Pengantar Machine Learning Operations (MLOps)
- Pengenalan Machine Learning Operations
- Permasalahan Umum ketika Membangun Sistem Machine Learning
- Machine Learning Life Cycle
- MLOps Maturity
- Tools Penunjang MLOps
- Rangkuman Pengantar Machine Learning Operations (MLOps)
- Pengenalan Machine Learning Operations
- Permasalahan Umum ketika Membangun Sistem Machine Learning
- Machine Learning Lifecycle
- MLOps Maturity
- Tools Penunjang MLOps
Pengenalan Machine Learning Operations
Setelah perjalanan panjang kita arungi bersama di samudera ilmu yang sangat luas, akhirnya kita bertemu kembali dalam kondisi yang penuh kebahagiaan untuk menuntaskan perjalanan sebagai seorang machine learning engineer terbaik.
Sebagai informasi, pada kelas ini kita tidak hanya belajar machine learning—kita akan membedah lebih jauh apa itu sistem machine learning. Mungkin pada materi kelas sebelumnya Anda berpikir bahwa algoritma dan model machine learning merupakan bagian terpenting dari sistem machine learning. Namun, sebenarnya machine learning yang Anda pelajari sebelumnya adalah bagian kecil dari sebuah sistem machine learning.
Artinya, perjalanan yang sudah kita lalui bersama-sama bukanlah akhir dari segalanya. Karena sampai pada kelas ini Anda hanya mempelajari cara untuk membangun sebuah model (model dev) tetapi belum bisa digunakan oleh pengguna secara umum. Dengan kata lain, proses tersebut masih memiliki kepingan puzzle yang hilang dan perlu dilengkapi agar menjadi sebuah sistem utuh.
Tenang saja, Anda tidak salah jalan karena sampai saat ini masih di jalur yang tepat. Bekal pengetahuan untuk membangun model machine learning merupakan ilmu yang sangat mahal dan menjadi bahan bakar yang sangat penting sampai pada tahapan ini.
Sebagai seorang Machine Learning Engineer, keahlian Anda tidak hanya terbatas pada membangun model yang akurat. Dengan kata lain, model yang baik saja tidak cukup. Bayangkan Anda memiliki model state of the art (terbaik pada masanya) tetapi hanya bisa berjalan pada notebook atau local environment, tentunya itu menjadi sia-sia, ‘kan?
Model tersebut harus dapat diterapkan dan memberikan nilai bisnis yang nyata. Di sinilah MLOps memainkan peran penting sebagai jembatan antara developer dan pengguna. Mungkin tebersit di benak Anda, “Apa sih MLOps itu? Kok tiba-tiba muncul?” Tenang, tidak perlu terburu-buru. Kita akan mengupas tuntas semuanya pada kelas Membangun Sistem Machine Learning ini. So, siapa yang siap jadi rockstar MLOps di kemudian hari? Siapkan diri kalian, nyalakan semangat, dan mari kita mulai!
Developer, Operations, Devops, MLOps, apa itu?
Sebagai seorang Developer, IT Operations atau apa pun jenis profesi yang digeluti saat ini, kami yakin Anda sudah pernah berkecimpung dalam proses pengembangan suatu aplikasi atau pun proses serupa lainnya. Jika belum, setidaknya mungkin Anda sudah familier dengan proses tersebut.
Hal ini dibuktikan dari perjalanan Anda yang telah mempelajari berbagai algoritma umum untuk membuat model machine learning dan mengimplementasikannya dalam berbagai studi kasus di industri. Anda juga telah belajar mengenai machine learning system design yang mensyaratkan sebuah sistem machine learning bersifat reliable, scalable, adaptable, dan maintainable.
Kita semua tahu bahwa proses pengembangan aplikasi itu kompleks, bahkan di beberapa kasus agar dapat men-_deploy_ ke lingkungan produksi, kemungkinan perlu melibatkan banyak pihak.
Dulu, pengembangan perangkat lunak (software development) dan operasi teknologi informasi (IT operations) berjalan secara terpisah. Tim pengembang fokus pada pembuatan kode dan fitur baru, sementara tim operasional bertanggung jawab untuk deployment dan pemeliharaan sistem. Dengan pendekatan ini, tentu saja ada permasalahan yang muncul yaitu GAP pengetahuan antara tim developer dan operations.
GAP ini sering kali menimbulkan banyak permasalahan seperti siklus rilis yang lambat, kurangnya komunikasi, hingga masalah stabilitas. Mengapa hal itu bisa terjadi? Mari kita bahas satu per satu.
- Siklus Rilis yang Lambat: perubahan kode dan rilis fitur baru memakan waktu lama karena proses deployment manual dan birokrasi antar tim.
- Kurangnya Komunikasi: misinterpretasi dan kesalahan saat deployment dapat terjadi karena proses komunikasi yang kurang baik antara pengembang dan tim operasional.
- Masalah Stabilitas: perubahan kode yang tidak terintegrasi dengan baik sering kali menyebabkan masalah stabilitas dan downtime.
- Kurangnya Visibilitas: setiap tim biasanya memiliki tools yang berbeda-beda dengan akses yang terbatas. Dengan perbedaan ini, terkadang kita tidak bisa melihat pekerjaan satu sama lain yang mengakibatkan proses pengembangan saling menunggu bola panas.
Selain permasalahan di atas, terdapat satu permasalahan ultimate yang biasa terjadi di sebuah perusahaan yaitu struktur tim yang tertutup. Mengapa hal tersebut bisa menjadi momok yang menakutkan? Sini-sini, mari kita bahas bersama.
Semakin bertambahnya usia, ilmu bahkan ego tentu Anda sangat paham bahwa semakin banyak orang yang bergabung dalam suatu proses, semakin banyak pula perspektif dan ide yang bisa kita dapatkan. Akan tetapi, terkadang itu malah menghadirkan masalah lain karena setiap orang memiliki perspektif dan keinginan yang berbeda-beda.

Begitu juga dalam proses pengembangan aplikasi yang melibatkan banyak pihak di dalamnya. Jika semua orang memiliki ego dan idealisnya masing-masing, tentu tim tidak akan mencapai hasil yang maksimal. Permasalahan kian muncul satu per satu, dan yang paling mengerikan, tim dibubarkan kembali karena permasalahan komunikasi.
Misalnya, dalam sebuah proyek machine learning, seorang data scientist/ML engineer ingin menggunakan arsitektur model yang sangat kompleks karena ia percaya bahwa solusi tersebut adalah yang terbaik, meskipun proses pelatihannya memakan waktu lama dan sulit diimplementasikan. Di sisi lain, seorang engineer (operations) lebih mengutamakan model yang ringan dan efisien agar dapat berjalan dengan baik di lingkungan produksi. Jika keduanya bersikeras dengan idealismenya tanpa mencari titik temu, proyek bisa terhambat, bahkan gagal dieksekusi.
Ego dan idealisme yang tidak dikelola dengan baik sering kali membuat keputusan lebih sulit diambil, padahal solusi terbaik seringkali lahir dari kompromi dan kolaborasi.
Tenang saja, itu merupakan skenario terburuk yang terjadi karena hal kecil. Sebenarnya ketika membangun sebuah aplikasi kita tidak akan berhubungan dengan berbagai macam pihak secara langsung. Umumnya, proses ini melibatkan 2 tim penting, yakni Developer dan IT Operations.
Dua jenis profesi ini sering kali kita sebut sejak awal materi, memangnya siapa sih mereka itu? Baiklah, untuk Anda yang mungkin masih asing dengan keduanya, yuk kita bahas bersama di bawah ini.
- Developer: seseorang atau tim yang mampu merancang (plan), menulis kode (code), mengemas kode (build), dan menguji (test) perangkat lunak atau aplikasi.
- IT Operations: biasa disingkat sebagai Operations, adalah seseorang atau tim yang bertanggung jawab untuk merilis (release) dan menggelar (deploy) aplikasi, serta mengoperasikan (operate) dan memantau (monitor) infrastruktur (seperti server) yang menjalankan aplikasi tersebut.
Developer dan IT Operations adalah dua tim yang krusial karena memiliki tujuan yang sama, yakni menyajikan aplikasi yang komprehensif dan stabil ke pengguna; tetapi sering kali mereka tertutup satu sama lain dan seakan-akan tercerai. Baik Developer maupun IT Operations, mereka memiliki prioritas, peralatan, dan pola kerjanya sendiri-sendiri sehingga sering kali menimbulkan pergolakan saat mereka bekerja sama.
Developer biasanya dituntut untuk cepat mengembangkan fitur, memperbaiki bug, dan menambah fitur pada sebuah aplikasi. Sayangnya, fokus pada kecepatan sering membuat kualitas kode terabaikan. Di sisi lain, IT Operations bertugas menjaga infrastruktur tetap stabil dan bebas dari bug (gangguan). Masalahnya, perubahan dari aplikasi—terutama dengan intensitas deployment yang tinggi—sering kali mengganggu stabilitas tersebut.
Konflik ini sering berujung pada kurangnya pemahaman dan komunikasi. Developer cenderung “melempar kode” ke IT Operations tanpa memikirkan bagaimana kode tersebut berjalan di production dengan dalih “Kodenya berjalan di laptopku”.

Sementara IT Operations menerima kode tanpa memahami tujuannya. Ketika ini terjadi tentunya masalah akan muncul, biasanya kedua tim saling menyalahkan. Developer menganggap IT Operations kurang kompeten menjalankan kode, sementara IT Operations menuduh kualitas kode Developer yang buruk sebagai biang keladinya.

Kondisi seperti ini menciptakan bottleneck yang menghambat kolaborasi dan efisiensi tim. Ujungnya, kondisi saling menyalahkan seperti ini tentu saja bisa memicu kekacauan di dalam perusahaan sehingga membuat proses delivery aplikasi atau fitur menjadi berantakan. Apa akibatnya? Pengguna merasa kecewa, memberikan feedback negatif, dan perusahaan berisiko kehilangan pasar. Bayangkan, hanya karena hal ini, seluruh perusahaan jadi kacau balau atau lebih buruknya bisa saja perusahaan “bungkus”!

Nah, seiring dengan perkembangan teknologi dan meningkatnya tuntutan pasar, perusahaan perlu merilis software dengan lebih cepat dan responsif. Kebutuhan untuk merampingkan proses pengembangan dan deployment pun semakin mendesak. Inilah yang melahirkan konsep DevOps, gabungan dari kata Developer (atau Development) dan IT Operations (atau Operations).
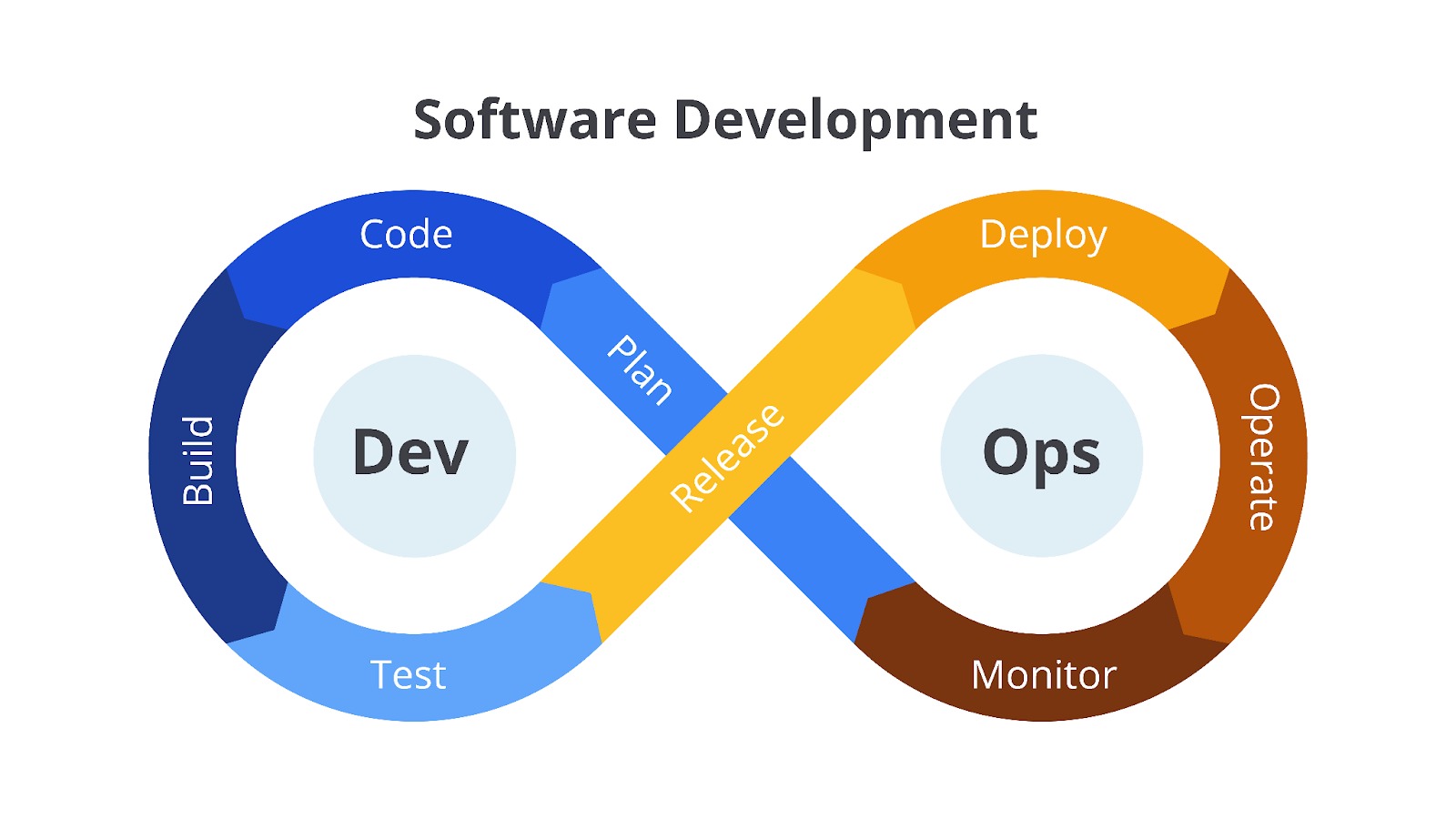
DevOps adalah kombinasi dari filosofi kultur/budaya, sekumpulan praktik, dan rangkaian alat (tools) yang dapat meningkatkan kemampuan organisasi/perusahaan untuk menyajikan (deliver) aplikasi atau perangkat lunak secara cepat.
Perusahaan yang mengadopsi pendekatan modern seperti DevOps dapat mengembangkan dan memperbaiki produk jauh lebih cepat dibandingkan dengan model tradisional. Proses ini memungkinkan perusahaan untuk memberikan layanan yang lebih baik kepada pengguna sekaligus bersaing lebih efektif di pasar.
Seperti yang sudah dijelaskan, DevOps merupakan kombinasi dari filosofi kultur, praktik, dan tools. Jika Anda bingung dengan ketiga istilah tersebut, berikut adalah uraiannya.
- Filosofi kultur atau budaya yang dimaksud adalah dengan menghilangkan segala hambatan yang terjadi pada proses pengembangan aplikasi dan menerapkan berbagi tanggung jawab yang sesuai ke masing-masing tim.
- Praktik di sini bertujuan untuk mencapai kecepatan dan kualitas proses pengembangan aplikasi, yakni dengan merampingkan prosedur terkait bagaimana cara tim bekerja.
- Tools yang dimaksud adalah dengan memanfaatkan peralatan atau perangkat lunak yang selaras dengan proses pengembangan aplikasi dan mengotomatiskan tugas-tugas yang berulang agar tidak dilakukan secara manual. Dengan demikian, hal itu dapat membuat proses rilis menjadi lebih efisien dan aplikasi menjadi lebih andal.
DevOps menekankan kolaborasi yang solid dan efisiensi maksimal, memungkinkan tim untuk berinovasi lebih cepat dan menerima feedback pengguna yang lebih baik, yang pada akhirnya meningkatkan nilai bisnis.
Dengan DevOps, Developer dan IT Operations yang sebelumnya terpisah kini dapat bersatu, berkolaborasi, dan berkomunikasi dengan lebih efektif. Sudah saatnya mengucapkan selamat tinggal kekacauan internal—saatnya menciptakan harmoni dan produktivitas dalam tim.
Catatan Penting
Jika Anda ingin mengetahui DevOps lebih jauh jangan sungkan untuk berkunjung ke kelas Belajar Dasar-Dasar DevOps, ya.
Welcome, MLOps!
Berdasarkan cerita di atas, DevOps telah terbukti sukses dalam mempercepat dan meningkatkan proses pengembangan perangkat lunak. Dengan kisah sukses tersebut penggabungan divisi, job load, dan kolaborasi ini menjadi salah satu pilihan terbaik untuk mengakselerasi bisnis di berbagai bidang bahkan finansial.
Prinsip-prinsip yang sama dapat diterapkan pada pengembangan dan deployment model Machine Learning (ML). Di sinilah MLOps berperan untuk menghilangkan GAP antara Machine Learning Developer dan tim Operations sehingga dapat memberikan pelayanan terbaik kepada pengguna dan meningkatkan revenue bisnis.
Sebelumnya, Anda mungkin berpikir bahwa pembangunan model machine learning hanya berkutat pada proses iteratif sederhana. Di mana tahapannya dimulai dari pengumpulan dan pengolahan data hingga pelatihan dan evaluasi model saja.
Dengan menggunakan pendekatan di atas, tentunya proses tersebut sudah memenuhi hasrat Anda sebagai peneliti atau AI enthusiast karena dapat menghasilkan model terbaik pada studi kasus yang sedang diemban.
Namun, permasalahan besar muncul ketika Anda ingin mencari “validasi” atas performa model machine learning yang sudah dibuat. Bagaimana caranya? Tentunya Anda perlu men-_deploy_ model yang sudah dibangun agar dapat dikonsumsi oleh pengguna secara umum.
Sayangnya, sampai sekarang kita belum mempelajari cara men-_deploy_ dan memelihara model dengan baik di lingkungan produksi. Walhasil, kita perlu meminta bantuan dari tim Operations atau tim Back-End untuk menangani tahapan tersebut.
Masih ingatkan permasalahan Developer dan Operations pada segmen DevOps? Yup! Permasalahan tersebut dapat terulang kembali ketika kita memiliki proses kerja yang berbeda dan memiliki dependensi satu sama lain. Hal ini bisa saja menghambat proses kerja, kolaborasi bahkan hingga pencairan revenue perusahaan. Tentunya Anda juga tidak mau berdampak pada keterlambatan penggajian, ‘kan?
Berangkat dari permasalahan tersebut, MLOps hadir untuk mengurangi dan/atau bahkan menghilangkan permasalahan tersebut. Dengan mengadopsi praktik MLOps, perusahaan dapat mengotomatisasi proses, meningkatkan kolaborasi, memastikan kualitas model, dan memaksimalkan nilai bisnis dari investasi dalam Machine Learning. Bye-bye problems~
Pertanyaannya, apa sih MLOps itu? Machine Learning Operations (MLOps) adalah sebuah proses yang bertujuan untuk menerapkan dan memelihara model machine learning dalam produksi secara andal dan efisien.
Bayangkan Anda seorang chef yang tidak hanya menciptakan resep yang lezat (model machine learning), tetapi juga harus memastikan hidangan tersebut dapat disajikan secara konsisten kepada banyak pelanggan dengan kualitas yang sama (produksi model). MLOps adalah proses yang memastikan hal tersebut bisa terjadi dengan sangat baik.
Seperti yang kita tahu bahwa pengembangan model machine learning hanyalah langkah awal. Tantangan sebenarnya muncul ketika model tersebut harus digunakan dalam dunia nyata, tanpa MLOps model machine learning beresiko mengalami penurunan performa, sulit dipantau, dan tidak dapat diandalkan. Jadi, jika Anda berpikiran bahwa pembangunan model machine learning itu hanya menghasilkan model sepertinya Anda keliru.
MLOps mengadopsi karakteristik DevOps seperti CI/CD, otomatisasi, dan monitoring, tetapi disesuaikan dengan kebutuhan khusus pengembangan model machine learning. MLOps bertugas untuk menjembatani kesenjangan antara Data Scientist yang mengembangkan model dan tim engineering yang bertanggung jawab untuk membawa model tersebut ke produksi. Dari gabungan DevOps dan proses pengembangan machine learning, MLOps memiliki siklus pengembangan seperti berikut.
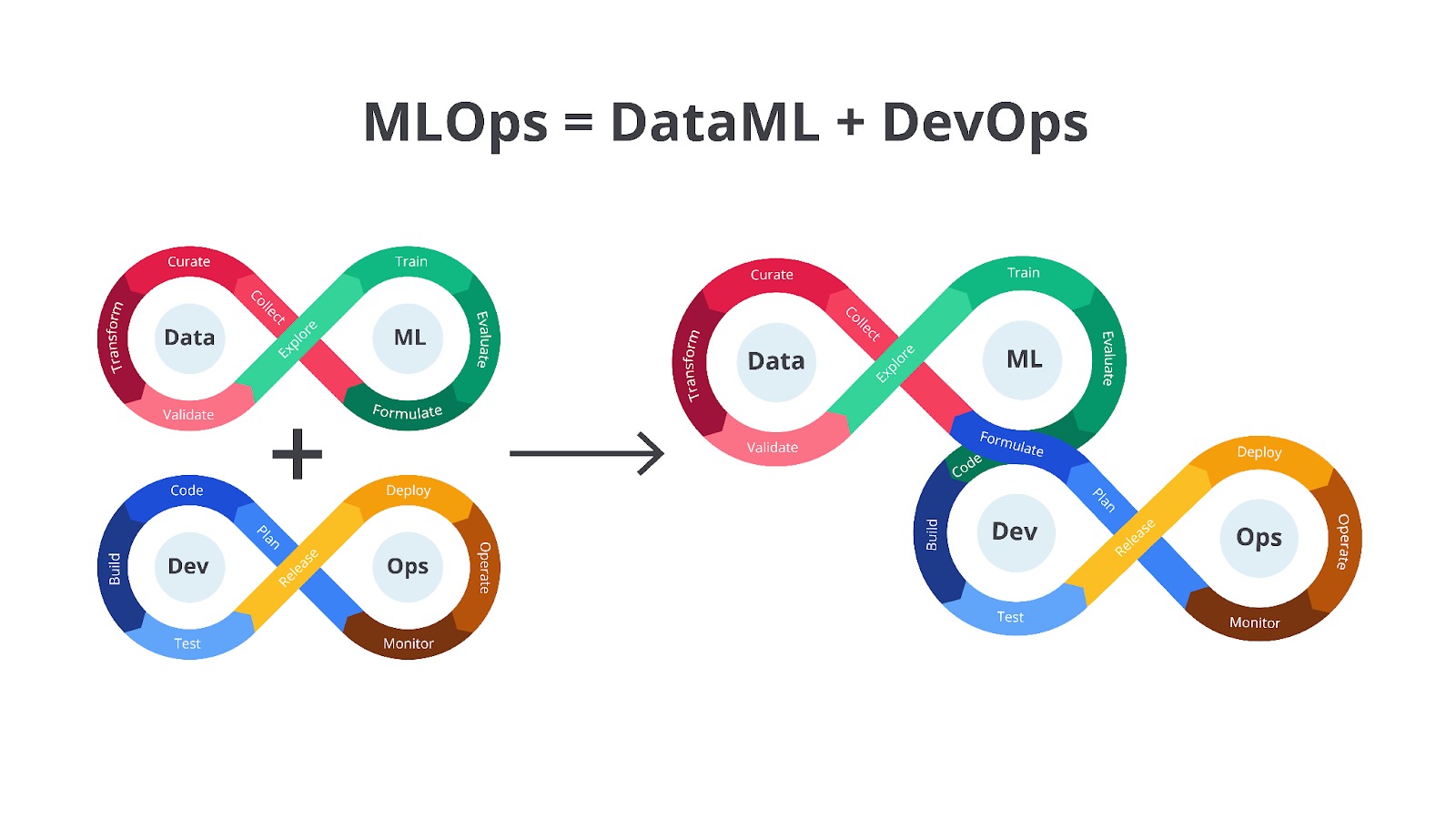
Ilustrasi di atas menggambarkan siklus pengembangan yang saat ini umum dijumpai dalam proyek pengembangan sistem machine learning di industri. Pada proses pengembangannya, setiap tahapan memiliki peran dan kepentingan yang berbeda-beda. Namun, sebelum kita membahas siklus pengembangan machine learning, alangkah lebih baiknya kita mempelajari permasalahan umum ketika membangun sistem machine learning. Dengan begitu, Anda akan lebih paham alasan dan peran MLOps pada proses pengembangan sistem machine learning.
Permasalahan Umum ketika Membangun Sistem Machine Learning
Membangun sistem Machine Learning itu seperti petualangan seru yang penuh dengan tantangan menarik. Biasanya kita memulai dengan mengumpulkan data, ibarat mencari harta karun informasi. Kemudian, data tersebut kita bersihkan dan rapikan, seperti menyiapkan bahan-bahan terbaik untuk sebuah mahakarya. Setelah itu, kita latih model Machine Learning layaknya mendidik seorang murid polos hingga ia mampu melakukan tugas-tugas luar biasa. Yang paling menyenangkan adalah kita bisa melihat model tersebut bekerja dan memberikan manfaat nyata di dunia.
Namun, untuk mencapai tahapan tersebut tentu tidak semulus jalan tol Cipularang. Berbagai macam permasalahan akan muncul ketika Anda membangun sistem machine learning tanpa menerapkan prinsip MLOps. Penasaran kan apa saja permasalahan yang sering muncul? Yuk, kita bahas satu per satu.
-
Kurangnya Reproduksibilitas
Salah satu permasalahan utama adalah kurangnya reproduksibilitas ketika proyek akan didelegasikan (handoff) ke orang baru. Tanpa dokumentasi yang baik, parameter model, versi data, dan konfigurasi lingkungan sering kali tidak tercatat dengan rapi. Hal ini menyulitkan anggota tim untuk mereproduksi hasil eksperimen sebelumnya atau memahami bagaimana suatu hasil dicapai. Akibatnya, kolaborasi antar anggota tim terhambat, dan proses pengembangan model menjadi tidak efisien karena waktu terbuang untuk mengulangi langkah-langkah yang seharusnya dapat dihindari. -
Manajemen Data yang Tidak Efisien
Manajemen data yang tidak efisien juga menjadi salah satu faktor yang mengakibatkan kendala signifikan. Data mungkin tersimpan di berbagai lokasi tanpa struktur yang jelas, dan versi data tidak dikontrol dengan baik. Inkonsistensi data dapat terjadi ketika model dilatih dengan dataset yang berbeda tanpa kita sadari sehingga menghasilkan performa yang tidak konsisten dan sulit diandalkan. Hal ini menyebabkan kesulitan dalam melacak perubahan dataset karena dengan ketidaktahuan ini dapat meningkatkan risiko penggunaan data usang atau tidak relevan.Bayangkan ketika Anda diminta untuk melakukan re-training, tetapi tidak mengetahui versi dataset yang digunakan sebelumnya. Tentunya hal tersebut akan menjadi masalah karena Anda tidak dapat melakukan tracking terhadap model yang sudah dibangun.
-
Proses Deployment yang Kompleks dan Rentan Kesalahan
Proses deployment merupakan tahapan yang kompleks dan rentan terhadap kesalahan, jika kita tidak melakukannya dengan baik, hal ini dapat memunculkan masalah lain di kemudian hari. Tanpa pendekatan terstruktur, deployment model di lingkungan produksi akan dilakukan secara manual tanpa otomatisasi atau pengujian yang memadai. Hal ini tidak hanya memperlambat proses deployment, tetapi juga meningkatkan risiko kesalahan konfigurasi yang dapat menyebabkan kegagalan sistem. Selain itu, kurangnya skalabilitas dapat mengakibatkan kesulitan untuk memperbarui atau mengganti model dengan cepat sesuai kebutuhan bisnis. -
Monitoring dan Maintenance Model yang Buruk
Monitoring dan maintenance model yang kurang baik dapat menyebabkan model drift dan degradasi performa. Tanpa sistem monitoring yang efektif, perubahan dalam data atau environment tidak dapat terdeteksi sehingga membuat model menjadi kurang akurat seiring berjalannya waktu.Ketidakmampuan untuk menyesuaikan model dengan data baru atau pola perilaku pengguna dapat berdampak negatif pada keputusan bisnis, dan pengguna mungkin kehilangan kepercayaan pada perusahaan tempat kita bekerja.
-
Kesulitan dalam Kolaborasi Tim
Kesulitan dalam kolaborasi tim muncul ketika tidak ada standar dan alat yang mendukung kerja sama. Kode dan model yang tidak terintegrasi dengan baik dapat menyebabkan duplikasi pekerjaan dan komunikasi yang buruk. Efisiensi rendah dalam proses pengembangan dapat terjadi karena anggota tim bekerja pada ruang lingkupnya masing-masing tanpa menyadari kontribusi satu sama lain.Hal ini sering kali terjadi ketika kita tidak mengimplementasikan MLOps sehingga masing-masing tim bekerja tanpa kolaborasi yang baik—setiap tim bekerja sendiri dengan egonya masing-masing.
-
Skalabilitas Sistem yang Terbatas
Skalabilitas sistem yang terbatas menjadi tantangan ketika volume data dan permintaan pengguna meningkat drastis. Sistem yang dibangun seadanya tanpa mempertimbangkan skalabilitas ataupun infrastruktur yang baik dapat mengalami penurunan performa, peningkatan risiko downtime, dan memberikan pengalaman pengguna yang buruk. Hal ini dapat berdampak negatif pada reputasi perusahaan dan kepuasan pelanggan. -
Model Drift dan Degradasi Performa
Dalam dunia machine learning, model drift adalah fenomena di mana performa model menurun seiring waktu karena perubahan dalam distribusi data atau lingkungan operasional. Tanpa pendekatan MLOps, tim sering kali gagal mendeteksi dan mengatasi model drift ini. Akibatnya, prediksi yang dihasilkan menjadi tidak akurat sehingga dapat berdampak negatif pada keputusan bisnis dan kepercayaan pengguna terhadap sistem. Pemantauan terus-menerus dan pembaruan model secara berkala memiliki peran krusial untuk memastikan model tetap relevan dan berkinerja optimal. -
Kesulitan dalam Melacak Eksperimen dan Versi Model
Melacak (tracking) eksperimen dan versi model adalah aspek penting dalam pengembangan machine learning yang selalu terlupakan. Tanpa version control system dan manajemen eksperimen yang baik, sangat sulit rasanya untuk mengetahui konfigurasi model mana yang memberikan performa terbaik. Kesulitan ini mengakibatkan pengambilan keputusan yang tidak optimal karena tim tidak memiliki informasi yang diperlukan untuk memilih atau meningkatkan model secara efektif. Selain itu, waktu dan sumber daya terbuang untuk mengulangi eksperimen yang seharusnya dapat dihindari.Masih ingatkan pada kelas Pengembangan Machine Learning yang mengharuskan Anda melatih model selama 30 sampai 60 menit untuk data tidak terstruktur? Waktu tersebut masih tergolong sebentar karena pada tahap produksi, model dapat dilatih berjam-jam atau bahkan berhari-hari. Dengan menerapkan model tracking yang baik, Anda tidak perlu membuang-buang waktu sehingga dapat berinovasi dengan lebih baik.
-
Isu Kepatuhan dan Regulasi
Dalam era data yang semakin diatur oleh regulasi seperti GDPR (General Data Protection Regulation) atau HIPAA, kepatuhan terhadap peraturan menjadi aspek yang tidak bisa diabaikan. Mungkin Anda berpikir GPDR tidak berlaku di Indonesia, sayangnya GDPR tidak hanya berlaku di Uni Eropa, melainkan untuk seluruh bisnis di dunia yang menyimpan dan mengolah data pribadi, termasuk bisnis di Indonesia.Tanpa dokumentasi, pengetahuan dan kontrol yang memadai, sulit bagi perusahaan untuk memastikan bahwa sistem machine learning mereka memenuhi standar kepatuhan yang ditetapkan. Risiko hukum dan reputasi yang tercemar menjadi konsekuensi serius dari kelalaian ini, termasuk potensi denda dan kehilangan kepercayaan dari pelanggan serta mitra bisnis.
-
Akumulasi Technical Debt (Utang Teknis)
Technical debt terjadi ketika solusi sementara atau kode yang kurang optimal dibiarkan tanpa perbaikan atau refactoring karena merasa semuanya berjalan dengan normal. Dalam konteks machine learning tanpa MLOps, akumulasi technical debt dapat membuat sistem menjadi kompleks dan sulit diperbaiki karena sudah menumpuk.
Hal ini dapat meningkatkan biaya operasional dan memperlambat pengembangan fitur baru karena tim harus berurusan dengan kode yang sulit dipahami dan rentan terhadap _bug_. Dalam jangka panjang, _technical debt_ berperan layaknya bom waktu, dan ketika hal tersebut “meledak” akan menyebabkan inovasi terhambat karena _load_ tim menjadi tidak seimbang karena harus memperbaiki semuanya dalam satu waktu.
- Integrasi yang Tidak Efektif dengan Sistem Lain
Sistem machine learning yang tidak terintegrasi dengan baik ke dalam ekosistem teknologi perusahaan dapat menimbulkan berbagai masalah. Data mungkin tidak mengalir dengan lancar antara sistem sehingga fungsi model tidak dimanfaatkan sepenuhnya. Akibatnya, potensi penuh dari machine learning tidak tercapai dan pengguna tidak mendapatkan manfaat optimal dari sistem yang ada.
Integrasi yang efektif membutuhkan perencanaan dan implementasi yang matang, sesuatu yang sering diabaikan tanpa pendekatan MLOps.
-
Kurangnya Standar dan Best Practices
Tanpa standar dan best practice yang diterapkan secara konsisten, pengembangan machine learning dapat menjadi liar dan tidak terstruktur. Kode yang dihasilkan kemungkinan dapat berjalan tetapi berkualitas rendah, sulit dipahami, dan sulit dipelihara. Hal ini menyulitkan onboarding anggota tim baru dan menghambat kolaborasi. Selain itu, tanpa panduan yang jelas, sulit untuk menerapkan teknologi atau metode baru sehingga menghambat inovasi dan efisiensi tim secara keseluruhan. -
Masalah Keamanan
Keamanan adalah aspek kritis dalam pengembangan sistem machine learning, terutama ketika berurusan dengan data sensitif seperti kesehatan, legal, undang-undang, dan lain sebagainya. Tanpa perhatian yang memadai terhadap keamanan, sistem menjadi rentan terhadap serangan seperti pencurian data atau manipulasi model. Pelanggaran keamanan tidak hanya menimbulkan kerugian finansial tetapi juga dapat merusak reputasi perusahaan.
Salah satu contoh masalah keamanan yang sering terjadi saat ini adalah _prompt injection_. Prompt injection dapat menyamarkan instruksi berbahaya sebagai input yang dikirimkan oleh pengguna, sehingga dapat mengelabui LLM agar mengabaikan instruksi pengembang dalam prompt sistem. Akibatnya, LLM yang Anda miliki dapat menghasilkan informasi yang keliru, melanggar aturan atau bahkan menyerang.
- Penggunaan Sumber Daya yang Tidak Optimal
Efisiensi penggunaan sumber daya komputasi adalah faktor penting dalam operasional machine learning. Tanpa monitoring dan optimasi yang tepat, model dapat menggunakan sumber daya secara berlebihan sehingga meningkatkan biaya operasional secara signifikan.
Inefisiensi ini juga dapat membatasi ketersediaan sumber daya untuk tugas lain yang penting, serta memiliki dampak lingkungan akibat konsumsi komputasi yang lebih tinggi. Faktanya, ketika Anda men-_deploy_ model ke lingkungan produksi, performa bukanlah satu-satunya hal terpenting karena di lain sisi _cost_ pemeliharaan memiliki dampak yang lebih besar terhadap stabilitas perusahaan.
- Ketergantungan pada Individu Tertentu
Ketika pengetahuan tentang sistem terpusat pada individu tertentu tanpa dokumentasi yang memadai, risiko operasional terhambat akan meningkat dengan signifikan. Bayangkan jika individu tersebut sedang cuti atau meninggalkan perusahaan, pemeliharaan dan pengembangan sistem akan terhambat.
Mungkin Anda berpikir bahwa kondisi seperti ini akan menguntungkan posisi Anda di perusahaan, tetapi hal ini merupakan keputusan yang tidak bijak karena akan merugikan perusahaan di kemudian hari. Anda boleh saja mengambil semua pekerjaan, tetapi pastikan membuat dokumentasi yang baik sehingga ketika Anda keluar, perusahaan dapat berjalan dengan normal.
-
Kurangnya Feedback Loop dari Pengguna
Feedback dari pengguna adalah komponen vital untuk meningkatkan kualitas model dan memastikan relevansi sistem di dunia nyata. Tanpa mekanisme yang efektif untuk mengumpulkan dan menganalisis feedback, tim pengembang mungkin tidak menyadari masalah atau kebutuhan yang muncul. Akibatnya, model mungkin tidak memenuhi harapan atau kebutuhan pengguna yang dapat mengurangi kepuasan dan retensi pengguna. -
Kesulitan dalam Manajemen Infrastruktur
Seperti yang kita tahu, proses pelatihan model membutuhkan resource yang cukup besar atau minimal memiliki GPU agar mempercepat proses pembuatan model. Hal ini juga berdampak ketika kita mencoba untuk men-_deploy_ model ke lingkungan produksi.
Bayangkan Anda melatih model dengan GPU RTX 3060, tetapi hanya menggunakan CPU ketika di lingkungan produksi. Tentunya, Anda akan mengalami permasalahan serius karena perbedaan infrastruktur yang signifikan. Sebagai contoh ketika melakukan inference LLM dengan RTX 3060, sistem akan menghasilkan 40-45 token per detik sedangkan ketika menggunakan CPU hanya menghasilkan 5-10 token per detik. Tentunya itu akan mengurangi kepuasan pelanggan, ‘kan?
Dari permasalahan tersebut, Anda wajib menerapkan manajemen infrastruktur yang baik sehingga dapat memberikan hasil maksimal kepada pengguna. Namun, tetap jangan lupakan untuk menghitung _operational cost_ juga ya.
-
Ketidakmampuan untuk Melakukan Eksperimen Cepat
Tanpa pipeline yang efisien, tim akan kesulitan melakukan eksperimen dan pengujian model baru secara cepat. Hal ini memperlambat inovasi dan respons terhadap tren pasar atau kebutuhan bisnis yang berubah sehingga perusahaan dapat kehilangan keunggulan kompetitif. -
Kurangnya Dokumentasi dan Transparansi
Dokumentasi yang buruk menyebabkan kurangnya transparansi dalam proses pengembangan, menyulitkan audit, reproduksi hasil, atau penelusuran asal mula masalah. Kurangnya dokumentasi meningkatkan risiko kesalahan berulang dan menghambat pembelajaran dari pengalaman sebelumnya sehingga mengurangi efektivitas tim secara keseluruhan.
Waaahhh, banyak sekali ternyata permasalahan yang muncul ketika kita mulai mengimplementasikan model machine learning ke lingkungan produksi. Mungkin sampai pada kelas ini, Anda belum pernah merasakan permasalahan di atas karena model yang kita bangun masih terisolasi di lingkungan development.
Permasalahan di atas akan muncul ketika Anda tidak menerapkan prinsip MLOps dalam pembangunan sistem machine learning. Tanpanya, kita akan menghadapi berbagai macam tantangan mulai dari mengelola model, kesulitan untuk memastikan kualitas dan keandalan, serta memenuhi persyaratan bisnis dan regulasi.
Memangnya peran MLOps itu apa sih? Kok kelihatannya penting banget? Singkatnya, MLOps memiliki peran yang sangat penting ketika kita membangun sistem machine learning karena MLOps ini bertujuan untuk mengotomatisasi dan meningkatkan kualitas serta kecepatan pengembangan, deployment, dan pemeliharaan model machine learning dalam produksi.
Agar Anda semakin paham, mari kita tilik kembali peran MLOps untuk menyelesaikan permasalahan yang sudah dibahas sebelumnya.
-
Model Drift dan Degradasi Performa
Model drift terjadi ketika distribusi data berubah seiring waktu, menyebabkan penurunan akurasi model. Permasalahan ini kerap terjadi karena kita tidak melakukan monitoring dengan baik atau bahkan tidak ada monitoring sama sekali setelah membuat model machine learning.MLOps menyediakan alat untuk memantau performa model secara kontinu sehingga dapat meminimalisasi permasalahan model drift. Dengan metrik yang jelas, developer dapat mendeteksi penurunan performa segera setelah terjadi. Tidak berhenti di sana, sistem juga dapat mengirim peringatan otomatis ketika performa model menurun di bawah ambang tertentu.
Last but not least, MLOps memungkinkan otomatisasi proses retraining model dengan data terbaru (atau gabungan dengan data lama) untuk memastikan model tetap akurat dan relevan. Waahh, keren ‘kan? Simpan dahulu kagumnya, itu baru peran pertama.
-
Kurangnya Automasi dalam Pipeline ML
Proses manual dalam pipeline machine learning meningkatkan risiko kesalahan dan memperlambat pengembangan sehingga proses manual acapkali menjadi masalah bagi perusahaan. Di sinilah peran MLOps akan terlihat dengan jelas karena MLOps dapat mengotomatisasi seluruh pipeline, termasuk pengumpulan data, pra-pemrosesan, pelatihan, validasi, dan deployment.Tidak hanya itu, dengan menerapkan prinsip CI/CD, kita dapat memastikan bahwa setiap perubahan kode atau data dapat diintegrasikan dan di-_deploy_ secara cepat dan aman. Setelah semua proses berjalan dengan mulus, kini perusahaan memiliki sistem yang up-to-date sepanjang waktu sehingga Anda dapat mengerjakan pekerjaan lain yang lebih krusial.
-
Kesulitan dalam Melacak Eksperimen dan Versi Model
Pada dasarnya, kita semua merupakan manusia normal yang tidak memiliki kemampuan untuk menerawang. Oleh karena itu, tanpa tracking yang baik, sulit rasanya untuk mengetahui konfigurasi model mana yang memberikan performa terbaik. Di lain sisi, kita juga tidak bisa melihat apakah performa model yang kita simpan pada tahap produksi ini sudah sesuai atau mengalami overfitting.MLOps memiliki kemampuan untuk melakukan experiment tracking dengan menggunakan tools seperti MLflow atau Weights & Biases untuk mencatat parameter, metrik, dan hasil setiap eksperimen.
Lalu, bagaimana dengan permasalahan versi untuk model atau dataset? Tenang, MLOps juga dapat melacak versi dataset dan model untuk memastikan setiap eksperimen dapat dibandingkan dan direproduksi.
Last one, metadata management merupakan dokumentasi yang biasanya dianggap sebelah mata, disepelekan, bahkan diabaikan. Mengapa hal tersebut bisa terjadi? Biasanya, untuk menambahkan metadata, kita harus melakukan injeksi menggunakan kode yang tidak sederhana. Akibatnya, developer sering mengabaikan karena dirasa tidak penting.
Hingga akhirnya, ketika model perlu diduplikasi, kita akan kebingungan karena tidak memiliki informasi metadata. Oleh karena itu, dengan menerapkan MLOps, kita dapat melakukan penyimpanan metadata yang terstruktur agar memudahkan pencarian dan analisis eksperimen sebelumnya.
-
Akumulasi Technical Debt (Utang Teknikal)
Technical debt adalah metafora untuk menggambarkan implikasi jangka panjang dari mengambil jalan pintas atau membuat keputusan suboptimal selama pengembangan perangkat lunak, termasuk machine learning. Layaknya utang finansial, technical debt akan menimbulkan “bunga” di kemudian hari dalam bentuk peningkatan biaya pemeliharaan, kesulitan dalam implementasi fitur baru, dan penurunan kualitas.Dengan menerapkan prinsip MLOps, Anda dapat meminimalisir technical debt. Bagaimana caranya? Mari kita bahas beberapa peran MLOps untuk mengatasi permasalahan ini.
- MLOps mengotomatiskan banyak proses dalam pengembangan machine learning sehingga mengurangi kesalahan developer.
- MLOps dapat melakukan monitoring performa model sehingga dapat mendeteksi masalah lebih awal sebelum menjadi masalah besar. Alerting otomatis memberi tahu tim tentang anomali atau penurunan performa.
- MLOps melacak setiap versi model, kode, dan data yang dapat memudahkan untuk kembali ke versi sebelumnya jika diperlukan dan memastikan reproduksibilitas eksperimen.
- MLOps mendorong pembangunan pipeline data yang robust dan dapat diandalkan, mampu menangani berbagai format data dan skenario.
- MLOps menyediakan kerangka kerja untuk mengelola model yang di-deploy, termasuk metadata management dan access control, mengurangi risiko, dan meningkatkan transparansi.
- MLOps memfasilitasi kolaborasi yang lebih baik antara data scientist, ML engineer, dan tim operasional, serta mengurangi miskomunikasi yang dapat menyebabkan technical debt.
- MLOps mendorong praktik dokumentasi yang baik untuk kode, data, dan model, memudahkan pemeliharaan dan kolaborasi di masa mendatang.
- Dengan memanfaatkan containerization dan infrastruktur as code, MLOps memastikan bahwa lingkungan pengembangan dan produksi lebih konsisten dan mudah direproduksi sehingga mengurangi masalah kompatibilitas dan dependensi.
Itu dia peran-peran yang MLOps miliki untuk menanggulangi permasalahan “besar” yang akan terjadi ketika Anda membuat sistem machine learning seadanya. Harapannya, dengan mengetahui ini, Anda akan makin andal untuk membangun model machine learning yang siap didistribusikan kepada pengguna.
Dengan demikian, penerapan MLOps tidak hanya mengatasi permasalahan teknis tetapi juga memberikan nilai tambah bagi perusahaan melalui peningkatan produktivitas, kualitas, dan kecepatan dalam menyediakan solusi machine learning yang efektif.
Nah, agar petualangan ini berjalan lancar dan menyenangkan, Anda perlu mempelajari siklus hidup MLOps yang merupakan proses tak berujung untuk membantu mengelola setiap tahapan dengan efisien. Dengan ini, kita bisa menghindari hambatan dan memastikan proyek Machine Learning sukses dan membawa revenue ke perusahaan.
Dengan banyaknya permasalahan yang kita bahas, mungkin tebersit sebuah pertanyaan di benak Anda “Bagaimana cara kita menerapkan MLOps dengan prinsip DevOps?” Tenang saja, jika di materi sebelumnya Anda sudah mengetahui alur pengembangan machine learning, sekarang saatnya mempelajari siklus pembangunan model machine learning yang menerapkan prinsip DevOps. Tanpa basa-basi lagi, cuss berangkat!
Machine Learning Life Cycle
Seperti yang sudah Anda pelajari pada materi Pengenalan Machine Learning Operations, saat ini kita tidak lagi membahas siklus pengembangan machine learning sederhana yang terdiri dari data preparation dan training model saja.
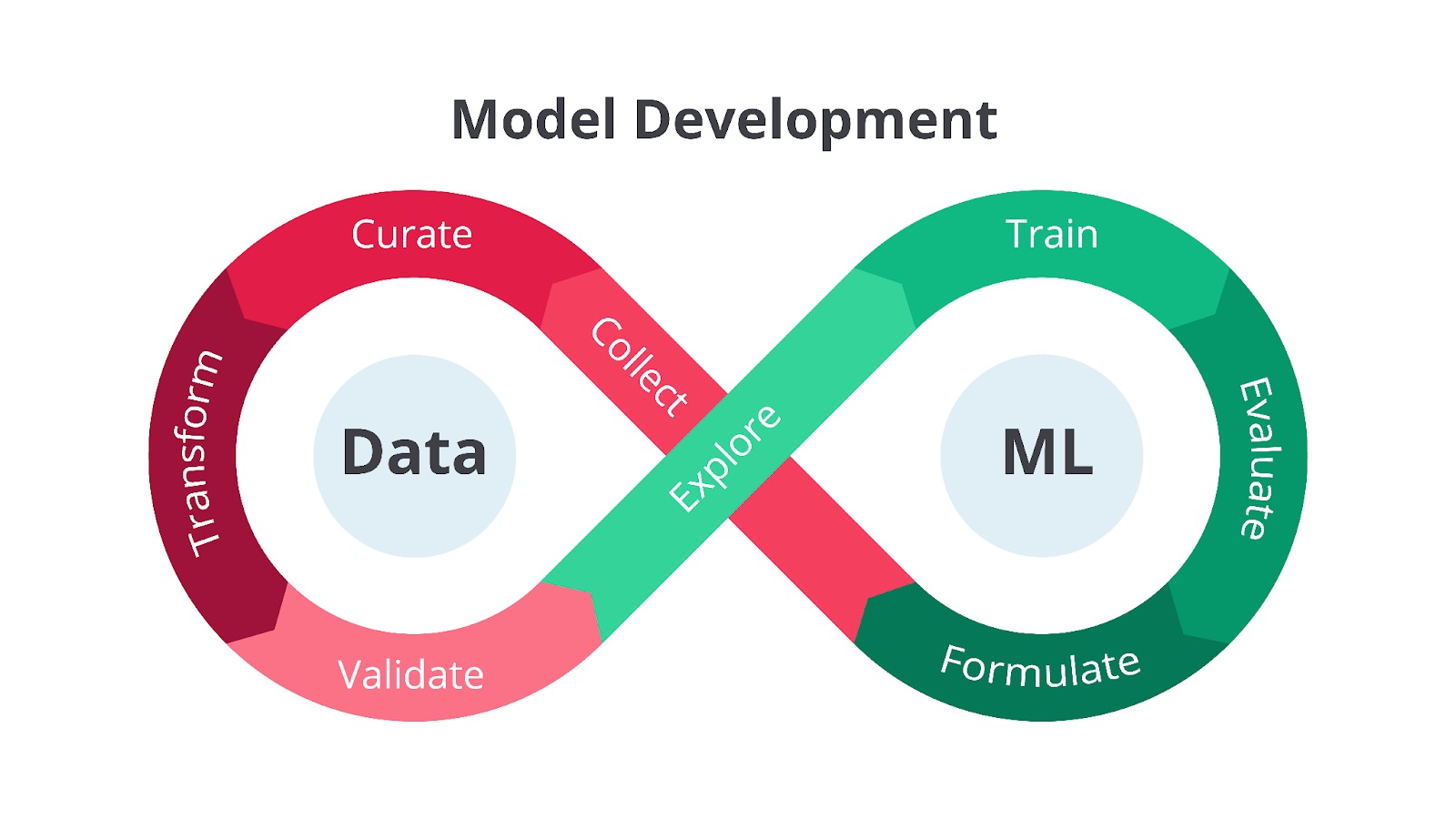
Pada materi ini, kita akan membahas mengenai life cycle (siklus hidup) yang umum digunakan dalam pengembangan sistem machine learning pada tahapan produksi. Seperti yang Anda ketahui, pengembangan sistem machine learning merupakan sebuah proses iteratif sehingga sering digambarkan sebagai sebuah siklus.
Pada skala industri, pengembangan sistem machine learning biasanya melibatkan banyak tim dengan keahlian yang berbeda-beda. Selain perbedaan keahlian, setiap tim juga memiliki peran dan kepentingan yang berbeda-beda. Idealnya setiap tim akan saling terhubung dan bekerja sama dalam menerapkan prinsip MLOps untuk menghasilkan sistem machine learning yang reliable, scalable, adaptable, dan maintainable.
Pada perusahaan yang sudah matang dan stabil, idealnya seorang data scientist akan membuat model machine learning dan “melempar” model yang sudah jadi kepada ML engineer dan software engineer untuk melakukan integrasi dengan sistem yang sudah ada pada lingkungan produksi. Proses tersebut setidaknya membutuhkan beberapa tim yang saling melempar dan menunggu.
Tentunya proses tersebut memakan waktu yang lama, bahkan tidak sedikit juga menimbulkan permasalahan karena setiap tim memiliki beban pekerjaan yang berbeda-beda. Setidaknya dengan menggunakan proses ini, kita melibatkan beberapa tim yang dapat Anda lihat pada diagram berikut.
Ilustrasi di atas menggambarkan kolaborasi yang saat ini umum dijumpai dalam proyek pengembangan sistem machine learning di industri. Lalu, di mana letak permasalahannya? Jika perusahaan tempat Anda bekerja sudah stabil dan memiliki komunikasi yang baik, tentu kolaborasi tersebut sangat ideal untuk dilakukan.
Sayangnya, komunikasi antar tim tidak sebaik yang kita perkirakan. Ego antar tim serta rasa kepemilikan yang terpecah menjadi alasan utama masalah komunikasi muncul ke permukaan, hal ini menjadi salah satu penyebab utama kegagalan dari sebuah proyek machine learning. Belum lagi jika terdapat salah satu anggota yang memiliki rasa “lebih tinggi” dibandingkan yang lainnya, bayangkan akan sesulit apa kolaborasi yang terjadi. Menyeramkan, ‘kan?
Padahal seharusnya setinggi apa pun posisi seseorang tidak berarti bisa menentukan segalanya tanpa mempertimbangkan masukan dari anggota tim. Karena pada dasarnya tim dibuat agar dapat memaksimalkan proyek yang sedang dikerjakan, sehingga kerja sama tim lebih penting dari kebutuhan atau ego personal.

Kembali ke pembahasan utama, tentunya seluruh tim baik itu data engineer, developer (pada kasus ini machine learning engineer atau data scientist) dan operations memiliki tujuan yang sama yaitu menyelesaikan permasalahan bisnis serta mendapatkan revenue.
Salah satu tujuan utama lainnya yaitu membuat perpindahan tugas antar tim dengan lancar tanpa menemui hambatan. Tentunya, hal ini didasari dengan visibilitas antar tim yang baik, komunikasi lancar, hingga tidak ada kebutuhan politik atau individu.
Dengan cerita seperti itu, sebenarnya Anda dapat membangun sistem machine learning sesuai dengan prinsipnya yaitu reliable, scalable, adaptable, dan maintainable. Berikut siklus pengembangan machine learning jika Anda menerapkan prinsip kolaborasi antar tim.
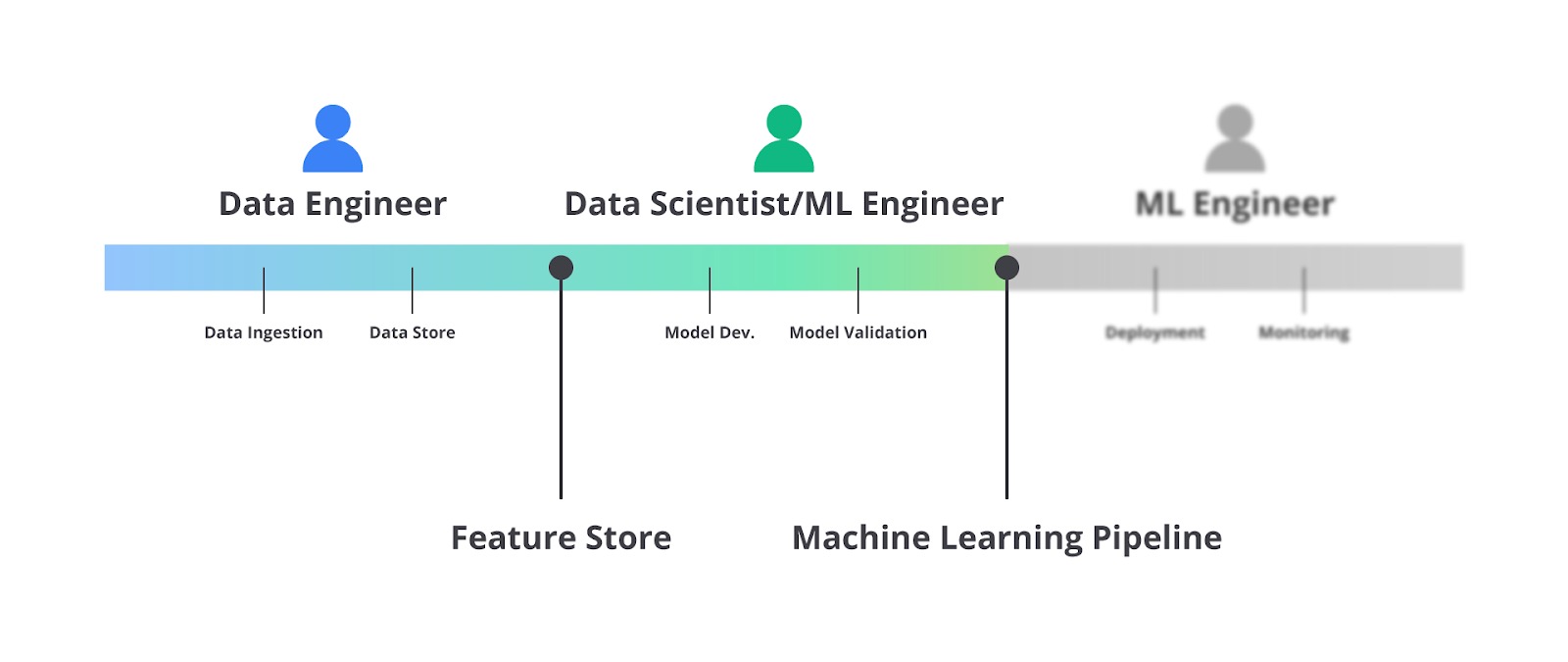
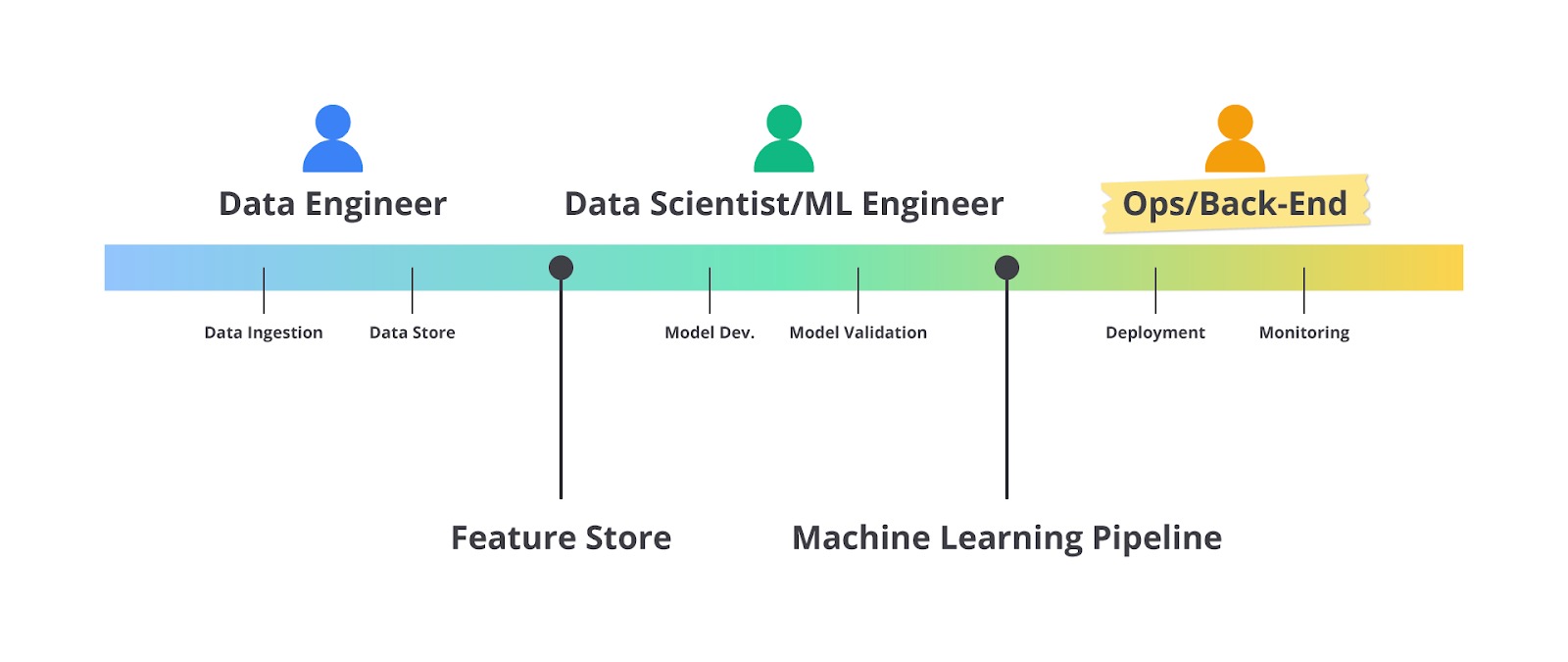
Gambar di atas menunjukkan alur kolaborasi antara data engineer, machine learning engineer, developer, dan operations engineer dalam membangun end-to-end sistem machine learning. Masing-masing peran memiliki tugas spesifik yang saling melengkapi untuk memastikan bahwa data, model, aplikasi, dan infrastruktur berjalan optimal, mulai dari pengumpulan data hingga deployment di lingkungan produksi.
Sebagai seorang developer, kami yakin sebagian besar dari Anda mungkin sudah mengetahui peran dan kewajiban semua tim yang terlibat. Namun, supaya lebih detail dalam memahami tugasnya, mari kita bedah satu per satu melalui sebuah cerita pendek berikut.
Perjalanan Membangun Sistem Machine Learning yang Ideal
Di sebuah perusahaan e-commerce yang berkembang pesat, tim manajemen menghadapi sebuah tantangan besar. Meskipun jumlah pengguna terus meningkat, tingkat kepuasan pelanggan menurun karena rekomendasi produk yang diberikan tidak relevan dan sering kali meleset dari kebutuhan pengguna. Banyak pelanggan mengeluhkan bahwa mereka merasa tidak diberikan rekomendasi yang sesuai oleh platform sehingga perusahaan kehilangan peluang untuk meningkatkan penjualan melalui personalisasi pengalaman pengguna. Data sudah tersedia dalam jumlah besar, tetapi sistem rekomendasi sederhana yang digunakan saat ini tidak lagi mampu menangkap preferensi kompleks dari jutaan pelanggan.
Untuk mengatasi masalah ini, perusahaan membentuk tim lintas fungsi yang terdiri dari empat spesialis dengan keahlian unik, yaitu Dita, Raka, Andi, dan Santi.

Tim ini diberikan misi untuk membangun sistem rekomendasi berbasis machine learning yang mampu memberikan prediksi yang relevan, cepat, dan akurat kepada pelanggan. Dengan pengalaman mereka masing-masing, tim mulai menyusun rencana strategis untuk memecahkan masalah ini dengan pembagian pekerjaan seperti berikut.
- Dita, seorang Data Engineer yang berpengalaman dalam mengelola dan memproses data skala besar.
- Raka, seorang Machine Learning Engineer yang ahli dalam membangun model prediktif dan optimasi algoritma.
- Andi, seorang Developer yang berfokus pada pengembangan aplikasi dan integrasi backend.
- Santi, seorang Operations Engineer yang andal dalam deployment, monitoring, dan menjaga sistem tetap berjalan stabil di produksi.
Tugas pertama dilakukan oleh Dita. Tugas Dita adalah memastikan data tersedia dan dapat diolah oleh tim lainnya. Dita memulainya dengan mengumpulkan data dari berbagai sumber, seperti database transaksi, log pengguna, dan data eksternal dari API mitra. Setelah data terkumpul, Dita mengidentifikasi data yang relevan, lalu memvalidasi dan membersihkan data tersebut. Dengan alat bantu ETL (Extract, Transform, Load), Dita memastikan data yang sudah diproses disimpan dengan rapi di sebuah data warehouse yang aman dan terstruktur.
Selanjutnya, data diberikan ke Machine Learning Engineer bernama Raka. Raka menerima data dari pipeline yang sudah diatur oleh Dita dan mulai mengeksplorasi data tersebut. Dia menganalisis pola-pola yang ada, seperti preferensi pengguna terhadap kategori produk tertentu, serta tren musiman dalam pembelian. Berdasarkan analisis ini, Raka mulai merancang model machine learning yang sesuai. Dia memilih algoritma yang tepat, melatih modelnya menggunakan data historis, dan mengevaluasi performanya. Ketika model awalnya menunjukkan hasil yang belum optimal, Raka mengoptimasi model tersebut dengan tuning hyperparameter dan mencoba beberapa pendekatan lainnya. Akhirnya, dia menghasilkan model rekomendasi yang mampu memberikan prediksi akurat.
Model sudah siap, tetapi belum cukup sampai di sini. Sekarang kita membutuhkan tim developer untuk mengintegrasikan model ke dalam aplikasi yang digunakan oleh pelanggan.
Di sinilah peran Developer bernama Andi dimulai. Andi menerima model yang sudah dilatih oleh Raka dan mulai merencanakan arsitektur sistem yang akan mengintegrasikan model tersebut ke aplikasi perusahaan. Dia mengembangkan API backend yang memungkinkan aplikasi frontend untuk memanggil prediksi dari model. Selain itu, Andi juga membangun antarmuka pengguna yang intuitif agar pelanggan dapat langsung merasakan manfaat rekomendasi yang diberikan. Setelah sistem selesai dikembangkan, Andi melakukan serangkaian pengujian—dari unit testing hingga pengujian integrasi—untuk memastikan semua komponen bekerja dengan baik. Model dan aplikasi kemudian dikemas dalam container menggunakan Docker sehingga siap untuk di-deploy.
API sudah siap, sekarang giliran tim operasi memastikan bahwa model dan aplikasi ini dapat berjalan lancar di lingkungan produksi.
Tugas terakhir berada di tangan Operations Engineer bernama Santi. Santi bertanggung jawab untuk mengkonfigurasi infrastruktur di cloud, mengatur cluster Kubernetes untuk menjalankan container model dan aplikasi, serta memastikan sistem dapat menangani lonjakan pengguna pada jam sibuk. Setelah deployment selesai, Santi mengatur monitoring untuk memantau performa model, seperti waktu respons dan akurasi prediksi di dunia nyata. Santi juga memastikan bahwa jika model mulai mengalami penurunan performa (model drift), ada pipeline retraining otomatis yang akan memperbarui model dengan data terbaru. Dengan pemantauan yang baik, Santi dapat segera mendeteksi dan memperbaiki masalah jika terjadi gangguan.
Dengan kolaborasi dari semua tim, sistem rekomendasi yang canggih kini berjalan di lingkungan produksi, memberikan pengalaman yang lebih baik bagi pelanggan dan memberikan dampak nyata bagi bisnis perusahaan.
Dari kisah di atas, terlihat bagaimana setiap peran memiliki tugas spesifik yang saling melengkapi.
- Data Engineer memastikan data berkualitas tinggi tersedia untuk model.
- Machine Learning Engineer mengembangkan model yang akurat dan optimal.
- Developer mengintegrasikan model ke dalam aplikasi yang ramah pengguna.
- Operations Engineer menjaga sistem tetap andal dan dapat diperbarui di lingkungan produksi.
Kolaborasi yang solid di antara mereka memungkinkan sistem machine learning ini sukses diimplementasikan, dari tahap data mentah hingga ke aplikasi yang digunakan pelanggan.
Sayangnya cerita di atas (kemungkinan) terjadi ketika Anda bekerja pada sebuah perusahaan yang sudah matang sehingga pembagian tugas menjadi sangat jelas dan terarah. Namun, tidak berarti proses tersebut selalu berjalan dengan baik lho. Terdapat beberapa permasalahan yang sering muncul seiring berjalannya waktu seperti berikut.
- Komunikasi yang Kompleks
Kolaborasi lintas tim sering menghadapi hambatan komunikasi, seperti miskomunikasi atau waktu tunggu untuk keputusan. - Koordinasi yang Rumit
Sinkronisasi antar tim membutuhkan tools dan proses manajemen yang efektif untuk menghindari konflik atau tumpang tindih pekerjaan. - Biaya Lebih Tinggi
Dibutuhkan lebih banyak sumber daya untuk membentuk tim, menggunakan alat kolaborasi, dan menjalankan infrastruktur yang mendukung. - Ketergantungan Antar Tim
Jika satu tim mengalami hambatan, keseluruhan proses bisa tertunda. - Potensi Konflik Prioritas
Setiap tim mungkin memiliki prioritas berbeda yang bisa menghambat pengambilan keputusan.
Seperti yang kita tahu, jika membangun sistem ML tanpa MLOps, siklus pengembangan model ML sering kali bersifat tertutup, manual, dan tidak terstruktur. Tanpa adanya kolaborasi seperti cerita di atas, tentu saja (hampir) mustahil bagi pengguna dapat menggunakan sistem berbasis machine learning yang memuaskan.
Lalu, apa solusinya? Tentu saja MLOps karena metode ini mengintegrasikan prinsip-prinsip DevOps ke dalam siklus hidup ML sehingga menciptakan proses yang lebih terstruktur, otomatis, dan efisien.
Di lain sisi, MLOps mengatasi bottleneck dalam hal komunikasi antar tim karena dengan menguasai materi ini membuat Anda menjadi lebih independen sehingga fleksibel untuk mengembangan sebuah sistem tanpa mengurangi performanya.
Dengan menerapkan MLOps, perusahaan dapat mengatasi bottleneck yang umum terjadi dalam machine learning workflow tradisional. MLOps memungkinkan proses pengembangan dan deployment (penyebaran) model yang lebih cepat, efisien, dan terukur sehingga organisasi dapat memaksimalkan nilai bisnis dari machine learning.
Siklus hidup MLOps terdiri dari beberapa tahapan yang saling berhubungan, yang dirancang untuk memastikan pengembangan, deployment, dan pemeliharaan model ML yang efisien dan berkelanjutan. Umumnya, tahapan ini biasanya terbagi menjadi tugas ML developer dan tim Operations. Namun, dengan pendekatan MLOps, kemampuan ini setidaknya harus diketahui atau bahkan dikuasai oleh seorang machine learning engineer.
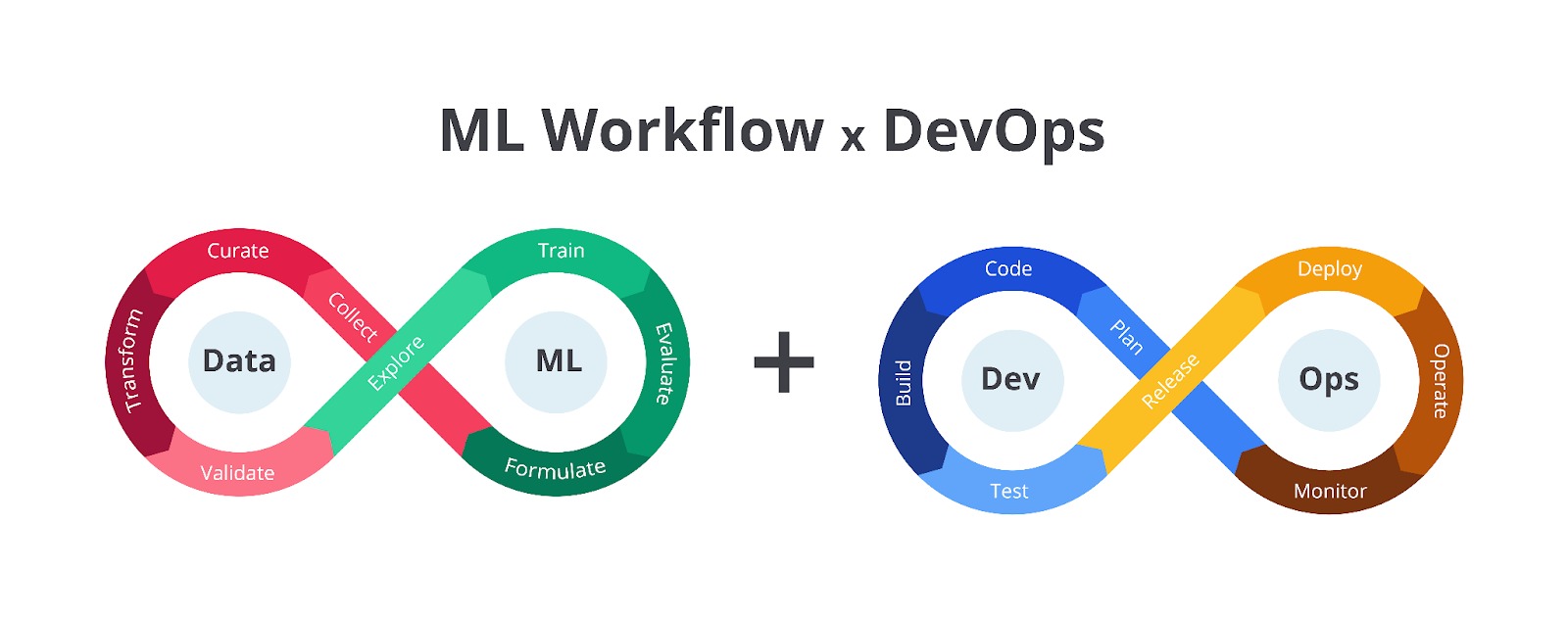
Dengan menggabungkan pengetahuan pembangunan model machine learning dan keterampilan operations, Anda dapat mengikis barrier gap antar tim sehingga dapat membangun sistem machine learning dengan lebih mulus.
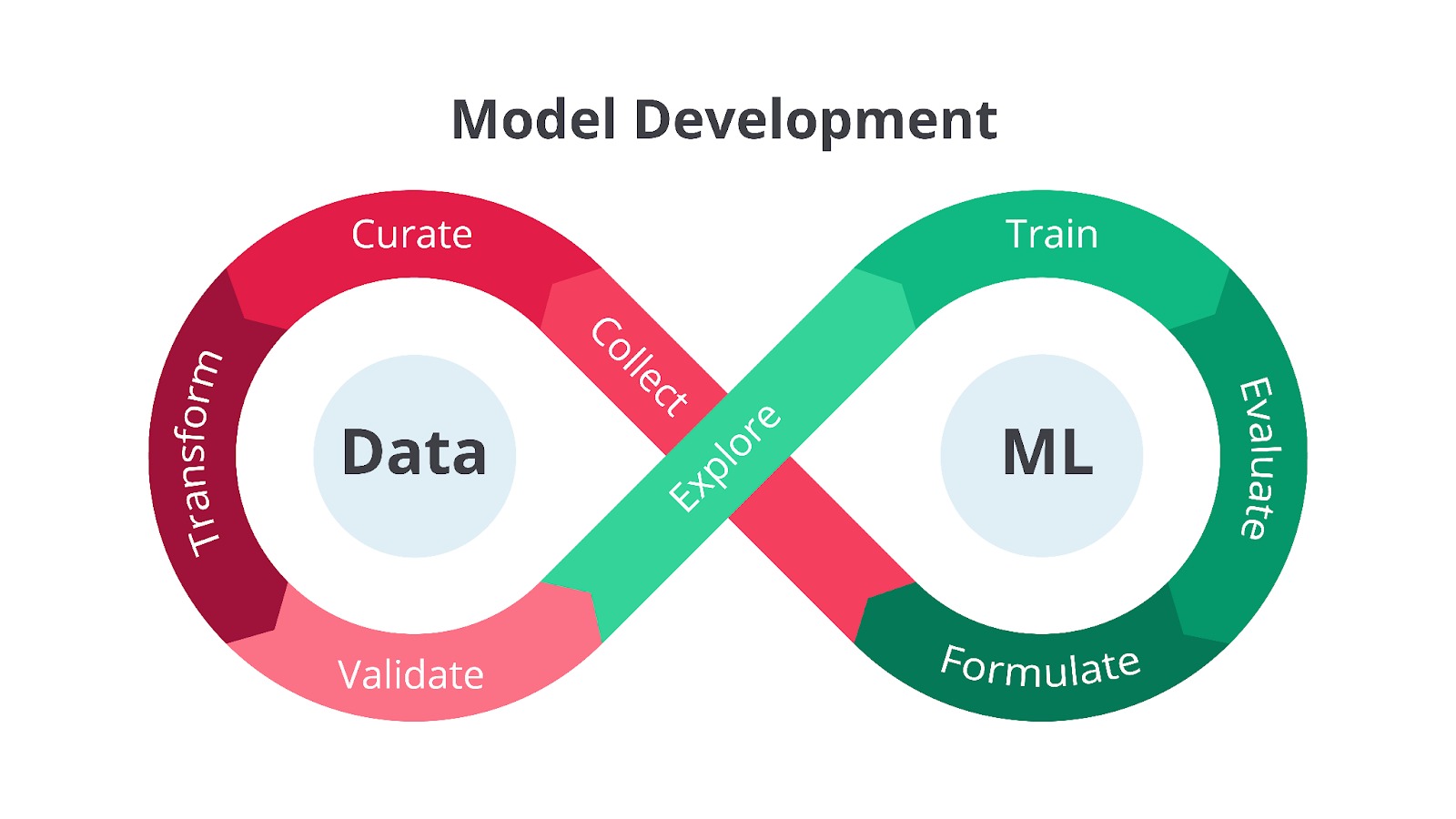
Penggabungan tersebut menghasilkan sebuah siklus pengembangan yang sedari tadi kita bahas, yaitu MLOps. Terdapat berbagai macam gambar yang merepresentasikan siklus pengembangan MLOps ini, tetapi pada materi ini mari kita gunakan siklus pengembangan berikut.
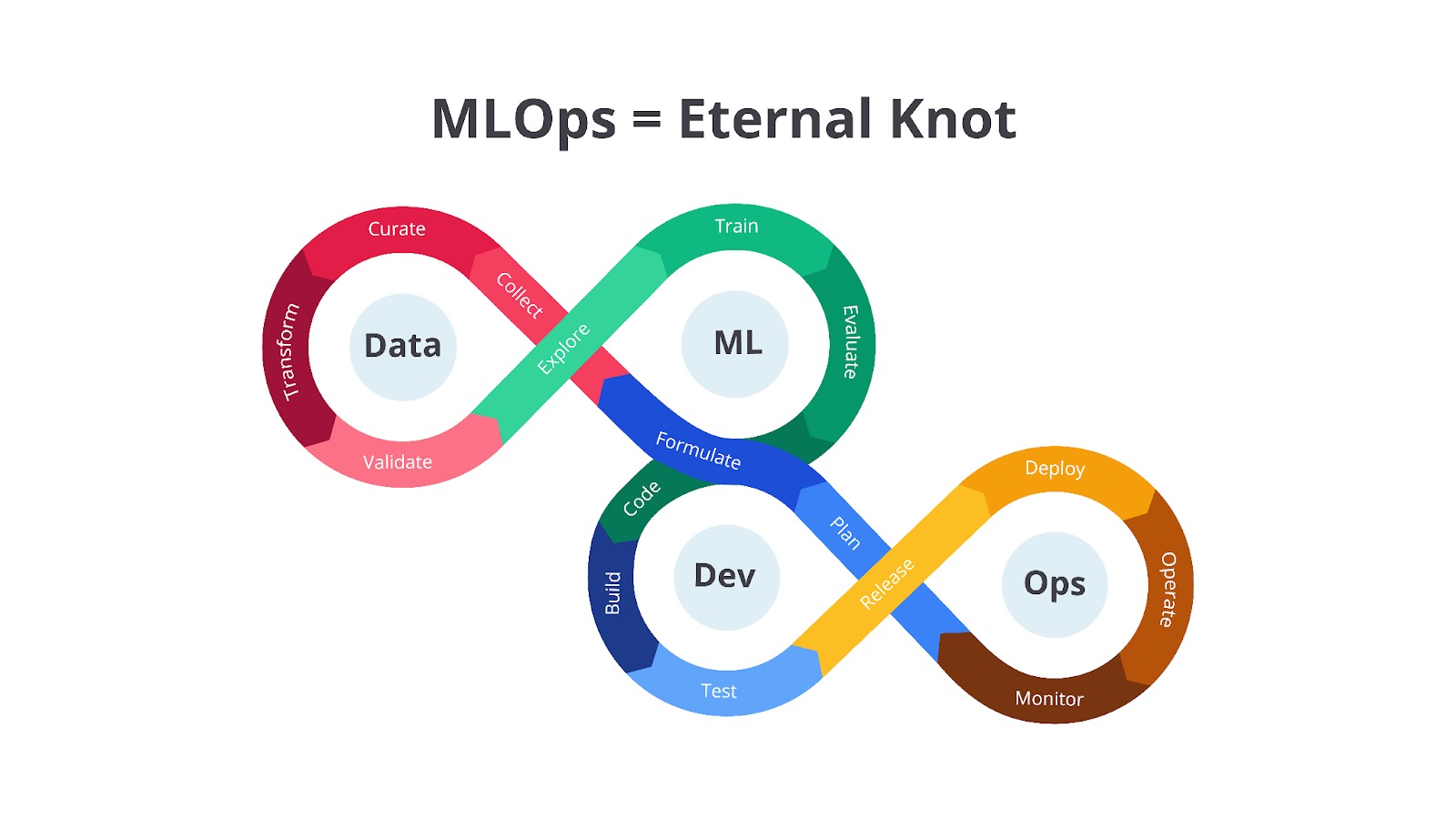
Siklus pengembangan di atas menunjukkan hubungan erat antara setiap divisi melalui panah yang saling terhubung. Dengan kata lain, siklus pengembangan ini memiliki sifat Eternal Knot yaitu menggambarkan siklus hidup MLOps yang berkelanjutan dan tidak pernah berakhir.
Sifat Eternal knot membuat model ML perlu terus diperbarui dan ditingkatkan seiring waktu untuk beradaptasi dengan perubahan data dan kebutuhan bisnis. Menariknya, hasil dari satu tahap dapat memengaruhi tahap lainnya sehingga tim perlu terus memantau dan memperbarui model ML berdasarkan data dan performa di dunia nyata.
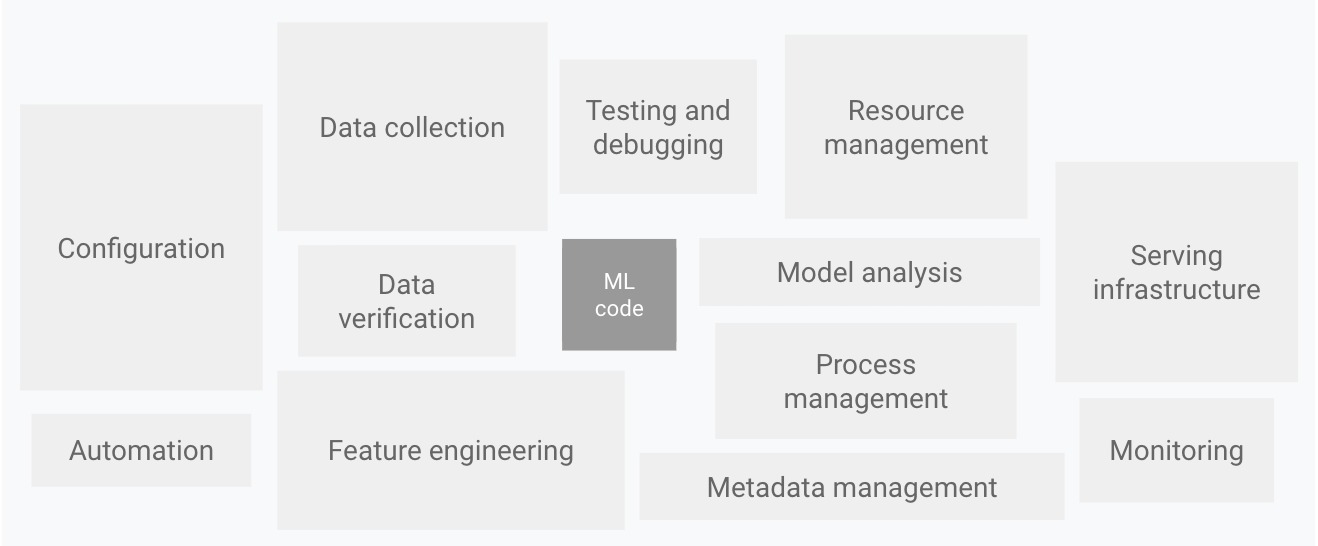
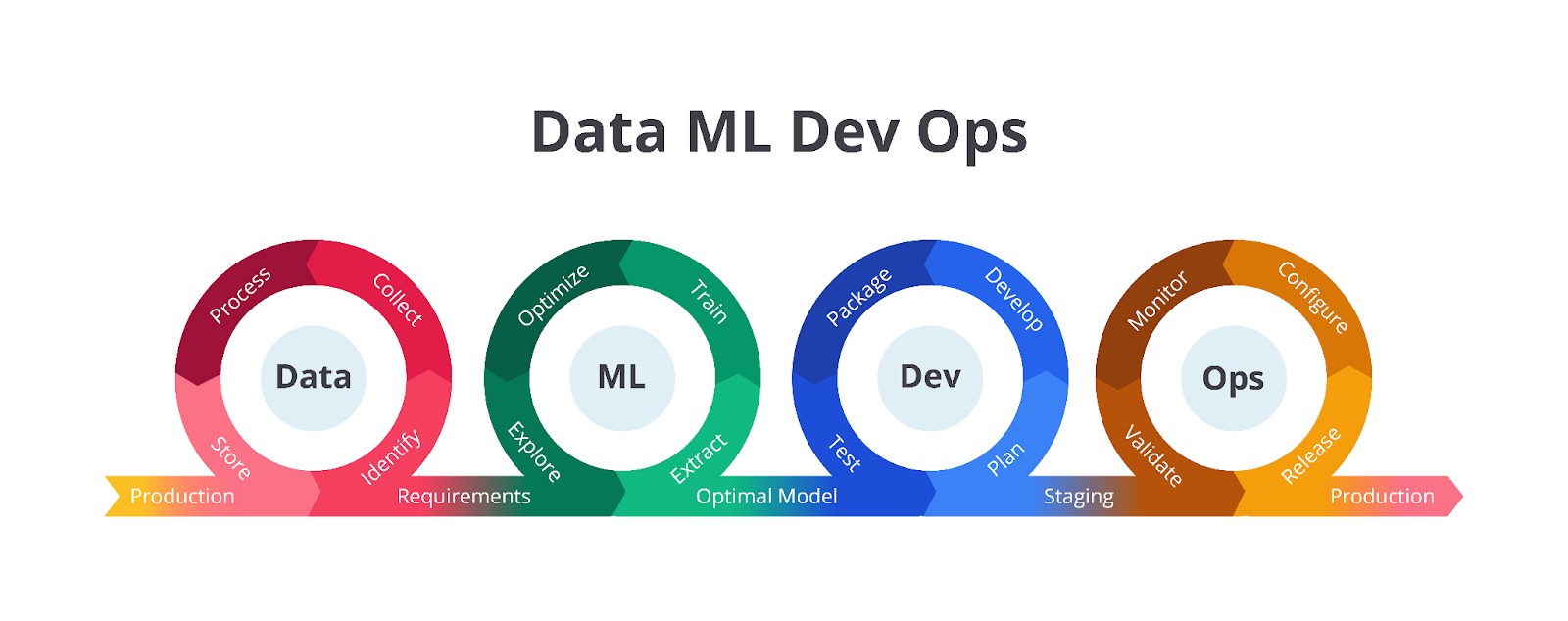
Siklus ini dibagi menjadi tiga bagian utama yaitu Data, ML, dan Ops yang saling terhubung dan berinteraksi satu sama lain melalui tahapan-tahapan yang spesifik. Selain itu, terdapat tim Dev yang berperan penting dalam menghubungkan bagian Data dan ML. Secara berurutan, kurang lebih tugas dari masing-masing tahapan ini seperti berikut.
- Data
Tahapan ini berfokus pada pengelolaan data, yang merupakan fondasi dari model ML. Tahapan-tahapan dalam bagian ini digambarkan dengan warna cokelat dan panah yang membentuk lingkaran, menunjukkan sifat iteratif dan berkelanjutan dari pengelolaan data.- Collect: tahap pertama yaitu mengumpulkan data dari berbagai sumber.
- Curate: setelah data dikumpulkan, data perlu dikurasi untuk memastikan kualitas dan relevansinya. Tahap ini melibatkan proses seleksi, pembersihan, dan organisasi data.
- Transform: data yang dikumpulkan biasanya masih mentah dan perlu ditransformasi ke format yang sesuai untuk pelatihan model. Tahap ini meliputi proses seperti normalisasi, standarisasi, dan encoding.
- Validate: data yang telah ditransformasi perlu divalidasi untuk memastikan kualitas dan konsistensinya. Tahap ini melibatkan pemeriksaan error, inkonsistensi, dan outlier.
- Explore: setelah data divalidasi, data perlu dieksplorasi untuk memahami karakteristik dan pola yang terkandung di dalamnya. Tahap ini melibatkan analisis statistik dan visualisasi data.
- Machine Learning
Tahapan ini digambarkan dengan warna hijau, merupakan inti dari siklus hidup MLOps. Tahapan-tahapan dalam bagian ini berfokus pada pembangunan dan evaluasi model ML.- Formulate: tahapan ini dimulai dengan memformulasikan masalah ML dan mendefinisikan tujuan yang ingin dicapai. Tahap ini melibatkan pemilihan algoritma dan metrik evaluasi.
- Train: model ML dilatih menggunakan data yang telah dipersiapkan. Gambar menunjukkan ikon otak dengan sirkuit yang merepresentasikan proses pelatihan model.
- Evaluate: model yang telah dilatih dievaluasi menggunakan metrik yang telah ditentukan. Tahap ini melibatkan pengujian performa model pada validation set.
- Developer
Tahapan ini berfungsi sebagai penghubung antara bagian Data dan ML. Tahapan-tahapan dalam bagian ini berfokus pada pengembangan kode dan infrastruktur yang diperlukan untuk membangun model ML.- Code: data scientist atau software engineer menulis kode untuk pra-pemrosesan data, pembangunan model, dan otomatisasi proses.
- Build: kode yang telah ditulis dibangun menjadi paket atau container yang siap untuk dijalankan. Tahap ini melibatkan proses kompilasi, pengemasan, dan pengujian kode.
- Test: paket atau container yang telah dibangun diuji untuk memastikan fungsionalitas dan performanya. Tahap ini melibatkan pengujian unit, pengujian integrasi, dan pengujian sistem.
- Release: setelah diuji, paket atau container dirilis dan siap untuk digunakan dalam tahapan selanjutnya.
- Operations
Tahap yang digambarkan dengan warna kuning, berfokus pada deployment, monitoring, dan pemeliharaan model ML di lingkungan produksi.- Plan: pertama-tama tahapan ini perlu merencanakan strategi deployment dan monitoring model. Tahap ini melibatkan pemilihan infrastruktur dan tools yang akan digunakan.
- Deploy: model yang telah dievaluasi perlu di-_deploy_ ke lingkungan produksi.
- Operate: model yang telah di-_deploy_ perlu dikonfigurasi kembali sehingga dapat digunakan untuk membuat prediksi.
- Monitor: performa model dipantau secara terus-menerus untuk mendeteksi penurunan performa atau masalah lainnya.
Apakah semuanya sudah selesai ketika sampai pada tahap operations? Sayangnya tidak. Seperti yang sudah kita bahas sebelumnya tahapan ini bersifat endless.
Setiap hasil dari satu tahapan penuh ini dapat digunakan untuk memperbaiki atau mengoptimalkan tahapan sebelumnya. Misalnya, hasil evaluasi model di bagian ML dapat digunakan untuk memperbaiki tahap pra-pemrosesan data di bagian Data. Tujuannya agar model machine learning yang Anda miliki tidak mengalami data drift atau model drift.
For Your Information
Model machine learning dilatih menggunakan data historis, tetapi ketika digunakan di dunia nyata, model tersebut dapat mengalami “penuaan” dan kehilangan akurasi seiring waktu karena fenomena yang disebut drift. Drift adalah perubahan pada karakteristik data yang digunakan untuk melatih model machine learning dari waktu ke waktu. Hal ini dapat menyebabkan model menjadi kurang akurat dari yang diharapkan.
Dengan kata lain, drift adalah penurunan kemampuan model untuk membuat prediksi yang akurat akibat perubahan lingkungan tempat model tersebut digunakan.
Berdasarkan tipenya, drift ini bisa dibagi menjadi dua sudut pandang yaitu data drift dan model drift.
- Data drift merujuk pada perubahan distribusi data input yang digunakan oleh model machine learning (ML) di lingkungan produksi setelah model dilatih.
- Model drift merujuk pada penurunan performa model ML seiring waktu akibat perubahan hubungan antara variabel input dan variabel target. Berbeda dengan data drift yang berfokus pada perubahan distribusi data input, model drift berfokus pada perubahan hubungan antara variabel. Model drift dapat terjadi meskipun distribusi data input tetap sama.
Dengan menerapkan siklus pengembangan di atas, Anda dapat memperbesar kemungkinan untuk membuat sebuah sistem machine learning yang reliable, scalable, adaptable, dan maintainable.
Pada dasarnya MLOps merupakan kombinasi dari filosofi kultur serta praktik dalam mengelola dan melakukan standardisasi terhadap keseluruhan proses pengembangan sistem machine learning beserta pengoperasiannya dalam sistem produksi. Keseluruhan proses ini meliputi otomatisasi dan monitoring di semua tahapan konstruksi sistem machine learning termasuk integrasi, pengujian, deployment, dan manajemen infrastruktur.
Prinsip MLOps memungkinkan Machine Learning Architect untuk melihat keseluruhan penggunaan resource pada sistem machine learning. Selain itu, prinsip MLOps juga mempermudah Machine Learning Architect untuk melihat seluruh proses dalam data pipeline. Kedua hal ini dapat mempermudah Machine Learning Architect dalam mengidentifikasi masalah dan membuat solusi jangka panjang.
MLOps Maturity
Setelah Anda paham betul tentang machine learning life cycle, tentu tidak serta merta kita bisa menerapkan automasi pada seluruh tahapan pada pipeline pengembangan machine learning. MLOps life cycle memiliki beberapa tahapan untuk mengukur sejauh mana sebuah perusahaan menerapkan prinsip MLOps yang ditentukan oleh _maturity level (_level kematangan).
MLOps Maturity Level adalah kerangka kerja yang menggambarkan sejauh mana proses operasional machine learning di sebuah organisasi sudah terotomasi, terstruktur, dan terintegrasi. Tingkatan ini membantu organisasi memahami posisi mereka dalam implementasi MLOps dan memberikan arahan untuk pengembangan lebih lanjut.
Selain itu, tingkatan ini juga menggambarkan kemampuan sebuah perusahaan dalam mengelola dan mengoperasikan siklus hidup machine learning, mulai dari pengembangan model hingga pengelolaan model dalam produksi.
Lalu, bagaimana cara menentukan penerapan level yang tepat? Level ini dapat ditentukan dengan menilai kualitatif aspek manusia/budaya, proses/struktur, dan objek/teknologi. Seiring meningkatnya maturity level, semakin tinggi juga tingkat kesulitannya, tetapi memberikan dampak yang sangat besar.
Layaknya kehidupan yang berkembang, MLOps juga memiliki perkembangan yang sedari tadi kita bahas (maturity level). Menariknya, tidak seperti manusia yang memiliki level perkembangan pasti (anak-anak, remaja, dewasa, lansia), MLOps ini tidak memiliki guideline pasti mengenai maturity level.
Hal ini menyebabkan setiap perusahaan bisa saja mengadopsi dan menerapkan hal yang berbeda-beda. Namun, Google dan Microsoft memberikan guideline bagi para developer dengan mengategorikan maturity level menjadi tiga hingga lima level.
Perbedaan jumlah level dalam MLOps Maturity Models mencerminkan tujuan, fokus, dan kebutuhan yang berbeda-beda dari masing-masing organisasi atau industri yang mengadopsinya. Model tiga level lebih compact dan memperlihatkan perbedaan yang cukup signifikan antar levelnya, sementara model lima level memberikan rincian yang lebih mendalam untuk perusahaan ketika mereka membutuhkan metriks yang lebih detail dalam menerapkan MLOps.
Sebagai seorang developer, tidak ada ruginya jika kita mempelajari kedua pendekatan yang digagas oleh Google dan Microsoft. Tanpa berlama-lama lagi, mari kita bahas mulai dari Google.
MLOps Maturity Levels: Google
Seperti yang sudah kita pelajari pada materi sebelumnya, MLOps (Machine Learning Operations) merupakan disiplin yang mengintegrasikan praktik DevOps dengan machine learning untuk meningkatkan kolaborasi antara tim pengembang (developer) dan tim operasi (ops). Namun, sistem ML berbeda dengan sistem perangkat lunak lainnya dalam beberapa hal berikut ini.
- Keahlian Tim: dalam proyek ML, tim biasanya mencakup data scientist atau ML engineer yang berfokus pada analisis data eksploratif, pengembangan model, dan eksperimen. Peran ini mungkin berbeda dengan software engineer berpengalaman yang dapat membangun layanan kelas produksi.
- Pengembangan: ML bersifat eksperimental, tidak ada guideline atau algoritma konkrit. Anda harus mencoba berbagai fitur, algoritma, teknik pemodelan, dan konfigurasi parameter untuk menemukan solusi yang paling tepat untuk masalah tersebut secepat mungkin. Tantangannya adalah melacak atau mencatat apa yang berhasil dan apa yang tidak, dan menjaga produktivitas sambil memaksimalkan penggunaan kembali kode.
- Pengujian: menguji sistem ML lebih rumit daripada menguji sistem perangkat lunak lainnya. Selain pengujian unit dan integrasi biasa, Anda perlu melakukan validasi terhadap data, evaluasi kualitas model, dan validasi model.
- Deployment: dalam sistem ML, penerapan tidak sesederhana menerapkan model ML yang dibangun sebagai layanan prediksi offline pada lokal komputer Anda. Sistem ML mengharuskan Anda untuk menerapkan alur untuk melatih ulang dan men-_deploy_ model secara otomatis. Alur ini menambah kompleksitas dan mengharuskan Anda untuk mengotomatiskan langkah-langkah yang dilakukan secara manual sebelum melatih dan memvalidasi model baru.
- Production: model ML dapat mengalami penurunan kinerja tidak hanya karena strukturnya kurang optimal, tetapi juga karena data yang terus berkembang dan berubah. Dengan kata lain, performa model dapat menurun dengan lebih banyak cara daripada sistem perangkat lunak konvensional, dan Anda perlu mempertimbangkan penurunan ini. Oleh karena itu, developer perlu mencatat statistik ringkasan data dan memantau kinerja model untuk mengirim pemberitahuan atau melihat kembali ketika nilai menyimpang dari ekspektasi developer.
Sejujurnya_,_ sistem ML dan sistem perangkat lunak lainnya serupa dalam CI dari source control, unit testing, integration testing, dan continuous delivery module atau package. Namun, dalam sistem ML terdapat beberapa perbedaan penting yang perlu kita catat.
- CI (continuous integration) pada pembangunan sistem ML tidak lagi hanya menguji dan memvalidasi kode dan komponen, tetapi juga menguji dan memvalidasi data, skema data, dan model.
- CD (continuous delivery/deployment) tidak lagi tentang satu paket perangkat lunak atau layanan, tetapi sistem (alur pelatihan ML) yang harus secara otomatis menerapkan layanan lain (layanan prediksi model).
- CT (continuous training) adalah properti baru untuk pengembangan sistem ML, yang berkaitan dengan retraining dan deployment model secara otomatis.
Google mengembangkan model MLOps Maturity dengan membagi tahapan penerapan MLOps ke dalam tiga level yang bertujuan untuk memberikan gambaran jelas mengenai perjalanan transformasi dalam pengelolaan machine learning di dalam organisasi.
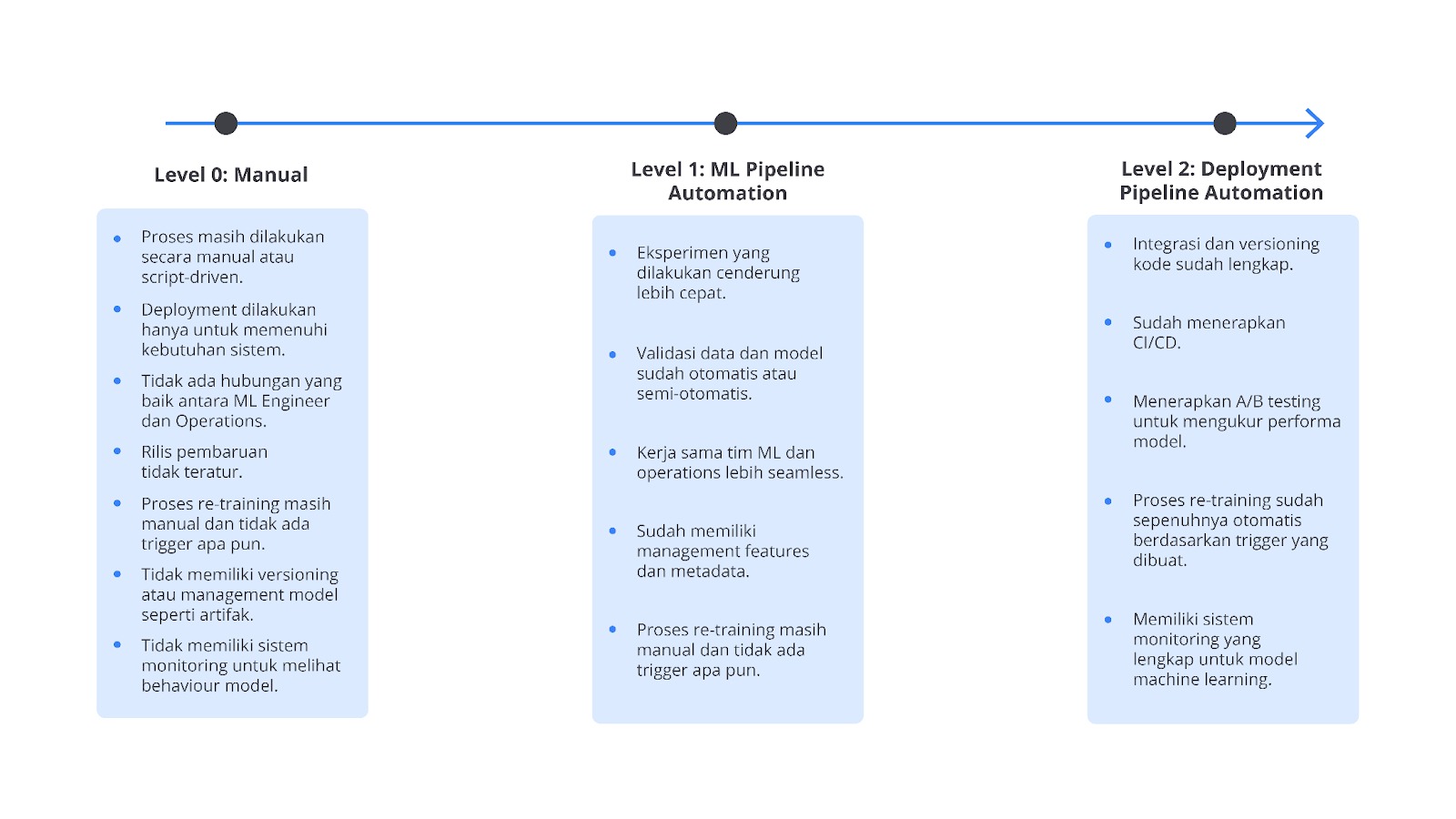
Maturity level MLOps Google menekankan pada tiga aspek utama yaitu automasi, pemantauan, dan pengelolaan model secara sistematis. Setiap level dalam model ini menggambarkan bagaimana suatu organisasi dapat mengatasi tantangan dalam menerapkan machine learning dengan praktik terbaik, meningkatkan proses otomatisasi, dan mengelola model machine learning yang lebih terintegrasi dan continuous (berkelanjutan).
Level 0: Manual Process
Pada level ini semua proses machine learning dilakukan secara manual. Contohnya, Anda perlu membersihkan data menggunakan script Python sederhana, melatih model secara lokal di komputer (atau Google Colab), dan mencatat hasil eksperimen di spreadsheet.
Deployment dilakukan dengan cara mentransfer file model secara manual ke server produksi, misalnya menggunakan protokol SCP (Secure Copy). Pada tahap ini, tidak ada sistem tracking eksperimen sehingga sulit untuk mereproduksi model ketika dibutuhkan.
Selain itu, Perusahaan tidak memiliki sistem monitoring yang baik untuk model yang sudah di-_deploy_. Sebagai contoh, sebuah startup yang baru memulai perjalanan machine learning mereka mungkin menjalankan model prediksi permintaan pelanggan secara manual, tanpa adanya pipeline yang terstruktur. Terlihat familier, ‘kan? Itu karena seluruh proses tersebut merupakan tahapan yang biasa Anda lakukan pada kelas-kelas sebelumnya.
Kelemahan utama pada tahap ini adalah risiko kesalahan manual yang tinggi, kurangnya efisiensi, dan sulitnya melacak atau memperbaiki performa model. Selain kekurangan ini, tahapan ini memiliki berbagai macam tantangan yang perlu kita hadapi seperti berikut ini.
- Rentan terhadap kesalahan manual: tidak ada standar proses yang menyebabkan inkonsistensi sehingga terkadang developer melupakan hal yang perlu dilakukan ketika memperbarui model.
- Menghabiskan banyak waktu: setiap langkah membutuhkan intervensi manual yang memakan waktu, belum lagi jika kita bergantung kepada orang lain. Dengan kata lain, kita tidak bisa memburu-buru mereka untuk menyelesaikan permasalahan ini.
- Sulit mereproduksi eksperimen: ketiadaan pelacakan parameter dan hasil eksperimen menyulitkan developer untuk memperbarui atau mengubah model. Dengan ini, Anda perlu melakukan eksplorasi dan training dari awal untuk setiap proses pengembangan. Capek ‘kan?
- Minim monitoring: model yang di-deploy pada fase produksi berisiko mengalami penurunan performa tanpa terdeteksi. Bayangkan ketika performa model menurun seiring berjalannya waktu, apa yang akan terjadi? Yup, keluhan dan amarah pengguna akan membanjiri customer services perusahaan yang mengakibatkan kehilangan kepercayaan dan pool pengguna. Tentunya Anda tidak mau ini terjadi ‘kan?
Level 1: Automated Training and Deployment
Pada Level 1, perusahaan mulai mengadopsi beberapa automasi dalam machine learning life cycle. Pipeline digunakan untuk preprocessing data, pelatihan model, dan evaluasi hasil eksperimen. Lalu, apa bedanya dengan level 0? Pada level ini, Anda dapat menggunakan berbagai macam tools untuk membantu melakukan tracking, training, dan monitoring. Pada intinya, tahapan ini merupakan transisi dari proses pembangunan sistem ML manual menuju CI/CD/CT sepenuhnya pada level 2.
Untuk menerapkan level 1 Anda dapat menggunakan tools seperti MLflow Tracking (akan kita pelajari nanti) yang bertugas untuk membantu pelacakan parameter, metrik, dan artifact model. Lalu deployment model dilakukan melalui pipeline CI/CD sederhana yang memberikan struktur lebih baik dibandingkan cara manual.
Dengan menerapkan level 1, sistem machine learning yang dibangun dapat menghindari permasalahan yang sering terjadi pada level sebelumnya. Beberapa keuntungan yang dapat Anda rasakan meliputi hal-hal berikut.
- Reproduksibilitas meningkat: Dengan pelacakan eksperimen, hasil eksperimen dapat diulang.
- Efisiensi meningkat: Pipeline otomatis mempercepat preprocessing dan pelatihan.
- Deployment lebih terstruktur: CI/CD memastikan model di-deploy dengan standar yang konsisten.
Pada tahap ini meskipun ada kemajuan yang signifikan dalam mengotomatisasi beberapa aspek, pengelolaan model seperti retraining dan integrasinya masih terbatas karena tidak seluruhnya otomatis. Selain itu terdapat beberapa tantangan yang akan Anda hadapi ketika menerapkan level ini pada sistem ML yang dibangun.
- Meskipun sudah menerapkan automasi, beberapa tahapan seperti retraining model atau penyesuaian model berdasarkan feedback dari produksi mungkin masih memerlukan intervensi manual.
- Proses automasi masih terisolasi dan belum terintegrasi dengan baik di seluruh pipeline ML.
- Pengelolaan dan pemantauan model di tahap produksi masih terbatas pada dashboard sederhana yang tidak memberikan informasi mendalam atau real-time.
Level 2: CI/CD pipeline automation
Pada sistem yang lebih kompleks dan membutuhkan perubahan komponen pipeline yang cepat, kita perlu menerapkan mekanisme CI/CD ke dalam sistem machine learning tersebut. Hal ini tentunya memungkinkan kita secara otomatis melakukan proses build, test, dan deploy komponen pipeline ke dalam sistem produksi.
Menariknya, pada level ini perusahaan telah menerapkan automasi penuh dalam pipeline ML mereka, mencakup Continuous Integration (CI) dan Continuous Delivery/Development (CD). Proses-proses yang sebelumnya manual, seperti deployment dan retraining, sekarang dilakukan secara otomatis dengan pipeline CI/CD yang terintegrasi. Model dan eksperimen diatur secara sistematis agar dapat menerima umpan balik berkelanjutan dari lingkungan produksi untuk pembaruan dan perbaikan model. Sehingga, pipeline yang terjadi pada level ini mencakup hal-hal berikut ini.
- Development and Experimentation: pengembang secara iteratif mencoba algoritma ML baru dan pemodelan baru yang langkah-langkah eksperimennya sudah diatur seperti sebuah fungsi. Output dari tahap ini adalah source code yang berisikan pipeline ML yang siap digunakan kapan saja.
- Pipeline Continuous Integration: Anda perlu membangun source code dan menjalankan berbagai pengujian. Output dari tahap ini adalah komponen alur (package, executables, dan artifacts) yang akan digunakan pada tahap selanjutnya.
- Pipeline Continuous Delivery: Anda menerapkan artifact yang dihasilkan pada tahap CI ke lingkungan produksi. Output dari tahap ini adalah sebuah pipeline yang diterapkan dengan menggunakan model terbaru.
- Automated Triggering: seluruh pipeline dijalankan secara otomatis dalam produksi berdasarkan jadwal atau sebagai respons terhadap trigger (contoh performance model). Output dari tahap ini adalah model terbaru yang di-_deploy_ ke registri model.
- Model Continuous Delivery: Anda melakukan sharing model sebagai layanan prediksi. Output dari tahap ini adalah layanan prediksi model yang bisa digunakan oleh pengguna.
- Monitoring: Anda mengumpulkan statistik tentang kinerja model berdasarkan data langsung. Output dari tahap ini adalah trigger untuk menjalankan pipeline atau untuk menjalankan siklus eksperimen baru.
Terlihat padat dan menantang ‘kan? Tenang saja, benefit yang didapatkan dengan menerapkan pipeline di atas juga sebanding serta tidak kalah menggiurkan jika dibandingkan level 1. Jika perusahaan Anda menerapkan pipeline tersebut, setidaknya kalian akan mendapatkan keuntungan berikut.
- Pipelines otomatis memungkinkan integrasi model dan deployment secara berkelanjutan. Setiap perubahan model atau pembaruan kode langsung diuji dan di-_deploy_ ke produksi secara otomatis tanpa campur tangan manusia.
- Pada level ini, model dapat diperbarui dengan otomatis jika performa model menurun atau jika ada data baru yang signifikan. Proses retraining dapat dipicu secara otomatis berdasarkan kriteria tertentu. Bye-bye under perform!
- Pemantauan model dilakukan dengan lebih transparan dengan logging yang tidak pernah berhenti. Setiap model yang di-deploy dapat dipantau untuk memastikan bahwa performanya tetap stabil, dan jika ada penurunan performa, sistem bisa langsung memberikan pemberitahuan.
- Feedback dari data organik, hasil analisis performa atau data baru dapat digunakan untuk meningkatkan model secara otomatis. Model yang ada bisa diperbarui tanpa perlu campur tangan manusia sehingga menciptakan siklus yang lebih efisien.
- Perusahaan dapat menangani lebih banyak eksperimen (RnD) karena model di level ini memiliki pipeline otomatis sehingga bisa menangani banyak eksperimen secara paralel, serta mempercepat proses training dan evaluasi.
Bagaimana, sangat menarik, ya? Memang dunia ini tidak ada habisnya, sekarang saatnya Anda melangkah lebih jauh lagi. Jadi, jangan terlena dengan keseruan mengeksplorasi algoritma saja karena sebetulnya tugas kita tidak hanya sampai di situ. Dengan menerapkan prinsip MLOps, baik itu level paling dasar hingga mahir, tentunya semua itu akan membuka skill baru. Oleh karena itu, semakin jauh Anda melangkah, semakin dekat juga dengan julukan Machine Learning Engineer.
Oke sebagai pendinginan, mari kita rekap dahulu sebelum lanjut ke MLOps yang digagas Microsoft.
Pada dasarnya, model MLOps Google terbagi menjadi tiga level maturity yang memberikan gambaran umum tentang cara perusahaan mengembangkan proses machine learning mereka, mulai dari yang manual hingga sepenuhnya terotomatisasi. Fokus utama dari model ini adalah pada automasi dan integrasi antara pipeline machine learning dengan pengelolaan model serta pemantauan yang lebih baik.
Organisasi yang mulai bertransformasi dari Level 0 ke Level 2 akan merasakan peningkatan berbagai macam hal seperti efisiensi, kecepatan, dan kualitas model, sembari mengurangi risiko kesalahan manusia dan downtime. Pada akhirnya, setiap tahapan memungkinkan pengembangan model machine learning yang lebih matang, stabil, dan dapat diandalkan, dengan potensi untuk terus berkembang lebih lanjut dengan menggunakan alat-alat otomatisasi yang lebih canggih.
MLOps Maturity Level: Microsoft
Sampai di sini, Anda sudah bergelut dengan berbagai macam hal yang tidak pernah kita temui pada kelas-kelas sebelumnya, salah satunya MLOps maturity level. Bagaimana menurut Anda maturity level dari Google, menarik sekali, ya? Namun, bukan berarti kita sudah menyelesaikan journey to the west—Menamatkan semua pengetahuan terkait MLOps khususnya maturity level.
Karena sebetulnya sampai saat ini (setidaknya 2024), tidak ada guideline khusus mengenai MLOps maturity level sehingga wajar jika nantinya Anda menemukan hal yang berbeda-beda. At least, kita dapat mempelajari dua sudut pandang dari raksasa teknologi saat ini yaitu Google dan Microsoft.
Sama halnya dengan Google, MLOps Maturity Model yang digagas oleh Microsoft memberikan framework untuk menilai dan mengukur tingkat kematangan perusahaan dalam mengimplementasikan praktik Machine Learning Operations (MLOps).
Model ini membantu organisasi memahami tahapan-tahapan yang perlu mereka lalui untuk mengoptimalkan pengelolaan dan operasionalisasi model machine learning dalam produksi, serta meningkatkan kolaborasi antara tim data science dan tim IT/ops.
Microsoft mengembangkan lima level maturity yang dirancang untuk membantu developer memahami tahapan-tahapan yang perlu mereka jalani dalam mengoperasikan model machine learning secara efektif dan efisien. Serupa tapi tak sama dengan Google, setiap level di sini menggambarkan kematangan sistem dalam melakukan otomatisasi, integrasi, dan pengelolaan siklus hidup model ML yang lebih baik.
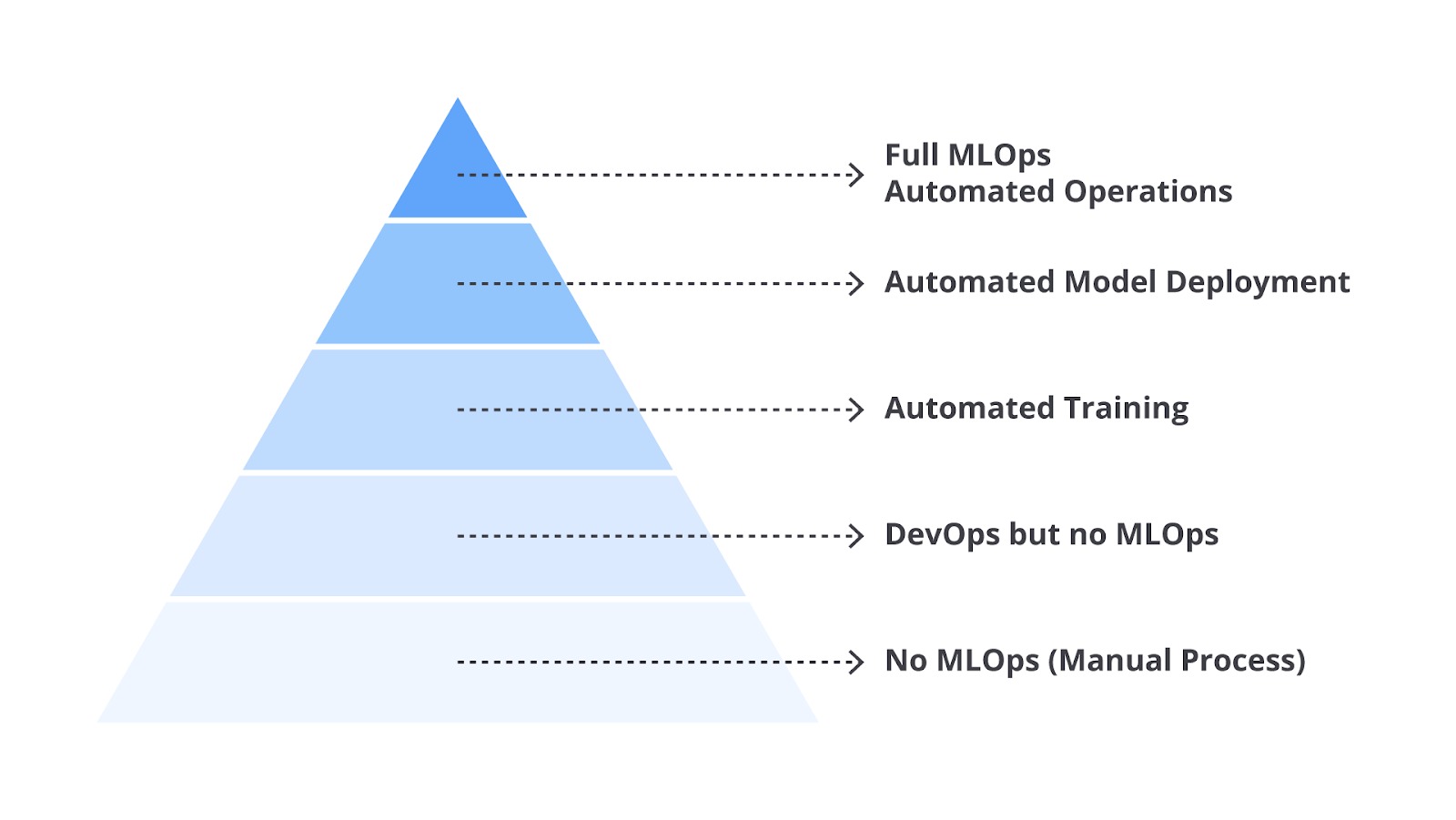
Seperti yang dapat Anda lihat pada gambar di atas, sudah sangat jelas gagasan Microsoft ini sebenarnya sama saja dengan Google, perbedaannya hanya dibuat lebih detail pada setiap levelnya. Masing-masing tahapan di atas menggambarkan transformasi dari pembuatan sistem machine learning manual hingga full automated operations. Tanpa berlama-lama lagi, mari kita bahas satu per satu agar lebih memahami perbedaannya.
Level 0: No MLOps
Pada level ini, pembangunan model ML dilakukan secara manual tanpa adanya integrasi antara tools dan sistem. Machine learning engineer dan tim operasional bekerja secara terpisah tanpa pengelolaan versi yang terstruktur atau otomatisasi dalam pipeline. Sehingga, masih terdapat GAP antara tim yang bekerja sama dan terkadang efeknya menyebabkan kolaborasi menjadi tidak sempurna.
Biasanya para developer menggunakan Jupyter Notebook untuk eksperimen model tanpa menggunakan version control untuk kode atau model. Namun, tahap deployment tidak menggunakan satupun pipeline otomatis untuk mempersiapkan data atau melatih model sehingga eksperimen dilakukan secara individual.
Dengan kebiasaan di atas, PM (project manager) dapat dengan mudah menentukan MLOps maturity level yang digunakan oleh perusahaan tersebut. Beberapa karakteristik utama dari level ini mencakup hal-hal berikut ini.
- Eksperimen Terisolasi: model dikembangkan dan dieksperimenkan secara manual dengan sedikit atau tanpa pengelolaan versi data dan model.
- Pengelolaan Versi: tidak ada pengelolaan versi yang jelas. Model dan data tidak dikelola dalam repositori terpusat, biasanya hanya disimpan pada environment lokal sang developer.
- Proses Manual: semua aspek mulai dari pemrosesan data hingga pelatihan model dilakukan secara manual dan tidak terotomatisasi.
Mungkin proses ini terlihat normal bagi beberapa orang, tetapi siapa sangka terdapat berbagai macam tantangan ketika menerapkan level ini pada skala produksi.
- Kehilangan waktu dan sumber daya. Hal ini bisa terjadi karena semua dilakukan secara manual dan tim cenderung menghabiskan banyak waktu untuk menyelesaikan tugas yang repetitif tanpa adanya efisiensi.
- Risiko kegagalan dan ketidakakuratan. Hal ini diakibatkan oleh tidak adanya pengelolaan model dan data yang baik. Model yang ada bisa menjadi usang atau kurang akurat seiring berjalannya waktu.
- Kurangnya kolaborasi antar tim. Masalah komunikasi antara tim yang bertanggung jawab atas eksperimen dan tim operasional menyebabkan inkonsistensi dalam proses.
Level ini memanglah zona nyaman bagi semua orang, karena setiap tim tidak perlu memberi effort lebih untuk menunjang sistem yang dibangun. Namun, kesulitan untuk mengatur siklus sistem machine learning kerap menjadi momok bagi para developer dan menyebabkan technical debt di kemudian hari.
Level 1: DevOps but no MLOps
Pada level ini, perusahaan mulai menerapkan prinsip DevOps untuk pengembangan aplikasi, tetapi belum mengintegrasikan proses machine learning ke dalam alur DevOps tersebut.
Karakteristik pengembangan sistem machine learning pada level ini cenderung masih sama dengan level sebelumnya. Namun, terdapat beberapa karakteristik yang berbeda pada sisi DevOpsnya.
- Pada tahap ini, beberapa pipeline sudah terotomatisasi, tetapi model machine learning masih dikelola secara manual oleh tim ML engineer.
- Meskipun kode aplikasi dideploy melalui pipeline DevOps, model ML masih diunggah dan dideploy secara manual sehingga tidak terintegrasi ke dalam pipeline DevOps.
- Source Code dikelola menggunakan sistem version control seperti Git, tetapi data dan model ML tidak memiliki pengelolaan versi yang jelas.
- Monitoring diterapkan pada aplikasi, tetapi tidak pada model machine learning di produksi.
Walaupun terdengar tidak ada bedanya bagi tim ML Engineer, tetapi level ini memberikan benefit yang sangat besar. Dengan menerapkan level ini, tim tidak akan lagi mengalami permasalahan pada sisi DevOps karena seluruh sistem (kecuali ML) sudah memiliki pipeline otomatis untuk melakukan pembaharuan secara terus menerus.
Sayangnya, karena ini masih tergolong level bocil, tentu saja level ini memiliki berbagai macam tantangan dan kekurangan juga. Walaupun beberapa permasalahan sudah teratasi, berikut tantangan yang akan kita hadapi ketika menerapkan level ini pada skala produksi.
- Kurangnya integrasi pipeline untuk machine learning menyebabkan inefisiensi dalam pengelolaan model.
- Model ML masih sulit dipantau, dan performanya sulit dievaluasi secara real-time.
- Performa sistem yang dibangun sangat bergantung terhadap tim ML Engineer atau Data Scientist untuk pembaruan model.
- Kesulitan mendapatkan feedback dari model yang sudah di-_deploy_ sehingga developer tidak memiliki acuan pasti untuk memperbaharui model.
- Kesulitan untuk membuat ulang model karena tidak memiliki history atau metadata model ML.
Pada intinya, level ini menyajikan beberapa automated pipeline seperti automated builds, dan automated tests for application code. Namun, masih membangun model machine learning secara “primitive”.
Level 2: Automated Training
Pada level ini, perusahaan mulai mengotomatisasi proses pelatihan dan evaluasi model. Proses tersebut diterapkan untuk membantu data scientist mempercepat eksperimen dan memastikan proses yang lebih konsisten.
Mulai dari sini seluruh tahapan sudah mulai terotomatisasi sehingga mengurangi “gesekan” antar tim, terhindar dari “asal” update model ML hingga menghilangkan ketergantungan kepada satu tim.
Karakteristik utama dari level 2 ini mencakup pipeline training otomatis, pengelolaan versi model dan dana, automasi tuning, hingga eksperimen yang teratur. Hah, bagaimana maksudnya? Tenang, mari kita bahas masing-masing poin dengan lebih detail.
- Pada level ini, pipeline untuk preprocessing data, pelatihan model, dan evaluasi model dibuat dan dijalankan secara otomatis. Pipeline yang dibuat dapat dijalankan secara terjadwal atau berdasarkan pemicu tertentu (misalnya, data baru masuk, performa, atau waktu).
- Model dan dataset tidak lagi hanya dibuat lalu dilupakan, pada level ini model dan dataset perlu dikelola dengan baik menggunakan sistem version control. Sistem seperti MLflow atau Azure Machine Learning digunakan untuk melacak hasil eksperimen dan versi model. Lalu, apa keuntungannya? Untungnya ~dunia masih berputar~ developer akan sangat mudah untuk melakukan replikasi model karena memiliki history yang sangat lengkap.
- Last but not least, pencarian hyperparameter sudah terotomatisasi untuk mengoptimalkan performa model.
- Keseluruhan tim tidak lagi bergantung pada data scientist, pada tahap ini semua orang dapat dengan mudah mereproduksi eksperimen karena sudah tercatat secara otomatis.
Namun, jangan terlalu senang terlebih dahulu karena semua yang berlebihan itu tidak baik. Ingat, kita baru mencapai level 2, masih terdapat 2 level lagi untuk menamatkan MLOps maturity level yang digagas oleh Microsoft. Pada tahapan ini, kita juga mendapatkan tantangan yang tidak “ramah”. Berikut beberapa tantangan yang akan Anda hadapi ketika menerapkan level ini.
- Walaupun proses re-training sudah otomatis, tetapi deployment model ke lingkungan produksi masih dilakukan secara manual.
- Monitoring model pada tahap produksi belum sepenuhnya otomatis.
- Beberapa developer mengalami kesulitan untuk menerapkan proses otomatisasi pada sistem ML yang dibangun sehingga perlu knowledge tambahan daripada hanya membangun model machine learning saja.
Tenang saja, tantangan yang akan kalian hadapi bukanlah akhir dari dunia. Sebetulnya di balik tantangan tersebut, Anda dan tim akan menerima keuntungan yang sangat besar ketika memiliki banyak sistem ML yang perlu dikelola pada waktu yang bersamaan. So, jangan patah semangat karena ini baru level 2!
Level 3: Automated Model Deployment
Pada level ini, deployment model machine learning ke lingkungan produksi sudah sepenuhnya otomatis. Perusahaan Anda mulai menggunakan pipeline CI/CD untuk memastikan model dapat di-deploy dengan konsisten dan cepat.
Karakteristik utama dari level ini dapat dilihat berdasarkan automated deployment, registry model, monitoring, dan feedback loop. Mungkin bagi beberapa orang terdengar asing, ya? Oleh karena itu, mari kita tilik masing-masing karakteristiknya secara saksama.
- Pipeline CI/CD digunakan untuk otomatisasi deployment model ke produksi sehingga proses validasi model dilakukan sebelum deployment, termasuk pengujian performa dan integrasi.
- Model yang telah dilatih dan divalidasi disimpan ke dalam Model Registry seperti Azure ML Registry atau MLflow Model Registry.
- Sistem monitoring diterapkan untuk memonitor performa model di produksi. Tujuan monitoring ini mencakup deteksi model drift atau data drift.
- Yang paling penting adalah feedback dari dunia nyata (pengguna asli), seperti data baru atau performa model untuk memperbarui model berdasarkan acuan yang pasti (tidak lagi feeling developer).
Pada tahapan ini, proses rilis model tidak lagi bergantung pada tangan manusia a.k.a manual, karena deployment yang dilakukan sudah menggunakan pipeline otomatis. Di lain sisi, seluruh metriks mulai dari metadata model, performa, hingga status model dapat dilihat oleh developer sehingga meminimalisasi degradasi performa model ML. Dengan seluruh keuntungan tersebut, bukan berarti tidak ada tantangan yang akan kalian hadapi.
Setidaknya ada dua tantangan yang perlu kita hadapi ketika menerapkan level 2.
- Perlu sistem monitoring yang lebih canggih untuk mendeteksi perubahan performa model secara proaktif seperti Prometheus x Grafana.
- Integrasi antara pipeline training otomatis dan deployment otomatis bisa menjadi kompleks karena pada level ini ML Engineer tidak lagi berhadapan dengan notebook saja, melainkan bersamaan dengan tools MLOps lainnya seperti MLflow.
Level 4: Full MLOps Automated Operations
Ini adalah tingkat tertinggi dari gagasan Microsoft mengenai MLOps maturity level yang seluruh prosesnya telah diotomatisasi sepenuhnya. Perusahaan memiliki kemampuan untuk memperbarui model secara otomatis berdasarkan perubahan data atau performa model tanpa campur tangan manusia.
Tak perlu banyak basa-basi, mari kita lihat karakteristik dari level ultimate MLOps gagasan Microsoft.
- Automasi Penuh
Semua proses, mulai dari pengumpulan data, preprocessing, pelatihan, validasi, deployment, hingga pemantauan, dilakukan secara otomatis. Pipeline ini mendukung Continuous Training (CT) dan Continuous Deployment (CD). - Adaptasi Mandiri
Model secara otomatis beradaptasi dengan perubahan data melalui pembaruan atau retraining yang dipicu oleh sistem monitoring. - Monitoring Lanjutan
Sistem monitoring mendeteksi masalah seperti data drift atau model drift secara real-time. Tools monitoring yang digunakan memberikan rekomendasi tindakan atau memicu pipeline retraining. - Eksperimen Berkelanjutan
Eksperimen dan optimasi model dilakukan secara terus-menerus, termasuk tuning hyperparameter otomatis dan eksplorasi model baru. - Zero-downtime System
Dengan menerapkan sistem yang sepenuhnya terotomatisasi, tentu saja akan meminimalisasi down atau bahkan Anda (hampir) tidak pernah merasakan apa itu down system. Menarik sekali ‘kan?
Seiring meningkatnya benefit yang dirasakan, tentu saja berbanding lurus dengan effort yang perlu kita berikan. Untuk menerapkan level 4 ini, seluruh tim membutuhkan infrastruktur yang sangat canggih demi mendukung otomatisasi skala besar, artinya kita perlu memilih tools yang akan digunakan atau membuat pipeline ini dari scratch. Di lain sisi, kompleksitas pengelolaan model dalam jumlah besar di berbagai lingkungan produksi juga acapkali menjadi masalah yang serius karena memerlukan versi library yang spesifik.
Woaaahh, padahal baru teorinya saja, tetapi seru sekali ‘kan? Tenang saja, nantinya sedikit demi sedikit Anda juga akan mempelajari praktiknya. Namun, sebelum kita melangkah ke hal yang lebih jauh, mari kita rangkum terlebih dahulu MLOps maturity level dari Microsoft ini.
Intinya, MLOps Maturity Model dari Microsoft terdiri dari lima level yang memberikan roadmap bagi perusahaan untuk mengoptimalkan pengelolaan siklus hidup machine learning. Setiap level memberikan keuntungan dan tantangan yang berbeda, mulai dari manual process di Level 0, hingga automated adaptive systems di Level 4. Dengan mengikuti model ini, perusahaan dapat secara bertahap meningkatkan efisiensi, stabilitas, dan skalabilitas operasional mereka dalam mengelola model machine learning.
Sampai di sini, kita sudah memahami MLOps maturity level, walaupun perspektif ini muncul hanya dari dua perusahaan, tetapi kredibilitasnya sudah tidak diragukan lagi. Kelak, jika menemukan perspektif yang berbeda dan lebih cocok dengan kultur perusahaan, Anda sudah memiliki dasar yang cukup kuat sehingga tidak perlu belajar dari nol lagi.
Kesimpulan dari kedua perspektif ini sebenarnya sama saja, yaitu menerapkan ML di lingkungan produksi tidak hanya menerapkan model sebagai API untuk prediksi, melainkan menerapkan alur ML yang dapat mengotomatiskan pelatihan ulang dan penerapan model baru.
Menyiapkan sistem CI/CD memungkinkan developer dapat menguji dan menerapkan implementasi pipeline secara otomatis. Sistem ini memungkinkan Anda mengatasi perubahan cepat dalam data dan lingkungan bisnis perusahaan.
Perlu diingat, Anda tidak perlu tergesa-gesa untuk mengubah semua proses dari satu tingkat ke tingkat lainnya (manual ke otomatis). Anda dapat menerapkan level ini secara bertahap untuk membantu meningkatkan otomatisasi pengembangan dan produksi sistem ML yang dibangun.
Tenang saja, take your time. Anda boleh kok membaca kembali dari awal secara perlahan. Pastikan Anda benar-benar paham sebelum lanjut ke materi berikutnya. Sebagai intermezzo, silakan resapi cerita singkat di bawah ini agar Anda lebih paham alur penerapan MLOps maturity level, ya.
Short Story - Perjalanan Tim Pendekar ML Menuju MLOps Maturity
Di sebuah startup bernama SmartSales, tim data science berusaha mengembangkan solusi machine learning untuk memprediksi penjualan mingguan berdasarkan data historis dan tren pasar. Perjalanan mereka mencerminkan peningkatan kematangan MLOps, dari Level 0: No MLOps hingga Level 4: Full MLOps Automated Operations.
Pada awal berdirinya SmartSales, tim data science terdiri dari dua orang yang bekerja secara manual. Mereka menggunakan Jupyter Notebook di laptop masing-masing untuk membersihkan data, melatih model, dan mengevaluasi hasilnya. Setiap kali ingin mencoba model baru, mereka harus mengunduh data dari dashboard internal, menjalankan preprocessing secara manual, dan mengekspor model sebagai file .pkl.
Deployment model dilakukan dengan cara sederhana, mereka mengunggah file model ke server menggunakan protokol SCP. Tidak ada sistem pengelolaan versi atau pipeline yang memudahkan reproduksi eksperimen. Ketika hasil model yang diprediksi berbeda dari ekspektasi tim manajemen, mereka kesulitan mengetahui penyebabnya karena kurangnya dokumentasi dan pemantauan.

Akibatnya, mereka berdua mengalami tiga permasalahan yang cukup membosankan.
- Model sering kali usang karena tidak ada retraining otomatis.
- Tidak ada monitoring performa model di lingkungan produksi.
- Banyak waktu terbuang untuk tugas manual dan berulang.
Setelah beberapa bulan, tim operasional SmartSales memutuskan untuk menggunakan prinsip DevOps untuk deployment aplikasi mereka. Sekarang, aplikasi web yang menampilkan prediksi penjualan sudah menggunakan pipeline CI/CD. Namun, model machine learning masih dikelola secara manual.
Data scientist mengirimkan model yang sudah dilatih kepada tim DevOps yang kemudian memasukkan model ke dalam aplikasi web. Meskipun deployment aplikasi lebih terstruktur, proses deployment model masih lambat karena membutuhkan koordinasi antara tim data science dan tim DevOps. Model yang sudah dibuat tidak di-_monitoring_ setelah di-_deploy_, sehingga performanya tidak diketahui hingga ada keluhan dari manajemen.
Dari sini, mereka sudah memiliki kemajuan yaitu deployment aplikasi menggunakan CI/CD pipeline dan kode aplikasi sudah dikelola dalam sistem version control seperti Git. Namun, masalah masih tersisa mencakup deployment model machine learning masih manual dan tidak adanya sistem untuk memantau performa model di produksi.

Merasa kewalahan dengan eksperimen yang sering berulang, tim data science mulai mengotomatisasi pipeline pelatihan model. Mereka menggunakan Azure Machine Learning untuk membuat pipeline otomatis yang mencakup preprocessing data, pelatihan model, dan evaluasi hasil.
Setiap kali data baru tersedia, pipeline secara otomatis memulai proses preprocessing dan pelatihan model. Hasil eksperimen, seperti parameter dan metrik model, dicatat menggunakan MLflow Tracking sehingga mereka dapat membandingkan performa antar eksperimen. Model terbaik disimpan dalam Model Registry untuk memastikan versi model yang digunakan selalu terdokumentasi.
Namun, deployment ke produksi masih membutuhkan intervensi manual dari tim operasional. Ketika model perlu diperbarui, tim data science masih harus memberitahu tim DevOps untuk mengunggah model baru.

Dari proses ini masih menyisakan permasalahan yang cukup besar yaitu proses deployment model ke produksi masih manual dan tidak ada sistem pemantauan otomatis untuk mendeteksi penurunan performa model.
Tim SmartSales menyadari bahwa deployment manual menjadi hambatan besar dalam iterasi model. Mereka memutuskan untuk mengintegrasikan pipeline CI/CD untuk deployment model. Setelah model terbaik dipilih dari Model Registry, pipeline CI/CD secara otomatis memvalidasi model, mengemasnya dalam Docker container, dan mendeploy-nya ke produksi menggunakan Kubernetes.
Sistem monitoring mulai diterapkan untuk memantau performa model di produksi. Mereka menggunakan Prometheus untuk mendeteksi data drift atau model drift, sedangkan Grafana untuk menampilkan dashboard performa model. Jika performa model menurun, pipeline otomatis mengirimkan peringatan kepada data scientist untuk mengevaluasi model.
Setelah beberapa iterasi, SmartSales berhasil mencapai Full MLOps Automated Operations. Mereka membangun pipeline end-to-end yang mencakup Continuous Training (CT) dan Continuous Deployment (CD). Pipeline ini memungkinkan model diperbarui secara otomatis berdasarkan data baru atau hasil monitoring performa.
Ketika sistem monitoring mendeteksi adanya data drift, pipeline otomatis memulai pelatihan ulang model menggunakan data terbaru. Hasil pelatihan dicatat dalam MLflow Tracking, dan model baru secara otomatis didaftarkan ke Model Registry. Pipeline CI/CD kemudian memvalidasi model baru dan menggantikan model lama di tahap produksi tanpa gangguan pada sistem yang sedang berjalan.
Sistem ini juga mendukung hyperparameter tuning otomatis untuk memastikan model yang dilatih memiliki performa terbaik. Semua eksperimen dan hasilnya tercatat dengan baik, memungkinkan tim untuk terus melakukan inovasi tanpa mengganggu sistem produksi.

Sampai pada tahap ini, semua proses mulai dari pelatihan, deployment, hingga monitoring dilakukan secara otomatis. Di lain sisi, model juga dapat secara otomatis beradaptasi dengan perubahan data sehingga tim data science memiliki lebih banyak waktu untuk inovasi karena tugas-tugas manual telah diotomatisasi.
Cerita di atas mencerminkan bagaimana perusahaan dapat menerapkan MLOps maturity level mereka, mulai dari proses manual hingga sepenuhnya terotomatisasi. Dengan mengikuti lima level MLOps Maturity, tim SmartSales berhasil meningkatkan efisiensi, konsistensi, dan performa model machine learning mereka. Perjalanan ini membutuhkan komitmen untuk berinvestasi dalam teknologi, membangun pipeline yang terintegrasi, dan mengembangkan kemampuan tim untuk menghadapi kompleksitas yang semakin meningkat.
Kami juga sangat menunggu cerita penerapan MLOps di proyek yang akan Anda kembangkan kelak. Namun, cerita di atas tidak menyebutkan tools yang digunakan secara spesifik. Agar lebih terbayang, mari kita bahas satu per satu tools yang biasanya digunakan untuk menerapkan MLOps pada proyek pengembangan machine learning pada materi berikutnya. Stay tune, ya!
Tools Penunjang MLOps
Dalam era perkembangan teknologi yang semakin cepat, machine learning (ML) telah menjadi salah satu bagian terpenting di berbagai industri. Mulai dari perbankan, kesehatan, hingga e-commerce; penerapan ML membuka peluang besar untuk meningkatkan efisiensi, akurasi, dan personalisasi layanan. Namun, keberhasilan penerapan ML tidak hanya bergantung pada algoritma yang digunakan, tetapi juga pada cara developer mengelola proses pengembangan, implementasi, dan pemeliharaannya. Inilah alasannya Anda perlu mempelajari Machine Learning Operations (MLOps).
Dalam MLOps, tools tambahan berperan sebagai penunjang utama untuk memastikan seluruh siklus hidup model ML berjalan lancar, efisien, dan dapat diandalkan. Tanpa tools yang memadai, proses ini bisa menjadi sangat rumit, tidak efisien, bahkan rentan terhadap kesalahan. Sejujurnya, Anda dapat melakukan seluruh proses MLOps tanpa bantuan tools sama sekali, tetapi hal tersebut sangatlah memakan waktu dan belum tentu efisien karena Anda tidak akan mengelola satu model machine learning selama bekerja.
Seperti yang kita tahu, pembangunan sistem ML tidak berhenti pada proses pelatihan model. Siklus hidup ML meliputi berbagai tahap, mencakup beberapa poin berikut.
- Pengumpulan data: mengintegrasikan data dari berbagai sumber dan memastikan kualitasnya.
- Preprocessing dan Feature Engineering: membersihkan data, melakukan transformasi, dan mengekstraksi fitur yang relevan.
- Pengembangan dan Pelatihan Model: menggunakan algoritma untuk melatih model berdasarkan data.
- Evaluasi: mengukur performa model menggunakan metrik tertentu.
- Deployment: mengintegrasikan model ke dalam aplikasi atau sistem produksi.
- Monitoring dan Maintenance: memastikan performa model tetap optimal seiring perubahan data dan kebutuhan bisnis.
Setiap tahap ini memiliki tantangan tersendiri yang tidak bisa dibilang mudah. Tools tambahan dapat membantu Anda mengelola setiap tahap dengan cara yang lebih sistematis, mengurangi pekerjaan manual, dan meminimalkan risiko kesalahan.
Di lain sisi, tanpa tools yang dirancang untuk kolaborasi, komunikasi antar tim bisa terhambat. Tools seperti Git untuk version control atau DVC untuk manajemen data memungkinkan tim bekerja secara paralel dan terkoordinasi dengan baik. Tools ini juga memastikan setiap anggota tim memiliki akses ke versi data dan kode terbaru.
Salah satu tantangan terbesar dalam membangun sistem ML adalah memastikan bahwa hasil yang diperoleh dapat direproduksi di masa mendatang. Dalam penelitian atau pengembangan model, kita sering kali menggunakan dataset, kode, dan konfigurasi tertentu. Jika tidak didokumentasikan atau dikelola dengan baik, hasil yang sama tidak dapat diulang.
Kami sangat paham mungkin beberapa dari Anda memiliki sifat idealis yang sangat tinggi sehingga enggan untuk menggunakan bantuan tools yang sudah ada. Namun, menggunakan tools tambahan dalam MLOps bukan hanya pilihan, tetapi kebutuhan dalam menghadapi tantangan kompleksitas, kolaborasi, reproduksibilitas, dan skalabilitas.
Tools ini membantu kita bekerja lebih efisien, mengurangi kesalahan, dan memastikan bahwa model ML yang kita kembangkan dapat memberikan nilai maksimal bagi organisasi.
Seiring dengan perkembangan teknologi, pemahaman, dan kemampuan menggunakan tools MLOps yang tepat akan menjadi keterampilan yang sangat berharga bagi para praktisi machine learning. Dengan demikian, investasi waktu dan upaya untuk mempelajari dan menerapkan tools ini adalah langkah strategis untuk sukses di bidang machine learning.
Untuk mencapai objektif tersebut, mari kita bahas tools penunjang MLOps berdasarkan kegunaannya mulai dari version control hingga cloud-native tools.
Ragam Tools Penunjang MLOps
Tentunya sampai di sini Anda sudah memahami bahwa tahapan MLOps memiliki struktur yang kompleks dan melibatkan berbagai macam stakeholders. Sehingga, penentuan tools yang akan digunakan merupakan tahapan awal yang sangat penting untuk menunjang seluruh tahapan yang akan Anda lakukan, terlebih jika ingin menerapkan MLOps maturity level tertinggi. Sebelum itu, mari kita bagi tools yang bisa Anda gunakan berdasarkan perannya.
Version Control dan Collaboration
Dalam pengembangan proyek machine learning, kita sering kali bekerja dengan tim yang terdiri dari data engineer, data scientist, dan DevOps engineer. Mereka memerlukan akses yang sama terhadap kode, data, dan model. Bayangkan jika Anda melakukan perubahan penting pada kode, lalu anggota tim lain mengubah file yang sama—ini dapat menyebabkan konflik atau bahkan kehilangan data. Version control menjadi solusi untuk melacak semua perubahan tersebut.
Anda dapat menggunakan beberapa tools berikut sebagai penunjang version control sistem ML yang akan dibangun.
-
Git
Git adalah standar terbaik untuk version control. Dengan Git, Anda dapat melacak setiap perubahan pada kode, mengembalikan ke versi sebelumnya, atau bekerja pada fitur baru tanpa mengganggu kode utama.Contoh kasusnya, Anda sedang membuat fitur baru. Anda bisa membuat branch baru untuk fitur itu, mengerjakannya secara terpisah, lalu menggabungkannya kembali ke main branch setelah selesai.
-
DVC (Data Version Control)
Git tidak dirancang untuk menangani file besar seperti dataset khususnya dengan akun free. DVC hadir untuk mengatasi masalah ini dengan kemampuan yang memungkinkan Anda melacak data yang besar tanpa harus mengatur konfigurasi atau pricing account.Contoh kasusnya jika dataset Anda berubah dari 1 juta menjadi 1,5 juta baris. Dengan DVC, Anda bisa membandingkan versi dataset sebelumnya dan dataset baru dengan mudah dan tanpa batasan.
-
Collaborative Platform
Platform seperti GitHub, GitLab, dan Bitbucket mempermudah kolaborasi tim dengan fitur seperti pull request, code review, dan CI/CD (Continuous Integration/Continuous Deployment).
Dengan menggunakan tools yang dapat mengatasi version control, Anda dapat memastikan bahwa setiap anggota tim bekerja pada kode yang sama, mempermudah rollback jika terjadi bug ketika deploy, dan dapat berkolaborasi bahkan ketika bekerja remote atau WFA.
Environment Management
Pernahkah Anda mendengar istilah “It works on my machine”? Masalah ini sering terjadi ketika kode berjalan baik di komputer developer, tetapi gagal di server produksi. Environment management memastikan semua perangkat lunak, library, dan konfigurasi yang dibutuhkan tersedia dalam kondisi yang sama, terlepas dari tempat kode dijalankan. Berikut beberapa tools yang dapat Anda gunakan.
-
Docker
Docker adalah alat untuk membuat container, yaitu lingkungan virtual yang memuat aplikasi beserta semua dependensinya. Contoh sederhananya, Anda membuat model dengan menggunakan TensorFlow versi 2.13.0. Docker dapat memastikan TensorFlow versi ini akan digunakan di semua lingkungan yang akan Anda buat kelak sehingga menghindari conflict dan error pada lingkungan baru. -
Conda
Conda adalah alat untuk mengelola versi Python dan dependensi lainnya dalam sebuah environment yang terisolasi. Contoh paling umumnya, Anda membuat environment khusus untuk proyek A dengan pustaka pandas versi 1.3.0 dan scikit-learn versi 0.24. Untuk proyek B, Anda bisa membuat environment lain dengan pustaka yang berbeda. Hal ini berguna untuk melakukan eksplorasi dan menghindari permasalahan versi yang acapkali berubah tanpa adanya pemberitahuan. -
Virtualenv
Alternatif lainnya ketika Anda “alergi” dengan Conda adalah Virtualenv. Virtualenv memungkinkan Anda membuat environment Python yang terpisah tanpa menginstal aplikasi tambahan.
Inti dari environment management ini agar Anda dapat menghindari conflict antar library, mempermudah pemindahan proyek dari local env ke production, dan memastikan stabilitas kode di lingkungan produksi. Terlihat sederhana, tetapi perannya sangat penting, ‘kan?
Experiment Tracking
Saat melatih model machine learning, kita sering mencoba berbagai kombinasi hyperparameter, algoritma, dan dataset. Tanpa pencatatan yang baik, sulit untuk mengetahui konfigurasi mana yang menghasilkan model terbaik. Experiment tracking membantu mencatat setiap eksperimen yang dilakukan. Nah, dari sini kita mulai mengenal tools yang nantinya akan sering digunakan pada kelas ini yaitu MLflow. Mungkin ini hanya sneak peek nya saja, ya. Untuk, detailnya nantikan di materi berikutnya.
-
MLflow
MLflow dapat mencatat konfigurasi hyperparameter, hasil, dan artefak model. Anda juga bisa menggunakan UI-nya untuk membandingkan eksperimen sehingga dapat membandingkan keseluruhan proses dengan lebih mudah -
Weights & Biases (W&B)
W&B adalah platform pencatatan eksperimen yang menyediakan GUI agar pengguna dapat melihat visual yang lebih interaktif dibandingkan hanya tulisan saja. Selain itu, Anda juga bisa memantau eksperimen secara real-time ketika melakukan pelatihan ataupun inference. -
Neptune.ai
Alternatif lain yang cocok untuk proyek ML skala besar dengan integrasi pipeline yang sudah disediakan.
Dengan menggunakan tools experiment tracking, Anda dapat menghindari kebingungan saat mencoba banyak eksperimen, mempermudah dokumentasi model, dan mempercepat iterasi dengan informasi dari eksperimen sebelumnya.
Model Training dan Hyperparameter Tuning
Melatih model ML memerlukan waktu dan sumber daya yang besar, terutama jika modelnya cukup besar dan memiliki permasalahan kompleks. Hyperparameter tuning dapat membantu kita menemukan konfigurasi terbaik untuk meningkatkan akurasi model.
Pada materi ini, kita tidak akan membahas terlalu banyak mengenai optimasi model dan hyperparameter tuning karena Anda sudah mempelajari semuanya pada kelas sebelumnya. Namun, kita akan membahas sedikit mengenai tools yang biasa digunakan untuk melakukan optimisasi.
-
Optuna
Framework yang memungkinkan Anda melakukan optimasi hyperparameter dengan metode seperti Bayesian optimization. -
Ray Tune
Cocok untuk eksperimen yang membutuhkan distribusi komputasi. Contohnya, ketika Anda menjalankan eksperimen di server dengan banyak GPU, Ray Tune membagi eksperimen Anda ke beberapa GPU untuk mempercepat proses. -
TensorFlow dan PyTorch
Framework ini memiliki pustaka bawaan untuk pelatihan dan optimasi model, termasuk distribusi dan early stopping.
Model Deployment
Setelah model dilatih dan diuji, langkah berikutnya adalah menjadikannya “hidup” di lingkungan produksi. Model deployment adalah proses mengintegrasikan model ke dalam aplikasi atau sistem yang akan menggunakannya. Tantangan utama dalam deployment adalah memastikan bahwa model berjalan dengan stabil, efisien, dan mudah diakses.
Terdapat banyak sekali tools yang dapat menunjang deployment ini, tetapi pada kelas ini, kita akan membahas beberapa saja mencakup tools berikut.
-
TensorFlow Serving
Dirancang khusus untuk model TensorFlow, tools ini mempermudah deployment dengan menyediakan endpoint REST API untuk inferensi. -
TorchServe
Sesuai namanya, tools ini dibuat untuk melakukan deployment model PyTorch. Kelebihan TorchServe dapat memudahkan developer untuk membuat API inferensi tanpa menulis banyak kode tambahan. -
Seldon Core
Framework open-source berbasis Kubernetes untuk deployment skala besar. Seldon Core Mendukung berbagai framework ML dan memungkinkan deployment model dalam skala besar.
Pipeline Automation
Pipeline automation adalah proses mengotomasi alur pembangunan sistem ML, mulai dari pengumpulan data hingga deployment model. Biasanya developer melakukan semua tahapannya secara manual. Namun, dengan automasi, semua langkah dapat dilakukan dengan konsisten dan terkoordinasi.
Berikut beberapa tools yang dapat membantu developer membuat pipeline automation untuk pembangunan sistem machine learning.
- Apache Airflow
Tools orkestrasi workflow yang fleksibel, tools ini Cocok untuk mengotomasi pipeline data dan ML.- Contoh penerapannya, Anda memiliki pipeline yang mencakup pengolahan data harian, pelatihan ulang model, dan evaluasi performa. Airflow mengatur semua proses ini secara otomatis.
- Kubeflow Pipelines
Bagian dari Kubeflow yang dirancang untuk membuat dan menjalankan pipeline ML di Kubernetes.- Contohnya perusahaan Anda ingin menjalankan pipeline pada infrastruktur berbasis cloud dengan Kubernetes. Kubeflow Pipelines mempermudah orkestrasi tugas-tugas ML.
- Prefect
Alternatif modern untuk orkestrasi pipeline yang lebih Pythonic.- Contoh sederhananya Anda ingin mengotomasi proses preprocessing data sebelum dilatih ulang. Prefect memungkinkan Anda membuat pipeline sederhana dan efisien.
Monitoring dan Observability
Fun fact, model ML di produksi tidak akan selalu berjalan sempurna seperti pada proses pelatihan dan evaluasi. Perubahan data (data drift), pergeseran distribusi, atau masalah performa dapat mengurangi akurasi model. Oleh karena itu, kita perlu melakukan monitoring dan observability agar dapat membantu mendeteksi masalah ini sebelum berdampak besar.
Berikut beberapa tools yang dapat membantu kita melakukan monitoring terhadap model ML yang sudah dibangun.
-
Prometheus
Sistem monitoring populer yang mengumpulkan metrik dari server atau aplikasi. -
Grafana
Tools visualisasi untuk data metrik. Memungkinkan Anda membuat dashboard yang interaktif. -
**Evidently AI
**Tools khusus untuk memantau data drift dan performa model ML. Menariknya, Evidently AI dapat diintegrasikan dengan Prometheus dan Grafan dengan sangat mudah.
Data Management
Data adalah inti dari machine learning. Namun, data sering kali tidak terstruktur, kotor, atau sulit diakses. Dengan manajemen data yang baik, Anda dapat memastikan bahwa model ML yang dibangun menggunakan data berkualitas tinggi dan siap dipertanggungjawabkan.
Tools ini berguna untuk melakukan preprocessing data, mulai dari pembersihan data hingga seluruh proses data wrangling.
-
Great Expectations
Alat untuk validasi kualitas data dan mendokumentasikan proses data pipeline. -
Delta Lake
Layer penyimpanan berbasis Apache Spark yang mendukung transaksi ACID dan versioning data. -
Pandas dan PySpark
Framework utama untuk pengolahan data. Pandas digunakan untuk dataset kecil, sedangkan PySpark untuk dataset besar.
Testing dan CI/CD
Testing memastikan bahwa semua bagian sistem bekerja sesuai dengan fungsinya. Lalu, CI/CD (Continuous Integration/Continuous Deployment) memastikan perubahan kode dapat diintegrasikan dan diterapkan dengan cepat dan tidak mengalami permasalahan.
Berikut beberapa tools yang dapat Anda pelajari untuk melakukan testing dan CI/CD.
-
pytest
Framework testing Python yang fleksibel untuk menguji model ML. Contohnya, jika Anda ingin memastikan bahwa fungsi preprocessing data menghasilkan output yang benar pytest dapat digunakan untuk membuat pengujian otomatis seperti unit testing dan semacamnya. -
Jenkins
Platform CI/CD yang memungkinkan Anda mengotomasi build, testing, dan deployment. Contoh penerapannya yaitu setiap kali kode baru ditambahkan, Jenkins menjalankan pipeline yang mencakup pengujian unit, pelatihan model, dan deployment. -
GitHub Actions
Alternatif modern untuk CI/CD yang terintegrasi langsung dengan GitHub (paid version). Contohnya, jika Anda ingin otomatisasi pipeline setiap kali ada push ke repository, GitHub Actions dapat menjalankan pipeline tersebut secara otomatis tanpa ada intervensi dari pengguna.
Dengan memahami dan menggunakan tools di atas, Anda dapat membangun pipeline MLOps yang efisien, andal, dan mudah dikelola. Setiap alat memiliki keunggulannya sendiri sehingga Anda dapat memilih sesuai kebutuhan proyek Anda. Eiitss, di luar tools yang sudah kita bahas di atas, tentunya masih banyak tools lainnya yang dapat Anda pelajari secara mandiri, ya.
Pada kelas ini, kita tidak akan menggunakan seluruh tools yang sudah dibahas di atas. Inti dari kelas ini adalah membangun sistem machine learning yang menerapkan prinsip MLOps menggunakan MLflow.
Pertanyaannya, mengapa MLflow? Karena MLflow mencakup empat komponen utama pada MLOps yaitu Tracking, Projects, Models, dan Registry. Meskipun MLflow tidak secara langsung menangani semua aspek yang dibahas di atas, ia memiliki fitur yang dapat mendukung banyak dari kebutuhan MLOps tersebut. Pada materi berikutnya, kita akan berkenalan dan membahas tuntas tools bernama MLflow ini.
So, jangan sampai kehabisan bensin dahulu, ya. Silakan gunakan waktu sebaik mungkin untuk beristirahat, beribadah, dan menyiapkan diri untuk melangkah ke materi berikutnya. Sampai jumpa!
Rangkuman Pengantar Machine Learning Operations (MLOps)
Pengenalan Machine Learning Operations
Sebagai seorang Machine Learning Engineer, keahlian Anda tidak hanya terbatas pada membangun model yang akurat. Dengan kata lain, model yang baik saja tidak cukup. Bayangkan Anda memiliki model state of the art (terbaik pada masanya) tetapi hanya bisa berjalan pada notebook atau local environment, tentunya itu menjadi sia-sia.
Developer, Operations DevOps, MLOps, apa itu?
Dalam dunia pengembangan aplikasi, baik sebagai Developer, IT Operations, atau peran lainnya, Anda mungkin sudah familiar dengan kompleksitas prosesnya. Pengembangan aplikasi, apalagi yang melibatkan deployment ke lingkungan produksi, seringkali membutuhkan kolaborasi banyak pihak.
Dulu, software development dan IT operations berjalan terpisah. Developer fokus membuat kode dan fitur baru, sementara Operations bertanggung jawab atas deployment dan pemeliharaan. Pendekatan ini menciptakan GAP pengetahuan antar tim, yang memicu berbagai masalah. Siklus rilis menjadi lambat karena deployment manual dan birokrasi. Kurangnya komunikasi menyebabkan misinterpretasi dan kesalahan. Perubahan kode yang tidak terintegrasi dengan baik menimbulkan masalah stabilitas. Kurangnya visibilitas antar tim, karena perbedaan tools dan akses, membuat proses pengembangan menjadi terhambat.
Selain itu, struktur tim yang tertutup menjadi masalah utama. Perbedaan perspektif dan idealisme antar individu, jika tidak dikelola dengan baik, dapat menghambat pengambilan keputusan dan kolaborasi. Dalam proyek machine learning, misalnya, seorang data scientist mungkin menginginkan model yang kompleks, sementara seorang engineer dari tim operations mungkin lebih memilih model yang ringan. Tanpa titik temu, proyek bisa terhambat.
Secara umum, proses pengembangan aplikasi melibatkan dua tim utama: Developer (merancang, menulis, mengemas, dan menguji kode) dan IT Operations (merilis, men-deploy, mengoperasikan, dan memantau infrastruktur). Kedua tim ini memiliki tujuan yang sama: menyajikan aplikasi yang stabil kepada pengguna. Namun, perbedaan prioritas, tools, dan pola kerja seringkali menimbulkan konflik. Developer dituntut cepat, yang terkadang mengorbankan kualitas. IT Operations fokus pada stabilitas, yang sering terganggu oleh perubahan dari aplikasi. Konflik ini berujung pada kurangnya pemahaman dan komunikasi, yang seringkali berujung pada saling menyalahkan.
Kondisi ini menciptakan bottleneck yang menghambat kolaborasi dan efisiensi, yang pada akhirnya dapat merugikan perusahaan. Pengguna kecewa, feedback negatif, dan perusahaan berisiko kehilangan pasar.
Untuk mengatasi masalah ini, dan seiring dengan meningkatnya tuntutan pasar akan rilis software yang lebih cepat, muncullah konsep DevOps. DevOps adalah gabungan dari filosofi budaya, praktik, dan tools untuk meningkatkan kemampuan perusahaan dalam menyajikan aplikasi secara cepat.
DevOps menekankan kolaborasi, menghilangkan hambatan, dan otomatisasi. Filosofi DevOps melibatkan berbagi tanggung jawab. Praktiknya merampingkan prosedur kerja tim. Tools DevOps mengotomatiskan tugas-tugas berulang.
Dengan DevOps, Developer dan IT Operations dapat bersatu, berkolaborasi, dan berkomunikasi dengan lebih efektif, sehingga dapat meningkatkan inovasi, feedback pengguna, dan nilai bisnis.
Welcome, MLOps!
Kesuksesan DevOps dalam mempercepat pengembangan perangkat lunak menginspirasi penerapan prinsip serupa pada Machine Learning, yang kemudian dikenal sebagai MLOps. MLOps bertujuan untuk menghilangkan GAP antara Machine Learning Engineer dan tim Operations, demi pelayanan terbaik kepada pengguna dan peningkatan revenue bisnis.
Pengembangan model ML seringkali dianggap hanya sebatas proses iteratif sederhana mulai dari pengumpulan data, pengolahan, pelatihan, dan evaluasi model. Pendekatan ini mungkin memuaskan ketika proses pembelajaran, tetapi masalah muncul ketika model perlu “divalidasi” dengan deployment agar dapat digunakan secara luas. Tanpa pengetahuan tentang deployment dan pemeliharaan model di lingkungan produksi, bantuan tim Operations atau Back-End menjadi krusial.
Berangkat dari situ, permasalahan klasik antara Developer dan Operations, seperti yang terjadi sebelum DevOps, dapat terulang. Perbedaan proses kerja dan dependensi dapat menghambat kolaborasi dan bahkan berdampak pada keuangan perusahaan.
MLOps hadir untuk mengatasi masalah ini. Dengan mengadopsi MLOps, perusahaan dapat mengotomatisasi proses, meningkatkan kolaborasi, memastikan kualitas model, dan memaksimalkan nilai bisnis dari investasi ML.
Machine Learning Operations adalah proses untuk menerapkan dan memelihara model ML di produksi secara andal dan efisien. Analoginya, seorang chef tidak hanya membuat resep (model ML), tetapi juga memastikan hidangan tersaji konsisten (produksi model).
Pengembangan model hanyalah langkah awal; tantangan sebenarnya adalah penggunaan model di dunia nyata. Tanpa MLOps, model berisiko mengalami penurunan performa, sulit dipantau, dan tidak dapat diandalkan.
MLOps mengadopsi karakteristik DevOps (CI/CD, otomatisasi, monitoring) yang disesuaikan untuk ML. MLOps menjembatani ML Engineer (pengembang model) dan tim engineering (operations).
Siklus pengembangan MLOps mencerminkan gabungan DevOps dan proses pengembangan ML, dengan setiap tahapan memiliki peran penting. Memahami permasalahan umum dalam membangun sistem ML akan memperjelas alasan dan peran MLOps.
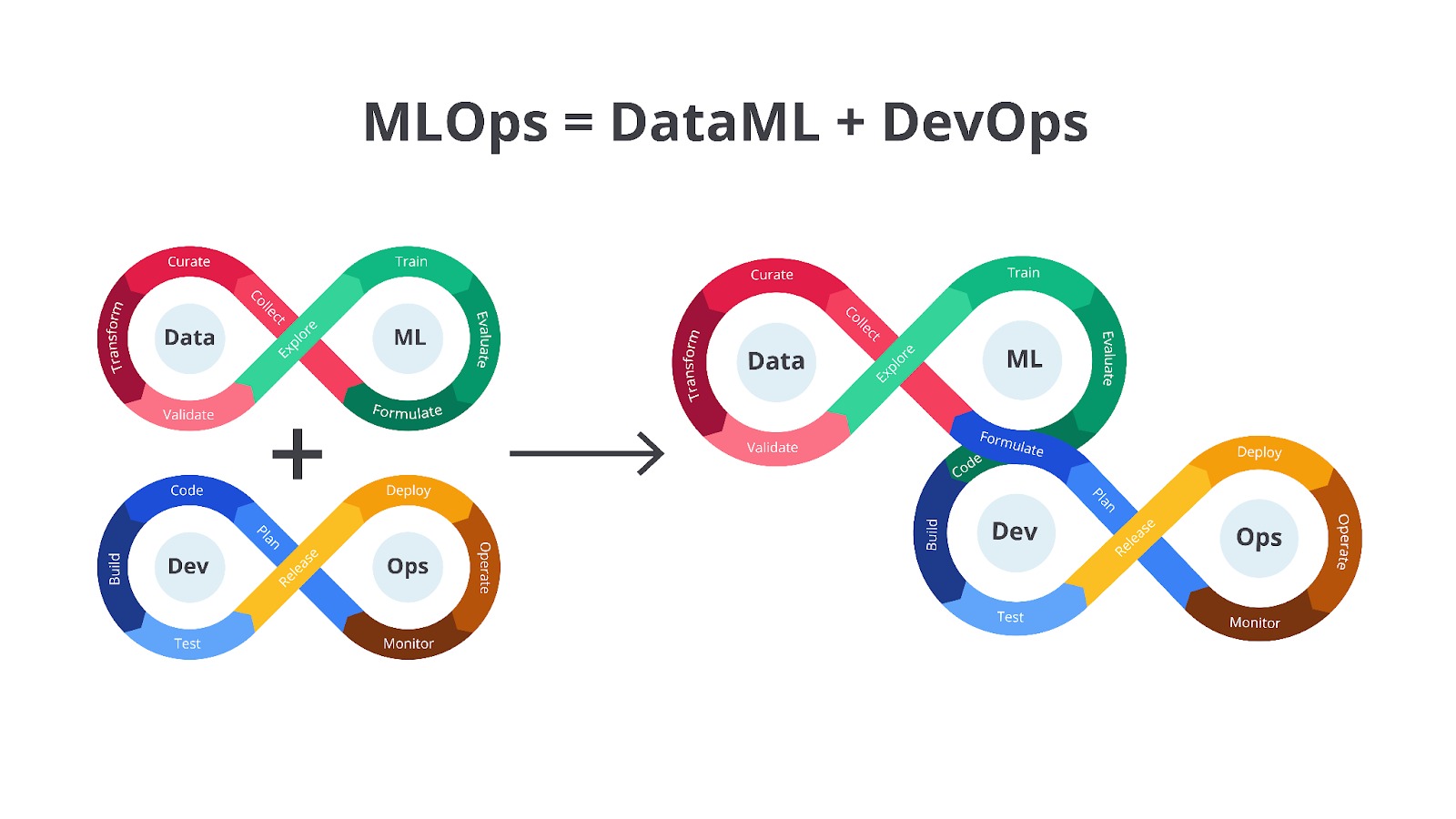
Permasalahan Umum ketika Membangun Sistem Machine Learning
Membangun sistem Machine Learning ibarat petualangan menantang yang dimulai dari pengumpulan dan pembersihan data, berlanjut ke pelatihan model, hingga akhirnya model tersebut berfungsi dan memberikan manfaat. Namun, perjalanan ini tidak selalu mulus. Tanpa penerapan prinsip MLOps, berbagai kendala siap menghadang.
Untuk mengatasi semua tantangan, MLOps hadir sebagai solusi. MLOps berperan penting dalam mengotomatisasi dan meningkatkan kualitas serta kecepatan pengembangan, deployment, dan pemeliharaan model ML.
MLOps menyediakan alat untuk monitoring performa model secara kontinu, mendeteksi model drift, dan mengotomatisasi retraining. Lebih dari itu, MLOps mengotomatisasi seluruh pipeline ML, menerapkan prinsip CI/CD, serta memfasilitasi experiment tracking, pelacakan versi dataset dan model, dan metadata management.
MLOps juga berkontribusi dalam mengurangi technical debt melalui otomatisasi, monitoring, version control, pipeline data yang robust, kerangka kerja pengelolaan model, kolaborasi tim, dokumentasi, dan containerization.
Dengan demikian, MLOps memungkinkan perusahaan untuk meningkatkan produktivitas, kualitas, dan kecepatan dalam menghadirkan sistem ML. Memahami siklus hidup MLOps adalah kunci untuk mengelola setiap tahapan secara efisien dan memastikan keberhasilan proyek ML. Pertanyaan selanjutnya yang muncul adalah bagaimana menerapkan MLOps dengan prinsip DevOps.
Machine Learning Lifecycle
Dalam skala industri, pengembangan sistem machine learning biasanya melibatkan berbagai tim dengan keahlian, peran, dan kepentingan yang berbeda. Idealnya, tim-tim ini berkolaborasi dan menerapkan prinsip MLOps untuk menciptakan sistem yang reliable, scalable, adaptable, dan maintainable.
Dalam perusahaan yang mapan, data scientist biasanya membuat model machine learning, yang kemudian diserahkan kepada ML engineer dan software engineer untuk diintegrasikan ke dalam sistem produksi. Proses ini melibatkan beberapa tim yang saling “melempar” tugas dan menunggu, yang dapat memakan waktu dan menimbulkan masalah karena perbedaan beban kerja.
Meskipun kolaborasi ini ideal, komunikasi antar tim seringkali tidak berjalan mulus. Ego tim dan rasa kepemilikan yang terpecah dapat menjadi sumber masalah, bahkan menyebabkan kegagalan proyek. Padahal, kerja sama tim seharusnya lebih diutamakan daripada kebutuhan atau ego individu.
Pada dasarnya, semua tim, baik data engineer, developer (termasuk machine learning engineer atau data scientist), maupun operations, memiliki tujuan yang sama yaitu menyelesaikan masalah bisnis dan menghasilkan revenue.
Tujuan penting lainnya adalah memastikan transisi tugas antar tim yang lancar, yang didukung oleh visibilitas, komunikasi yang baik, dan tidak adanya kepentingan politik atau individu.
MLOps Maturity
MLOps Maturity Level adalah kerangka kerja yang menunjukkan tingkat otomatisasi, struktur, dan integrasi proses operasional machine learning dalam sebuah organisasi. Tingkatan ini membantu perusahaan memahami posisi mereka dan memberikan arahan pengembangan.
Tingkatan ini juga mencerminkan kemampuan perusahaan dalam mengelola siklus hidup machine learning, dari pengembangan hingga pengelolaan model di produksi.
Level kematangan ditentukan secara kualitatif berdasarkan aspek manusia/budaya, proses/struktur, dan objek/teknologi. Semakin tinggi levelnya, semakin tinggi tingkat kesulitannya, tetapi dampaknya juga semakin besar.
Berbeda dengan level perkembangan manusia yang pasti, MLOps maturity level tidak memiliki guideline yang baku. Setiap perusahaan dapat mengadopsi pendekatan yang berbeda. Namun, Google dan Microsoft menyediakan guideline dengan mengkategorikan maturity level menjadi tiga hingga lima level. Perbedaan jumlah level ini mencerminkan perbedaan tujuan, fokus, dan kebutuhan masing-masing organisasi.
MLOps Maturity Levels: Google
Sistem ML berbeda dengan sistem perangkat lunak lain dalam beberapa hal seperti keahlian tim, pengembangan yang bersifat eksperimental, pengujian yang lebih kompleks (validasi data, evaluasi kualitas model), deployment yang tidak sederhana (pipeline untuk retraining dan deployment otomatis), dan production yang memerlukan pemantauan statistik data dan kinerja model.
Sistem ML dan perangkat lunak serupa dalam hal CI (source control, unit testing, integration testing, continuous delivery) tetapi dalam sistem ML terdapat beberapa hal yang berbeda.
- CI juga menguji dan memvalidasi data, skema data, dan model.
- CD adalah sistem (pipeline pelatihan ML) yang menerapkan layanan prediksi model.
- CT (continuous training) adalah properti baru untuk retraining dan deployment model otomatis.
Google membagi tahapan penerapan MLOps menjadi tiga level seperti berikut.
- Level 0: semua proses manual, rentan kesalahan, memakan waktu, sulit mereproduksi eksperimen, dan minim monitoring.
- Level 1: automated Training and Deployment. Mulai mengadopsi otomatisasi (pipeline untuk preprocessing, pelatihan, evaluasi). Reproduksibilitas dan efisiensi meningkat, deployment lebih terstruktur. Namun, retraining dan penyesuaian model masih memerlukan intervensi manual.
- Level 2: CI/CD pipeline automation. Otomatisasi penuh dengan CI/CD. Deployment dan retraining otomatis, monitoring transparan, feedback dari data organik, dan dapat menangani lebih banyak eksperimen.
MLOps Maturity Level: Microsoft
Microsoft juga memiliki model maturity dengan lima level:
- Level 0: No MLOps. Pembangunan model manual, tanpa integrasi tools dan sistem. Eksperimen terisolasi, tanpa pengelolaan versi, dan proses manual.
- Level 1: DevOps but no MLOps. Menerapkan DevOps untuk aplikasi, tetapi belum mengintegrasikan ML. Pipeline otomatis untuk aplikasi, tetapi model ML masih dikelola manual.
- Level 2: Automated Training. Otomatisasi pelatihan dan evaluasi model. Pipeline otomatis, pengelolaan versi model dan data, otomatisasi tuning, dan eksperimen teratur. Namun, deployment model masih manual.
- Level 3: Automated Model Deployment. Deployment model otomatis dengan CI/CD. Registry model, monitoring, dan feedback loop.
- Level 4: Full MLOps Automated Operations. Otomatisasi penuh, adaptasi mandiri, monitoring lanjutan, eksperimen berkelanjutan, dan zero-downtime system.
Tools Penunjang MLOps
Dalam era teknologi yang berkembang pesat, machine learning (ML) telah menjadi pilar penting di berbagai industri, dari perbankan hingga e-commerce. Penerapan ML membuka peluang untuk meningkatkan efisiensi, akurasi, dan personalisasi layanan. Namun, keberhasilan ML tidak hanya bergantung pada algoritma, tetapi juga pada pengelolaan proses pengembangan, implementasi, dan pemeliharaannya. Inilah mengapa Machine Learning Operations (MLOps) menjadi krusial.
MLOps membutuhkan tools tambahan untuk memastikan seluruh siklus hidup model ML berjalan lancar, efisien, dan andal. Tanpa tools yang memadai, proses ini bisa menjadi rumit dan rentan kesalahan. Meskipun MLOps dapat dilakukan tanpa tools, hal ini akan memakan waktu dan belum tentu efisien, terutama karena Anda akan mengelola banyak model ML.
Siklus hidup ML tidak hanya berhenti pada pelatihan model, tetapi meliputi pengumpulan data, preprocessing dan feature engineering, pengembangan dan pelatihan model, evaluasi, deployment, serta monitoring dan maintenance. Setiap tahap memiliki tantangan tersendiri. Tools tambahan membantu mengelola setiap tahap secara sistematis, mengurangi pekerjaan manual, dan meminimalkan risiko kesalahan.
Selain itu, tools MLOps memfasilitasi kolaborasi tim. Tools seperti Git (untuk version control) atau DVC (untuk manajemen data) memungkinkan tim bekerja secara paralel dan terkoordinasi, serta memastikan setiap anggota tim memiliki akses ke versi terbaru.
Reprodusibilitas adalah tantangan besar lainnya. Tanpa dokumentasi dan pengelolaan yang baik, hasil eksperimen ML sulit direproduksi. Tools MLOps membantu mengatasi masalah ini.
Menggunakan tools tambahan dalam MLOps adalah kebutuhan, bukan hanya pilihan. Tools ini membantu mengatasi kompleksitas, meningkatkan kolaborasi, memastikan reproduksibilitas, dan mencapai skalabilitas. Tools ini juga meningkatkan efisiensi, mengurangi kesalahan, dan memastikan model ML memberikan nilai maksimal.
Memahami dan menggunakan tools MLOps yang tepat adalah keterampilan berharga. Investasi waktu dan upaya untuk mempelajari dan menerapkan tools ini adalah langkah strategis.
Berikut adalah beberapa tools penunjang MLOps, dikategorikan berdasarkan perannya:
- Version Control dan Collaboration:
- Git: standar version control untuk melacak perubahan kode.
- DVC (Data Version Control): melacak perubahan pada dataset besar.
- Collaborative Platform (GitHub, GitLab, Bitbucket): memfasilitasi kolaborasi tim dengan fitur pull request, code review, dan CI/CD.
- Environment Management:
- Docker: membuat container, lingkungan virtual yang berisi aplikasi dan dependensinya.
- Conda: mengelola versi Python dan dependensi dalam environment terisolasi.
- Virtualenv: alternatif Conda untuk membuat environment Python terpisah.
- Experiment Tracking:
- MLflow: mencatat konfigurasi hyperparameter, hasil, dan artefak model, serta menyediakan UI untuk perbandingan.
- Weights & Biases (W&B): platform pencatatan eksperimen dengan visualisasi interaktif dan pemantauan real-time.
- Neptune.ai: alternatif untuk proyek ML skala besar dengan integrasi pipeline.
- Model Training dan Hyperparameter Tuning:
- Optuna: framework untuk optimasi hyperparameter dengan metode seperti Bayesian optimization.
- Ray Tune: cocok untuk eksperimen yang membutuhkan distribusi komputasi.
- TensorFlow dan PyTorch: framework dengan pustaka bawaan untuk pelatihan dan optimasi model.
- Model Deployment:
- TensorFlow Serving: untuk deployment model TensorFlow dengan endpoint REST API.
- TorchServe: untuk deployment model PyTorch.
- Seldon Core: framework open-source berbasis Kubernetes untuk deployment skala besar.
- Pipeline Automation:
- Apache Airflow: tools orkestrasi workflow yang fleksibel.
- Kubeflow Pipelines: bagian dari Kubeflow untuk membuat dan menjalankan pipeline ML di Kubernetes.
- Prefect: alternatif modern untuk orkestrasi pipeline yang lebih Pythonic.
- Monitoring dan Observability:
- Prometheus: sistem monitoring yang mengumpulkan metrik.
- Grafana: tools visualisasi untuk data metrik.
- Evidently AI: tools khusus untuk memantau data drift dan performa model ML.
- Data Management:
- Great Expectations: alat untuk validasi kualitas data.
- Delta Lake: layer penyimpanan berbasis Apache Spark yang mendukung transaksi ACID dan versioning data.
- Pandas dan PySpark: framework untuk pengolahan data.
- Testing dan CI/CD:
- pytest: framework testing Python yang fleksibel.
- Jenkins: platform CI/CD untuk otomatisasi build, testing, dan deployment.
- GitHub Actions: alternatif CI/CD yang terintegrasi dengan GitHub.
This file is located at: _chapters/992-membangun-sistem-machine-learning/010-pengantar-mlops.md