) direpresentasikan sebagai [0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1]
Merepresentasikan Dokumen sebagai Vektor
Dari tabel tersebut, setiap ulasan kini telah berubah menjadi sebuah vektor angka.
Inilah inti dari metode Bag of Words—mengubah teks menjadi representasi numerik berdasarkan frekuensi kata.
Vektor-vektor ini kemudian dapat digunakan oleh algoritma machine learning, seperti Naive Bayes, logistic regression, atau SVM untuk menganalisis dan mempelajari pola dari ulasan yang bersifat positif ataupun negatif.
Metode Bag of Words adalah pendekatan yang sederhana, tapi efektif untuk mengubah teks menjadi data numerik.
Meski tidak memperhatikan struktur atau urutan kata, metode ini mampu menangkap informasi penting dari keberadaan dan jumlah kata, yang cukup untuk banyak kasus klasifikasi teks dasar.
Implementasi BoW dengan Python
Pada bagian sebelumnya, kita sudah belajar konsep dan cara melakukan perhitungan manual menggunakan metode Bag of Words. Agar kemampuan kita semakin baik, pada bagian ini akan disajikan contoh implementasi metode BoW menggunakan bahasa pemrograman Python.
Untungnya, kita tidak perlu menulis kode dari nol untuk menghitung frekuensi kata dan membuat vektor. Library scikit-learn pada Python menyediakan alat yang sangat praktis untuk ini, yaitu CountVectorizer.
- from sklearn.feature_extraction.text import CountVectorizer
-
import pandas as pd
- # Data ulasan
- reviews = [“Saya suka belajar Matematika.”,
- ”Belajar matematika menyenangkan.”,
- ”Matematika itu menyenangkan.”,
- ”Belajar matematika sangat penting.”,
- ”Matematika adalah ilmu dasar.”
-
]
- # Membuat objek CountVectorizer
-
vectorizer = CountVectorizer()
- # Menghitung representasi BoW
-
X = vectorizer.fit_transform(reviews)
- # Menampilkan hasilnya dalam bentuk array
-
bow_array = X.toarray()
- # Menampilkan kata-kata dalam BoW
-
words = vectorizer.get_feature_names_out()
- # Menampilkan hasil representasi BoW
- print(“Kata-kata dalam BoW:”, words)
- print(“jumlah kata dalam bow:”, len(words))
- print(“Representasi BoW:”)
-
bow_array
- # Menampilkan hasilnya dalam bentuk array dan konversi ke DataFrame
- bow_array = X.toarray()
-
words = vectorizer.get_feature_names_out()
- # Membuat DataFrame dari BoW
- df_bow = pd.DataFrame(bow_array, columns=words)
- df_bow
Berikut adalah penjelasan singkat dan padat tentang kode di atas.
- Data ulasan: Kumpulan lima ulasan yang akan diproses menjadi representasi Bag of Words (BoW).
- CountVectorizer: Digunakan untuk mengubah teks menjadi representasi BoW dengan menghitung frekuensi kemunculan kata-kata unik dalam ulasan.
- fit_transform(): Menghitung dan mengubah ulasan menjadi vektor BoW.
- toarray(): Mengonversi hasil BoW yang berupa matriks sparse menjadi array biasa.
- get_feature_names_out(): Mengambil daftar kata-kata unik yang ditemukan dalam semua ulasan.
- pandas DataFrame: Hasil BoW disimpan dalam bentuk DataFrame untuk memudahkan pembacaan serta analisis lebih lanjut dengan kolom-kolom berupa kata-kata dan baris berupa ulasan.
Oke, kini Anda sudah mengetahui cara mengimplementasikan bag-of-word dalam bahasa pemrograman Python. Luar biasa!
Pertimbangan Penggunaan BoW
Ada hal yang perlu Anda perhatikan saat berinteraksi dengan BoW, yaitu ia tidak peduli pada urutan kata dalam sebuah kalimat atau dokumen. Metode ini hanya menghitung keberadaan serta frekuensi kata sehingga struktur kalimat dan hubungan antar kata diabaikan.
Misalkan ada dua kalimat ini: “Ilham mengejar Rina” dan “Rina mengejar Ilham”. Dalam konteks bahasa manusia, kedua kalimat ini memiliki arti yang sangat berbeda karena subjek dan objeknya bertukar posisi. Namun, bagi BoW, kedua kalimat ini akan direpresentasikan oleh vektor yang identik (jika hanya menghitung frekuensi kata) sebab keduanya mengandung kata-kata yang sama (“Ilham”, “mengejar”, “Rina”) dengan frekuensi sama.
Lebih jauh lagi, metode Bag of Words memiliki keterbatasan dalam menangkap nuansa makna yang bergantung pada susunan kata atau kehadiran kata negasi. Misalnya, bandingkan kalimat berikut.
- “Saya suka film ini”
- “Saya tidak suka film ini”
Secara struktur, kedua kalimat memiliki kata-kata yang hampir sama. Namun, jika kata “tidak” tak ada dalam kosakata (misalnya karena dihapus saat pra-pemrosesan), Bag of Words akan menganggap kedua kalimat tersebut sangat mirip secara numerik, padahal maknanya justru berlawanan secara emosional.
Hal ini menunjukkan bahwa Bag of Words tidak mempertimbangkan konteks, urutan kata, atau relasi antar kata sehingga kesulitan dalam memahami hal berikut.
- Negasi (“tidak suka” ≠ “suka”)
- Sarkasme
- Perubahan makna karena struktur kalimat
Akibatnya, representasi BoW tidak mampu menangkap makna semantik yang lebih dalam dari teks.
Matematika dalam Natural Language Processing (NLP): TF-IDF: Memberi Bobot Kata
Kita telah memahami bahwa metode Bag of Words (BoW) mengubah teks menjadi vektor numerik berdasarkan frekuensi kata. BoW adalah fondasi yang baik, tetapi kita juga telah mengidentifikasi beberapa kelemahan utamanya.
- Tidak Mempertimbangkan Urutan Kata: BoW tidak menangkap konteks atau makna yang berubah karena susunan kata (misalnya, “saya suka” vs. “suka saya”).
- Masalah Dimensi Tinggi dan Sparsity: Untuk kosakata yang sangat besar, vektor menjadi sangat panjang dan sebagian besar isinya nol. Ini akan memakan banyak memori dan komputasi.
- Tidak Membedakan Kata Penting dari Kata Umum: Kata-kata yang sangat sering muncul (seperti “dan”, “di”, “yang”) dianggap sama pentingnya dengan kata-kata spesifik yang lebih informatif hanya karena frekuensinya tinggi.
Nah, untuk mengatasi ketiga kelemahan ini, hadirlah teknik yang lebih canggih, tapi tetap berbasis frekuensi: TF-IDF (Term Frequency-Inverse Document Frequency).
Konsep Inti TF-IDF: Menilai Pentingnya Kata dalam Konteks
TF-IDF (Term Frequency-Inverse Document Frequency) adalah teknik pembobotan kata yang populer dalam pencarian informasi dan text mining. Tujuannya adalah menilai seberapa penting suatu kata dalam sebuah dokumen, relatif terhadap seluruh kumpulan dokumen (korpus).
TF-IDF bekerja dengan memberikan bobot numerik kepada setiap kata dalam dokumen. Semakin tinggi bobot TF-IDF sebuah kata, semakin relevan atau unik kata tersebut bagi dokumen itu dalam konteks korpus yang lebih besar.
Komponen TF-IDF
TF-IDF terdiri dari dua komponen utama sebagai berikut.
Term Frequency (TF)
TF mengukur seberapa sering sebuah kata (atau term) muncul dalam satu dokumen spesifik. Semakin sering sebuah kata muncul dalam dokumen, semakin tinggi nilai TF-nya, yang mengindikasikan bahwa kata tersebut mungkin penting untuk dokumen itu.
Jika sebuah kata muncul berkali-kali dalam sebuah artikel, kemungkinan besar artikel tersebut memang membahas topik yang terkait dengan kata itu.
Ada beberapa cara menghitung TF, tetapi yang paling sederhana adalah berikut.

Contoh: Jika sebuah kata muncul dua kali dari total sepuluh kata dalam dokumen, TF = 2/10 = 0.2
Inverse Document Frequency (IDF)
IDF mengukur seberapa “langka” atau “unik” sebuah kata dalam seluruh koleksi dokumen (korpus).
Jika sebuah kata muncul pada banyak dokumen dalam korpus, nilai IDF-nya akan rendah (karena kata itu umum). Sebaliknya, jika sebuah kata hanya muncul dalam sedikit dokumen (atau hanya pada satu dokumen saja), nilai IDF-nya akan tinggi (karena kata itu khas dan informatif).
Agar lebih jelas, mari lihat contoh cara IDF bekerja dalam membedakan kata-kata umum dan kata-kata khas pada korpus dokumen perfilman. Kata-kata seperti “dan”, “di”, atau “yang” muncul hampir pada semua dokumen sehingga tidak efektif untuk membedakan satu dokumen dari yang lain.
Sebaliknya, kata-kata seperti “sinematografi” atau “plot twist” mungkin jarang muncul, tetapi jika ada, biasanya sangat spesifik dan relevan terhadap topik film. IDF dirancang untuk menurunkan bobot kata-kata umum dan menaikkan bobot kata-kata yang lebih khas serta informatif.
Berikut adalah cara untuk menghitung IDF.

Misalkan kita memiliki lima dokumen ulasan film dan kata yang ingin dihitung IDF-nya adalah
t = “sinematografi”
Lalu diketahui
- N = 5 (jumlah total dokumen)
- df(“sinematografi”) = 1 (kata “sinematografi” hanya muncul dalam 1 dokumen)
Jadi, rumusnya berikut.
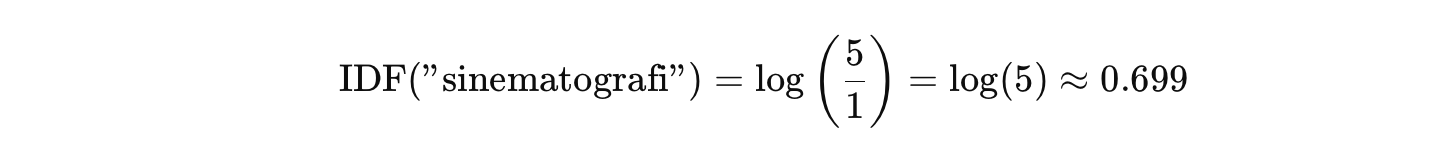
Artinya, karena kata “sinematografi” hanya muncul dalam satu dokumen, nilainya tinggi. Ini menandakan bahwa kata tersebut cukup unik dan relevan secara spesifik untuk dokumen itu.
Sebaliknya, coba kita hitung untuk kata berikut.
t = “yang”
- df(“yang”) = 5 (muncul pada semua dokumen)
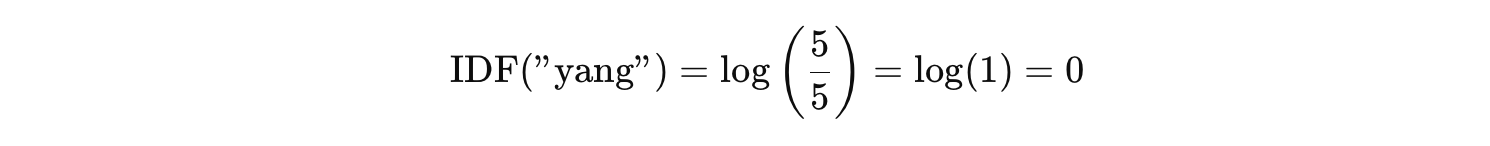
Nilainya nol karena kata “yang” terlalu umum—tidak membantu membedakan dokumen satu dengan yang lain.
Untuk menghindari pembagian dengan nol jika sebuah kata tidak muncul dalam dokumen mana pun–atau untuk memberikan bobot pada kata yang muncul dalam semua dokumen–sering kali ditambahkan +1 pada pembilang dan/atau penyebut, misalnya seperti ini.

Perhitungan TF-IDF
Setelah menghitung nilai term frequency (TF) dan inverse document frequency (IDF) untuk setiap kata dalam dokumen, kita memperoleh bobot akhir TF-IDF dengan mengalikan kedua komponen tersebut.
Persamaannya berikut.

Sebuah kata akan memiliki bobot TF-IDF yang tinggi jika ia sering muncul dalam sebuah dokumen tertentu (TF tinggi) dan jarang muncul dalam dokumen-dokumen lain pada korpus (IDF tinggi). Ini adalah kombinasi yang menunjukkan relevansi dan kekhasan.
Bayangkan kita punya lima dokumen ulasan film. Kita ingin menghitung TF-IDF untuk kata “sinematografi” dalam Dokumen 2 dengan informasi sebagai berikut.
Kata “sinematografi” muncul sebanyak 3 kali pada Dokumen 2, yang memiliki total 100 kata. Jadi, penghitungan TF sebagai berikut.
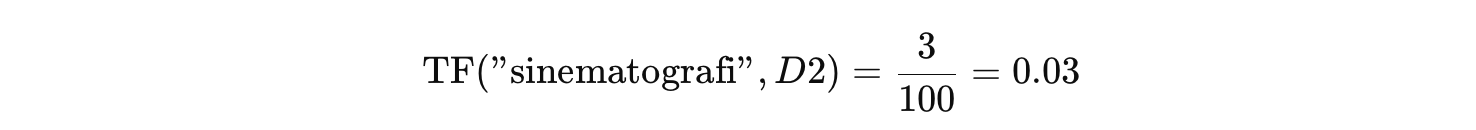
Kemudian diketahui bahwa kata “sinematografi” hanya muncul dalam 1 dari 5 dokumen. Jadi, penghitungan IDF sebagai berikut.
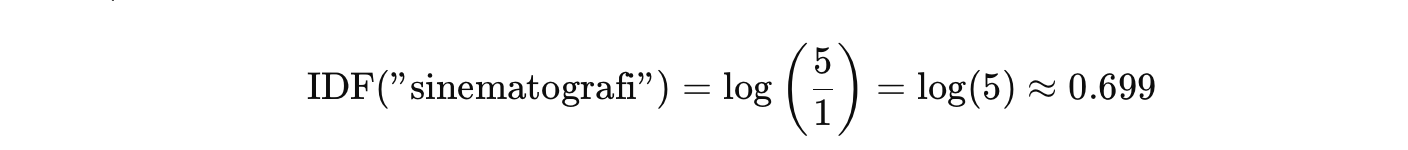
Dengan demikian, hasil akhir penghitungan TF-IDF adalah berikut.
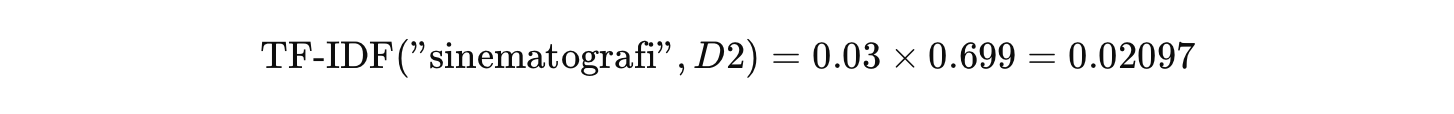
Artinya, bobot 0.02097 menunjukkan bahwa kata “sinematografi” cukup penting dalam Dokumen 2 karena cukup sering muncul dan jarang ada pada dokumen lain.
Menggunakan TF-IDF untuk Ulasan Matematika
Kali ini kita akan kembali dalam skenario ulasan matematika yang kita gunakan pada materi sebelumnya. Kita akan mengubah ulasan teks menjadi representasi angka menggunakan metode TF-IDF dengan langkah-langkah berikut.
Menyusun Kosakata Unik (Vocabulary)
Langkah pertama adalah seperti yang sudah dilakukan dalam Bag of Words (BoW), yaitu menyusun kosakata unik yang muncul di seluruh kumpulan ulasan pembelajaran matematika.
Berikut adalah beberapa contoh ulasan yang berhasil dikumpulkan.
- Dokumen 1: “Saya suka belajar Matematika.”
- Dokumen 2: “Belajar matematika menyenangkan.”
- Dokumen 3: “Matematika itu menyenangkan.”
- Dokumen 4: “Belajar matematika sangat penting.”
- Dokumen 5: “Matematika adalah ilmu dasar.”
Dari ulasan di atas, kosakata unik yang dihasilkan adalah sebelas kata.
‘adalah’, ‘belajar’, ‘dasar’, ‘ilmu’, ‘itu’, ‘matematika’, ‘menyenangkan’, ‘penting’, ‘sangat’, ‘saya’, ‘suka’
Menghitung Term Frequency (TF)
Term frequency (TF) mengukur seberapa sering sebuah kata muncul dalam suatu dokumen (ulasan). Rumusnya adalah berikut.

Dalam kasus ini, jumlah total kata dalam “Dokumen 1” adalah 4, yakni ([‘Saya’, ‘suka’, ‘belajar’, ‘Matematika’]). Kita hitung TF untuk setiap kata seperti berikut.

Dengan cara yang sama kita bisa menghitung TF untuk masing-masing dokumen atau ulasan sehingga akan mendapatkan hasil berikut.
Menghitung Inverse Document Frequency (IDF)
IDF mengukur seberapa penting suatu kata dalam seluruh koleksi dokumen. Semakin jarang kata muncul dalam koleksi, semakin tinggi nilai IDF-nya. IDF sangat berguna untuk menurunkan bobot kata yang sering muncul dalam semua dokumen, misalnya kata-kata umum seperti “dan” atau “adalah” yang tidak memberikan banyak informasi.

Pada perhitungan di atas, kata “Matematika” muncul dalam setiap dokumen. Jadi, kita simpulkan bahwa
- df(“Matematika”) = 5 (yaitu 5 dokumen).
- N = 5 (total jumlah dokumen).
- Hasilnya, IDF(“Matematika”) = 1
Karena kata ini muncul dalam setiap dokumen, IDF-nya menjadi 0, yang berarti kata ini tidak memberikan banyak informasi untuk membedakan dokumen.
Dengan cara yang sama, kita bisa menghitung IDF untuk setiap kata unik sehingga akan mendapatkan hasil berikut.

Menghitung TF-IDF
Setelah menghitung TF dan IDF, kita dapat mengalikan keduanya untuk mendapatkan TF-IDF. TF-IDF mengukur pentingnya sebuah kata dalam dokumen dengan mempertimbangkan seberapa sering kata tersebut muncul dalam dokumen (TF) dan seberapa jarang kata tersebut muncul pada seluruh dokumen (IDF).
Rumus TF-IDF adalah berikut.

Dari data TF dan IDF yang sudah dihitung sebelumnya, kita dapat menghitung nilai TF-IDF untuk setiap kata pada Dokumen 1.
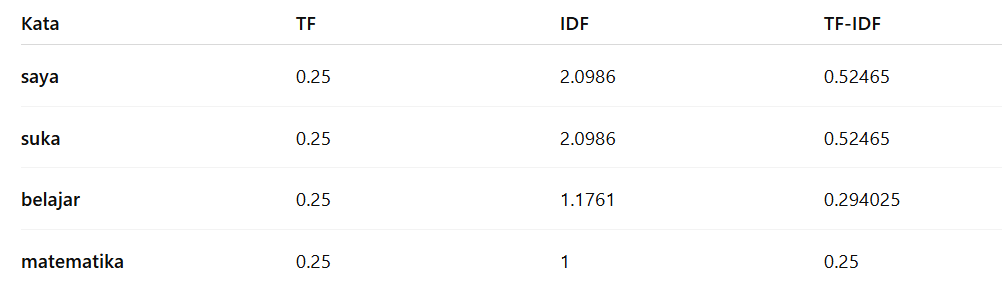
Dengan cara yang sama, kita dapat menghitung TF-IDF untuk setiap kata pada dokumen sehingga akan mendapatkan hasil berikut.
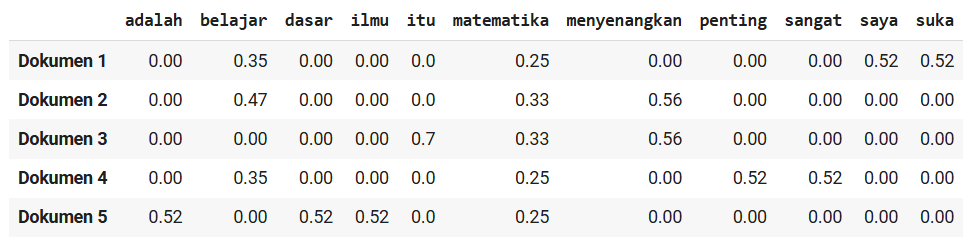
Dari hasil TF-IDF di atas, kita dapat melihat bahwa nilai bobot untuk kata matematika berbeda dalam tiap dokumennya, bergantung pada kata lain dalam dokumen tersebut. Berdasarkan data tersebut, kita dapat mendapat kesimpulan sebagai berikut.
- TF mengukur frekuensi kemunculan kata dalam satu dokumen.
- IDF mengukur seberapa penting kata tersebut di seluruh koleksi dokumen.
- TF-IDF adalah perkalian antara TF dan IDF, yang memberikan bobot lebih pada kata-kata penting untuk membedakan dokumen.
Ini adalah cara manual menghitung TF, IDF, dan TF-IDF yang dapat digunakan dalam tugas seperti klasifikasi teks atau pencarian informasi.
Implementasi TF-IDF dengan Python
Setelah memahami konsep dasar dan perhitungan manual TF-IDF, saatnya kita lihat cara mengimplementasikannya dengan efisien menggunakan Python.
Kode yang akan dibahas ini bertujuan untuk menghitung TF (term frequency), IDF (inverse document frequency), dan TF-IDF dari kumpulan data ulasan teks menggunakan Python, lalu menyajikan hasilnya dalam bentuk tabel menggunakan pandas.
Langkah 1: Persiapan Library dan Data
Pertama, kita perlu mengimpor beberapa library terlebih dahulu, antara lain berikut.
pandasuntuk manipulasi data tabular.mathdigunakan untuk perhitungan logaritma.Counterdari collections digunakan untuk menghitung frekuensi kata.
Selain itu, kita juga menyiapkan data ulasan yang akan dipakai. Variabel reviews adalah kumpulan dokumen berupa ulasan pendek yang akan dianalisis.
- import pandas as pd
- import math
-
from collections import Counter
- # Data ulasan
- reviews = [
- ”saya suka belajar matematika”,
- ”belajar matematika menyenangkan”,
- ”matematika itu menyenangkan”,
- ”belajar matematika sangat penting”,
- ”matematika adalah ilmu dasar”
- ]
Langkah 2: Membangun Kosakata
Kemudian, kita menggabungkan semua teks, menjadikannya huruf kecil, memecah menjadi kata, lalu membuat daftar kata unik yang telah diurutkan.
- # Membuat daftar kata unik di seluruh dokumen (ubah set menjadi list dan urutkan)
- all_words = sorted(list(set(“ “.join(reviews).lower().split())))
Langkah 3: Menghitung Term Frequency (TF)
Selanjutnya, kita menghitung proporsi kemunculan setiap kata dalam satu dokumen merujuk pada rumus ini TF = (jumlah kata tertentu) / (total kata dalam dokumen).
- # Menghitung TF untuk setiap dokumen
- def compute_tf(doc):
- word_count = Counter(doc.lower().split())
- total_words = len(doc.split())
- tf = {word: count / total_words for word, count in word_count.items()}
- return tf
Langkah 4: Menghitung Inverse Document Frequency (IDF)
Setelah itu, kita menghitung seberapa umum atau jarang suatu kata muncul dalam seluruh dokumen dengan rumus: IDF = log10((N + 1) / (df + 1)) + 1
- N = jumlah dokumen
- df = jumlah dokumen yang mengandung kata tersebut
- Tambahan +1 untuk mencegah pembagian nol atau log(0)
- # Menghitung IDF untuk seluruh koleksi dokumen
- def compute_idf(reviews, all_words):
- N = len(reviews)
- idf = {}
- for word in all_words:
- df = sum(1 for review in reviews if word in review.lower())
- idf[word] = math.log10((N + 1) / (df + 1)) + 1 # Ditambahkan +1 untuk mencegah pembagian dengan nol
- return idf
Langkah 5: Menghitung TF-IDF
Langkah berikutnya adalah kita mengalikan nilai TF dengan IDF untuk setiap kata pada setiap dokumen. Di sini kita memberikan bobot yang menekankan kata-kata penting (unik untuk dokumen tertentu).
- # Menghitung TF-IDF
- def compute_tfidf(reviews, all_words):
- idf = compute_idf(reviews, all_words)
- tfidf = []
- for review in reviews:
- tf = compute_tf(review)
- tfidf.append({word: tf.get(word, 0) * idf[word] for word in all_words})
- return tfidf
Langkah 6: Mengeksekusi Perhitungan
Setelah kita membuat fungsi untuk menghitung TF, IDF, dan TF-IDF, kini saatnya mengeksekusi fungsi tersebut.
- tf_results = [compute_tf(review) for review in reviews]
- idf_results = compute_idf(reviews, all_words)
- tfidf_results = compute_tfidf(reviews, all_words)
Langkah 7: Membuat Tabel Pandas
Untuk memudahkan dalam melihat hasil perhitungan TF, IDF, dan TF-IDF sebelumnya, kali ini kita membuat tabel data frame untuk masing-masing.
Kode ini akan menampilkan frekuensi relatif kata pada tiap dokumen.
- # Membuat DataFrame untuk TF
- df_tf = pd.DataFrame(tf_results, columns=all_words)
- df_tf.index = [f”Dokumen {i+1}” for i in range(len(tf_results))]
- df_tf = df_tf.fillna(0).round(2)
- df_tf
Inilah hasil untuk tabel TF yang menunjukkan seberapa sering kata muncul dalam dokumen.
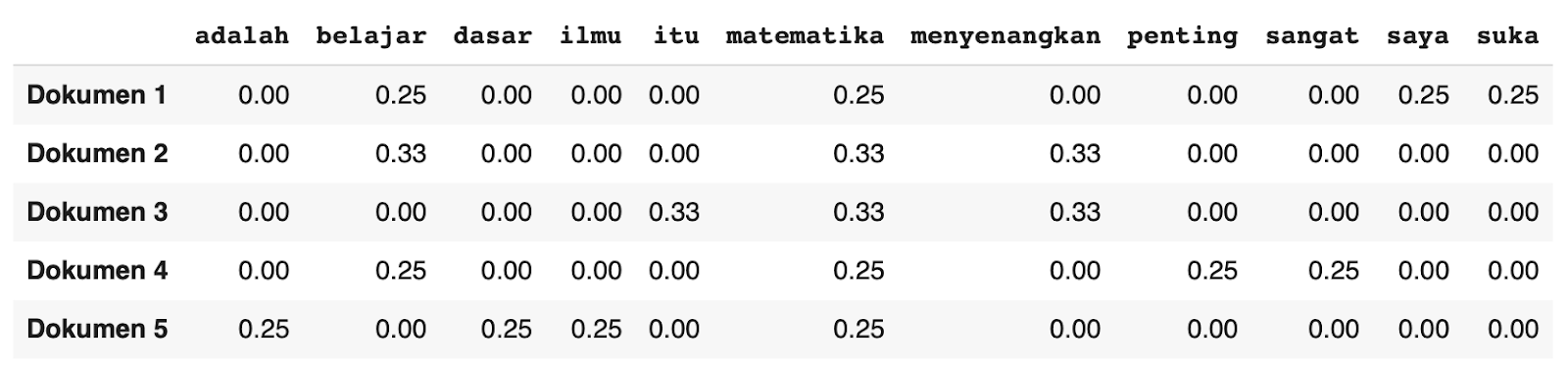
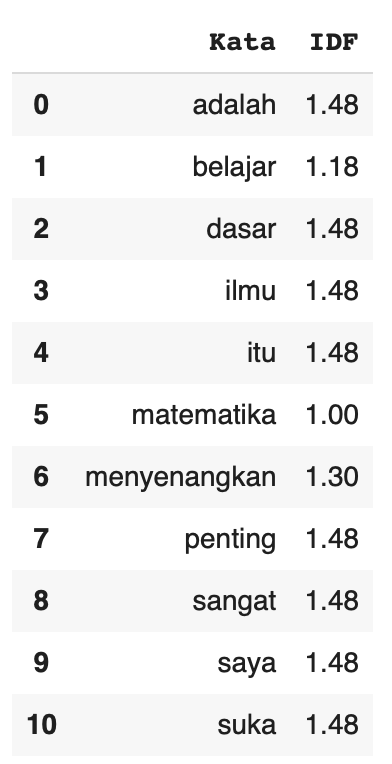
Kemudian, kode berikut akan menampilkan nilai IDF dari setiap kata dalam kosakata.
- df_idf = pd.DataFrame(list(idf_results.items()), columns=[“Kata”, “IDF”])
- df_idf = df_idf.round(2)
- df_idf
Inilah tampilan hasil untuk tabel IDF yang menunjukkan seberapa unik kata dalam seluruh dokumen.
Terakhir, kode berikut menampilkan bobot pentingnya kata pada tiap dokumen berdasarkan kombinasi TF dan IDF.
- df_tfidf = pd.DataFrame(tfidf_results, columns=all_words)
- df_tfidf.index = [f”Dokumen {i+1}” for i in range(len(tfidf_results))]
- df_tfidf = df_tfidf.round(2)
- df_tfidf
Inilah tampilan hasil untuk tabel TF-IDF yang menunjukkan bobot pentingnya kata dalam konteks dokumen.
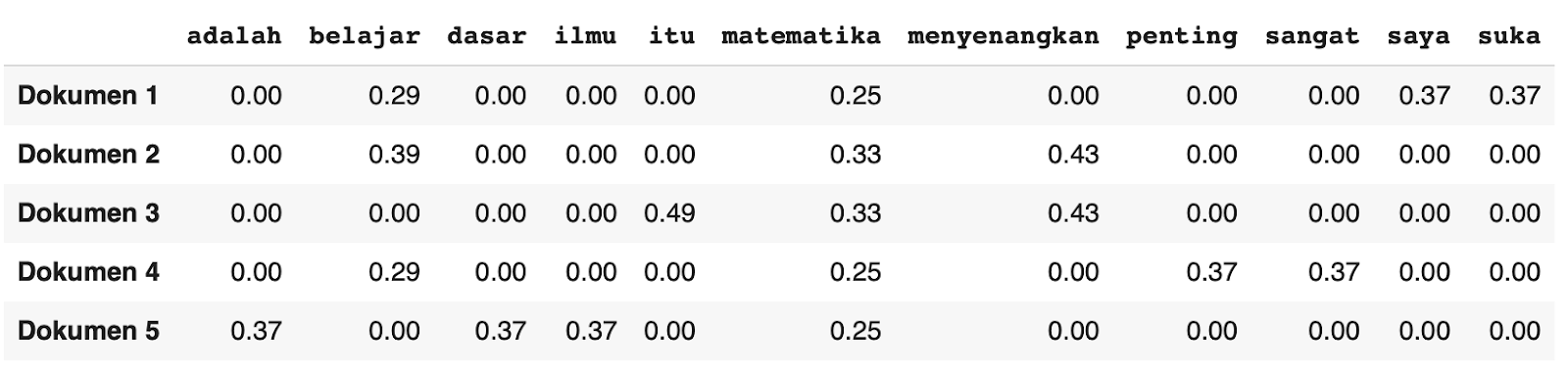
Perhatikan tabel TF-IDF di atas. Setiap baris mewakili satu ulasan, sementara setiap kolom merepresentasikan satu kata unik dari seluruh kumpulan ulasan (atau yang kita sebut korpus). Nilai yang kita lihat pada setiap sel adalah bobot TF-IDF untuk kata tertentu dalam ulasan spesifik.
Nilai bobot yang lebih tinggi mengindikasikan bahwa kata tersebut sangat relevan dan spesifik untuk ulasan itu. Ini biasanya berarti kata tersebut sering muncul dalam ulasan tersebut, tetapi jarang atau bahkan tidak muncul sama sekali pada ulasan lain dalam korpus.
Menariknya, Anda akan melihat bahwa kata “matematika” memiliki bobot TF-IDF yang relatif seragam dalam semua ulasan. Ini terjadi karena “matematika” muncul pada setiap ulasan dalam korpus.
Dalam filosofi TF-IDF, kata-kata yang sering muncul pada banyak dokumen biasanya memiliki nilai IDF lebih rendah karena dianggap kurang mampu membedakan satu dokumen dari yang lain. Namun karena kemunculannya tetap proporsional dan tidak terlalu dominan, nilai TF-IDF “matematika” tetap memiliki bobot sedang.
Sebaliknya, kata-kata seperti “saya”, “suka”, “itu”, “sangat”, “penting”, “adalah”, “ilmu”, dan “dasar” bisa memiliki bobot TF-IDF lebih tinggi ketika hanya muncul pada satu atau dua ulasan, menjadikannya lebih khas untuk dokumen tempat mereka muncul.
Pertimbangan Penggunaan TF-IDF
Oke, sampai saat ini kita sudah berhasil menghitung TF-IDF menggunakan Python. Ada beberapa hal yang harus Anda perhatikan saat menggunakan teknik TF-IDF ini.
Meskipun TF-IDF lebih unggul dibandingkan metode Bag of Words (BoW) karena lebih informatif dengan mengurangi bobot kata umum, tetap saja pendekatan TF-IDF ini masih memiliki beberapa keterbatasan penting yang mirip dengan BoW.
- Pertama, TF-IDF tidak mempertimbangkan urutan kata. Artinya, dua kalimat dengan susunan kata berbeda, tapi makna yang sangat berbeda tetap bisa dianggap serupa. Sebagai contoh, kalimat “Ilham mengejar Rina” dan “Rina mengejar Ilham” akan diberikan bobot kata yang sama oleh TF-IDF meskipun maknanya jelas berbeda.
- Kedua, TF-IDF kesulitan menangkap konteks negasi atau ironi. Misalnya, kalimat “Saya suka film ini” dan “Saya tidak suka film ini” dapat dianggap mirip jika kata “tidak” diabaikan selama pra-pemrosesan, padahal maknanya berlawanan.
- Ketiga, TF-IDF tidak memahami makna semantik antar kata. Kalimat seperti “Saya ingin membeli mobil baru” dan “Saya ingin membeli rumah baru” mungkin dianggap serupa, padahal secara makna dan konteks sangat berbeda.
Oleh karena itu, untuk menangkap konteks, makna, dan hubungan antar kata secara lebih mendalam, pendekatan lanjutan seperti Word Embedding lebih sesuai.
Matematika dalam Natural Language Processing (NLP): Word Embedding
Word Embedding adalah teknik pada natural language processing (NLP) yang digunakan untuk mengonversi kata-kata dalam teks menjadi representasi numerik, biasanya berbentuk vektor berdimensi rendah. Tujuannya adalah menangkap makna semantik dan hubungan antar kata dalam sebuah korpus teks.
Dengan Word Embedding, kata-kata yang memiliki makna serupa atau sering muncul dalam konteks serupa akan memiliki representasi numerik lebih mirip, memungkinkan mesin untuk “memahami” dan memproses bahasa manusia dengan lebih efektif.
Berbeda dengan teknik lama, seperti Bag of Words (BoW) atau TF-IDF yang hanya memperhitungkan frekuensi kata, Word Embedding berfokus pada makna kata dalam konteks kalimat sehingga menghasilkan representasi kata yang lebih kaya dan bermakna.
Cara Kerja Word Embedding
Dalam Word Embedding, setiap kata dalam vocabulary direpresentasikan sebagai vektor numerik berdimensi rendah, biasanya terdiri dari puluhan hingga ratusan dimensi. Dimensi-dimensi ini tidak ditentukan secara manual, tetapi dipelajari secara otomatis melalui proses pelatihan algoritma yang memanfaatkan konteks kemunculan kata dalam teks.
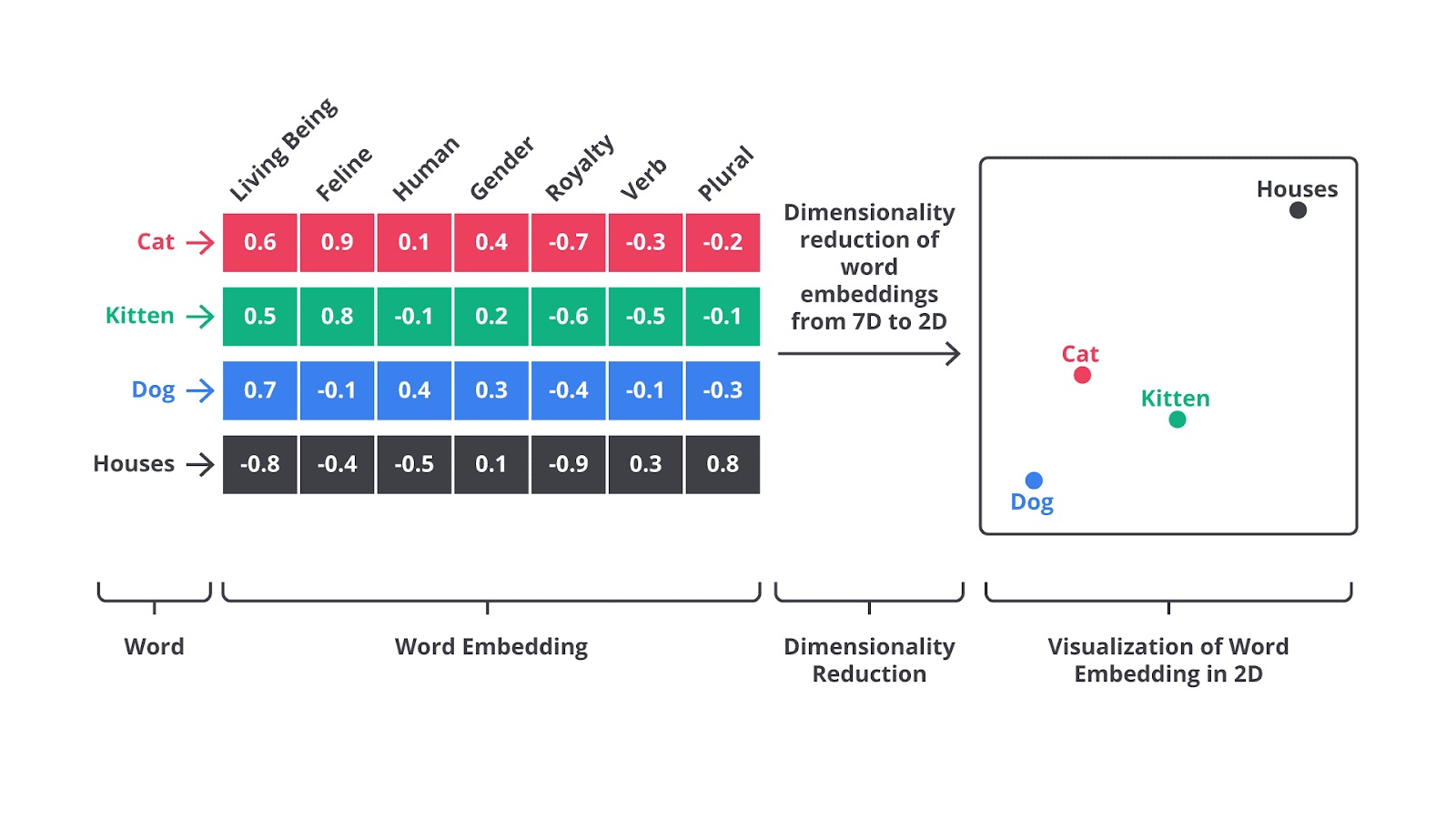
Sebagai contoh, dalam Word Embedding terjadi hal berikut.
- Kata “cat” dan “kitten” akan memiliki vektor yang mirip karena keduanya memiliki makna yang berkaitan—yakni sama-sama merujuk pada hewan kucing.
- Sebaliknya, kata “cat” dan “car”, yang memiliki makna sangat berbeda, akan direpresentasikan oleh vektor yang berjauhan dalam ruang vektor.
Alasan Word Embedding Lebih Unggul dari Representasi Tradisional
Berikut adalah beberapa keunggulan utama dari Word Embedding dibandingkan teknik lain, seperti Bag of Words (BoW) dan TF-IDF.
- Efisien dan Padat (Compact Representation)
Berbeda dengan BoW atau TF-IDF yang menghasilkan vektor sangat besar dan sparse (banyak nilai nol), Word Embedding merepresentasikan kata dalam vektor padat berdimensi rendah (biasanya puluhan hingga ratusan dimensi) sehingga membuat analisis teks lebih efisien secara komputasi untuk disimpan serta diproses. - Menangkap Konteks dan Makna
Word Embedding dapat membedakan makna kata yang sama berdasarkan konteks penggunaannya. Misalnya, kata “apel” dalam kalimat “Saya makan apel setelah makan siang” akan direpresentasikan secara berbeda dibandingkan dengan “Upacara apel di sekolah dimulai pukul tujuh pagi”. Meskipun sama-sama menggunakan kata “apel”, maknanya berbeda—yang satu merujuk pada buah, sedangkan yang lain merujuk pada kegiatan formal di sekolah. Word Embedding mampu mengenali perbedaan ini dengan melihat kata-kata di sekitarnya. - Mengenali Kemiripan Makna (Sinonim)
Kata-kata yang sering digunakan dalam konteks yang sama—seperti “dokter” dan “perawat”—akan direpresentasikan dengan vektor mirip. Ini tidak dapat dicapai oleh BoW atau TF-IDF. - Menangkap Pola Semantik Lebih Dalam
Word Embedding juga dapat mengenali pola semantik atau asosiasi antar kata berdasarkan konteks global. Misalnya, kata “sekolah” dan “belajar”, “uang” dan “transaksi”, atau “bank” dan “uang” sering muncul bersama dalam konteks serupa sehingga vektornya akan lebih mirip dibandingkan kata-kata yang tidak terkait.
Jenis Word Embedding
Salah satu metode paling populer dalam membangun Word Embedding adalah Word2Vec. Metode ini dirancang untuk mempelajari representasi vektor dari kata-kata berdasarkan konteksnya dalam kalimat.
Word2Vec memiliki dua arsitektur utama dengan pendekatan yang berbeda dalam memahami hubungan antar kata, yaitu CBOW (Continuous Bag of Words) dan Skip-gram. Meskipun keduanya untuk menghasilkan embedding berkualitas tinggi, cara kerja internal dan kekuatan masing-masing model memiliki perbedaan yang khas.
CBOW (Continuous Bag of Words)
CBOW memprediksi kata target berdasarkan kata-kata konteks di sekitarnya. Dalam hal ini, CBOW menangkap hubungan antar kata dalam konteks tertentu, yang sangat berguna untuk memahami makna kata pada konteks kalimat.
Pendekatan ini efektif untuk mempelajari makna kata dalam kalimat dengan asumsi bahwa kata-kata di sekitar membawa informasi penting.
Misalkan kita memiliki kalimat berikut: “saya suka belajar matematika”.
Jika kata “suka” adalah kata target yang ingin diprediksi, kata-kata “saya”, “belajar”, dan “matematika” menjadi kata konteks yang digunakan untuk memprediksi kata target “suka”.
Supaya lebih jelas, berikut adalah cara kerja dari CBOW.
- Input: Kata-kata konteks (di sekitar kata target).
- Output: Kata target.
- Jendela Konteks: CBOW menggunakan jendela konteks yang mengelilingi kata target. Misalnya, jendela konteks adalah dua maka dua kata sebelum dan dua kata setelah kata target digunakan untuk memprediksi kata tersebut.
CBOW menggunakan kata-kata konteks untuk memprediksi kata target. Dengan kata lain, model ini mengasumsikan bahwa kata-kata yang berada dalam jendela konteks (di sekitar kata target) membawa informasi penting untuk menentukan kata yang tengah.
Dengan menggunakan CBOW, model mempelajari vektor representasi dari kata-kata konteks–seperti (“Saya”, “belajar”, “Matematika”)–dan menggunakannya untuk memprediksi kata target–misalnya (“suka”). Ini membuat CBOW efisien dalam pelatihan dan cocok untuk dataset besar.
Skip-gram
Skip-gram melakukan kebalikan dari CBOW: ia memprediksi kata-kata konteks berdasarkan kata target. Dengan ini, Skip-gram fokus pada mempelajari hubungan semantik antar kata dengan cara memperkirakan kata-kata di sekitar kata target.
Ini membuatnya sangat efektif untuk menangkap kata-kata langka dan hubungan semantik yang lebih kompleks karena dapat memanfaatkan kata target guna memprediksi banyak kata konteks yang ada di sekitarnya.
Misalkan kita memiliki kalimat yang sama: “saya suka belajar matematika”.
Jika kata “suka” adalah kata target, Skip-gram akan mencoba memprediksi kata-kata konteks “saya”, “belajar”, dan “matematika” dari kata target “suka”.
Skip-gram bekerja dengan cara yang berfokus pada kata target dan mencoba untuk memprediksi banyak kata konteks yang mengelilinginya.
Jelasnya, berikut adalah cara kerja dari metode skip-gram.
- Input: Kata target (misalnya, “suka”).
- Output: Kata-kata konteks (misalnya, [“Saya”, “belajar”, “Matematika”]).
- Jendela Konteks: Sama seperti CBOW, Skip-gram juga menggunakan jendela konteks untuk menentukan kata-kata yang akan diprediksi berdasarkan kata target.
Intinya, Skip-gram mempelajari representasi vektor dari kata target–misalnya (“suka”)–dengan memanfaatkannya untuk memprediksi kata-kata konteks yang mengelilinginya–seperti (“Saya”, “belajar”, “Matematika”).
Perbandingan CBOW dan Skip-gram
Setelah memahami cara kerja masing-masing arsitektur, kita dapat melihat kelebihan serta kekurangan dari CBOW dan Skip-gram secara berdampingan. Meskipun keduanya memiliki tujuan sama, pendekatan yang digunakan memberikan karakteristik performa dan hasil embedding berbeda.
- CBOW lebih unggul dalam hal efisiensi pelatihan dan sangat cocok digunakan pada dataset berukuran besar. Namun, pendekatan ini kurang efektif dalam menangkap makna kata-kata yang jarang muncul.
- Sebaliknya, Skip-gram lebih andal dalam mempelajari hubungan semantik antar kata, terutama untuk kata-kata langka. Meskipun demikian, metode ini membutuhkan waktu pelatihan yang lebih lama dibandingkan CBOW.
Kedua arsitektur ini—CBOW dan Skip-gram—merupakan fondasi utama dari Word2Vec. Keduanya memungkinkan kata-kata dikonversi menjadi representasi numerik (embedding) yang dapat dipahami dan diolah oleh mesin. Meskipun berbeda dalam cara mereka memproses kata konteks dan kata target, keduanya berperan penting untuk membangun model bahasa yang lebih canggih serta efisien.
Implementasi Word Embedding dengan Python
Untuk merasakan langsung cara Word2Vec bekerja, kita akan menggunakan library gensim dalam Python. gensim adalah library NLP open-source yang menyediakan implementasi Word2Vec yang sangat dioptimalkan dan mudah digunakan.
Kode yang akan dibahas dalam materi ini bertujuan untuk melatih dua model Word2Vec menggunakan dua pendekatan berbeda—CBOW (Continuous Bag of Words) dan Skip-gram—dengan dataset sederhana dalam bahasa Indonesia. Setelah pelatihan, model digunakan untuk menampilkan vektor representasi kata dan kata-kata yang paling mirip dengan kata “matematika”.
Langkah 1: Impor Library
Pertama, kita mengimpor class Word2Vec dari library gensim yang digunakan untuk membangun dan melatih model word embedding.
# Import library yang diperlukan from gensim.models import Word2Vec
Langkah 2: Dataset Contoh
Selanjutnya, mari kita membuat dataset contoh yang terdiri dari lima kalimat sederhana yang sudah dipisahkan per kata (tokenized). Format input ini sesuai dengan kebutuhan gensim, yaitu list of list of tokens (nested list).
# Dataset contoh sentences = [ [‘saya’, ’suka’, ’belajar’, ’matematika’], [‘belajar’, ’matematika’, ’sangat’, ’menyenangkan’], [‘matematika’, ’itu’, ’menyenangkan’], [‘belajar’, ’matematika’, ’penting’], [‘matematika’, ’adalah’, ’ilmu’, ’dasar’] ]
Langkah 3: Pelatihan Model CBOW
Kemudian, kita gunakan kode berikut untuk melatih model menggunakan CBOW.
# Pelatihan menggunakan CBOW cbow_model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, sg=0) # sg=0 untuk CBOW
Berikut penjelasannya.
vector_size=50→ Setiap kata akan direpresentasikan dalam vektor berdimensi 50.window=3→ Ukuran jendela konteks sejauh 3 kata di kiri dan kanan target.min_count=1→ Kata dengan frekuensi 1 pun tetap dimasukkan.sg=0→ Menandakan bahwa arsitektur yang digunakan adalah CBOW.
Langkah 4: Pelatihan Model Skip-gram
Selanjutnya, kita gunakan kode ini untuk melatih model menggunakan skip-gram.
# Pelatihan menggunakan Skip-gram skipgram_model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, sg=1) # sg=1 untuk Skip-gram
Untuk detail penjelasannya sama seperti CBOW, tetapi bagian sg=1 artinya model menggunakan arsitektur Skip-gram. Skip-gram memprediksi konteks berdasarkan kata target.
Langkah 5: Menyimpan Model
Kedua model disimpan dalam file .bin agar bisa digunakan kembali tanpa perlu melatih ulang.
# Menyimpan model untuk evaluasi lebih lanjut cbow_model.save(“cbow_model.bin”) skipgram_model.save(“skipgram_model.bin”)
Langkah 6: Melihat Vektor Representasi
Pada kode berikut, kita menampilkan vektor representasi dari kata “matematika” yang telah dipelajari oleh masing-masing model.
# Menampilkan vektor untuk kata tertentu print(“Vektor kata ‘matematika’ dari model CBOW:”) print(cbow_model.wv[‘matematika’]) print(“\nVektor kata ‘matematika’ dari model Skip-gram:”) print(skipgram_model.wv[‘matematika’])
Langkah 7: Melihat Kemiripan antara Dua Kata
Kemudian, untuk membandingkan kemiripan kata “saya” dan “belajar”, kita gunakan baris kode berikut.
# Mengukur kesamaan antara dua kata dalam kedua model similarity_cbow = cbow_model.wv.similarity(‘saya’, ’belajar’) similarity_skipgram = skipgram_model.wv.similarity(‘saya’, ’belajar’) print(“\nKesamaan antara ‘saya’ dan ‘belajar’ dalam model CBOW:”) print(similarity_cbow) print(“\nKesamaan antara ‘saya’ dan ‘belajar’ dalam model Skip-gram:”) print(similarity_skipgram)
Fungsi similarity(kata1, kata2) dari gensim akan menghitung cosine similarity antara dua vektor kata. Nilai hasilnya berada dalam rentang -1 sampai 1.
- Semakin mendekati 1 → semakin mirip secara semantik
- Semakin mendekati -1 → semakin berbeda atau tidak terkait
Langkah 8: Melihat Kata yang Paling Mirip
Terakhir, kita mengambil tiga kata yang paling mirip dengan “matematika” berdasarkan similaritas kosinus dari representasi vektor. Ini digunakan untuk melihat jika model berhasil memahami hubungan semantik antar kata.
# Menampilkan kata yang paling mirip dengan ‘matematika’ dalam kedua model print(“\nKata-kata yang paling mirip dengan ‘matematika’ dalam model CBOW:”) print(cbow_model.wv.most_similar(‘matematika’, topn=3)) print(“\nKata-kata yang paling mirip dengan ‘matematika’ dalam model Skip-gram:”) print(skipgram_model.wv.most_similar(‘matematika’, topn=3))
Setelah menjalankan kode di atas, Anda akan melihat serangkaian output yang memberikan gambaran nyata tentang cara Word Embeddings bekerja.
Pertama, Anda akan disajikan dengan vektor kata untuk “matematika” dari kedua model (CBOW dan Skip-gram).

Vektor-vektor ini adalah serangkaian angka (dalam kasus kita, 50 angka) yang secara matematis merepresentasikan makna kata tersebut dalam konteks dataset pelatihan. Penting untuk dicatat bahwa vektor-vektor ini akan berbeda antara model CBOW dan Skip-gram karena masing-masing arsitektur mempelajari representasi kata dengan cara yang unik berdasarkan tujuan prediksinya.
Selanjutnya, Anda akan melihat nilai kesamaan antara kata “saya” dan “belajar” dalam kedua model.

Nilai ini, yang biasanya dihitung menggunakan cosine similarity, mengindikasikan seberapa dekat makna kedua kata tersebut dalam ruang vektor yang dilatih. Nilai yang mendekati 1 menunjukkan kesamaan semantik yang tinggi, sementara nilai yang mendekati -1 menunjukkan ketidakmiripan signifikan.
Nilai negatif, seperti pada gambar, menunjukkan tidak ada hubungan semantik yang terbangun, kemungkinan karena dataset terlalu kecil.
Perlu diingat bahwa dengan dataset yang sangat kecil seperti contoh kita, hasil kesamaan mungkin tidak selalu intuitif atau mencerminkan kesamaan semantik dunia nyata secara sempurna. Ini karena model memiliki konteks yang terbatas untuk belajar hubungan antar kata.
Terakhir, fungsi most_similar akan menampilkan daftar kata-kata yang vektornya paling dekat dengan vektor “matematika”.

Ini secara efektif menunjukkan kata-kata mana–menurut pemahaman model–yang memiliki makna atau konteks penggunaan paling mirip dengan “matematika” berdasarkan dataset pelatihan.
Sekali lagi, dengan dataset yang kecil, hasil ini mungkin tidak selalu sempurna, tapi tetap memberikan ilustrasi jelas tentang cara model “mempelajari” hubungan semantik antar kata dan mengelompokkan kata-kata yang terkait secara konseptual.
Meskipun dataset yang kita gunakan sangat sederhana, contoh praktis ini secara efektif mendemonstrasikan prinsip dasar penggunaan Word2Vec dengan arsitektur CBOW dan Skip-gram untuk menghasilkan Word Embeddings.
Dalam aplikasi NLP dunia nyata yang lebih kompleks, model-model ini dilatih pada korpus teks yang sangat besar—sering kali terdiri dari jutaan atau bahkan miliaran kata. Hal ini memungkinkan mereka untuk menghasilkan representasi kata yang jauh lebih kaya, akurat, dan bermakna, yang kemudian menjadi dasar fundamental untuk berbagai tugas NLP tingkat lanjut, seperti terjemahan mesin, analisis sentimen, ekstraksi informasi, atau bahkan sistem rekomendasi cerdas.
Matematika dalam Natural Language Processing (NLP): Cosine Similarity
Cosine similarity adalah salah satu metode paling umum guna mengukur kesamaan antara dua vektor dalam ruang vektor berdimensi tinggi, yang terutama digunakan pada natural language processing (NLP) untuk mengukur kemiripan antar teks atau dokumen.
Ini adalah teknik yang sangat berguna ketika kita bekerja dengan teks yang telah dikonversi menjadi representasi vektor, seperti Bag of Words (BoW), TF-IDF, atau Word Embedding. Kita sudah bersinggungan dengan cosine similarity ini pada latihan implementasi Word Embedding dengan Python sebelumnya.
Cara Kerja Cosine Similarity
Pada dasarnya, cosine similarity mengukur seberapa dekat dua vektor dengan menghitung sudut antara keduanya. Semakin kecil sudut antara dua vektor, semakin besar kemiripannya. Jika dua vektor sejajar (sudut 0 derajat), kesamaannya sangat tinggi, dan jika mereka tegak lurus (sudut 90 derajat), tidak ada kesamaan di antara keduanya.
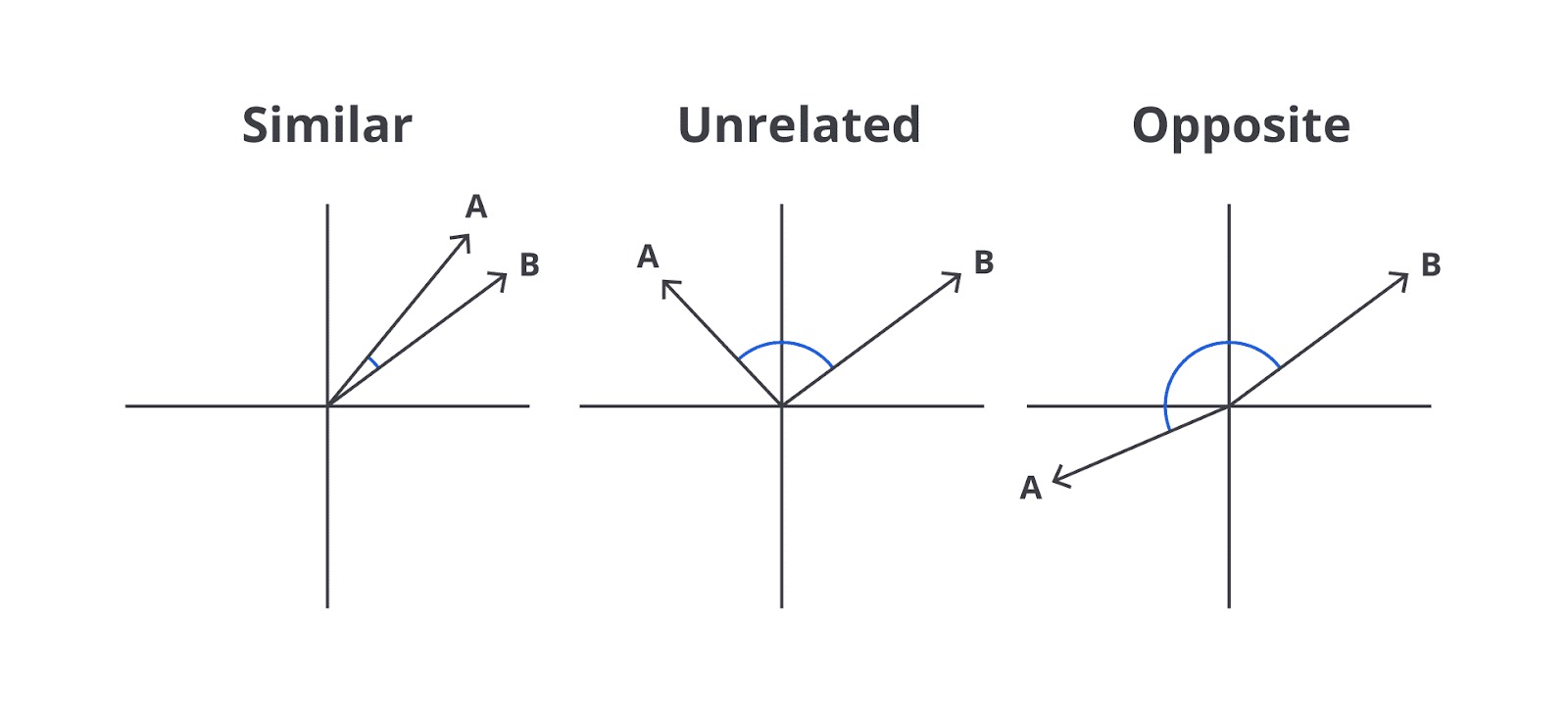
Dalam konteks NLP, cosine similarity sering digunakan untuk membandingkan dua dokumen atau dua kalimat dan menentukan sejauh mana mereka serupa. Misalnya, dalam sistem pencarian informasi, kita ingin mengetahui seberapa mirip query yang diberikan dengan dokumen pada database. Di sinilah cosine similarity berperan penting.
Pentingnya Cosine Similarity
Sebelum memahami lebih dalam tentang cosine similarity, mari kita lihat alasan ini sangat penting, khususnya dalam NLP.
- Pencocokan Dokumen atau Kalimat
Cosine similarity digunakan untuk mengukur kemiripan dua teks. Misalnya, dalam aplikasi pencarian dokumen atau sistem rekomendasi, kita sering kali ingin mengetahui kemiripan dua teks berdasarkan kata-kata yang ada di dalamnya. Cosine similarity memungkinkan kita untuk melakukan ini dengan efektif. - Tidak Terpengaruh oleh Panjang Dokumen
Salah satu keunggulan dari cosine similarity adalah bahwa ia tidak terpengaruh oleh panjang dokumen. Artinya, meskipun dua dokumen memiliki panjang yang sangat berbeda, cosine similarity hanya memperhitungkan arah vektor (yaitu hubungan antara kata-kata dalam dokumen), bukan panjang total dokumen. - Kemampuan Mengukur Keterkaitan Semantik
Cosine similarity dapat digunakan untuk mengukur keterkaitan semantik antara dua kalimat atau dokumen. Misalnya, dua kalimat dengan banyak kata bersama-sama dalam konteks serupa akan memiliki nilai cosine similarity yang tinggi.
Implementasi Cosine Similarity dengan Python
Dalam pembelajaran natural language processing (NLP), memahami cara mengukur kemiripan antar dokumen adalah fondasi penting. Kali ini, kita akan membandingkan dua kalimat sederhana dalam bahasa Indonesia menggunakan tiga pendekatan berbeda: Bag of Words (BoW), TF-IDF, dan Word Embedding dengan Word2Vec.
Langkah 1: Impor Library
Kita mulai dengan mengimpor beberapa library yang dibutuhkan, termasuk gensim dan scikit-learn.
- import gensim
- from gensim.models import Word2Vec
- from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
- from sklearn.metrics.pairwise import cosine_similarity
Langkah 2: Menyiapkan Dokumen
Dua kalimat pendek akan digunakan sebagai data uji sebagai berikut.
- # Dua dokumen yang akan dibandingkan
- doc1 = ”Saya suka belajar matematika”
- doc2 = “Belajar matematika sangat menyenangkan”
Langkah 3: Mengukur Kemiripan dengan Bag of Words (BoW)
Pendekatan ini mengubah setiap dokumen menjadi vektor berdasarkan frekuensi kata.
-
# 1. **Bag of Words (BoW)**
- # Menggunakan CountVectorizer dari Scikit-learn untuk Bag of Words
- count_vectorizer = CountVectorizer()
- bow_matrix = count_vectorizer.fit_transform([doc1, doc2])
Kemudian, cosine similarity dihitung sebagai berikut.
- # Menghitung cosine similarity untuk BoW
- bow_similarity = cosine_similarity(bow_matrix[0:1], bow_matrix[1:2])
- print(f”Cosine Similarity (BoW): {bow_similarity[0][0]}”)
Catatan: BoW tidak mempertimbangkan makna atau urutan kata—hanya menghitung keberadaan dan frekuensi.
Langkah 4: Mengukur Kemiripan dengan TF-IDF
TF-IDF (Term Frequency–Inverse Document Frequency) memberikan bobot lebih pada kata-kata penting yang tidak sering muncul dalam semua dokumen. Kita menghitung TF-IDF dengan kode berikut.
-
# 2. **TF-IDF**
- # Menggunakan TfidfVectorizer dari Scikit-learn untuk TF-IDF
- tfidf_vectorizer = TfidfVectorizer()
-
tfidf_matrix = tfidf_vectorizer.fit_transform([doc1, doc2])
- # Menghitung cosine similarity untuk TF-IDF
- tfidf_similarity = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:2])
- print(f”Cosine Similarity (TF-IDF): {tfidf_similarity[0][0]}”)
Catatan: TF-IDF mengurangi bobot kata yang terlalu umum (seperti “belajar”) dan menonjolkan kata yang khas untuk satu dokumen.
Langkah 5: Persiapan Dataset untuk Word2Vec
Setelah menghitung BoW dan TF-IDF, sekarang kita akan melakukan representasi semantik menggunakan Word2Vec (CBOW dan Skip-gram).
- Model Word2Vec memerlukan input dalam format token seperti ini.
-
# 3. **CBOW dan Skip-gram dengan Word2Vec**
- # Membuat dataset kalimat (dalam bentuk list of words)
- sentences = [
- doc1.split(), # Kata-kata dalam doc1
- doc2.split() # Kata-kata dalam doc2
- ]
Langkah 6: Melatih Model Word2Vec
Pertama, kita gunakan kode ini untuk melatih model dengan teknik CBOW.
- # Melatih model Word2Vec dengan CBOW (sg=0) dan Skip-gram (sg=1)
- # CBOW
- cbow_model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, sg=0)
Lanjut, sekarang giliran kita melatih model dengan teknik Skip-gram dengan baris kode berikut.
- # Skip-gram
- skipgram_model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, sg=1)
Penjelasan parameternya berikut.
vector_size=50: Panjang vektor representasi kata.window=3: Jangkauan konteks kata.min_count=1: Kata dengan frekuensi 1 tetap disertakan.sg=0untuk CBOW dansg=1untuk Skip-gram.
Langkah 7: Mendapatkan Representasi Dokumen
Kita ambil rata-rata vektor kata untuk setiap dokumen.
-
# Menghitung rata-rata vektor kata untuk kedua dokumen dalam kedua model
- def get_document_vector(model, words):
- # Ambil rata-rata vektor kata untuk dokumen
- word_vectors = [model.wv[word] for word in words if word in model.wv]
- if len(word_vectors) == 0:
- return [0] * model.vector_size
- return sum(word_vectors) / len(word_vectors)
Lalu, dihitung untuk masing-masing model.
- # Menghitung vektor untuk dokumen 1 dan dokumen 2 dengan CBOW
- doc1_vector_cbow = get_document_vector(cbow_model, doc1.split())
-
doc2_vector_cbow = get_document_vector(cbow_model, doc2.split())
- # Menghitung vektor untuk dokumen 1 dan dokumen 2 dengan Skip-gram
- doc1_vector_skipgram = get_document_vector(skipgram_model, doc1.split())
- doc2_vector_skipgram = get_document_vector(skipgram_model, doc2.split())
Langkah 8: Menghitung Kemiripan dengan Word2Vec
Dengan vektor dokumen yang didapat, kita hitung cosine similarity.
- # Menghitung cosine similarity antara dokumen 1 dan 2 menggunakan CBOW dan Skip-gram
- cosine_cbow = cosine_similarity([doc1_vector_cbow], [doc2_vector_cbow])
-
cosine_skipgram = cosine_similarity([doc1_vector_skipgram], [doc2_vector_skipgram])
- print(f”Cosine Similarity (CBOW): {cosine_cbow[0][0]}”)
- print(f”Cosine Similarity (Skip-gram): {cosine_skipgram[0][0]}”)
Penutup: Interpretasi Hasil
Untuk dua kalimat berikut
- doc1: “Saya suka belajar matematika”
- doc2: “Belajar matematika sangat menyenangkan”
Kita telah menghitung tingkat kemiripan antara keduanya menggunakan empat pendekatan representasi teks. Setelah kode di atas dijalankan, hasilnya berikut.

Berikut detail penjelasannya.
- BoW (0.5)
Pendekatan Bag of Words menghitung kemiripan berdasarkan jumlah kata yang sama antar dokumen, tanpa memperhatikan makna atau urutan. Nilai 0.5 menunjukkan bahwa setengah dari vektor representasi kedua dokumen ini identik, yang masuk akal karena keduanya memiliki beberapa kata yang sama, seperti “belajar” dan “matematika”. - TF-IDF (0.34)
TF-IDF mempertimbangkan seberapa penting suatu kata dalam konteks dokumen tertentu. Nilai kemiripan lebih rendah dibandingkan BoW karena kata-kata umum, seperti “belajar” dan “matematika”, mungkin dianggap tidak terlalu membedakan sehingga bobotnya dikurangi. - Word2Vec (0.27)
Word2Vec mencoba memahami arti kata dengan mempelajari konteksnya. Baik pendekatan CBOW maupun Skip-gram menghasilkan nilai cosine similarity yang lebih rendah(≈ 0.27) dibandingkan BoW dan TF-IDF. Hal ini wajar karena hal berikut.- Dataset terlalu kecil untuk melatih model yang benar-benar mampu memahami hubungan semantik antar kata.
- Kata-kata seperti “suka” dan “menyenangkan” tidak muncul dalam konteks cukup beragam untuk membentuk representasi semantik yang kuat.
Meskipun nilai similarity rendah, pendekatan ini lebih menjanjikan jika diterapkan pada korpus yang lebih besar karena mempertimbangkan makna dan konteks.
Kesimpulan
BoW cocok untuk kasus sederhana. TF-IDF lebih kontekstual. Word2Vec unggul pada pemahaman makna, tapi butuh data lebih besar.
Anda bisa akses kode lengkap yang dijelaskan dalam topik natural language processing pada link berikut: Modul 6 - Natural Language Processing.ipynb
Matematika dalam Time Series
Setelah kita mempelajari implementasi matematika pada bidang computer vision dan natural language processing, kini kita akan beralih ke salah satu jenis data yang sangat spesifik serta memiliki karakteristik unik: data deret waktu (time series).
Berbeda dengan dataset tradisional ketika setiap observasi sering diasumsikan independen, data time series memiliki ketergantungan waktu yang intrinsik, yakni sebuah nilai pada waktu tertentu sangat mungkin dipengaruhi oleh nilai-nilai pada masa lalu.
Pemahaman mendalam tentang struktur statistik data ini adalah kunci untuk membangun model prediksi yang akurat dan melakukan inferensi yang valid. Dalam materi ini, kita akan fokus pada cara memahami data time series sebagai proses statistik dan kemudian memformulasikan model ARIMA yang canggih.
Pengertian Data Time Series
Data time series atau deret waktu adalah kumpulan observasi yang diurutkan secara kronologis. Karakteristik utamanya adalah adanya dependensi antar observasi berdasarkan urutan waktu.
Sebagai contoh, harga saham hari ini sangat dipengaruhi oleh harga kemarin, penjualan bulan ini mungkin mengikuti pola yang sama dengan bulan yang sama tahun lalu, dan sebagainya.
Memahami sifat fundamental ini adalah langkah pertama menuju analisis yang efektif.
Konsep Proses Stokastik
Dalam konteks statistika, sebuah data time series yang kita amati di dunia nyata hanyalah sebuah realisasi tunggal dari suatu entitas yang lebih besar dan abstrak, yaitu proses stokastik.
Proses stokastik dapat dibayangkan sebagai sebuah ‘mesin’ teoretis yang mengikuti aturan acak yang menghasilkan nilai-nilai secara terus-menerus seiring berjalannya waktu.
Setiap nilai dalam time series yang kita amati (misalnya, harga saham harian selama setahun) adalah satu dari kemungkinan tak terhingga “jalur” atau “lintasan” yang bisa dihasilkan oleh proses stokastik yang mendasarinya.
Kunci dari proses stokastik adalah bahwa nilai pada waktu tertentu (Yt) bukan hanya variabel acak, melainkan juga dipengaruhi oleh nilai-nilai sebelumnya (Yt−1,Yt−2, dst.). Inilah yang membedakannya secara mendasar dari data yang bersifat independen dan terdistribusi identik, seperti yang biasa diasumsikan dalam statistik dasar.
Konsep ini secara langsung berhubungan dengan gagasan variabel acak bersama (joint random variables) dan distribusi bersama (joint distribution). Untuk time series, kita tidak hanya tertarik pada distribusi probabilitas suatu variabel acak Yt secara terisolasi, tetapi juga pada distribusi probabilitas gabungan dari seluruh urutan variabel acak: (Y1,Y2,…,Yt). Memahami bahwa probabilitas satu nilai bergantung pada nilai sebelumnya (melalui probabilitas kondisional) adalah inti dari pemodelan proses stokastik.
Pemahaman time series sebagai realisasi dari proses stokastik ini sangat fundamental. Ini adalah landasan teoritis yang memungkinkan kita untuk melakukan hal berikut.
- Memodelkan Ketergantungan Waktu: Mengidentifikasi dan menghitung bahwa nilai di masa lalu memengaruhi nilai di masa depan.
- Membuat Prediksi: Memproyeksikan nilai-nilai di masa depan berdasarkan pola historis yang diidentifikasi dari proses stokastik yang mendasarinya.
- Menganalisis Sifat Data: Menentukan bahwa sebuah deret waktu memiliki sifat-sifat tertentu seperti stasioneritas (akan dibahas selanjutnya) yang sangat krusial untuk pemilihan model.
Matematika dalam Time Series: Komponen Statistik Time Series
Meskipun time series bisa tampak sangat kompleks dan tidak teratur pada pandangan pertama, sebagian besar time series yang kita temui di dunia nyata dapat secara efektif dipecah menjadi beberapa komponen statistik yang lebih sederhana dan dapat dipahami.
Proses ini, yang kita kenal sebagai dekomposisi time series, adalah langkah analitis yang sangat penting. Tujuannya adalah mengidentifikasi dan memisahkan pola-pola yang mendasari data, memisahkan bagian yang relatif dapat diprediksi dari elemen-elemen bersifat acak atau tidak dapat dijelaskan.
Secara umum, sebuah time series Yt dapat dimodelkan sebagai kombinasi (baik secara penjumlahan untuk model aditif maupun perkalian untuk model multiplikatif) dari empat komponen utama.
- Trend (Tt): Merepresentasikan perubahan jangka panjang dalam rata-rata time series yang bisa meningkat, menurun, atau tetap datar seiring waktu (misalnya, peningkatan penjualan smartphone selama dekade terakhir).
- Seasonality (St): Pola yang berulang secara periodik dan konsisten dalam jangka waktu tetap, disebabkan oleh faktor-faktor musiman atau kalender yang dapat diprediksi (misalnya, peningkatan penjualan es krim di musim panas setiap tahun).
- Cyclical (Ct): Mencerminkan fluktuasi jangka panjang yang tidak memiliki periode tetap, sering kali terkait dengan siklus bisnis atau ekonomi yang durasinya bervariasi selama beberapa tahun (misalnya, siklus boom dan bust ekonomi).
- Residual/Noise (Rt atau εt): Ini adalah komponen yang tersisa setelah trend, seasonality, dan cyclical pattern dihilangkan. Residual ini merepresentasikan variasi yang tidak dapat dijelaskan oleh pola-pola tersebut, dan idealnya, ia bersifat acak murni atau yang kita sebut sebagai white noise.
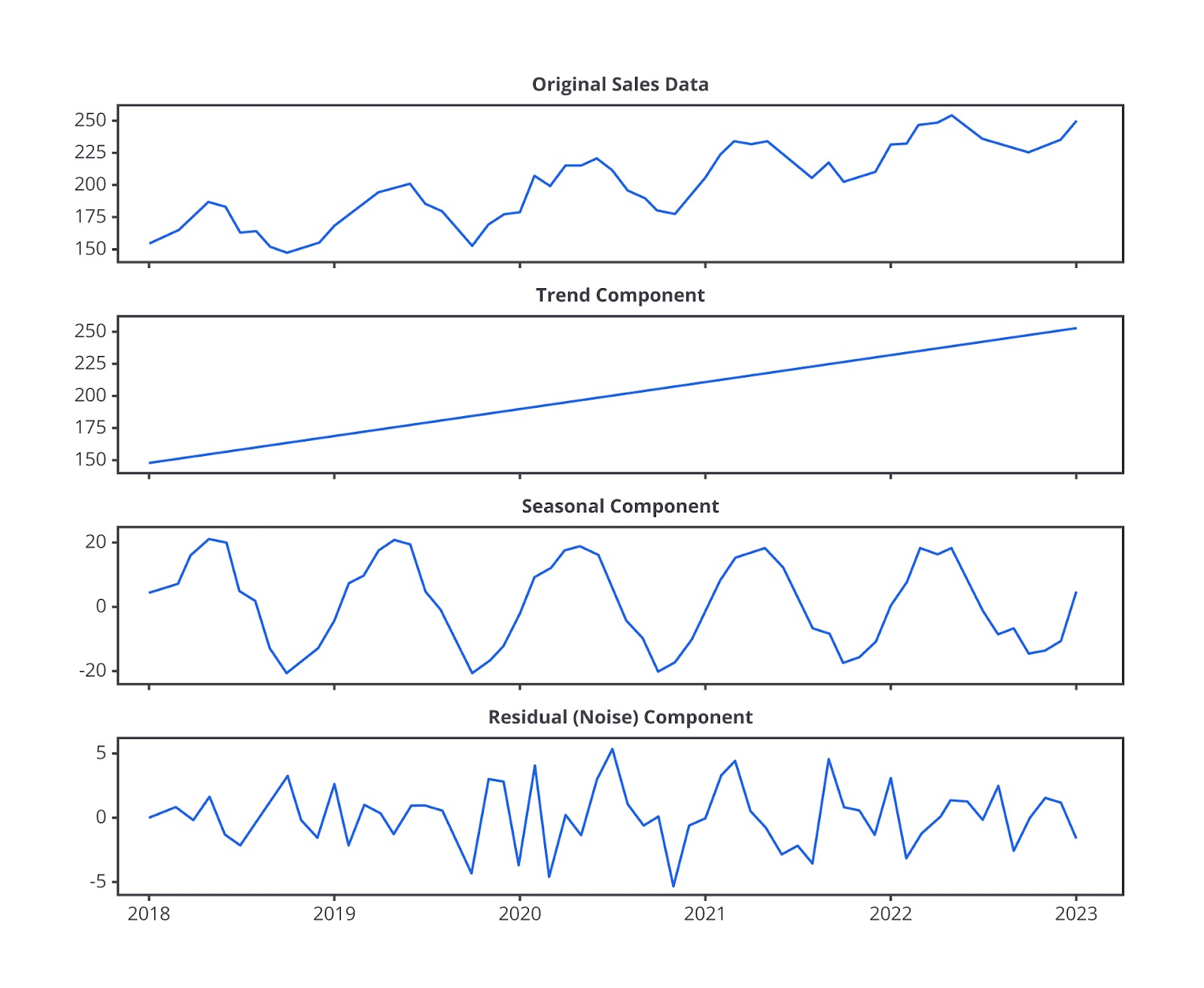
Dari sudut pandang statistika, komponen-komponen ini memiliki definisi yang presisi.
- Trend mencerminkan perubahan dalam nilai mean time series seiring dengan berjalannya waktu.
- Seasonality mengindikasikan adanya periodisitas atau pola berulang yang konsisten dalam mean atau variansi deret waktu pada interval waktu yang tetap.
- Sementara itu, white noise (Rt) adalah target ideal kita untuk komponen residual. Kumpulan variabel acak yang membentuk white noise diasumsikan bersifat independen dan terdistribusi identik dengan rata-rata nol serta variansi yang konstan. Jika residual dari model kita menyerupai white noise, itu adalah indikasi yang sangat baik bahwa model telah berhasil menangkap semua pola secara sistematis dan terprediksi dalam data.
Penerapan dari konsep dekomposisi time series ini sangat praktis dan penting. Dengan memisahkan time series dalam bagian-bagian komponennya, kita memperoleh kemampuan untuk melakukan hal berikut.
- Memahami Struktur Data: Mendapatkan wawasan jelas tentang pola-pola yang mendasari data, seperti adanya pertumbuhan jangka panjang yang dominan atau pola musiman yang kuat.
- Melakukan Prediksi yang Lebih Baik: Setelah mengidentifikasi trend dan seasonality, kita dapat memproyeksikan komponen-komponen yang dapat diprediksi ini ke masa depan serta kemudian menggunakan model statistik lebih canggih untuk memodelkan residual.
- Mendeteksi Anomali/Outlier: Nilai-nilai residual yang sangat besar (positif atau negatif) setelah pola trend dan seasonality dihilangkan dapat mengindikasikan anomali atau outlier dalam data.
- Menginformasikan Keputusan Bisnis: Misalnya, memahami trend penjualan membantu perencanaan strategis jangka panjang, sementara memahami pola musiman penjualan sangat vital untuk manajemen inventaris dan alokasi staf.
Pemahaman time series sebagai realisasi dari proses stokastik dengan komponen-komponen ini adalah fondasi kokoh untuk membangun model peramalan seperti ARIMA, yang akan kita bahas nanti dalam modul ini.
Matematika dalam Time Series: Stasioneritas: Asumsi Kritis untuk Inferensi
Setelah memahami bahwa time series adalah realisasi dari proses stokastik dengan komponen, seperti trend dan seasonality, kini kita akan membahas sebuah konsep yang sangat fundamental serta krusial dalam pemodelan deret waktu: stasioneritas.
Mengapa stasioneritas begitu penting? Pasalnya, sebagian besar model time series yang kuat, termasuk ARIMA, mengasumsikan bahwa data yang dianalisis sudah bersifat stasioner. Jika data tidak stasioner, prediksi yang dihasilkan model bisa menjadi tidak akurat atau bahkan tidak valid.
Definisi Stasioneritas
Saat bekerja dengan data time series, salah satu langkah penting yang sering kali menjadi syarat utama sebelum membangun model adalah membuat data menjadi stasioner. Namun, apa sebenarnya maksud dari “stasioner”? Mengapa hal ini sangat penting?
Dalam konteks statistik, data stasioner berarti data tersebut stabil secara statistik sepanjang waktu. Artinya, rata-rata (mean), sebaran data (variance), dan hubungan antar nilai-nilai pada waktu yang berbeda (autokorelasi) tidak berubah seiring waktu.
Untuk membayangkannya lebih mudah, coba pikirkan data yang “bergetar” di sekitar nilai rata-rata tertentu, tidak naik terus, tidak juga turun drastis. Itulah karakteristik utama data stasioner. Dengan kata lain, meskipun ada fluktuasi, itu tidak membentuk tren jangka panjang atau pola musiman yang kuat.
Sebaliknya, jika data terus naik (misalnya karena pertumbuhan bisnis) atau terus menurun (seperti popularitas suatu produk yang menurun), data tersebut tidak stasioner karena mean-nya berubah seiring waktu.
Kenapa Stasioneritas Itu Penting?
Model time series seperti ARIMA bekerja dengan asumsi bahwa pola-pola dalam data tidak berubah secara drastis dari waktu ke waktu. Jika data tidak stasioner, model akan kesulitan “belajar” dari masa lalu untuk memprediksi masa depan. Ini karena pola yang ditemukan di awal mungkin tidak berlaku lagi beberapa waktu kemudian.
Bayangkan Anda ingin memprediksi penjualan bulan depan dengan melihat data dua tahun terakhir. Jika tren penjualannya naik tajam setiap bulan, model akan kesulitan menemukan pola yang stabil. Namun, jika tren tersebut dihilangkan terlebih dahulu, fluktuasi yang tersisa bisa dimodelkan dengan lebih baik.
Singkatnya, membuat data stasioner membantu model fokus pada pola yang bisa dipelajari, bukan terganggu oleh tren besar atau pola musiman yang bisa menyesatkan prediksi.
Cara Membuat Data Stasioner: Differencing
Salah satu cara paling sederhana dan efektif untuk membuat data stasioner adalah dengan menggunakan teknik yang disebut differencing. Teknik ini dilakukan dengan menghitung selisih antara satu nilai dengan nilai sebelumnya.
Penjualan Hari Ini = 130 unit
Penjualan Kemarin = 120 unit
Hasil Differencing = 130 - 120 = 10
Dengan melakukan ini untuk seluruh time series, kita akan mendapatkan data baru yang disebut sebagai first difference. Teknik ini akan menghilangkan tren linier dari data. Jika tren masih kuat, kita bisa melakukan differencing lagi—ini disebut second difference.
Namun, tidak perlu langsung melakukan differencing dua kali. Umumnya, satu kali sudah cukup untuk sebagian besar kasus.
Visualisasi: Cek dengan Plot
Setelah melakukan differencing, penting untuk memeriksa jika data sudah terlihat stasioner. Ini bisa dilakukan secara visual.
- Plot data asli: Biasanya terlihat naik atau turun secara umum.
- Plot hasil differencing: Harusnya garis berfluktuasi di sekitar nol, tanpa pola naik/turun jangka panjang.
Berikut adalah contoh kode sederhana untuk menunjukkan metode differencing dalam bahasa pemrograman Python.
- # Re-import all necessary libraries due to code execution state reset
- import pandas as pd
- import numpy as np
-
import matplotlib.pyplot as plt
- # Langkah 1.2: Buat data deret waktu sintetis
- np.random.seed(42)
- dates = pd.date_range(start=‘2020-01-01’, periods=100, freq=‘MS’)
- base_sales = np.linspace(100, 200, 100)
- seasonality = 10 * np.sin(np.linspace(0, 3 * np.pi, 100))
- noise = np.random.normal(0, 10, 100)
- sales_data = base_sales + seasonality + noise
-
df = pd.DataFrame({‘Sales’: sales_data}, index=dates)
- # Hitung differencing
-
df[‘Differencing’] = df[‘Sales’].diff()
- # Plot data asli dan setelah differencing
-
plt.figure(figsize=(10, 5))
- # Plot data asli
- plt.subplot(2, 1, 1)
- plt.plot(df[‘Sales’], label=‘Data Asli’, color=‘blue’)
- plt.title(‘Data Penjualan Asli’)
-
plt.legend()
- # Plot differencing
- plt.subplot(2, 1, 2)
- plt.plot(df[‘Differencing’], label=‘Differencing’, color=‘orange’)
- plt.title(‘Setelah Differencing’)
-
plt.legend()
- plt.tight_layout()
- plt.show()
Setelah kodenya dijalankan, ini hasilnya.
Dengan plot ini, Anda bisa langsung melihat ketika data setelah dilakukan differencing sudah terlihat stabil dan fluktuatif di sekitar garis nol. Grafik yang awalnya bergerak secara fluktuatif akan menjadi stasioner.
Tujuannya adalah mencapai stasioneritas, bukan menghilangkan semua variasi. Jika setelah satu kali differencing data sudah tampak fluktuatif secara acak, itu sudah cukup. Terlalu banyak differencing bisa menghilangkan informasi penting dalam data.
Untuk memastikan lebih lanjut, Anda bisa menggunakan uji statistik, seperti Augmented Dickey–Fuller (ADF test), tapi itu akan dibahas lebih detail dalam bagian selanjutnya.
Membuat data menjadi stasioner adalah langkah awal yang sangat penting dalam analisis time series. Dengan teknik sederhana seperti differencing, Anda bisa menghilangkan tren dan menjadikan data lebih “siap” untuk dimodelkan.
Matematika dalam Time Series: Mengenal ACF & PACF
Setelah kita berhasil membuat data time series menjadi stasioner, langkah penting berikutnya adalah memahami bahwa data tersebut saling terkait dari waktu ke waktu. Dalam dunia analisis time series, ada dua alat bantu utama yang sangat populer untuk menganalisis hubungan ini, yaitu ACF (autocorrelation function) dan PACF (partial autocorrelation function).
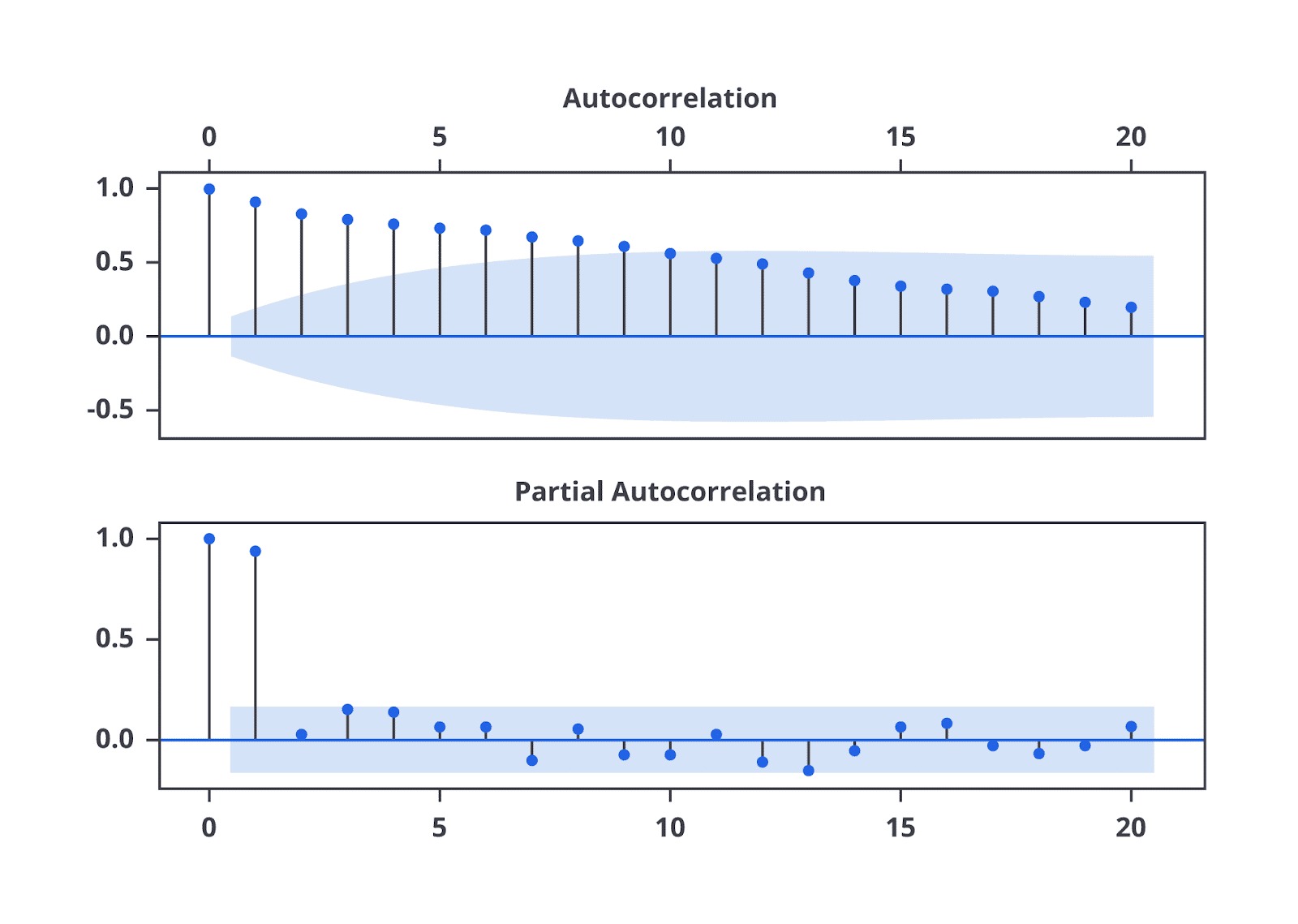
Kedua fungsi ini sangat berguna karena memberikan wawasan tentang pola keterkaitan antar waktu, yang akan membantu kita dalam menentukan parameter terbaik saat membangun model ARIMA.
Apa Itu Autocorrelation Function (ACF)?
Autocorrelation function (ACF) mengukur seberapa mirip nilai data saat ini dengan nilai-nilai pada masa lalu. Dalam konteks time series, kita menyebut tingkat keterlambatan sebagai lag. Misalnya berikut.
- Lag-1 berarti membandingkan nilai hari ini dengan nilai kemarin,
- Lag-2 berarti membandingkan hari ini dengan dua hari yang lalu,
- dan seterusnya.
ACF akan menghitung korelasi antara setiap nilai dengan versi tertundanya sendiri untuk setiap lag yang ditentukan. Korelasi ini digambarkan dalam bentuk plot batang, yakni setiap batang mewakili tingkat korelasi untuk satu lag.
Contoh pertanyaan yang bisa dijawab oleh ACF sebagai berikut.
- Apakah penjualan hari ini dipengaruhi oleh penjualan kemarin?
- Apakah ada pola mingguan, misalnya penjualan hari ini mirip dengan penjualan seminggu yang lalu.
Jika batang pada lag tertentu sangat tinggi dan melewati batas signifikan, itu artinya ada hubungan statistik yang kuat antara nilai sekarang dengan nilai dalam lag tersebut.
Apa Itu Partial Autocorrelation Function (PACF)?
Apabila ACF menghitung hubungan total antara nilai saat ini dan nilai sebelumnya, PACF berfokus pada hubungan langsung.
PACF mencoba menjawab pertanyaan berikut.
“Apakah nilai pada lag ke-3 memengaruhi nilai hari ini setelah mempertimbangkan efek dari lag ke-1 dan lag ke-2?”
Dengan kata lain, PACF membantu kita menyaring hubungan yang benar-benar relevan secara langsung, tanpa “gangguan” dari lag-lag sebelumnya. Ini sangat penting karena dalam dunia nyata banyak hubungan terlihat signifikan, padahal sebenarnya hanya “diturunkan” dari hubungan yang lebih pendek.
Layaknya ACF, hasil PACF juga divisualisasikan dalam bentuk plot batang, dengan garis batas untuk menandai korelasi parsial tersebut signifikan atau tidak.
Hubungan ACF dan PACF dengan Model ARIMA
Kedua fungsi ini (ACF dan PACF) memiliki peran sangat penting dalam membentuk model ARIMA (AutoRegressive Integrated Moving Average) karena mereka membantu kita menentukan parameter berikut.
- p (jumlah lag untuk komponen AR/AutoRegressive)
- q (jumlah lag untuk komponen MA/Moving Average)
Mari kita bahas kaitannya lebih lanjut.
Matematika dalam Time Series: Komponen Model ARIMA
Setelah memahami bahwa fungsi ACF dan PACF membantu kita mengidentifikasi pola keterkaitan dalam data time series, kini saatnya kita menggunakannya untuk membangun model prediksi yang konkret. Di sinilah model ARIMA hadir sebagai salah satu alat paling populer dalam analisis deret waktu.
Model ARIMA (AutoRegressive Integrated Moving Average) merupakan gabungan dari tiga komponen matematis yang masing-masing merepresentasikan jenis pola berbeda dalam data time series: pola ketergantungan terhadap nilai masa lalu, kebutuhan akan stasioneritas, dan pengaruh kesalahan prediksi sebelumnya.
Untuk benar-benar memahami logika di balik ARIMA, kita akan membedah masing-masing komponennya secara terpisah: dimulai dari model AR (AutoRegressive), dilanjutkan ke model MA (Moving Average), dan akhirnya menggabungkannya dalam kerangka ARIMA yang utuh.
Mari kita mulai dengan komponen pertama: Model AR (AutoRegressive).
Model AR (AutoRegressive)
Model AR atau AutoRegressive adalah salah satu komponen utama dalam model ARIMA. Istilah “AutoRegressive” sendiri bisa diartikan sebagai regresi terhadap dirinya sendiri. Artinya, nilai saat ini diprediksi berdasarkan nilai-nilai masa lalu dari variabel itu sendiri.
Bayangkan Anda ingin memprediksi jumlah pengunjung toko hari ini. Dalam model AR, Anda tidak memerlukan data lain—cukup melihat berapa jumlah pengunjung kemarin, dua hari lalu, tiga hari lalu, dan seterusnya. Nilai-nilai tersebut akan digunakan untuk memperkirakan nilai hari ini.
Model AR menyatakan hal berikut.
- Semakin besar nilai p, semakin banyak nilai masa lalu (lag) yang digunakan.
- Nilai saat ini adalah kombinasi linear dari nilai masa lalu.
Rumus Model AR
Dalam memodelkan data time series menggunakan pendekatan AutoRegressive (AR), kita akan sering menjumpai dua bentuk rumus yang tampak mirip, tapi memiliki perbedaan penting. Keduanya merepresentasikan gagasan inti yang sama bahwa nilai saat ini dapat diprediksi dari nilai-nilai masa lalu, tetapi memiliki implikasi berbeda dalam praktik.
Rumus 1: AR Tanpa Konstanta

Rumus ini menunjukkan bahwa nilai saat ini (Xt) merupakan kombinasi linear dari nilai-nilai sebelumnya ditambah gangguan acak εt. Bentuk ini tidak memiliki konstanta dan mengasumsikan bahwa data telah distandarkan atau telah melalui proses differencing sehingga rata-ratanya (mean) mendekati nol.
Model ini sangat cocok digunakan saat kondisi berikut.
- Data telah distasionerkan dengan differencing.
- Kita hanya ingin memodelkan fluktuasi atau deviasi terhadap nol, bukan level absolut dari datanya.
Rumus 2: AR dengan Konstanta

Versi ini menambahkan sebuah konstanta c atau sering disebut intercept. Komponen ini berguna untuk menangkap rata-rata data yang tidak nol, atau dengan kata lain, untuk memodelkan level dasar dari deret waktu.
Model ini lebih tepat digunakan saat kondisi berikut.
- Data belum di-differencing dan masih memiliki tren atau rata-rata tetap.
- Kita ingin memprediksi nilai absolut dari data (bukan hanya perubahannya).
- Model harus menangkap kecenderungan nilai mendekati titik keseimbangan yang bukan nol.
Menentukan Nilai p dengan PACF
Untuk menentukan jumlah nilai masa lalu (p) yang relevan, kita menggunakan PACF (partial autocorrelation function).
Ciri khas dari model AR adalah bahwa plot PACF akan terputus (cut-off) setelah lag ke-p. Artinya, batang-batang signifikan hanya muncul hingga lag ke-p. Setelah itu, batang akan kecil dan berada dalam batas kepercayaan (tidak signifikan lagi).
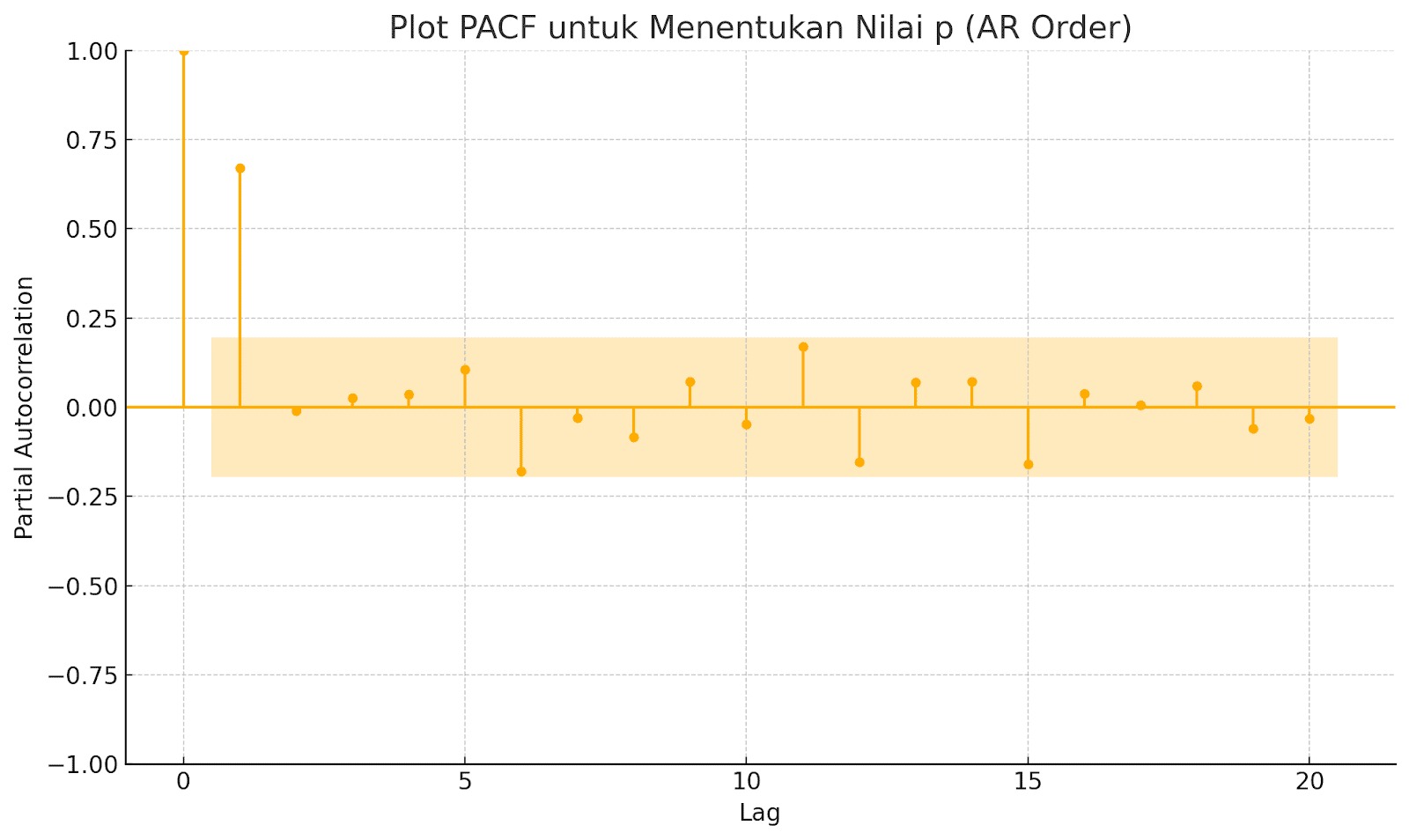
Gambar di atas adalah plot PACF (partial autocorrelation function) yang menunjukkan cara menentukan nilai p (order AR) dalam model AR.
- Terlihat bahwa batang signifikan hanya muncul pada lag ke-1, lalu nilai PACF turun dan berada dalam batas kepercayaan (daerah oranye).
- Ini menandakan bahwa model AR(1) adalah pilihan yang tepat untuk data ini.
Plot seperti ini berguna untuk mengidentifikasi jumlah lag (p) yang benar-benar relevan secara statistik dalam model ARIMA.
Model MA (Moving Average)
Model MA atau Moving Average adalah komponen kedua dalam ARIMA. Berbeda dengan model AR yang menggunakan nilai data masa lalu, model MA menggunakan kesalahan prediksi (error) dari masa lalu sebagai dasar untuk memprediksi nilai sekarang.
Misalkan kemarin Anda memprediksi penjualan sebesar 100 unit, tetapi realisasinya ternyata 120 unit. Artinya Anda melakukan kesalahan prediksi (error) sebesar 20+. Nah, model MA beranggapan bahwa kesalahan ini turut memengaruhi nilai pada hari ini.
Dengan kata lain,
“Hari ini bisa dipengaruhi oleh seberapa besar saya meleset kemarin.”
Model MA tidak menggunakan nilai observasi masa lalu secara langsung, tetapi menggunakan besarnya error (residual) dari prediksi sebelumnya. Model ini cocok saat fluktuasi atau noise masa lalu dianggap memengaruhi nilai saat ini.
Secara matematis, model MA dengan q lag dituliskan sebagai berikut.

Untuk menentukan berapa banyak lag error (q) yang relevan (q), kita menggunakan ACF (autocorrelation function).
Ciri khas dari model MA adalah bahwa ACF akan terputus (cut-off) setelah lag ke-q. Artinya, batang-batang yang signifikan hanya muncul hingga lag ke-q dan setelah itu menghilang.
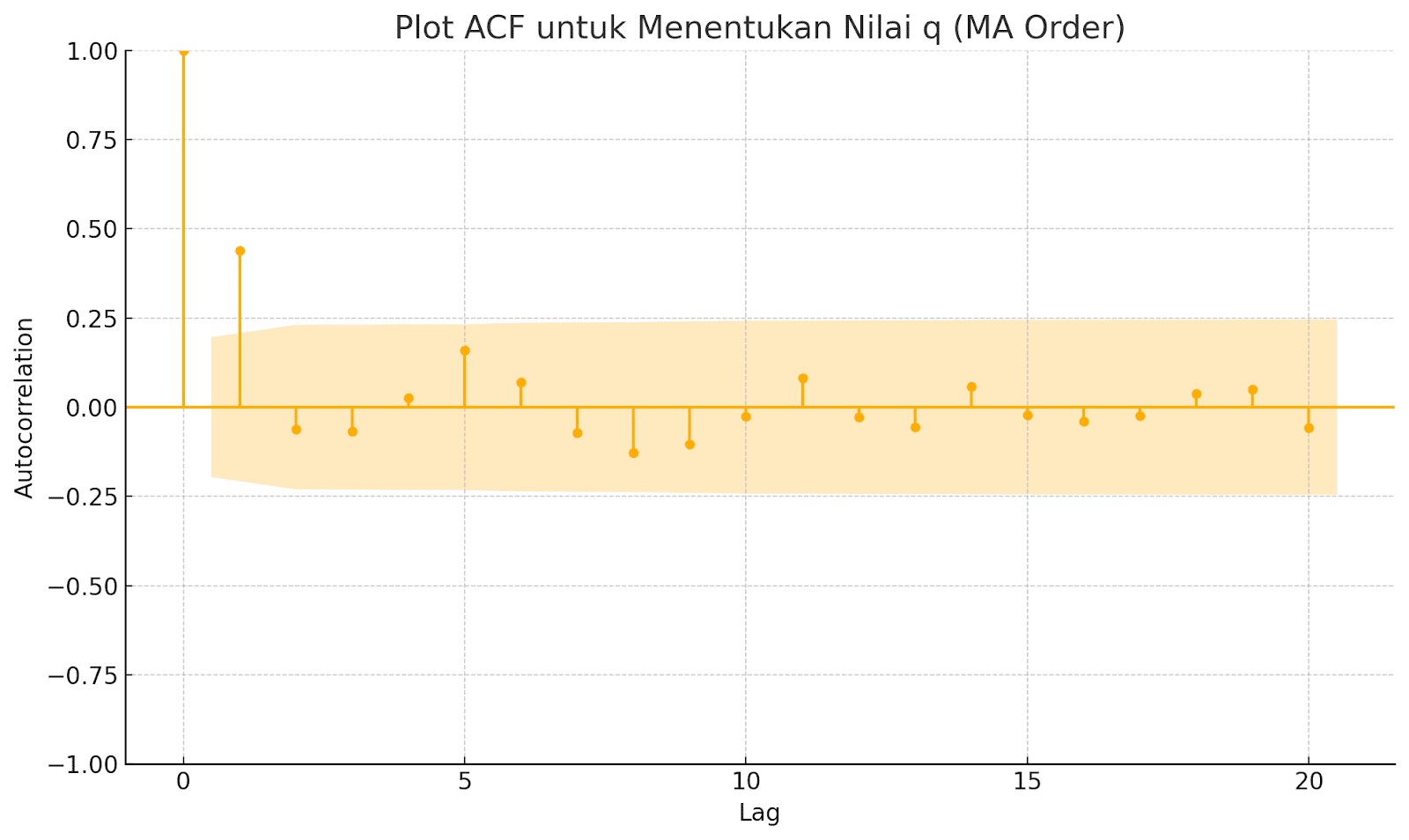
Gambar di atas adalah plot ACF (autocorrelation function) untuk data yang dihasilkan dari proses MA(1).
- Terlihat bahwa batang autokorelasi signifikan hanya pada lag ke-1.
- Setelah lag ke-1, batang-batang berada dalam batas kepercayaan (daerah oranye) dan tidak signifikan secara statistik.
Model ARIMA (Gabungan AR, I, MA)
Setelah memahami dasar-dasar, seperti ACF, PACF, serta konsep stasioneritas dan differencing, kini saatnya kita merangkai semuanya dalam sebuah model prediksi time series yang sangat populer, yaitu ARIMA.
ARIMA adalah singkatan dari AutoRegressive Integrated Moving Average. Meskipun namanya terdengar rumit, sebenarnya logika di balik model ini cukup mudah untuk dipahami.
Secara sederhana, ARIMA adalah model statistik yang digunakan untuk meramalkan nilai masa depan dari sebuah time series berdasarkan nilai masa lalu dan pola kesalahan (error) yang terjadi sebelumnya.
Model ini menggabungkan tiga komponen utama yang sudah kita pelajari sebelumnya, antara lain berikut.
- AR (AutoRegressive): bagian ini menggunakan nilai-nilai masa lalu (lag) untuk memprediksi nilai saat ini.
- I (Integrated): bagian ini merujuk pada differencing, yaitu proses mengubah data agar menjadi stasioner (stabil/tidak dipengaruhi tren).
- MA (Moving Average): bagian ini menggunakan kesalahan prediksi dari masa lalu (error) untuk memperbaiki prediksi saat ini.
Ketiga komponen tersebut ditulis dalam bentuk model ARIMA dengan notasi berikut.
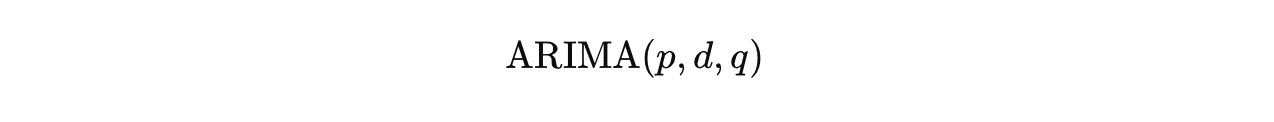
Mari kita bahas ketiga parameter ARIMA satu per satu agar lebih jelas.
- p (AutoRegressive Order) adalah jumlah lag yang digunakan dalam komponen AR. Jika p = 2, model menggunakan Yt-1 dan Yt-2 untuk memprediksi Yt. Parameter ini biasanya ditentukan dengan melihat plot PACF.
- d (Differencing Order) menunjukkan jumlah data perlu di-differencing agar menjadi stasioner. Jika data menunjukkan tren naik atau turun, kita melakukan differencing untuk menghilangkan tren tersebut. Biasanya, d = 1 sudah cukup untuk membuat data menjadi stasioner. Nilai ini ditentukan dengan melihat plot data dan hasil dari ADF Test.
- q (Moving Average Order) adalah jumlah lag dari kesalahan masa lalu dalam komponen MA. Contoh: Jika q = 1, model menggunakan error pada waktu t−1 untuk memperbaiki prediksi Yt. Nilai q ditentukan dengan melihat plot ACF.
Matematika dalam Time Series: Membangun Model ARIMA
Membangun model ARIMA sebenarnya tidak serumit yang dibayangkan, asalkan kita mengikuti langkah-langkahnya secara sistematis. Model ini sangat berguna untuk memprediksi data time series yang memiliki pola tertentu di masa lalu.
Berikut adalah panduan praktis enam langkah dalam membangun model ARIMA yang dapat Anda ikuti, dari awal hingga tahap prediksi. Sebelum memulai, pastikan kita sudah memiliki sebuah data time series terlebih dahulu. Jika kita belum memiliki, jalan kode di bawah ini untuk membuat sebuah data time series yang acak.
Langkah 1: Mengimpor Library dan Menyiapkan Data Time Series
Dimulai dengan mengimpor library penting untuk analisis time series, seperti pandas, numpy, matplotlib, seaborn, serta modul dari statsmodels untuk uji stasioneritas dan pemodelan ARIMA.
Kemudian, kita membuat dataset sintetis penjualan mingguan selama 100 minggu dengan pola tren naik dan noise acak, lalu menyimpannya pada file CSV.
Selanjutnya, data penjualan disimulasikan menggunakan distribusi normal yang diakumulasi agar membentuk tren, kemudian dikemas dalam DataFrame, dibulatkan, dan disimpan sebagai file bernama data_penjualan.csv untuk analisis lanjutan.
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
- from statsmodels.tsa.stattools import adfuller # Untuk Uji ADF (stationarity test)
- from statsmodels.graphics.tsaplots import plot_acf, plot_pacf # Untuk ACF/PACF plots
-
from statsmodels.tsa.arima.model import ARIMA # Model ARIMA
- # Set random seed agar hasil tetap konsisten
-
np.random.seed(42)
- # Generate tren penjualan mingguan (misalnya dari 100 naik perlahan)
- minggu = np.arange(1, 101)
-
penjualan = 100 + np.cumsum(np.random.normal(loc=1.5, scale=5, size=100)) # tren naik + noise
- # Buat DataFrame
- df = pd.DataFrame({
- ’minggu’: minggu,
- ’penjualan’: np.round(penjualan, 2) # dibulatkan 2 angka desimal
-
})
- # Simpan ke file CSV
-
df.to_csv(‘data_penjualan.csv’, index=False)
- print(“Data berhasil dibuat dan disimpan sebagai data_penjualan.csv”)
Langkah 2: Ubah Data Menjadi Stasioner
Langkah berikutnya sebelum menerapkan ARIMA adalah memastikan bahwa data kita sudah stasioner. Sebagaimana yang sudah dibahas sebelumnya, data stasioner adalah data dengan rata-rata dan variansi yang konstan dari waktu ke waktu.
Bagaimana cara memeriksanya?
- Visual: Plot data time series. Jika data menunjukkan tren naik/turun atau memiliki pola musiman yang jelas, kemungkinan besar data tersebut belum stasioner.
- Statistik: Gunakan augmented dickey-fuller (ADF) Test untuk menguji stasioneritas secara statistik. Jika nilai p-value lebih kecil dari 0.05, data dapat dianggap stasioner.
Jika data belum stasioner, kita bisa melakukan differencing, yaitu menghitung selisih antara nilai saat ini dan nilai sebelumnya (misalnya: hari ini – kemarin). Jika sekali differencing belum cukup, kita bisa melakukannya dua kali. Nilai d dalam ARIMA mengacu pada berapa kali differencing ini dilakukan.
Untuk melakukan tahap ini, silakan lihat pada kode di bawah ini.
- # Contoh data: penjualan mingguan
-
df = pd.read_csv(‘data_penjualan.csv’) # misalnya memiliki kolom ‘penjualan’
- # Hitung differencing
-
df[‘diff’] = df[‘penjualan’].diff()
- # Plot sebelum dan sesudah differencing
- plt.figure(figsize=(10, 5))
- plt.subplot(2, 1, 1)
- plt.plot(df[‘penjualan’], label=‘Data Asli’)
- plt.title(‘Data Penjualan Asli’)
-
plt.legend()
- plt.subplot(2, 1, 2)
- plt.plot(df[‘diff’], label=‘Differencing’, color=‘orange’)
- plt.title(‘Setelah Differencing’)
-
plt.legend()
- plt.tight_layout()
- plt.show()
Kode di atas akan menampilkan dua buah grafik, yang pertama adalah visualisasi data penjualan asli, sedangkan yang kedua adalah data yang sudah dilakukan differencing.
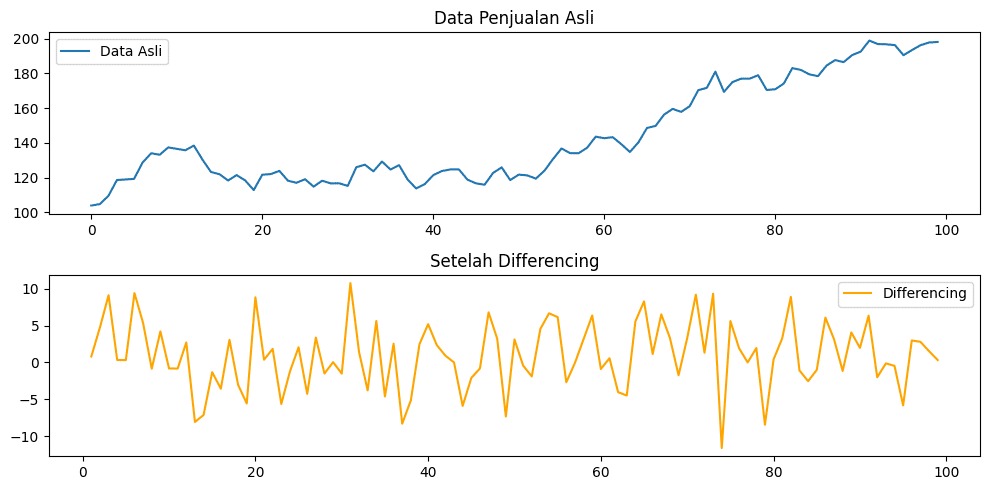
Langkah 3: Analisis ACF dan PACF
Setelah data stasioner, kita perlu mengetahui berapa banyak lag dari nilai masa lalu dan berapa banyak lag dari error masa lalu yang akan digunakan dalam model.
Di sinilah plot ACF (autocorrelation function) dan PACF (partial autocorrelation function) berperan penting.
- ACF membantu Anda menentukan nilai q, yaitu jumlah lag dari error (kesalahan prediksi masa lalu) yang relevan. Jika ACF menunjukkan lonjakan besar pada lag 1 dan 2, q bisa jadi 2.
- PACF membantu Anda menentukan nilai p, yaitu jumlah lag dari nilai observasi masa lalu yang langsung berpengaruh. Jika PACF signifikan sampai lag 1, p = 1.
Untuk melakukan tahap ini, silakan jalankan kode di bawah ini.
- # Misal data sudah di-differencing: df[‘diff’]
-
plt.figure(figsize=(12, 5))
- # ACF plot
- plt.subplot(1, 2, 1)
- plot_acf(df[‘diff’].dropna(), lags=20, ax=plt.gca())
-
plt.title(‘ACF - Autokorelasi’)
- # PACF plot
- plt.subplot(1, 2, 2)
- plot_pacf(df[‘diff’].dropna(), lags=20, ax=plt.gca(), method=‘ywm’)
-
plt.title(‘PACF - Autokorelasi Parsial’)
- plt.tight_layout()
- plt.show()
Kode di atas digunakan untuk menampilkan visualisasi ACF dan PACF, yakni dari data tersebut kita dapat menentukan nilai p dan q yang akan digunakan pada pemodelan ARIMA nantinya. Inilah visualisasinya.
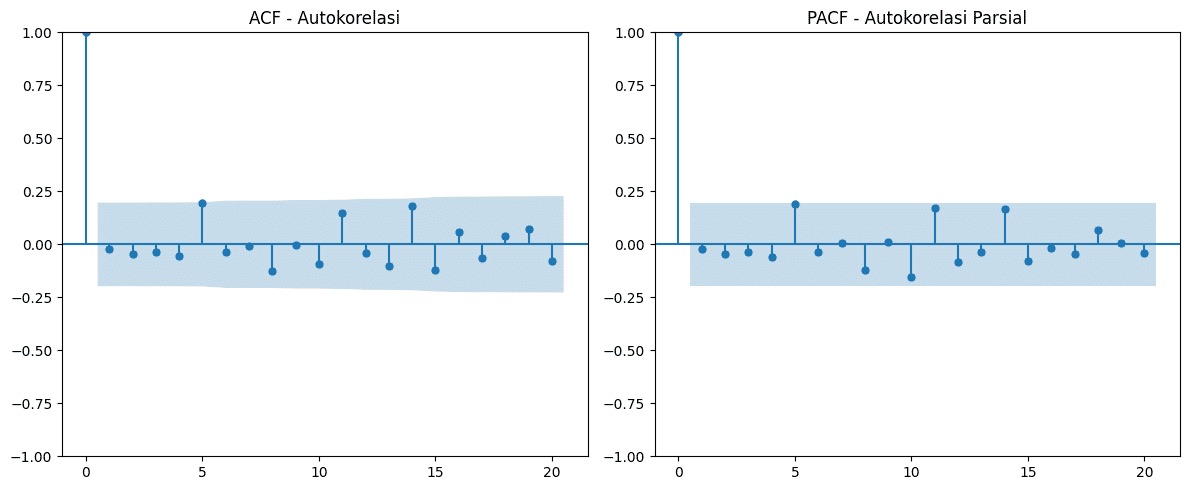
Perhatikan grafik ACF dan PACF di atas. Batang yang melewati batas kepercayaan dianggap signifikan secara statistik dan menunjukkan adanya hubungan autokorelasi pada lag tersebut.
Langkah 4: Membangun Model ARIMA
Setelah menentukan nilai p, d, dan q, sekarang saatnya kita membangun model ARIMA.
- model = ARIMA(df[‘penjualan’], order=(1, 1, 1))
- model_fit = model.fit()
- print(model_fit.summary())
Pada kode di atas, kita membangun model ARIMA dengan parameter (p=1, d=1, q=1). Baris model = ARIMA(...) mendefinisikan model berdasarkan data penjualan, model.fit() melatih model tersebut, dan model_fit.summary() menampilkan ringkasan hasil estimasi, termasuk koefisien, statistik signifikan, serta informasi diagnostik lainnya.
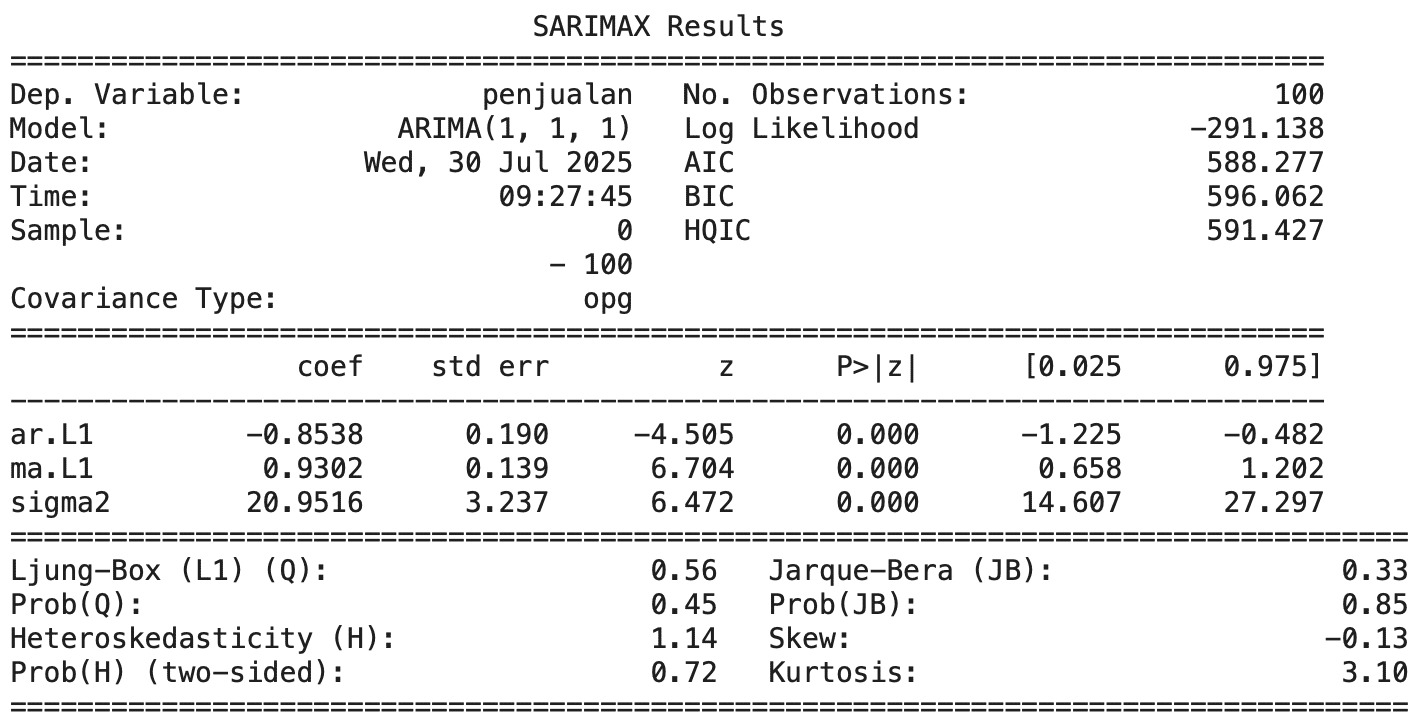
Ini adalah langkah inti untuk melakukan prediksi time series.
Langkah 5: Evaluasi Model
Setelah model dilatih, kita perlu memastikan bahwa model tersebut sudah cukup baik untuk digunakan. Ada dua hal utama yang perlu diperhatikan: kualitas prediksi dan karakteristik residual.
Residual adalah selisih antara nilai yang diprediksi dan nilai aktual. Idealnya, residual harus acak, tanpa pola yang terlihat, dan menyerupai white noise. Jika residual masih memiliki pola (misalnya tren), berarti model belum cukup baik.
Uji Statistik
- Gunakan AIC dan BIC untuk membandingkan model. Semakin rendah nilainya, semakin baik model (dengan asumsi kompleksitas wajar).
- Gunakan uji Ljung-Box untuk memeriksa jika residual masih mengandung autokorelasi. Jika tidak, model dianggap telah menangkap pola utama dalam data.
Jangan lupa juga untuk memvisualisasikan hasil prediksi dan residual agar Anda bisa melihat jika prediksi model cukup akurat serta adakah penyimpangan besar.
Silakan jalankan kode berikut.
- # — Prediksi —
-
df[‘forecast’] = model_fit.predict(start=1, end=len(df)-1, typ=‘levels’) # karena d=1, mulai dari indeks 1
- # — Visualisasi: Aktual vs Prediksi —
- plt.figure(figsize=(10, 4))
- plt.plot(df[‘penjualan’], label=‘Aktual’)
- plt.plot(df[‘forecast’], label=‘Prediksi’, linestyle=’–’)
- plt.title(‘Aktual vs Prediksi’)
- plt.legend()
- plt.tight_layout()
-
plt.show()
- # — Analisis Residual —
-
residuals = model_fit.resid
- plt.figure(figsize=(12, 4))
- plt.subplot(1, 2, 1)
- sns.histplot(residuals, kde=True, bins=20)
-
plt.title(‘Distribusi Residual’)
- plt.subplot(1, 2, 2)
- plt.plot(residuals)
- plt.title(‘Plot Residual’)
- plt.tight_layout()
-
plt.show()
- # — Uji Ljung-Box —
- ljung_result = acorr_ljungbox(residuals, lags=[10], return_df=True)
- print(“\nHasil Uji Ljung-Box (lag=10):”)
-
print(ljung_result)
- # — Evaluasi AIC dan BIC —
- print(f”\nAIC: {model_fit.aic}”)
- print(f”BIC: {model_fit.bic}”)
Setelah kode dijalankan, ia akan menampilkan visualisasi berikut.
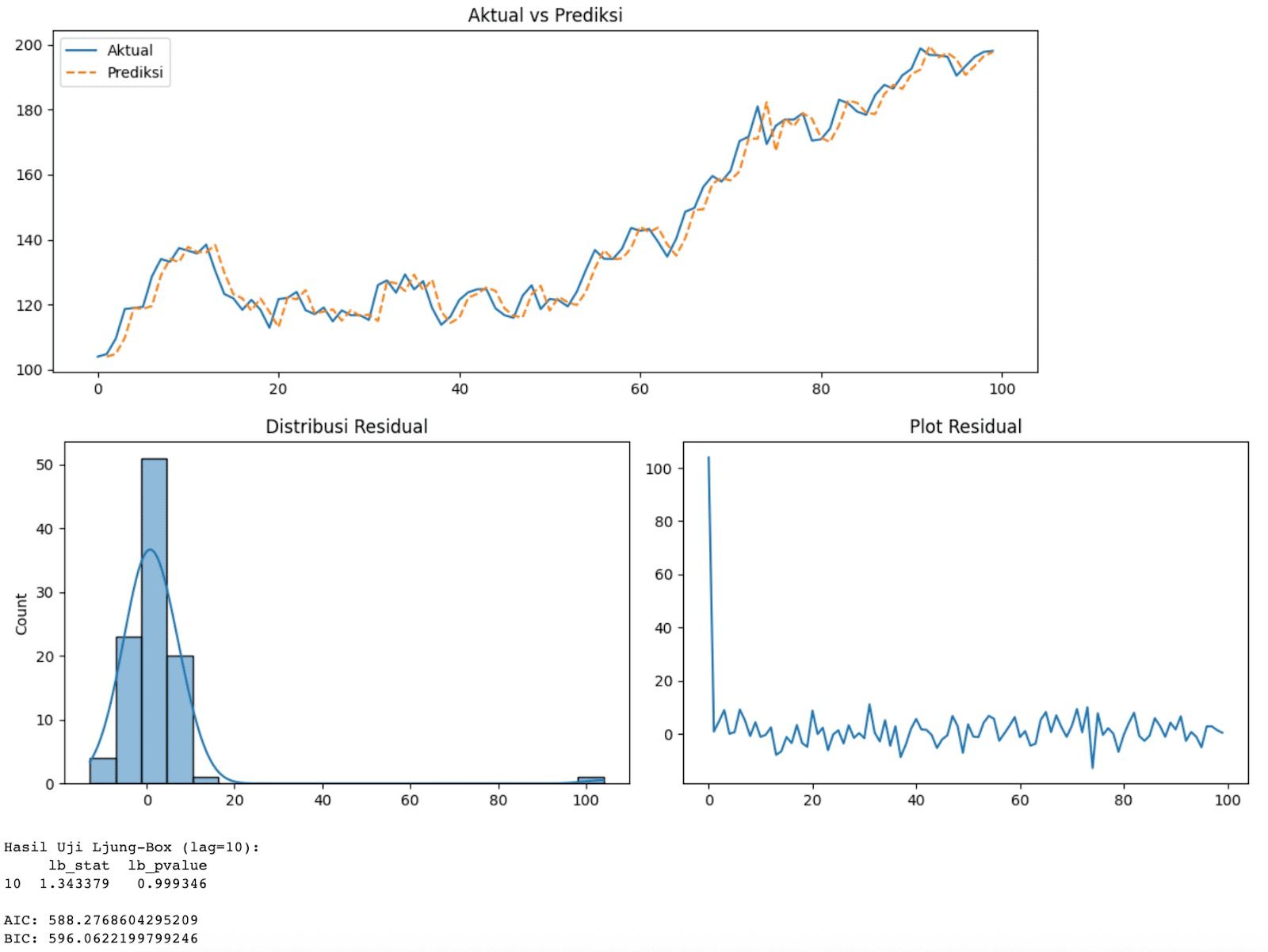
Model ARIMA yang telah dibangun menunjukkan performa cukup baik berdasarkan hasil evaluasi. Penjelasannya berikut.
- Plot aktual vs prediksi: memastikan bahwa model mengikuti pola data asli. Dalam kasus ini, plot prediksi berhasil mengikuti pola data aktual secara umum, menandakan model mampu menangkap tren yang ada.
- Plot dan histogram residual: mengecek residual acak (seperti white noise). Residual terlihat tersebar secara acak dan membentuk distribusi mendekati normal yang menunjukkan bahwa kesalahan prediksi tidak bersifat sistematis.
- Uji Ljung-Box: menguji jika residual masih memiliki autokorelasi. Hasil uji Ljung-Box menghasilkan p-value di atas 0.05, menandakan bahwa residual tidak lagi mengandung autokorelasi signifikan dan sudah menyerupai white noise.
- AIC/BIC: nilai lebih rendah = model lebih baik (dengan asumsi kompleksitas seimbang). Bisa dilihat bahwa nilai AIC dan BIC yang relatif rendah memperkuat bahwa model ini efisien dan tidak overfitting.
Dengan demikian, model ARIMA ini dapat dianggap layak untuk digunakan dalam prediksi time series.
Langkah 6: Lakukan Prediksi dan Interpretasi
Setelah yakin bahwa model sudah memadai, kita bisa menggunakannya untuk membuat prediksi masa depan.
Model ARIMA dapat memproyeksikan nilai beberapa langkah ke depan, misalnya prediksi tujuh hari ke depan. Hasil prediksi biasanya juga disertai dengan interval kepercayaan, yaitu rentang atas dan bawah dari prediksi yang mencerminkan ketidakpastian model.
Contoh kode prediksinya berikut.
- # Prediksi 7 langkah ke depan
-
forecast = model_fit.predict(start=len(df), end=len(df)+6, typ=‘levels’)
- print(“Prediksi 7 hari ke depan:”)
- for idx, value in forecast.items():
- print(f”Hari ke-{idx}: {value:.2f}”)
Ketika kode dijalankan, kita akan mendapatkan prediksi untuk tujuh hari ke depan berdasarkan model ARIMA yang dibuat.

Kita juga bisa menampilkan prediksi dalam bentuk grafik garis agar lebih mudah dianalisis dengan kode berikut.
- # Gabungkan data historis dan prediksi untuk visualisasi
- minggu_forecast = np.arange(len(df), len(df) + len(forecast))
-
df_pred = pd.Series(forecast.values, index=minggu_forecast)
- # Plot data aktual dan prediksi
- plt.figure(figsize=(10, 5))
- plt.plot(df[‘penjualan’], label=‘Data Historis’)
- plt.plot(df_pred, label=‘Prediksi 7 Hari ke Depan’, linestyle=’–’, marker=‘o’)
- plt.title(‘Prediksi Penjualan Menggunakan ARIMA’)
- plt.xlabel(‘Minggu’)
- plt.ylabel(‘Penjualan’)
- plt.legend()
- plt.grid(True)
- plt.tight_layout()
- plt.show()
Hasilnya akan menampilkan visualisasi seperti ini.
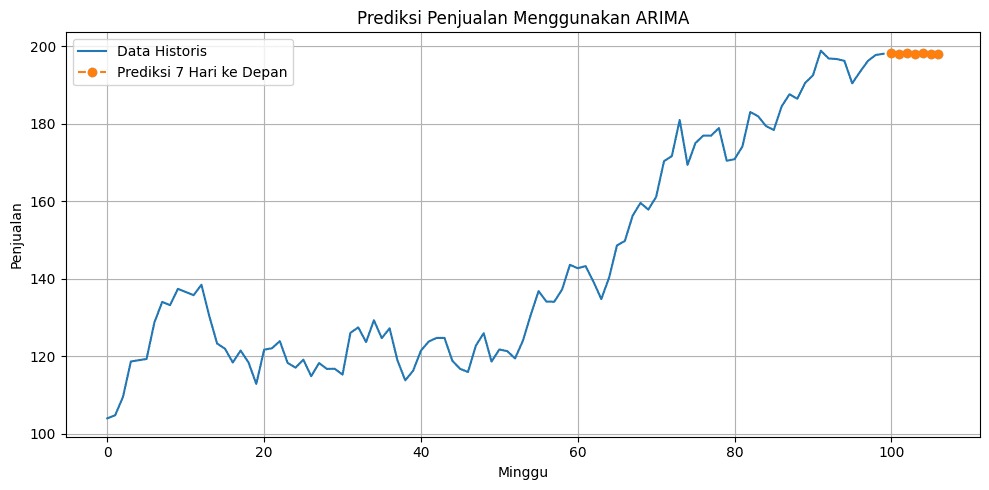
Grafik di atas adalah visualisasi hasil prediksi tujuh hari ke depan menggunakan model ARIMA. Garis biru menunjukkan data historis penjualan mingguan, sementara garis putus-putus dengan titik menunjukkan hasil prediksi dari minggu ke-101 hingga 107.
Grafik ini membantu kita melihat bahwa model memproyeksikan tren penjualan tetap stabil mendekati nilai terakhir, yang konsisten dengan karakteristik data time series yang sudah di-differencing dan dipelajari oleh model.
Anda bisa akses kode lengkap yang dijelaskan dalam topik time series pada link berikut: Modul 6 - Time Series.ipynb
Rangkuman Matematika pada Algoritma AI
Berikut adalah rangkuman untuk materi Matematika pada Algoritma AI.
Matematika dalam Computer Vision
- Representasi Gambar sebagai Matriks
Gambar digital direpresentasikan sebagai matriks piksel dengan nilai intensitas (grayscale) atau RGB (warna). Setiap piksel menjadi elemen numerik yang bisa dianalisis secara statistik dan aljabar linier. - Statistik Dasar Gambar: Histogram
Histogram digunakan untuk memvisualisasikan distribusi intensitas piksel dalam gambar. Membantu mengidentifikasi pencahayaan, kontras, dan potensi noise dalam gambar. - Statistik Spasial: Variansi dan Korelasi Antar Piksel
Menganalisis perbedaan nilai antar piksel dalam area kecil gambar untuk mendeteksi pola, tekstur, dan struktur lokal. Berguna dalam klasifikasi tekstur dan segmentasi. - Operasi Konvolusi dan Kernel
Konvolusi digunakan untuk mengekstrak fitur penting dengan cara menggeser kernel (filter) pada gambar dan menghitung hasil penjumlahan bobot. Aplikasi penting dalam deteksi tepi, blur, dan sharpening. - Deteksi Tepi dan Gradien
Menggunakan operator, seperti Sobel atau Prewitt untuk menghitung perubahan intensitas antar piksel. Konsep gradien sangat penting dalam mengenali batas objek. - Ekstraksi Fitur Tekstur: GLCM dan Fitur Haralick
Gray-Level Co-occurrence Matrix (GLCM) menghitung seberapa sering pasangan nilai piksel muncul berdekatan dalam arah tertentu. Fitur Haralick seperti Contrast, Entropy, dan Homogeneity membantu klasifikasi tekstur. - Reduksi Dimensi dan PCA
Principal component analysis (PCA) digunakan untuk mereduksi dimensi citra sambil mempertahankan informasi penting. Umum digunakan sebelum klasifikasi atau kompresi gambar.
Matematika dalam Natural Language Processing
- Distribusi Kata & WordCloud
Digunakan untuk memahami frekuensi kata dalam korpus teks. WordCloud memvisualisasikan kata-kata berdasarkan frekuensinya, berguna dalam analisis sentimen dan pencarian informasi. - Representasi Frekuensi Kata: Bag-of-Words (BoW)
Mengubah dokumen teks menjadi vektor berdasarkan frekuensi kata, tanpa memperhatikan urutan atau konteks. Berguna untuk model sederhana seperti klasifikasi teks dasar. - Pembobotan Kata: TF-IDF (Term Frequency–Inverse Document Frequency)
Memberi bobot pada kata berdasarkan seberapa sering kata muncul dalam dokumen tertentu dibandingkan korpus secara keseluruhan. Lebih informatif daripada BoW karena mengurangi pengaruh kata umum. - Representasi Semantik: Word Embedding
Teknik seperti CBOW dan Skip-gram (Word2Vec) digunakan untuk menangkap makna kata dalam bentuk vektor berdimensi rendah. Kata dengan makna serupa memiliki representasi vektor yang mirip. - Pengukuran Kemiripan: Cosine Similarity
Digunakan untuk mengukur kesamaan antar teks atau dokumen berdasarkan representasi vektor (BoW, TF-IDF, Word Embedding). Nilai kemiripan ditentukan berdasarkan sudut antar vektor.
Matematika dalam Time Series
- Proses Stokastik dan Dependensi Waktu
Data time series dipandang sebagai proses stokastik, yakni nilai saat ini bergantung pada nilai-nilai sebelumnya. Ini berbeda dengan data i.i.d. yang asumsi dasarnya saling bebas. - Stasioneritas dan Differencing
Stasioneritas berarti data memiliki rata-rata dan variansi yang konstan sepanjang waktu. Jika tidak stasioner (misalnya ada tren), differencing dilakukan untuk menghilangkan tren tersebut. - Autokorelasi (ACF) dan Autokorelasi Parsial (PACF)
ACF digunakan untuk mengukur korelasi antara nilai saat ini dan nilai-nilai sebelumnya. PACF mengukur korelasi langsung setelah mengontrol pengaruh dari lag antara. Keduanya penting dalam menentukan parameter AR dan MA. - Model AR (AutoRegressive)
Model AR memprediksi nilai sekarang berdasarkan kombinasi linear dari nilai-nilai sebelumnya. Dikenali dari plot PACF yang terputus pada lag ke-p. - Model MA (Moving Average)
Model MA menggunakan kesalahan (error) dari prediksi sebelumnya untuk memperkirakan nilai sekarang. Dikenali dari plot ACF yang terputus pada lag ke-q. - Model ARIMA (Autoregressive Integrated Moving Average)
Menggabungkan AR, I (differencing), dan MA dalam satu model untuk menangani tren serta autokorelasi. Ditulis sebagai ARIMA(p, d, q), yakni p = AR order, d = differencing order, q = MA order. - Evaluasi Model Time Series
Evaluasi dilakukan dengan mengamati residual (sisa prediksi), memastikan mereka acak (white noise), serta melihat nilai AIC, BIC, dan uji Ljung-Box untuk memvalidasi model.
This file is located at: _chapters/991-belajar-matematika-untuk-data-science/060-matematika-pada-algoritma-ai.md