Distribusi Statistik
- Konsep Dasar Probabilitas dan Variabel Acak
- Distribusi Probabilitas
- Distribusi Diskret
- Distribusi Kontinu
- Konsep Central Limit Theorem (CLT)
- Simulasi Probabilitas dan Metode Monte Carlo
- Studi Kasus: Estimasi Pi dengan Metode Monte Carlo
- Studi Kasus: Simulasi Pelemparan Dadu dengan Metode Monte Carlo
- Studi Kasus: Estimasi Waktu Pengerjaan Proyek dengan Metode Monte Carlo
- Rangkuman Distribusi Statistik
Konsep Dasar Probabilitas dan Variabel Acak
Dalam dunia probabilitas, kita berusaha untuk memahami kemungkinan kejadian yang dapat terjadi berdasarkan data atau percobaan acak. Probabilitas adalah cabang matematika yang mempelajari peluang terjadinya suatu kejadian. Dalam probabilitas, kita menggunakan konsep-konsep dasar, seperti ruang sampel, kejadian, serta variabel acak untuk membangun model yang dapat digunakan untuk menghitung peluang terjadinya kejadian tertentu.
Di sini, kita akan membahas konsep-konsep dasar ini untuk membangun pemahaman yang kokoh tentang probabilitas, yang nantinya akan memudahkan dalam menganalisis dan menginterpretasikan data acak.
Variabel Acak
Ketika berbicara tentang variabel acak, kita mengacu pada nilai yang mungkin diambil oleh suatu percobaan acak. Dalam statistik dan probabilitas, kita mengklasifikasikan variabel acak menjadi dua kategori utama: variabel acak diskret dan variabel acak kontinu. Perbedaan utama antara keduanya adalah jenis nilai yang bisa mereka ambil.
Mari kita jelaskan masing-masing jenis variabel acak ini secara lebih rinci.
Variabel Acak Diskret
Variabel acak diskret adalah jenis variabel yang hanya dapat mengambil sejumlah nilai terbatas dan dapat dihitung. Dengan kata lain, nilai-nilai yang dapat diambil oleh variabel ini bersifat terpisah atau diskret, dan tidak ada nilai di antara dua nilai yang berbeda.
Misalnya, jika kita mengamati jumlah orang yang datang ke sebuah toko, kita hanya bisa menghitung angka, yakni 1, 2, 3, dan seterusnya. Tidak ada “angka pecahan” seperti 2,5 orang karena jumlah orang yang datang tidak dapat dibagi menjadi nilai lebih kecil.
Salah satu ciri utama dari variabel acak diskret adalah bahwa jumlah nilai yang dapat diambil terbatas dan terhitung. Contoh konkret lainnya adalah hasil dari pelemparan dadu, yang hanya bisa menghasilkan nilai {1, 2, 3, 4, 5, 6}. Hasil pelemparan dadu jelas terbatas pada enam angka ini dan tidak ada kemungkinan munculnya angka lainnya, seperti 3,5 atau 2,3.

Hal sama juga berlaku pada jumlah mobil yang lewat di jalan dalam satu hari. Meskipun kita bisa mendapatkan angka besar, seperti 50, 100, atau 200 mobil, jumlah ini tetap terbatas pada bilangan bulat yang dapat dihitung.
Contoh lain dari variabel acak diskret adalah jumlah kecelakaan yang terjadi dalam sebulan. Kita bisa mengamati bahwa jumlah kecelakaan itu mungkin 0, 1, 2, 3, dan seterusnya, tetapi tidak ada nilai yang bisa berada di antara angka-angka tersebut. Misalnya, kita tidak bisa mengatakan bahwa terjadi “2,5 kecelakaan” dalam satu bulan.
Variabel acak diskret sering digunakan dalam konteks yang melibatkan perhitungan jumlah kejadian, seperti jumlah orang, jumlah barang, atau jumlah kejadian tertentu pada periode waktu tertentu. Dalam kata lain, variabel ini sangat berguna pada analisis dengan melibatkan perhitungan objek atau kejadian yang terpisah dan terhitung.
Variabel Acak Kontinu
Di sisi lain, variabel acak kontinu adalah variabel yang dapat mengambil nilai apa pun dalam rentang tertentu, yang bisa sangat presisi dan mencakup angka desimal. Ini berarti bahwa antara dua nilai berbeda, ada banyak nilai yang mungkin terjadi.
Sebagai contoh, jika mengukur tinggi badan seseorang, kita tidak hanya bisa mendapatkan angka bulat, seperti 170 cm atau 175 cm. Sebaliknya, kita bisa mengukur tinggi badan dalam satuan yang lebih presisi, seperti 170,5 cm, 170,75 cm, atau bahkan 170,123 cm.

Dengan kata lain, variabel acak kontinu memungkinkan untuk memperoleh nilai-nilai dalam bentuk desimal yang sangat terperinci, tergantung pada alat pengukuran.
Keunikan dari variabel acak kontinu adalah bahwa ia dapat mengambil nilai dalam rentang tak terhingga, artinya kita bisa memiliki nilai antara dua angka yang sudah ada. Misalnya, dalam mengukur waktu yang dibutuhkan untuk menyelesaikan suatu tugas, waktu bisa berupa nilai, seperti 10,2 detik, 10,45 detik, atau bahkan 10,348 detik. Setiap kali mengukur waktu, kita bisa mendapatkan nilai dengan lebih banyak angka di belakang koma, menunjukkan bahwa variabel kontinu bisa sangat presisi.
Contoh lain dari variabel acak kontinu adalah suhu udara. Suhu dapat diukur dalam satuan yang sangat kecil, seperti 25,4°C, 25,39°C, atau 25,399°C, menunjukkan bahwa kita dapat memiliki banyak nilai di antara dua angka suhu berbeda.

Hal ini menunjukkan bahwa variabel acak kontinu tidak hanya terbatas pada angka bulat, tetapi dapat bergerak secara halus antara dua titik.
Dengan kata lain, variabel acak kontinu digunakan dalam konteks yang melibatkan pengukuran lebih halus, yakni saat nilai-nilai tidak terhitung dan bisa bervariasi secara halus. Ini sering diterapkan dalam pengukuran yang melibatkan waktu, suhu, berat badan, atau jarak.
Hubungan Variabel Acak dengan Data Science
Mungkin Anda bertanya, “Mengapa kita perlu mempelajari variabel acak? Apa hubungannya dengan proyek data science?” Jika pertanyaan tersebut muncul dalam benak Anda, selamat! Itu adalah tanda bahwa Anda berpikir kritis.
Di dunia data science, setiap dataset yang Anda gunakan pada dasarnya merupakan kumpulan dari berbagai variabel acak. Artinya, nilai-nilai dalam dataset tersebut tidak muncul secara tetap, tetapi memiliki unsur ketidakpastian (acak) yang dapat dianalisis secara statistik.
Memahami jika suatu variabel bersifat diskret atau kontinu akan membantu Anda dalam beberapa hal.
- Memilih jenis distribusi probabilitas yang sesuai (misalnya binomial untuk diskret, normal untuk kontinu).
- Memilih teknik analisis statistik atau pemodelan yang tepat.
- Menginterpretasikan hasil analisis secara lebih akurat.
Penting untuk diingat bahwa setiap variabel acak memiliki pola distribusi (yang menunjukkan persebaran nilai-nilai dari variabel tersebut). Dengan mengenali dan memahami distribusi ini, Anda dapat mengambil keputusan berbasis data yang lebih informatif, terutama dalam proses prediksi, inferensi, ataupun pengambilan keputusan bisnis.
Lantas, bagaimana distribusi probabilitas itu? Kita akan bahas dalam materi berikutnya.
Distribusi Probabilitas
Saat mempelajari probabilitas dan statistik, kita tak hanya ingin tahu “berapa peluang sebuah kejadian terjadi”, tetapi juga ingin melihat keseluruhan pola distribusi dari nilai-nilai yang mungkin. Di sinilah kita mengenal distribusi probabilitas, yaitu sebuah alat penting untuk memahami persebaran probabilitas dalam ruang kemungkinan.
Secara umum, distribusi probabilitas membantu kita menjawab pertanyaan seperti berikut.
- Seberapa besar peluang variabel acak bernilai tertentu?
- Berapa probabilitas bahwa suatu nilai lebih kecil dari batas tertentu?
- Bagaimana bentuk sebaran data? Apakah menyebar rata, melingkup ke tengah, atau condong ke satu sisi?
Bayangkan kamu sedang bermain dadu atau mengamati tinggi badan teman-teman sekelasmu. Kedua hal ini melibatkan variabel acak, tapi jenisnya berbeda: hasil dadu adalah diskret (1 sampai 6), sedangkan tinggi badan adalah kontinu (bisa 160.2 cm, 163.5 cm, dst.).
Nah, distribusi probabilitas adalah alat bantu kita untuk memahami cara probabilitas tersebar dalam berbagai kemungkinan yang bisa muncul dari variabel-variabel itu. Dengan kata lain, distribusi probabilitas menjawab pertanyaan seperti “Berapa besar kemungkinan dapat angka 4 dari lemparan dadu?” atau “Berapa peluang seseorang memiliki tinggi badan kurang dari 170 cm?”
Secara umum, ada tiga jenis distribusi probabilitas yang perlu Anda ketahui.
- PMF (probability mass function) digunakan untuk variabel diskret, seperti jumlah anak dalam keluarga atau hasil lemparan koin.
- PDF (probability density function) digunakan untuk variabel kontinu, seperti suhu udara atau waktu tunggu di halte.
- CDF (cumulative distribution function) membantu kita melihat total peluang yang sudah terkumpul sampai suatu nilai tertentu dan bisa digunakan baik untuk variabel diskret maupun kontinu.
Intinya, distribusi probabilitas adalah cara kita mengubah angka-angka peluang menjadi pemahaman yang lebih visual serta sistematis sehingga lebih mudah dianalisis dan dipakai dalam pengambilan keputusan.
Mari kita bahas satu per satu. Yuk, kita mulai dari yang paling sederhana.
PMF (Probability Mass Function): Semua Nilai Bisa Dihitung Satu per Satu
Bayangkan Anda sedang bermain dadu. Anda tahu bahwa hasil dari lemparan dadu hanya bisa berupa angka bulat dari 1 hingga 6, tidak mungkin mendapatkan angka 3.7 atau 5.5, kan?
Inilah yang kita sebut variabel diskret—variabel yang hanya bisa mengambil nilai-nilai tertentu dan terpisah.
Nah, PMF adalah fungsi yang memberi tahu kita probabilitas setiap nilai dari variabel diskret. Dalam kasus dadu yang adil, setiap angka memiliki peluang sama, yaitu berikut.
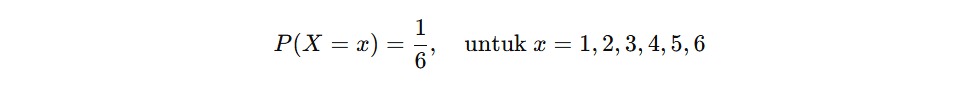
Artinya, peluang munculnya angka 2 adalah 1/6, begitu pula dengan angka-angka lainnya.
Ciri khas dari PMF adalah berikut.
- Probabilitasnya tidak pernah negatif dan tidak boleh lebih dari 1.
- Jika kamu menjumlahkan semua probabilitas dari setiap nilai yang mungkin, hasilnya pasti 1. Ini karena sesuatu pasti terjadi (hasilnya pasti salah satu dari 1 sampai 6).
PMF banyak digunakan dalam distribusi-distribusi terkenal, seperti Bernoulli (kejadian sukses/gagal), binomial (jumlah sukses dalam beberapa percobaan), dan Poisson (jumlah kejadian dalam satuan waktu).
Contoh lain? Coba pikirkan: jumlah anak dalam satu keluarga, hasil survei pilihan A/B/C, atau jumlah pelanggan yang datang ke toko dalam sehari. Semuanya bisa dianalisis dengan PMF.
PDF (Probability Density Function): Ketika Nilai Bisa Apa Saja dalam Rentang
Sekarang bayangkan Anda sedang mencatat tinggi badan teman-teman sekelas. Apakah ada yang tingginya 165.0 cm persis? Mungkin jarang. Justru yang terjadi adalah nilai tinggi bisa sangat beragam: 162.7 cm, 165.3 cm, 168.1 cm, dan seterusnya. Tak terbatas pada angka bulat.
Inilah ciri dari variabel acak kontinu. Nilainya bisa berada di mana saja dalam suatu rentang.
Lalu, bagaimana kita menghitung probabilitasnya?
Di sinilah PDF (probability density function) berperan. PDF tidak memberikan probabilitas langsung seperti PMF, tetapi menunjukkan kepadatan probabilitas di sekitar nilai tertentu. Jadi, jika kamu melihat puncak kurva PDF pada nilai 170 cm, artinya tinggi badan 170 cm punya kepadatan probabilitas yang lebih tinggi dibandingkan tinggi 150 cm.
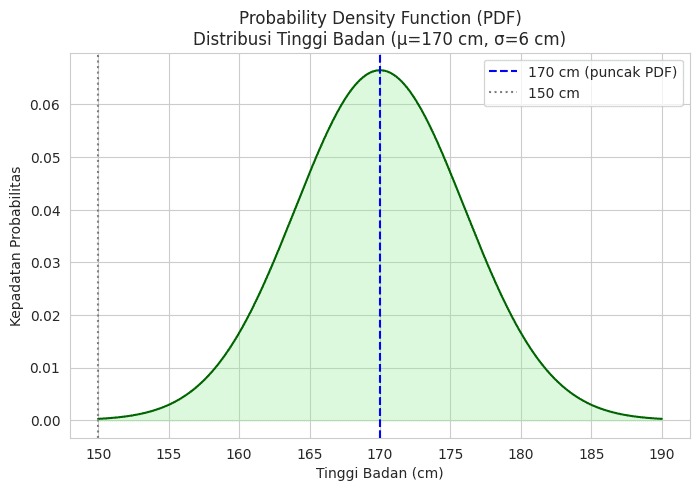
Ingat: probabilitas sebuah nilai tunggal pada variabel kontinu adalah nol. Kita hanya bisa menghitung probabilitas dalam suatu rentang.
Contohnya berikut.
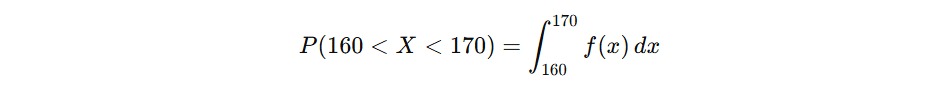
Artinya, kita menghitung luas area di bawah kurva PDF antara 160 dan 170. Itulah probabilitasnya.
Total luas seluruh kurva PDF, dari −∞ sampai ∞, haruslah 1. Karena kita tahu bahwa nilai variabel pasti berada di suatu tempat dalam rentang tersebut.
PDF sangat berguna dalam distribusi seperti distribusi normal (Gaussian) yang terkenal dengan bentuk “lonceng”-nya, dan juga distribusi uniform, yakni ketika semua nilai dalam rentang tertentu memiliki kepadatan yang sama.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - PDF.ipynb
CDF (Cumulative Distribution Function): Melihat Akumulasi Peluang
CDF (cumulative distribution function) adalah fungsi yang memberitahu kita total peluang suatu kejadian terjadi kurang dari atau sama dengan nilai tertentu.
Kalau PMF dan PDF memberi informasi titik per titik, CDF memberi gambaran akumulatif. Ia menjawab pertanyaan seperti “Seberapa besar kemungkinan bahwa tinggi badan seseorang kurang dari atau sama dengan 170 cm?”
CDF untuk Variabel Diskrit
Untuk data diskret, seperti hasil lemparan dadu, CDF bekerja dengan menjumlahkan probabilitas setiap kemungkinan hasil hingga nilai yang kita inginkan. Misalnya, untuk mengetahui peluang mendapat angka kurang dari atau sama dengan 3, CDF akan menjumlahkan peluang mendapat 1, 2, dan 3.
Jika X adalah variabel acak diskret dengan fungsi probabilitas (PMF) P(X=x), CDF didefinisikan sebagai berikut.
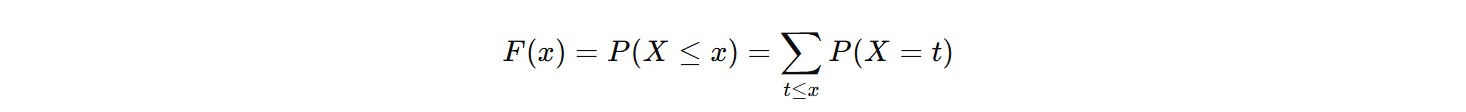
Artinya, CDF pada titik x adalah jumlah semua probabilitas nilai X yang kurang dari atau sama dengan x.
CDF untuk Variabel Kontinu
Untuk data kontinu seperti tinggi badan teman sekelas, cumulative distribution function (CDF) digunakan untuk mencari peluang kumulatif hingga titik tertentu.
CDF dihitung dengan menjumlahkan (atau mengintegralkan) seluruh area di bawah kurva fungsi kerapatan probabilitas (PDF), mulai dari batas bawah (umumnya sangat kecil atau −∞) hingga titik tinggi badan yang kita cari.
Contoh praktis:
Jika kita ingin tahu peluang seseorang memiliki tinggi badan kurang dari atau sama dengan 175 cm, nilai CDF di titik 175 cm akan memberikan total area di bawah kurva PDF dari paling kiri sampai 175 cm.
Jika X adalah variabel acak kontinu (misalnya tinggi badan) dengan PDF f(x), CDF didefinisikan sebagai berikut.
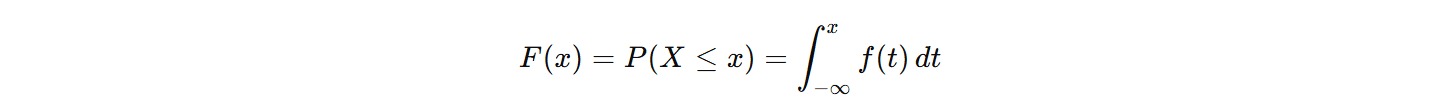
- F(x): Nilai CDF pada titik x, yaitu peluang tinggi badan ≤ x cm.
- f(t): Fungsi PDF (misal, distribusi normal tinggi badan).
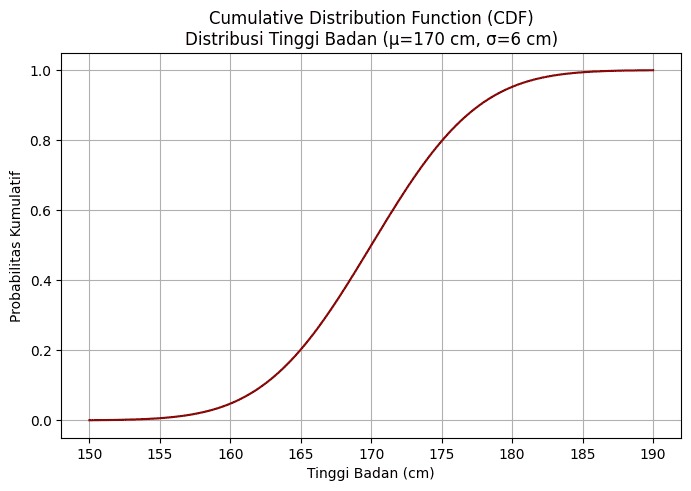
Pada grafik CDF tinggi badan di atas, sumbu x adalah tinggi badan (cm) dan sumbu y adalah probabilitas kumulatif. Nilai CDF selalu naik dari 0 ke 1.
Jika pada titik 175 cm nilai CDF = 0.80, 80% siswa memiliki tinggi ≤ 175 cm.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - CDF.ipynb
Keterkaitan PMF, PDF, dan CDF
Setelah mempelajari PMF, PDF, dan CDF secara terpisah, kini saatnya kita melihat bahwa ketiganya saling berkaitan. Meskipun berasal dari jenis variabel yang berbeda (diskret dan kontinu) PMF, PDF, dan CDF sebenarnya saling melengkapi serta bersama-sama membentuk kerangka berpikir probabilistik yang lengkap.
Bayangkan Anda sedang mempelajari cara sebuah nilai dari suatu kejadian bisa muncul dan ingin tahu seberapa besar peluangnya. Jika bekerja dengan variabel diskret, seperti jumlah pelanggan di toko atau jumlah anak dalam keluarga, Anda akan menggunakan PMF.
PMF ini ibaratnya memberi tahu Anda peluang untuk setiap nilai yang mungkin secara spesifik. Misalnya, “Berapa besar peluang sebuah keluarga memiliki tepat dua anak?” PMF cocok untuk menjawab pertanyaan tersebut.
Namun, jika tidak hanya ingin tahu satu nilai, tetapi ingin tahu juga berapa besar peluang untuk nilai yang lebih kecil atau sama dengan suatu angka, Anda membutuhkan CDF.
Untuk variabel diskret, CDF ini adalah penjumlahan dari nilai-nilai PMF yang berada pada atau di bawah angka tersebut. Artinya, CDF membantu Anda melihat peluang secara bertahap atau akumulatif (tidak hanya di satu titik), tetapi dari titik paling kecil sampai pada titik yang sedang diperhatikan.
Ketika beralih pada variabel kontinu, seperti tinggi badan atau waktu tunggu, Anda tak lagi bisa menghitung peluang satu per satu karena jumlah nilai yang mungkin sangat banyak dan bisa mendekati tak terhingga. Di sinilah Anda akan bekerja dengan PDF.
PDF tidak memberi nilai peluang secara langsung seperti PMF, tetapi memberi informasi tentang kepadatan peluang—yakni saat nilai-nilai itu lebih sering muncul dalam rentang tertentu.
PDF membantu Anda melihat daerah yang “ramai” atau “sepi” dalam distribusi nilai. Namun, untuk tahu seberapa besar peluang dari awal sampai titik tertentu, Anda tetap membutuhkan CDF. Jadi, dalam konteks variabel kontinu, PDF menjadi bagian yang menyusun CDF. Anda bisa membayangkan PDF seperti garis-garis kecil penyusun kurva dan CDF adalah bentuk besar dari kurva itu.
Secara visual, Anda bisa membayangkan CDF seperti bukit yang perlahan naik. Ketika berada di kaki bukit, Anda baru mengumpulkan sedikit peluang. Semakin berjalan ke kanan, Anda makin banyak menanjak karena semakin banyak nilai peluang yang terkumpul. PDF, dalam analogi ini, adalah kemiringan dari bukit itu. Ketika bukit curam, PDF tinggi—artinya banyak peluang terkumpul dalam jarak pendek. Ketika bukit mendatar, PDF kecil—tidak banyak peluang yang terkumpul di sana.
Untuk variabel diskret, grafik CDF akan tampak seperti tangga—melonjak di titik tertentu, lalu datar sampai melonjak lagi. Untuk variabel kontinu, CDF tampak lebih mulus—seperti garis lengkung yang perlahan naik tanpa jeda.
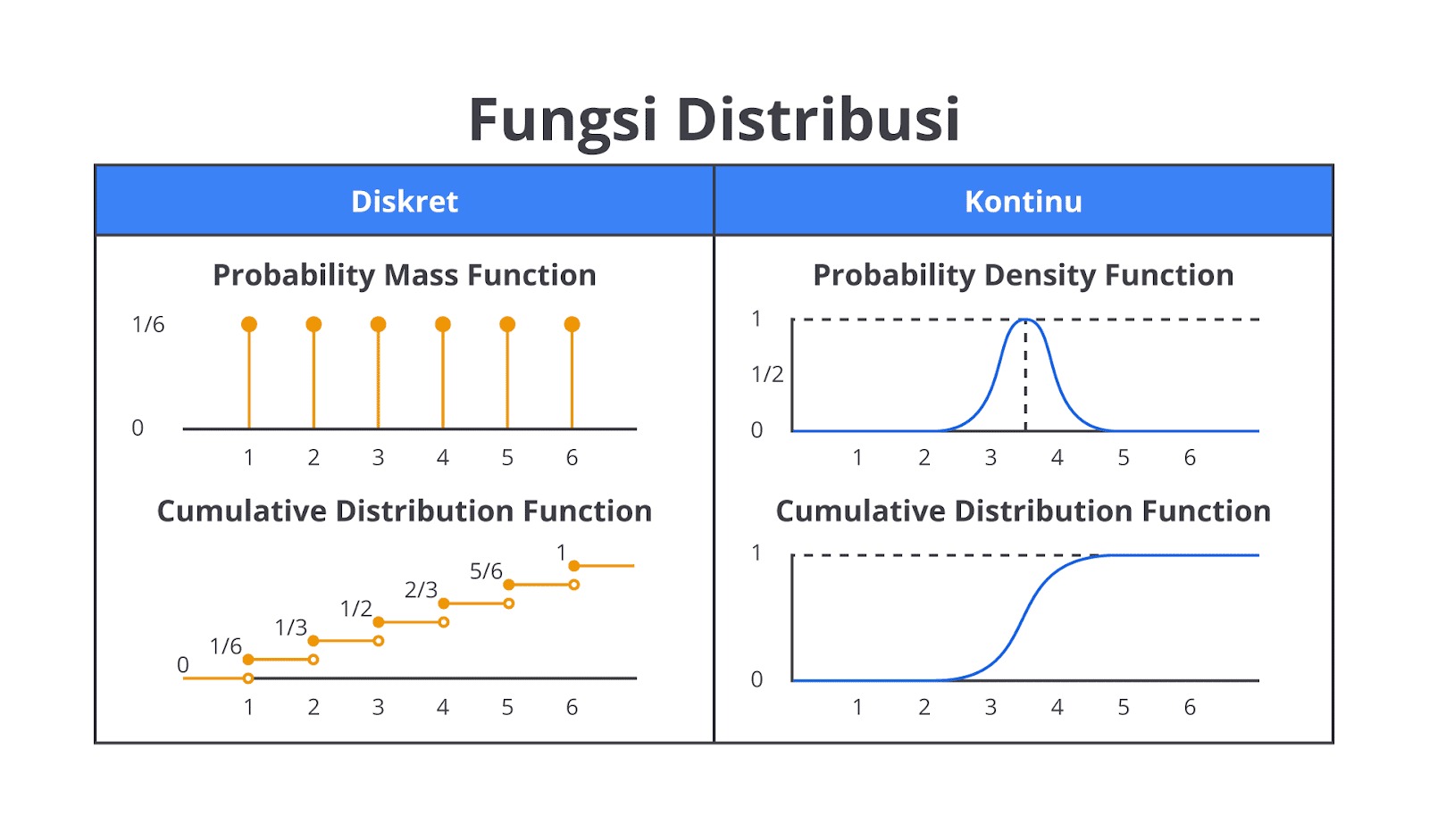
Jadi, meskipun PMF dan PDF melayani jenis data yang berbeda, keduanya memiliki peran yang mirip: memberi kita informasi tentang peluang pada titik-titik tertentu. Adapun CDF, baik untuk diskret maupun kontinu, adalah fungsi yang memberi kita gambaran total peluang dari sisi kiri garis angka hingga titik tertentu.
Memahami hubungan ini penting karena dalam banyak kasus nyata, Anda tidak hanya akan menggunakan satu fungsi. Misalnya, Anda bisa menggunakan PDF untuk tahu letak peluang paling padat dan menggunakan CDF untuk tahu besar peluang yang sudah terkumpul sampai titik ini. Atau dalam kasus data diskret, Anda bisa menggabungkan PMF dan CDF untuk membuat keputusan klasifikasi atau penilaian risiko.
Ketika Anda mulai menjelajah distribusi-distribusi yang lebih kompleks, seperti binomial, Poisson, normal, dan sebagainya; pemahaman tentang cara PMF, PDF, serta CDF saling berinteraksi akan menjadi landasan penting. Mereka bukan hanya alat bantu menghitung peluang, tetapi juga cara berpikir dalam menilai ketidakpastian dan membuat keputusan berbasis data.
Dengan kata lain, PMF, PDF, dan CDF bukan tiga hal terpisah, melainkan tiga bagian dari satu sistem saling mendukung—seperti titik, garis, serta bentuk yang bersama-sama membantu kita membaca dan menggambarkan peta dunia peluang.
Distribusi Diskret
Dalam perjalanan kita menggali dunia data science, ada satu konsep yang akan sering Anda jumpai dan menjadi fondasi banyak hal: distribusi probabilitas. Coba bayangkan ini seperti sebuah “peta tersembunyi” dari setiap kejadian acak. Peta ini tidak hanya menunjukkan semua kemungkinan hasil yang bisa terjadi, tapi yang lebih penting, memberi tahu kita seberapa besar kemungkinan setiap hasil itu akan muncul. Ini ibarat daftar semua hidangan di restoran favorit Anda, lengkap dengan seberapa sering setiap hidangan itu dipesan!
Di dunia nyata, data yang kita temui sering kali datang dalam bentuk “hitungan” atau angka bulat terpisah. Misalnya, kita bisa menghitung jumlah mobil yang lewat di jalan atau jumlah keluhan pelanggan yang masuk. Kita tidak mungkin punya “setengah” mobil lewat, kan? Untuk jenis data seperti inilah kita menggunakan distribusi probabilitas diskret.
Sederhananya, distribusi diskret adalah model matematika untuk variabel yang hasilnya hanya bisa berupa nilai-nilai yang bisa kita hitung satu per satu, dengan jelas ada jeda di antaranya. Pikirkan seperti menekan tombol pada kalkulator: 1, 2, 3 … ada “lompatan” antara setiap angka.
Contoh Paling Gampang
- Berapa jumlah anggota keluarga Anda? (Bisa 3, 4, tapi tidak mungkin 3.75.)
- Berapa banyak bintang yang Anda lihat di langit malam? (Bisa 100, 200, tapi tidak mungkin 150.8.)
- Hasil lemparan sebuah dadu standar (pasti 1, 2, 3, 4, 5, atau 6).
Lalu, apa bedanya dengan yang “kontinu”? Kebalikannya, distribusi kontinu bisa mengambil nilai apa saja dalam sebuah rentang. Contohnya seperti tinggi badan (bisa 165 cm, 165.7 cm, 165.789 cm, dan seterusnya tanpa batas di antara angka-angka itu) atau suhu ruangan. Namun, fokus kita sekarang adalah yang diskret, ya.
Untuk memudahkan pemahaman, mari kita kenalan lebih dekat dengan tiga jenis distribusi diskret yang paling sering digunakan dan sangat penting dalam analisis data: distribusi Bernoulli, distribusi binomial, dan distribusi Poisson.
Distribusi Bernoulli
Pernahkah Anda menghadapi situasi ketika hanya ada dua kemungkinan hasil? Misalnya, “berhasil atau gagal”, “ya atau tidak”, “benar atau salah”? Misalnya, apakah seorang pengunjung baru akan berlangganan newsletter Anda? Apakah sebuah transaksi di toko online itu fraud atau bukan? Nah, untuk skenario satu kali percobaan dengan dua hasil semacam ini, distribusi Bernoulli adalah jawabannya.
Distribusi Bernoulli adalah model yang sangat sederhana, tapi powerful. Ia menggambarkan hasil dari satu peristiwa tunggal yang hanya bisa berakhir dengan dua kemungkinan hasil.
- “Sukses” (Success): Ini adalah hasil yang diminati atau ingin kita amati. Probabilitas terjadinya sukses ini kita simbolkan dengan huruf kecil p.
- “Gagal” (Failure): Ini adalah hasil lainnya. Karena hanya ada dua kemungkinan, probabilitas gagal otomatis menjadi 1−p.

Contoh kejadiannya adalah seperti pada kasus Anda melempar sebuah koin dan berharap mendapatkan gambar kepala.
- Anda melempar koin satu kali saja. Kita definisikan “sukses” adalah munculnya gambar kepala maka p=0.5. “Gagal” berarti muncul ekor, dengan probabilitas 1−p=0.5.
- Seorang sales menelepon prospek satu kali. “Sukses” adalah prospek setuju membeli (p), “Gagal” adalah prospek menolak (1−p).
Satu-satunya parameter yang perlu Anda ketahui untuk distribusi Bernoulli adalah p, yaitu probabilitas terjadinya “sukses”. Cara menghitung probabilitasnya cukup sederhana, kita menggunakan persamaan probability mass function (PMF).
- Probabilitas mendapatkan hasil sukses (biasanya kita beri kode X = 1): P(X = 1)= p
- Probabilitas mendapatkan hasil gagal (biasanya kita beri kode X = 0): P(X = 0)= 1−p
Mari kita lihat visualisasi berikut.
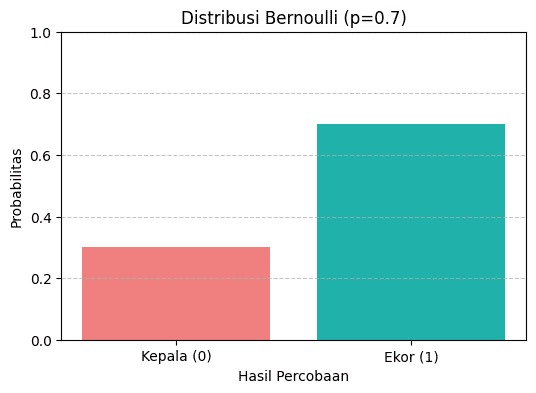
Pada grafik ini, kita melihat distribusi Bernoulli untuk percobaan melempar koin yang tidak seimbang (p = 0,3 untuk kepala, p = 0,7 untuk ekor).
- Sumbu-x: hasil percobaan, yaitu Kepala (0) dan Ekor (1).
- Sumbu-y: probabilitas masing-masing hasil.
Maknanya berikut.
- Tinggi batang merah (Kepala/0):
menunjukkan probabilitas mendapatkan kepala, yaitu P(X = 0) = 1 − p = 0,3. - Tinggi batang hijau (Ekor/1):
menunjukkan probabilitas mendapatkan ekor, yaitu P(X = 1) = p = 0,7.
Walaupun hanya ada dua batang (karena hanya dua kemungkinan hasil), visualisasi seperti ini sangat membantu untuk membayangkan peluang masing-masing hasil pada percobaan Bernoulli.
- Jika melakukan percobaan sekali, kemungkinan besar Anda akan mendapatkan ekor (karena batang ekor lebih tinggi).
- Jika p diubah, tinggi kedua batang juga akan berubah, mengikuti nilai peluang yang baru.
Distribusi Bernoulli cocok untuk peristiwa dengan dua kemungkinan hasil (sukses/gagal, ya/tidak, kepala/ekor) dan visualisasi ini menggambarkan proporsi peluang tiap hasil dengan sangat jelas. Meskipun kelihatannya sangat sederhana, Bernoulli adalah fondasi yang kuat! Anda akan menemukannya di mana-mana sewaktu kondisi berikut.
- Membangun model klasifikasi biner (misalnya, memprediksi apakah email itu “spam” atau “bukan spam”).
- Menganalisis hasil satu kejadian dalam A/B testing (misal: apakah satu pengguna tertentu berhasil konversi?).
- Memodelkan keputusan yang hanya punya dua opsi.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Distribusi Bernoulli.ipynb
Distribusi Binomial
Oke, kita sudah tahu tentang satu kali percobaan “ya atau tidak” (Bernoulli). Sekarang, bagaimana jika kita mengulang percobaan “ya atau tidak” ini berkali-kali dan ingin tahu berapa banyak keberhasilan yang didapatkan dari sekian banyak pengulangan itu?
Misalnya, dari 100 pengunjung website, berapa banyak yang akan mengklik iklan Anda? Atau dari 20 pertanyaan ujian pilihan ganda, berapa banyak yang akan Anda jawab benar secara acak? Nah, di sinilah distribusi binomial mulai digunakan.
Distribusi binomial digunakan untuk memodelkan jumlah sukses yang kita peroleh dalam serangkaian n percobaan independen dan identik. Setiap percobaan itu sendiri haruslah percobaan Bernoulli (artinya, punya dua hasil, dan probabilitas sukses p sama untuk setiap percobaan). Kata kunci di sini adalah “independen” (hasil satu percobaan tidak memengaruhi yang lain) serta “identik” (kondisi dan probabilitasnya sama pada setiap percobaan).
Berikut adalah beberapa contoh kasus yang cocok untuk penggunaan distribusi binomial.
- Anda melempar koin 10 kali. Anda ingin tahu probabilitas mendapatkan 3 kepala, 5 kepala, atau 7 kepala.
- Anda mengirim email promosi ke 50 pelanggan. Anda ingin tahu probabilitas tepat 10 di antara mereka yang akan melakukan pembelian.
- Anda menguji 20 produk dari lini produksi. Anda ingin tahu probabilitas tepat 2 produk yang cacat.
Distribusi binomial punya dua parameter yang harus Anda tentukan.
- n: Ini adalah jumlah total percobaan yang Anda lakukan. (Misalnya, 10 lemparan koin, 50 email terkirim, 20 produk diuji).
- p: Ini adalah probabilitas sukses dalam satu kali percobaan. (Sama seperti p pada Bernoulli).
Cara menghitung probabilitas pada distribusi binomial adalah dengan menggunakan persamaan probability mass function (PMF). Persamaan ini digunakan untuk menentukan probabilitas memperoleh tepat x kali sukses dari n percobaan dengan setiap percobaan memiliki peluang sukses p dan peluang gagal q = 1 - p.
Rumusnya adalah berikut.

Mari kita lihat visualisasi berikut yang menunjukkan probabilitas untuk setiap kemungkinan jumlah sukses.
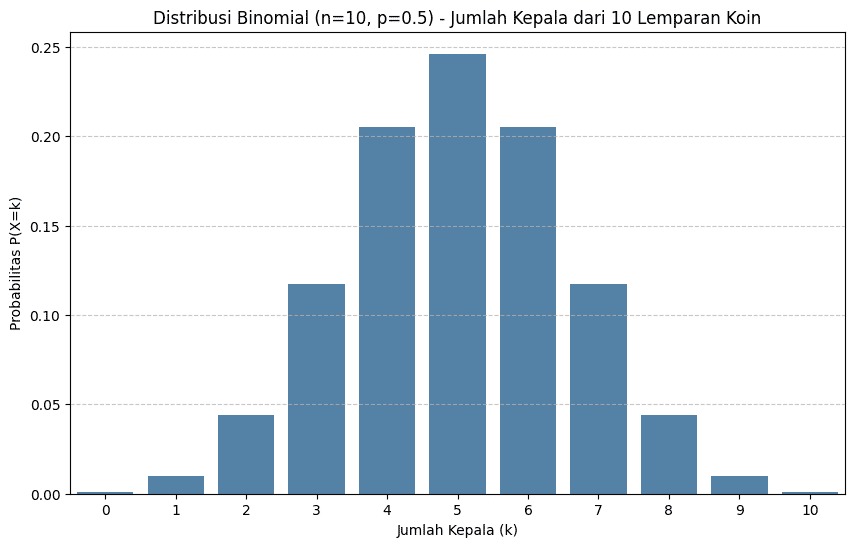
Pada contoh di atas, kita menyimulasikan kondisi pelemparan sebuah koin sebanyak 10 kali. Karena koinnya adil, probabilitas munculnya kepala (atau sukses) adalah 0.5 pada setiap lemparan.
Melalui visualisasi grafik batang yang dihasilkan, kita dapat mengamati bahwa distribusi probabilitas terpusat di sekitar 5 kepala, menunjukkan bahwa mendapatkan 5 kepala dari 10 lemparan adalah hasil paling mungkin. Batang-batang grafik akan terlihat simetris, menurun secara bertahap menjauhi angka 5, dan kita bisa melihat probabilitas spesifik seperti mendapatkan tepat 5 kepala adalah sekitar 0.2461, sementara probabilitas mendapatkan 0 kepala sangatlah kecil, yaitu 0.0010.
Sekarang, mari kita perhatikan visualisasi berikutnya.
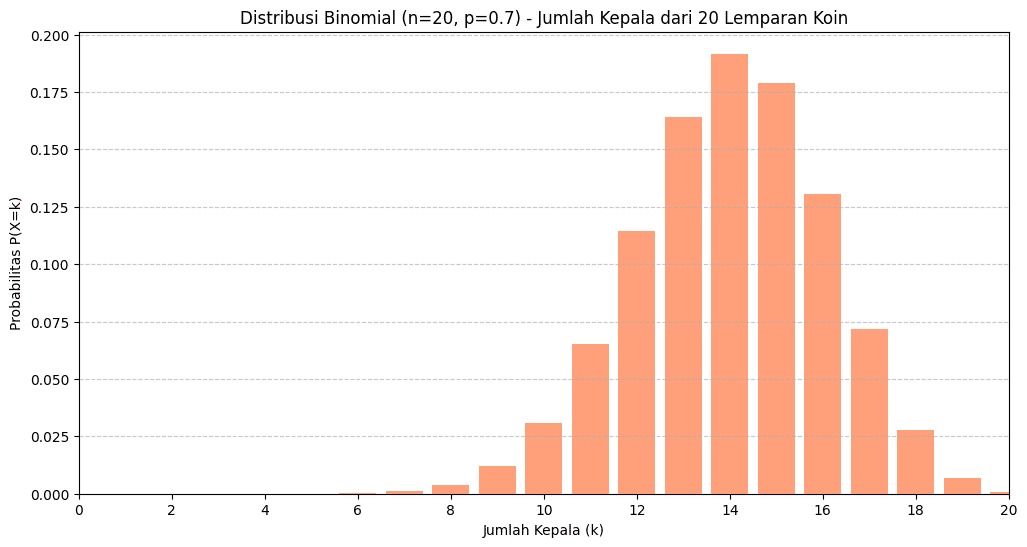
Pada contoh ini, kita menyimulasikan pelemparan sebuah koin sebanyak 20 kali, tapi dengan probabilitas muncul kepala (sukses) lebih tinggi, yaitu 0.7 pada setiap lemparan. Ini menggambarkan skenario ketika koinnya “berat sebelah” sehingga peluang muncul kepala jauh lebih besar daripada ekor.
Grafik batang yang dihasilkan menunjukkan distribusi probabilitas jumlah kepala dari 0 hingga 20.
- Berbeda dengan distribusi sebelumnya, kali ini puncak distribusi tidak lagi berada di tengah, tetapi bergeser ke kanan, yaitu di sekitar nilai 14 kepala (karena rata-rata = n × p = 20 × 0.7 = 14).
- Probabilitas mendapatkan tepat 14 kepala adalah sekitar 0.1847.
- Adapun probabilitas mendapatkan 10 kepala turun drastis menjadi sekitar 0.0368.
Visualisasi ini juga menunjukkan hal berikut.
- Distribusi tidak simetris; semakin banyak kepala yang didapat, probabilitasnya meningkat hingga puncak (14 kepala), lalu menurun kembali.
- Hasil yang paling mungkin didapatkan adalah jumlah kepala di sekitar 14.
- Probabilitas mendapatkan jumlah kepala yang jauh dari rata-rata (misal 0, 5, atau 20) sangat kecil, hampir tidak pernah terjadi dalam simulasi ini.
Dengan mengubah nilai p, kita bisa melihat bahwa bentuk distribusi binomial berubah sesuai dengan kemungkinan sukses pada setiap percobaan.
Visualisasi ini sangat membantu untuk memahami bahwa distribusi binomial sangat dipengaruhi oleh nilai p dan puncak distribusi akan bergeser sesuai dengan ekspektasi jumlah sukses.
Pertanyaan pemungkasnya, “Kapan distribusi binomial sering dipakai dalam data science?”
- A/B Testing: Ini merupakan contoh pengaplikasian distribusi binomial yang paling sering. Anda menguji dua versi (A dan B) sebuah desain dan ingin tahu berapa keberhasilan (misal: konversi) dari setiap versi.
- QC (Quality Control): Memprediksi berapa banyak barang cacat yang mungkin muncul dalam sampel dari sebuah lini produksi.
- Survei dan Polling: Memahami berapa banyak orang yang akan setuju dengan sebuah pernyataan dari sejumlah responden.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Distribusi Binomial.ipynb
Distribusi Poisson
Bayangkan Anda bekerja di sebuah kafe dan ingin tahu berapa banyak pelanggan yang masuk setiap 15 menit. Atau Anda adalah seorang manajer gudang yang ingin tahu jumlah kerusakan pada paket yang terjadi per kilometer pengiriman.
Ini adalah jenis kejadian yang terjadi secara acak, dalam sebuah interval waktu atau ruang yang tetap, dan sering kali (tetapi tidak selalu) dianggap relatif jarang. Nah, untuk skenario ini, distribusi Poisson adalah alat statistik yang sempurna!
Distribusi Poisson digunakan untuk memodelkan jumlah kejadian dari suatu peristiwa dalam sebuah interval waktu atau ruang yang telah ditentukan. Ada beberapa asumsi penting agar distribusi Poisson bisa diterapkan dengan baik.
- Kejadian tersebut harus terjadi secara independen. Artinya, satu kejadian tidak memengaruhi bahwa kejadian lain akan terjadi segera setelahnya.
- Kejadian terjadi dengan rata-rata laju (rate) yang diketahui dan konstan sepanjang interval tersebut. Ini berarti rata-rata kejadian per menit (atau per meter atau per jam) tidak berubah-ubah secara signifikan dalam interval yang sama.
- Kejadian itu sendiri cenderung jarang terjadi dalam interval sangat singkat dan mustahil ada banyak kejadian yang terjadi secara instan pada waktu yang sama.
Beberapa contoh kasus penggunaan distribusi Poisson dalam konteks sehari-hari adalah berikut.
- Jumlah email spam yang Anda terima per hari.
- Jumlah panggilan darurat yang diterima rumah sakit per jam.
- Jumlah kecelakaan lalu lintas di sebuah persimpangan sibuk per bulan.
- Jumlah pelanggan yang tiba di kasir supermarket per lima menit.
- Jumlah error atau cacat yang ditemukan pada sebuah gulungan kabel sepanjang 100 meter.
Distribusi Poisson hanya punya satu parameter yang perlu Anda ketahui: λ (dibaca “lambda”).
- λ adalah rata-rata jumlah kejadian yang diharapkan akan terjadi dalam interval yang Anda tentukan. Ini adalah “laju” kejadian tersebut.
- Ada satu sifat menarik dari distribusi Poisson: nilai λ ini juga sama dengan variansi dari distribusi tersebut! Ini adalah hubungan unik yang sering digunakan dalam analisis data.
Bagaimana cara menghitung probabilitas pada distribusi Poisson? Untuk menghitung probabilitas terjadinya tepat x kejadian dalam suatu interval waktu atau ruang tertentu, jika rata-rata kejadiannya adalah λ (lambda), kita dapat menggunakan probability mass function (PMF) dari distribusi Poisson.
Rumusnya adalah berikut.

Mari kita lihat contoh visualisasinya. Bayangkan Anda adalah seorang data analyst e-commerce. Grafik Poisson ini menunjukkan probabilitas jumlah pesanan per 15 menit dengan rata-rata (λ) 8 pesanan. Puncaknya di angka 8, secara visual mengonfirmasi bahwa 8 pesanan adalah kejadian paling mungkin.
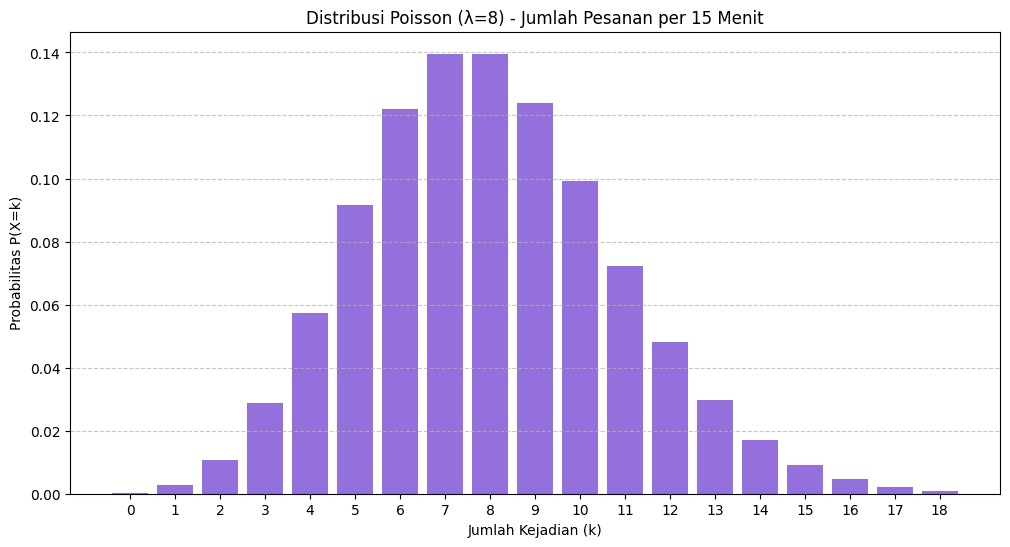
Probabilitas mendapatkan tepat 8 pesanan adalah yang tertinggi, yaitu 0.1396. Sementara itu, probabilitas untuk kejadian lebih ekstrem, seperti tepat 15 pesanan jauh lebih rendah, hanya 0.0090, terlihat dari batang yang sangat pendek di sisi kanan grafik. Visualisasi ini krusial untuk perencanaan kapasitas, memastikan sumber daya cukup saat puncak pesanan.
Sekarang, mari kita terapkan distribusi Poisson pada kasus jumlah panggilan telepon yang diterima sebuah kantor setiap jam.
Misalkan, rata-rata panggilan yang masuk adalah λ = 3 panggilan per jam. Pada grafik berikut, kita melihat probabilitas untuk setiap kemungkinan jumlah panggilan dalam satu jam, dari 0 hingga 8 panggilan.
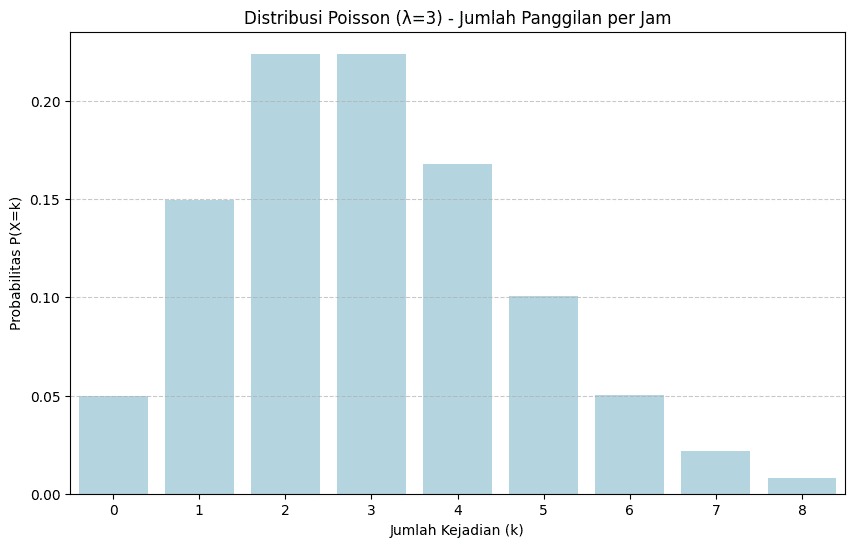
Penjelasannya berikut.
- Puncak batang grafik berada pada angka 3, artinya 3 panggilan adalah jumlah yang paling mungkin diterima dalam satu jam.
- Probabilitas menerima tepat 3 panggilan adalah sekitar 0.2240, tertinggi di antara semua kemungkinan.
- Sementara itu, probabilitas menerima tepat 0 panggilan jauh lebih kecil, hanya sekitar 0.0498, dan probabilitas mendapat 7 panggilan hanya 0.0216.
- Ini tergambar jelas dari tinggi batang pada setiap nilai k; semakin jauh dari rata-rata, probabilitasnya semakin kecil dan batangnya semakin pendek.
Visualisasi seperti ini sangat penting untuk operasional kantor. Dengan mengetahui probabilitas distribusi jumlah panggilan, manajemen bisa mengatur jumlah staf atau kapasitas layanan yang sesuai untuk mengantisipasi jam-jam sibuk ataupun sepi. Jika probabilitas menerima banyak panggilan sangat kecil, kantor bisa lebih efisien dalam menyiapkan sumber daya.
Perhatikan juga cara bentuk distribusi Poisson berubah seiring dengan perubahan nilai λ. Jika λ kecil, distribusinya akan condong ke kiri (lebih banyak nol kejadian). Semakin besar λ, bentuknya akan semakin menyerupai lonceng (mirip distribusi normal untuk λ yang besar).
Distribusi Poisson juga memiliki hubungan dengan binomial. Ketika jumlah percobaan dalam distribusi binomial sangat besar dan peluang sukses sangat kecil, binomial akan mendekati bentuk Poisson. Hal ini menjadikan distribusi Poisson sebagai model yang praktis ketika kita tidak tahu jumlah percobaannya, tetapi tahu berapa banyak kejadian biasanya muncul.
Distribusi Poisson sangat efektif untuk memodelkan jumlah kejadian acak dalam interval waktu tertentu, yakni untuk pesanan e-commerce, panggilan telepon, pelanggan datang ke restoran, dan lain-lain. Dengan visualisasi ini, perencanaan sumber daya menjadi lebih berbasis data dan akurat.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Distribusi Poisson.ipynb
Distribusi Kontinu
Halo, para pembelajar data science yang tekun! Setelah kita mengarungi lautan distribusi probabilitas diskret, yang mengurusi data dengan hasil berupa angka bulat dan terpisah, kini saatnya kita berpindah ke samudra lain yang tak kalah luas dan penting: distribusi probabilitas kontinu.
Jenis distribusi ini adalah “peta probabilitas” yang dirancang khusus untuk data yang sifatnya “mengalir” tanpa putus, artinya, data yang dapat mengambil nilai apa pun dalam sebuah rentang yang tidak terbatas oleh angka bulat saja. Ini adalah inti dari pemodelan banyak fenomena alamiah dan terapan.
Secara fundamental, distribusi probabilitas kontinu adalah model matematika untuk variabel acak yang dapat mengambil nilai apa pun dalam sebuah rentang berkelanjutan (kontinu).
Ini berarti, antara dua nilai yang mungkin, sekecil apa pun perbedaannya, selalu ada nilai-nilai lain yang tak terhingga di antaranya. Pikirkan tentang mengukur sesuatu dengan sangat presisi: bukan hanya 170 cm atau 171 cm, melainkan juga bisa 170.5 cm, 170.53 cm, bahkan 170.5387 cm.
Contoh klasik dari variabel kontinu meliputi hal-hal berikut.
- Tinggi badan seseorang: Anda bisa punya tinggi 165.23 cm.
- Suhu ruangan saat ini: bisa 25.75 derajat Celcius.
- Waktu yang dibutuhkan untuk menyelesaikan suatu tugas: bisa 3.45 menit.
- Berat sebuah objek: misalnya 5.78 kilogram.
Karakteristik penting dari distribusi kontinu adalah bahwa kita tidak bisa menghitung probabilitas untuk satu titik nilai spesifik (misalnya, probabilitas seseorang memiliki tinggi tepat 170.5387 cm adalah nol karena ada tak terhingga kemungkinan nilai lain di sekitarnya).
Sebaliknya, untuk distribusi kontinu, kita berbicara tentang probabilitas suatu variabel acak berada dalam sebuah rentang tertentu. Probabilitas ini dihitung sebagai area di bawah kurva probability density function (PDF) dalam rentang tersebut. PDF ini sendiri tidak memberikan probabilitas langsung, tetapi “kepadatan” probabilitas pada titik tertentu. Total area di bawah seluruh kurva PDF akan selalu sama dengan 1, merepresentasikan probabilitas kumulatif dari semua kemungkinan hasil.
Dalam materi ini, kita akan mendalami beberapa distribusi kontinu yang paling fundamental serta sering digunakan: distribusi uniform kontinu, distribusi normal, distribusi t-Student, dan distribusi chi-square.
Distribusi Uniform Kontinu
Bayangkan Anda tiba di halte bus dan tahu pasti bahwa bus akan datang dalam sepuluh menit ke depan, tapi tidak punya informasi tambahan apa pun. Apakah bus akan datang pada menit pertama, pada menit kelima, atau mungkin tepat pada menit ke-9.34? Jika setiap momen dalam rentang sepuluh menit itu memiliki peluang yang sama persis untuk kedatangan bus, ini adalah gambaran sempurna dari distribusi uniform kontinu.
Distribusi ini paling sederhana di antara distribusi kontinu lainnya, mencerminkan situasi ketika tidak ada satu pun nilai dalam rentang tertentu yang lebih mungkin terjadi daripada lainnya.
Distribusi uniform kontinu secara khusus menggambarkan skenario ketika sebuah variabel acak memiliki probabilitas sama rata untuk mengambil nilai apa pun dalam sebuah rentang atau interval yang ditentukan (misalnya, dari a hingga b).
Secara visual, distribusi ini direpresentasikan oleh sebuah kurva berbentuk persegi panjang yang datar.
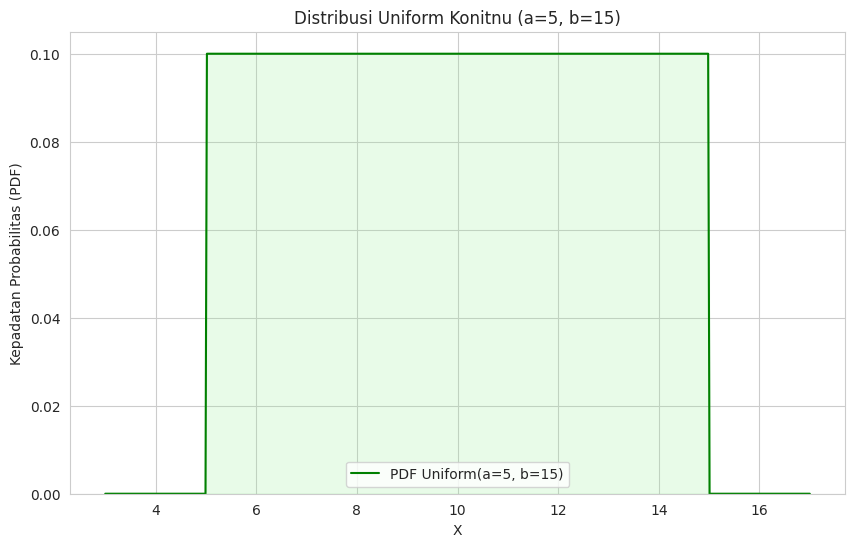
Tinggi kurva ini konstan di seluruh interval [a,b] dan probabilitasnya nol di luar interval tersebut. Agar total area di bawah kurva (yang merupakan total probabilitas) sama dengan 1, tinggi kurva tersebut secara matematis harus disesuaikan menjadi berikut.
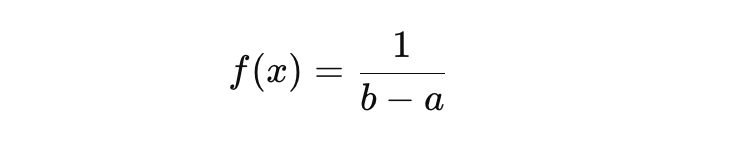
Ini memastikan bahwa luas persegi panjang (tinggi dikalikan lebar interval b−a) adalah 1. Konsep distribusi uniform kontinu sangat berguna untuk memodelkan kejadian ketika Anda tahu bahwa suatu peristiwa akan terjadi dalam batasan waktu atau nilai tertentu, tetapi tidak memiliki informasi tambahan yang menunjukkan bahwa satu momen atau nilai lebih mungkin daripada lainnya.
Distribusi uniform kontinu secara eksklusif ditentukan oleh dua parameter yang mendefinisikan batas-batas intervalnya.
- a: Ini adalah batas bawah dari interval tersebut.
- b: Ini adalah batas atas dari interval tersebut.
Mari kita lihat contoh visualisasinya.
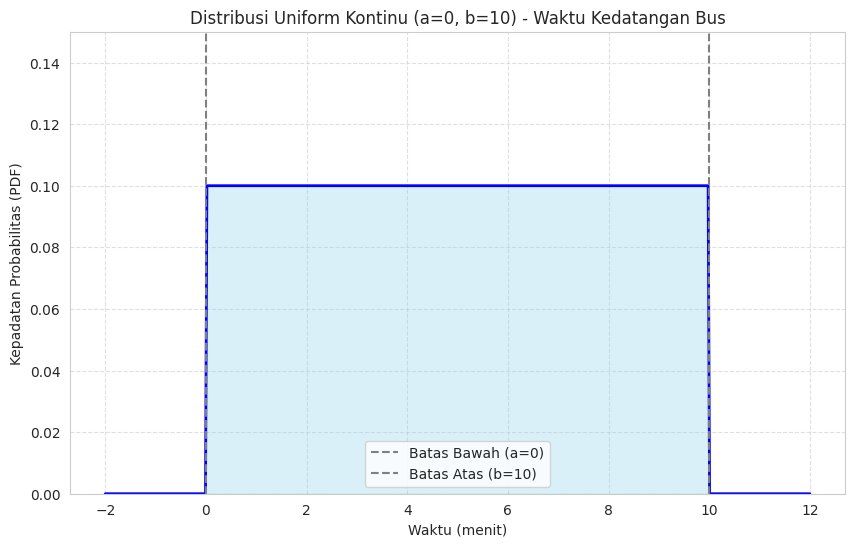
Visualisasi di atas menampilkan grafik berbentuk persegi panjang datar yang terentang dari a (0 menit) hingga b (10 menit). Tingginya adalah 1/(b-a), yang dalam kasus ini adalah 1/10=0.1. Ini secara visual menunjukkan bahwa setiap titik waktu di antara 0 dan 10 menit memiliki “kepadatan probabilitas” yang sama. Di luar rentang ini, ketinggian kurva adalah nol, artinya probabilitasnya nol.
Ketika menghitung probabilitas bus datang antara menit 2 dan 7, kita sebenarnya menghitung luas area persegi panjang dari 2 hingga 7, yaitu berikut.
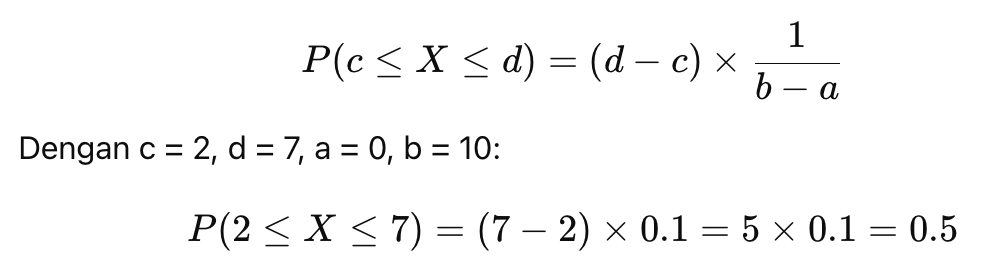
Dengan demikian, probabilitas bus datang antara menit 2 dan 7 adalah 0.5.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Distribusi Uniform Kontinu.ipynb
Distribusi Normal/Gaussian
Jika ada satu distribusi yang harus Anda kuasai dalam data science, itu adalah distribusi normal, sering juga dikenal sebagai distribusi Gaussian. Mengapa begitu penting? Karena distribusi normal secara menakjubkan mampu menggambarkan pola penyebaran data dari begitu banyak fenomena di alam semesta, baik di alam maupun dalam kehidupan sosial dan ekonomi.
Bayangkan data seperti tinggi badan manusia dewasa, tekanan darah, skor tes IQ yang diambil dari populasi besar, pengukuran error pada eksperimen ilmiah, atau bahkan kinerja rata-rata saham dalam jangka panjang; semuanya cenderung berkumpul di sekitar nilai rata-rata serta menyebar secara simetris, membentuk kurva indah dan familier yang kita sebut kurva lonceng.
Karakteristik Kurva Distribusi Normal
Kurva distribusi normal memiliki bentuk yang sangat khas dan mudah dikenali: ia simetris serta menyerupai lonceng (bell-shaped curve).
- Puncak di Tengah: Bagian tertinggi dari kurva selalu berada tepat di nilai rata-rata (mean). Ini secara intuitif menunjukkan bahwa nilai-nilai paling dekat dengan rata-rata adalah yang paling sering diamati atau memiliki kepadatan probabilitas tertinggi.
- Simetris Sempurna: Kurva adalah cerminan sempurna di sisi kiri dan kanan dari nilai rata-rata. Ini menyiratkan bahwa probabilitas penyimpangan ke atas dari rata-rata sama dengan probabilitas penyimpangan ke bawah dengan besar yang sama.
- Menurun Gradual ke Samping (Ekor): Semakin jauh kita bergerak dari rata-rata (baik ke kiri maupun ke kanan), semakin rendah ketinggian kurva (kepadatan probabilitasnya). Ini menunjukkan bahwa nilai-nilai ekstrem (sangat tinggi atau sangat rendah) semakin jarang terjadi.
- Asimtotik terhadap Sumbu Horizontal: Secara teoretis, ekor kurva ini membentang tanpa batas ke kedua arah, mendekati (tetapi tidak pernah menyentuh) sumbu horizontal. Ini mengindikasikan bahwa secara matematis, nilai yang sangat, sangat ekstrem masih mungkin terjadi, meskipun dengan probabilitas yang sangat, sangat kecil.
Distribusi normal secara presisi didefinisikan oleh hanya dua parameter yang mengontrol bentuk dan posisinya.
- Mean (μ): Ini adalah nilai rata-rata populasi. Parameter ini menentukan pusat atau lokasi puncak kurva lonceng. Jika μ bergeser, seluruh kurva akan bergeser ke kiri atau kanan pada sumbu horizontal.
- Standar Deviasi (σ): Ini adalah standar deviasi populasi. Parameter ini menentukan penyebaran atau lebar kurva.
- Jika σ bernilai kecil, kurva akan menjadi sempit dan tinggi (data sangat terkonsentrasi di sekitar mean, variasinya kecil).
- Jika σ bernilai besar, kurva akan menjadi lebar dan datar (data lebih tersebar luas dari mean, variasinya besar).
Z-score: Standardisasi Skor
Z-score adalah alat statistika yang sangat powerful untuk menstandardisasi dan menormalkan observasi dari sebuah distribusi normal. Z-score mengukur seberapa jauh sebuah observasi individual dari rata-rata distribusi dalam satuan standar deviasi.
Formula Z-score
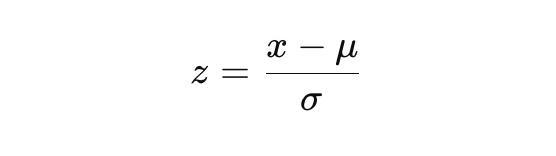
- x: Nilai observasi spesifik yang ingin Anda ubah menjadi Z-score.
- μ: Rata-rata populasi dari distribusi tersebut.
- σ: Standar deviasi populasi dari distribusi tersebut.
Dengan Z-score, kita dapat melakukan hal berikut.
- Membandingkan Observasi dari Distribusi yang Berbeda: Misalnya, Anda mendapat nilai 85 dalam ujian matematika (rata-rata kelas 70, standar deviasi 10) dan nilai 90 dalam ujian Fisika (rata-rata kelas 80, standar deviasi 5). Dengan Z-score, Anda bisa tahu pada mata pelajaran mana Anda benar-benar lebih unggul relatif terhadap teman-teman sekelas.
- Mengidentifikasi Outlier: Observasi dengan Z-score yang sangat besar (misalnya, lebih dari +3 atau kurang dari -3) dianggap sebagai outlier karena sangat jauh dari rata-rata.
- Menghitung Probabilitas Menggunakan Tabel Z Standar: Setelah dikonversi ke Z-score, kita dapat menggunakan tabel Z standar (atau fungsi CDF) dari distribusi normal standar (dengan μ=0,σ=1) untuk menemukan probabilitas terkait.
Berikut adalah contoh ilustrasi dari distribusi normal dengan z-score.
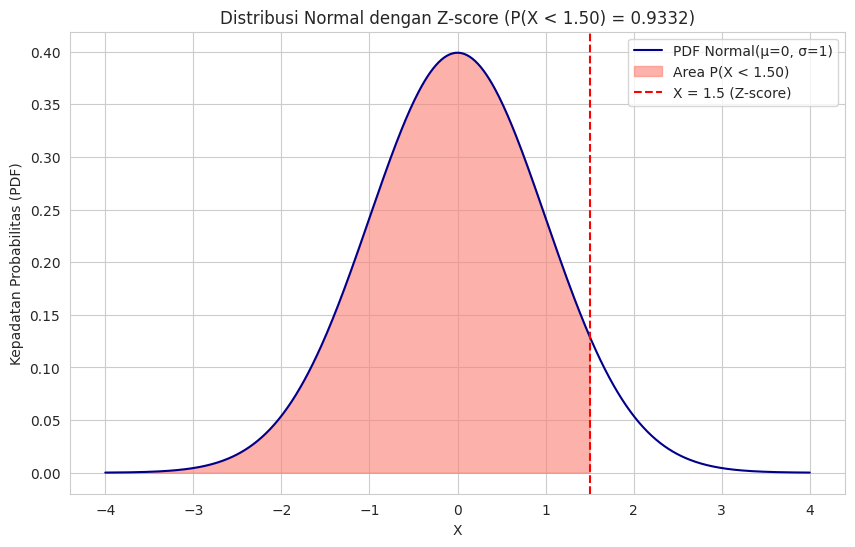
Gambar di atas menunjukkan kurva distribusi normal standar (mean = 0, standar deviasi = 1).
- Garis lengkung biru menggambarkan probability density function (PDF) dari distribusi normal standar.
- Area merah muda di bawah kurva memperlihatkan probabilitas kumulatif P(X < 1.5), yaitu luas area di bawah kurva dari −∞ sampai Z-score 1.5.
- Garis vertikal merah putus-putus menunjukkan posisi Z-score = 1.5.
Pada visualisasi ini, kita dapat melihat bahwa sekitar 93.32% data pada distribusi normal standar terletak di sebelah kiri Z-score 1.5. Area inilah yang sering dicari saat kita menghitung probabilitas dari nilai Z tertentu pada distribusi normal standar.
Visualisasi ini membantu memperjelas konsep Z-score. Semakin besar nilai Z-score, semakin jauh letak nilai dari rata-rata. Luas area di bawah kurva hingga titik Z-score tertentu dapat diinterpretasikan sebagai probabilitas kumulatif hingga nilai tersebut.
Area di Bawah Kurva = Probabilitas
Sebagaimana pada semua distribusi kontinu, probabilitas sebuah variabel acak yang berdistribusi normal berada dalam rentang tertentu dihitung sebagai luas area di bawah kurva probability density function (PDF) pada rentang tersebut.
Seluruh area di bawah kurva normal selalu bernilai 1 (atau 100%) yang merepresentasikan total probabilitas dari semua kemungkinan hasil.
Selain itu, distribusi normal juga memiliki aturan empiris “68-95-99.7”. Ini adalah aturan praktis yang sangat terkenal dan berguna untuk distribusi normal.
- Sekitar 68% dari data akan berada dalam 1 standar deviasi dari mean (μ±1σ).
- Sekitar 95% dari data akan berada dalam 2 standar deviasi dari mean (μ±2σ).
- Sekitar 99.7% dari data akan berada dalam 3 standar deviasi dari mean (μ±3σ).
Aturan ini memberikan intuisi cepat tentang penyebaran data dan sangat membantu dalam interpretasi awal.
Contoh Distribusi untuk Skor IQ
Mari kita lihat visualisasinya dengan contoh skor IQ berikut.
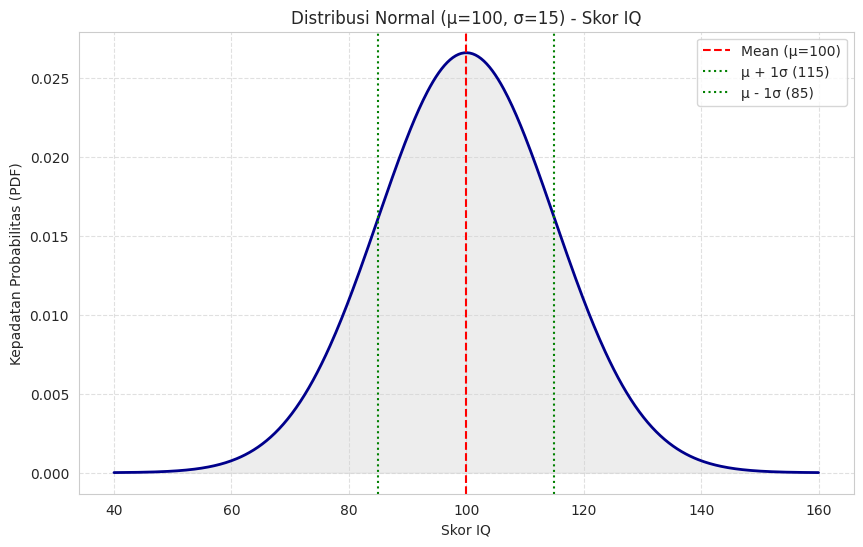
Visualisasi di atas menunjukkan kurva lonceng yang sangat familier. Puncak kurva berada tepat pada nilai rata-rata IQ (100) menunjukkan bahwa skor 100 adalah yang paling umum. Lebar kurva ditentukan oleh standar deviasi (15). Garis putus-putus hijau menandai jarak 1 standar deviasi dari mean (yaitu skor 85 dan 115).
Dengan Z-score, kita dapat menghitung seberapa “normal” atau “ekstrem” sebuah skor. Misalnya, skor 120 memiliki Z-score 1.33 (standar deviasi di atas rata-rata) dan kita bisa menghitung bahwa probabilitas orang memiliki skor IQ lebih tinggi dari itu adalah 0.0912 atau 9.12% dari populasi.
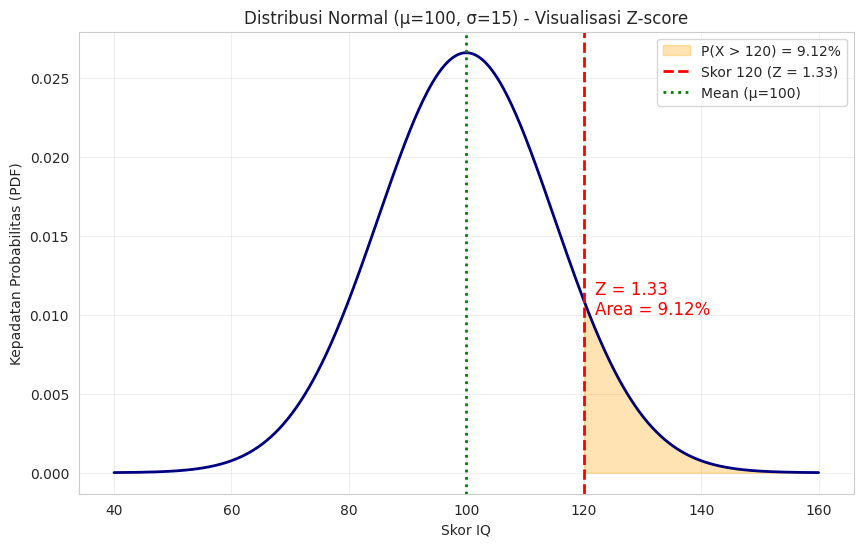
Visualisasi ini sangat membantu untuk memahami persebaran data “normal” dan cara nilai-nilai individu menempatkan diri dalam distribusi tersebut.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Distribusi Normal
Distribusi t-Student
Distribusi t-Student digunakan ketika ukuran sampel relatif kecil (biasanya kurang dari 30) dan kita tidak mengetahui standar deviasi populasi (σ), hanya standar deviasi sampel (s). Distribusi t-Student memiliki ekor yang lebih tebal dan lebih lebar daripada distribusi normal, yang mengakomodasi ketidakpastian lebih besar dalam data yang lebih sedikit.
Pada distribusi normal, probabilitas untuk nilai yang jauh dari rata-rata menurun dengan cepat. Pada distribusi t, probabilitas nilai ekstrem tidak menurun secepat itu sehingga “ekornya” terlihat lebih tebal atau lebih panjang.
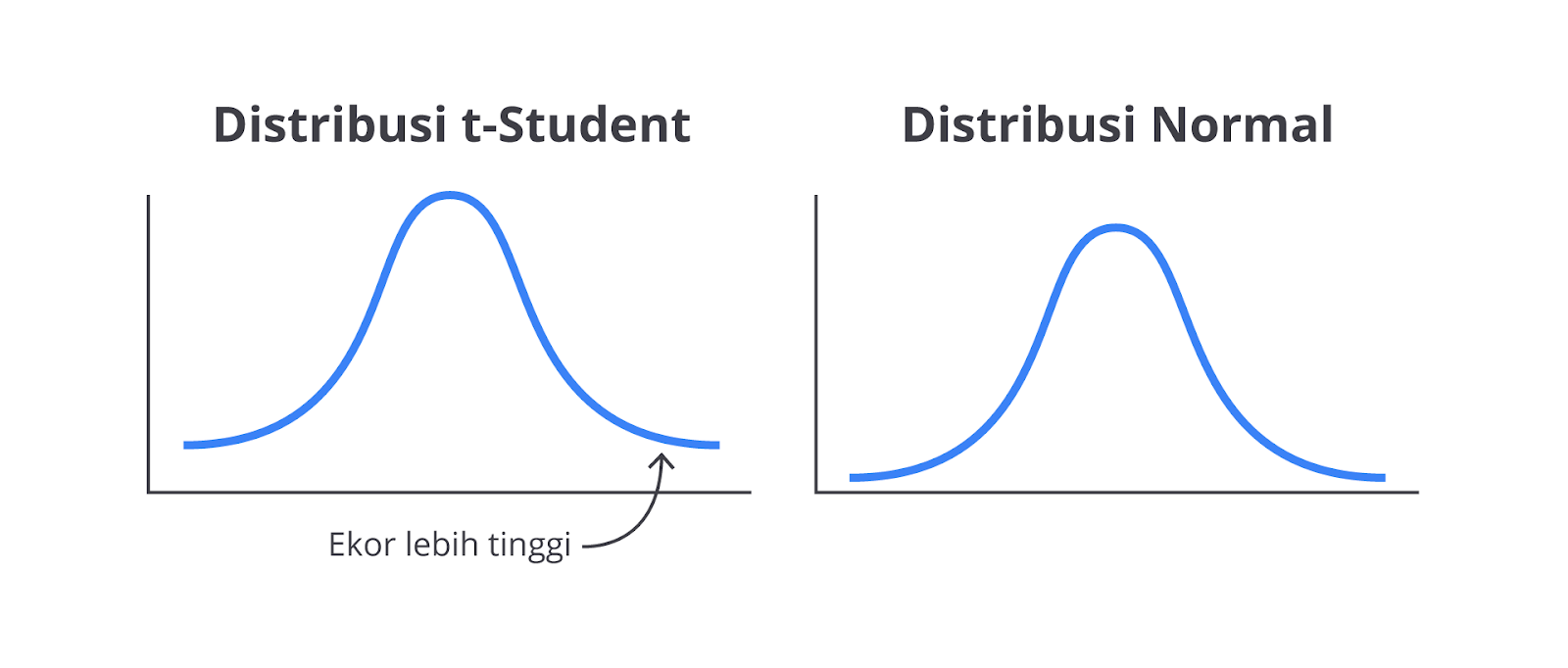
Karakteristik distribusi t-Student sebagai berikut.
- Lebar dan Ekor Lebih Tebal: Dibandingkan dengan distribusi normal, distribusi t memiliki ekor yang lebih tebal, yang berarti distribusi ini lebih sensitif terhadap sampel kecil dan lebih sering memberikan nilai ekstrem daripada distribusi normal.
- Derajat Kebebasan (df): Distribusi t bergantung pada degree of freedom alias derajat kebebasan (df=n−1), yang dihitung berdasarkan ukuran sampel. Semakin besar ukuran sampel, distribusi t akan semakin mendekati distribusi normal.
Distribusi t-Student digunakan dalam pengujian hipotesis, khususnya uji t untuk menguji perbedaan rata-rata sampel terhadap nilai rata-rata populasi, ketika ukuran sampel kecil dan standar deviasi populasi tidak diketahui.
Jika sebuah penelitian menguji bahwa rata-rata waktu layanan pelanggan lebih cepat dari target sembilan menit dengan sampel kecil (misalnya, 15 pelanggan), distribusi t digunakan untuk menghitung nilai t-statistik dan p-value untuk menguji jika perbedaan tersebut signifikan.
Distribusi Chi-Square (χ²)
Distribusi chi-square sering digunakan dalam uji independensi dan uji goodness-of-fit untuk variabel kategorikal. Distribusi ini hanya memiliki nilai non-negatif karena variabel-variabel yang dihitung menggunakan distribusi ini biasanya berbentuk kuadrat (misalnya, dalam uji varians atau analisis frekuensi).
Karakteristik distribusi chi-square sebagai berikut.
- Distribusi Satu Arah: Distribusi chi-square hanya terdistribusi di sisi kanan sumbu X (nilai-nilai positif).
- Derajat Kebebasan (df): Distribusi chi-square bergantung pada derajat kebebasan (df), yang biasanya dihitung berdasarkan jumlah kategori dalam data.
Distribusi chi-square digunakan untuk uji chi-square yang bertujuan menguji jika dua variabel kategorikal saling independen atau distribusi data yang diamati cocok dengan distribusi yang diharapkan.
Misalkan kita ingin menguji adakah hubungan antara jenis kelamin dan preferensi produk (A atau B) dalam survei. Uji chi-square dapat digunakan untuk menguji jika distribusi frekuensi jawaban yang diamati berbeda secara signifikan dari harapan.
Konsep Central Limit Theorem (CLT)
Setelah mengetahui distribusi diskret dan kontinu, selanjutnya kita akan mengulas sebuah teorema yang sangat vital, central limit theorem (CLT), yang merupakan salah satu konsep paling mendasar dan penting dalam distribusi probabilitas.
CLT menyatakan bahwa rata-rata sampel dari sejumlah besar sampel acak yang diambil dari populasi apa pun akan cenderung mendekati distribusi normal, terlepas dari bentuk distribusi populasi asal asalkan ukuran sampel cukup besar.
Ini berarti bahwa bahkan jika data asal tidak terdistribusi normal, distribusi rata-rata sampel akan tetap mengikuti distribusi normal saat ukuran sampel cukup besar (umumnya n ≥ 30).
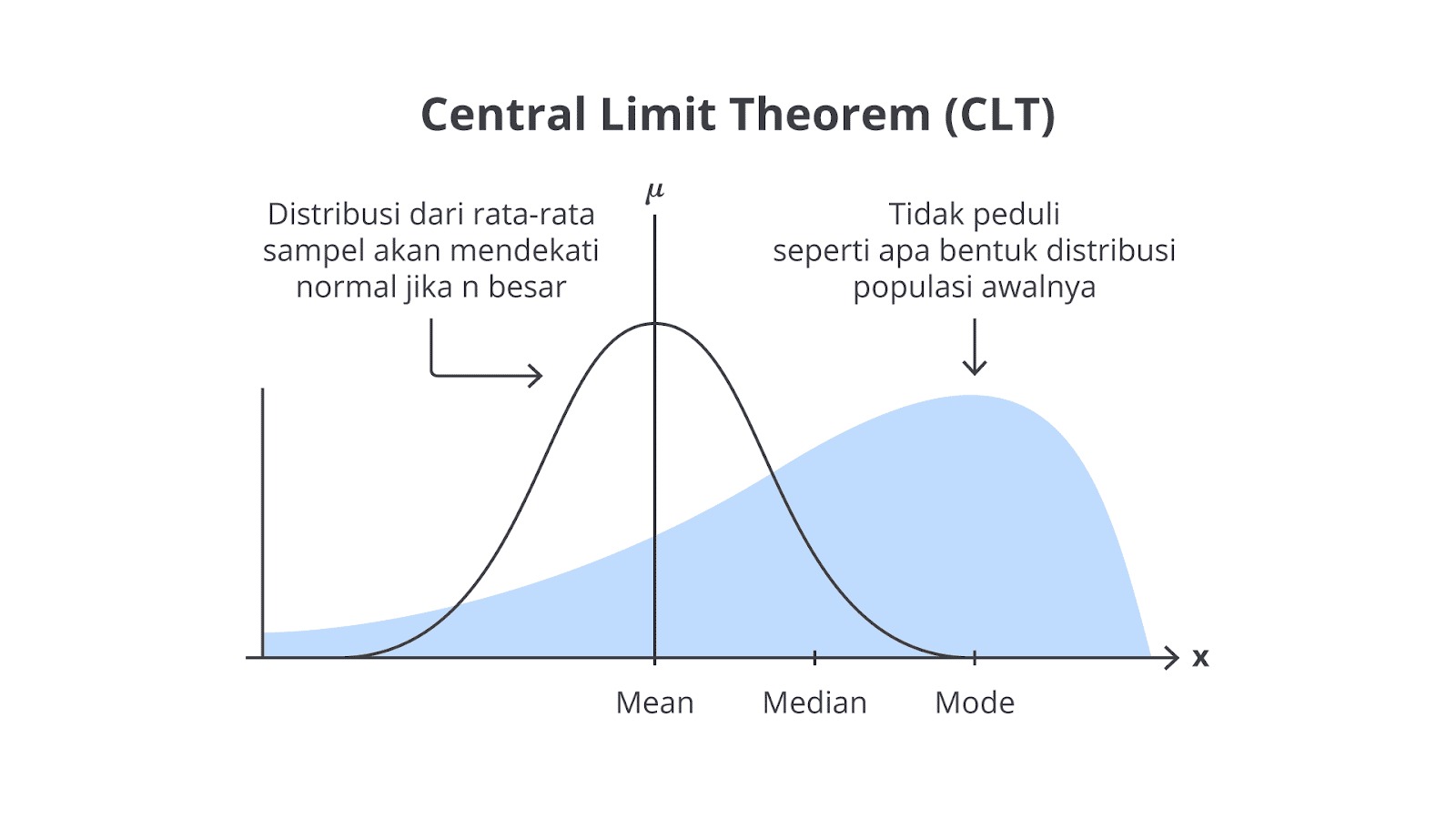
Supaya lebih terbayang, mari kita demonstrasikan melalui visualisasi berikut.
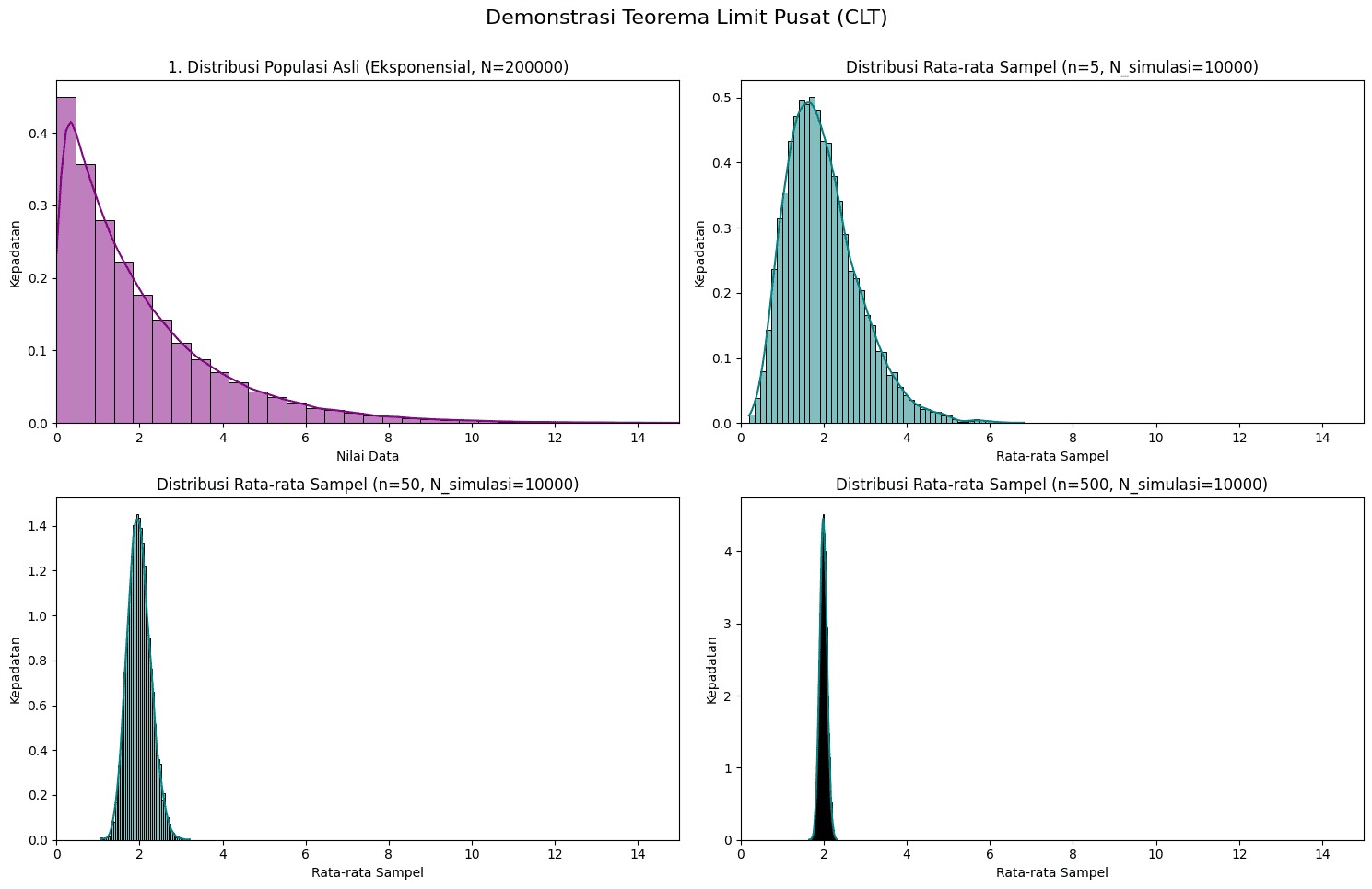
Visualisasi di atas memperlihatkan kekuatan central limit theorem (CLT) dalam statistik, khususnya bahwa distribusi rata-rata sampel dapat menjadi normal meskipun populasi asalnya sangat tidak normal.
- Panel Kiri Atas – Distribusi Populasi Asli
Pada grafik pertama (kiri atas), kita melihat distribusi populasi asli yang diambil dari distribusi eksponensial. Distribusi ini sangat miring ke kanan (right-skewed), dengan banyak data terkonsentrasi pada nilai kecil dan ekor panjang ke kanan. Contoh nyata: waktu tunggu pada layanan pelanggan, waktu antar-kedatangan dalam sistem antrian, dll. Ini adalah bentuk populasi yang jelas tidak normal. - Panel Kanan Atas – Rata-rata Sampel Ukuran Kecil (n = 5)
Grafik kanan atas menunjukkan distribusi rata-rata sampel dari 10.000 simulasi, masing-masing sampel berukuran kecil (n = 5). Bentuk distribusi rata-rata sampel masih mirip populasi asli, cenderung miring ke kanan, meskipun mulai terlihat sedikit lebih “lebar di tengah”. Artinya, kalau ukuran sampel kecil, rata-rata sampel masih sangat dipengaruhi oleh bentuk populasi aslinya. - Panel Kiri Bawah – Rata-rata Sampel Ukuran Sedang (n = 50)
Grafik kiri bawah menampilkan distribusi rata-rata sampel dengan ukuran sampel lebih besar (n = 50). Bentuk distribusi semakin mendekati normal (kurva lonceng). Simetri dan puncak di tengah mulai tampak jelas, meskipun populasi aslinya tetap miring. - Panel Kanan Bawah – Rata-rata Sampel Ukuran Besar (n = 500)
**Pada grafik kanan bawah, rata-rata sampel diambil dari **sampel sangat besar (n = 500). Distribusi rata-rata sampel kini sangat mendekati distribusi normal sempurna! Data “ngumpul” sangat rapat di sekitar rata-rata, distribusi sangat simetris, dan variansnya jauh lebih kecil dibandingkan populasi asli.
Apa yang bisa kita petik dari demonstrasi di atas? Pada konsep CLT, tidak peduli seberapa miring atau aneh bentuk distribusi populasi, distribusi rata-rata sampel akan mendekati normal jika ukuran sampel cukup besar. Semakin besar ukuran sampel (n), semakin “normal” distribusi rata-rata sampel.
CLT ini adalah alasan kita boleh menggunakan metode statistik berbasis normal meski data mentahnya bukan normal, asalkan menggunakan rata-rata dari sampel besar.
Misalkan kita memiliki data waktu layanan pelanggan yang sangat tidak terdistribusi normal (mungkin ada beberapa pelanggan yang sangat lama dilayani, sementara sebagian besar pelanggan lainnya dilayani dengan cepat) sebagai berikut.
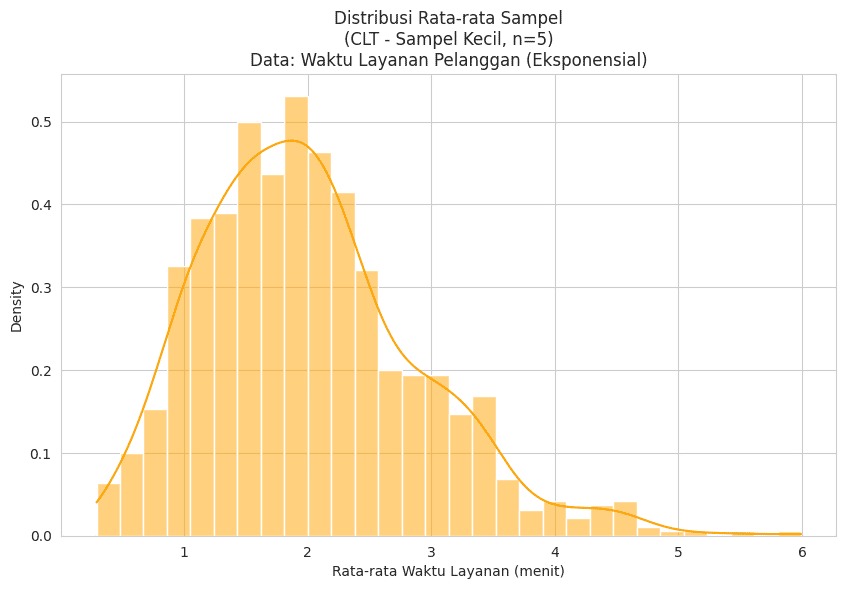
Meski distribusi asalnya tidak normal, jika kita mengambil banyak sampel acak dan menghitung rata-rata sampel untuk setiap sampel, distribusi rata-rata sampel ini akan cenderung mendekati distribusi normal.
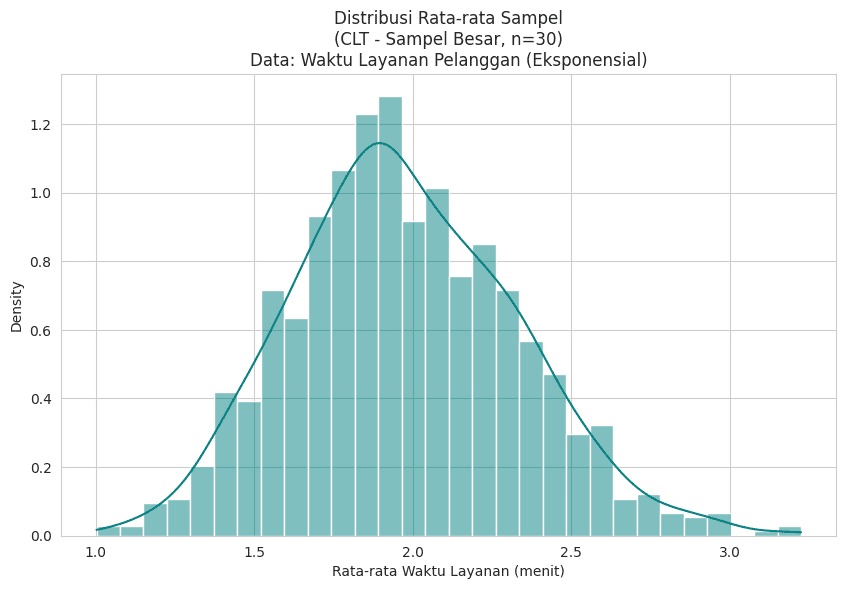
Data asli dari fenomena ini mungkin terlihat sangat tidak beraturan atau memiliki distribusi yang aneh (mungkin sangat miring, punya dua puncak, dsb.). Anda tidak tahu bentuk distribusi populasi aslinya, tetapi Anda ingin tahu tentang rata-ratanya. Nah, di sinilah teorema limit pusat (CLT) datang sebagai pahlawan super statistika!
Jika mengambil banyak sampel acak dari populasi mana pun (ya, populasi mana pun, tidak peduli bentuk distribusinya) dan Anda menghitung rata-rata dari setiap sampel tersebut, distribusi dari rata-rata sampel-rata-rata sampel ini akan mendekati bentuk kurva lonceng yang sempurna (distribusi normal). Ini akan terjadi asalkan ukuran setiap sampel yang Anda ambil itu cukup besar.
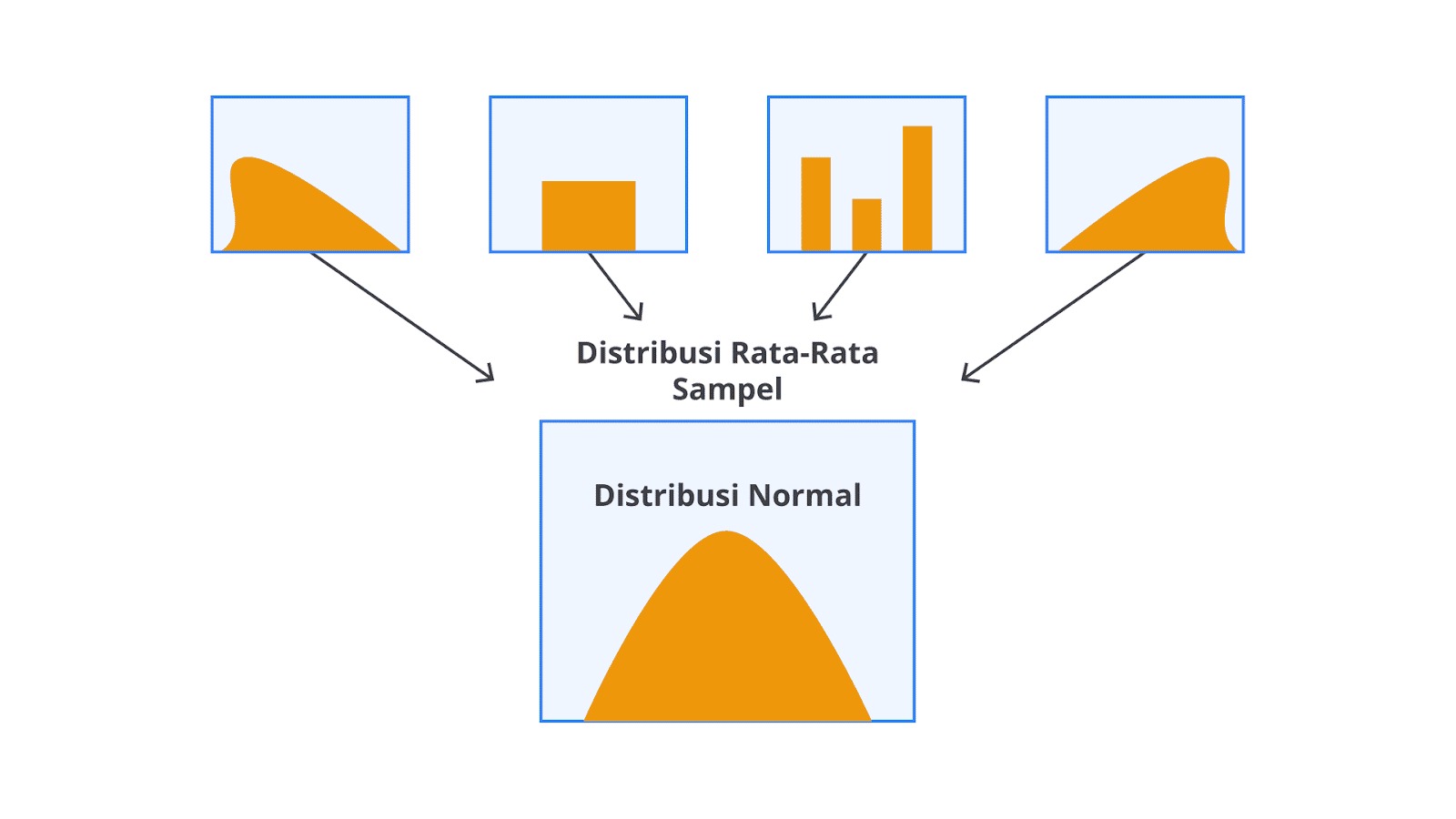
Umumnya, ukuran sampel n ≥ 30 sering dianggap sebagai ambang batas yang memadai agar CLT mulai bekerja dengan baik. Semakin besar ukuran sampel Anda, semakin sempurna distribusi normal yang akan terbentuk dari rata-rata sampel tersebut.
Mari kita bedah konsepnya.
- Ada populasi asli. Pikirkan ini sebagai “seluruh alam semesta” data yang ingin Anda pelajari. Distribusinya bisa apa saja. Mungkin waktu yang dihabiskan dalam website itu kebanyakan sebentar (distribusi miring), atau jumlah klaim asuransi (distribusi Poisson), atau apa pun.
- Kita ambil sampel (berulang kali). Bayangkan Anda melakukan eksperimen ribuan kali. Setiap kali, Anda mengambil sekelompok orang (sampel) dari populasi asli. Ukuran kelompok ini (n) harus sama setiap kali (misal, selalu 30 orang). Setelah mengambil kelompok itu, Anda hitung rata-rata dari kelompok tersebut (misal: rata-rata waktu yang dihabiskan oleh 30 orang itu). Lalu, Anda catat rata-rata ini dan kembalikan kelompok itu ke populasi (agar populasi tidak berkurang). Anda ulangi proses ini ribuan kali sehingga memiliki ribuan nilai rata-rata sampel.
- Muncullah kurva lonceng. Sekarang, bayangkan Anda membuat histogram dari semua ribuan rata-rata sampel yang dikumpulkan itu. Apa yang akan Anda lihat? Sebuah kurva lonceng yang indah dan simetris (distribusi normal)! Ini terjadi secara otomatis, meskipun data populasi asli Anda sama sekali tidak normal.
- Pusat Lonceng: Puncak kurva lonceng ini akan berada tepat pada rata-rata populasi asli (yang sebenarnya ingin Anda ketahui!).
- Lebar Lonceng: Lebar kurva (standar deviasinya) akan semakin kecil jika ukuran sampel (n) Anda semakin besar. Ini berarti rata-rata sampel Anda akan semakin akurat mendekati rata-rata populasi.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Central Limit Theorem.ipynb
Simulasi Probabilitas dan Metode Monte Carlo
Kita telah memperoleh pemahaman fundamental mengenai distribusi probabilitas diskret dan kontinu, serta signifikansi konsep CLT (central limit theorem), yang secara kolektif membentuk fondasi kuat dalam analisis ketidakpastian.
Namun demikian, dalam menghadapi kompleksitas sistem dunia nyata yang melibatkan interaksi multivariabel acak, penyelesaian analitis sering kali menjadi tidak praktis atau bahkan tidak mungkin. Bagaimana kita dapat memprediksi total durasi proyek dengan berbagai ketidakpastian pada setiap fasenya atau mengestimasi probabilitas terjadinya peristiwa yang sangat kompleks?
Dalam konteks ini, simulasi probabilitas, khususnya metode Monte Carlo, menawarkan pendekatan komputasi yang revolusioner. Alih-alih mencari solusi matematis yang eksak, metode ini memungkinkan kita untuk menjalankan ribuan hingga jutaan eksperimen virtual.
Dengan memanfaatkan pengetahuan tentang distribusi probabilitas, kita dapat secara acak menghasilkan data yang mereplikasi perilaku sistem nyata secara iteratif, kemudian menganalisis distribusi hasilnya.
Materi ini akan memperkenalkan Anda pada konsep simulasi probabilistik, mendemonstrasikan prinsipnya melalui estimasi Pi (π) dengan metode Monte Carlo, serta mengaplikasikannya dalam simulasi risiko proyek. Tujuannya adalah membekali Anda dengan kemampuan untuk mengubah ketidakpastian yang kompleks menjadi wawasan terukur dan actionable.
Konsep Simulasi Probabilistik
Setelah menguasai berbagai distribusi probabilitas, kita tahu cara memodelkan perilaku variabel acak secara individual. Namun, dunia nyata sering kali menghadirkan tantangan lebih besar: sistem yang kompleks, yakni ketika banyak variabel acak berinteraksi satu sama lain melalui cara rumit dan hasil akhirnya sulit diprediksi hanya dengan rumus tunggal.
Dalam situasi inilah simulasi probabilistik menjadi alat yang sangat berharga. Ia memungkinkan kita untuk “menghidupkan” model-model probabilitas, menjalankan eksperimen virtual berulang kali untuk memahami perilaku sistem secara keseluruhan di bawah kondisi ketidakpastian. Ini adalah cara bagi kita untuk belajar dari “percobaan” yang tak terhingga tanpa harus menghadapi risiko atau biaya di dunia nyata.
Pentingnya Simulasi dalam Menghadapi Ketidakpastian
Dalam berbagai domain, mulai dari keuangan, manajemen proyek, operasional bisnis, hingga ilmu pengetahuan, ketidakpastian adalah elemen yang tak terhindarkan.
Variabel-variabel seperti harga saham di masa depan, waktu penyelesaian tugas proyek, jumlah permintaan produk, atau tingkat kegagalan komponen mesin, semuanya memiliki elemen acak yang signifikan. Mengabaikan ketidakpastian ini dapat mengarah pada keputusan yang kurang optimal atau bahkan berisiko tinggi.
Simulasi probabilistik hadir sebagai alat yang sangat powerful untuk menghadapi dan memahami ketidakpastian ini. Berikut adalah uraian pentingnya kita melakukan simulasi probabilistik.
-
Memahami Perilaku Sistem Kompleks
Ketika sistem terlalu rumit, terdiri dari banyak komponen yang berinteraksi dan setiap komponennya memiliki perilaku sendiri yang tidak pasti, rumus analitis mungkin tidak mampu memberikan gambaran lengkap.Simulasi memungkinkan kita untuk mengamati bahwa sistem secara keseluruhan bereaksi dan berperilaku di bawah berbagai kombinasi kondisi acak. Kita bisa melihat pola muncul dari interaksi variabel-variabel tersebut, yang mungkin tidak terlihat dari analisis bagian per bagian.
-
Mengestimasi Probabilitas Kejadian Langka
Ada kejadian-kejadian yang probabilitasnya sangat kecil (misalnya, kegagalan sistem kritis atau krisis keuangan ekstrem). Dalam kasus seperti ini, pengamatan langsung di dunia nyata mungkin tidak praktis atau memerlukan waktu yang sangat lama.Simulasi memungkinkan kita untuk “memaksa” terjadinya jutaan skenario secara virtual sehingga dapat mengestimasi probabilitas kejadian langka tersebut dengan lebih akurat dan memberikan wawasan yang tidak mungkin didapat dari data historis terbatas.
-
Mengukur dan Menghitung Risiko dan Peluang
Dengan menjalankan simulasi berulang kali, kita tidak hanya mendapatkan satu perkiraan nilai (misalnya, perkiraan waktu proyek), tetapi seluruh distribusi probabilitas dari kemungkinan hasil.Ini memungkinkan kita untuk menghitung berbagai metrik risiko, seperti probabilitas proyek melebihi anggaran, probabilitas investasi mengalami kerugian tertentu, atau rentang waktu penyelesaian proyek yang paling mungkin. Di sisi lain, kita juga bisa mengidentifikasi peluang keuntungan atau hasil positif lain beserta probabilitasnya.
-
Mendukung Pengambilan Keputusan Berbasis Data yang Kuat
Daripada hanya mengandalkan asumsi sederhana atau perkiraan “titik tunggal” yang tidak mencerminkan ketidakpastian, simulasi memberikan distribusi probabilitas hasil yang jauh lebih kaya.Informasi ini memungkinkan para pengambil keputusan untuk memahami seluruh spektrum kemungkinan hasil, mengevaluasi trade-off antara risiko dan imbalan, serta pada akhirnya, membuat keputusan yang lebih informasional, terukur, dan kuat (robust) dalam menghadapi ketidakpastian. Ini adalah inti dari analisis risiko kuantitatif dalam berbagai industri.
Studi Kasus: Estimasi Pi dengan Metode Monte Carlo
Setelah memahami konsep dasar simulasi probabilistik, salah satu cara terbaik untuk benar-benar merasakan dan memahami prinsip kerja metode Monte Carlo adalah dengan menggunakannya untuk memecahkan masalah yang tampaknya tidak berhubungan dengan probabilitas sama sekali, yaitu mengestimasi nilai Pi (π).
Ini adalah contoh klasik dan elegan yang menunjukkan bahwa keacakan dapat dimanfaatkan untuk memecahkan masalah deterministik.
Konsep di balik estimasi Pi dengan Monte Carlo berakar pada hubungan antara luas area geometri dan probabilitas. Bayangkan sebuah skenario sederhana.
- Kita memiliki sebuah persegi yang berpusat di titik (0,0) dengan panjang sisi 2. Artinya, koordinat X dan Y persegi ini membentang dari -1 hingga 1. Luas dari persegi ini adalah 2 × 2 = 4 satuan luas.
- Dalam persegi ini, kita tempatkan sebuah lingkaran yang juga berpusat pada (0,0) dengan jari-jari (radius) 1. Lingkaran ini persis pas menyentuh keempat sisi persegi. Luas dari lingkaran ini adalah π×r2=π×12=π satuan luas.
Prinsip Monte Carlo kemudian diimplementasikan melalui serangkaian langkah berikut.
-
Pengambilan Sampel Acak: Kita secara acak dan seragam (mengikuti distribusi uniform) “melemparkan” sejumlah besar titik (misalnya, N titik) ke dalam area persegi. Ini berarti setiap titik (x,y) akan memiliki koordinat X serta Y yang dihasilkan secara acak antara -1 dan 1.
-
Penentuan Lokasi Relatif: Untuk setiap titik yang dilemparkan, kita kemudian memeriksa bahwa titik tersebut jatuh dalam lingkaran atau di luar lingkaran (tapi masih dalam persegi). Cara paling mudah untuk memeriksanya adalah dengan menghitung jarak kuadrat titik dari pusat (0,0), yaitu x2+y2. Jika x2+y2 ≤ r2 (dalam kasus ini 12), titik itu berada dalam lingkaran.
Perhitungan Proporsi: Kita menghitung berapa proporsi titik-titik yang jatuh dalam lingkaran terhadap total jumlah titik yang dilemparkan.
-
Estimasi Berbasis Rasio Luas: Karena titik-titik dilemparkan secara acak dan seragam di seluruh area persegi, proporsi titik yang jatuh dalam lingkaran harus secara statistik kira-kira sama dengan rasio luas lingkaran terhadap luas persegi.
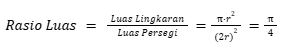 Dari sini, kita bisa mendapatkan estimasi nilai
Dari sini, kita bisa mendapatkan estimasi nilai
 Ini adalah ilustrasi sempurna dari Hukum Bilangan Besar dalam probabilitas: semakin banyak titik (semakin banyak simulasi) yang kita “lemparkan”, semakin akurat estimasi Pi akan mendekati nilai sebenarnya.
Ini adalah ilustrasi sempurna dari Hukum Bilangan Besar dalam probabilitas: semakin banyak titik (semakin banyak simulasi) yang kita “lemparkan”, semakin akurat estimasi Pi akan mendekati nilai sebenarnya.
Oke, mari kita langsung implementasikan dalam bahasa pemrograman Python.
Langkah 1: Import Library
Untuk melakukan simulasi estimasi Pi ini dalam Python, kita akan memanfaatkan beberapa fungsi dan library kunci seperti berikut.
- import random # Modul untuk menghasilkan angka acak
- import matplotlib.pyplot as plt # Untuk membuat plot dan visualisasi
- import numpy as np # Untuk operasi numerik, khususnya np.pi untuk nilai Pi sebenarnya
Penjelasannya berikut.
- random.uniform(a, b): Ini adalah fungsi dari modul random pada Python. Ia menghasilkan sebuah bilangan floating-point (desimal) acak yang didistribusikan secara uniform di antara dua batas yang diberikan, yaitu a (batas bawah) dan b (batas atas). Fungsi ini sangat penting untuk “melemparkan” titik acak secara merata ke seluruh area persegi.
- matplotlib.pyplot.scatter: Ini adalah fungsi dari library matplotlib yang digunakan untuk membuat plot sebar (scatter plot). Dengan ini, kita dapat memvisualisasikan setiap titik yang dilemparkan dan melihat bahwa mereka tersebar dalam persegi dan lingkaran. Titik-titik yang jatuh dalam lingkaran akan kita beri warna berbeda (misalnya, biru) dari titik-titik yang jatuh di luar lingkaran (misalnya, merah) sehingga visualisasi menjadi sangat intuitif.
- numpy: Digunakan untuk nilai π yang sebenarnya sebagai perbandingan.
Langkah 2: Inisialisasi Penghitung & Tempat Penyimpanan Titik
Sebelum simulasi, kita siapkan penghitung dan list untuk titik-titik dengan kode berikut.
- # — Kondisi Simulasi Monte Carlo untuk Estimasi Pi —
- num_points = 50000 # Jumlah total titik yang akan “dilemparkan”. Semakin besar, semakin akurat.
- # Inisialisasi penghitung untuk titik-titik yang jatuh di dalam lingkaran
- points_in_circle = 0
- # Inisialisasi daftar untuk menyimpan koordinat titik-titik (untuk visualisasi)
- circle_x = [] # Koordinat X untuk titik di dalam lingkaran
- circle_y = [] # Koordinat Y untuk titik di dalam lingkaran
- square_x = [] # Koordinat X untuk titik di luar lingkaran (tapi masih di dalam persegi)
- square_y = [] # Koordinat Y untuk titik di luar lingkaran (tapi masih di dalam persegi)
- # Definisi geometri: Persegi dari (-1,-1) ke (1,1), lingkaran jari-jari 1 di pusat (0,0)
Langkah 3: Lempar Titik Secara Acak
Lemparkan titik-titik ke dalam persegi secara acak dan merata.
- # Lakukan proses “pelemparan” titik sebanyak num_points kali
- for _ in range(num_points):
- # Hasilkan koordinat X dan Y secara acak dan uniform antara -1 dan 1
- x = random.uniform(-1, 1)
- y = random.uniform(-1, 1)
Setiap titik punya koordinat x dan y antara -1 dan 1.
Langkah 4: Cek Apakah Titik dalam Lingkaran
Untuk setiap titik, hitung jarak kuadrat ke pusat, lalu cek posisinya.
- # Hitung jarak kuadrat titik dari pusat (0,0)
- # Jarak kuadrat = x^2 + y^2. Ini menghindari perhitungan akar kuadrat yang lebih lambat.
-
distance_squared = x**2 + y**2
- # Periksa apakah titik berada di dalam lingkaran (jarak kuadrat <= jari-jari kuadrat)
- # Jari-jari lingkaran adalah 1, jadi jari-jari kuadrat juga 1.
- if distance_squared <= 1:
- points_in_circle += 1 # Tambah penghitung jika titik di dalam lingkaran
- circle_x.append(x) # Simpan koordinat untuk visualisasi titik dalam lingkaran
- circle_y.append(y)
- else:
- square_x.append(x) # Simpan koordinat untuk visualisasi titik luar lingkaran
- square_y.append(y)
Jika x2+y2 ≤ 1, titik dalam lingkaran (ditandai biru). Jika lebih dari 1, titik di luar lingkaran (ditandai merah).
Langkah 5: Estimasi Nilai Pi
Setelah semua titik dilempar, hitung rasio jumlah titik dalam lingkaran.
- # — Estimasi Pi —
- # Rasio = (Titik di dalam Lingkaran) / (Total Titik)
- # Kita tahu Rasio = Luas Lingkaran / Luas Persegi = Pi / 4
- # Jadi, Pi = 4 * Rasio
-
pi_estimate = 4 * (points_in_circle / num_points)
- print(f”Total titik yang dilemparkan: {num_points}”)
- print(f”Jumlah titik yang jatuh di dalam lingkaran: {points_in_circle}”)
- print(f”Estimasi nilai Pi: {pi_estimate:.6f}”) # Cetak estimasi Pi dengan 6 angka desimal
- print(f”Nilai Pi sebenarnya (dari NumPy): {np.pi:.6f}”) # Bandingkan dengan nilai Pi dari NumPy
Rasio ini dikalikan 4 karena luas persegi 4 satuan, luas lingkaran π satuan.
Langkah 6: Visualisasikan Hasil
Tampilkan hasil dengan warna berbeda untuk titik di dalam dan luar lingkaran.
- # — Visualisasi Hasil —
-
plt.figure(figsize=(8, 8)) # Membuat “kanvas” plot dengan ukuran 8x8 inci (persegi)
- # Plot titik-titik yang jatuh di dalam lingkaran (biru)
- plt.scatter(circle_x, circle_y, color=‘blue’, s=1, label=‘Titik Dalam Lingkaran’, alpha=0.5)
-
# ‘s=1’ membuat ukuran titik sangat kecil, ‘alpha=0.5’ membuatnya sedikit transparan.
- # Plot titik-titik yang jatuh di luar lingkaran (merah)
-
plt.scatter(square_x, square_y, color=‘red’, s=1, label=‘Titik Luar Lingkaran’, alpha=0.5)
- # Menggambar lingkaran referensi (bukan titik hasil simulasi, tapi untuk visualisasi saja)
- circle = plt.Circle((0, 0), 1, color=‘green’, fill=False, linestyle=’–’, linewidth=2, label=‘Batas Lingkaran’)
-
plt.gca().add_patch(circle) # Menambahkan objek lingkaran ke plot
- # Menggambar persegi referensi (bukan titik hasil simulasi)
-
plt.plot([-1, 1, 1, -1, -1], [-1, -1, 1, 1, -1], color=‘black’, linestyle=’-‘, linewidth=2, label=‘Batas Persegi’)
- plt.title(f’Estimasi Pi dengan Metode Monte Carlo ({num_points} Titik)\nEstimasi π: {pi_estimate:.6f}’)
- plt.xlabel(‘Koordinat X’)
- plt.ylabel(‘Koordinat Y’)
- plt.xlim(-1.1, 1.1) # Mengatur batas sumbu X agar ada sedikit ruang di sekitar persegi
- plt.ylim(-1.1, 1.1) # Mengatur batas sumbu Y
- plt.gca().set_aspect(‘equal’, adjustable=‘box’) # Penting! Memastikan skala sumbu X dan Y sama agar lingkaran tidak terlihat elips
- plt.legend(loc=‘upper right’) # Menampilkan legenda di pojok kanan atas
- plt.grid(True, linestyle=’:’, alpha=0.6) # Menambahkan grid
- plt.show() # Menampilkan plot
- Titik biru: di dalam lingkaran.
- Titik merah: di luar lingkaran, tapi dalam persegi.
- Garis hijau: batas lingkaran.
- Garis hitam: batas persegi.
Setelah memahami langkah-langkah kode di atas, kita bisa melihat hasilnya secara visual melalui plot yang dihasilkan. Visualisasi di bawah ini secara langsung menunjukkan proses dan hasil dari kode yang telah dijalankan.
Dengan semakin banyak titik yang dilemparkan (misal: 100, 1.000, atau lebih), distribusi titik biru akan semakin membentuk lingkaran yang halus, dan estimasi nilai π (Pi) pada judul plot akan semakin mendekati nilai aslinya.
Proporsi antara jumlah titik biru dan jumlah total titik inilah yang menjadi dasar estimasi nilai π dengan metode Monte Carlo.
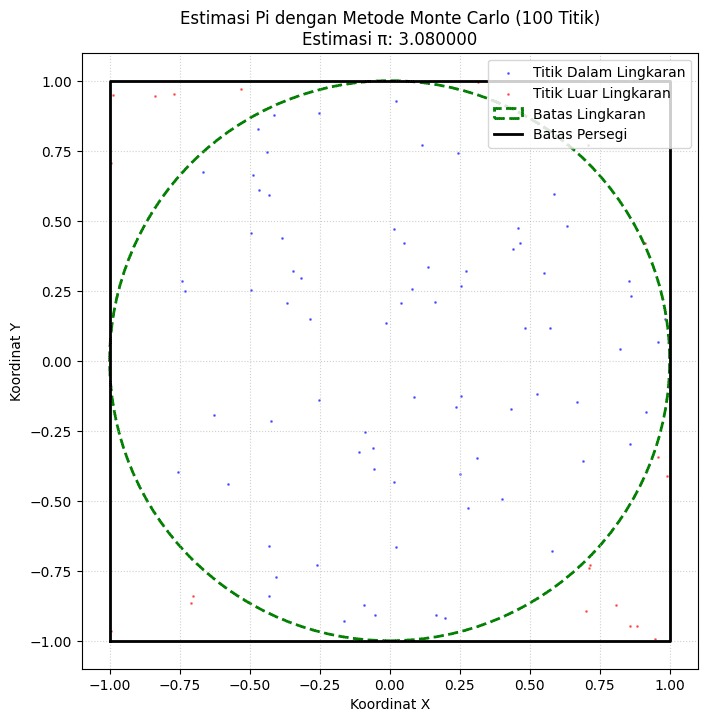 |
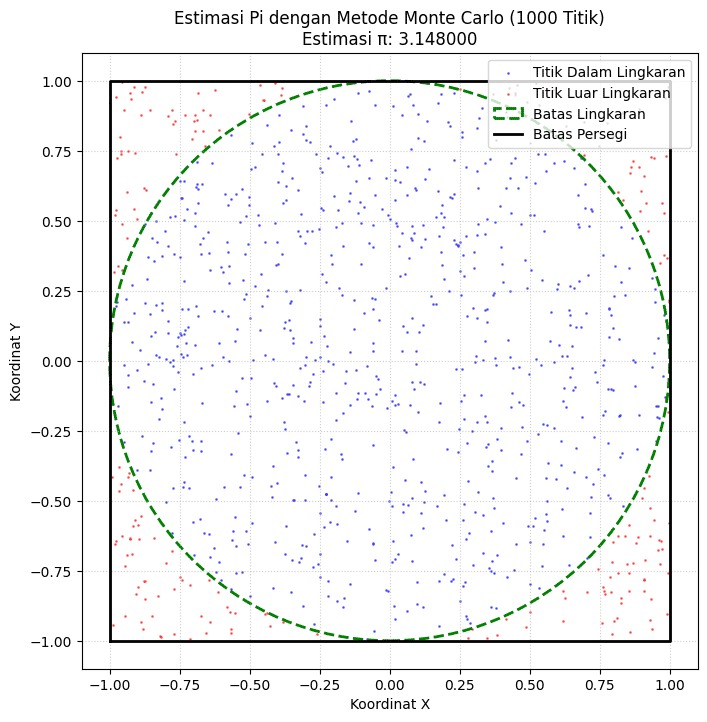 |
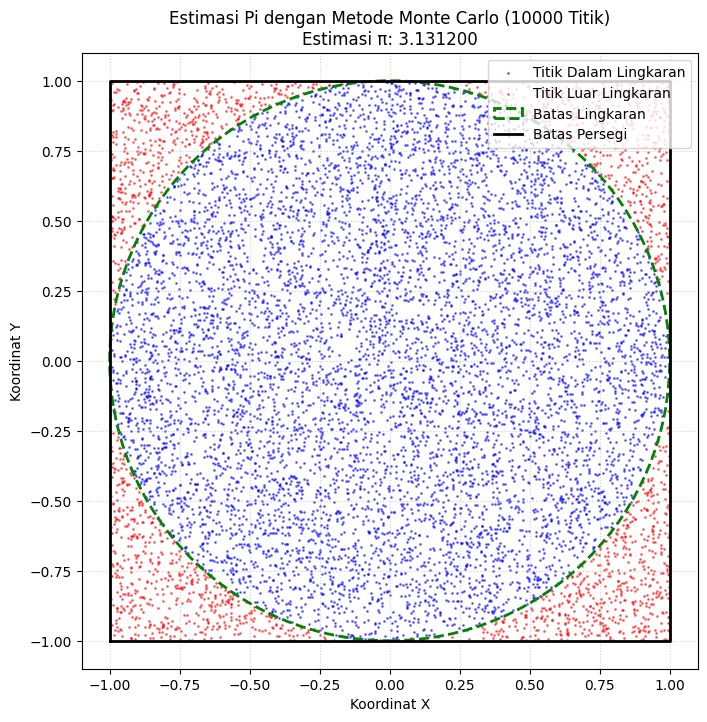 |
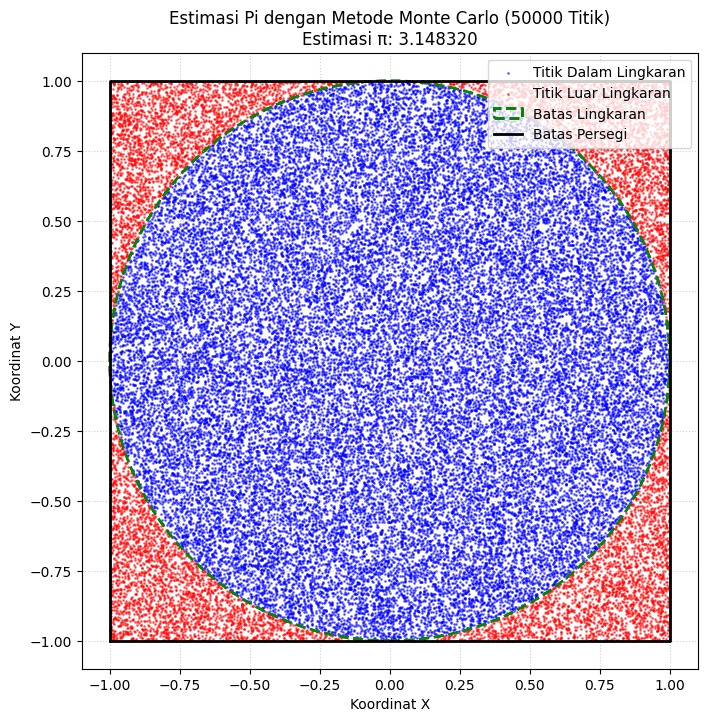 |
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Monte Carlo Estimasi Pi.ipynb
Studi Kasus: Simulasi Pelemparan Dadu dengan Metode Monte Carlo
Sebagai pengingat, simulasi Monte Carlo adalah teknik untuk memperkirakan probabilitas kejadian dengan melakukan eksperimen acak berulang kali. Dalam statistika, Monte Carlo sering digunakan saat probabilitas teoretis sulit dihitung secara langsung, atau untuk membangun intuisi tentang peluang.
Kali ini, studi kasus yang akan kita lakukan adalah memperkirakan probabilitas mendapatkan jumlah tertentu (misal, 7) saat melempar dadu.
Mari kita mulai.
Langkah 1: Menyusun Fungsi Simulasi Sederhana (2 Dadu, Target 7)
Pertama, kita akan membangun fungsi simulasi Monte Carlo khusus untuk kasus dua dadu dan mencari peluang mendapatkan jumlah 7.
import random # Impor modul ‘random’ untuk menghasilkan angka acak
— Fungsi Utama Simulasi Monte Carlo —
total_dadu = 2 def simulasi_lempar_dadu_monte_carlo(jumlah_iterasi): ””” Melakukan simulasi Monte Carlo untuk memperkirakan probabilitas mendapatkan jumlah 7 saat melempar dua dadu standar 6 sisi.
Args: jumlah_iterasi (int): Berapa kali simulasi (percobaan) akan diulang.
Returns: float: Estimasi probabilitas mendapatkan jumlah 7. ”””
# Langkah 3.1: Inisialisasi penghitung untuk hasil yang diinginkan jumlah_hasil_tujuh = 0
# Langkah 3.2: Mulai perulangan (iterasi) simulasi for i in range(jumlah_iterasi): # Langkah 3.3.1: Hasilkan angka acak untuk dadu pertama (antara 1 dan 6) dadu1 = random.randint(1, 6)
# Langkah 3.3.2: Hasilkan angka acak untuk dadu kedua (antara 1 dan 6) dadu2 = random.randint(1, 6)
# Langkah 3.3.3: Periksa kondisi yang diinginkan (jumlah dadu = 7) if (dadu1 + dadu2) == 7: # Langkah 3.3.4: Jika kondisi terpenuhi, tambahkan ke penghitung jumlah_hasil_tujuh += 1
# Langkah 4.1: Hitung probabilitas dari hasil simulasi probabilitas_estimasi = jumlah_hasil_tujuh / jumlah_iterasi
# Langkah 4.2: Kembalikan probabilitas yang diestimasi return probabilitas_estimasi
Penjelasannya berikut.
- Fungsi ini melempar dua dadu acak sebanyak jumlah_iterasi kali.
- Setiap kali hasil penjumlahan kedua dadu = 7, penghitung ditambah.
- Probabilitas estimasi = jumlah keberhasilan / jumlah iterasi.
Langkah 2: Menjalankan Simulasi dengan Jumlah Iterasi Berbeda
Semakin banyak iterasi, estimasi Monte Carlo semakin mendekati probabilitas teoretis.
# — Bagian untuk Menjalankan dan Menguji Simulasi — if __name__ == ”__main__”: print(“— Memulai Simulasi Monte Carlo —”) print(“Tujuan: Memperkirakan probabilitas mendapatkan jumlah 7 dari dua dadu.”) print(“Probabilitas Teoritis: 6/36 = 1/6 (sekitar 0.1667)\n”)
# Langkah 5.1: Tentukan jumlah iterasi yang berbeda untuk melihat efeknya iterasi_kecil = 100 iterasi_menengah = 10000 iterasi_besar = 1000000
print(f”Melakukan simulasi dengan {iterasi_kecil} iterasi…”) estimasi_kecil = simulasi_lempar_dadu_monte_carlo(iterasi_kecil) print(f”Estimasi Probabilitas (100 iterasi): {estimasi_kecil:.4f}\n”)
print(f”Melakukan simulasi dengan {iterasi_menengah} iterasi…”) estimasi_menengah = simulasi_lempar_dadu_monte_carlo(iterasi_menengah) print(f”Estimasi Probabilitas (10.000 iterasi): {estimasi_menengah:.4f}\n”)
print(f”Melakukan simulasi dengan {iterasi_besar} iterasi…”) estimasi_besar = simulasi_lempar_dadu_monte_carlo(iterasi_besar) print(f”Estimasi Probabilitas (1.000.000 iterasi): {estimasi_besar:.4f}\n”)
# Langkah 5.2: Bandingkan dengan probabilitas teoritis print(“— Perbandingan —”) print(f”Probabilitas Teoritis (Matematis): 0.1667”) print(“Observasi: Semakin banyak iterasi, estimasi Monte Carlo semakin mendekati nilai teoritis.”)
Langkah 3: Generalisasi – Simulasi untuk Jumlah Dadu dan Target Berapa pun
Agar kode lebih fleksibel, buat fungsi yang dapat menerima jumlah dadu dan target total apa saja.
def simulasi_dadu_monte_carlo_inti(jumlah_dadu, target_jumlah, jumlah_iterasi): ””” Melakukan inti simulasi Monte Carlo untuk memperkirakan probabilitas mendapatkan ‘target_jumlah’ ketika melempar ‘jumlah_dadu’ dadu standar 6 sisi.
Args: jumlah_dadu (int): Jumlah dadu yang akan dilempar. target_jumlah (int): Jumlah total yang ingin dicari probabilitasnya. jumlah_iterasi (int): Berapa kali simulasi (percobaan) akan diulang.
Returns: float: Estimasi probabilitas mendapatkan ‘target_jumlah’. ””” # Validasi dasar parameter input inti if not isinstance(jumlah_dadu, int) or jumlah_dadu <= 0: raise ValueError(“Jumlah dadu harus bilangan bulat positif.”) if not isinstance(target_jumlah, int) or target_jumlah <= 0: raise ValueError(“Jumlah target harus bilangan bulat positif.”) if not isinstance(jumlah_iterasi, int) or jumlah_iterasi <= 0: raise ValueError(“Jumlah iterasi harus bilangan bulat positif.”)
# Batas minimum dan maksimum yang mungkin untuk total dari jumlah dadu tertentu min_possible_sum = jumlah_dadu * 1 max_possible_sum = jumlah_dadu * 6 if target_jumlah < min_possible_sum or target_jumlah > max_possible_sum: raise ValueError(f”Jumlah target ({target_jumlah}) di luar rentang yang mungkin untuk {jumlah_dadu} dadu. Rentang: {min_possible_sum}-{max_possible_sum}.”)
jumlah_hasil_sesuai_target = 0
for _ in range(jumlah_iterasi): total_pelemparan_saat_ini = 0 # Lempar setiap dadu dan jumlahkan hasilnya for _ in range(jumlah_dadu): total_pelemparan_saat_ini += random.randint(1, 6)
# Periksa apakah total pelemparan sesuai dengan target_jumlah if total_pelemparan_saat_ini == target_jumlah: jumlah_hasil_sesuai_target += 1
probabilitas_estimasi = jumlah_hasil_sesuai_target / jumlah_iterasi return probabilitas_estimasi
Penjelasannya berikut.
- Fungsi ini dapat menerima jumlah dadu yang ingin dilempar dan target jumlah yang dicari.
- Simulasi dilakukan
jumlah_iterasikali.
Langkah 4: Menyusun Antarmuka Interaktif (opsional)
Supaya bisa eksplorasi skenario berbeda, buat antarmuka yang meminta input pengguna.
def run_dadu_monte_carlo_simulation(): ””” Memulai interaksi dengan pengguna untuk menjalankan simulasi Monte Carlo pelemparan dadu secara dinamis. ””” print(“— Selamat Datang di Simulasi Monte Carlo Pelemparan Dadu —”) print(“Program ini akan membantu Anda memperkirakan probabilitas”) print(“mendapatkan jumlah total tertentu dari sejumlah dadu.\n”)
try: # Input dari pengguna num_dadu = int(input(“Masukkan jumlah dadu yang akan dilempar (misal: 2, 3, 4): “)) target_sum = int(input(“Masukkan jumlah total yang ingin Anda cari probabilitasnya (misal: 7 untuk 2 dadu): “)) num_iterasi = int(input(“Masukkan jumlah iterasi simulasi (semakin besar, semakin akurat, misal: 1000000): “))
print(f”\nMemulai simulasi dengan {num_dadu} dadu, mencari jumlah {target_sum} sebanyak {num_iterasi} iterasi…”)
# Panggil fungsi inti simulasi estimasi_probabilitas = simulasi_dadu_monte_carlo_inti(num_dadu, target_sum, num_iterasi)
print(f”\n— Hasil Simulasi —”) print(f”Estimasi Probabilitas mendapatkan jumlah {target_sum} dari {num_dadu} dadu adalah: {estimasi_probabilitas:.6f}”)
# Opsional: Berikan konteks untuk 2 dadu dan jumlah 7 if num_dadu == 2 and target_sum == 7: print(“\n(Catatan: Untuk 2 dadu dan target 7, probabilitas teoritisnya adalah 6/36 ≈ 0.166667)”) elif num_dadu == 1: # Probabilitas teoritis untuk satu dadu adalah 1/6 untuk setiap angka print(f”\n(Catatan: Untuk 1 dadu dan target {target_sum}, probabilitas teoritisnya adalah 1/6 ≈ 0.166667)”)
except ValueError as e: print(f”\nKesalahan input: {e}. Pastikan Anda memasukkan angka bulat yang valid.”) except Exception as e: print(f”\nTerjadi kesalahan tak terduga: {e}”)
print(“\n— Simulasi Selesai —”)
Langkah 5: Observasi & Analisis Hasil
Langkah terakhir, Anda bisa uji coba jalankan fungsi yang telah dibuat dengan kode berikut.
run_dadu_monte_carlo_simulation()
Saat menjalankan kode, kita bisa menentukan sendiri hal berikut.
- Jumlah dadu yang akan dilempar.
- Jumlah total yang ingin dicari probabilitasnya.
- Jumlah iterasi simulasi.
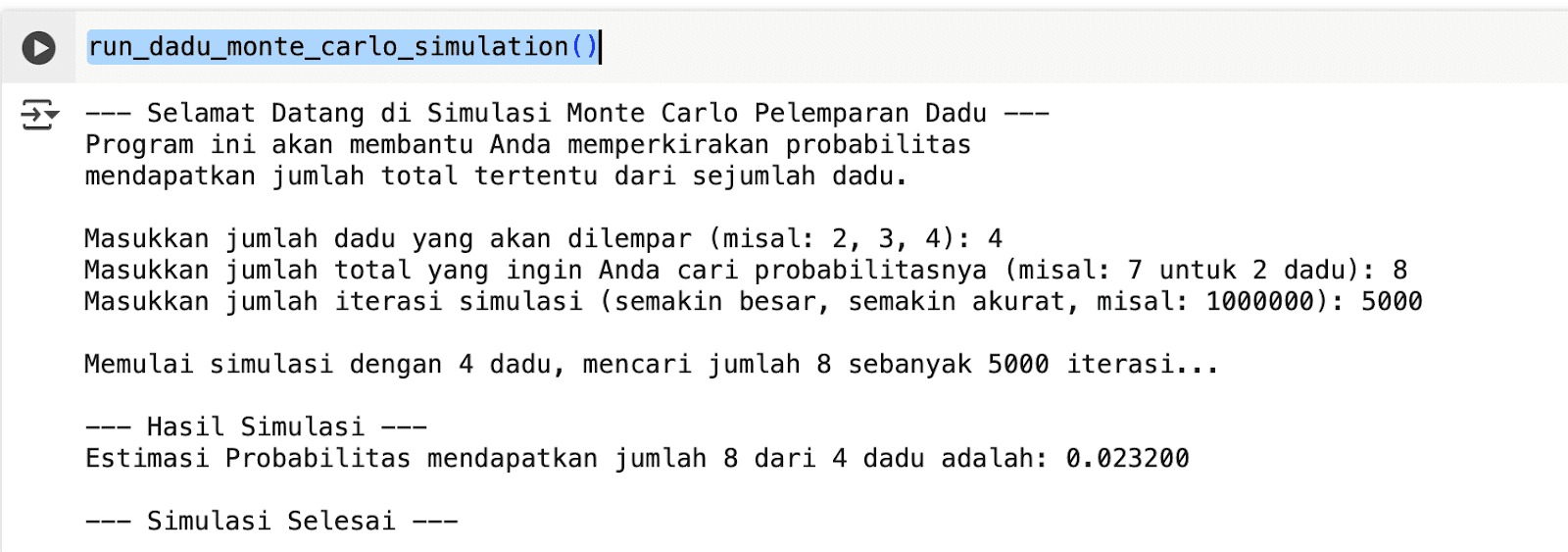
Setelah hasilnya keluar, Anda perlu membandingkan hasil simulasi dengan probabilitas teoretis (untuk kasus sederhana, bisa dihitung manual). Selain itu, coba ganti jumlah dadu dan target untuk melihat perubahan peluang dari setiap input yang kita masukkan. Terakhir, eksplorasi juga efek jumlah iterasi: semakin banyak iterasi, hasil simulasi semakin stabil.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Monte Carlo Pelemparan Dadu.ipynb
Studi Kasus: Estimasi Waktu Pengerjaan Proyek dengan Metode Monte Carlo
Setelah kita mencoba sejumlah studi kasus estimasi Pi dan simulasi pelemparan dadu, kini saatnya beralih ke aplikasi praktis yang konkret. Kita akan secara langsung mengerjakan sebuah proyek estimasi waktu menggunakan metode Monte Carlo.
Ini bukan sekadar latihan, melainkan representasi dari cara seorang data scientist dapat memberikan wawasan krusial dalam manajemen proyek di dunia nyata.
Data Proyek: Mendefinisikan Ketidakpastian Tugas
Setiap proyek, terutama yang kompleks, terdiri dari serangkaian tugas dengan durasi yang tidak pasti. Dalam proyek ini–yang akan disebut “Proyek Pengembangan Aplikasi”–data didefinisikan sebagai daftar tugas, yakni ketika setiap tugas memiliki tiga estimasi waktu yang mencerminkan ketidakpastiannya, antara lain berikut.
- Optimis: Waktu tersingkat yang diharapkan untuk menyelesaikan tugas, jika semua berjalan sangat lancar.
- Paling Mungkin (Most Likely): Waktu yang paling realistis atau sering kali diperlukan dengan asumsi kondisi normal.
- Pesimis: Waktu terlama yang mungkin dibutuhkan, jika terjadi hambatan atau masalah yang signifikan.
Contoh data tugas proyek yang akan kita gunakan sebagai berikut.
- Perencanaan Awal: Estimasi waktu antara 3 hingga 10 hari, dengan 5 hari sebagai yang paling mungkin.
- Pengembangan Fitur X: Estimasi waktu antara 8 hingga 20 hari, dengan 12 hari sebagai yang paling mungkin.
- Pengembangan Fitur Y: Estimasi waktu antara 6 hingga 15 hari, dengan 9 hari sebagai yang paling mungkin.
- Pengujian Integrasi: Estimasi waktu antara 4 hingga 10 hari, dengan 6 hari sebagai yang paling mungkin.
- Deployment & Pelatihan: Estimasi waktu antara 2 hingga 8 hari, dengan 4 hari sebagai yang paling mungkin.
| Nama | Optimis | Paling Mungkin | Pesimis |
|---|---|---|---|
| Perencanaan Awal | 3 | 5 | 10 |
| Pengembangan Fitur X | 8 | 12 | 20 |
| Pengembangan Fitur Y | 6 | 9 | 15 |
| Pengujian Integrasi | 4 | 6 | 10 |
| Deployment & Pelatihan | 2 | 4 | 8 |
Menggunakan ketiga estimasi ini, kita bisa membangun model distribusi untuk setiap tugas (biasanya distribusi Triangular atau PERT), dan menjalankan simulasi Monte Carlo untuk mengamati ribuan kemungkinan jalur proyek yang berbeda.
Setiap simulasi secara acak memilih durasi untuk setiap tugas dari distribusi waktu yang telah ditentukan, lalu menjumlahkannya untuk memproyeksikan durasi total proyek. Dengan menjalankan ribuan iterasi, kita dapat membangun distribusi probabilitas hasil proyek secara keseluruhan, yang memberikan wawasan mendalam seperti berikut.
- Berapa peluang proyek selesai tepat waktu?
- Pada titik mana risiko keterlambatan paling besar muncul?
- Seberapa besar ketidakpastian total waktu penyelesaian?
Visualisasi dari hasil simulasi ini biasanya berupa kurva distribusi seperti pada gambar berikut.
Ini menunjukkan peluang keberhasilan, potensi keterlambatan, dan range waktu penyelesaian proyek. Dengan pemahaman ini, manajer proyek dapat lebih siap menyusun jadwal realistis, menetapkan buffer waktu, dan membuat keputusan strategis yang lebih akurat.
Proses Menghitung Estimasi Manajemen Proyek
Dengan data proyek yang sudah didefinisikan, kita akan menjalankan proses simulasi Monte Carlo menggunakan fungsi simulasi_waktu_proyek_monte_carlo. Alurnya berikut.
Langkah 1: Import Library yang Dibutuhkan
Pertama, kita perlu meng-import library yang dibutuhkan dalam studi kasus ini.
- import random
- import matplotlib.pyplot as plt # Digunakan untuk visualisasi hasil
- import numpy as np # Digunakan untuk perhitungan statistik dasar
- random: Untuk menghasilkan waktu acak tiap tugas sesuai dengan distribusi.
- matplotlib.pyplot: Untuk visualisasi hasil simulasi.
- numpy: Untuk analisis statistik dasar.
Langkah 2: Definisikan Fungsi Simulasi Monte Carlo
Fungsi simulasi_waktu_proyek_monte_carlo() bertanggung jawab melakukan ribuan simulasi dari total durasi proyek.
- def simulasi_waktu_proyek_monte_carlo(tugas_proyek, jumlah_iterasi):
- ”””
-
Melakukan simulasi Monte Carlo untuk mengestimasi total waktu penyelesaian proyek.
- Args:
- tugas_proyek (list of dict): Daftar tugas, di mana setiap tugas adalah dict
- dengan ‘nama’, ‘optimis’, ‘paling_mungkin’, ‘pesimis’.
- Contoh: [{‘nama’: ‘Desain’, ‘optimis’: 5, ‘paling_mungkin’: 7, ‘pesimis’: 12}]
-
jumlah_iterasi (int): Berapa kali simulasi akan diulang.
- Returns:
- list: Daftar total waktu penyelesaian proyek dari setiap iterasi.
- ”””
- if not isinstance(tugas_proyek, list) or not tugas_proyek:
- raise ValueError(“Daftar tugas_proyek tidak boleh kosong.”)
- if not isinstance(jumlah_iterasi, int) or jumlah_iterasi <= 0:
-
raise ValueError(“Jumlah iterasi harus bilangan bulat positif.”)
-
hasil_total_waktu_proyek = []
-
print(f”Memulai simulasi dengan {jumlah_iterasi} iterasi…”)
- for i in range(jumlah_iterasi):
- total_waktu_proyek_saat_ini = 0
- for tugas in tugas_proyek:
- # Validasi input untuk setiap tugas
- if not all(k in tugas for k in [‘nama’, ’optimis’, ’paling_mungkin’, ’pesimis’]):
- raise ValueError(“Setiap tugas harus memiliki kunci ‘nama’, ‘optimis’, ‘paling_mungkin’, ‘pesimis’.”)
- if not (tugas[‘optimis’] <= tugas[‘paling_mungkin’] <= tugas[‘pesimis’]):
-
raise ValueError(f”Urutan waktu tidak valid untuk tugas ‘{tugas[‘nama’]}’: optimis <= paling_mungkin <= pesimis.”)
- # Mengambil sampel waktu tugas dari distribusi triangular
- waktu_tugas = random.triangular(
- tugas[‘optimis’],
- tugas[‘pesimis’],
- tugas[‘paling_mungkin’]
- )
- total_waktu_proyek_saat_ini += waktu_tugas
-
hasil_total_waktu_proyek.append(total_waktu_proyek_saat_ini)
- return hasil_total_waktu_proyek
Pada tahap pertama, kita mendefinisikan proyek sebagai kumpulan tugas. Setiap tugas didefinisikan sebagai tiga jenis estimasi waktu berikut.
- optimis: paling cepat jika semua berjalan lancar.
- pesimis: paling lambat jika terjadi hambatan.
- paling_mungkin: durasi yang paling realistis.
Estimasi ini digunakan untuk menggambarkan ketidakpastian durasi setiap tugas secara lebih masuk akal. Kemudian, fungsi simulasi_waktu_proyek_monte_carlo akan menjalankan simulasi ribuan kali.
Setiap kali simulasi dijalankan, kita seolah-olah sedang menyelesaikan proyek satu kali. Dalam simulasi tersebut, untuk setiap tugas, sistem akan mengambil waktu secara acak dari rentang antara estimasi optimis hingga pesimis. Pengambilan acak ini tidak sembarangan, tapi mengikuti bentuk distribusi triangular, yang memberikan peluang terbesar pada nilai paling mungkin.
Hasil dari semua waktu tugas ini kemudian dijumlahkan untuk menghasilkan total durasi proyek pada simulasi tersebut.
Proses tersebut diulang berkali-kali sesuai dengan jumlah iterasi yang ditentukan, misalnya dalam kasus ini 100.000 kali. Artinya, kita memiliki 100.000 skenario proyek yang masing-masing memiliki total durasi berbeda-beda, tergantung hasil acak yang muncul. Semua hasil ini dikumpulkan dalam satu daftar.
Langkah 3: Analisis Statistik & Visualisasi
Fungsi analisis_dan_visualisasi() menghitung statistik dasar dan menampilkan distribusi durasi proyek dalam bentuk histogram.
- def analisis_dan_visualisasi(hasil_simulasi, nama_proyek=“Proyek Anda”, target_waktu=None):
- ”””
-
Melakukan analisis statistik dan memvisualisasikan hasil simulasi.
- Args:
- hasil_simulasi (list): Daftar total waktu penyelesaian proyek dari simulasi.
- nama_proyek (str): Nama proyek untuk judul plot.
- target_waktu (float, optional): Waktu target untuk menghitung probabilitas selesai tepat waktu.
- ”””
- if not hasil_simulasi:
- print(“Tidak ada data hasil simulasi untuk dianalisis.”)
-
return
- # Statistik dasar
- rata_rata_waktu = np.mean(hasil_simulasi)
- median_waktu = np.median(hasil_simulasi)
- std_dev_waktu = np.std(hasil_simulasi)
- min_waktu = np.min(hasil_simulasi)
-
max_waktu = np.max(hasil_simulasi)
- print(f”\n— Analisis Hasil Simulasi untuk {nama_proyek} —”)
- print(f”Jumlah Iterasi: {len(hasil_simulasi)}”)
- print(f”Waktu Penyelesaian Rata-rata: {rata_rata_waktu:.2f} hari”)
- print(f”Waktu Penyelesaian Median: {median_waktu:.2f} hari”)
- print(f”Standar Deviasi Waktu: {std_dev_waktu:.2f} hari”)
- print(f”Waktu Penyelesaian Minimum: {min_waktu:.2f} hari”)
-
print(f”Waktu Penyelesaian Maksimum: {max_waktu:.2f} hari”)
- # Probabilitas selesai dalam persentil tertentu
- persentil_50 = np.percentile(hasil_simulasi, 50) # Median
- persentil_75 = np.percentile(hasil_simulasi, 75)
- persentil_90 = np.percentile(hasil_simulasi, 90)
-
persentil_95 = np.percentile(hasil_simulasi, 95)
- print(f”\nProbabilitas Proyek Selesai Dalam:”)
- print(f” 50% kemungkinan: <= {persentil_50:.2f} hari”)
- print(f” 75% kemungkinan: <= {persentil_75:.2f} hari”)
- print(f” 90% kemungkinan: <= {persentil_90:.2f} hari”)
-
print(f” 95% kemungkinan: <= {persentil_95:.2f} hari”)
- if target_waktu is not None:
- jumlah_selesai_tepat_waktu = sum(1 for waktu in hasil_simulasi if waktu <= target_waktu)
- probabilitas_tepat_waktu = jumlah_selesai_tepat_waktu / len(hasil_simulasi)
-
print(f”\nProbabilitas Proyek Selesai pada atau sebelum {target_waktu} hari: {probabilitas_tepat_waktu:.2%}”)
- # Visualisasi (Histogram)
- plt.figure(figsize=(10, 6))
- plt.hist(hasil_simulasi, bins=50, edgecolor=‘black’, alpha=0.7, color=‘skyblue’)
- plt.axvline(rata_rata_waktu, color=‘red’, linestyle=‘dashed’, linewidth=1, label=f’Rata-rata: {rata_rata_waktu:.2f} hari’)
- if target_waktu is not None:
- plt.axvline(target_waktu, color=‘green’, linestyle=‘dashed’, linewidth=1, label=f’Target: {target_waktu:.2f} hari’)
- plt.title(f’Distribusi Waktu Penyelesaian {nama_proyek} (Simulasi Monte Carlo)’)
- plt.xlabel(‘Total Waktu Penyelesaian (hari)’)
- plt.ylabel(‘Frekuensi’)
- plt.legend()
- plt.grid(axis=‘y’, alpha=0.75)
- plt.show()
Fungsi analisis_dan_visualisasi() akan menghitung berbagai statistik dari hasil simulasi. Fungsi ini memberikan informasi seperti rata-rata waktu proyek, median waktu, nilai maksimum dan minimum, serta peluang proyek selesai dalam target waktu tertentu.
Untuk membantu pemahaman, hasil simulasi juga divisualisasikan dalam bentuk histogram sehingga kita bisa melihat penyebaran durasi proyek secara langsung. Dengan cara ini, kita bisa memahami risiko keterlambatan serta peluang keberhasilan proyek secara lebih nyata dan berdasarkan data.
Proses ini secara efektif menciptakan sebuah distribusi probabilitas empiris dari total waktu penyelesaian proyek dengan mempertimbangkan ketidakpastian pada setiap komponennya.
Interpretasi: Mengubah Angka Menjadi Wawasan Proyek yang Actionable
Setelah simulasi menghasilkan 100.000 kemungkinan waktu penyelesaian proyek, langkah selanjutnya adalah menginterpretasikan data ini untuk mendapatkan wawasan yang dapat menuntun pengambilan keputusan.
Fungsi analisis_dan_visualisasi() akan membantu kita dalam tahap ini. Hasil distribusi waktu pengerjaan proyek pada 100.000 percobaan adalah berikut.
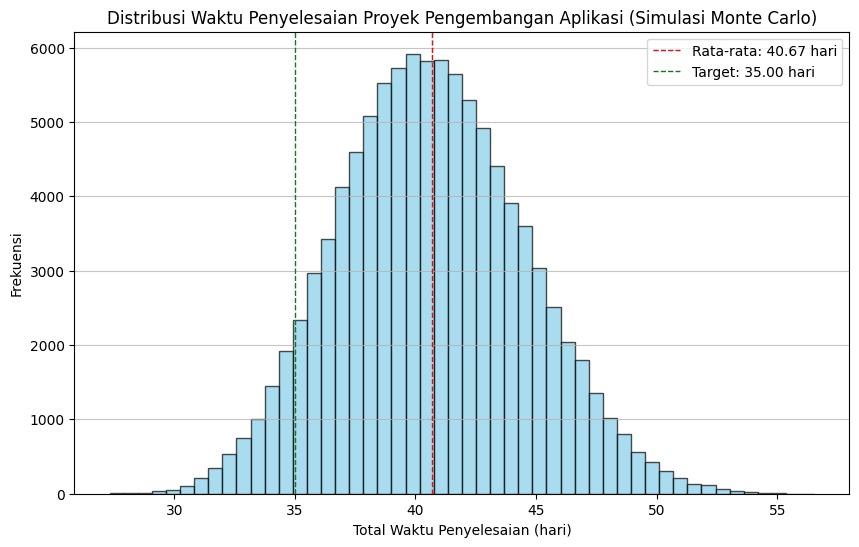
Berdasarkan grafik visualisasi di atas, kita dapat menghitung beberapa aspek statistik yang akan mampu memberikan gambaran lebih spesifik mengenai interpretasi data.
Memulai simulasi dengan 100000 iterasi…
-– Analisis Hasil Simulasi untuk Proyek Pengembangan Aplikasi —
Jumlah Iterasi: 100000
Waktu Penyelesaian Rata-rata: 40.67 hari
Waktu Penyelesaian Median: 40.56 hari
Standar Deviasi Waktu: 3.86 hari
Waktu Penyelesaian Minimum: 27.32 hari
Waktu Penyelesaian Maksimum: 56.52 hari
Probabilitas Proyek Selesai Dalam:
50% kemungkinan: <= 40.56 hari
75% kemungkinan: <= 43.28 hari
90% kemungkinan: <= 45.75 hari
95% kemungkinan: <= 47.21 hari
Probabilitas Proyek Selesai pada atau sebelum 35 hari: 6.72%
Analisis Statistik Deskriptif
- Waktu Penyelesaian Rata-rata (40.67 hari): Ini adalah waktu penyelesaian yang paling sering atau diharapkan. Ini merupakan estimasi titik sentral untuk durasi proyek.
- Waktu Penyelesaian Median (40.56 hari): Ini adalah nilai tengah dari semua hasil simulasi. Kedekatannya dengan rata-rata menunjukkan distribusi waktu proyek cenderung simetris.
- Standar Deviasi Waktu (3.86 hari): Ini mengukur seberapa bervariasi kemungkinan durasi proyek. Angka yang lebih besar menunjukkan ketidakpastian proyek lebih tinggi.
- Waktu Penyelesaian Minimum (27.34 hari) & Maksimum (56.52 hari): Ini menunjukkan rentang ekstrem dari waktu penyelesaian yang mungkin terjadi berdasarkan simulasi.
Probabilitas Berdasarkan Persentil
Ini adalah metrik kunci untuk perencanaan yang realistis.
- 50% kemungkinan: <= 40.56 hari: Ada 50% peluang proyek selesai dalam 40.56 hari atau lebih cepat.
- 75% kemungkinan: <= 43.28 hari: Untuk memiliki keyakinan 75% proyek akan selesai, kita harus merencanakan sekitar 43.28 hari.
- 90% kemungkinan: <= 45.75 hari: Jika ingin probabilitas keberhasilan 90%, proyek harus dialokasikan 45.75 hari.
- 95% kemungkinan: <= 47.21 hari: Untuk keyakinan sangat tinggi (95%), durasi sekitar 47.21 hari diperlukan.
Hasil simulasi menunjukkan probabilitas proyek selesai pada atau sebelum 35 hari adalah 6.72%. Ini adalah angka yang sangat penting.
Implikasi untuk Pengambilan Keputusan
Probabilitas yang sangat rendah (6.72%) untuk menyelesaikan proyek dalam 35 hari memiliki implikasi signifikan. Ini berarti risiko proyek terlambat sangat tinggi (sekitar 93.18%) jika target 35 hari dipertahankan.
Sebagai seorang profesional data scientist, Anda harus merekomendasikan negosiasi ulang target waktu agar lebih realistis (misalnya, menjadi 43 atau 45 hari), atau mengusulkan alokasi sumber daya tambahan pada tugas-tugas kritis jika target 35 hari mutlak diperlukan.
Analisis ini memungkinkan pengambilan keputusan yang proaktif dan berbasis bukti, bukan sekadar intuisi.
Anda bisa lihat kode Python yang digunakan dalam materi ini lebih lanjut pada Google Colab berikut: Modul 3 - Estimasi Waktu Pengerjaan Proyek.ipynb
Rangkuman Distribusi Statistik
Konsep Dasar Probabilitas dan Variabel Acak
Probabilitas adalah cabang matematika yang mempelajari peluang terjadinya suatu peristiwa. Nilainya berada di antara 0 (mustahil) dan 1 (pasti terjadi).
- Ruang Sampel (Sample Space): Semua kemungkinan hasil percobaan acak.
- Kejadian (Event): Himpunan hasil tertentu yang kita amati dari ruang sampel.
Variabel Acak adalah besaran yang nilainya ditentukan oleh hasil percobaan acak.
- Variabel Acak Diskret: Nilainya dapat dihitung satu per satu dan jumlahnya terbatas (contoh: jumlah pelanggan per hari, hasil lemparan dadu).
- Variabel Acak Kontinu: Nilainya berada pada rentang tertentu dan bisa berupa desimal (contoh: tinggi badan, suhu, waktu penyelesaian tugas).
Hubungan dengan Data Science
- Membantu memilih distribusi probabilitas yang tepat (misal binomial untuk diskret, normal untuk kontinu).
- Menentukan metode analisis statistik yang sesuai.
- Memahami pola data untuk pengambilan keputusan berbasis probabilitas.
Fungsi Distribusi
Distribusi probabilitas menunjukkan persebaran peluang pada seluruh kemungkinan nilai variabel acak.
- PMF (probability mass function): Digunakan untuk variabel diskret, menunjukkan peluang untuk setiap nilai spesifik. Contoh: peluang mendapat angka 4 pada dadu.
- PDF (probability density function): Digunakan untuk variabel kontinu, menunjukkan kepadatan probabilitas di sekitar nilai tertentu. Probabilitas dihitung dari luas area di bawah kurva dalam rentang tertentu.
- CDF (cumulative distribution function): Menunjukkan peluang kumulatif sampai suatu nilai. Dapat digunakan baik untuk variabel diskret maupun kontinu.
Ketiganya saling terkait: PMF/PDF menggambarkan peluang di titik tertentu, sedangkan CDF menunjukkan akumulasi peluang hingga titik itu.
Distribusi Diskret
Digunakan ketika variabel acak hanya dapat memiliki nilai tertentu. Tiga distribusi penting adalah berikut.
- Distribusi Bernoulli
- Satu percobaan dengan dua kemungkinan hasil: sukses (p) atau gagal (1-p).
- Contoh: lempar koin, konversi iklan online.
- Distribusi Binomial
- Menghitung jumlah sukses dalam n percobaan independen dengan probabilitas sukses p tetap.
- Contoh: jumlah pelanggan yang membeli produk dari 50 email promosi.
- Distribusi Poisson
- Menghitung jumlah kejadian dalam interval waktu atau ruang tertentu, dengan rata-rata λ kejadian per interval.
- Cocok untuk peristiwa yang jarang, misalnya jumlah panggilan masuk per jam.
Distribusi Kontinu
Digunakan untuk variabel acak yang nilainya dapat berupa angka real dalam rentang tertentu. Contoh distribusi sebagai berikut.
- Distribusi Uniform Kontinu: Semua nilai dalam rentang memiliki peluang sama. Contoh: waktu kedatangan bus dalam rentang 0–10 menit jika benar-benar acak.
- Distribusi Normal (Gaussian): Bentuk kurva lonceng, simetris terhadap rata-rata μ, dengan lebar kurva ditentukan oleh simpangan baku σ. Banyak fenomena alam dan sosial mengikuti distribusi ini.
- Distribusi t-Student: Mirip distribusi normal tetapi dengan ekor lebih tebal; digunakan ketika ukuran sampel kecil dan standar deviasi populasi tidak diketahui.
- Distribusi Chi-Square: Digunakan untuk analisis varians dan uji independensi pada data kategorikal.
Konsep Central Limit Theorem (CLT)
- Menyatakan bahwa rata-rata sampel dari ukuran besar akan mendekati distribusi normal meskipun data asal tidak normal.
- Implikasi: kita dapat menggunakan metode statistik berbasis normal untuk rata-rata sampel.
- Contoh: jika kita mengukur waktu layanan pelanggan dari banyak sampel acak, distribusi rata-rata waktu tersebut akan berbentuk kurva normal saat n cukup besar (≥30).
- Penting untuk inferensi statistik karena memvalidasi penggunaan distribusi normal dalam estimasi dan pengujian.
Simulasi Probabilitas dan Metode Monte Carlo
- Pendekatan komputasi dengan menggunakan angka acak untuk memodelkan sistem kompleks yang sulit dianalisis secara matematis.
- Proses umum:
- Membuat model probabilitas.
- Menghasilkan angka acak sesuai distribusi yang diinginkan.
- Menjalankan simulasi berulang kali.
- Menganalisis distribusi hasil simulasi untuk estimasi atau prediksi.
- Kelebihan: dapat memodelkan interaksi multivariabel acak, menghitung risiko, dan memperkirakan probabilitas kejadian langka.
This file is located at: _chapters/991-belajar-matematika-untuk-data-science/030-distribusi-statistik.md