Statistik Inferensial
- Pengantar Statistik Inferensial
- Estimasi Parameter Populasi: Pengantar
- Estimasi Parameter Populasi: Mean Populasi
- Estimasi Parameter Populasi: Proporsi Populasi
- Konsep Dasar Uji Hipotesis
- Metode Pengujian Hipotesis
- Pemilihan Jenis Uji Statistik
- Pengujian Rata-Rata dengan z-test dan t-test
- Variasi t-Test
- Uji ANOVA (Analysis of Variance)
- Regresi Linear
- Uji Non-Parametrik
- Rangkuman Statistik Inferensial
- Pengantar Statistik Inferensial
- Estimasi Parameter Populasi: Pengantar
- Estimasi Parameter Populasi: Mean Populasi
- Estimasi Parameter Populasi: Proporsi Populasi
- Konsep Dasar Uji Hipotesis
- Metode Pengujian Hipotesis
- Pemilihan Jenis Uji Statistik
- Pengujian Rata-Rata dengan z-test dan t-test
- Variasi t-Test
- Uji ANOVA (Analysis of Variance)
- Regresi Linear
- Uji Non-Parametrik
Pengantar Statistik Inferensial
Setelah sebelumnya Anda mempelajari klasifikasi data, ukuran pemusatan dan penyebaran data, serta distribusi data dalam materi Data Univariat dan Multivariat; kemudian memahami konsep dasar probabilitas hingga teorema Bayes dalam materi Dasar-Dasar Probabilitas; lalu belajar distribusi probabilitas dan penerapannya pada materi Distribusi Statistik; kini saatnya Anda melangkah ke fase yang lebih aplikatif dan strategis dalam analisis data: Statistik Inferensial.
Pentingnya Statistik Inferensial
Statistik inferensial adalah jembatan antara data sampel dan populasi secara keseluruhan. Bayangkan Anda memiliki data hasil survei dari 100 pengguna, padahal total pengguna ada ribuan. Apakah Anda bisa menyimpulkan bahwa hasil dari 100 pengguna ini berlaku untuk semuanya? Bagaimana tingkat kepastian Anda terhadap kesimpulan itu? Di sinilah statistik inferensial berperan.
Melalui statistik inferensial, kita dapat melakukan hal-hal berikut.
- Mengestimasi karakteristik populasi (seperti rata-rata atau proporsi) berdasarkan sampel.
- Menguji hipotesis untuk menentukan bahwa suatu dugaan terhadap populasi dapat diterima secara statistik.
- Membuat keputusan berbasis data, baik dalam bisnis, sains, maupun rekayasa sistem.
Dalam praktik data science, statistik inferensial memiliki peran krusial karena sebagian besar data science tidak bekerja dengan seluruh populasi, tetapi hanya dengan sampel dari data besar.
Dalam fase analisis, Anda pun hampir selalu memulai fasenya dengan sebuah hipotesis. Misalnya:
- Apakah penjualan bulan ini benar-benar menurun secara signifikan?
- Apakah kampanye marketing berhasil meningkatkan jumlah pengguna baru?
- Apakah perubahan desain aplikasi berdampak positif pada durasi kunjungan pengguna?
Pertanyaan-pertanyaan tersebut tidak bisa dijawab hanya dengan melihat data saja. Anda perlu memastikan dugaan tersebut dengan pendekatan ilmiah dan statistik. Statistik inferensial membantu Anda untuk:
- Mengubah hipotesis menjadi pertanyaan kuantitatif yang bisa diuji.
- Menentukan apakah perbedaan yang Anda lihat pada data bersifat kebetulan atau benar-benar mencerminkan kondisi nyata.
- Mengukur tingkat kepastian dari kesimpulan yang diambil, sehingga keputusan yang Anda buat tidak hanya berdasar intuisi, tapi berdasar bukti.
Jadi, Anda akan diajak untuk mempelajari cara mengambil kesimpulan berdasarkan sampelnya. Tertarik? Simak terus materinya ya.
Cakupan Materi
Modul ini akan mengajak Anda untuk tidak sekadar menghitung, tetapi juga berpikir kritis terhadap hasil analisis, termasuk memahami ketidakpastian dan risiko kesalahan yang mungkin terjadi saat mengambil keputusan dari data.
Pada materi ini, nanti kita akan membahas mengenai beberapa hal seperti berikut.
- Menghitung confidence interval untuk estimasi rata-rata dan proporsi.
- Menyusun dan menguji hipotesis dengan pendekatan parametrik dan non-parametrik.
- Memahami distribusi sampling dan dampaknya terhadap akurasi analisis.
- Melakukan uji perbandingan (seperti t-test, ANOVA) dalam konteks nyata.
- Mendesain dan menganalisis eksperimen A/B menggunakan Python.
Estimasi Parameter Populasi: Pengantar
Setelah memahami pentingnya statistik inferensial dalam mengambil keputusan berbasis data, langkah pertama yang perlu kita kuasai adalah cara memperkirakan karakteristik dari populasi secara matematis, hanya berdasarkan informasi dari sampel. Proses ini dikenal dengan istilah estimasi parameter populasi.
Dalam konteks inferensial, parameter merujuk pada nilai sebenarnya dari karakteristik populasi—seperti rata-rata (mean) atau proporsi—yang biasanya tidak kita ketahui secara langsung. Oleh karena itu, kita menggunakan data sampel untuk membangun dugaan (estimasi) terhadap parameter tersebut disertai dengan tingkat keyakinan tertentu.
Materi ini akan membahas dua bentuk estimasi yang paling umum digunakan dalam statistik inferensial.
- Estimasi Mean Populasi: ketika data bersifat numerik dan kontinu.
- Estimasi Proporsi Populasi: ketika data dikategorikan dalam dua kelompok (biner), seperti “puas” atau “tidak puas”.
Keduanya merupakan fondasi dari berbagai analisis lanjutan, mulai dari pengujian hipotesis hingga eksperimen A/B yang akan Anda temui di bagian akhir materi ini.
Estimasi Parameter Populasi: Mean Populasi
Dalam dunia nyata, kita jarang sekali memiliki akses ke seluruh populasi. Misalnya, sebuah perusahaan teknologi mungkin ingin mengetahui berapa lama waktu rata-rata yang dibutuhkan pelanggan untuk menyelesaikan satu sesi layanan dalam aplikasinya. Namun, dengan jutaan pengguna aktif, tentu mustahil (atau setidaknya sangat tidak efisien) untuk mengumpulkan data dari setiap pengguna. Oleh karena itu, kita memilih sebagian kecil data—yang disebut sampel—untuk digunakan sebagai dasar pengambilan keputusan.
Namun, karena hanya melihat sebagian kecil dari keseluruhan data, kita tidak bisa sekadar mengasumsikan nilai rata-rata sampel sebagai kebenaran mutlak. Sebaliknya, kita perlu memperkirakan nilai mean populasi (μ) dengan interval kepercayaan tertentu. Inilah yang disebut dengan estimasi mean dalam statistik inferensial.
Estimasi Titik vs Estimasi Interval
Secara umum, ada dua pendekatan dalam melakukan estimasi terhadap nilai mean populasi.
- Estimasi Titik (Point Estimate)
Estimasi titik menggunakan satu nilai tunggal, yaitu rata-rata sampel (x bar), sebagai perkiraan terhadap nilai mean populasi (μ). Pendekatan ini sederhana, cepat, dan intuitif. Namun, karena berasal dari sampel, nilainya dapat bervariasi tergantung siapa saja yang terpilih dalam sampel. - Estimasi Interval (Interval Estimate)
Karena estimasi titik tidak cukup memberikan informasi tentang tingkat kepastian, kita memperluasnya menjadi confidence interval (CI). CI adalah rentang nilai yang masuk akal untuk parameter populasi yang sebenarnya (dan kita yakin nilai mean populasi berada) berdasarkan data sampel dengan tingkat kepercayaan tertentu, misalnya, 90%, 95%, atau 99%. Contohnya, kita bisa menyatakan “Dengan tingkat kepercayaan 95%, waktu rata-rata pelayanan pelanggan berkisar antara 7,8 hingga 8,6 menit.”
Estimasi interval jauh lebih informatif karena ia menyertakan ketidakpastian alami dalam pengambilan sampel. Jadi, dalam pengambilan keputusan berbasis data, pendekatan ini jauh lebih disarankan. Begitu juga dengan materi ini, kita akan fokus ke pendekatan estimasi interval.
Kondisi untuk Menghitung Confidence Interval
Sebelum menghitung confidence interval (CI) untuk rata-rata populasi, ada dua pertanyaan penting yang harus Anda jawab terlebih dahulu.
- Apakah standar deviasi populasi (σ) diketahui?
- Berapa besar ukuran sampel (n) Anda?
Jawaban dari dua pertanyaan ini akan menentukan rumus yang tepat serta jenis distribusi yang harus digunakan (normal atau t-Student).
Kondisi 1: σ Diketahui (Distribusi Normal/Z)
Jika mengetahui standar deviasi populasi (σ)–misalnya dari laporan historis, eksperimen sebelumnya, atau dokumentasi resmi—Anda boleh menggunakan distribusi Z (normal).

Kondisi ini digunakan ketika σ diketahui dan data berdistribusi normal (atau n besar). Interval yang dihasilkan biasanya lebih sempit karena kita mengasumsikan informasi tentang populasi sangat lengkap. Namun, kasus ini jarang terjadi dalam dunia nyata.
Kondisi 2: σ Tidak Diketahui dan n < 30 (Distribusi t-Student)
Jika σ tidak diketahui (yang sangat umum terjadi) dan ukuran sampel Anda kecil (kurang dari 30), ketidakpastian menjadi lebih tinggi. Oleh karena itu, kita menggunakan distribusi t, yang memiliki bentuk lebih lebar dibanding distribusi normal (Z).

Distribusi t memperhitungkan ketidakpastian lebih besar karena kita mengestimasi deviasi dari data sampel, bukan mengetahui nilainya secara pasti. Oleh karena itu, intervalnya lebih lebar untuk menjaga tingkat kepercayaan yang sama.
Studi Kasus: Estimasi Waktu Layanan Pelanggan
Bayangkan Anda bekerja sebagai manajer data di sebuah perusahaan yang menyediakan layanan pelanggan melalui aplikasi digital. Anda dihadapkan pada kebutuhan untuk mengetahui rata-rata waktu yang dibutuhkan pelanggan dalam menyelesaikan satu sesi layanan. Namun, dengan ribuan pelanggan aktif setiap hari, melakukan pengukuran terhadap seluruh populasi sangat tidak efisien—baik dari segi waktu maupun sumber daya.
Untuk mendapatkan gambaran yang representatif, Anda memutuskan menggunakan teknik sampling. Dari seluruh populasi pelanggan, Anda mengambil sampel acak sebanyak 50 orang. Pemilihan secara acak ini penting agar setiap pelanggan memiliki peluang yang sama untuk terpilih sehingga hasilnya dapat mewakili populasi secara keseluruhan.
Setelah sampel ditentukan, Anda mengumpulkan data waktu layanan dari masing-masing pelanggan yang terpilih. Data yang dicatat adalah waktu (dalam menit) yang dibutuhkan oleh setiap pelanggan untuk menyelesaikan satu sesi layanan di aplikasi.
Dengan 50 data waktu layanan di tangan, Anda kemudian melakukan analisis statistik sederhana:
- Rata-rata (mean) waktu layanan dari 50 pelanggan adalah 8.2 menit. Perlu diperhatikan, 8.2 menit berarti 8 menit dan 12 detik (karena 0.2 x 60 detik = 12 detik), bukan 8 menit 20 detik.
- Standar deviasi (s) dari sampel adalah 1.4 menit. Ini menunjukkan seberapa besar variasi waktu layanan antar pelanggan dalam sampel.
- Ukuran sampel (n) tentu saja adalah 50, sesuai jumlah pelanggan yang diambil.
Karena data hanya diambil dari sebagian pelanggan, Anda ingin memperkirakan rata-rata waktu layanan untuk seluruh populasi dengan tingkat keyakinan tertentu. Anda memilih tingkat kepercayaan 95% sebagai standar umum dalam statistik untuk memastikan hasil estimasi cukup andal dan bisa digunakan dalam pengambilan keputusan.
Dari seluruh proses ini, Anda mendapatkan angka-angka penting berikut:
- Rata-rata waktu layanan pelanggan (x̄): 8.2 menit
- Standar deviasi sampel (s): 1.4 menit
- Ukuran sampel (n): 50 pelanggan
- Tingkat kepercayaan: 95%
Dengan data ini, Anda bisa melanjutkan ke tahap perhitungan estimasi interval kepercayaan rata-rata waktu layanan untuk seluruh pelanggan.
Menghitung Estimasi Mean Populasi secara Manual
Karena standar deviasi populasi (σ) tidak diketahui dan jumlah sampel (n) cukup besar (n > 30), kita akan menggunakan distribusi t-Student.
Rumus yang digunakan sebagai berikut.
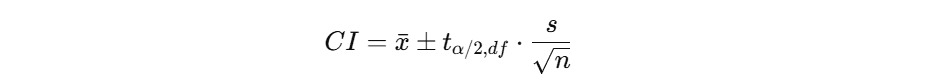
- x_bar = 8.2
- s = 1.4
- n = 50
- df = n−1=49
- Tingkat kepercayaan = 95% → α = 100% - 95% = 5%
- (Nilai t kritis) t0.025, 49= 2.009 → dari tabel distribusi t untuk tingkat kepercayaan 95%.
Hitung nilai margin of error sebagai berikut.

Jadi, confidence interval-nya adalah berikut.
Cl = 8,2 ± 0.398
Nilai minimal = 7.80 menit
Nilai maksimal = 8.60 menit
Jika kita ubah angka desimalnya ke detik, hasilnya berikut.
Batas Bawah: 7.80 menit
0.80 menit × 60 detik = 48 detik
Jadi: 7 menit 48 detik
Batas Atas: 8.60 menit
0.60 menit × 60 detik = 36 detik
Jadi: 8 menit 36 detik
Berdasarkan hasil perhitungan tersebut, kita bisa mengatakan hal berikut.
“Dengan tingkat keyakinan 95%, rata-rata waktu yang dibutuhkan pelanggan untuk menyelesaikan satu sesi layanan berada antara 7 menit 48 detik hingga 8 menit 36 detik.”
Artinya, jika perusahaan mengklaim bahwa waktu pelayanan mereka adalah kurang dari 7 menit, klaim tersebut tidak didukung oleh data yang tersedia. Perusahaan sebaiknya mempertimbangkan untuk melakukan optimasi atau melihat lebih dalam alasan rata-rata waktu layanan bisa lebih lama dari target.
Menghitung Estimasi Mean Populasi dengan Python
Selain dapat dihitung dengan cara manual, Anda dapat mencari nilai mean populasi dengan memanfaatkan library math dan scipy pada Python untuk melakukan perhitungan nilai estimasi mean populasi ini.
Anda bisa menggunakan tools seperti Google Colab untuk mengikuti latihan ini.
Langkah 1: Mendefinisikan Nilai Variabel
Kita definisikan dulu kondisi sesuai dengan kasus yang akan dikerjakan. Pada kasus ini, kita memiliki x rata-rata 8,2 menit, standar deviasi 1,4 menit, dan ukuran sampel 50 pelanggan. Kita akan menggunakan library scipy.stats untuk perhitungan statistik dan math untuk operasi matematika dasar seperti akar kuadrat.
Silakan salin dan tempel kode berikut ke Google Colab Anda.
- import scipy.stats as stats
-
import math
- # Tentukan rata-rata sampel (x_bar), deviasi standar sampel (s), ukuran sampel (n), dan tingkat kepercayaan
- x_bar = 8.2 # Rata-rata waktu layanan dari sampel (menit)
- s = 1.4 # Standar deviasi waktu layanan dari sampel (menit)
- n = 50 # Jumlah pelanggan dalam sampel
-
confidence_level = 0.95 # Tingkat kepercayaan yang diinginkan (95%)
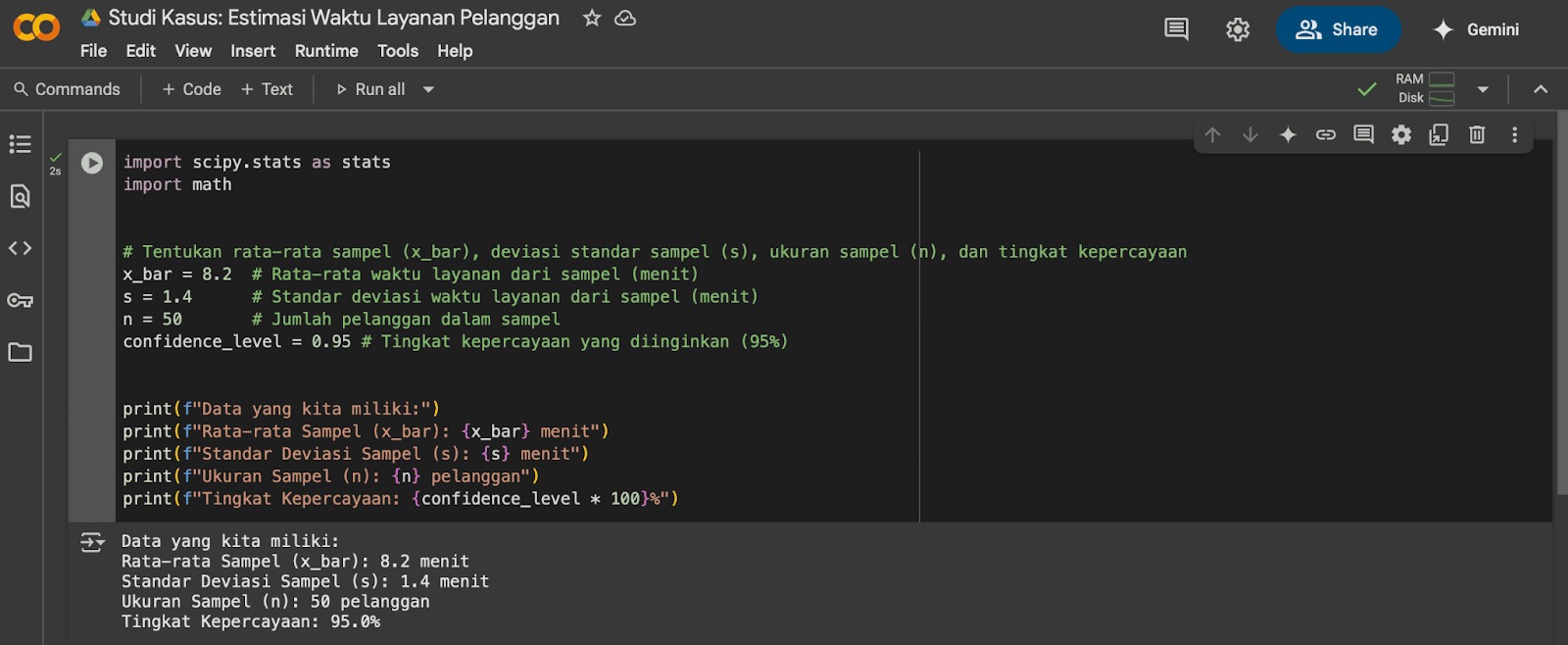
- print(f”Data yang kita miliki:”)
- print(f”Rata-rata Sampel (x_bar): {x_bar} menit”)
- print(f”Standar Deviasi Sampel (s): {s} menit”)
- print(f”Ukuran Sampel (n): {n} pelanggan”)
- print(f”Tingkat Kepercayaan: {confidence_level * 100}%”)
Inilah tampilan pada Google Colab.
Langkah 2: Menentukan Derajat Kebebasan dan Tingkat Signifikansi (Alpha)
Selanjutnya, kita perlu dua nilai kunci untuk perhitungan statistik kita: derajat kebebasan dan tingkat signifikansi (alpha).
Derajat kebebasan adalah angka yang merepresentasikan jumlah informasi independen yang tersedia untuk mengestimasi suatu parameter statistik. Dalam banyak uji, derajat kebebasan (degree of freedom) berhubungan dengan ukuran sampel dan jumlah parameter yang diestimasi.
Saat menghitung estimasi rata-rata populasi, nilai derajat kebebasan ditentukan dengan rumus `df = n-1`, yakni n adalah jumlah data dalam sampel dan dikurangi nilai 1 karena telah digunakan untuk menghitung rata-rata sampel itu sendiri.
Ilustrasi sederhananya sebagai berikut.
Misalnya, Anda memiliki tiga angka dan diketahui rata-ratanya harus 10. Jika Anda bebas memilih tiga angka tersebut, tidak ada batasan yang terjadi sehingga mampu memilih angka berapa pun. Namun, ketika Anda menetapkan “Ketiga angka ini harus memiliki rata-rata 10”, angka ketiga harus mengikuti supaya rata-ratanya tetap 10.
Contohnya, jika Anda memilih angka pertama 9 dan angka kedua 11, agar rata-ratanya tetap 10, angka ketiga haruslah 10. Perhitungannya seperti berikut.
(9 + 11 + 10)/3 = 30/3 = 10
Dengan demikian, hanya dua dari tiga angka yang benar-benar bebas dipilih. Inilah yang dimaksud dengan satu derajat kebebasan telah digunakan sehingga sisanya adalah `n-1`.
Di sisi lain, tingkat signifikansi (alpha) adalah batas toleransi risiko yang kita tetapkan saat melakukan uji statistik. Ia menyatakan “Seberapa besar kemungkinan kita salah menolak hipotesis nol (H0) padahal H0 sebenarnya benar.”
Rumus tingkat signifikansi adalah `1 - confidence interval`, jika confidence interval adalah 0.95, tingkat signifikansinya adalah 0.05.
Catatan: Kita akan membahas hipotesis lebih lanjut pada materi berikutnya.
Sekarang, tambahkan kode berikut sebagai baris baru pada Google Colab Anda (klik tombol + Code).
- # Hitung alpha (tingkat signifikansi)
-
alpha = (1 - confidence_level)
- # Hitung derajat kebebasan (df)
-
df = n - 1
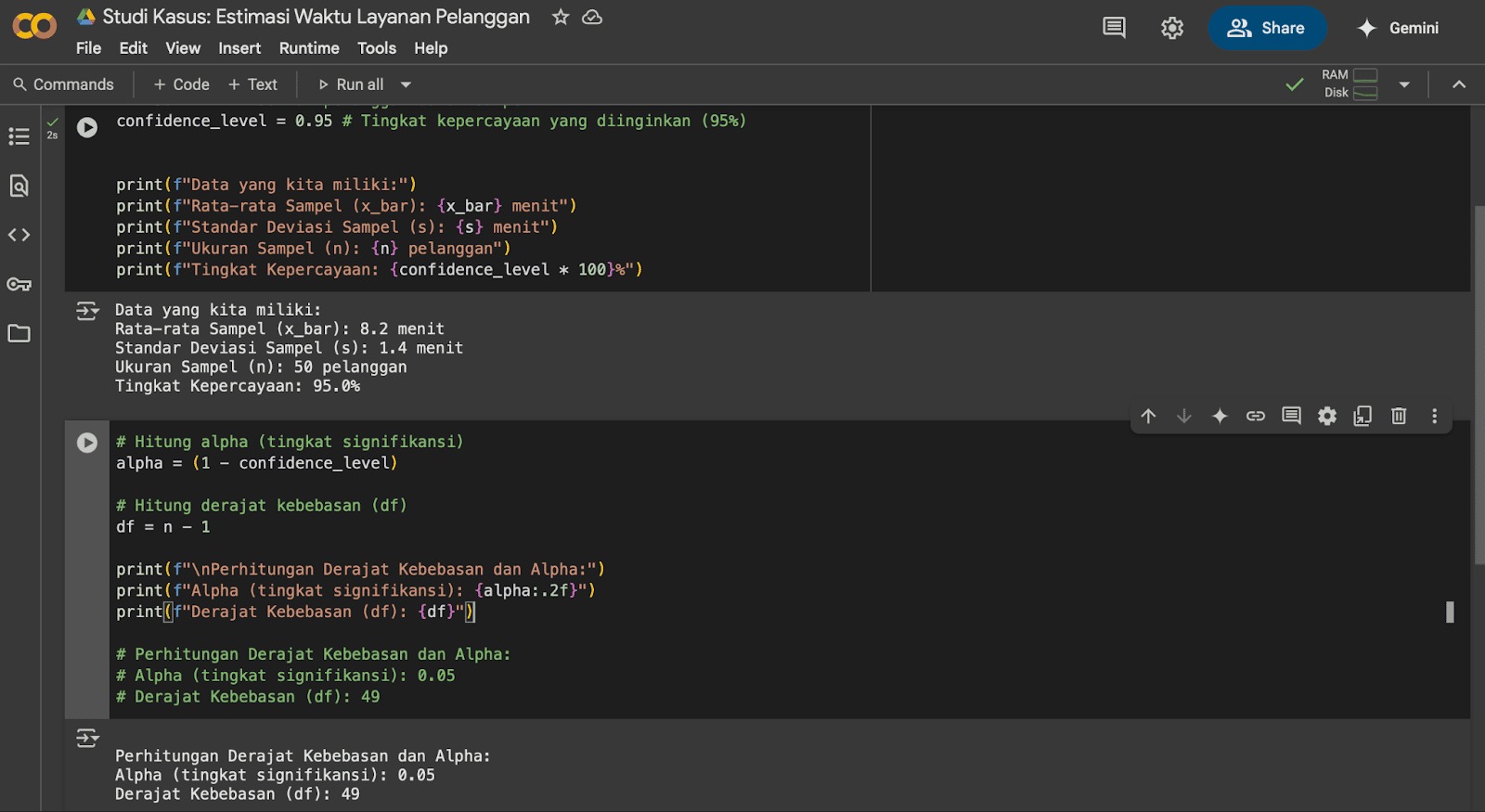
- print(f”\nPerhitungan Derajat Kebebasan dan Alpha:”)
- print(f”Alpha (tingkat signifikansi): {alpha:.2f}”)
-
print(f”Derajat Kebebasan (df): {df}”)
- # Perhitungan Derajat Kebebasan dan Alpha:
- # Alpha (tingkat signifikansi): 0.05
- # Derajat Kebebasan (df): 49
Dari langkah kedua ini kita akan mendapatkan nilai derajat kebebasan dan nilai tingkat kepercayaan (alpha).
Ini tampilan pada Google Colab.
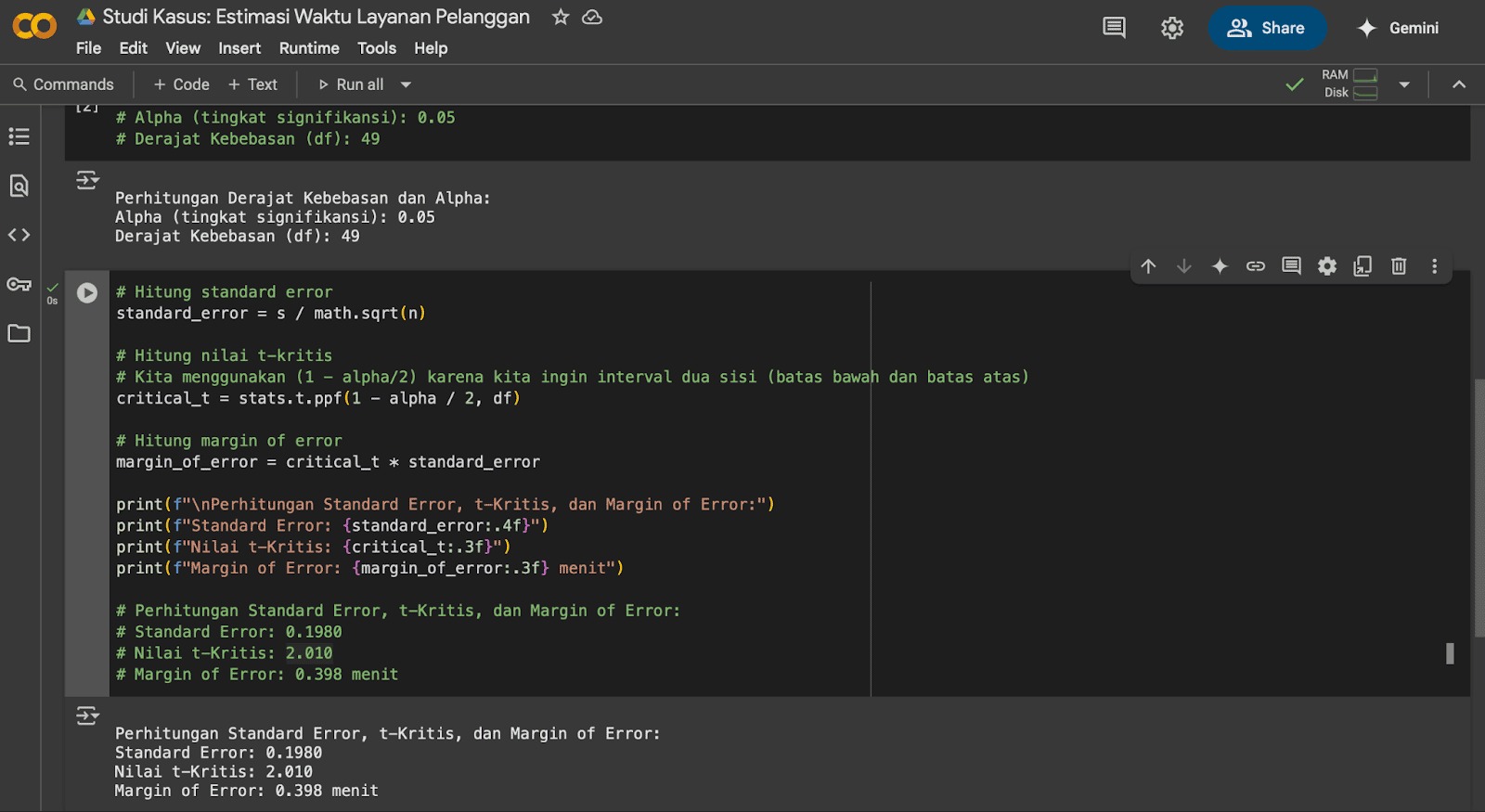
Langkah 3: Menghitung Nilai t Kritis dan Margin Kesalahan (Margin of Error)
Ini adalah bagian inti dari perhitungan, yakni kita menentukan seberapa “lebar” interval kepercayaan. Jika sebelumnya kita menggunakan nilai dari tabel distribusi t secara langsung, kali ini kita akan menggunakan fungsi stats.t.ppf() untuk mencari nilai t pada distribusi t-student sesuai dengan probabilitas yang diinginkan dan derajat kebebasan (df) dari sampel.
Tambahkan kode berikut pada Google Colab Anda.
- # Hitung standard error
-
standard_error = s / math.sqrt(n)
- # Hitung nilai t-kritis
- # Kita menggunakan (1 - alpha/2) karena kita ingin interval dua sisi (batas bawah dan batas atas)
-
critical_t = stats.t.ppf(1 - alpha / 2, df)
- # Hitung margin of error
-
margin_of_error = critical_t * standard_error
- print(f”\nPerhitungan Standard Error, t-Kritis, dan Margin of Error:”)
- print(f”Standard Error: {standard_error:.4f}”)
- print(f”Nilai t-Kritis: {critical_t:.3f}”)
-
print(f”Margin of Error: {margin_of_error:.3f} menit”)
- # Perhitungan Standard Error, t-Kritis, dan Margin of Error:
- # Standard Error: 0.1980
- # Nilai t-Kritis: 2.010
- # Margin of Error: 0.398 menit
Inilah tampilan pada Google Colab.
Langkah 4: Menghitung Rentang Confidence Interval (Interval Kepercayaan)
Sekarang kita memiliki semua yang dibutuhkan untuk menentukan rentang interval kepercayaan. Tambahkan kode berikut pada Google Colab Anda.
- # Hitung batas bawah interval kepercayaan
-
lower_bound = x_bar - margin_of_error
- # Hitung batas atas interval kepercayaan
-
upper_bound = x_bar + margin_of_error
- print(f”\nInterval Kepercayaan:”)
- print(f”Batas Bawah (Lower Bound) = {lower_bound:.3f} menit”)
-
print(f”Batas Atas (Upper Bound) = {upper_bound:.3f} menit”)
- # Interval Kepercayaan:
- # Batas Bawah (Lower Bound) = 7.802 menit
- # Batas Atas (Upper Bound) = 8.598 menit
Begini tampilan pada Google Colab.
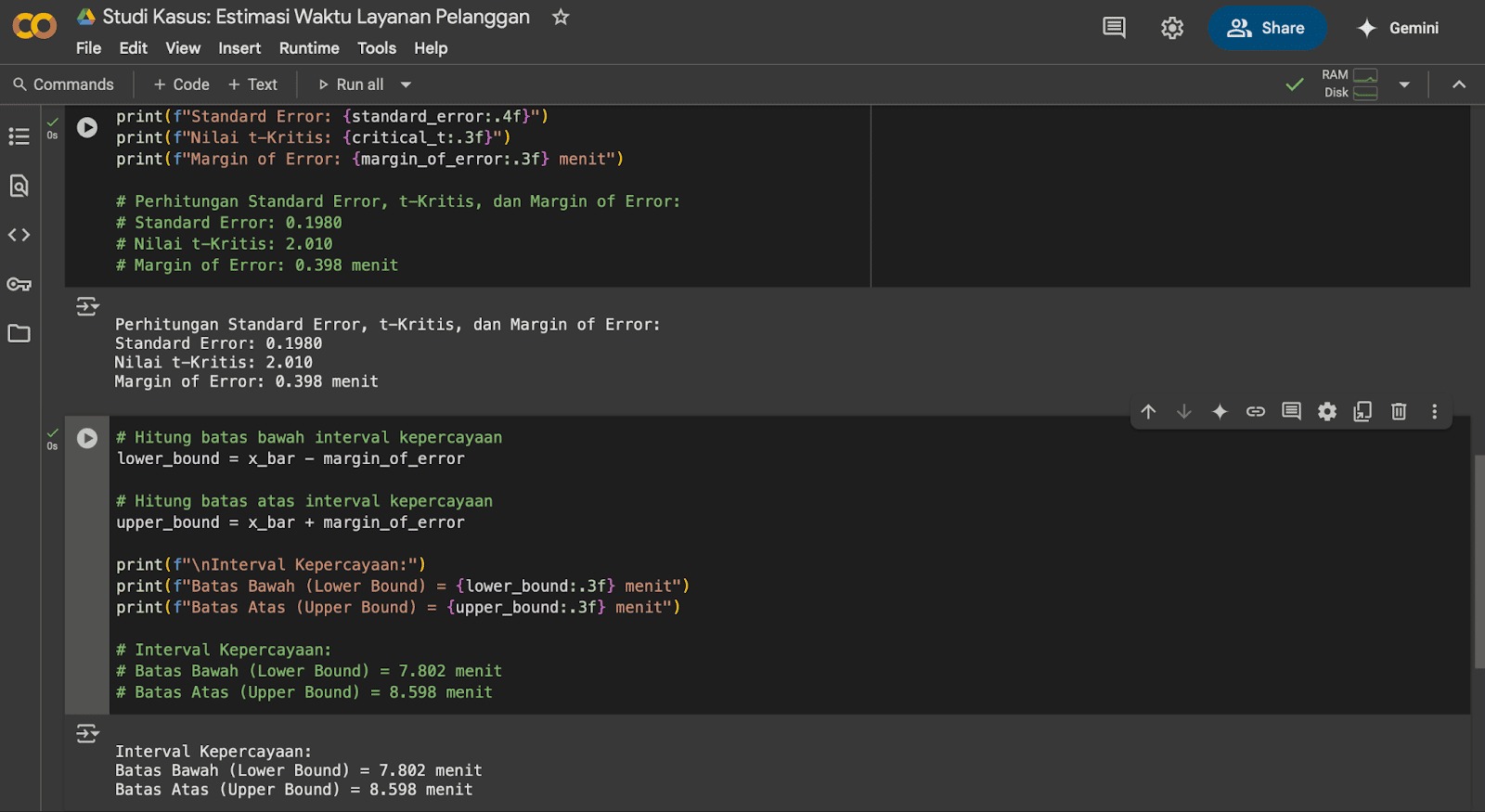
Jadi, dengan tingkat kepercayaan 95%, kita bisa mengatakan bahwa rata-rata waktu layanan pelanggan yang sebenarnya berada di antara 7.802 menit dan 8.598 menit.
Langkah Tambahan: Konversi dari Desimal ke Menit
Untuk membuatnya lebih mudah dipahami dalam konteks waktu, mari kita ubah nilai desimal menit ini dalam format menit dan detik yang lebih intuitif.
Tambahkan kode berikut pada Google Colab Anda.
- # Fungsi untuk mengonversi desimal menit ke menit dan detik
- def convert_decimal_to_minute_second(decimal_minutes):
- minutes = int(decimal_minutes) # Mengambil bagian menit
- seconds = (decimal_minutes - minutes) * 60 # Mengambil bagian detik
- seconds = round(seconds) # Membulatkan detik menjadi angka bulat
-
return minutes, seconds
- minutes_1, seconds_1 = convert_decimal_to_minute_second(lower_bound)
-
minutes_2, seconds_2 = convert_decimal_to_minute_second(upper_bound)
- print(f”\nOutput Akhir (dalam format menit dan detik):”)
- print(f”Lower Bound = {lower_bound:.3f} menit = {minutes_1} menit {seconds_1} detik”)
-
print(f”Upper Bound = {upper_bound:.3f} menit = {minutes_2} menit {seconds_2} detik”)
- # Output Akhir (dalam format menit dan detik):
- # Lower Bound = 7.802 menit = 7 menit 48 detik
- # Upper Bound = 8.598 menit = 8 menit 36 detik
Begini tampilan pada Google Colab.
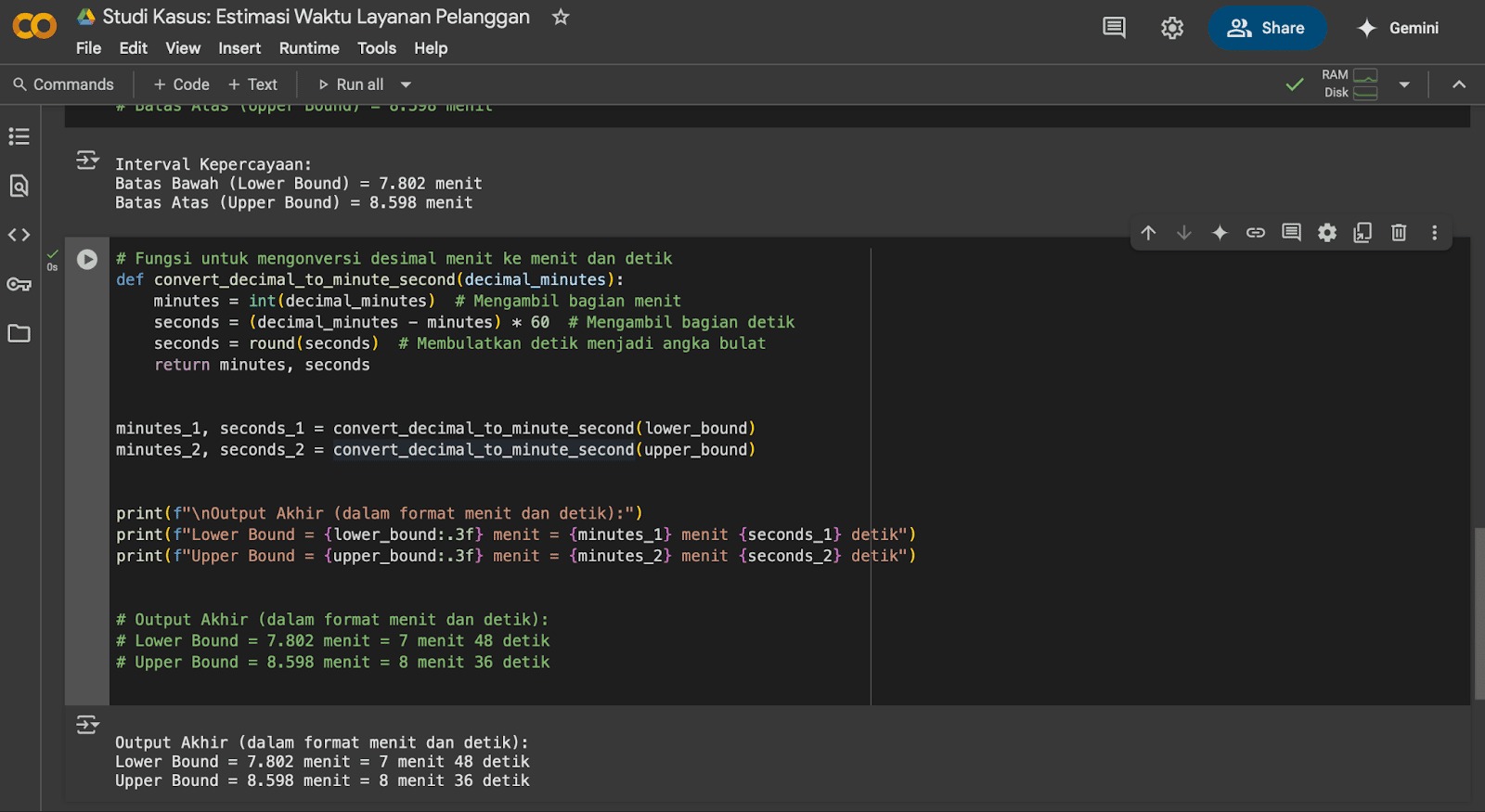
Fungsi convert_decimal_to_minute_second mengambil angka desimal (menit) serta memisahkannya menjadi bagian menit utuh dan bagian desimal yang kemudian dikonversi ke detik. Misalnya, 7.802 menit akan menjadi 7 menit dan 0.802 * 60 = 48.12 detik, yang dibulatkan menjadi 48 detik.
Berdasarkan analisis data sampel tersebut, kita 95% yakin bahwa waktu layanan rata-rata sebenarnya untuk semua pelanggan adalah antara 7 menit 48 detik dan 8 menit 36 detik. Ini memberikan gambaran yang jauh lebih informatif dan mudah dipahami daripada sekadar melaporkan rata-rata sampel tunggal!
Untuk memahami kode estimasi mean populasi di atas dengan lebih detail, Anda bisa akses Google Colab pada link berikut. Jika Anda ingin memahami lebih dalam mengenai cara kerja dari persamaan ini, silakan akses laman berikut.
Estimasi Parameter Populasi: Proporsi Populasi
Selain estimasi rata-rata, kita juga sering kali ingin memperkirakan proporsi dalam populasi, terutama ketika data yang dihadapi adalah kategori biner (mis. “ya” atau “tidak”, “puas” atau “tidak puas”).
Estimasi proporsi adalah salah satu metode dasar dalam statistik inferensial yang digunakan untuk memperkirakan proporsi suatu kelompok atau kategori pada suatu populasi. Misalnya, jika ingin mengetahui berapa persen pelanggan puas dengan produk/layanan atau berapa banyak orang yang memilih suatu pilihan dalam survei politik, Anda akan menggunakan estimasi proporsi.
Sebagai contoh, dalam sebuah survei yang melibatkan 500 responden, Anda ingin tahu berapa persen dari mereka yang memilih opsi A dibandingkan dengan opsi B. Ini adalah situasi yang umum ketika estimasi proporsi digunakan.
Namun, dalam banyak kasus, kita tidak bisa mengukur seluruh populasi (misalnya, semua pelanggan yang ada) sehingga hanya mengambil sampel. Berdasarkan sampel ini, kita ingin memperkirakan proporsi yang berlaku di seluruh populasi.
Rumus Confidence Interval untuk Proporsi
Sama halnya dengan estimasi rata-rata, estimasi proporsi juga memiliki confidence interval (CI) yang memberikan gambaran seberapa yakin kita terhadap hasil estimasi dari sampel. Untuk menghitung confidence interval untuk proporsi, kita menggunakan rumus berikut.
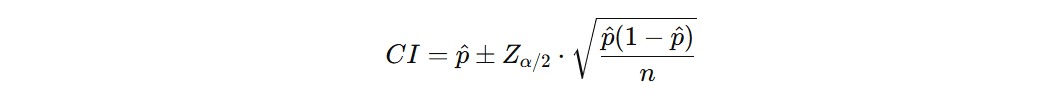
Penjelasan
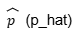 = proporsi sampel. Ini adalah proporsi yang kita hitung dari data sampel. Misalnya, jika 60 dari 100 orang yang disurvei puas dengan layanan, p = 60/100 = 0.60.
= proporsi sampel. Ini adalah proporsi yang kita hitung dari data sampel. Misalnya, jika 60 dari 100 orang yang disurvei puas dengan layanan, p = 60/100 = 0.60.- Za/2 = nilai z sesuai dengan tingkat kepercayaan yang diinginkan. Misalnya, untuk tingkat kepercayaan 95%, nilai Za/2 adalah 1.96.
- n = jumlah responden atau ukuran sampel. Ini adalah jumlah orang yang Anda survei dalam sampel. Semakin besar ukuran sampel, semakin akurat estimasi proporsi yang Anda dapatkan.
Studi Kasus: Estimasi Proporsi Pengguna yang Puas
Sebuah perusahaan aplikasi baru saja meluncurkan fitur baru dan ingin mengetahui berapa banyak pengguna yang puas dengan fitur baru tersebut. Untuk itu, mereka melakukan survei terhadap 200 pengguna dan menemukan bahwa 132 dari mereka puas dengan fitur tersebut.
Kita bisa mencari nilai estimasi proporsi populasi dengan memanfaatkan library Python yang sama seperti sebelumnya, yaitu math dan scipy. Anda bisa menggunakan tools seperti Google Colab untuk mengikuti latihan ini.
Langkah 1: Menghitung Proporsi Sampel
Langkah pertama adalah menghitung proporsi sampel 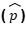 , yaitu persentase pengguna yang puas berdasarkan hasil survei.
, yaitu persentase pengguna yang puas berdasarkan hasil survei.
Silakan salin dan tempel kode berikut pada Google Colab Anda.
- import math
-
import scipy.stats as stats
- # Data yang diberikan
- n = 200 # Ukuran sampel
-
x = 132 # Jumlah pengguna yang puas
- # Hitung proporsi sampel (p_hat)
-
p_hat = x / n
- print(f”Jumlah pengguna yang disurvei (n): {n}”)
- print(f”Jumlah pengguna yang puas (x): {x}”)
-
print(f”Proporsi sampel (p_hat): {p_hat:.4f}”)
- # Jumlah pengguna yang disurvei (n): 200
- # Jumlah pengguna yang puas (x): 132
- # Proporsi sampel (p_hat): 0.6600
Ini tampilannya pada Google Colab.
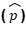 (dibaca “p_hat”) adalah proporsi sampel sebagai estimasi terbaik kita untuk proporsi populasi berdasarkan data yang dimiliki. Kita menghitungnya dengan membagi jumlah pengguna yang puas (x) dengan total pengguna yang disurvei (n). Dari perhitungan, kita mendapatkan bahwa 0.66 atau 66% dari pengguna dalam sampel merasa puas.
(dibaca “p_hat”) adalah proporsi sampel sebagai estimasi terbaik kita untuk proporsi populasi berdasarkan data yang dimiliki. Kita menghitungnya dengan membagi jumlah pengguna yang puas (x) dengan total pengguna yang disurvei (n). Dari perhitungan, kita mendapatkan bahwa 0.66 atau 66% dari pengguna dalam sampel merasa puas.
Langkah 2: Menghitung Confidence Interval
Untuk membangun interval kepercayaan, kita perlu menentukan tingkat kepercayaan yang diinginkan dan menemukan nilai Z-kritis yang sesuai.
Silakan salin dan tempel kode berikut pada Google Colab Anda.
- # Tingkat kepercayaan
- confidence_level = 0.95
-
alpha = 1 - confidence_level
- # Hitung nilai Z-kritis
- # Untuk interval kepercayaan dua sisi, kita menggunakan alpha/2
-
z_critical = stats.norm.ppf(1 - alpha / 2)
- print(f”\nTingkat Kepercayaan: {confidence_level * 100}%”)
- print(f”Alpha (tingkat signifikansi): {alpha:.2f}”)
-
print(f”Nilai Z-kritis: {z_critical:.3f}”)
- # Tingkat Kepercayaan: 95.0%
- # Alpha (tingkat signifikansi): 0.05
- # Nilai Z-kritis: 1.960
Berikut tampilannya dalam Google Colab.
Karena ukuran sampel cukup besar (n > 30), kita menggunakan distribusi normal standar dan menemukan nilai Z-kritis. stats.norm.ppf adalah fungsi yang memberikan nilai Z pada persentil tertentu. Untuk interval dua sisi (batas bawah dan batas atas), kita menggunakan 1 - alpha / 2. Nilai Z-kritis untuk 95% tingkat kepercayaan adalah sekitar 1.960.
Langkah 3: Menghitung Standard Error dan Margin of Error
Selanjutnya, kita akan menghitung standard error dan margin of error. Margin of error ini akan menentukan lebar interval kepercayaan kita.
Salin dan tempel kode berikut pada Google Colab Anda.
- # Hitung standard error proporsi
- # Rumus: sqrt((p_hat * (1 - p_hat)) / n)
-
standard_error = math.sqrt((p_hat * (1 - p_hat)) / n)
- # Hitung margin of error
-
margin_of_error = z_critical * standard_error
- print(f”\nStandard Error Proporsi: {standard_error:.4f}”)
-
print(f”Margin of Error: {margin_of_error:.4f}”)
- # Standard Error Proporsi: 0.0335
- # Margin of Error: 0.0657
Berikut tampilannya pada Google Colab.
Apabila dituliskan menjadi sebuah rumus matematis, seperti ini perhitungannya.
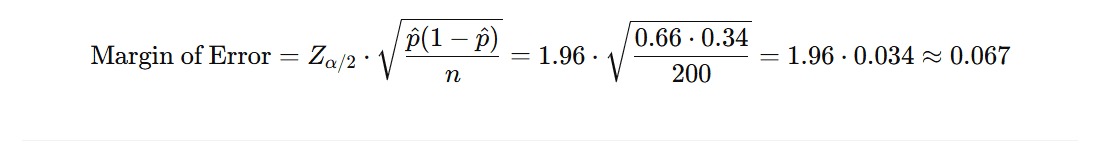
Langkah 4: Menghitung Batas Bawah dan Batas Atas Confidence Interval
Sekarang, kita bisa menentukan nilai confidence interval dengan menambahkan dan mengurangi margin of error dari proporsi sampel.
Salin dan tempel kode berikut pada Google Colab Anda.
- # Hitung batas bawah interval kepercayaan
-
lower_bound = p_hat - margin_of_error
- # Hitung batas atas interval kepercayaan
-
upper_bound = p_hat + margin_of_error
- print(f”\nInterval Kepercayaan Proporsi Pengguna yang Puas:”)
- print(f”Batas Bawah (Lower Bound): {lower_bound:.4f} atau {lower_bound*100:.2f}%”)
-
print(f”Batas Atas (Upper Bound): {upper_bound:.4f} atau {upper_bound*100:.2f}%”)
- # Interval Kepercayaan Proporsi Pengguna yang Puas:
- # Batas Bawah (Lower Bound): 0.5943 atau 59.43%
- # Batas Atas (Upper Bound): 0.7257 atau 72.57%
Tampilan pada Google Colab-nya seperti ini.
Apabila dituliskan menjadi sebuah rumus matematis, seperti ini perhitungannya.

Jadi, confidence interval untuk proporsi pengguna yang puas adalah berikut.
CI = (0.593,0.727)
Untuk memahami kode estimasi proporsi populasi dengan lebih detail, Anda bisa melihat pada link berikut.
Berdasarkan perhitungan ini, kita dapat menyatakan hal berikut.
“Dengan tingkat keyakinan 95%, proporsi pengguna yang puas terhadap fitur aplikasi diperkirakan berada antara 59,3% hingga 72,7%.”
Ini berarti bahwa 95% dari waktu, proporsi pengguna yang puas akan berada dalam rentang ini jika survei dilakukan berulang kali.
Menggunakan confidence interval memberikan gambaran yang lebih lengkap dibandingkan hanya menyebutkan proporsi sampel saja (66%). Jika perusahaan hanya mengandalkan angka 66%, mereka mungkin mengabaikan ketidakpastian data. Namun dengan confidence interval, kita dapat memprediksi rentang proporsi yang sebenarnya kemungkinan besar berada.
Faktor yang Memengaruhi Confidence Interval
Beberapa faktor yang memengaruhi lebar confidence interval untuk proporsi adalah berikut.
- Ukuran Sampel (n): Semakin besar ukuran sampel, semakin kecil margin of error dan semakin sempit interval. Ini menunjukkan bahwa estimasi menjadi lebih akurat seiring bertambahnya data yang digunakan.
- Tingkat Kepercayaan (Confidence Level): Semakin tinggi tingkat kepercayaan yang diinginkan, seperti 99% dibandingkan dengan 95%, interval kepercayaan akan semakin lebar. Ini karena kita perlu memasukkan lebih banyak kemungkinan nilai untuk menjaga tingkat kepercayaan yang lebih tinggi.
- Variabilitas Data (Penyebaran Data): Jika proporsi sampel mendekati 0 atau 1 (misalnya hampir semua orang puas atau hampir semua tidak puas), interval kepercayaan bisa lebih sempit. Sebaliknya, jika proporsi sekitar 0.5, interval kepercayaan akan lebih lebar karena ketidakpastian yang lebih besar.
Estimasi proporsi adalah salah satu alat yang sangat berguna dalam statistik inferensial, terutama ketika bekerja dengan data kategorikal atau biner. Dengan menghitung confidence interval untuk proporsi, kita mendapatkan gambaran lebih akurat dan terukur tentang penerapan hasil sampel pada populasi yang lebih besar. Estimasi proporsi memberi kita kepercayaan diri lebih tinggi dalam keputusan yang dibuat berdasarkan data, baik dalam konteks bisnis, riset pasar, maupun eksperimen A/B.
Konsep Dasar Uji Hipotesis
Setelah mempelajari estimasi parameter populasi, yakni kita menghitung confidence interval untuk rata-rata dan proporsi, langkah berikutnya dalam statistik inferensial adalah menguji klaim atau dugaan tentang populasi. Estimasi parameter memberi kita gambaran tentang suatu nilai populasi berdasarkan data sampel, tetapi sering kali ingin menguji bahwa klaim atau pernyataan tertentu tentang populasi benar. Di sinilah uji hipotesis berperan.
Uji hipotesis adalah metode statistik yang digunakan untuk menguji sebuah pernyataan (biasanya tentang rata-rata atau proporsi populasi) berdasarkan sampel data. Uji ini memberi kita cara untuk membuat keputusan berbasis data jika suatu klaim dapat diterima atau ditolak.
Sebagai contoh, setelah mengetahui estimasi waktu rata-rata layanan pelanggan (misalnya 8,2 menit), perusahaan mungkin ingin menguji bahwa waktu layanan tersebut lebih cepat dari target sembilan menit. Inilah yang akan kita bahas dalam materi ini: cara menguji klaim tentang populasi menggunakan data sampel.
Hipotesis Nol dan Alternatif
-
Hipotesis nol (H₀)
Hipotesis nol (H₀) adalah pernyataan yang menyatakan bahwa tidak ada efek, tidak ada perbedaan, atau tidak ada hubungan antara variabel yang sedang diuji. Hipotesis ini sering dianggap sebagai hipotesis yang “tradisional” atau “default”, yang kita anggap benar sampai ada bukti cukup untuk menolaknya.Misalnya, jika kita menguji klaim bahwa waktu layanan pelanggan rata-rata adalah sembilan menit, hipotesis nol akan menyatakan bahwa waktu layanan rata-rata adalah sembilan menit.
H0:μ = 9
-
Hipotesis Alternatif (H₁)
Sebaliknya, hipotesis alternatif (H₁) adalah pernyataan yang menyatakan bahwa ada perbedaan, efek, atau hubungan signifikan antara variabel yang diuji. Hipotesis alternatif adalah klaim yang ingin kita uji dan lihat jika data sampel mendukungnya.Menggunakan contoh yang sama, hipotesis alternatif bisa menyatakan bahwa waktu layanan pelanggan rata-rata tidak sama dengan sembilan menit. Ini bisa berupa klaim bahwa waktu layanan lebih cepat atau lebih lama dari yang diharapkan.
H1:μ ≠ 9
Dengan dua hipotesis ini, kita akan melakukan uji statistik untuk menentukan bahwa data yang dikumpulkan memberikan bukti cukup kuat untuk menolak hipotesis nol dan menerima hipotesis alternatif.
Jenis Kesalahan dalam Pengujian
Dalam uji hipotesis, kita tidak pernah bisa 100% yakin tentang keputusan yang dibuat. Selalu ada kemungkinan bahwa kita membuat kesalahan dalam menerima atau menolak hipotesis nol. Oleh karena itu, ada dua jenis kesalahan yang bisa terjadi ketika kita melakukan uji hipotesis.
- Type I Error (False Positive)
- Type II Error (False Negative)
Keduanya berkaitan dengan kesalahan yang dibuat ketika kita mengambil keputusan berdasarkan data sampel. Penting untuk kita memahami keduanya agar bisa mengontrol dan meminimalkan risiko kesalahan dalam pengambilan keputusan berbasis statistik.
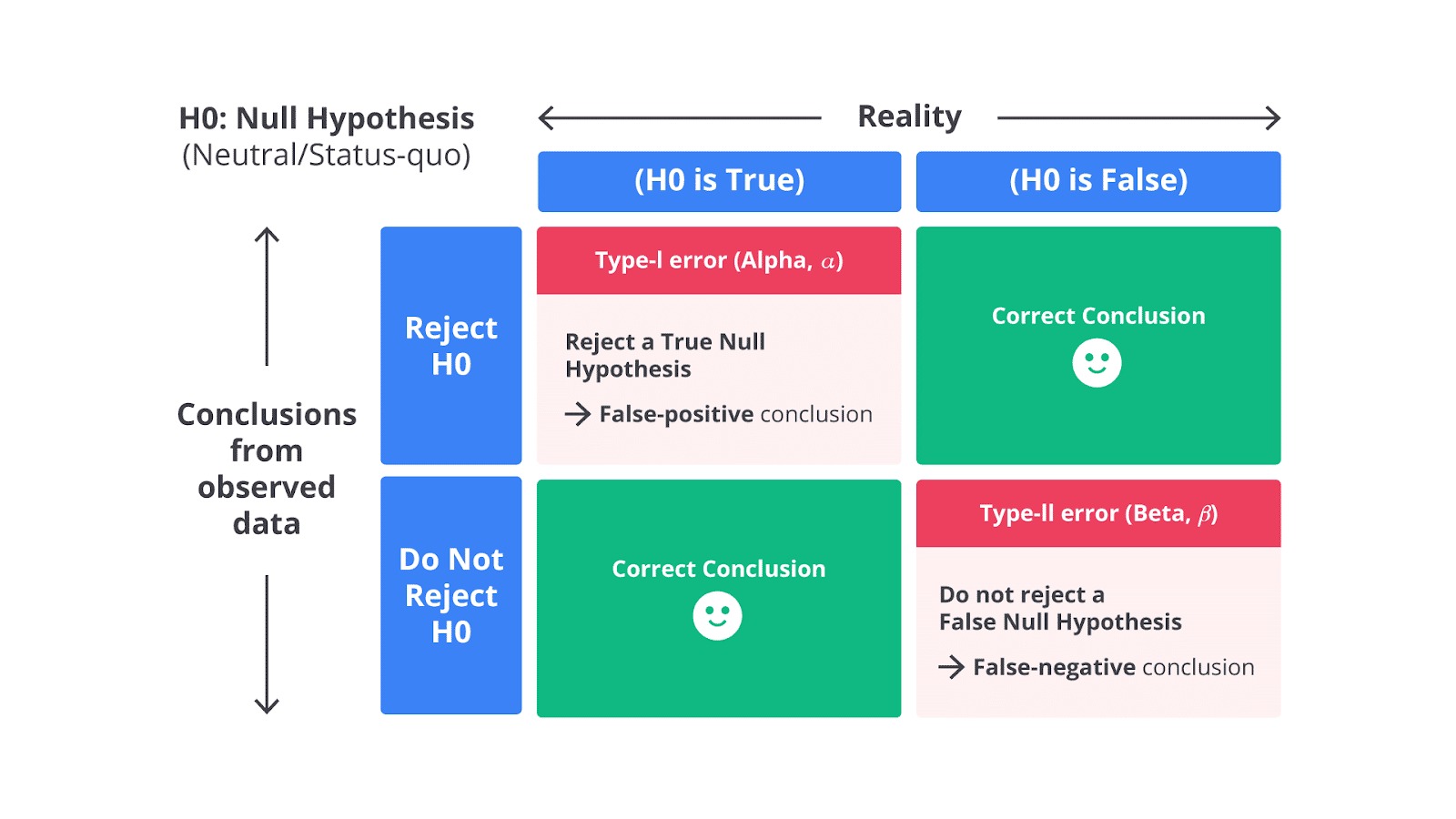
Type I Error (False Positive)
Type I Error adalah kesalahan yang terjadi ketika kita menolak hipotesis nol yang sebenarnya benar. Dengan kata lain, kita percaya bahwa ada efek atau perbedaan yang signifikan dalam data, padahal kenyataannya tidak ada perbedaan atau efek tersebut.
Contoh Type I Error
Misalkan perusahaan melakukan uji hipotesis untuk mengetahui bahwa waktu layanan pelanggan lebih cepat dari target sembilan menit. Setelah melakukan uji hipotesis, hasilnya menunjukkan bahwa waktu layanan rata-rata lebih cepat dari sembilan menit. Perusahaan pun memutuskan untuk menolak hipotesis nol yang menyatakan bahwa waktu layanan adalah sembilan menit.
Namun sebenarnya, tidak ada perbedaan nyata antara waktu layanan pelanggan dengan target sembilan menit. Keputusan untuk menolak hipotesis nol dan mengklaim bahwa layanan lebih cepat dari sembilan menit adalah Type I Error.
Probabilitas Type I Error biasanya disebut α (alpha) atau level signifikansi, yang umumnya diatur ke nilai 0.05 (5%). Nilai α ini adalah ambang batas yang kita tentukan sebelum uji hipotesis. Misalnya, jika α = 0.05, kita siap menerima bahwa ada 5% kemungkinan kita membuat kesalahan Type I, yaitu menolak hipotesis nol yang sebenarnya benar.
Type II Error (False Negative)
Type II Error adalah kesalahan yang terjadi ketika kita gagal menolak hipotesis nol yang sebenarnya salah. Dengan kata lain, kita menganggap tidak ada efek atau perbedaan dalam data, padahal kenyataannya ada perbedaan atau efek yang signifikan.
Kembali pada contoh perusahaan yang menguji bahwa waktu layanan pelanggan lebih cepat dari target sembilan menit. Namun, setelah melakukan uji hipotesis, perusahaan gagal menolak hipotesis nol dan menerima bahwa waktu layanan adalah sembilan menit. Padahal, waktu layanan sebenarnya lebih cepat dari sembilan menit.
Keputusan untuk menerima hipotesis nol adalah kesalahan Type II karena data menunjukkan perbedaan yang signifikan, tetapi keputusan akhirnya menyatakan tidak ada perbedaan.
Probabilitas Type II Error biasanya disebut β (beta). Misalnya, jika β = 0.2, artinya ada 20% kemungkinan kita akan gagal mendeteksi perbedaan yang sebenarnya ada. Peningkatan ukuran sampel dapat membantu mengurangi risiko Type II Error. Sebab semakin banyak data yang dimiliki, semakin besar kemungkinan kita mendeteksi perbedaan atau efek yang ada.
Mengelola Kedua Jenis Kesalahan
Dalam statistik, kita harus memilih level signifikansi (α) dan meminimalkan risiko Type I Error tanpa mengabaikan Type II Error. Namun, ada trade-off (pengorbanan) antara keduanya.
- Menurunkan α (Level Signifikansi): Jika kita mengatur α menjadi lebih kecil (misalnya, 0.01 daripada 0.05), kita mengurangi kemungkinan Type I Error, tetapi hal ini akan meningkatkan risiko Type II Error (karena kita lebih sulit menolak hipotesis nol).
- Meningkatkan Ukuran Sampel: Dengan menambah ukuran sampel, kita bisa menurunkan probabilitas Type II Error (β) dan meningkatkan kemampuan uji untuk mendeteksi perbedaan yang sebenarnya ada. Namun, ini juga meningkatkan biaya dan waktu yang diperlukan untuk eksperimen.
- Menggunakan Uji Satu Arah (One-Tailed Test) atau Dua Arah (Two-Tailed Test): Terkadang, kita memilih untuk menggunakan uji satu arah (misalnya, hanya menguji jika waktu layanan lebih cepat dari sembilan menit) atau dua arah (menguji jika waktu layanan berbeda dari sembilan menit dalam kedua arah). Pilihan ini dapat memengaruhi jenis kesalahan yang mungkin terjadi.
Dampak pada Pengambilan Keputusan
Kedua jenis kesalahan ini (Type I dan Type II) sangat penting dalam pengambilan keputusan berbasis statistik.
- Type I Error (False Positive) berisiko mengambil keputusan yang salah dengan menganggap ada efek padahal sebenarnya tidak ada. Misalnya, perusahaan mungkin mengklaim bahwa mereka telah meningkatkan layanan pelanggan, padahal tidak ada perbedaan signifikan.
- Type II Error (False Negative) berisiko mengabaikan temuan penting dengan gagal mendeteksi efek yang benar-benar ada. Misalnya, perusahaan mungkin melewatkan peluang untuk meningkatkan layanan karena menganggap bahwa tidak ada perbedaan signifikan dengan target.
Oleh karena itu, penting untuk memilih tingkat signifikansi dan ukuran sampel yang tepat sesuai dengan konteks bisnis atau penelitian Anda. Semakin banyak data yang dimiliki, semakin besar kemampuan kita untuk mendeteksi perbedaan signifikan dan mengurangi risiko kedua jenis kesalahan ini.
Menyusun Hipotesis
Sebelum melakukan uji hipotesis, langkah pertama yang harus kita lakukan adalah menyusun hipotesis itu sendiri. Menyusun hipotesis dengan benar sangat penting karena hipotesis inilah yang akan diuji menggunakan data sampel untuk menarik kesimpulan tentang populasi.
Ada dua jenis hipotesis yang sering kita temui dalam uji hipotesis: hipotesis parametrik dan hipotesis non-parametrik.
Hipotesis Parametrik
Hipotesis parametrik adalah hipotesis berkaitan dengan parameter populasi yang sudah diketahui atau diasumsikan mengikuti distribusi tertentu. Biasanya, distribusi normal digunakan sebagai asumsi dasar dalam uji parametrik.
Dalam uji parametrik, kita membuat klaim tentang rata-rata (mean), varians, atau parameter lainnya dari populasi. Misalnya, kita ingin menguji bahwa rata-rata waktu layanan pelanggan lebih cepat dari target tertentu.
Contoh Hipotesis Parametrik
- H₀ (Hipotesis Nol): Rata-rata waktu layanan adalah sembilan menit (H₀ : μ = 9).
- H₁ (Hipotesis Alternatif): Rata-rata waktu layanan lebih cepat dari sembilan menit (H₁ : μ < 9).
Uji parametrik lebih kuat jika asumsi distribusi data yang normal dapat diterima karena uji ini dapat memberikan hasil lebih presisi dengan menggunakan lebih sedikit data sampel.
Hipotesis Non-Parametrik
Hipotesis non-parametrik digunakan ketika kita tidak dapat membuat asumsi tentang distribusi data atau data yang dianalisis tidak memenuhi asumsi distribusi tertentu (misalnya, distribusi normal). Uji non-parametrik lebih fleksibel karena tidak bergantung pada parameter distribusi tertentu, seperti mean atau varians.
Dalam uji non-parametrik, kita biasanya berfokus pada ranking/urutan data atau menguji perbedaan antara dua kelompok tanpa mengasumsikan distribusi khusus.
Contoh Hipotesis Non-Parametrik
- H₀ (Hipotesis Nol): Tidak ada perbedaan antara dua grup (misalnya, dua kelompok yang menggunakan dua metode layanan yang berbeda).
- H₁ (Hipotesis Alternatif): Ada perbedaan antara dua grup (misalnya, satu metode layanan lebih cepat daripada yang lainnya).
Uji non-parametrik digunakan ketika data tidak memenuhi asumsi distribusi normal atau ketika kita bekerja dengan data ordinal (data yang memiliki urutan, tetapi tidak memiliki jarak yang terukur antara nilai-nilai).
Langkah Menentukan Hipotesis
Menulis hipotesis secara tepat sangat penting dalam menentukan jenis uji yang akan dilakukan dan memastikan bahwa penelitian Anda berjalan dengan benar. Berikut adalah langkah-langkah yang perlu diikuti dalam menyusun hipotesis.
- Tentukan Pertanyaan Penelitian
Langkah pertama adalah mengidentifikasi pertanyaan penelitian yang ingin Anda jawab. Pertanyaan ini akan menjadi dasar untuk menyusun hipotesis. Contohnya berikut.- Apakah waktu rata-rata layanan pelanggan lebih cepat dari sembilan menit?
- Apakah fitur baru dalam aplikasi meningkatkan kepuasan pengguna?
- Tentukan Jenis Hipotesis
Setelah memiliki pertanyaan penelitian, Anda perlu menentukan bahwa akan menggunakan hipotesis parametrik atau non-parametrik.- Jika data Anda bersifat kontinu (misalnya, waktu layanan, penghasilan, atau ukuran lainnya) dan berdistribusi normal, gunakan hipotesis parametrik.
- Jika data Anda adalah ordinal (misalnya, peringkat) atau tidak memenuhi asumsi distribusi normal, gunakan hipotesis non-parametrik.
-
Tulis Hipotesis Nol (H₀) dan Hipotesis Alternatif (H₁)
Hipotesis nol (H₀) adalah pernyataan yang tidak ada perbedaan atau tidak ada efek. Ini adalah hipotesis yang Anda akan coba tolak. Sementara itu, hipotesis alternatif (H₁) adalah pernyataan yang menyatakan ada perbedaan atau efek. Ini adalah hipotesis yang Anda coba buktikan.Contoh
- H₀ (Hipotesis Nol): Tidak ada perbedaan antara waktu layanan pelanggan saat ini dan target sembilan menit.
- H₁ (Hipotesis Alternatif): Waktu layanan pelanggan lebih cepat dari target sembilan menit.
-
Tentukan Arah Uji (Jika Ada)
Jika ingin menguji bahwa nilai parameter lebih besar (>) atau lebih kecil (<) dari nilai tertentu, Anda menggunakan uji satu arah. Sebaliknya, jika Anda menguji bahwa nilai parameter berbeda (≠) dari nilai tertentu tanpa peduli arahnya (baik lebih besar maupun lebih kecil), gunakan uji dua arah.Contoh Uji Satu Arah (One-Tailed Test)
Kita menggunakan uji satu arah apabila hanya ingin mengetahui pada satu sisi perubahan (misal, hanya tertarik jika waktu layanan menjadi lebih cepat, bukan lebih lambat).- H₀: Rata-rata waktu layanan = 9 menit.
- H₁: Rata-rata waktu layanan < 9 menit.
Contoh Uji Dua Arah (Two-Tailed Test)
Kita menggunakan uji dua arah apabila perubahan ke dua arah sama-sama penting (misal, waktu layanan lebih cepat atau lebih lambat, dua-duanya berpengaruh).
- H₀: Rata-rata waktu layanan = 9 menit.
- H₁: Rata-rata waktu layanan ≠ 9 menit.
Menyusun hipotesis adalah langkah yang penting dalam uji hipotesis. Baik dalam konteks bisnis maupun ilmiah, menyusun hipotesis secara jelas dan tepat akan memberikan dasar yang kuat untuk menguji klaim serta menarik kesimpulan yang valid dari data. Menyusun hipotesis dengan benar memungkinkan kita untuk menggunakan teknik statistik secara lebih terarah dan efektif dalam mengambil keputusan berbasis data.
Metode Pengujian Hipotesis
Setelah mempelajari dasar-dasar uji hipotesis dalam materi sebelumnya, termasuk memahami hipotesis nol (H₀) dan hipotesis alternatif (H₁) serta jenis kesalahan yang dapat terjadi selama pengujian (seperti Type I dan Type II error), langkah selanjutnya adalah memahami cara pengujian hipotesis dilakukan dalam praktik.
Pada materi ini, kita akan membahas tentang metode pengujian hipotesis yang lebih terperinci. Di dalamnya, kita akan mengulas lebih dalam mengenai jenis arah uji (uji satu arah dan dua arah), yang akan menentukan bentuk pengujian berdasarkan pertanyaan penelitian dan asumsi yang dibuat mengenai populasi yang diuji.
Jenis Arah Uji
Sebagai pengingat kembali, uji satu arah digunakan ketika kita ingin menguji bahwa parameter tertentu lebih besar atau lebih kecil dari nilai yang dihipotesiskan. Sementara itu, uji dua arah digunakan ketika kita ingin menguji bahwa parameter tersebut berbeda dari nilai yang dihipotesiskan, baik lebih besar maupun lebih kecil.
Pemahaman tentang jenis arah uji ini akan menjadi dasar untuk memahami cara kita memutuskan letak batas pengujian dan cara kita menilai bahwa perbedaan yang ditemukan signifikan.
Mari kita telusuri lebih dalam.
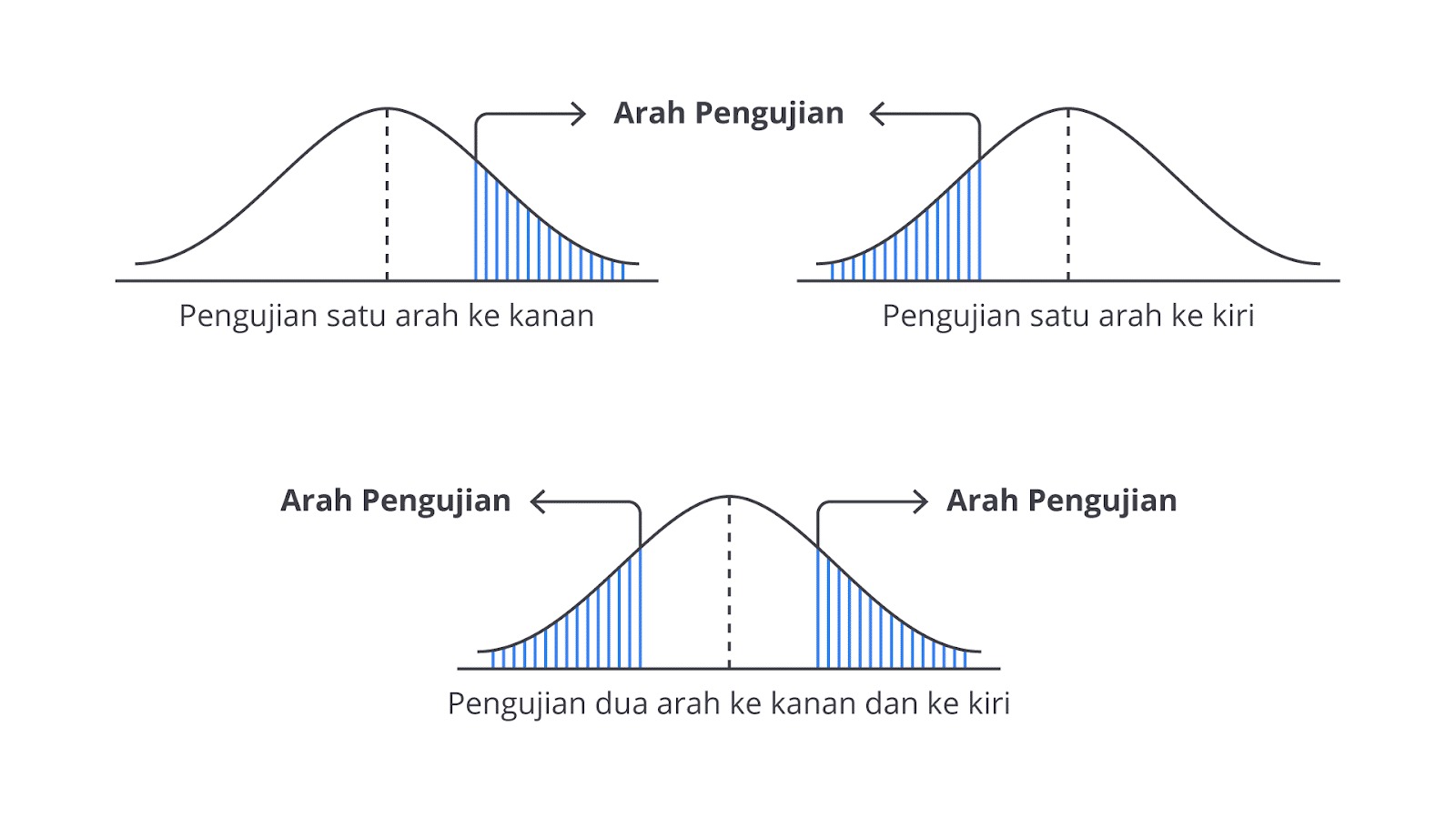
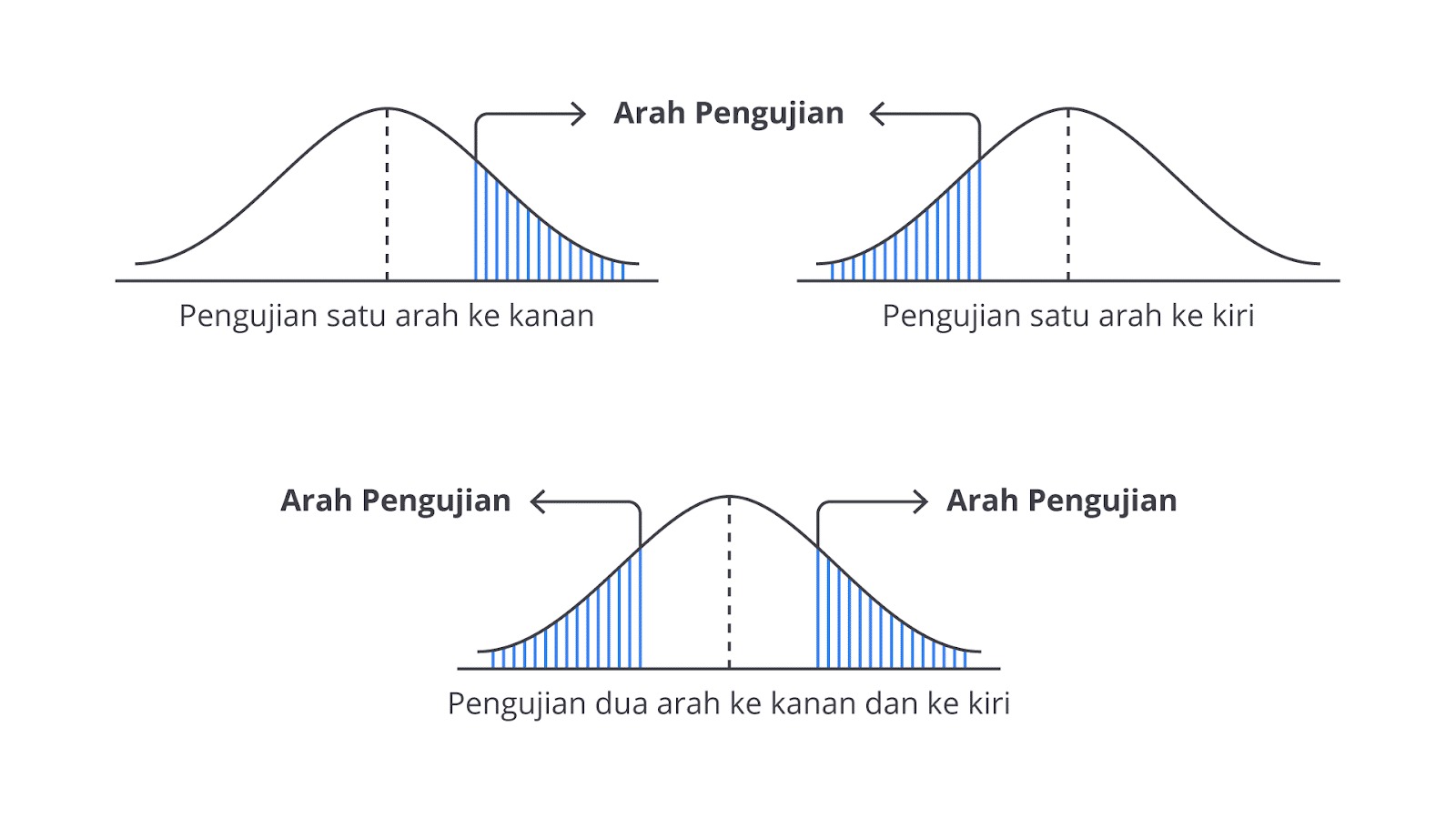
Uji Satu Arah
Uji satu arah (one-tailed test) digunakan ketika kita ingin menguji bahwa suatu parameter (misalnya, rata-rata atau proporsi) lebih besar (uji satu arah ke kanan “>”) atau lebih kecil (uji satu arah ke kiri “<”) daripada nilai tertentu, tetapi bukan keduanya. Uji ini fokus pada satu sisi distribusi dan digunakan ketika kita sudah memiliki prediksi arah untuk hasilnya.
Misalkan sebuah perusahaan ingin menguji bahwa waktu layanan pelanggan lebih cepat dari sembilan menit sebagai target yang telah ditetapkan. Hipotesisnya sebagai berikut.
- Hipotesis Nol (H₀): Waktu rata-rata layanan pelanggan sembilan menit (μ = 9).
- Hipotesis Alternatif (H₁): Waktu rata-rata layanan pelanggan kurang dari sembilan menit (μ < 9).
Dalam kasus ini, perusahaan hanya tertarik untuk menguji bahwa waktu layanan lebih cepat (<) dari target sembilan menit. Tidak ada minat untuk mengetahui bahwa waktu layanan lebih lama (>) dari sembilan menit, jadi ini adalah contoh uji satu arah.
Uji satu arah lebih terfokus dan memberikan kekuatan statistik lebih besar untuk mendeteksi perbedaan pada satu sisi distribusi karena seluruh area tingkat signifikansi (α) terfokus pada satu sisi (lebih kecil atau lebih besar).
Uji Dua Arah
Uji dua arah (two-tailed test) digunakan ketika kita ingin menguji bahwa suatu parameter berbeda (≠) dari nilai tertentu, tanpa memedulikan arah perbedaannya (tidak peduli lebih besar atau lebih kecil). Uji ini memeriksa kedua sisi distribusi, artinya kita ingin tahu bahwa parameter yang diuji lebih besar atau lebih kecil dari nilai tertentu.
Misalkan perusahaan ingin menguji bahwa waktu layanan pelanggan benar-benar berbeda dari target sembilan menit, baik lebih cepat maupun lebih lambat. Hipotesisnya sebagai berikut.
- Hipotesis Nol (H₀): Waktu rata-rata layanan pelanggan sembilan menit (μ = 9).
- Hipotesis Alternatif (H₁): Waktu rata-rata layanan pelanggan bukan sembilan menit (μ ≠ 9).
Di sini, perusahaan tidak hanya tertarik mengetahui bahwa waktu layanan lebih cepat, tetapi juga ingin tahu bahwa waktu layanan lebih lambat dari sembilan menit. Oleh karena itu, ini adalah uji dua arah karena kita menguji dua kemungkinan perbedaan—baik lebih cepat maupun lebih lambat.
Uji dua arah digunakan ketika kita tidak memiliki prediksi arah jelas untuk perbedaan yang mungkin ada. Misalnya, jika kita hanya ingin menguji bahwa ada perbedaan, tanpa memedulikan jika itu lebih besar atau lebih kecil, kita menggunakan uji dua arah.
Pemilihan antara Uji Satu Arah dan Dua Arah
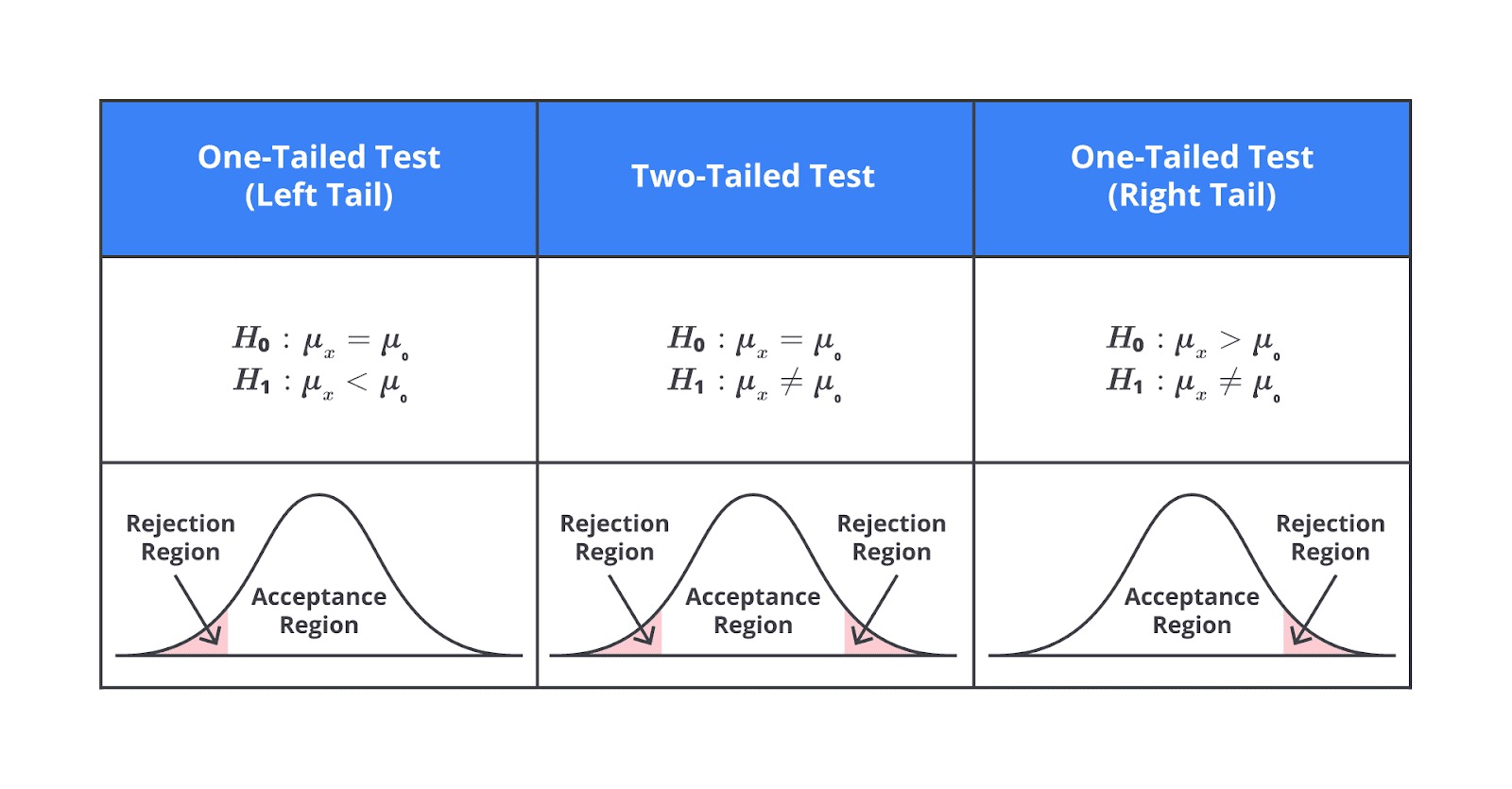
Pemilihan antara uji satu arah atau dua arah tergantung pada tujuan penelitian dan pertanyaan yang ingin dijawab.
Jika Anda memiliki prediksi arah yang jelas tentang perilaku parameter, seperti apakah nilai tersebut lebih besar atau lebih kecil dari nilai tertentu, uji satu arah adalah pilihan tepat.
Uji satu arah digunakan ketika Anda hanya tertarik pada perbedaan dalam satu arah, misalnya, membandingkan jika sesuatu lebih cepat, lebih tinggi, atau lebih efektif. Sebagai contoh, jika seorang manajer ingin mengetahui apakah penjualan bulan ini lebih tinggi dari bulan lalu, ini adalah uji satu arah karena hanya ada satu arah yang relevan, yaitu apakah penjualan lebih tinggi.
Di sisi lain, jika Anda ingin mengetahui bahwa parameter yang diuji berbeda dari nilai tertentu tanpa memedulikan bahwa nilai tersebut lebih besar atau lebih kecil, uji dua arah lebih tepat.
Uji dua arah digunakan ketika tidak ada prediksi sebelumnya mengenai arah perbedaan yang terjadi. Sebagai contoh, sebuah rumah sakit mungkin ingin menguji bahwa rata-rata waktu tunggu pasien berbeda dari target 15 menit, tanpa memedulikan lebih cepat atau lebih lambat. Dalam hal ini, uji dua arah digunakan untuk melihat bahwa ada perbedaan sama sekali, baik lebih cepat maupun lebih lambat.
Nilai Statistik Uji, Kritis, dan p-value
Dalam uji hipotesis, setelah kita menentukan hipotesis nol (H₀) dan hipotesis alternatif (H₁) serta memilih jenis uji yang tepat (satu arah atau dua arah), langkah selanjutnya adalah menguji hasilnya. Di sinilah nilai statistik uji, kritis, dan p-value berperan penting untuk membantu kita memutuskan untuk menolak hipotesis nol atau menerima hipotesis alternatif.
Nilai Statistik Uji
Nilai statistik uji adalah ukuran kuantitatif dari seberapa jauh data sampel yang diamati “menyimpang” dari hal yang akan kita harapkan jika hipotesis nol (H0) benar. Ini adalah metrik yang mengukur “kekuatan bukti” terhadap H0.
Misalnya, dalam uji Z-test untuk proporsi, Z-statistik mengukur seberapa besar perbedaan proporsi sampel yang kita temukan dan dinormalisasi oleh standar error perbedaan tersebut.
Nilai absolut yang besar dari statistik uji ini (misalnya, Z-statistik 2.5 atau -3.0) menunjukkan bahwa perbedaan yang diamati sangat tidak biasa jika H0 itu benar sehingga memberikan indikasi awal adanya efek yang kuat.
Nilai ini adalah input utama untuk menghitung P-value; semakin ekstrem nilai statistik uji, semakin kecil P-value yang dihasilkan.
Nilai Kritis
Nilai kritis adalah batas nilai pada distribusi statistik yang membagi area-area letak kita akan menolak hipotesis nol dan letak kita akan menerima hipotesis nol. Dalam uji hipotesis, kita akan menghitung nilai statistik uji (seperti t-statistik atau z-statistik) dan membandingkannya dengan nilai kritis.
- Jika nilai statistik uji yang dihitung lebih ekstrem (lebih besar atau lebih kecil, tergantung arah uji) daripada nilai kritis, kita menolak hipotesis nol.
- Jika nilai statistik uji lebih kecil daripada nilai kritis, kita menerima hipotesis nol.
Nilai kritis dihitung berdasarkan tingkat signifikansi (α) yang telah ditentukan sebelumnya, yang biasanya ditetapkan sebagai 0.05 (5%) atau 0.01 (1%). Tingkat signifikansi ini menunjukkan seberapa besar kita bersedia menerima kemungkinan melakukan kesalahan tipe I (menolak hipotesis nol yang benar).
Misalnya, jika melakukan uji satu arah dengan tingkat signifikansi α = 0.05, kita akan mencari nilai kritis pada distribusi t (untuk uji t) atau distribusi normal (untuk uji z). Jika nilai statistik uji lebih besar dari nilai kritis, kita menolak hipotesis nol.
p-Value
p-value adalah inti dari interpretasi uji hipotesis. p-value (probability value) adalah probabilitas mendapatkan hasil yang sama ekstrem atau lebih ekstrem dari data yang diamati, dengan asumsi bahwa hipotesis nol adalah benar. Dalam kata lain, p-value memberi kita gambaran tentang seberapa konsisten data sampel dengan hipotesis nol.
- Jika p-value kecil (lebih kecil dari α), itu menunjukkan bahwa data sampel tidak konsisten dengan hipotesis nol sehingga kita dapat menolak hipotesis nol.
- Jika p-value besar (lebih besar dari α), itu menunjukkan bahwa data sampel konsisten dengan hipotesis nol sehingga kita menerima hipotesis nol.
Misalkan kita melakukan uji hipotesis dengan α = 0.05 dan mendapatkan p-value = 0.03. Karena p-value lebih kecil dari 0.05, kita akan menolak hipotesis nol dan menyimpulkan bahwa ada bukti yang cukup untuk mendukung hipotesis alternatif.
Penting untuk diingat bahwa P-value BUKAN probabilitas bahwa hipotesis nol itu benar dan juga BUKAN probabilitas bahwa hipotesis alternatif itu salah. Ia hanya mengukur seberapa ekstrem data kita jika H0 benar.
Hubungan antara Nilai Kritis dan p-Value
Nilai kritis dan p-value adalah dua cara berbeda untuk menguji hasil uji hipotesis, tetapi keduanya memberikan kesimpulan yang sama.
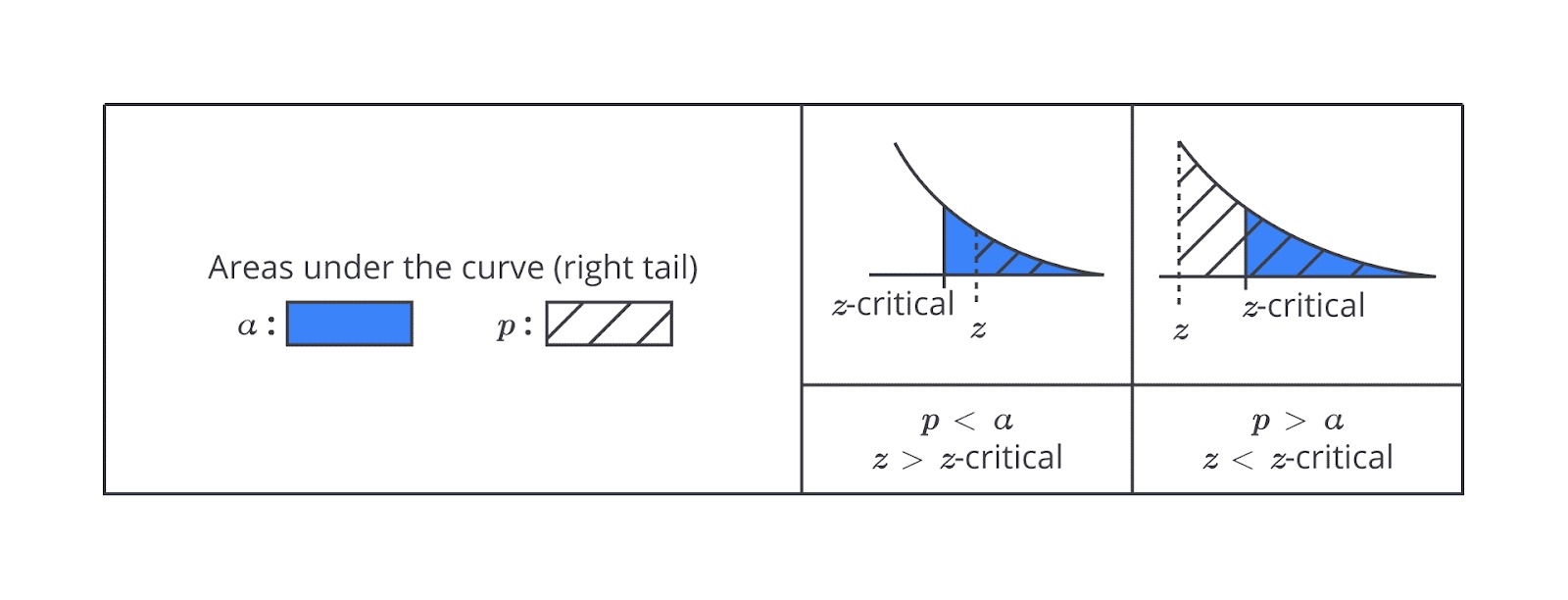
Jika nilai statistik uji lebih besar (atau lebih kecil) dari nilai kritis, p-value akan lebih kecil dari tingkat signifikansi (α), dan kita akan menolak hipotesis nol. Sebaliknya, jika nilai statistik uji lebih kecil dari nilai kritis, p-value akan lebih besar dari α, dan kita akan menerima hipotesis nol.
Dengan kata lain, nilai kritis memberikan batasan yang lebih jelas untuk menentukan keputusan, sedangkan p-value memberi kita ukuran seberapa kuat bukti yang ada untuk menolak hipotesis nol.
Pemilihan Jenis Uji Statistik
Setelah mempelajari jenis arah uji dan cara kita menggunakan nilai kritis serta p-value untuk membuat keputusan dalam uji hipotesis, langkah selanjutnya adalah memahami cara yang tepat dalam memilih jenis uji statistik.
Pada uji statistik, pemilihan jenis uji yang tepat sangat penting untuk mendapatkan hasil akurat dan dapat diandalkan. Salah satu keputusan pertama yang perlu diambil adalah bahwa kita akan menggunakan z-test atau t-test untuk menguji hipotesis. Pemilihan antara kedua uji ini bergantung pada beberapa faktor, seperti apakah standar deviasi populasi diketahui dan seberapa besar ukuran sampel yang kita miliki.
Pada dasarnya, z-test dan t-test digunakan untuk menguji perbedaan antara rata-rata sampel dan rata-rata populasi. Namun, keduanya memiliki perbedaan dalam asumsi dasar dan kondisi penggunaan.
Penggunaan z-test
z-test digunakan ketika memiliki data yang terdistribusi normal dan kita mengetahui standar deviasi populasi (σ). z-test sering digunakan untuk sampel besar (biasanya n ≥ 30) karena distribusi sampel besar mendekati distribusi normal, berkat central limit theorem (CLT).
Berikut adalah beberapa kondisi untuk menggunakan z-test.
- Ukuran Sampel Besar (n ≥ 30): Karena ukuran sampel yang besar menghasilkan distribusi sampel lebih mendekati distribusi normal, kita bisa menggunakan z-test meskipun tidak mengetahui standar deviasi sampel secara tepat.
- Standar Deviasi Populasi Diketahui: z-test membutuhkan informasi tentang standar deviasi populasi (σ), yang biasanya diperoleh dari riset sebelumnya atau data yang telah ada. Standar deviasi ini digunakan untuk menghitung sebaran atau variabilitas data di sekitar rata-rata populasi.
- Distribusi Data Normal atau Hampir Normal: Jika data mengikuti distribusi normal atau ukuran sampel cukup besar untuk mengandalkan CLT, z-test bisa digunakan untuk menguji hipotesis.
Mari kita ambil contoh. Misalkan sebuah pabrik memproduksi komponen dengan rata-rata panjang 10 cm dan standar deviasi 0.5 cm. Jika ingin menguji bahwa panjang rata-rata komponen dari sampel acak berukuran 50 komponen berbeda dari 10 cm, kita bisa menggunakan z-test karena tahu standar deviasi populasi.
Penggunaan t-test
t-test digunakan ketika ukuran sampel lebih kecil (biasanya n < 30) atau ketika kita tidak mengetahui standar deviasi populasi. t-test juga sering digunakan ketika menguji rata-rata sampel dan ingin memperhitungkan ketidakpastian lebih besar yang terjadi pada sampel kecil.
Berikut adalah beberapa kondisi untuk menggunakan t-test.
- Ukuran Sampel Kecil (n < 30): t-test digunakan terutama ketika ukuran sampel kecil. Ketidakpastian lebih besar dalam sampel kecil memerlukan distribusi t, yang lebih lebar dan memiliki ekor lebih tebal dibanding distribusi normal.
- Standar Deviasi Populasi Tidak Diketahui: Ketika kita tidak mengetahui standar deviasi populasi, tetapi memiliki informasi tentang standar deviasi sampel (s), t-test adalah pilihan yang tepat.
- Distribusi Data Normal: Sama seperti z-test, t-test juga mengasumsikan bahwa data yang kita uji berasal dari distribusi normal atau setidaknya mendekati normal. Jika distribusi data sangat miring atau tidak normal, uji non-parametrik mungkin lebih cocok.
Misalkan kita menguji bahwa rata-rata waktu yang dibutuhkan pelanggan untuk menyelesaikan satu sesi layanan lebih cepat dari sembilan menit. Jika hanya memiliki sampel kecil dari 15 pelanggan dan tidak mengetahui standar deviasi populasi, kita akan menggunakan t-test untuk menguji hipotesis bahwa waktu rata-rata layanan lebih cepat dari sembilan menit.
Kapan Menggunakan Z-Test dan T-Test?
Pemilihan antara z-test dan t-test tergantung pada dua faktor utama: ukuran sampel dan pengetahuan kita tentang standar deviasi populasi. Jika ukuran sampel cukup besar (biasanya lebih dari 30) dan kita tahu standar deviasi populasi, z-test adalah pilihan yang tepat. Namun, jika ukuran sampel kecil (kurang dari 30) atau kita tidak tahu standar deviasi populasi, t-test harus digunakan.
Berikut adalah diagram alur untuk membantu dalam menentukan penggunaan z-test atau t-test.
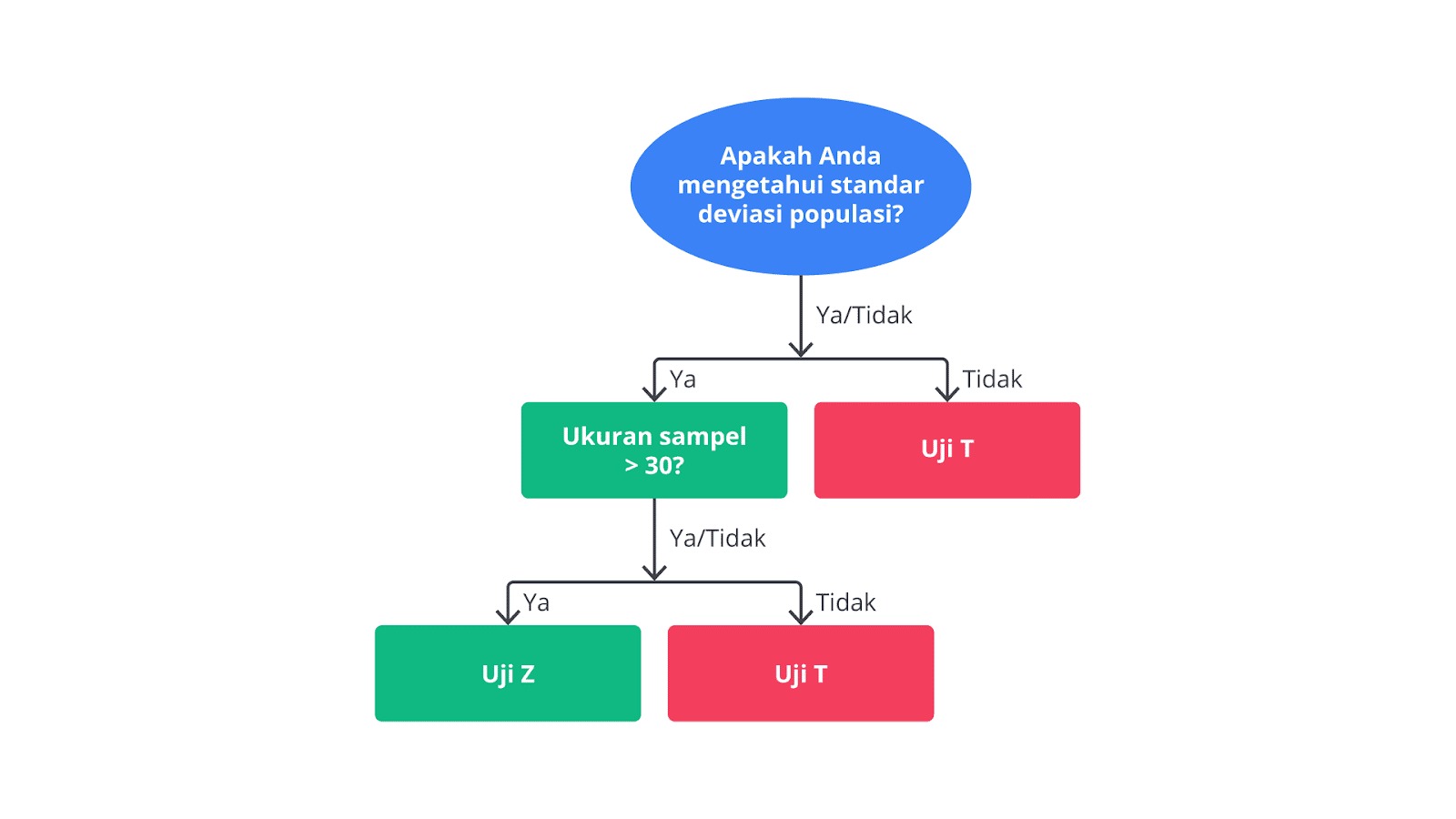
Dengan pemahaman ini, kita dapat dengan lebih mudah memilih uji statistik yang tepat dan memastikan hasil analisis lebih valid.
Pengujian Rata-Rata dengan z-test dan t-test
Salah satu aplikasi paling umum dalam statistik inferensial adalah menguji rata-rata suatu populasi atau sampel dan membandingkannya dengan nilai yang sudah diketahui atau dihipotesiskan.
Untuk itu, kita dapat menggunakan z-test dan t-test, tergantung pada beberapa faktor, seperti ukuran sampel dan pengetahuan kita tentang standar deviasi populasi. Kedua uji ini memiliki pendekatan yang serupa, tetapi berbeda dalam hal asumsi dasar dan kondisi penggunaannya.
z-Test untuk Rata-rata
z-test digunakan ketika data memenuhi beberapa kondisi, terutama ketika ukuran sampel besar (n ≥ 30) dan kita mengetahui standar deviasi populasi (σ).
Berikut adalah langkah-langkah menggunakan z-test untuk rata-rata.
- Tentukan Hipotesis
Hipotesis nol (H₀) biasanya mengklaim bahwa rata-rata sampel sama dengan rata-rata populasi yang dihipotesiskan, sedangkan hipotesis alternatif (H₁) menyatakan bahwa ada perbedaan. Contohnya berikut.- H₀: μ = μ0 (rata-rata sampel sama dengan rata-rata populasi yang dihipotesiskan).
- H₁: μ ≠ μ0 (rata-rata sampel tidak sama dengan rata-rata populasi yang dihipotesiskan).
-
Hitung Statistik z-test
Rumus untuk menghitung statistik z-test sebagai berikut.

- Tentukan Nilai Kritis atau p-value
Setelah menghitung statistik z-test, kita dapat membandingkannya dengan nilai kritis dari distribusi normal atau menghitung p-value untuk menentukan bahwa hasilnya signifikan pada tingkat signifikansi yang ditentukan (α). - Ambil Keputusan
- Jika z-statistik lebih besar dari nilai kritis atau jika p-value lebih kecil dari α, tolak hipotesis nol.
- Jika z-statistik lebih kecil dari nilai kritis atau jika p-value lebih besar dari α, terima hipotesis nol.
Contoh Penerapan

Misalkan kita menguji bahwa rata-rata waktu layanan pelanggan dari sebuah perusahaan adalah 10 menit. Rata-rata sampel dari 50 pelanggan adalah 9.6 menit dan standar deviasi populasi yang diketahui adalah 2 menit. Apakah waktu layanan pelanggan lebih cepat dari 10 menit?
Langkah 1: Tentukan Hipotesis
- H₀: μ = 10
- H₁: μ < 10
Langkah 2: Hitung Statistik z-test
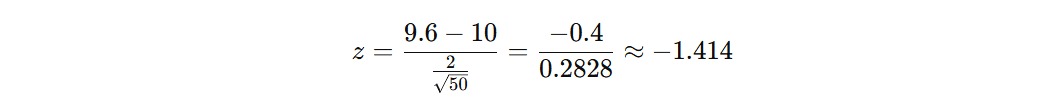
Langkah 3: Tentukan Nilai Kritis
Untuk α = 0.05 dan uji satu arah, nilai kritis z adalah -1.645.
Langkah 4: Ambil Keputusan
Karena -1.414 lebih besar dari -1.645, kita gagal menolak hipotesis nol.
t-Test untuk Rata-Rata
t-test digunakan ketika kita memiliki sampel kecil (biasanya n < 30) atau tidak tahu standar deviasi populasi, hanya standar deviasi sampel yang tersedia.
Berikut adalah langkah-langkah menggunakan t-test untuk rata-rata.
- Tentukan Hipotesis
Hipotesis nol (H₀) dan hipotesis alternatif (H₁) akan mirip dengan yang digunakan dalam z-test. Misalnya berikut.- H₀: μ = μ0 (rata-rata sampel sama dengan rata-rata populasi yang dihipotesiskan).
- H₁: μ ≠ μ0 (rata-rata sampel tidak sama dengan rata-rata populasi yang dihipotesiskan).
-
Hitung Statistik t-test
Rumus untuk menghitung statistik t-test adalah berikut.

- Tentukan Nilai Kritis atau p-value
Bandingkan statistik t-test dengan nilai kritis dari distribusi t dengan derajat kebebasan (df = n−1) untuk tingkat signifikansi α atau hitung p-value. - Ambil Keputusan
- Jika t-statistik lebih besar dari nilai kritis atau p-value lebih kecil dari α, kita menolak hipotesis nol.
- Jika t-statistik lebih kecil dari nilai kritis atau p-value lebih besar dari α, kita menerima hipotesis nol.
Contoh Penerapan

Misalkan kita ingin menguji bahwa rata-rata waktu tunggu pasien berbeda dari 15 menit. Dari sampel 12 pasien, kita mendapatkan rata-rata waktu tunggu 16 menit dengan standar deviasi sampel 3 menit. Apakah rata-rata waktu tunggu pasien berbeda dari 15 menit?
- Hipotesis
- H₀: μ = 15
- H₁: μ ≠ 15
-
Hitung Statistik t-test
**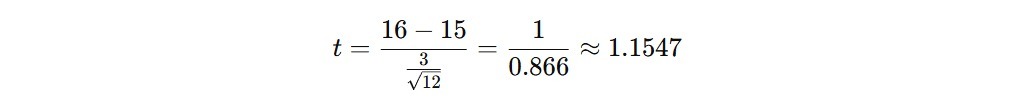 **
** - Tentukan Nilai Kritis
Untuk α = 0.05 dan df = 11, nilai kritis t untuk uji dua arah adalah ± 2.201. Karena 1.1547 lebih kecil dari 2.201, kita gagal menolak hipotesis nol.
Variasi t-Test
Setelah memahami jenis uji statistik yang tepat (z-test dan t-test) serta menggunakan keduanya untuk menguji rata-rata, sekarang kita akan masuk lebih spesifik tentang t-test dan variasinya, termasuk one-sample t-test, paired t-test, dan independent t-test.
t-test sangat bergantung pada distribusi t-Student. Pemahaman tentang distribusi probabilitas akan membantu kita menentukan jenis t-test sesuai dengan data yang dimiliki. Dengan demikian, memilih distribusi secara tepat merupakan langkah awal yang penting dalam mengaplikasikan t-test pada penelitian atau eksperimen.
Dengan pemahaman tentang distribusi probabilitas ini, kita siap untuk memahami cara menguji perbedaan antarkelompok atau perbedaan dalam rata-rata menggunakan t-test, baik untuk data berpasangan (paired) maupun dua grup yang independen.
One-Sample t-Test
One-sample t-test—disebut juga uji t satu sampel—adalah prosedur inferensi statistik yang menanyakan “seberapa rasional bila kita menggeneralisasi rata-rata sebuah sampel kecil sebagai rata-rata seluruh populasi?”
Asal tahu saja, yang kita lakukan pada materi sebelumnya dengan menggunakan t-Test untuk menguji rata-rata adalah contoh dari one-sample t-test.
One-sample t-test (uji t satu sampel) kerap kali digunakan untuk menguji bahwa rata-rata populasi (μ) sama dengan, lebih besar, atau lebih kecil daripada suatu nilai acuan (μ₀) ketika memenuhi kondisi berikut.
- Kita hanya memiliki satu sampel berukuran kecil hingga sedang.
- Standar deviasi populasi (σ) tidak diketahui—kita menggantinya dengan standar deviasi sampel (s).
- Distribusi data dalam populasi diasumsikan mendekati normal; jika n cukup besar (≈ ≥ 30), central limit theorem (CLT) membantu memenuhi asumsi ini.
Salah satu contoh skenario penggunaan one-sample t-test adalah pada konteks pendidikan untuk menguji efek kurikulum matematika baru. Bayangkan Anda adalah guru matematika yang baru saja menerapkan kurikulum inovatif dalam satu kelas. Pemerintah menetapkan standar kelulusan nasional sebesar 75 poin pada ujian akhir. Anda ingin tahu hal berikut secara ilmiah.
“Apakah rata-rata nilai siswa setelah kurikulum baru berbeda dari standar 75?”
Karena hanya satu kelompok (kelas Anda saja) yang hendak dibandingkan dengan satu angka acuan, metode statistik yang tepat adalah one-sample t-test dua sisi.
Supaya lebih tergambar, berikut adalah langkah-langkah menggunakan one-sampe t-test dalam contoh kasus penerapan kurikulum matematika tersebut.
1. Merumuskan Hipotesis
- Hipotesis nol (H₀): μ = 75
Rata-rata nilai siswa sama dengan standar nasional. - Hipotesis alternatif (H₁): μ ≠ 75
Rata-rata nilai siswa tidak sama (lebih tinggi atau lebih rendah) dari 75.
Uji dua sisi dipilih karena dalam kasus ini katakanlah Anda terbuka pada kemungkinan kurikulum ini menaikkan atau menurunkan skor rata-rata.
2. Mengumpulkan dan Meringkas Data
Anda menguji 17 siswa (n = 17) dan memperoleh hal berikut.
- Rata-rata sampel (xˉxˉ) = 78,2
- Simpangan baku sampel (s) = 8,5
Ukuran sampel < 30 dan deviasi standar populasi tidak diketahui → syarat one-sample t-test terpenuhi.
3. Menghitung Statistik t
Gunakan rumus dasar berikut.
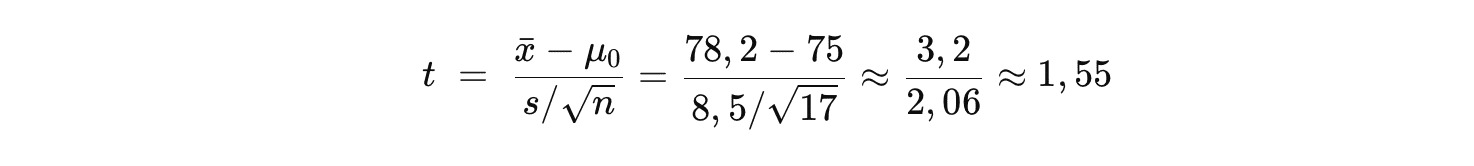
- df (derajat kebebasan) = n – 1 = 16
- α (tingkat signifikansi) = 0,05 (umum dipakai)
4. Menentukan Nilai Kritis/p-value
- Nilai kritis t dua sisi untuk df = 16 pada α = 0,05 ≈ ±2,12.
- Hasil hitung statistik t 1,55 tidak melewati ambang ±2,12.
- Alternatif: perhitungan p-value memberi angka ≈ 0,14 (> 0,05).
5. Pengambilan Keputusan
| Karena ** | t | = 1,55 < 2,12** dan p-value > 0,05, Anda sebagai guru gagal menolak H₀. |
Itu artinya, secara statistik kita belum menemukan bukti bahwa rata-rata nilai kelas yang diuji berbeda dari standar 75. Selisih 3,2 poin bisa saja muncul akibat variasi acak dalam sampel kecil.
Paired t-Test
Paired t-test atau uji t berpasangan adalah salah satu jenis uji statistik yang digunakan untuk membandingkan dua set data yang berpasangan atau saling terkait. Uji ini sering digunakan dalam eksperimen atau studi dengan melibatkan pengukuran yang sama pada individu yang sama dalam dua kondisi berbeda atau dua waktu berbeda.
Dalam praktiknya, paired t-test digunakan ketika kita ingin mengetahui adanya perbedaan signifikan antara dua kondisi yang diukur pada kelompok yang sama. Kondisi-kondisi ini bisa berupa pengukuran sebelum dan sesudah perlakuan atau pengukuran dalam dua kondisi berbeda.
Misalnya, untuk menguji perubahan dalam nilai sebelum dan sesudah suatu intervensi atau perlakuan. Contoh lain, kita juga bisa menggunakan paired t-test untuk menguji bahwa waktu pelayanan pada suatu aplikasi layanan pelanggan berbeda sebelum dan setelah dilakukan pembaruan fitur.

Beberapa contoh situasi penggunaan paired t-test sebagai berikut.
- Pengukuran Sebelum dan Sesudah: Mengukur hasil tes matematika siswa sebelum dan setelah mereka mengikuti program pelatihan.
- Pengukuran dalam Dua Kondisi: Mengukur tekanan darah pasien sebelum dan setelah pemberian obat tertentu.
- Perbandingan Dua Kondisi Terkait: Menguji performa suatu produk atau layanan sebelum dan setelah pembaruan fitur.
Uji ini sangat berguna ketika kita ingin melihat bahwa suatu perubahan atau intervensi memberikan dampak signifikan pada kelompok yang sama karena setiap pasangan data bersifat terkait atau berpasangan.
Langkah Menggunakan Paired t-Test
Menggunakan paired t-test melibatkan serangkaian langkah terstruktur untuk memastikan hasil yang valid. Berikut adalah langkah-langkah yang lebih rinci tentang cara menghitung dan menginterpretasikan paired t-test.
1. Tentukan Hipotesis
Langkah pertama dalam paired t-test adalah merumuskan hipotesis yang akan diuji. Hipotesis nol (H₀) biasanya menyatakan bahwa tidak ada perbedaan rata-rata antara dua kondisi atau waktu, sedangkan hipotesis alternatif (H₁) menyatakan bahwa ada perbedaan rata-rata yang signifikan.
- H₀ (Hipotesis Nol): μselisih=0 (tidak ada perbedaan rata-rata antara kondisi 1 dan kondisi 2).
- H₁ (Hipotesis Alternatif): μselisih≠ 0 (ada perbedaan rata-rata antara kondisi 1 dan kondisi 2).
Jika hipotesis alternatif menunjukkan perbedaan dua arah (uji dua sisi), kita menggunakan uji dua arah, yakni hipotesis alternatif menyatakan adanya perbedaan tanpa menentukan arah perbedaannya. Namun, jika hanya tertarik untuk mengetahui bahwa suatu nilai lebih besar atau lebih kecil dari nilai tertentu, kita menggunakan uji satu arah.
2. Hitung Selisih Antar Pasangan
Langkah selanjutnya adalah menghitung selisih antara kedua kondisi atau waktu pengukuran untuk setiap pasangan data. Setiap individu atau entitas dalam data memiliki dua nilai yang akan dibandingkan, selisih ini dihitung sebagai berikut.
di=xi1−xi2
Berikut penjelasannya.
- xi1 adalah nilai pada kondisi pertama (misalnya, sebelum pengobatan atau sebelum perlakuan).
- xi2 adalah nilai pada kondisi kedua (misalnya, setelah pengobatan atau setelah perlakuan).
- di adalah selisih antara nilai pada kondisi pertama dan kedua untuk pasangan ke-i.
Langkah ini sangat penting karena paired t-test bekerja berdasarkan perbedaan antar pasangan data, bukan hanya perbandingan antar dua kelompok yang berbeda.
3. Hitung Rata-Rata dan Standar Deviasi dari Selisih
Setelah menghitung selisih, langkah selanjutnya adalah menghitung rata-rata dan standar deviasi dari selisih data tersebut. Hal ini dilakukan untuk memahami sebaran atau variasi antara kedua kondisi yang diuji.
- Rata-rata selisih (d) dihitung dengan rumus berikut.
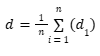 Dalam rumus tersebut, n adalah jumlah pasangan data dan d1 adalah selisih untuk pasangan ke-i.
Dalam rumus tersebut, n adalah jumlah pasangan data dan d1 adalah selisih untuk pasangan ke-i. - Standar deviasi dari selisih (sd) dihitung sebagai berikut.
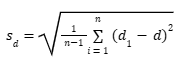 Dalam rumus tersebut, sd adalah standar deviasi dari selisih dan d adalah rata-rata selisih.
Dalam rumus tersebut, sd adalah standar deviasi dari selisih dan d adalah rata-rata selisih.
4. Hitung Statistik t-test
Setelah memiliki rata-rata dan standar deviasi dari selisih, kita dapat menghitung statistik t-test menggunakan rumus berikut.

Statistik t-test ini digunakan untuk mengetahui seberapa besar perbedaan rata-rata antara kedua kondisi relatif terhadap variasi data.
5. Tentukan Nilai Kritis atau p-value
Setelah menghitung nilai t, langkah selanjutnya adalah membandingkannya dengan nilai kritis dari distribusi t dengan derajat kebebasan df = n−1. Nilai kritis ini tergantung pada tingkat signifikansi α yang telah ditentukan sebelumnya (misalnya, α = 0.05).
6. Ambil Keputusan
Keputusan akhir didasarkan pada perbandingan antara statistik t-test yang dihitung dan nilai kritis atau p-value berikut.
- Jika statistik t-test lebih besar (atau lebih kecil) dari nilai kritis atau p-value lebih kecil dari α, kita menolak hipotesis nol dan menyimpulkan bahwa ada perbedaan yang signifikan antara kedua kondisi atau waktu pengukuran.
- Jika statistik t-test tidak melebihi nilai kritis atau p-value lebih besar dari α, kita gagal menolak hipotesis nol dan menyimpulkan bahwa tidak ada perbedaan yang signifikan.
Independent t-test
Independent t-test atau uji t dua sampel independen adalah salah satu jenis uji statistik untuk membandingkan rata-rata dua kelompok yang tidak saling berhubungan atau independen satu sama lain.
Uji ini digunakan ketika kita ingin mengetahui bahwa ada perbedaan signifikan antara rata-rata dua kelompok tersebut dengan asumsi bahwa data pada kedua kelompok berasal dari populasi berbeda atau perlakuan berbeda.
Uji ini sangat penting untuk banyak eksperimen dan analisis dalam berbagai bidang, termasuk pendidikan, kesehatan, serta penelitian sosial.
Contoh aplikasi dari independent t-test adalah ketika kita ingin membandingkan rata-rata hasil ujian dua kelas yang diajarkan dengan metode pengajaran berbeda. Contoh lain, saat kita ingin membandingkan dua produk berbeda, yaitu masing-masing kelompok mencoba satu produk dan mengukur skor kepuasan.

Sebelum menggunakan independent t-test, ada beberapa asumsi yang perlu dipenuhi agar hasil uji kita valid.
- Independensi Data: Setiap data pada kedua grup harus independen, yang berarti tidak ada keterkaitan antara data dalam satu grup dengan grup lainnya.
- Normalitas: Data dalam setiap grup sebaiknya terdistribusi normal, meskipun dengan ukuran sampel yang cukup besar. Central limit theorem (CLT) memungkinkan kita untuk menggunakan t-test meskipun data tidak terdistribusi normal.
- Kesamaan Varians (Homogenitas Varians): Varians dalam kedua grup harus serupa. Untuk memeriksa asumsi ini, kita bisa menggunakan uji Levene (Levene’s test). Jika varians kedua grup tidak sama, kita harus melakukan t-test dengan asumsi varians tidak sama. Jika asumsi normalitas atau kesamaan varians tidak terpenuhi, kita bisa mempertimbangkan untuk menggunakan uji non-parametrik, seperti uji Mann-Whitney.
Berikut adalah langkah-langkah menggunakan independent t-test.
1. Tentukan Hipotesis
Sebagaimana dengan semua uji hipotesis, langkah pertama adalah merumuskan hipotesis nol dan hipotesis alternatif.
- H₀ (Hipotesis Nol): μselisih=0 (tidak ada perbedaan rata-rata antara kondisi 1 dan kondisi 2).
- H₁ (Hipotesis Alternatif): μselisih≠ 0 (ada perbedaan rata-rata antara kondisi 1 dan kondisi 2).
2. Periksa Asumsi
Sebelum melakukan t-test, kita perlu memeriksa asumsi yang disebutkan sebelumnya.
- Normalitas: Kita dapat menggunakan uji normalitas seperti Shapiro-Wilk untuk memeriksa bahwa data berdistribusi normal.
- Homogenitas Varians: Levene’s test digunakan untuk memeriksa bahwa varians kedua grup sama. Jika p-value dari hasil Levene’s test lebih besar dibanding α, asumsi homogenitas varians terpenuhi.
3. Hitung Statistik t-Test
Rumus untuk menghitung statistik t-test terhadap dua sampel independen adalah berikut.

4. Tentukan Derajat Kebebasan (df)
Derajat kebebasan (degree of freedom) untuk independent t-test dihitung sebagai berikut.
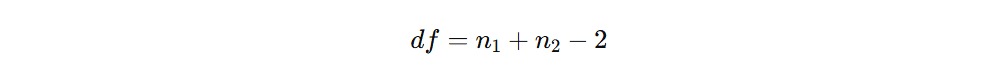
Dalam rumus tersebut, n1 dan n2 adalah ukuran sampel masing-masing kelompok.
5. Tentukan Nilai Kritis atau p-value
Berdasarkan derajat kebebasan (df) dan tingkat signifikansi α yang telah ditentukan (misalnya α = 0.05), kita dapat mencari nilai kritis dari tabel distribusi t. Sebagai alternatif, kita dapat menghitung p-value yang mengukur probabilitas untuk mendapatkan hasil lebih ekstrem jika hipotesis nol benar.
6. Ambil Keputusan
- Jika statistik t-test lebih besar (atau lebih kecil) dari nilai kritis atau jika p-value lebih kecil dari α, kita menolak hipotesis nol dan menyimpulkan bahwa ada perbedaan yang signifikan antara dua kelompok.
- Jika statistik uji t lebih kecil dari nilai kritis atau p-value lebih besar dari α, kita gagal menolak hipotesis nol, yang berarti tidak ada perbedaan signifikan antara kedua kelompok.
Uji ANOVA (Analysis of Variance)
ANOVA (Analysis of variance) adalah teknik statistik yang digunakan untuk menguji perbedaan antara rata-rata lebih dari dua kelompok atau perlakuan. Uji ANOVA digunakan untuk menentukan bahwa ada perbedaan yang signifikan antara rata-rata kelompok-kelompok tersebut. Teknik ini sangat berguna dalam eksperimen yang melibatkan lebih dari dua grup, yakni t-test tidak dapat digunakan karena hanya menguji dua grup saja.
Uji ANOVA memiliki beberapa varian, salah satunya adalah ANOVA satu arah (one-way ANOVA) yang akan kita bahas secara mendalam pada bagian ini.
ANOVA Satu Arah
ANOVA satu arah (one-way ANOVA) adalah teknik statistik untuk menguji perbedaan rata-rata antara tiga kelompok atau lebih yang terpisah. Uji ini sangat berguna untuk menentukan bahwa ada perbedaan signifikan dalam rata-rata suatu variabel antara beberapa grup yang berbeda. Uji ini sering digunakan dalam eksperimen atau studi dengan melibatkan lebih dari dua grup yang diberi perlakuan berbeda.
Sebagai contoh, jika ingin membandingkan tiga metode pengajaran berbeda pada siswa, kita bisa menggunakan ANOVA satu arah untuk mengetahui bahwa salah satu metode pengajaran lebih efektif dari yang lain.

Prinsip dasar dari ANOVA satu arah adalah membandingkan varians antarkelompok dengan varians dalam kelompok. Varians antarkelompok mengukur seberapa besar perbedaan rata-rata antara kelompok satu dengan yang lainnya, sedangkan varians dalam kelompok mengukur seberapa tersebar nilai-nilai pada masing-masing kelompok.
- Jika varians antarkelompok lebih besar dibandingkan dengan varians dalam kelompok, ada indikasi bahwa perbedaan antara kelompok lebih besar daripada perbedaan yang disebabkan oleh variabilitas acak pada kelompok. Dengan kata lain, kita bisa menyimpulkan bahwa ada perbedaan yang signifikan antarkelompok.
- Jika varians antarkelompok hampir sama dengan varians dalam kelompok, kita gagal menolak hipotesis nol. Istilah kata, kita tidak dapat menyimpulkan bahwa ada perbedaan yang signifikan antara kelompok.
Dengan kata lain, ANOVA satu arah memeriksa jika perbedaan rata-rata antarkelompok cukup besar untuk menyarankan bahwa perbedaan tersebut bukan hanya akibat kebetulan.
Asumsi ANOVA
Sebelum menggunakan ANOVA, ada beberapa asumsi dasar yang perlu dipenuhi agar uji ini valid. Jika asumsi-asumsi ini tidak dipenuhi, hasil dari uji ANOVA mungkin tidak akurat atau tidak dapat diandalkan. Berikut adalah asumsi-asumsi utama dalam ANOVA.
Normalitas Data
Data pada setiap kelompok harus terdistribusi normal. Ini berarti bahwa data untuk setiap grup harus mengikuti distribusi normal atau setidaknya mendekati normal. Untuk memeriksa normalitas, kita bisa menggunakan uji normalitas, seperti Shapiro-Wilk atau melihat grafik histogram dan Q-Q plot.
Homogenitas Varians (Homogenitas Varian)
Asumsi ini menyatakan bahwa varians antarkelompok harus sama. Dalam kata lain, kelompok-kelompok yang dibandingkan seharusnya memiliki sebaran data serupa. Untuk menguji asumsi ini, kita bisa menggunakan uji Levene atau uji Bartlett. Jika p-value dari uji Levene lebih besar dari α (misalnya, 0.05), kita bisa menganggap varians antarkelompok homogen.
Independensi Data
Data dalam setiap grup harus bersifat independen. Artinya, pengukuran dalam satu grup tidak boleh memengaruhi pengukuran pada grup lainnya. Asumsi ini sangat penting. Jika data tidak independen, ANOVA tidak dapat digunakan.
Misalnya, dalam eksperimen ketika pengukuran pada satu individu atau objek dapat memengaruhi pengukuran pada individu atau objek lain, uji ANOVA mungkin tidak cocok.
Langkah-Langkah dalam Uji ANOVA
Berikut adalah langkah-langkah yang dilakukan saat uji ANOVA.
1. Mengatur Hipotesis
Langkah pertama dalam uji ANOVA adalah menyusun hipotesis nol (H₀) dan hipotesis alternatif (H₁).
- Hipotesis Nol (H₀): Tidak ada perbedaan rata-rata antarkelompok. Semua kelompok memiliki rata-rata yang sama.
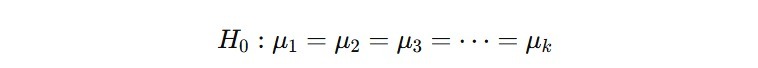
Adapun μ1,μ2,…….μk adalah rata-rata dari kelompok-kelompok yang diuji. - Hipotesis Alternatif (H₁): Ada setidaknya satu kelompok yang rata-ratanya berbeda dengan kelompok lainnya.
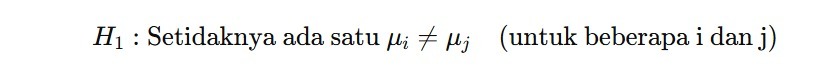
2. Menghitung Statistik Uji F
Setelah menyusun hipotesis, langkah selanjutnya adalah menghitung statistik uji F, yang digunakan untuk menentukan bahwa ada perbedaan signifikan antara rata-rata kelompok. Rumus untuk statistik uji F adalah berikut.

- Varians antarkelompok mengukur berapa besar perbedaan rata-rata antara kelompok.
- Varians dalam kelompok mengukur seberapa besar variasi data pada masing-masing kelompok.
Jika nilai F yang dihitung cukup besar, ini menunjukkan bahwa perbedaan antarkelompok lebih besar daripada variasi dalam kelompok, yang bisa menjadi indikasi bahwa perbedaan tersebut signifikan.
3. Menentukan p-value dan Nilai Kritis
Setelah menghitung statistik uji F, kita akan menggunakan distribusi F untuk mencari p-value, yang menggambarkan probabilitas untuk mendapatkan nilai lebih ekstrem jika hipotesis nol benar. Berdasarkan p-value dan derajat kebebasan (df), kita dapat mengambil keputusan untuk menolak atau gagal menolak hipotesis nol.
Untuk uji ANOVA, derajat kebebasan antarkelompok dihitung sebagai dfantara=k−1, yakni k adalah jumlah kelompok; sedangkan derajat kebebasan dalam kelompok dihitung sebagai dfdalam=N−k, yakni N adalah total jumlah data di semua kelompok.
4. Ambil Keputusan
- Jika p-value lebih kecil dari tingkat signifikansi α (misalnya 0.05), kita menolak hipotesis nol dan menyimpulkan bahwa ada perbedaan rata-rata signifikan antara kelompok-kelompok yang diuji.
- Jika p-value lebih besar dari α, kita gagal menolak hipotesis nol, yang berarti bukti tidak cukup untuk mengatakan bahwa ada perbedaan rata-rata secara signifikan antara kelompok.
Studi Kasus: Menguji Perbedaan Rata-Rata Skor Rasa Cappuccino pada Waralaba Kopi
Sebuah perusahaan waralaba kopi yang memiliki tiga cabang—Cabang A, B, dan C—di kota yang sama sangat peduli dengan konsistensi rasa cappuccino mereka. Untuk memastikan hal ini, mereka melakukan uji rasa buta (blind test). Panelis diminta untuk mencicipi cappuccino dari setiap cabang tanpa mengetahui asalnya, lalu memberikan skor rasa dari 0 sampai 10.
Data skor dari panelis adalah berikut.
cabang_A = [8.5, 8.0, 9.0, 8.7, 8.4]
cabang_B = [7.0, 6.5, 7.2, 7.1, 6.8]
cabang_C = [9.0, 9.5, 8.7, 9.2, 9.1]
Tujuan utama dari pengujian ini adalah memastikan bahwa ada perbedaan yang signifikan pada rata-rata skor rasa cappuccino di antara ketiga cabang tersebut. Ini krusial karena konsistensi rasa adalah indikator kunci kualitas layanan mereka.
Untuk mencapai tujuan ini, kita akan menguji hipotesis berikut.
- H₀ (Hipotesis Nol): Rata-rata skor rasa cappuccino adalah sama untuk semua cabang (tidak ada perbedaan signifikan).
- H₁ (Hipotesis Alternatif): Ada perbedaan rata-rata skor rasa dalam setidaknya satu cabang (setidaknya ada satu cabang yang rasa kopinya berbeda dari lainnya).
Jika hasil analisis menunjukkan bahwa kita harus menolak H₀, itu berarti ada bukti statistik yang kuat bahwa konsistensi rasa cappuccino antarcabang memang bermasalah. Kita kemudian perlu melakukan analisis lanjutan (post-hoc test) untuk mengetahui cabang yang memiliki rata-rata skor rasa berbeda.
Anda bisa menggunakan tools seperti Google Colab untuk mengikuti latihan ini.
Langkah 1: Persiapan Data dan Visualisasi
Kita akan menggunakan data skor rasa yang diberikan untuk masing-masing cabang.
Silakan salin dan tempel kode berikut ke Google Colab Anda.
- import numpy as np
- import pandas as pd
- import scipy.stats as stats
- import matplotlib.pyplot as plt
-
import seaborn as sns
- # Data skor rasa cappuccino yang Anda berikan (skala 0-10)
- cabang_A = [8.5, 8.0, 9.0, 8.7, 8.4]
- cabang_B = [7.0, 6.5, 7.2, 7.1, 6.8]
-
cabang_C = [9.0, 9.5, 8.7, 9.2, 9.1]
- # Gabungkan data ke dalam DataFrame untuk kemudahan analisis dan visualisasi
- data = pd.DataFrame({
- ’Cabang’: [‘A’] * len(cabang_A) + [‘B’] * len(cabang_B) + [‘C’] * len(cabang_C),
- ’Skor_Rasa’: cabang_A + cabang_B + cabang_C # Menggabungkan list secara langsung
-
})
- # Tampilkan rata-rata skor per cabang untuk melihat perbedaan awal
- print(“Rata-rata Skor Rasa per Cabang:”)
-
print(data.groupby(‘Cabang’)[‘Skor_Rasa’].mean())
- # Output
- # Rata-rata Skor Rasa per Cabang:
- # Cabang
- # A 8.52
- # B 6.92
-
# C 9.10
- # Visualisasikan distribusi skor rasa per cabang menggunakan Box Plot
- plt.figure(figsize=(10, 6))
- sns.boxplot(x=‘Cabang’, y=‘Skor_Rasa’, data=data)
- plt.title(‘Distribusi Skor Rasa Cappuccino per Cabang’)
- plt.xlabel(‘Cabang’)
- plt.ylabel(‘Skor Rasa’)
- plt.grid(axis=‘y’, linestyle=’–’, alpha=0.7)
- plt.show()
Inilah tampilan pada Google Colab setelah kodenya dijalankan.
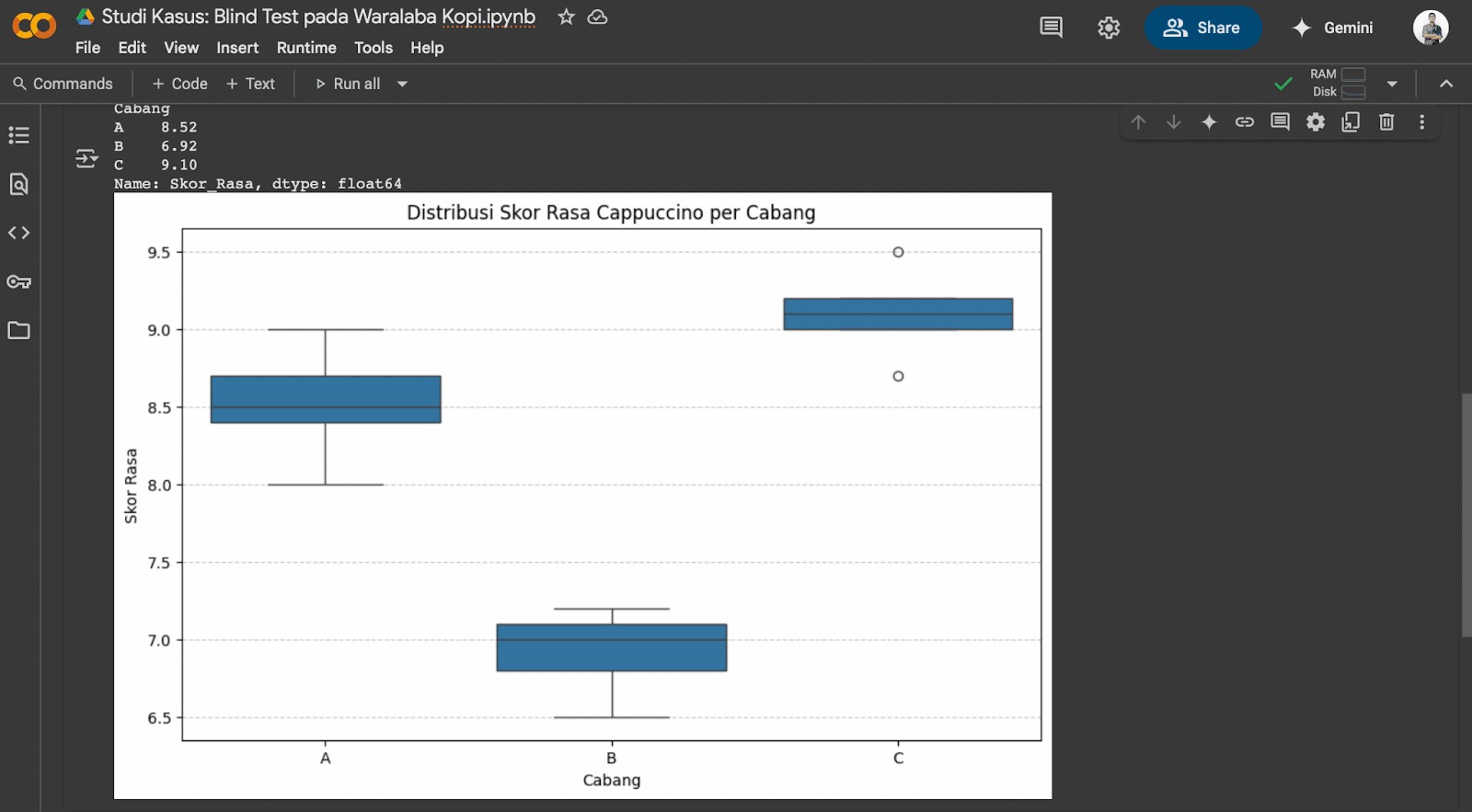
Langkah 2: Melakukan Uji ANOVA
Setelah data siap, kita akan langsung menjalankan uji ANOVA.
Hipotesis yang akan kita uji sebagai berikut.
- H₀ (Hipotesis Nol): Rata-rata skor rasa sama untuk semua cabang.
- H₁ (Hipotesis Alternatif): Ada perbedaan rata-rata skor rasa pada setidaknya satu cabang.
Kita akan menggunakan tingkat signifikansi (α) 0.05.
Salin dan tempel kode berikut pada Google Colab Anda.
- # Lakukan uji ANOVA satu arah menggunakan skor dari masing-masing cabang
-
f_statistic, p_value = stats.f_oneway(cabang_A, cabang_B, cabang_C)
- print(f”\n— Hasil Uji ANOVA —”)
- print(f”F-statistik: {f_statistic:.4f}”)
-
print(f”P-value: {p_value:.4f}”)
- # — Hasil Uji ANOVA —
- # F-statistik: 63.9532
- # P-value: 0.0000
Inilah tampilan pada Google Colab.
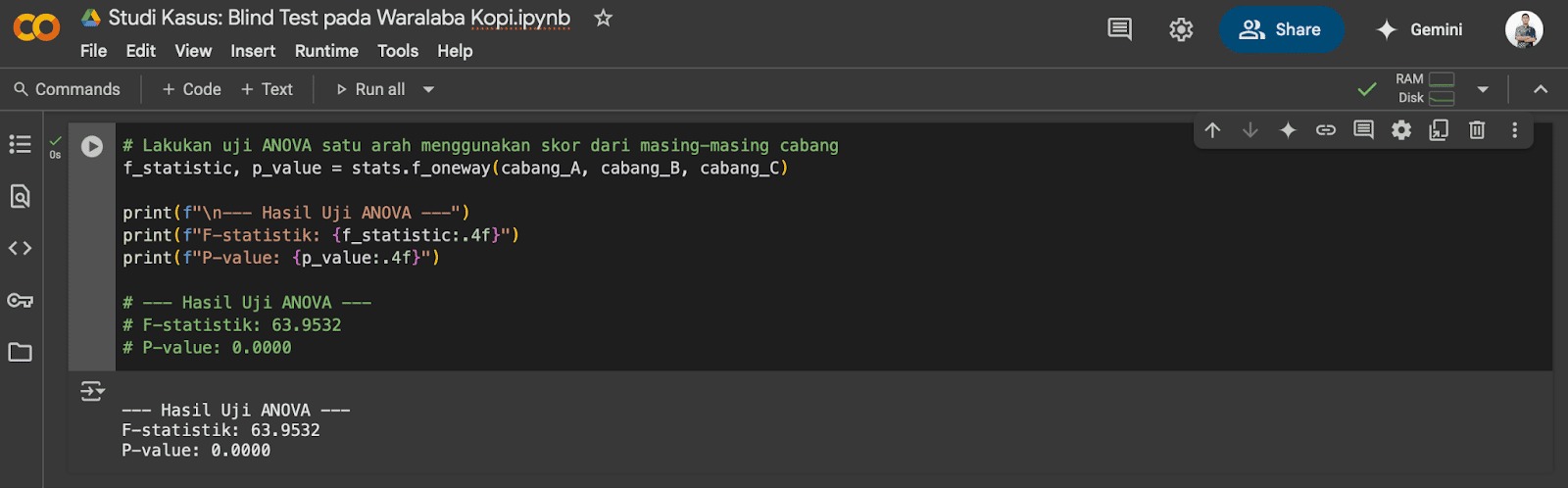
Langkah 3: Menarik Kesimpulan
Langkah terakhir adalah menarik kesimpulan berdasarkan p-value yang didapatkan dari uji ANOVA dibandingkan dengan tingkat signifikansi (α) yang kita tentukan (0.05).
Salin dan tempel kode berikut pada Google Colab Anda.
- # Menarik kesimpulan berdasarkan p-value
- alpha = 0.05
-
print(f”Tingkat signifikansi (alpha): {alpha}”)
- if p_value < alpha:
- print(“\nKesimpulan: P-value < alpha. Kita menolak Hipotesis Nol (H₀).”)
- print(“Artinya, ada perbedaan rata-rata skor rasa cappuccino yang signifikan di setidaknya satu cabang.”)
- print(“Untuk mengetahui cabang mana yang berbeda, Anda dapat melanjutkan dengan uji post-hoc (misalnya, Tukey HSD).”)
- else:
- print(“\nKesimpulan: P-value >= alpha. Kita gagal menolak Hipotesis Nol (H₀).”)
- print(“Artinya, tidak ada bukti statistik yang cukup untuk menyatakan adanya perbedaan rata-rata skor rasa cappuccino antar cabang.”)
- print(“Ini menunjukkan konsistensi rasa antar cabang, setidaknya berdasarkan data ini.”)
Berikut adalah tampilan pada Google Colab.
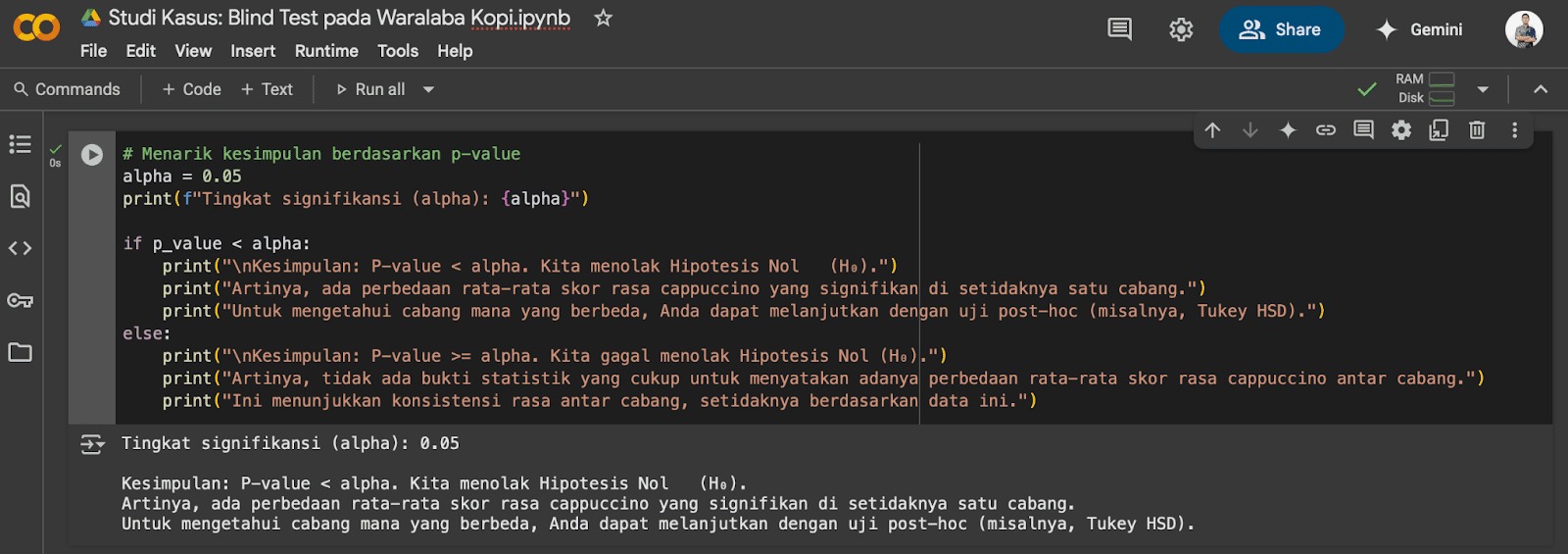
Berdasarkan hasil analisis ANOVA yang telah dilakukan, dengan tingkat signifikansi (alpha) 0.05, kita menemukan bahwa p-value hasil uji lebih kecil dari alpha tersebut.
Ini berarti kita menolak hipotesis nol (H₀) yang menyatakan bahwa rata-rata skor rasa cappuccino sama untuk semua cabang. Dengan demikian, ada perbedaan rata-rata skor rasa cappuccino yang signifikan secara statistik pada setidaknya satu dari tiga cabang.
Untuk mengetahui cabang mana saja yang rata-rata skor rasanya berbeda secara spesifik, analisis lanjutan diperlukan seperti uji post-hoc (misalnya, Tukey HSD). Untuk memahami lebih detail mengenai kodenya bisa melihat pada link berikut.
Regresi Linear
Regresi linear adalah salah satu metode statistik yang paling umum digunakan untuk memodelkan hubungan antara satu atau lebih variabel independen (prediktor) dengan sebuah variabel dependen (respons). Tujuan dari regresi linear adalah untuk menemukan hubungan linear paling sesuai dengan data yang ada sehingga kita dapat memprediksi nilai variabel dependen berdasarkan nilai variabel independen.
Regresi linear dapat dibagi menjadi dua jenis.
- Regresi Linear Sederhana (Simple Linear Regression): Digunakan untuk memodelkan hubungan antara satu variabel independen dan satu variabel dependen.
- Regresi Linear Berganda (Multiple Linear Regression): Digunakan untuk memodelkan hubungan antara dua atau lebih variabel independen dan satu variabel dependen.
Pada bagian ini, kita akan membahas secara mendalam mengenai regresi linear sederhana, yang merupakan dasar dari analisis regresi linear.
Regresi Linear Sederhana
Regresi linear sederhana adalah jenis regresi saat kita mencoba untuk menemukan hubungan linear antara satu variabel independen (X) dan satu variabel dependen (Y). Model regresi linear sederhana dapat dituliskan dalam bentuk persamaan matematika sebagai berikut.
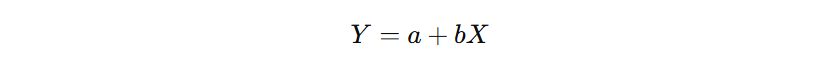
Artinya:
- Y adalah variabel dependen (respons) yang ingin kita prediksi.
- X adalah variabel independen (prediktor) yang digunakan untuk memprediksi Y.
- a adalah intercept (titik potong), yaitu nilai Y ketika X = 0.
- b adalah slope (kemiringan), yaitu perubahan rata-rata dalam Y untuk setiap unit perubahan pada X.
Langkah Menghitung Nilai Intercept dan Slope
Untuk mencari a (intercept) dan b (slope) dalam model regresi linear sederhana Y = a+bX, kita dapat menggunakan metode kuadrat terkecil (least squares method). Metode ini bertujuan meminimalkan jumlah kuadrat perbedaan antara nilai yang diprediksi oleh model regresi dan nilai sebenarnya (data observasi).
Rumus untuk Menghitung b (Slope)
Slope (b) menunjukkan seberapa besar perubahan pada Y untuk setiap perubahan satu unit pada X. Rumus untuk menghitung b adalah berikut.

Rumus untuk Menghitung a (Intercept)
Intercept (a) adalah nilai Y ketika X = 0. Ini adalah titik potong garis regresi dengan sumbu Y. Rumus untuk menghitung a adalah berikut.
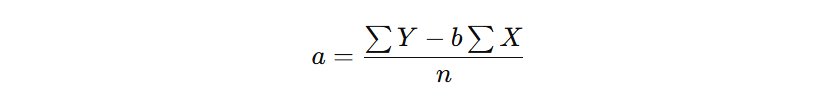
Dengan menggunakan nilai b yang telah dihitung sebelumnya, kita dapat menghitung a.
Interpretasi Slope dan Intercept
- Intercept (a): Intercept atau titik potong adalah nilai Y pada saat nilai X = 0 (dengan kata lain (0, b)). Dalam konteks dunia nyata, ini adalah nilai dasar dari variabel dependen yang tidak dipengaruhi oleh variabel independen. Jika model regresi digunakan untuk memprediksi harga rumah berdasarkan luas tanah (X), intercept adalah harga rumah ketika luas tanahnya 0.
- Slope (b): Slope atau kemiringan adalah ukuran dari perubahan rata-rata Y seiring dengan perubahan 1 unit pada X. Misalnya, jika b = 3, untuk setiap kenaikan 1 unit pada X, nilai Y diperkirakan akan naik sebesar 3 unit.
Sebagai contoh, jika kita memiliki persamaan linear y = 2x + 1, nilai intercept-nya adalah (0, 1) dan nilai slope-nya adalah 2.
Evaluasi Model
Setelah model regresi linear sederhana dibangun, langkah selanjutnya adalah melakukan evaluasi model tersebut. Evaluasi model penting untuk mengetahui seberapa baik model dapat memprediksi variabel dependen berdasarkan variabel independen.
Ada beberapa cara untuk mengevaluasi model regresi linear, seperti menggunakan koefisien determinasi (R²) guna menilai seberapa baik model menjelaskan data, menggunakan uji t untuk menguji signifikansi hubungan antara variabel, dan memeriksa residual guna memastikan bahwa asumsi dasar dari regresi linear terpenuhi (misal normalitas dan homogenitas varians).
Mari kita telaah lebih lanjut.
Koefisien Determinasi (R²)
Koefisien determinasi (R²) adalah ukuran statistik yang menunjukkan seberapa baik model regresi sederhana dapat menjelaskan variabilitas dalam data. Nilai R² berkisar antara 0 dan 1.
- R² = 0 berarti model tidak dapat menjelaskan sama sekali variabilitas dalam data.
- R² = 1 berarti model dapat menjelaskan seluruh variabilitas dalam data.
Secara umum, semakin tinggi nilai R², semakin baik model tersebut dalam memprediksi variabel dependen.
Untuk menghitung R², kita dapat menggunakan rumus berikut.

Jika kita menggunakan model regresi untuk memprediksi skor ujian berdasarkan waktu belajar dan mendapatkan nilai R² = 0.95, ini berarti model dapat menjelaskan 95% variabilitas dalam skor ujian berdasarkan waktu belajar.
Uji Signifikansi Parameter (Uji t)
Untuk menguji bahwa slope (b) dalam model regresi berbeda secara signifikan dari 0, kita dapat menggunakan uji t. Uji ini akan memberi tahu kita bahwa perubahan dalam X secara signifikan berhubungan dengan perubahan pada Y.
Hipotesis untuk uji t adalah berikut.
- H₀ (Hipotesis Nol): Slope b = 0 (tidak ada hubungan antara X dan Y).
- H₁ (Hipotesis Alternatif): Slope b ≠ 0 (ada hubungan antara X dan Y).
Untuk melakukan uji t, kita menghitung statistik t sebagai berikut.

Nilai t yang besar menunjukkan bahwa hubungan antara X dan Y signifikan, sementara nilai t yang kecil menunjukkan bahwa hubungan tersebut tidak signifikan.
Residual dan Asumsi Model
Setelah membangun model regresi, kita juga perlu memeriksa residual untuk memastikan bahwa asumsi dasar regresi linear terpenuhi. Residual adalah selisih antara nilai yang diprediksi oleh model dan nilai sebenarnya.
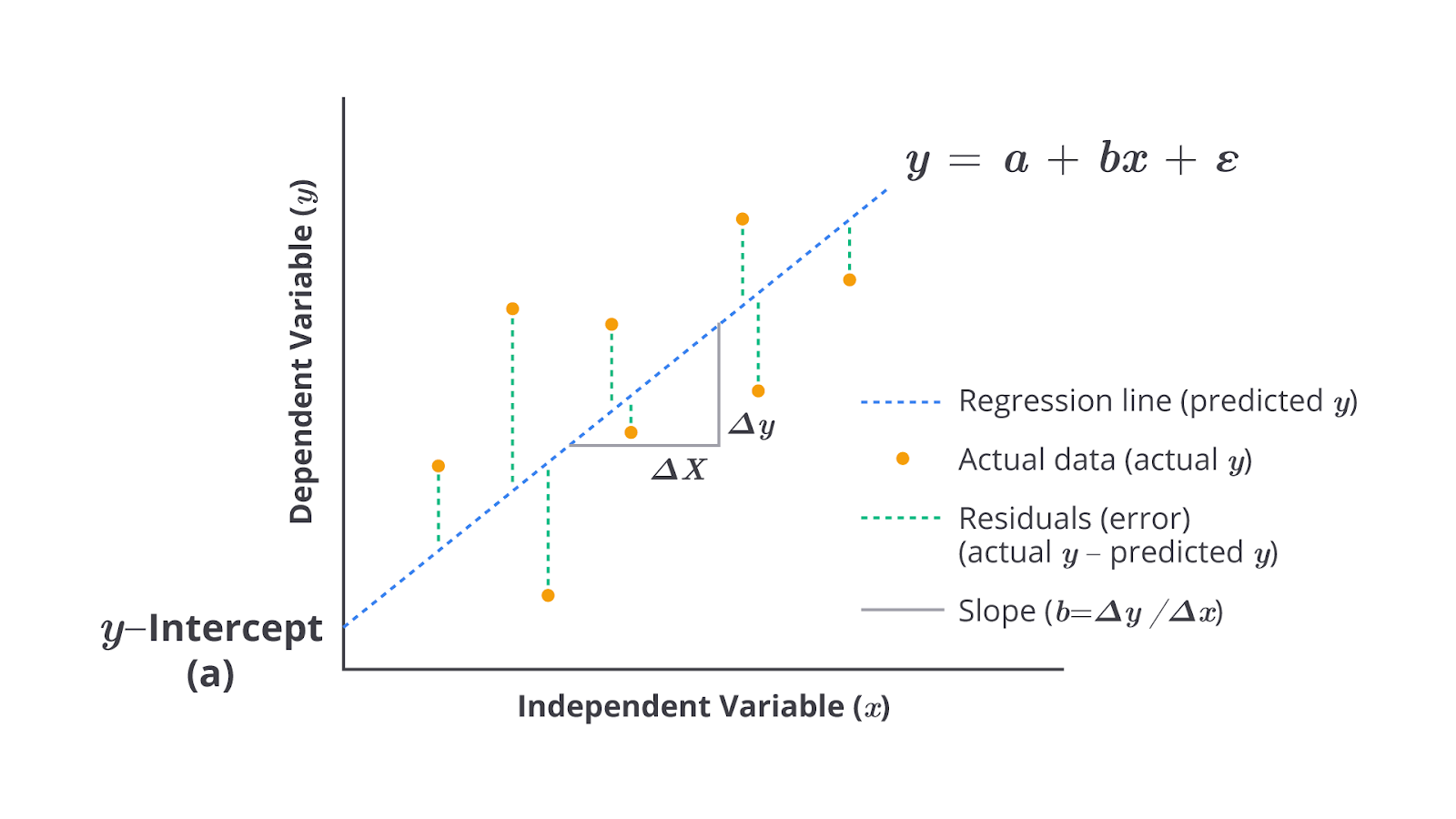
Penting untuk memeriksa residual karena hal-hal berikut.
- Normalitas Residual: Residual seharusnya terdistribusi normal. Jika residual tidak terdistribusi normal, kita mungkin perlu melakukan transformasi data.
- Homogenitas Varians (Homoskedastisitas): Varians residual harus tetap konstan di seluruh rentang nilai prediksi. Jika varians residual berubah seiring perubahan nilai prediksi (terjadi heteroskedastisitas), model mungkin perlu diperbaiki.
- Independensi Residual: Residual seharusnya tidak saling berkorelasi. Jika residual terkorelasi, ini bisa menunjukkan masalah dalam model atau data yang tidak terstruktur dengan baik.
Jika semua langkah evaluasi model ini dilakukan dengan benar, regresi linear sederhana dapat memberikan wawasan kuat tentang hubungan antara dua variabel dan dapat digunakan untuk membuat prediksi yang berguna.
Studi Kasus: Mengamati Hubungan Jam Belajar dan Nilai Ujian Siswa
Kali ini kita akan mempelajari aplikasi praktis dari regresi linear untuk mengamati hubungan antara jam belajar seorang siswa dan nilai ujian yang mereka dapatkan.
Kita punya informasi dari 10 siswa. Variabel Jam Belajar (X) adalah faktor yang kita duga memengaruhi nilai dengan durasi belajar mereka mulai dari 1 jam hingga 10 jam. Sementara itu, Nilai Ujian (y) adalah hasil yang ingin kita pahami dan prediksi dengan nilai-nilai seperti 51, 58, 55, dan seterusnya. Data ini menunjukkan tren umum bahwa semakin lama belajar, nilai cenderung lebih tinggi.
Penting untuk diingat bahwa nilai ujian ini tidak sempurna; kita telah menambahkan sedikit ‘noise’ atau ketidaksempurnaan acak. Ini membuat data kita lebih realistis sebab di dunia nyata tidak semua siswa yang belajar dalam jumlah jam yang sama akan selalu mendapatkan nilai persis identik.
Anda bisa menggunakan tools seperti Google Colab untuk mengikuti latihan ini.
Langkah 1: Menyiapkan dan Memvisualisasi Data
Untuk data X dan Y bisa kita simulasikan dengan Python menggunakan persamaan berikut. Silakan salin kode berikut dan tempel pada Google Colab Anda.
import numpy as np import matplotlib.pyplot as plt
Membuat generator angka acak dengan seed tertentu
rng = np.random.default_rng(seed=42) # Gunakan seed yang sama setiap kali
Data contoh: Jam Belajar (X) dan Nilai Ujian (y)
X: Jumlah jam belajar (variabel independen/prediktor)
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1) # reshape agar menjadi kolom
y: Nilai ujian yang diperoleh (variabel dependen/yang diprediksi)
Kita tambahkan sedikit “noise” atau ketidaksempurnaan agar lebih realistis
y = np.array([51, 58, 55, 65, 75, 72, 78, 85, 88, 95]) + 10 - rng.normal(10) # sedikit noise y = y.reshape(-1, 1) # reshape agar menjadi kolom
Visualisasi data
plt.figure(figsize=(8, 6)) plt.scatter(X, y, alpha=0.8, color=’blue’, label=’Data Asli (Jam Belajar vs Nilai Ujian)’) plt.title(‘Hubungan antara Jam Belajar dan Nilai Ujian’) plt.xlabel(‘Jam Belajar (X)’) plt.ylabel(‘Nilai Ujian (y)’) plt.grid(True) plt.legend() plt.show()
Berdasarkan data X dan Y yang masing-masing merupakan variabel independen dan dependen, kita dapat memvisualisasikan datanya seperti pada grafik berikut.
Langkah 2: Menghitung Koefisien Regresi
Langkah ini menghitung nilai slope (m) dan intercept (b) menggunakan metode kuadrat terkecil. Metode ini bertujuan meminimalkan jumlah kuadrat dari perbedaan antara nilai aktual dan nilai prediksi (residual). Rumus untuk m melibatkan perbandingan kovariansi antara X dan y dengan variansi X, sementara b dihitung dengan menyesuaikan rata-rata y berdasarkan m dan rata-rata X.
Tambahkan kode berikut pada Google Colab Anda.
# Menghitung rata-rata X dan y X_mean = np.mean(X) y_mean = np.mean(y)
Menghitung numerator dan denominator untuk slope (m)
numerator = np.sum((X - X_mean) * (y - y_mean)) denominator = np.sum((X - X_mean)**2)
Menghitung slope (m)
m = numerator / denominator
Menghitung intercept (b)
b = y_mean - m * X_mean
print(f”Koefisien Regresi (m): {m:.4f}”) print(f”Intercept Regresi (b): {b:.4f}”)
Output
Koefisien Regresi (m): 4.8000
Intercept Regresi (b): 45.4953
Berikut adalah tampilan dalam Google Colab.
Dalam model regresi linear ini, koefisien regresi (m = 4.8) menunjukkan bahwa untuk setiap peningkatan satu unit pada variabel independen (X), variabel dependen (y) diperkirakan meningkat sekitar 4.8 unit. Sementara itu, intercept (b = 45.4953) adalah nilai perkiraan variabel dependen (y) ketika variabel independen (X) bernilai nol.
Dengan menggunakan nilai m dan b yang telah kita hitung sebelumnya, model matematis untuk prediksi (garis regresi) adalah berikut.
Nilai siswa = 4.8 * (jam belajar) + 45.4953
Langkah 3: Menggambar Garis Ramalan
Kita sudah punya angka ‘m’ dan ‘b’. Sekarang kita bisa “menggambar” garis ramalan di atas titik-titik data asli. Gunakan kode berikut pada Google Colab Anda.
# Membuat prediksi menggunakan koefisien yang ditemukan y_pred = m * X + b
Visualisasi data asli dan garis regresi
plt.figure(figsize=(8, 6)) plt.scatter(X, y, alpha=0.7, label=’Data Asli’) plt.plot(X, y_pred, color=’red’, linewidth=2, label=’Garis Regresi’) plt.title(‘Regresi Linear Sederhana dengan Garis Prediksi’) plt.xlabel(‘Variabel Independen (X)’) plt.ylabel(‘Variabel Dependen (y)’) plt.grid(True) plt.legend() plt.show()
Inilah tampilan dalam Google Colab setelah kode dijalankan.
Garis merah pada grafik tersebut adalah model kita dan bisa dipakai untuk memprediksi! Misalnya, kalau ada siswa yang belajar 6.5 jam, kita bisa lihat pada garis merah, perkiraan nilai ujiannya.
Langkah 4: Seberapa Bagus Ramalan Kita? (R-squared)
Nilai R-squared (R²) adalah metrik penting yang memberi tahu kita seberapa baik model regresi dalam menjelaskan variasi pada data dependen. Nilai R² berkisar antara 0 hingga 1.
Jika R² mendekati 1, itu berarti garis prediksi kita sangat akurat dan efektif dalam menjelaskan perubahan pada nilai ujian berdasarkan jam belajar. Dengan kata lain, hampir semua perubahan nilai ujian dapat bergantung pada lamanya waktu belajar.
Sebaliknya, jika R² mendekati 0, ini mengindikasikan bahwa model kita kurang mampu menjelaskan variasi nilai ujian, menunjukkan bahwa mungkin ada faktor-faktor lain yang jauh lebih signifikan daripada hanya jam belajar dalam memengaruhi hasil ujian.
Mari kita hitung. Tambahkan kode berikut ke Google Colab Anda.
# Menghitung Sum of Squares of Residuals (SS_res) SS_res = np.sum((y - y_pred)**2)
Menghitung Total Sum of Squares (SS_tot)
SS_tot = np.sum((y - y_mean)**2)
Menghitung R-squared
r_squared = 1 - (SS_res / SS_tot)
print(f”R-squared: {r_squared:.4f}”)
Output
R-squared: 0.9631
Begini tampilan pada Google Colab.
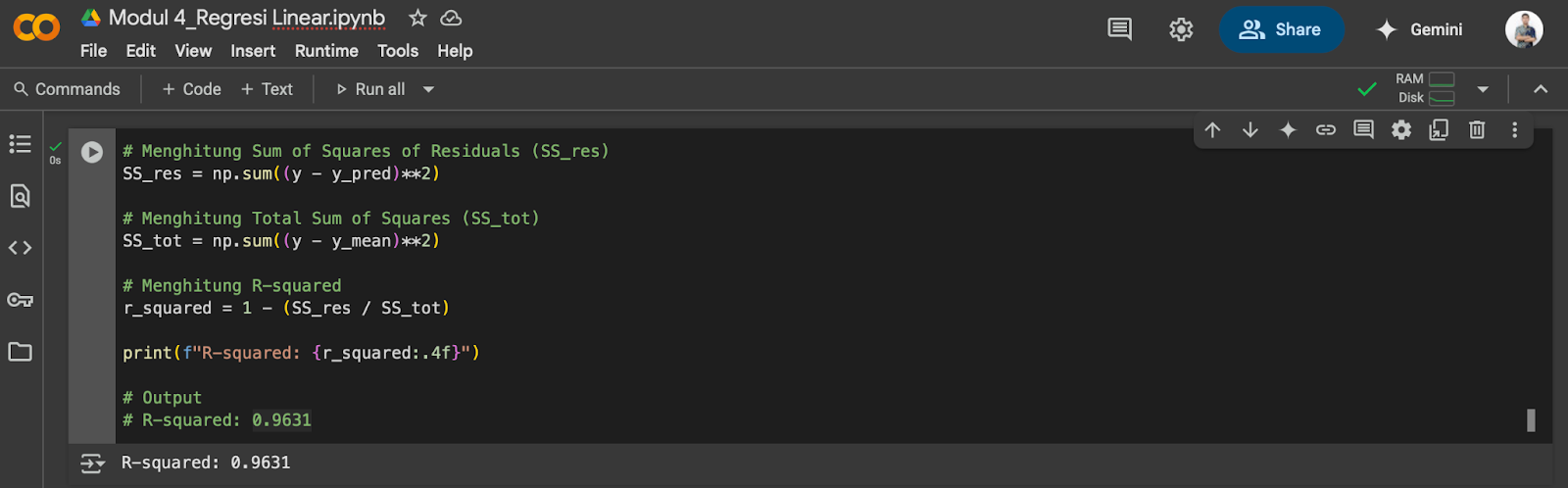
Nilai R-squared (R2) sebesar 0.9631 ini sangat baik! Ini berarti bahwa 96.31% dari variasi atau perbedaan pada nilai ujian dapat dijelaskan oleh jumlah jam belajar. Dengan kata lain, model regresi linear kita (yang menggunakan jam belajar) adalah prediktor yang sangat kuat dan akurat untuk nilai ujian. Hanya sekitar 3.69% variasi nilai ujian yang mungkin disebabkan oleh faktor lain di luar jam belajar yang tidak ditangkap oleh model ini.
Langkah Tambahan: Prediksi Nilai Ujian untuk 6.5 Jam Belajar
Karena model sudah dilatih dan kita sudah dapat kemiringan (m) garisnya sekitar 4.8 (tiap 1 jam belajar, nilainya bertambah 4.8 poin) dan titik awal (b)-nya sekitar 45.4953 (nilai dasar kalau belajar 0 jam), mari kita prediksi nilai ujian untuk siswa yang belajar 6.5 jam.
# Ini dia angka kemiringan dan titik awal yang udah kita hitung
Jam belajar yang mau kita tebak nilainya
jam_belajar_baru = 6.5
Hitung nilai ujiannya
nilai_ujian_prediksi = m * jam_belajar_baru + b
print(f”Kalau seseorang belajar selama {jam_belajar_baru} jam, kita prediksi nilai ujiannya sekitar: {nilai_ujian_prediksi:.2f}”)
Dengan model regresi ini, jika seseorang belajar selama 6.5 jam, nilai ujiannya diprediksi sekitar 76.70. Untuk memahami kode studi kasus mengamati hubungan jam belajar dan nilai ujain siswa dengan lebih detail bisa melihat pada link berikut.
Uji Non-Parametrik
Kita sudah belajar banyak soal uji parametrik sebelumnya, seperti uji t dan ANOVA. Kita tahu bahwa uji parametrik mengasumsikan bahwa data mengikuti distribusi tertentu (biasanya distribusi normal) dan memiliki varians yang homogen. Namun, kita menyadari bahwa dalam praktiknya, tidak semua data memenuhi asumsi-asumsi tersebut.
Pada kondisi seperti itu, kita perlu menggunakan pendekatan yang lebih fleksibel dan tidak bergantung pada distribusi data tertentu. Inilah alasan uji non-parametrik menjadi alat yang sangat berguna dalam analisis statistik.
Pengertian Uji Non-Parametrik
Pada dasarnya, uji non-parametrik adalah jenis uji statistik untuk menganalisis data yang tidak memenuhi asumsi dasar dari uji parametrik, seperti normalitas dan kesamaan varians. Uji ini lebih tahan terhadap penyimpangan dari distribusi normal, seperti data ordinal, data dengan outlier ekstrem, atau data yang tidak terdistribusi normal.
Uji non-parametrik tidak bergantung pada asumsi distribusi tertentu, yang membuatnya sangat berguna dalam situasi ketika data bersifat ordinal, nominal, atau tidak terdistribusi normal. Meskipun uji parametrik lebih kuat jika asumsi-asumsinya dipenuhi, uji non-parametrik adalah alternatif yang lebih kuat saat asumsi tersebut tidak dapat dipenuhi.
Uji non-parametrik digunakan dalam berbagai situasi berikut.
- Data Ordinal atau Nominal: Ketika data bersifat kategorikal (nominal) atau urutan (ordinal), yakni tidak mungkin untuk menghitung rata-rata.
- Data Tidak Terdistribusi Normal: Jika distribusi data tidak normal atau distribusi populasi tidak diketahui, uji non-parametrik adalah pilihan yang tepat.
- Ukuran Sampel Kecil: Uji non-parametrik sering digunakan ketika ukuran sampel kecil karena tidak membutuhkan distribusi normal untuk validitasnya.
- Skala Data yang Tidak Memenuhi Asumsi: Jika data memiliki skala yang tidak memenuhi asumsi, seperti data dengan outlier ekstrem atau variasi tidak seragam, uji non-parametrik bisa memberikan hasil lebih kuat.
Jenis Uji Non-Parametrik
Materi ini akan fokus ke pembahasan uji non-parametrik yang umum digunakan, seperti Mann-Whitney U, Wilcoxon Signed-Rank, dan Kruskal-Wallis. Semua uji ini berguna untuk situasi bahwa data tidak dapat diperlakukan dengan uji parametrik yang mengandalkan asumsi distribusi tertentu.
Uji Mann-Whitney U
Uji Mann-Whitney U adalah uji non-parametrik untuk membandingkan dua grup independen yang tidak terdistribusi normal atau ketika data bersifat ordinal. Uji ini digunakan untuk mengetahui bahwa dua grup memiliki distribusi yang serupa atau tidak. Uji ini adalah alternatif dari t-test dua sampel independen (independent t-test) ketika asumsi distribusi normal tidak terpenuhi.
Pada uji ini, kita membandingkan ranking data antar dua grup, bukan nilai-nilai data asli. Tujuan utamanya adalah untuk menguji bahwa ada perbedaan yang signifikan dalam distribusi data antara kedua grup.
Untuk dua grup yang masing-masing berukuran n1 dan n2, statistik uji U (alias Mann-Whitney U) dihitung sebagai berikut.
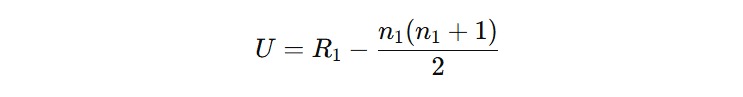
Jika U1 adalah nilai untuk grup pertama, kita juga menghitung U2 untuk grup kedua dengan rumus yang sama. Nilai U yang lebih kecil antara U1 dan U2 digunakan sebagai statistik uji.
Interpretasinya berikut.
- Jika nilai U sangat kecil, berarti ada perbedaan yang signifikan antara kedua grup dan kita dapat menolak hipotesis nol.
- Jika nilai U besar, kita gagal menolak hipotesis nol yang menyatakan bahwa kedua grup berasal dari distribusi yang sama.
Uji Wilcoxon Signed-Rank
Uji Wilcoxon Signed-Rank digunakan untuk menguji perbedaan berpasangan antara dua kondisi (misal data pengukuran sebelum dan setelah). Uji ini adalah alternatif non-parametrik dari t-test berpasangan (paired t-test) ketika data tidak terdistribusi normal atau data bersifat ordinal. Uji ini mengukur bahwa ada perbedaan signifikan antara dua kondisi yang berpasangan dengan cara membandingkan peringkat selisih antara pasangan data.
Untuk menghitung statistik uji W (alias Wilcoxon Signed-Rank), langkah-langkahnya adalah berikut.
- Hitung selisih (d) antara pasangan data, yaitu di=xi-yi .
- Jika di = 0, abaikan pasangan data tersebut dari analisis.
-
Hitung nilai mutlak selisih di dan urutkan dari yang terkecil ke terbesar (beri peringkat atau rank pada nilai di ). - Beri tanda positif jika di > 0 dan negatif jika di < 0.
- Hitung jumlah peringkat bertanda positif dan negatif.
- Statistik uji W adalah jumlah peringkat selisih yang positif.
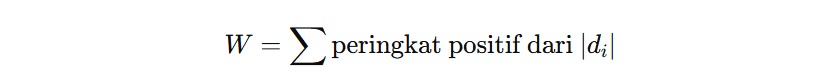
- Nilai W kemudian digunakan untuk menentukan p-value.
- Jika nilai W cukup besar dan p-value lebih kecil dari α (biasanya 0.05), kita menolak hipotesis nol dan menyimpulkan ada perbedaan yang signifikan antara dua kondisi.
Uji Kruskal-Wallis
Uji Kruskal-Wallis adalah uji statistik non-parametrik yang digunakan untuk membandingkan tiga atau lebih kelompok independen, mirip dengan ANOVA satu arah. Namun, tidak seperti ANOVA, uji Kruskal-Wallis tidak mengasumsikan data Anda terdistribusi normal atau memiliki varians yang sama di antara kelompok. Sebaliknya, ia bekerja dengan peringkat data, menjadikannya pilihan kuat untuk data ordinal atau data interval/rasio yang distribusinya tidak diketahui atau tidak normal.
Inti dari uji Kruskal-Wallis adalah mengubah semua nilai data dari setiap kelompok menjadi peringkat. Setelah semua data (dari semua kelompok digabungkan) diberi peringkat dari yang terkecil (peringkat 1) hingga terbesar, peringkat-peringkat ini kemudian dijumlahkan kembali untuk setiap kelompok asalnya.
Uji ini kemudian membandingkan rata-rata peringkat antarkelompok untuk menentukan jika ada perbedaan signifikan yang bisa disimpulkan bahwa kelompok-kelompok tersebut berasal dari populasi berbeda.
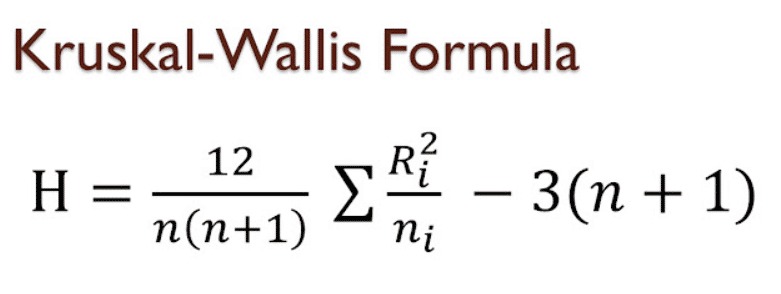
Artinya
- H adalah statistik uji Kruskal-Wallis.
- N adalah jumlah total seluruh observasi dari semua kelompok (N = n1+n2+⋯+nk).
- k adalah jumlah kelompok yang sedang dibandingkan.
- ni adalah jumlah observasi dalam kelompok ke-i.
- Ri adalah jumlah ranking pada kelompok ke-i.
Nilai H adalah statistik uji utama dari Kruskal-Wallis. Nilai H yang besar menunjukkan adanya perbedaan signifikan di antara rata-rata peringkat antargrup, menyiratkan bahwa grup-grup tersebut berasal dari distribusi yang berbeda. Sebaliknya, nilai H yang kecil menunjukkan kurangnya bukti untuk perbedaan tersebut. Nilai H ini kemudian dibandingkan dengan distribusi Chi-square untuk menentukan p-value dan menarik kesimpulan statistik.
Konsep Power Statistik
Power statistik adalah sebuah ukuran krusial dalam kerangka uji hipotesis. Power didefinisikan sebagai probabilitas suatu uji statistik untuk secara benar menolak hipotesis nol (H₀), yaitu ketika hipotesis alternatif (H₁) sesungguhnya benar. Dengan kata lain, power mengukur kemampuan uji statistik untuk mendeteksi perbedaan atau efek yang memang ada dalam populasi yang diwakili oleh sampel data.
Tingkat power yang tinggi mengindikasikan bahwa uji statistik tersebut memiliki sensitivitas lebih besar dalam mengidentifikasi efek nyata sehingga mengurangi risiko kesalahan tipe II (β). Sebaliknya, power yang rendah berarti uji tersebut lebih rentan untuk gagal mendeteksi efek yang ada, meskipun efek tersebut sebetulnya nyata dalam populasi.
Power statistik sangat fundamental dalam perancangan eksperimen dan interpretasi hasil uji hipotesis. Pemahaman ini memungkinkan peneliti untuk melakukan hal berikut.
- Menentukan Ukuran Sampel yang Optimal: Power digunakan dalam analisis power a priori untuk menghitung ukuran sampel minimum yang diperlukan guna mendeteksi efek dengan ukuran tertentu pada tingkat signifikansi yang ditetapkan. Ini mencegah pemborosan sumber daya akibat sampel terlalu besar atau kegagalan mendeteksi efek akibat sampel terlalu kecil.
- Menilai Kredibilitas Hasil Negatif: Apabila suatu uji menghasilkan kesimpulan bahwa tidak ada perbedaan signifikan (gagal menolak H₀), pemahaman tentang power memungkinkan evaluasi jika kegagalan ini disebabkan oleh tidak adanya efek nyata atau karena uji tersebut memiliki power yang tidak memadai untuk mendeteksinya.
Definisi formal power statistik adalah 1 - β, yakni β adalah probabilitas melakukan kesalahan tipe II (yaitu, kesalahan untuk tidak menolak hipotesis nol yang salah).
Faktor-Faktor yang Memengaruhi Power Statistik
Beberapa parameter kunci secara langsung memengaruhi tingkat power suatu uji statistik.
- Ukuran Sampel (n): Power uji meningkat seiring dengan peningkatan ukuran sampel. Sampel yang lebih besar memberikan lebih banyak informasi sehingga meningkatkan kemampuan uji untuk mendeteksi perbedaan atau efek yang ada.
- Variansi Data (σ2): Semakin kecil variansi atau sebaran data dalam kelompok, semakin tinggi power uji. Data yang lebih homogen atau konsisten memungkinkan perbedaan antarkelompok lebih mudah terdeteksi.
- Tingkat Signifikansi (α): Meningkatkan nilai α (misalnya, dari 0.05 menjadi 0.10) akan meningkatkan power uji karena hal ini membuat syarat untuk menolak H₀ menjadi lebih longgar. Namun, perlu dicatat bahwa peningkatan α juga meningkatkan probabilitas kesalahan tipe I (menolak H₀ padahal H₀ benar).
- Ukuran Efek (Effect Size): Ini adalah magnitudo atau kekuatan sebenarnya dari perbedaan atau hubungan dalam populasi. Semakin besar ukuran efeknya, semakin tinggi power uji. Perbedaan yang substansial lebih mudah dideteksi dibandingkan perbedaan yang sangat kecil.
Dengan mengendalikan dan memahami faktor-faktor ini, Anda dapat merancang eksperimen yang lebih efisien serta menarik kesimpulan lebih akurat dari analisis statistik.
Cara Meningkatkan Power
Power dari suatu uji statistik adalah kemampuannya untuk menolak hipotesis nol yang salah, atau dengan kata lain, mendeteksi perbedaan yang benar-benar ada dalam data. Power yang tinggi berarti kita memiliki peluang lebih besar untuk mendeteksi perbedaan nyata (bila ada) dan menghindari kesalahan tipe II (false negative).
Ada beberapa faktor yang memengaruhi power dari sebuah tes statistik. Faktor-faktor ini berperan penting dalam menentukan seberapa sensitif uji yang kita lakukan terhadap perbedaan atau efek pada populasi.
Berikut adalah faktor-faktor utama yang memengaruhi power statistik.
1. Menambah Jumlah Sampel
Cara paling langsung untuk meningkatkan power adalah dengan menambah ukuran sampel. Semakin besar ukuran sampel, semakin baik tes kita dalam mendeteksi perbedaan atau efek yang ada. Ukuran sampel yang lebih besar memberikan estimasi lebih presisi tentang parameter populasi, mengurangi variabilitas sampling, dan dengan demikian meningkatkan kemampuan deteksi tes.
Sebagai contoh, jika kita ingin menguji bahwa ada perbedaan rata-rata waktu layanan antara dua toko, menambah jumlah pelanggan yang diobservasi dalam setiap toko akan meningkatkan power dari uji yang dilakukan karena kita memiliki lebih banyak data untuk mengidentifikasi perbedaan yang mungkin ada.

Namun, menambah ukuran sampel juga berarti biaya yang lebih tinggi dalam hal waktu dan sumber daya, jadi hal ini perlu dipertimbangkan dengan bijak.
2. Mengurangi Variabilitas (Variansi Data)
Cara lain untuk meningkatkan power adalah dengan mengurangi variabilitas dalam data. Jika data kita memiliki banyak variabilitas atau noise, lebih sulit untuk mendeteksi perbedaan yang signifikan. Oleh karena itu, kita harus berusaha untuk meminimalkan faktor yang dapat menyebabkan variabilitas dalam eksperimen.
Contohnya, dalam percobaan medis, jika kita dapat mengontrol variabel-variabel lain yang memengaruhi hasil (seperti diet, usia, atau jenis kelamin), kita dapat mengurangi variabilitas pada data dan meningkatkan power. Menggunakan kelompok yang lebih homogen atau mengendalikan faktor-faktor lain dapat membantu mencapai hal ini.

Selain itu, penggunaan teknik pengukuran yang lebih presisi atau perangkat yang lebih akurat juga dapat mengurangi variabilitas dalam pengukuran dan meningkatkan kekuatan tes.
3. Menggunakan Nilai Alpha yang Lebih Tinggi (Dengan Konsekuensi)
Menurunkan nilai alpha akan mengurangi kemungkinan kesalahan tipe I, tetapi ini juga akan mengurangi power. Sebaliknya, meningkatkan nilai alpha (misalnya dari 0,05 menjadi 0,10) akan meningkatkan power, tetapi juga meningkatkan kemungkinan melakukan kesalahan tipe I (false positive).
- Alpha yang Lebih Tinggi (misalnya 0,10): Dengan meningkatkan alpha, kita mengurangi ambang batas untuk menolak hipotesis nol sehingga tes menjadi lebih sensitif terhadap perbedaan. Namun, ini akan meningkatkan risiko menerima hipotesis alternatif yang salah.
- Konsekuensi: Meningkatkan alpha bisa meningkatkan power, tetapi harus berhati-hati, karena kita lebih mudah menolak hipotesis nol meskipun itu sebenarnya benar, yang bisa menyebabkan kesalahan tipe.
Rangkuman Statistik Inferensial
Pengantar Statistik Inferensial
Kini saatnya Anda melangkah ke fase yang lebih aplikatif dan strategis dalam analisis data: Statistik Inferensial.
Pentingnya Statistik Inferensial
Melalui statistik inferensial, kita dapat melakukan hal-hal berikut.
- Mengestimasi karakteristik populasi (seperti rata-rata atau proporsi) berdasarkan sampel.
- Menguji hipotesis untuk menentukan bahwa suatu dugaan terhadap populasi dapat diterima secara statistik.
- Membuat keputusan berbasis data, baik dalam bisnis, sains, maupun rekayasa sistem.
Estimasi Parameter Populasi: Pengantar
Dalam konteks inferensial, parameter merujuk pada nilai sebenarnya dari karakteristik populasi—seperti rata-rata (mean) atau proporsi—yang biasanya tidak kita ketahui secara langsung. Oleh karena itu, kita menggunakan data sampel untuk membangun dugaan (estimasi) terhadap parameter tersebut disertai dengan tingkat keyakinan tertentu.
Estimasi Parameter Populasi: Mean Populasi
Dalam dunia nyata, kita jarang sekali memiliki akses ke seluruh populasi. Oleh karena itu, kita memilih sebagian kecil data—yang disebut sampel—untuk digunakan sebagai dasar pengambilan keputusan.
Namun, karena hanya melihat sebagian kecil dari keseluruhan data, kita tidak bisa sekadar mengasumsikan nilai rata-rata sampel sebagai kebenaran mutlak. Sebaliknya, kita perlu memperkirakan nilai mean populasi (μ) dengan interval kepercayaan tertentu. Inilah yang disebut dengan estimasi mean dalam statistik inferensial.
Estimasi Titik vs Estimasi Interval
Secara umum, ada dua pendekatan dalam melakukan estimasi terhadap nilai mean populasi.
- Estimasi Titik (Point Estimate): Estimasi titik menggunakan satu nilai tunggal, yaitu rata-rata sampel (x bar), sebagai perkiraan terhadap nilai mean populasi (μ).
- Estimasi Interval (Interval Estimate): Karena estimasi titik tidak cukup memberikan informasi tentang tingkat kepastian, kita memperluasnya menjadi confidence interval (CI).
Kondisi untuk Menghitung Confidence Interval
Kondisi 1: σ Diketahui (Distribusi Normal/Z)
Jika mengetahui standar deviasi populasi (σ)–misalnya dari laporan historis, eksperimen sebelumnya, atau dokumentasi resmi—Anda boleh menggunakan distribusi Z (normal).
Kondisi 2: σ Tidak Diketahui dan n < 30 (Distribusi t-Student)
Jika σ tidak diketahui (yang sangat umum terjadi) dan ukuran sampel Anda kecil (kurang dari 30), ketidakpastian menjadi lebih tinggi. Oleh karena itu, kita menggunakan distribusi t, yang memiliki bentuk lebih lebar dibanding distribusi normal (Z).
Estimasi Parameter Populasi: Proporsi Populasi
Estimasi proporsi adalah salah satu metode dasar dalam statistik inferensial yang digunakan untuk memperkirakan proporsi suatu kelompok atau kategori pada suatu populasi. Misalnya, jika ingin mengetahui berapa persen pelanggan puas dengan produk/layanan atau berapa banyak orang yang memilih suatu pilihan dalam survei politik, Anda akan menggunakan estimasi proporsi.
Rumus Confidence Interval untuk Proporsi
Sama halnya dengan estimasi rata-rata, estimasi proporsi juga memiliki confidence interval (CI) yang memberikan gambaran seberapa yakin kita terhadap hasil estimasi dari sampel. Untuk menghitung confidence interval untuk proporsi, kita menggunakan rumus berikut.
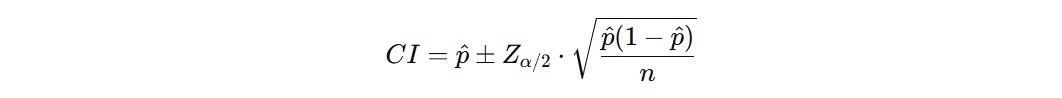
Penjelasan
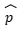 (p_hat) = proporsi sampel. Ini adalah proporsi yang kita hitung dari data sampel. Misalnya, jika 60 dari 100 orang yang disurvei puas dengan layanan, p = 60/100 = 0.60.
(p_hat) = proporsi sampel. Ini adalah proporsi yang kita hitung dari data sampel. Misalnya, jika 60 dari 100 orang yang disurvei puas dengan layanan, p = 60/100 = 0.60.- Za/2 = nilai z sesuai dengan tingkat kepercayaan yang diinginkan. Misalnya, untuk tingkat kepercayaan 95%, nilai Za/2 adalah 1.96.
- n = jumlah responden atau ukuran sampel. Ini adalah jumlah orang yang Anda survei dalam sampel. Semakin besar ukuran sampel, semakin akurat estimasi proporsi yang Anda dapatkan.
Faktor yang Memengaruhi Confidence Interval
Beberapa faktor yang memengaruhi lebar confidence interval untuk proporsi adalah berikut.
- Ukuran Sampel (n)
- Tingkat Kepercayaan (Confidence Level)
- Variabilitas Data (Penyebaran Data)
Konsep Dasar Uji Hipotesis
Uji hipotesis adalah metode statistik yang digunakan untuk menguji sebuah pernyataan (biasanya tentang rata-rata atau proporsi populasi) berdasarkan sampel data. Uji ini memberi kita cara untuk membuat keputusan berbasis data jika suatu klaim dapat diterima atau ditolak.
Hipotesis Nol dan Alternatif
- Hipotesis nol (H₀)
Hipotesis nol (H₀) adalah pernyataan yang menyatakan bahwa tidak ada efek, tidak ada perbedaan, atau tidak ada hubungan antara variabel yang sedang diuji. Hipotesis ini sering dianggap sebagai hipotesis yang “tradisional” atau “default”, yang kita anggap benar sampai ada bukti cukup untuk menolaknya. - Hipotesis Alternatif (H₁)
Sebaliknya, hipotesis alternatif (H₁) adalah pernyataan yang menyatakan bahwa ada perbedaan, efek, atau hubungan signifikan antara variabel yang diuji. Hipotesis alternatif adalah klaim yang ingin kita uji dan lihat jika data sampel mendukungnya.
Dengan dua hipotesis ini, kita akan melakukan uji statistik untuk menentukan bahwa data yang dikumpulkan memberikan bukti cukup kuat untuk menolak hipotesis nol dan menerima hipotesis alternatif.
Jenis Kesalahan dalam Pengujian
Dalam uji hipotesis, kita tidak pernah bisa 100% yakin tentang keputusan yang dibuat. Selalu ada kemungkinan bahwa kita membuat kesalahan dalam menerima atau menolak hipotesis nol. Oleh karena itu, ada dua jenis kesalahan yang bisa terjadi ketika kita melakukan uji hipotesis.
- Type I Error (False Positive)
- Type II Error (False Negative)
Keduanya berkaitan dengan kesalahan yang dibuat ketika kita mengambil keputusan berdasarkan data sampel. Penting untuk kita memahami keduanya agar bisa mengontrol dan meminimalkan risiko kesalahan dalam pengambilan keputusan berbasis statistik.
Menyusun Hipotesis
Ada dua jenis hipotesis yang sering kita temui dalam uji hipotesis: hipotesis parametrik dan hipotesis non-parametrik.
Hipotesis Parametrik
Hipotesis parametrik adalah hipotesis berkaitan dengan parameter populasi yang sudah diketahui atau diasumsikan mengikuti distribusi tertentu. Biasanya, distribusi normal digunakan sebagai asumsi dasar dalam uji parametrik.
Hipotesis Non-Parametrik
Hipotesis non-parametrik digunakan ketika kita tidak dapat membuat asumsi tentang distribusi data atau data yang dianalisis tidak memenuhi asumsi distribusi tertentu (misalnya, distribusi normal). Uji non-parametrik lebih fleksibel karena tidak bergantung pada parameter distribusi tertentu, seperti mean atau varians.
Metode Pengujian Hipotesis
Pada materi ini, kita akan membahas tentang metode pengujian hipotesis yang lebih terperinci. Di dalamnya, kita akan mengulas lebih dalam mengenai jenis arah uji (uji satu arah dan dua arah), yang akan menentukan bentuk pengujian berdasarkan pertanyaan penelitian dan asumsi yang dibuat mengenai populasi yang diuji.
Jenis Arah Uji
Sebagai pengingat kembali, uji satu arah digunakan ketika kita ingin menguji bahwa parameter tertentu lebih besar atau lebih kecil dari nilai yang dihipotesiskan. Sementara itu, uji dua arah digunakan ketika kita ingin menguji bahwa parameter tersebut berbeda dari nilai yang dihipotesiskan, baik lebih besar maupun lebih kecil.
Pemahaman tentang jenis arah uji ini akan menjadi dasar untuk memahami cara kita memutuskan letak batas pengujian dan cara kita menilai bahwa perbedaan yang ditemukan signifikan.
Nilai Statistik Uji, Kritis, dan p-value
Berikut adalah penjelasan ringkas terkait nilai statistik uji, kritis, dan p-value.
Nilai Statistik Uji
Nilai statistik uji adalah ukuran kuantitatif dari seberapa jauh data sampel yang diamati “menyimpang” dari hal yang akan kita harapkan jika hipotesis nol (H0) benar. Ini adalah metrik yang mengukur “kekuatan bukti” terhadap H0.
Nilai Kritis
Nilai kritis adalah batas nilai pada distribusi statistik yang membagi area-area letak kita akan menolak hipotesis nol dan letak kita akan menerima hipotesis nol. Dalam uji hipotesis, kita akan menghitung nilai statistik uji (seperti t-statistik atau z-statistik) dan membandingkannya dengan nilai kritis.
p-Value
p-value adalah inti dari interpretasi uji hipotesis. p-value (probability value) adalah probabilitas mendapatkan hasil yang sama ekstrem atau lebih ekstrem dari data yang diamati dengan asumsi bahwa hipotesis nol adalah benar. Dalam kata lain, p-value memberi kita gambaran tentang seberapa konsisten data sampel dengan hipotesis nol.
Pemilihan Jenis Uji Statistik
Pada dasarnya, z-test dan t-test digunakan untuk menguji perbedaan antara rata-rata sampel dan rata-rata populasi. Namun, keduanya memiliki perbedaan dalam asumsi dasar dan kondisi penggunaan.
Penggunaan z-test
z-test digunakan ketika memiliki data yang terdistribusi normal dan kita mengetahui standar deviasi populasi (σ). z-test sering digunakan untuk sampel besar (biasanya n ≥ 30) karena distribusi sampel besar mendekati distribusi normal, berkat central limit theorem (CLT).
Penggunaan t-test
t-test digunakan ketika ukuran sampel lebih kecil (biasanya n < 30) atau ketika kita tidak mengetahui standar deviasi populasi. t-test juga sering digunakan ketika menguji rata-rata sampel dan ingin memperhitungkan ketidakpastian lebih besar yang terjadi pada sampel kecil.
Pengujian Rata-Rata dengan z-test dan t-test
Salah satu aplikasi paling umum dalam statistik inferensial adalah menguji rata-rata suatu populasi atau sampel dan membandingkannya dengan nilai yang sudah diketahui atau dihipotesiskan.
Untuk itu, kita dapat menggunakan z-test dan t-test, tergantung pada beberapa faktor, seperti ukuran sampel dan pengetahuan kita tentang standar deviasi populasi.
z-Test untuk Rata-rata
z-test digunakan ketika data memenuhi beberapa kondisi, terutama ketika ukuran sampel besar (n ≥ 30) dan kita mengetahui standar deviasi populasi (σ).
t-Test untuk Rata-Rata
t-test digunakan ketika kita memiliki sampel kecil (biasanya n < 30) atau tidak tahu standar deviasi populasi, hanya standar deviasi sampel yang tersedia.
Variasi t-Test
Setelah memahami jenis uji statistik yang tepat (z-test dan t-test) serta menggunakan keduanya untuk menguji rata-rata, sekarang kita akan masuk lebih spesifik tentang t-test dan variasinya, termasuk one-sample t-test, paired t-test, dan independent t-test.
One-Sample t-Test
One-sample t-test—disebut juga uji t satu sampel—adalah prosedur inferensi statistik yang menanyakan “seberapa rasional bila kita menggeneralisasi rata-rata sebuah sampel kecil sebagai rata-rata seluruh populasi?”
Asal tahu saja, yang kita lakukan pada materi sebelumnya dengan menggunakan t-Test untuk menguji rata-rata adalah contoh dari one-sample t-test.
One-sample t-test (uji t satu sampel) kerap kali digunakan untuk menguji bahwa rata-rata populasi (μ) sama dengan, lebih besar, atau lebih kecil daripada suatu nilai acuan (μ₀) ketika memenuhi kondisi berikut.
- Kita hanya memiliki satu sampel berukuran kecil hingga sedang.
- Standar deviasi populasi (σ) tidak diketahui—kita menggantinya dengan standar deviasi sampel (s).
- Distribusi data dalam populasi diasumsikan mendekati normal; jika n cukup besar (≈ ≥ 30), central limit theorem (CLT) membantu memenuhi asumsi ini.
Paired t-Test
Paired t-test atau uji t berpasangan adalah salah satu jenis uji statistik yang digunakan untuk membandingkan dua set data yang berpasangan atau saling terkait. Uji ini sering digunakan dalam eksperimen atau studi dengan melibatkan pengukuran yang sama pada individu yang sama dalam dua kondisi berbeda atau dua waktu berbeda.
Dalam praktiknya, paired t-test digunakan ketika kita ingin mengetahui adanya perbedaan signifikan antara dua kondisi yang diukur pada kelompok yang sama. Kondisi-kondisi ini bisa berupa pengukuran sebelum dan sesudah perlakuan atau pengukuran dalam dua kondisi berbeda.
Independent t-test
Independent t-test atau uji t dua sampel independen adalah salah satu jenis uji statistik untuk membandingkan rata-rata dua kelompok yang tidak saling berhubungan atau independen satu sama lain.
Uji ini digunakan ketika kita ingin mengetahui bahwa ada perbedaan signifikan antara rata-rata dua kelompok tersebut dengan asumsi bahwa data pada kedua kelompok berasal dari populasi berbeda atau perlakuan berbeda.
Uji ini sangat penting untuk banyak eksperimen dan analisis dalam berbagai bidang, termasuk pendidikan, kesehatan, serta penelitian sosial.
Uji ANOVA (Analysis of Variance)
ANOVA (Analysis of variance) adalah teknik statistik yang digunakan untuk menguji perbedaan antara rata-rata lebih dari dua kelompok atau perlakuan. Uji ANOVA digunakan untuk menentukan bahwa ada perbedaan yang signifikan antara rata-rata kelompok-kelompok tersebut. Teknik ini sangat berguna dalam eksperimen yang melibatkan lebih dari dua grup, yakni t-test tidak dapat digunakan karena hanya menguji dua grup saja.
Uji ANOVA memiliki beberapa varian, salah satunya adalah ANOVA satu arah (one-way ANOVA) yang akan kita bahas secara mendalam pada bagian ini.
ANOVA Satu Arah
ANOVA satu arah (one-way ANOVA) adalah teknik statistik untuk menguji perbedaan rata-rata antara tiga kelompok atau lebih yang terpisah. Uji ini sangat berguna untuk menentukan bahwa ada perbedaan signifikan dalam rata-rata suatu variabel antara beberapa grup yang berbeda. Uji ini sering digunakan dalam eksperimen atau studi dengan melibatkan lebih dari dua grup yang diberi perlakuan berbeda.
Asumsi ANOVA
Berikut adalah asumsi-asumsi yang harus dipenuhi sebelum melakukan uji agar hasilnya valid.
Normalitas Data
Data pada setiap kelompok harus terdistribusi normal. Ini berarti bahwa data untuk setiap grup harus mengikuti distribusi normal atau setidaknya mendekati normal. Untuk memeriksa normalitas, kita bisa menggunakan uji normalitas, seperti Shapiro-Wilk atau melihat grafik histogram dan Q-Q plot.
Homogenitas Varians (Homogenitas Varian)
Asumsi ini menyatakan bahwa varians antarkelompok harus sama. Dalam kata lain, kelompok-kelompok yang dibandingkan seharusnya memiliki sebaran data serupa. Untuk menguji asumsi ini, kita bisa menggunakan uji Levene atau uji Bartlett. Jika p-value dari uji Levene lebih besar dari α (misalnya, 0.05), kita bisa menganggap varians antarkelompok homogen.
Independensi Data
Data dalam setiap grup harus bersifat independen. Artinya, pengukuran dalam satu grup tidak boleh memengaruhi pengukuran pada grup lainnya. Asumsi ini sangat penting. Jika data tidak independen, ANOVA tidak dapat digunakan.
Misalnya, dalam eksperimen ketika pengukuran pada satu individu atau objek dapat memengaruhi pengukuran pada individu atau objek lain, uji ANOVA mungkin tidak cocok.
Regresi Linear
Regresi linear adalah salah satu metode statistik yang paling umum digunakan untuk memodelkan hubungan antara satu atau lebih variabel independen (prediktor) dengan sebuah variabel dependen (respons). Tujuan dari regresi linear adalah untuk menemukan hubungan linear paling sesuai dengan data yang ada sehingga kita dapat memprediksi nilai variabel dependen berdasarkan nilai variabel independen.
Regresi Linear Sederhana
Regresi linear sederhana adalah jenis regresi saat kita mencoba untuk menemukan hubungan linear antara satu variabel independen (X) dan satu variabel dependen (Y). Model regresi linear sederhana dapat dituliskan dalam bentuk persamaan matematika sebagai berikut.
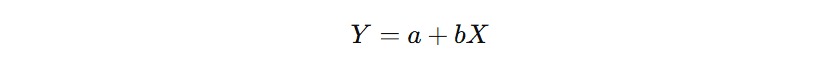
Artinya
- Y adalah variabel dependen (respons) yang ingin kita prediksi.
- X adalah variabel independen (prediktor) yang digunakan untuk memprediksi Y.
- a adalah intercept (titik potong), yaitu nilai Y ketika X = 0.
- b adalah slope (kemiringan), yaitu perubahan rata-rata dalam Y untuk setiap unit perubahan pada X.
Evaluasi Model
Ada beberapa cara untuk mengevaluasi model regresi linear, seperti menggunakan koefisien determinasi (R²) guna menilai seberapa baik model menjelaskan data, menggunakan uji t untuk menguji signifikansi hubungan antara variabel, dan memeriksa residual guna memastikan bahwa asumsi dasar dari regresi linear terpenuhi (misal normalitas dan homogenitas varians).
Mari kita telaah lebih lanjut.
Koefisien Determinasi (R²)
Koefisien determinasi (R²) adalah ukuran statistik yang menunjukkan seberapa baik model regresi sederhana dapat menjelaskan variabilitas dalam data. Nilai R² berkisar antara 0 dan 1.
- R² = 0 berarti model tidak dapat menjelaskan sama sekali variabilitas dalam data.
- R² = 1 berarti model dapat menjelaskan seluruh variabilitas dalam data.
Secara umum, semakin tinggi nilai R², semakin baik model tersebut dalam memprediksi variabel dependen.
Uji Signifikansi Parameter (Uji t)
Untuk menguji bahwa slope (b) dalam model regresi berbeda secara signifikan dari 0, kita dapat menggunakan uji t. Uji ini akan memberi tahu kita bahwa perubahan dalam X secara signifikan berhubungan dengan perubahan pada Y.
Hipotesis untuk uji t adalah berikut.
- H₀ (Hipotesis Nol): Slope b = 0 (tidak ada hubungan antara X dan Y).
- H₁ (Hipotesis Alternatif): Slope b ≠ 0 (ada hubungan antara X dan Y).
Residual dan Asumsi Model
Setelah membangun model regresi, kita juga perlu memeriksa residual untuk memastikan bahwa asumsi dasar regresi linear terpenuhi. Residual adalah selisih antara nilai yang diprediksi oleh model dan nilai sebenarnya.
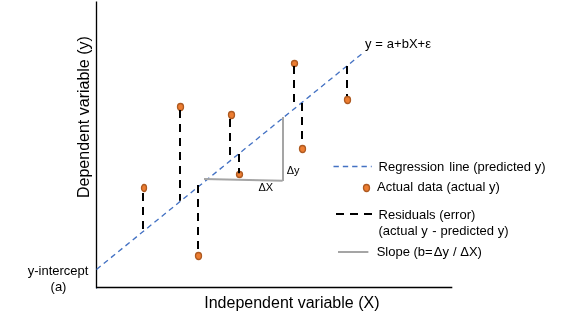
Penting untuk memeriksa residual karena hal-hal berikut.
- Normalitas Residual: Residual seharusnya terdistribusi normal. Jika residual tidak terdistribusi normal, kita mungkin perlu melakukan transformasi data.
- Homogenitas Varians (Homoskedastisitas): Varians residual harus tetap konstan di seluruh rentang nilai prediksi. Jika varians residual berubah seiring perubahan nilai prediksi (terjadi heteroskedastisitas), model mungkin perlu diperbaiki.
- Independensi Residual: Residual seharusnya tidak saling berkorelasi. Jika residual terkorelasi, ini bisa menunjukkan masalah dalam model atau data yang tidak terstruktur dengan baik.
Jika semua langkah evaluasi model ini dilakukan dengan benar, regresi linear sederhana dapat memberikan wawasan kuat tentang hubungan antara dua variabel dan dapat digunakan untuk membuat prediksi yang berguna.
Uji Non-Parametrik
Kita sudah belajar banyak soal uji parametrik sebelumnya, seperti uji t dan ANOVA. Kita tahu bahwa uji parametrik mengasumsikan bahwa data mengikuti distribusi tertentu (biasanya distribusi normal) dan memiliki varians yang homogen. Namun, kita menyadari bahwa dalam praktiknya, tidak semua data memenuhi asumsi-asumsi tersebut.
Pada kondisi seperti itu, kita perlu menggunakan pendekatan yang lebih fleksibel dan tidak bergantung pada distribusi data tertentu. Inilah alasan uji non-parametrik menjadi alat yang sangat berguna dalam analisis statistik.
Pengertian Uji Non-Parametrik
Pada dasarnya, uji non-parametrik adalah jenis uji statistik untuk menganalisis data yang tidak memenuhi asumsi dasar dari uji parametrik, seperti normalitas dan kesamaan varians. Uji ini lebih tahan terhadap penyimpangan dari distribusi normal, seperti data ordinal, data dengan outlier ekstrem, atau data yang tidak terdistribusi normal.
Uji non-parametrik tidak bergantung pada asumsi distribusi tertentu, yang membuatnya sangat berguna dalam situasi ketika data bersifat ordinal, nominal, atau tidak terdistribusi normal. Meskipun uji parametrik lebih kuat jika asumsi-asumsinya dipenuhi, uji non-parametrik adalah alternatif yang lebih kuat saat asumsi tersebut tidak dapat dipenuhi.
Jenis Uji Non-Parametrik
Berikut adalah jenis-jenis uji non-parametrik.
Uji Mann-Whitney U
Uji Mann-Whitney U adalah uji non-parametrik untuk membandingkan dua grup independen yang tidak terdistribusi normal atau ketika data bersifat ordinal. Uji ini digunakan untuk mengetahui bahwa dua grup memiliki distribusi yang serupa atau tidak. Uji ini adalah alternatif dari t-test dua sampel independen (independent t-test) ketika asumsi distribusi normal tidak terpenuhi.
Pada uji ini, kita membandingkan ranking data antar dua grup, bukan nilai-nilai data asli. Tujuan utamanya adalah untuk menguji bahwa ada perbedaan yang signifikan dalam distribusi data antara kedua grup.
Uji Wilcoxon Signed-Rank
Uji Wilcoxon Signed-Rank digunakan untuk menguji perbedaan berpasangan antara dua kondisi (misal data pengukuran sebelum dan setelah). Uji ini adalah alternatif non-parametrik dari t-test berpasangan (paired t-test) ketika data tidak terdistribusi normal atau data bersifat ordinal. Uji ini mengukur bahwa ada perbedaan signifikan antara dua kondisi yang berpasangan dengan cara membandingkan peringkat selisih antara pasangan data.
Uji Kruskal-Wallis
Uji Kruskal-Wallis adalah uji statistik non-parametrik yang digunakan untuk membandingkan tiga atau lebih kelompok independen, mirip dengan ANOVA satu arah. Namun, tidak seperti ANOVA, uji Kruskal-Wallis tidak mengasumsikan data Anda terdistribusi normal atau memiliki varians yang sama di antara kelompok. Sebaliknya, ia bekerja dengan peringkat data, menjadikannya pilihan kuat untuk data ordinal atau data interval/rasio yang distribusinya tidak diketahui atau tidak normal.
Inti dari uji Kruskal-Wallis adalah mengubah semua nilai data dari setiap kelompok menjadi peringkat. Setelah semua data (dari semua kelompok digabungkan) diberi peringkat dari yang terkecil (peringkat 1) hingga terbesar, peringkat-peringkat ini kemudian dijumlahkan kembali untuk setiap kelompok asalnya.
Uji ini kemudian membandingkan rata-rata peringkat antarkelompok untuk menentukan jika ada perbedaan signifikan yang bisa disimpulkan bahwa kelompok-kelompok tersebut berasal dari populasi berbeda.
Konsep Power Statistik
Power statistik adalah sebuah ukuran krusial dalam kerangka uji hipotesis. Power didefinisikan sebagai probabilitas suatu uji statistik untuk secara benar menolak hipotesis nol (H₀), yaitu ketika hipotesis alternatif (H₁) sesungguhnya benar. Dengan kata lain, power mengukur kemampuan uji statistik untuk mendeteksi perbedaan atau efek yang memang ada dalam populasi yang diwakili oleh sampel data.
Cara Meningkatkan Power
Power dari suatu uji statistik adalah kemampuannya untuk menolak hipotesis nol yang salah, atau dengan kata lain, mendeteksi perbedaan yang benar-benar ada dalam data. Power yang tinggi berarti kita memiliki peluang lebih besar untuk mendeteksi perbedaan nyata (bila ada) dan menghindari kesalahan tipe II (false negative).
Ada beberapa faktor yang memengaruhi power dari sebuah tes statistik. Faktor-faktor ini berperan penting dalam menentukan seberapa sensitif uji yang kita lakukan terhadap perbedaan atau efek pada populasi.
Berikut adalah faktor-faktor utama yang memengaruhi power statistik.
- Menambah Jumlah Sampel
Cara paling langsung untuk meningkatkan power adalah dengan menambah ukuran sampel. Semakin besar ukuran sampel, semakin baik tes kita dalam mendeteksi perbedaan atau efek yang ada. Ukuran sampel yang lebih besar memberikan estimasi lebih presisi tentang parameter populasi, mengurangi variabilitas sampling, dan dengan demikian meningkatkan kemampuan deteksi tes. - Mengurangi Variabilitas (Variansi Data)
Cara lain untuk meningkatkan power adalah dengan mengurangi variabilitas dalam data. Jika data kita memiliki banyak variabilitas atau noise, lebih sulit untuk mendeteksi perbedaan yang signifikan. Oleh karena itu, kita harus berusaha untuk meminimalkan faktor yang dapat menyebabkan variabilitas dalam eksperimen. - Menggunakan Nilai Alpha yang Lebih Tinggi (Dengan Konsekuensi)
Menurunkan nilai alpha akan mengurangi kemungkinan kesalahan tipe I, tetapi ini juga akan mengurangi power. Sebaliknya, meningkatkan nilai alpha (misalnya dari 0,05 menjadi 0,10) akan meningkatkan power, tetapi juga meningkatkan kemungkinan melakukan kesalahan tipe I (false positive).
This file is located at: _chapters/991-belajar-matematika-untuk-data-science/040-statistik-inferensial.md