Membangun dan Mengelola Metadata dengan Tools Open-Source
- Pengenalan Version Control
- Jenis-Jenis Version Control System
- Tools yang Umum Digunakan
- Dasar-Dasar Penggunaan Version Control
- Pengenalan MLflow: Tracking dan Project
- Pengenalan MLflow: Model dan Model Registry
- Pengenalan MLflow: Pipelines dan Keypoints
- Version Control dengan MLflow
- Metadata dan Sekitarnya
- Latihan: Membuat Version Control Menggunakan MLflow
- Rangkuman Membangun dan Mengelola Metadata dengan Tools Open-Source
Pengenalan Version Control
“The more that you read, the more things you will know. The more that you learn, the more places you’ll go.” – Dr. Seus, American children’s author.
Selamat datang kembali di kelas Membangun Sistem Machine Learning. Setelah mempelajari seluk-beluk MLOps pada modul sebelumnya, bukan berarti pembelajaran Anda berhenti di sini karena sejatinya menjadi seorang machine learning engineer merupakan perjalanan yang sangat panjang.
Sesuai dengan kutipan di atas, semakin banyak pembelajaran yang dilalui, niscaya kelak akan mengantarkan Anda menuju posisi pekerjaan yang sesuai dengan kapabilitasnya.
Pada kesempatan kali ini, kita akan membahas version control sebagai salah satu langkah pertama sebelum mengupas tuntas MLOps di materi berikutnya.
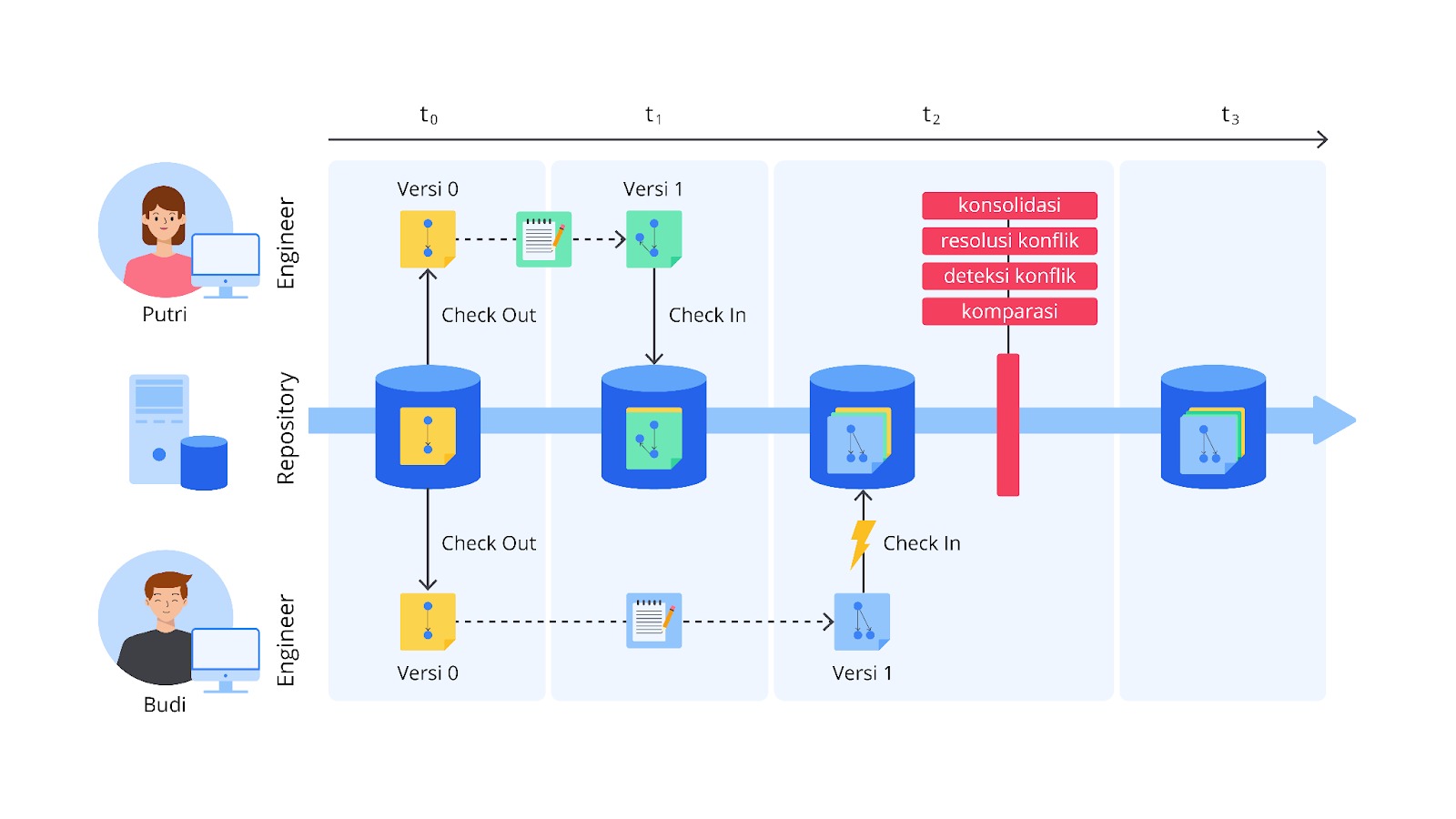
Version control adalah salah satu pilar penting dalam pengembangan perangkat lunak secara umum maupun spesifik seperti data science dan machine learning. Dalam dunia yang serba cepat dan kolaboratif ini, pengelolaan perubahan pada kode, data, dan dokumen menjadi hal yang krusial. Bayangkan Anda membuat sebuah proyek besar tanpa sistem yang bisa melacak perubahan—bisa kacau, bukan? Sebagai manusia yang tak lepas dari kata “lupa”, tentu akan sedikit kewalahan jika ingin melakukan rollback (kembali ke kode sebelumnya), apalagi ketika kode memiliki jumlah history perubahan yang sangat banyak tanpa adanya identitas.
Version control mengajarkan kita bahwa setiap perubahan perlu dicatat dan dievaluasi, bukan hanya dilakukan secara ugal-ugalan. Tahapan ini merupakan bentuk refleksi teknis dalam kerja tim maupun individu.
Selain itu, kita juga belajar tentang kolaborasi yang lebih baik, pengelolaan risiko, hingga memastikan bahwa setiap langkah kita terdokumentasi dengan rapi. Di sinilah teknologi seperti Git, Subversion, atau bahkan platform seperti MLflow dalam machine learning memainkan peran penting.
Nah, pada modul ini, mari kita eksplorasi bersama bagaimana version control dapat meningkatkan efisiensi dan kualitas pekerjaan seorang machine learning engineer, serta menjadikan proyek kita lebih terorganisasi dan terkontrol. Siapkan semangat Anda karena perjalanan kita baru saja dimulai!
Definisi dan Pentingnya Version Control
Version control adalah sistem atau pendekatan yang digunakan untuk mencatat, mengelola, dan melacak perubahan pada file atau kumpulan file seiring waktu. Dalam dunia teknologi, version control sangat erat kaitannya dengan pengembangan perangkat lunak, dokumentasi, hingga pengelolaan data. Namun, version control tidak hanya berkutat di teknologi saja melainkan dapat diterapkan secara umum pada berbagai macam bidang.
Mungkin sebagai siswa Anda familier dengan revisi tugas hingga file revisian yang dibuat menjadi sangat banyak dengan nama yang berbeda-beda.

Penamaan file tugas yang berubah-ubah dan menjamur menjadi banyak file seperti gambar di atas merupakan masalah umum dalam pengembangan proyek, terutama jika tidak menggunakan version control system. Sekilas terlihat sederhana dan tidak ada masalah, ya? Jangan salah, masalah kecil seperti ini akan menjadi sebuah issue yang sangat besar ketika kita tidak aware dengan ancaman yang menghantuinya. Setidaknya beberapa masalah berikut akan hadir ketika kita menghiraukan hal sepele ini.
- Jika nama file berubah-ubah (misal, laporan_akhir.docx menjadi laporan_revisi1.docx, lalu laporan_revisi_final.docx), penulis dapat dengan mudah kehilangan jejak revisi mana yang terbaik atau perubahan apa yang dilakukan di setiap revisi. Mencari file yang tepat menjadi sulit dan memakan waktu karena kita cenderung membuka dokumen satu per satu hingga menemukan versi yang dicari.
- Adanya banyak revisi dengan nama yang mirip atau berbeda sedikit menyebabkan duplikasi file yang tidak perlu, membengkaknya ruang penyimpanan, dan mempersulit manajemen.
- Jika beberapa orang bekerja pada file yang sama secara bersamaan tanpa version control system, konflik terhadap versi sangat mungkin terjadi. Seseorang mungkin menimpa perubahan yang dilakukan orang lain tanpa sadar sehingga mengakibatkan permasalahan yang cukup serius.
- Berbagi dan menggabungkan perubahan menjadi sangat kompleks dan rawan kesalahan.
Dari sini, kita semua tahu tanpa sistem kontrol versi (VCS), mengelola proyek dengan banyak file dan revisi yang berubah-ubah menimbulkan beberapa masalah serius. Beberapa hal di antaranya seperti kehilangan jejak perubahan dan revisi, duplikasi file yang tidak perlu, konflik versi yang sulit diselesaikan, kesulitan dalam kolaborasi, dan risiko kehilangan data. Secara keseluruhan, ini mengakibatkan inefisiensi, potensi kesalahan, dan manajemen proyek yang kacau.
Berangkat dari permasalahan seperti ini, kita perlu menerapkan version control system agar terhindar dari permasalahan yang terlihat sepele, tetapi mematikan. Dengan menggunakan VCS, setiap perubahan disimpan dalam bentuk yang serupa sehingga memungkinkan pengguna untuk melihat riwayat perubahan, memulihkan versi sebelumnya, atau bahkan menggabungkan kontribusi dari beberapa orang dalam tim.

Pendekatan ini sering digunakan pada proyek berbasis teknologi, seperti pengembangan perangkat lunak, dokumentasi teknis, hingga pengelolaan data dalam proyek analitik. Versi-versi yang dikelola mencakup kode program, dokumen, gambar, atau file lainnya yang sering mengalami pembaruan.
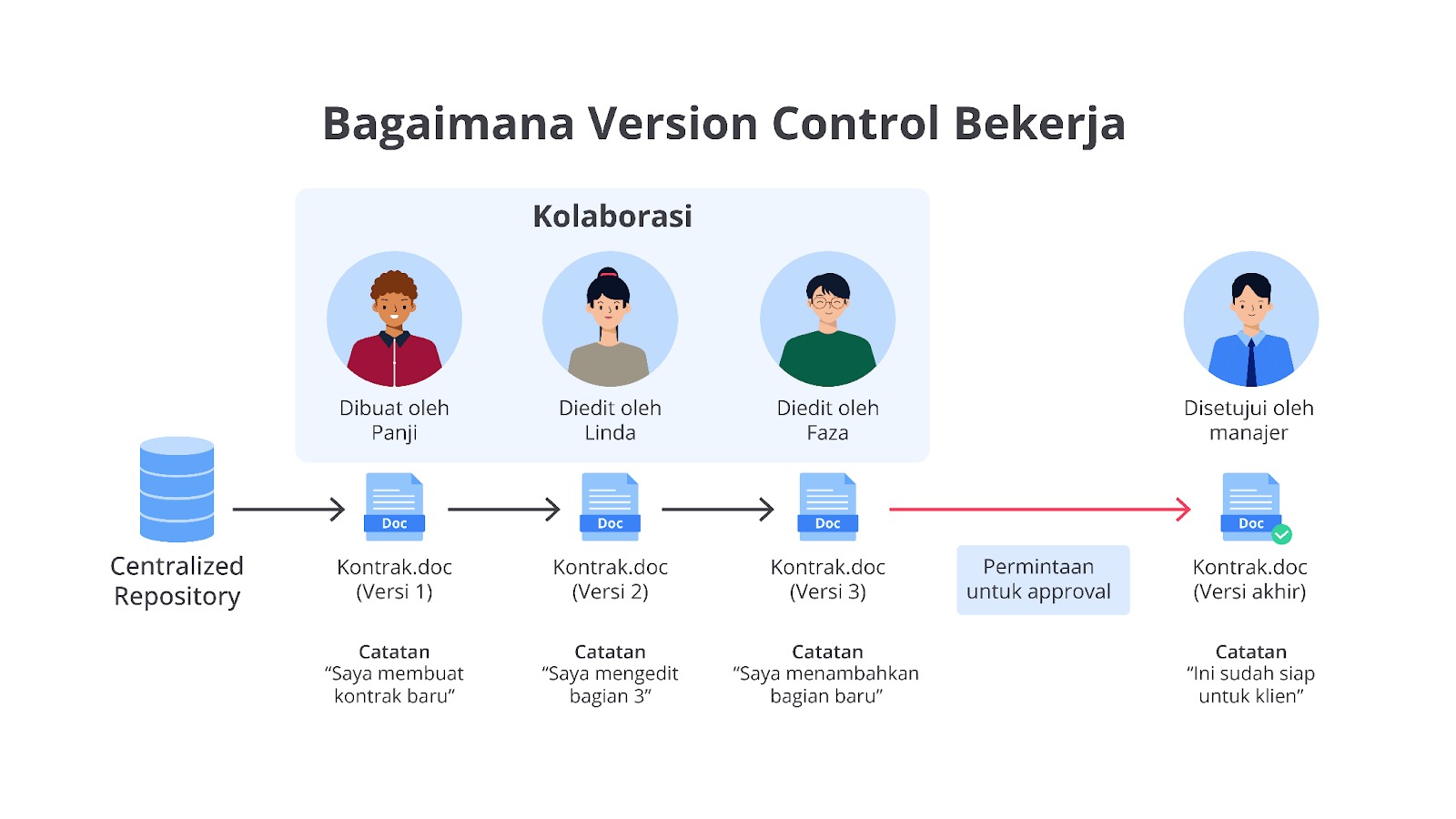
Version control bekerja dengan cara mencatat perubahan yang dilakukan pada file dan menyimpannya sebagai snapshot. Setiap snapshot setidaknya mencatat informasi berikut.
- Nama pengguna yang membuat perubahan.
- Waktu dilakukannya perubahan.
- Bagian yang berubah dari file tersebut.
Sistem ini memungkinkan pengguna untuk melihat riwayat perubahan secara detail, mengembalikan file ke kondisi sebelumnya jika diperlukan, hingga mengintegrasikan kontribusi dari banyak pengguna tanpa konflik.
Bagaimana menurut Anda? Apakah dari penjelasan di atas sudah dapat menyimpulkan peran dari VCS ini? Bagus, tetapi jika Anda belum yakin dan membutuhkan validasi, mari kita bahas bersama-sama peran VCS yang sering dianggap sepele.
-
Melacak Riwayat Perubahan
Version control memungkinkan pengguna untuk melacak setiap perubahan yang dilakukan pada file. Dengan mencatat siapa yang mengubah, apa yang diubah, dan kapan perubahan itu terjadi, developer dapat mengetahui asal-usul perubahan dengan lebih detail, memahami alasan di balik perubahan yang dilakukan, hingga membandingkan versi yang berbeda untuk menganalisis dampaknya. Sebagai contoh, jika sebuah bug ditemukan dalam program, pengembang dapat melihat riwayat versi untuk mengidentifikasi kapan bug tersebut muncul dan memperbaikinya—rollback, atau memperbarui kode. -
Reproduksi dan Pemulihan
Dalam proyek apa pun, terkadang perubahan yang salah dapat terjadi, baik disengaja maupun tidak. Dengan version control, developer dapat dengan mudah mengembalikan file atau proyek ke versi sebelumnya tanpa kehilangan data penting dan mengidentifikasi titik perubahan yang menyebabkan masalah untuk mencegah terulangnya kesalahan yang sama.Contohnya, jika sebuah dokumen atau skrip yang penting secara tidak sengaja dihapus atau diubah, versi sebelumnya masih dapat diakses tanpa harus memulai dari awal.
-
Kolaborasi Menjadi Lebih Efektif
Dalam proyek yang melibatkan banyak anggota tim, version control memungkinkan semua anggota untuk bekerja pada file yang sama tanpa khawatir akan saling tumpang tindih atau kehilangan hasil kerja mereka. Fitur seperti branching (pencabangan) dan merging (penggabungan) memungkinkan setiap anggota tim bekerja pada cabang yang terpisah tanpa mengganggu file utama dan dapat mengintegrasikan perubahan dari seluruh anggota tim ke dalam satu versi final secara terorganisasi.Contohnya, dalam pengembangan perangkat lunak, seorang developer dapat membuat cabang untuk menambahkan fitur baru, sementara developer lain memperbaiki bug di cabang lain. Kedua perubahan tersebut dapat digabungkan dengan mudah pada satu file yang sama tanpa harus membuat nama yang berbeda. Waktunya berkata bye-bye file_final_banget.docx!
-
Efisiensi dan Produktivitas
Version control membantu mengurangi pekerjaan manual dengan menyediakan tools untuk mengotomasi pencatatan perubahan, integrasi file, dan manajemen versi. Hal ini memungkinkan tim agar lebih fokus pada pengembangan inti proyek dan menghindari duplikasi kerja atau kebingungan terkait versi terbaru dari file.Sebagai contoh, dalam pengembangan perangkat lunak, integrasi otomatis melalui sistem seperti Git memudahkan tim untuk memeriksa apakah perubahan yang baru kompatibel dengan versi saat ini atau tidak.
-
Audit Menjadi Lebih Mudah
Version control menciptakan jejak audit yang lengkap sehingga memungkinkan developer untuk melacak setiap perubahan dengan transparansi penuh. Hal ini sangat penting dalam proyek yang membutuhkan akuntabilitas tinggi, seperti proyek penelitian atau pengembangan produk yang diawasi oleh regulasi ketat.Sebagai contoh, dalam proyek ilmiah, pencatatan perubahan data eksperimen memastikan bahwa semua hasil dapat direproduksi dan diverifikasi. For your information, perubahan hyperparameter dan metriks dalam pengembangan model machine learning juga perlu Anda catat agar memudahkan reproduksibilitas sistem.
-
Eksperimen Pengembangan
Dalam proyek yang membutuhkan sisi kreatif atau inovatif seperti pengembangan model, sering kali diperlukan eksperimen untuk menghasilkan banyak versi dari produk yang sama. Version control memungkinkan pengguna untuk menciptakan cabang eksperimental tanpa memengaruhi versi utama hingga membandingkan hasil dari berbagai eksperimen secara terpisah sebelum memutuskan versi terbaik.Sebagai contoh, dalam desain model machine learning, Anda perlu melakukan hyperparameter tuning dengan mengalokasikan puluhan, ratusan, bahkan ribuan kombinasi, tentunya akan sulit jika kita harus mencatat satu per satu sebelum memilih model terbaik. Dengan menerapkan VCS kita dapat memilih model terbaik dengan lebih mudah karena sudah ditulis secara otomatis oleh sistem.
-
Manajemen Risiko
Dengan version control, risiko kehilangan data akibat kesalahan manusia atau kerusakan sistem dapat diminimalisasi. Bahkan, jika terjadi masalah teknis seperti kerusakan perangkat keras atau file yang terhapus secara tidak sengaja, semua perubahan dan file sebelumnya tetap aman dalam repositori version control.
Nah, melalui penjelasan di atas, kita telah melihat bagaimana VCS berperan krusial dalam menanggulangi masalah-masalah yang timbul akibat penamaan file yang berubah-ubah dan banyaknya revisi. Dengan kemampuannya melacak perubahan, mengelola cabang, menangani konflik, dan menyediakan riwayat versi akan memberikan berbagai macam benefit dalam pengembangan proyek. Hal ini menghilangkan kekhawatiran kita terhadap kehilangan jejak revisi, duplikasi file, dan kesulitan dalam berkolaborasi.
Dengan demikian, dapat disimpulkan bahwa dengan version control, tim dapat bekerja secara lebih terorganisasi, efisien, dan transparan. Dalam dunia kerja yang modern, proyek akan terus berkembang dan semakin kompleks sehingga peran version control bukan hanya sekadar alat, tetapi sebuah kebutuhan untuk mengelola pekerjaan dengan baik dan memastikan keberhasilan jangka panjang.
Nah, untuk memilih kebutuhan tersebut ternyata tidak bisa asal atau cherry picking lho. Sebenarnya tools VCS ini memiliki beberapa jenis yang perlu Anda sesuaikan dengan proyek yang sedang dikerjakan.
Selanjutnya, agar Anda dapat memilih tools VCS yang paling cocok mari kita pelajari terlebih dahulu jenis-jenis VCS beserta kegunaannya.
Jenis-Jenis Version Control System
Sampai di sini, kita telah memahami definisi dan betapa pentingnya peran VCS dalam mengelola proyek, terutama yang melibatkan banyak file dan perubahan. Dengan kata lain, VCS ibarat asisten digital yang andal untuk mencatat setiap detail revisi, mempermudah kolaborasi, dan menjadi penyelamat saat terjadi kesalahan.
Nah, dengan pemahaman dasar ini, pertanyaan selanjutnya adalah, “Apakah hanya ada satu jenis asisten digital seperti ini?” Tentu saja tidak. Sama seperti aplikasi yang memiliki beragam variasi, dunia VCS pun menawarkan berbagai pilihan dengan karakteristik dan fungsinya masing-masing.
Secara umum, untuk membantu pengelolaan perubahan pada file dan dokumen proyek, version control systems (VCS) dapat dikategorikan menjadi beberapa tipe utama, yaitu Distributed, Centralized, Lock-based, dan Optimistic. Setiap tipe memiliki karakteristik, keunggulan, dan kelemahan yang dirancang untuk memenuhi kebutuhan proyek dengan kompleksitas dan skala yang berbeda. Pada materi ini, kita akan membahas masing-masing tipe ini secara lebih detail.
Distributed Version Control System (DVCS)
DVCS merupakan sistem yang memungkinkan setiap developer memiliki salinan lengkap dari repositori utama termasuk semua file, perubahan, dan riwayat. Dengan pendekatan ini, pengguna dapat bekerja secara independen tanpa bergantung pada koneksi internet atau server utama. Semua perubahan dicatat secara lokal dan sinkronisasi dengan repositori pusat atau pengguna lain dilakukan ketika diperlukan.
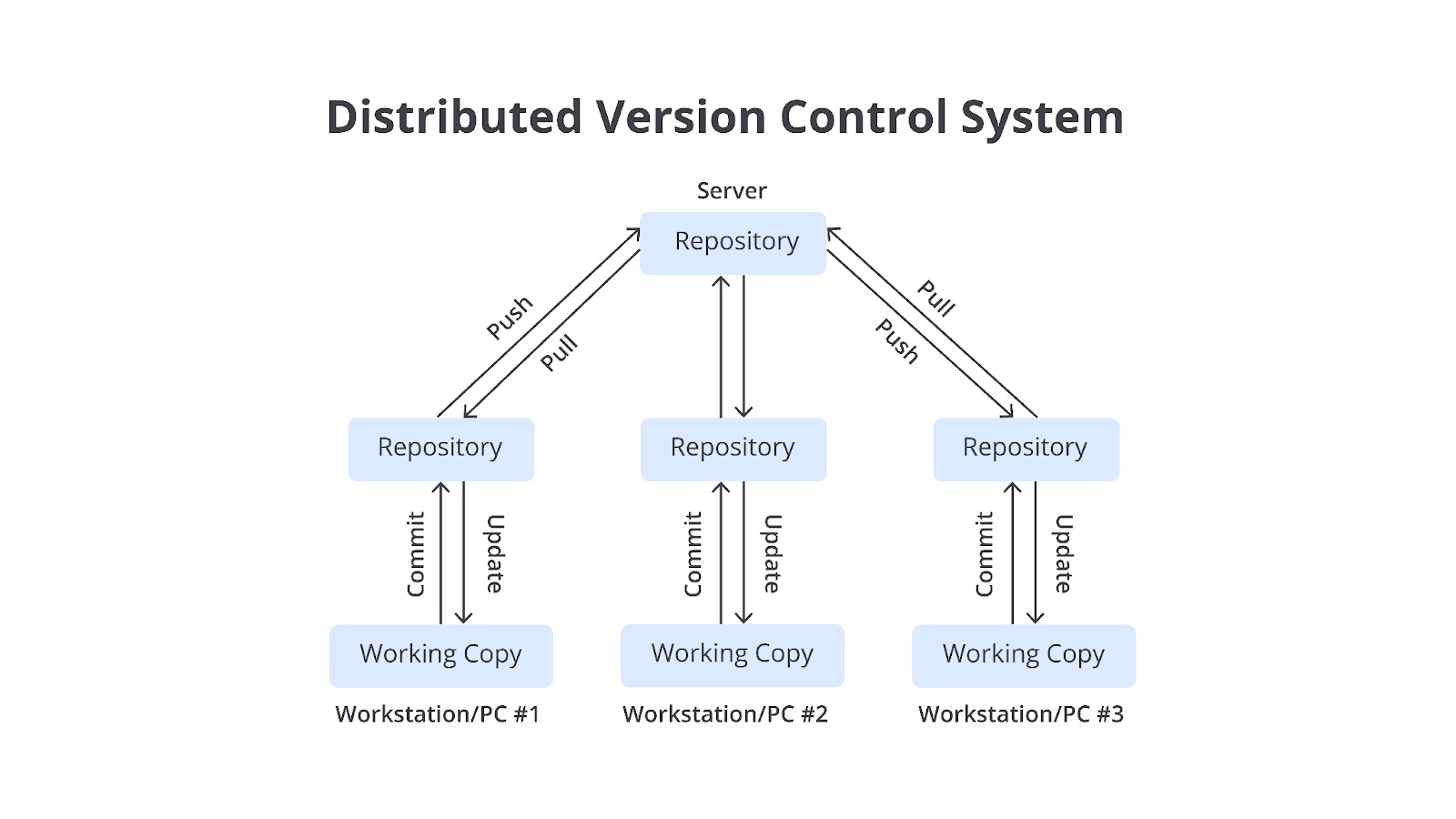
Keunggulan utama DVCS adalah fleksibilitasnya dalam mendukung pekerjaan offline serta memiliki keamanan data yang tinggi. Hal ini karena setiap pengguna memiliki salinan lengkap repositori sehingga risiko kehilangan data akibat kerusakan server dapat diminimalisasi. Selain itu, sistem ini memiliki kemampuan branching dan merging yang sangat fleksibel sehingga cocok untuk proyek kolaborasi yang melibatkan banyak eksperimen atau pengembangan secara paralel.
Namun, pendekatan ini membutuhkan lebih banyak ruang penyimpanan karena seluruh data pada suatu repositori harus disalin ke setiap device pengguna, serta kompleksitas yang lebih tinggi dibandingkan sistem lainnya.
Centralized Version Control System (CVCS)
Berbeda dengan DVCS, CVCS mengandalkan server terpusat untuk menyimpan semua file, perubahan, dan riwayat versi. Setiap pengguna atau developer akan terhubung ke server utama untuk mengunduh file (checkout), melakukan perubahan, dan mengunggah kembali perubahan tersebut (commit).
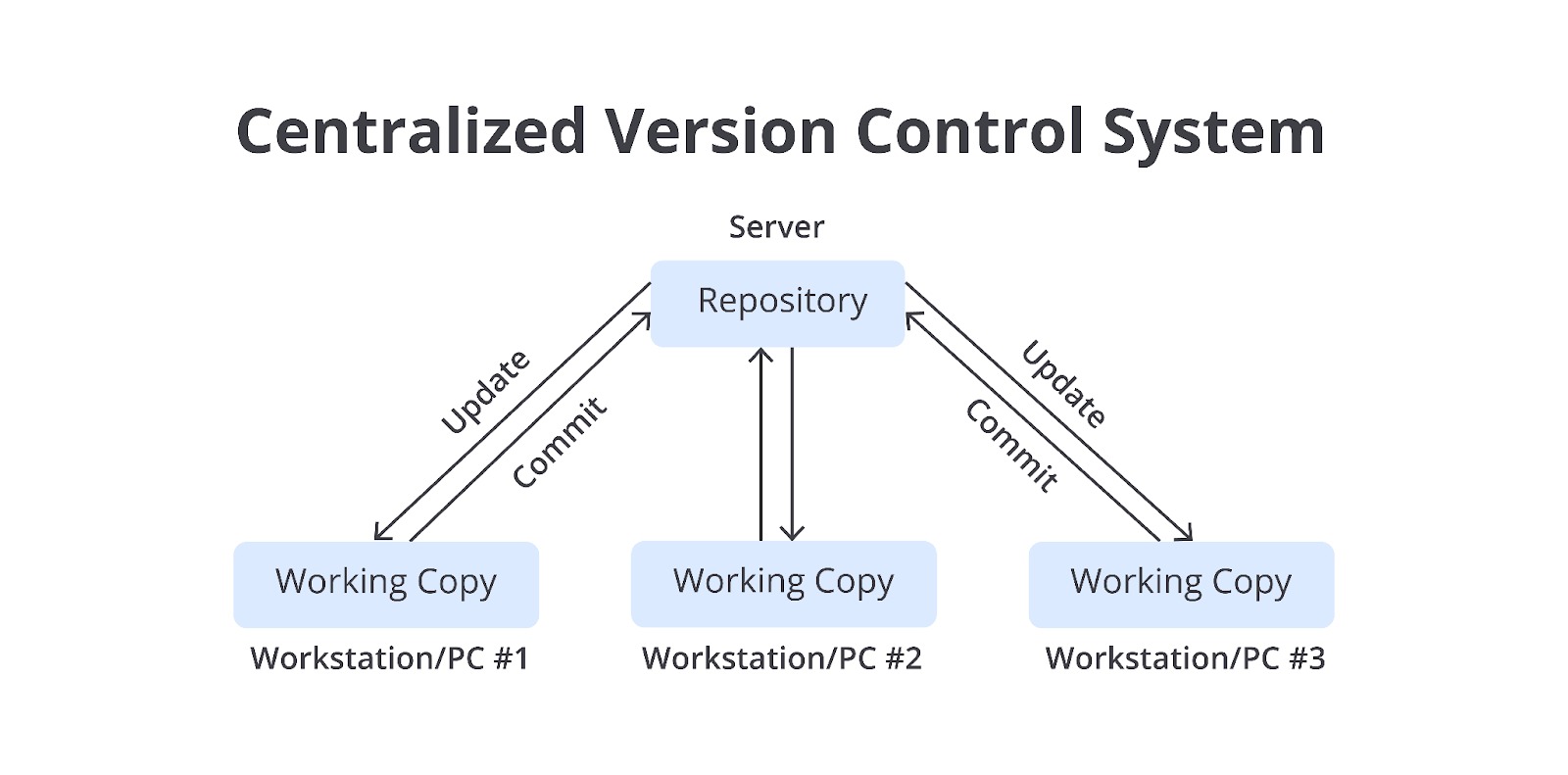
Keunggulan utama CVCS adalah struktur yang lebih sederhana dan mudah digunakan untuk tim kecil atau proyek dengan kebutuhan kolaborasi yang terorganisir. Semua data tersimpan di server pusat, sehingga memudahkan pengelolaan akses dan pencatatan perubahan secara terpusat. Namun, kelemahan utama sistem ini adalah ketergantungan tinggi pada server pusat. Jika server bermasalah atau tidak dapat diakses, seluruh tim tidak dapat bekerja.
Meski lebih sederhana dibandingkan DVCS, CVCS memiliki keterbatasan dalam mendukung pekerjaan offline dan tidak sefleksibel DVCS dalam menangani branching.
Lock-based Version Control System
Lock-based adalah tipe VCS di mana file yang sedang diedit oleh satu pengguna akan “dikunci” (locked), sehingga pengguna lain tidak dapat melakukan perubahan pada file tersebut hingga dilepas baik itu karena selesai atau berpindah. Pendekatan ini dirancang untuk menghindari konflik saat banyak pengguna bekerja pada file yang sama secara bersamaan.
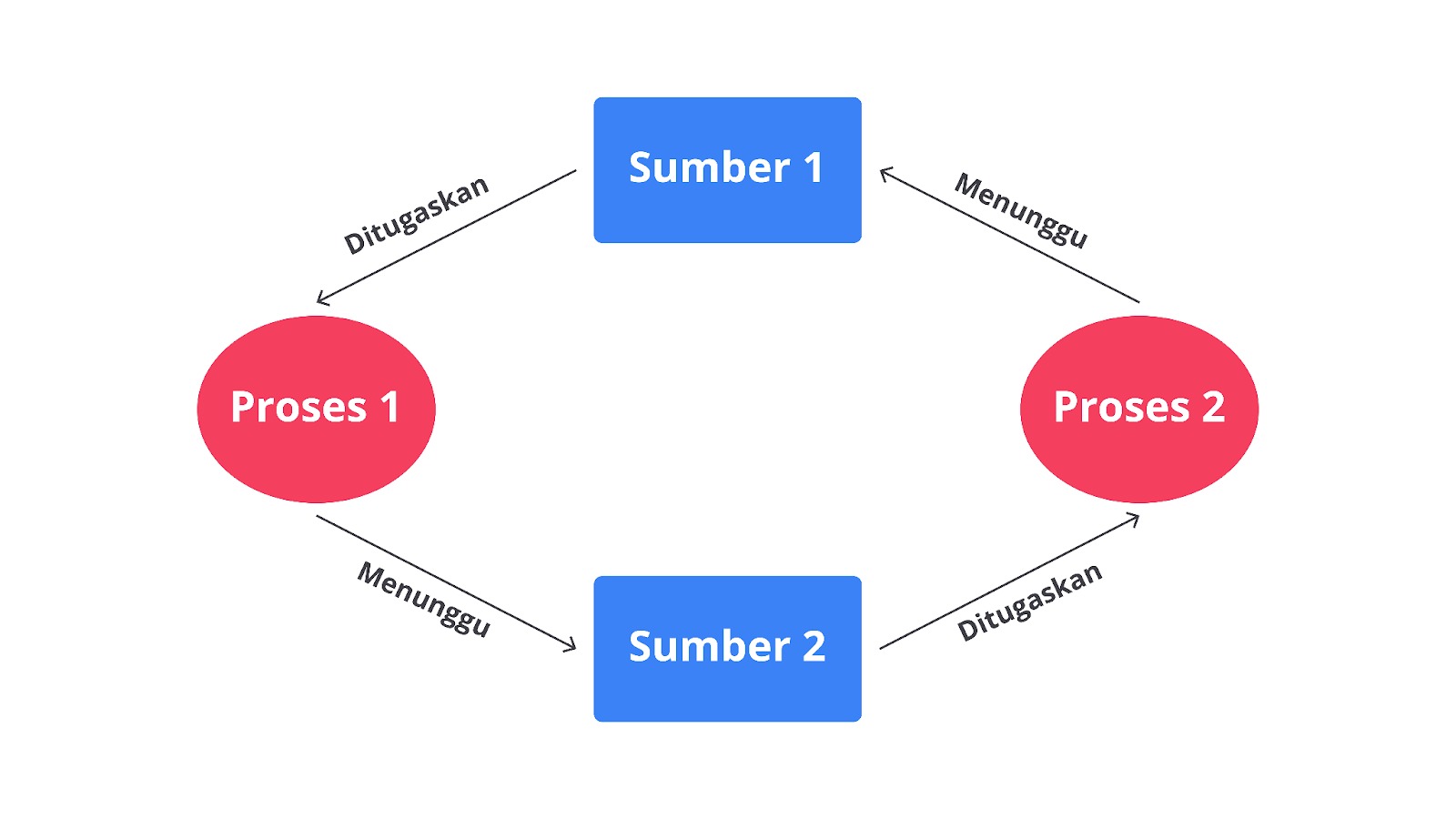
Keunggulan utama sistem ini adalah kemampuannya dalam memastikan bahwa tidak ada perubahan yang saling tumpang tindih, sehingga sangat cocok untuk file yang tidak mudah digabungkan (merge), seperti dokumen binari, desain grafis, atau CAD. Namun, pendekatan ini dapat membatasi kolaborasi karena pengguna lain harus menunggu kunci dilepas sebelum dapat mengedit file yang sama.
Biasanya lock-based systems sering digunakan dalam proyek-proyek desain atau media, di mana konflik file sulit untuk diselesaikan melalui penggabungan otomatis.
Optimistic
Optimistic VCS mengambil pendekatan yang lebih fleksibel dibandingkan lock-based systems. Dalam sistem ini, beberapa pengguna dapat mengedit file yang sama secara bersamaan tanpa adanya penguncian. Ketika perubahan dilakukan, sistem akan mencoba menggabungkan (merge) perubahan tersebut secara otomatis. Jika terjadi konflik, pengguna perlu menyelesaikannya secara manual.
Keunggulan utama sistem ini adalah kemampuannya mendukung kolaborasi yang dinamis sehingga semua pengguna dapat bekerja tanpa harus saling menunggu. Pendekatan ini sangat efisien untuk file yang dapat digabungkan dengan mudah, seperti source code atau teks. Namun, sistem ini membutuhkan upaya tambahan untuk menyelesaikan konflik jika penggabungan yang dilakukan secara otomatis gagal/crash.
Optimistic VCS sering digunakan dalam pengembangan perangkat lunak, di mana pengembang bekerja secara independen pada bagian yang sama dari proyek.
Sampai di sini kita telah berpetualang menjelajahi berbagai jenis Version Control System, mulai dari Distributed VCS (DVCS) yang bagaikan pasukan gerilya dengan fleksibilitas dan kebebasan, Centralized VCS (CVCS) yang seperti kerajaan terpusat dengan kendali penuh di satu server utama, hingga sistem yang lebih spesifik seperti Lock-based VCS yang menjaga file dengan ketat dan Optimistic VCS yang mengedepankan asumsi minim konflik. Masing-masing memiliki keunikan, kekuatan, dan kelemahannya sendiri; ibarat berbagai macam senjata dengan fungsi dan kegunaannya masing-masing.
Anda dapat melihat perbedaan keempat tipe VCS, melalui tabel berikut.
| Jenis VCS | Cara Kerja |
|---|---|
| Distributed VCS (DVCS) | Memungkinkan setiap developer memiliki salinan lengkap dari repositori utama termasuk semua file, perubahan, dan riwayat. |
| Centralized VCS (CVCS) | Mengandalkan server terpusat untuk menyimpan semua file, perubahan, dan riwayat versi. |
| Lock-based VCS | File yang diedit akan dikunci, mencegah pengguna lain mengubahnya hingga dibuka kembali. |
| Optimistic VCS | Semua bisa mengedit file, konflik diselesaikan saat merge. |
Sekarang, setelah memahami medan pertempuran dan jenis-jenis senjata yang tersedia, saatnya kita memilih perkakas yang tepat untuk memenangkan pertempuran tersebut. Memahami konsep jenis-jenis VCS saja tidak cukup, kita perlu menguasai tools atau perangkat lunak VCS yang akan menjadi andalan kita. Ibarat seorang ksatria yang harus memilih pedang dan perisainya, kita pun perlu memilih tools VCS yang sesuai dengan kebutuhan. Jadi, mari kita selami dunia perkakas Version Control System dan temukan tools yang akan membawa kita menuju manajemen kode yang efektif, kolaborasi yang solid, dan proyek yang sukses. So, sudah siap untuk petualangan selanjutnya? Let’s goooooo~
Tools yang Umum Digunakan
Sebagai seorang developer, tentu kita semua membutuhkan “alat tempur” terbaik untuk menunjang pekerjaan yang beragam agar menghasilkan output maksimal. Sampai pada tahap ini kita telah memahami konsep dan jenis-jenis Version Control System. Sekarang, saatnya kita berkenalan dengan bintang utama dalam dunia version control yaitu perangkat lunaknya atau tools-nya.
Pada materi ini, kita akan mengeksplorasi berbagai tools VCS yang populer digunakan, seperti Git, SVN, dan Mercurial (akan kita pelajari nanti). Kita akan menilik cara kerja dari beberapa tools tersebut dan memilih tools yang tepat untuk proyek yang sedang dikerjakan.
Loh, ngomong-ngomong VCS, sepertinya Google Workspace sudah memiliki kemampuan seperti itu, ya? Apakah itu termasuk VCS?
Tidak guys, Google Workspace bukanlah tools Version Control System (VCS) seperti Git, SVN, atau Mercurial. Google Workspace lebih tepat dikategorikan sebagai platform kolaborasi online yang menyediakan berbagai aplikasi untuk produktivitas dan kerja sama tim.
Memang betul Google Docs, Sheets, Colab, dan Slides memiliki fitur version history yang memungkinkan Anda melihat perubahan yang dilakukan dan kembali ke versi sebelumnya. Namun, fitur ini terbatas dan tidak sekompleks fitur yang ditawarkan oleh VCS sesungguhnya.
Jadi tolong dicatat, meskipun Google Workspace dan Sistem Kontrol Versi (VCS) sama-sama menawarkan fitur untuk melacak perubahan, keduanya memiliki tujuan dan fungsi yang sangat berbeda. Google Workspace adalah platform kolaborasi online yang dirancang untuk produktivitas dan kerja sama tim secara umum dengan fitur utama seperti pengeditan dokumen bersama, penyimpanan file, dan komunikasi. Fitur version history di Google Docs, Colab, Sheets, dan Slides memang berguna, tetapi lebih ditujukan untuk dokumen yang relatif sederhana dan tidak sekompleks fitur VCS.
Sementara itu, VCS seperti Git, SVN, dan Mercurial dirancang khusus untuk manajemen source code dan proyek pengembangan software. VCS menawarkan fitur-fitur advanced seperti branching, merging, commit yang deskriptif, dan rollback yang canggih. Fitur-fitur tersebut dapat mendukung alur kerja pengembangan software yang kompleks dan proyek berskala besar dengan banyak kontributor.
Singkatnya, Google Workspace unggul dalam kolaborasi dokumen, sedangkan VCS adalah alat yang tak tergantikan dalam pengembangan software profesional. Keduanya dapat digunakan bersamaan untuk produktivitas yang optimal, tetapi memiliki peran yang berbeda dan tidak dapat saling menggantikan.
Berikut perbedaan utama antara Google Workspace dan Version Control System (VCS).
| Fitur | Google Workspace | Version Control System (VCS) |
|---|---|---|
| Melacak perubahan | Ya | Ya |
| Kembali ke versi sebelumnya | Ya | Ya |
| Mendukung Kolaborasi | Ya (via real-time collaboration) | Ya (via branch dan merge) |
| Branching & merging | No | Ya |
| Sistem Kontrol Terdistribusi | No | Ya |
| Pesan Komit dan Perbedaannya | No | Ya |
Sedari tadi, kita sudah menyinggung Git, SVN, dan Mercurial, mungkin beberapa dari Anda sudah familier dengan tools tersebut, tetapi tenang saja jika belum terbiasa karena pada materi ini, kita akan mengupas tuntas pengertian tools tersebut bersama-sama.
Sekilas Informasi
Sebelum dapat mempraktikkan Control System pada pengembangan machine learning, ada hal dasar yang harus benar-benar Anda pahami terlebih dahulu. Tahukah Anda apa yang dimaksud dengan istilah “integration” dalam prinsip continuous integration? Sebenarnya, apa sih yang diintegrasikan?
Jadi, integrasi di sini adalah penggabungan kode baru atau perubahan kode yang ditulis oleh satu atau banyak kontributor (bisa Developer, IT Operations, Tester/QA, dsb) ke dalam satu proyek aplikasi atau perangkat lunak. Proses integrasi ini biasanya dilakukan dengan merge (menggabungkan) feature branch ke main branch melalui pull request.
Materi ini merupakan dasar sebelum Anda mengelola version control system dengan Mlflow (akan kita pelajari nanti). So, jangan sampai di-_skip_ ya!
Git
Ada beberapa hal yang acapkali ditanyakan saat mengembangkan aplikasi, di antaranya sebagai berikut.
- “Bagaimana cara mengelola source code aplikasi yang dibangun oleh banyak developer?”
- “Bagaimana cara agar beberapa developer bisa mengerjakan sebuah proyek menggunakan codebase yang sama?”
- “Bagaimana agar fitur yang sedang dikerjakan seorang Developer tidak bertabrakan dengan pekerjaan Developer lain?”
Pernahkah Anda merasa frustrasi karena kehilangan kode berharga? Atau bingung menentukan versi file mana yang terbaru saat bekerja dalam tim? Atau mungkin pusing tujuh keliling saat harus menggabungkan perubahan kode dari beberapa orang? Tenang, Anda tidak sendirian! Banyak developer di luar sana yang juga mengalami hal serupa. Kabar baiknya, ada solusi jitu untuk mengatasi semua masalah itu Version Control System (VCS) atau Source Control Management, seperti Git.

Dengan Version Control, ibarat memiliki asisten digital super canggih, setiap developer bisa bekerja sama dalam satu codebase yang sama dengan mudah. Bayangkan, Anda bisa melacak setiap perubahan yang terjadi, mengetahui siapa yang mengubah kode, mengerjakan fitur baru tanpa mengganggu kode utama, dan masih banyak lagi kemudahan lainnya.
Menariknya lagi, Git ini bisa dijalankan di komputer lokal maupun di server. Nah, jika aplikasi dikembangkan oleh banyak developer, menggunakan Git server atau Git hosting menjadi pilihan yang cerdas. Ini akan memastikan source code yang dimiliki setiap developer selalu sinkron dan up-to-date. Ibarat sebuah perpustakaan pusat tempat semua orang bisa mengakses versi buku terbaru.
Anda bisa membuat Git server sendiri, atau lebih mudahnya lagi, menggunakan layanan berbasis cloud yang sudah populer seperti GitHub atau GitLab. Dengan Git hosting, mengelola repositori (tempat penyimpanan kode) menjadi jauh lebih praktis dan efisien.
Mungkin sebagian dari Anda sudah tidak asing dengan Git, bahkan mungkin sudah setia menggunakan GitHub sebagai Git hosting untuk menyimpan source code di internet.
Nah, bagi Anda yang baru ingin berkenalan dengan Git, jangan khawatir. Berikut beberapa istilah dalam Git yang perlu Anda ketahui agar semakin akrab dengannya.
Repository
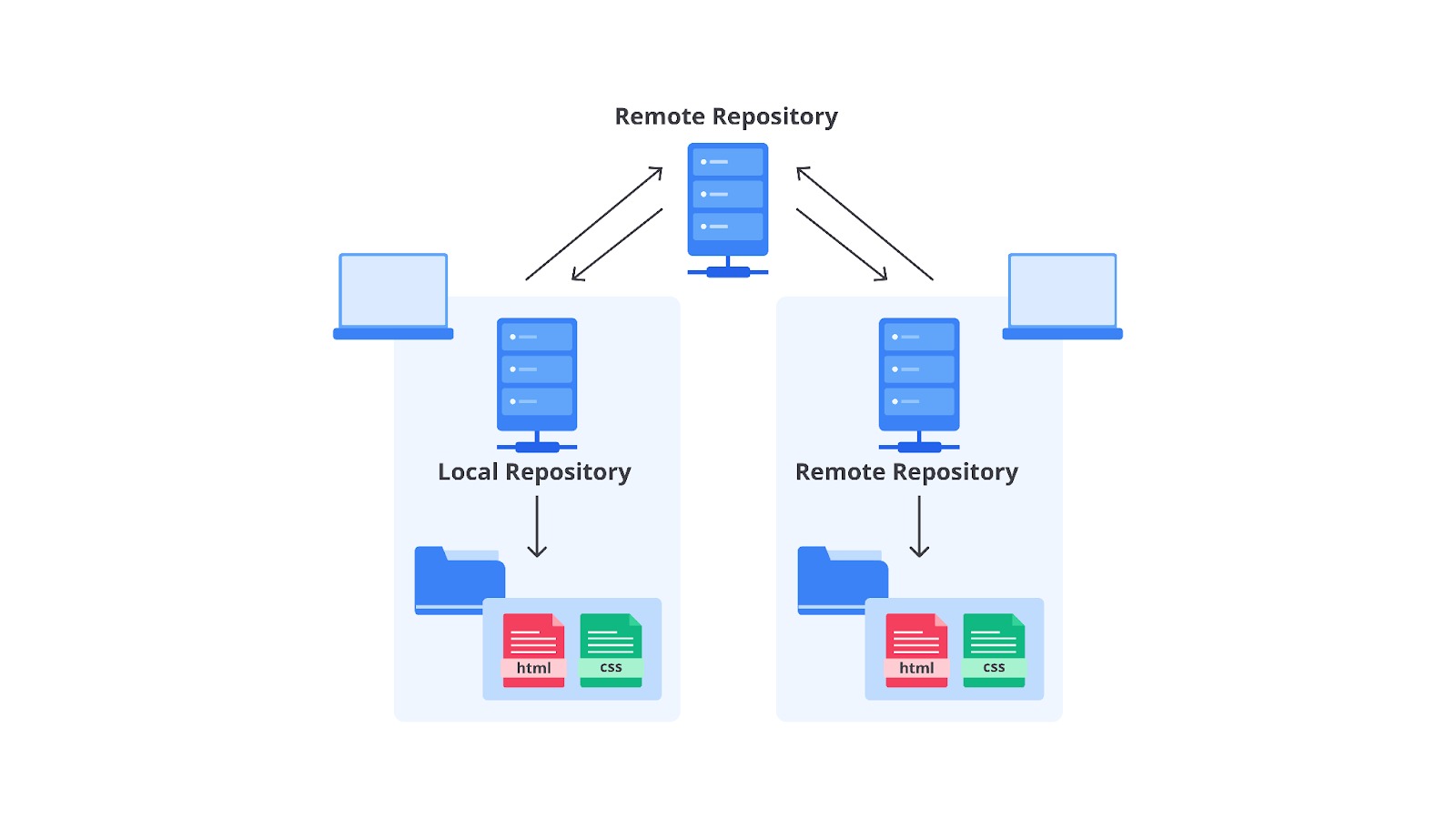
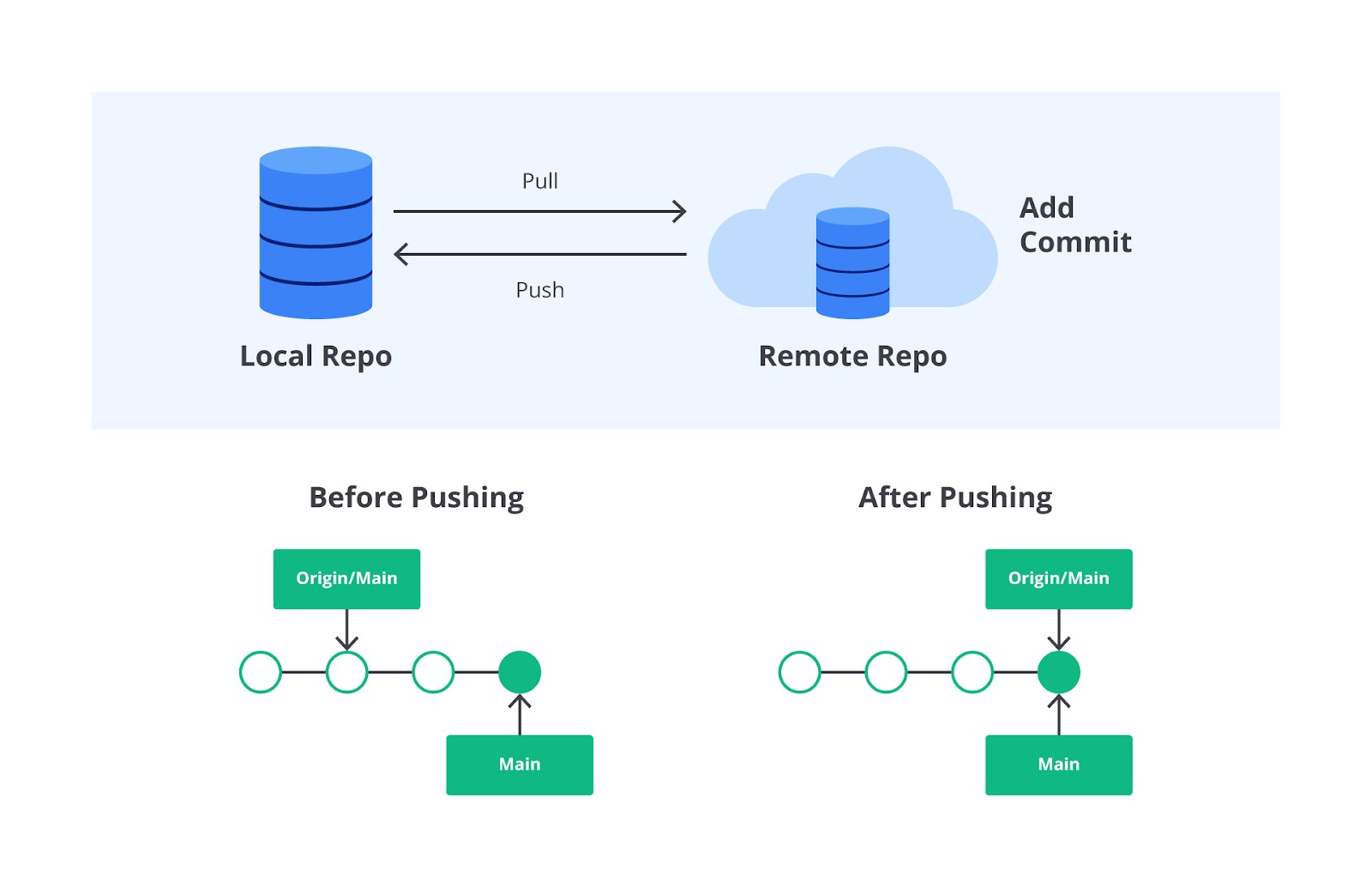
Repository adalah istilah yang digunakan sebagai penyimpanan source code. Repository dapat bersifat local dan remote. Local repository merupakan repository yang berada di komputer pribadi developer dan digunakan selama proses penulisan kode. Sementara itu, remote repository adalah repository yang berada di server. Ia menjadi repository induk agar repository lokal dapat selalu tersinkron dan up-to-date. Jika kita berkolaborasi dengan banyak Developer, remote repository adalah solusinya. Salah satu contoh remote repository adalah GitHub repository.
Clone
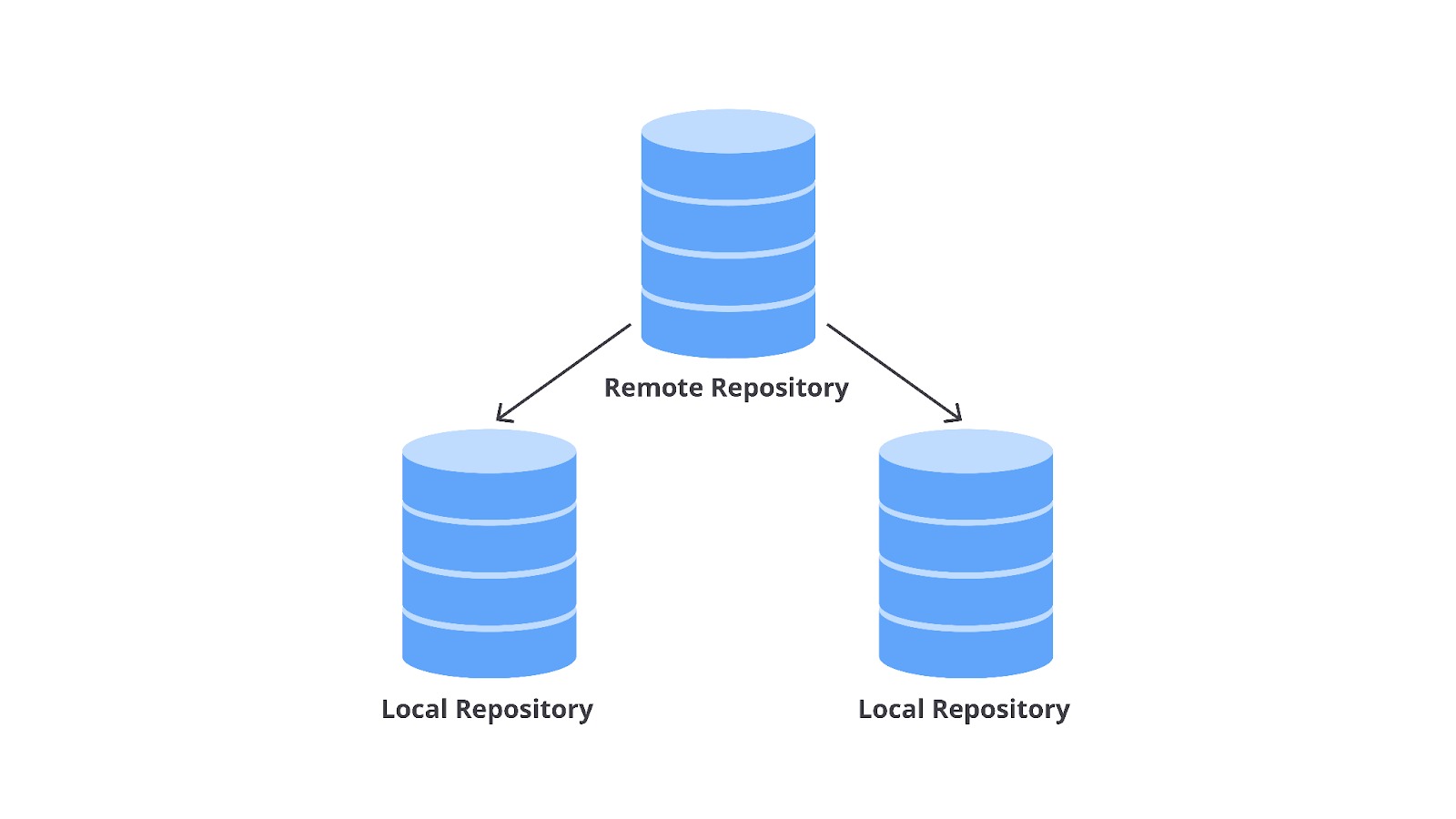
Clone (cloning) adalah proses menyalin atau mengkloning repositori dari remote repository (misal, GitHub repository) ke local repository (komputer pribadi) untuk mempermudah penambahan, pengubahan, atau penghapusan kode; perbaikan konflik saat penggabungan branch (merge conflict); dan sebagainya. Saat Anda melakukan clone repository, itu berarti Anda mengambil salinan lengkap dari semua data yang dimiliki repository pada saat itu, termasuk semua versi dari setiap berkas dan folder untuk proyek tersebut.
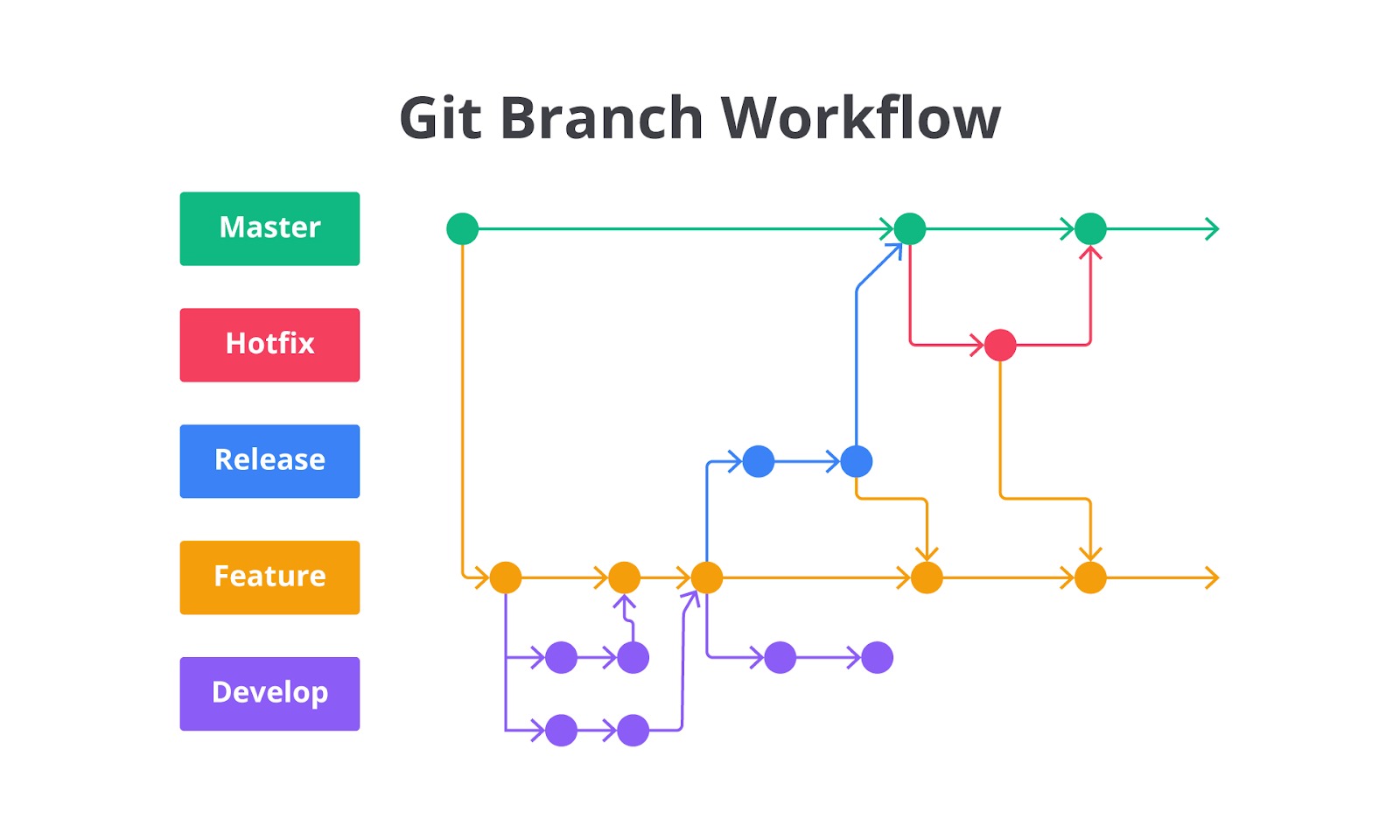
Branch
Sebagaimana yang kita tahu, git adalah version control system, di mana versioning ini salah satunya diatur oleh fitur branch (cabang). Setiap git repository memiliki minimal satu branch, yakni main branch (cabang utama). Umumnya, seluruh source code aplikasi yang sudah matang berada di main branch. Bila seorang developer hendak mengembangkan fitur baru, ia perlu membuat branch baru agar source code yang sudah matang tidak terganggu.
Commit
Commit merupakan sebuah aksi yang dilakukan Developer untuk membuat rekam jejak (snapshot) terhadap perubahan kode yang ia tulis. Seorang Developer akan melakukan commit ketika kode yang dituliskan sudah benar atau sudah mencapai poin-poin tertentu. Jika Developer tersebut mengalami kesalahan dalam menuliskan kode berikutnya, ia dapat dengan mudah mengembalikan source code ke versi di mana ia melakukan commit. Penting Anda ingat bahwa aksi commit haruslah dilakukan untuk perubahan kode sekecil mungkin. Tujuannya agar perubahan kode selalu terekam dengan baik.
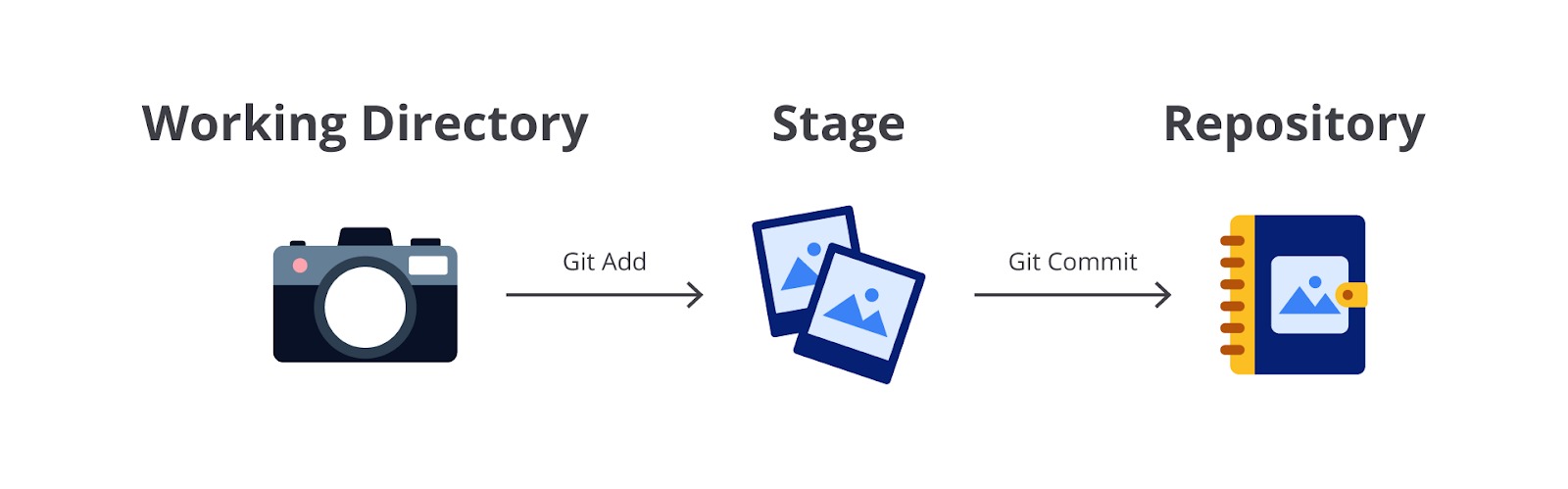
Ketika Anda menggunakan antarmuka GitHub, Anda dapat secara langsung menggunakan perintah git commit untuk menyimpan setiap perubahan yang dilakukan. Namun, ketika menggunakan local repository, Anda harus mengoperasikan git add sebelum memanggil git commit.
Git add berguna untuk menambahkan berkas yang dimodifikasi di working directory (direktori saat ini) ke dalam daftar antrean perubahan (stage), sedangkan git commit berfungsi untuk menambahkan berkas yang dimodifikasi tadi ke repository (ke local jika di komputer pribadi; ke remote jika langsung dari GitHub).
Push
Perintah git push merupakan tindakan lanjutan dari perintah git commit. Push merupakan aksi untuk mengirim perubahan kode dari local repository ke remote repository. Push dilakukan untuk memperbarui kode yang ada di remote dengan kode di local.
Pull Request
Pull Request adalah sebuah pengajuan/permintaan (request) untuk menggabungkan perubahan kode pada suatu branch ke branch lain. Contohnya, ketika mengembangkan fitur pada branch B dan pengembangannya sudah selesai serta kode yang ditulis sudah matang, Anda bisa melakukan pull request dari branch B ke main branch agar fitur yang sedang dikembangkan dapat diterapkan pada aplikasi.
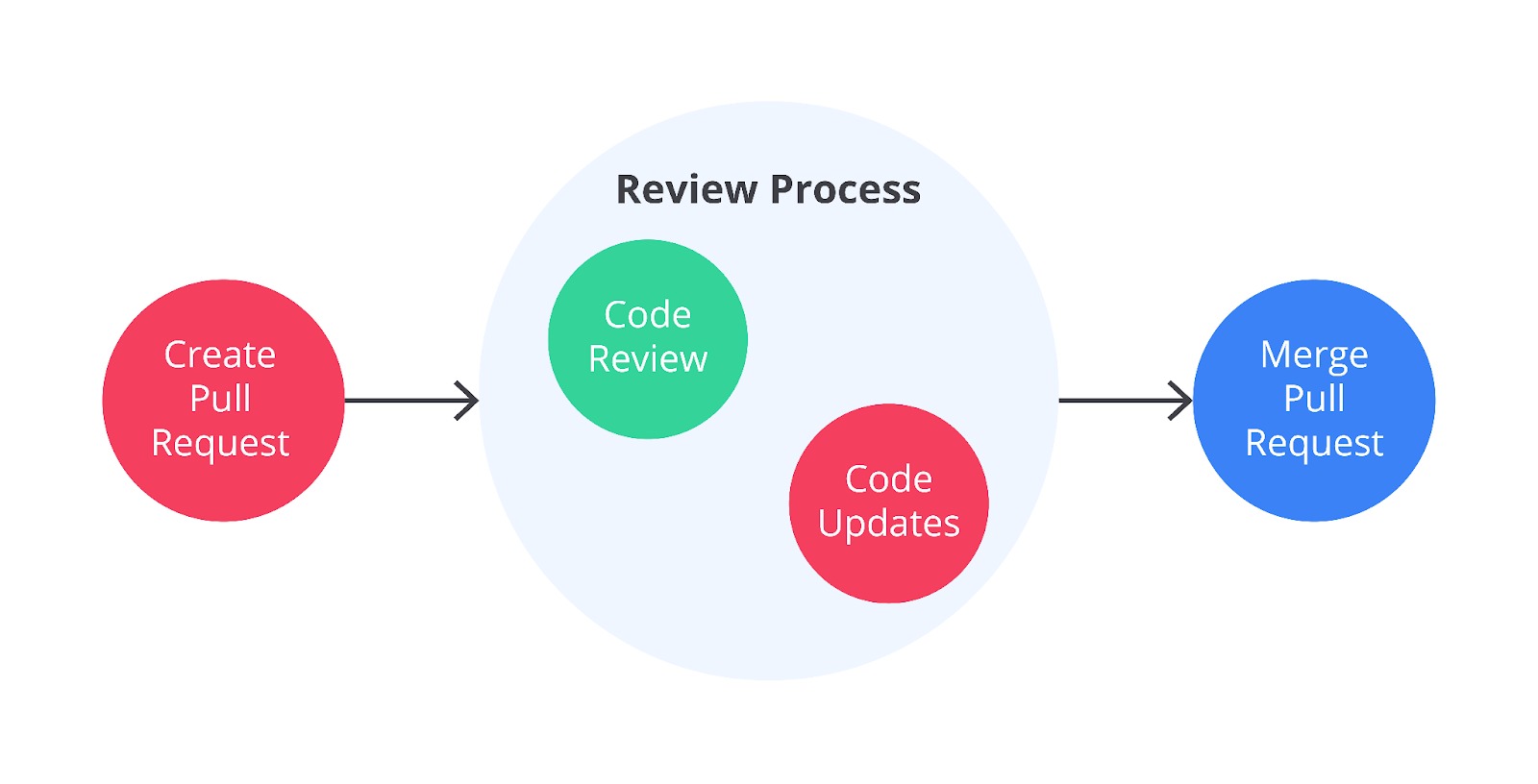
Biasanya, proses pull request akan membutuhkan review dari developer lain (peer review) dan/atau sebuah test hingga akhirnya bisa bergabung ke main branch.
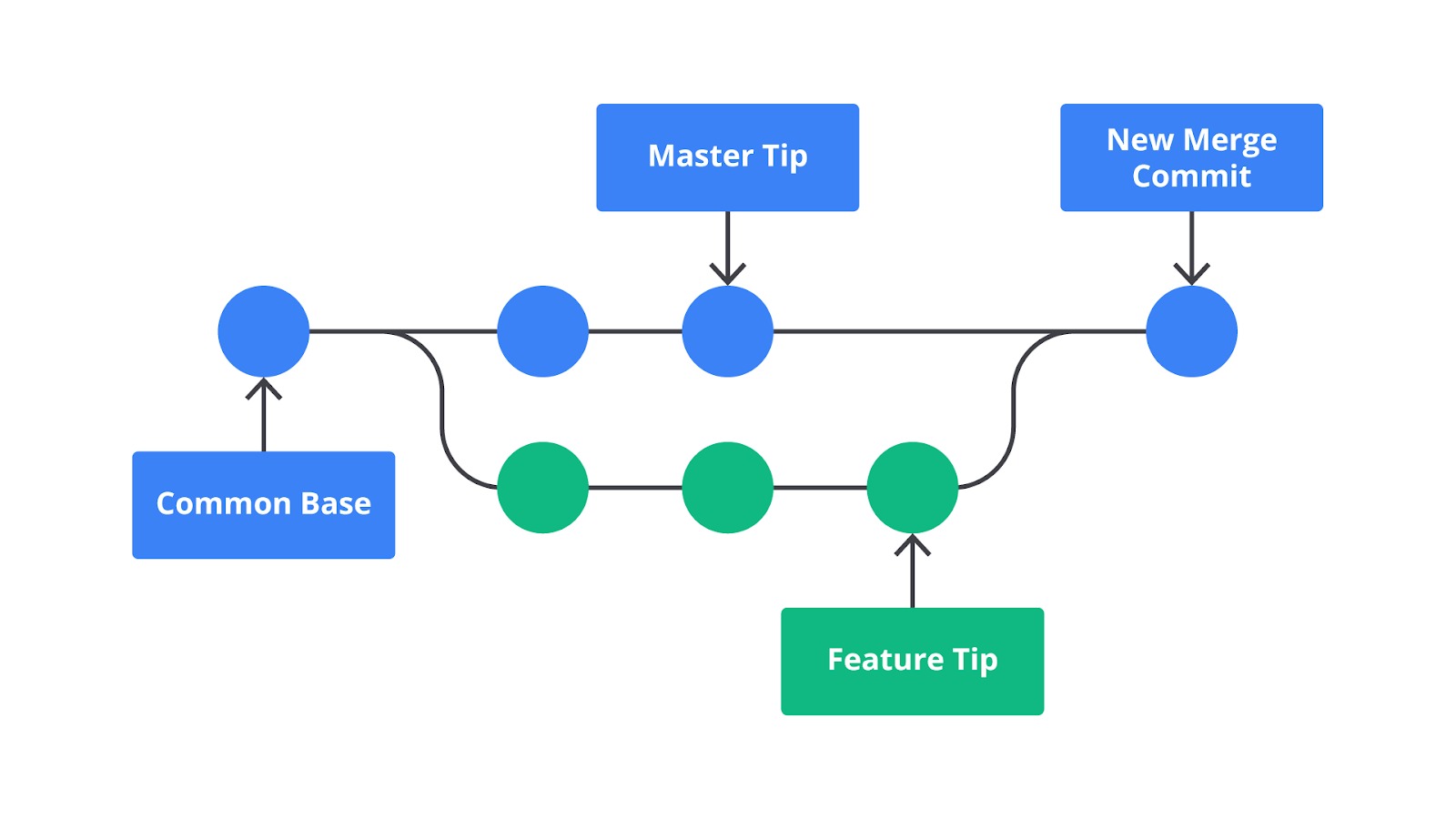
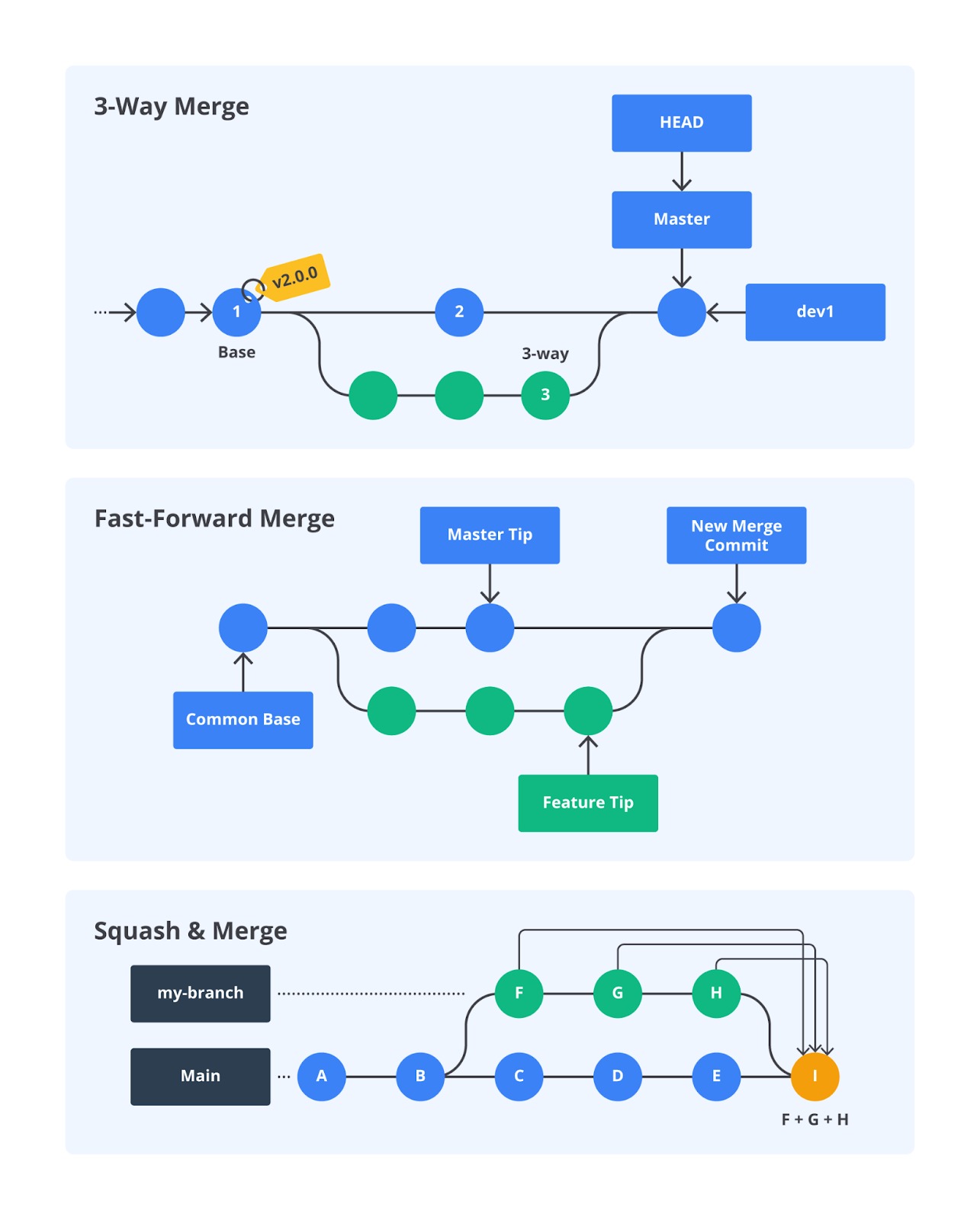
Merge
Merge merupakan aksi untuk menggabungkan perubahan kode pada suatu branch ke branch lain. Merge dapat dilakukan melalui atau tanpa pull request. Saat kita melakukan merge, Anda akan dihadapkan dengan beberapa opsi metode merge, seperti fast-forward merge, 3-way merge, squash and merge, dll.
Pastikan Anda benar-benar paham dengan semua istilah di atas sebab kita akan sering memakainya selama belajar di kelas ini. Lebih lengkapnya, Anda bisa belajar di kelas Belajar Dasar Git dengan GitHub.
SVN
SVN atau Apache Subversion adalah salah satu jenis Centralized Version Control System (CVCS) yang digunakan untuk melacak perubahan pada file dan direktori dalam proyek pengembangan perangkat lunak. Dikembangkan oleh CollabNet pada tahun 2000 dan saat ini dikelola oleh Apache Software Foundation, SVN dirancang untuk menggantikan sistem CVS (Concurrent Versions System) yang memiliki banyak keterbatasan.

SVN memungkinkan pengguna untuk mengelola versi dari file proyek, baik itu source code, dokumen, maupun aset digital lainnya. Sistem ini sangat populer sebelum munculnya Distributed Version Control Systems (DVCS) seperti Git.
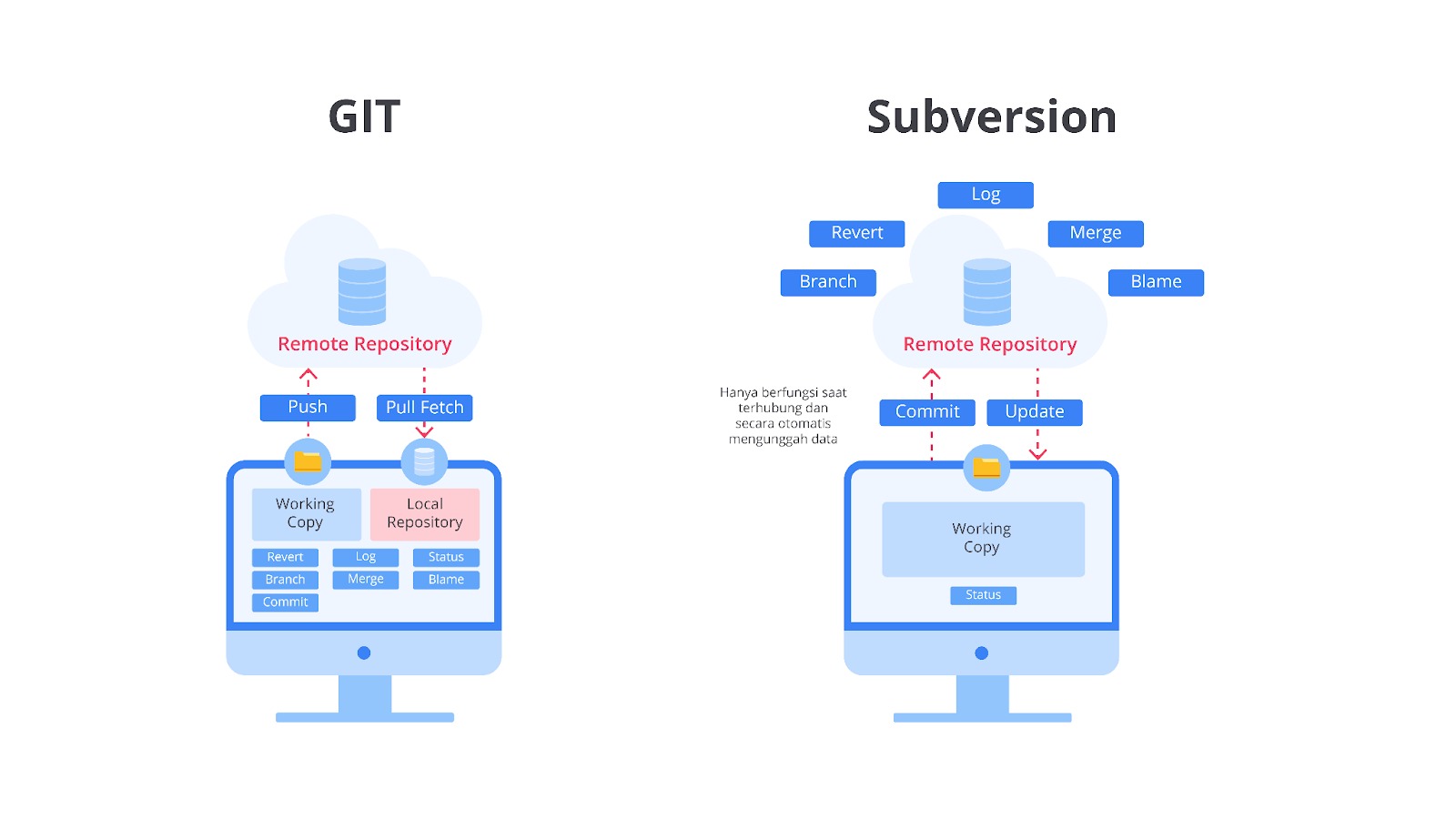
Apa bedanya dengan Git? Lalu, bagaimana SVN bekerja? SVN menggunakan server pusat untuk menyimpan semua data proyek, termasuk file, riwayat perubahan, dan metadata terkait.
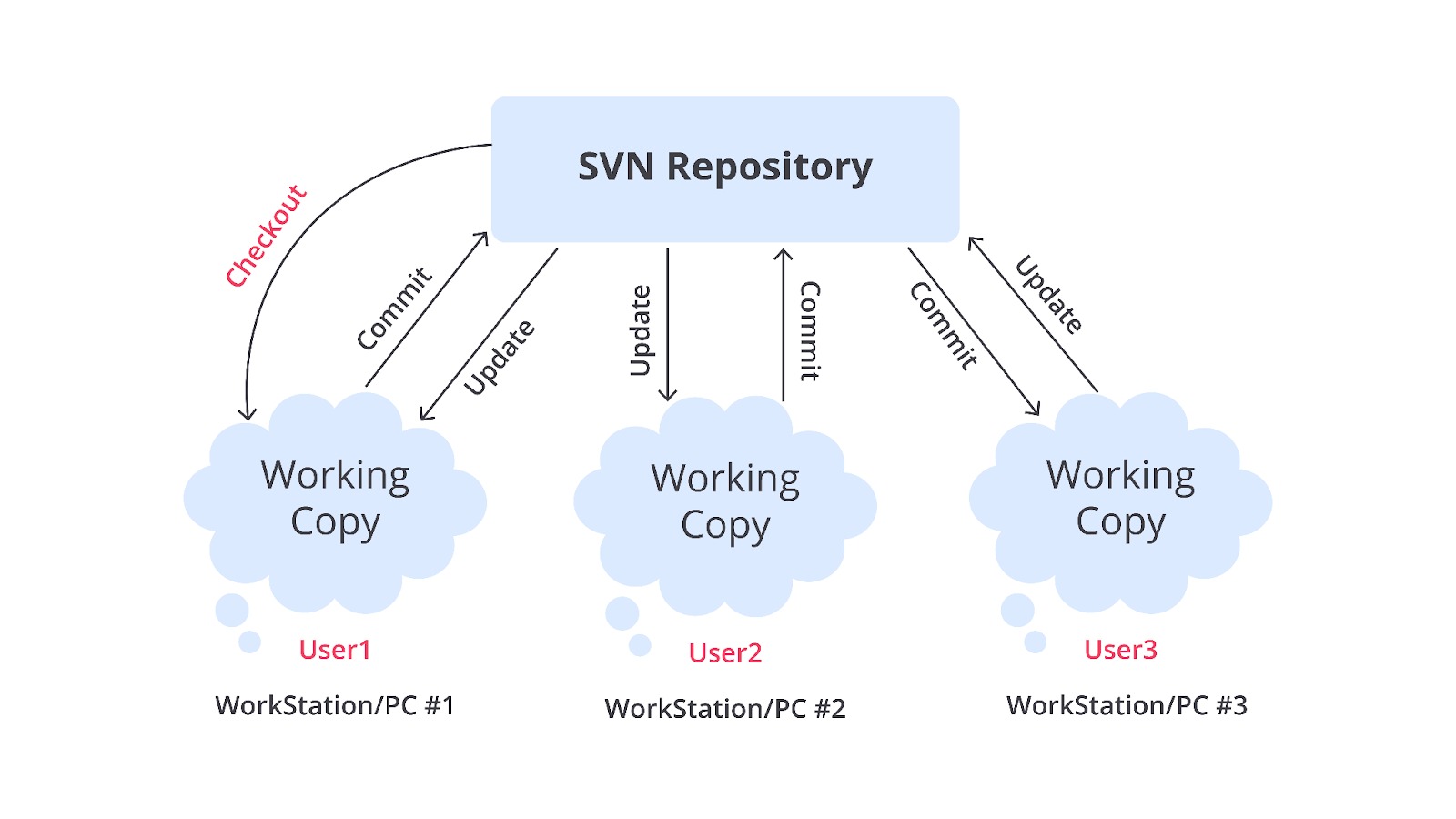
Pengguna dapat mengakses server pusat untuk melakukan Checkout, Commit, dan Update pada proyek yang sedang dikerjakan.
Quick Recap
Checkout: mengunduh salinan file ke komputer lokal.
Commit: mengunggah perubahan file ke server pusat.
Update: mengambil perubahan terbaru dari server ke salinan lokal.
Biasanya repositori SVN berfungsi sebagai tempat penyimpanan pusat untuk semua file dan perubahan, sedangkan salinan lokal adalah versi sementara yang dimiliki setiap pengguna. Ketika pengguna membuat perubahan pada file lokal, mereka harus segera melakukan commit untuk menyinkronkan perubahan tersebut ke repositori pusat.
Layaknya tools VCS seperti Git, SVN juga memiliki beberapa fitur yang tidak kalah menarik. Beberapa di antaranya seperti berikut.
- **Versioning Direktori dan File
**SVN tidak hanya melacak perubahan pada file, tetapi juga pada direktori, termasuk operasi seperti penggantian nama, penghapusan, dan pemindahan direktori. - Atomic Commit
**SVN memastikan bahwa semua perubahan yang dilakukan selama proses commit diterapkan secara **atomic. Artinya, jika ada kesalahan, semua perubahan akan dibatalkan sehingga repositori tidak pernah berada dalam kondisi setengah selesai atau pun crash. - Branching dan Tagging
**SVN memungkinkan pengguna untuk membuat **branch (cabang) atau tag (label) dengan cepat. Ini memungkinkan pengelolaan eksperimen atau rilis proyek tanpa mengganggu versi utama. - Riwayat Revisi yang Lengkap
**Setiap perubahan yang dilakukan di repositori dicatat sebagai **revisi dengan nomor unik. Pengguna dapat dengan mudah melihat riwayat revisi untuk melacak perubahan atau mengembalikan versi sebelumnya. - **Dukungan untuk Binary Files
**SVN dapat menangani file biner dengan baik, seperti gambar atau dokumen, tanpa mengabaikan perubahan yang terjadi. - **Locking File
**SVN mendukung penguncian file untuk mencegah konflik saat file sedang diedit oleh beberapa pengguna, terutama file yang sulit digabungkan (merge). - **Protokol Akses Beragam
**SVN mendukung beberapa protokol akses, seperti HTTP, HTTPS, SSH, dan protokol SVN bawaan sehingga memudahkan pengguna untuk mengakses repositori dari berbagai lingkungan. - **Multi-Platform
**SVN dapat digunakan pada berbagai sistem operasi seperti Windows, Linux, dan macOS, serta memiliki antarmuka grafis tambahan (seperti TortoiseSVN) untuk mempermudah pengguna yang tidak terbiasa dengan antarmuka baris perintah.
Dari penjelasan di atas, kita dapat melihat bahwa SVN memiliki fitur-fitur dasar yang cukup lengkap untuk mengelola version control, seperti versioning direktori dan file, atomic commit, branching, dan tagging. Namun, untuk memahami SVN secara menyeluruh, kita perlu melihat lebih dari sekedar fitur-fitur dasarnya. SVN juga memiliki beberapa keunggulan spesifik yang menjadi ciri khasnya dan berkontribusi pada popularitasnya yang bertahan lama. Mari kita bahas keunggulan-keunggulan SVN tersebut satu per satu.
- **Stabil dan Teruji
**SVN telah digunakan selama lebih dari dua dekade dalam proyek-proyek besar sehingga dianggap sebagai alat yang stabil dan tepercaya. - **Repositori Terpusat
**Semua data disimpan di satu tempat, memudahkan pengelolaan akses, dan pencatatan perubahan. - **Dukungan untuk File Besar
**SVN lebih efisien dalam menangani file besar atau biner dibandingkan dengan beberapa DVCS seperti Git. - **Atomic Commit
**Fitur ini memastikan repositori tidak pernah berada dalam keadaan korup atau setengah selesai akibat kegagalan commit. - **Mudah Dipahami
**Untuk pengguna baru, konsep CVCS seperti SVN sering kali lebih sederhana dibandingkan DVCS karena pengguna tidak perlu memahami repositori lokal.
Kita telah melihat sisi terang dari SVN dengan kestabilannya yang teruji, repositori terpusat yang memudahkan pengelolaan, kemampuannya menangani file besar, atomic commit yang menjaga integritas data, dan kemudahan pemahamannya bagi pemula. Fitur-fitur ini membuat SVN bersinar di berbagai skenario.
Namun, ibarat sebuah timbangan, setiap kelebihan pasti memiliki sisi lain yang perlu dipertimbangkan. Untuk mendapatkan gambaran yang utuh, mari kita timbang dan lihat beberapa hal yang menjadi kekurangan SVN agar dapat memilih tools yang paling tepat sesuai kebutuhan.
- Ketergantungan pada Server Pusat
Karena semua data disimpan di server pusat, jika server tidak tersedia (downtime), pengguna tidak dapat melakukan commit atau mendapatkan pembaruan. - **Tidak Mendukung Pekerjaan Offline
**SVN mengharuskan koneksi ke server pusat untuk sebagian besar operasi. Tanpa koneksi, pengguna hanya dapat mengedit file tetapi tidak dapat melakukan commit atau update. - **Branching dan Merging yang Kurang Efisien
**Meski mendukung branching, proses merging di SVN kurang fleksibel dan efisien dibandingkan sistem seperti Git. Karena pendekatannya yang berbasis salinan, ketergantungan pada server pusat, serta kurangnya mekanisme pelacakan perubahan yang terintegrasi membuatnya kurang fleksibel dan efisien dibandingkan Git. - **Kinerja Menurun pada Repositori Besar
**Ketika repositori menjadi sangat besar, kinerja SVN dapat menurun, terutama untuk operasi checkout atau commit. - **Kurangnya Keamanan Data Lokal
**Karena pengguna tidak memiliki salinan penuh dari repositori, risiko kehilangan data lebih tinggi jika terjadi masalah pada server pusat.
Kita telah menimbang kekurangan SVN, seperti ketergantungan pada koneksi server pusat, proses branching dan merging yang lebih rumit, serta potensi masalah kinerja pada repositori yang sangat besar. Namun, perlu diingat bahwa tidak ada tools yang sempurna untuk semua situasi. Ibarat memilih alat yang tepat untuk pekerjaan tertentu, SVN pun memiliki skenario ideal di mana kekurangannya dapat diminimalisasi dan kekuatannya justru bersinar. Jadi, kapan sebaiknya kita menggunakan SVN? Mari kita lihat situasi dan kondisi yang membuat SVN menjadi pilihan yang tepat.
- Proyek yang Membutuhkan Struktur Terpusat
SVN sangat cocok untuk proyek yang membutuhkan pengelolaan terpusat. Dalam struktur ini, semua file dan riwayat versi disimpan di server pusat sehingga memudahkan pengelolaan akses dan kontrol atas data. Pertanyaannya, apa kapan ini bisa disebut relevan? Tenang, mari kita bahas beberapa kondisinya.- Ketika tim ingin memiliki repositori tunggal untuk semua file.
- Ketika manajer proyek ingin memonitor perubahan dengan cara yang lebih terpusat.
- Ketika keamanan repositori di server pusat menjadi prioritas utama.
Contoh sederhananya, perusahaan dengan kebijakan IT yang ketat, seperti lembaga pemerintah atau perusahaan besar, mungkin lebih memilih SVN karena struktur terpusatnya memberikan kontrol yang lebih besar atas siapa yang dapat mengakses repositori.
- Proyek dengan File Biner Besar
SVN memiliki kemampuan untuk menangani file biner besar seperti gambar, video, atau file desain yang tidak mudah digabungkan (merge). Sistem ini lebih efisien dalam menyimpan perubahan pada file biner dibandingkan dengan Git yang terkadang mengalami masalah kinerja untuk file besar. Pemilihan SVN akan lebih relevan ketika memenuhi kondisi berikut.- Dalam proyek desain grafis atau CAD (Computer-Aided Design).
- Dalam proyek media yang melibatkan file video, audio, atau animasi.
- Ketika perubahan file biner perlu dilacak secara rinci.
Seperti penjelasan di atas, pemilihan SVN dapat dilakukan ketika studio animasi atau perusahaan desain ingin melacak perubahan pada file desain grafis dan aset media.
-
Proyek dengan Tim Kecil hingga Menengah
SVN cocok untuk tim yang relatif kecil hingga menengah, terutama jika tim tersebut bekerja secara terorganisasi dan tidak membutuhkan banyak eksperimen paralel. Struktur yang terpusat dapat mengurangi kebutuhan untuk memahami konsep cabang (branching) yang kompleks sehingga lebih mudah diadopsi pada proyek skala kecil. -
Proyek dengan Infrastruktur Stabil
Karena SVN bergantung pada server pusat, sistem ini lebih cocok untuk proyek dengan infrastruktur jaringan yang stabil dan dapat diandalkan. Ketika server selalu tersedia, pengembang dapat bekerja tanpa hambatan, tetapi ketika infrastruktur kantor kurang stabil maka akan mengakibatkan “kurang kerjaan” alias tidak bisa bekerja dengan maksimal. -
Proyek yang Memerlukan Penguncian File (File Locking)
SVN menyediakan fitur file locking, yang memungkinkan pengguna untuk mengunci file tertentu agar tidak diubah oleh pengguna lain selama proses pengeditan. Fitur ini sangat penting untuk file yang tidak dapat digabungkan (merge) dengan mudah, seperti dokumen Word, spreadsheet, atau file biner lainnya. -
Proyek Tradisional atau Warisan (Legacy Projects)
Alasan ultimate-nya yaitu banyak proyek warisan (legacy) yang masih menggunakan SVN karena sudah diadopsi sejak lama dan migrasi ke sistem lain dianggap terlalu mahal atau kompleks. Selain itu, organisasi dengan kebijakan konservatif mungkin tetap menggunakan SVN karena stabilitas dan familiaritasnya.
Hingga saat ini, SVN tetap menjadi salah satu tools yang relevan dalam beberapa situasi tertentu, terutama ketika struktur terpusat, pengelolaan file besar, atau stabilitas repositori menjadi kebutuhan utama. Meskipun tidak sepopuler Git dalam dunia pengembangan perangkat lunak modern, SVN memiliki keunggulan dalam proyek-proyek dengan fokus pada pengelolaan sederhana, infrastruktur stabil, atau kebutuhan khusus seperti file locking.
Nah, setelah menyelami seluk-beluk Git dan SVN, kita jadi tahu bahwa masing-masing memiliki kekuatan dan kelemahannya sendiri. Git dengan branching dan merging yang powerful dan SVN dengan kemudahan pengelolaan repositori terpusat. Namun, bagaimana jika Anda mencari pilihan lainnya dalam kategori DVCS yang menawarkan keseimbangan antara fitur dan kemudahan penggunaan? Di sinilah Mercurial hadir sebagai pemain yang patut diperhitungkan. Mari kita berkenalan dengan Mercurial dan melihat apa yang membuatnya spesial.
Mercurial
Mercurial adalah sistem Distributed Version Control System (DVCS) yang cepat, efisien, dan dirancang untuk menangani proyek-proyek pengembangan perangkat lunak untuk berbagai macam skala proyek. Dikembangkan oleh Matt Mackall pada tahun 2005, Mercurial bertujuan untuk menyediakan sistem version control yang ringan, cepat, dan mudah digunakan, terutama bagi pengguna yang membutuhkan pengelolaan proyek dengan banyak file dan kolaborator.

Mercurial merupakan tools open-source yang dapat membantu tim melacak perubahan pada file proyek, mendukung kolaborasi, dan memastikan integritas data. Sebagai DVCS, Mercurial memungkinkan setiap pengguna memiliki salinan lengkap dari repositori, termasuk semua file, perubahan, dan riwayat proyek. Fitur ini memungkinkan pengguna bekerja secara independen dan offline tanpa bergantung pada server pusat.
Mercurial dapat menjadi pilihan lain ketika Anda mulai bosan menggunakan Git atau SVN karena memiliki karakteristik yang perlu dipertimbangkan, beberapa diantaranya seperti berikut.
- Kinerja Cepat: dirancang untuk menangani proyek besar dengan respons yang cepat, bahkan dengan ribuan file.
- Portabilitas: mendukung berbagai sistem operasi, termasuk Windows, macOS, dan Linux.
- Sederhana dan Ramah Pengguna: memiliki antarmuka baris perintah (CLI) yang intuitif dan konsisten sehingga mudah dipelajari oleh pemula.
- Reproduksi Penuh: setiap pengguna memiliki salinan lengkap dari repositori yang mencakup semua riwayat versi.
- Keamanan: menggunakan algoritma hashing kriptografi untuk melindungi data dan memastikan integritas repositori.
- Dukungan untuk Branching: Mercurial menyediakan mekanisme branching yang fleksibel dan efisien untuk pengembangan paralel.
Dengan karakteristik di atas, Mercurial didukung oleh berbagai macam fitur yang siap Anda gunakan untuk menunjang berbagai macam proyek. Sebenarnya, fiturnya tidak jauh beda dengan Git, tetapi Anda tidak boleh melewatkan penjelasannya, ya. Berikut fitur utama dari Mercurial yang perlu Anda ketahui.
- Repositori Terdistribusi
Setiap pengguna memiliki repositori lengkap, memungkinkan mereka bekerja offline dan menjaga keamanan data tanpa bergantung kepada satu server pusat. -
Branching yang Fleksibel
Mercurial menyediakan dua jenis branching yaitu Named Branches—Cabang dengan nama tertentu yang tercatat dalam repositori— dan Anonymous Branches—Cabang sementara yang dibuat dengan mekanisme seperti bookmark— sehingga branching pada Mercurial mudah dikelola dan mendukung pengembangan paralel. - **Mekanisme Merging yang Kuat
**Mercurial menggunakan algoritma merge otomatis untuk menyelesaikan konflik dengan opsi penyelesaian manual jika diperlukan. - **Antarmuka yang Konsisten
**Semua perintah Mercurial memiliki sintaks yang sederhana dan seragam, seperti hg commit, hg push, dan hg pull. Mirip dengan Git, ya? Tentu saja karena keduanya serupa tapi tak sama.???? - **Keamanan dan Integritas Data
**Mercurial menggunakan hashing SHA-1 untuk memastikan setiap perubahan dicatat dengan aman dan repositori tidak dapat dimodifikasi tanpa jejak. - Portabilitas
Dapat digunakan di berbagai sistem operasi tanpa perubahan signifikan, menjadikannya alat yang fleksibel untuk tim lintas platform. - **Kompatibilitas dengan Proyek Besar
**Mercurial dirancang untuk menangani proyek besar dengan banyak file dan pengguna tanpa penurunan kinerja yang signifikan.
Tentu saja, sebagai pilihan ketiga setelah Git dan SVN, Mercurial ini memiliki beberapa kekurangan yang menyebabkan popularitasnya kalah dari Git yang kini menjadi standar de facto untuk version control.
Salah satu kekurangannya adalah Mercurial memiliki ekosistem yang lebih sedikit dibandingkan Git sehingga banyak tools atau services yang tidak kompatibel sehingga perlu penanganan khusus. Kondisi tersebut mengakibatkan komunitas pengguna Mercurial tidak sebesar Git Community. Oleh karena itu, pengguna baru mungkin kesulitan mendapatkan dukungan atau tutorial dibandingkan dengan Git yang memiliki komunitas besar.
Setelah sekian lama, perjalanan materi ini telah membawa kita berkenalan dengan Git, SVN, dan Mercurial, tiga tools VCS yang mumpuni dengan fitur-fitur andalannya. Kita telah belajar tentang konsep distributed versus centralized, branching, merging, commit, dan berbagai istilah penting lainnya. Ibarat seorang musisi yang telah mengenal berbagai jenis instrumen, kini saatnya kita beralih dari teori ke praktik. Mari kita pelajari dasar-dasar penggunaan VCS yang akan memandu Anda dalam mengelola kode, berkolaborasi, dan melacak perubahan dengan efektif, terlepas dari tools VCS apa pun yang Anda gunakan.
Dasar-Dasar Penggunaan Version Control
Kita telah mempelajari konsep Version Control System dan berkenalan dengan berbagai tools-nya. Cukup dengan teori, saatnya beraksi sesuai dengan kutipan Tim Sanders berikut.
“Education without application is just entertainment. “ — Tim Sanders, Former Yahoo chief solutions officer.
Tidak afdal rasanya jika kita tidak langsung terjun ke lapangan untuk merasakan experience penuh materi ini. Sekarang, kita akan mempraktikkan semua itu dengan menggunakan Git, tools VCS yang paling populer di kalangan developer. Untuk mendapatkan pengalaman yang lebih seru, kita akan menggunakan GitHub, platform hosting Git yang luar biasa lengkap. So, sudah siap untuk petualangan coding yang sesungguhnya? Mari kita mulai praktik sederhana menggunakan GitHub.
GitHub adalah platform berbasis cloud untuk hosting, mengelola, dan berkolaborasi dalam proyek perangkat lunak menggunakan Git yang sudah kita pelajari. Tools ini dibuat pada tahun 2008 dan kini dimiliki oleh Microsoft. GitHub mendukung pengembangan perangkat lunak secara individu maupun tim, memungkinkan kolaborasi yang lebih mudah, transparan, dan terorganisasi seperti Git yang sudah kita bahas pada materi sebelumnya.

Nah, kita tidak akan membahas pengertian dan fitur-fitur pada GitHub karena sejatinya tools ini merupakan implementasi Git sehingga semua materinya sudah kita pahami sepenuhnya.
Hal pertama yang perlu kita lakukan adalah menuju halaman website GitHub dan masuk ke akun pribadi Anda. Pada tutorial ini, kita asumsikan Anda sudah memiliki akun GitHub yang siap digunakan sehingga halaman awal setelah masuk akun terlihat seperti berikut.
Selanjutnya, silakan klik tombol “New” untuk membuat sebuah repositori baru sehingga menampilkan interface berikut.
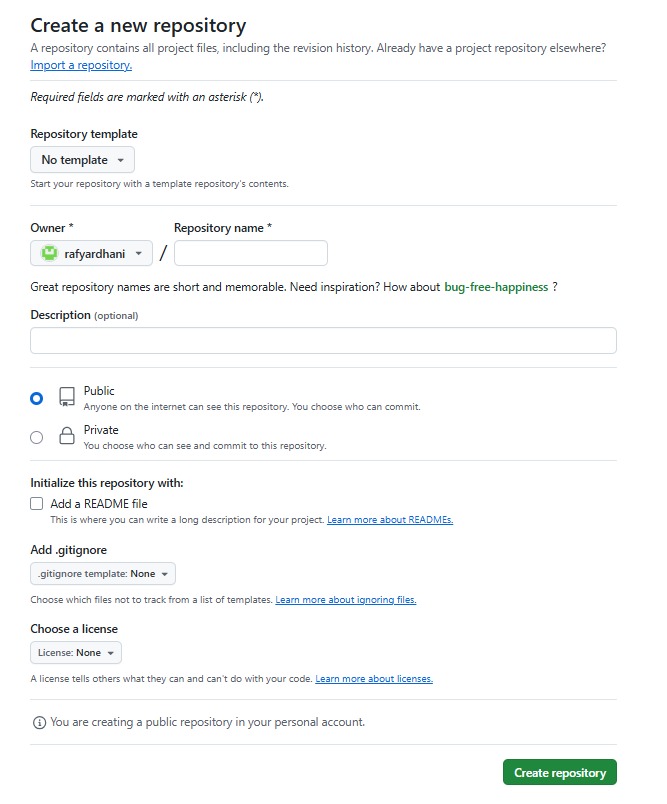
Pada halaman pembuatan repository, Anda akan diminta mengisi beberapa informasi yang dapat disesuaikan dengan kebutuhan proyek. Beberapa hal penting yang perlu Anda ingat mencakup poin-poin berikut.
- Owner
Berisikan username pemilik repository Github. Menariknya, Anda bisa memilih akun pribadi Anda atau organisasi jika Anda menjadi anggota organisasi di GitHub. - Repository Name
Masukkan nama untuk repository. Contohnya latihan-mlsystem. - Description (Optional)
Tambahkan deskripsi singkat tentang repository Anda. Contoh: Repository untuk belajar GitHub pada kelas Membangun System Machine Learning. - Privacy Settings
- Public: semua orang bisa melihat repository ini (open-source).
- Private: repositori ini hanya dapat diakses oleh Anda dan pengguna yang Anda undang termasuk anggota organisasi.
- Initialize Repository
Centang “Add a README” file jika Anda ingin langsung memiliki file README, biasanya digunakan untuk menjelaskan proyek Anda secara detail. - Opsional
- Tambahkan file .gitignore untuk mengecualikan file tertentu dari version control (pilih template yang sesuai dengan jenis proyek Anda).
- Tambahkan License untuk menetapkan lisensi proyek sesuai dengan kebutuhan proyek Anda.
Setelah mengisi semua detail, klik tombol “Create repository” di bagian bawah halaman. Repositori baru Anda akan dibuat secara otomatis dan Anda akan diarahkan ke halaman utama repositori tersebut.
Halaman ini memiliki banyak sekali tombol action yang dapat Anda pilih untuk melanjutkan proyek. Namun, Anda tidak perlu risau karena pada materi ini kita tidak akan menggunakan semua tombol action pada bagian navbar. Sebagai tahapan awal, mari kita fokus pada section utama yang berisikan dua cara untuk memulai menggunakan repositori baru.
Quick Setup
Pada bagian ini, GitHub memberikan dua cara untuk memulai menggunakan repositori baru.
- Set up in Desktop: opsi ini digunakan untuk mengatur repositori menggunakan aplikasi GitHub Desktop.
- HTTPS/SSH URL: URL repositori yang dapat digunakan untuk menghubungkan repositori lokal ke repositori GitHub menggunakan protokol HTTPS atau SSH.
Membuat Repositori Baru dari Command Line
GitHub menyarankan langkah-langkah untuk menginisialisasi repositori baru di komputer lokal Anda dan menghubungkannya ke repositori di GitHub dengan mengikut langkah-langkah berikut.
-
**Autentikasi Akun GitHub
**Jika ini merupakan kali pertama Anda menggunakan GitHub pada terminal, pastikan Anda sudah memberikan akses akun yang akan digunakan pada terminal komputer. Anda dapat menggunakan perintah berikut untuk mengonfigurasi Git agar menggunakan PAT sebagai kredensial.- git config --global user.name “NamaAnda”
- git config --global user.email “email@example.com”
Setelah semua env dipastikan aman, Anda harus memasukkan sebuah kode sebagai password untuk mengakses repository GitHub. Anda dapat membaca dokumentasi resmi GitHub berikut untuk mendapatkan personal access token (PAT).
Ganti “NamaAnda” dengan username github dan “email@example.com” dengan email yang terhubung dengan github Anda.
-
(Opsional) Buat File README.md
Jalankan Perintah berikut pada command line untuk membuat file README.md dengan konten awal # latihan-mlsystem.echo “# latihan-mlsystem” » README.md

File ini biasanya digunakan untuk menjelaskan proyek Anda, tidak ada batasan tertentu untuk mengenai isinya tetapi biasanya penjelasan lengkap mulai dari deskripsi dan penggunaan proyek.
-
Inisialisasi Repositori Lokal
Selanjutnya jalankan perintah berikut pada command line yang sama. Anda perlu memastikan bahwa repositori yang digunakan sudah benar, ya.git init

Perintah ini mengubah direktori lokal Anda menjadi repositori Git sehingga nantinya Anda dapat melakukan sinkronisasi setiap kali merubah source code pada direktori lokal.
-
Tambahkan File ke Staging
Gunakan perintah berikut untuk menambahkan file README.md ke staging area commit.git add README.md

-
Commit Perubahan
Fungsi commit untuk mencatat perubahan pertama dengan pesan “first commit” sebagai deskripsinya. Anda dapat menyesuaikan pesan sesuai dengan perubahan yang dilakukan.git commit -m “first commit”

-
Buat Cabang Utama (Main/Master)
Perintah ini mengubah nama branch default menjadi main/master sesuai dengan nama branch yang Anda tentukan.git branch -M main

-
Hubungkan ke Repositori GitHub
Gunakan perintah berikut untuk menghubungkan repositori lokal Anda ke repositori GitHub dengan URL yang disediakan.git remote add origin https://github.com/
/<nama\_repo>.git [](# "dos-d12e80a38638757606dcb22482ee281920250317130446.png") -
Push ke Repositori GitHub
Terakhir, gunakan perintah mengunggah (push) branch main ke repositori GitHub sehingga semua perubahan Anda dapat dilihat di GitHub.git push -u origin main

Dengan mengikuti tahapan di atas, Anda telah berhasil menghubungkan repositori lokal dengan remote repositori GitHub sehingga kelak Anda dapat melakukan sinkronisasi setiap perubahan dan menyalin seluruh proyek ke lingkungan kerja yang baru.
Jika masih ada hambatan, jangan sungkan untuk bertanya via Forum Diskusi ya.
Eh, tetapi bagaimana kalau kita sudah memiliki sebuah proyek yang sudah rampung? Tenang, GitHub juga menyediakan fitur untuk mengunggah (push) seluruh repositori yang sudah Anda kerjakan sejak zaman dahulu kala.
Menghubungkan Repositori yang Sudah Ada ke GitHub
Jika Anda memiliki repositori lokal yang sudah ada dan ingin menghubungkannya ke repositori GitHub tentu kita tidak perlu mengikuti semua langkah pada metode sebelumnya. Pada metode ini hanya terdapat tiga langkah secara umum (dapat Anda sesuaikan) dengan tahapan seperti berikut.
-
Tambahkan Remote Repository
Gunakan perintah yang sama untuk menambahkan repositori GitHub sebagai remote dengan nama origin seperti pada metode sebelumnya. Pastikan Anda sudah berada pada direktori yang diinginkan ya.- git remote add origin https://github.com/
/<nama\_repository>.git
- git remote add origin https://github.com/
-
Ganti Nama Cabang Utama
Perintah ini mengubah nama branch default menjadi main/master sesuai dengan nama branch yang Anda tentukan.- git branch -M main
-
Push Perubahan ke GitHub
Terakhir, gunakan perintah mengunggah (push) branch main ke repositori GitHub sehingga semua perubahan Anda dapat dilihat di GitHub.- git push -u origin main
Dengan mengikuti langkah-langkah di atas Anda dapat memulai bekerja dengan repositori GitHub baik dengan membuat repositori baru dari awal maupun menghubungkan repositori yang sudah ada di komputer Anda. Setelah selesai, Anda dapat mulai menambahkan file, mengelola versi kode, dan berkolaborasi dengan tim Anda menggunakan repositori GitHub tersebut.
Apakah semuanya selesai setelah kita menamatkan materi GitHub? Tentu saja tidak karena ini merupakan tahapan awal bahkan tidak mencakup 10% materi kelas Membangun System Machine Learning.
GitHub itu ibarat potongan puzzle penting dalam alur kerja pengembangan software, yang menyediakan platform untuk kolaborasi dan manajemen kode yang efektif. Namun, dalam proyek machine learning, puzzle tersebut belum lengkap. Kita membutuhkan kepingan lain untuk melacak eksperimen, mengelola model, dan memastikan reproducibility. Kepingan puzzle yang hilang itu salah satunya adalah MLflow.
Hah, apa hubungannya dengan MLflow?
Untuk menjawab pertanyaan tersebut mari kita lihat bagaimana MLflow melengkapi puzzle alur kerja machine learning kita, membuatnya lebih utuh dan efisien.
Pengenalan MLflow: Tracking dan Project
Sejauh ini kita telah mengetahui bahwa GitHub menjadi tools yang sangat berguna dalam pengembangan software dengan menyediakan platform untuk berkolaborasi, mengelola versi kode, dan melacak perubahan. Namun, materi tersebut belum memasuki tahapan pengembangan machine learning.
Sampai di sini, tentu banyak sekali pertanyaan untuk mengatasi permasalahan pembangunan model machine learning pada kelas-kelas sebelumnya.
- Bagaimana kita melacak berbagai eksperimen yang kita jalankan?
- Bagaimana kita mengelola versi model yang berbeda-beda?
- Bagaimana kita memastikan bahwa hasil yang kita dapatkan dapat direproduksi kembali?
Di sinilah MLflow hadir sebagai solusi yang Andal. So, Mari kita berkenalan dengan MLflow, sebuah platform open-source yang dirancang khusus untuk menyederhanakan dan menstandardisasi machine learning lifecycle.
Mungkin tebersit di benak Anda “apa sih MLflow itu?” Tenang saja, mari kita bahas secara runut dari awal.
MLflow adalah platform open-source yang dirancang untuk mengelola alur kerja machine learning (ML) secara end-to-end. MLflow membantu para data scientist, machine learning engineer, dan tim pengembang untuk mencatat, melacak, mengelola, dan mendistribusikan model ML dengan lebih mudah. Dengan MLflow, semua elemen penting dalam proyek ML, seperti eksperimen, parameter, metrik, artefak, dan model, dapat dikelola secara terpusat.

MLflow dapat digunakan bersama dengan berbagai library machine learning seperti TensorFlow, PyTorch, Scikit-learn, XGBoost, dan 20 library lainnya.

Platform ini juga mendukung integrasi dengan alat CI/CD seperti GitHub untuk mempermudah implementasi dan manajemen model di lingkungan produksi. Tidak berhenti di sini, sebagai tools yang sangat powerful tentunya MLflow memiliki berbagai macam fitur yang siap membantu Anda membangun sistem machine learning.
Lalu, bagaimana cara menggunakan semua fitur di atas? Eitss, sebagai permulaan, mari kita bahas cara menginstal MLflow pada local environment terlebih dahulu_._ Sebenarnya, proses yang dilakukan sama saja dengan library lainnya. Anda dapat menggunakan pip sebagai tools untuk menginstal MLflow seperti berikut.
- pip install mlflow
Namun, jika ingin menguji fitur-fitur baru dan memvalidasi versi MLflow lainnya, Anda dapat menginstal kandidat rilis terbaru dengan menggunakan kode berikut.
- pip install --pre mlflow
Last but not least, jika Anda ingin menguji versi spesifik kandidat rilis MLflow, silakan gunakan kode berikut, ya.
- pip install mlflow==2.14.0rc0
Sebagai informasi, pada kelas ini kita akan menggunakan versi 2.18.0 sehingga Anda dapat melakukan instalasi dengan menggunakan kode berikut jika ingin menyamakan dengan tutorial.
- pip install mlflow==2.18.0
Seluruh pilihan di atas menjelaskan cara menginstal MLflow pada working environment yang akan Anda gunakan. Tentu saja Anda tidak perlu menggunakan ketiga tahapan tersebut, silakan sesuaikan dengan kebutuhan dan kenyamanan, ya.
Sampai di sini, Anda sebenarnya sudah dapat menggunakan ML. Jadi tanpa berlama-lama lagi, mari kita bahas saksama seluruh fitur yang nantinya akan Anda gunakan untuk membuat submission di kelas ini.
MLflow Tracking
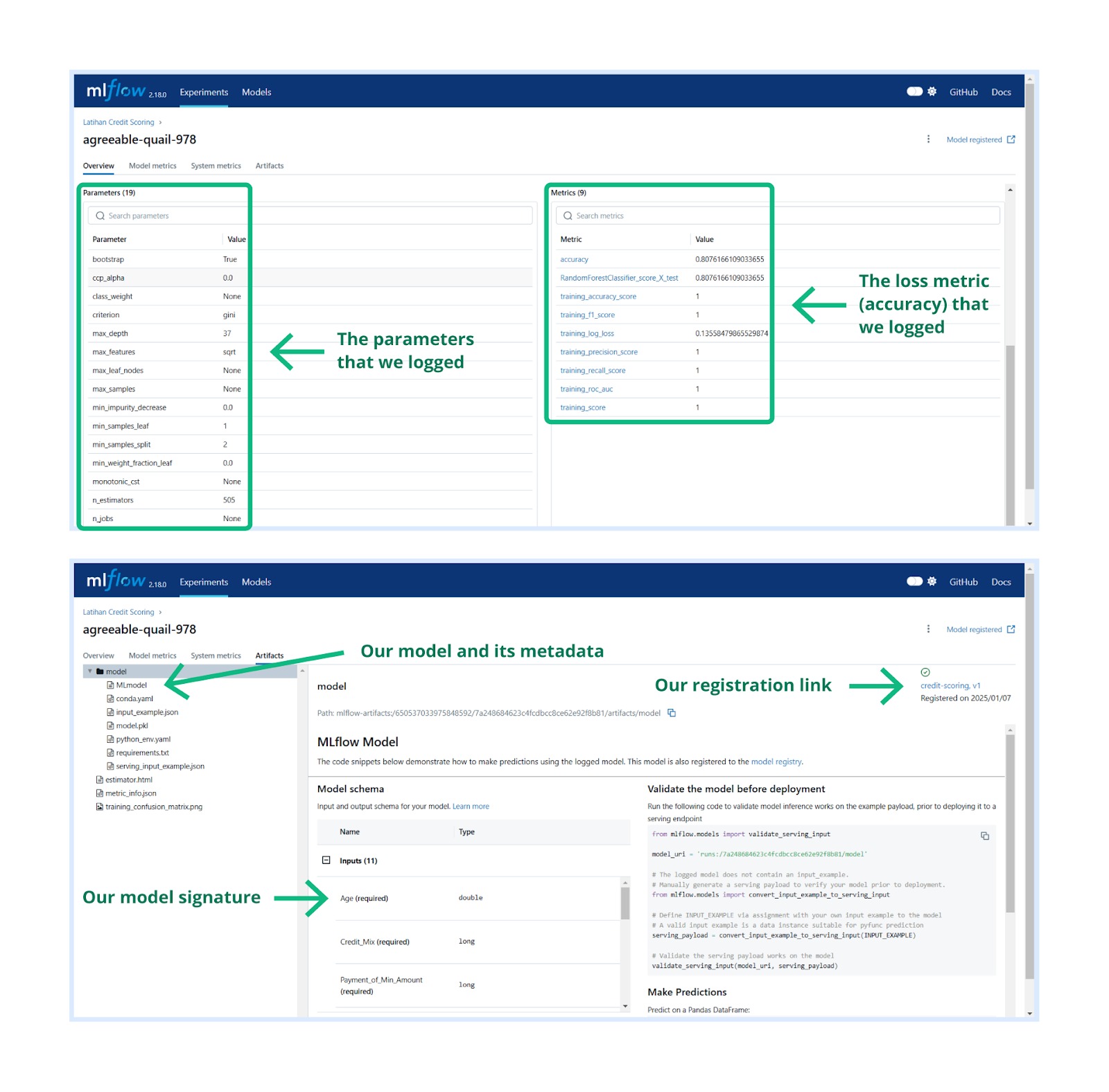
MLflow Tracking adalah komponen yang memungkinkan pengguna untuk mencatat dan melacak eksperimen machine learning. Dengan fitur ini, semua informasi penting seperti parameter, metrik, kode sumber, dan artefak (seperti file model) dapat didokumentasikan secara otomatis.
Jika tebersit sebuah pertanyaan di benak Anda, “mengapa proses pencatatan ini menjadi sangat penting ketika kita membangun sebuah model?” berarti Anda menikmati perjalanan ini. Mari kita flashback sejenak pada kelas sebelumnya ketika proses pencatatan metriks harus dilakukan secara manual sehingga kerap dilupakan atau bahkan tidak diingat sama sekali.
Sekilas perilaku di atas terlihat tidak ada salahnya ‘kan? Hal itu karena tujuan dalam membangun model machine learning tetaplah terpenuhi. Namun, ini akan menjadi bom waktu (tech debt) karena akan memberikan dampak di kemudian hari seperti ketika ingin mereplikasi model, melihat hyperparameter hingga performa ketika model dilatih.
Nah, di sinilah peran krusial MLflow dibutuhkan. MLflow dapat mempermudah pengelolaan eksperimen dengan mencatat informasi seperti parameter, metrik, dan artefak model secara otomatis. Dengan MLflow Tracking, pengguna dapat membandingkan hasil eksperimen, memastikan reproduktibilitas, dan mendokumentasikan eksperimen dalam satu tempat terpusat.
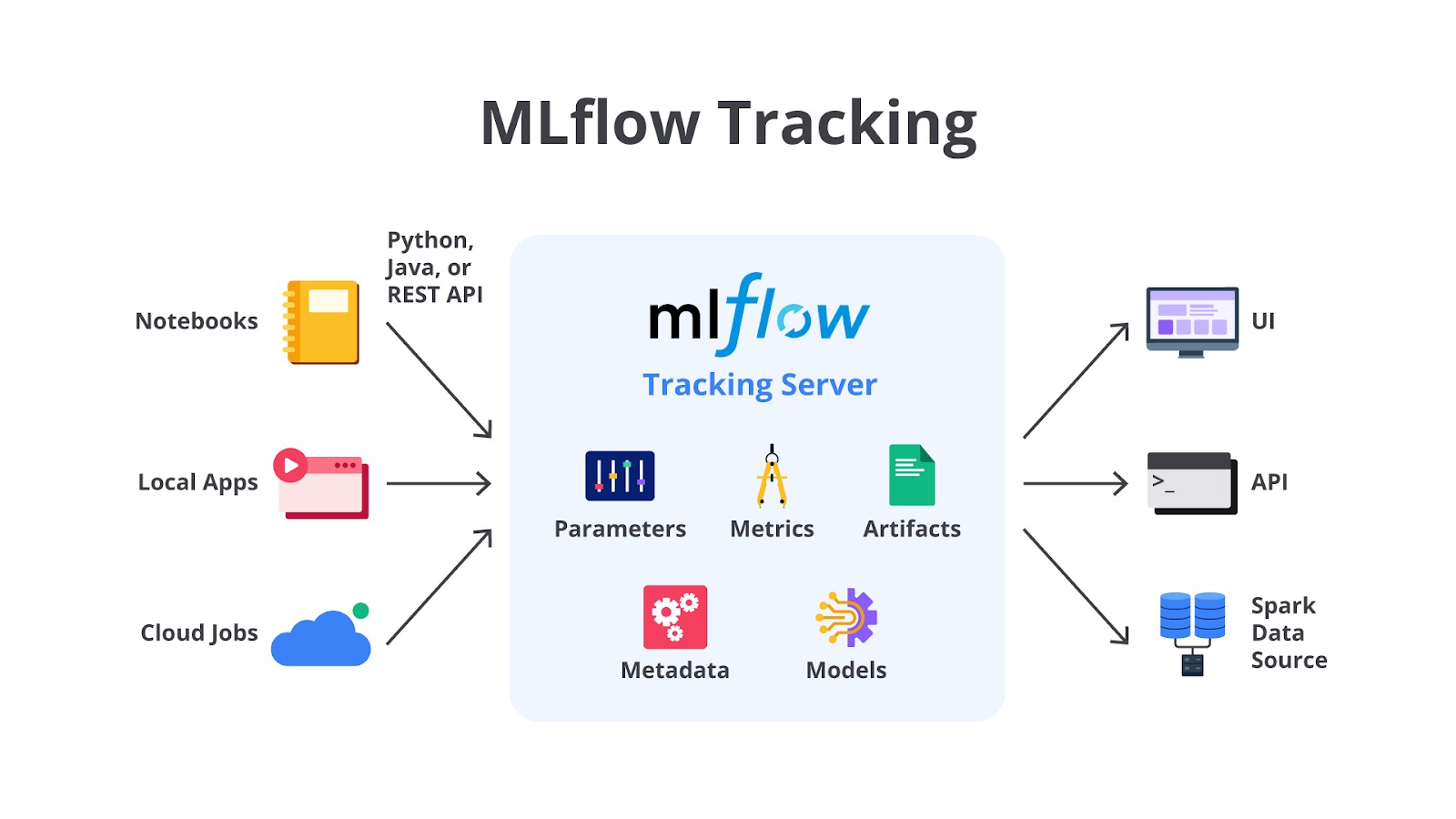
Berdasarkan gambar di atas, terdapat beberapa hal yang dapat kita tracking dengan menggunakan MLflow mencakup parameters, metrics, artifacts, metadata dan models. Pada masing-masing komponen setidaknya Anda dapat mencatat hal-hal seperti berikut.
-
Pencatatan Parameter
Parameter adalah konfigurasi model atau hyperparameter yang digunakan selama pelatihan, seperti learning_rate, batch_size, atau number_of_layers.MLflow mencatat semua parameter eksperimen sehingga pengguna dapat menganalisis pengaruhnya terhadap performa model.
-
Pencatatan Metrik
Metrik adalah hasil evaluasi model, seperti accuracy, precision, recall, atau loss.MLflow dapat mencatat metrik secara otomatis dan terstruktur untuk mempermudah perbandingan antar eksperimen.
-
Pencatatan Artefak, Metadata dan Models
Artefak adalah output yang dihasilkan selama eksperimen, seperti file model yang telah dilatih (model.pkl), file visualisasi, atau dataset yang diproses.MLflow dapat menyimpan semua artefak sehingga pengguna dapat mengaksesnya kembali di masa depan ketika dibutuhkan.
- Pencatatan Kode dan Versi
MLflow dapat mencatat informasi tentang kode yang digunakan dalam eksperimen, termasuk versi Git atau jalur file. Hal ini memastikan bahwa eksperimen dapat direproduksi dengan menggunakan versi kode yang sama. - Pelacakan Multi-Platform
MLflow Tracking dapat digunakan secara lokal, di server terpusat, atau di cloud, serta memungkinkan pelacakan eksperimen yang terdistribusi di berbagai lingkungan.
Bagaimana keren ‘kan? Dari sini kita sudah tahu bahwa MLflow merupakan kepingan puzzle yang sangat penting untuk membangun sistem machine learning, tentunya kepingan ini memiliki beberapa komponen penting yang perlu Anda ingat agar dapat menjalankan tracking dengan lengkap. Berikut merupakan komponen penting dalam MLflow Tracking.
- Run
Seperti yang kita tahu bahwa MLflow Tracking dapat membantu Anda mencatat dan mengelola informasi penting dari setiap eksekusi kode machine learning Anda. Informasi ini disimpan dalam bentuk metadata dan artifacts yang terkait dengan setiap “run”. Dengan demikian, Anda dapat dengan mudah melacak, membandingkan, dan mereproduksi eksperimen machine learning Anda. Setiap “run” akan mencatat dua hal penting seperti berikut.- Metadata yang berisikan berbagai informasi yang berkaitan dengan “run” yang mencakup beberapa hal berikut.
- Metrik: performa model, misalnya akurasi, presisi, recall, F1-score.
- Parameter: nilai-nilai yang digunakan untuk mengonfigurasi model atau proses pelatihan, misalnya learning rate, jumlah epoch, jenis algoritma.
- Waktu mulai dan selesai (runtime) menjalankan fungsi “run”.
- Informasi lain yang dianggap penting.
- Metadata yang berisikan berbagai informasi yang berkaitan dengan “run” yang mencakup beberapa hal berikut.
- Artifacts yang mencakup file-file output yang dihasilkan dari “run” tersebut, seperti bobot model, gambar, dan file yang relevan.
- Bobot model: file yang berisi parameter model yang telah dilatih.
- Gambar: visualisasi data, grafik performa model, atau gambar lainnya.
- File-file output lainnya yang relevan.
-
Experiment
Kumpulan run yang terkait dikelompokkan ke dalam Experiment. Contohnya jika Anda mencoba berbagai hyperparameter untuk model tertentu, semua run dapat dikelompokkan dalam satu experiment. -
Tracking Server
Tracking Server adalah server pusat yang menyimpan semua data eksperimen. MLflow dapat diatur untuk menyimpan data ini di berbagai backend, seperti environment lokal, database (seperti MySQL, PostgreSQL) dan Cloud storage. - UI MLflow Tracking
MLflow menyediakan antarmuka web untuk melihat dan membandingkan semua run yang tercatat dalam experiment. Antarmuka ini memungkinkan pengguna untuk memfilter, mengurutkan, dan menganalisis data eksperimen.
Dengan memahami komponen di atas, Anda akan lebih mudah untuk mempelajari penggunaan MLflow tracking pada materi berikutnya. Disclaimer, pada tahap ini, kita tidak akan menjelaskan kodenya secara detail, tetapi hanya memperlihatkan contoh penggunaannya agar terbayang ketika akan berpindah ke latihan di materi berikutnya. Materi ini mendorong Anda untuk mencoba latihan yang sama, tetapi hal tersebut tidaklah wajib.
Menjalankan Tracking Runs
Nah, untuk mencatat dan mengelola eksperimen, MLflow Tracking menyediakan serangkaian fungsi yang disebut API (Application Programming Interface). Buat kalian yang belum familier dengan API mari kita ambil analogi sederhana. API ini ibarat sekumpulan tombol dan perintah yang bisa kita gunakan untuk berinteraksi dengan MLflow Tracking.
Sebagai contoh, kita bisa memanggil fungsi mlflow.start_run() untuk memulai sebuah “run” baru. Ingat, “run” itu seperti satu kali percobaan atau eksekusi kode machine learning kita. Setelah memulai “run”, kita bisa menggunakan fungsi-fungsi pencatatan lainnya seperti berikut.
- mlflow.log_param(): fungsi ini digunakan untuk mencatat parameter yang kita gunakan dalam “run” tersebut.
- mlflow.log_metric(): fungsi ini digunakan untuk mencatat metrik yang dihasilkan dari “run” tersebut.
Selain contoh di atas, masih banyak fungsi-fungsi lain yang disediakan oleh API MLflow Tracking ini. Untuk penjelasan yang lebih detail dan lengkap mengenai cara penggunaan API ini, Anda bisa merujuk ke dokumentasi resmi Tracking API. Di sana, Anda akan menemukan panduan lengkap beserta contoh-contoh kode yang akan membantu untuk memahami cara kerja setiap fungsi.
Jangan ragu untuk membuka dokumentasi tersebut dan mempelajari lebih lanjut. Semakin Anda memahami API ini, semakin mudah bagi Anda untuk melacak dan mengelola eksperimen machine learning.
Pada materi ini, kita akan menuliskan beberapa contoh penggunaan API MLflow beserta fungsinya. Sekali lagi, pada tahap ini, kita tidak akan membahas terlalu dalam mengenai kodenya, ya. Mari kita mulai dengan pencatatan yang sederhana.
-
import mlflow
- with mlflow.start_run():
- mlflow.log_param(“n_estimators”, 100)
- mlflow.log_param(“max_depth”, 5)
- # Baris ini berisikan kode untuk membangun model ML.
- …
- mlflow.log_metric(“accuracy”, accuracy)
- mlflow.sklearn.log_model(model, “random_forest_model”)
Kode di atas menunjukkan kerangka dasar dalam menggunakan MLflow Tracking. Anda memulai “run”, mencatat parameter, menjalankan kode machine learning, dan mencatat metrik yang dihasilkan. Pada kasus ini, kita akan mencatat n_estimator dan max_depth dengan menyimpan accuracy sebagai log_metric beserta karakteristik modelnya.
Dengan cara ini, MLflow membantu Anda melacak dan mengelola eksperimen machine learning dengan rapi dan terstruktur. Anda dapat melihat kembali semua “run” yang telah dilakukan, membandingkan parameter dan metriknya, dan dengan mudah mereproduksi hasil eksperimen.
Pro Tips
Anda dapat melihat semua metrics yang dicatat pada folder yang sama dengan working repository ketika Anda tidak mengatur **mlflow.set_tracking_uri(uri=”http://
Dengan menggunakan kode sebelumnya, Anda dapat menyimpan beberapa metrics yang ingin diabadikan. Namun, bagaimana jika pimpinan atau tim Anda ingin menyimpan seluruh metrics untuk tujuan tertentu? Tentu akan menjadi masalah karena kita harus menuliskan seluruh metrics pada masing-masing algoritma yang digunakan.
Chill, ada cara yang lebih cepat dan praktis untuk menangani permasalahan tersebut yaitu dengan menggunakan fitur Auto-logging.
Fitur powerful ini memungkinkan Anda untuk mencatat metrik, parameter, dan bahkan model tanpa perlu menulis kode pencatatan secara eksplisit. Bayangkan, Anda tidak perlu lagi repot-repot memanggil fungsi log_ satu per satu. Cukup dengan memanggil satu fungsi sakti mlflow.autolog() dan MLflow akan secara otomatis mencatat berbagai informasi.
Lalu, bagaimana cara menggunakannya?
Anda hanya perlu memanggil mlflow.autolog() sebelum kode pelatihan model. Sesederhana itu, lho.
-
import mlflow
- mlflow.autolog()
- # Baris ini berisikan kode untuk membangun model ML.
- …
Hebatnya lagi, auto-logging ini mendukung berbagai library machine learning populer, seperti Scikit-learn, XGBoost, PyTorch, Keras, Spark dan masih banyak lagi.
Untuk informasi lebih lanjut mengenai library yang didukung dan cara penggunaan API auto-logging untuk masing-masing library, Anda dapat merujuk ke Dokumentasi Automatic Logging. Di sana, Anda akan menemukan panduan lengkap dan contoh-contoh kode yang akan membantu untuk menguasai fitur auto-logging ini.
Intinya, dengan auto-logging Anda dapat menghemat waktu dan tenaga, serta fokus pada eksperimen machine learning Anda.
Menariknya, MLflow juga menyediakan satu fungsi yang sangat bermanfaat ketika Anda tidak menggunakan auto-logging yaitu MLflow Tracking Datasets.
Tracking datasets adalah salah satu aspek penting dalam proses pengembangan machine learning, karena perubahan pada dataset dapat berdampak besar pada hasil eksperimen dan performa model. Dengan MLflow, selain mencatat parameter, metrik, dan artefak, Anda juga dapat mencatat informasi terkait dataset yang digunakan selama eksperimen, seperti versi dataset, lokasi penyimpanan, atau hash unik dataset. Ini memastikan bahwa eksperimen dapat direproduksi dengan dataset yang sama. Wow, keren banget kan?
Mungkin, beberapa orang akan memiliki pertanyaan, “mengapa Tracking datasets penting?” Mari kita bahas alasan utamanya.
- Reproduktibilitas Eksperimen
Dataset adalah bagian inti dari machine learning. Jika dataset tidak dilacak, sulit untuk menjalankan ulang eksperimen dengan hasil yang konsisten (menggunakan dataset yang sama). - Kolaborasi
Saat bekerja dalam tim, mencatat versi dataset membantu anggota tim lain menggunakan dataset yang sama untuk eksperimen mereka. Hal ini akan meminimalisasi perbedaan output dari orang yang berbeda - Manajemen Versi Dataset
Dataset sering diperbarui, seperti penambahan data baru atau pembersihan data. Tracking membantu mengelola perubahan ini dengan baik karena Anda akan memiliki visibilitas yang baik.
Saat ini MLflow sudah memiliki fitur bawaan untuk melacak dataset secara langsung, tetapi Anda juga dapat mencatat informasi terkait dataset sebagai bagian dari parameter, artefak, atau dengan menghitung hash unik dataset. Tenang saja, walaupun banyak cara, tetapi penggunaan Tracking Dataset masih tergolong mudah kok. Mari kita bahas beberapa pendekatan yang dapat Anda lakukan.
-
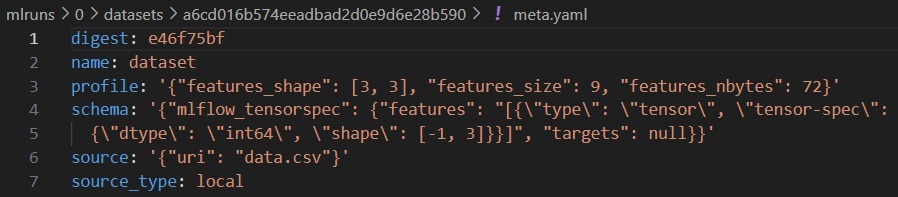
Menggunakan fitur mlflow.log_input()
mlflow.log_input()adalah fungsi yang memungkinkan pengguna untuk mencatat informasi tentang input ke dalam eksperimen ML. Input ini dapat berupa dataset, file konfigurasi, atau data lain yang digunakan untuk melatih model.- import numpy as np
-
import mlflow
- array = np.asarray([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
-
dataset = mlflow.data.from_numpy(array, source=“data.csv”)
- with mlflow.start_run():
- mlflow.log_input(dataset, context=“training”)
Sehingga, akan menghasilkan log file seperti berikut.
-
Tracking Informasi Dataset Sebagai Log Parameter
Jika dataset disimpan di lokasi tertentu atau memiliki nama versi, Anda dapat mencatat informasi tersebut menggunakan mlflow.log_param().-
import mlflow
- # Log dataset information
- dataset_version = “v1.0”
-
dataset_path = “/data/dataset.csv”
- mlflow.log_param(“dataset_version”, dataset_version)
- mlflow.log_param(“dataset_path”, dataset_path)
Sehingga, akan menghasilkan log file seperti berikut.
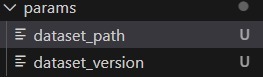


-
-
Tracking Dataset Sebagai Artefak
Anda dapat mengunggah dataset ke MLflow sebagai artefak menggunakan mlflow.log_artifact(). Ini memastikan dataset yang digunakan selama eksperimen tersimpan sepenuhnya dengan eksperimen tersebut.- import numpy as np
-
import mlflow
-
dataset_path = “Telco-Customer-Churn.csv”
- with mlflow.start_run():
- mlflow.log_artifact(dataset_path, artifact_path=“datasets”)
Sehingga, Anda dapat melihat kembali dataset yang digunakan pada file log seutuhnya seperti berikut.
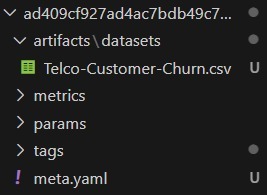
Dataset akan tersimpan secara langsung di MLflow sehingga mudah diakses dan digunakan ulang. Namun, hal ini tidak efisien jika Anda menggunakan dataset yang besar dan tidak memiliki penyimpanan yang cukup.
-
Tracking Dataset dengan Hash Unik
Jika dataset terlalu besar untuk diunggah sebagai artefak dan perusahaan memiliki concern terhadap data privacy, Anda dapat membuat hash unik dari dataset (misalnya, dengan algoritma hashing seperti SHA-256) dan mencatat hash tersebut sebagai parameter.- import hashlib
-
import mlflow
- # Generate hash of dataset
- def generate_dataset_hash(file_path):
- sha256_hash = hashlib.sha256()
- with open(file_path, “rb”) as f:
- for byte_block in iter(lambda: f.read(4096), b””):
- sha256_hash.update(byte_block)
-
return sha256_hash.hexdigest()
- dataset_path = “Telco-Customer-Churn.csv”
-
dataset_hash = generate_dataset_hash(dataset_path)
- with mlflow.start_run():
- mlflow.log_param(“dataset_hash”, dataset_hash)
Dengan begitu, orang lain di luar perusahaan Anda tidak akan mengetahui informasi mengenai dataset yang digunakan.
-
Mengintegrasikan Dataset Version Control (DVC)
Jika Anda menggunakan Data Version Control (DVC) untuk melacak perubahan dataset, Anda dapat mengintegrasikan MLflow dan DVC. Dalam hal ini, versi dataset yang tercatat di DVC dapat dilacak di MLflow sebagai parameter. Untuk pengetahuan tambahan, silakan buka dokumentasi DVC secara mandiri karena pada kelas ini, kita tidak akan menggunakan bantuan DVC untuk membangun model machine learning.
Hufftt, tarik nafas sejenak, jangan lupa beristirahat, ya. Hingga saat ini, kita telah mengeksplorasi MLflow Tracking yang dapat membantu dalam mencatat berbagai aspek penting dalam eksperimen machine learning, mulai dari parameter, metrik, model, hingga dataset. Kita telah menggunakan API untuk mencatat informasi tersebut secara terstruktur.
Namun, bagaimana cara kita melihat dan menganalisis semua informasi yang telah terkumpul itu? Bukankah saat ini Anda hanya dapat mengaksesnya melalui IDE yang digunakan? Tentu itu sangat melelahkan terutama jika kita memiliki banyak eksperimen.
Di sinilah MLflow Tracking UI mengambil alih kendali report dari IDE favorit menjadi sebuah visualisasi. Tracking UI menyediakan antarmuka grafis yang user-friendly sehingga memungkinkan kita untuk memvisualisasikan, membandingkan, dan mengelola run eksperimen dengan mudah secara interaktif.
Tracking UI memberikan visual untuk memeriksa eksperimen yang jauh lebih efisien dibandingkan mencatat dan menganalisis data eksperimen secara manual melalui IDE atau repositori langsung.
Pada intinya, MLflow memiliki kemampuan yang sangat cocok untuk menunjang pembangunan sistem machine learning. Mari kita tengok beberapa fitur yang sangat berguna pada proses pengembangan model.
- Membandingkan Eksperimen
Misalnya, Anda menjalankan eksperimen dengan parameter yang berbeda seperti learning_rate dan batch_size. Dalam Tracking UI, Anda dapat memfilter eksperimen berdasarkan parameter tertentu (misalnya, learning_rate=0.01) dan melihat grafik perbandingan akurasi antar run dengan parameter yang berbeda.
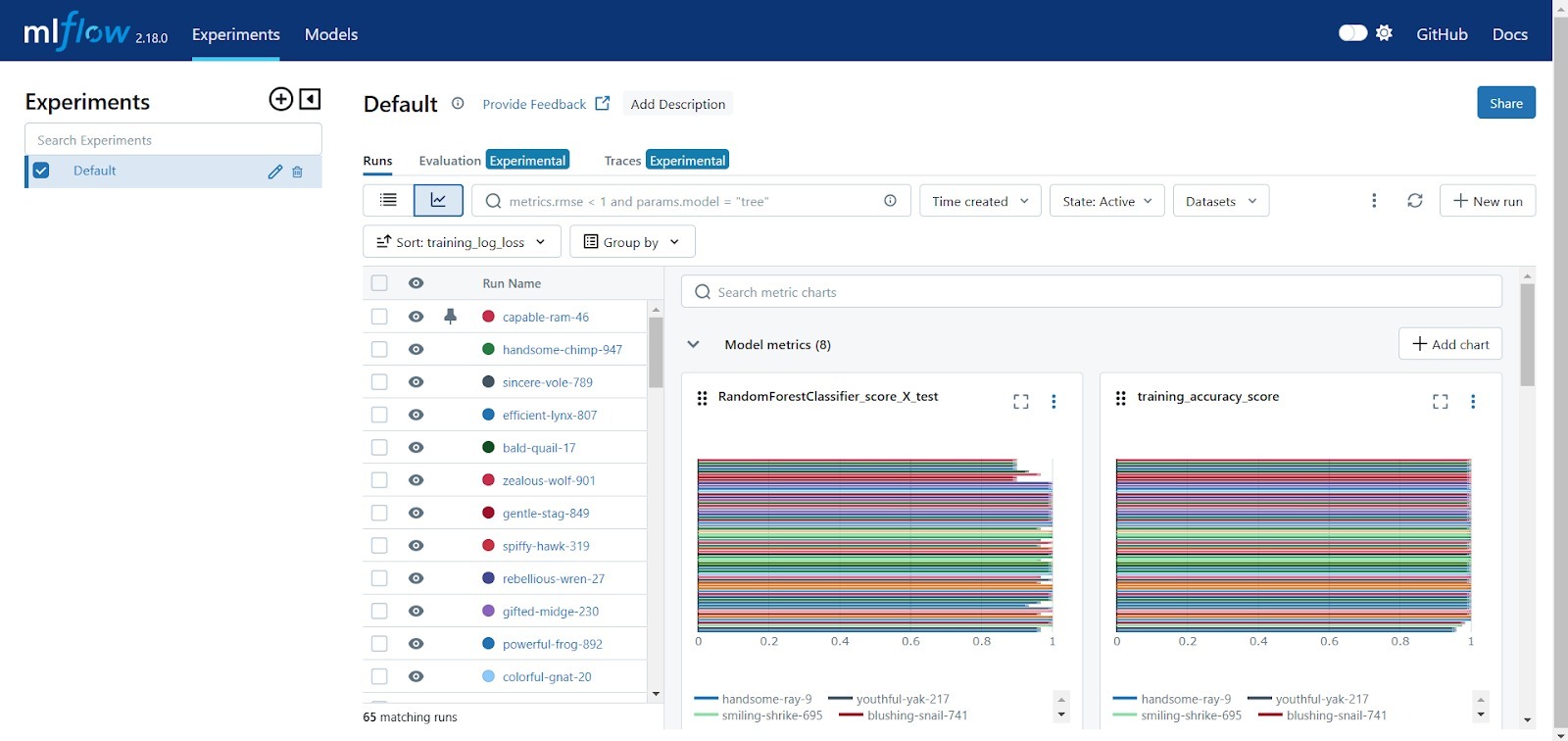
-
**Mengunduh Artefak Model
**Setelah melatih beberapa model, Anda tentu ingin menggunakan model dengan akurasi tertinggi. Dalam Tracking UI, Anda dapat mengunduh seluruh artefak dengan sangat mudah, dimulai dari membuka run dengan akurasi tertinggi, lalu klik link artefak untuk mengunduh model yang telah dilatih.
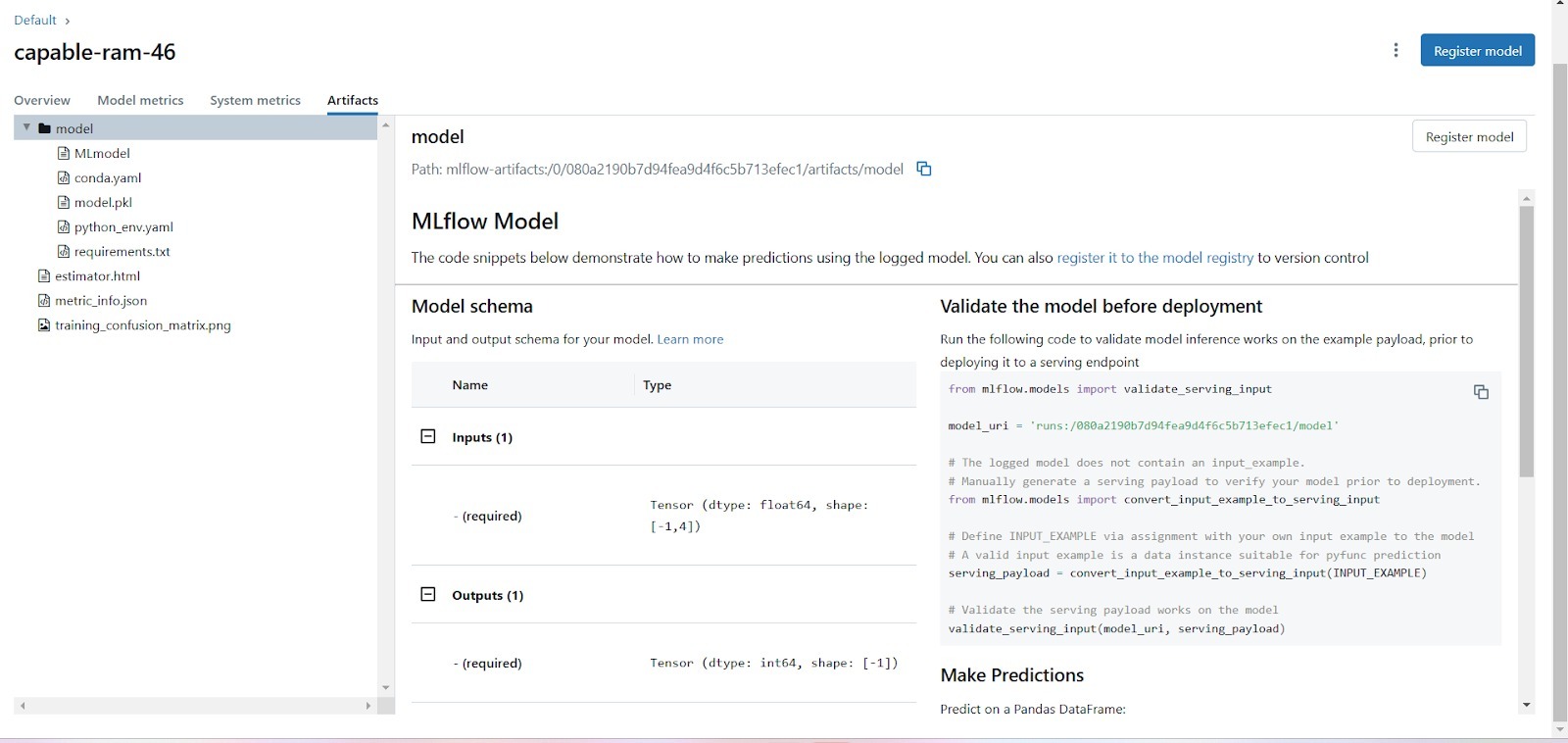
- **Melihat Perbedaan Versi Kode
**Jika Anda mencatat versi kode selama eksperimen, Tracking UI memungkinkan Anda melihat perbedaan hasil antar versi kode untuk setiap run yang berbeda. Selain itu, Tracking UI juga dapat membandingkan hyperparameter yang digunakan ketika model dilatih.

Dengan fitur-fitur MLflow Tracking di atas, kita dapat mengelola dan melacak setiap detail eksperimen machine learning kita, dari kode hingga data. Namun, bagaimana kita dapat mengakses semua informasi tersebut dengan cepat dan melakukan analisis mendalam? Tenang, interface berbasis web ini menyediakan akses yang mudah dan terorganisasi ke semua run dan eksperimen yang telah kita catat. Jika Anda ingin mencatat setiap proses ke direktori mlruns secara lokal, jalankan perintah berikut pada direktori yang ingin Anda catat.
- # Opsi pertama
-
mlflow ui --port 5000
- # Opsi kedua
- mlflow server --host 127.0.0.1 --port 8080
Kode di atas sebenarnya memiliki tujuan yang sama yaitu menjalankan MLflow Tracking Server, tetapi bedanya pada pilihan pertama Anda secara default akan menjalankan server secara lokal. Di sisi lain, pilihan kedua memberikan keleluasaan untuk mengatur alamat IP baik itu pada server lokal ataupun alamat remote dari sebuah VM atau server yang Anda miliki.
Ketika Anda menjalankan salah satu pilihan di atas, terminal aktif yang digunakan akan menunjukkan output seperti berikut.
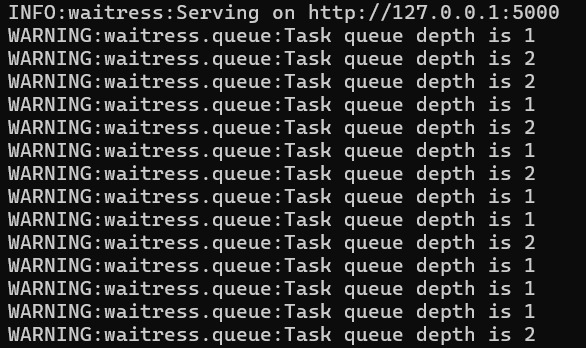
Artinya, MLflow Tracking UI sudah dapat dijalankan. Lalu, bagaimana cara menghentikannya? Mudah saja, Anda bisa masuk kembali ke terminal yang menjalankan Tracking UI dan memberikan perintah “CTRL + C” untuk mengakhiri sesinya. Namun, jika ingin mengakses UI tersebut melalui peramban (browser) favorit Anda dengan memasukkan alamat berikut ke uri peramban.
- # Opsi 1
- http://localhost:
# by default port = 5000 - # Opsi 2
- http://127.0.0.1:
Sehingga, perintah tersebut akan menampilkan halaman seperti berikut.
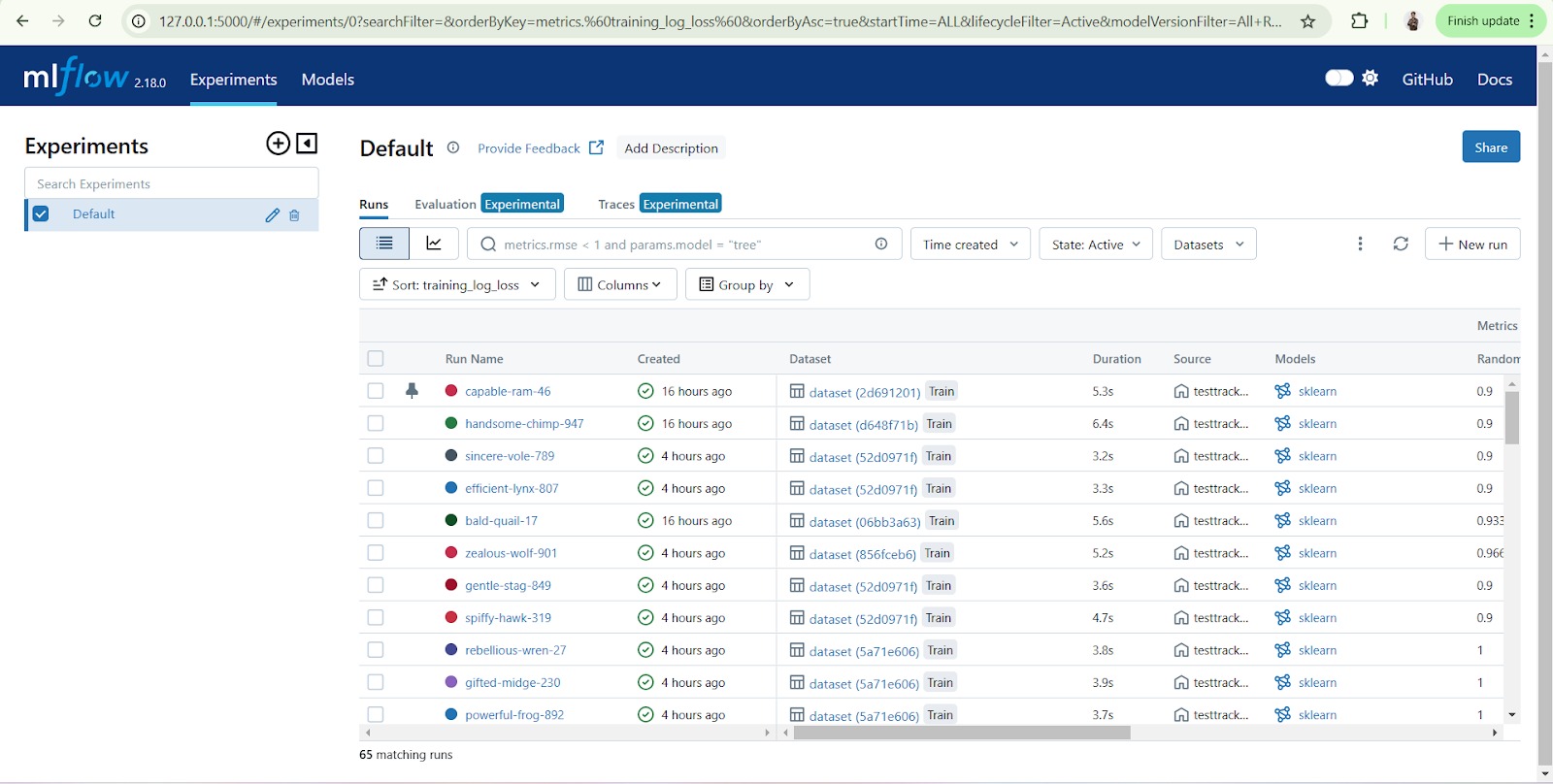
Contoh di atas merupakan salah satu common set-up untuk menerapkan MLflow Tracking UI pada lingkungan lokal (localhost). Namun, kemampuan MLflow tidak terbatas pada lingkungan lokal saja. Anda juga dapat mengombinasikan Tracking UI dengan databases atau bahkan dengan sebuah cloud storage yang dapat disesuaikan dengan alur kerja atau kebutuhan proyek. Sebagai gambaran, perhatikan common setups berikut untuk menerapkan MLflow Tracking UI pada berbagai situasi.
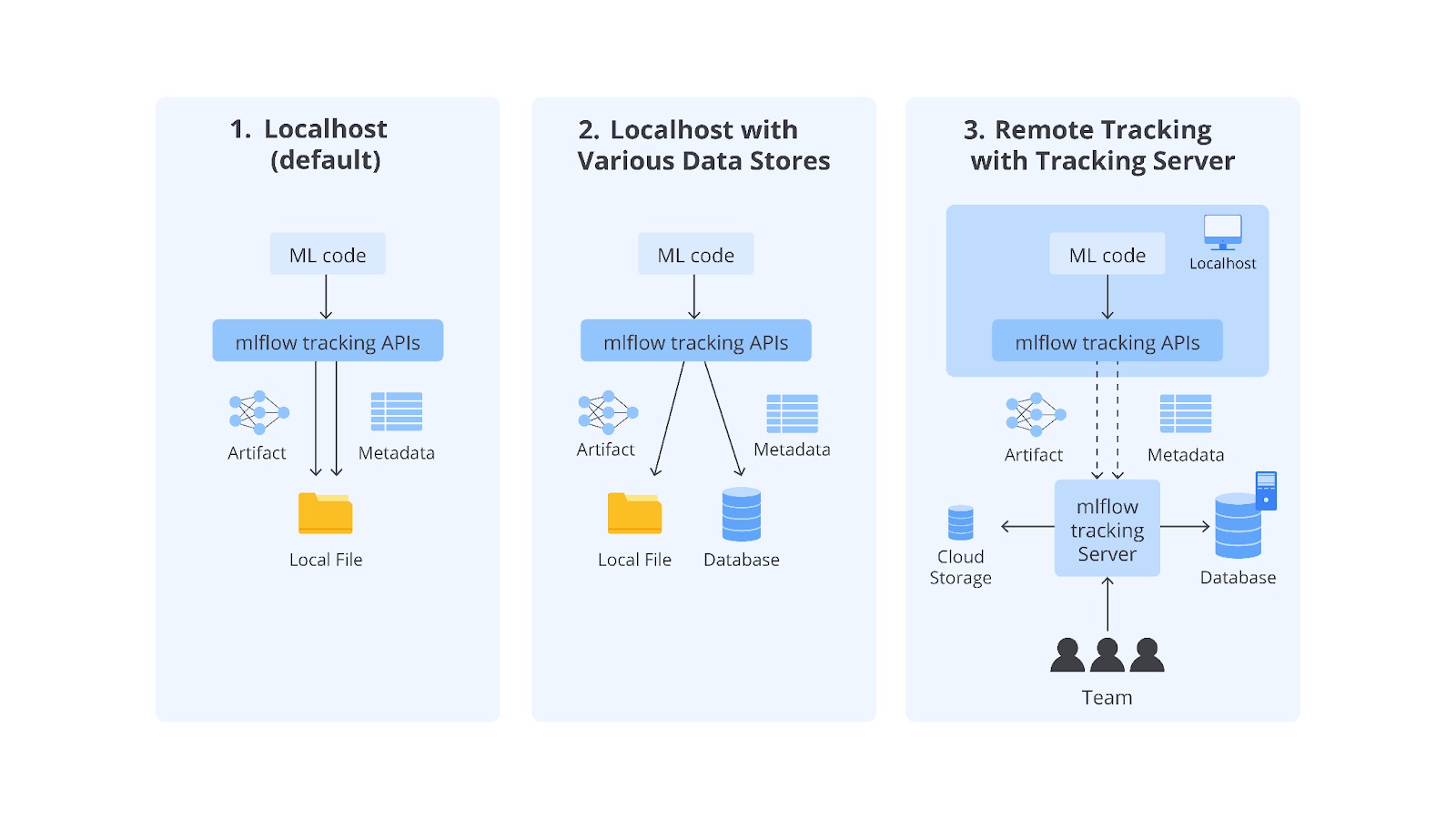
Berdasarkan gambar di atas, MLflow Tracking UI menyediakan tiga pilihan utama, masing-masing dirancang untuk memenuhi kebutuhan yang berbeda. Pengaturan localhost (default) sangat cocok untuk proyek individu atau eksperimen awal, sementara Local Tracking with Local Database memberikan keamanan tambahan untuk menyimpan data di database lokal. Di sisi lain, Remote Tracking with MLflow Tracking Server merupakan solusi terbaik untuk kolaborasi tim dan proyek berskala besar dengan integrasi cloud dan skalabilitas tinggi. Perhatikan tabel berikut sebagai rekap perbedaan ketiga pilihan tersebut.
| Setup | Lokasi Metadata | Lokasi Artefak | Kolaborasi | Skala Proyek |
|---|---|---|---|---|
| Localhost (Default) | mlruns/ (lokal) | mlruns / (lokal) | Tidak mendukung | Eksperimen individu atau proyek kecil |
| Local Tracking with Local Database | Database lokal (SQLite/MySQL) | Direktori lokal | Terbatas | Proyek dengan data terstruktur |
| Remote Tracking Server | Database remote (PostgreSQL/MySQL) | Cloud storage atau remote | Mendukung | Proyek tim besar atau enterprise |
Jadi, silakan sesuaikan dengan kebutuhan Anda. Sebagai informasi, pada kelas ini, kita hanya akan menggunakan pengaturan localhost, ya.
MLflow Project
Bayangkan Anda telah melakukan serangkaian eksperimen machine learning yang menarik dan ingin membagikannya kepada kolega atau supervisor Anda. Anda juga telah menggunakan MLflow Tracking untuk mencatat semua detail penting dan MLflow Tracking UI untuk menganalisis hasilnya.
Namun, bagaimana kita membungkus semua kode, dependensi, dan konfigurasi tersebut agar orang lain dapat dengan mudah menjalankannya kembali? Apakah kita perlu menjalankan semua tahapannya dari nol? Tenang saja, di sinilah MLflow Projects berperan sebagai sebuah solusi yang sangat membantu.
Ibarat membungkus kado, MLflow Projects memungkinkan Anda untuk mengemas proyek machine learning menjadi format yang rapi dan portable. MLflow Projects membantu pengguna mendokumentasikan dan mengemas proyek machine learning dalam format yang terstandarisasi. Setiap proyek akan berisi file konfigurasi (MLproject) yang menjelaskan cara menjalankan proyek tersebut sehingga proyek dapat dipindahkan antar lingkungan dengan mudah.
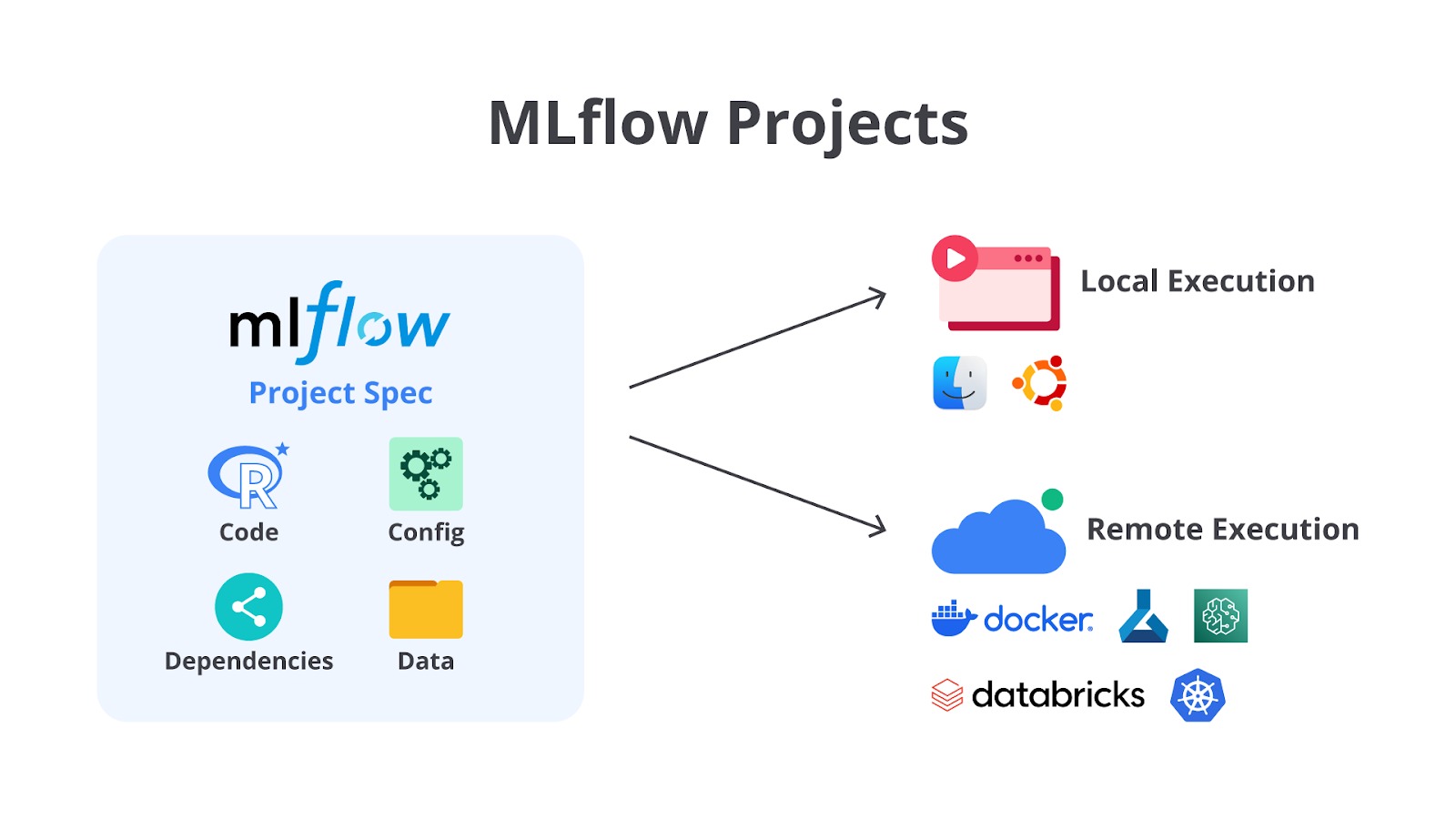
Seperti induknya, MLflow Projects juga mendukung penggunaan berbagai bahasa pemrograman (seperti Python, R, atau Java), library ML (seperti TensorFlow, PyTorch, atau Scikit-learn), serta manajemen dependensi dengan Conda atau Docker.
Setelah membuat proyek machine learning menggunakan MLflow, Anda dapat dengan mudah menjalankan MLflow project dengan membuat satu buah file bernama MLproject. File ini adalah inti dari MLflow Projects, berisi metadata dan instruksi tentang cara menjalankan proyek seperti berikut.
- name: my_ml_project
- conda_env: conda.yaml
- entry_points:
- main:
- parameters:
- alpha: {type: float, default: 0.5}
- l1_ratio: {type: float, default: 0.1}
- command: “python train.py –alpha {alpha} –l1_ratio {l1_ratio}”
Dengan menambahkan kode di atas, sebenarnya Anda sudah dapat menjalankan MLproject pada lingkungan yang baru atau bahkan VM sekalipun. Untuk memperjelas struktur di atas, mari kita bahas terlebih dahulu satu per satu komponennya.
- name: nama proyek yang sedang Anda bangun atau dapat disesuaikan dengan kebutuhan perusahaan.
- conda_env: file yang mendefinisikan lingkungan Conda untuk proyek, Anda dapat mengambil file .yaml ini berdasarkan artefak yang dibuat ketika menjalankan logging pada saat membangun model machine learning.
- entry_points: entry points adalah cara untuk menentukan fungsi atau skrip utama dalam proyek. Setiap entry point dapat dikonfigurasi untuk menerima parameter yang disesuaikan. Biasanya ini merupakan sebuah perintah untuk menjalankan proyek. Setiap entry point dapat memiliki beberapa komponen, contohnya pada kasus di atas terdiri dari dua komponen.
- parameters: parameter yang dapat disesuaikan saat menjalankan proyek.
- command: perintah yang dijalankan dengan parameter yang diberikan.
Lazimnya ini berisikan perintah untuk menjalankan file .py beserta hyperparameter yang digunakan oleh pengembang agar mudah direplikasi tanpa mengubah performa model secara signifikan.
Intinya dengan menggunakan file MLproject, Anda dapat mendefinisikan parameter, dependensi, dan cara menjalankan proyek dengan jelas. Pembuatan MLflow Project ini memungkinkan Anda untuk mengintegrasikan pipeline ML dengan lingkungan yang konsisten, memastikan hasil eksperimen dapat direproduksi di mana saja.
Terus gimana cara membuat MLproject, bang?
Tenang, jangan terburu-buru karena materi ini berfokus pada teorinya terlebih dahulu. Untuk mengisi rasa penasaran Anda mengenai pembuatan MLproject, mari kita berlatih menjalankan MLproject menggunakan repositori yang sudah disediakan oleh MLflow pada repositori berikut https://github.com/mlflow/mlflow-example.
For your information, repositori tersebut merupakan hasil forking dari repositori MLflow dengan tujuan pembelajaran agar memiliki akses penuh terhadap source code.
Pada latihan kali ini, kita akan menggunakan Conda sebagai lingkungan yang terisolasi. Kami sangat menyarankan Anda untuk selalu membuat lingkungan baru pada setiap proyek. Hal ini untuk meminimalisasi masalah yang berhubungan dengan dependency pada library yang akan digunakan.
Biasanya ketika akan menginstal Python melalui Anaconda ataupun miniconda, Anda dapat menggunakan conda sebagai package manager dan environment management system dengan menggunakan langkah-langkah berikut.
- Membuka terminal atau PowerShell.
-
Jalankan perintah berikut untuk membuat environment baru dengan versi Python yang sudah disesuaikan.
- conda create --name
python\=3.12.7
- conda create --name
-
Aktifkan virtual environment dengan menjalankan perintah berikut.
- conda activate
- conda activate
-
Instal semua library yang dibutuhkan menggunakan requirements.txt ataupun menuliskan library yang dibutuhkan secara eksplisit seperti berikut ini.
- pip install mlflow==2.18.0
- Fork repositori MLflow ke akun GitHub yang akan Anda gunakan.
- Terakhir, Anda perlu menjalankan script code yang berisikan perintah untuk membangun sebuah model machine learning.
Langkah tersebut mungkin terlihat sederhana karena melewati beberapa tahapan saja. Namun, bagaimana jika Anda hanya perlu memperbarui model dan memastikan versi library yang digunakan harus sesuai? Nah, di sini MLproject memiliki satu sintaks ajaib yang dapat menjalankan seluruh proses di atas dengan menggunakan satu baris kode saja yaitu mlflow run “repository”. Perhatikan kode berikut.
- mlflow run https://github.com/
/mlflow-example.git -P alpha=0.5
Dengan menjalankan satu perintah di atas, Anda dapat melewati seluruh tahapan yang sebelumnya masih manual. Sehingga, hasil akhirnya akan membuatkan lingkungan baru dengan nama acak, tetapi memiliki versi dependencies yang sudah ditentukan pada file requirements.txt.
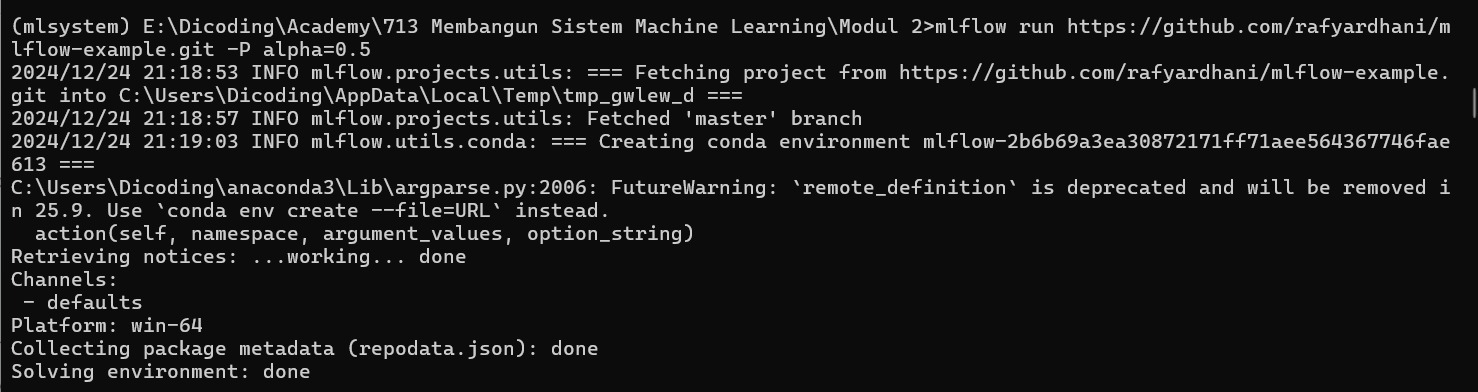
Jika semuanya berjalan dengan baik, kode di atas akan melanjutkan eksekusi source code yang sudah dibuat sehingga model machine learning dapat langsung dibangun beserta evaluasi performanya.
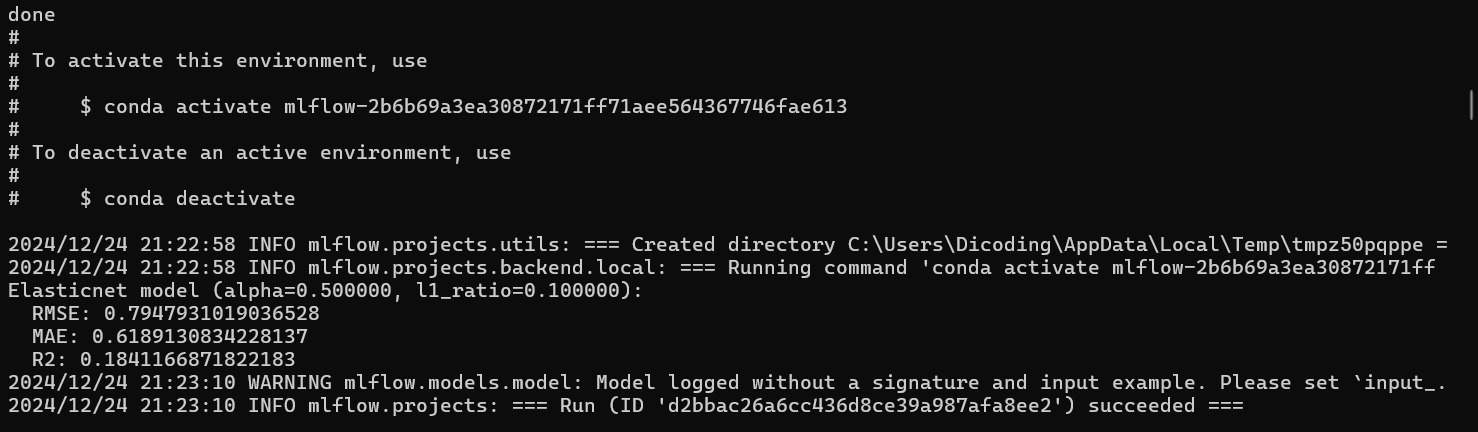
Lalu, bagaimana jika kita sudah memiliki environment yang sama atau ingin menjalankan kembali proyek tersebut? Kalem, MLflow dapat mengatasi permasalahan tersebut dengan baik.
Ketika ingin memperbarui model, Anda dapat menggunakan kode yang sama tanpa harus membangun environment dari nol lagi. MLflow akan mencari id yang sama lalu menjalankan perintah untuk membangun model saja.
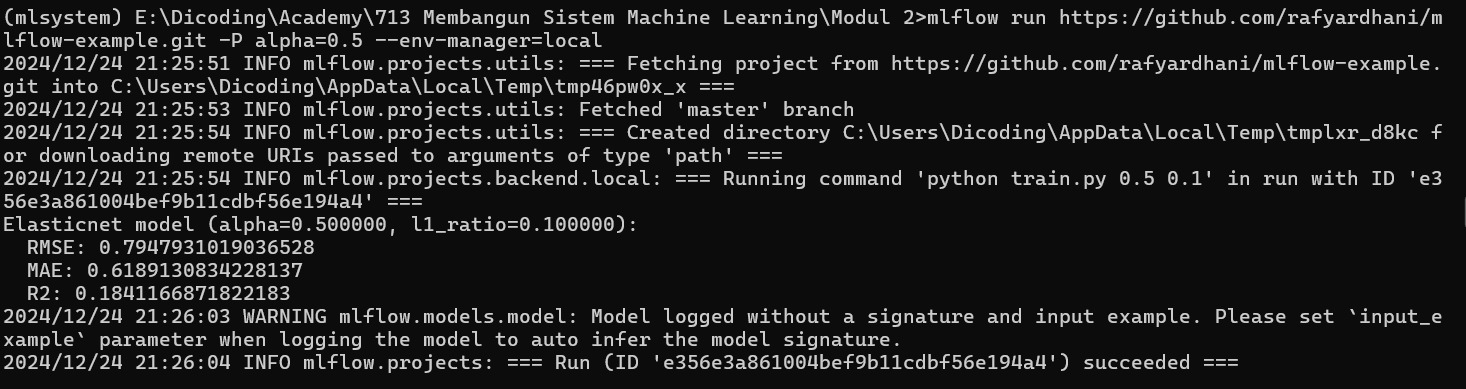
Seluruh parameter dan file yang dihasilkan oleh Tracking akan disimpan pada repositori yang Anda tentukan. By default, ketika Anda tidak mengatur **mlflow.set_tracking_uri(uri=”http://
Bagaimana, sangat sederhana, bukan? Sekarang Anda dapat mereplikasi proyek dan memperbarui model tanpa mengeluarkan upaya yang besar di mana pun dan kapan pun.
Pro Tips
Anda dapat menggunakan beberapa cara untuk menjalankan MLproject mulai dari HTTPS (seperti pada latihan), SSH, hingga GitHub CLI.
Kapan menggunakan pilihan di atas?
- HTTPS: ketika Anda hanya ingin mencoba dan tidak memiliki konfigurasi SSH.
- SSH: ketika sering berinteraksi dengan repository privat atau sudah terbiasa menggunakan SSH key.
- GitHub CLI: ketika Anda juga memanfaatkan fitur manajemen repository GitHub lainnya atau bekerja dalam alur CI/CD yang lebih kompleks.
Pemilihan metode bergantung pada preferensi dan kebutuhan Anda terhadap keamanan, kemudahan, dan fleksibilitas akses.
Nah, sampai di sini Anda sudah mengetahui dua fitur utama dari MLflow, tetapi masih berkutat pada teorinya saja. Kami yakin rasa penasaran Anda sangat bergejolak untuk terjun ke praktikum.
Tahan sejenak karena Anda akan mempelajari fitur lainnya terlebih dahulu lalu pada materi berikutnya baru kita akan berlatih menggunakan MLflow mulai dari tracking hingga membuat MLproject.
Pengenalan MLflow: Model dan Model Registry
Setelah mempelajari dua fitur umum yang digunakan, kini Anda telah berada di tahap kedua berkenalan dengan MLflow. Pada tahap ini kita akan mempelajari dua fitur lainnya yang dapat membantu pembangunan sistem machine learning yaitu MLflow Model dan MLflow Registry Model.
Agar tidak terlalu panjang, mari kita mulai dengan membahas fitur MLflow Model. Goo.
MLflow Model
Pada materi MLflow Projects, kita telah belajar bagaimana mengemas kode machine learning kita menjadi format yang terstandarisasi dan reproducible sehingga memungkinkan developer untuk menjalankan kembali eksperimen dengan mudah dan membagikannya dengan orang lain.
Namun, tujuan akhir dari banyak proyek machine learning adalah menerapkan model yang agar dapat digunakan untuk membuat prediksi oleh pengguna secara umum. Berbagai pertanyaan muncul, bagaimana kita mengelola berbagai versi model yang kita hasilkan? Bagaimana kita menerapkannya (deploy) ke dalam produksi? Di sinilah MLflow Models mengambil alih kendali setelah melewati proses pelatihan.
MLflow Models adalah salah satu komponen utama dari MLflow yang dirancang untuk menyimpan, mengelola, dan mendistribusikan model machine learning. MLflow Models memungkinkan pengguna untuk menyimpan model dalam format standar yang dapat digunakan ulang di berbagai platform dan mempermudah deployment model ke lingkungan produksi.
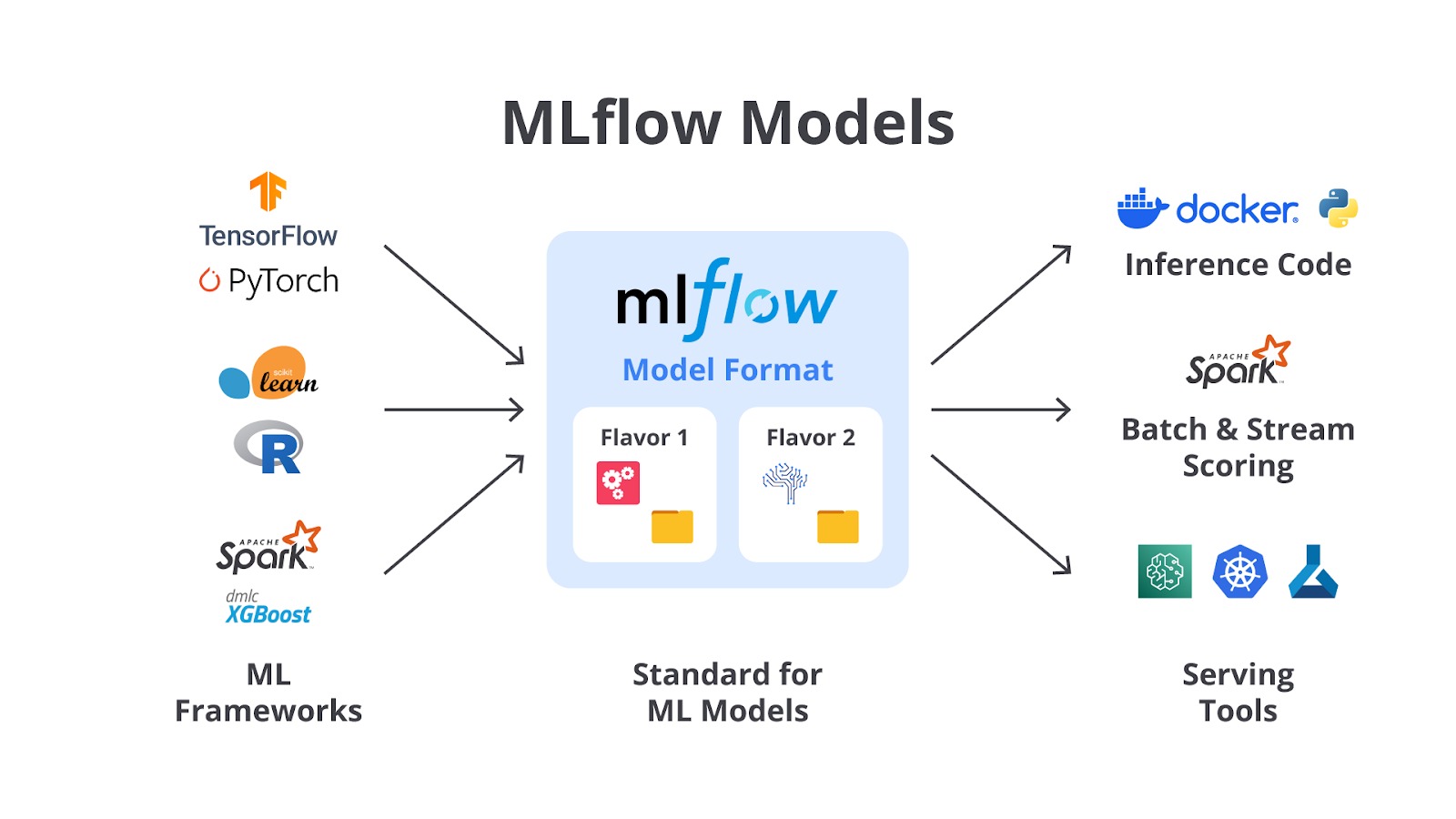
Dengan MLflow Models, Anda dapat mengelola siklus hidup model, mencatat metrik, menyimpan artefak, serta mendistribusikan model untuk deployment dalam berbagai bentuk, seperti REST API, layanan cloud, atau library lokal. By default, struktur direktori model yang dibuat oleh MLflow Tracking akan menghasilkan folder seperti berikut.
model/
├── MLmodel # Metadata model
├── conda.yaml # Lingkungan Conda untuk menjalankan model
├── model.pkl # File model (berbeda sesuai framework)
MLmodel: berisi metadata tentang model, termasuk format, input/output, dan dependencies.
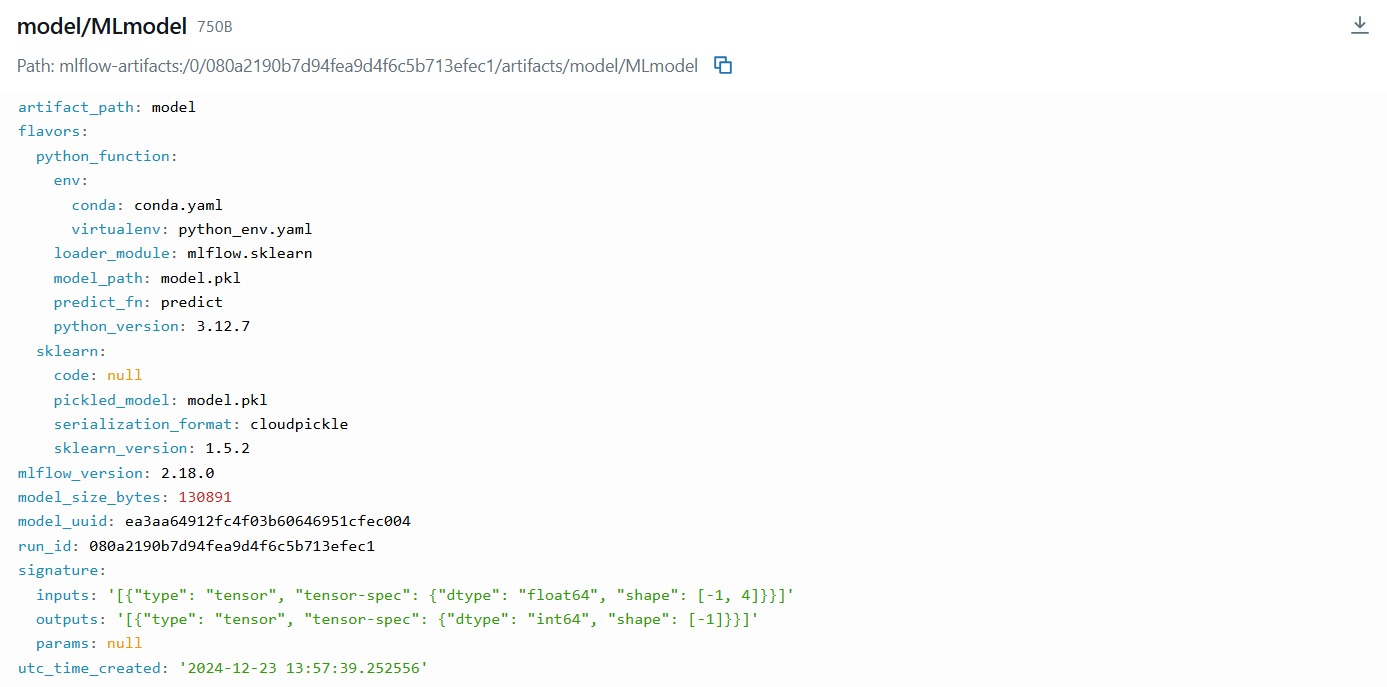
conda.yaml: mendefinisikan lingkungan Conda untuk menjalankan model.
model.pkl: file model yang disimpan dalam format spesifik framework.
Selanjutnya, MLflow Models mendukung deployment ke berbagai platform mulai dari local deployment, REST API, hingga cloud deployment.
Local Deployment: menjalankan model di lingkungan lokal.
REST API: menyediakan endpoint REST untuk prediksi.
Cloud Deployment: deploy model ke layanan cloud seperti AWS Sagemaker atau Azure ML.
Kabar baiknya, MLflow Tracking UI sudah menyediakan informasi mulai dari skema model, validasi model sebelum deployment hingga contoh kode untuk melakukan prediksi.
Dari kode di atas, kita bisa mengetahui berbagai informasi mengenai karakteristik model yang mencakup skema input dan output. Sebagai contoh, mari kita pelajari arti skema model yang ada pada gambar di atas.
| Nama | Tipe | Penjelasan |
|---|---|---|
| Input | Tensor (dtype: float64, shape: [-1,4]) | Tipe ini menggambarkan tensor dengan elemen bertipe float64 yang masing-masing dimensi tensornya sebesar empat dan dimensi pertama fleksibel (-1) untuk mengakomodasi jumlah sampel yang berubah-ubah, sering kali digunakan untuk input batch data dalam proses inference. |
| Output | Tensor (dtype: int64, shape: [-1]) | Output ini memiliki elemen bertipe integer 64-bit dan berbentuk vektor satu dimensi dengan panjang yang fleksibel (ditentukan saat runtime). Umumnya digunakan untuk menyimpan label target atau indeks dalam machine learning. |
Selain penjelasan skema model di atas, Anda juga dapat melakukan validasi dan test inference menggunakan kode yang disediakan oleh Tracking UI. Pada tahap ini, Tracking UI hanya menyediakan struktur nya saja sehingga Anda tetap harus menyesuaikan input data yang akan diprediksi.
Nerd Tips
Jika Anda menggunakan Windows sebagai sistem operasi, silakan atur Environment Variables untuk MLflow terlebih dahulu dengan mengikuti langkah-langkah berikut.
- Buka halaman Start dan cari “Edit the system environment variables”
- Selanjutnya pilih tombol “Environment Variables…”
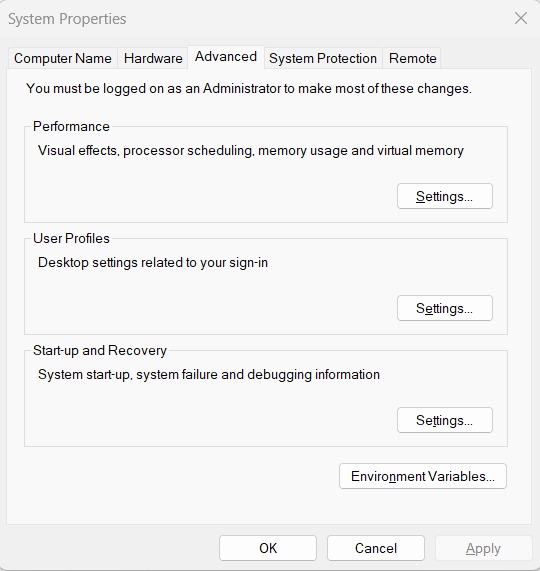
- Pada menu “System variables” silakan tekan tombol “New…”
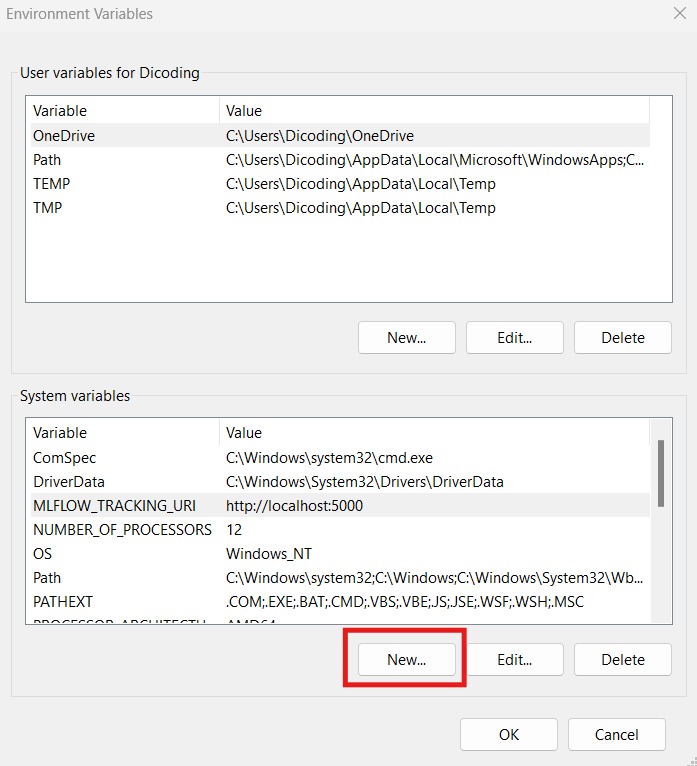
- Buat sebuah environment baru agar sistem operasi yang Anda gunakan dapat mengakses MLflow. Silakan atur Variable name dengan MLFLOW_TRACKING_URI dan sesuaikan Variable Value dengan port yang Anda gunakan, ya.
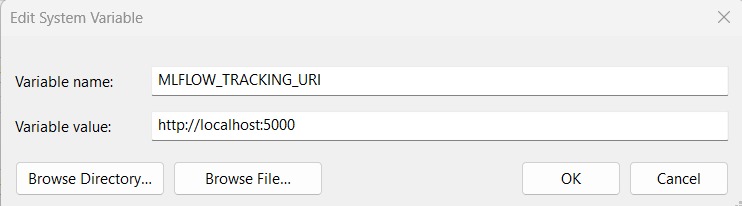
- Terakhir, Anda perlu menyimpan semua perubahan dan membuka ulang aplikasi yang sudah terlanjur berjalan seperti terminal, IDE, dan lain sebagainya.
Sebagai contoh dan pengisi rasa penasaran Anda, mari kita coba memvalidasi model sebelum melakukan deployment pada latihan berikutnya. Pada kasus ini, kita akan menggunakan model yang sederhana yaitu untuk memprediksi Iris.
Pada latihan ini, pastikan Anda menggunakan model Iris Classifier yang sudah dibuat sebelumnya. Jika, Anda kehilangan jejak silakan gunakan kode di sini untuk melatih model Iris dan menyimpannya di MLflow Server.
Jika semuanya sudah beres, mari kita mulai dengan mengimpor library yang akan digunakan. Silakan Anda buat berkas baru (disarankan) pada folder yang sama dengan latihan sebelumnya dan berikan nama file validasi.py (bisa disesuaikan).
- from mlflow.models import validate_serving_input
- from mlflow.models import convert_input_example_to_serving_input
Tugas pertama kita memang sangat sederhana yaitu sebagai importir kelas kakap. Namun, kita juga perlu tahu fungsi dari library yang digunakan. Oleh karena itu, mari kita bahas fungsi dari kedua library yang memiliki peran penting untuk melakukan validasi skema model.
- validate_serving_input: fungsi ini digunakan untuk memvalidasi bahwa input yang diberikan cocok dengan model yang disimpan dan dapat digunakan untuk prediksi.
- convert_input_example_to_serving_input: fungsi ini mengonversi contoh input (input_example) ke format yang sesuai untuk dilakukan prediksi pada model yang siap digunakan (serving).
Selanjutnya, Anda perlu mendefinisikan URI Iris model yang disimpan di MLflow pada lokal komputer agar dapat digunakan dan divalidasi. Dalam hal ini, model disimpan pada run ID 080a2190b7d94fea9d4f6c5b713efec1 (setiap run memiliki ID yang berbeda, silakan sesuaikan dengan run_id pada model Iris Anda).
- model_uri = ‘runs:/<run_id>/model’
Untuk memvalidasi format data agar sesuai dengan payload serving, Anda dapat menggunakan fungsi convert_input_example_to_serving_input(). Fungsi ini bertugas untuk mengonversi INPUT_EXAMPLE menjadi payload yang sesuai untuk prediksi melalui REST API atau pengujian lainnya.
- serving_payload = convert_input_example_to_serving_input(INPUT_EXAMPLE)
Dengan menggunakan kode di atas, Anda perlu mendefinisikan nilai dari INPUT_EXAMPLE yang sesuai dengan kebutuhan model. Setelah format input dianggap benar, fungsi tersebut akan mengonversi data agar sesuai dengan kebutuhan REST API.
| Format INPUT_EXAMPLE | Format Serving_Payload |
|---|---|
| 1. [ 2. [ 3. 6.6, 4. 3, 5. 4.4, 6. 1.4 7. ], 8. [ 9. 6.9, 10. 3.1, 11. 4.9, 12. 1.5 13. ], 14. [ 15. 6.2, 16. 3.4, 17. 5.4, 18. 2.3 19. ], 20. [ 21. 5.7, 22. 2.8, 23. 4.5, 24. 1.3 25. ], 26. [ 27. 5.5, 28. 2.6, 29. 4.4, 30. 1.2 31. ] 32. ] |
1. { 2. “inputs”: [ 3. [ 4. 6.6, 5. 3, 6. 4.4, 7. 1.4 8. ], 9. [ 10. 6.9, 11. 3.1, 12. 4.9, 13. 1.5 14. ], 15. [ 16. 6.2, 17. 3.4, 18. 5.4, 19. 2.3 20. ], 21. [ 22. 5.7, 23. 2.8, 24. 4.5, 25. 1.3 26. ], 27. [ 28. 5.5, 29. 2.6, 30. 4.4, 31. 1.2 32. ] 33. ] 34. } |
Pada hakikatnya, tahapan ini muncul karena model tidak memiliki INPUT_EXAMPLE sehingga Anda perlu membuat contoh input secara manual untuk divalidasi.
Lalu muncul sebuah pertanyaan, bagaimana jika Anda atau rekan kerja tidak mengetahui contoh nilai tersebut? Pilihannya cukup sederhana yaitu menanyakan nilainya ke developer atau menggunakan nilai acak dengan format yang sesuai dengan skema model.
Eitss, walaupun kedua pilihan di atas terlihat mudah, tetapi keduanya dibayang-bayangi oleh permasalahan yang cukup serius. Contohnya, ketika Anda selalu bertanya terkait contoh input kepada developer model pasti terdapat waktu kosong karena menunggu balasan. Di lain sisi, ketika Anda menggunakan nilai acak kemungkinan tidak merepresentasikan nilai asli sehingga akan menghasilkan output yang tidak benar.
Untuk mengatasi permasalahan di atas, sebenarnya Anda tinggal menambahkan log_model pada tahapan logging dengan tujuan membuat file input_example.json dan serving_input_example.json (akan kita pelajari nanti).
Tahapan terakhirnya, kita perlu menguji format payload agar sesuai dengan skema inference REST API menggunakan fungsi validate_serving_input().
- print(validate_serving_input(model_uri, serving_payload
Fungsi di atas bertugas untuk menjalankan beberapa testing yang dapat memastikan model dapat bekerja dengan baik di lingkungan produksi, salah satunya memastikan input sesuai dengan skema model menggunakan kode berikut.
- # Contoh kode validasi, tidak perlu dijalankan.
- try:
- pyfunc_model = mlflow.pyfunc.load_model(model_uri, dst_path=output_dir)
- parsed_input = _parse_json_data(
- serving_input,
- pyfunc_model.metadata,
- pyfunc_model.metadata.get_input_schema(),
- )
- return pyfunc_model.predict(parsed_input.data, params=parsed_input.params)
- finally:
- if output_dir and os.path.exists(output_dir):
- shutil.rmtree(output_dir)
Nah, sampai di sini sebenarnya Anda sudah dapat melakukan prediksi melalui lokal environment MLflow dengan sangat mudah karena contoh kodenya telah disediakan pada kolom artefak.
- import mlflow
-
import pandas as pd
-
logged_model = ‘runs:/
/model' - # Load model as a PyFuncModel.
-
loaded_model = mlflow.pyfunc.load_model(logged_model)
- # Predict on a Pandas DataFrame.
-
predict = loaded_model.predict(pd.DataFrame([[6.7, 3.1, 5.6, 2.4]]))
- print(predict)

Bagaimana menurut Anda? Penggunaan MLflow Model ini sangat membantu ‘kan? Anda dapat melakukan serving model pada berbagai platform yang sesuai dengan skala proyek yang sedang dibangun. Kelak, Anda juga akan mempelajari cara melakukan serving model MLflow melalui REST API agar dapat digunakan pada lingkungan yang lebih luas. So, jangan berhenti sampai di sini, ya.
Sampai di sini, kita telah mempelajari cara MLflow Models membantu mengemas model machine learning dalam format standar, sehingga mudah di-deploy dan digunakan. Namun, dalam proyek machine learning yang kompleks, kita tidak hanya memiliki satu model. Kita memiliki berbagai versi model yang dilatih dengan data dan konfigurasi yang berbeda.
Pertanyaan pun muncul, bagaimana kita mengelola siklus hidup berbagai model ini? Bagaimana kita memantau versi model mana yang terbaik dan siap untuk di-deploy ke produksi? Di sinilah Anda memerlukan sebuah fitur bernama MLflow Model Registry.
Namun, MLflow Registry Model itu apa, ya?
Tahan sebentar rasa penasaran Anda. Mari kita berpindah ke materi berikutnya yaitu MLflow Model Registry. Kuyy~
MLflow Model Registry
MLflow Model Registry adalah komponen dari MLflow yang dirancang untuk mengelola siklus hidup model machine learning secara terpusat. Model Registry memungkinkan pengguna untuk melacak versi model, memberikan anotasi, mengelola tahapan (staging, production, archived), dan mencatat metadata terkait model yang telah dicatat di MLflow Tracking.
Bayangkan Anda memiliki berbagai macam eksperimen model dengan karakteristik yang berbeda-beda seperti berikut.
Lalu, Anda perlu memilih satu buah model yang nantinya akan di-_serving_ pada tahap production. Tentunya, tidak mungkin Anda menggunakan run id sebagai “kode” API yang akan digunakan oleh pengguna lainnya. Di sisi lain, hal tersebut juga tidak efisien dan bukan best practice untuk menggunakan model pada tahap production.
Dengan kondisi tersebut, MLflow menyediakan sebuah UI yang berfungsi untuk menandai model terbaik dan memindahkannya kepada stage yang sesuai.
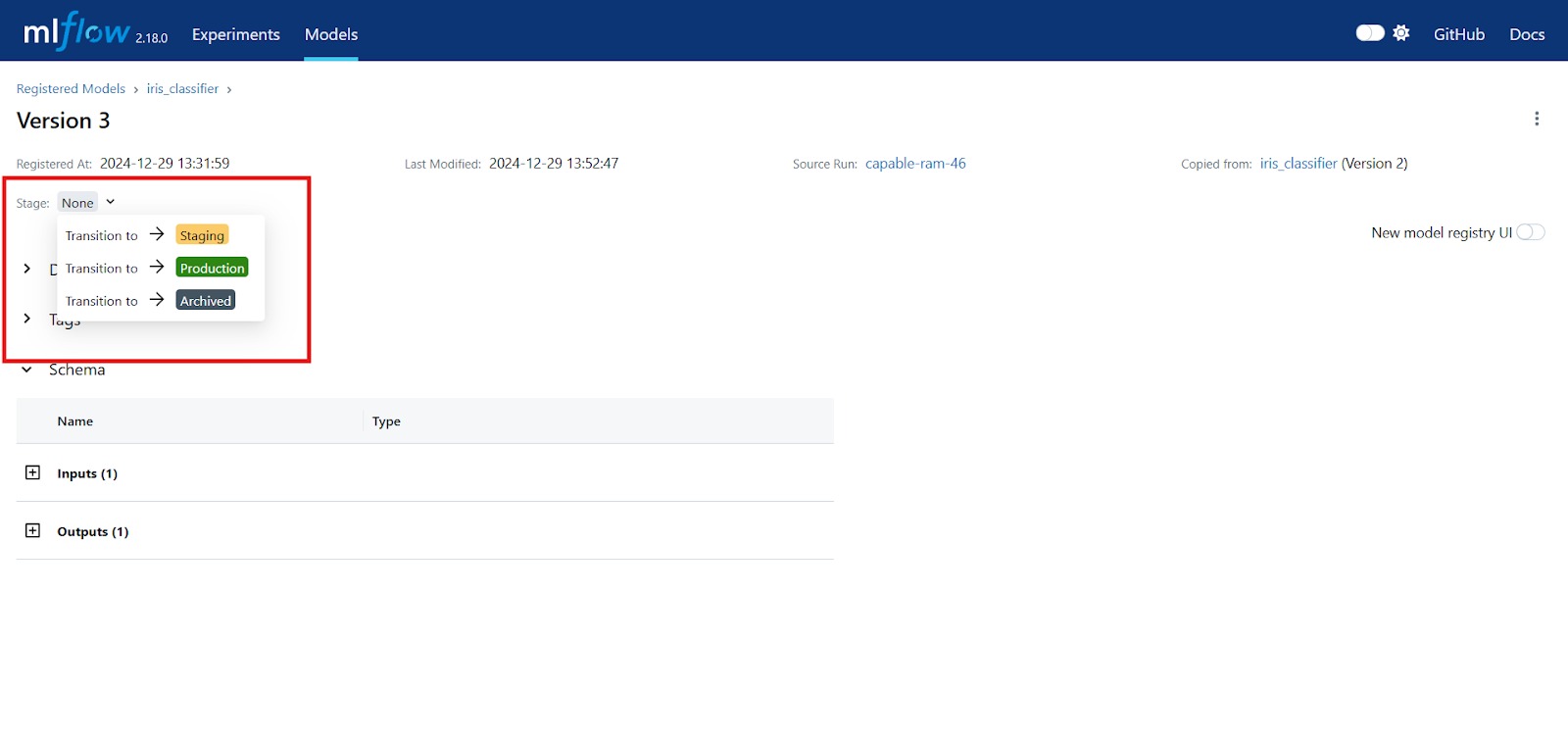
Dengan mengubah tahapan stage menjadi Staging atau Production Anda tidak memerlukan lagi run id sebagai penanda model yang akan digunakan.
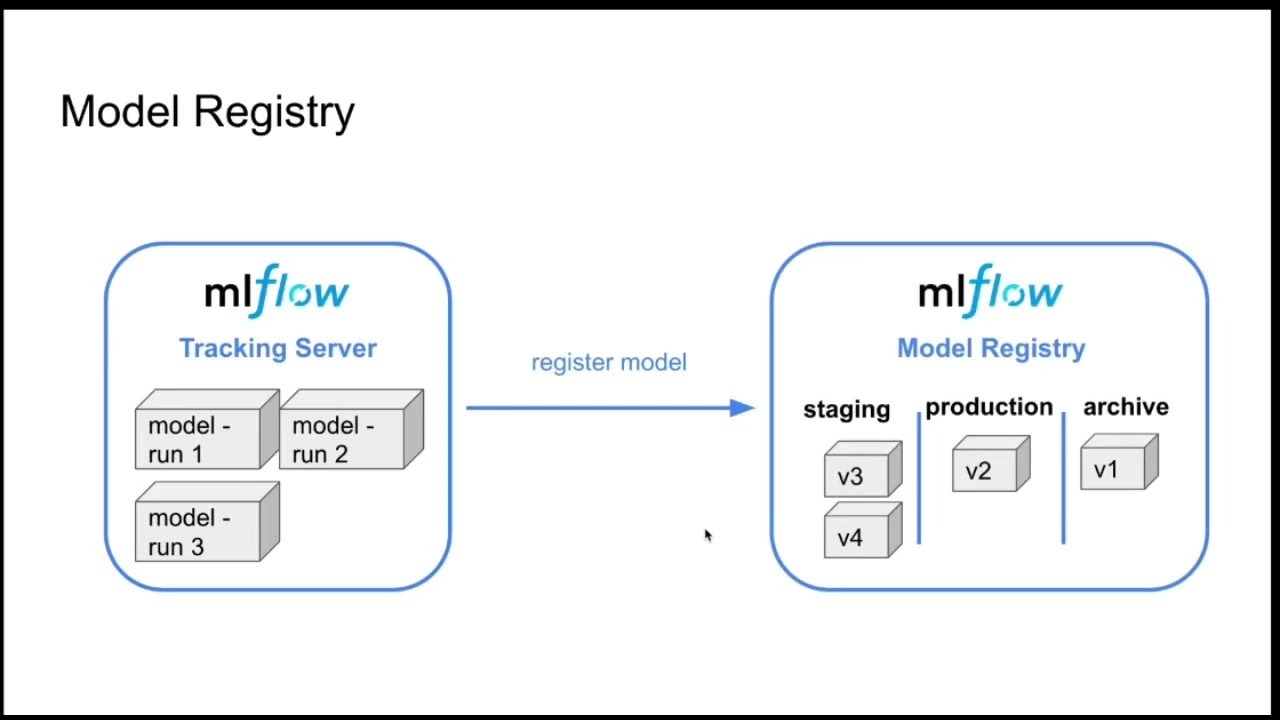
Wait, apa bedanya Staging dan Production? Pertanyaan yang bagus. Mari kita jelaskan keduanya sebelum menerapkan tahapan tersebut menggunakan MLflow.
Staging
Tahapan Staging adalah tahap pengujian atau validasi model sebelum model dipindahkan ke produksi. Model yang ada di tahap ini biasanya telah melewati pelatihan dan evaluasi dasar, tetapi masih memerlukan pengujian tambahan di lingkungan yang lebih realistis.
Tujuan utama dari tahap staging yaitu untuk melakukan pengujian dan validasi. Model akan diuji di lingkungan staging (mirip dengan produksi tetapi tidak digunakan oleh pengguna akhir) sehingga model dapat dibandingkan dengan model lain untuk menentukan performa terbaik. Biasanya tahapan ini mencakup validasi terhadap dataset terbaru, pengujian integrasi dengan aplikasi atau pipeline produksi hingga penyesuaian parameter jika diperlukan.
Anda dapat mengubah status model ke tahap staging ketika model baru selesai dilatih dan dievaluasi, tetapi belum diverifikasi untuk deployment atau ketika model membutuhkan pengujian lebih lanjut, seperti uji kompatibilitas dengan pipeline atau aplikasi.
Production
Tahapan Production adalah tahap di mana model siap digunakan oleh aplikasi atau layanan yang digunakan oleh pengguna akhir. Model yang ada di tahap ini adalah model terbaik yang telah melewati pengujian dan validasi secara lengkap.
Biasanya developer akan mengubah status model menjadi production ketika model telah diverifikasi sepenuhnya di tahap staging atau ketika model siap digunakan untuk memproses data nyata dan memberikan hasil yang digunakan langsung oleh pengguna akhir.
Archived
Pada tahapan ini, model sudah dianggap usang dan tidak lagi relevan dengan keadaan saat ini. Sehingga model disimpan sebagai artefak dengan tujuan sebagai bentuk dokumentasi semata.
Setelah Anda mengetahui perbedaan staging, production dan archived, tentunya akan sia-sia jika kita tidak menerapkannya pada proyek yang sedang dibangun. Dengan menggunakan MLflow Tracking UI, Anda sudah diberikan interface untuk mengubah tahapan model dengan sangat mudah dan fleksibel.
For your information, pada Mlflow versi < 2.9.0 Anda dapat mengubah stage model yang sudah didaftarkan pada MLflow Tracking UI dengan mengubah stage model seperti berikut.
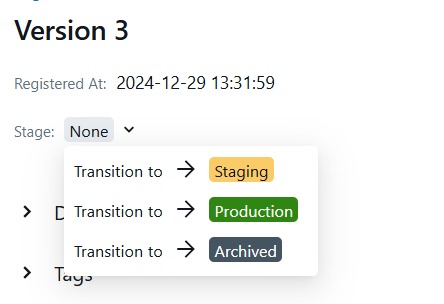
Sehingga, pada tahap ini, Anda dapat melakukan prediksi tanpa menggunakan run id melainkan menggunakan tahapan stage yang dipilih. Mari kita coba dengan tahapan staging terlebih dahulu.
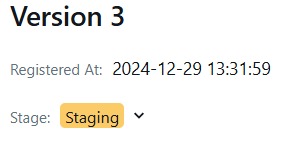
Pada tahap ini, Anda perlu membuat sebuah kode yang dapat melakukan inference layaknya pada stage development. Kurang lebih pada tahap staging, Anda perlu membuat kode seperti berikut.
- import mlflow.pyfunc
-
import pandas as pd
- # URI model dalam Model Registry
-
model_uri = “models:/iris_classifier/Staging” # MLflow Old Version < 2.9.0
- # Load model
-
model = mlflow.pyfunc.load_model(model_uri)
- # Gunakan model untuk prediksi
- input_data = pd.DataFrame([[6.7, 3.1, 5.6, 2.4]])
- predictions = model.predict(input_data)
- print(predictions)
Mungkin tebersit di benak Anda sebuah pertanyaan “Loh, lalu apa bedanya dengan menggunakan run id? Bukannya keduanya bisa melakukan inference seperti di atas, ya?” Memang benar, tetapi ada beberapa hal yang membuat keduanya serupa tapi tak sama.
Dengan menggunakan Model Registry, Anda akan mendapatkan banyak keuntungan dibandingkan langsung memanfaatkan Run ID seperti berikut.
- Manajemen versi model: Model Registry menyediakan sistem versi yang lebih terstruktur. Seperti yang Anda ketahui, Run ID merupakan kode unik yang dihasilkan ketika membangun model machine learning. Hal ini menyulitkan jika Anda ingin melacak versi model, apalagi jika ada beberapa model yang berbeda untuk kasus penggunaan yang sama.
- Pengelolaan siklus hidup: stages seperti Staging dan Production mempermudah transisi model.
- Kolaborasi tim: informasi tambahan seperti deskripsi dan tag membantu tim memahami model dengan lebih baik. Penggunaan Run ID akan menyulitkan tim untuk berkolaborasi karena tidak ada anotasi atau metadata yang menjelaskan model tersebut.
- Skalabilitas: mempermudah pengelolaan model dalam proyek besar dengan banyak eksperimen. Ketika ada banyak model dan eksperimen, pengelolaan model menggunakan Run ID menjadi tidak praktis karena Anda harus mencari dan mengubah Run ID satu per satu.
- Reproduktibilitas: semua versi dan metadata model terdokumentasi dengan baik.
- Integrasi CI/CD: model Registry memungkinkan deployment yang lebih efisien dan otomatis.
Oleh karena itu, untuk proyek machine learning berskala besar atau yang melibatkan banyak tim, MLflow Model Registry adalah pilihan yang jauh lebih efisien dibandingkan mengandalkan Run ID saja.
Masalah terbesar ketika Anda mengandalkan Run ID sebagai API akan muncul ketika memperbarui model secara berkala. Penggunaan Run ID mengharuskan anggota tim untuk mengetahui Run ID yang spesifik untuk setiap eksperimen sehingga Anda perlu mengubah Run ID setiap kali mengubah model.
Dengan menggunakan Model Registry, Anda tidak lagi berhadapan dengan masalah tersebut karena setiap kali memperbarui model Anda hanya perlu mendaftarkan model dan voilaa API yang digunakan sudah otomatis menggunakan model versi terbaru.
Sayangnya, fitur stage ini sudah deprecated khususnya pada MLflow versi > 2.9.0 karena terdapat beberapa batasan yang cukup mengganggu. Namun, Anda tak perlu risau karena MLflow masih menyediakan fitur tersebut hingga versi 2.18.0 dengan toggle on/off. Di lain sisi, MLflow juga menyediakan fitur pengganti yang tak kalah cemerlang untuk menggantikan stage yaitu aliases.
Alasan Tracking UI mengubah fitur stage menjadi aliases yaitu sebagai upaya MLflow untuk meningkatkan fleksibilitas dan kegunaan sistem manajemen modelnya. Jika Anda perhatikan, fitur stage memiliki tahapan model seperti None, Staging, Production, dan Archived sehingga membangun sistem hierarki yang kaku.
Dengan kondisi tersebut, model hanya dapat berada di satu tahap tertentu pada suatu waktu sehingga tidak ada fleksibilitas untuk menciptakan tahapan tambahan sesuai dengan kebutuhan spesifik organisasi.
Pertanyaannya, bagaimana jika tim Anda membutuhkan tahapan lain, seperti testing, review, atau beta? Tentu ini menjadi sebuah permasalahan yang tidak ada solusinya. Oleh karena itu, MLflow membuat sistem aliases yang memberikan fleksibilitas lebih karena tidak dibatasi oleh hierarki tertentu. Fitur ini memungkinkan developer menyesuaikan manajemen siklus hidup model berdasarkan alur kerja mereka.
Jika menggunakan fitur “New model registry UI”, Anda dapat menggunakan fitur aliases ini dan meninggalkan fitur stage pada materi sebelumnya.
Lalu, untuk mengubah status model Anda hanya perlu memberikan Aliases pada model yang akan digunakan.
Selanjutnya, Anda diminta untuk mengisi nama alias yang akan digunakan, contohnya mari kita gunakan testingv1 pada model yang ingin digunakan.
Dengan melakukan tahapan di atas, kini Anda sudah dapat melakukan inference berdasarkan nama alias yang sudah di atur. Kelebihannya, Anda juga dapat memberikan nama alias terhadap beberapa model lainnya yang sudah didaftarkan sehingga dapat membandingkan performa model secara langsung.
- import mlflow.pyfunc
-
import pandas as pd
- # URI model dalam Model Registry
- model_uri_testing = “models:/iris_classifier@testingv1” # Update Version
-
model_uri_evaluasi = “models:/iris_classifier@evaluasi” # Update Version
- # Load model
- model_test = mlflow.pyfunc.load_model(model_uri_testing)
-
model_evaluasi = mlflow.pyfunc.load_model(model_uri_evaluasi)
- # Gunakan model untuk prediksi
- input_data = pd.DataFrame([[6.7, 3.1, 5.6, 2.4]])
- predictions1 = model_test.predict(input_data)
- print(“Hasil prediksi testing: “,predictions1)
- predictions2 = model_evaluasi.predict(input_data)
- print(“Hasil prediksi evaluasi: “,predictions2)
Dengan fitur terbaru ini, Anda dapat mengubah beberapa model sekaligus untuk tujuan tertentu. Terlihat sederhana ‘kan? Namun, fitur ini sangat membantu developer untuk membangun dan menguji beberapa model dalam satu waktu yang sama. Sehingga, kita memiliki fleksibilitas untuk mengubah status model kapanpun dengan lebih mudah.
Setelah memahami bagaimana MLflow Model Registry membantu kita dalam mengelola model, kini saatnya kita beralih ke aspek yang lebih luas mencakup pengelolaan alur kerja machine learning secara keseluruhan. Untuk itu, pada materi berikutnya kita akan mempelajari MLflow Pipelines (Experimental) beserta keypoint dari tools MLflow.
Sedikit spoiler, MLflow Pipelines menawarkan framework yang dapat membangun dan mengotomatiskan alur kerja machine learning, dari pra-pemrosesan data hingga deployment. Menarik ‘kan? Oleh karena itu, mari kita eksplorasi lebih dalam tentang fitur dan manfaat yang ditawarkan oleh MLflow Pipelines.
Pengenalan MLflow: Pipelines dan Keypoints
Akhirnya, kita sampai di akhir materi pengenalan MLflow. Setelah berkelana kesana-kemari kita akan berkenalan dengan salah satu tools yang saat ini masih dikembangkan yaitu MLflow Pipelines. Selain itu, Anda juga akan mempelajari keypoint atau summary dari materi pengenalan MLflow.
Harapannya, materi ini dapat membantu Anda untuk mengembangkan sistem machine learning dengan signifikan dikemudian hari. Sampai di titik ini mungkin Anda sudah tidak sabar untuk menyelesaikan materi ini, tanpa basa-basi lagi mari kita berangkat!
MLflow Pipelines (Experimental)
MLflow Pipelines merupakan fitur eksperimental dari MLflow yang dirancang untuk menyediakan kerangka kerja modular, terstruktur, dan terotomatisasi untuk pengembangan machine learning. Fitur ini membantu kita untuk membangun pipeline pengembangan dan deployment model dengan lebih mudah dan efisien, sekaligus memastikan konsistensi alur kerja. Sayangnya, sesuai dengan namanya fitur ini masih berupa eksperimen yang berarti kita tidak dapat menggunakan fitur ini selain menggunakan MLflow versi 1.30.1 (setidaknya sampai 29 Desember 2024).
Pipelines ini dapat mengotomatiskan seluruh proses pembangunan model dengan standar yang sudah ditentukan oleh MLflow. Sehingga nantinya, developer hanya perlu mengubah sumber data sesuai dengan kebutuhan lalu pipelines akan menjalankan semua tahapannya. Bagaimana ini bisa terjadi? Sederhananya, Anda perlu membuat sebuah template mencakup seluruh prosesnya sehingga nantinya proyek yang dibangun terdiri dari beberapa file berikut.
- ├── pipeline.yaml
- ├── requirements.txt
- ├── steps
- │ ├── ingest.py
- │ ├── split.py
- │ ├── transform.py
- │ ├── train.py
- │ ├── custom_metrics.py
- ├── profiles
- │ ├── local.yaml
- │ ├── databricks.yaml
- ├── tests
- │ ├── ingest_test.py
- │ ├── …
- │ ├── train_test.py
- │ ├── …
Seperti yang dapat Anda lihat pada struktur di atas, MLflow Pipelines terdiri dari beberapa komponen utama yang dirancang untuk mempermudah pengembangan, pengujian, dan pengelolaan pipeline machine learning.
Komponen pertama adalah pipeline.yaml, file konfigurasi utama yang mendefinisikan atribut dan perilaku setiap tahapan pipeline secara deklaratif. File ini mencakup informasi seperti dataset input untuk pelatihan model dan kriteria performa yang harus dipenuhi sebelum model dipromosikan ke produksi.
Selanjutnya, requirements.txt adalah file yang mencantumkan semua dependensi Python yang diperlukan untuk menjalankan pipeline fungsinya untuk memastikan lingkungan eksekusi memiliki paket yang sama dengan tahap pengembangan.
Komponen berikutnya adalah direktori steps yang berisi setiap tahapan yang dilakukan pada satu pipeline. Sebagai contoh, dalam template MLflow Pipelines Regression, file seperti steps/train.py digunakan untuk menentukan jenis model dan parameter pelatihan, sementara steps/custom_metrics.py mendefinisikan metriks untuk mengevaluasi model.
Lalu, untuk mendukung kustomisasi konfigurasi di berbagai lingkungan, terdapat direktori profiles yang menyimpan file profil seperti profiles/local.yaml untuk pengembangan lokal dan profiles/databricks.yaml untuk pengembangan di platform Databricks. Profil ini memungkinkan pipeline menggunakan konfigurasi yang sesuai dengan lingkungan tertentu, misalnya dataset lokal atau penyimpanan MLflow lokal.
Terakhir, direktori tests menyediakan pengujian otomatis untuk memastikan setiap langkah dalam pipeline berfungsi sebagaimana mestinya. Sebagai contoh, template MLflow Pipelines Regression mencakup pengujian untuk melakukan transformasi di steps/transform.py dan melatih model pada steps/train.py. Dengan struktur ini, MLflow Pipelines memberikan kerangka kerja yang terorganisasi untuk membangun, menguji, dan menjalankan pipeline machine learning secara efisien di berbagai lingkungan. Untuk informasi lebih lengkapnya, silakan cek secara berkala pada halaman resmi MLflow 1.30.0 pada tautan di sini ya.
Keypoints Penerapan MLflow
Ibarat sebuah toolkit canggih, MLflow menyediakan berbagai fitur powerful seperti Tracking, Projects, Models, Model Registry, dan Pipelines (Experimental) yang masing-masing memiliki fungsi spesifik. Kita telah mempelajari fungsi-fungsi tersebut secara detail. Namun, bagaimana toolkit ini benar-benar membantu kita dalam pekerjaan kita? Apa manfaat nyata yang dapat kita rasakan dengan menggunakan toolkit MLflow ini dalam proyek machine learning kita? Mari kita beralih dari pemahaman fitur ke pemahaman manfaat dan melihat penerapan MLflow dapat mentransformasi cara kita bekerja.
Seperti yang sudah kita pelajari pada kelas sebelumnya, pengelolaan proyek machine learning sering kali menjadi tantangan besar ketika dilakukan secara manual tanpa tools seperti MLflow. Dalam skenario tanpa MLflow, pencatatan eksperimen biasanya dilakukan secara manual menggunakan spreadsheet atau file teks di mana parameter, metrik, dan artefak disimpan secara terpisah sehingga kerap kali membuat developer malas untuk melakukannya. Namun, MLflow datang dengan secercah harapan untuk menyelesaikan permasalahan tersebut.

Pendekatan ini tidak hanya rawan kesalahan, tetapi juga menyulitkan tim untuk membandingkan eksperimen atau melacak hasil secara konsisten. Selain itu, reproduksi model menjadi sulit karena tidak ada sistem bawaan untuk mencatat dependensi library atau versi environment yang digunakan sehingga eksperimen tidak dapat dijalankan ulang dengan hasil yang sama di berbagai lingkungan.
Berbeda dengan pendekatan manual, MLflow menyediakan sistem terintegrasi melalui MLflow Tracking untuk mencatat semua parameter, metrik, dan artefak secara otomatis. Dengan antarmuka MLflow UI, pengguna dapat dengan mudah membandingkan hasil eksperimen dan menentukan model terbaik untuk digunakan.
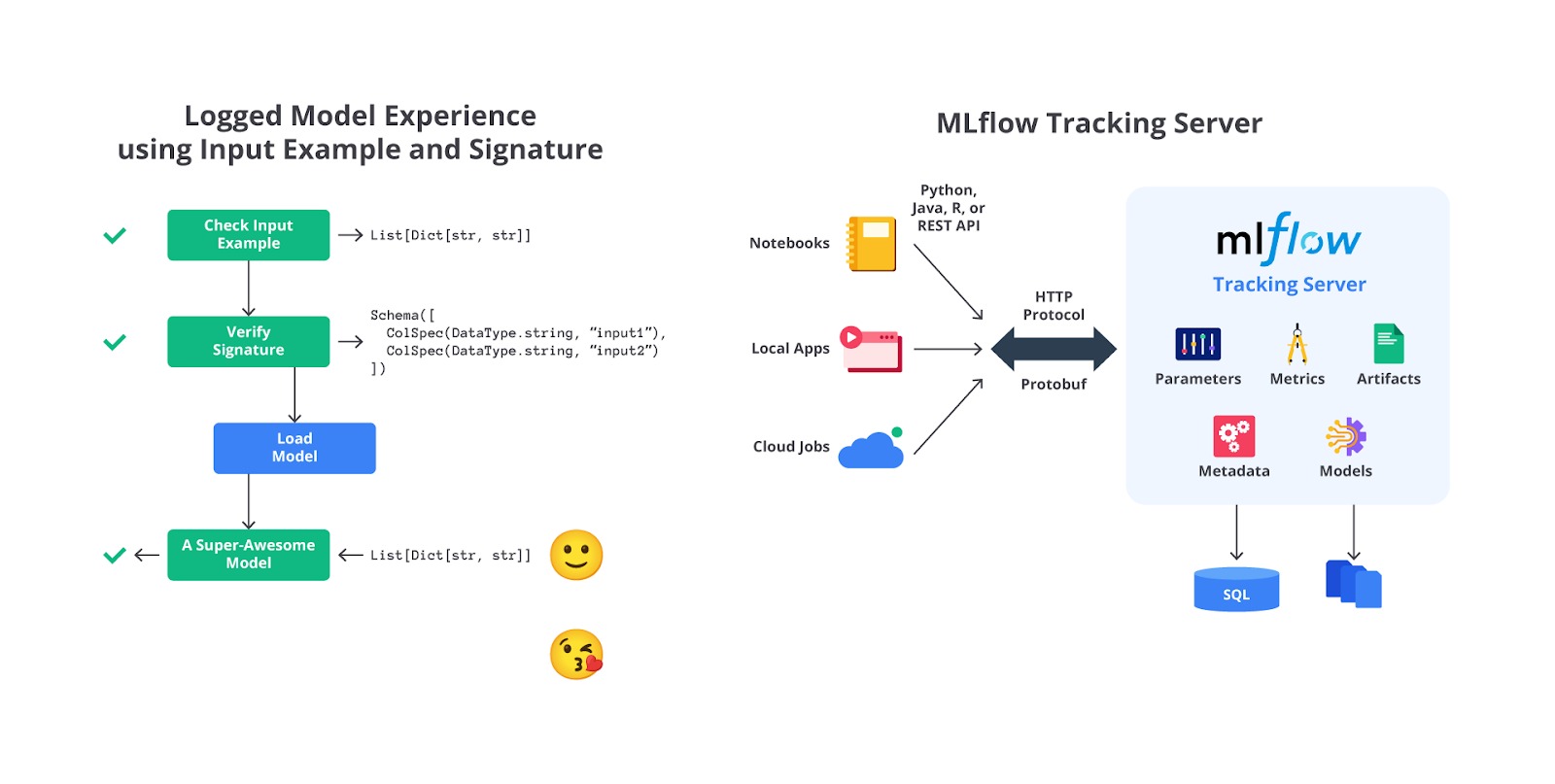
Di lain sisi, fitur MLflow Projects dapat membantu memastikan proyek dapat dikemas dalam format standar sehingga eksperimen dapat direproduksi dengan lingkungan yang sama, baik itu menggunakan Conda, Docker, atau lingkungan lain. Hal ini mengurangi risiko inkonsistensi hasil yang sering terjadi dalam pengelolaan manual.
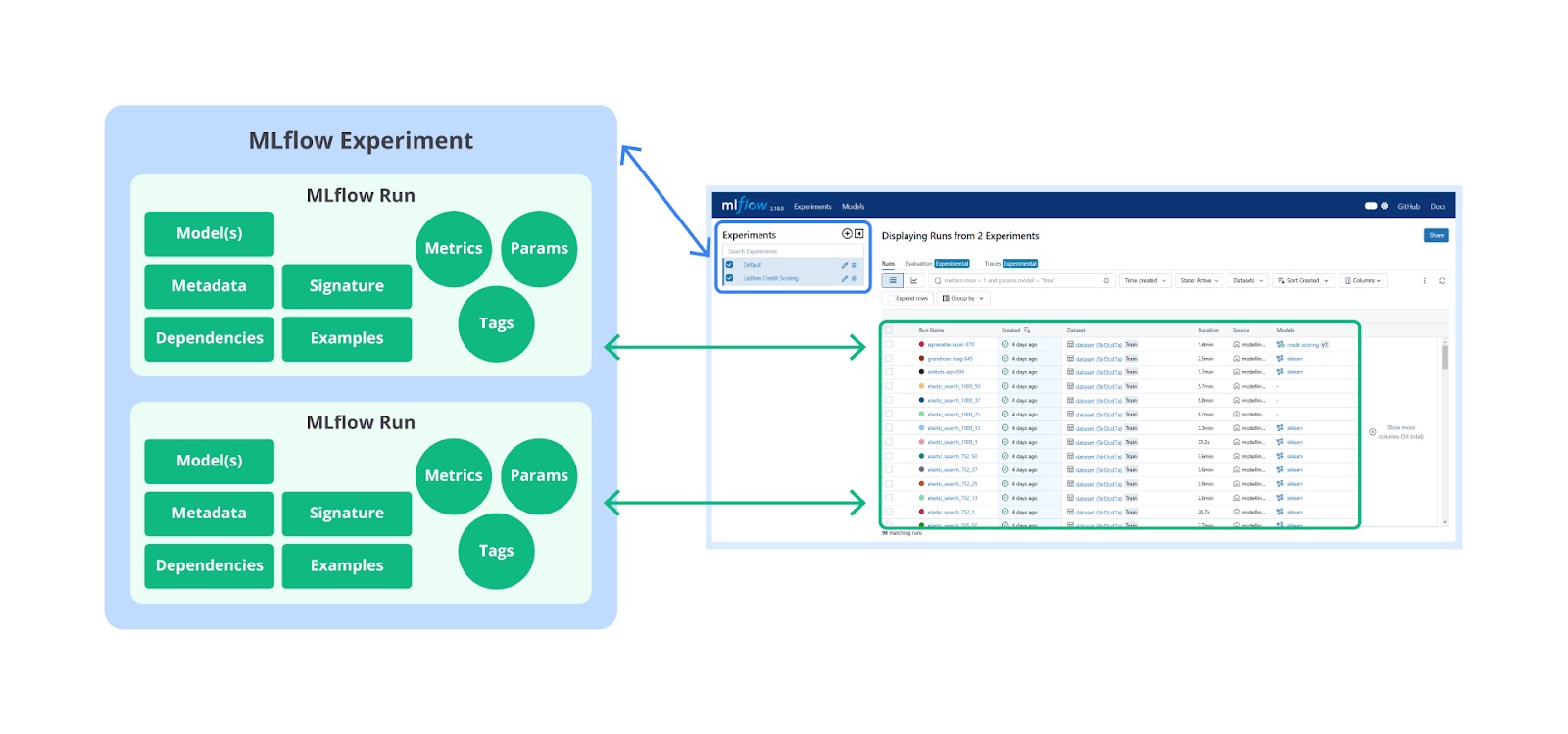
Masalah lainnya muncul ketika kita berbicara tentang pengelolaan model, dengan pendekatan manual biasanya mengandalkan penamaan file seperti model_v1.pkl atau model_final.pkl yang rentan terhadap kehilangan data dan sulit untuk dilacak. Dengan hadirnya MLflow masalah ini dapat diatasi dengan Model Registry sehingga manajemen versi model lebih terstruktur dan perubahan setiap versi dapat dicatat dengan baik.
Model juga dapat diberi status seperti Staging, Production dan tag lainnya sehingga mempermudah transisi model dari satu tahap ke tahap lainnya. Dengan format standar yang disediakan MLflow, model dapat langsung di-_deploy_ sebagai REST API atau layanan cloud tanpa harus menulis ulang kode deployment.
Kolaborasi tim juga menjadi lebih efisien dengan MLflow. Tanpa alat seperti MLflow penulisan parameter, metrik, dan informasi eksperimen sering kali tersebar di berbagai dokumen yang sulit diakses oleh anggota tim lain atau bahkan tidak ada sama sekali.
MLflow menyimpan semua informasi ini dalam satu platform terpusat yang dapat diakses melalui interface lengkap dengan deskripsi dan anotasi untuk memberikan konteks tambahan pada eksperimen atau model. Hal ini tidak hanya meningkatkan efisiensi kerja tim, tetapi juga memastikan transparansi dalam setiap langkah pengembangan.
Selain itu, MLflow juga memungkinkan integrasi dengan pipeline otomatis melalui CI/CD. Model yang telah dicatat di registry dapat langsung di-_deploy_ ke lingkungan produksi tanpa kesalahan manual.
Overall, kehadiran MLflow dapat mengatasi berbagai tantangan dalam pengelolaan proyek machine learning, dari pencatatan eksperimen, reproduksi hasil, hingga deployment model. Dengan MLflow, alur kerja menjadi lebih transparan, efisien, dan siap untuk produksi. Tanpa MLflow, pengelolaan proyek sering kali tidak terstruktur, sulit direproduksi, dan kurang kolaboratif sehingga menghambat pengembangan dan implementasi model di lingkungan nyata.
Sampai di sini, kita sudah mempelajari berbagai macam fitur MLflow yang sangat bermanfaat. Namun, pada modul ini, kita tidak hanya berbicara mengenai MLflow, masih ingatkan materi pertama yang ada pada modul ini? Yup, version control system. Kedua alat tersebut merupakan kepingan penting yang dapat kita gunakan untuk membangun model machine learning yang andal.
Sederhananya dengan menggabungkan fitur MLflow dan version control seperti GitHub, kita dapat mencapai tingkat reproducibility dan kolaborasi yang jauh lebih seamless. Penasaran kan bagaimana keduanya berkolaborasi? Tenang, pada materi berikutnya kita akan membahas version control dengan MLflow secara detail.
Version Control dengan MLflow
Sejauh ini, kita telah mengenal dua kepingan puzzle penting dalam alur kerja machine learning modern, yaitu GitHub (platform untuk berkolaborasi dan mengelola kode dengan version control) dan MLflow (toolkit untuk mengelola eksperimen, model, dan alur kerja machine learning).
Namun, puzzle ini belum lengkap. Kita masih membutuhkan kepingan lain untuk menyatukan keduanya dan menciptakan alur kerja yang lebih otomatis dan reproducible. Kepingan puzzle tersebut adalah integrasi version control yang lebih erat dengan MLflow. Di sinilah continuous integration yang sudah kita pelajari pada modul sebelumnya berperan. Tanpa berlama-lama lagi mari kita lihat bagaimana cara menyatukan GitHub, MLflow, dan GitHub Actions dapat melengkapi puzzle alur kerja kita, menghadirkan otomatisasi dan efisiensi yang lebih tinggi.
Eh, kok tiba-tiba ada GitHub Actions? Apa itu GitHub Actions?
Tenang, mungkin beberapa dari kalian masih asing dengan GitHub Actions karena pada materi sebelumnya kita hanya membahas fitur umum yang disediakan oleh GitHub. Don’t worry, karena kita akan membahas GitHub Actions terlebih dahulu agar Anda semakin mahir dalam melakukan version control khususnya pada proyek pembangunan machine learning.
Tentu sampai pada tahap ini Anda perlu memastikan sudah membaca materi GitHub dengan jelas. Namun, jika Anda masih ragu silakan baca kembali materi sebelumnya ya. Tenang saja, kita dengan senang hati akan selalu menunggu proses belajar Anda dari awal sampai akhir. Jika sudah, mari kita berangkat ke materi berikutnya mengenai GitHub Actions.
GitHub Actions adalah salah satu fitur Continuous Integration (CI) dan Continuous Delivery (CD) bawaan GitHub yang memungkinkan Anda mengotomatiskan alur kerja pengembangan perangkat lunak langsung dari repositori GitHub. Dengan GitHub Actions, Anda dapat membuat skrip untuk membangun, menguji, dan menerapkan kode, serta mengintegrasikannya dengan berbagai layanan eksternal.

GitHub Actions memiliki beberapa fitur utama seperti Automasi Workflow yang dapat menjalankan tugas-tugas otomatis berdasarkan trigger seperti push, pull request, atau jadwal tertentu. Selain itu, Actions mendukung berbagai sistem operasi (Linux, macOS, Windows) dan bahasa pemrograman sehingga sangat fleksibel untuk berbagai macam latar belakang. Menariknya, GitHub Actions juga menyediakan ribuan fungsi yang siap digunakan untuk berbagai kebutuhan pengembangan proyek yang disimpan pada marketplace-nya.
Ngomong-ngomong soal fitur, berikut beberapa komponen yang perlu Anda ketahui sebelum kita memulai praktik menggunakan fitur GitHub Actions.
-
Workflow
Sebuah file konfigurasi dalam format YAML berisikan serangkaian tugas yang akan dijalankan secara otomatis berdasarkan trigger tertentu. Workflow ini berjalan di lingkungan GitHub-hosted runners atau self-hosted runners, sehingga tidak akan membebani environment lokal Anda. -
Events
Sebuah trigger yang akan memicu jalannya workflow. Contohnya Push ke branch, pull request, issue baru, atau jadwal tertentu. -
Jobs
Job adalah kumpulan langkah-langkah untuk menjalankan tugas tertentu. Faktanya, setiap workflow bisa terdiri dari satu atau lebih jobs yang dijalankan secara paralel atau berurutan. -
Steps
Langkah-langkah dalam sebuah job yang menjalankan tugas seperti menginstal dependensi, menjalankan tes, atau membangun aplikasi (pada kasus ini membangun model machine learning). -
Actions
Tugas-tugas individual yang dapat digunakan kembali dalam langkah-langkah workflow. Contohnya menginstal Python, memeriksa kode dengan linter, atau mengirim notifikasi.
Jika digambarkan secara umum, workflow yang akan dijalankan oleh GitHub Actions kurang lebih akan seperti berikut.
Mungkin sejauh ini akan tebersit beberapa pertanyaan di benak Anda mengenai hal-hal berikut ini.
- Bukannya kita akan belajar version control dengan MLflow?
- Mengapa MLflow membutuhkan version control sejauh ini?
- Bukannya version control GitHub itu menyimpan perubahan kode saja, ya?
Betul teman-teman, pada dasarnya kita menggunakan GitHub untuk menyimpan perubahan kode yang dilakukan oleh developer. Namun, mari kita kembalikan pertanyaannya ke diri Anda. Apakah kalian merasa puas dengan menyimpan kode saja tanpa melakukan CI/CD? Tentu jawabannya tidak karena sejatinya kita bisa melakukan hal yang jauh lebih keren dengan menggunakan tools yang sebelumnya hanya berperan sebagai repositori.
Oleh karena itu, kita akan menyelam lebih dalam mengenai version control menggunakan GitHub dan MLflow pada materi ini. Mari kita mulai dari hal yang paling sederhana untuk menjawab pertanyaan kedua dan ketiga.
Pada dasarnya kedua tools ini dapat diintegrasikan untuk membangun alur kerja otomatis (automated workflow) yang mencakup proses pelatihan, pencatatan eksperimen, pengelolaan model, dan deployment ke lingkungan produksi.

Salah satu keuntungan menghubungkan GitHub Actions dan MLflow yaitu tim dapat mengotomatiskan dan mengelola proyek machine learning secara lebih efisien. Hubungan ini sangat relevan dalam konteks machine learning modern yang membutuhkan kolaborasi antar tim, integrasi pipeline, dan deployment model yang konsisten.
Sederhananya, Anda tidak perlu lagi melakukan training model pada komputer lokal dan melakukan push setiap saat, karena dengan menggunakan kedua tools ini Anda hanya perlu mengubah code dan voila GitHub secara otomatis akan menjalankan pipeline dan menyimpan model terbaru.
Bagaimana, sampai di sini Anda sudah paham kan teori dan keuntungan mengenai penggunaan MLflow dan GitHub? Jika belum, silakan baca kembali materi ini dan gunakan forum diskusi untuk membahas hal yang membuat Anda penasaran ya.
Waahh, banyak sekali ya bekal materi yang perlu kita persiapkan untuk menjadi seorang machine learning engineer. Namun, ada sebuah pepatah yang mengatakan hasil tidak akan mengkhianati proses. Oleh karena itu, tetap semangat ya karena selanjutnya kita akan mempraktikkan teori pada materi ini.
“Theory is splendid, but until put into practice, it is valueless.” — James Cash Penney, businessman and entrepreneur
Seperti pada kutipan di atas, materi saja tidak cukup untuk mengantarkan Anda menjadi seorang machine learning engineer yang andal. Oleh karena itu, kita perlu mencoba menerapkan teori-teori di atas menjadi sebuah latihan sederhana.
Sebagai catatan, latihan ini akan menggunakan repositori yang sama dengan latihan MLproject sebelumnya. Selain itu, ada beberapa objektif yang akan kita capai pada latihan ini yaitu version control dan continuous integration (CI).
Pertama-tama, lakukanlah copy repositori yang akan digunakan ke akun GitHub Anda dan pastikan hanya ada folder “Project” yang ada pada folder lokal Anda dengan struktur folder seperti berikut.

Tujuannya agar Anda dapat melakukan perubahan secara fleksibel dan tidak bergantung kepada pemilik repositori untuk melakukan pull requests.
Selain melakukan meng-copy secara manual, Anda juga dapat melakukan forking pada repository berikut ini. Ketika Anda ingin melakukan latihan ini dari awal, pastikan tidak mencentang bagian “Copy the master branch only”. Sebagai informasi, master branch dari repositori ini sudah memiliki kode lengkap untuk menjalankan GitHub Actions.
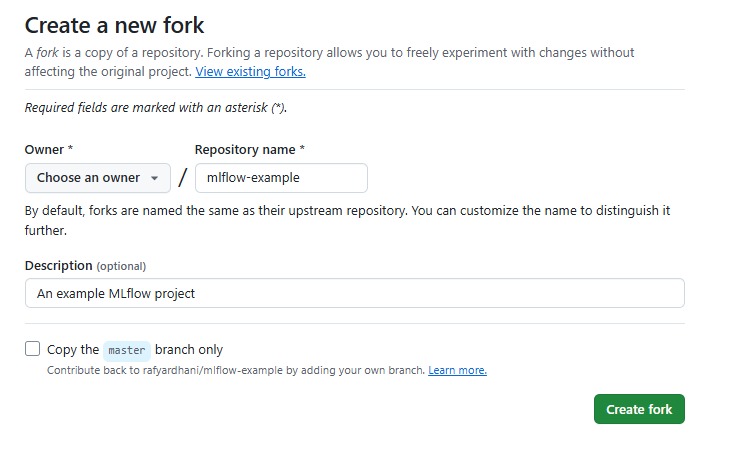
Selanjutnya, silakan clone repositori yang sudah Anda set-up pada sebuah environment yang akan digunakan baik itu local environment ataupun virtual machine. Lalu hapus terlebih dahulu folder workflow yang sudah ada.
Penting, jika melakukan forking pastikan Anda menghapus folder .workflow agar tidak menghasilkan error karena duplikasi file. Lalu push kembali kode tersebut ke direktori yang sama.
Jika sudah, silakan buka repositori tersebut menggunakan IDE atau Code Editor favorit Anda. For your information, pada latihan ini, kami akan menggunakan Visual Studio Code sebagai Code Editor untuk menjalankan proyek machine learning. Struktur awal dari latihan ini setidaknya Anda memiliki kerangka folder Project seperti berikut.
Sampai pada tahap ini, Anda dapat menyimpan seluruh perubahan yang dilakukan terhadap seluruh file yang berada di repositori tersebut. Namun, proses tersebut belum memenuhi objektif yang akan kita lakukan yaitu membuat model machine learning menggunakan GitHub Actions berdasarkan perubahan kode yang dibuat.
Untuk menyelesaikan permasalahan tersebut, silakan kembali ke halaman repositori proyek GitHub. Pada halaman ini, Anda perlu menekan tombol fitur bernama “Actions” sehingga akan menampilkan halaman seperti berikut.
GitHub akan menyediakan beberapa rekomendasi yang Actions yang cocok untuk proyek yang sedang dibangun, pada latihan kali ini kita tidak akan menggunakan opsi rekomendasi melainkan mengatur Actions secara mandiri melalui opsi “set up a workflow yourself” (Link berada di bawah tulisan “Choose a workflow”). Namun, kelak Anda dapat menyesuaikan Actions yang digunakan sesuai dengan kebutuhan proyek, ya.
Pada halaman ini, Anda akan diarahkan menuju blank page yang harus dilengkapi dengan kode yang akan dijalankan.
Sebagai informasi, Anda dapat menggunakan fitur Marketplace pada tab sebelah kanan sesuai dengan kebutuhan proyek. Namun, saat ini kita tidak akan menggunakan fitur tersebut karena akan membuat Actions secara mandiri melalui kode berikut.
-
name: CI MLflow
- on:
- push:
- branches:
- - master
- pull_request:
- branches:
-
- master
- env:
- CSV_URL: “Project/wine-quality.csv”
- TARGET_VAR: “quality”
- ALPHA: 0.5
- L1_RATIO: 0.5
-
RANDOM_STATE: 42
- jobs:
- build:
-
runs-on: ubuntu-latest
- steps:
- # Checks-out your repository under $GITHUB_WORKSPACE
-
- uses: actions/checkout@v3
- # Setup Python 3.12.7
- - name: Set up Python 3.12.7
- uses: actions/setup-python@v4
- with:
-
python-version: “3.12.7”
- # Check Env Variables
- - name: Check Env
-
run: -
echo $CSV_URL
- # Install mlflow
- - name: Install dependencies
-
run: - python -m pip install --upgrade pip
-
pip install mlflow
- # Run as a mlflow project
- - name: Run mlflow project
-
run: - mlflow run Project --env-manager=local
Setelah kode di atas rampung, Anda dapat harus menyimpan workflow tersebut dengan menekan tombol “commit changes…” di pojok kanan atas pada halaman yang sama.

Selanjutnya simpan workflow tersebut dengan nama main.yml (bisa disesuaikan) dan simpan hasilnya. Untuk melihat hasilnya Anda bisa kembali ke menu Actions, seharusnya sekarang sudah ada workflow yang dijalankan secara otomatis.
Pada materi ini, kita tidak akan membahas secara detail kode di atas karena Anda akan mempelajari seluk-beluknya pada materi berikutnya. Namun, secara singkat kode di atas merupakan pipeline CI menggunakan GitHub Actions untuk menjalankan eksperimen machine learning menggunakan MLflow. Pada kasus ini, pipeline akan dipicu oleh perubahan (push) atau pull request ke branch master. Beberapa tahapan yang akan dilakukan pipeline ini melibatkan beberapa proses seperti berikut.
- Setup Environment: bertugas mengatur instalasi Python 3.12.7 dan mendefinisikan variabel yang digunakan seperti lokasi data, target variabel, dan hyperparameter.
- Check Environment: bertugas untuk memvalidasi ketersediaan dataset.
- Install Dependencies: menginstal library MLflow, mengapa bukan requirements.txt? Karena file tersebut akan dijalankan ketika perintah run dijalankan kelak.
- Run MLflow Project: menjalankan eksperimen dari folder Project yang berisikan MLproject.
Tugas utama kode di atas adalah mengotomatisasi eksperimen ML dan memastikan semuanya berjalan dengan baik ketika developer melakukan sebuah perubahan. Anda dapat melihat seluruh proses yang dilakukan pada halaman Actions dengan memilih workflow yang dijalankan.
Sampai pada tahap ini, apa pun perubahan yang Anda lakukan pada branch master akan menjadi trigger untuk menjalankan proses CI dan membangun sebuah model jika seluruh proses berhasil dilakukan.

Eittss, sepertinya ada yang kurang. Ke manakah model yang telah dibuat? Kok tidak tersimpan di mana pun? Santai-santai, hal tersebut sangatlah wajar mengingat kita belum mengatur steps untuk menyimpan model atau pun menentukan URL MLflow tracking.
Jika Anda perhatikan terdapat beberapa steps yang akan menghapus seluruh file sementara yang dibuat ketika menjalankan Actions. Hal ini karena perintah yang kita buat hanya mencakup membuat model dan melakukan evaluasi performa model.
Lalu, bagaimana solusinya? Sebenarnya, ada berbagai macam cara untuk menyimpan model yang dibuat baik itu melalui tracking uri atau pun menyimpan ke suatu repositori. Namun, pada latihan kali ini objektifnya hanya melatih dan melakukan evaluasi model. Sekilas informasi, Anda akan mulai menyimpan model hasil training pada materi berikutnya, ya.
Selamat! Anda kini telah memahami bagaimana GitHub Actions dan MLflow dapat bekerja sama untuk merevolusi alur kerja machine learning. Kini, pengembangan machine learning yang Anda lakukan sudah berada di level berbeda. Anda sudah tidak perlu membuat dan mengatur model secara manual melalui code editor ataupun Google Colab.
Namun, tunggu dulu, petualangan kita belum berakhir sampai di sini. Di akhir modul, kita akan langsung hands-on membangun model machine learning menggunakan MLflow dan GitHub secara lengkap menggunakan sebuah studi kasus. Pastinya sangat menyenangkan ‘kan? Oleh karena itu, jangan sampai kehabisan bahan bakar, ya.
Silakan persiapkan secangkir kopi dan camilan terlebih dahulu karena selanjutnya kita akan membahas materi “pendinginan” mulai dari metadata hingga dokumentasi model. Jika sudah siap kembali, kami tunggu di materi berikutnya. Semangat!
Metadata dan Sekitarnya
Setelah mendaki gunung yang menantang dengan latihan mini version control dan CI, kini saatnya kita menikmati pemandangan dari puncak. Kita akan berjalan santai sambil melihat-lihat metadata pada proyek MLflow. Anggap saja ini seperti tur berpemandu di mana kita akan menemukan informasi-informasi menarik yang melengkapi proyek. Jadi, lepaskan lelah Anda sejenak dan mari kita nikmati perjalanan yang lebih ringan ini.
Metadata adalah data tentang data—informasi yang menjelaskan detail penting mengenai eksperimen machine learning, seperti parameter model, metriks, informasi data yang digunakan, serta konfigurasi environment eksekusi.
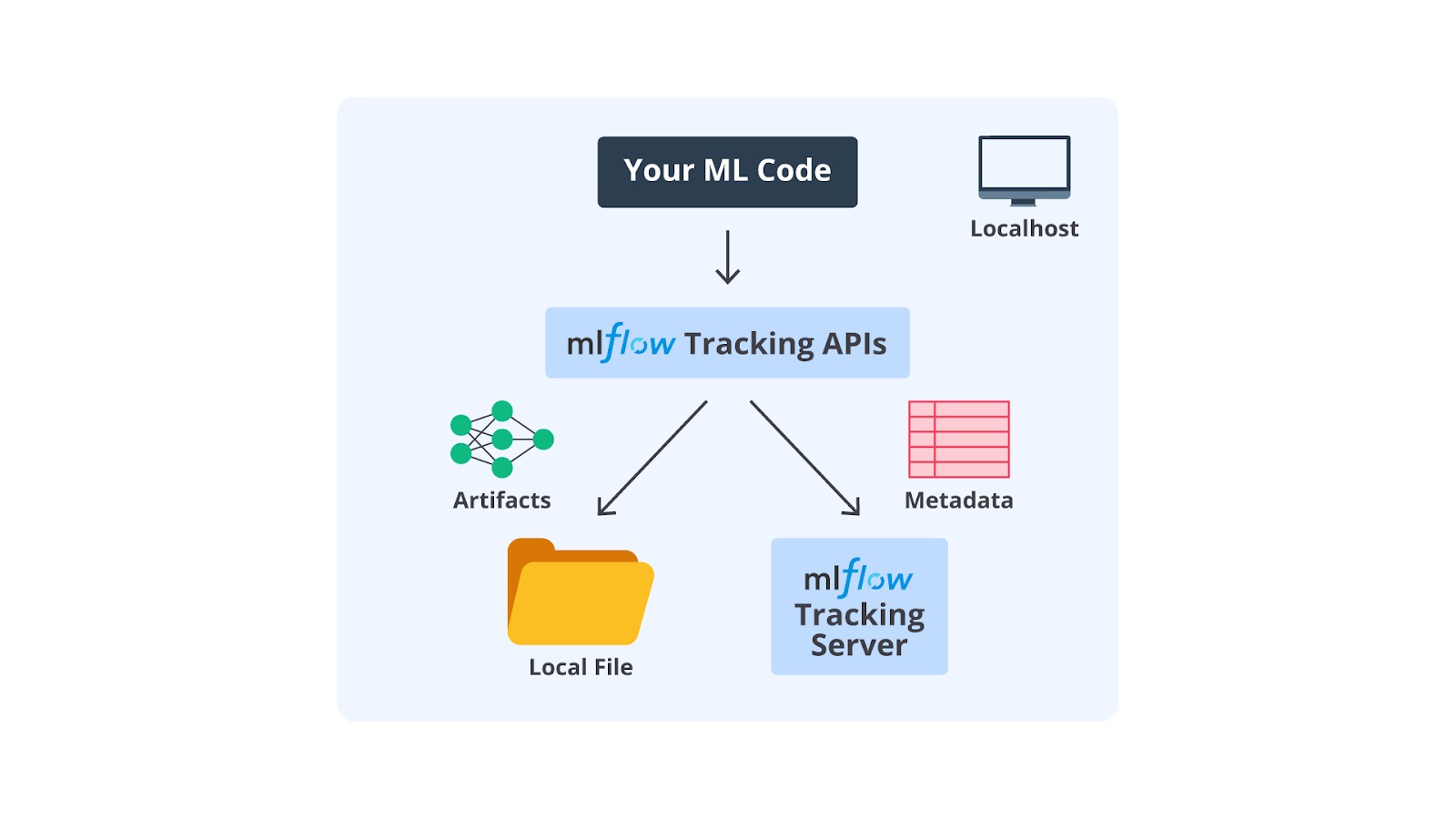
Dalam sistem machine learning modern, metadata memiliki peran yang sangat penting karena dapat meningkatkan reproducibility, monitoring, dan kolaborasi antar tim. Tanpa pengelolaan metadata yang baik, eksperimen akan sulit dilacak, hasil tidak dapat direproduksi dengan akurat, dan iterasi pengembangan model menjadi tidak efisien.
Permasalahan di atas sering kali dianggap sepele dan dihiraukan, tetapi ketika Anda membangun proyek dengan skala yang lebih besar dan bekerja sebagai tim maka masalah tersebut akan menjadi bom waktu.
Agar terhindar dari technical debt di masa depan, mari kita bahas sedikit mengenai peran metadata dalam pembangunan model machine learning bersama-sama.
Pentingnya Metadata dalam ML Systems
Tanpa metadata yang lengkap, eksperimen sulit diulang, hasil menjadi tidak konsisten, dan pengembangan model menjadi lebih lambat serta rentan terhadap kesalahan.
Bayangkan ketika Anda masuk ke sebuah perusahaan, Anda diminta untuk memperbaharui model machine learning. Namun, hanya disediakan modelnya saja tanpa hal lainnya. Anda perlu mempelajari baris demi baris untuk mengetahui karakteristik model agar dapat mereplikasi machine learning yang sudah ada. Tentunya hal tersebut sangat melelahkan dan belum tentu hasilnya baik.
Oleh karena itu, pengelolaan metadata adalah salah satu aspek paling krusial dalam membangun sistem machine learning yang andal dan terstruktur. Biasanya metadata dalam sistem machine learning mencakup informasi tentang parameter dan metrik eksperimen, versi data dan preprocessing, serta konfigurasi environment.
Parameter dan Metriks Eksperimen
Parameter eksperimen adalah nilai-nilai yang mengatur cara kerja model selama proses pelatihan. Ada dua jenis parameter yang biasanya dicatat sebagai metadata yaitu hyperparameter dan parameter model internal.
- Hyperparameter
Hyperparameter adalah parameter yang ditetapkan sebelum proses pelatihan dimulai. Contohnya meliputi:- n_estimators dalam RandomForestClassifier: jumlah pohon dalam ensemble.
- learning_rate dalam model Gradient Boosting: kecepatan pembaruan bobot selama proses pelatihan.
- batch_size dalam neural network: jumlah sampel yang diproses sebelum memperbarui bobot.
Singkatnya, hyperparameter merupakan nilai yang dapat diatur oleh pengembang secara eksplisit sebelum pelatihan dimulai.
- Parameter Model Internal
Selain hyperparameter, model juga memiliki parameter internal, seperti bobot pada neural networks atau koefisien dalam regresi linier. Parameter ini dihasilkan selama proses pelatihan dan penting untuk mencatat hasil akhir dari eksperimen. Dengan kata lain, kita tidak bisa mengatur parameter ini secara eksplisit karena seluruh prosesnya dilakukan oleh komputer.
Dengan mencatat parameter, tim dapat memahami dan mengulangi eksperimen dengan konfigurasi yang sama. Sebagai contoh, jika suatu eksperimen menghasilkan model dengan akurasi tinggi, tim dapat menggunakan metadata untuk mengulang eksperimen tersebut dengan nilai yang sama.
Di sisi lain, metrik adalah nilai-nilai yang digunakan untuk mengevaluasi performa model pada dataset validasi atau pengujian. Pentingnya mencatat metrik adalah agar tim dapat membandingkan berbagai eksperimen dan memilih model terbaik berdasarkan hasil yang terukur.
Sebagai contoh, jika menjalankan beberapa eksperimen dengan berbagai kombinasi hyperparameter, Anda dapat menggunakan metrik seperti akurasi atau F1-score sebagai dasar untuk memilih model yang akan di-deploy. Selain itu, metriks ini bisa menjadi dokumentasi yang sangat berguna ketika Anda melakukan pitching produk ke stakeholder atau leader tim.
Informasi Data
Menyimpan informasi data bukan hanya teori belaka, tetapi memang kebutuhan dalam proyek machine learning yang krusial. Metadata memberikan transparansi, reproducibility, dan pemahaman yang lebih baik tentang data sehingga menghasilkan model yang lebih andal, keputusan yang lebih baik, dan kolaborasi yang lebih efektif.
Tanpa metadata, proyek machine learning ibarat kapal yang berlayar tanpa kompas dan peta, rentan tersesat dan sulit mencapai tujuan. Ketika tidak menyimpan informasi data, kelak Anda akan kesulitan ketika mengevaluasi model saat terjadi data drifting karena tidak memiliki visibilitas terhadap data yang digunakan.
Agar terhindar dari permasalahan tersebut, kita perlu menyimpan beberapa informasi seperti versi data beserta proses preprocessing yang dilakukan. Mari kita bahas satu per satu.
- Versi Data
Dalam proyek machine learning dataset sering kali berubah seiring waktu. Perubahan ini bisa disebabkan oleh penambahan data baru, perbaikan data yang salah, atau perubahan format data. Oleh karena itu, sangat penting untuk mencatat versi dataset yang digunakan dalam setiap eksperimen.
Mencatat versi data memungkinkan tim untuk melacak perubahan dataset dan menganalisis pengaruh perubahan data terhadap performa model. Jika model di-deploy ke produksi dan performanya menurun, tim dapat melihat apakah penurunan performa disebabkan oleh perubahan data. -
Proses Preprocessing
Tidak hanya informasi data, proses preprocessing juga merupakan komponen vital yang sering kali terlupakan ketika membangun model machine learning. Salah satu akibatnya melupakan preprocessing yaitu model tidak dapat memproses data baru dengan baik bahkan bisa saja terjadi eror yang tidak diinginkan.Preprocessing adalah tahap penting dalam pipeline machine learning di mana data mentah diubah menjadi format yang dapat digunakan oleh model. Setiap langkah preprocessing harus dicatat sebagai metadata karena preprocessing memengaruhi hasil akhir model. Jika preprocessing tidak dicatat, eksperimen akan sulit diulang dengan hasil yang sama.
Dengan mencatat proses preprocessing sebagai metadata, Anda dapat memastikan bahwa model yang sama dapat diuji atau di-deploy di masa depan menggunakan langkah preprocessing yang identik.
Konfigurasi Environment
Pembangunan model machine learning biasanya terdiri dari berbagai macam library yang menopang proses pelatihan. Faktanya, setiap library memiliki versi tertentu yang dapat memengaruhi hasil eksperimen.
Sebagai contoh, jika Anda menggunakan versi lama dari scikit-learn, hasil pelatihan model mungkin berbeda dibandingkan dengan versi terbaru yang memiliki perbaikan atau perubahan algoritma. Worst case-nya, jika Anda menggunakan versi yang berbeda ketika pelatihan dan replikasi model, kode yang dibuat menjadi eror.
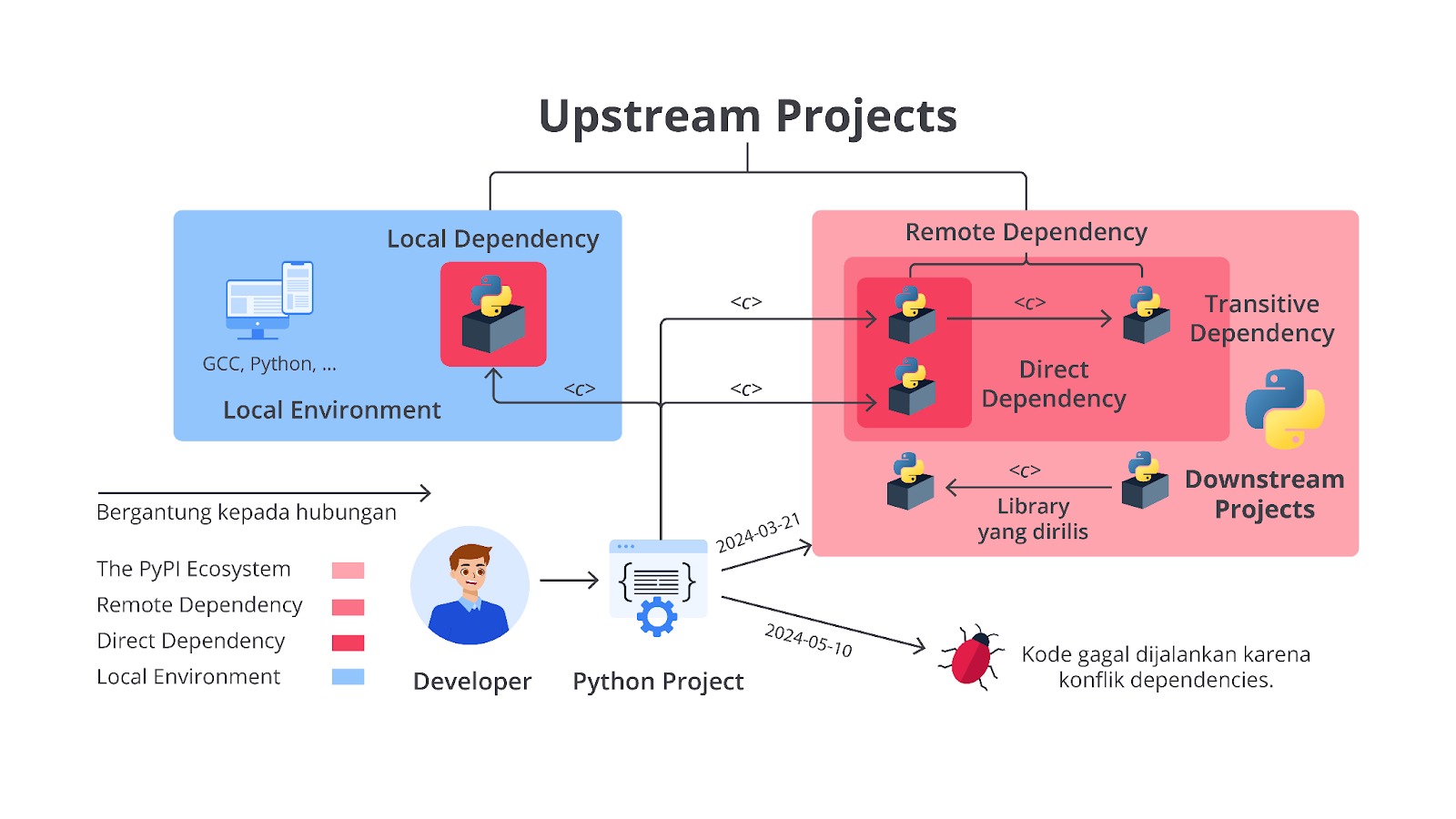
Dengan mencatat versi library yang digunakan dalam setiap eksperimen Anda dapat memastikan bahwa proyek dapat dijalankan ulang dengan hasil yang sama serta menghindari konflik.
Tahapan di atas tentu terlihat merepotkan ketika dilakukan secara manual, terlebih karena seorang programmer sering kali malas berhubungan dengan dokumentasi karena lebih suka ngoding.
Namun tenang saja, pada materi ini, Anda sudah mempelajari penggunaan MLflow Tracking agar dapat melakukan logging secara otomatis. Sebelumnya kita sekilas sudah membahas fitur ini, tetapi tidak secara detail. Oleh karena itu, mari kita bayar pengetahuan yang sebelumnya tertunda.
Mengelola Metadata dengan MLflow
Tahukah Anda dengan menggunakan MLflow, pencatatan metadata dapat dilakukan secara otomatis maupun manual, serta disimpan dalam format standar yang mudah diakses dan dianalisis. Pada materi ini, kita akan membahas secara detail bagaimana MLflow membantu dalam pengelolaan metadata melalui fitur logging otomatis dan manual, serta penyimpanan metadata dalam format standar.
Logging Otomatis
MLflow menyediakan fitur autologging yang memungkinkan pencatatan metadata secara otomatis selama eksperimen berlangsung tanpa menulis banyak kode tambahan. Fitur ini sangat berguna karena secara otomatis mencatat berbagai informasi penting seperti berikut.
- Parameter model: semua hyperparameter yang digunakan dalam pelatihan model akan dicatat.
- Metrik hasil: metrik performa seperti akurasi, precision, recall, atau loss akan dicatat secara otomatis.
- Artefak model: model yang telah dilatih akan disimpan sebagai artefak sehingga dapat digunakan kembali atau di-deploy di masa depan.
- Informasi environment: versi library, Python, dan sistem operasi juga akan dicatat sehingga reproducibility eksperimen terjamin.
Autologging ini mendukung banyak framework machine learning populer, seperti scikit-learn, TensorFlow, Keras, dan XGBoost.
Manfaat utama logging otomatis adalah mempermudah pencatatan metadata tanpa beban tambahan bagi pengembang. Setiap kali eksperimen dijalankan, semua informasi penting langsung tercatat di MLflow Tracking Server sehingga memudahkan tim untuk melacak hasil eksperimen.
Kekurangannya, autologging ini tidak mencatat beberapa file tambahan seperti contoh input, dataset, dan payloads. Di lain sisi, terkadang kita juga tidak membutuhkan beberapa informasi sehingga kerap kali membebankan penyimpanan komputer.
Logging Manual
Selain autologging, MLflow juga mendukung pencatatan metadata secara manual. Logging manual memberikan fleksibilitas lebih baik, terutama jika Anda ingin mencatat informasi tambahan yang tidak didukung oleh autologging.
Dalam logging manual, Anda secara eksplisit memberikan perintah untuk mencatat parameter, metrik, dan artefak menggunakan fungsi-fungsi bawaan MLflow seperti mlflow.log_param(), mlflow.log_metric(), dan mlflow.log_artifact().
Anda dapat melihat seluruh fungsi bawaan dari MLflow pada tautan berikut: mlflow.log.
Kekurangannya, Anda perlu menuliskan beberapa baris kode tambahan menyesuaikan dengan metadata yang dibutuhkan. Sehingga, setiap kali model machine learning dibangun, Anda akan mendapatkan metadata yang sama.
Menariknya, untuk mengatasi kekurangan kedua metode di atas Anda juga dapat menggabungkan beberapa fungsi yang tidak didukung oleh autologging dengan manual logging. Hal ini memberikan informasi yang sangat lengkap dan sesuai dengan kebutuhan proyek Anda.
Sampai di sini, Anda perlu menentukan secara mandiri penggunaan logging yang sesuai dengan kebutuhan proyek tim. Ketiga pilihan di atas tidak ada yang benar atau salah karena semuanya kembali ke kebutuhan proyek Anda.
Menyimpan Metadata
Setelah metadata dicatat baik melalui logging otomatis, manual atau hybrid MLflow akan menyimpan semua informasi tersebut dalam format standar yang terstruktur. Metadata disimpan pada sebuah repository sehingga dapat diambil dalam bentuk file JSON untuk analisis lebih lanjut.
Setiap eksperimen yang dijalankan di MLflow akan dicatat sebagai run, yang memiliki Run ID unik. Informasi ini disimpan dalam direktori khusus di MLflow, di mana setiap run memiliki direktori terpisah dengan file JSON yang mencatat semua metadata.
Manfaat penyimpanan metadata dalam format standar ini adalah memudahkan integrasi dengan sistem lain. Metadata dapat diambil dan dianalisis menggunakan script Python atau digunakan sebagai input untuk pipeline machine learning yang lebih kompleks.
Sekarang, Anda sudah memahami seluruh teori beserta secercah praktik mengenai pembangunan model machine learning. Sampai di sini, mari kita sudahi terlebih dahulu teori-teori yang sangat menyenangkan ini.
Kini Anda siap untuk mengintegrasikan tools yang telah kita pelajari untuk membangun sistem machine learning dengan level yang berbeda. Kita akan menggabungkan MLflow, GitHub, dan GitHub Actions untuk menciptakan alur kerja yang otomatis dan reproducible, di mana metadata akan menjadi bagian integral dari proses tersebut. Tanpa berlama-lama, mari kita langsung praktik dan melihat integrasi ketiga tools ini yang dapat meningkatkan efisiensi dan kualitas proyek machine learning kita.
Latihan: Membuat Version Control Menggunakan MLflow
Kita telah menjelajahi berbagai fitur MLflow, mempelajari version control dengan GitHub, dan mencoba mengintegrasikan keduanya. Selanjutnya, mari kita terapkan semua pengetahuan tersebut dalam konteks yang spesifik dan relevan yaitu studi kasus credit scoring.
Credit scoring adalah salah satu aplikasi penting dari machine learning di industri keuangan yang modelnya digunakan untuk menilai kelayakan kredit seseorang. Dalam latihan ini, kita akan membangun sistem version control menggunakan MLflow untuk model credit scoring. Kita akan melacak eksperimen, mengelola versi model, dan berkolaborasi menggunakan GitHub. Siap untuk menyelami dunia credit scoring dan mempraktikkan keterampilan MLflow dan GitHub Anda? Kencangkan sabuk pengaman, siapkan secangkir kopi dan semangkuk camilan, mari kita mulai!
Nah, pada proses credit scoring analysis, kita perlu mempertimbangkan berbagai faktor yang memengaruhi kemampuan peminjam dalam memenuhi kewajibannya (melunasi hutang). Berikut beberapa di antaranya.
-
Credit history
Riwayat kredit seorang peminjam merupakan faktor utama dalam penentuan kelayakan dari sebuah kredit. Hal ini untuk menilai seberapa sering peminjam melakukan kredit serta apakah pembayaran kredit dilakukan secara tepat waktu. -
Credit utilization ratio
Faktor berikutnya adalah besar perbandingan (rasio) antara jumlah kredit yang digunakan oleh peminjam dengan total kredit yang tersedia untuknya (credit limit). Hal ini mengindikasikan seberapa besar tekanan keuangan yang dimiliki seorang peminjam. Biasanya semakin besar nilai rasionya, semakin tinggi pula resiko dari pinjaman tersebut. -
Length of credit history
Durasi riwayat kredit juga merupakan salah satu faktor penting dalam menilai resiko dari sebuah pinjaman. Semakin panjang riwayat penggunaan kredit, semakin banyak data yang dapat digunakan untuk menilai kelayakan dari sebuah pinjaman. -
Credit mix
Variasi jenis kredit seperti kartu kredit, pinjaman, mortgages, dll. Portofolio kredit yang terdiversifikasi menunjukkan kemampuan manajemen utang yang baik. -
New credit
Faktor berikutnya adalah seberapa sering seorang peminjam mengajukan pinjaman baru. Semakin sering seseorang mengajukan pinjaman baru, biasanya menunjukkan keuangan yang tidak stabil.
Nah, itulah beberapa faktor yang biasanya digunakan dalam perhitungan credit scoring analysis. Pada praktiknya credit scoring ini sering digunakan sebagai acuan dalam menentukan apakah sebuah pinjaman disetujui atau tidak. Selain itu, tidak jarang credit scoring ini dijadikan pertimbangan dalam penentuan bunga (interest rate) dari sebuah pinjaman.
Oke, itulah pembahasan singkat terkait credit scoring analysis. Pada materi berikutnya, kita akan mulai mengerjakan salah satu contoh proyek dari credit scoring analysis. Proyek ini seharusnya dapat dikerjakan sesuai dengan tahapan yang terdapat dalam CRISP-DM seperti pada gambar berikut.
Namun, pada latihan kali ini, kita tidak akan membahas seluruh tahapannya karena latihan ini akan berfokus pada pembuatan version control dan pembangunan model menggunakan MLflow.
Seperti latihan pada umumnya, kami sangat menyarankan Anda untuk selalu membuat virtualenv baru pada setiap proyek. Hal ini untuk meminimalisasi masalah yang berhubungan dengan dependency pada library yang akan digunakan. Jika Anda menggunakan conda, silakan gunakan kode berikut untuk membuat virtual environment yang sama dengan latihan ini.
- conda create --name credit_scoring python=3.12.7
Untuk menunjang proses latihan ini, pastikan Anda sudah menginstal semua library yang dibutuhkan menggunakan perintah berikut.
- pip install numpy pandas matplotlib scikit-learn joblib mlflow
Pada latihan ini, kita akan langsung menerapkan MLflow untuk membangun version control model credit scoring. Kita tidak akan membahas secara detail tahapan data cleaning dan preprocessing karena diasumsikan Anda telah memiliki pemahaman yang memadai mengenai hal tersebut pada kelas sebelumnya. Jika memerlukan penyegaran terkait data cleaning dan preprocessing, Anda dapat merujuk kembali ke kelas Machine Learning untuk Pemula atau Belajar Pengembangan Machine Learning.
Namun, jika Anda penasaran mengenai cleaning dan preprocessing yang dilakukan pada latihan kali ini, silakan kunjungi repositori di sini. Sebagai informasi, repositori tersebut juga berisikan file-file pendukung seperti joblib untuk melakukan seluruh proses transformasi data.
Tanpa berlama-lama lagi, mari kita start pembangunan proyek credit-scoring dimulai dari pembuatan sebuah repositori pada platform GitHub. Silakan ikuti langkah-langkah yang ada pada materi sebelumnya, ya.
Jika sudah, Anda perlu menjalankan kembali MLflow server agar dapat melakukan tracking terhadap model yang akan dibangun melalui kode berikut.
- mlflow server --host 127.0.0.1 --port 5000
Psstt, saat ini kita masih menggunakan localhost agar semua siswa bisa mengikuti dengan lancar. Kelak, kita juga akan mempelajari materi opsional agar dapat men-deploy model di sebuah host atau server.
Jika Anda sudah menjalankan kode di atas, harusnya halaman Tracking UI sudah dapat diakses melalui tautan yang sama seperti konfigurasi tersebut yaitu 127.0.0.1:5000. Jika mengikuti seluruh latihan sebelumnya, Anda akan menemukan tab Experiments yang bernamakan Default. Eksperimen tersebut merupakan berbagai macam logging berdasarkan model machine learning selama Anda mengikuti kelas ini.
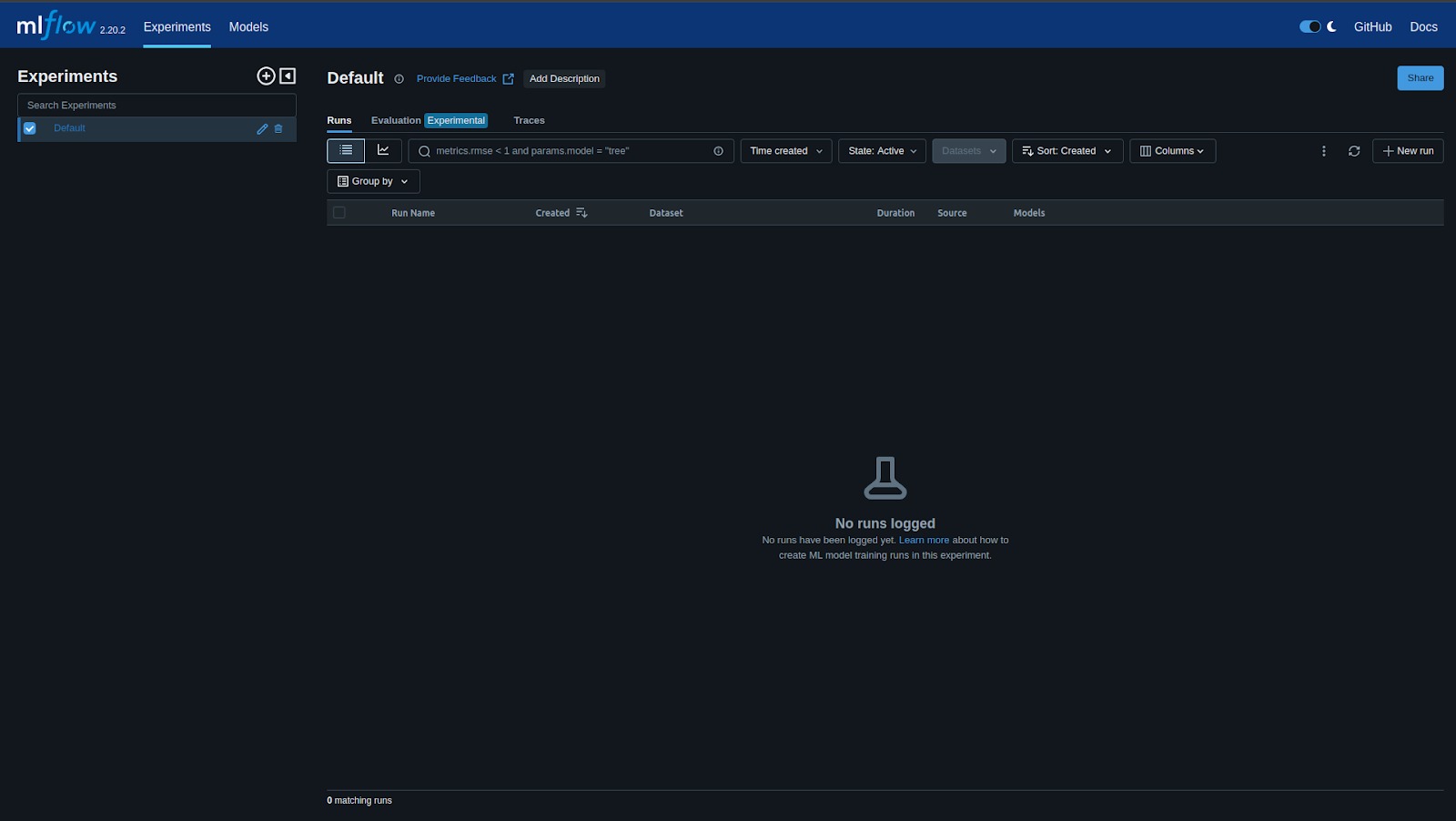
Anyway, pada latihan ini, kita akan mencatat seluruh logging pembuatan model credit-scoring ke server yang sudah dibuat dengan nama eksperimen sesuai proyek yang dijalankan.
Breaking News
Perlu Anda ingat, pada latihan kali ini seluruh tahapan data cleaning dan preprocessing sudah dilakukan secara mandiri. Anda dapat mengikuti tahapan tersebut dengan melihat repositori yang sudah disediakan atau langsung menggunakan dataset yang sudah siap digunakan dengan nama train_pca.csv dan test_pca.csv.
Pertama-tama, untuk memulai latihan ini Anda harus membuat sebuah file pada folder yang sama dengan penyimpanan dataset dengan nama modelling.py (bisa disesuaikan) dan mengisikan library yang akan digunakan.
- import mlflow
- import pandas as pd
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.model_selection import train_test_split
- import random
- import numpy as np
Kemudian, agar eksperimen yang dijalankan dapat disimpan pada Tracking UI silakan tambahkan kode set_tracking_uri() seperti berikut.
- mlflow.set_tracking_uri(“http://127.0.0.1:5000/”)
Langkah berikutnya, agar data hasil pelatihan dapat tersimpan pada satu pipeline silakan gunakan fungsi set_experiment() seperti berikut.
- mlflow.set_experiment(“Latihan Credit Scoring”)
Fungsi di atas akan mengatur nama eksperimen yang dijalankan dengan tujuan mengisolasi hasil eksplorasi pada proyek-proyek tertentu saja. Selanjutnya, kita perlu mengakses dataset dan membagi dataset menjadi data train dan test menggunakan kode berikut.
-
data = pd.read_csv(“train_pca.csv”)
- X_train, X_test, y_train, y_test = train_test_split(
- data.drop(“Credit_Score”, axis=1),
- data[“Credit_Score”],
- random_state=42,
- test_size=0.2
- )
Jika Anda perhatikan kode di atas, kita melakukan hard code terhadap dataset yang akan digunakan. Hal tersebut kurang elok dan akan menghasilkan masalah jika Anda membutuhkan dataset yang berubah-ubah. Tenang saja, permasalahan tersebut dapat kita selesaikan ketika membuat MLproject dengan cara mengubah file_path yang sebelumnya statis menjadi parameter yang dinamis (akan kita pelajari nanti).
Sebelum kita masuk ke tahap utama pembangunan model, terdapat sebuah detail kecil yang sangat membantu ketika pengujian atau melakukan kolaborasi antar tim, yaitu menyimpan snippet atau sample input. Caranya sangat mudah, Anda hanya perlu memisahkan beberapa sampel data seperti berikut.
- input_example = X_train[0:5]
Mengapa hal ini penting? Bayangkan Anda diberikan model legacy (turunan) dari sebuah perusahaan dan tidak tahu menahu mengenai skema input yang digunakan. Tentunya sulit untuk menebak skemanya terlebih jika tidak ada dokumentasi sedikit pun sehingga Anda perlu mengorek metadata model dan ketika sudah dapat belum tentu rentang datanya benar.
Yang paling parah, Anda harus menebak-nebak input berdasarkan shape sebuah model. Tentunya itu sangat melelahkan ‘kan? Karena menebak-nebak skema model itu sangat sulit sehingga dengan adanya hal kecil seperti ini akan menghindari tim Anda dari tech debt di kemudian hari.
Setelah semuanya rampung, Anda perlu menggunakan sebuah fungsi yang bertugas untuk mengelola proyek machine learning mulai dari melatih, mencatat, hingga menyimpan model ke suatu direktori.
- with mlflow.start_run():
- # Log parameters
- n_estimators = 505
- max_depth = 37
- mlflow.autolog()
- # Train model
- model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
- mlflow.sklearn.log_model(
- sk_model=model,
- artifact_path=“model”,
- input_example=input_example
- )
- model.fit(X_train, y_train)
- # Log metrics
- accuracy = model.score(X_test, y_test)
- mlflow.log_metric(“accuracy”, accuracy)
Kode di atas dimulai dengan menggunakan fungsi with mlflow.start_run() yang bertugas untuk membuat sesi eksperimen baru untuk mencatat semua aktivitas terkait. Pada tahap awal, parameter model seperti n_estimators dan max_depth didefinisikan, lalu fitur autologging diaktifkan melalui mlflow.autolog(). Fitur ini memungkinkan MLflow untuk secara otomatis mencatat parameter, metrik, dan informasi lainnya tanpa memerlukan banyak kode tambahan.
Model RandomForestClassifier kemudian dibuat menggunakan parameter yang telah didefinisikan sebelumnya, dan model tersebut dicatat sebagai artefak menggunakan mlflow.sklearn.log_model. Fungsi ini menyimpan model dalam format yang kompatibel dengan MLflow, termasuk informasi tentang input model melalui parameter input_example.
Setelah itu, model dilatih dengan data pelatihan (X_train dan y_train) menggunakan metode .fit(). Setelah pelatihan selesai, metrik akurasi dihitung pada data pengujian (X_test, y_test) menggunakan metode .score() dari model. Hasil metrik ini kemudian dicatat ke dalam eksperimen dengan fungsi mlflow.log_metric(“accuracy”, accuracy). Semua parameter, model, dan metrik yang dicatat selama eksperimen dapat diakses melalui antarmuka MLflow Tracking sehingga memungkinkan evaluasi dan reproduksi eksperimen di masa depan.
Setelah semua kode sudah dimasukkan pada satu file yang sama, silakan Anda eksekusi file Python tersebut dan tunggu proses pelatihan dijalankan. Seharusnya kode yang Anda miliki berisikan kode seperti berikut ini.
Ketika proses pelatihan selesai, Anda dapat melihat seluruh model beserta metriks yang dicatat melalui MLflow Tracking UI sesuai dengan alamat dan port yang telah diatur sebelumnya.
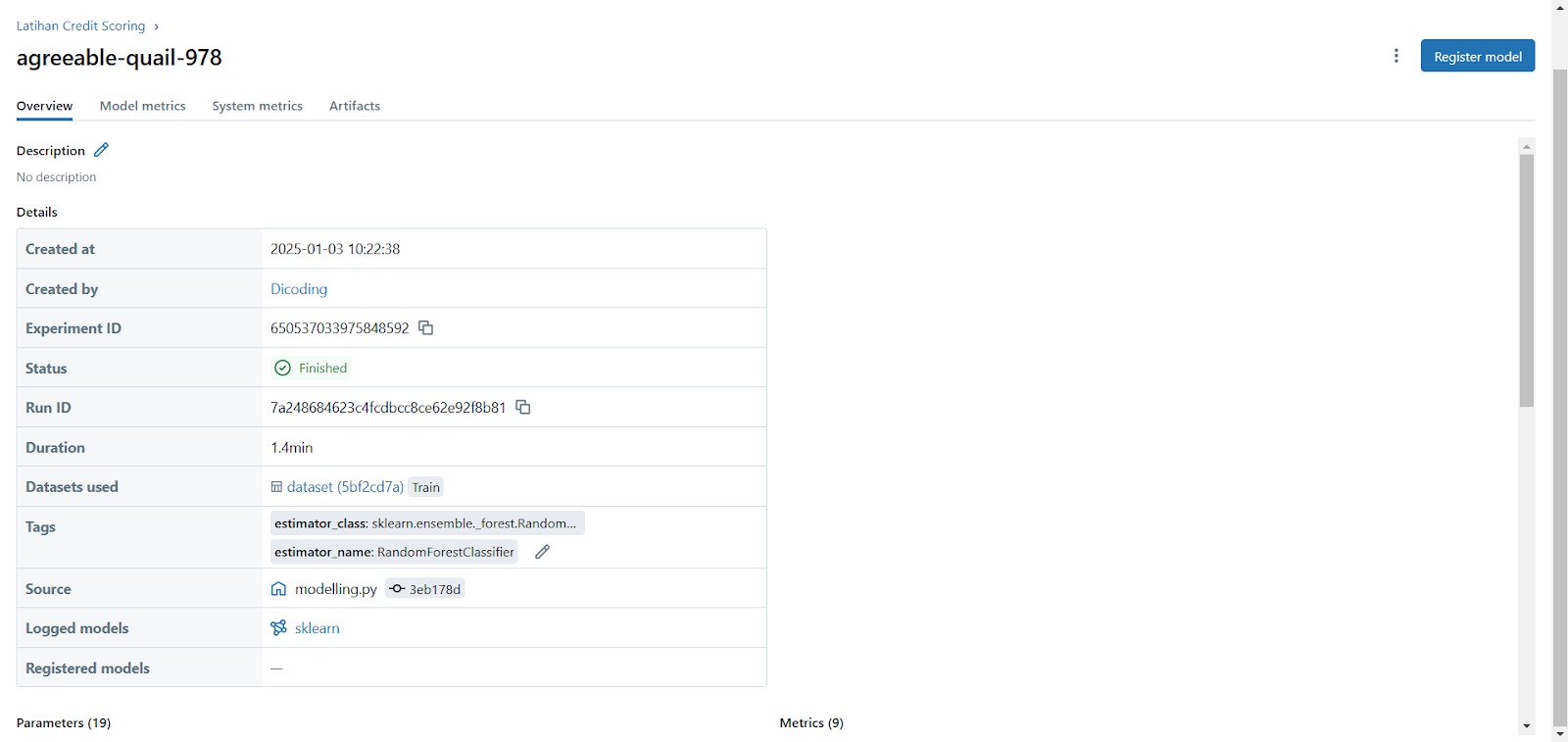
Menariknya, Anda juga dapat melihat parameter dan metriks secara lengkap jika nantinya ingin mereplikasi model untuk suatu keperluan tertentu.
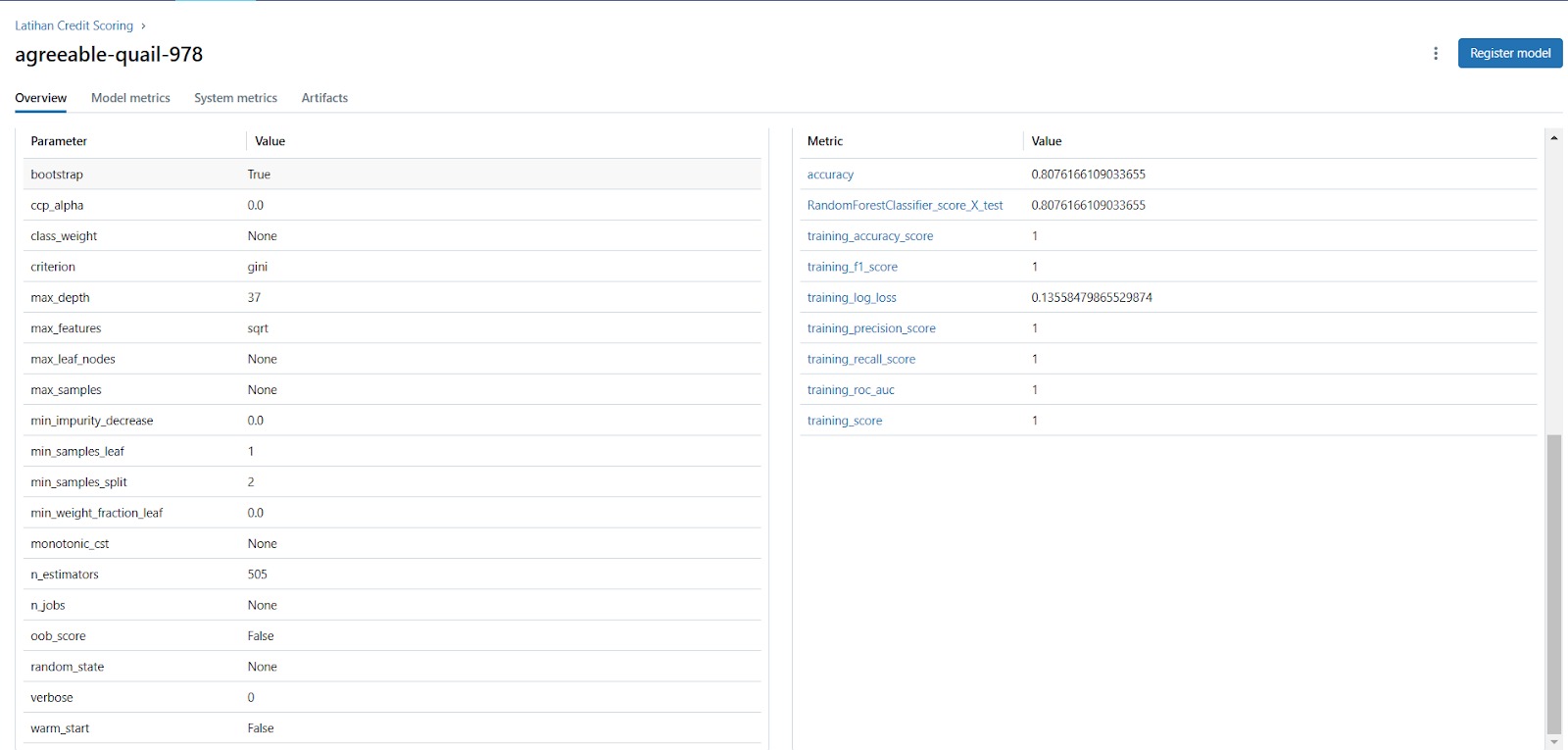
Good job, sampai di titik ini Anda telah berhasil membuat sebuah pipeline yang dapat mencatat setiap training yang dilakukan. Namun, apakah Anda menemukan suatu kejanggalan berdasarkan kode pelatihan di atas? Yup, hyperparameter! Berdasarkan kode di atas, Anda perlu mencari kombinasi hyperparameter terbaik secara mandiri dengan melakukan trial and errors sebanyak mungkin.
Tentunya itu sangat melelahkan dan memakan waktu yang sangat lama. Terlebih pada latihan kali ini, kita juga menggunakan dataset yang cukup besar sehingga pelatihan cenderung lebih lama daripada latihan sebelumnya.
Untuk menyelesaikan permasalahan tersebut, masih ingatkah Anda dengan hyperparameter tuning pada kelas Machine Learning untuk Pemula? Bagus, karena pada dasarnya, materi tersebut dapat membantu kita untuk menyelesaikan permasalahan ini.
Sederhananya, kita hanya perlu menambahkan section baru mengenai hyperparameter tuning, lalu kita akan menyimpan seluruh proses agar dapat dibandingkan dan mencari yang terbaik. Untuk detailnya, silakan perhatikan kode berikut terlebih dahulu sebelum kita bahas secara mendalam.
Penting
Untuk efisiensi daya komputasi, silakan gunakan salah satu kode pelatihan baik itu menggunakan metode hyperparameter tuning atau pun secara eksplisit seperti kode sebelumnya.
Agar tidak tercampur serta bisa melakukan perbandingan dengan latihan sebelumnya, silakan Anda buat sebuah file baru bernama modellingopt.py dengan awalan yang sama seperti latihan sebelumnya dengan kode seperti berikut.
- import mlflow
- import pandas as pd
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.model_selection import train_test_split
- import random
-
import numpy as np
-
mlflow.set_tracking_uri(“http://127.0.0.1:5000/”)
- # Create a new MLflow Experiment
-
mlflow.set_experiment(“Latihan Credit Scoring”)
-
data = pd.read_csv(“train_pca.csv”)
- X_train, X_test, y_train, y_test = train_test_split(
- data.drop(“Credit_Score”, axis=1),
- data[“Credit_Score”],
- random_state=42,
- test_size=0.2
- )
- input_example = X_train[0:5]
Namun, proses pelatihannya kini akan sedikit berubah. Anda perlu menambahkan section baru untuk melatih model menggunakan optimasi hyperparameter. Kurang lebih Anda bisa memodifikasi kode sebelumnya menjadi seperti berikut.
- # Mendefinisikan Metode Random Search
- n_estimators_range = np.linspace(10, 1000, 5, dtype=int) # 5 evenly spaced values
-
max_depth_range = np.linspace(1, 50, 5, dtype=int) # 5 evenly spaced values
- best_accuracy = 0
-
best_params = {}
- for n_estimators in n_estimators_range:
- for max_depth in max_depth_range:
- with mlflow.start_run(run_name=f”elastic_search_{n_estimators}_{max_depth}”):
-
mlflow.autolog()
- # Train model
- model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=42)
-
model.fit(X_train, y_train)
- # Evaluate model
- accuracy = model.score(X_test, y_test)
-
mlflow.log_metric(“accuracy”, accuracy)
- # Save the best model
- if accuracy > best_accuracy:
- best_accuracy = accuracy
- best_params = {“n_estimators”: n_estimators, “max_depth”: max_depth}
- mlflow.sklearn.log_model(
- sk_model=model,
- artifact_path=“model”,
- input_example=input_example
- )
Pada akhirnya, Anda akan memiliki sebuah file baru yang berisikan kode untuk melatih model dengan menerapkan hyperparameter tuning. Seharusnya kode tersebut akan terlihat seperti ini.
Kode di atas mendemonstrasikan proses hyperparameter tuning menggunakan model RandomForestClassifier dengan bantuan MLflow untuk mencatat eksperimen. Hyperparameter yang diuji adalah jumlah estimator (n_estimators) dan kedalaman maksimum pohon keputusan (max_depth).
Kedua parameter ini diatur untuk dieksplorasi dalam rentang nilai tertentu menggunakan metode perulangan yang setiap kombinasi nilainya diuji untuk menemukan model dengan akurasi terbaik. Detailnya, kode di atas akan menjalankan langkah-langkah seperti berikut.
-
Menentukan Rentang Hyperparameter
Pertama, kita perlu mendefinisikan rentang nilai untuk dua hyperparameter yang akan digunakan.-
n_estimators_range: menggunakan fungsi np.linspace untuk menghasilkan lima nilai secara acak di antara 10 sampai 1000.
-
max_depth_range: menghasilkan lima nilai yang terdistribusi merata antara 1 sampai 50.
-
-
Variabel untuk Menyimpan Hasil Terbaik
Selanjutnya, kita perlu mendefinisikan dua variabel yang akan digunakan untuk melacak hasil terbaik selama iterasi dijalankan.-
best_accuracy: menyimpan akurasi tertinggi yang dicapai selama proses pelatihan.
-
best_params: menyimpan kombinasi hyperparameter yang menghasilkan akurasi terbaik.
-
-
Loop Untuk Hyperparameter Tuning
Perulangan ini ditandai dengan dua buah loop yang bergandengan dengan tugas yang berbeda.-
Loop pertama bertugas untuk mengulang seluruh data berdasarkan nilai n_estimators.
-
Loop kedua bertugas untuk mengulang seluruh data berdasarkan nilai max_depth.
-
-
Mencatat Eksperimen Menggunakan MLflow
Setiap kombinasi parameter diuji dalam eksperimen MLflow yang terpisah menggunakan with mlflow.start_run(). Nama eksperimen diberikan berdasarkan kombinasi hyperparameter saat ini (elastic_search_<n_estimators>_<max_depth>). -
Training dan Evaluation Model
-
Model RandomForestClassifier dibuat berdasarkan nilai hyperparameter n_estimators dan max_depth. Di lain sisi, kita juga menggunakan hyperparameter random_state=42 untuk hasil yang konsisten.
-
Model dilatih menggunakan data pelatihan (X_train, y_train) dengan metode .fit().
-
Akurasi model dihitung menggunakan data pengujian (X_test, y_test) melalui metode .score().
-
-
Mencatat Seluruh Metrics pada MLflow Tracking
Dengan mlflow.autolog(), semua parameter, metrik, dan artefak model secara otomatis dicatat ke MLflow Tracking. Di lain sisi, kode ini juga menambahkan akurasi model sebagai metrics tambahan secara eksplisit menggunakan mlflow.log_metric(“accuracy”, accuracy) agar dapat dibandingkan secara langsung. -
Menyimpan Model Yang Lebih Baik
Jika akurasi model yang dibangun lebih tinggi daripada best_accuracy sebelumnya, hasil tersebut akan memperbarui variabel best_accuracy dan menyimpan model pada Tracking.
Silakan ambil secangkir kopi dan beristirahat sejenak karena proses ini cukup memakan waktu (tergantung spesifikasi). Setelah seluruh iterasi selesai, variabel best_accuracy dan best_params menyimpan informasi tentang model dengan performa terbaik dan kombinasi hyperparameter yang digunakan. Semua eksperimen dan model dicatat ke MLflow, memungkinkan pengguna untuk memantau dan membandingkan hasil melalui MLflow Tracking UI.
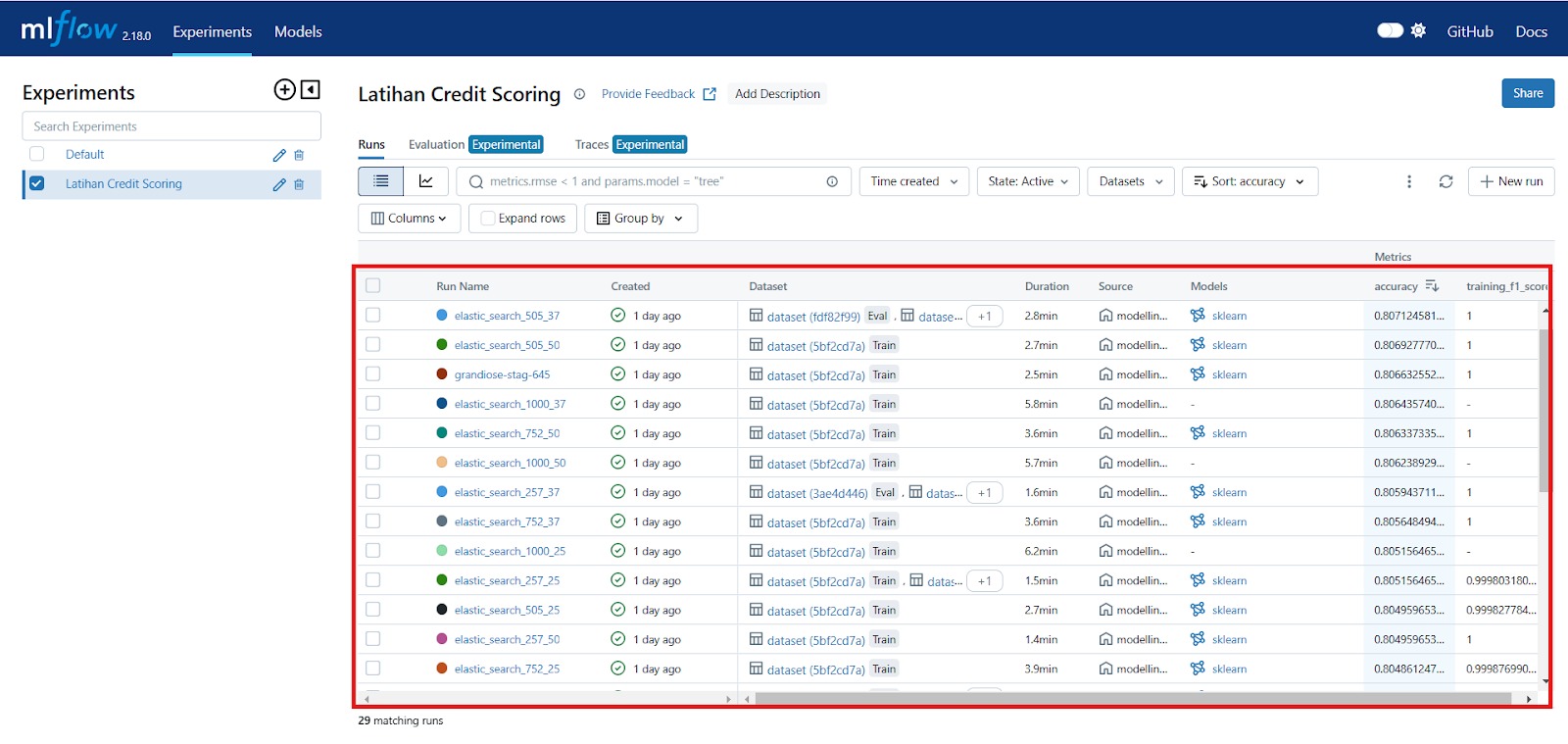
Menariknya, MLflow juga menyediakan fitur yang dapat membandingkan berbagai macam parameter dan metriks agar Anda dapat melihat dan memilih model terbaik dengan lebih mudah seperti berikut.
Silakan Anda pilih seluruh eksperimen seperti berikut lalu pilih tombol “Compare” untuk membandingkan seluruh eksperimen yang sudah dilakukan.
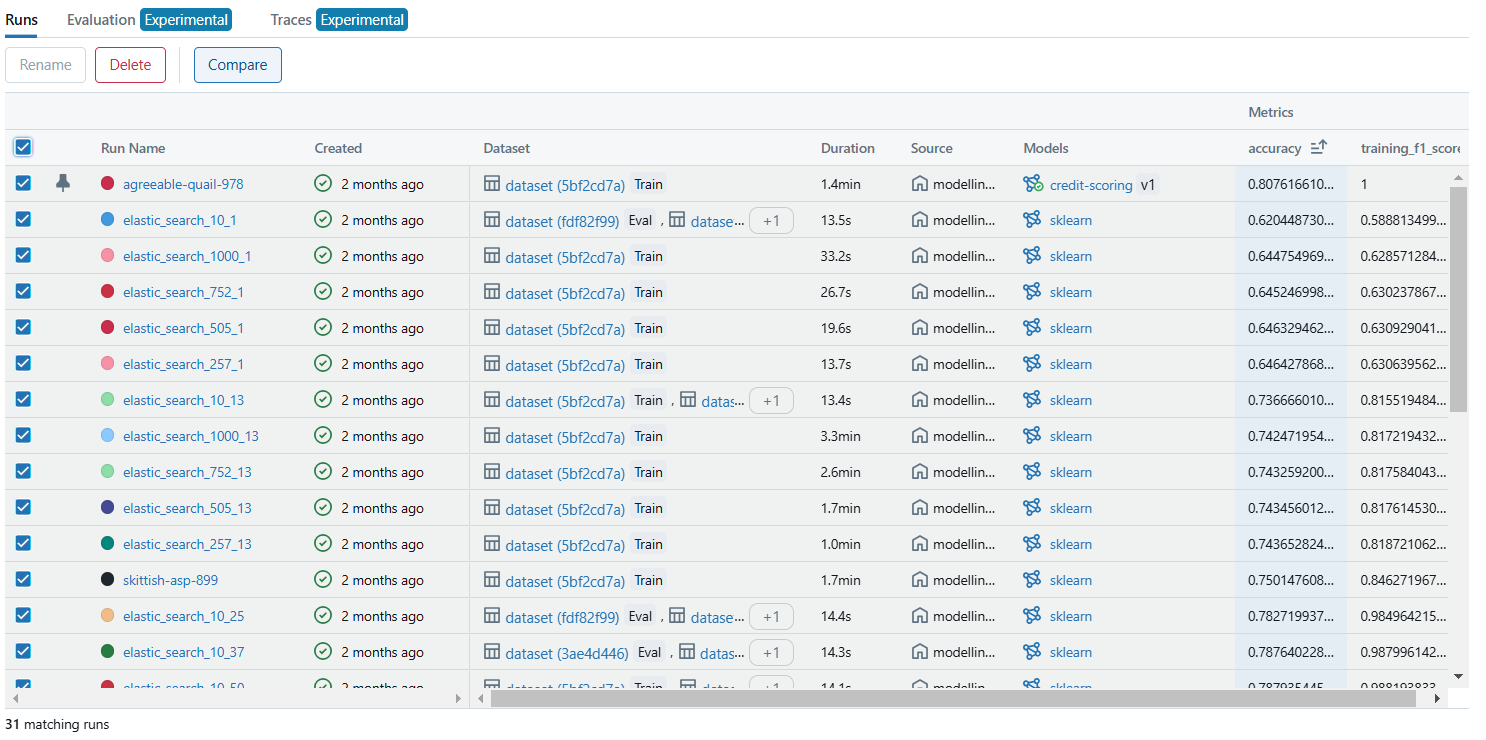
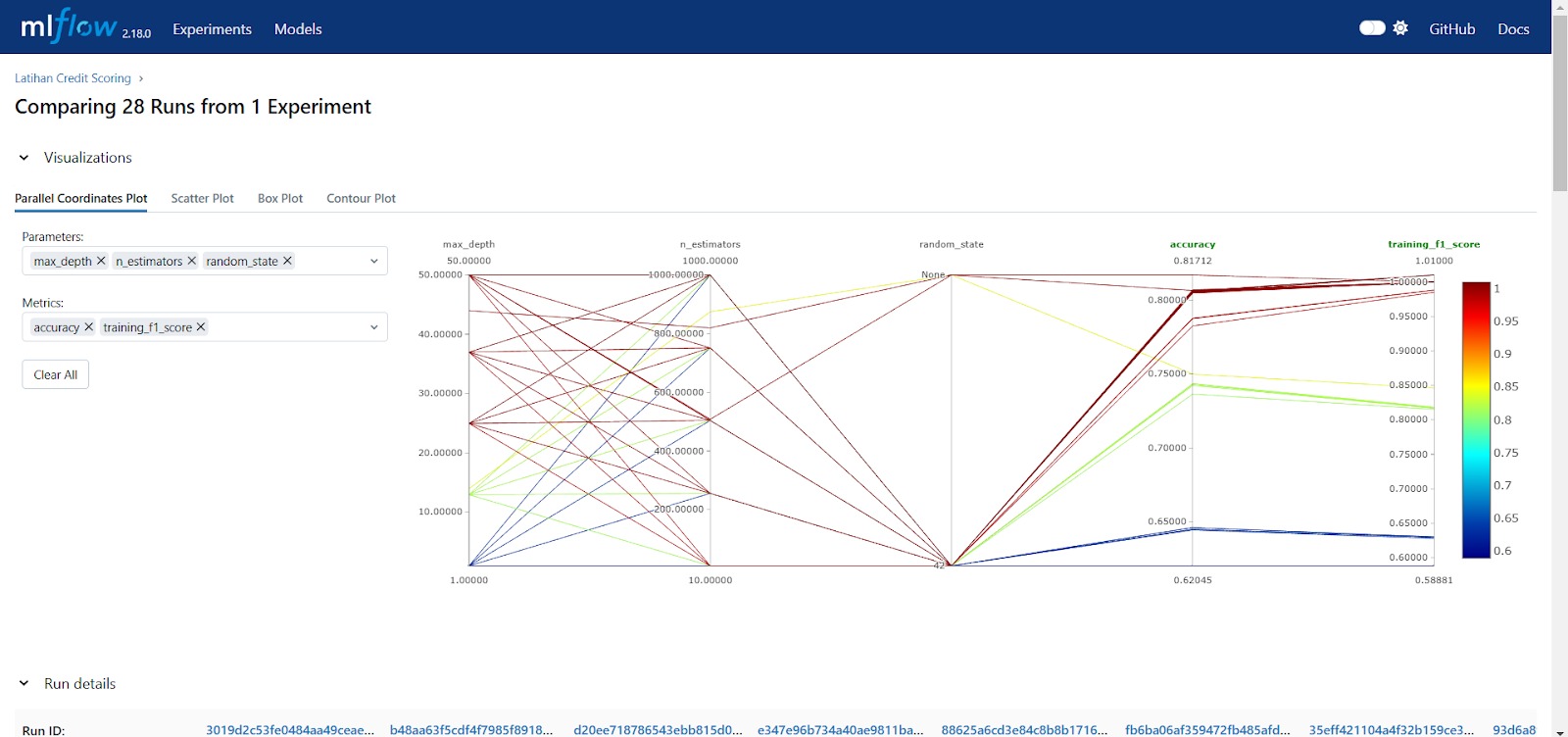
Apakah sampai di sini semuanya sudah selesai? Tentunya tidak, karena selanjutnya kita perlu membuat MLproject agar dapat melakukan proses CI menggunakan GitHub Actions. Hal pertama yang perlu kita lakukan yaitu membuat sebuah folder MLproject yang berisikan dependensi beserta perintah untuk menjalankan MLflow run.
Untuk memulai latihan CI, silakan Anda buat sebuah folder proyek baru dengan struktur seperti berikut ini.
- ├── Latihan-CI (folder)
- ├── MLproject (folder)
- ├── (nantinya file Anda ada di sini)
Setelah folder dibuat, Anda perlu membuat satu file bernama MLproject—ya, betul namanya memang sama dengan folder yang dibuat. Sebagai catatan, nama file ini tidak boleh diubah karena sintaks dasar pada perintah mlflow run akan mencari file ini secara default.
-
name: latihan-cs-mlflow
-
conda_env: conda.yaml
- entry_points:
- main:
- parameters:
- n_estimators: {type: int, default: 505}
- max_depth: {type: int, default: 35}
- dataset : {type: string, default: “train_pca.csv”}
- command: “python modelling.py {n_estimators} {max_depth} {dataset}”
Kode di atas merupakan file konfigurasi MLflow Project yang berfungsi untuk mendefinisikan dan mengatur cara menjalankan proyek machine learning secara otomatis menggunakan MLflow Pipelines atau MLflow CLI. Tujuan utama dari file ini adalah untuk menyediakan struktur standar agar proyek dapat dijalankan di berbagai lingkungan dengan parameter yang terdefinisi sempurna.
Jika Anda perhatikan, terdapat tiga buah struktur utama dari file MLproject yang meliputi name, conda_env, dan entry_points. Kami yakin, beberapa dari Anda mungkin belum familier dengan struktur tersebut karena materi tersebut condong ke software engineering. Oleh karena itu, mari kita bahas sekilas agar memiliki perspektif yang sama.
-
name: latihan-cs-mlflow
Bagian ini mendefinisikan nama proyek sebagai latihan-cs-mlflow. Nama ini berguna sebagai identitas proyek ketika Anda menjalankan atau membagikan proyek tersebut. Dengan adanya nama ini proyek dapat dengan mudah dikenali, terutama jika ada banyak proyek yang serupa di lingkungan pengembangan Anda. -
conda_env: conda.yaml
File conda.yaml biasanya berisi informasi tentang versi Python dan library yang diperlukan agar proyek dapat berjalan dengan baik. Anda dapat membuat file ini secara mandiri atau mengunduh conda.yaml melalui logging MLflow Tracking UI yang sudah dibuat sebelumnya. -
Entry_points:
Entry point adalah perintah yang akan dijalankan oleh MLflow ketika proyek dieksekusi. Dalam kode ini, hanya ada satu entry point bernama main, yang bertanggung jawab untuk menjalankan skrip modelling.py dengan parameters yang dapat disesuaikan untuk menjalankan command.-
Parameter
Bagian ini mendefinisikan parameter yang bisa diubah oleh pengguna saat menjalankan proyek. Pada kasus ini kita akan menggunakan n_estimators, max_depth dan dataset. Jika Anda lupa mengenai hyperparameter yang digunakan silakan kunjungi kelas Machine Learning untuk Pemula, ya. -
Command
Bagian ini mendefinisikan perintah yang akan dijalankan oleh MLflow saat entry point main dipanggil. Perintah ini menjalankan skrip Python bernama modelling.py dengan parameter yang dapat kita sesuaikan (ataupun dibiarkan default).
-
Sebagai informasi, nantinya Anda bisa menambahkan beberapa entry points yang berisikan perintah lainnya sesuai dengan proyek yang sedang dibangun.
Intinya, kode di atas memberikan fleksibilitas kepada pengguna sehingga dapat dengan mudah menjalankan eksperimen, bahkan dengan konfigurasi hyperparameter yang berbeda tanpa perlu mengubah kode asli secara manual.
Setelah file MLproject ditemukan, fungsi runs akan mencari file conda.yaml agar dapat mengeksekusi dan menginstal dependencies dan library yang dibutuhkan untuk membangun ulang proyek machine learning pada environment yang baru. Hal ini sangat penting dalam pengembangan proyek machine learning yang melibatkan banyak eksperimen dan kolaborasi tim, karena memastikan bahwa semua anggota tim bekerja di lingkungan yang sama dan menghasilkan hasil yang konsisten.
Seperti yang sudah kita bahas sebelumnya, terdapat beberapa cara untuk membuat file conda.yaml mulai dari membuat secara manual, menggunakan pip freeze atau pipreqs, hingga mengunduh file .yaml melalui artefak MLflow. Pada latihan ini, kita akan menggunakan file conda.yaml yang dihasilkan ketika membangun model sebelumnya seperti berikut.
Anda dapat mengunduh file di atas atau melakukan copy seluruh isi file tersebut ke direktori MLproject yang sebelumnya sudah dibuat dengan mengambil dari artefak yang disediakan oleh MLflow Tracking UI.
Silakan Anda pilih model yang sebelumnya di latih melalui MLflow Tracking UI, lalu pilih menu artifacts dan pilih conda.yaml.
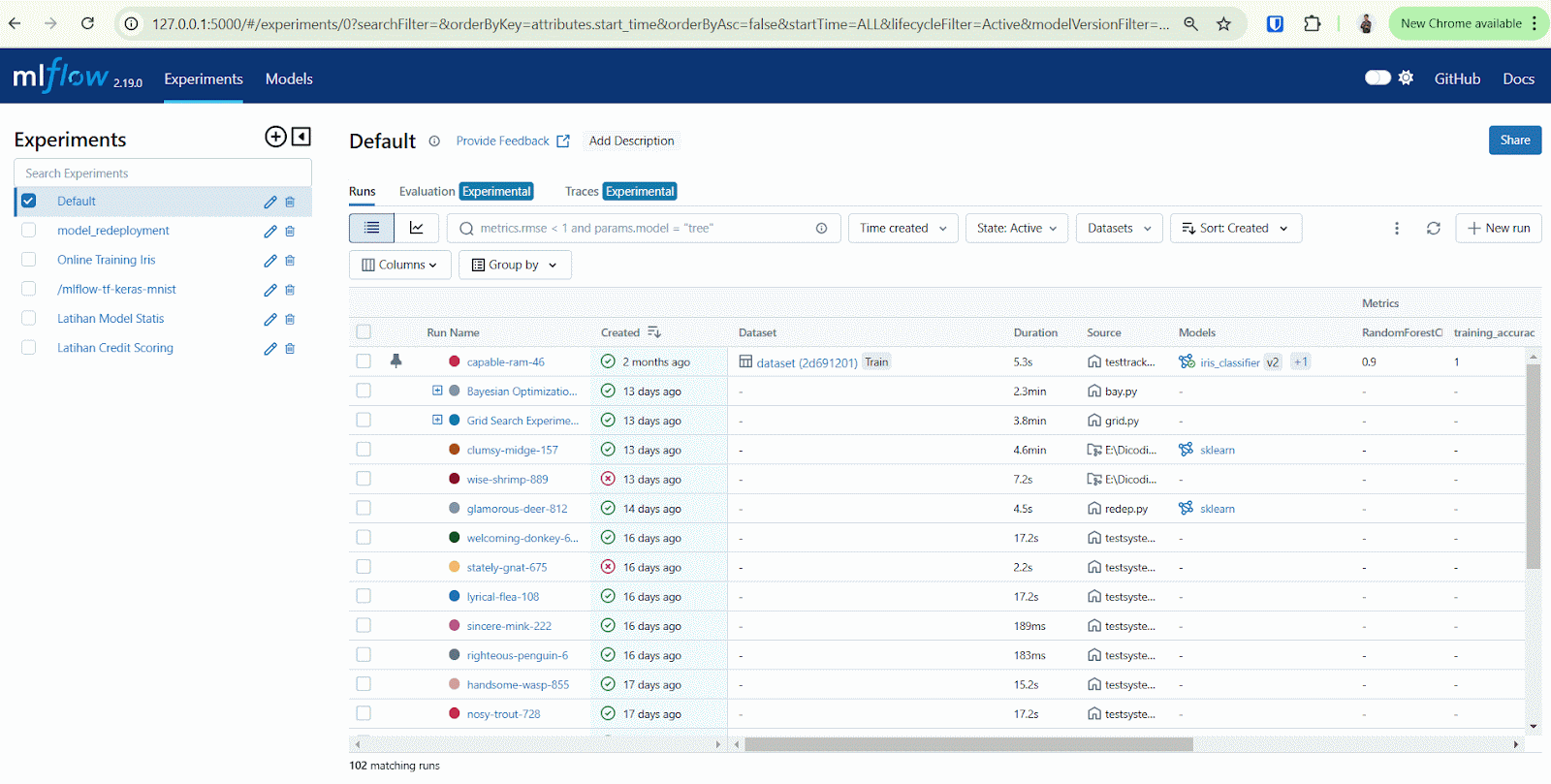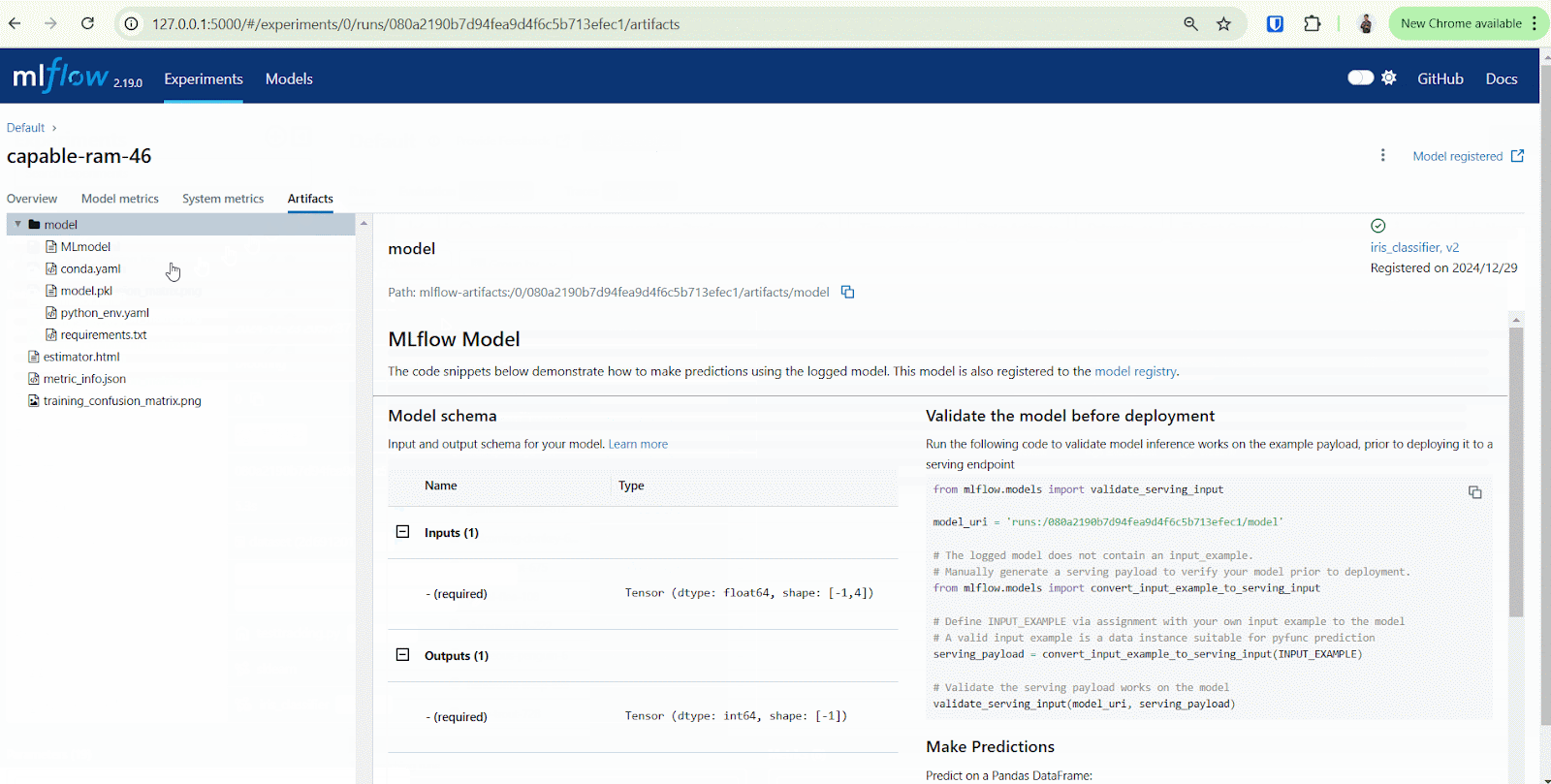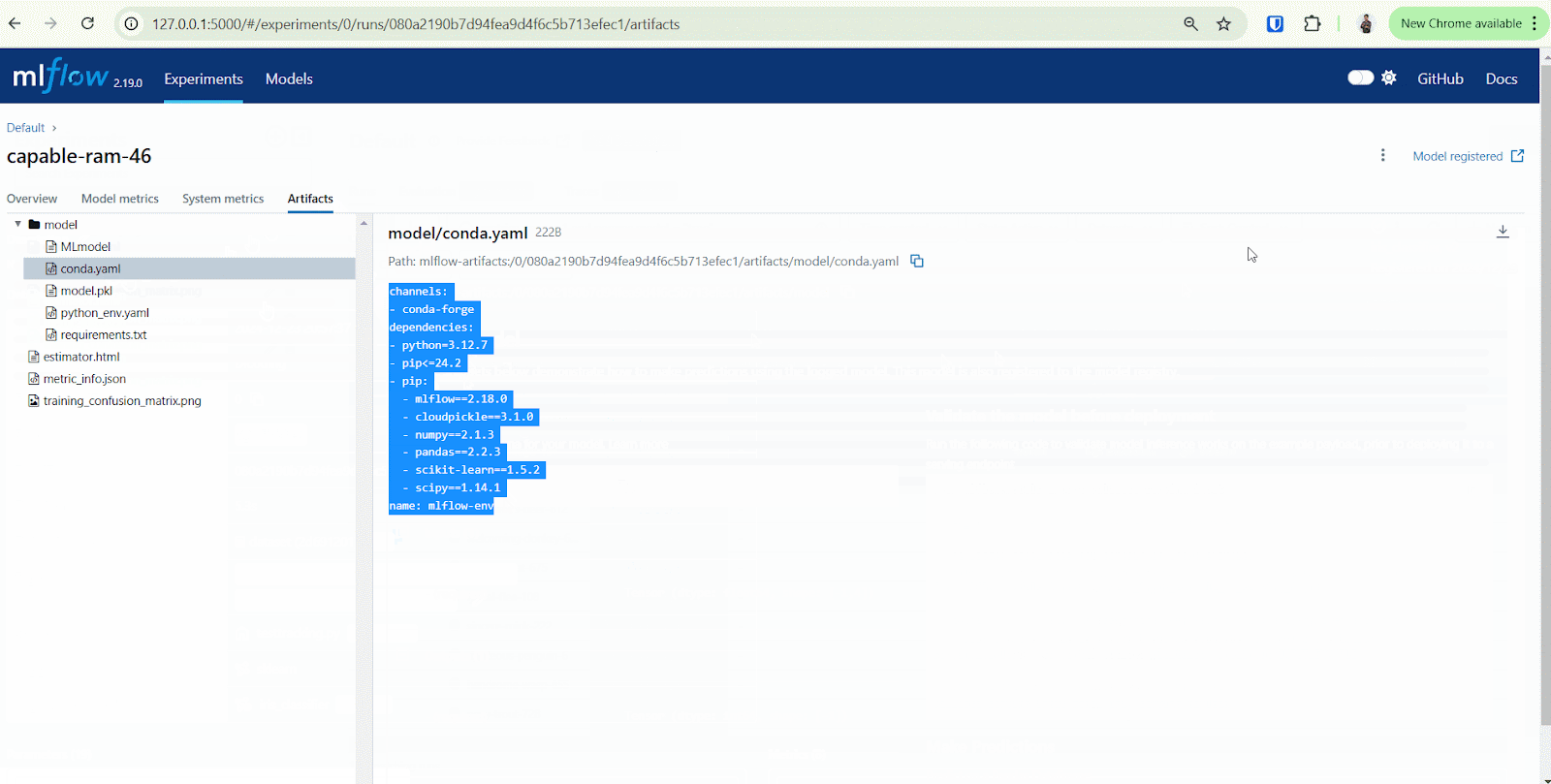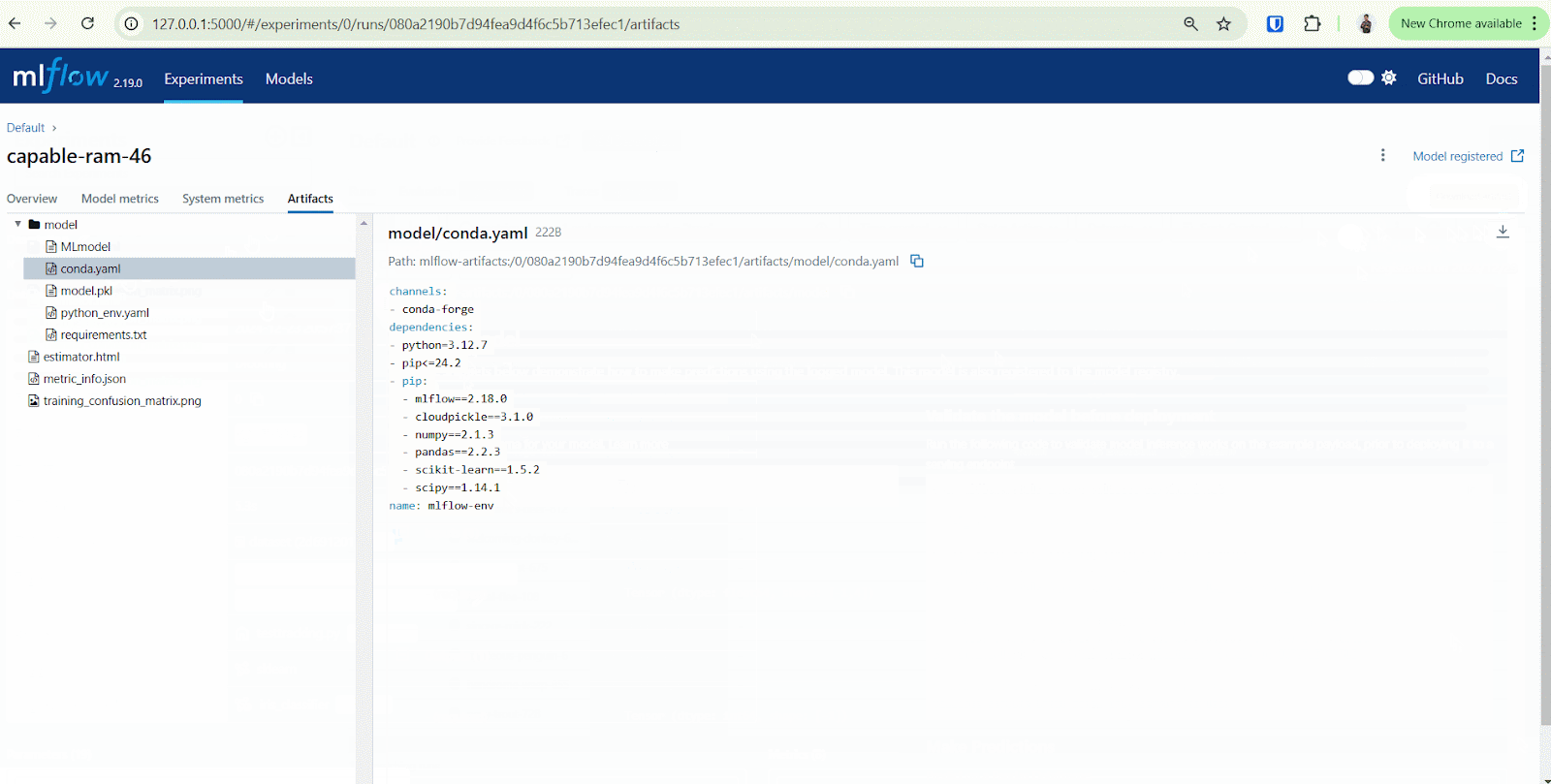
Satu hal yang perlu Anda perhatikan yaitu mengenai nama file yang disimpan. Pastikan nama file beserta alamat penyimpanan yang dipanggil pada file MLproject dan .yaml memiliki nama yang sama.
Setelah environment untuk membangun model sudah siap landas, Anda perlu membuat satu file modelling.py untuk membuat ulang model machine learning. Kurang lebih, isi file modelling ini sama dengan kode yang Anda gunakan ketika melatih model di lingkungan lokal komputer. Namun, terdapat beberapa perbedaan yang perlu Anda perhatikan. Sebelum kita menilik perbedaannya bersama-sama, silakan Anda amati kode berikut dan cari perbedaannya.
- import mlflow
- import pandas as pd
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.model_selection import train_test_split
- import random
- import numpy as np
- import os
- import warnings
-
import sys
- if __name__ == “__main__”:
- warnings.filterwarnings(“ignore”)
-
np.random.seed(40)
- file_path = sys.argv[3] if len(sys.argv) > 3 else os.path.join(os.path.dirname(os.path.abspath(__file__)), “train_pca.csv”)
-
data = pd.read_csv(file_path)
- X_train, X_test, y_train, y_test = train_test_split(
- data.drop(“Credit_Score”, axis=1),
- data[“Credit_Score”],
- random_state=42,
- test_size=0.2
- )
- input_example = X_train[0:5]
- n_estimators = int(sys.argv[1]) if len(sys.argv) > 1 else 505
-
max_depth = int(sys.argv[2]) if len(sys.argv) > 2 else 37
- with mlflow.start_run():
- model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
-
model.fit(X_train, y_train)
-
predicted_qualities = model.predict(X_test)
- mlflow.sklearn.log_model(
- sk_model=model,
- artifact_path=“model”,
- input_example=input_example
- )
- model.fit(X_train, y_train)
- # Log metrics
- accuracy = model.score(X_test, y_test)
- mlflow.log_metric(“accuracy”, accuracy)
Berdasarkan kode di atas, apakah Anda menemukan sesuatu hal yang berbeda? Yup, kini kode di atas tidak memiliki tracking_uri sebagai penyimpanan metrics dan model setelah model berhasil dibangun.
Mungkin tebersit di benak Anda sebuah pertanyaan “Mengapa kita menghapus tracking_uri? Bukankah dengan begitu kita tidak bisa menyimpan artefak dan metrics yang dihasilkan?” Jika Anda berpikir demikian, jawabannya adalah benar teman-teman. Namun, tracking_uri ini dapat digunakan kembali ketika Anda memiliki sebuah VM atau server yang terhubung dengan MLflow Tracking UI.
Alasan latihan ini menghilangkan tracking_uri karena kita tidak akan menggunakan atau membuat VM/server (setidaknya sampai pada materi ini) untuk menyimpan seluruh metrics beserta artefak model yang dibuat. Selain itu, GitHub Actions sebagai platform untuk menjalankan CI pada proyek ini tidak dapat mengakses ip local atau remote repository MLflow Tracking UI.
Lalu, bagaimana solusinya? Salah satu yang bisa dilakukan ketika tidak memiliki bucket, VM, Server, dan lain sebagainya yaitu menyimpan seluruh logging model pada repositori GitHub itu sendiri.
Tentunya dengan menggunakan cara ini, Anda tidak dapat melihat UI dan membandingkan model secara langsung, tetapi hal itu bukan menjadi masalah besar. Asumsinya, penggunaan MLproject ini sudah diatur sedemikian rupa sehingga ketika dijalankan akan menghasilkan model terbaik yang sudah Anda hasilkan sebelumnya.
Pro Tips
Sejatinya, best practices untuk menjalankan MLflow Project adalah ketika Anda sudah memiliki tim yang bekerja bersamaan beserta infrastruktur yang mendukung. Nantinya, seluruh perubahan yang dibuat oleh ML Engineer akan terintegrasi dengan sebuah VM yang dapat dimonitoring oleh Lead atau stakeholder yang bertanggung jawab untuk melakukan deployment.
Kondisi ini juga bisa dilakukan dengan catatan Anda bersedia untuk membayar sebuah VM atau server untuk menjalankan MLflow Tracking UI secara online.
Sebenarnya, terdapat satu buah server gratis untuk menggunakan tracking secara online yaitu Dagshub tetapi dengan syarat dan ketentuan yang berlaku.
Sampai di sini, seharusnya Anda sudah memiliki sebuah struktur folder yang berisikan MLproject, conda.yaml, dan modelling.py dengan urutan seperti berikut.
Selanjutnya, Anda perlu menambahkan dataset yang akan dilatih oleh file modelling.py, pada tahap ini, Anda dapat menggunakan berbagai sumber baik itu cloud repository seperti GitHub, Google Drive, Kaggle ataupun menyimpan langsung pada repository MLproject ini.
Karena latihan ini bertujuan untuk membiasakan alur kerjanya terlebih dahulu, kita akan menggunakan dataset yang disimpan pada repository MLproject. Namun, dengan situasi seperti ini, Anda perlu mengubah penyimpanan dataset setiap kali ingin melakukan re-training.
Sebenarnya, Anda dapat mengubah alamat dataset yang digunakan menjadi sebuah alamat tautan yang terhubung ke suatu database ataupun penyimpanan online lainnya. Namun, Anda perlu menambahkan proses cleaning dan preprocessing pada MLproject atau GitHub Actions (akan kita pelajari nanti).
Selamat, sampai pada tahap ini, Anda dapat menjalankan MLproject pada lingkungan kerja yang baru tanpa khawatir mengalami konflik dependency dan library lagi. Sebelum masuk ke GitHub Actions untuk melakukan proses CI, silakan gunakan kode berikut pada environment local guna memastikan seluruh tahapannya berjalan dengan baik. Sebagai catatan, pastikan Tracking UI yang ada pada komputer lokal Anda masih berjalan dengan baik.
- mlflow run <path ke MLproject> --env-manager=local
Jika semuanya berjalan dengan lancar, kode tersebut akan menghasilkan artefak dan metrics yang disimpan pada penyimpanan lokal Anda. Bagaimana, keren ‘kan? Kini Anda dapat membuat model dengan dataset dan hyperparameter yang dinamis hanya dengan satu baris kode. Namun, seluruh proses tersebut masih sangat kuno karena Anda harus mengubah kode, menjalankan MLproject, dan menyimpan model dari lokal komputer ke cloud repository.
Sekarang, bayangkan kita ingin membangun pipeline yang secara otomatis menjalankan eksperimen tersebut setiap kali ada perubahan kode. Di sinilah GitHub Actions berperan sebagai kunci untuk membangun pipeline tersebut. Dengan menghubungkan MLproject dan GitHub Actions, kita dapat merangkai proses training, evaluasi, dan deployment model menjadi alur kerja yang otomatis dan efisien.
Pada latihan ini, kita akan berfokus untuk membuat pipeline CI hingga tahap training dan evaluasi. Anda perlu menyimpan seluruh folder MLproject pada GitHub repository pribadi agar memiliki akses penuh terhadap seluruh perubahan yang terjadi.
Kami sangat menyarankan untuk membuat repository baru lalu push folder latihan ini agar terhindar dari conflict workflow.
Jika repository tersebut sudah dibuat dan seluruh folder MLproject sudah tersimpan dengan baik, selanjutnya Anda akan bermain-main pada halaman Actions dengan memilih “set up a workflow yourself” seperti pada latihan sebelumnya.
Masih ingatkan, workflow CI yang sudah Anda buat pada latihan sebelumnya? Kini saatnya kami membayar hutang karena pada latihan ini kita akan membahas dengan sangat detail workflow CI yang akan dibangun. Mari kita mulai dengan menambahkan nama dan kondisi yang akan memicu workflow ini dijalankan.
-
name: CI
- on:
- push:
- branches:
- - main
- pull_request:
- branches:
- - main
Pada kode di atas, baris “name : CI” mendefinisikan nama workflow sebagai CI. Nama ini digunakan untuk mengidentifikasi workflow pada GitHub Actions. Selanjutnya, kode yang dimulai dengan “on:” merupakan kondisi (events) yang akan memicu workflow CI. Dua jenis peristiwa utama yang didefinisikan di sini adalah push dan pull_request, keduanya mengacu pada branch main. Dengan kode tersebut, workflow akan dijalankan setiap kali ada perubahan (commit) yang di-push dan pull request terhadap branch main.
Setelah dua kondisi tersebut terpenuhi, kita perlu mendefinisikan env yang akan digunakan selama proses CI dijalankan. Pada kasus ini, kita akan menggunakan dataset yang disimpan pada repository MLproject sehingga hanya menambahkan kode berikut.
- env:
- CSV_URL: “MLproject/train_pca.csv”
Selanjutnya, Anda perlu mengatur konfigurasi workflow CI (Continuous Integration) pada GitHub Actions yang bertujuan untuk menjalankan proyek machine learning berbasis MLflow Project.
Workflow ini bertugas untuk mengotomatiskan proses pengecekan repositori, menyiapkan lingkungan Python, menginstal dependensi yang diperlukan, dan menjalankan proyek yang didefinisikan dalam file MLproject. Biasanya, kode ini diawali dengan tag “jobs:” yang bertugas mendefinisikan daftar pekerjaan (jobs) yang akan dijalankan dalam workflow. Dalam kode ini, kita hanya akan menggunakan satu job bernama build yang akan dijalankan pada OS ubuntu.
Untuk mengerjakan suatu pekerjaan, tentunya kita perlu mendefinisikan langkah-langkah yang akan dilalui. Pada kasus ini, langkah-langkah tersebut akan ditandai dengan nama “steps:” yang berisikan berbagai macam perintah.
- jobs:
- build:
-
runs-on: ubuntu-latest
- steps:
Mari kita breakdown steps yang akan dilalui pada latihan ini.
| Actions | Penjelasan |
|---|---|
| - uses: actions/checkout@v3 | Kode ini menggunakan perintah bawaan GitHub actions/checkout@v3 untuk mengambil kode dari repositori ke dalam direktori kerja runner. Kode repositori akan diunduh ke lokasi $GITHUB_WORKSPACE, yang merupakan direktori default untuk semua file proyek selama workflow berjalan. |
| # Setup Python 3.12.7 - name: Set up Python 3.12.7 uses: actions/setup-python@v4 with: python-version: “3.12.7” |
Kode ini menggunakan perintah actions/setup-python@v4 untuk menyiapkan lingkungan Python versi 3.12.7 di runner. Langkah ini memastikan bahwa proyek berjalan dengan versi Python yang diinginkan, sehingga menghindari masalah kompatibilitas versi. |
| # Check Env Variables - name: Check Env run: | echo $CSV_URL |
Langkah ini digunakan untuk memastikan bahwa variabel lingkungan telah disiapkan dengan benar sebelum menjalankan proyek. |
| # Install mlflow - name: Install dependencies run: | python -m pip install –upgrade pip pip install mlflow |
Menginstal MLflow yang akan digunakan untuk menjalankan proyek. |
| # Run as a mlflow project - name: Run mlflow project run: | mlflow run MLproject –env-manager=local |
Proses ini akan menjalankan semua langkah yang didefinisikan dalam file MLproject, seperti pelatihan model atau evaluasi hasil dengan parameter yang telah ditentukan. |
Dengan langkah-langkah di atas, Anda dapat memastikan bahwa setiap perubahan pada kode di repositori akan langsung diuji dan dijalankan dalam lingkungan yang konsisten. Namun, permasalahan pada latihan sebelumnya masih belum terselesaikan.
Dengan menggunakan workflow di atas, Anda tidak menyimpan hasil pelatihan apa pun sehingga semuanya akan menguap dengan begitu saja. Solusinya, Anda hanya perlu menambahkan satu steps tambahan yang berisikan perintah untuk menyimpan logging MLflow.
Berhubung kita memiliki beberapa batasan, maka pada latihan ini kita akan menyimpan seluruh artefak pada repository GitHub yang sama dengan folder MLproject.
- # Save models to GitHub Repository
- - name: Save mlruns to repo
-
run: - git config --global user.name $
- git config --global user.email $
- git add mlruns/
- git commit -m “Save mlruns from CI run”
- git push origin master
Sejatinya, kode di atas merupakan langkah-langkah dasar untuk melakukan penyimpanan (commit & push) ke GitHub. Namun, karena proses ini akan dilakukan pada VM yang dibuat oleh GitHub Actions Anda perlu menambahkan credentials akun GitHub yang akan digunakan.
Tantangannya, ketika membuat repository bersifat public maka Anda perlu menyimpan credentials yang digunakan menggunakan fitur secrets yang disediakan oleh GitHub. Silakan ikuti langkah-langkah berikut jika Anda belum familier dengan penggunaan secrets.
-
Pada halaman repository GitHub, silakan pilih menu Settings yang ada pada navbar.
-
Pilih menu Secrets and variables > Actions.**
 **
** -
Terakhir, buatlah beberapa variabel yang berisikan credentials untuk menjalankan proyek.
Setelah berhasil membuat secrets, Anda dapat menjalankan workflow CI tersebut dengan aman dan terhindar dari penyalahgunaan data oleh orang lain. Pada akhirnya, kode Actions yang Anda simpan akan berisikan perintah seperti berikut.
-
name: CI
- on:
- push:
- branches:
- - main
- pull_request:
- branches:
-
- main
- env:
-
CSV_URL: “MLproject/train_pca.csv”
- jobs:
- build:
-
runs-on: ubuntu-latest
- steps:
- # Checks-out your repository under $GITHUB_WORKSPACE
-
- uses: actions/checkout@v3
- # Setup Python 3.12.7
- - name: Set up Python 3.12.7
- uses: actions/setup-python@v4
- with:
-
python-version: “3.12.7”
- # Check Env Variables
- - name: Check Env
-
run: -
echo $CSV_URL
- # Install mlflow
- - name: Install dependencies
-
run: - python -m pip install --upgrade pip
-
pip install mlflow
- # Run as a mlflow project
- - name: Run mlflow project
-
run: -
mlflow run MLproject --env-manager=local
- # Save models to GitHub Repository
- - name: Save mlruns to repo
-
run: - git config --global user.name $
- git config --global user.email $
- git add mlruns/
- git commit -m “Save mlruns from CI run”
- git push origin master
Sebagai catatan, pastikan ketika menyimpan dan melakukan commit kode GitHub Actions tersebut, Anda tidak mengubah ekstensi file (.yml). By default, file yang Anda buat akan tersimpan pada sebuah folder dengan struktur .github\workflow\<nama_workflow>.yml.
Selain itu, GitHub repository hanya menerima file dengan ukuran maksimal 100 MB. Oleh karena itu, Anda dapat menggunakan fitur LFS pada GitHub untuk menyimpan file dengan ukuran lebih dari 100 MB.
Optional Side Quests
Setelah menyelesaikan semua tahapan pada latihan ini tentunya kita merasa owning the world karena dapat menerapkan proses CI pada proyek ML apa pun. Namun, sebenarnya terdapat sebuah permasalahan yang cukup mengganggu karena sering kali terjadi ketika membangun model machine learning.
Sekilas informasi, GitHub hanya bisa menyimpan file normal dengan ukuran maksimal 100 Mb. Terus apa masalahnya? Nah, masalah terjadi ketika Anda membuat model machine learning dengan ukuran lebih dari batasan normal GitHub. Ukuran model machine learning tidak hanya bergantung terhadap ukuran dataset, tetapi dipengaruhi juga oleh pemilihan algoritma dan kompleksitas model. Sehingga, acapkali model yang kita buat melewati batas tersebut.
Tentu terdapat berbagai macam pilihan untuk mengatasi permasalahan tersebut, mulai dari penggunaan Bucket, Cloud Repository, VM, hingga menyewa services. Namun, hampir seluruh opsi tersebut membutuhkan biaya tambahan sehingga tidak ramah untuk mahasiswa atau sekadar riset pribadi.
Duitnya dari mana?
Sebagai media pembelajaran yang ramah terhadap semua kalangan, terdapat pilihan gratis yang dapat kalian pelajari untuk mengatasi permasalahan tersebut.
Pertama, Anda dapat menggunakan GitHub LFS agar dapat menyimpan file dengan ukuran di atas 100 Mb ke repository yang sama. Dengan menggunakan pilihan ini, Anda dapat memodifikasi kode CI sebelumnya dengan mengubah run Save mlruns to repo menjadi seperti berikut.
- - name: Set up Git LFS
-
run: - git config --global user.name $
- git config --global user.email $
- git lfs install
- git lfs track “mlruns/**”
- git add .gitattributes
-
git commit -m “Track large files in mlruns with Git LFS” true -
git push origin main
- # Save models to GitHub Repository
- - name: Save mlruns to repo
-
run: - git config --global user.name $
- git config --global user.email $
- git add -f mlruns/
-
git commit -m “Save mlruns from CI run” true - git push origin main
Kini Anda dapat menyimpan file dengan ukuran lebih dari 100 Mb ke repository GitHub sehingga tidak ada masalah ketika membangun model machine learning menggunakan GitHub Actions. Kekurangannya, GitHub LFS juga memiliki batasan terlebih ketika Anda menggunakan akun gratis. Jika penasaran, Anda dapat membaca informasi tersebut pada tautan di sini.
Kedua, Anda dapat memanfaatkan Google Drives sebagai media penyimpanan artefak model machine learning. Dengan demikian, batasan penyimpanan Google Drives ini mengikuti limitasi dari akun Google yang Anda atau tim pengembang gunakan. Kelebihannya, metode ini memiliki fleksibilitas yang lebih tinggi karena terintegrasi dengan Google Workspace.
- - name: Install Python dependencies
-
run: -
pip install --upgrade google-auth google-auth-oauthlib google-auth-httplib2 google-api-python-client
- - name: Upload to Google Drive
- env:
- GDRIVE_CREDENTIALS: $ # Mengambil kredensial dari GitHub Secrets
- GDRIVE_FOLDER_ID: $ # Mengambil kredensial dari GitHub Secrets
-
run: - python MLproject/upload_to_gdrive.py
Metode ini membutuhkan beberapa tahapan yang perlu Anda lakukan mulai dari membuat akun pada Google Cloud Console hingga membagikan folder Google Drives. Jika Anda berminat menggunakan metode ini silakan ikuti langkah-langkah berikut.
-
Membuat/Menentukan Google Cloud Project
-
Buka Google Cloud Console
-
Di bagian atas (samping logo Google Cloud), klik pilih project atau select project.
-
Jika belum punya project, klik New Project / Project Baru.
-
Beri nama sesuai keinginan, misalnya: “drive-api-project”.
-
Pastikan organisasi/billing account-nya benar (jika ada).
-
Klik Create.
-
-
Pastikan Anda sekarang aktif di project tersebut.
-
-
Mengaktifkan Google Drive API di Project
-
Masih di Google Cloud Console, buka menu APIs & Services > Library.
-
Cari Google Drive API.
-
Klik Enable (jika belum diaktifkan).
-
Tunggu beberapa saat hingga statusnya menjadi API Enabled.
-
-
Membuat Service Account
-
Di Google Cloud Console, buka menu APIs & Services > Credentials.
-
Klik + CREATE CREDENTIALS dan pilih Service account.
-
Di form pembuatan:
-
Masukkan Service account name (misalnya: “drive-api-service”).
-
Service account ID akan terisi otomatis (berformat something@project-id.iam.gserviceaccount.com).
-
-
(Opsional) Di langkah berikutnya, Anda bisa beri peran (role) tertentu, tetapi untuk Drive akses sering kali tidak diatur di sisi GCP IAM, melainkan di sisi Drive/Google Workspace.
-
Klik Done/Selesai.
-
-
Membuat JSON Key (Credentials) untuk Service Account
-
Masih di halaman Credentials, klik nama service account yang baru dibuat (atau klik tombol Manage service accounts).
-
Pada service account tersebut, cari bagian Keys. Klik ADD KEY > Create new key.
-
Pilih JSON, lalu klik Create.
-
Akan otomatis mendownload file .json. Inilah yang nanti dipakai di kode Python Anda (via service_account_info).
-
Penting: File .json ini adalah credential sensitif, jangan bagikan ke publik atau commit secara terbuka di repo.
-
Mengundang Service Account ke Shared Drive (Drive Bersama)
Langkah ini penting jika Anda ingin service account dapat menyimpan langsung di Shared Drive.-
Buka drive.google.com dengan akun Anda (yang memiliki hak Manager / Content manager di Shared Drive).
-
Pilih Shared Drives/Drive bersama di sisi kiri.
-
Buka Shared Drive yang ingin Anda gunakan.
-
Klik nama Shared Drive > Manage members/Kelola anggota.
-
Masukkan alamat email service account (formatnya seperti service-account-name@project-id.iam.gserviceaccount.com).
-
Beri peran minimal Content Manager atau Editor.
-
Simpan.
-
Sekarang service account tersebut adalah anggota Shared Drive dan dapat mengunggah/membaca file di sana (tergantung peran yang Anda berikan).
-
Membuat GitHub Secret Keys
-
Buatlah secret baru yang dengan nama GDRIVE_CREDENTIALS yang berisikan file credentials dari .json yang dibuat oleh API Services seperti berikut.
- {
- “type”: “service_account”,
- “project_id”: “”,
- “private_key_id”: “”,
- “private_key”: “”,
- “client_email”: “”,
- “client_id”: “”,
- “auth_uri”: “”,
- “token_uri”: “”,
- “auth_provider_x509_cert_url”: “”,
- “client_x509_cert_url”: “”,
- “universe_domain”: “”
- }
Pastikan Anda menyertakan value dari masing-masing key di atas ya.
-
Terakhir, buat juga secret key dengan nama GDRIVE_FOLDER_ID yang berisikan ID folder Google Drives seperti contoh berikut ini.
https://drive.google.com/drive/folders/1f5ecMJvCs6jYT2kkeNn0zoZ9xyXAWFRC
**Nantinya](https://drive.google.com/drive/folders/1f5ecMJvCs6jYT2kkeNn0zoZ9xyXAWFRC%EF%BF%BCNantinya), secret tersebut hanya berisikan kode terakhir dari tautan Google Drives seperti berikut [1f5ecMJvCs6jYT2kkeNn0zoZ9xyXAWFRC**
-
Langkah terakhirnya, Anda perlu menambahkan sebuah file yang bertugas menyimpan seluruh logging ke Google Drives. Contohnya, Anda dapat melihat kode upload_to_gdrive.py.
Selamat! Anda telah berhasil menyelesaikan seluruh rangkaian latihan version control dan Continuous Integration menggunakan MLflow dan GitHub Actions. Pencapaian ini menandakan dedikasi dan kegigihan Anda dalam mempelajari konsep-konsep penting dalam pengembangan machine learning modern.
Anda kini telah dibekali dengan keterampilan praktis untuk membangun alur kerja yang reproducible, terotomatisasi, dan efisien. Teruslah bereksperimen dan menerapkan pengetahuan yang telah Anda peroleh untuk menghasilkan solusi machine learning yang inovatif dan berdampak.
Catatan Penting
Materi ini bukanlah best practices yang sering digunakan di industri karena mengandalkan platform gratis secara end-to-end, nantinya Anda akan belajar best practices penggunaan GitHub Actions yang dipadukan dengan MLflow dan Docker pada materi selanjutnya.
Silakan beristirahat sejenak, membuat secangkir kopi, dan melihat pemandangan di luar sana. Selanjutnya, kita akan membahas materi tidak kalah seru yaitu mengenai pembangunan model yang lebih mahir. Jika sudah siap kembali, kami tunggu pada modul berikutnya. Semangat!
Rangkuman Membangun dan Mengelola Metadata dengan Tools Open-Source
Version Control
Version control merupakan salah satu pilar penting dalam pengembangan perangkat lunak secara umum maupun spesifik seperti data science dan machine learning. Dalam dunia yang serba cepat dan kolaboratif ini, pengelolaan perubahan pada kode, data, dan dokumen menjadi hal yang krusial. Bayangkan Anda membuat sebuah proyek besar tanpa sistem yang bisa melacak perubahan—bisa kacau, bukan? Sebagai manusia yang tak lepas dari kata “lupa”, tentu akan sedikit kewalahan jika ingin melakukan rollback (kembali ke kode sebelumnya), apalagi ketika kode memiliki jumlah history perubahan yang sangat banyak tanpa adanya identitas.
Version control adalah sistem atau pendekatan yang digunakan untuk mencatat, mengelola, dan melacak perubahan pada file atau kumpulan file seiring waktu. Dalam dunia teknologi, version control sangat erat kaitannya dengan pengembangan perangkat lunak, dokumentasi, hingga pengelolaan data. Namun, version control tidak hanya berkutat di teknologi saja melainkan dapat diterapkan secara umum pada berbagai macam bidang.
Tanpa version control system (VCS) biasanya kita akan menemui beberapa permasalahan seperti berikut ini.
- Kehilangan jejak perubahan: sulit melacak revisi mana yang terbaik atau perubahan apa yang dilakukan.
- Duplikasi file: ruang penyimpanan membengkak dan manajemen file menjadi sulit.
- Konflik versi: jika beberapa orang bekerja pada file yang sama, perubahan dapat saling menimpa.
- Kolaborasi yang rumit: berbagi dan menggabungkan perubahan menjadi sulit dan rawan kesalahan.
Masalah-masalah ini mengakibatkan inefisiensi, potensi kesalahan, dan manajemen proyek yang kacau. Oleh karena itu, VCS menjadi sangat penting karena pendekatan ini menyimpan setiap perubahan sebagai snapshot, yang mencakup informasi seperti berikut.
- Nama pengguna yang membuat perubahan.
- Waktu perubahan.
- Bagian file yang berubah.
Dengan VCS, pengguna dapat melihat riwayat perubahan, mengembalikan file ke versi sebelumnya, dan mengintegrasikan kontribusi dari banyak pengguna tanpa konflik. Lalu, apa peran VCS? Mari kita bahas beberapa peran pentingnya.
- Melacak Riwayat Perubahan: memungkinkan pelacakan setiap perubahan (siapa, apa, kapan), memahami alasan perubahan, dan membandingkan versi.
- Reproduksi dan Pemulihan: memudahkan pengembalian file ke versi sebelumnya jika terjadi kesalahan, tanpa kehilangan data.
- Kolaborasi yang Lebih Efektif: memungkinkan banyak anggota tim bekerja pada file yang sama tanpa konflik, dengan fitur branching (pencabangan) dan merging (penggabungan).
- Efisiensi dan Produktivitas: mengurangi pekerjaan manual dengan otomatisasi pencatatan perubahan, integrasi file, dan manajemen versi.
- Audit yang Lebih Mudah: menciptakan jejak audit yang lengkap, penting untuk proyek yang membutuhkan akuntabilitas tinggi.
- Eksperimen Pengembangan: memungkinkan pembuatan cabang eksperimental tanpa memengaruhi versi utama, dan membandingkan hasil eksperimen.
- Manajemen Risiko: meminimalkan risiko kehilangan data akibat kesalahan manusia atau kerusakan sistem.
VCS mengatasi masalah yang timbul akibat penamaan file yang berubah-ubah dan banyaknya revisi. VCS memberikan kemampuan untuk melacak perubahan, mengelola cabang, menangani konflik, dan menyediakan riwayat versi. VCS menghilangkan kekhawatiran tentang kehilangan jejak revisi, duplikasi file, dan kesulitan kolaborasi.
Jenis-Jenis Version Control
Setelah memahami pentingnya version control system (VCS) sebagai “asisten digital” yang andal untuk mengelola perubahan, kolaborasi, dan pemulihan, kita perlu mengetahui bahwa ada berbagai jenis VCS, masing-masing dengan karakteristik dan fungsinya sendiri.
Secara umum, VCS dapat dikategorikan menjadi empat tipe utama yaitu Distributed, Centralized, Lock-based, dan Optimistic. Setiap tipe memiliki keunggulan dan kelemahan, yang dirancang untuk memenuhi kebutuhan proyek yang berbeda.
- Distributed Version Control System (DVCS)
- Setiap developer memiliki salinan lengkap repositori (semua file, perubahan, dan riwayat).
- Developer dapat bekerja secara independen tanpa koneksi internet atau server utama.
- Sinkronisasi dengan repositori pusat atau pengguna lain dilakukan saat diperlukan.
- Keunggulan
- Fleksibilitas (bekerja offline), keamanan data tinggi (setiap pengguna memiliki salinan lengkap), branching dan merging yang fleksibel.
- Kelemahan
- Membutuhkan lebih banyak ruang penyimpanan, kompleksitas lebih tinggi.
- Centralized Version Control System (CVCS)
- Mengandalkan server terpusat untuk menyimpan semua file, perubahan, dan riwayat versi.
- Developer terhubung ke server utama untuk checkout (mengunduh file), melakukan perubahan, dan commit (mengunggah perubahan).
- Keunggulan
- Struktur sederhana, mudah digunakan untuk tim kecil atau proyek dengan kolaborasi terorganisir.
- Kelemahan
- Ketergantungan tinggi pada server pusat, kurang fleksibel dalam branching, dan tidak mendukung pekerjaan offline.
- Lock-based Version Control System
- File yang sedang diedit “dikunci” (locked), mencegah pengguna lain mengubahnya.
- Keunggulan
- Memastikan tidak ada perubahan yang saling menimpa, cocok untuk file yang tidak mudah digabungkan (misalnya, file biner, desain grafis).
- Kelemahan
- Membatasi kolaborasi, pengguna lain harus menunggu kunci dilepas.
- Optimistic Version Control System
- Beberapa pengguna dapat mengedit file yang sama secara bersamaan tanpa penguncian.
- Sistem mencoba menggabungkan (merge) perubahan secara otomatis.
- Jika terjadi konflik, pengguna perlu menyelesaikannya secara manual.
- Keunggulan
- Mendukung kolaborasi dinamis, efisien untuk file yang mudah digabungkan (misalnya, source code, teks).
- Kelemahan
- Membutuhkan upaya tambahan untuk menyelesaikan konflik jika penggabungan otomatis gagal.
Setelah memahami jenis-jenis VCS, langkah selanjutnya adalah memilih tools atau perangkat lunak VCS yang sesuai dengan kebutuhan, ibarat seorang ksatria memilih pedang dan perisainya. Memahami konsep saja tidak cukup; kita perlu menguasai tools VCS yang akan menjadi andalan dalam manajemen kode, kolaborasi, dan kesuksesan proyek.
Tools yang Umum Digunakan
Sebagai developer, kita membutuhkan “alat tempur” terbaik untuk menunjang pekerjaan. Setelah memahami konsep dan jenis-jenis VCS, saatnya berkenalan dengan tools VCS populer seperti Git, SVN, dan Mercurial.
Git
Git adalah tools VCS yang sangat populer. Git memungkinkan developer bekerja sama dalam satu codebase yang sama, melacak perubahan, mengetahui siapa yang mengubah kode, dan mengerjakan fitur baru tanpa mengganggu kode utama. Git dapat dijalankan di komputer lokal maupun di server (Git server atau Git hosting seperti GitHub atau GitLab).
Istilah Penting dalam Git yang perlu Anda ketahui.
- Repository: penyimpanan source code (lokal atau remote).
- Clone: menyalin repositori dari remote ke lokal.
- Branch: cabang untuk pengembangan fitur baru tanpa mengganggu kode utama (main branch).
- Commit: merekam jejak (snapshot) perubahan kode.
- Push: mengirim perubahan kode dari lokal ke remote repository.
- Pull Request: pengajuan untuk menggabungkan perubahan kode antar branch.
- Merge: menggabungkan perubahan kode antar branch.
SVN (Apache Subversion)
SVN adalah Centralized Version Control System (CVCS) yang melacak perubahan pada file dan direktori. SVN menggunakan server pusat untuk menyimpan semua data proyek. Pengguna melakukan checkout (mengunduh), commit (mengunggah perubahan), dan update (mengambil perubahan terbaru).
Berikut fitur SVN yang perlu Anda ketahui.
- Versioning direktori dan file.
- Atomic commit (semua perubahan diterapkan atau dibatalkan).
- Branching dan tagging.
- Riwayat revisi lengkap.
- Dukungan untuk binary files.
- File locking.
- Protokol akses beragam (HTTP, HTTPS, SSH, SVN).
- Multi-platform (Windows, Linux, macOS).
Keunggulan SVN.
- Stabil dan teruji.
- Repositori terpusat.
- Dukungan untuk file besar.
- Atomic commit.
- Mudah dipahami (konsep CVCS lebih sederhana).
Kekurangan SVN.
- Ketergantungan pada server pusat.
- Tidak mendukung pekerjaan offline.
- Branching dan merging kurang efisien.
- Kinerja menurun pada repositori besar.
- Kurangnya keamanan data lokal.
Lalu, kapan Menggunakan SVN?
- Proyek yang membutuhkan struktur terpusat.
- Proyek dengan file biner besar.
- Proyek dengan tim kecil hingga menengah.
- Proyek dengan infrastruktur stabil.
- Proyek yang memerlukan file locking.
- Proyek tradisional atau warisan (legacy projects).
Mercurial
Mercurial adalah Distributed Version Control System (DVCS) yang cepat, efisien, dan mudah digunakan. Mercurial memungkinkan setiap pengguna memiliki salinan lengkap repositori.
Karakteristik Mercurial.
- Kinerja cepat.
- Portabilitas (mendukung berbagai sistem operasi).
- Sederhana dan ramah pengguna (antarmuka baris perintah intuitif).
- Reproduksi penuh (setiap pengguna memiliki salinan lengkap repositori).
- Keamanan (menggunakan hashing kriptografi).
- Dukungan untuk branching.
Fitur Mercurial.
- Repositori terdistribusi.
- Branching yang fleksibel ( Named Branches dan Anonymous Branches).
- Mekanisme merging yang kuat.
- Antarmuka yang konsisten (perintah seperti hg commit, hg push, hg pull).
- Keamanan dan integritas data (menggunakan hashing SHA-1).
- Portabilitas.
- Kompatibilitas dengan proyek besar.
Kekurangan Mercurial.
- Ekosistem yang lebih kecil dibandingkan Git.
- Komunitas pengguna yang lebih kecil.
Pengenalan MLflow
MLflow adalah platform open-source yang dirancang untuk mengelola alur kerja machine learning (ML) secara end-to-end. MLflow membantu para data scientist, machine learning engineer, dan tim pengembang untuk mencatat, melacak, mengelola, dan mendistribusikan model ML dengan lebih mudah. Dengan MLflow, semua elemen penting dalam proyek ML, seperti eksperimen, parameter, metrik, artefak, dan model, dapat dikelola secara terpusat.

MLflow dapat digunakan bersama dengan berbagai library machine learning seperti TensorFlow, PyTorch, Scikit-learn, XGBoost, dan 20 library lainnya.

Platform ini juga mendukung integrasi dengan alat CI/CD seperti GitHub untuk mempermudah implementasi dan manajemen model di lingkungan produksi. Tidak berhenti di sini, sebagai tools yang sangat powerful tentunya MLflow memiliki berbagai macam fitur yang siap membantu Anda membangun sistem machine learning.
Tools ini memiliki beberapa fitur utama yang wajib Anda ketahui seperti berikut ini.
-
MLflow Tracking
MLflow Tracking adalah komponen yang memungkinkan pengguna untuk mencatat dan melacak eksperimen machine learning. Dengan fitur ini, semua informasi penting seperti parameter, metrik, kode sumber, dan artefak (seperti file model) dapat didokumentasikan secara otomatis. -
MLflow Project
MLflow Projects membantu pengguna mendokumentasikan dan mengemas proyek machine learning dalam format yang terstandarisasi. Setiap proyek akan berisi file konfigurasi (MLproject) yang menjelaskan cara menjalankan proyek tersebut sehingga proyek dapat dipindahkan antar lingkungan dengan mudah. -
MLflow Model
MLflow Models adalah salah satu komponen utama dari MLflow yang dirancang untuk menyimpan, mengelola, dan mendistribusikan model machine learning. MLflow Models memungkinkan pengguna untuk menyimpan model dalam format standar yang dapat digunakan ulang di berbagai platform dan mempermudah deployment model ke lingkungan produksi. -
MLflow Model Registry
MLflow Model Registry adalah komponen dari MLflow yang dirancang untuk mengelola siklus hidup model machine learning secara terpusat. Model Registry memungkinkan pengguna untuk melacak versi model, memberikan anotasi, mengelola tahapan (staging, production, archived), dan mencatat metadata terkait model yang telah dicatat di MLflow Tracking. -
MLflow Pipelines (Experimental)
MLflow Pipelines merupakan fitur eksperimental dari MLflow yang dirancang untuk menyediakan kerangka kerja modular, terstruktur, dan terotomatisasi untuk pengembangan machine learning. Fitur ini membantu kita untuk membangun pipeline pengembangan dan deployment model dengan lebih mudah dan efisien, sekaligus memastikan konsistensi alur kerja. Sayangnya, sesuai dengan namanya fitur ini masih berupa eksperimen yang berarti kita tidak dapat menggunakan fitur ini selain menggunakan MLflow versi 1.30.1 (setidaknya sampai 29 Desember 2024).
Version Control dengan MLflow
Kita telah mengenal GitHub (platform kolaborasi dan version control kode) dan MLflow (toolkit untuk mengelola eksperimen, model, dan alur kerja ML). Namun, untuk menciptakan alur kerja yang otomatis dan reproducible, kita perlu mengintegrasikan keduanya dengan version control yang lebih erat, melalui continuous integration. Di sinilah GitHub Actions berperan.
Apa itu GitHub Actions?
GitHub Actions adalah fitur Continuous Integration (CI) dan Continuous Delivery (CD) bawaan GitHub untuk mengotomatiskan alur kerja pengembangan perangkat lunak langsung dari repositori GitHub.
GitHub Actions memungkinkan pembuatan skrip untuk membangun, menguji, dan menerapkan kode, serta integrasi dengan layanan eksternal. Berikut adalah beberapa fitur Utama GitHub Actions.
- Automasi Workflow: menjalankan tugas otomatis berdasarkan trigger (push, pull request, jadwal).
- Fleksibilitas: mendukung berbagai sistem operasi dan bahasa pemrograman.
- Marketplace: sebuah direktori penyimpanan yang berisikan ribuan fungsi siap pakai.
Komponen GitHub Actions yang perlu Anda ketahui.
- Workflow: file konfigurasi YAML berisi tugas yang dijalankan otomatis.
- Events: trigger yang memicu workflow (misalnya, push ke branch).
- Jobs: kumpulan langkah untuk tugas tertentu ( workflow bisa terdiri dari beberapa jobs).
- Steps: langkah dalam job (misalnya, instal dependensi, jalankan tes).
- Actions: tugas individual yang dapat digunakan kembali.
Mengapa Integrasi GitHub, MLflow, dan GitHub Actions Penting?
Meskipun GitHub primernya digunakan untuk menyimpan perubahan kode, integrasi dengan MLflow dan GitHub Actions memungkinkan automated workflow yang mencakup pelatihan, pencatatan eksperimen, pengelolaan model, dan deployment.
Integrasi ini dapat memberikan beberapa keuntungan seperti berikut.
- Otomatisasi: tidak perlu lagi training model secara manual di komputer lokal dan push setiap saat. Cukup ubah kode, dan GitHub Actions akan menjalankan pipeline dan menyimpan model terbaru.
- Efisiensi: mengotomatiskan dan mengelola proyek ML dengan lebih efisien.
- Kolaborasi: mendukung kolaborasi antar tim.
- Konsistensi: memastikan integrasi pipeline dan deployment model yang konsisten.
Metadata dan Sekitarnya
Metadata adalah data tentang data, yaitu informasi yang menjelaskan detail eksperimen machine learning (ML), seperti parameter model, metrik, informasi data, dan konfigurasi environment. Metadata sangat penting dalam sistem ML modern karena meningkatkan reproducibility, monitoring, dan kolaborasi tim. Tanpa pengelolaan metadata yang baik, eksperimen sulit dilacak, hasil tidak dapat direproduksi, dan iterasi pengembangan model menjadi tidak efisien.
Pentingnya Metadata dalam Sistem ML
Tanpa metadata yang lengkap, eksperimen sulit diulang, hasil tidak konsisten, dan pengembangan model menjadi lambat dan rentan kesalahan. Pengelolaan metadata adalah aspek krusial dalam membangun sistem ML yang andal dan terstruktur. Metadata biasanya mencakup:
- Parameter dan Metrik Eksperimen
- Hyperparameter: parameter yang ditetapkan sebelum pelatihan misalnya, n_estimators di RandomForestClassifier, learning_rate, batch_size.
- Parameter Model Internal: parameter yang dihasilkan selama pelatihan misalnya, bobot pada neural networks, koefisien regresi linier.
- Metrik: nilai evaluasi performa model misalnya, akurasi, presisi, recall, F1-score, loss.
- Informasi Data
- Versi Data: mencatat versi dataset yang digunakan, penting karena dataset sering berubah.
- Proses Preprocessing: mencatat langkah-langkah preprocessing data, karena preprocessing memengaruhi hasil akhir model.
- Konfigurasi Environment
Mencatat versi library yang digunakan, penting karena versi library dapat memengaruhi hasil eksperimen dan menghindari konflik dependensi.
Mengelola Metadata dengan MLflow
MLflow membantu pengelolaan metadata dengan fitur logging otomatis dan manual, serta penyimpanan metadata dalam format standar.
- Logging Otomatis (Autologging)
- Mencatat metadata secara otomatis (parameter model, metrik hasil, artefak model, informasi environment).
- Mendukung banyak framework ML (scikit-learn, TensorFlow, Keras, XGBoost).
- Kelebihan
- Mempermudah pencatatan metadata.
- Kekurangan
- Tidak mencatat beberapa file tambahan (contoh input, dataset, payloads), dan terkadang mencatat informasi yang tidak dibutuhkan.
- Logging Manual
- Memberikan fleksibilitas lebih baik, terutama untuk mencatat informasi yang tidak didukung autologging.
- Menggunakan fungsi-fungsi seperti mlflow.log_param(), mlflow.log_metric(), mlflow.log_artifact().
- Kekurangan
- Memerlukan penulisan kode tambahan.
- Logging Hybrid
- Menggabungkan autologging dan manual logging untuk fleksibilitas dan kelengkapan.
- Penyimpanan Metadata
- MLflow menyimpan metadata dalam format standar yang terstruktur (file JSON) dalam sebuah repositori.
- Setiap eksperimen dicatat sebagai run dengan Run ID unik.
- Memudahkan integrasi dengan sistem lain.
This file is located at: _chapters/992-membangun-sistem-machine-learning/020-metadata-dengan-tools-open-source.md