Data Univariat dan Multivariat
- Pengantar Matematika untuk Data Science
- Klasifikasi Data dalam Data Science
- Data Kategorikal Univariat
- Data Kuantitatif Univariat: Pengantar
- Data Kuantitatif Univariat: Pengertian
- Data Kuantitatif Univariat: Ukuran Pemusatan Data
- Data Kuantitatif Univariat: Ukuran Penyebaran Data
- Data Kuantitatif Univariat: Standardisasi dan Normalisasi Data
- Data Kuantitatif Univariat: Distribusi Data
- Data Kuantitatif Univariat: Distribusi Probabilitas
- Data Kategorikal Multivariat
- Data Kuantitatif Multivariat
- Pengantar Matematika untuk Data Science
- Klasifikasi Data dalam Data Science
- Data Kategorikal Univariat
- Data Kuantitatif Univariat: Pengantar
- Data Kuantitatif Univariat: Pengertian
- Data Kuantitatif Univariat: Ukuran Pemusatan Data
- Data Kuantitatif Univariat: Ukuran Penyebaran Data
- Data Kuantitatif Univariat: Standardisasi dan Normalisasi Data
- Data Kuantitatif Univariat: Distribusi Data
- Data Kuantitatif Univariat: Distribusi Probabilitas
- Data Kategorikal Multivariat
- Data Kuantitatif Multivariat
Pengantar Matematika untuk Data Science
Halo, teman-teman data! Semoga kalian semua dalam kondisi sehat dan baik. Selamat bergabung di Kelas Belajar Matematika untuk Data Science!
Kami sangat antusias melihat minat Anda untuk menggali lebih dalam dan memperkuat keterampilan di dunia data science. Di kelas ini, kita akan membahas konsep-konsep matematika yang sangat penting untuk mendukung perjalanan Anda menjadi data scientist yang terampil.
Kelas ini dibuat untuk Anda yang ingin menghubungkan teori matematika dengan penerapannya dalam data science secara praktis. Jadi, pastikan Anda siap untuk belajar matematika dan teman-temannya.
Semoga Anda menikmati proses belajar ini, dan jika ada pertanyaan, jangan ragu untuk bertanya di forum diskusi kelas.
Keterkaitan Matematika dan Ilmu Data Science
Pada era digital saat ini, data telah menjadi bagian tak terpisahkan dari kehidupan kita. Setiap hari, kita menghasilkan dan mengonsumsi data dalam berbagai bentuk—mulai dari transaksi keuangan, informasi media sosial, hingga hasil pengukuran sensor di dunia industri. Namun, untuk bisa memahami dan memanfaatkan data dengan baik, kita membutuhkan alat yang tepat. Di sinilah peran matematika dalam data science menjadi sangat penting.
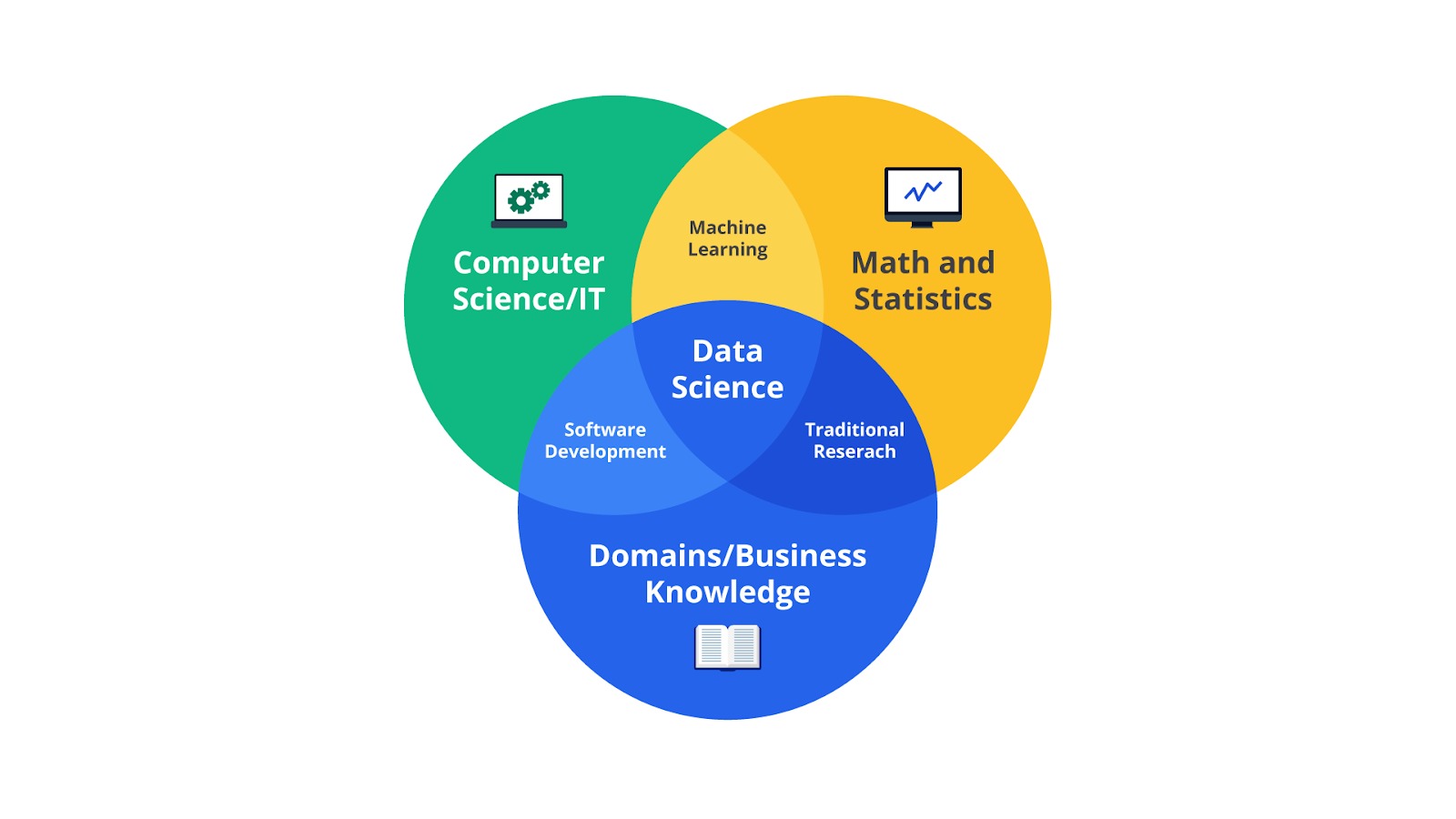
Data science adalah bidang yang menggabungkan berbagai disiplin, seperti matematika, statistika, dan ilmu komputer untuk mengekstraksi wawasan dari data. Semua ilmu tersebut kemudian ditopang oleh domain knowledge, yakni pemahaman mendalam tentang konteks bisnis, industri, atau masalah nyata yang sedang dianalisis.
Matematika adalah bahasa universal yang memungkinkan kita menganalisis pola, membuat prediksi, serta menyusun model yang dapat membantu dalam pengambilan keputusan. Matematika berperan dalam mengolah, memahami, serta menafsirkan data dengan cara yang sistematis dan akurat.
Peran Matematika dalam Data Science
Matematika adalah elemen fundamental dalam data science karena memungkinkan kita untuk memahami, menganalisis, dan mengolah data secara sistematis. Tanpa pemahaman yang kuat terhadap konsep matematika, seorang data scientist akan kesulitan dalam menafsirkan pola pada data, membangun model prediktif, serta mengoptimalkan algoritma machine learning.
Dalam dunia data science, empat cabang utama matematika yang paling berperan adalah statistika, probabilitas, aljabar linear, dan kalkulus. Masing-masing memiliki kegunaan unik dan diterapkan dalam berbagai aspek analisis data, mulai dari eksplorasi data hingga pengembangan model kecerdasan buatan.
Statistika: Memahami Data dan Membuat Kesimpulan
Statistika adalah cabang matematika yang digunakan untuk mengumpulkan, menganalisis, menafsirkan, dan menyajikan data. Dalam data science, statistika berperan untuk memahami distribusi data, menguji hipotesis, serta melakukan estimasi dan inferensi statistik. Dengan statistika, kita dapat mengukur variabilitas data, mengidentifikasi pola, serta membuat keputusan berbasis data. Berikut adalah peran statistika dalam data science.
- Eksplorasi Data: Statistika deskriptif digunakan untuk memahami distribusi data melalui ukuran seperti mean, median, standar deviasi, dan distribusi frekuensi.
- Inferensi Statistik: Membantu kita dalam menarik kesimpulan dari sampel ke populasi menggunakan uji hipotesis dan interval kepercayaan.
- Pengambilan Keputusan: Statistika memungkinkan kita melakukan pengujian signifikan, seperti t-test (uji t) atau ANOVA, untuk menentukan bahwa suatu perbedaan dalam data bermakna secara statistik.
Contoh Penerapan
Statistika dapat digunakan pada kasus perusahaan yang ingin mengevaluasi efektivitas strategi pemasaran baru mereka, memastikan bahwa hal tersebut dapat meningkatkan penjualan atau tidak. Caranya, mereka perlu mengumpulkan data penjualan sebelum dan sesudah kampanye pemasaran. Kemudian, kedua data tersebut dibandingkan, lalu menggunakan uji-t untuk melihat bahwa ada perbedaan signifikan antara kedua periode perubahan penjualan tersebut.
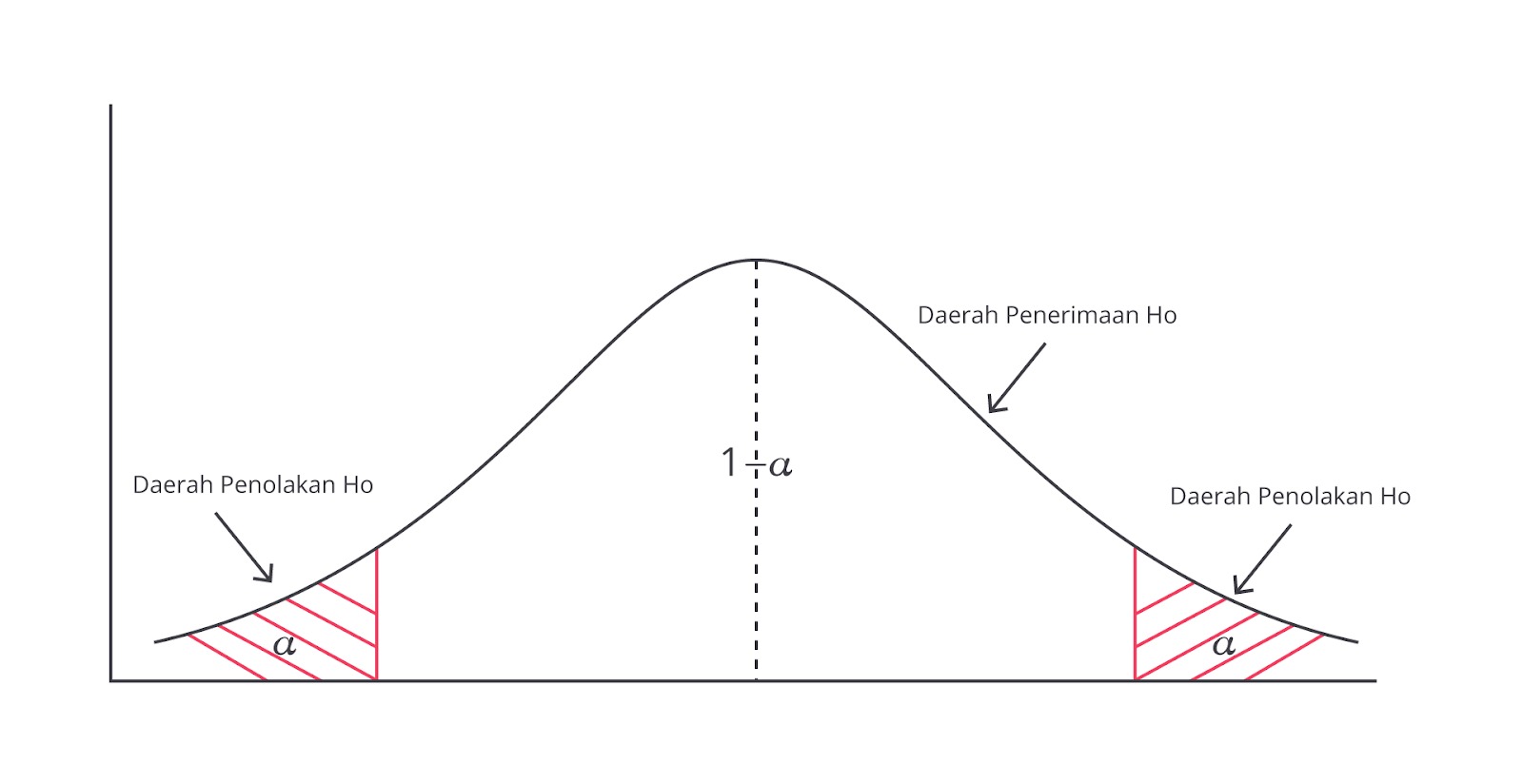
Gambar di atas menunjukkan proses pengambilan keputusan dalam statistik melalui uji hipotesis. Jika hasil uji jatuh dalam daerah penolakan H₀ (area yang diarsir), kesimpulannya adalah strategi baru berhasil meningkatkan penjualan secara statistik. Namun jika tidak, berarti belum ada bukti yang cukup kuat untuk menyatakan bahwa strategi tersebut efektif.
Probabilitas: Mengukur Ketidakpastian dalam Data
Probabilitas adalah cabang matematika yang berkaitan dengan peluang suatu kejadian terjadi. Pada data science, probabilitas digunakan untuk membuat prediksi, mengukur ketidakpastian, serta membangun model probabilistik dalam machine learning. Peran probabilitas dalam data science sebagai berikut.
- Prediksi dan Peramalan: Digunakan dalam model probabilistik, seperti Naive Bayes Classifier untuk klasifikasi teks dan analisis spam.
- Model Probabilistik: Banyak algoritma machine learning menggunakan probabilitas, seperti Hidden Markov Model (HMM) dalam natural language processing (NLP) atau pemrosesan bahasa alami.
- Distribusi Probabilitas: Digunakan untuk memahami kemungkinan berbagai kejadian, seperti distribusi normal, binomial, dan Poisson.
Contoh Penerapan
Probabilitas biasa digunakan dalam memprediksi cuaca. Perhatikan gambar hari Rabu dengan peluang hujan 90%.
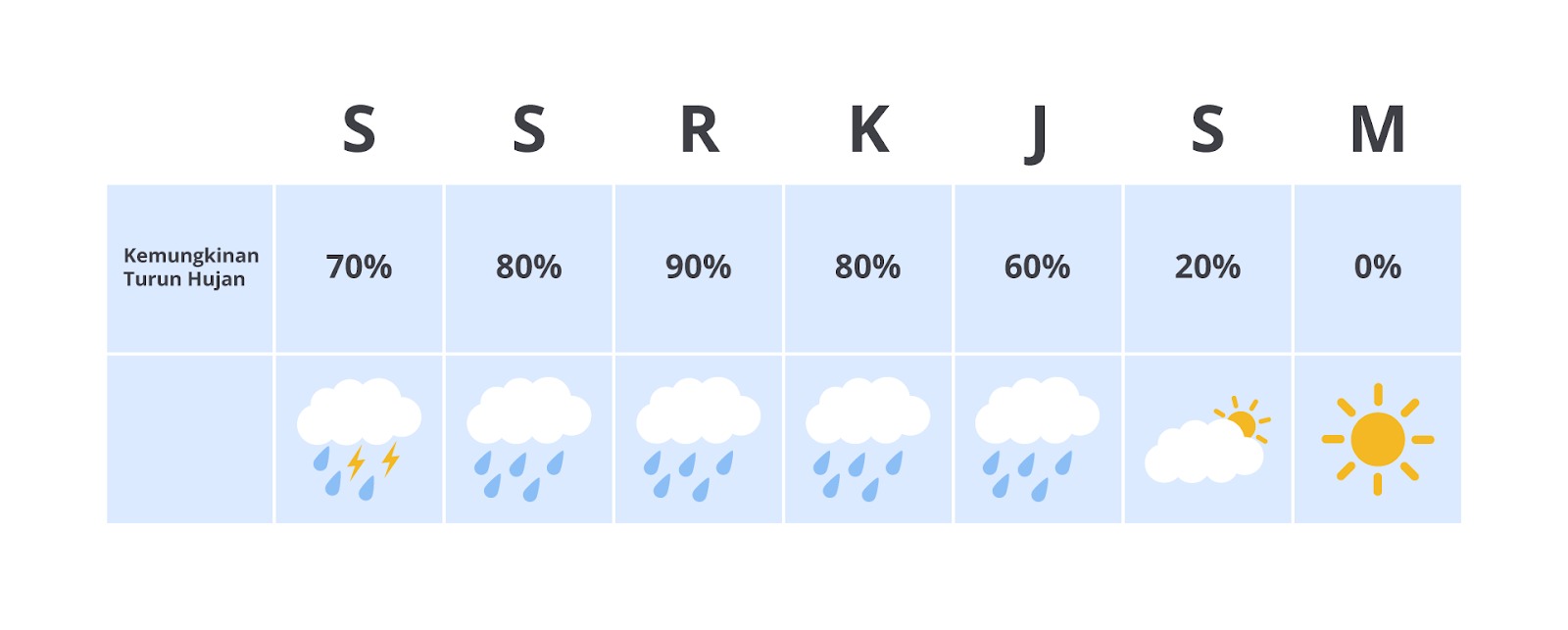
Jika memiliki acara di luar ruangan, Anda harus bersiap dengan payung atau jas hujan. Namun, jika hari Sabtu peluangnya hanya 20%, hujan kemungkinan kecil terjadi.
Probabilitas membantu kita membuat keputusan yang lebih baik berdasarkan data, bukan hanya perkiraan insting semata.
Aljabar Linear: Struktur Data dalam Bentuk Matriks dan Vektor
Aljabar linear adalah cabang matematika yang menangani matriks dan vektor–yakni komponen dasar dalam banyak algoritma machine learning serta deep learning. Hampir semua model AI modern menggunakan operasi berbasis matriks untuk memproses dan menganalisis data. Berikut adalah peran aljabar linear dalam data science.
- Pemrosesan Data dalam Bentuk Matriks: Banyak dataset yang disusun dalam bentuk tabel (matriks), seperti pada data gambar dalam deep learning.
- Reduksi Dimensi: Teknik seperti principal component analysis (PCA) menggunakan aljabar linear untuk menyederhanakan data tanpa kehilangan informasi utama.
- Optimasi Model Machine Learning: Algoritma seperti regresi linear dan neural networks menggunakan operasi matriks untuk mempercepat perhitungan serta meningkatkan efisiensi komputasi.
Contoh Penerapan
Aljabar linear diterapkan pada PCA (principal component analysis), yakni metode statistik yang digunakan untuk menyederhanakan data.
Dalam kompresi gambar, principal component analysis (PCA) digunakan untuk mengurangi dimensi gambar tanpa kehilangan banyak detail. Ini memungkinkan penyimpanan gambar lebih efisien dan pemrosesan lebih cepat dalam aplikasi, seperti pengenalan wajah.
Salah satu ilustrasi PCA yang paling sederhana adalah untuk mengurangi dimensi dari sebuah data 3D menjadi 2D tanpa kehilangan representasi dari datanya.
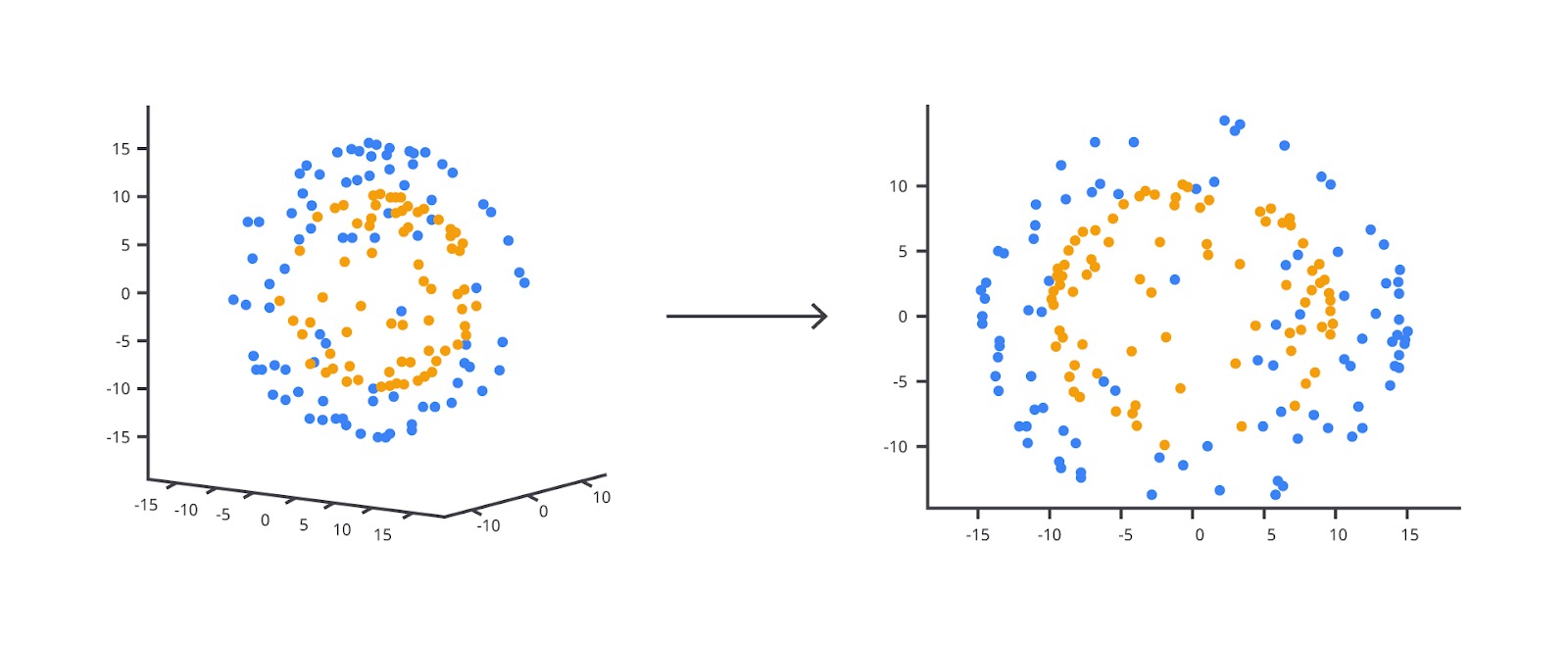
Gambar di atas menunjukkan dua bagian.
- Kiri: Data dalam ruang tiga dimensi (3D)—kita bisa lihat titik-titik data tersebar dalam ruang.
- Kanan: Hasil proyeksi pada dua dimensi (2D)—PCA telah mengurangi satu dimensi, tetapi struktur utama data tetap terlihat.
Agar mempermudah penjelasan, bayangkan Anda memotret sebuah benda 3D, seperti apel dari sudut tertentu. Meski foto itu 2D, kita masih bisa mengenali bentuknya. PCA bekerja dengan cara serupa: memproyeksikan data berdimensi tinggi ke dimensi yang lebih rendah, sambil tetap mempertahankan informasi penting.
Ini sangat berguna misalnya saat kita ingin menyimpan gambar atau mengenali wajah secara otomatis—PCA membantu mempercepat dan menyederhanakan proses tersebut tanpa banyak kehilangan informasi.
Kalkulus: Optimasi Model Machine Learning
Kalkulus adalah cabang matematika yang mempelajari perubahan nilai dalam suatu fungsi. Pada data science, kalkulus sangat penting untuk optimasi model machine learning, seperti dalam proses training model dengan algoritma gradient descent. Peran kalkulus dalam data science sebagai berikut.
- Optimasi Model: Digunakan untuk menentukan cara model dapat mencapai error minimum dengan menyesuaikan bobot menggunakan gradient descent.
- Perhitungan Turunan: Membantu kita memahami bahwa perubahan kecil dalam suatu variabel memengaruhi output model.
- Backpropagation dalam Neural Networks: Digunakan dalam pembelajaran deep learning untuk mengoptimalkan bobot neuron.
Contoh Penerapan
Dalam proses pelatihan model seperti neural network, gradient descent digunakan sebagai algoritma untuk menyesuaikan bobot model agar meminimalkan kesalahan (error/loss).
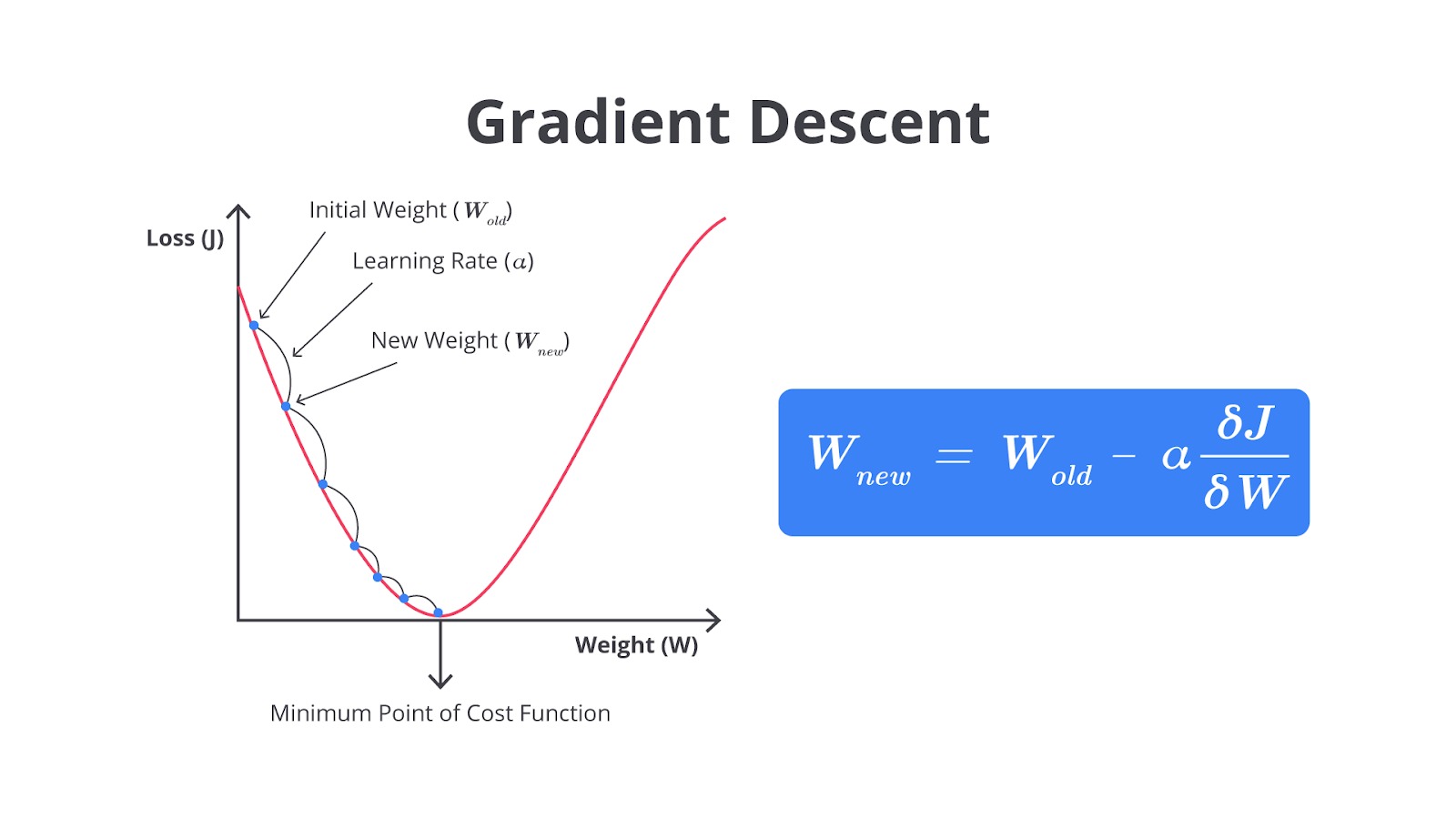
Gradient descent menggunakan konsep turunan dalam kalkulus untuk mengetahui arah perubahan bobot yang paling optimal sehingga model dapat belajar secara lebih efisien. Dengan mengikuti arah tersebut, model memperbarui bobotnya secara bertahap sampai mencapai titik dengan error terkecil.
Gradient descent sangat penting karena memungkinkan model untuk belajar dari kesalahan, memperbarui parameter secara sistematis, dan akhirnya menemukan konfigurasi terbaik yang menghasilkan prediksi paling akurat.
Fokus Pembelajaran: Statistika dan Probabilitas
Meskipun ada empat cabang utama matematika yang berperan penting dalam data science—statistika, probabilitas, aljabar linear, serta kalkulus, kelas ini akan berfokus pada statistika dan probabilitas. Alasannya adalah karena kedua cabang ini adalah inti dari proses analisis data yang dilakukan sehari-hari oleh para data scientist.
Dalam praktik data science, hampir semua proses awal hingga pengambilan keputusan berbasis data melibatkan statistika dan probabilitas.
- Saat melakukan eksplorasi data, kita menggunakan statistika deskriptif untuk memahami karakteristik data.
- Saat membuat inferensi dari sampel ke populasi, statistika inferensial menjadi alat utama.
- Untuk membuat prediksi atau mengukur ketidakpastian suatu kejadian, kita mengandalkan teori probabilitas.
Berikut adalah beberapa alasan fokus pembelajaran akan diarahkan pada statistika dan probabilitas.
- Keterkaitan Langsung dengan Data: Setiap dataset mengandung ketidakpastian dan variasi. Statistika dan probabilitas memberi kita alat untuk menanganinya secara sistematis.
- Landasan untuk Machine Learning: Banyak algoritma machine learning berbasis probabilistik (Naïve Bayes, Gaussian Process, dll.) atau menggunakan konsep statistika (seperti evaluasi model dengan uji statistik).
- Keterbacaan Luas: Pemahaman statistika dan probabilitas memungkinkan seorang data scientist untuk menjelaskan hasil temuannya kepada stakeholder non-teknis dengan bahasa yang mudah dipahami serta berbasis angka.
Dengan kata lain, statistika dan probabilitas adalah bahasa universal dalam data science. Oleh karena itu, modul ini akan secara khusus memperdalam kedua bidang tersebut agar Anda memiliki fondasi kuat sebelum melangkah ke penerapan teknis dan algoritma yang lebih kompleks.
Klasifikasi Data dalam Data Science
Di dunia data science, data menjadi aset utama untuk mengambil keputusan dan membangun model machine learning. Namun, sebelum bisa melakukan analisis yang kompleks atau melatih model, kita perlu memahami jenis-jenis data yang dihadapi.
Dalam bidang data science, memahami jenis data sangat penting sebelum melakukan analisis atau membangun model. Setiap data memiliki karakteristik berbeda yang menentukan cara terbaik untuk mengolah dan menginterpretasikannya. Misalnya, data yang berupa kategori seperti warna atau jenis kelamin tidak bisa dihitung atau dioperasikan secara matematis, sementara data berbentuk angka, seperti tinggi badan atau suhu dapat dianalisis menggunakan metode statistik.
Bayangkan kita ingin menganalisis pola belanja pelanggan di sebuah toko. Ada banyak informasi yang bisa dikumpulkan, seperti jenis produk yang dibeli (kategori), jumlah barang yang dibeli (angka), usia pelanggan (angka), hingga metode pembayaran yang digunakan (kategori).
Semua informasi ini adalah data, tetapi tidak semuanya bisa diperlakukan dengan cara yang sama. Oleh karena itu, penting untuk mengenali perbedaan data berdasarkan sifatnya, jumlah variabelnya, dan level pengukurannya. Semua klasifikasi tersebut akan memengaruhi kita dalam melakukan analisis dan metode pengolahan data.
Klasifikasi Data Berdasarkan Sifat
Secara umum, data dapat dikategorikan dalam dua kelompok utama berdasarkan sifatnya: data kategorikal dan data kuantitatif. Pemahaman ini sangat penting karena akan memengaruhi metode analisis yang digunakan, baik dalam eksplorasi data, statistika, maupun machine learning.
Data Kategorikal
Data kategorikal adalah data yang tidak berbentuk angka, tetapi terdiri dari kategori atau label yang menunjukkan karakteristik tertentu dari objek atau individu. Data kategorikal tidak bisa dioperasikan secara matematis seperti penjumlahan atau pengurangan, tetapi ia bisa dihitung frekuensinya atau dikategorikan/dikelompokkan lebih lanjut.
Data kategorikal sering kali digunakan untuk mengelompokkan objek atau individu dalam kategori yang berbeda. Kita sering menemukan data kategorikal dalam kehidupan sehari-hari, misalnya saat mengklasifikasikan jenis kelamin, status pernikahan, atau jenis kendaraan. Contoh data kategorikal sebagai berikut.
- Jenis Kelamin: Laki-Laki, Perempuan.
- Status Pernikahan: Menikah, Lajang, Cerai.
- Jenis Kendaraan: Mobil, Motor, Sepeda.
Sekarang, bayangkan Anda memiliki dataset berisi metode pembayaran yang digunakan oleh pelanggan, seperti tunai, kartu kredit, dan e-wallet. Anda takkan bisa menghitung rata-rata dari kategori ini, tetapi kita bisa melihat seberapa sering masing-masing kategori muncul. Dalam hal ini, analisis frekuensi atau persentase akan lebih berguna daripada metode statistik yang digunakan untuk data numerik.
Data Kuantitatif
Coba bayangkan Anda sedang bekerja dengan dataset yang berisi informasi tentang pendapatan bulanan sebuah toko. Angka-angka tersebut tentu bisa kita gunakan untuk melakukan perhitungan statistik, bukan?
Berbeda dengan data kategorikal, data kuantitatif atau numerik adalah data berbentuk angka yang bisa diukur atau dihitung, yakni pendapatan, umur, berat badan, dan sebagainya. Data kuantitatif memungkinkan kita untuk melakukan operasi matematika, seperti penjumlahan, pengurangan, atau perhitungan rata-rata. Sebagai contoh, kita bisa menghitung rata-rata usia pelanggan atau total pengeluaran pelanggan dalam sebulan. Dengan demikian, data kuantitatif memberikan kita informasi yang lebih mendalam untuk membangun model prediktif.
Berikut adalah contoh dari data kuantitatif.
- Pendapatan Bulanan: Rp7.000.000.
- Usia Pelanggan: 35 tahun.
- Berat Badan: 70 kg.
Saat Anda menganalisis data pelanggan, tentu data-data tersebut bisa kita hitung, seperti melakukan rata-rata pendapatan atau melihat distribusi usia. Ini adalah contoh data kuantitaitf yang sangat berguna dalam banyak analisis.
Klasifikasi Data Berdasarkan Level Pengukuran
Setelah kita memahami klasifikasi data berdasarkan sifat dan jumlah variabelnya, kini saatnya menggali lebih dalam dengan mengetahui data berdasarkan level pengukurannya, yaitu data nominal, ordinal, interval, dan rasio. Dalam analisis data, level pengukuran menentukan cara data dapat diklasifikasikan dan dianalisis.
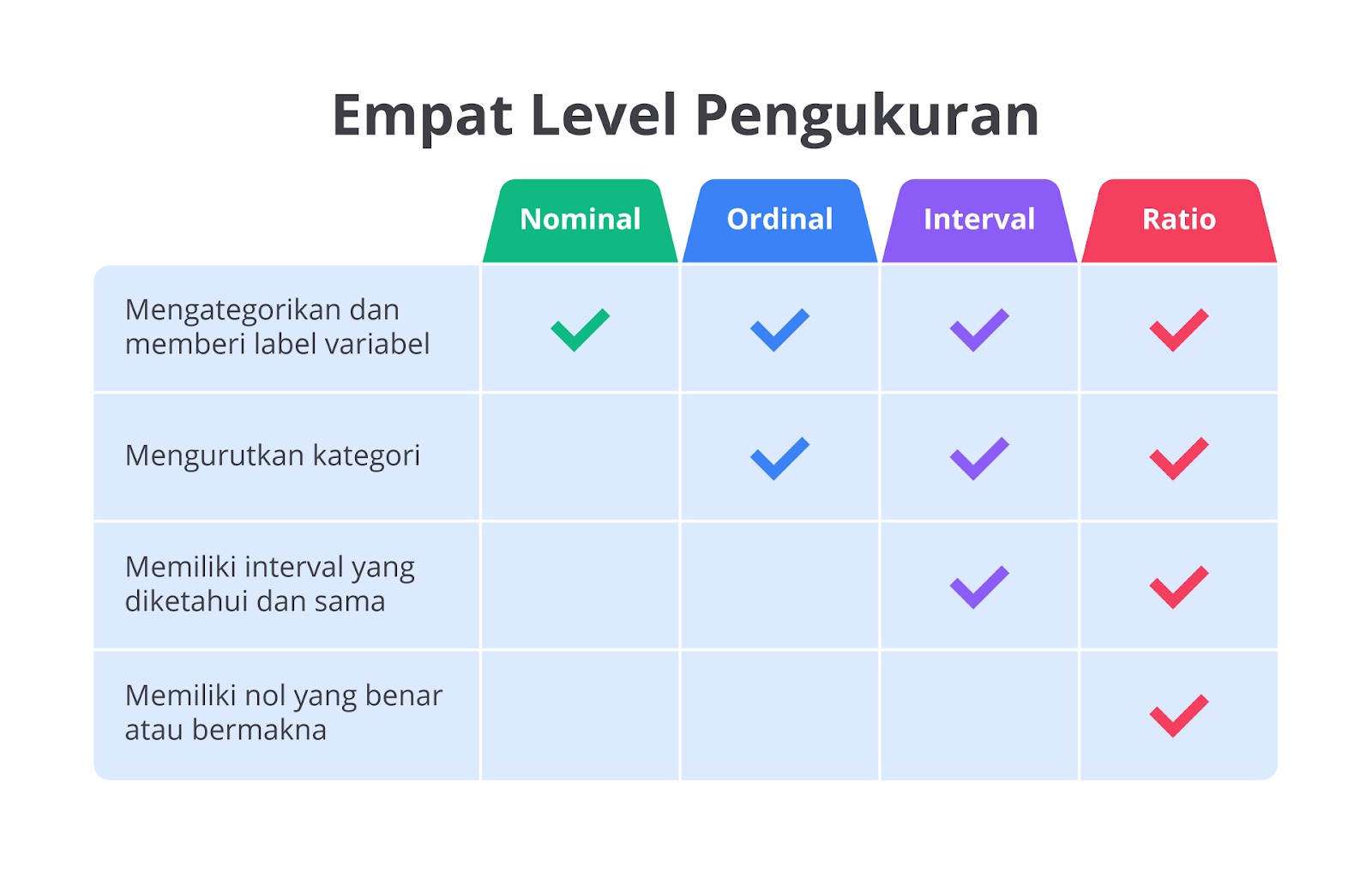
Masing-masing jenis data ini memiliki karakteristik yang sangat penting untuk dipahami. Pasalnya, cara kita menganalisis dan menginterpretasikan data akan sangat bergantung pada jenis data yang dimiliki.
Data Nominal
Data nominal adalah jenis data kategorikal yang paling dasar. Data ini hanya digunakan untuk mengidentifikasi atau mengelompokkan objek, individu, atau variabel dalam kategori tertentu, tanpa ada urutan atau ranking di antara kategori-kategori tersebut. Dengan kata lain, setiap kategori dalam data nominal setara dan tidak ada kategori yang lebih tinggi atau lebih rendah dari lainnya.

Berikut adalah contoh data yang termasuk dalam data nominal.
- Jenis Kelamin: Laki-Laki, Perempuan.
- Warna Kendaraan: Merah, Biru, Hitam.
- Jenis Makanan: Pizza, Burger, Pasta.
- Tipe Hewan Peliharaan: Kucing, Anjing, Ikan.
Singkatnya, data nominal adalah jenis data yang hanya berfungsi sebagai label atau kategori tanpa memiliki urutan atau tingkatan. Data ini tidak memiliki nilai numerik yang bisa dihitung atau dibandingkan secara matematis.
Pada data nominal, satu-satunya operasi yang bisa dilakukan adalah mengelompokkan atau menghitung frekuensi kemunculan setiap kategori.
Mari kita ambil contoh. Bayangkan kalian sedang bekerja dengan data pelanggan sebuah restoran. Jenis makanan yang dipesan bisa dikategorikan menjadi beberapa jenis, seperti pizza, burger, atau pasta. Namun, tidak ada kategori yang lebih penting atau lebih rendah di antara ketiganya.
Semua kategori tersebut hanya digunakan untuk mengelompokkan data berdasarkan tipe makanan yang dipilih oleh pelanggan. Tidak ada cara untuk mengukur atau menghitung perbedaan antara jenis-jenis makanan ini karena mereka hanya mewakili kelompok yang berbeda.
Data nominal sangat sering digunakan dalam berbagai analisis frekuensi atau proporsi. Misalnya, kalian bisa menghitung jumlah pelanggan yang memilih pizza, yang memilih burger, dan yang memilih pasta.
Ini adalah contoh sederhana tentang cara data nominal digunakan untuk mengelompokkan objek dalam kategori tertentu. Tidak ada urutan, hanya pengelompokan.
Data Ordinal
Data ordinal memiliki sifat kategorikal seperti data nominal, tetapi dengan tambahan karakteristik urutan atau tingkatan. Artinya, data ini mengandung informasi mengenai ranking atau posisi relatif dari satu kategori terhadap kategori lainnya. Namun, meskipun ada urutan antara kategori, kita tidak bisa menghitung seberapa besar jarak atau perbedaan antara kategori-kategori tersebut.
Data ordinal memiliki kategori seperti nominal, tetapi dengan tambahan sifat urutan atau tingkatan.
Data ordinal sering kita temui dalam kehidupan sehari-hari. Misalnya, ketika menilai sesuatu berdasarkan tingkat kepuasan, kita tidak hanya ingin mengetahui bahwa seseorang puas atau tidak puas, tetapi juga ingin mengetahui bahwa mereka sangat puas, puas, atau tidak puas.
Kendati ada urutan yang jelas (sangat puas → puas → tidak puas), kita tidak dapat mengukur secara pasti seberapa besar perbedaan antara satu kategori dengan kategori lainnya.

Berikut adalah contoh data yang termasuk dalam data ordinal.
- Tingkat Kepuasan Pelanggan: Sangat Puas, Puas, Netral, Tidak Puas, Sangat Tidak Puas.
- Peringkat Lomba: 1, 2, 3 (Urutan peringkat dalam suatu kompetisi).
- Tingkat Pendidikan: SD, SMP, SMA, Sarjana (Urutan berdasarkan tingkat pendidikan).
Sekarang, bayangkan Anda sedang menganalisis data penilaian layanan di sebuah hotel. Pelanggan memberikan rating berdasarkan tiga kategori: Sangat Baik, Baik, dan Buruk. Meskipun tahu urutannya, kita tidak tahu seberapa besar perbedaan antara Sangat Baik dan Baik. Namun, kita tahu bahwa Sangat Baik lebih baik daripada Baik, dan Baik lebih baik daripada Buruk.
Data ordinal acapkali dipakai untuk memahami peringkat atau ranking dari suatu kelompok. Analisis ini sangat berguna dalam banyak kasus, terutama ketika kita perlu mengetahui urutan preferensi atau penilaian subjektif. Namun, perlu diingat bahwa meskipun ada urutan, kita tidak bisa menghitung perbedaan yang jelas atau konsisten antara satu kategori dan kategori lain.
Data Interval
Berbeda dengan data ordinal, data interval memiliki urutan jelas dan jarak yang sama antara kategori-kategori. Data interval adalah data dengan nilai numerik dengan selisih yang bisa diukur, tetapi tidak memiliki nol mutlak. Nol dalam skala interval bukan berarti “tidak ada”, melainkan hanya sebagai titik referensi.
Dalam data interval, kita bisa melakukan operasi penjumlahan dan pengurangan. Artinya, data interval memungkinkan kita untuk menghitung selisih antara kategori-kategori tersebut. Hal ini membuat perbedaan data interval dengan data numerik semakin jelas.
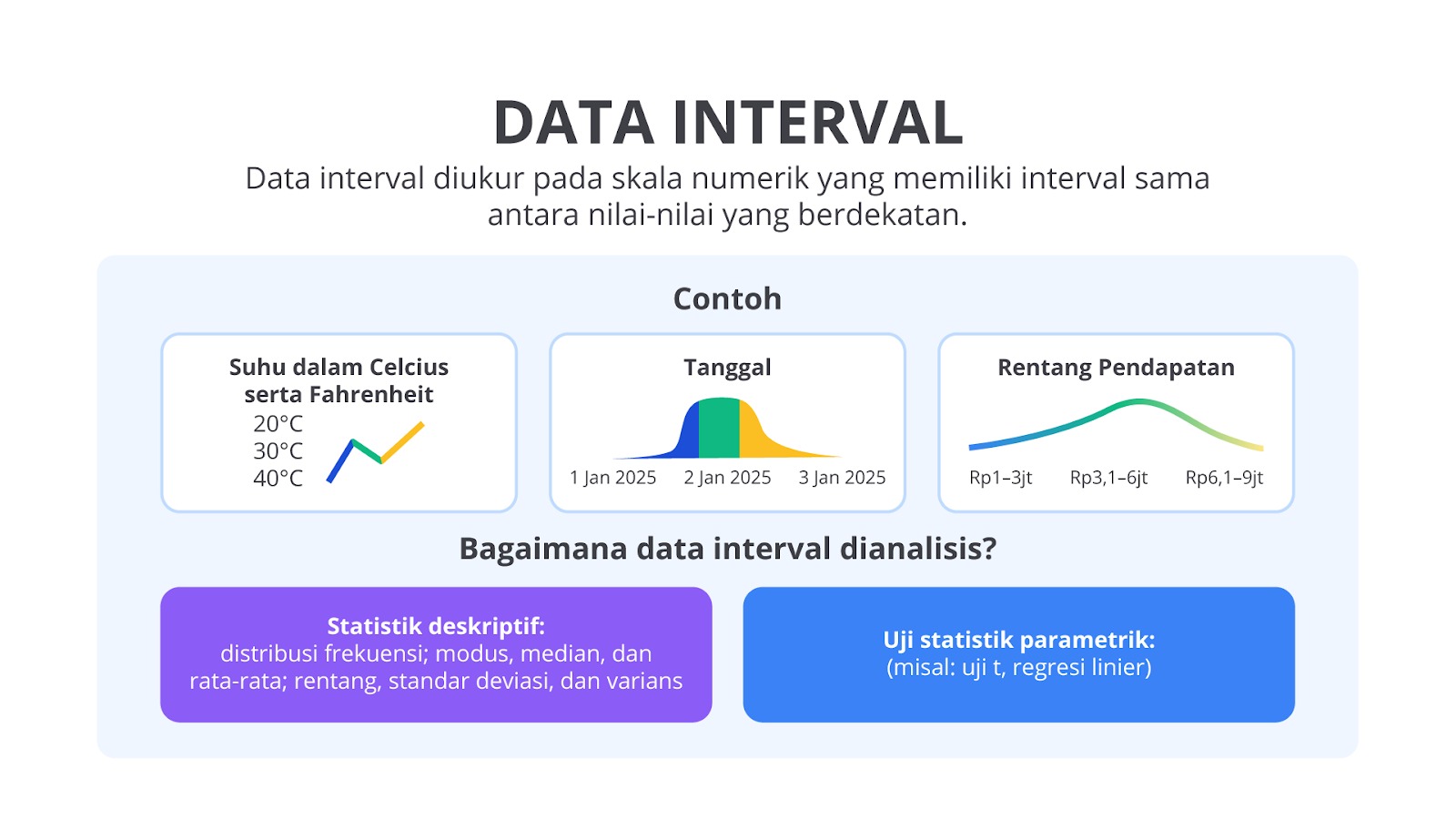
Berikut adalah contoh data yang termasuk data interval.
- Suhu dalam Celcius atau Fahrenheit: 20°C, 30°C, 40°C.
- Tanggal: 1 Januari 2025, 2 Januari 2025, 3 Januari 2025.
Contoh data interval sangat umum ditemukan dalam pengukuran suhu atau tanggal. Bayangkan kalian mengukur suhu di dua tempat berbeda: Kantor A memiliki suhu 22°C dan Kantor B memiliki suhu 28°C. Perbedaan suhu antara kedua tempat tersebut adalah 6°C. Namun, perhatikan bahwa 0°C bukan berarti tidak ada suhu sama sekali, tetapi titik yang lebih rendah dalam skala suhu. Ini adalah ciri khas dari data interval.
Data Rasio
Data rasio adalah jenis data yang memiliki semua karakteristik data interval, tetapi dengan tambahan nol mutlak. Nol mutlak berarti tidak adanya suatu atribut yang diukur. Dengan demikian, perhitungan rasio antara nilai-nilai dalam data ini menjadi bermakna.
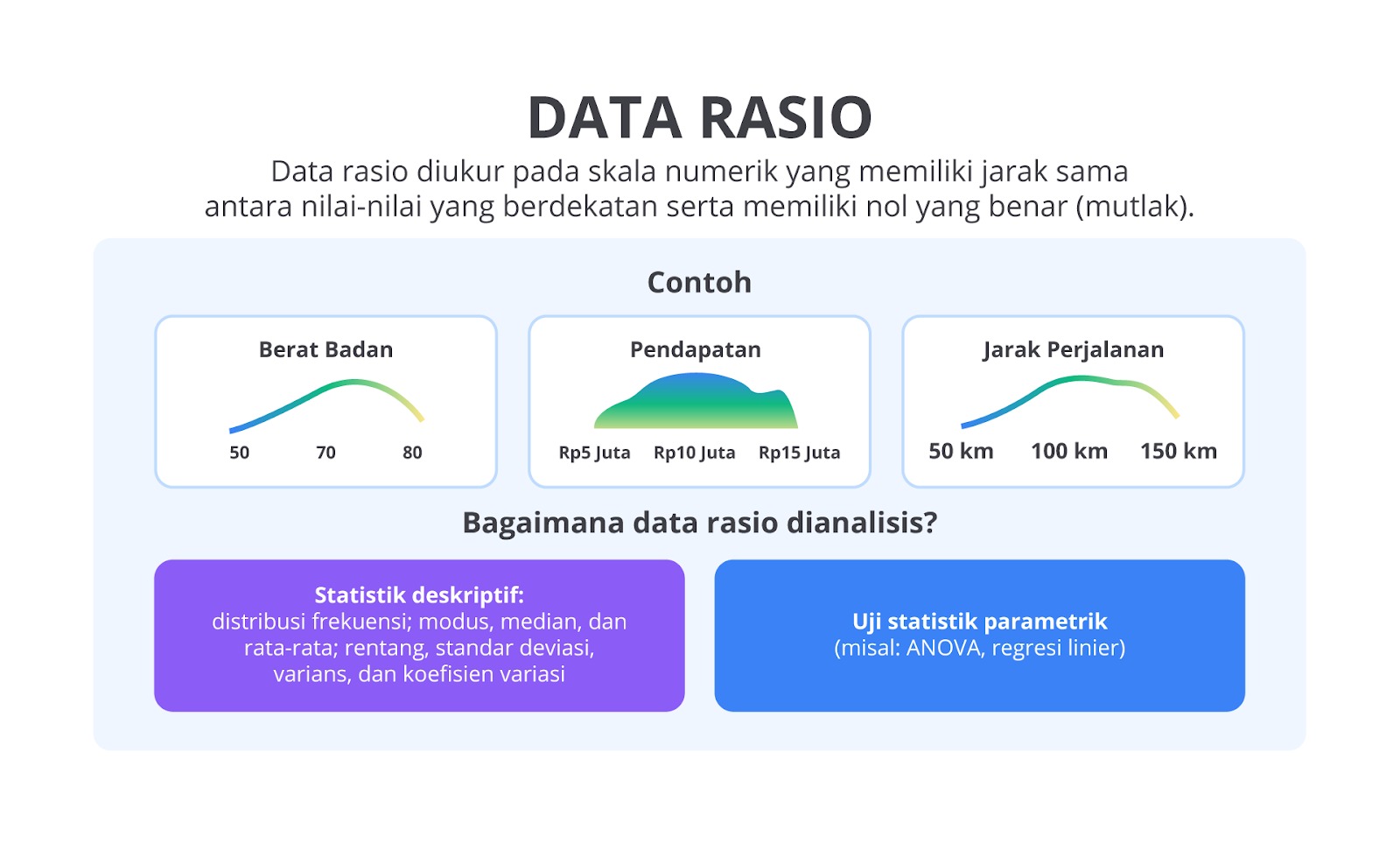
Berikut adalah contoh data yang termasuk data rasio.
- Berat Badan: 50 kg merupakan dua kali lebih berat dari 25 kg.
- Pendapatan: Rp10 juta berarti dua kali lebih besar dari Rp5 juta.
- Jarak Perjalanan: 100 km artinya dua kali lebih jauh dari 50 km.
Data rasio memungkinkan semua operasi matematika dasar, termasuk perkalian dan pembagian, karena nol memiliki arti yang benar-benar menunjukkan ketiadaan suatu nilai. Dengan memahami level pengukuran data ini, kita dapat memilih metode analisis yang sesuai, serta memastikan interpretasi hasil yang akurat dalam studi data science.
Klasifikasi Data Berdasarkan Jumlah Variabel
Dalam data science, kita sering berhadapan dengan dataset yang berisi berbagai informasi. Namun, tidak semua analisis memerlukan jumlah variabel yang sama. Beberapa analisis mungkin hanya berfokus pada satu variabel, sementara lainnya memeriksa hubungan antara banyak variabel sekaligus.
Oleh karena itu, data dapat dikategorikan berdasarkan jumlah variabel yang dianalisis, antara lain data univariat dan data multivariat.
Data Univariat (Satu Variabel)
Data univariat adalah data yang hanya memiliki satu variabel atau satu jenis pengamatan. Dalam analisis data univariat, kita hanya fokus pada satu aspek dari dataset tanpa mempertimbangkan hubungan antarvariabel lainnya.
Bayangkan kita ingin menganalisis tinggi badan siswa di sebuah kelas. Jika kita hanya menghitung rata-rata tinggi badan, median, standar deviasi, atau menampilkan distribusinya dalam histogram, itu termasuk analisis univariat.
Berikut adalah contoh penggunaan dari data univariat.
- Tinggi Badan Siswa dalam Satu Kelas: Kita hanya menganalisis tinggi badan tanpa mempertimbangkan faktor lain, seperti berat badan atau usia.
- Jumlah Pelanggan di Toko per Hari: Kita hanya melihat jumlah pelanggan setiap hari tanpa memperhitungkan faktor lain, seperti cuaca atau hari kerja.
- Nilai Ujian Matematika Siswa: Kita hanya berfokus pada distribusi nilai ujian tanpa mempertimbangkan mata pelajaran lain.
Data Multivariat (Banyak Variabel)
Data multivariat adalah data dengan lebih dari satu variabel yang diukur atau diamati dalam satu waktu. Dalam analisis multivariat, kita tidak hanya melihat satu variabel, tetapi juga menganalisis hubungan antarvariabel untuk menemukan pola atau korelasi.
Sebagai contoh, bila ingin memahami faktor-faktor yang memengaruhi berat badan siswa, kita tidak hanya melihat berat badan saja, tetapi juga tinggi badan, usia, dan pola makan. Dengan melihat lebih dari satu variabel, kita bisa menemukan pola hubungan antara faktor-faktor tersebut.
Dengan kata lain, data univariat hanya berfokus pada satu variabel, sedangkan data multivariat mempertimbangkan lebih dari satu variabel sekaligus. Ini memungkinkan kita untuk memahami hubungan antarfaktor yang berbeda.
Dalam analisisnya, kita bisa menggunakan scatter plot untuk melihat hubungan antara tinggi dan berat atau menggunakan regresi linear dalam memahami hubungan antara variabel-variabel tersebut.
Berikut adalah contoh penggunaan dari data multivariat.
- Menganalisis Hubungan antara Tinggi Badan, Berat Badan, dan Umur Siswa: Dengan membandingkan ketiga variabel ini, kita bisa mengetahui bahwa siswa yang lebih tinggi cenderung memiliki berat badan lebih besar.
- Meneliti Faktor Pengaruh Pendapatan Seseorang: Faktor seperti usia, tingkat pendidikan, dan pengalaman kerja bisa dianalisis bersama untuk memahami bahwa hal-hal tersebut memengaruhi pendapatan seseorang.
- Analisis Pola Belanja Pelanggan: Data yang mencakup usia pelanggan, preferensi produk, dan jumlah pembelian dapat digunakan untuk memprediksi kebiasaan belanja di masa depan.
Memahami perbedaan ini sangat penting dalam data science karena metode analisis yang digunakan akan berbeda tergantung pada jumlah variabel yang terlibat. Analisis univariat digunakan untuk memahami karakteristik individu suatu variabel, sedangkan analisis multivariat digunakan untuk memahami keterkaitan antarvariabel yang dapat digunakan dalam model prediktif dan pengambilan keputusan.
Data Kategorikal Univariat
Pernahkah kalian mengisi survei online yang menanyakan jenis kelamin, preferensi makanan, atau metode pembayaran favorit? Atau mungkin kalian pernah melihat laporan bisnis yang menampilkan kategori produk paling laris di toko online? Semua informasi ini adalah contoh dari data kategorikal.
Apa Itu Data Kategorikal?
Data kategorikal adalah jenis data berisi kategori atau label, bukan angka yang bisa dihitung secara matematis. Data ini kerap digunakan untuk mengelompokkan objek atau individu berdasarkan karakteristik tertentu, seperti warna, jenis kelamin, preferensi makanan, status pekerjaan, atau metode pembayaran.
Data kategorikal univariat berarti data yang bersifat kategorikal dan hanya memiliki satu variabel atau satu jenis pengamatan. Dalam analisis data kategorikal univariat, kita hanya fokus pada satu aspek dari dataset tanpa mempertimbangkan hubungan antarvariabel lainnya. Pada materi kali ini, data-data yang disajikan dan dijelaskan hanya yang bersifat univariat atau satu variabel.
Dalam data science, memahami jenis data kategorikal amat penting karena menentukan cara kita menganalisis, memvisualisasikan, dan menarik kesimpulan dari data. Tanpa pemahaman yang baik, kita bisa salah dalam memilih metode analisis atau mengambil keputusan.
Berbeda dari data kuantitatif yang bisa dihitung rata-ratanya, data kategorikal lebih sering dianalisis dengan menghitung frekuensinya dan melihat distribusi kategori dalam dataset.
Misalnya, jika ingin mengetahui metode pembayaran yang paling sering digunakan pelanggan di sebuah toko, kita tidak bisa menghitung “tunai + e-wallet”, tetapi kita bisa melihat jumlah pelanggan yang menggunakan masing-masing metode pembayaran. Inilah alasan teknik representasi data kategorikal sangat penting dan akan kita bahas lebih lanjut dalam bagian berikutnya.
Representasi Data Kategorikal
Di dunia data science, data kategorikal harus direpresentasikan dengan baik agar bisa dianalisis dan digunakan dalam berbagai model. Berbeda dengan data kuantitatif yang bisa dihitung langsung dalam bentuk angka, data kategorikal sering kali berbentuk label atau kategori sehingga perlu diorganisasi dengan format yang lebih mudah dibaca dan diproses.
Beberapa metode umum untuk merepresentasikan data kategorikal adalah tabel frekuensi, cross tabulation (tabulasi silang), dan encoding data kategorikal. Setiap metode memiliki kegunaan berbeda tergantung pada konteks analisis yang dilakukan.
Tabel Frekuensi
Salah satu cara paling sederhana untuk merepresentasikan data kategorikal adalah dengan tabel frekuensi. Tabel ini menunjukkan berapa kali setiap kategori muncul dalam dataset sehingga kita bisa memahami distribusi data secara lebih jelas.
Sebagai contoh, bayangkan kita memiliki data tentang preferensi minuman dari 200 pelanggan di sebuah kafe. Data ini bisa kita susun dalam bentuk tabel frekuensi sebagai berikut.
| Minuman | Frekuensi (Jumlah Pelanggan) |
|---|---|
| Kopi | 80 |
| Teh | 70 |
| Jus | 50 |
Dari tabel ini, kita dapat dengan cepat melihat bahwa kopi adalah minuman yang paling banyak dipilih, sementara jus adalah yang paling sedikit diminati. Informasi ini bisa digunakan oleh pemilik kafe untuk menentukan stok minuman atau strategi pemasaran yang lebih efektif.
Tabel frekuensi sering digunakan dalam analisis eksplorasi data karena sangat sederhana, tetapi cukup informatif. Kita juga bisa menambahkan persentase pada tabel untuk melihat distribusi data dalam skala yang lebih proporsional.
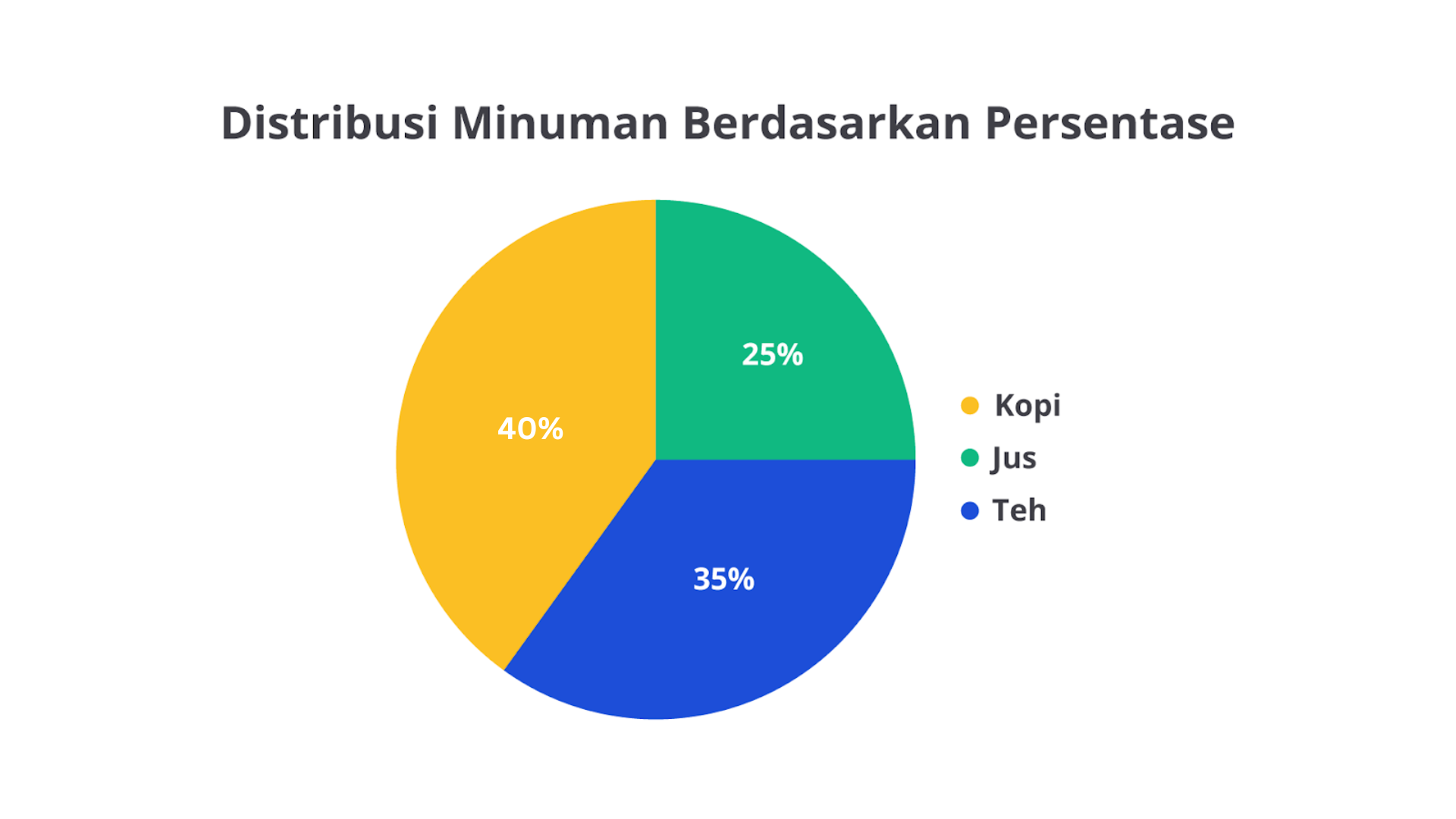
Contoh tabel frekuensi yang dilengkapi persentase.
| Minuman | Frekuensi | Persentase (%) |
|---|---|---|
| Kopi | 80 | 40% |
| Teh | 70 | 35% |
| Jus | 50 | 25% |
Dengan tabel ini, kita bisa melihat bahwa 40% pelanggan memilih kopi, 35% memilih teh, dan 25% memilih jus. Ini memberikan perspektif yang lebih jelas tentang proporsi setiap kategori dalam keseluruhan dataset.
Cross Tabulation (Tabulasi Silang)
Tabel frekuensi hanya menunjukkan distribusi satu variabel kategorikal. Namun, dalam banyak kasus, kita ingin mengetahui interaksi dua atau lebih variabel kategorikal antara satu dengan yang lain. Untuk keperluan ini, kita menggunakan cross tabulation atau tabel kontingensi.
Cross tabulation membantu kita melihat hubungan antarkategori dalam dua variabel, misalnya hubungan antara jenis kelamin pelanggan dan preferensi minuman.
Sebagai contoh, jika ingin mengetahui adakah perbedaan preferensi minuman antara laki-laki dan perempuan di kafe yang sama, kita bisa menyusun tabel seperti berikut.
| Jenis Kelamin | Kopi | Teh | Jus | Total |
|---|---|---|---|---|
| Laki-laki | 40 | 30 | 20 | 90 |
| Perempuan | 40 | 40 | 30 | 110 |
| Total | 80 | 70 | 50 | 200 |
Tabel ini memberi kita wawasan tambahan. Kita bisa melihat bahwa jumlah pelanggan laki-laki dan perempuan yang memilih kopi hampir sama (40 orang dalam masing-masing kelompok), tetapi perempuan lebih cenderung memilih teh dibandingkan laki-laki.
Dalam analisis statistik, kita sering menggunakan uji Chi-Square untuk mengukur jika ada hubungan yang signifikan antara dua variabel dalam tabel kontingensi seperti ini. Jika hasil uji statistik menunjukkan hubungan yang signifikan, kita bisa menyimpulkan bahwa jenis kelamin memengaruhi preferensi minuman.
Encoding Data Kategorikal
Dalam banyak kasus, terutama dalam machine learning, kita perlu mengubah data kategorikal menjadi format numerik agar bisa diproses oleh algoritma. Ini disebut sebagai encoding data kategorikal. Ada beberapa metode encoding yang umum digunakan, yaitu one-hot encoding dan label encoding.
Label Encoding
Label encoding adalah teknik lain yang digunakan untuk mengonversi data kategorikal menjadi format numerik. Teknik ini memberikan setiap kategori label numerik yang unik. Label encoding mengonversi kategori menjadi angka, yang berguna ketika kategori memiliki urutan masuk akal atau memiliki skala tertentu.
Misalkan kita memiliki data Metode Pembayaran sebagai berikut.
- Tunai
- Kartu Kredit
- E-Wallet
Dengan label encoding, data akan diubah menjadi angka, seperti berikut.
| Metode Pembayaran | Metode Pembayaran Encoded | |
| 0 | Tunai | 2 |
| 1 | Kartu Kredit | 1 |
| 2 | E-Wallet | 0 |
Pada tabel ini, setiap kategori diubah menjadi angka yang unik. Dalam contoh ini,
- “E-Wallet” diberikan label 0,
- “Kartu Kredit” diberikan label 1, dan
- “Tunai” diberikan label 2.
Label encoding sering digunakan ketika kategori memiliki urutan tertentu yang relevan dengan analisis. Misalnya, jika data kategorikal berisi nilai peringkat atau skala (misalnya “Rendah”, “Sedang”, “Tinggi”), label encoding dapat digunakan untuk mewakili hubungan urutan tersebut.
One-Hot Encoding
One-hot encoding adalah teknik untuk mengonversi data kategorikal menjadi format numerik yang dapat diproses oleh algoritma machine learning. Teknik ini bekerja dengan membuat kolom baru untuk setiap kategori pada variabel kategorikal dan memberi nilai 1 jika data termasuk kategori tersebut serta 0 jika tidak.
| Metode Pembayaran E-Wallet | Metode Pembayaran Kartu Kredit | Metode Pembayaran Tunai | |
| 0 | False | False | True |
| 1 | False | True | False |
| 2 | True | False | False |
Pada tabel di atas, kita membuat tiga kolom baru, masing-masing untuk “Tunai”, “Kartu Kredit”, dan “E-Wallet”. Setiap baris akan memiliki nilai 1 pada kolom sesuai dengan kategori yang ada dan nilai 0 pada kolom lainnya.
One-hot encoding sangat berguna ketika kategori tidak memiliki urutan atau hubungan numerik antara satu dan yang lain. Misalnya, kategori “Kartu Kredit”, “E-Wallet”, dan “Tunai” tidak memiliki urutan yang pasti sehingga encoding ini sangat tepat untuk digunakan.
Visualisasi Data Kategorikal dalam Data Science
Di dunia data science, memahami data tidak cukup hanya dengan melihat angka dalam tabel. Visualisasi adalah salah satu cara terbaik untuk memahami pola, tren, dan distribusi dalam data, terutama ketika kita bekerja dengan data kategorikal.
Data kategorikal sering kali berupa label atau kategori, bukan angka. Ini membuatnya lebih sulit untuk ditafsirkan secara langsung dibandingkan data kuantitatif. Oleh karena itu, kita memerlukan teknik visualisasi yang tepat agar bisa dengan mudah menganalisis pola, membandingkan kategori, dan menemukan insight tersembunyi dalam data kategorikal.
Dalam materi ini, kita akan membahas beberapa jenis visualisasi yang paling umum digunakan untuk data kategorikal, yaitu bar chart, pie chart, dan pareto chart. Setiap metode memiliki keunggulan dan penggunaannya masing-masing tergantung pada tujuan analisis yang ingin kita capai.
Bar Chart: Menampilkan Perbandingan Kategori Secara Jelas
Salah satu cara paling populer untuk merepresentasikan data kategorikal adalah bar chart atau diagram batang. Pada grafik ini, setiap kategori direpresentasikan oleh sebuah batang dan tinggi batang menunjukkan frekuensi atau jumlah kemunculan kategori tersebut dalam dataset.
Mari kita ambil contoh kasus seorang pemilik restoran yang ingin memahami jenis makanan yang paling sering dipesan oleh pelanggan. Ia memiliki data jumlah pesanan untuk empat kategori makanan utama.
| Kategori Makanan | Jumlah Pesanan |
|---|---|
| Makanan Cepat Saji | 450 |
| Makanan Sehat | 300 |
| Dessert | 250 |
| Minuman | 500 |
Jika data ini disajikan dalam bentuk bar chart, pemilik restoran dapat dengan cepat melihat bahwa minuman dan makanan cepat saji adalah kategori paling populer, sedangkan dessert memiliki jumlah pesanan paling sedikit.
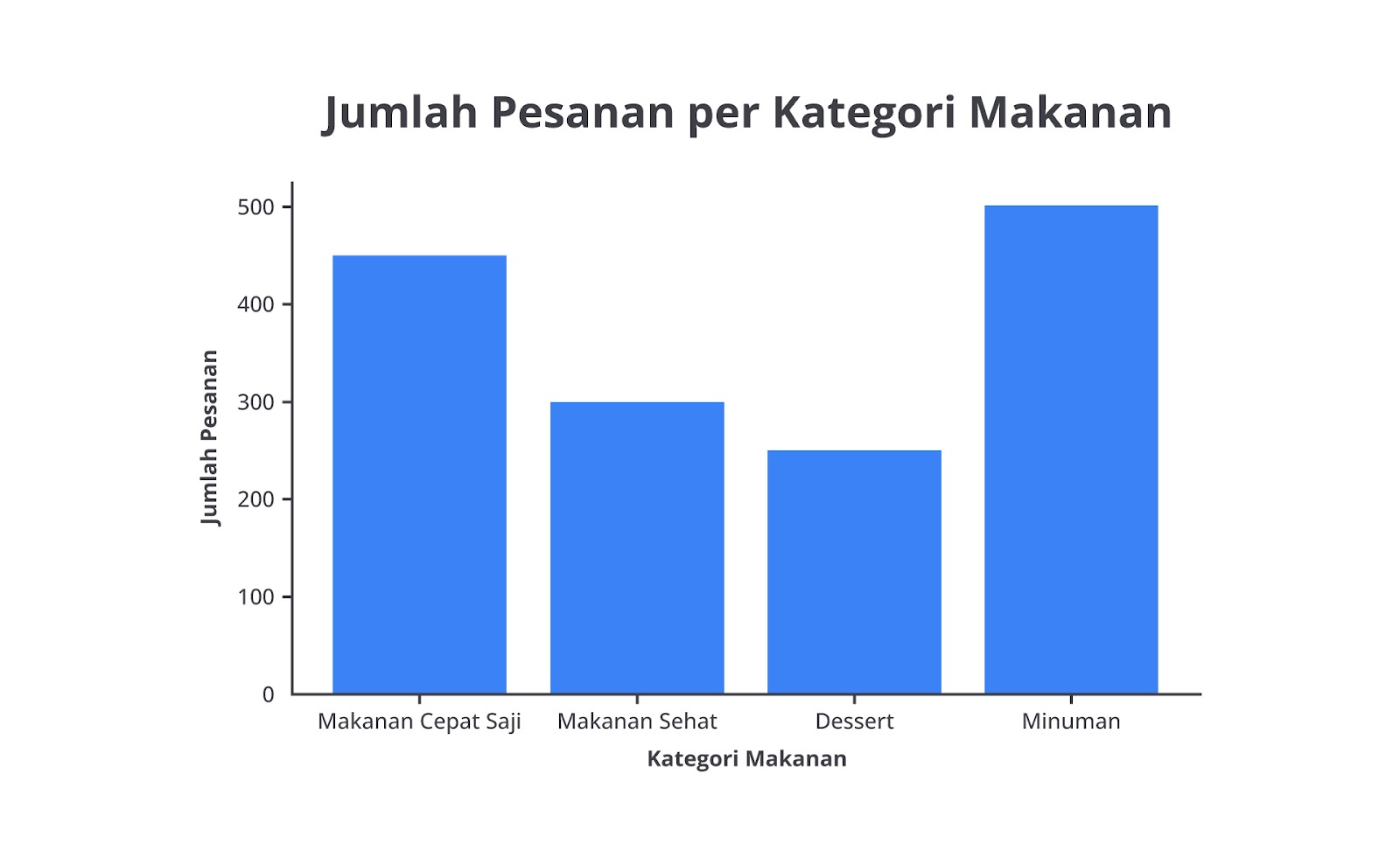
Dengan informasi ini, ia bisa memutuskan untuk meningkatkan promosi pada menu dessert atau menambah variasi dalam menu makanan sehat.
Pie Chart: Memahami Proporsi Antarkategori
Pie chart atau diagram lingkaran sangat berguna ketika kita ingin melihat proporsi antar kategori dalam dataset. Setiap bagian dalam pie chart mewakili persentase suatu kategori terhadap total data.
Sebagai contoh, bayangkan sebuah supermarket yang ingin menganalisis metode pembayaran yang digunakan oleh pelanggan dalam satu bulan. Data yang dikumpulkan menunjukkan bahwa dari 1.000 transaksi yang terjadi ditemukan sebagai berikut.
- 500 transaksi menggunakan e-wallet.
- 300 transaksi menggunakan kartu kredit.
- 200 transaksi menggunakan tunai.
Apabila informasi di atas disajikan dalam bentuk tabel, hasilnya berikut.
| Metode Pembayaran | Jumlah Transaksi |
|---|---|
| E-Wallet | 500 |
| Kartu Kredit | 300 |
| Tunai | 200 |
Dalam bentuk tabel, data ini mungkin sulit untuk ditafsirkan dengan cepat. Sekarang, coba kita sajikan dalam bentuk pie chart.
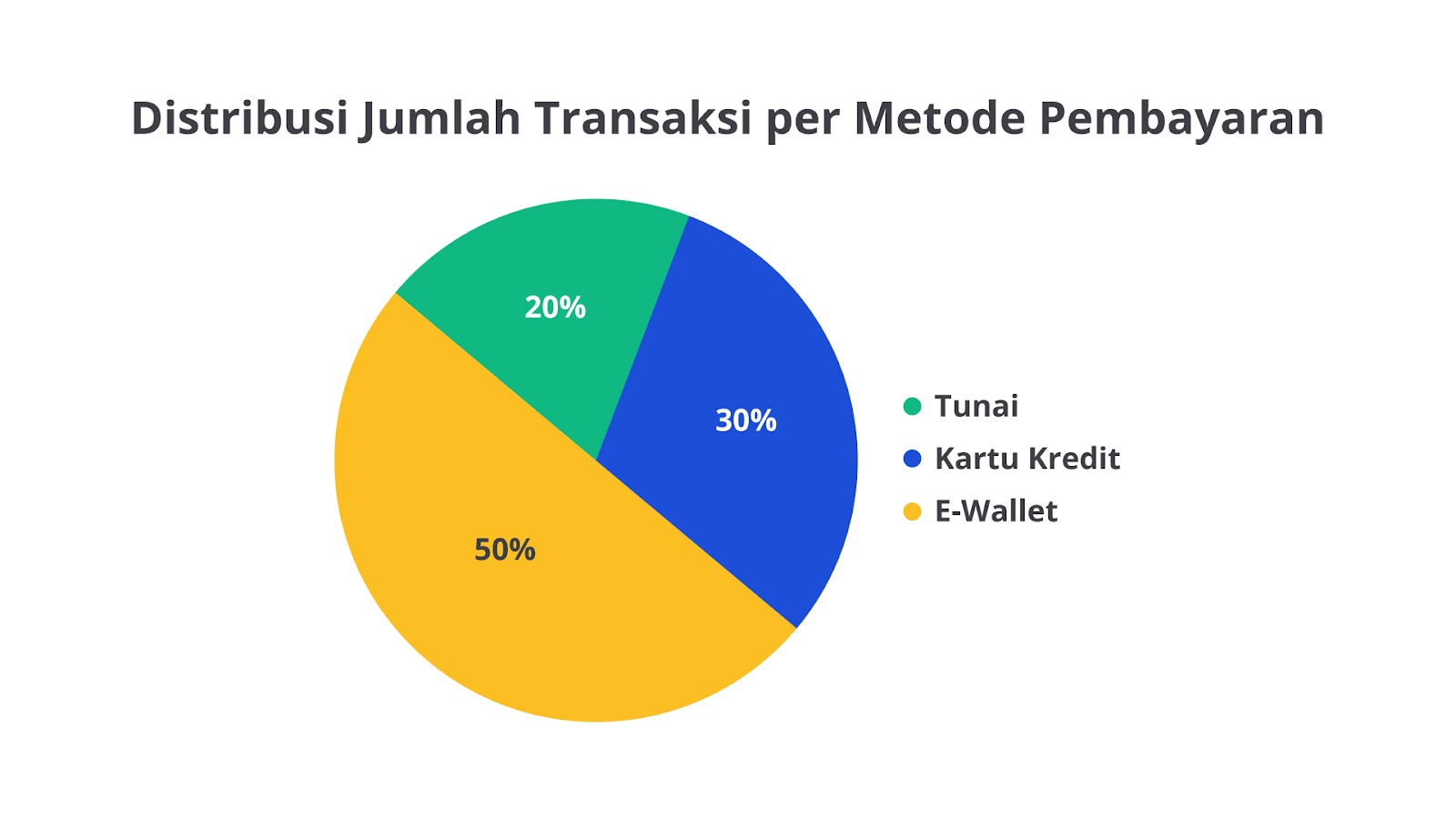
Namun, ketika disajikan dalam pie chart, manajer supermarket bisa langsung melihat bahwa e-wallet mendominasi metode pembayaran dengan 50% dari total transaksi. Informasi ini bisa digunakan untuk meningkatkan promosi melalui cashback pada pembayaran dengan e-wallet atau menambahkan metode pembayaran digital lainnya.
Pareto Chart: Mengidentifikasi Faktor yang Paling Berpengaruh
Pareto chart adalah kombinasi antara bar chart dan line chart untuk menentukan kategori yang memiliki dampak terbesar dalam suatu analisis. Metode ini berdasarkan prinsip Pareto (80/20), yang menyatakan bahwa 80% dari efek biasanya berasal dari 20% penyebab utama.
Sebagai contoh, bayangkan sebuah perusahaan e-commerce ingin mengidentifikasi alasan utama pelanggan mengajukan keluhan atau komplain terhadap layanan mereka. Setelah mengumpulkan data selama tiga bulan, mereka menemukan lima kategori utama keluhan pelanggan sebagai berikut.
| Jenis Keluhan | Jumlah Keluhan |
|---|---|
| Keterlambatan Pengiriman | 400 |
| Produk Tidak Sesuai | 350 |
| Layanan Pelanggan Lambat | 150 |
| Kesalahan Pembayaran | 75 |
| Kualitas Produk Buruk | 50 |
Jika data ini hanya disajikan dalam tabel, mungkin sulit untuk mengetahui kategori yang harus diprioritaskan dalam perbaikan layanan. Namun, dengan Pareto chart, kita bisa melihat bahwa hanya dua kategori utama, yaitu “Keterlambatan Pengiriman” dan “Produk Tidak Sesuai” yang menyumbang hampir 75% dari total keluhan.
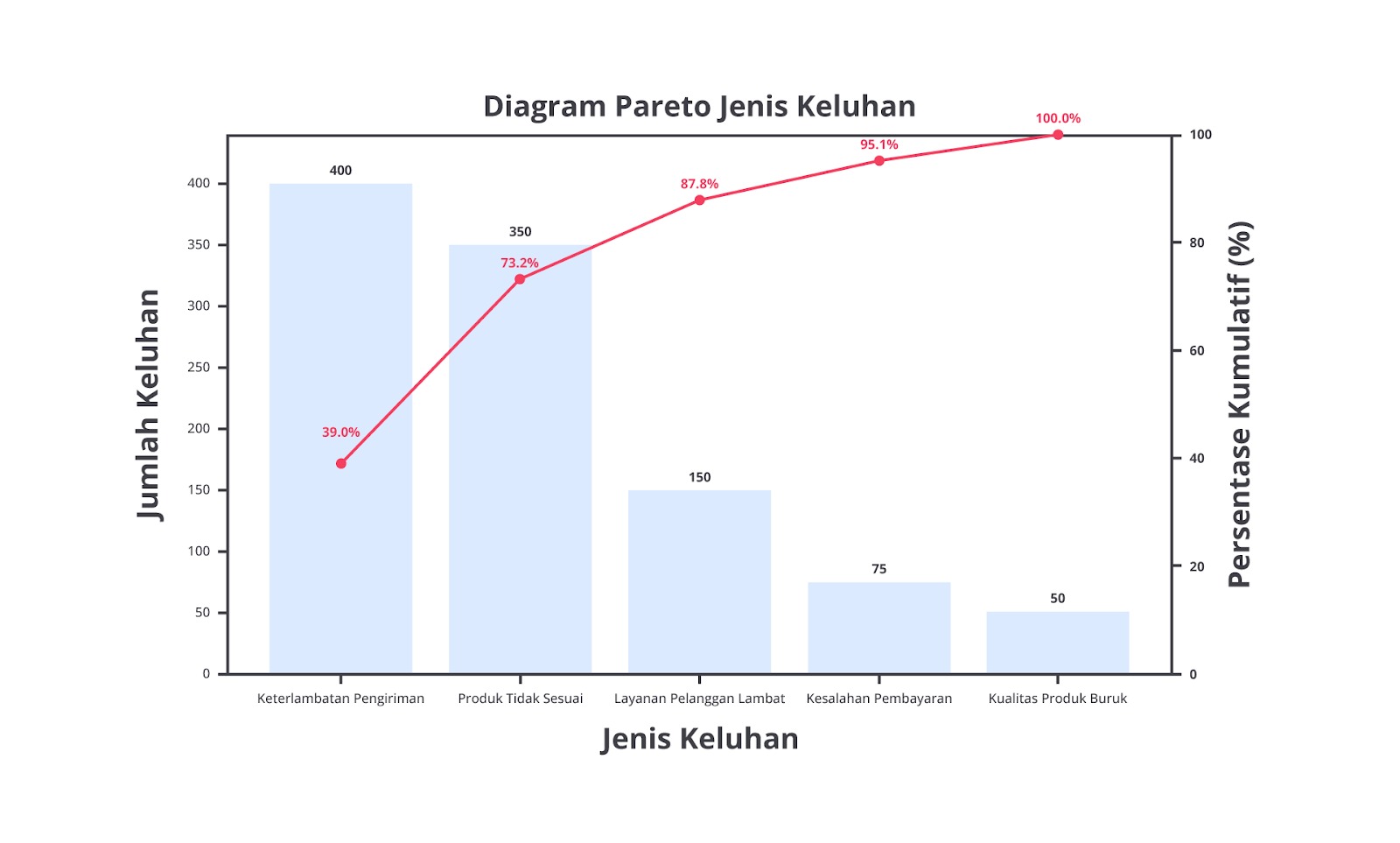
Melalui insight ini, perusahaan dapat segera fokus pada meningkatkan kecepatan pengiriman dan memastikan produk sesuai dengan deskripsi di laman web–karena perbaikan dalam dua aspek ini akan menyelesaikan mayoritas keluhan pelanggan.
Ukuran Kecenderungan Data Kategorikal
Dalam data kuantitatif, kita sering menggunakan mean atau median sebagai ukuran kecenderungan sentral. Namun, dalam data kategorikal, ukuran kecenderungan yang paling umum digunakan adalah modus (mode). Modus adalah kategori yang paling sering muncul dalam suatu dataset.
Contohnya, jika data warna favorit sebagai berikut: Merah, biru, biru, hijau, merah, biru, kuning, merah, biru, biru.
Modus dari data tersebut adalah biru–karena warna ini muncul paling banyak dibandingkan yang lain.
Modus sangat berguna dalam berbagai analisis, misalnya dalam memahami preferensi pelanggan atau tren pasar.
Data kategorikal memainkan peran penting pada analisis data, terutama ketika memahami distribusi kategori dan tren dalam dataset. Dengan memahami cara merepresentasikan dan memvisualisasikan data kategorikal, kita dapat mengambil keputusan yang lebih baik dalam berbagai bidang, seperti pemasaran, riset pelanggan, serta analisis sosial.
Data Kuantitatif Univariat: Pengantar
Dalam dunia data science, angka bukan sekadar angka. Di balik setiap nilai numerik, ada informasi penting yang bisa mengungkap pola, perilaku, hingga prediksi. Data kuantitatif menjadi fondasi utama dalam banyak analisis data, mulai dari statistik deskriptif sederhana hingga model prediktif yang kompleks.
Pada submodul ini, kita akan menyelami berbagai aspek penting dari data kuantitatif. Kita akan memulai dengan memahami bahwa pemusatan data, seperti rata-rata, median, dan modus memberi gambaran umum dari data. Lalu, kita akan mempelajari penyebaran data, seperti variansi dan standar deviasi yang menunjukkan seberapa bervariasi nilai-nilai tersebut.
Tak hanya itu, kita juga akan membahas bahwa standardisasi dan normalisasi membantu untuk membandingkan data dari skala berbeda agar bisa dianalisis secara adil dan objektif. Kita juga akan mengenali berbagai bentuk distribusi data dan memahami pentingnya mengenali distribusi tersebut dalam proses analisis.
Akhirnya, kita akan melihat bahwa konsep distribusi probabilitas tidak hanya menjadi teori matematika, tetapi juga berperan nyata pada banyak aplikasi data science, seperti dalam model prediksi cuaca, rekomendasi produk, hingga deteksi anomali.
Dengan pemahaman kuat tentang data kuantitatif, Anda akan memiliki fondasi analitis yang kokoh dalam perjalananmu sebagai data scientist. Mari kita mulai!
Data Kuantitatif Univariat: Pengertian
Data kuantitatif adalah jenis data yang bisa dihitung dan diukur. Data ini berbentuk angka dan bisa digunakan pada berbagai analisis statistik untuk mendapatkan wawasan yang lebih dalam. Contoh umum dari data kuantitatif meliputi tinggi badan, berat badan, suhu, jumlah pelanggan, pendapatan bulanan, dan nilai ujian.
Data kuantitatif univariat berarti data yang bersifat kuantitatif dan hanya memiliki satu variabel atau satu jenis pengamatan. Dalam materi kali ini, data-data yang disajikan dan dijelaskan hanya yang bersifat univariat atau satu variabel.
Berbeda dengan data kategorikal yang hanya mengelompokkan objek dalam kategori, data kuantitatif memungkinkan kita melakukan berbagai perhitungan, seperti mencari rata-rata, mengukur penyebaran data, serta memahami pola distribusi. Dalam analisis data, pemahaman mengenai ukuran pemusatan, ukuran penyebaran, standardisasi, normalisasi, serta distribusi data menjadi sangat penting.
Data Kuantitatif Univariat: Ukuran Pemusatan Data
Ketika bekerja dengan data kuantitatif, kita sering ingin mengetahui cara data tersebut tersebar dan adakah nilai khas yang mewakili dataset tersebut. Dalam kehidupan sehari-hari, kita sering mendengar istilah seperti rata-rata nilai ujian siswa, median pendapatan masyarakat, atau mode warna mobil yang paling sering dibeli.
Semua istilah tersebut adalah bagian dari ukuran pemusatan data (central tendency), yaitu metode untuk menemukan nilai yang mewakili pusat atau titik tengah dari suatu distribusi data. Ini membantu dalam memahami nilai yang mewakili mayoritas data.
Dalam statistik, ada tiga ukuran pemusatan data utama yang digunakan.
- Mean (rata-rata), yakni nilai rata-rata dari sekumpulan angka.
- Median (nilai tengah), yakni angka yang berada tepat di tengah ketika data diurutkan.
- Mode (Modus), yakni angka yang paling sering muncul dalam dataset.
Setiap ukuran memiliki kegunaan masing-masing, tergantung pada sifat data dan tujuan analisis. Mari kita bahas satu per satu dengan lebih mendalam!
Mean (Rata-Rata): Menghitung Nilai Tengah Data
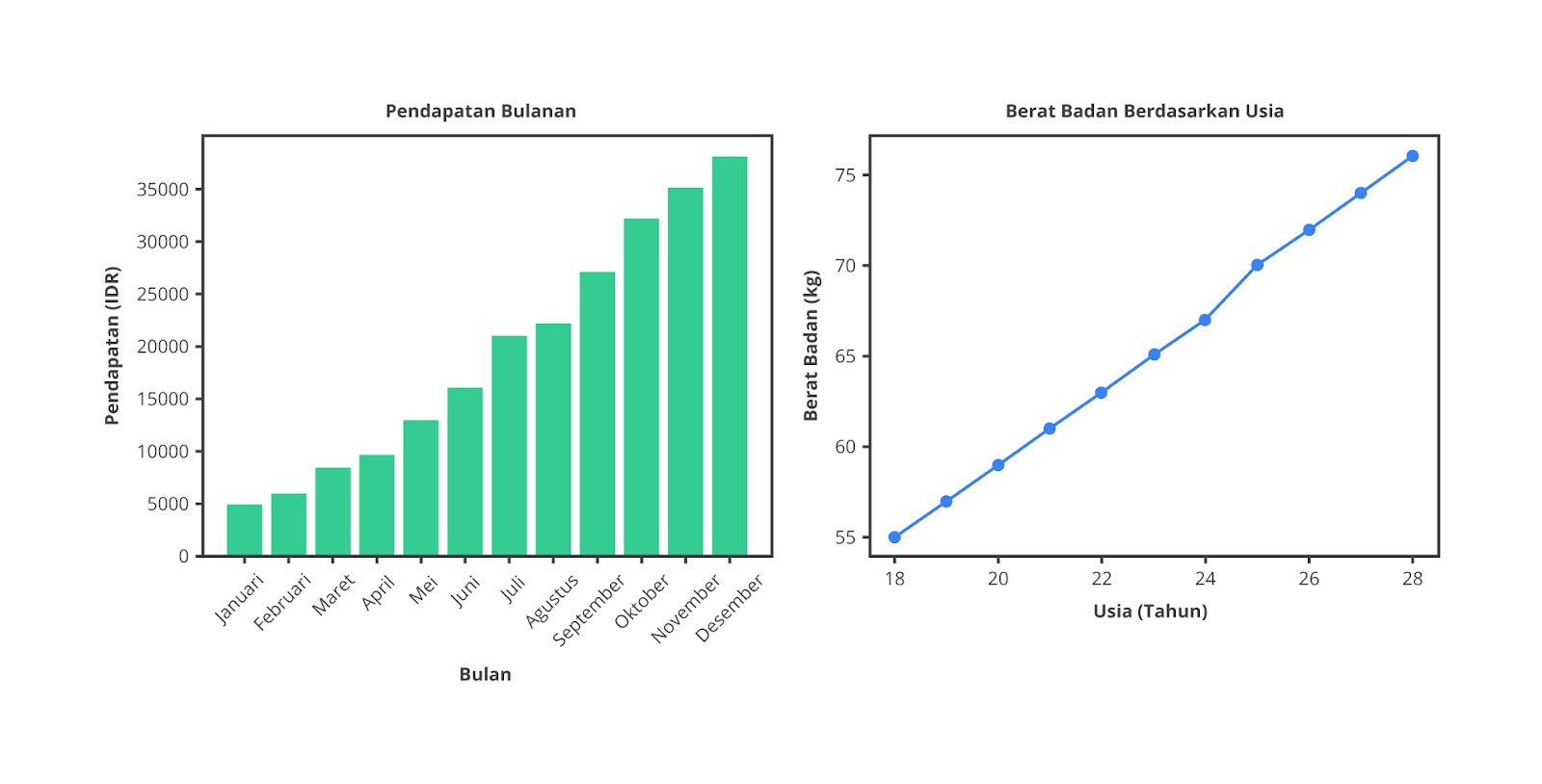
Mean atau rata-rata adalah jumlah semua nilai dalam dataset dibagi dengan jumlah total data. Mean sangat berguna ketika kita ingin mengetahui nilai rata-rata dari sekumpulan angka. Mean adalah ukuran pemusatan yang paling sering digunakan pada analisis data karena memberikan gambaran umum tentang nilai tipikal dalam dataset.

Ketika seseorang berbicara tentang nilai rata-rata suatu data, mereka biasanya merujuk pada mean. Sebagai contoh, bayangkan seorang guru ingin mengetahui rata-rata nilai ujian dari 5 siswa di kelasnya. Nilai mereka adalah sebagai berikut: 80, 85, 90, 75, dan 95.
Untuk menghitung mean, kita perlu menjumlahkan semua nilai terlebih dahulu.
80 + 85 + 90 + 75 + 95 = 425
Kemudian, kita membagi jumlah total nilai tersebut dengan jumlah siswa.
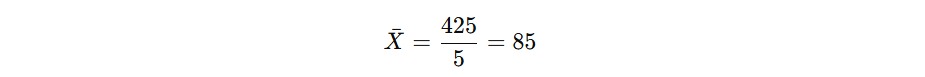
Jadi, rata-rata nilai ujian siswa di kelas tersebut adalah 85.
Mean sering digunakan pada bidang keuangan, sains, dan bisnis untuk memahami tren umum dalam dataset. Namun, ada satu kelemahan utama dari mean: sensitif terhadap outlier (nilai yang jauh lebih besar atau lebih kecil dari mayoritas data).
Jika ada satu nilai sangat besar atau sangat kecil dibandingkan yang lain, rata-rata bisa menjadi tidak akurat. Misalnya, apabila ada satu siswa yang mendapat nilai 20, mean akan turun secara drastis, meskipun sebagian besar siswa mendapatkan nilai tinggi.
Median (Nilai Tengah): Mencari Titik Tengah Data
Median adalah nilai yang berada di tengah dalam urutan dataset (dari yang terkecil ke terbesar). Perhitungan median ditentukan dari jumlah data yang dimiliki, ganjil atau genap. Jika kita memiliki dataset dengan jumlah angka ganjil, median adalah angka yang berada tepat di tengah. Namun, jika jumlah angka genap, median dihitung sebagai rata-rata dari dua angka tengah.

Mari kita simulasikan. Katakanlah kita memiliki dataset berisi nilai siswa sebagai berikut.
75, 80, 85, 90, 95
Langkah pertama adalah memastikan data diurutkan dari kecil ke besar. Jika jumlah data ganjil (5 angka), median adalah angka pada urutan tengah, yaitu 85.
Contoh lain, anggap saja kita memiliki dataset berisi nilai siswa yang terdiri dari enam angka sebagai berikut.
75, 80, 85, 90, 95, 100
Jika data tersebut genap (terdiri dari enam angka), median dihitung dengan mengambil rata-rata dari dua angka di tengah.
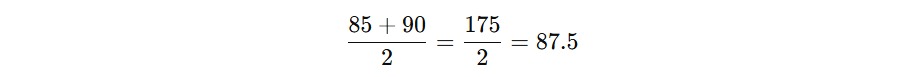
Jadi, median dalam dataset ini adalah 87.5.
Median adalah ukuran pemusatan yang lebih stabil terhadap outlier dibandingkan mean. Ini sangat berguna dalam situasi saat data memiliki outlier atau distribusi yang tidak simetris.
Misalnya, dalam analisis pendapatan masyarakat, biasanya ada segelintir orang yang memiliki pendapatan sangat tinggi, sementara mayoritas orang memiliki pendapatan lebih rendah. Dalam kasus ini, median lebih akurat dibandingkan mean karena tidak terpengaruh oleh individu dengan pendapatan ekstrem.
Mode (Modus): Mencari Nilai yang Paling Sering Muncul
Mode atau modus adalah nilai yang paling sering muncul dalam dataset. Modus digunakan terutama dalam data kategorikal, tetapi juga bisa berlaku dalam data kuantitatif.
Berbeda dengan mean dan median yang selalu memiliki satu nilai unik, sebuah dataset bisa memiliki satu mode, lebih dari satu mode, atau bahkan tidak memiliki mode sama sekali.
Misalkan kita memiliki dataset nilai ujian berikut.
80, 85, 85, 90, 95, 85, 100
Angka 85 muncul sebanyak 3 kali, lebih sering daripada angka lainnya, maka modus dalam dataset ini adalah 85. Karena mode pada dataset tersebut hanya satu, itu disebut unimodal.
Dalam beberapa kasus, ada dataset yang memiliki lebih dari satu mode. Contohnya berikut.
75, 80, 85, 85, 90, 90, 95
Karena 85 dan 90 muncul masing-masing dua kali, dataset ini memiliki dua modus: 85 dan 90. Ada dua angka yang muncul dengan frekuensi sama maka dataset tersebut disebut bimodal.
Mode sangat berguna dalam data kategorikal atau data diskret, misalnya dalam survei pelanggan. Jika kita mengumpulkan data tentang warna mobil paling populer di jalan raya, mode akan menunjukkan warna yang paling sering dipilih oleh konsumen.
Kapan Menggunakan Mean, Median, atau Mode?
Ketiga ukuran pemusatan ini memiliki keunggulan dan kelemahan masing-masing. Tabel berikut menunjukkan perbandingan singkat.
| Ukuran Pemusatan | Kelebihan | Kekurangan | Kapan Digunakan? |
|---|---|---|---|
| Mean (Rata-Rata) | Mudah dihitung, mewakili seluruh data. | Sensitif terhadap outlier. | Jika data simetris tanpa outlier. |
| Median (Nilai Tengah) | Tidak terpengaruh oleh outlier. | Tidak mempertimbangkan semua angka dalam dataset. | Jika data memiliki outlier atau distribusi miring. |
| Mode (Modus) | Berguna untuk data kategorikal atau nominal. | Tidak selalu ada atau bisa lebih dari satu. | Jika ingin mengetahui nilai yang paling sering muncul. |
Memilih ukuran pemusatan secara tepat tergantung pada karakteristik data yang kita miliki.
- Jika data memiliki distribusi normal tanpa outlier, mean adalah pilihan terbaik.
- Jika ada nilai ekstrem dalam dataset, median lebih akurat.
- Jika kita ingin melihat nilai yang paling umum muncul, mode adalah pilihan tepat.
Memahami konsep mean, median, dan mode akan membantu kita dalam menginterpretasikan data dengan lebih baik, mengambil keputusan yang lebih informatif, dan memilih metode analisis secara tepat sesuai dengan konteksnya.
Data Kuantitatif Univariat: Ukuran Penyebaran Data
Dalam analisis data, kita tidak hanya ingin mengetahui letak pusat data berada (seperti yang kita pelajari dalam mean, median, dan mode), tetapi juga seberapa tersebar data tersebut.
Dua dataset bisa memiliki rata-rata yang sama, tetapi mungkin memiliki pola distribusi sangat berbeda. Oleh karena itu, penting bagi kita untuk memahami ukuran penyebaran data untuk mendapatkan gambaran lebih akurat tentang variasi atau keragaman dataset yang sedang kita analisis.
Sebagai contoh, bayangkan ada dua kelas yang mengikuti ujian. Kedua kelas tersebut memiliki rata-rata nilai ujian yang sama, yaitu 75. Akan tetapi, satu kelas memiliki nilai yang sangat bervariasi (ada siswa yang mendapat nilai 40 dan ada yang mendapat 100), sementara kelas lainnya memiliki nilai yang lebih merata (semua siswa mendapatkan nilai antara 70 hingga 80). Dalam situasi seperti ini, mengukur penyebaran data menjadi sangat penting untuk memudahkan proses analisis.
Beberapa ukuran penyebaran yang umum digunakan adalah range, variance, standard deviation, interquartile range (IQR), dan coefficient of variation (CV). Mari kita telaah satu per satu.
Range: Menentukan Jarak antara Nilai Maksimum dan Minimum
Range (jangkauan) adalah ukuran penyebaran paling sederhana, yang menunjukkan perbedaan antara nilai terbesar dan nilai terkecil dalam dataset. Dengan kata lain, range berarti selisih antara nilai maksimum dan nilai minimum dalam dataset.

Sebagai contoh, misalkan kita memiliki data nilai ujian siswa seperti berikut.
50, 60, 70, 80, 90, 100
Jadi,dapat diketahui nilai-nilai berikut.
- Nilai maksimum dalam dataset = 100
- Nilai minimum dalam dataset = 50
- Range = 100 - 50 = 50
Jangkauan nilai dalam dataset ini adalah 50.
Range sangat berguna untuk mendapatkan gambaran awal tentang sebaran data. Namun, ada kelemahan besar: range hanya melihat dua nilai ekstrem (maksimum dan minimum) sehingga bisa sangat dipengaruhi oleh outlier (nilai yang sangat jauh dari kebanyakan data lainnya).
Variance & Standard Deviation: Mengukur Sebaran Data terhadap Mean
Jika range hanya melihat dua titik ekstrem, variance (variansi) dan standard deviation (standar deviasi) memberi kita ukuran yang lebih akurat tentang seberapa jauh setiap titik data dari rata-rata.
Variansi menunjukkan ukuran seberapa tersebar/jauh data atau nilai pada dataset dari mean (rata-rata) dalam bentuk kuadrat, sedangkan standar deviasi adalah akar kuadrat dari varians dan dinyatakan dalam satuan yang sama dengan data aslinya.


Standar deviasi adalah salah satu ukuran penyebaran paling umum dalam statistik. Jika standar deviasi rendah, berarti data cenderung berdekatan dengan mean. Jika standar deviasi tinggi, berarti data lebih tersebar dari mean.
Contoh: Jika dua kelas memiliki nilai ujian rata-rata 85, tetapi
- Kelas A memiliki nilai yang berkisar antara 83 hingga 87.
- Kelas B memiliki nilai yang berkisar antara 70 hingga 100.
Meskipun mean kedua kelas sama, kelas B memiliki standar deviasi lebih besar. Ini menunjukkan bahwa nilainya lebih bervariasi.
Interquartile Range (IQR): Menangani Outlier dalam Sebaran Data
IQR adalah ukuran penyebaran yang lebih tahan terhadap outlier karena hanya melihat rentang antara kuartil pertama (Q1) dan kuartil ketiga (Q3) dalam urutan data. Sederhananya, IQR dihitung sebagai selisih antara kuartil ketiga (Q3) dan kuartil pertama (Q1) dengan rumus sebagai berikut.

Sebagai contoh, kita memiliki data yang sudah diurutkan seperti ini.
10, 20, 30, 40, 50, 60, 70, 80, 90
Dengan data tersebut, hal berikut dapat diketahui.
- Q1 (kuartil pertama) = 25
- Q3 (kuartil ketiga) = 75
- IQR = 75 - 25 = 50
Coefficient of Variation (CV): Membandingkan Variasi pada Berbagai Dataset
Coefficient of Variation atau CV mengukur seberapa besar penyebaran relatif dibandingkan dengan mean dalam bentuk persentase.

CV digunakan ketika kita ingin membandingkan variabilitas dua dataset dengan mean yang sangat berbeda. Contoh dari penggunaan CV adalah seperti pada kasus berikut.
- Harga beras rata-rata 10.000/kg dengan standar deviasi 1.000.
- Harga minyak goreng rata-rata 25.000/liter dengan standar deviasi 5.000.
Jika kita hanya melihat standar deviasi, minyak goreng tampak lebih bervariasi. Namun, dengan menghitung CV hasilnya berikut.
- CV Beras = 1.000/10.000×100% = 10%
- CV Minyak Goreng = 5.000/25.000×100% = 20%
Jadi, kita bisa menyimpulkan bahwa harga minyak goreng lebih fluktuatif dibandingkan harga beras secara relatif terhadap harga rata-ratanya.
Data Kuantitatif Univariat: Standardisasi dan Normalisasi Data
Ketika bekerja dengan data, sering kali kita menemukan bahwa setiap fitur atau variabel dalam dataset memiliki skala yang berbeda-beda. Misalnya, jika sedang menganalisis data tentang kesehatan seseorang, kita mungkin memiliki variabel seperti berikut.
- Tinggi badan dalam cm (misalnya: 160 cm, 170 cm, 180 cm).
- Berat badan dalam kg (misalnya: 50 kg, 70 kg, 90 kg).
- Kadar gula darah dalam mg/dL (misalnya: 80 mg/dL, 120 mg/dL, 150 mg/dL).
Karena angka-angka ini memiliki rentang yang sangat berbeda, beberapa algoritma machine learning dan analisis statistik bisa kesulitan dalam memprosesnya. Variabel dengan skala yang lebih besar bisa memiliki pengaruh lebih besar dibandingkan variabel dengan skala kecil, meskipun sebenarnya kedua variabel sama pentingnya.
Oleh karena itu, kita perlu menyamakan skala semua variabel agar tidak ada fitur yang mendominasi analisis. Proses ini disebut standardisasi atau normalisasi data.
Ada beberapa metode yang umum digunakan untuk melakukan normalisasi data, seperti z-score, min-max scaling, dan robust scaling.
Standard Score (Z-Score): Mengubah Data ke Distribusi Standar
Z-Score adalah metode standardisasi yang menyatakan seberapa jauh sebuah nilai dari rata-rata (mean) dalam satuan standar deviasi. Dengan cara ini, rata-rata data akan menjadi 0 dan standar deviasi akan menjadi 1.
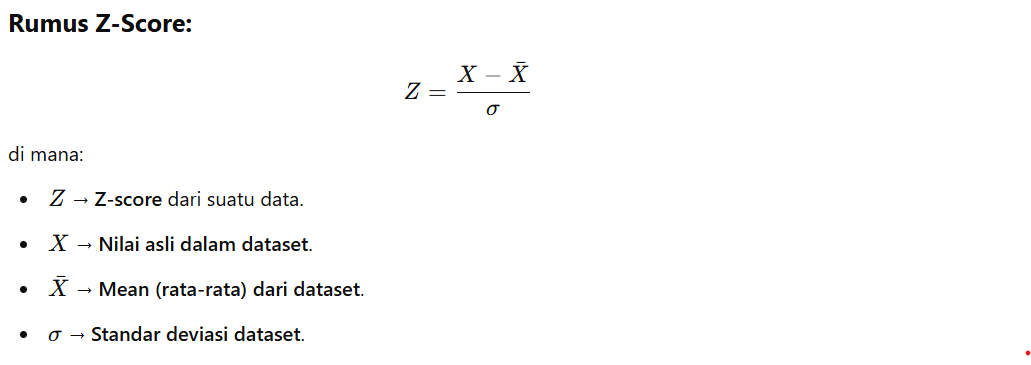
Sebagai contoh, jika suatu nilai memiliki Z-Score = 2, itu berarti nilainya 2 standar deviasi di atas rata-rata. Jika Z-Score = -1.5, nilai tersebut 1.5 standar deviasi di bawah rata-rata.
Z-Score berguna jika kita ingin mengubah data menjadi distribusi normal standar dengan rata-rata 0 dan standar deviasi 1. Teknik ini sering digunakan dalam statistik dan machine learning, terutama pada algoritma yang sensitif terhadap skala data, seperti regresi linier dan KNN.
Namun, jika dataset memiliki outlier (nilai ekstrem yang sangat besar atau sangat kecil), Z-Score bisa terpengaruh sehingga perlu dipertimbangkan penggunaannya.
Min-Max Scaling: Mengubah Data ke Rentang yang Ditentukan
Min-Max Scaling adalah teknik normalisasi data yang mengonversi semua nilai dalam rentang tertentu, biasanya 0 hingga 1. Teknik ini berguna ketika kita ingin memastikan semua data memiliki skala yang sama tanpa mengubah distribusinya.

Misalkan kita memiliki dataset tinggi badan siswa sebagai berikut.
150 cm, 160 cm, 170 cm, 180 cm, 190 cm.
Data di atas dapat diketahui sebagai berikut.
- Nilai minimum dalam dataset = 150 cm.
- Nilai maksimum dalam dataset = 190 cm.
- Jika kita ingin menghitung Min-Max Scaling untuk tinggi 180 cm, hasilnya berikut.
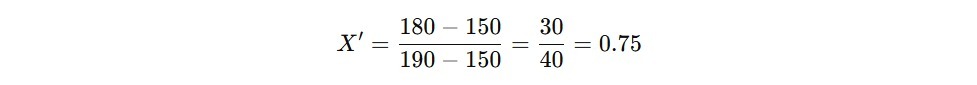
Jadi, setelah normalisasi, tinggi 180 cm memiliki nilai 0.75 dalam skala 0-1.
Min-Max Scaling sangat berguna jika kita ingin membatasi data dalam rentang tertentu, terutama dalam neural networks dan SVM. Namun, metode ini sensitif terhadap outlier karena nilai ekstrem akan menentukan skala keseluruhan dataset.
Robust Scaling: Menangani Outlier dengan Median dan IQR
Berbeda dengan Z-Score dan Min-Max Scaling yang bisa terpengaruh oleh outlier, Robust Scaling menggunakan median dan interquartile range (IQR) untuk normalisasi. Karena median tidak dipengaruhi oleh nilai ekstrem, metode ini lebih stabil untuk dataset yang memiliki outlier.

Mari kita ambil contoh. Misalkan kita memiliki dataset tinggi badan berikut:
150, 160, 170, 180, 190, 200, 300.
Data di atas dapat diketahui sebagai berikut.
- Median = 180 cm.
- Q1 = 160 cm, Q3 = 200 cm.
- IQR = 200 - 160 = 40.
- Jika kita menghitung nilai normalisasi untuk tinggi 190 cm, hasilnya berikut.
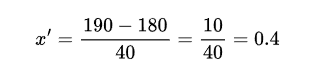
Robust Scaling sangat cocok jika dataset memiliki outlier karena ia tidak terpengaruh oleh nilai ekstrem.
Jadi, Pilih Metode Mana?
Ketiga teknik yang dijabarkan di atas memiliki tujuan yang sama, yaitu menormalkan data, tetapi dengan metode yang berbeda. Pilihan teknik yang tepat sangat bergantung pada kondisi dataset, terutama jika dataset tersebut memiliki banyak outlier.
Z-Score dan Min-Max Scaling sangat berguna jika kita ingin data berada dalam skala tertentu atau mengikuti distribusi normal, tetapi keduanya sensitif terhadap nilai ekstrem. Sementara itu, Robust Scaling lebih cocok untuk dataset yang memiliki banyak nilai ekstrem karena metode ini lebih stabil.
| Metode | Skala Hasil | Sensitif Terhadap Outlier | Kapan Digunakan |
| Z-Score | Rata-rata = 0, standar deviasi = 1 | Sangat sensitif terhadap outlier. | Saat data harus mengikuti distribusi normal standar. Digunakan dalam regresi linier, KNN, atau algoritma yang sensitif terhadap skala data. |
| Min-Max Scaling | Rentang (misalnya, 0 hingga 1) | Sensitif terhadap outlier. | Saat data harus mengikuti distribusi normal standar. Digunakan dalam regresi linier, KNN, atau algoritma yang sensitif terhadap skala data. |
| Robust Scaling | Tidak tetap (berdasarkan IQR). | Tidak sensitif terhadap outlier. | Ketika dataset mengandung outlier yang harus dihindari, cocok untuk data terdistribusi tidak normal. |
Dengan memahami karakteristik masing-masing teknik, kita bisa memilih metode normalisasi yang paling sesuai dengan jenis dan kondisi data yang dimiliki sehingga proses analisis serta pembuatan model bisa berjalan lebih optimal.
Data Kuantitatif Univariat: Distribusi Data
Saat bekerja dengan data, kita sering ingin mengetahui cara data itu tersebar. Apakah sebagian besar nilai berkumpul di sekitar rata-rata? Apakah ada nilai yang jauh lebih besar atau lebih kecil dari lainnya? Atau apakah data memiliki kecenderungan condong ke satu sisi?
Distribusi data menggambarkan bahwa nilai-nilai dalam suatu dataset tersebar. Distribusi data membantu kita memahami pola atau kecenderungan data dalam dataset, seperti jika data terkonsentrasi di sekitar nilai tertentu atau tersebar luas. Pemahaman tentang distribusi data sangat penting dalam analisis statistik, machine learning, dan pengambilan keputusan bisnis berbasis data.
Dengan memahami distribusi data, kita bisa memilih metode analisis yang tepat, mengidentifikasi outlier, dan membuat prediksi lebih akurat.
Sebagai contoh, jika kita menganalisis tinggi badan siswa di suatu sekolah, sebagian besar siswa mungkin memiliki tinggi antara 160 cm hingga 175 cm, sementara ada beberapa siswa yang sangat pendek atau sangat tinggi. Untuk menggambarkan pola ini, kita perlu memahami jenis-jenis distribusi data yang umum digunakan dalam analisis statistik.
Distribusi data dapat berbentuk simetris (normal) atau tidak simetris (skewed). Selain itu, distribusi juga dapat dikategorikan berdasarkan seberapa tajam atau datar puncaknya (kurtosis).
Distribusi Normal (Gaussian Distribution)
Distribusi normal adalah salah satu distribusi yang paling banyak ditemukan pada statistik dan sangat penting dalam analisis data. Distribusi ini sering disebut sebagai kurva lonceng atau bell curve karena bentuknya yang menyerupai lonceng, dengan sebagian besar nilai data terpusat di sekitar rata-rata (mean) dan semakin sedikit nilai yang terletak jauh dari rata-rata tersebut.
Dalam distribusi normal, data tersebar simetris di sekitar mean, artinya nilai yang lebih tinggi dan lebih rendah dari rata-rata memiliki kemungkinan hampir sama untuk muncul pada dataset. Semakin jauh dari mean, semakin sedikit jumlah data yang berada di area tersebut.
Distribusi normal sering digunakan untuk menggambarkan data alami yang mengikuti pola distribusi sangat umum, seperti tinggi badan, berat badan, nilai ujian, dan banyak data lainnya yang terdistribusi secara simetris.
Berikut adalah beberapa contoh kasus penggunaan distribusi normal.
- Nilai ujian siswa dalam suatu kelas sering mengikuti distribusi normal dengan mayoritas siswa mendapatkan nilai rata-rata dan hanya sedikit yang mendapat nilai sangat tinggi atau sangat rendah.
- Tinggi badan populasi manusia juga sering mengikuti pola distribusi normal, yakni sebagian besar orang memiliki tinggi rata-rata, dan hanya sedikit yang sangat pendek atau sangat tinggi.
- Kesalahan dalam pengukuran sensor atau eksperimen ilmiah cenderung mengikuti distribusi normal karena adanya variasi acak.
Karakteristik Distribusi Normal
Distribusi normal memiliki beberapa karakteristik utama yang membuatnya sangat berguna dalam statistik dan analisis data. Beberapa karakteristik utama dari distribusi normal adalah berikut.
-
Simetris
Distribusi normal bersifat simetris, yang berarti bahwa data terdistribusi secara seimbang di kedua sisi rata-rata. Sebagian besar nilai data terletak dekat dengan rata-rata dan semakin jauh dari rata-rata, semakin sedikit nilai data yang ada. Artinya, data di sebelah kiri rata-rata akan memiliki bentuk yang identik dengan data di sebelah kanan rata-rata. Dalam distribusi normal, mean, median, dan mode berada pada titik yang sama. Ini menunjukkan bahwa rata-rata data berada pada pusat distribusi dan data terdistribusi dengan cara yang seimbang. -
Pola Lonceng
Distribusi normal memiliki bentuk lonceng yang khas. Sebagian besar data terkonsentrasi di sekitar rata-rata (mean) dan data yang lebih jauh dari rata-rata semakin jarang ditemui. Semakin jauh data dari rata-rata, semakin kecil kemungkinannya untuk muncul. -
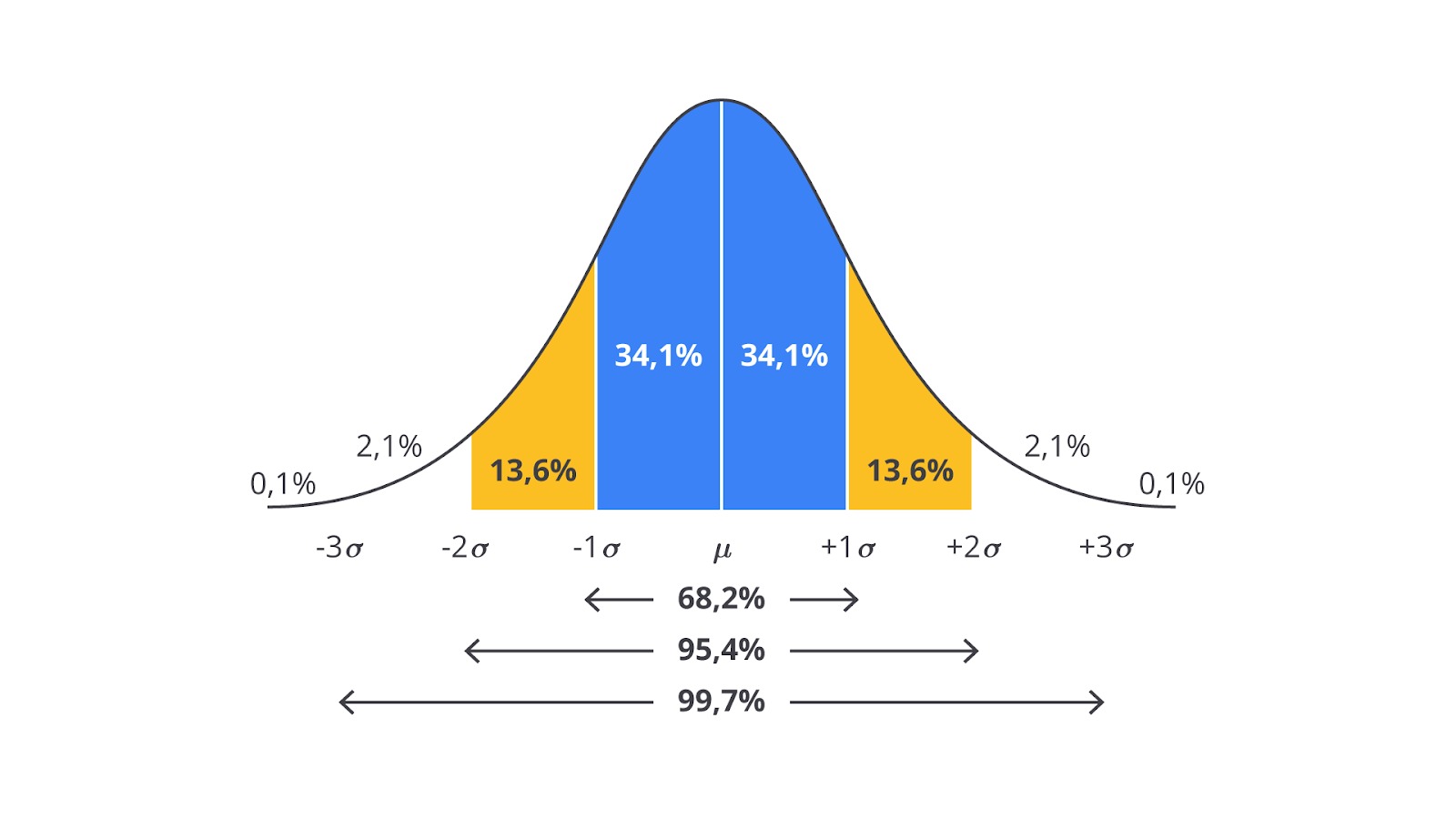
Empirical Rule (Aturan 68-95-99.7)
Salah satu sifat penting dari distribusi normal adalah aturan 68-95-99.7%, yang menggambarkan seberapa banyak data yang terletak dalam jarak tertentu dari rata-rata.- 68% data terletak dalam 1 standar deviasi dari rata-rata.
- 95% data terletak dalam 2 standar deviasi dari rata-rata.
- 99.7% data terletak dalam 3 standar deviasi dari rata-rata.
Ini berarti bahwa sebagian besar data terletak sangat dekat dengan rata-rata. Hanya sedikit data yang terletak lebih jauh dari 2 atau 3 standar deviasi dari rata-rata. Hal ini sangat berguna ketika kita ingin memeriksa variabilitas data atau mendeteksi outlier (nilai yang jauh dari rata-rata).
- Puncak yang Halus dan Tidak Ada Ekor
Kurva distribusi normal memiliki puncak yang tajam di tengah (di sekitar mean) dan menurun secara halus ke kedua sisi. Kurva ini tidak memiliki ekor tajam, yang membedakannya dari beberapa distribusi lain yang lebih runcing atau lebih meluas.
Pentingnya Pemahaman Distribusi Normal
Distribusi normal adalah salah satu asumsi yang digunakan oleh banyak model statistik dan algoritma machine learning. Pemahaman tentang distribusi normal sangat penting dalam data science karena banyak teknik analisis yang mengasumsikan bahwa data mengikuti distribusi ini. Berikut adalah beberapa alasan distribusi normal sangat penting.
- Pemodelan yang Lebih Sederhana
Banyak algoritma dalam statistik dan machine learning, seperti regresi linier dan analisis varians (ANOVA), mengasumsikan bahwa data memiliki distribusi normal. Ini memungkinkan kita untuk menggunakan model lebih sederhana nan efektif yang sering kali lebih efisien dan dapat diandalkan untuk membuat prediksi atau inferensi. - Analisis Outlier
Dengan mengetahui distribusi data, kita bisa lebih mudah mendeteksi outlier. Dalam distribusi normal, nilai yang berada lebih dari 3 standar deviasi dari rata-rata dianggap sangat ekstrem dan dapat dianggap sebagai outlier. - Perhitungan Probabilitas
Distribusi normal memungkinkan kita untuk menghitung probabilitas dari nilai tertentu yang berada pada dataset. Misalnya, dengan mengetahui bahwa data terdistribusi normal, kita bisa menggunakan tabel distribusi normal atau fungsi distribusi kumulatif untuk memperkirakan peluang suatu nilai terjadi. - Asumsi dalam Model Machine Learning
Beberapa algoritma machine learning, seperti Naive Bayes, sering mengasumsikan bahwa fitur dalam data mengikuti distribusi normal. Jika data kita terdistribusi normal, model ini akan memberikan hasil yang lebih baik karena asumsinya terpenuhi.
Mengingat banyaknya model yang mengasumsikan distribusi normal, penting bagi kita untuk memeriksa bahwa data yang kita miliki mengikuti distribusi ini atau perlu dilakukan transformasi agar sesuai dengan asumsi distribusi normal.
Distribusi Skewed (Miring)
Sementara distribusi normal adalah bentuk distribusi yang sering kali ideal dan simetris, tidak semua data mengikuti pola distribusi ini. Banyak dataset yang memiliki skewness atau kemiringan, yang mengarah pada distribusi skewed (miring).
Distribusi skewed terjadi ketika data tidak terdistribusi secara simetris atau lebih terkonsentrasi di satu sisi dari distribusi. Dengan kata lain, ada lebih banyak nilai yang berada di satu sisi dibandingkan sisi lainnya.
Dalam distribusi skewed, kita dapat melihat bahwa data tidak terdistribusi secara merata di sekitar rata-rata (mean), tetapi condong ke sisi tertentu—baik sisi kiri maupun sisi kanan dari distribusi.
Apa Itu Skewness?
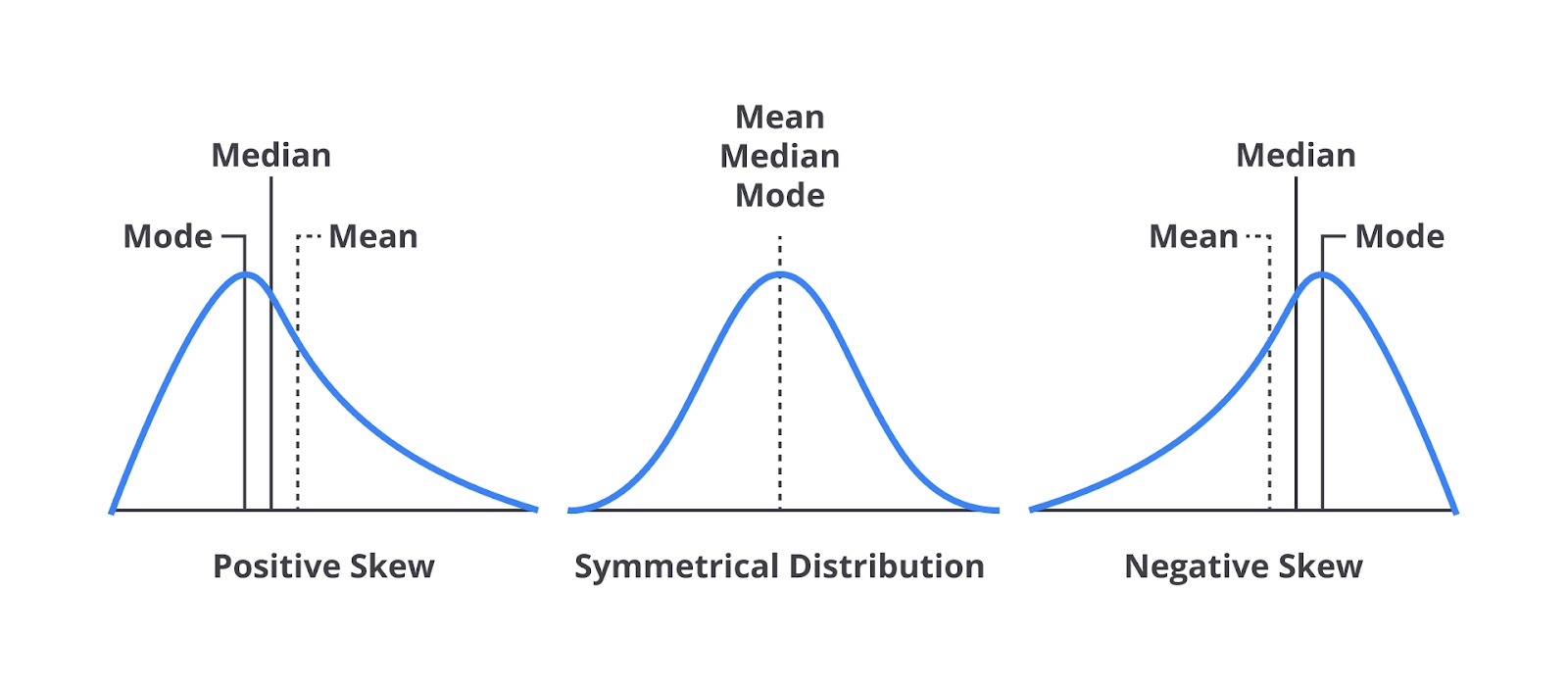
Skewness adalah ukuran dari asimetri distribusi data. Jika distribusi data lebih terpusat pada satu sisi dan memiliki ekor yang panjang di sisi lain, data tersebut dianggap skewed. Ada dua jenis distribusi skewed yang paling umum, yaitu skewed positif (positive skew atau right-skewed) dan skewed negatif (negative skew atau left-skewed).
Memahami jenis distribusi skewed sangat penting dalam data science karena data yang terdistribusi miring bisa memengaruhi analisis dan pemilihan model secara tepat. Misalnya, jika data skewed, kita mungkin perlu melakukan transformasi data (seperti log transformation) untuk membuat distribusi lebih mendekati distribusi normal sebelum menerapkan beberapa algoritma atau model statistik yang mengasumsikan distribusi normal.
Distribusi Skewed Positif (Right-Skewed)
Pada distribusi skewed positif, ekor distribusi lebih panjang di sisi kanan, yang disebut right-skewed. Dalam distribusi ini, sebagian besar data terkumpul di sisi kiri distribusi, sementara nilai-nilai yang sangat besar (dibandingkan mayoritas data) menarik rata-rata ke kanan, menyebabkan distribusi menjadi miring.
Berikut adalah karakteristik dari distribusi skewed positif.
- Ekor lebih panjang di sisi kanan.
- Mean > median > mode: rata-rata (mean) lebih besar daripada median dan mode karena beberapa nilai ekstrem yang tinggi menarik rata-rata lebih tinggi.
- Sebagian besar data terletak di sisi kiri. Data lebih kecil muncul lebih sering, tetapi ada beberapa nilai sangat besar yang mendorong distribusi ke kanan.
Berikut adalah beberapa contoh dari distribusi skewed positif.
- Pendapatan Individu dalam Suatu Negara: Sebagian besar orang mungkin memiliki pendapatan menengah ke bawah, tetapi ada sebagian kecil orang dengan pendapatan yang sangat tinggi, seperti miliarder atau CEO, yang menyebabkan distribusi pendapatan menjadi skewed ke kanan.
- Harga Rumah: Sebagian besar rumah mungkin memiliki harga relatif terjangkau, tetapi ada beberapa rumah yang sangat mahal, seperti rumah mewah atau rumah yang sangat besar. Ini menyebabkan distribusi harga rumah menjadi miring ke kanan.
Distribusi Skewed Negatif (Left-Skewed)
Pada distribusi skewed negatif, ekor distribusi lebih panjang di sisi kiri, yang disebut left-skewed. Dalam distribusi ini, sebagian besar data terletak di sisi kanan distribusi, tetapi ada beberapa nilai sangat kecil (dibandingkan mayoritas data) yang menyebabkan distribusi miring ke kiri.
Berikut adalah karakteristik dari distribusi skewed negatif.
- Ekor lebih panjang di sisi kiri.
- Mean < Median < Mode: rata-rata lebih kecil daripada median dan mode karena adanya nilai ekstrem yang sangat kecil menarik rata-rata lebih rendah.
- Sebagian besar data terletak di sisi kanan. Data lebih besar muncul lebih sering, tetapi ada beberapa nilai sangat kecil yang menarik distribusi ke kiri.
Berikut adalah beberapa contoh dari distribusi skewed negatif.
- Usia Pensiun: Sebagian besar orang mungkin pensiun pada usia sekitar 60 tahun, tetapi ada sebagian kecil orang yang memilih untuk pensiun lebih awal, pada usia 40-an, yang menyebabkan distribusi usia pensiun menjadi skewed ke kiri.
- Skor Ujian yang Sangat Mudah: Jika sebuah ujian terlalu mudah, sebagian besar siswa akan mendapatkan nilai tinggi, tetapi ada beberapa siswa yang tetap mendapat nilai rendah karena alasan tertentu. Ini menyebabkan distribusi skewed negatif.
Pertimbangan Menghadapi Data Skewed
Memahami bahwa data kita terdistribusi miring (skewed) sangat penting karena distribusi skewed dapat memengaruhi hasil analisis dan pengambilan keputusan. Dalam banyak kasus, distribusi skewed menunjukkan adanya outlier atau nilai ekstrem yang dapat memengaruhi penggunaan model statistik dan algoritma.
Berikut adalah beberapa hal yang perlu dipertimbangkan ketika kita memiliki data yang skewed.
- Transformasi Data: Jika data skewed, kita perlu melakukan transformasi data (seperti log transformasi, sqrt transformasi, atau Box-Cox transformasi) untuk mengurangi pengaruh nilai ekstrem dan membuat distribusi lebih mendekati distribusi normal.
- Pemilihan Model yang Tepat: Beberapa model machine learning dan statistik lebih sensitif terhadap distribusi data. Misalnya, model seperti regresi linier dan SVM mengasumsikan bahwa data terdistribusi normal, jadi transformasi data skewed sangat penting untuk meningkatkan akurasi model.
- Deteksi Outlier: Memahami distribusi data skewed juga membantu dalam deteksi outlier, yang bisa menjadi penting pada analisis data. Dalam distribusi skewed positif, misalnya, kita dapat mengidentifikasi nilai ekstrem sangat tinggi yang tidak biasa.
Kurtosis: Mengukur Puncak dan Sebaran Data
Kurtosis adalah ukuran statistik yang mengukur tinggi dan lebar puncak distribusi data. Dalam kata lain, kurtosis memberikan gambaran tentang seberapa terpusat data di sekitar rata-rata (mean) dibandingkan dengan distribusi normal.
Kurtosis dapat membantu kita memahami bahwa data kita memiliki lebih banyak nilai yang terkonsentrasi di sekitar rata-rata atau lebih tersebar dalam berbagai nilai.
Pada distribusi normal, kurtosis mendekati nilai 3 (angka tiga adalah standar kurtosis distribusi normal), yang dikenal dengan sebutan mesokurtic. Namun, distribusi data bisa memiliki kurtosis lebih tinggi (leptokurtic) atau kurtosis lebih rendah (platykurtic) tergantung pada bentuk distribusinya.
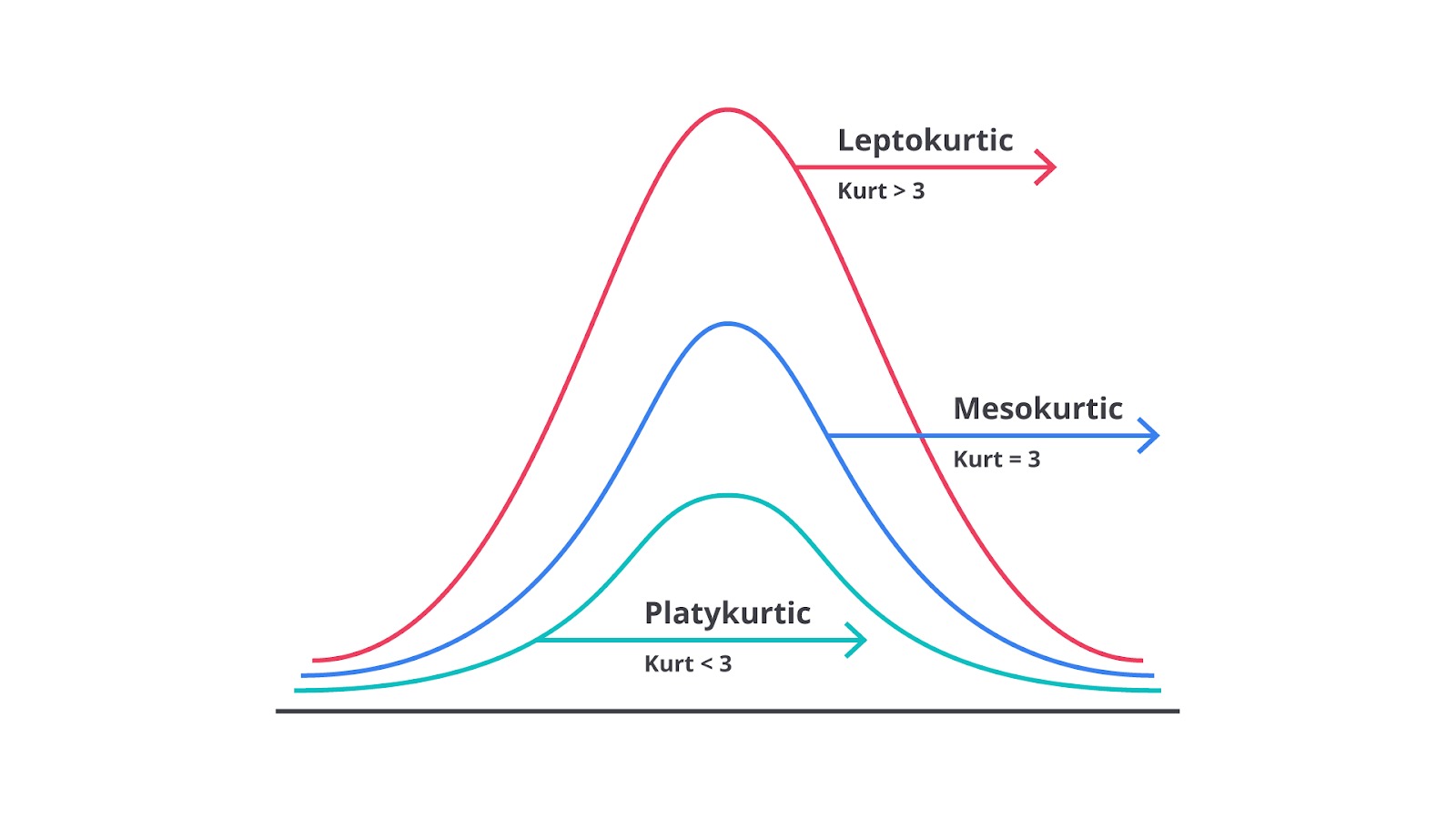
Kurtosis mengukur dua hal utama sebagai berikut.
- Tinggi Puncak Distribusi: Seberapa tajam atau datar puncak distribusi data.
- Lebar Distribusi: Seberapa jauh data tersebar dari rata-rata. Kurtosis yang lebih tinggi menunjukkan lebih banyak data terkonsentrasi di sekitar rata-rata, sementara kurtosis yang lebih rendah menunjukkan distribusi lebih datar dengan data lebih tersebar.
Kurtosis sering kali digunakan untuk mengidentifikasi distribusi data yang tidak normal, terutama untuk mendeteksi bahwa data memiliki banyak nilai ekstrem yang terpusat di sekitar rata-rata (seperti pada distribusi leptokurtic) atau lebih banyak nilai tersebar (seperti pada distribusi platykurtic).
Sebagaimana yang disebutkan sebelumnya, ada tiga jenis kurtosis utama untuk menggambarkan bentuk distribusi data. Mari kita jabarkan.
Mesokurtic
Mesokurtic adalah jenis distribusi dengan kurtosis yang sama dengan distribusi normal. Distribusi ini memiliki puncak moderat dan simetris. Data terdistribusi secara seimbang di sekitar rata-rata dengan sebagian besar data terletak di sekitar rata-rata dan semakin sedikit data yang terletak lebih jauh dari rata-rata. Distribusi normal itu sendiri adalah mesokurtic.
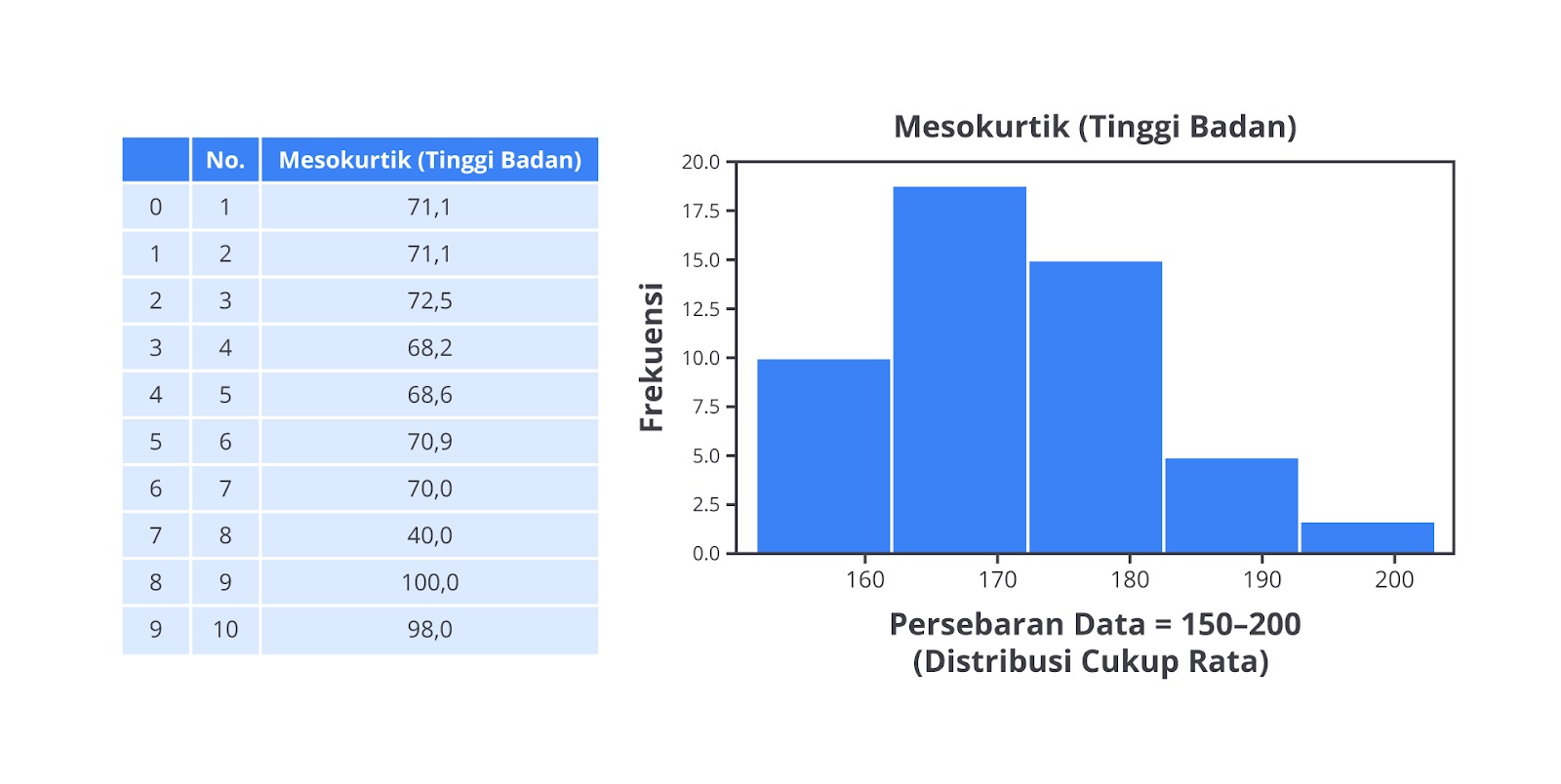
Misalnya, distribusi tinggi badan siswa di sekolah yang terdistribusi secara normal dan memiliki puncak yang moderat di sekitar rata-rata tinggi badan.
Berikut adalah beberapa karakteristik dari mesokurtic.
- Kurtosis mendekati 3.
- Puncak moderat, distribusi data simetris, dan tidak terlalu runcing atau datar.
- 68% data terletak dalam 1 standar deviasi dari rata-rata, 95% data dalam 2 standar deviasi, dan 99.7% data dalam 3 standar deviasi dari rata-rata.
Leptokurtic
Leptokurtic adalah distribusi dengan puncak yang tajam, yakni sebagian besar data terkonsentrasi di sekitar rata-rata. Distribusi ini memiliki ekor lebih panjang atau lebih banyak data yang terletak jauh dari rata-rata sehingga distribusi terlihat lebih tajam di sekitar nilai tengahnya.
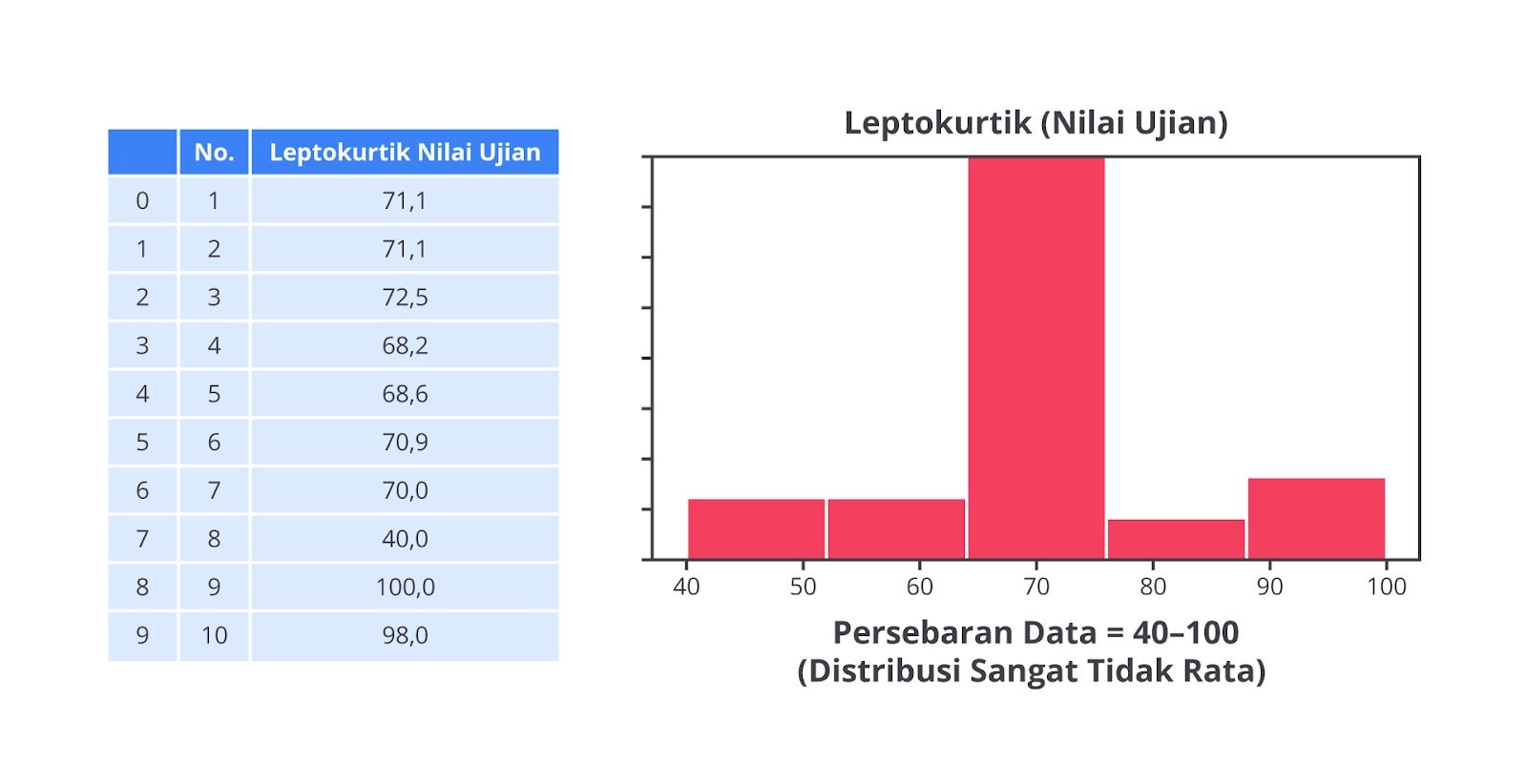
Sebagai contoh, dalam sebuah ujian kelas, jika sebagian besar siswa mendapatkan nilai sangat dekat dengan rata-rata dan hanya sedikit siswa yang memiliki nilai ekstrem sangat tinggi atau rendah, distribusi nilai ujian tersebut bisa dikatakan leptokurtic.
Jika menggambar histogram nilai ujian siswa, kita akan melihat distribusi dengan puncak lebih tinggi di sekitar nilai rata-rata dan ekor lebih panjang, yang menggambarkan lebih banyak data terkonsentrasi di sekitar rata-rata.
Berikut adalah beberapa karakteristik dari leptokurtic.
- Kurtosis lebih besar dari 3 (angka 3 adalah standar kurtosis distribusi normal).
- Puncak distribusi lebih tajam dibandingkan distribusi normal dan data terkonsentrasi lebih banyak di sekitar rata-rata.
- Ekor lebih panjang, artinya ada lebih banyak data yang jauh dari rata-rata (menunjukkan adanya outlier atau nilai ekstrem).
Platykurtic
Platykurtic adalah distribusi dengan puncak yang datar dibandingkan distribusi normal. Dalam distribusi ini, data lebih tersebar merata dan tidak terkonsentrasi dengan banyak di sekitar rata-rata. Distribusi platykurtic memiliki ekor lebih pendek tipis, artinya data lebih banyak tersebar dan tidak banyak yang terpusat di sekitar rata-rata.
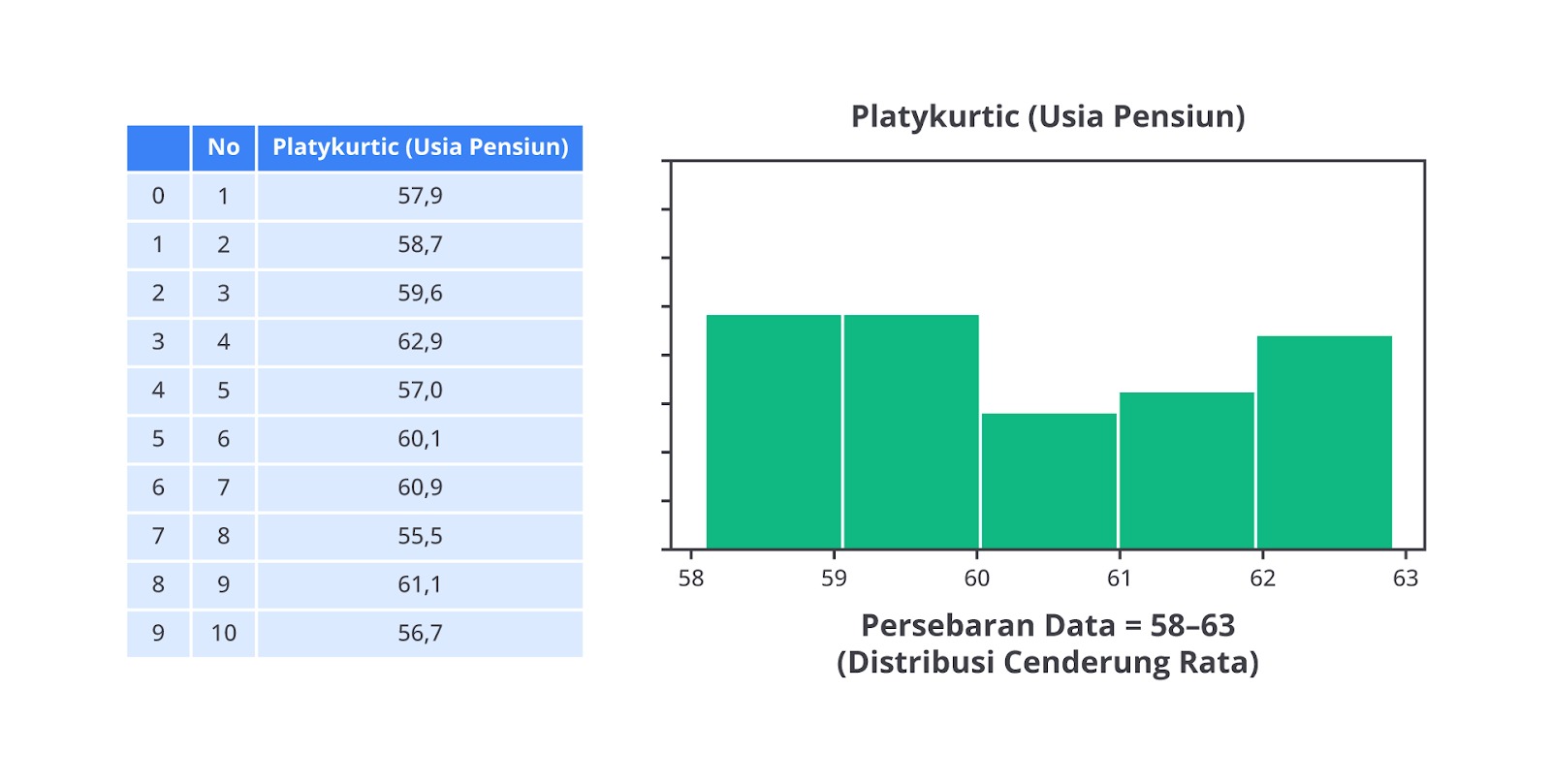
Misalnya, distribusi umur pensiun di suatu negara. Sebagian besar orang pensiun pada usia sekitar 60–65 tahun, tetapi ada beberapa orang pensiun lebih awal dan ada juga yang lebih lama. Ini bisa menghasilkan distribusi yang lebih datar dengan data lebih tersebar secara merata di sekitar usia pensiun rata-rata.
Jika menggambar histogram usia pensiun, kita akan melihat distribusi dengan puncak yang lebih datar. Ini menunjukkan bahwa data tersebar lebih merata di sekitar usia pensiun dan tidak ada konsentrasi yang tajam di sekitar rata-rata.
Berikut adalah beberapa karakteristik dari platykurtic.
- Kurtosis kurang dari 3.
- Puncak datar, lebih sedikit data yang terkonsentrasi di sekitar rata-rata.
- Ekor lebih tipis, artinya data lebih tersebar di sepanjang distribusi.
Data Kuantitatif Univariat: Distribusi Probabilitas
Distribusi probabilitas adalah konsep dasar dalam statistik yang menggambarkan kemungkinan nilai-nilai yang diambil oleh variabel acak dalam suatu dataset. Dengan kata lain, distribusi probabilitas memberi kita informasi tentang seberapa besar kemungkinan setiap nilai dalam dataset muncul.
Distribusi ini sangat penting dalam data science karena memungkinkan kita untuk memahami pola dalam data, membuat prediksi lebih baik, dan mengambil keputusan berbasis data yang lebih akurat.
Di dunia nyata, kita sering kali dihadapkan dengan situasi saat perlu memperkirakan kemungkinan terjadinya suatu peristiwa atau nilai dalam dataset, seperti memprediksi penjualan bulan depan atau pelanggan yang akan membeli produk berdasarkan data historis.
Untuk itu, pemahaman tentang distribusi probabilitas sangatlah penting, terutama saat kita belajar data science dan machine learning. Pasalnya, berbagai model machine learning dan statistik sering mengandalkan distribusi probabilitas untuk membuat estimasi atau prediksi.
Regresi Linier
Dalam regresi linier, sering diasumsikan bahwa data yang digunakan mengikuti distribusi normal. Regresi linier sendiri adalah salah satu teknik statistik yang paling umum digunakan untuk prediksi dan analisis hubungan antarvariabel. Tujuan utamanya adalah memodelkan hubungan antara satu atau lebih variabel independen (fitur) dan sebuah variabel dependen (target).
Salah satu alasan penting di balik penggunaan asumsi distribusi normal dalam regresi linier adalah untuk memastikan validitas model dan keakuratan hasil analisis.
Untuk memastikan bahwa model regresi linier memberikan hasil yang valid, kita mengasumsikan bahwa error (kesalahan) atau residual (selisih antara prediksi dan nilai aktual) mengikuti distribusi normal. Hal ini membantu kita dalam memperkirakan interval kepercayaan dan melakukan uji hipotesis dengan lebih akurat.
Dengan mengetahui bahwa data mengikuti distribusi normal, kita dapat membuat prediksi yang lebih terstandardisasi dan lebih dapat diandalkan. Tanpa asumsi ini, prediksi kita mungkin tidak sepenuhnya akurat.
Contoh Penerapan: Katakanlah kita ingin memprediksi harga rumah berdasarkan ukuran rumah, jumlah kamar tidur, dan faktor lainnya. Dalam regresi linier, kita mengasumsikan bahwa perbedaan antara prediksi harga rumah dan harga rumah yang sebenarnya (residual) mengikuti distribusi normal.
Naive Bayes
Naive Bayes adalah algoritma machine learning yang digunakan untuk klasifikasi. Algoritma ini didasarkan pada teorema Bayes yang mengasumsikan bahwa fitur (variabel input) bersifat independen satu sama lain.
Namun, ada asumsi lain yang digunakan dalam Naive Bayes, yaitu bahwa fitur dalam dataset mengikuti distribusi probabilitas tertentu, sering kali distribusi tersebut diasumsikan mengikuti distribusi normal. Dengan demikian, kita bisa menggunakan parameter distribusi normal seperti mean dan standar deviasi untuk menghitung probabilitas bagi setiap kelas.
Meskipun asumsi independensi antara fitur sering kali tidak sepenuhnya akurat, Naive Bayes tetap dapat memberikan hasil yang sangat efektif, bahkan ketika asumsi distribusi normal tidak dipenuhi.
Contoh Penerapan: Dalam masalah klasifikasi email spam, fitur seperti jumlah kata-kata tertentu dalam email (misalnya, kata “gratis” atau “promo”) dapat dihitung. Jika mengasumsikan bahwa frekuensi kata-kata tertentu mengikuti distribusi normal, kita bisa menghitung probabilitas bahwa email tersebut adalah spam atau bukan spam.
Monte Carlo Simulations
Monte Carlo Simulations adalah teknik statistik yang digunakan untuk memperkirakan hasil atau estimasi ketidakpastian dalam model stochastic (yang melibatkan variabel acak). Teknik ini menggunakan distribusi probabilitas untuk menghasilkan simulasi atau perkiraan hasil berdasarkan input yang bervariasi secara acak. Ini sangat berguna untuk mengestimasi kemungkinan hasil dalam situasi yang melibatkan ketidakpastian atau variasi data.
Monte Carlo banyak digunakan dalam bidang keuangan untuk memodelkan risiko dan memperkirakan nilai pasar dari berbagai instrumen keuangan berdasarkan distribusi probabilitas harga.
Contoh Penerapan: Dalam analisis risiko investasi, Monte Carlo dapat digunakan untuk menyimulasikan harga saham di masa depan dengan menggunakan distribusi probabilitas historis untuk harga saham. Dengan demikian, kita dapat memproyeksikan kemungkinan kerugian atau keuntungan yang mungkin terjadi dalam investasi.
Data Kategorikal Multivariat
Halo, teman-teman data! Setelah pada materi-materi sebelumnya data dengan hanya satu variabel (univariat) banyak dibahas–baik kategorikal maupun kuantitatif–kini kita masuk ke pembahasan data dengan banyak variabel (multivariat).
Semoga kalian dalam keadaan sehat dan siap karena sekarang kita akan mulai belajar dari data kategorikal multivariat.
Dalam dunia data science, kita sering bekerja dengan data yang melibatkan lebih dari satu variabel kategorikal, seperti jenis kelamin, preferensi produk, dan kategori usia. Menganalisis hubungan antarvariabel ini sangat penting untuk menemukan wawasan yang lebih dalam.
Pada materi ini, kita akan membahas bagaimana cara mengolah, menganalisis, dan memvisualisasikan data kategorikal multivariat. Materi ini sangat relevan bagi Anda yang ingin mengembangkan keterampilan dalam menganalisis data lebih kompleks, seperti analisis pasar, demografi, dan riset kesehatan. Ini berguna saat data tidak hanya terdiri dari satu variabel, tetapi beberapa variabel kategorikal yang saling berinteraksi.
Pengenalan Data Kategorikal Multivariat
Data kategorikal sering kali dianggap sebagai tipe data paling mudah dipahami sebab biasanya berisi label yang menggambarkan kategori atau kelompok. Namun, dalam data science, kita tidak hanya ingin mengetahui jumlah kategori, tetapi juga pengaruh hubungan antar kategori terhadap keseluruhan analisis.
Data kategorikal multivariat merujuk pada data dengan lebih dari satu variabel kategorikal yang saling berinteraksi atau saling memengaruhi. Data ini terdiri dari kategori-kategori yang memiliki atribut tertentu, misalnya jenis kelamin (laki-laki/perempuan), status pernikahan (menikah, lajang), dan kategori usia (20–30, 30–40, dst.). Dalam analisis multivariat, kita tidak hanya memeriksa satu variabel saja, tetapi juga hubungan antara beberapa variabel kategorikal untuk menemukan pola atau asosiasi yang lebih kompleks.
Menganalisis data kategorikal multivariat memungkinkan kita untuk menggali pola-pola interaksi antarvariabel yang sering kali lebih kompleks dibandingkan data kategorikal univariat.
Perbedaan Data Kategorikal Univariat dan Multivariat
Secara umum, berikut adalah perbedaan antara data kategorikal univariat dan multivariat.
-
Data Kategorikal Univariat
Data kategorikal univariat adalah data yang hanya melibatkan satu variabel kategorikal dalam analisis. Dalam analisis univariat, kita hanya menganalisis satu aspek data, seperti jenis kelamin saja atau hanya preferensi produk tanpa memperhitungkan variabel lain.Sebagai contoh, kita mungkin hanya ingin mengetahui sebaran jenis kelamin pada suatu dataset pelanggan tanpa mempertimbangkan faktor lain, seperti usia atau pendapatan.Pada data tersebut, kita hanya menganalisis sebaran dari data jenis kelamin dan ditemukan bahwa 60% pelanggan adalah pria dan 40% adalah wanita.
Pelanggan Jenis Kelamin 0 A Pria 1 B Wanita 2 C Pria 3 D Wanita 4 E Pria 5 F Pria 6 G Wanita 7 H Pria 8 I Wanita 9 J Pria -
Data Kategorikal Multivariat
Berbeda dengan univariat yang hanya melibatkan satu variabel, data kategorikal multivariat ditujukan pada analisis dua atau lebih variabel kategorikal secara bersamaan untuk memahami hubungan atau interaksi antara variabel-variabel tersebut.Sebagai contoh, kita dapat menganalisis jenis kelamin dan preferensi produk dalam kaitannya dengan kelompok usia untuk mengetahui bahwa pria dan wanita dari kelompok usia yang berbeda lebih cenderung memilih produk tertentu.
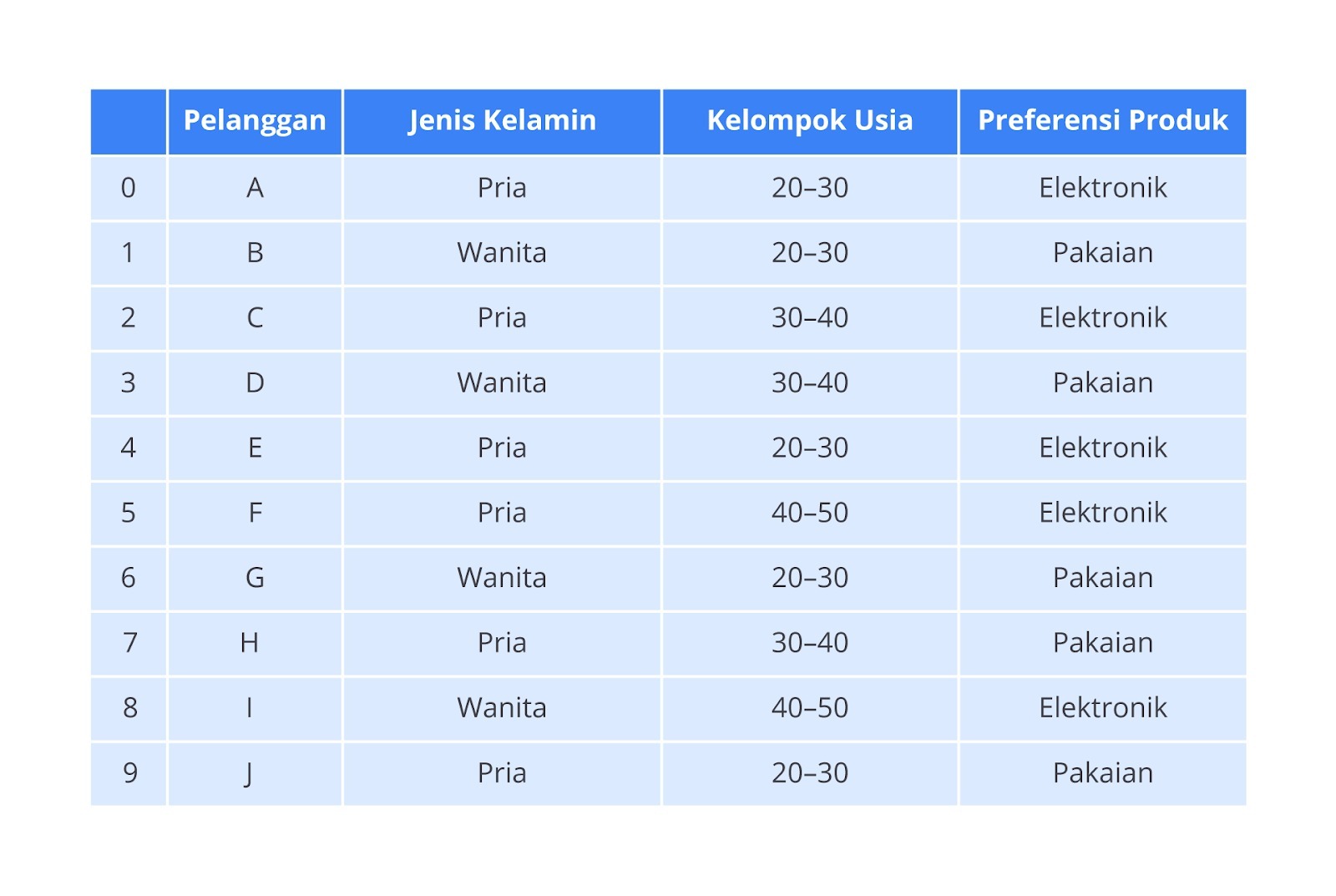
Dari data tersebut, kita bisa mendapatkan wawasan, seperti pria berusia 20–30 tahun cenderung lebih memilih produk elektronik, sedangkan wanita dalam kelompok usia yang sama lebih suka membeli pakaian. Dengan cara ini, kita bisa menggali lebih banyak wawasan dan pola preferensi yang lebih dalam. Analisis multivariat ini membantu kita memahami kompleksitas data dan mengidentifikasi pola yang tidak dapat terlihat hanya dengan analisis univariat.
Penerapan Data Kategorikal Multivariat
Analisis data kategorikal multivariat sangat berguna dalam berbagai bidang untuk menggali wawasan lebih mendalam dan membantu pengambilan keputusan yang lebih tepat. Mari kita lihat beberapa penerapan data kategorikal multivariat dalam berbagai bidang untuk mengetahui dampak penggunaannya lebih lanjut.
Analisis Pasar
Dalam analisis pasar, kita bisa menggabungkan sejumlah variabel, seperti untuk memahami preferensi produk dari berbagai kelompok konsumen.
Sebagai contoh, sebuah perusahaan pakaian ingin merancang kampanye pemasaran yang lebih terarah. Mereka menganalisis data pelanggan berdasarkan jenis kelamin, usia, dan preferensi produk untuk mengidentifikasi segmen pasar yang lebih tertarik pada produk-produk tertentu.
Kita bisa mengetahui bahwa pria dengan pendapatan tinggi lebih cenderung membeli elektronik premium atau wanita dengan usia tertentu lebih suka membeli produk kecantikan.
Dengan informasi ini, perusahaan dapat membuat kampanye pemasaran yang lebih efektif dan lebih terfokus pada kebutuhan konsumen.
Studi Demografi
Dalam studi demografi, analisis multivariat digunakan untuk memahami hubungan antara berbagai variabel pada suatu populasi. Hal ini penting untuk merancang kebijakan sosial atau program bantuan yang lebih tepat sasaran.
Sebagai contoh, pemerintah dapat menggunakan analisis multivariat untuk memahami distribusi status pernikahan, pendidikan, dan pekerjaan dalam suatu wilayah. Sebagai contoh, kita bisa mengetahui bahwa pasangan yang menikah dan memiliki pendidikan tinggi lebih cenderung memiliki pekerjaan dalam bidang tertentu.
Dengan demikian, mereka bisa merancang program kesejahteraan yang lebih tepat sasaran berdasarkan kelompok-kelompok yang memiliki karakteristik serupa.
Riset Kesehatan
Pada riset kesehatan, analisis multivariat digunakan untuk meneliti hubungan antara berbagai variabel dalam memahami faktor-faktor risiko dari penyakit tertentu.
Sebagai contoh, para peneliti di rumah sakit dapat melakukan analisis multivariat untuk mengeksplorasi pengaruh jenis kelamin, gaya hidup (merokok), dan riwayat keluarga penyakit jantung terhadap prevalensi penyakit jantung.
Dengan contoh tersebut, misal, kita dapat mengetahui bahwa pria merokok lebih berisiko mengalami penyakit jantung dibandingkan dengan wanita yang merokok. Hasil analisis ini membantu mereka untuk merancang program kesehatan lebih spesifik untuk kelompok-kelompok yang lebih berisiko.
Analisis Asosiasi dan Hubungan Antarvariabel Kategorikal
Setelah memahami konsep dasar data kategorikal, langkah selanjutnya dalam analisis adalah melihat bahwa hubungan antara variabel-variabel kategorikal dapat diidentifikasi dan diuji. Dalam dunia nyata, kita sering menemui situasi ketika ingin mengetahui adakah pola atau kecenderungan antara dua kategori tertentu—misalnya, apakah jenis kelamin seseorang memengaruhi preferensi produk yang dibelinya?
Untuk menjawab pertanyaan seperti ini, kita memerlukan alat analisis yang dapat memperlihatkan interaksi antara dua variabel dalam bentuk yang mudah dibaca dan dianalisis. Salah satu alat yang paling umum digunakan dalam analisis hubungan antarvariabel kategorikal adalah tabel kontingensi.
Tabel Kontingensi: Mengukur Asosiasi Antarvariabel Kategorikal
Tabel kontingensi adalah alat statistik yang digunakan untuk mengukur asosiasi antara dua atau lebih variabel kategorikal. Tabel ini memperlihatkan frekuensi dari kombinasi kategori dalam dataset, yang membantu kita melihat hubungan atau pola antara variabel yang sedang dianalisis.
Sebagai contoh, jika ingin menganalisis bahwa ada hubungan antara jenis kelamin (laki-laki/perempuan) dan preferensi produk (elektronik/pakaian), kita dapat menggunakan tabel kontingensi untuk melihat frekuensi dari masing-masing kategori. Bayangkan kita mengumpulkan data dari 400 pelanggan dan ingin mengetahui bahwa ada hubungan antara kedua kategori tersebut. Berikut adalah contoh tabel kontingensi yang menggambarkan data tersebut.
| Elektronik | Pakaian | Total | |
| Laki-laki | 150 | 50 | 200 |
| Perempuan | 120 | 80 | 200 |
| Total | 270 | 130 | 400 |
Dari tabel ini, kita dapat menarik beberapa wawasan, misalnya berikut.
- Pria cenderung lebih memilih elektronik, sementara wanita lebih memilih pakaian.
- Lebih sedikit wanita yang memilih elektronik (120) dibandingkan dengan pria (150), tetapi ada lebih banyak wanita yang membeli pakaian.
Tabel ini memberikan gambaran yang sangat jelas tentang interaksi antara dua variabel kategorikal. Namun, apakah pola ini signifikan atau hanya kebetulan? Untuk itulah kita menggunakan uji Chi-Square.
Uji Chi-Square: Menguji Independensi Antarvariabel Kategorikal
Uji Chi-Square digunakan untuk menguji bahwa dua variabel kategorikal independen atau terkait satu sama lain. Apabila dua variabel independen, distribusi frekuensi yang diamati dalam tabel kontingensi akan sama dengan distribusi yang diharapkan jika kedua variabel tersebut tidak berhubungan.
Dengan kata lain, uji ini melihat bahwa perbedaan antara frekuensi yang diamati dan frekuensi yang diharapkan cukup besar untuk menyimpulkan bahwa ada hubungan signifikan antara kedua variabel.
Langkah-Langkah Uji Chi-Square
Berikut adalah langkah-langkah sistematis dalam melakukan uji Chi-Square.
- Menyusun Tabel Kontingensi
Seperti penjelasan sebelumnya, kita mulai dengan membuat tabel yang menggambarkan kombinasi kategori dari kedua variabel. -
Menghitung Frekuensi yang Diharapkan (E)
Gunakan rumus berikut untuk menghitung frekuensi yang diharapkan pada setiap kombinasi kategori.
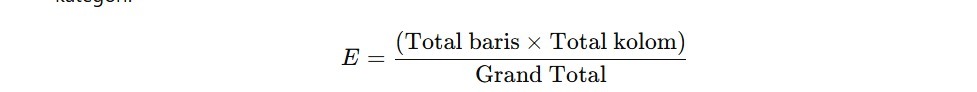
-
Menghitung Nilai Chi-Square (χ²)
Rumus untuk menghitung nilai Chi-Square adalah berikut.

- Menentukan Nilai P dan Mengambil Keputusan.
Setelah menghitung nilai Chi-Square, kita bandingkan dengan nilai kritis dari distribusi Chi-Square pada tingkat signifikansi yang telah ditentukan (misalnya, 0.05). Jika nilai Chi-Square lebih besar dari nilai kritis, kita menolak hipotesis nol (H₀) dan menyimpulkan bahwa ada hubungan signifikan antara kedua variabel. Hubungan signifikan merujuk pada hasil analisis data yang menunjukkan ada efek atau hubungan yang tidak mungkin terjadi hanya karena kebetulan.
Data Kuantitatif Multivariat
Setelah mempelajari cara menganalisis data kategorikal multivariat, kini kita akan masuk ke tahap data kuantitatif multivariat.
Di dunia nyata, data jarang berdiri sendiri. Sering kali, berbagai variabel saling berkaitan dan berinteraksi dalam satu konteks yang sama. Misalnya, ketika kita ingin memahami faktor-faktor yang memengaruhi harga rumah, kita tidak hanya melihat ukuran rumah, tetapi juga lokasi, jumlah kamar, usia bangunan, dan berbagai variabel lainnya secara bersamaan.
Untuk itulah kita memerlukan pendekatan multivariat: pendekatan yang mampu menangkap pola hubungan antar banyak variabel sekaligus dan memberikan wawasan lebih menyeluruh tentang struktur data yang dimiliki.
Sebelum mempelajari metode dan teknik yang digunakan, mari kita mulai dengan mengenali data kuantitatif multivariat dan karakteristiknya terlebih dahulu.
Pengenalan Data Kuantitatif Multivariat
Data kuantitatif multivariat merujuk pada analisis yang melibatkan lebih dari satu variabel kuantitatif untuk memahami hubungan antarvariabel. Dalam banyak kasus, data ini sering digunakan untuk mengidentifikasi pola, hubungan, atau tren lebih rumit yang tidak dapat dilihat hanya dengan analisis univariat (satu variabel).
Oleh karena itu, analisis multivariat menjadi penting karena memungkinkan kita untuk memahami pengaruh bersama dari beberapa variabel terhadap satu atau lebih hasil atau mengidentifikasi pola/hubungan yang lebih kompleks antara variabel-variabel tersebut. Pada akhirnya, analisis multivariat dapat meningkatkan prediksi dengan mempertimbangkan lebih banyak faktor secara simultan.
Sebagai contoh, dalam analisis penjualan produk, kita mungkin tertarik untuk mengetahui bahwa harga, pengeluaran iklan, dan musim berhubungan dengan penjualan produk.
Data yang terlihat pada gambar di atas menunjukkan data yang mencakup informasi mengenai harga produk, pengeluaran iklan, musim, dan penjualan produk. Setiap baris mewakili satu periode atau pengamatan dan setiap kolom mewakili variabel berbeda yang relevan dalam analisis ini.
Data tersebut dapat digunakan untuk analisis multivariat, seperti menggunakan regresi linier multivariat untuk melihat bahwa harga, pengeluaran iklan, dan musim memengaruhi penjualan produk. Melalui teknik ini, kita dapat mengetahui hubungan antara variabel-variabel tersebut, misal pengaruh pengeluaran iklan terhadap penjualan dibandingkan dengan harga produk, atau pengaruh musim pada hasil penjualan.
Korelasi dan Kovarians dalam Data Multivariat
Dalam analisis data multivariat, kita sering kali tertarik untuk mempelajari hubungan antara beberapa variabel. Dua konsep yang sangat penting dalam mengukur hubungan antara dua atau lebih variabel dalam data multivariat adalah korelasi dan kovarians.
Kedua konsep ini memungkinkan kita untuk mengukur sejauh mana variabel-variabel tersebut berhubungan satu sama lain, tetapi dengan cara yang sedikit berbeda.
Penjelasan Korelasi
Korelasi adalah ukuran yang digunakan untuk mengetahui seberapa kuat hubungan linier antara dua variabel. Dalam data multivariat, korelasi membantu kita untuk memahami bahwa dua variabel bergerak bersama dan jika hubungan tersebut positif, negatif, atau tidak ada hubungan sama sekali. Koefisien korelasi Pearson (r) adalah ukuran yang paling sering digunakan untuk mengukur kekuatan dan arah hubungan antara dua variabel kuantitatif.
Nilai koefisien korelasi (r) berkisar antara -1 hingga 1.
- r = 1: Korelasi positif sempurna. Ini berarti kedua variabel bergerak ke arah yang sama dalam hubungan linier.
- r = -1: Korelasi negatif sempurna. Ini berarti kedua variabel bergerak ke arah yang berlawanan dalam hubungan linier.
- r = 0: Tidak ada hubungan linier antara kedua variabel.
Sebagai contoh, jika menganalisis hubungan antara pendapatan dan pengeluaran, kita mungkin menemukan korelasi positif, yang berarti semakin tinggi pendapatan, semakin tinggi pengeluaran.
Untuk lebih memperjelas, berikut adalah gambaran visual dari nilai koefisien korelasi dan pengaruh hal itu terhadap data.
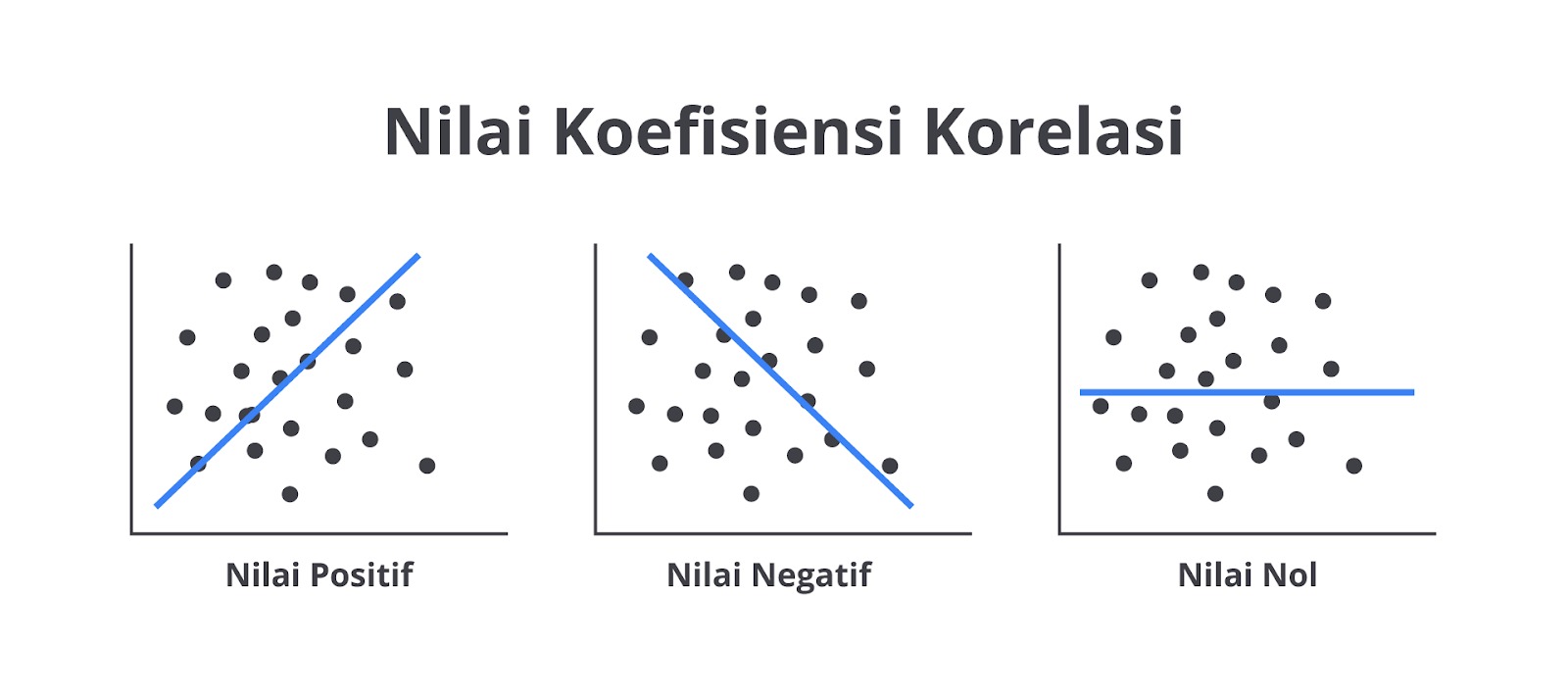
Berikut adalah penjelasan interpretasi dari visualisasi koefisien korelasi di atas.
- Nilai positif: Ketika nilai korelasi positif (antara 0 dan 1), kedua variabel bergerak ke arah yang sama. Misalnya, saat satu variabel naik, variabel lainnya juga naik.
- Nilai negatif: Ketika nilai korelasi negatif (antara 0 dan -1), kedua variabel bergerak ke arah yang berlawanan. Misalnya, ketika satu variabel naik, yang lainnya turun.
- Nilai nol: Ketika nilai korelasi adalah 0, berarti tidak ada hubungan linier antara dua variabel tersebut. Peningkatan atau penurunan satu variabel tidak memengaruhi variabel lainnya.
Untuk menghitung koefisien korelasi Pearson, kita menggunakan rumus berikut.

Penjelasan Kovarians
Kovarians mengukur sejauh mana dua variabel berfluktuasi bersama. Jika kovarians dua variabel positif, ini menunjukkan bahwa kedua variabel cenderung bergerak ke arah yang sama. Sebaliknya, jika kovarians negatif, ini menunjukkan bahwa kedua variabel cenderung bergerak ke arah yang berlawanan. Jika kovarians bernilai 0, ini menunjukkan bahwa tidak ada hubungan linier antara kedua variabel.
Namun, salah satu kekurangan kovarians adalah bahwa ia tidak memiliki skala tetap sehingga sulit untuk menginterpretasikan seberapa kuat hubungan antara variabel hanya berdasarkan nilai kovarians. Hal ini berbeda dengan korelasi yang terstandardisasi antara -1 dan 1.
Kovarians antara dua variabel X dan Y dihitung dengan rumus berikut.
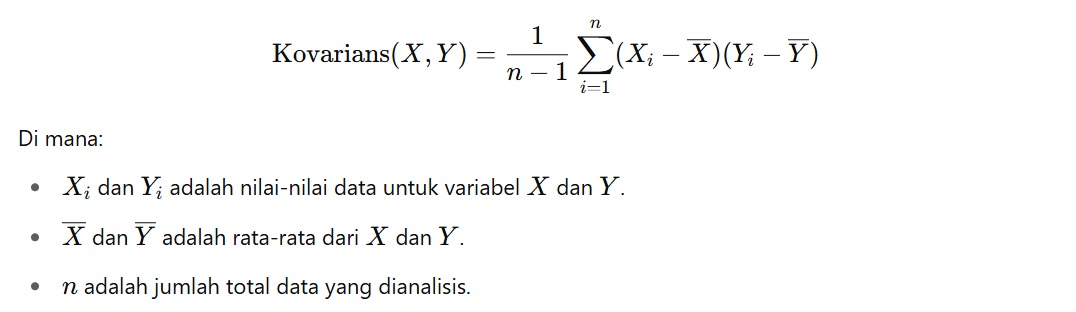
Perbedaan Utama Korelasi dan Kovarians
Kita sudah tahu penjelasan dari korelasi dan kovarians. Keduanya adalah ukuran statistik yang menilai hubungan antara dua variabel, tetapi keduanya berbeda dalam beberapa aspek utama.
Untuk lebih mempertegas perbedaan di antara keduanya, simak tabel berikut.
| Topik | Korelasi | Kovarians |
|---|---|---|
| Hal yang Diukur | Arah dan kekuatan hubungan (skala antara -1 dan 1). | Arah hubungan (positif, negatif, atau tidak ada hubungan). |
| Skala | Selalu antara -1 dan 1 (standar). | Tergantung pada satuan variabel (tidak terstandardisasi). |
| Interpretasi | Lebih mudah ditafsirkan karena terstandardisasi dan dapat dibandingkan di seluruh kumpulan data. | Lebih sulit ditafsirkan karena nilainya bergantung pada skala data. |
| Satuan | Tidak ada satuan (tidak berdimensi). | Memiliki unit (karena berdasarkan data asli). |
| Kasus Penggunaan | Berguna untuk membandingkan hubungan antar himpunan data yang berbeda. | Berguna untuk memahami arah hubungan dalam satu kumpulan data. |
| Contoh | Jika korelasinya +0,8, artinya hubungan positif yang kuat. | Bila kovariansinya +100, artinya variabel-variabel bergerak bersama, tetapi seberapa kuat? |
Penerapan Korelasi dan Kovarians dalam Data Multivariat
Korelasi lebih sering digunakan daripada kovarians dalam analisis data multivariat karena korelasi memberikan hasil yang terstandardisasi antara -1 dan 1 sehingga lebih mudah untuk diinterpretasikan. Sementara itu, kovarians memberikan nilai bergantung pada satuan pengukuran variabel, yang menjadikannya lebih sulit untuk membandingkan antarvariabel dengan skala berbeda.
Korelasi juga lebih berguna ketika kita ingin mengukur kekuatan hubungan linier antarvariabel. Kovarians lebih berguna apabila kita hanya tertarik untuk melihat jika dua variabel bergerak bersama.
Kendati demikian, korelasi dan kovarians sangat penting dalam analisis multivariat, yakni ketika kita mengamati lebih dari satu variabel. Dalam analisis regresi linier multivariat, korelasi dan kovarians antara variabel independen sangat penting untuk mengevaluasi jika ada hubungan yang kuat antara variabel independen dan dependen.
Korelasi dan kovarians juga digunakan untuk seleksi fitur dan reduksi dimensi, seperti dalam principal component analysis (PCA), yakni kita mencari variabel yang memiliki hubungan kuat dengan variabel lainnya.
Selain itu, dalam pengolahan data yang melibatkan banyak variabel, seperti analisis klaster atau analisis faktor, mengukur korelasi dan kovarians antara variabel sangat membantu dalam memahami cara variabel-variabel tersebut berinteraksi dan membentuk struktur pada data.
Rangkuman Data Univariat dan Multivariat
Pengantar Matematika untuk Data Science
Keterkaitan Matematika dan Ilmu Data Science
Data science adalah bidang yang menggabungkan berbagai disiplin, seperti matematika, statistika, dan ilmu komputer untuk mengekstraksi wawasan dari data. Semua ilmu tersebut kemudian ditopang oleh domain knowledge, yakni pemahaman mendalam tentang konteks bisnis, industri, atau masalah nyata yang sedang dianalisis.
Matematika adalah bahasa universal yang memungkinkan kita menganalisis pola, membuat prediksi, serta menyusun model yang dapat membantu dalam pengambilan keputusan. Matematika berperan dalam mengolah, memahami, serta menafsirkan data dengan cara yang sistematis dan akurat.
Peran Matematika dalam Data Science
Matematika adalah elemen fundamental dalam data science karena memungkinkan kita untuk memahami, menganalisis, dan mengolah data secara sistematis. Tanpa pemahaman yang kuat terhadap konsep matematika, seorang data scientist akan kesulitan dalam menafsirkan pola pada data, membangun model prediktif, serta mengoptimalkan algoritma machine learning.
Dalam dunia data science, empat cabang utama matematika yang paling berperan adalah statistika, probabilitas, aljabar linear, dan kalkulus. Masing-masing memiliki kegunaan unik dan diterapkan dalam berbagai aspek analisis data, mulai dari eksplorasi data hingga pengembangan model kecerdasan buatan.
Fokus Pembelajaran: Statistika dan Probabilitas
Meskipun ada empat cabang utama matematika yang berperan penting dalam data science—statistika, probabilitas, aljabar linear, serta kalkulus, kelas ini akan berfokus pada statistika dan probabilitas. Alasannya adalah karena kedua cabang ini adalah inti dari proses analisis data yang dilakukan sehari-hari oleh para data scientist.
Klasifikasi Data dalam Data Science
Klasifikasi Data Berdasarkan Sifat
Secara umum, data dapat dikategorikan dalam dua kelompok utama berdasarkan sifatnya: data kategorikal dan data kuantitatif.
Data Kategorikal
Data kategorikal adalah data yang tidak berbentuk angka, tetapi terdiri dari kategori atau label yang menunjukkan karakteristik tertentu dari objek atau individu.
Data Kuantitatif
Berbeda dengan data kategorikal, data kuantitatif atau numerik adalah data berbentuk angka yang bisa diukur atau dihitung, yakni pendapatan, umur, berat badan, dan sebagainya. Data kuantitatif memungkinkan kita untuk melakukan operasi matematika, seperti penjumlahan, pengurangan, atau perhitungan rata-rata.
Klasifikasi Data Berdasarkan Level Pengukuran
Setelah kita memahami klasifikasi data berdasarkan sifat dan jumlah variabelnya, kini saatnya menggali lebih dalam dengan mengetahui data berdasarkan level pengukurannya, yaitu data nominal, ordinal, interval, dan rasio.
Data Nominal
Data nominal adalah jenis data kategorikal yang paling dasar. Data ini hanya digunakan untuk mengidentifikasi atau mengelompokkan objek, individu, atau variabel dalam kategori tertentu, tanpa ada urutan atau ranking di antara kategori-kategori tersebut.
Data Ordinal
Data ordinal memiliki sifat kategorikal seperti data nominal, tetapi dengan tambahan karakteristik urutan atau tingkatan. Artinya, data ini mengandung informasi mengenai ranking atau posisi relatif dari satu kategori terhadap kategori lainnya.
Data Interval
Berbeda dengan data ordinal, data interval memiliki urutan jelas dan jarak yang sama antara kategori-kategori. Data interval adalah data dengan nilai numerik dengan selisih yang bisa diukur, tetapi tidak memiliki nol mutlak. Nol dalam skala interval bukan berarti “tidak ada”, melainkan hanya sebagai titik referensi.
Data Rasio
Data rasio adalah jenis data yang memiliki semua karakteristik data interval, tetapi dengan tambahan nol mutlak. Nol mutlak berarti tidak adanya suatu atribut yang diukur. Dengan demikian, perhitungan rasio antara nilai-nilai dalam data ini menjadi bermakna.
Klasifikasi Data Berdasarkan Jumlah Variabel
Data dapat dikategorikan berdasarkan jumlah variabel yang dianalisis, antara lain data univariat dan data multivariat.
Data Univariat (Satu Variabel)
Data univariat adalah data yang hanya memiliki satu variabel atau satu jenis pengamatan. Dalam analisis data univariat, kita hanya fokus pada satu aspek dari dataset tanpa mempertimbangkan hubungan antarvariabel lainnya.
Data Multivariat (Banyak Variabel)
Data multivariat adalah data dengan lebih dari satu variabel yang diukur atau diamati dalam satu waktu. Dalam analisis multivariat, kita tidak hanya melihat satu variabel, tetapi juga menganalisis hubungan antarvariabel untuk menemukan pola atau korelasi.
Data Kategorikal Univariat
Apa Itu Data Kategorikal?
Data kategorikal adalah jenis data berisi kategori atau label, bukan angka yang bisa dihitung secara matematis. Data ini kerap digunakan untuk mengelompokkan objek atau individu berdasarkan karakteristik tertentu, seperti warna, jenis kelamin, preferensi makanan, status pekerjaan, atau metode pembayaran.
Data kategorikal univariat berarti data yang bersifat kategorikal dan hanya memiliki satu variabel atau satu jenis pengamatan. Dalam analisis data kategorikal univariat, kita hanya fokus pada satu aspek dari dataset tanpa mempertimbangkan hubungan antarvariabel lainnya. Pada materi kali ini, data-data yang disajikan dan dijelaskan hanya yang bersifat univariat atau satu variabel.
Representasi Data Kategorikal
Beberapa metode umum untuk merepresentasikan data kategorikal adalah tabel frekuensi, cross tabulation (tabulasi silang), dan encoding data kategorikal. Setiap metode memiliki kegunaan berbeda tergantung pada konteks analisis yang dilakukan.
Visualisasi Data Kategorikal dalam Data Science
Beberapa jenis visualisasi yang paling umum digunakan untuk data kategorikal, yaitu bar chart, pie chart, dan pareto chart. Setiap metode memiliki keunggulan dan penggunaannya masing-masing tergantung pada tujuan analisis yang ingin kita capai.
Ukuran Kecenderungan Data Kategorikal
Dalam data kuantitatif, kita sering menggunakan mean atau median sebagai ukuran kecenderungan sentral. Namun, dalam data kategorikal, ukuran kecenderungan yang paling umum digunakan adalah modus (mode). Modus adalah kategori yang paling sering muncul dalam suatu dataset.
Contohnya, jika data warna favorit sebagai berikut: merah, biru, biru, hijau, merah, biru, kuning, merah, biru, biru.
Modus dari data tersebut adalah biru–karena warna ini muncul paling banyak dibandingkan yang lain.
Modus sangat berguna dalam berbagai analisis, misalnya dalam memahami preferensi pelanggan atau tren pasar.
Data Kuantitatif Univariat: Pengantar
Pada submodul ini, kita akan menyelami berbagai aspek penting dari data kuantitatif. Dengan pemahaman kuat tentang data kuantitatif, Anda akan memiliki fondasi analitis yang kokoh dalam perjalananmu sebagai data scientist. Mari kita mulai!
Data Kuantitatif Univariat: Pengertian
Data kuantitatif adalah jenis data yang bisa dihitung dan diukur. Data ini berbentuk angka dan bisa digunakan pada berbagai analisis statistik untuk mendapatkan wawasan yang lebih dalam. Contoh umum dari data kuantitatif meliputi tinggi badan, berat badan, suhu, jumlah pelanggan, pendapatan bulanan, dan nilai ujian.
Data kuantitatif univariat berarti data yang bersifat kuantitatif dan hanya memiliki satu variabel atau satu jenis pengamatan. Dalam materi kali ini, data-data yang disajikan dan dijelaskan hanya yang bersifat univariat atau satu variabel.
Data Kuantitatif Univariat: Ukuran Pemusatan Data
Dalam statistik, ada tiga ukuran pemusatan data utama yang digunakan.
- Mean (rata-rata), yakni nilai rata-rata dari sekumpulan angka.
- Median (nilai tengah), yakni angka yang berada tepat di tengah ketika data diurutkan.
- Mode (Modus), yakni angka yang paling sering muncul dalam dataset.
Setiap ukuran memiliki kegunaan masing-masing, tergantung pada sifat data dan tujuan analisis.
Data Kuantitatif Univariat: Ukuran Penyebaran Data
Beberapa ukuran penyebaran yang umum digunakan adalah range, variance, standard deviation, interquartile range (IQR), dan coefficient of variation (CV). Mari kita telaah satu per satu.
Range: Menentukan Jarak antara Nilai Maksimum dan Minimum
Range (jangkauan) adalah ukuran penyebaran paling sederhana, yang menunjukkan perbedaan antara nilai terbesar dan nilai terkecil dalam dataset. Dengan kata lain, range berarti selisih antara nilai maksimum dan nilai minimum dalam dataset.
Variance & Standard Deviation: Mengukur Sebaran Data terhadap Mean
Variansi menunjukkan ukuran seberapa tersebar/jauh data atau nilai pada dataset dari mean (rata-rata) dalam bentuk kuadrat, sedangkan standar deviasi adalah akar kuadrat dari varians dan dinyatakan dalam satuan yang sama dengan data aslinya.
Interquartile Range (IQR): Menangani Outlier dalam Sebaran Data
IQR adalah ukuran penyebaran yang lebih tahan terhadap outlier karena hanya melihat rentang antara kuartil pertama (Q1) dan kuartil ketiga (Q3) dalam urutan data. Sederhananya, IQR dihitung sebagai selisih antara kuartil ketiga (Q3) dan kuartil pertama (Q1) dengan rumus sebagai berikut.
Coefficient of Variation (CV): Membandingkan Variasi pada Berbagai Dataset
Coefficient of Variation atau CV mengukur seberapa besar penyebaran relatif dibandingkan dengan mean dalam bentuk persentase. CV digunakan ketika kita ingin membandingkan variabilitas dua dataset dengan mean yang sangat berbeda.
Data Kuantitatif Univariat: Standardisasi dan Normalisasi Data
Kita perlu menyamakan skala semua variabel agar tidak ada fitur yang mendominasi analisis. Proses ini disebut standardisasi atau normalisasi data.
Ada beberapa metode yang umum digunakan untuk melakukan normalisasi data, seperti z-score, min-max scaling, dan robust scaling.
| Metode | Skala Hasil | Sensitif Terhadap Outlier | Kapan Digunakan |
| Z-Score | Rata-rata = 0, standar deviasi = 1 | Sangat sensitif terhadap outlier. | Saat data harus mengikuti distribusi normal standar. Digunakan dalam regresi linier, KNN, atau algoritma yang sensitif terhadap skala data. |
| Min-Max Scaling | Rentang (misalnya, 0 hingga 1) | Sensitif terhadap outlier. | Saat data harus mengikuti distribusi normal standar. Digunakan dalam regresi linier, KNN, atau algoritma yang sensitif terhadap skala data. |
| Robust Scaling | Tidak tetap (berdasarkan IQR). | Tidak sensitif terhadap outlier. | Ketika dataset mengandung outlier yang harus dihindari, cocok untuk data terdistribusi tidak normal. |
Data Kuantitatif Univariat: Distribusi Data
Distribusi data dapat berbentuk simetris (normal) atau tidak simetris (skewed). Selain itu, distribusi juga dapat dikategorikan berdasarkan seberapa tajam atau datar puncaknya (kurtosis).
Distribusi Normal (Gaussian Distribution)
Distribusi normal adalah salah satu distribusi yang paling banyak ditemukan pada statistik dan sangat penting dalam analisis data. Distribusi ini sering disebut sebagai kurva lonceng atau bell curve karena bentuknya yang menyerupai lonceng, dengan sebagian besar nilai data terpusat di sekitar rata-rata (mean) dan semakin sedikit nilai yang terletak jauh dari rata-rata tersebut.
Distribusi Skewed (Miring)
Distribusi skewed terjadi ketika data tidak terdistribusi secara simetris atau lebih terkonsentrasi di satu sisi dari distribusi. Dengan kata lain, ada lebih banyak nilai yang berada di satu sisi dibandingkan sisi lainnya.
Dalam distribusi skewed, kita dapat melihat bahwa data tidak terdistribusi secara merata di sekitar rata-rata (mean), tetapi condong ke sisi tertentu—baik sisi kiri maupun sisi kanan dari distribusi.
Kurtosis: Mengukur Puncak dan Sebaran Data
Kurtosis adalah ukuran statistik yang mengukur tinggi dan lebar puncak distribusi data. Dalam kata lain, kurtosis memberikan gambaran tentang seberapa terpusat data di sekitar rata-rata (mean) dibandingkan dengan distribusi normal.
Kurtosis dapat membantu kita memahami bahwa data kita memiliki lebih banyak nilai yang terkonsentrasi di sekitar rata-rata atau lebih tersebar dalam berbagai nilai.
Pada distribusi normal, kurtosis mendekati nilai 3 (angka tiga adalah standar kurtosis distribusi normal), yang dikenal dengan sebutan mesokurtic. Namun, distribusi data bisa memiliki kurtosis lebih tinggi (leptokurtic) atau kurtosis lebih rendah (platykurtic) tergantung pada bentuk distribusinya.
Data Kuantitatif Univariat: Distribusi Probabilitas
Pemahaman tentang distribusi probabilitas sangatlah penting, terutama saat kita belajar data science dan machine learning. Pasalnya, berbagai model machine learning dan statistik sering mengandalkan distribusi probabilitas untuk membuat estimasi atau prediksi.
Regresi Linier
Dalam regresi linier, sering diasumsikan bahwa data yang digunakan mengikuti distribusi normal. Regresi linier sendiri adalah salah satu teknik statistik yang paling umum digunakan untuk prediksi dan analisis hubungan antarvariabel. Tujuan utamanya adalah memodelkan hubungan antara satu atau lebih variabel independen (fitur) dan sebuah variabel dependen (target).
Naive Bayes
Naive Bayes adalah algoritma machine learning yang digunakan untuk klasifikasi. Algoritma ini didasarkan pada teorema Bayes yang mengasumsikan bahwa fitur (variabel input) bersifat independen satu sama lain.
Monte Carlo Simulations
Monte Carlo Simulations adalah teknik statistik yang digunakan untuk memperkirakan hasil atau estimasi ketidakpastian dalam model stochastic (yang melibatkan variabel acak).
Data Kategorikal Multivariat
Pengenalan Data Kategorikal Multivariat
Data kategorikal multivariat merujuk pada data dengan lebih dari satu variabel kategorikal yang saling berinteraksi atau saling memengaruhi. Dalam analisis multivariat, kita tidak hanya memeriksa satu variabel saja, tetapi juga hubungan antara beberapa variabel kategorikal untuk menemukan pola atau asosiasi yang lebih kompleks.
Analisis Asosiasi dan Hubungan Antarvariabel Kategorikal
Salah satu alat yang paling umum digunakan dalam analisis hubungan antarvariabel kategorikal adalah tabel kontingensi.
Tabel Kontingensi: Mengukur Asosiasi Antarvariabel Kategorikal
Tabel kontingensi adalah alat statistik yang digunakan untuk mengukur asosiasi antara dua atau lebih variabel kategorikal. Tabel ini memperlihatkan frekuensi dari kombinasi kategori dalam dataset, yang membantu kita melihat hubungan atau pola antara variabel yang sedang dianalisis.
Uji Chi-Square: Menguji Independensi Antarvariabel Kategorikal
Uji Chi-Square digunakan untuk menguji bahwa dua variabel kategorikal independen atau terkait satu sama lain. Apabila dua variabel independen, distribusi frekuensi yang diamati dalam tabel kontingensi akan sama dengan distribusi yang diharapkan jika kedua variabel tersebut tidak berhubungan.
Dengan kata lain, uji ini melihat bahwa perbedaan antara frekuensi yang diamati dan frekuensi yang diharapkan cukup besar untuk menyimpulkan bahwa ada hubungan signifikan antara kedua variabel.
Data Kuantitatif Multivariat
Sebelum mempelajari metode dan teknik yang digunakan, mari kita mulai dengan mengenali data kuantitatif multivariat dan karakteristiknya terlebih dahulu.
Pengenalan Data Kuantitatif Multivariat
Data kuantitatif multivariat merujuk pada analisis yang melibatkan lebih dari satu variabel kuantitatif untuk memahami hubungan antarvariabel. Dalam banyak kasus, data ini sering digunakan untuk mengidentifikasi pola, hubungan, atau tren lebih rumit yang tidak dapat dilihat hanya dengan analisis univariat (satu variabel).
Korelasi dan Kovarians dalam Data Multivariat
Dalam analisis data multivariat, kita sering kali tertarik untuk mempelajari hubungan antara beberapa variabel. Dua konsep yang sangat penting dalam mengukur hubungan antara dua atau lebih variabel dalam data multivariat adalah korelasi dan kovarians.
Kedua konsep ini memungkinkan kita untuk mengukur sejauh mana variabel-variabel tersebut berhubungan satu sama lain, tetapi dengan cara yang sedikit berbeda.
Perbedaan Utama Korelasi dan Kovarians
Untuk lebih mempertegas perbedaan di antara keduanya, simak tabel berikut.
| Topik | Korelasi | Kovarians |
| Hal yang Diukur | Arah dan kekuatan hubungan (skala antara -1 dan 1). | Arah hubungan (positif, negatif, atau tidak ada hubungan). |
| Skala | Selalu antara -1 dan 1 (standar). | Tergantung pada satuan variabel (tidak terstandardisasi). |
| Interpretasi | Lebih mudah ditafsirkan karena terstandardisasi dan dapat dibandingkan di seluruh kumpulan data. | Lebih sulit ditafsirkan karena nilainya bergantung pada skala data. |
| Satuan | Tidak ada satuan (tidak berdimensi). | Memiliki unit (karena berdasarkan data asli). |
| Kasus Penggunaan | Berguna untuk membandingkan hubungan antar himpunan data yang berbeda. | Berguna untuk memahami arah hubungan dalam satu kumpulan data. |
| Contoh | Jika korelasinya +0,8, artinya hubungan positif yang kuat. | Bila kovariansinya +100, artinya variabel-variabel bergerak bersama, tetapi seberapa kuat? |
Penerapan Korelasi dan Kovarians dalam Data Multivariat
Korelasi lebih sering digunakan daripada kovarians dalam analisis data multivariat karena korelasi memberikan hasil yang terstandardisasi antara -1 dan 1 sehingga lebih mudah untuk diinterpretasikan. Sementara itu, kovarians memberikan nilai bergantung pada satuan pengukuran variabel, yang menjadikannya lebih sulit untuk membandingkan antarvariabel dengan skala berbeda.
Korelasi juga lebih berguna ketika kita ingin mengukur kekuatan hubungan linier antarvariabel. Kovarians lebih berguna apabila kita hanya tertarik untuk melihat jika dua variabel bergerak bersama.
Kendati demikian, korelasi dan kovarians sangat penting dalam analisis multivariat, yakni ketika kita mengamati lebih dari satu variabel. Dalam analisis regresi linier multivariat, korelasi dan kovarians antara variabel independen sangat penting untuk mengevaluasi jika ada hubungan yang kuat antara variabel independen dan dependen.
Korelasi dan kovarians juga digunakan untuk seleksi fitur dan reduksi dimensi, seperti dalam principal component analysis (PCA), yakni kita mencari variabel yang memiliki hubungan kuat dengan variabel lainnya.
Selain itu, dalam pengolahan data yang melibatkan banyak variabel, seperti analisis klaster atau analisis faktor, mengukur korelasi dan kovarians antara variabel sangat membantu dalam memahami cara variabel-variabel tersebut berinteraksi dan membentuk struktur pada data.
This file is located at: _chapters/991-belajar-matematika-untuk-data-science/010-data-univariat-dan-multivariat.md