Understanding reasoning models
1 Understanding reasoning models
This chapter covers
- What “reasoning” means specifically in the context of LLMs
- The conventional pre-training and post-training stages of LLMs
- Key approaches to improving reasoning abilities in LLMs
- How reasoning differs from pattern matching
- Why we should build reasoning models from scratch
Welcome to the next stage of large language models (LLMs): reasoning. LLMs have transformed how we process and generate text, but their success has been largely driven by statistical pattern recognition. However, new advances in reasoning methodologies now enable LLMs to tackle more complex tasks, such as solving logical puzzles and advanced math problems involving multi-step arithmetic. Moreover, reasoning is an essential technique for making “agentic” AI practical. Understanding reasoning methodologies is the central focus of this book.
In Build a Reasoning Model (From Scratch), you will learn the inner workings of LLM reasoning methods through a hands-on, code-first approach. We will start from a pre-trained LLM and extend it step by step with reasoning capabilities. We implement these reasoning components ourselves, from scratch, to see how these methods work in practice.
If you are curious about how LLMs themselves are built and trained, my earlier book Build A Large Language Model (From Scratch) published by Manning (http://mng.bz/orYv) provides a detailed coverage of these foundations, but it is not required for following along here. By the end of this book, you will understand how reasoning models work and be equipped to design, prototype, and evaluate the main methods for improving reasoning in LLMs.
With its focus on practical applications and explanations, this book is written to speak to LLM engineers, machine learning researchers, applied scientists, and software developers alike.
1.1 Defining reasoning in the context of LLMs
What is LLM-based reasoning? The answer and discussion of this question itself would provide enough content to fill a book. However, this would be a different kind of book than this practical, hands-on coding focused book that implements LLM reasoning methods from scratch rather than arguing about reasoning on a conceptual or philosophical level. Nonetheless, I think it’s important to briefly define what we mean by reasoning in the context of LLMs.
So, before we get to the coding portions of this book in the upcoming chapters, I want to kick off this book with this section that defines reasoning in the context of LLMs, what the main techniques are that improve the so-called reasoning behaviors of LLMs, and briefly explain how it relates to pattern matching and logical reasoning. This will lay the groundwork for further discussions on how LLMs are currently built, how they handle reasoning tasks, and what they are good and not so good at.
In the context of LLMs, reasoning means the model shows how it got to an answer by explaining the intermediate steps before giving the final response.
Furthermore, the current definition of a reasoning model is an LLM that has been improved to explain its steps before giving an answer, where explaining the intermediate steps often increases the accuracy on complex tasks such as coding, logical puzzles, and math problems.
Chain-of-Thought (CoT)
Reasoning in LLMs is often referred to as chain-of-thought (CoT). In this process, the model generates a series of intermediate steps or explanations that show how it arrives at its final answer. Instead of jumping straight to the result, researchers and engineers often say the model “thinks” through the problem step by step. In other words, the model makes its reasoning process explicit and easier to follow.
Note that in this book, we use the terms “reasoning” and “thinking” as they are commonly used in the context of LLMs by researchers and engineers working on LLMs and the so-called reasoning models. However, this does not imply that LLMs actually reason or think in the same way humans do.
Figure 1.1 illustrates how a conventional LLM generates the answer to a user’s question.
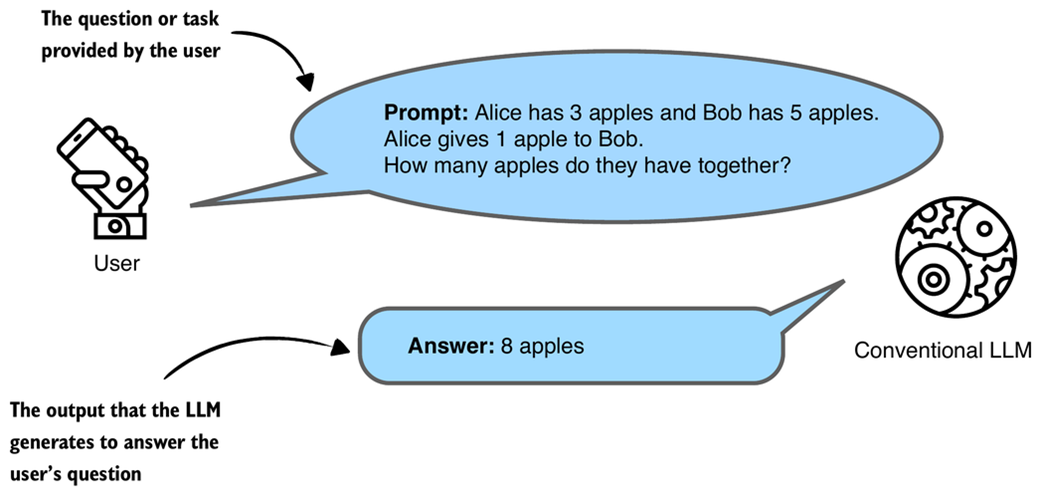 Figure 1.1 A simplified illustration of how a conventional, non-reasoning LLM might respond to a question with a short answer.
Figure 1.1 A simplified illustration of how a conventional, non-reasoning LLM might respond to a question with a short answer.
As shown in figure 1.1, a conventional might not show how it came up with its answer. While the answer might be correct it doesn’t help the user understand the process behind the answer.
Figure 1.2 illustrates a simple example of multi-step (CoT) reasoning in an LLM.
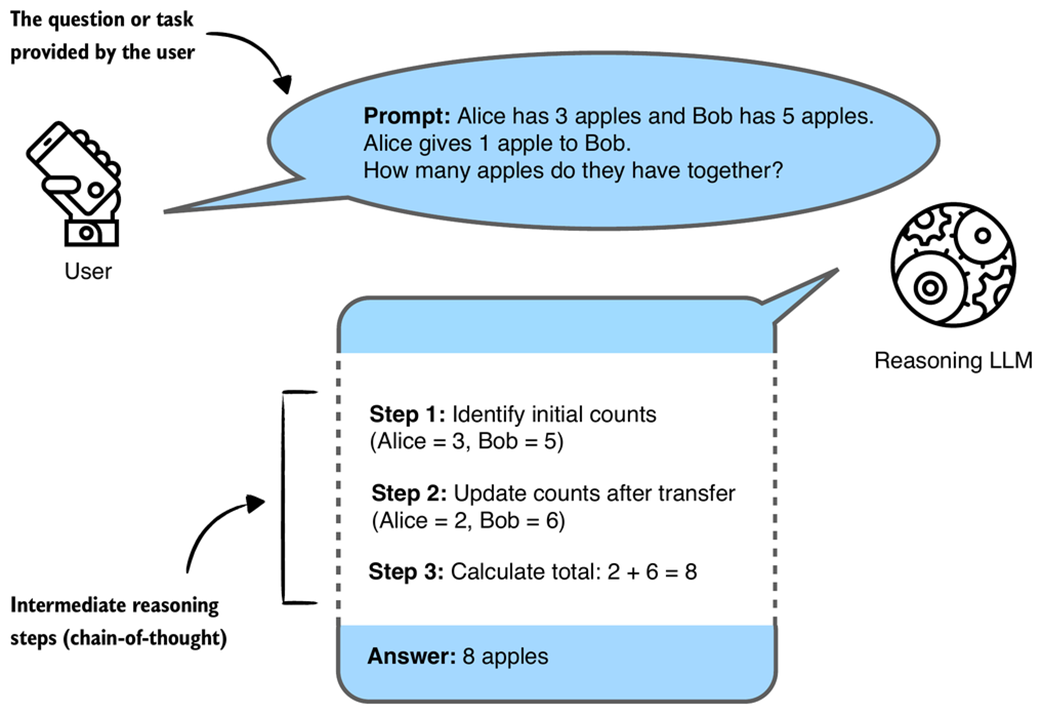 Figure 1.2 A simplified illustration of how a reasoning LLM might tackle a multi-step reasoning task using a chain-of-thought. Rather than just recalling a fact, the model combines several intermediate reasoning steps to arrive at the correct conclusion. The intermediate reasoning steps may or may not be shown to the user, depending on the implementation.
Figure 1.2 A simplified illustration of how a reasoning LLM might tackle a multi-step reasoning task using a chain-of-thought. Rather than just recalling a fact, the model combines several intermediate reasoning steps to arrive at the correct conclusion. The intermediate reasoning steps may or may not be shown to the user, depending on the implementation.
LLM-produced intermediate reasoning steps, as shown in figure 1.2, look very much like a person articulating internal thoughts aloud. Yet how closely these methods (and the resulting reasoning processes) mirror human reasoning remains an open research question, one this book does not attempt to answer. It’s not even clear that such a question can be definitively answered.
While figure 1.1 is a typical example of chain-of-thought reasoning, it is important to emphasize that LLM reasoning differs from traditional, deterministic reasoning.
For instance, a symbolic logic engine or theorem prover follows strict, rule-based steps that guarantee consistency and correctness. (A symbolic logic engine works like following a recipe where every step is fixed and must produce the same result each time. To use a cooking analogy, if you follow the steps exactly, you always end up with the same dish.)
In contrast, an LLM generates reasoning autoregressively, which means that it is predicting one token at a time based on statistical patterns in its training data. As a result, the LLM’s “reasoning steps” are not guaranteed to be logically sound, even if they look convincing.
Instead, this book focuses on explaining and implementing the fundamental techniques that improve LLM-based reasoning and thus make LLMs better at handling complex tasks. My hope is that by gaining hands-on experience with these methods, you will be better prepared to understand and improve those reasoning methods being developed and maybe even explore how they compare to human reasoning.
LLM versus human reasoning
Reasoning processes in LLMs may superficially resemble human thought, particularly in how intermediate steps are articulated. However, it is important to recognize a key difference: humans can engage in deterministic reasoning by deliberately applying rules of logic or by reasoning over an internal model of the world. Deterministic here means that if we start with the same facts and follow the same steps, we will always reach the same conclusion. In contrast, current LLM reasoning is probabilistic, meaning that it generates one token at a time based on statistical patterns in training data, without guarantees of logical consistency.
Humans often reason by consciously manipulating concepts, intuitively understanding abstract relationships, or generalizing from a few examples. LLMs, by contrast, work by picking up patterns from huge amounts of text rather than relying on built-in reasoning rules or any kind of conscious thought.
In short, although the outputs of reasoning-enhanced LLMs can appear human-like, the underlying mechanisms differ substantially and remain an active area of exploration.
1.2 Understanding the standard LLM training pipeline
This section briefly summarizes how conventional (non-reasoning) LLMs are typically trained so that we can understand where their limitations lie. This background will also help frame our upcoming discussions on the differences between pattern matching and logical reasoning.
Before applying any specific reasoning methodology, conventional LLM training is usually structured into two stages: pre-training and post-training, which are illustrated in figure 1.3.
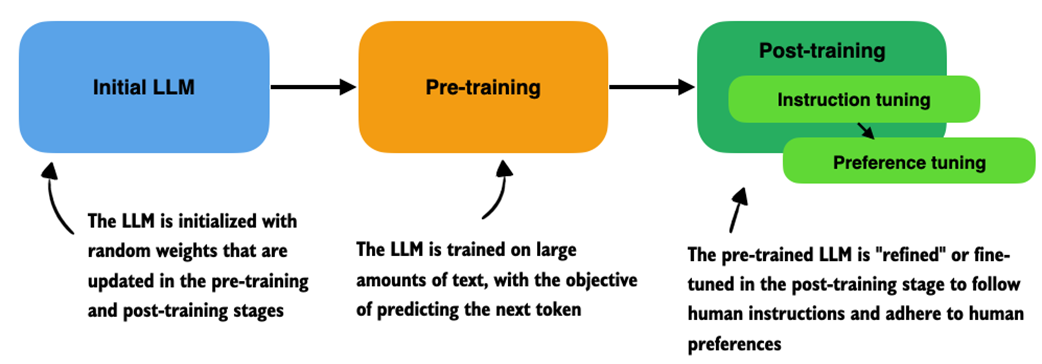 Figure 1.3 Overview of a typical LLM training pipeline. The process begins with an initial model initialized with random weights, followed by pre-training on large-scale text data to learn language patterns by predicting the next token. Post-training then refines the model through instruction fine-tuning and preference fine-tuning, which enables the LLM to follow human instructions better and align with human preferences.
Figure 1.3 Overview of a typical LLM training pipeline. The process begins with an initial model initialized with random weights, followed by pre-training on large-scale text data to learn language patterns by predicting the next token. Post-training then refines the model through instruction fine-tuning and preference fine-tuning, which enables the LLM to follow human instructions better and align with human preferences.
In the pre-training stage of a typical LLM training pipeline, as shown in figure 1.3, LLMs are trained on massive amounts (many terabytes) of unlabeled text, which includes books, websites, research articles, and many other sources. The pre-training objective (goal) for the LLM is to learn to predict the next word (i.e., token) in these texts.
Words and tokens
A token is a small unit of text that a language model processes. A token can be a full word, part of a word, or even punctuation, depending on how the text is split by a so-called tokenizer.
For example, the sentence “An LLM can be useful.” might be broken into tokens like “An”, “ L”, “LM”, “ can”, “ be”, “ useful”, and “.” by a common tokenizer. These tokens are then converted into numerical IDs that the model can ingest.
A tokenizer is a model or tool that is not directly part of the LLM itself but is nonetheless a critical component of the LLM text processing and generation pipeline. We will see how tokenization works in practice in the next chapter.
LLMs become highly capable when pre-trained on massive datasets, which typically involves several terabytes of text (equivalent to around 300 to 400 billion tokens). This training requires thousands of GPUs running for many months and can cost millions of dollars. Here, “capable” means that the LLMs begin to generate text that closely resembles human writing. Also, to some extent, pre-trained LLMs will begin to exhibit so-called emergent properties, which means that they will be able to perform tasks that they were not explicitly trained to do, including translation, code generation, and so on.
However, these pre-trained models merely serve as base models for the post-training stage, which uses two key techniques: supervised fine-tuning (often abbreviated as SFT in the literature and also known as instruction tuning) and preference tuning (often implemented via a technique called Reinforcement Learning with Human Feedback) to teach LLMs to respond to user queries, which are illustrated in figure 1.4.
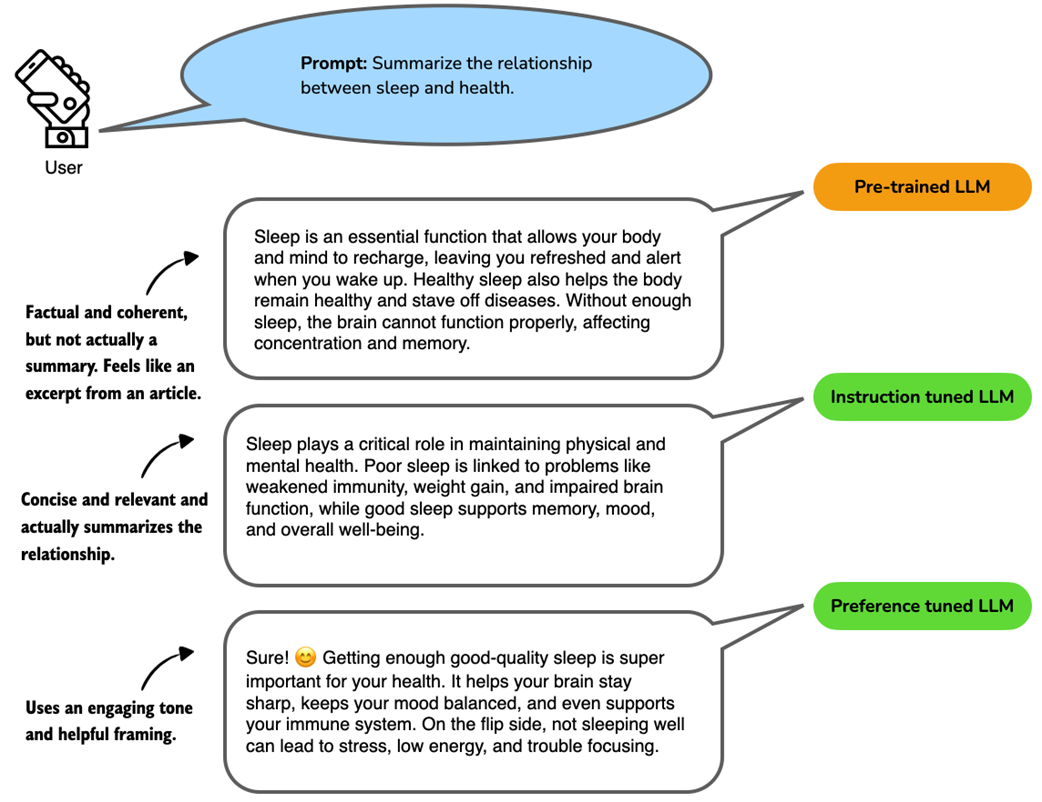 Figure 1.4 Example responses from a language model at different training stages. The prompt asks for a summary of the relationship between sleep and health. The pre-trained LLM produces a relevant but unfocused answer without directly following the instructions. The instruction-tuned LLM generates a concise and accurate summary aligned with the prompt. The preference-tuned LLM further improves the response by using a friendly tone and engaging language, which makes the answer more relatable and user-centered.
Figure 1.4 Example responses from a language model at different training stages. The prompt asks for a summary of the relationship between sleep and health. The pre-trained LLM produces a relevant but unfocused answer without directly following the instructions. The instruction-tuned LLM generates a concise and accurate summary aligned with the prompt. The preference-tuned LLM further improves the response by using a friendly tone and engaging language, which makes the answer more relatable and user-centered.
As shown in figure 1.4, instruction tuning improves an LLM’s capabilities of personal assistance-like tasks such as question-answering, summarizing and translating text, and many more. The preference tuning stage then refines these capabilities. As the term implies, preference tuning helps tailor responses to user preferences. (Some readers may be familiar with terms like Reinforcement Learning with Human Feedback or RLHF, which are specific techniques to implement preference tuning.)
In short, we can think of pre-training as “raw language prediction” (via next-token prediction) that gives the LLM some basic properties and capabilities to produce coherent texts. The post-training stage then improves the task understanding of LLMs via instruction tuning and refines the LLM to create answers with preferred stylistic choices via preference tuning.
However, it is worth noting that even an instruction-tuned model is not yet a “chatbot.” A chat interface adds another layer that guides the model’s responses in an interactive, multi-turn setting. This typically involves a system prompt, conversation history management, and other orchestration (an example of this is implemented in appendix G).
NOTE
These pre-training and post-training stages mentioned above are covered in my book “Build A Large Language Model (From Scratch)” (http://mng.bz/orYv) published by Manning. The book you are reading now does not require detailed knowledge of these stages. Concretely, in the next chapter, we will load a model that has already undergone the expensive pre-training and post-training stages mentioned above, so that we can focus on the methodology that is specific to reasoning models in the subsequent chapters.
1.3 Improving LLM reasoning with training and inference techniques
Reasoning in the context of LLMs became popular in the public eye with the announcement of OpenAI’s o1 in ChatGPT on September 12, 2024, which popularized the concept of reasoning in LLMs. In the announcement article (https://openai.com/index/introducing-openai-o1-preview/), OpenAI mentioned that “We’ve developed a new series of AI models designed to spend more time thinking before they respond.”
Furthermore, OpenAI wrote: “These enhanced reasoning capabilities may be particularly useful if you’re tackling complex problems in science, coding, math, and similar fields.”
A few months later, in January 2025, DeepSeek released the DeepSeek-R1 model and technical report (https://arxiv.org/abs/2501.12948), which details training methodologies to develop reasoning models, which made big waves as they not only made freely and openly available a model that competes with and exceeds the performance of the proprietary o1 model but also shared a blueprint on how to train such a model.
This book aims to explain how these methodologies used to develop reasoning models work by implementing similar methods from scratch.
The different approaches to developing and improving an LLM’s reasoning capabilities can be grouped into three broad categories, as illustrated in figure 1.4.
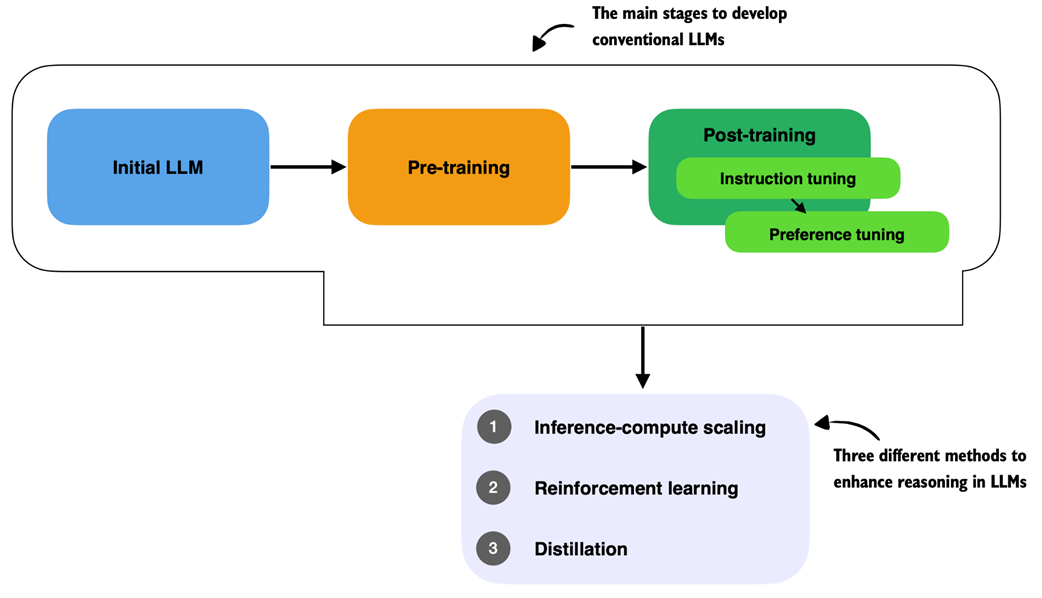 Figure 1.5 Three approaches commonly used to improve reasoning capabilities in LLMs. These methods (inference-compute scaling, reinforcement learning, and distillation) are typically applied after the conventional training stages (initial model training, pre-training, and post-training with instruction and preference tuning), but reasoning techniques can also be applied to the pre-trained base model.
Figure 1.5 Three approaches commonly used to improve reasoning capabilities in LLMs. These methods (inference-compute scaling, reinforcement learning, and distillation) are typically applied after the conventional training stages (initial model training, pre-training, and post-training with instruction and preference tuning), but reasoning techniques can also be applied to the pre-trained base model.
As illustrated in figure 1.5, these methods are applied to LLMs that have undergone the conventional pre-training and post-training phases, including instruction and preference tuning.
- Inference-time compute scaling (also often called inference compute scaling, test-time scaling, or other variations) includes methods that improve model reasoning capabilities at inference time (when a user prompts the model) without training or modifying the underlying model weights. The core idea is to trade off increased computational resources for improved performance, which helps make even fixed models more capable through techniques such as chain-of-thought reasoning, and various sampling procedures. This topic will be the focus of chapters 4 and 5.
- Reinforcement learning (RL) refers to training methods that improve a model’s reasoning capabilities by encouraging it to take actions that lead to high reward signals. These rewards can be broad, such as task success or heuristic scores, or they can be narrowly defined and verifiable, such as correct answers in math problems or coding tasks. Unlike Inference-time compute scaling, which can improve reasoning performance without modifying the model, RL updates the model’s weights during training. This enables the model to learn and refine reasoning strategies through trial and error, based on the feedback it receives from the environment. We will explore RL in more detail in chapters 6 and 7.
Reinforcement learning for reasoning and preference tuning
In the context of developing reasoning models, it is important to distinguish the RL approach here from reinforcement learning with human feedback (RLHF), which is used during preference tuning when developing a conventional LLM as illustrated previously in figure 1.5.
Both settings use the same underlying process (RL) but they differ primarily in how the reward is obtained and validated (human judgments for RLHF versus automated verifiers or environments for reasoning RL).
RLHF incorporates explicit human evaluations or rankings of model outputs as reward signals, directly guiding the model toward human-preferred behaviors. In contrast, RL in the context of reasoning models typically relies on automated or environment-based reward signals, which can be more objective but potentially less aligned with human preferences. For instance, RL in a reasoning model development pipeline might train a model to excel at mathematical proofs by providing explicit rewards for correctness. In contrast, RLHF would involve human evaluators ranking various responses to encourage outputs that align closely with human standards and subjective preferences.
- Distillation involves transferring complex reasoning patterns learned by powerful, larger models into smaller or more efficient models. Within the context of LLMs, this typically means performing supervised fine-tuning (SFT) using high-quality labeled instruction datasets generated by a larger, more capable model. This technique is commonly referred to as knowledge distillation or simply distillation in LLM literature. However, it’s important to note that this differs slightly from traditional knowledge distillation in deep learning, where a smaller (“student”) model typically learns from both the outputs and the logits produced by a larger (“teacher”) model. This topic is discussed further in chapter 8.
1.4 Modeling language through pattern matching
As mentioned in the previous section, during pre-training, LLMs are exposed to vast quantities of text and learn to predict the next token by identifying and reproducing statistical associations in that data. This process enables them to generate fluent and coherent text, but it is fundamentally rooted in surface-level correlations rather than deep understanding.
LLMs respond to prompts by generating text continuations that are statistically consistent with the patterns seen during training. In essence, they match patterns between input and output, rather than deducing answers through logical inference.
Consider the following example:
Prompt
The capital of Germany is…
Response
Berlin.
An LLM producing the answer “Berlin” is not logically deducing the answer. Instead, it is recalling a strong statistical association learned from training data. This behavior reflects what we refer to as pattern matching, which means that the model completes text based on learned correlations and not by applying structured reasoning steps.
But what about tasks that go beyond pattern recognition, i.e., tasks where a correct answer depends on drawing conclusions from given facts? This brings us to a different kind of capability: logical reasoning.
Logical reasoning involves systematically coming up with conclusions using rules. Unlike pattern matching, it depends on intermediate reasoning steps and the ability to recognize contradictions or draw implications based on formal relationships.
Consider the following prompt as an example:
- Prompt: “All birds can fly. A penguin is a bird. Can a penguin fly?”
There are two ways to evaluate this.
First, in a closed-world (prompt only) setting, from the two premises (claims, assumptions) in the prompt (“All birds can fly” and “A penguin is a bird”), the valid answer is “Yes, a penguin can fly.”
Second, in an open-world (with background knowledge) setting, if we also allow background knowledge not included in the prompt (for example, that penguins cannot fly), this external fact conflicts with the conclusion derived from the premises, as shown in figure 1.6. A reasoning system should notice the inconsistency and either ask for clarification or weaken the first statement (for example, “Most birds can fly, with exceptions such as penguins”).
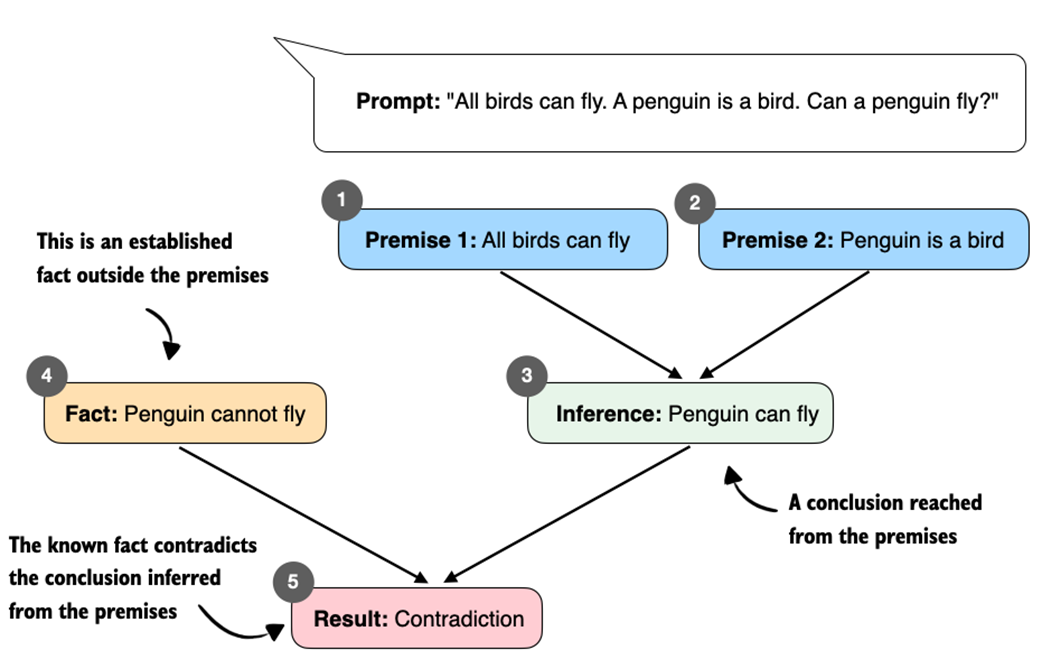 Figure 1.6 Illustration of how contradictory premises lead to a logical inconsistency. From “All birds can fly” and “A penguin is a bird,” we infer “Penguin can fly.” This conclusion conflicts with the established fact “Penguin cannot fly,” which results in a contradiction.
Figure 1.6 Illustration of how contradictory premises lead to a logical inconsistency. From “All birds can fly” and “A penguin is a bird,” we infer “Penguin can fly.” This conclusion conflicts with the established fact “Penguin cannot fly,” which results in a contradiction.
Figure 1.6 shows how a system based on logical reasoning could process the previously introduced “All birds can fly…” prompt.
In contrast, a statistical (pattern-matching) LLM does not explicitly track contradictions, such as the one shown in figure 1.6, but instead predicts based on learned text distributions. For instance, if information such as “All birds can fly” is reinforced strongly in training data, the model may confidently answer: “Yes, penguins can fly.”
In the next section, we will look at a concrete example of how an LLM handles this “All birds can fly…” prompt.
Logical reasoning and rule-based systems
Why are explicit rule-based systems not more popular? Rule-based systems were used widely in the ’80s and ’90s for medical diagnosis, legal decisions, and engineering. They are still used in critical domains (medicine, law, aerospace), which often require explicit inference and transparent decision processes. However, they are hard to implement as they largely rely on human-crafted heuristics. (Heuristics are simple decision rules that give a good-enough answer quickly without guaranteeing an optimal one.) In contrast, deep neural networks, including LLMs, do not implement hand-written rules; they learn decision patterns from data and can be highly flexible when trained at scale.
1.5 Simulating reasoning without explicit rules
In the previous section, we saw how contradictory premises can lead to logical inconsistencies. A conventional LLM does not explicitly track contradictions but generates responses based on learned text distributions.
Let’s see a concrete example, shown in figure 1.7, of how a non-reasoning-enhanced LLM like GPT-4o in OpenAI’s ChatGPT responds to the “All birds can fly…” prompt discussed in the previous section.
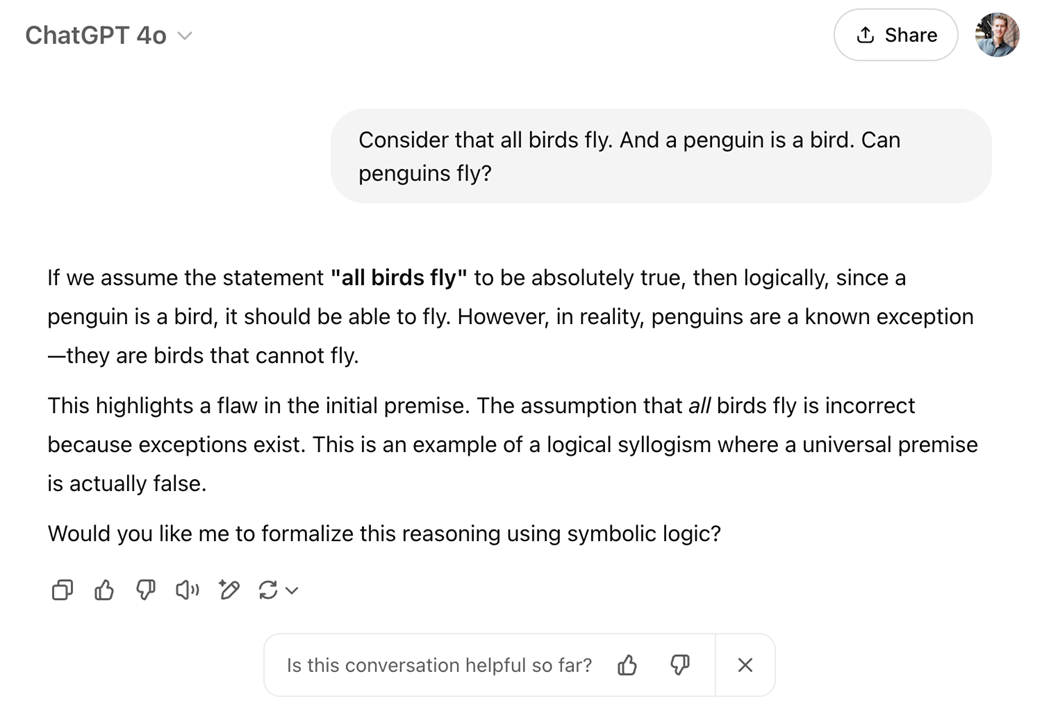 Figure 1.7 An illustrative example of how a language model (GPT-4o in ChatGPT) appears to “reason” about a contradictory premise.
Figure 1.7 An illustrative example of how a language model (GPT-4o in ChatGPT) appears to “reason” about a contradictory premise.
The example in figure 1.7 shows that GPT-4o appears to answer correctly even though this model is not considered a reasoning model, unlike OpenAI’s other offerings like o1, o3, o4-mini, and more recent GPT-5, which have been explicitly developed with reasoning methodology.
So, how did the 4o model generate its answer? Does this mean GPT-4o explicitly reasons logically? No, not necessarily. However, at a minimum 4o is highly effective at simulating logical reasoning in familiar contexts.
GPT-4o does not implement explicit contradiction-checking and instead generates answers based on probability-weighted patterns. This approach works well enough if training data includes many instances correcting the contradiction (e.g., text like “penguins cannot fly”) so that the model learns a statistical association between “penguins” and “not flying.” As we see in figure 1.7, this allows the model to answer correctly without explicitly implementing rule-based or explicit logical reasoning methodologies.
In other words, the model recognizes the contradiction implicitly because it has frequently encountered this exact reasoning scenario during training. This effectiveness relies heavily on statistical associations built from a lot of exposure to reasoning-like patterns in training data.
So, even when a conventional LLM seems to perform logical deduction as shown in figure 1.7, it’s not executing explicit, rule-based logic but is instead leveraging patterns from its vast training data.
Nonetheless, GPT-4o’s success here is a great illustration of how powerful implicit pattern matching can become when trained at a massive scale. However, these types of pattern-based reasoning models usually struggle in scenarios where:
- The logical scenario is novel (not previously encountered in training data).
- Reasoning complexity is high, involving intricate, multi-step logical relationships.
Logical reasoning and current reasoning LLM offerings
While GPT-4o is not officially labeled as a reasoning model, OpenAI offers several dedicated reasoning models, including o1, o3, o4-mini, and GPT-5. Moreover, other companies have been developing LLMs with explicit reasoning capabilities. As of this writing, popular examples include Anthropic’s Claude 4, xAI’s Grok 4, Google’s Gemini 2.5, DeepSeek’s R1, Alibaba’s Qwen3, and many more. The techniques employed by these models are the focus of this book. As we will see, this is achieved without implementing a rule-based reasoning pipeline (figure 1.6 illustrates the general idea of rule-based reasoning). Instead, the LLM learns or improves its reasoning capabilities as a result of the modified inference and training methodologies.
We might say that LLMs simulate logical reasoning through learned patterns, and we can improve it further with specific reasoning methods that include inference-compute scaling and post-training strategies like reinforcement learning, but they are not explicitly executing any rule-based logic internally.
Moreover, it’s worth mentioning that reasoning in LLMs exists on a spectrum. This means that even before the advent of dedicated reasoning models such as OpenAI’s o1 and DeepSeek-R1, LLMs were capable of simulating reasoning behavior. For instance, these models exhibited behaviors aligning with our earlier definition, such as generating intermediate steps to arrive at correct conclusions. What we now explicitly label a “reasoning model” is essentially a more refined version of this capability. And these improved reasoning capabilities are achieved by leveraging specific inference-compute scaling techniques (chapters 4 and 5) and targeted post-training methods, such as reinforcement learning (chapters 6 and 7), which are designed to improve and reinforce reasoning-like behavior.
1.6 Why build reasoning models from scratch?
Following the release of DeepSeek-R1 in January 2025, improving the reasoning abilities of LLMs has become one of the hottest topics in AI, and for good reason. Stronger reasoning skills allow LLMs to tackle more complex problems, making them more capable across various tasks users care about.
This shift is also reflected in a February 12, 2025, statement from OpenAI’s CEO:
“We will next ship GPT-4.5, the model we called Orion internally, as our last non-chain-of-thought model. After that, a top goal for us is to unify o-series models and GPT-series models by creating systems that can use all our tools, know when to think for a long time or not, and generally be useful for a very wide range of tasks.”
The quote above underlines the major shift from leading LLM providers towards reasoning models, where “chain-of-thought” refers to a prompting technique that guides language models to reason step-by-step to improve their reasoning capabilities, which we will cover in more detail in chapters 4 and 5.
Also noteworthy is the mention of knowing “when to think for a long time or not.” This hints at an important design consideration: reasoning is not always necessary or desirable.
For instance, reasoning models are designed to be good at complex tasks such as solving puzzles, advanced math problems, and challenging coding tasks. However, they are not necessary for simpler tasks like summarization, translation, or knowledge-based question answering. In fact, using reasoning models for everything can be inefficient and expensive. For instance, reasoning models are typically more expensive to use, more verbose, and sometimes more prone to errors due to “overthinking.” Also, here, the simple rule applies: use the right tool (or type of LLM) for the task.
Reasoning models are often more expensive than non-reasoning models for two reasons.
First, they tend to produce longer outputs because they include intermediate steps that explain how an answer is derived. As figure 1.8 illustrates, LLMs generate text one token at a time and each token requires a full forward pass. If a reasoning model’s answer is twice as long, generation involves roughly twice as many forward passes, which increases compute costs.
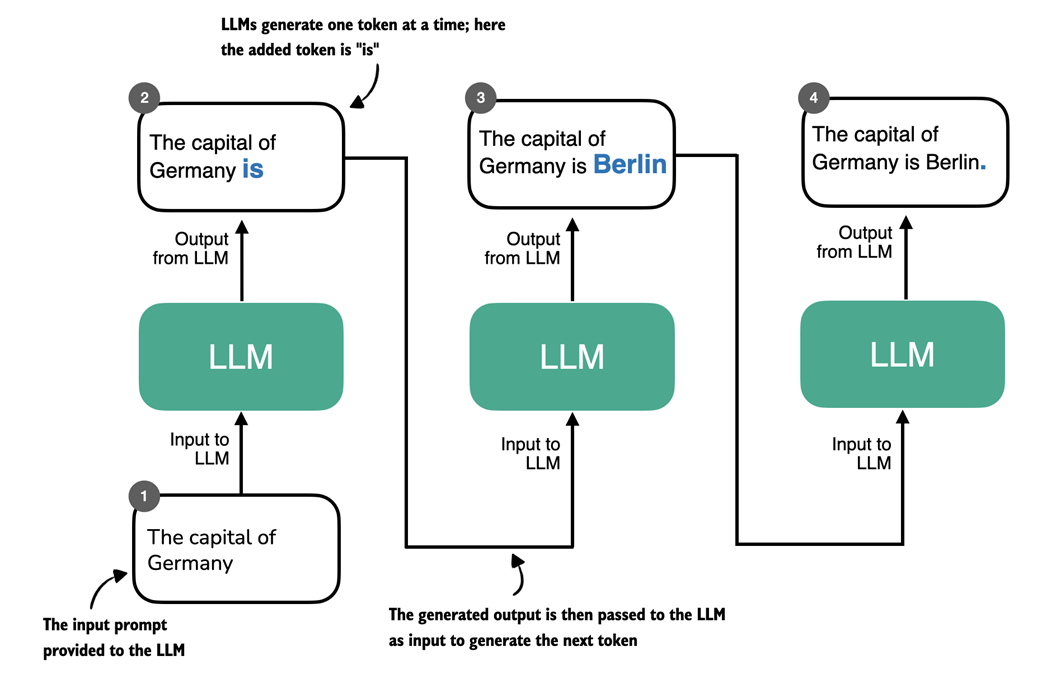 Figure 1.8 Token-by-token generation in an LLM. At each step, the LLM takes the full sequence generated so far and predicts the next token, which may represent a word, subword, or punctuation mark depending on the tokenizer. The newly generated token is appended to the sequence and used as input for the next step. This iterative decoding process is used in both standard language models and reasoning-focused models.
Figure 1.8 Token-by-token generation in an LLM. At each step, the LLM takes the full sequence generated so far and predicts the next token, which may represent a word, subword, or punctuation mark depending on the tokenizer. The newly generated token is appended to the sequence and used as input for the next step. This iterative decoding process is used in both standard language models and reasoning-focused models.
Second, many reasoning workflows require running the model several times for a single task, for example to sample multiple candidate solutions, call tools, or run a verifier. These additional calls multiply the total number of tokens processed and further increase cost beyond the single-call behavior shown in figure 1.8.
That’s exactly why it helps to implement these models and methods from scratch. It’s one of the best ways to understand how they work. And if we understand how LLMs and these reasoning models work, we can better understand these trade-offs.
1.7 A roadmap to reasoning models from scratch
Now that we have discussed reasoning in LLMs from a bird’s-eye view, the subsequent chapters will guide you through the process of coding and applying reasoning methods from scratch. We will tackle this in multiple stages, as outlined in figure 1.9.
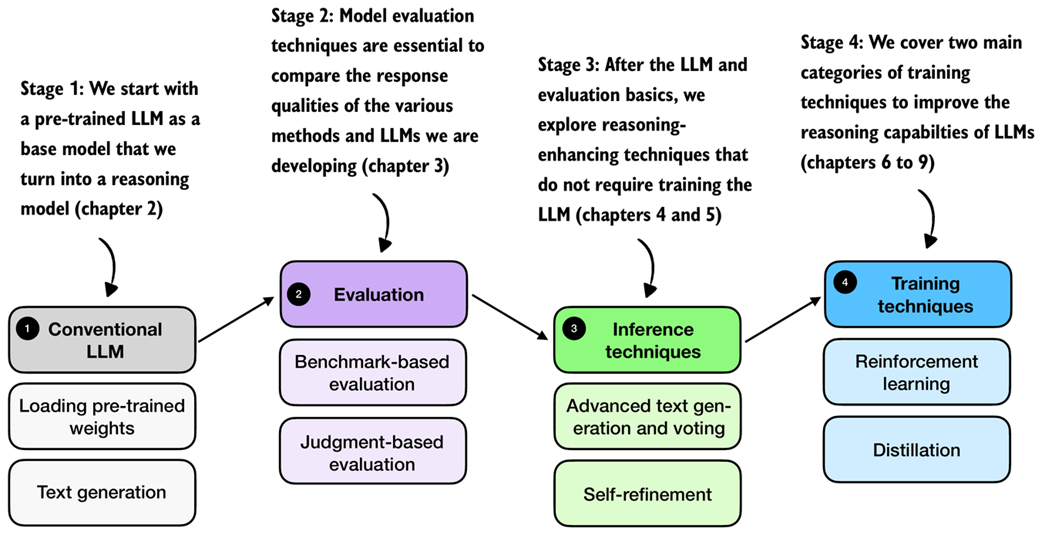 Figure 1.9 A mental model of the main reasoning model development stages covered in this book. We start with a conventional LLM as base model (stage 1). In stage 2, we cover evaluation strategies to track the reasoning improvements introduced via the reasoning methods in stages 3 and 4.
Figure 1.9 A mental model of the main reasoning model development stages covered in this book. We start with a conventional LLM as base model (stage 1). In stage 2, we cover evaluation strategies to track the reasoning improvements introduced via the reasoning methods in stages 3 and 4.
As shown in figure 1.9, we cover the reasoning model development in several stages. In stage 1 (next chapter), we load a conventional LLM that has already undergone the basic pre-training and instruction fine-tuning stages. Then, in stage 2, we cover common methods for evaluating LLMs and reasoning capabilities, so that we can measure the improvements we make when we apply reasoning-enhancing methods in stages 3 and 4.
Stage 3 covers inference techniques that can improve the response quality and reasoning behavior of LLMs. Note that these techniques can be applied to improve any LLM, conventional LLMs and LLMs that have been trained as reasoning models. Stage 4 will introduce training methods to develop reasoning models.
I am looking forward to the journey ahead and hope you are as well.
1.8 Summary
- Conventional LLM training occurs in several stages:
- Pre-training, where the model learns language patterns from vast amounts of text.
- Instruction fine-tuning, which improves the model’s responses to user prompts.
- Preference tuning, which aligns model outputs with human preferences.
- Reasoning methods are applied on top of a conventional LLM.
- Reasoning in LLMs refers to improving a model so that it explicitly generates intermediate steps (chain-of-thought) before producing a final answer, which often increases accuracy on multi-step tasks.
- Reasoning in LLMs is different from rule-based reasoning and it also likely works differently than human reasoning; currently, the common consensus is that reasoning in LLMs relies on statistical pattern matching.
- Pattern matching in LLMs relies purely on statistical associations learned from data, which enables fluent text generation but lacks explicit logical inference.
- Improving reasoning in LLMs can be achieved through:
- Inference-time compute scaling, enhancing reasoning without retraining (e.g., chain-of-thought prompting).
- Reinforcement learning, training models explicitly with reward signals.
- Supervised fine-tuning and distillation, using examples from stronger reasoning models.
- Building reasoning models from scratch provides practical insights into LLM capabilities, limitations, and computational trade-offs.