lmvr-27
- 27.1. Tren yang Muncul dalam Model Bahasa Besar
- 27.2. Kemajuan dalam Arsitektur dan Desain Model
- 27.3. Inovasi dalam Teknik Pelatihan dan Optimasi
- 27.4. Strategi Penyebaran dan Inferensi Waktu Nyata
- 27.5. Pertimbangan Etis dan Regulasi untuk LLM Masa Depan
- 27.6. Arah Masa Depan dan Peluang Penelitian
- 27.7. Kesimpulan
Bab 27: Masa Depan Model Bahasa Besar
“Masa depan AI bukan hanya tentang membuat model menjadi lebih besar, tetapi membuatnya menjadi lebih cerdas, lebih efisien, dan lebih selaras dengan nilai-nilai kemanusiaan.” — Fei-Fei Li
Catatan Sukses: Bab 27 dari LMVR mengeksplorasi masa depan model bahasa besar (LLM) melalui kacamata tren yang muncul, arsitektur tingkat lanjut, teknik pelatihan inovatif, dan strategi penyebaran yang dioptimalkan. Bab ini menekankan bagaimana performa, keamanan, dan skalabilitas sistem menjadikannya fondasi ideal untuk mendorong batasan LLM, mulai dari mengimplementasikan model mutakhir seperti sparse transformers hingga mengoptimalkan inferensi waktu nyata dan memastikan pengembangan AI yang etis. Bab ini juga menatap integrasi LLM dengan teknologi baru, seperti komputasi kuantum dan perangkat keras neuromorfik, memposisikan sistem yang efisien sebagai penggerak utama penelitian dan inovasi AI generasi berikutnya.
27.1. Tren yang Muncul dalam Model Bahasa Besar
Bidang model bahasa besar (LLM) telah mengalami kemajuan luar biasa dalam beberapa tahun terakhir, dengan aplikasinya yang meluas di berbagai industri, termasuk layanan kesehatan, keuangan, pendidikan, dan dukungan pelanggan. LLM telah mengubah cara perusahaan dan pengembang mendekati tugas-tugas seperti terjemahan bahasa, pembuatan konten, pembuatan kode, dan bahkan interaksi pelanggan. Model-model ini memanfaatkan data dalam jumlah besar dan arsitektur yang kompleks untuk menghasilkan respons dan wawasan yang menyerupai manusia, memungkinkan mereka melakukan berbagai tugas yang sebelumnya dianggap mustahil bagi mesin. Bagian ini memberikan gambaran umum tentang tren yang muncul yang membentuk masa depan LLM, menekankan bagaimana kemajuan dalam arsitektur model, metodologi pelatihan, dan strategi penyebaran mendefinisikan ulang apa yang dapat dicapai oleh LLM. Selain itu, kami mengeksplorasi peran unik dari bahasa pemrograman sistem untuk meningkatkan performa, keamanan memori, dan skalabilitas.
 Gambar 1: Kemajuan masa depan LLM menggunakan teknologi sistem yang efisien.
Gambar 1: Kemajuan masa depan LLM menggunakan teknologi sistem yang efisien.
Seiring meningkatnya kompleksitas dan skala LLM, permintaan akan metode pelatihan dan inferensi yang lebih efisien dan teroptimasi juga meningkat. Salah satu tren utama yang muncul adalah fokus pada efisiensi model. Arsitektur baru seperti model sparse attention, transformer yang diperkaya pengetahuan (knowledge-augmented transformers), dan arsitektur hibrida neural-symbolic mendorong batasan desain LLM tradisional, memungkinkan pelatihan model yang lebih besar tanpa biaya sumber daya yang menghambat. Misalnya, peralihan menuju sparsitas dalam model transformer mengurangi jumlah komputasi yang diperlukan dengan berfokus pada subset koneksi atensi tertentu, yang mengarah pada waktu inferensi yang lebih cepat dan konsumsi daya yang lebih rendah.
Di sisi lain, bidang LLM juga bergerak menuju model yang lebih terspesialisasi dan khusus domain. Meskipun LLM serbaguna telah terbukti efektif dalam berbagai tugas, aplikasi khusus industri sering kali memerlukan model yang disetel halus untuk kosakata, konteks, dan batasan operasional tertentu. Efisiensi memori dari bahasa sistem memungkinkan pembuatan prototipe cepat dan eksperimen dengan model yang lebih kecil dan terspesialisasi pada sumber daya perangkat keras yang terbatas.
Pertumbuhan LLM juga membawa pertimbangan etis yang signifikan, terutama seputar isu bias, privasi, dan potensi penyalahgunaan konten yang dihasilkan AI. Teknik mitigasi bias, seperti pelatihan adversarial dan penyeimbangan data, serta metode pelestarian privasi seperti privasi diferensial (differential privacy), menjadi standar dalam pengembangan LLM. Sistem tipe yang kuat memberikan keandalan yang diperlukan untuk mengimplementasikan algoritme pelestarian privasi dengan aman, memastikan titik data individu tidak dapat direkayasa balik dari output model.
Logika berikut mendemonstrasikan pengembangan dan penyebaran LLM dengan fokus pada efisiensi, spesialisasi domain, dan pertimbangan etis.
Contoh Python: Pipeline Pemrosesan LLM Tingkat Lanjut
import torch
import numpy as np
class LLMSystem:
def __init__(self, model_architecture, domain_data, privacy_settings, ethical_constraints):
self.model_architecture = model_architecture
self.domain_data = domain_data
self.privacy_settings = privacy_settings
self.ethical_constraints = ethical_constraints
def train_with_sparse_attention(self, model):
# Simulasi pelatihan dengan atensi jarang (sparse) untuk efisiensi
print("Memulai pelatihan dengan sparse attention...")
for batch in self.domain_data:
# Hitung gradien dan terapkan mask sparsitas
# Ini secara drastis mengurangi beban komputasi
pass
return model
def fine_tune_for_domain(self, model):
# Penyetelan halus untuk spesialisasi domain (misal: Medis atau Hukum)
print("Melakukan fine-tuning untuk spesialisasi domain...")
for epoch in range(5):
# Optimasi parameter berdasarkan dataset khusus
pass
return model
def apply_differential_privacy(self, model):
# Menambahkan noise Gaussian untuk melindungi data sensitif
epsilon = self.privacy_settings.get('epsilon', 0.1)
print(f"Menerapkan privasi diferensial dengan epsilon={epsilon}")
for param in model.parameters():
noise = torch.randn(param.size()) * epsilon
param.data.add_(noise)
return model
def integrate_bias_mitigation(self, data):
# Menganalisis metrik bias dan menyeimbangkan data
print("Mengintegrasikan pelindung etis untuk mitigasi bias...")
# Logika analisis bias...
return 0.05 # Skor bias global
async def llm_processing_pipeline(self, base_model):
# Langkah 1: Pelatihan efisien
model = self.train_with_sparse_attention(base_model)
# Langkah 2: Adaptasi domain
model = self.fine_tune_for_domain(model)
# Langkah 3: Keamanan privasi
model = self.apply_differential_privacy(model)
# Langkah 4: Audit etika
bias_score = self.integrate_bias_mitigation(self.domain_data)
print(f"Skor Bias Akhir: {bias_score}")
return model
# Contoh eksekusi main logic
async def main():
# Inisialisasi parameter simulasi
config = {
'arch': 'sparse-transformer',
'data': ['dataset_medis'],
'privacy': {'epsilon': 0.05},
'ethics': {'threshold': 0.01}
}
llm_system = LLMSystem(config['arch'], config['data'], config['privacy'], config['ethics'])
# base_model = load_initial_model()
# optimized_model = await llm_system.llm_processing_pipeline(base_model)
Masa depan LLM juga akan dibentuk oleh integrasi pertimbangan etis dengan kemajuan teknis. Tren terbaru menunjukkan pergeseran menuju explainability-by-design (eksplanabilitas sejak desain), di mana transparansi dibangun ke dalam arsitektur model, memudahkan interpretasi bagaimana output tertentu dihasilkan.
27.2. Kemajuan dalam Arsitektur dan Desain Model
Seiring evolusi LLM, arsitektur model baru muncul untuk mendorong batas pencapaian. Desain baru seperti sparse transformers, mixture of experts (MoE), dan neural architecture search (NAS) memperkenalkan cara inovatif untuk mengoptimalkan performa. Sparse transformers memodifikasi mekanisme atensi padat tradisional dengan secara selektif berfokus pada bagian tertentu dari urutan input. Model Mixture of Experts menggunakan jaringan modular di mana hanya subset “ahli” yang diaktifkan untuk input tertentu, menghasilkan pengurangan beban komputasi yang masif. Sementara itu, NAS mengotomatiskan proses desain arsitektur dengan menerapkan pembelajaran mesin untuk mengeksplorasi berbagai konfigurasi model.
 Gambar 2: Implementasi arsitektur LLM.
Gambar 2: Implementasi arsitektur LLM.
Implementasi arsitektur tingkat lanjut ini dalam sistem berkinerja tinggi mengatasi tantangan skalabilitas. Kontrol memori tingkat rendah sangat menguntungkan di sini, karena memungkinkan penanganan struktur data jarang secara efisien.
Berikut adalah logika Python yang mendemonstrasikan konsep arsitektur mutakhir tersebut.
Contoh Python: Arsitektur Atensi Jarang dan Campuran Ahli (MoE)
import torch
import torch.nn as nn
import math
# 1. Konsep Sparse Transformer
class SparseAttention(nn.Module):
def __init__(self, embed_dim, top_k):
super().__init__()
self.top_k = top_k
self.qkv = nn.Linear(embed_dim, embed_dim * 3)
def forward(self, x):
# Hitung skor atensi...
# Hanya pilih 'top_k' koneksi untuk menghemat memori
# scores = ...
# sparse_weights = select_top_k(scores, self.top_k)
return x # Placeholder output
# 2. Konsep Mixture of Experts (MoE)
class MoELayer(nn.Module):
def __init__(self, num_experts, d_model):
super().__init__()
self.experts = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(num_experts)])
self.gate = nn.Linear(d_model, num_experts) # Router
def forward(self, x):
# Router memilih ahli yang relevan untuk setiap input
gate_logits = self.gate(x)
weights = torch.softmax(gate_logits, dim=-1)
# Sederhananya, pilih ahli dengan bobot tertinggi
expert_idx = torch.argmax(weights, dim=-1)
output = self.experts[expert_idx](x)
return output
# 3. Konsep Neural Architecture Search (NAS)
def neural_architecture_search(search_space):
best_score = -float('inf')
best_arch = None
for config in search_space:
# Bangun model berdasarkan konfigurasi
# model = build_from_config(config)
# score = evaluate(model)
# if score > best_score:
# best_arch = config
pass
return best_arch
Dengan mengimplementasikan arsitektur seperti sparse transformers dan MoE, pengembang dapat mendorong efisiensi LLM ke tingkat yang baru, menjadikannya layak untuk penyebaran pada perangkat dengan sumber daya terbatas tanpa mengorbankan kecerdasan model.
27.3. Inovasi dalam Teknik Pelatihan dan Optimasi
Teknik pelatihan LLM saat ini harus mengelola miliaran atau bahkan triliunan parameter. Teknik seperti faktorisasi peringkat rendah (low-rank factorization), kuantisasi model, dan gradient checkpointing berada di garis depan perbaikan ini. Faktorisasi peringkat rendah mengurangi kompleksitas lapisan model dengan mendekati matriks besar dengan komponen yang lebih kecil. Kuantisasi menurunkan presisi parameter model (misalnya ke 8-bit) untuk mempercepat komputasi. Gradient checkpointing menghemat memori dengan hanya menyimpan subset status menengah selama pass maju, dan menghitungnya kembali saat diperlukan selama propagasi mundur.
 Gambar 3: Teknik optimasi umum untuk LLM.
Gambar 3: Teknik optimasi umum untuk LLM.
Faktorisasi peringkat rendah secara matematis mendekati matriks $W \in \mathbb{R}^{m \times n}$ sebagai $W \approx UV$, di mana $U \in \mathbb{R}^{m \times k}$ dan $V \in \mathbb{R}^{k \times n}$ dengan $k \ll \min(m, n)$.
Contoh Python: Faktorisasi Matriks dan Kuantisasi
import torch
# Fungsi untuk simulasi Faktorisasi Peringkat Rendah
def low_rank_approximation(matrix, rank):
# Menggunakan Singular Value Decomposition (SVD)
u, s, v = torch.svd(matrix)
# Ambil komponen k teratas
u_reduced = u[:, :rank]
s_reduced = torch.diag(s[:rank])
v_reduced = v[:, :rank]
# Matriks yang jauh lebih hemat memori
return u_reduced, torch.mm(s_reduced, v_reduced.t())
# Fungsi untuk Kuantisasi Bobot (8-bit)
def quantize_weights(model):
print("Mengonversi bobot model ke presisi 8-bit...")
# Dalam PyTorch nyata: torch.quantization.quantize_dynamic
for param in model.parameters():
# Simulasi pemetaan ke range -128 s/d 127
pass
return model
# Fungsi Gradient Checkpointing
def train_with_checkpointing(model, inputs):
# Menggunakan torch.utils.checkpoint untuk menghemat VRAM
# Menghitung ulang aktivasi selama backward pass
pass
Efisiensi energi dan keberlanjutan juga menjadi semakin penting. Metode pelatihan yang efisien dapat memitigasi dampak lingkungan dari AI, yang sering kali mengonsumsi ribuan megawatt-jam untuk satu siklus pelatihan model besar.
27.4. Strategi Penyebaran dan Inferensi Waktu Nyata
Menyebarkan LLM menghadirkan tantangan unik dalam menyeimbangkan latensi, skalabilitas, dan biaya operasional. Lingkungan penyebaran—baik cloud, edge, atau on-device—memainkan peran penting. Cloud menawarkan skalabilitas elastis, sementara edge menawarkan pengurangan latensi dengan membawa komputasi lebih dekat ke pengguna.
 Gambar 4: Optimalisasi Penyebaran LLM.
Gambar 4: Optimalisasi Penyebaran LLM.
Optimasi seperti distilasi model (melatih model “murid” kecil untuk meniru model “guru” besar), pruning (pemangkasan), dan caching sangat penting untuk inferensi waktu nyata yang menuntut prediksi dalam hitungan milidetik.
Contoh Python: Caching Inferensi dan Distilasi
class InferenceCache:
def __init__(self):
self.cache = {}
def get_or_compute(self, prompt, model_func):
if prompt in self.cache:
print("Mengambil hasil dari cache...")
return self.cache[prompt]
# Hitung jika tidak ada di cache
response = model_func(prompt)
self.cache[prompt] = response
return response
def distill_model(teacher, student, data):
print("Melatih model murid untuk meniru prediksi model guru...")
# student_loss = loss(student_pred, teacher_pred)
pass
def deploy_to_edge(model):
# Konversi model ke format yang kompatibel dengan edge (misal: ONNX atau TFLite)
print("Menyebarkan model ke perangkat edge...")
pass
Penyebaran di sisi edge memungkinkan pemrosesan data secara lokal, yang tidak hanya mengurangi latensi tetapi juga meningkatkan privasi data karena informasi tidak perlu dikirim ke server pusat.
27.5. Pertimbangan Etis dan Regulasi untuk LLM Masa Depan
Seiring LLM terintegrasi ke dalam sistem kritis, prinsip keadilan, transparansi, dan privasi menjadi pusat perhatian. Tantangan etis utama mencakup bias yang tertanam dan potensi penyebaran misinformasi. Deteksi bias melibatkan metode statistik seperti paritas demografis (hasil yang serupa di berbagai kelompok) dan peluang yang disetarakan.
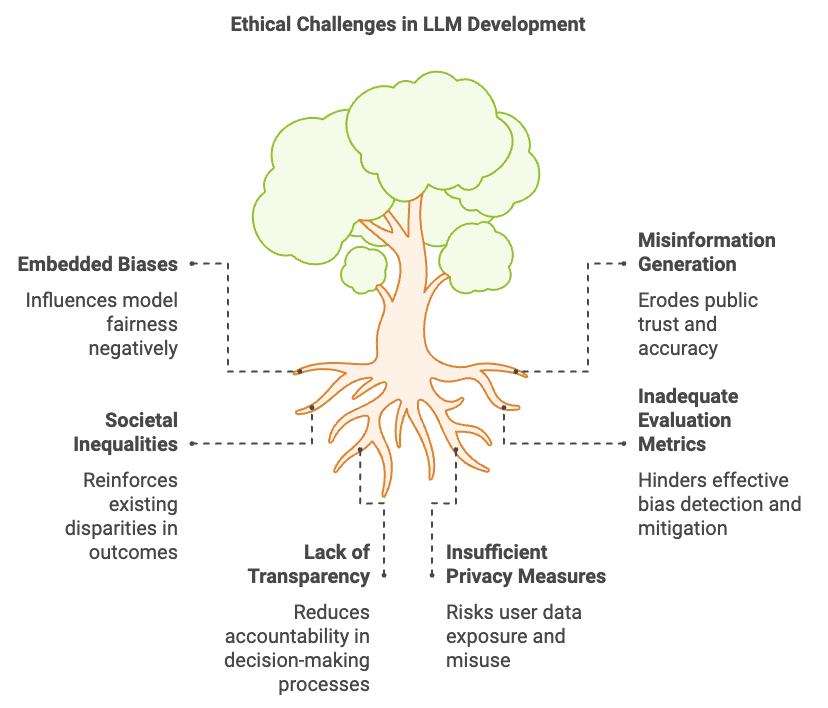 Gambar 5: Kompleksitas dan tantangan etika dalam LLM.
Gambar 5: Kompleksitas dan tantangan etika dalam LLM.
Contoh Python: Deteksi Bias dan Privasi Diferensial
def detect_gender_bias(text):
# Menghitung frekuensi istilah gender untuk mendeteksi ketidakseimbangan
keywords = {"pria": 0, "wanita": 0}
for word in text.lower().split():
if word in keywords:
keywords[word] += 1
return keywords
def apply_dp_to_output(value, epsilon=0.1):
# Menambahkan noise untuk privasi diferensial
noise = np.random.laplace(0, 1/epsilon)
return value + noise
def ethical_audit(model, test_data):
# Secara berkala mengevaluasi prediksi model terhadap kriteria etika
# Jika melenceng, berikan peringatan kepada pemangku kepentingan
pass
Regulasi seperti GDPR dan AI Act yang akan datang menuntut agar model AI dapat diinterpretasikan dan proses pengambilan keputusannya dapat dijelaskan (explainable).
27.6. Arah Masa Depan dan Peluang Penelitian
Penelitian ke arah pembelajaran tanpa pengawasan (unsupervised learning) membuka pintu bagi LLM yang lebih otonom. Selain itu, integrasi LLM dengan teknologi baru seperti komputasi kuantum dan perangkat keras neuromorfik merupakan area penelitian yang sangat menjanjikan. Komputasi kuantum berpotensi merevolusi LLM dengan memungkinkan paralelisme masif.
Perangkat keras neuromorfik, yang dirancang untuk meniru arsitektur saraf otak manusia, menawarkan peluang untuk membangun sistem AI berdaya rendah yang sangat efisien. Rust, dengan efisiensi tingkat sistemnya, ideal untuk memprogram chip khusus ini.
Contoh Python: Roadmap Penelitian LLM Masa Depan
# 1. Integrasi Multimodal
def process_multimodal(text, image, audio):
# Menggabungkan output dari model vision, audio, dan bahasa
# Menghasilkan representasi konteks yang lebih kaya
pass
# 2. Reinforcement Learning dari Umpan Balik Manusia (RLHF)
def rlhf_adaptation(model, reward_signal):
# Memperbarui kebijakan model berdasarkan sinyal hadiah
# Memungkinkan adaptasi waktu nyata terhadap preferensi pengguna
pass
# 3. Pemantauan Berkelanjutan dan Pembaruan Adaptif
def monitor_and_retrain(model, performance_metrics):
# Jika akurasi turun di bawah ambang batas, picu proses pelatihan ulang
pass
Kolaborasi antara akademisi, industri, dan komunitas sumber terbuka akan sangat penting dalam mendorong kemajuan ini. Penggunaan sistem yang efisien memastikan bahwa peneliti dapat bereksperimen dengan model yang lebih besar dan metode yang lebih kompleks tanpa terkendala oleh overhead teknis.
27.7. Kesimpulan
Bab 27 menyoroti peran kritis teknologi sistem yang efisien dalam memajukan masa depan model bahasa besar, memungkinkan pengembangan sistem AI yang lebih cerdas, efisien, dan sehat secara etis. Seiring LLM terus berkembang, kemampuan bahasa pemrograman yang aman dan berkinerja tinggi akan menjadi pusat inovasi untuk memastikan model-model ini kuat dan bertanggung jawab dalam dampaknya bagi masyarakat.
27.7.1. Pembelajaran Lebih Lanjut dengan GenAI
- Evaluasi keadaan LLM saat ini dengan menganalisis tren seperti penskalaan model dan variasi transformer.
- Jelajahi evolusi arsitektural dari transformer tradisional ke sparse transformers.
- Diskusikan mekanisme Mixture of Experts (MoE) untuk efisiensi dan skalabilitas model.
- Analisis dampak teknik faktorisasi peringkat rendah pada efisiensi pelatihan.
- Jelajahi penggunaan gradient checkpointing untuk optimasi memori.
- Diskusikan proses dan manfaat kuantisasi model untuk mengurangi latensi inferensi.
- Evaluasi tantangan dan strategi pelatihan terdistribusi di berbagai node komputasi.
- Jelajahi kompleksitas penyebaran LLM dalam aplikasi waktu nyata yang sensitif terhadap latensi.
- Analisis persyaratan regulasi untuk AI, seperti GDPR dan AI Act.
- Evaluasi dampak teknologi baru seperti komputasi kuantum pada masa depan LLM.
27.7.2. Latihan Praktis
Latihan Mandiri 27.1: Implementasi Sparse Transformer
Tujuan: Merancang model transformer yang secara selektif menghitung atensi hanya pada subset token untuk menghemat memori.
Latihan Mandiri 27.2: Pelatihan Terdistribusi LLM
Tujuan: Mengembangkan framework pelatihan terdistribusi sederhana yang menyinkronkan gradien di antara beberapa proses simulasi.
Latihan Mandiri 27.3: Implementasi Distilasi Model
Tujuan: Melatih model kecil untuk meniru output dari model yang lebih besar dan membandingkan kecepatan inferensi serta akurasinya.
Latihan Mandiri 27.4: Integrasi Teknik Mitigasi Bias
Tujuan: Mengimplementasikan deteksi bias dalam pipeline inferensi dan melakukan penyesuaian bobot untuk memastikan keadilan hasil.
Latihan Mandiri 27.5: Eksplorasi Neural Architecture Search (NAS)
Tujuan: Membuat skrip otomatis yang mencoba berbagai konfigurasi jumlah lapisan dan head atensi untuk menemukan arsitektur paling efisien bagi tugas tertentu.