Studi Kasus A/B Testing dengan Python
- Pengantar Studi Kasus A/B Testing dengan Python
- Perancangan A/B Testing
- Implementasi A/B Testing dengan Python
- Interpretasi Hasil dan Perumusan Keputusan
- Implikasi terhadap Keputusan Bisnis atau Produk
- Rangkuman Studi Kasus A/B Testing dengan Python
- Pengantar
- Perancangan A/B Testing
- Implementasi A/B Testing dengan Python
- Interpretasi Hasil dan Perumusan Keputusan
- Implikasi terhadap Keputusan Bisnis atau Produk
Pengantar Studi Kasus A/B Testing dengan Python
Pada materi sebelumnya, kita telah mengeksplorasi berbagai metode analisis data menggunakan Python, mulai dari menggunakan mean populasi untuk mengestimasi waktu layanan pelanggan, proporsi populasi untuk mengestimasi proporsi pengguna yang puas, uji ANOVA untuk membandingkan rata-rata skor dari hasil blind test, hingga regresi linear sederhana untuk memodelkan hubungan antarvariabel jam belajar dan nilai ujian siswa.
Pemahaman akan instrumen statistik dan kemampuan pemrograman ini berujung pada aplikasi praktis yang signifikan. Salah satu penerapannya yang paling krusial dalam domain bisnis digital dan pengembangan produk adalah A/B testing. Ini adalah sebuah metodologi eksperimental yang memungkinkan pengambilan keputusan berbasis data, jauh melampaui intuisi semata.
Oleh karena itu, pada materi ini kita akan telusuri secara komprehensif bagaimana A/B testing dirancang dan diimplementasikan menggunakan Python.
Perancangan A/B Testing
Sebelum masuk ke analisis data atau coding, langkah pertama dan paling krusial dalam A/B testing adalah perancangan yang matang. Tahap ini adalah cetak biru yang akan memandu seluruh proses Anda, memastikan bahwa eksperimen relevan, terukur, dan akhirnya memberikan wawasan yang dapat ditindaklanjuti.
Tujuan Eksperimen: Menetapkan Sasaran yang Jelas
Setiap A/B test harus dimulai dengan tujuan yang eksplisit dan terukur. Ini bukan sekadar ide umum, melainkan pernyataan spesifik tentang hal yang ingin Anda capai dan alasan pentingnya bagi bisnis.
Sebuah tujuan yang baik haruslah SMART: specific (spesifik), measurable (terukur), achievable (dapat dicapai), relevant (relevan), dan time-bound (memiliki batas waktu), meskipun dalam konteks A/B testing, fokus utamanya adalah pada spesifik, terukur, serta relevan.
Ambil contoh sederhana: sebuah perusahaan e-commerce ingin menguji bahwa perubahan warna tombol “Beli Produk” dari merah ke hijau dapat mendorong lebih banyak pembeli.
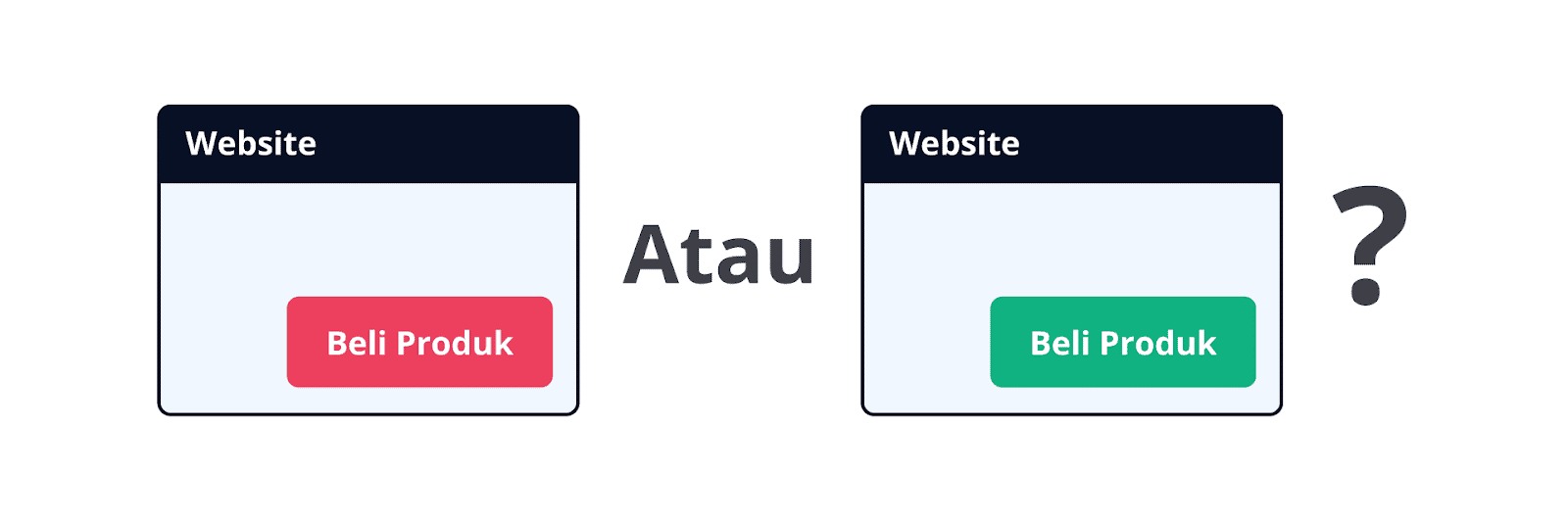
Tujuan di sini bukan hanya “mengubah warna tombol”, melainkan “meningkatkan persentase pengunjung yang menyelesaikan pembelian (tingkat konversi) dengan mengimplementasikan tombol ‘Beli Produk’ berwarna hijau di halaman produk”.
Tujuan ini jelas mendefinisikan perubahan yang dilakukan (warna tombol), metrik yang akan diukur (tingkat konversi), dan dampak yang diharapkan (peningkatan). Pentingnya tujuan ini terletak pada korelasinya yang langsung terhadap peningkatan pendapatan dan efisiensi operasional bisnis. Tanpa tujuan yang jelas, Anda berisiko melakukan eksperimen tanpa arah dan sulit menginterpretasikan hasilnya.
Formulasi Hipotesis: Membentuk Pertanyaan Uji Statistik
Setelah tujuan ditetapkan, langkah selanjutnya adalah menerjemahkannya dalam hipotesis nol (H₀) dan hipotesis alternatif (H₁). Kedua pernyataan ini adalah fondasi dari setiap uji statistik, yang akan memungkinkan Anda membuat kesimpulan berdasarkan probabilitas.
Hipotesis nol (H₀) selalu merupakan pernyataan tidak ada perbedaan, tidak ada efek, atau tidak ada hubungan. Ini adalah status quo atau asumsi default yang akan kita coba sangkal atau tolak berdasarkan bukti yang dikumpulkan dari data. Untuk contoh tombol “Beli Produk” tadi, H₀ akan berbunyi sebagai berikut.
“Rata-rata tingkat konversi untuk tombol merah (kontrol) adalah SAMA DENGAN rata-rata tingkat konversi untuk tombol hijau (perlakuan).“
Jadi dasarnya, H₀ berasumsi bahwa perubahan warna tombol tidak akan membuat perbedaan pada tingkat konversi.
Sebaliknya, hipotesis alternatif (H₁) adalah pernyataan yang ingin Anda buktikan atau dukung melalui data. H₁ adalah kebalikan dari H₀ dan bisa bersifat dua sisi atau satu sisi. Pilihan antara dua sisi dan satu sisi ini penting dan bergantung pada keyakinan awal serta tujuan spesifik Anda.
Jika hanya ingin tahu adakah perbedaan apa pun (bisa lebih tinggi atau lebih rendah), Anda menggunakan H₁ dua sisi.
“Rata-rata tingkat konversi tombol hijau TIDAK SAMA DENGAN rata-rata tingkat konversi tombol merah.”
Namun, jika memiliki alasan kuat untuk percaya bahwa perubahan akan terjadi ke arah tertentu (misalnya, Anda yakin tombol hijau akan meningkatkan konversi), Anda bisa menggunakan H₁ satu sisi.
“Rata-rata tingkat konversi tombol hijau LEBIH TINGGI DARI rata-rata tingkat konversi tombol merah.“
Menggunakan hipotesis satu sisi akan membuat uji lebih sensitif dalam mendeteksi perbedaan ke arah yang diprediksi, tetapi Anda harus yakin dengan asumsi arah tersebut.
Penentuan Metrik Utama: Mengukur Keberhasilan
Pemilihan metrik utama adalah aspek kritis lainnya dalam perancangan. Metrik ini adalah indikator kinerja kunci yang akan diukur untuk mengevaluasi apakah versi perlakuan (B) memang lebih baik dari versi kontrol (A) dalam mencapai tujuan eksperimen.
Metrik yang dipilih harus memenuhi kriteria keterukuran dan relevansi. Ini berarti Anda harus dapat mengumpulkan data untuk metrik ini secara akurat dan metrik tersebut harus secara langsung mencerminkan tujuan bisnis. Hindari “metrik vanity”, angka yang terlihat bagus, tetapi tidak memberikan dampak substansial pada tujuan bisnis.
Beberapa contoh metrik utama yang sering digunakan dalam A/B testing meliputi berikut.
-
Tingkat Konversi (Conversion Rate): Ini adalah metrik paling umum, terutama untuk _e-commerce_atau kampanye pemasaran. Didefinisikan sebagai persentase pengguna yang menyelesaikan tindakan yang diinginkan, seperti pembelian, pendaftaran akun, atau pengisian formulir. Rumusnya adalah berikut.
(Jumlah Pengguna yang Konversi / Jumlah Total Pengunjung) * 100%
Metrik ini sangat relevan jika tujuan Anda adalah mendorong aksi spesifik.
-
Click-Through Rate (CTR): Mengukur persentase pengguna yang melihat suatu elemen (misalnya, iklan, tombol, tautan) dan kemudian mengkliknya. Dihitung sebagai berikut.
(Jumlah Klik / Jumlah Tampilan) * 100%
CTR cocok untuk menguji daya tarik visual atau penempatan elemen.
- Waktu di Halaman (Time on Page): Mengukur rata-rata durasi pengunjung berada di suatu halaman tertentu. Metrik ini dapat menjadi indikator engagement atau kualitas konten, yakni waktu yang lebih lama mungkin menunjukkan halaman lebih menarik atau informatif.
-
Nilai Pesanan Rata-Rata (Average Order Value - AOV): Mengukur rata-rata total nilai pembelian per transaksi. Ini penting jika tujuan Anda adalah meningkatkan pendapatan total, bukan hanya volume transaksi. Ini dihitung sebagai berikut.
Total Pendapatan / Jumlah Transaksi
- Tingkat Retensi (Retention Rate): Mengukur persentase pengguna yang kembali atau terus menggunakan produk/layanan setelah periode tertentu. Ini krusial untuk aplikasi, layanan berlangganan, atau produk yang mengandalkan penggunaan berulang dan loyalitas pelanggan.
Memilih metrik secara tepat akan memastikan bahwa analisis Anda fokus pada data paling relevan untuk pengambilan keputusan dan bahwa eksperimen benar-benar berkontribusi pada pencapaian tujuan bisnis yang substansial.
Implementasi A/B Testing dengan Python
Setelah merancang eksperimen dan menentukan tujuan serta metrik, langkah selanjutnya adalah menerjemahkan rencana tersebut dalam kode Python. Ini melibatkan persiapan data, pemilihan metode analisis statistik yang sesuai, dan visualisasi hasil.
Anda bisa menggunakan tools seperti Google Colab untuk mengikuti latihan ini.
Mempersiapkan Eksperimen (Hipotesis, Confidence Interval, dan Alpha)
Dalam skenario A/B testing yang sesungguhnya, data akan dikumpulkan langsung dari platform atau website. Namun, untuk tujuan pembelajaran dan simulasi, kita akan membuat data fiktif yang merepresentasikan hasil eksperimen.
Kita akan membuat dua kelompok pengunjung, yakni kelompok A dan B. Kelompok A adalah orang-orang yang tidak melihat perubahan pada website, sedangkan kelompok B adalah orang-orang yang melihat perubahan pada website.
Dengan kedua kelompok tersebut, kita ingin melihat apakah terdapat konversi (kejadian sukses, seperti pembelian atau klik) yang terjadi pada masing-masing grup. Dengan kata lain, apakah perubahan yang dilakukan menimbulkan efek positif terhadap pengguna website?
Hipotesis yang akan kita uji adalah sebagai berikut.
- Hipotesis nol (H0): Tidak ada perbedaan konversi antara kedua proporsi (P1 == P2)
- Hipotesis alternatif (H1): Terdapat perbedaan konversi antara kedua proporsi (P1 != P2)
Selain itu, kita akan menggunakan tingkat kepercayaan (confidence interval) 95% dengan tingkat signifikansi (alpha) adalah 0.05%.
Kita akan menggunakan library NumPy pada Python untuk menyimulasikan data ini. Penting untuk menggunakan np.random.seed() agar data yang dihasilkan konsisten setiap kali kode dijalankan sehingga hasil analisis kita dapat direproduksi. Kita akan menentukan jumlah pengunjung pada setiap grup dan perkiraan tingkat konversi dasar, lalu menggunakan distribusi binomial untuk menyimulasikan jumlah konversi berdasarkan probabilitas tersebut.
- import numpy as np
- import pandas as pd
- import scipy.stats as stats
-
from statsmodels.stats.proportion import proportions_ztest
- import matplotlib.pyplot as plt
-
import seaborn as sns
- # Agar data acak selalu sama (untuk reproduktivitas)
-
np.random.seed(42)
- # — Simulasi Data Eksperimen —
- jumlah_pengunjung_A = 1000 # Jumlah pengunjung di Grup Kontrol (Versi A)
-
jumlah_pengunjung_B = 1000 # Jumlah pengunjung di Grup Perlakuan (Versi B)
- # Tingkat konversi baseline (Versi A)
-
tingkat_konversi_A_asli = 0.10 # 10%
- # Tingkat konversi target (Versi B) - kita simulasi sedikit lebih tinggi untuk melihat deteksi perbedaan
-
tingkat_konversi_B_asli = 0.12 # 12%
- # Menghasilkan jumlah konversi (keberhasilan) untuk setiap grup
- # np.random.binomial(n=1, p=prob, size=num_trials).sum() menyimulasikan ‘num_trials’ percobaan
- # setiap percobaan memiliki probabilitas ‘prob’ untuk berhasil.
- konversi_A = np.random.binomial(n=1, p=tingkat_konversi_A_asli, size=jumlah_pengunjung_A).sum()
-
konversi_B = np.random.binomial(n=1, p=tingkat_konversi_B_asli, size=jumlah_pengunjung_B).sum()
- print(f”Versi A (Kontrol): {konversi_A} konversi dari {jumlah_pengunjung_A} pengunjung.”)
-
print(f”Versi B (Perlakuan): {konversi_B} konversi dari {jumlah_pengunjung_B} pengunjung.”)
- # Hitung tingkat konversi yang diamati dari data simulasi
- tingkat_konversi_A_diamati = konversi_A / jumlah_pengunjung_A
-
tingkat_konversi_B_diamati = konversi_B / jumlah_pengunjung_B
- print(f”\nTingkat Konversi Diamati:”)
- print(f”Versi A: {tingkat_konversi_A_diamati:.4f}”)
- print(f”Versi B: {tingkat_konversi_B_diamati:.4f}”)
Mari lihat setiap bagian kode yang digunakan. Pada bagian kode berikut, kita menyiapkan dua kelompok pengguna yang masing-masing berisi 1000 pengunjung.
- # — Simulasi Data Eksperimen —
- jumlah_pengunjung_A = 1000 # Jumlah pengunjung di Grup Kontrol (Versi A)
- jumlah_pengunjung_B = 1000 # Jumlah pengunjung di Grup Perlakuan (Versi B)
Setelah itu, kita mensimulasikan tingkat konversi dengan menggunakan data acak yang mengikuti distribusi binomial. Kenapa harus mengikuti distribusi? Ingat bahwa distribusi binomial adalah jenis distribusi yang menghitung kemungkinan hasil dari percobaan tertentu yang hanya ada dua kemungkinan (1/0) sedangkan tindakan konversi adalah melakukan klik/tidak atau bisa juga melakukan pembelian atau tidak.
- # Tingkat konversi target (Versi B) - kita simulasi sedikit lebih tinggi untuk melihat deteksi perbedaan
-
tingkat_konversi_B_asli = 0.12 # 12%
- # Menghasilkan jumlah konversi (keberhasilan) untuk setiap grup
- # np.random.binomial(n=1, p=prob, size=num_trials).sum() menyimulasikan ‘num_trials’ percobaan
- # setiap percobaan memiliki probabilitas ‘prob’ untuk berhasil.
- konversi_A = np.random.binomial(n=1, p=tingkat_konversi_A_asli, size=jumlah_pengunjung_A).sum()
-
konversi_B = np.random.binomial(n=1, p=tingkat_konversi_B_asli, size=jumlah_pengunjung_B).sum()
- print(f”Versi A (Kontrol): {konversi_A} konversi dari {jumlah_pengunjung_A} pengunjung.”)
- print(f”Versi B (Perlakuan): {konversi_B} konversi dari {jumlah_pengunjung_B} pengunjung.”)
Dalam bagian kode di atas, Anda akan mendapatkan output yang menginformasikan berapa banyak orang yang berhasil dikonversi yang ternyata pada kelompok A terdapat 100 orang (dari 1000 orang) yang berhasil melakukan konversi, sedangkan kelompok B terdapat 112 orang (dari 1000 orang) yang berhasil melakukan konversi.
- Versi A (Kontrol): 100 konversi dari 1000 pengunjung.
- Versi B (Perlakuan): 112 konversi dari 1000 pengunjung.
Jika dlihat dalam bentuk persentase, tingkat konversi yang didapat adalah sebagai berikut.
- # Hitung tingkat konversi yang diamati dari data simulasi
- tingkat_konversi_A_diamati = konversi_A / jumlah_pengunjung_A
-
tingkat_konversi_B_diamati = konversi_B / jumlah_pengunjung_B
- print(f”\nTingkat Konversi Diamati:”)
- print(f”Versi A: {tingkat_konversi_A_diamati:.4f}”)
-
print(f”Versi B: {tingkat_konversi_B_diamati:.4f}”)
- # Output
- # Tingkat Konversi Diamati:
- # Versi A: 0.1000
- # Versi B: 0.1120
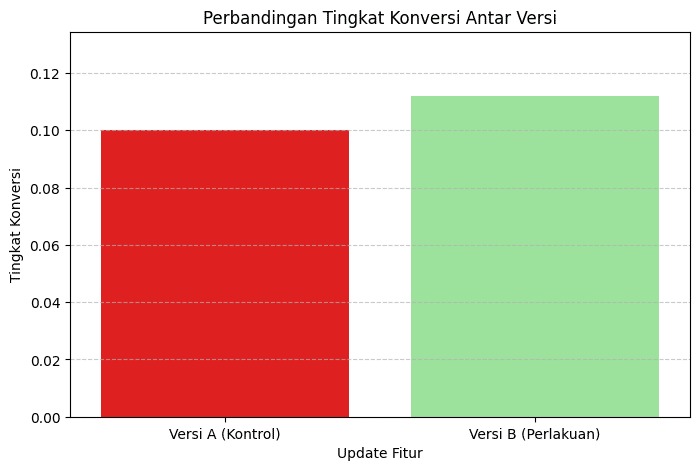
Sekilas, Anda mungkin langsung menyimpulkan bahwa nilai pada kelompok B lebih tinggi dibandingkan kelompok A. Namun, perbedaan tersebut belum cukup kuat untuk dijadikan dasar kesimpulan yang valid secara statistik. Kita perlu menguji apakah perbedaan tersebut benar-benar signifikan secara statistik atau hanya terjadi secara kebetulan.
Anda dapat menggunakan kode di bawah ini untuk melihat visualisasi data dari output di atas.
- # — Visualisasi Hasil —
- labels = [‘Versi A (Kontrol)’, ‘Versi B (Perlakuan)’]
-
konversi_rates = [tingkat_konversi_A_diamati, tingkat_konversi_B_diamati]
- plt.figure(figsize=(8, 5))
- # Membuat bar chart menggunakan Seaborn untuk visualisasi yang menarik
- sns.barplot(x=labels, y=konversi_rates, palette=[‘red’, ‘lightgreen’])
- plt.title(‘Perbandingan Tingkat Konversi Antar Versi’)
- plt.xlabel(‘Update Fitur’)
- plt.ylabel(‘Tingkat Konversi’)
- plt.ylim(0, max(konversi_rates) * 1.2) # Mengatur batas Y agar grafik terlihat jelas
- plt.grid(axis=‘y’, linestyle=’–’, alpha=0.7) # Menambahkan grid horizontal
-
plt.show()
- # — Hasil Uji Z-test Proporsi —
- # Z-statistik: -0.8717
- # P-value: 0.3834
Anda akan mendapatkan output seperti di bawah ini.
Pemilihan Jenis Uji Statistik
Setelah data disiapkan, langkah krusial berikutnya adalah memilih uji statistik yang tepat untuk membandingkan kedua kelompok. Pilihan uji bergantung pada jenis data metrik utama Anda. Untuk kasus membandingkan tingkat konversi (yang merupakan proporsi), Z-test untuk proporsi atau Chi-square test adalah pilihan yang paling umum dan tepat.
- Z-test untuk Proporsi: Uji ini cocok ketika ukuran sampel pada setiap grup cukup besar (umumnya > 30 dan jumlah keberhasilan serta kegagalan dalam setiap grup juga memadai). Uji ini secara langsung membandingkan perbedaan antara dua proporsi yang diamati dan menentukan bahwa perbedaan tersebut signifikan. Library
scipy.statsmenyediakan fungsiproportions_ztestyang efisien untuk tujuan ini. - Chi-square Test (χ2 test): Uji ini juga sering digunakan untuk membandingkan frekuensi atau proporsi antara kategori-kategori. Ia mengevaluasi jika ada hubungan yang signifikan antara dua variabel kategorikal (misalnya, grup A/B dan status konversi Ya/Tidak). Meskipun
proportions_ztestlebih langsung untuk perbandingan proporsi,chi2_contingencydariscipy.statsadalah alternatif yang valid dan sering kali memberikan hasil sangat mirip.
Dalam contoh ini, kita akan fokus pada Z-test untuk Proporsi karena itu adalah metode yang paling langsung untuk membandingkan dua tingkat konversi. Rumus z-test untuk Proporsi adalah sebagai berikut.

Kalkulasi Z-Test Menggunakan Python
Untuk memudahkan proses kalkulasi, kita akan menggunakan method dari scipy.stats.proportions_ztest untuk menghitung uji statistik yang dipilih, lalu memvisualisasikan hasilnya untuk memudahkan interpretasi.
- # — Melakukan Uji Z-test untuk Proporsi —
- # ‘count’ adalah jumlah keberhasilan (konversi) untuk masing-masing grup
- # ‘nobs’ adalah jumlah total observasi (pengunjung) untuk masing-masing grup
- # ‘alternative’=’two-sided’ berarti kita menguji apakah ada perbedaan (lebih tinggi atau lebih rendah), bukan hanya satu arah.
- z_statistic, p_value = proportions_ztest(
- count=[konversi_A, konversi_B],
- nobs=[jumlah_pengunjung_A, jumlah_pengunjung_B],
- alternative=‘two-sided’
-
)
- print(f”\n— Hasil Uji Z-test Proporsi —”)
- print(f”Z-statistik: {z_statistic:.4f}”)
-
print(f”P-value: {p_value:.4f}”)
- ## OUTPUT
- # — Hasil Uji Z-test Proporsi —
- # Z-statistik: -0.8717
- # P-value: 0.3834
Dalam Z-test untuk Proporsi, kita membandingkan tingkat keberhasilan (konversi) antara dua kelompok (Grup A dan B).
- konversi_A/konversi_B adalah jumlah keberhasilan.
- jumlah_pengunjung_A/jumlah_pengunjung_B adalah total percobaan di tiap grup.
- alternative=’two-sided’ berarti kita ingin tahu adakah perbedaan proporsi konversi, baik Grup B lebih tinggi maupun lebih rendah dari Grup A.
- z_statistic menunjukkan seberapa jauh perbedaan yang kita amati dari perkiraan jika tidak ada beda sebenarnya.
- p_value adalah probabilitas untuk melihat hasil jika memang tidak ada perbedaan. Jika P-value kecil (misal, < 0.05), artinya ada perbedaan proporsi konversi yang signifikan antara kedua grup.
Kita telah mendapatkan nilai z-statistik dan p-value berdasarkan kasus yang sedang diamati. Lantas, apa makna dari nilai-nilai tersebut? Tahan sejenak! Kita masuk ke bagian berikutnya, yakni interpretasi hasil dan perumusan keputusan.
Catatan: Untuk memahami kode implementasi A/B testing dengan lebih detail, silakan akses pada link berikut.
Interpretasi Hasil dan Perumusan Keputusan
Setelah melalui tahapan formulasi hipotesis, pengumpulan data, serta pelaksanaan uji statistik yang cermat, kita sampai pada fase yang sering dianggap sebagai puncak analisis seorang data scientist: interpretasi hasil dan perumusan keputusan.

Tahap ini adalah jembatan fundamental yang mengonversi output numerik kompleks menjadi wawasan yang dapat ditindaklanjuti dan keputusan bisnis yang strategis. Kemampuan untuk secara akurat membaca, memahami, dan menarik implikasi dari bukti statistik bukan hanya keterampilan teknis, melainkan sebuah kompetensi esensial yang membedakan analis data dari pengambil keputusan yang efektif.
Aturan Pengambilan Keputusan
Tahap ini merupakan titik krusial dalam seluruh proses analisis inferensial, yakni kita secara formal menentukan sikap kita terhadap hipotesis nol (H0). Ini adalah saat ketika kita, sebagai data scientist, harus memutuskan bahwa bukti yang dikumpulkan dari sampel cukup kuat untuk mengklaim adanya efek atau perbedaan pada tingkat populasi.
Keputusan ini tidak dilakukan secara subjektif, tetapi didasarkan pada perbandingan objektif antara P-value yang telah dihitung dengan tingkat signifikansi (α) yang telah kita tetapkan pada awal analisis.
Tingkat signifikansi (α) ini adalah ambang batas yang dipilih untuk mengukur seberapa besar risiko yang bersedia kita ambil dalam membuat kesalahan. Lebih spesifik, α merepresentasikan probabilitas kita untuk membuat kesalahan tipe I, yaitu situasi untuk menolak hipotesis nol (H0) padahal H0 sebenarnya benar (atau sering disebut false positive).
Nilai α yang paling umum dan diterima secara luas dalam berbagai disiplin ilmu adalah 0.05 (atau 5%). Ini berarti, kita bersedia menerima risiko 5% untuk salah menyimpulkan bahwa ada efek atau perbedaan, padahal sebenarnya tidak ada, dalam jangka panjang.
Tidak ada petunjuk khusus dalam menentukan nilai α, tapi ini adalah keputusan penting yang harus dibuat sebelum analisis data serta ini mencerminkan keseimbangan antara sensitivitas deteksi efek dan toleransi terhadap kesalahan.
Aturan keputusan formal yang kita ikuti sangat jelas dan biner, menjadi fondasi bagi semua kesimpulan statistik yang valid.
Skenario Pertama: Ketika Bukti Statistik Melawan Hipotesis Nol (P-value ≤ α)
Jika P-value yang Anda peroleh dari uji statistik adalah sama dengan atau lebih kecil dari tingkat signifikansi (α) yang telah ditetapkan, ini adalah momen Anda memiliki bukti substansial.
P-value yang kecil menunjukkan bahwa kemungkinan mendapatkan hasil yang diamati (atau lebih ekstrem) adalah sangat rendah apabila hipotesis nol (H0) benar. Dengan kata lain, hasil yang Anda lihat terlalu aneh untuk dianggap sebagai kebetulan belaka jika memang tidak ada perbedaan pada populasi.
Dalam kondisi ini, keputusan statistik yang Anda ambil adalah menolak hipotesis nol (H0). Ini adalah pernyataan yang kuat. Kesimpulan yang dapat Anda tarik adalah ada bukti statistik signifikan untuk mendukung hipotesis alternatif (H1).
Artinya, Anda dapat percaya dengan tingkat keyakinan tinggi bahwa perbedaan atau efek yang diamati pada sampel bukan hanya hasil dari variasi acak, melainkan merefleksikan perbedaan atau efek yang memang nyata dan ada pada tingkat populasi secara keseluruhan. Kita secara formal menyebut hasil ini sebagai “signifikan secara statistik”.
Skenario Kedua: Ketika Bukti Statistik Tidak Cukup Kuat Melawan Hipotesis Nol (P-value >α)
Sebaliknya, jika P-value yang Anda hitung adalah lebih besar dari tingkat signifikansi (α), interpretasinya berbeda. P-value yang relatif besar menunjukkan bahwa hasil yang Anda amati, meskipun mungkin ada sedikit perbedaan numerik, cukup mungkin terjadi bahkan jika hipotesis nol (H0) itu benar. Artinya, perbedaan yang Anda lihat bisa jadi hanya fluktuasi acak yang terjadi karena kebetulan dalam proses pengambilan sampel.
Dalam kasus ini, keputusan statistik yang Anda ambil adalah gagal menolak hipotesis nol (H0). Ini adalah formulasi yang sangat presisi dan hati-hati. Penting untuk ditekankan bahwa “gagal menolak H0” tidak sama dengan “menerima H0” atau menyatakan bahwa H0 itu benar. Ini hanya berarti bahwa, dengan data yang dimiliki saat ini, dan pada tingkat signifikansi yang dipilih, Anda tidak memiliki cukup bukti yang meyakinkan untuk mendukung kesimpulan adanya efek atau perbedaan nyata. Hasil ini kemudian disebut sebagai “tidak signifikan secara statistik”. Ini bukan berarti tidak ada efek sama sekali, melainkan bahwa data Anda tidak cukup kuat untuk membuktikannya.
Membaca Output Statistik dari Studi Kasus Sebelumnya
Setiap uji statistik yang kita jalankan–entah itu Z-test, T-test, ANOVA, atau Chi-Square–akan menghasilkan serangkaian nilai. Memahami makna di balik setiap angka ini adalah langkah pertama menuju interpretasi yang benar.
Mari terapkan aturan pengambilan keputusan di atas pada contoh hasil Z-test proporsi yang kita miliki. Pada hasil studi kasus A/B testing ini, kita mendapatkan nilai Z-statistik sebesar -0.8717 dan P-value sebesar 0.3834.
- -– Hasil Uji Z-test Proporsi -–
- Z-statistik: -0.8717
- P-value: 0.3834
Seperti yang telah disebutkan di awal, kita telah menetapkan tingkat signifikansi (α) sebesar 0.05. Ketika membandingkan P-value Anda (0.3834) dengan α (0.05), kita melihat bahwa 0.3834 > 0.05.
Berdasarkan aturan keputusan formal, karena P-value lebih besar dari α, kita gagal menolak hipotesis nol.
Ini berarti, meskipun ada sedikit perbedaan numerik yang diamati dalam tingkat konversi antara Versi A dan Versi B pada sampel Anda, perbedaan tersebut tidak cukup kuat atau konsisten secara statistik untuk menyimpulkan bahwa ada perbedaan nyata pada tingkat populasi.
Perbedaan kecil yang Anda lihat kemungkinan besar hanya disebabkan oleh variasi acak atau “kebetulan” dalam proses sampling, bukan karena Versi B secara intrinsik lebih baik atau lebih buruk daripada Versi A. Jadi, dengan data yang ada, kita tidak bisa secara meyakinkan mengklaim adanya peningkatan atau penurunan yang disebabkan oleh Versi B.
Implikasi terhadap Keputusan Bisnis atau Produk
Bagian terakhir dari proses analisis statistik, dan yang sering kali paling dinanti oleh pemangku kepentingan bisnis, adalah transformasi kesimpulan statistik menjadi rekomendasi konkret serta strategi yang dapat ditindaklanjuti.

Inilah momen seorang data scientist benar-benar memberikan nilai strategis bagi organisasi, mengubah angka dan probabilitas menjadi arah bisnis yang jelas. Pengambilan keputusan efektif dalam era data didorong oleh bukti statistik yang solid, bukan sekadar intuisi.
Skenario A: Ketika Hasil Statistik Menunjukkan Signifikansi (P-value ≤ α)
Apabila hasil uji statistik sudah menunjukkan adanya signifikansi statistik (yaitu, P-value yang Anda peroleh lebih kecil atau sama dengan tingkat signifikansi α yang telah ditentukan), ini adalah indikasi yang sangat kuat. Ini berarti Anda memiliki bukti meyakinkan bahwa versi, perlakuan, atau faktor yang diuji secara sistematis memiliki dampak berbeda dibandingkan dengan kontrol atau baseline.
Efek yang Anda amati dalam sampel tidak dapat dijelaskan hanya dengan kebetulan acak atau variasi sampling semata. Sebaliknya, ini menandakan adanya peluang nyata yang dapat dimanfaatkan (jika dampaknya positif) atau risiko yang perlu diatasi (jika dampaknya negatif).
Sebagai contoh, dalam konteks A/B testing yang kita bahas, jika uji Anda secara statistik membuktikan bahwa Versi B memiliki tingkat konversi yang signifikan lebih tinggi daripada Versi A, rekomendasi bisnisnya adalah meluncurkan Versi B ke seluruh basis pengguna atau audiens target.
Ini bukan hanya sekadar “mencoba sesuatu yang baru”, melainkan sebuah keputusan strategis didukung oleh data terukur dan dapat diandalkan, ini memberikan validasi kuat bagi inovasi yang telah dilakukan.
Demikian pula, dalam analisis yang lebih luas, jika sebuah model regresi menunjukkan bahwa “investasi pada layanan pelanggan” secara signifikan berkorelasi positif dengan “tingkat retensi pelanggan”, perusahaan memiliki dasar kuat untuk meningkatkan investasi di area layanan pelanggan. Ini sebab adanya hubungan yang terbukti secara statistik antara investasi tersebut dan loyalitas pelanggan.
Kesimpulannya, jika ada signifikansi, rekomendasi tindakan umumnya adalah implementasi perubahan, peningkatan skala operasi, realokasi sumber daya, atau penyesuaian strategi produk/pemasaran berdasarkan temuan yang terbukti efektif.
Skenario B: Ketika Hasil Statistik Tidak Menunjukkan Signifikansi (P-value > α)
Sebaliknya, jika hasil uji statistik menunjukkan tidak adanya signifikansi statistik, (yaitu P-value yang diperoleh lebih besar dari tingkat signifikansi α), interpretasinya adalah bahwa Anda tidak memiliki bukti statistik yang cukup kuat untuk menyimpulkan adanya perbedaan atau efek nyata antara versi atau perlakuan yang diuji dan kontrol.
Perbedaan kecil yang mungkin diamati dalam data sampel Anda kemungkinan besar hanya merupakan hasil dari variasi acak atau “noise” dalam data, bukan refleksi dari efek yang mendasari pada populasi. Penting untuk dipahami bahwa ini bukan berarti tidak ada efek sama sekali, melainkan bahwa data yang Anda miliki saat ini tidak cukup untuk membuktikannya pada tingkat kepercayaan yang dipilih.
Keputusan Bisnis Pada Studi Kasus Sebelumnya
Mengacu pada kasus Z-test yang dilakukan (dengan P-value 0.3834), karena P-value ini secara signifikan lebih besar dari α = 0.05, kita berada dalam skenario ini. Artinya, tidak ada bukti statistik yang kuat untuk menyatakan bahwa Versi B secara fundamental lebih baik atau lebih buruk dari Versi A. Meskipun mungkin ada sedikit perbedaan numerik pada tingkat konversi yang Anda amati dalam sampel, perbedaan ini tidak cukup kuat atau konsisten untuk disimpulkan berlaku pada seluruh populasi.
Dalam skenario ini, tindakan dan rekomendasi bisnis yang paling umum dan rasional adalah berikut.
- Tidak Meluncurkan Perubahan (Default Action)
Keputusan yang paling aman dan logis adalah tidak mengimplementasikan Versi B sebagai pengganti Versi A secara luas. Memaksa peluncuran perubahan tanpa bukti signifikansi dapat mengakibatkan pemborosan sumber daya (waktu, biaya pengembangan, biaya pemasaran) tanpa memberikan manfaat yang terukur. Ini adalah prinsip konservatif dalam pengambilan keputusan berbasis data: jangan membuat perubahan besar kecuali ada bukti yang kuat untuk mendukungnya. - Investigasi Lebih Lanjut (Jika Diperlukan secara Bisnis)
Meskipun hasil tidak signifikan, jika perbedaan yang diamati (meskipun kecil dan tidak signifikan secara statistik) masih dianggap penting secara bisnis, Anda tidak perlu menyerah. Ada beberapa opsi untuk investigasi lebih lanjut.- Pengumpulan Data Lebih Lanjut
Salah satu alasan utama hasil tidak signifikan adalah ukuran sampel awal yang terlalu kecil atau durasi eksperimen yang kurang memadai. Ini adalah kasus kesalahan tipe II (Type II Error), yaitu gagal menolak H0 padahal H0 itu sebenarnya salah (ada efek, tetapi tidak terdeteksi). Dengan menjalankan uji lebih lama, audiens lebih besar, atau desain eksperimen lebih sensitif (misalnya, sequential testing), kita dapat meningkatkan kekuatan statistik untuk mendeteksi efek kecil yang mungkin ada. - Analisis Segmentasi
Mungkin efeknya tidak signifikan secara keseluruhan, tetapi signifikan hanya pada segmen pengguna tertentu (misalnya, pengguna baru, pengguna dari demografi tertentu). Melakukan analisis sub-kelompok dapat mengungkap wawasan tersembunyi. - Revisi dan Uji Ulang
Jika ada hipotesis kuat atau keyakinan produk yang mendalam bahwa Versi B seharusnya lebih baik, tim dapat melakukan analisis kualitatif dan kuantitatif lebih mendalam untuk memahami alasan bahwa tidak ada perbedaan signifikan. Berdasarkan wawasan ini, Versi B dapat direvisi secara substansial, dan kemudian diuji ulang.
- Pengumpulan Data Lebih Lanjut
- Pentingnya Kehati-hatian
Krusial bagi seorang data scientist untuk menghindari membuat keputusan besar atau mengklaim adanya efek berdasarkan perbedaan yang tidak signifikan secara statistik. Ini adalah praktik keliru dan dapat mengarah pada keputusan bisnis yang tidak efektif, pemborosan sumber daya, atau bahkan kerugian, karena Anda beraksi berdasarkan kebetulan acak dan bukan pada bukti yang teruji.
Dengan demikian, tahap interpretasi dan pengambilan keputusan berdasarkan bukti statistik adalah siklus terakhir dari analisis data science. Ini memungkinkan organisasi untuk tidak hanya mengumpulkan dan menganalisis data, tetapi juga untuk secara cerdas mengubah wawasan statistik menjadi strategi yang terukur, rasional, serta efektif, memaksimalkan peluang keberhasilan proyek dan inisiatif bisnis.
Rangkuman Studi Kasus A/B Testing dengan Python
Berikut adalah rangkuman dari modul ini.
Pengantar
Pemahaman akan instrumen statistik dan kemampuan pemrograman ini berujung pada aplikasi praktis yang signifikan. Salah satu penerapannya yang paling krusial dalam domain bisnis digital dan pengembangan produk adalah A/B testing. Ini adalah sebuah metodologi eksperimental yang memungkinkan pengambilan keputusan berbasis data, jauh melampaui intuisi semata.
Perancangan A/B Testing
Sebelum masuk ke analisis data atau coding, langkah pertama dan paling krusial dalam A/B testing adalah perancangan yang matang. Tahap ini adalah cetak biru yang akan memandu seluruh proses Anda, memastikan bahwa eksperimen relevan, terukur, dan akhirnya memberikan wawasan yang dapat ditindaklanjuti.
Tujuan Eksperimen: Menetapkan Sasaran yang Jelas
Tujuan di sini bukan hanya “mengubah warna tombol”, melainkan “meningkatkan persentase pengunjung yang menyelesaikan pembelian (tingkat konversi) dengan mengimplementasikan tombol ‘Beli Produk’ berwarna hijau di halaman produk”.
Formulasi Hipotesis: Membentuk Pertanyaan Uji Statistik
Hipotesis nol (H₀) selalu merupakan pernyataan tidak ada perbedaan, tidak ada efek, atau tidak ada hubungan. Untuk contoh tombol “Beli Produk” tadi, H₀ akan berbunyi sebagai berikut.
Sebaliknya, hipotesis alternatif (H₁) adalah pernyataan yang ingin Anda buktikan atau dukung melalui data. H₁ adalah kebalikan dari H₀ dan bisa bersifat dua sisi atau satu sisi.
Penentuan Metrik Utama: Mengukur Keberhasilan
Beberapa contoh metrik utama yang sering digunakan dalam A/B testing meliputi berikut.
- Tingkat Konversi (Conversion Rate)
- Click-Through Rate (CTR)
- Waktu di Halaman (Time on Page)
- Nilai Pesanan Rata-Rata (Average Order Value - AOV)
- Tingkat Retensi (Retention Rate)
Implementasi A/B Testing dengan Python
Mari coba menerapkan A/B testing menggunakan Python dengan melakukan langkah-langkah berikut.
Persiapan Data Eksperimen A dan B
Kita akan menggunakan library NumPy pada Python untuk menyimulasikan data ini.
- import numpy as np
- import pandas as pd
- import scipy.stats as stats
-
from statsmodels.stats.proportion import proportions_ztest
- import matplotlib.pyplot as plt
-
import seaborn as sns
- # Agar data acak selalu sama (untuk reproduktivitas)
-
np.random.seed(42)
- # — Simulasi Data Eksperimen —
- jumlah_pengunjung_A = 1000 # Jumlah pengunjung di Grup Kontrol (Versi A)
-
jumlah_pengunjung_B = 1000 # Jumlah pengunjung di Grup Perlakuan (Versi B)
- # Tingkat konversi baseline (Versi A)
-
tingkat_konversi_A_asli = 0.10 # 10%
- # Tingkat konversi target (Versi B) - kita simulasi sedikit lebih tinggi untuk melihat deteksi perbedaan
-
tingkat_konversi_B_asli = 0.12 # 12%
- # Menghasilkan jumlah konversi (keberhasilan) untuk setiap grup
- # np.random.binomial(n=1, p=prob, size=num_trials).sum() menyimulasikan ‘num_trials’ percobaan
- # setiap percobaan memiliki probabilitas ‘prob’ untuk berhasil.
- konversi_A = np.random.binomial(n=1, p=tingkat_konversi_A_asli, size=jumlah_pengunjung_A).sum()
-
konversi_B = np.random.binomial(n=1, p=tingkat_konversi_B_asli, size=jumlah_pengunjung_B).sum()
- print(f”Versi A (Kontrol): {konversi_A} konversi dari {jumlah_pengunjung_A} pengunjung.”)
-
print(f”Versi B (Perlakuan): {konversi_B} konversi dari {jumlah_pengunjung_B} pengunjung.”)
- # Hitung tingkat konversi yang diamati dari data simulasi
- tingkat_konversi_A_diamati = konversi_A / jumlah_pengunjung_A
-
tingkat_konversi_B_diamati = konversi B / jumlah_pengunjung_B
- print(f”\nTingkat Konversi Diamati:”)
- print(f”Versi A: {tingkat_konversi_A_diamati:.4f}”)
- print(f”Versi B: {tingkat_konversi_B_diamati:.4f}”)
Pemilihan Jenis Uji Statistik
Setelah data disiapkan, langkah krusial berikutnya adalah memilih uji statistik yang tepat untuk membandingkan kedua kelompok. Pilihan uji bergantung pada jenis data metrik utama Anda.
Dalam contoh ini, kita akan fokus pada Z-test untuk Proporsi karena itu adalah metode yang paling langsung untuk membandingkan dua tingkat konversi.
Penggunaan Library scipy.stats dan Visualisasi Hasil
Dengan data yang sudah siap dan uji statistik yang dipilih, kita bisa melanjutkan pada analisis menggunakan library scipy.stats dalam Python, lalu memvisualisasikan hasilnya untuk memudahkan interpretasi.
- # — Melakukan Uji Z-test untuk Proporsi —
- # ‘count’ adalah jumlah keberhasilan (konversi) untuk masing-masing grup
- # ‘nobs’ adalah jumlah total observasi (pengunjung) untuk masing-masing grup
- # ‘alternative’=’two-sided’ berarti kita menguji apakah ada perbedaan (lebih tinggi atau lebih rendah),
- # bukan hanya satu arah. Jika kita yakin B HANYA bisa lebih tinggi, bisa pakai ‘larger’.
- z_statistic, p_value = proportions_ztest(
- count=[konversi_A, konversi_B],
- nobs=[jumlah_pengunjung_A, jumlah_pengunjung_B],
- alternative=‘two-sided’
-
)
- print(f”\n— Hasil Uji Z-test Proporsi —”)
- print(f”Z-statistik: {z_statistic:.4f}”)
- print(f”P-value: {p_value:.4f}”)
Karena P-value (0.3834) jauh lebih besar dari tingkat signifikansi umum (misalnya 0.05), kita gagal menolak hipotesis nol. Ini berarti tidak ada perbedaan yang signifikan secara statistik dalam tingkat konversi antara Versi A dan Versi B.
Perbedaan kecil yang terlihat kemungkinan besar hanya karena kebetulan atau variasi acak, bukan karena salah satu versi benar-benar lebih baik atau lebih buruk dari yang lain.
Interpretasi Hasil dan Perumusan Keputusan
Setelah melalui tahapan formulasi hipotesis, pengumpulan data, serta pelaksanaan uji statistik yang cermat, kita sampai pada fase yang sering dianggap sebagai puncak analisis seorang data scientist: interpretasi hasil dan perumusan keputusan.
Aturan Pengambilan Keputusan
Aturan keputusan formal yang kita ikuti sangat jelas dan biner, menjadi fondasi bagi semua kesimpulan statistik yang valid.
Skenario Pertama: Ketika Bukti Statistik Melawan Hipotesis Nol (P-value ≤ α)
Dalam kondisi ini, keputusan statistik yang Anda ambil adalah menolak hipotesis nol (H0). Ini adalah pernyataan yang kuat. Kesimpulan yang dapat Anda tarik adalah ada bukti statistik signifikan untuk mendukung hipotesis alternatif (H1).
Skenario Kedua: Ketika Bukti Statistik Tidak Cukup Kuat Melawan Hipotesis Nol (P-value >α)
Dalam kasus ini, keputusan statistik yang Anda ambil adalah gagal menolak hipotesis nol (H0). Ini adalah formulasi yang sangat presisi dan hati-hati. Penting untuk ditekankan bahwa “gagal menolak H0” tidak sama dengan “menerima H0” atau menyatakan bahwa H0 itu benar.
Membaca Output Statistik
Mari terapkan aturan pengambilan keputusan di atas pada contoh hasil Z-test proporsi yang kita miliki. Pada hasil studi kasus A/B testing ini, kita mendapatkan nilai Z-statistik sebesar -0.8717 dan P-value sebesar 0.3834.
Misalkan, seperti praktik umum, Anda telah menetapkan tingkat signifikansi (α) pada 0.05. Ketika membandingkan P-value Anda (0.3834) dengan α (0.05), kita melihat bahwa 0.3834 > 0.05.
Berdasarkan aturan keputusan formal, karena P-value lebih besar dari α, kita gagal menolak hipotesis nol.
Ini berarti, meskipun ada sedikit perbedaan numerik yang diamati dalam tingkat konversi antara Versi A dan Versi B pada sampel Anda, perbedaan tersebut tidak cukup kuat atau konsisten secara statistik untuk menyimpulkan bahwa ada perbedaan nyata pada tingkat populasi.
Implikasi terhadap Keputusan Bisnis atau Produk
Bagian terakhir dari proses analisis statistik, dan yang sering kali paling dinanti oleh pemangku kepentingan bisnis, adalah transformasi kesimpulan statistik menjadi rekomendasi konkret serta strategi yang dapat ditindaklanjuti.
Skenario A: Ketika Hasil Statistik Menunjukkan Signifikansi (P-value ≤ α)
Sebagai contoh, dalam konteks A/B testing yang kita bahas, jika uji Anda secara statistik membuktikan bahwa Versi B memiliki tingkat konversi yang signifikan lebih tinggi daripada Versi A, rekomendasi bisnisnya adalah meluncurkan Versi B ke seluruh basis pengguna atau audiens target.
Skenario B: Ketika Hasil Statistik Tidak Menunjukkan Signifikansi (P-value > α)
Mengacu pada kasus Z-test yang dilakukan (dengan P-value 0.3834), karena P-value ini secara signifikan lebih besar dari α = 0.05, kita berada dalam skenario ini. Artinya, tidak ada bukti statistik yang kuat untuk menyatakan bahwa Versi B secara fundamental lebih baik atau lebih buruk dari Versi A.
Dalam skenario ini, tindakan dan rekomendasi bisnis yang paling umum dan rasional adalah berikut.
- Tidak Meluncurkan Perubahan (Default Action)
- Investigasi Lebih Lanjut (Jika Diperlukan secara Bisnis)
- Pentingnya Kehati-hatian
This file is located at: _chapters/991-belajar-matematika-untuk-data-science/050-studi-kasus-ab-testing.md