Dasar-Dasar Probabilitas
- Konsep Dasar Probabilitas
- Aksioma: Aturan Dasar dalam Probabilitas
- Ruang Sampel: Semua Kemungkinan yang Bisa Terjadi
- Kejadian: Fokus dari Perhitungan Probabilitas
- Metode Penghitungan Probabilitas
- Probabilitas Bersyarat dan Teorema Bayes
- Algoritma Model Naive Bayes: Belajar dari Peluang
- Latihan Implementasi Algoritma Naive Bayes
- Rangkuman Dasar-Dasar Probabilitas
Konsep Dasar Probabilitas
Hai, selamat datang dalam materi kedua di kelas ini! Sebelumnya kita sudah membahas mengenai peran matematika pada data science. Pada modul ini, kita akan memperdalam pembahasan salah satu cabang matematika yang sudah disebutkan sebelumnya, yakni pengertian dan penggunaan probabilitas dalam data science.
Coba Anda bayangkan sedang berjalan keluar rumah dan melihat langit mendung. Anda bertanya-tanya dalam hati, “Kira-kira hujan enggak, ya, hari ini?” Atau mungkin Anda pernah iseng melempar koin dan berpikir, “Berapa besar, sih, kemungkinan koin ini jatuh di sisi gambar?” Nah, hal-hal seperti ini sebenarnya bisa dijelaskan dengan satu konsep matematika yang sangat penting dan luas manfaatnya, yaitu probabilitas.

Probabilitas adalah cabang matematika yang membantu kita mengukur ketidakpastian. Ia bukan sekadar tebakan, tetapi cara sistematis untuk memahami dan memperkirakan kemungkinan. Pada modul ini, kita akan menjelajahi dunia probabilitas dari yang paling mendasar—mulai dari definisi formal, aturan-aturan dasar, sampai cara berpikir tentang berbagai kejadian yang mungkin muncul dalam suatu eksperimen acak. Semuanya akan dibahas dengan gaya yang santai dan mudah Anda ikuti, dilengkapi ilustrasi nyata dari kehidupan sehari-hari.
Apa itu Probabilitas?
Pernah enggak, sih, Anda merasa ragu saat harus mengambil keputusan? Misalnya, pagi-pagi Anda lihat langit mendung dan mulai bertanya dalam hati, “Bawa payung enggak, ya?” Mungkin Anda lalu membuka aplikasi cuaca pada ponsel dan melihat bahwa kemungkinan hujan hari ini adalah 70%. Nah, angka 70% itulah contoh nyata dari probabilitas—ukuran matematis yang menggambarkan tingkat kemungkinan terjadinya suatu kejadian.

Secara sederhana, probabilitas adalah angka yang menunjukkan seberapa besar kemungkinan suatu kejadian akan terjadi. Probabilitas selalu bernilai di antara 0 dan 1, atau kalau dalam bentuk persen, antara 0% dan 100%.
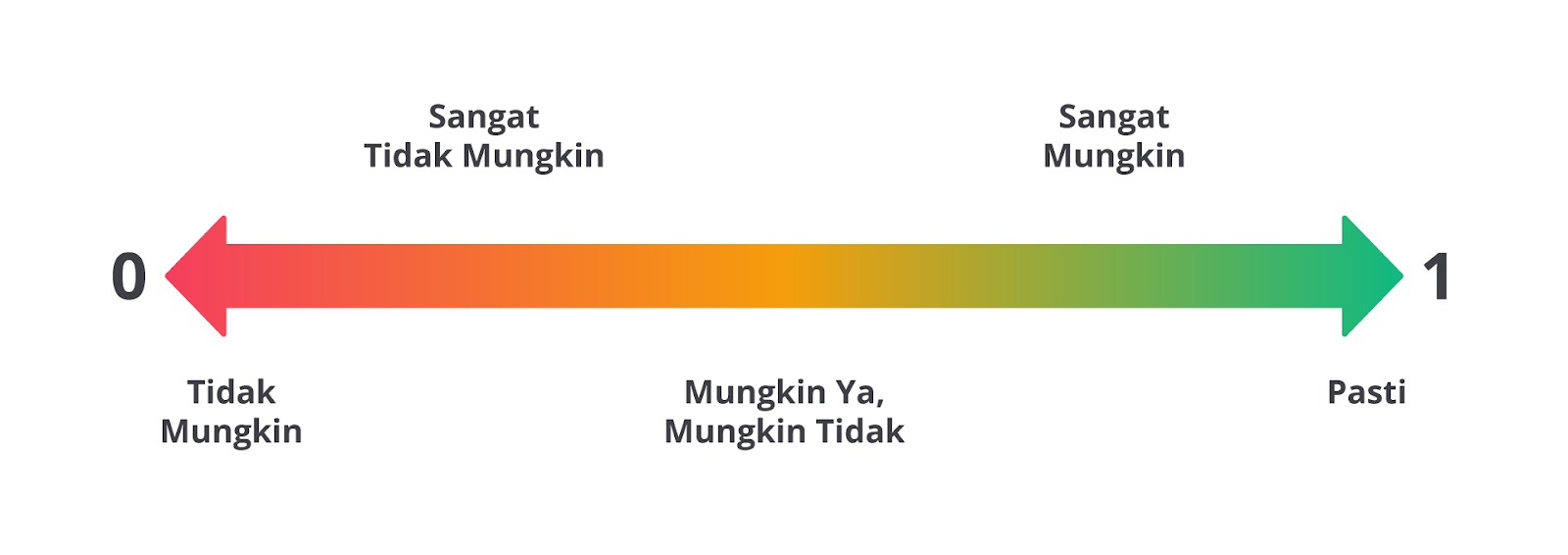
Jika probabilitas suatu kejadian adalah 0, artinya kejadian itu tidak mungkin terjadi. Sebaliknya, jika probabilitasnya adalah 1, kejadian tersebut pasti akan terjadi. Nilai-nilai di antara 0 dan 1 menggambarkan tingkat ketidakpastian—semakin dekat ke 1, semakin besar kemungkinan kejadian itu benar-benar terjadi. Semakin dekat ke 0, semakin kecil kemungkinannya.
Secara umum, rumus probabilitas adalah berikut.

Sebagai contoh klasik, bayangkan Anda melempar sebuah koin. Ada dua hasil yang mungkin terjadi: angka atau gambar.
Jika kita ingin menghitung peluang muncul angka, berikut adalah perhitungannya.

Kita bisa mengambil contoh lain yang lebih kompleks, seperti undian berhadiah. Misalnya, satu orang di antara 1 juta peserta akan menang hadiah utama. Dalam hal ini, probabilitas Anda menang adalah 1 banding 1 juta, atau 0,000001. Artinya, kemungkinan Anda menang sangat kecil—tetapi tidak nol. Jadi, masih ada peluang meskipun sangat tipis. Di sinilah probabilitas membantu kita untuk berpikir lebih rasional terhadap kemungkinan-kemungkinan.
Penerapan Probabilitas di Berbagai Bidang
Probabilitas tidak hanya muncul dalam permainan atau cuaca. Ia adalah bagian dari hampir semua aspek kehidupan manusia yang melibatkan ketidakpastian.
Dalam bidang medis, dokter menggunakan data pasien untuk memperkirakan risiko seseorang terkena penyakit tertentu. Probabilitas digunakan untuk membuat keputusan pengobatan, misalnya, “Pasien ini punya peluang 30% terkena komplikasi jika prosedur dilakukan.” Data semacam ini sangat penting untuk pengambilan keputusan medis yang lebih baik.
Dalam dunia teknologi, probabilitas menjadi fondasi dari banyak sistem pintar yang kita gunakan sehari-hari. Pernah merasa heran mengapa YouTube bisa merekomendasikan video yang sesuai dengan minat Anda? Atau mengapa Spotify tahu lagu yang Anda sukai? Jawabannya ada pada sistem yang menghitung probabilitas Anda menyukai suatu konten berdasarkan perilaku sebelumnya. Jadi, meski tidak menyadarinya, Anda sedang dipetakan dalam model probabilistik yang bekerja di balik layar.
Tak kalah menarik, probabilitas juga digunakan dalam keuangan, untuk memperkirakan risiko investasi atau fluktuasi pasar. Perusahaan asuransi menghitung premi berdasarkan probabilitas kerugian dan analis saham menggunakan probabilitas untuk memperkirakan harga di masa depan.
Bahkan dalam politik, lembaga survei menggunakan probabilitas untuk memprediksi hasil pemilu berdasarkan sampel populasi yang terbatas.
Hal yang menarik, manusia secara naluriah sebenarnya sudah “menggunakan” probabilitas sejak lama, meski tidak dengan angka-angka. Misalnya, ketika menilai aman atau tidak untuk menyeberang jalan, Anda secara tidak sadar memperkirakan kecepatan kendaraan, jarak, dan peluang tertabrak—semua itu adalah bentuk evaluasi probabilistik. Namun, tentu saja, untuk pengambilan keputusan yang lebih sistematis, kita butuh pendekatan matematis agar hasilnya lebih objektif dan bisa dianalisis.
Di dunia data science dan artificial intelligence, probabilitas menjadi alat utama dalam membuat mesin bisa “berpikir” secara tidak pasti. Misalnya, dalam pengenalan wajah, sistem tidak bilang “Ini pasti Amel 100%”, melainkan mengatakan, “Probabilitas ini adalah wajah Amel sebesar 98%.” Sistem seperti ini bekerja dengan model probabilistik yang mampu belajar dari data dan membuat keputusan meski informasi yang tersedia belum lengkap.
Dengan memahami probabilitas, Anda akan bisa berpikir lebih rasional saat menghadapi ketidakpastian. Anda bisa menghindari jebakan intuisi yang keliru (seperti berpikir bahwa koin akan “balik arah” setelah lima kali berturut-turut menunjukkan gambar), serta mulai membuat keputusan berdasarkan data dan logika. Dunia modern penuh dengan ketidakpastian—dan probabilitas membantu kita menavigasinya secara lebih bijak.
Aksioma: Aturan Dasar dalam Probabilitas
Sebagaimana dalam permainan yang punya aturan supaya tetap adil, dunia probabilitas juga memiliki “aturan main” yang menjadi fondasi bagi semua perhitungan di dalamnya. Aturan-aturan dasar ini disebut aksioma, yang pertama kali dirumuskan secara formal oleh seorang matematikawan asal Rusia, Andrey Kolmogorov, pada tahun 1933.
Aksioma dalam probabilitas adalah prinsip-prinsip yang harus selalu dipenuhi pada setiap sistem atau model probabilitas. Tanpa aksioma, kita akan kesulitan membangun logika probabilitas yang konsisten. Berikut adalah tiga aksioma dasar yang menjadi tiang penyangga dari seluruh teori probabilitas.
Aksioma Non-Negativitas
Setiap probabilitas suatu kejadian harus bernilai nol atau lebih, alias tidak boleh negatif. Secara matematis, kita bisa tulis sebagai berikut untuk setiap kejadian A.
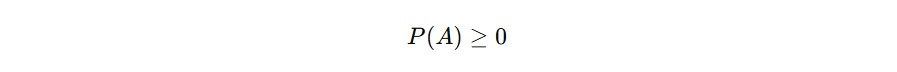
Artinya, tidak masuk akal untuk mengatakan bahwa peluang sebuah kejadian terjadi adalah -20%. Dalam dunia nyata, peluang suatu peristiwa terjadi bisa sangat kecil—mungkin hanya 0,00001 atau bahkan lebih kecil lagi, tetapi tetap saja tidak mungkin bernilai negatif.
Bayangkan Anda membeli satu tiket dari total satu juta tiket undian. Anda mungkin punya peluang menang yang sangat kecil, tetapi tetap saja nilainya positif—sekecil apa pun itu, asalkan tidak negatif. Aksioma ini menegaskan bahwa semua probabilitas harus punya dasar logika yang rasional dan bisa dikuantifikasi secara wajar.
Aksioma Normalisasi
Jika kita mempertimbangkan semua kemungkinan hasil dari suatu percobaan, total probabilitasnya harus sama dengan 1. Secara matematis, pernyataan tersebut ditulis sebagai berikut.
P(S) = 1
S adalah ruang sampel, yaitu himpunan dari semua hasil yang mungkin (akan dibahas lebih lanjut).
Aksioma ini masuk akal. Misal, ketika kita melakukan satu eksperimen (misalnya melempar dadu), pasti akan ada satu hasil yang keluar—entah itu angka 1, 2, sampai 6. Jadi, kalau kita menjumlahkan probabilitas dari semua hasil yang mungkin, jumlahnya pasti harus 1.
Contoh sederhananya, saat melempar satu dadu, peluang muncul angka 1 sampai 6 masing-masing adalah berikut.
P(1) + P(2) + P(3) + P(4) + P(5) + P(6) = 1
Aksioma ini penting agar model probabilitas tetap “lengkap” dan tidak meninggalkan kejadian apa pun di luar perhitungan.
Aksioma Adisi (Additivitas)
Kalau ada dua kejadian yang tidak bisa terjadi secara bersamaan (alias saling lepas), probabilitas gabungan dari keduanya adalah jumlah dari probabilitas masing-masing kejadian. Ini bisa ditulis sebagai berikut jika A∩B = ∅ (artinya A dan B tidak punya hasil yang sama).
P(A∪B) = P(A)+P(B)
Contohnya, bayangkan Anda melempar sebuah dadu dan ingin menghitung probabilitas munculnya angka 2 atau 5. Karena angka 2 dan 5 tidak bisa muncul bersamaan dalam satu lemparan, keduanya adalah kejadian yang saling lepas.
Kita tahu hal berikut.
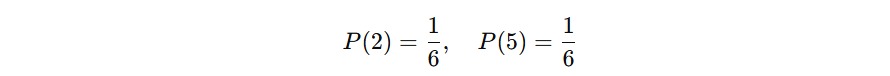
Karena keduanya tidak bisa terjadi bersamaan, perhitungan dilakukan sebagai berikut.
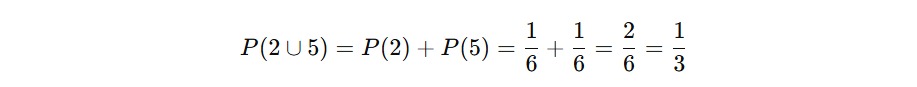
Aksioma ini sangat penting ketika Anda mulai bekerja dengan gabungan kejadian. Namun ingat, aksioma ini hanya berlaku jika kejadian tersebut saling lepas. Kalau tidak, kita harus menggunakan rumus umum gabungan berikut.
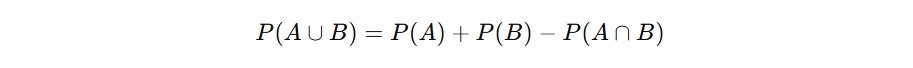
Ini untuk menghindari menghitung irisan dua kali.
Ruang Sampel: Semua Kemungkinan yang Bisa Terjadi
Setelah memahami probabilitas dan aturan dasarnya, sekarang saatnya kita berkenalan dengan salah satu konsep paling penting dalam teori probabilitas: ruang sampel. Kalau dianalogikan, ruang sampel itu seperti “peta” dari semua kemungkinan yang bisa terjadi dalam sebuah percobaan acak. Tanpa peta ini, kita akan kesulitan mengetahui posisi kejadian yang ingin dihitung probabilitasnya.
Secara sederhana, ruang sampel adalah kumpulan dari semua hasil yang mungkin terjadi saat kita melakukan suatu eksperimen atau percobaan acak. Dalam bahasa matematika, ruang sampel biasanya dilambangkan dengan huruf kapital S dan dituliskan dalam bentuk himpunan.
Untuk memahami konsep ini lebih baik, mari kita ambil beberapa contoh.
Bayangkan Anda sedang melempar sebuah dadu bersisi enam. Apa saja hasil yang bisa keluar? Jawabannya tentu saja: 1, 2, 3, 4, 5, atau 6. Tidak mungkin Anda mendapatkan angka tujuh atau nol dari dadu tersebut karena sisi dadu hanya ada enam.

Jadi, ruang sampel dari percobaan ini ditulis sebagai berikut.
S = {1,2,3,4,5,6}
Setiap angka dalam himpunan itu disebut sebagai anggota atau elemen dari ruang sampel dan masing-masing mewakili satu hasil yang mungkin terjadi. Dalam konteks ini, kita katakan bahwa ruang sampelnya adalah diskret karena hasil-hasil yang mungkin dapat dihitung satu per satu.
Sekarang, coba kita ubah eksperimennya. Misalnya Anda melempar dua koin sekaligus. Apa saja kemungkinan hasilnya?
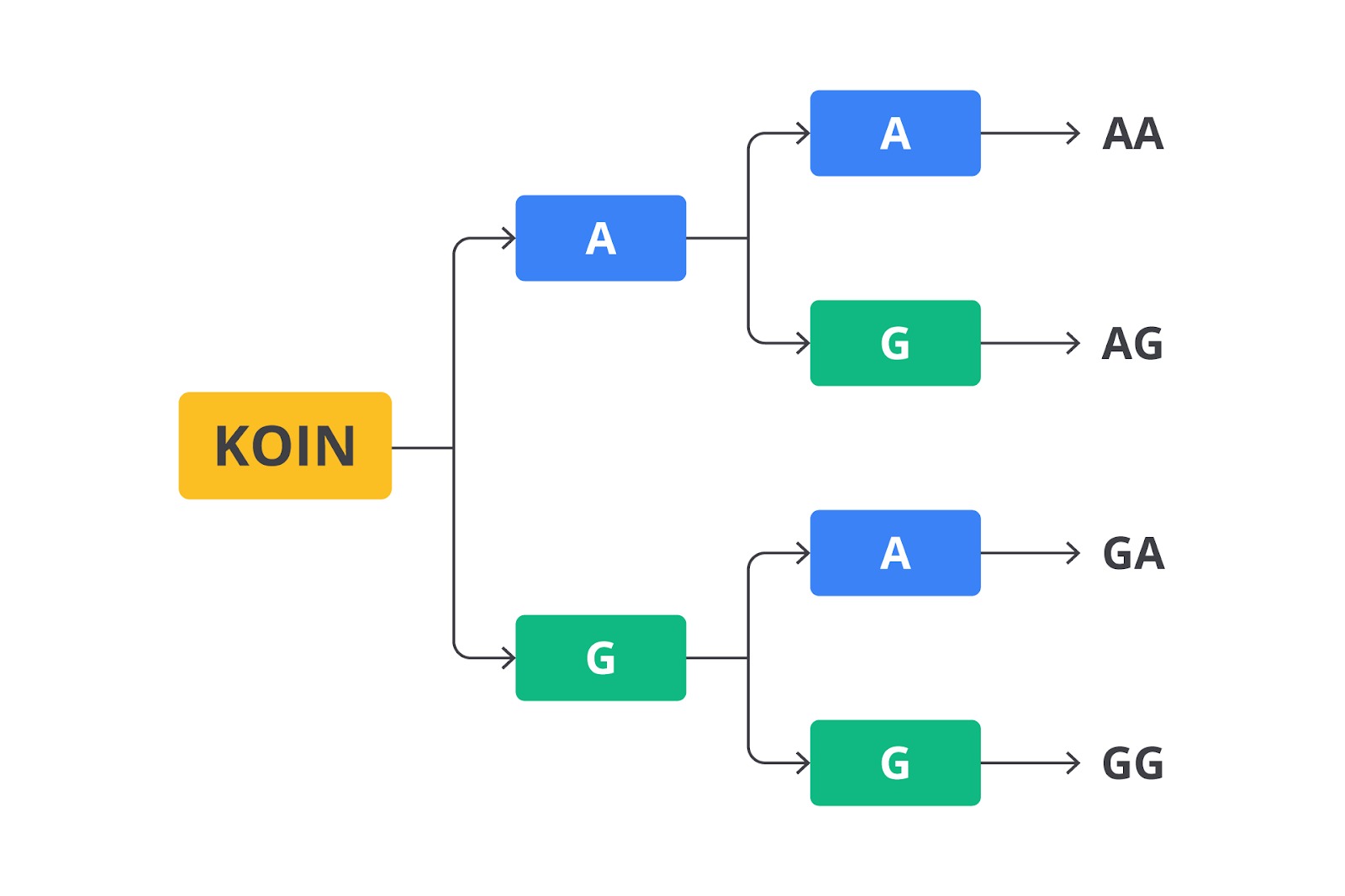
Karena satu koin bisa menghasilkan Angka (A) atau Gambar (G), dua koin akan menghasilkan gabungan dari dua huruf tersebut. Kita bisa menuliskannya seperti ini.
- Koin pertama A, koin kedua A → AA.
- Koin pertama A, koin kedua G → AG.
- Koin pertama G, koin kedua A → GA.
- Koin pertama G, koin kedua G → GG.
Jadi, ruang sampel dari percobaan melempar dua koin adalah berikut.
S = {AA,AG,GA,GG}
Perhatikan bahwa urutan penting di sini. “AG” dan “GA” dianggap berbeda karena koin yang muncul angka dan gambar bisa berbeda tergantung posisi (koin pertama vs. koin kedua). Ini menunjukkan bahwa dalam beberapa eksperimen, urutan kejadian juga memengaruhi ruang sampel.
Ruang sampel adalah landasan dari semua perhitungan probabilitas. Saat ingin menghitung peluang suatu kejadian, kita selalu membandingkan jumlah hasil yang mendukung kejadian itu dengan jumlah total hasil dalam ruang sampel.
Contohnya, jika ingin menghitung probabilitas muncul angka genap dari pelemparan satu dadu, kita lihat dulu hasil-hasil yang mendukung kejadian tersebut. Angka genap pada dadu adalah 2, 4, dan 6—ada tiga angka. Jumlah total hasil dalam ruang sampel adalah 6. Jadi, probabilitasnya dihitung sebagai berikut.
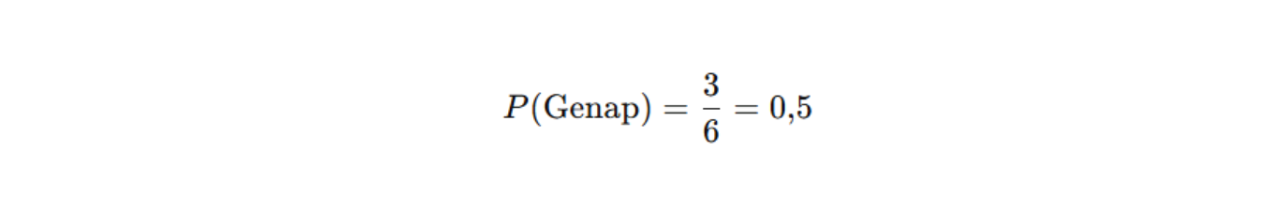
Tanpa mengetahui ruang sampel, kita tidak akan tahu hal yang mungkin terjadi dan hal yang tidak sehingga tidak mungkin bisa menghitung peluang dengan benar.
Tidak semua ruang sampel sesederhana lemparan koin atau dadu. Kadang ruang sampelnya bisa sangat besar atau bahkan tak hingga. Misalnya, jika Anda mengukur suhu udara di suatu kota, suhu bisa bernilai berapa pun dalam rentang tertentu, bahkan sampai angka desimal yang sangat kecil, seperti 27,314°C. Dalam kasus ini, ruang sampelnya bukan lagi berupa daftar hasil yang bisa dihitung satu-satu, tetapi berupa rentang nilai kontinu, seperti berikut.
S = [0∘C,50∘C]
Ruang sampel seperti ini disebut kontinu dan perhitungannya membutuhkan pendekatan berbeda, biasanya melibatkan fungsi distribusi serta integral. Namun tenang, dalam materi dasar ini, kita fokus dulu pada ruang sampel yang diskret—yang hasil-hasilnya bisa dihitung.
Kejadian: Fokus dari Perhitungan Probabilitas
Setelah mengenal ruang sampel sebagai daftar lengkap dari semua kemungkinan hasil yang dapat terjadi dalam suatu eksperimen acak, sekarang saatnya kita masuk ke bagian yang lebih spesifik: kejadian atau dalam bahasa Inggris disebut event.
Apa itu Kejadian?
Kalau ruang sampel adalah keseluruhan panggung pertunjukan, kejadian adalah adegan tertentu yang sedang kita soroti. Kejadian adalah bagian dari ruang sampel yang diperhatikan karena sesuai dengan pertanyaan atau fokus analisis kita.
Secara sederhana, kejadian adalah sekumpulan hasil yang kita amati, harapkan, atau ingin hitung peluang terjadinya. Dalam teori probabilitas, kejadian adalah subset dari ruang sampel, artinya ia adalah kumpulan beberapa (atau bahkan satu) elemen dari himpunan semua hasil yang mungkin terjadi.
Mari kita ambil contoh klasik: melempar sebuah dadu. Ruang sampelnya adalah berikut.
S = {1,2,3,4,5,6}
Sekarang, bayangkan Anda ingin mengetahui bermain ular tangga harus mendapatkan nilai empat pada dadu untuk finish dalam satu kali giliran sehingga kejadian yang diharapkan sebagai berikut.
A = {4}
Inilah contoh konkret dari kejadian. Himpunan ini mewakili semua hasil yang membuat peristiwa “muncul angka genap” menjadi benar. Nah, dari sinilah kita nanti bisa mulai menghitung probabilitasnya.
Diagram Venn: Membantu Anda Melihat Probabilitas
Terkadang, ketika kita mempelajari probabilitas dan melihat semua simbol serta rumus, rasanya seperti sedang membaca peta yang rumit tanpa tahu arah utara. Nah, agar Anda tidak merasa tersesat di dunia probabilitas, ada satu alat bantu visual yang sangat berguna: diagram Venn.
Diagram Venn adalah cara sederhana dan kuat untuk memvisualisasikan hubungan antar kejadian dalam ruang sampel. Ia membantumu “melihat” bahwa kejadian-kejadian saling beririsan, saling lepas, atau bahkan saling melengkapi. Ilustrasi dari notasi matematika dalam diagram Venn seperti berikut.
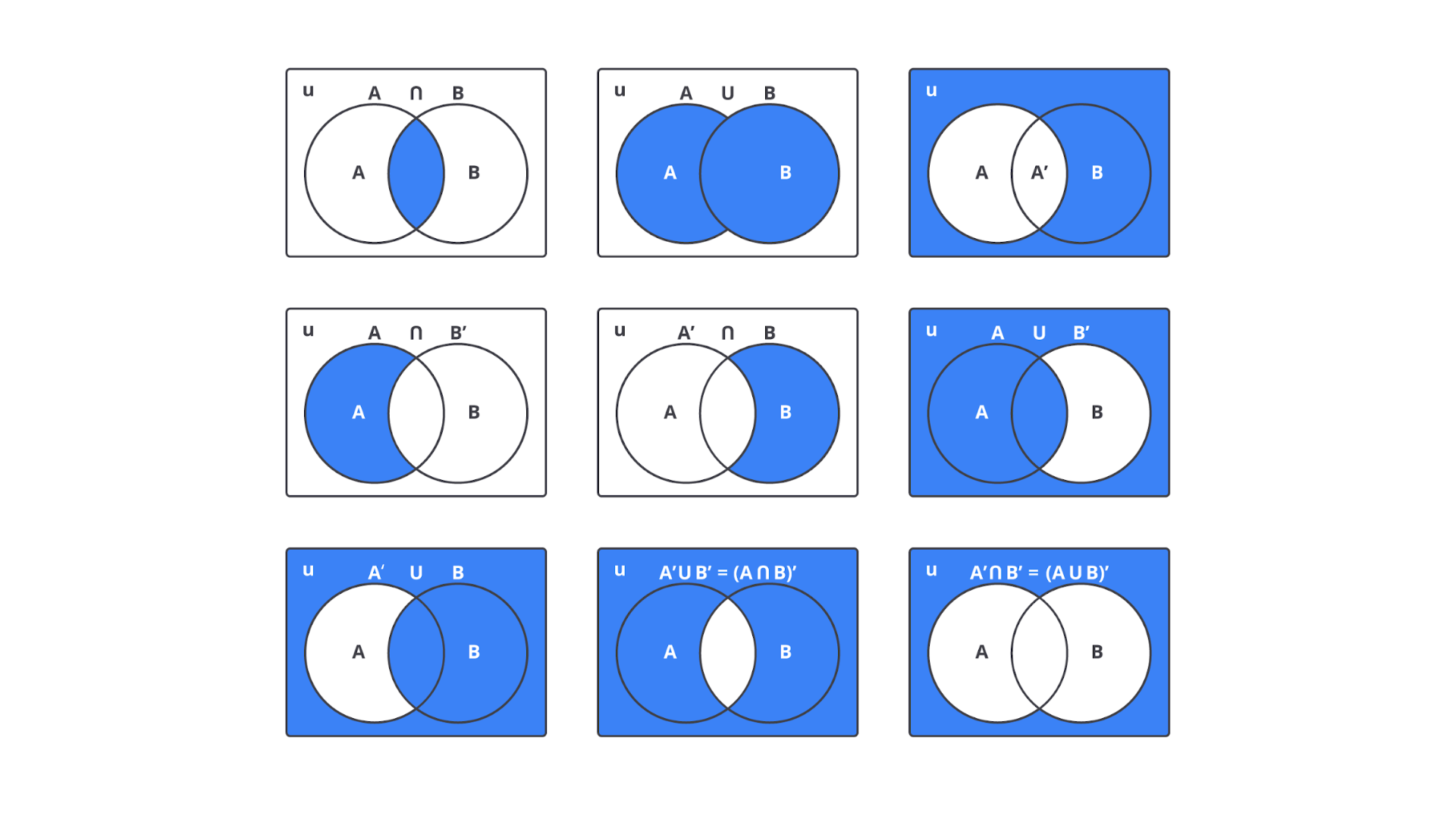
Dengan melihat diagram ini, Anda bisa lebih mudah memahami cara perhitungan probabilitas bekerja secara logis—tanpa harus selalu mengandalkan angka duluan.
Jenis-Jenis Kejadian
Dalam teori probabilitas, kejadian bisa memiliki beberapa bentuk atau jenis tergantung pada isi dan hubungannya dengan kejadian lain. Yuk, kita bahas satu per satu dengan contoh agar Anda makin paham.
Kejadian Sederhana (Simple Event)
Kejadian sederhana adalah kejadian yang hanya terdiri dari satu hasil dalam ruang sampel. Misalnya, Anda melempar dadu dan ingin tahu peluang munculnya angka empat saja. Jadi, kejadian B adalah berikut.
B = {4}
Kejadian ini hanya berisi satu elemen, yaitu angka empat (4), dan ini disebut sebagai kejadian sederhana. Kejadian seperti ini biasanya paling mudah dihitung dan sering menjadi bagian dari kejadian yang lebih besar.
Kejadian Majemuk (Compound Event)
Berbeda dengan kejadian sederhana, kejadian majemuk terdiri dari lebih dari satu hasil. Ini adalah jenis kejadian yang melibatkan gabungan dari beberapa kemungkinan. Misalnya, Anda ingin mengetahui peluang munculnya angka lebih dari dua, tetapi kurang dari lima saat melempar dadu. Kejadian tersebut adalah berikut.
C = {3,4}
Karena kejadian ini mencakup dua hasil dari ruang sampel, ia disebut sebagai kejadian majemuk. Dalam kehidupan nyata, banyak kejadian penting yang bersifat majemuk karena kita sering tertarik pada lebih dari satu kemungkinan.
Kejadian Mustahil dan Kejadian Pasti
Kadang-kadang, ada juga kejadian yang tidak mungkin terjadi, atau justru pasti terjadi. Ini dua kejadian ekstrem dari spektrum probabilitas.
-
Kejadian mustahil adalah kejadian yang tidak mengandung elemen sama sekali dari ruang sampel. Contoh: muncul angka delapan (8) saat melempar satu dadu enam sisi. Karena angka delapan tidak ada dalam ruang sampel {1,2,3,4,5,6}, kejadian ini adalah kejadian mustahil dan probabilitasnya sebagai berikut.
P = 0
-
Kejadian pasti adalah kejadian yang mencakup semua elemen dari ruang sampel. Contoh: “muncul angka antara 1 sampai 6” saat melempar dadu. Ini mencakup semua kemungkinan sehingga probabilitasnya berikut.
P = 1
Kejadian Saling Lepas: Tidak Bisa Terjadi Bersamaan
Salah satu hal penting yang perlu Anda pahami adalah konsep kejadian saling lepas atau dalam bahasa Inggris disebut mutually exclusive events. Dua kejadian dikatakan saling lepas jika tidak ada satu pun hasil yang bisa terjadi pada keduanya sekaligus.
Contohnya, dalam pelemparan satu buah dadu ada kejadian berikut.
- Kejadian D: muncul angka ganjil → D = {1,3,5}
- Kejadian E: muncul angka genap → E = {2,4,6}
Kalau kita perhatikan, tidak ada satu pun angka yang masuk pada kedua kejadian itu secara bersamaan. Angka tidak bisa sekaligus ganjil dan genap, jadi kejadian D dan E adalah saling lepas. Jika ingin menghitung peluang gabungan dari dua kejadian saling lepas, kita cukup menjumlahkan probabilitasnya.
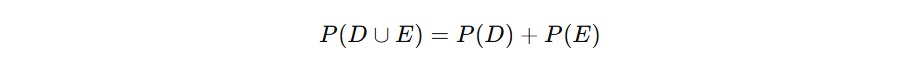
Sebaliknya, jika dua kejadian tidak saling lepas, artinya ada hasil yang mungkin terjadi pada keduanya. Misalnya berikut.
- Kejadian F: muncul angka kurang dari lima → F = {1,2,3,4}
- Kejadian G: muncul angka genap → G = {2,4,6}
Perhatikan bahwa angka 2 dan 4 ada dalam kedua kejadian, jadi F∩G = {2,4}. Artinya, F dan G tidak saling lepas dan kalau ingin menghitung peluang gabungannya, kita harus mengurangi bagian yang dihitung dua kali.
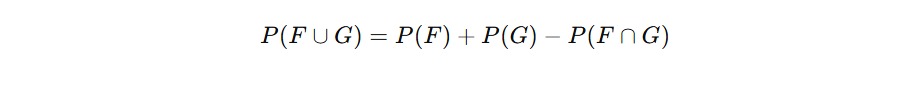
Mengapa kita harus tahu jenis-jenis kejadian ini? Jawabannya sederhana: karena setiap perhitungan probabilitas selalu didasarkan pada kejadian. Untuk bisa menjawab “berapa besar kemungkinan sesuatu terjadi?”, kita harus tahu dulu bentuk kejadiannya. Apakah sederhana atau majemuk? Apakah saling lepas atau tidak? Dengan memahami jenis-jenis ini, Anda akan lebih cermat dan tepat dalam menerapkan rumus probabilitas nanti.
Operasi pada Kejadian: Gabungan, Irisan, dan Komplemen
Sekarang Anda sudah mengenal definisi kejadian dan berbagai jenisnya. Namun, di dunia nyata, kejadian-kejadian ini sering kali tidak berdiri sendiri. Kita sering ingin tahu hal yang terjadi kalau dua kejadian digabung, hal yang terjadi di tengah-tengahnya, atau bahkan hal yang terjadi kalau kejadian itu tidak terjadi sama sekali. Nah, untuk menjawab pertanyaan-pertanyaan seperti itu, kita perlu memahami operasi pada kejadian.
Sama seperti operasi pada himpunan dalam matematika dasar, kita bisa melakukan operasi gabungan, irisan, dan komplemen terhadap dua atau lebih kejadian pada ruang sampel. Ketiga operasi ini sangat penting karena menjadi dasar dari banyak perhitungan probabilitas yang lebih kompleks nanti.
Gabungan (Union): A atau B
Bayangkan Anda sedang melempar dadu dan ingin tahu peluang munculnya angka lebih dari empat atau angka genap. Di sinilah Anda sedang bicara soal gabungan dua kejadian.
Secara definisi, gabungan dua kejadian A∪B adalah semua hasil dalam kejadian A, kejadian B, atau keduanya. Jadi, Anda tinggal menyatukan isi dari dua kejadian tersebut.
Misalnya berikut.
- A = {angka lebih dari 4} = {5, 6}
- B = {angka genap} = {2, 4, 6}
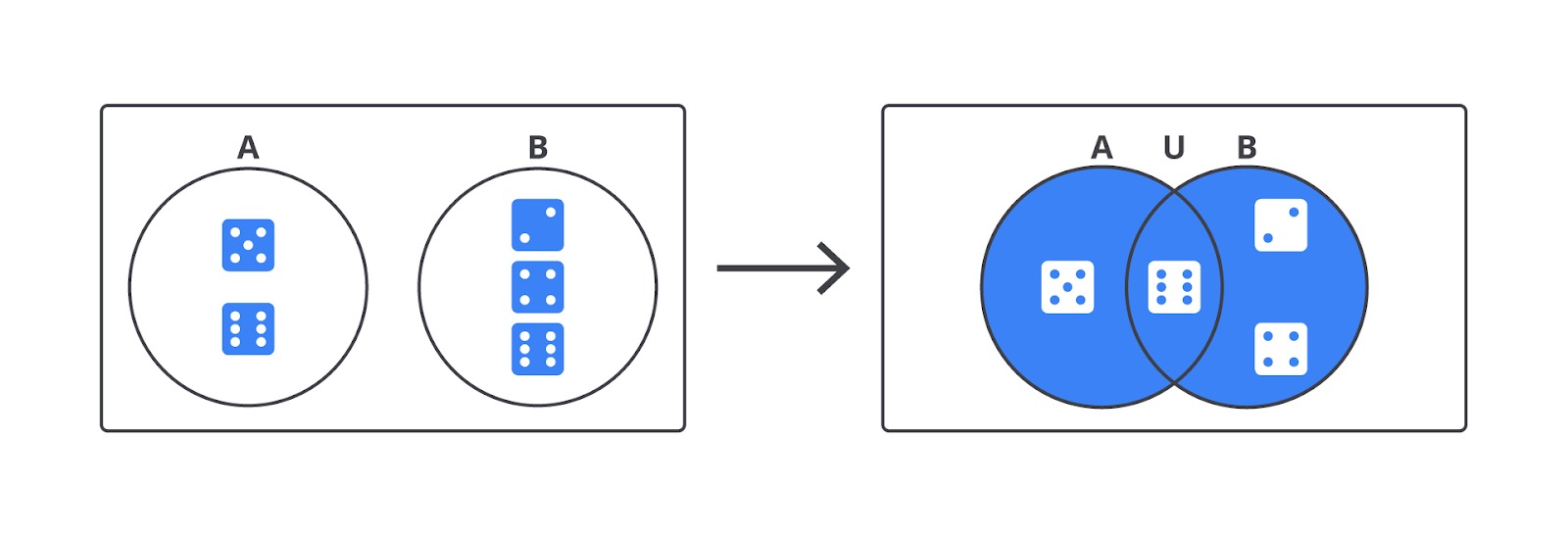
Jadi, A ∪ B = {2,4,5,6}
Nah, bagaimana cara menghitung probabilitas gabungan? Kita pakai rumus berikut.
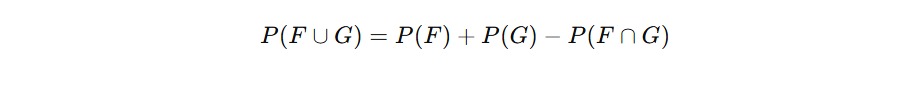
Mengapa harus dikurangi P(A∩B)? Karena hasil dalam kedua kejadian (yaitu irisan) akan terhitung dua kali kalau kita langsung menjumlahkan P(A)+P(B). Jadi kita perlu menguranginya sekali agar hasilnya akurat.
Irisan (Intersection): A dan B
Kalau gabungan adalah “A atau B”, irisan adalah “A dan B”. Artinya, kita ingin tahu hasil yang muncul dalam kedua kejadian sekaligus.
Dalam notasi matematika, irisan ditulis sebagai A∩B, berarti kita hanya mengambil hasil pada A dan juga B.
Kita lanjutkan contoh sebelumnya.
- A = {angka lebih dari 4} = {5, 6}
- B = {angka genap} = {2, 4, 6}
- Jadi, A∩B={6}
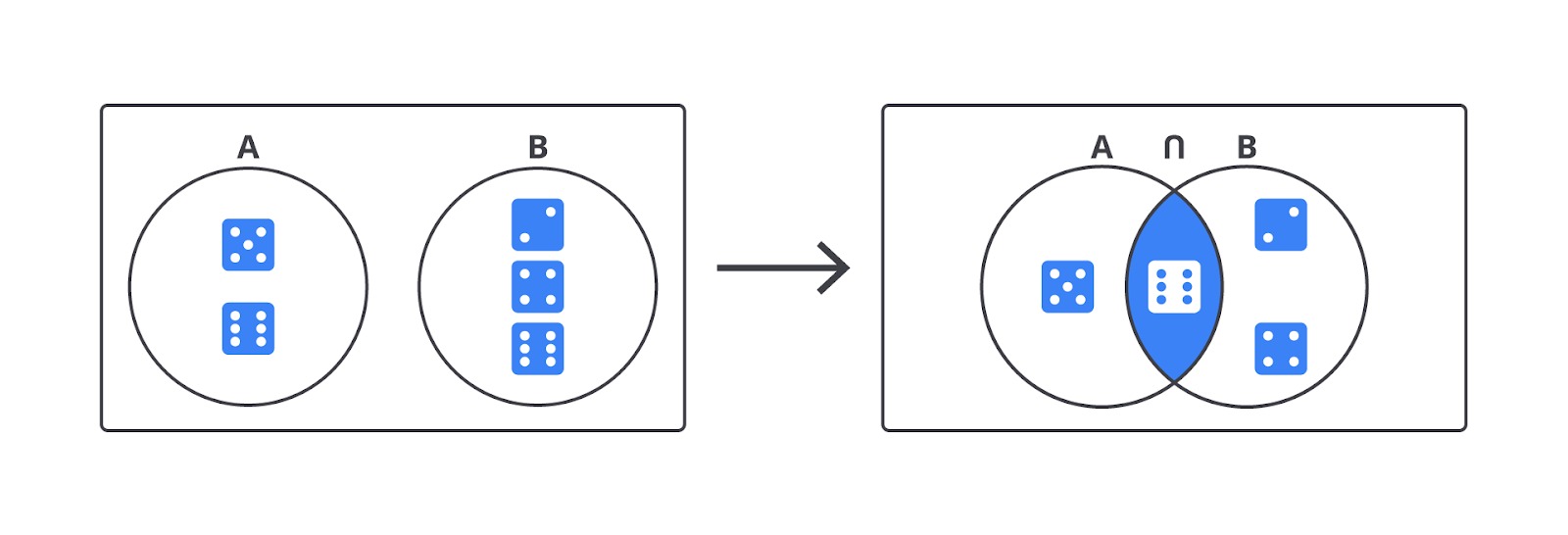
Jadi, hanya angka enam yang termasuk dalam kedua kejadian itu. Berikut adalah cara menghitung probabilitasnya.
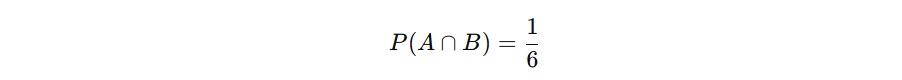
Irisan sangat penting terutama ketika Anda ingin mengetahui peluang dua kondisi terjadi bersamaan. Misalnya dalam dunia medis: “Apa peluang seseorang memiliki gejala X dan positif COVID?” Itu jelas kasus irisan.
Kalau dua kejadian saling lepas, berikut adalah rumus yang digunakan.
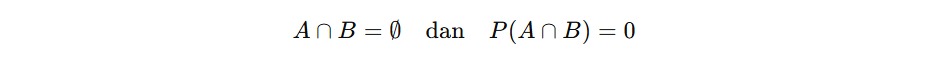
Komplemen (Complement): Tidak A
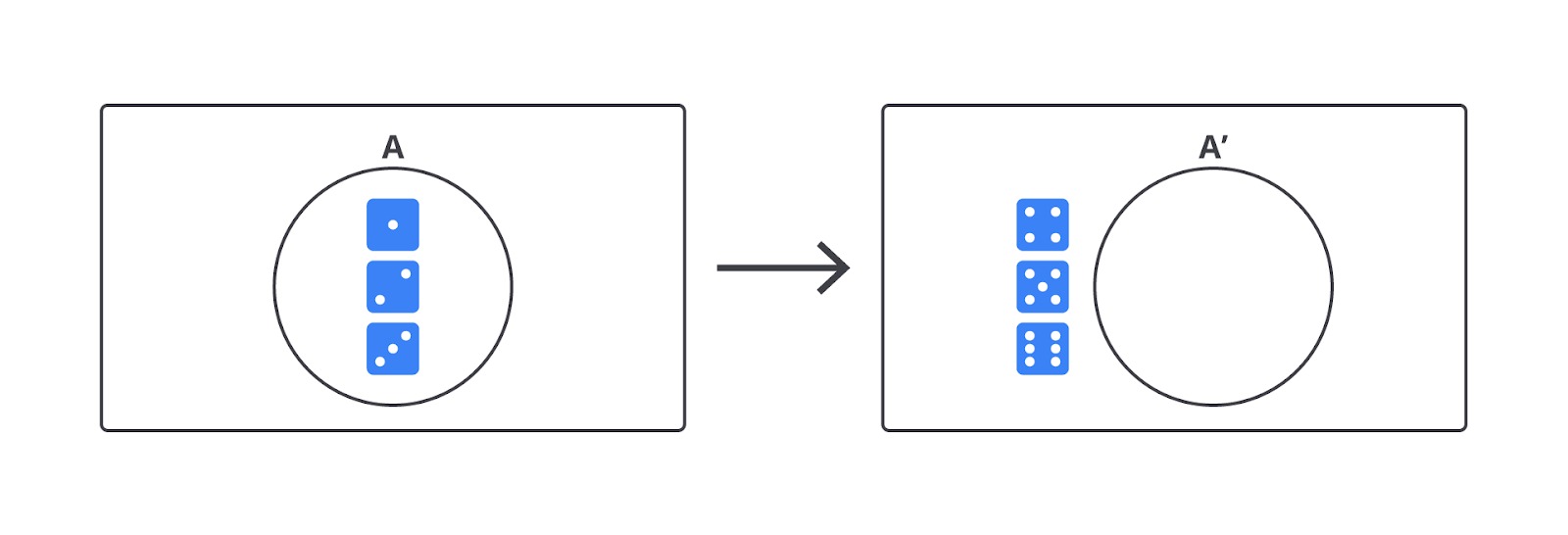
Sekarang kita bahas operasi yang sering kali dilupakan, tetapi sangat berguna: komplemen. Komplemen dari suatu kejadian A adalah semua hasil dalam ruang sampel yang tidak termasuk pada A. Dalam simbol, ditulis sebagai A′.
Misalnya berikut.
- Ruang sampel S = {1, 2, 3, 4, 5, 6}
- A = {1, 2, 3}
Kita lihat lingkaran di sebelah kiri memperlihatkan himpunan A, dan di sebelah kanan himpunan selain A.
Jadi, komplemen A adalah berikut.
A’ = { 4, 5, 6 }
Komplemen sangat berguna ketika kita lebih mudah menghitung peluang kejadian tidak terjadi. Bahkan, sering kali lebih praktis menghitung komplemen, lalu menguranginya dari 1.
Rumusnya sederhana.
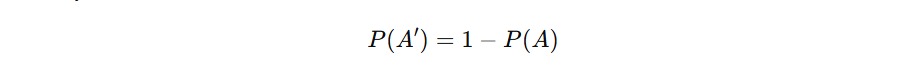
Contohnya berikut.
- P(A) = 0,4
- Jadi, P(A’) = 1 – 0,4 = 0,6
Komplemen sering muncul dalam pertanyaan yang berbunyi seperti berikut.
- “Berapa peluang seseorang tidak terinfeksi?”
- “Berapa peluang tidak muncul angka enam?”
Dengan memahami konsep komplemen, Anda bisa menghemat waktu perhitungan dan memperluas strategi pemecahan soal.
Metode Penghitungan Probabilitas
Setelah sebelumnya Anda memahami konsep dasar probabilitas, ruang sampel, dan cara kejadian saling berinteraksi, sekarang saatnya kita masuk ke bagian yang sangat penting: cara menghitung probabilitas itu sendiri.
Bayangkan Anda sedang bermain dadu, memilih kartu, atau menyusun orang dalam antrian—semua itu adalah situasi yang bisa melibatkan banyak kemungkinan. Namun, jangan khawatir. Pada materi ini, Anda akan belajar metode-metode yang nantinya membantu untuk menghitung jumlah kemungkinan dengan cepat dan akurat, tanpa perlu menulis semua kemungkinan satu per satu.
Yuk, kita mulai dengan salah satu teknik yang paling sering digunakan: aturan perkalian.
Aturan Perkalian: Probabilitas untuk Kejadian Majemuk
Pernahkah Anda bertanya, “Berapa banyak kemungkinan kombinasi pakaian yang bisa aku pakai jika aku punya tiga baju dan dua celana?” Atau, dalam konteks probabilitas, “Berapa peluang mendapatkan angka genap dari dua lemparan dadu?” Semua ini bisa dijawab dengan aturan perkalian.
Apa itu aturan perkalian?
Aturan ini digunakan ketika Anda ingin mengetahui jumlah total kemungkinan dari dua atau lebih kejadian yang terjadi secara berurutan.
Misalnya, Anda punya opsi berikut.
- Tiga pilihan baju: A, B, C
- Dua pilihan celana: X, Y
Jadi, jumlah kombinasi pakaian yang bisa Anda pakai adalah berikut.
3 × 2 = 6 kombinasi
Secara umum, jika kejadian pertama memiliki m kemungkinan dan kejadian kedua memiliki n kemungkinan, jumlah total pasangan yang mungkin adalah berikut.
m×n
Contoh dalam Probabilitas
Misalnya, Anda melempar dua buah dadu. Setiap dadu punya 6 kemungkinan hasil. Jadi, jumlah total pasangan hasil yang mungkin (dadu 1 dan dadu 2) adalah berikut.
6 × 6 = 36 kemungkinan
Jika Anda ingin tahu peluang munculnya “angka 4 pada dadu pertama DAN angka 6 pada dadu kedua”, perhitungannya berikut karena masing-masing hanya satu dari enam kemungkinan.
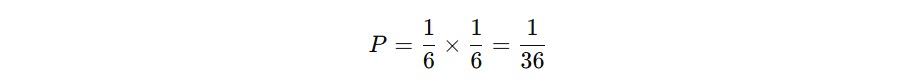
Aturan ini juga berlaku untuk lebih dari dua kejadian, misalnya memilih angka, lalu huruf, lalu warna. Tinggal kalikan jumlah kemungkinan dari masing-masing tahap.
Permutasi: Urutan Itu Penting
Bayangkan Anda diminta menyusun tiga orang—A, B, dan C—dalam satu barisan. Anda mungkin berpikir, “Ya sudah, pilih satu-satu.” Namun, berapa banyak susunan yang berbeda bisa dibuat?
Jawabannya berikut.
ABC,ACB,BAC,BCA,CAB,CBA
Ada 6 susunan dan ini disebut sebagai permutasi.
Permutasi digunakan ketika Anda ingin menghitung banyaknya susunan berbeda dari sejumlah objek dan urutan menjadi hal yang penting.

Rumus Permutasi
Jika Anda punya n objek dan ingin menyusunnya sebanyak r posisi (tanpa pengulangan), jumlah permutasi adalah berikut.
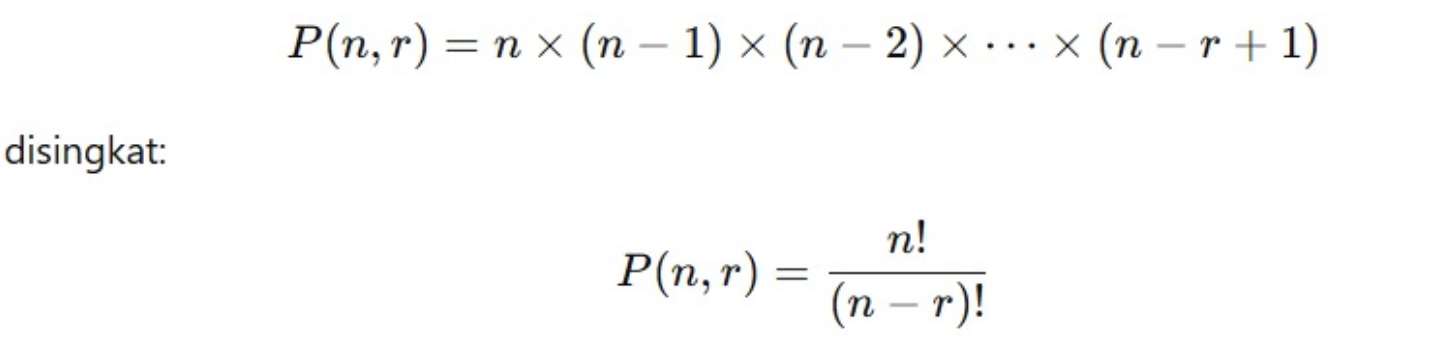
Contohnya:
Berapa banyak cara untuk menyusun empat orang dalam kursi yang hanya cukup untuk dua orang?
Gunakan rumus berikut.
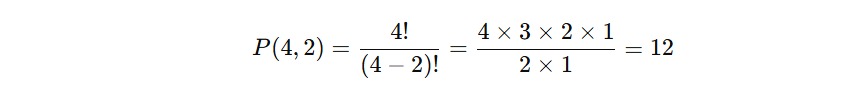
Jadi, ada 12 susunan berbeda.
Kombinasi: Urutan Tidak Penting
Kebalikan dari permutasi, kombinasi digunakan saat Anda hanya tertarik pada kelompok yang terbentuk, bukan urutannya.
Misalnya, dari sepuluh orang Anda ingin memilih lima orang untuk dijadikan tim. Anda tidak peduli siapa yang disebut duluan—yang penting siapa yang terpilih. Jadi, pasangan ABCDE sama saja dengan DEABC.

Rumus Kombinasi
Jika Anda punya n objek dan ingin memilih r objek tanpa memperhatikan urutan, jumlah kombinasi adalah berikut.
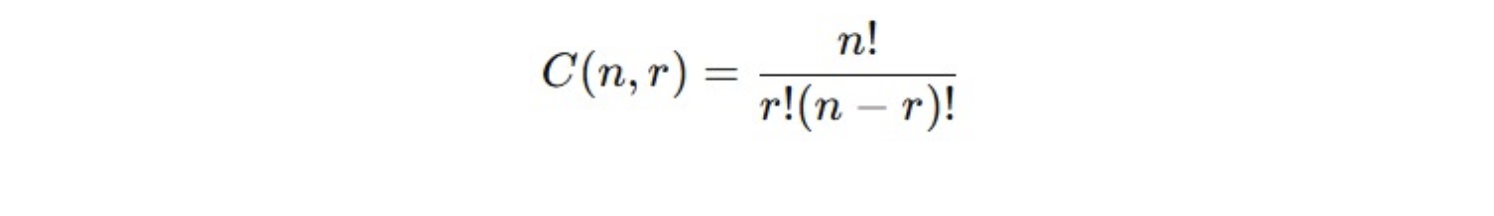
Contohnya:
Berapa banyak cara memilih dua orang dari total empat orang?
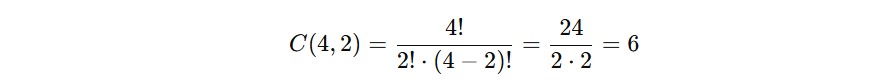
Artinya, hanya ada enam kombinasi berbeda, lebih sedikit dibanding permutasi karena kita tidak memperhitungkan susunannya.
Aturan Penjumlahan: Salah Satu dari Beberapa Kejadian
Aturan penjumlahan digunakan saat kita ingin menghitung probabilitas salah satu dari beberapa kejadian yang bisa terjadi, tanpa terjadi bersamaan.
Misalnya berikut.
- Kejadian A: muncul angka 1 atau 2 dari satu dadu > P(A) = 2/6
- Kejadian B: muncul angka 5 > P(B) = 1/ 6
Karena A dan B tidak punya irisan (tidak bisa terjadi bersamaan), kita bisa gunakan aturan penjumlahan sebagai berikut.
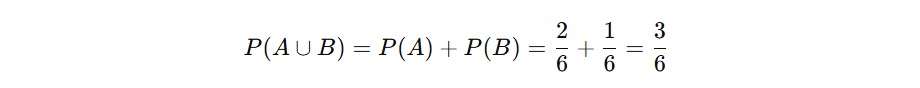
Kalau dua kejadian tidak saling lepas, Anda harus kurangi bagian irisan.
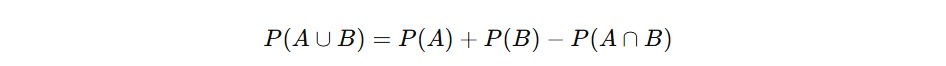
Aturan ini sangat penting saat Anda ingin menghitung peluang dari beberapa kondisi berbeda yang bisa terjadi secara terpisah.
Prinsip Pigeonhole: Ketika Jumlah Tidak Cukup
Prinsip ini terdengar lucu, tetapi sangat berguna. Ia disebut prinsip pigeonhole atau dalam bahasa sederhana: prinsip kotak merpati.
Bayangkan Anda punya lima merpati dan empat kotak. Jika semua merpati harus masuk ke kotak, pasti ada setidaknya satu kotak yang berisi lebih dari satu merpati.
Secara umum, prinsip ini mengatakan hal berikut.
Jika n objek ditempatkan dalam k wadah, dan n>k, paling tidak ada satu wadah yang berisi lebih dari satu objek.
Dengan kata lain, jika kamu punya lebih banyak objek daripada wadah untuk menempatkannya, akan selalu ada wadah yang terisi ganda.
Contoh penerapan:
Misalnya, Anda punya 13 orang dan ingin tahu adakah dua orang yang lahir dalam bulan yang sama. Anda tahu bahwa hanya ada 12 bulan dalam setahun dan Anda punya 13 orang.
- 13 > 12 → pasti ada minimal dua orang yang lahir dalam bulan yang sama.
Prinsip ini berguna dalam banyak soal logika dan pembuktian dalam probabilitas serta kombinatorika. Ia sering muncul saat kita membahas ketidakmungkinan distribusi merata dalam jumlah yang terbatas.
Latihan Menghitung
| #### Soal Untuk mempertajam pengetahuan Anda, mari kita berlatih menghitung dengan soal-soal berikut. Anda bisa menyiapkan catatan untuk menjawab soal secara mandiri, kemudian membandingkan hasilnya dengan kunci jawaban di bawah. 1. Ada lima siswa: Andi, Budi, Citra, Dodi, dan Eka. Mereka akan duduk berjejer dalam satu baris. Namun, Citra dan Dodi tidak boleh duduk bersebelahan. Berapa banyak susunan duduk yang mungkin? Hint: * Hitung total permutasi tanpa batasan. * Kurangi jumlah susunan ketika Citra dan Dodi bersebelahan. 2. Dari satu kelas yang berisi sepuluh siswa laki-laki dan delapan siswa perempuan, tiga orang akan dipilih untuk mengikuti lomba. Berapa peluang bahwa yang terpilih minimal satu perempuan? Hint: Gunakan pendekatan komplemen. * Hitung total kombinasi memilih 3 dari 18 siswa. * Kurangi kombinasi memilih semuanya laki-laki. 3. Dua buah dadu dilempar secara bersamaan. Berapa peluang bahwa jumlah kedua mata dadu adalah kelipatan tiga? Hint: * Buat semua pasangan dadu (36 kemungkinan). * Identifikasi pasangan yang menjumlahkan kelipatan tiga (misal: 3, 6, 9, 12). * Dari sana, pilih yang memiliki angka genap pada salah satu dadu. 4. Dalam proses data augmentation untuk analisis teks, Anda memiliki empat kata berbeda: “data”, “besar”, “analisis”, dan “cepat”. Berapa banyak kalimat berbeda (berbeda urutan) yang bisa Anda bentuk dari keempat kata tersebut? Hint: Gunakan permutasi dari empat objek unik. 5. Anda memiliki sepuluh fitur dalam dataset. Namun karena keterbatasan memori, Anda hanya bisa memilih tiga fitur untuk membangun model awal. Berapa banyak kombinasi subset fitur yang bisa Anda uji? Hint: Gunakan kombinasi: sepuluh data. 6. Dalam hyperparameter tuning (grid search), Anda mengatur sebagai berikut. * Tiga nilai learning rate * Empat jenis batch size * Dua jenis optimizer Berapa total kombinasi pengujian model yang mungkin? Hint: Gunakan aturan perkalian. |
| #### Kunci Jawaban 1. 5! - (4! x 2) = 72 2. 29/34 = 85.29% 3. Peluang 3 = 2 Peluang 6 = 5 Peluang 9 = 4 Peluang 12=1 = 2 + 5 + 4 + 1 = 12 4. 4! = 24 5. 120 6. Total kombinasi=3×4×2= 24 |
Probabilitas Bersyarat dan Teorema Bayes
Pernahkah Anda bertanya-tanya, “Kalau seseorang sedang demam, apakah itu berarti dia sedang flu?” Atau, “Kalau seseorang suka coding, apakah kemungkinan besar dia juga suka matematika?” Pertanyaan-pertanyaan seperti ini muncul karena kita tidak hanya ingin tahu bahwa sesuatu mungkin terjadi, tetapi juga seberapa mungkin itu terjadi jika sudah tahu informasi lain sebelumnya. Nah, di sinilah kita masuk ke dunia probabilitas bersyarat.
Probabilitas bersyarat adalah cara untuk memperbarui prediksi atau keyakinan kita terhadap suatu kejadian berdasarkan informasi yang sudah dimiliki. Jadi, alih-alih bertanya “Apa kemungkinan seseorang suka olahraga?”, kita bertanya lebih spesifik: “Apa kemungkinan seseorang suka olahraga jika kita tahu dia laki-laki?” Di sini, informasi tambahan—dalam hal ini jenis kelamin—berperan penting saat menentukan kemungkinan baru.
Definisi Probabilitas Bersyarat
Secara matematis, probabilitas bersyarat dari kejadian A yang terjadi jika diketahui kejadian B sudah terjadi, ditulis sebagai berikut.
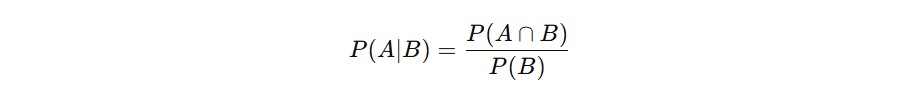
Artinya begini: dari semua kejadian saat B terjadi, kita ingin tahu seberapa besar bagian dari kejadian tersebut yang juga membuat A terjadi. Jadi, kita membatasi ruang pandang kita hanya pada kejadian B dan melihat berapa proporsi dari B yang juga termasuk A.
Agar lebih jelas, bayangkan Anda sedang menyaring data. Dari 100 karyawan di perusahaan, 70 adalah laki-laki. Dari keseluruhan karyawan, 40 orang adalah laki-laki yang suka olahraga. Nah, kalau Anda tahu seseorang adalah laki-laki (jadi hanya fokus ke 70 orang ini), berapa kemungkinan dia suka olahraga?
Jawabannya berikut.
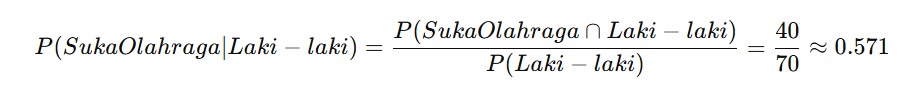
Jadi, sekitar 57,1% dari laki-laki di perusahaan tersebut suka olahraga. Tanpa informasi jenis kelamin, Anda hanya bisa menebak dari data global (misalnya, mungkin hanya 40% dari semua karyawan suka olahraga). Namun, karena punya informasi tambahan, Anda bisa mempersempit kemungkinan dengan lebih tepat.
Probabilitas bersyarat bukan hanya konsep matematika; ia hidup dan berfungsi dalam kehidupan kita sehari-hari. Kita menggunakannya, sadar atau tidak, hampir setiap saat ketika membuat keputusan berbasis informasi yang terbatas.
Misalnya berikut.
- Dalam dunia medis, dokter menilai bahwa seseorang mungkin terkena penyakit tertentu jika pasien menunjukkan gejala tertentu. Probabilitas sakit berdasarkan hasil tes medis adalah contoh nyata dari probabilitas bersyarat.
- Dalam keamanan siber, sistem deteksi penipuan menghitung kemungkinan sebuah transaksi adalah penipuan jika dilakukan pada waktu yang tidak biasa dan dari lokasi yang mencurigakan.
- Dalam bidang ritel, e-commerce sering memprediksi kemungkinan seseorang membeli produk X jika sebelumnya dia telah melihat produk Y dan Z.
Bayangkan jika kita membuat keputusan hanya berdasarkan probabilitas umum, tanpa mempertimbangkan konteks. Kita akan sering salah paham dan membuat prediksi yang tidak akurat. Probabilitas bersyarat memungkinkan untuk menyesuaikan keyakinan terhadap sesuatu berdasarkan informasi baru yang kita tahu.
Kembali ke contoh medis. Misalnya, penyakit langka hanya diderita oleh 1 dari 1000 orang. Namun, jika seseorang menunjukkan gejala khas penyakit itu, dokter tidak akan bilang “Ah, kemungkinannya kecil.” Sebaliknya, mereka akan berpikir, “Kalau gejala ini ada, peluangnya malah jadi lebih besar.” Itulah kekuatan dari berpikir dengan probabilitas bersyarat.
Jadi, probabilitas bersyarat adalah alat penting dalam memahami dunia yang kompleks dan penuh ketidakpastian. Ia membantu kita untuk lebih logis, lebih realistis, dan lebih bijak dalam mengambil keputusan—baik dalam analisis data maupun kehidupan sehari-hari.
Teorema Bayes: Ketika Arah Sebab dan Akibat Dibalik
Bayangkan Anda sedang belajar tentang gejala flu. Anda tahu bahwa orang yang terkena flu sering mengalami demam. Secara statistik, kita bisa bilang bahwa peluang seseorang mengalami demam jika dia terkena flu itu tinggi—mungkin 90% atau lebih. Namun, bagaimana kalau situasinya dibalik? Seseorang datang ke dokter dan mengatakan, “Saya demam.” Pertanyaannya menjadi: berapa besar kemungkinan dia terkena flu?
Nah, di sinilah Teorema Bayes masuk untuk menyelamatkan kita dari tebakan dan asumsi yang keliru. Ia membantu kita membalik arah hubungan probabilitas bersyarat, dari “jika flu maka demam” menjadi “jika demam maka flu.”
Secara matematis, teorema Bayes dituliskan sebagai berikut.
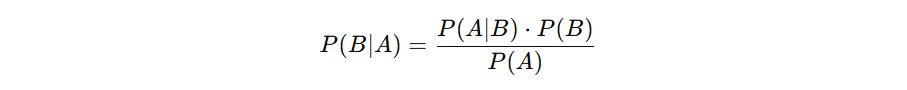
Kalau Anda belum familier dengan notasi ini, tenang dulu. Mari kita jabarkan secara perlahan.
- P(B∣A) adalah probabilitas bahwa B terjadi jika A sudah terjadi. Ini yang ingin kita cari.
- P(A∣B) adalah probabilitas bahwa A terjadi jika B benar. Biasanya ini informasi yang kita sudah tahu.
- P(B)) adalah probabilitas awal (prior) dari B terjadi, sebelum kita tahu apa-apa tentang A.
- P(A) adalah probabilitas total bahwa A terjadi dari semua kemungkinan yang bisa menyebabkannya.
Hal yang menarik di sini adalah bahwa kita bisa menghitung sesuatu yang awalnya tidak diketahui (sebab) hanya dari melihat akibat dan probabilitas-probabilitas yang bisa diukur.
Mari kita ambil contoh dari dunia medis lagi karena ini adalah salah satu bidang bahwa teorema Bayes sangat penting dan bahkan bisa menyelamatkan nyawa. Misalkan ada tes medis untuk mendeteksi penyakit langka. Berikut datanya.
-
Akurasi tes: jika seseorang benar-benar sakit, tes akan mendeteksinya dengan benar 99% dari waktu (P(Positif Sakit) = 0.99). - Frekuensi penyakit: hanya 0.1% dari populasi yang benar-benar memiliki penyakit ini (P(Sakit) = 0.001).
- Probabilitas seseorang mendapat hasil positif secara umum (baik karena memang sakit maupun karena tes salah membaca): misalnya 1% (P(Positif) = 0.01).
Sekarang, seseorang melakukan tes dan hasilnya positif. Pertanyaannya: apakah dia benar-benar sakit?
Jika hanya mengandalkan hasil tes (yang akurat 99%), banyak orang akan langsung menjawab, “Pasti iya.” Namun, itu tidak benar. Kita harus melihat seberapa umum penyakit ini terjadi.
Dengan teorema Bayes, kita dapat menghitungnya sebagai berikut.
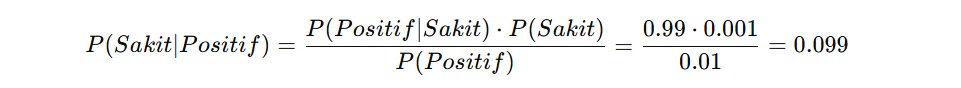
Artinya, meskipun tes sangat akurat, kemungkinan orang itu benar-benar sakit hanya sekitar 9.9%. Mengapa kecil? Karena penyakit ini sangat jarang—dan kemungkinan hasil positif muncul dari orang sehat (false positive) tetap cukup tinggi dibanding prevalensi penyakit itu sendiri.
Banyak orang secara naluriah salah menafsirkan probabilitas terbalik. Mereka menganggap bahwa jika tes akurat, hasilnya positif, yang berarti hampir pasti benar. Namun faktanya, jika kejadian (penyakit) itu jarang terjadi, meskipun tes sangat bagus, kebanyakan hasil positif masih bisa datang dari orang yang sebenarnya tidak sakit.
Teorema Bayes membantu untuk membuat penilaian lebih adil dan masuk akal karena ia mempertimbangkan konteks secara utuh: tidak hanya akurasi tes, tetapi juga seberapa umum kejadian yang sedang kita prediksi.
Bayangkan Anda seorang analis data yang sedang membangun model untuk deteksi penipuan transaksi. Jika hanya fokus pada “ciri khas penipuan”, tanpa memperhitungkan seberapa umum penipuan benar-benar terjadi, Anda akan menghasilkan banyak false alarm. Model Anda mungkin terlalu sensitif dan malah mengganggu pelanggan sah.
Metode Bayes pada Machine Learning
Dalam dunia pemelajaran mesin (machine learning), teorema Bayes bukan hanya alat statistik, tetapi menjadi kerangka berpikir untuk menghadapi data yang terus berubah. Inti dari pendekatan Bayesian adalah memadukan pengetahuan awal (prior) dengan data yang baru ditemukan (evidence) untuk menghasilkan keyakinan terbaru (posterior). Ini membuat pendekatan Bayesian sangat fleksibel dan adaptif.
Salah satu contoh paling terkenal adalah algoritma Naive Bayes, yang banyak digunakan untuk klasifikasi teks, seperti deteksi spam, analisis sentimen, dan pengelompokan dokumen. Meskipun sederhana, Naive Bayes efektif karena ia menghitung peluang suatu kelas berdasarkan fitur (seperti kata-kata) yang muncul dalam data dengan asumsi bahwa fitur tersebut saling independen. Kecepatannya membuat algoritma Naive Bayes sangat berguna untuk dataset besar.
Lebih lanjut, ada juga Bayesian network, yaitu model grafis yang memetakan hubungan antarvariabel dalam bentuk diagram sebab-akibat. Ini sangat membantu dalam bidang seperti diagnosis medis atau sistem pakar karena kita bisa melihat bahwa satu variabel memengaruhi variabel lain secara langsung.
Kemudian, dalam skenario yang lebih kompleks dan dinamis, kita menggunakan Bayesian inference, yang memungkinkan model untuk terus belajar seiring datangnya data baru. Alih-alih mengulang proses dari awal, model hanya perlu melakukan pembaruan pada keyakinan yang sudah ada—efisien dan realistis, terutama saat data sulit dikumpulkan sekaligus.
Keunggulan berpikir ala Bayes terletak pada kemampuannya beradaptasi. Ini sangat penting pada era big data dan AI, ketika informasi tidak selalu datang sekaligus, serta model yang baik adalah model yang bisa terus belajar—sedikit demi sedikit, tetapi terus-menerus.
Kontrol Teorema Bayes
Salah satu kekuatan terbesar dari pendekatan Bayesian adalah kemampuannya untuk berpikir secara fleksibel di tengah ketidakpastian. Tidak hanya berhenti pada menghitung peluang, teorema Bayes juga membuka pintu bagi kita untuk menyusun keyakinan, memperbarui informasi secara bertahap, serta yang tidak kalah penting adalah mengontrol dan mengoptimalkan parameter dalam proses prediksi.
Dalam konteks dunia nyata, model probabilistik yang dibangun dengan pendekatan Bayesian sering kali tidak langsung memberikan jawaban. Kita harus merancang dan menyusun modelnya secara hati-hati: menentukan asalkeyakinan awal, pengolahan data menjadi bukti, dan cara semua informasi itu disatukan untuk membentuk keyakinan akhir. Proses ini mencakup dua hal besar yang akan kita bahas di sini: kontrol parameter dan optimasi model.
Kontrol Parameter: Menentukan Arah Sebelum Melaju
Sebelum sebuah model Bayesian bisa memberikan jawaban, ia membutuhkan sesuatu yang disebut prior, yakni keyakinan awal terhadap nilai suatu parameter sebelum melihat data. Prior ini bukan sekadar angka yang ditentukan asal-asalan. Ia bisa didasarkan pada pengalaman masa lalu, pengetahuan ahli, asumsi logis, atau bahkan distribusi historis.
Misalnya, bayangkan Anda sedang membangun model prediksi churn pelanggan—keputusan seorang pelanggan akan berhenti menggunakan layanan atau tidak. Jika tahu dari studi sebelumnya bahwa tingkat churn rata-rata di industri adalah sekitar 15%, Anda bisa menggunakan itu sebagai prior: keyakinan awal sebelum melihat data pelanggan spesifik.
Secara matematis, teorema Bayes menggabungkan prior ini dengan informasi dari data dalam bentuk likelihood. Jadi, Anda mendapatkan posterior atau keyakinan yang diperbarui.
Dalam rumus ini, ada pernyataan berikut.
- P(θ) adalah prior–keyakinan awal terhadap parameter θ (dibaca: prior theta),
- P(D∣θ) adalah likelihood–seberapa cocok data D dengan parameter tersebut, dan
- P(θ∣D) adalah posterior–keyakinan akhir setelah data masuk.
Arti dari kontrol parameter adalah cara kita memilih prior P(θ) dan cara kita mengukur P(D∣θ). Jika kita punya banyak data berkualitas, prior bisa dibuat netral (misalnya distribusi seragam). Namun, jika data masih sedikit, prior yang informatif bisa membuat model kita lebih stabil.
Ada juga pendekatan empirical Bayes, yakni prior tidak ditentukan dari luar, tetapi diestimasi dari data itu sendiri. Ini membuat proses pembelajaran menjadi lebih “data-driven”, tetapi tetap dalam kerangka berpikir Bayesian.
Setelah kita memiliki formula untuk menghitung posterior, tantangan selanjutnya adalah bagaimana menemukan nilai parameter terbaik dari distribusi posterior tersebut? Inilah wilayah optimasi.
Dalam praktik, kita ingin tahu: dari semua kemungkinan nilai θ, mana yang paling mungkin setelah melihat data? Ada dua pendekatan populer untuk menjawab ini: maximum likelihood estimation (MLE) dan maximum a posteriori estimation (MAP).
Maximum Likelihood Estimation (MLE)
Maximum Likelihood Estimation (MLE) adalah pendekatan klasik yang hanya fokus pada data, tanpa mempertimbangkan prior. Kita memilih nilai θ yang memaksimalkan likelihood.
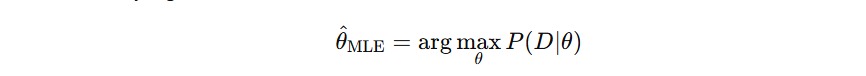
Pendekatan ini bagus saat Anda punya banyak data dan percaya bahwa data cukup representatif. Namun, ketika data terbatas, model ini bisa jadi overfitting karena tidak punya “penyeimbang”.
Maximum A Posteriori (MAP)
Maximum A Posteriori (MAP) adalah versi Bayesian dari MLE. Ia mempertimbangkan data dan prior secara bersamaan dan memilih parameter yang memaksimalkan posterior.
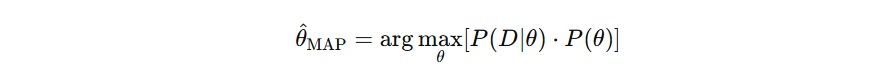
MAP lebih stabil dalam kondisi data kecil atau bising (noise–gangguan, kesalahan, atau variasi acak yang tak diinginkan pada data). Ia juga sangat fleksibel karena memungkinkan Anda “mengarahkan” model ke arah yang dianggap lebih mungkin tanpa mengabaikan data.
Optimasi Lebih Lanjut: Ketika Posterior Terlalu Kompleks
Dalam kasus-kasus nyata, bentuk posterior sering kali sangat kompleks dan tidak bisa dihitung secara eksak. Untuk itu, digunakan teknik optimasi yang lebih canggih, seperti berikut.
- Gradient Ascent atau Newton-Raphson: Ini digunakan jika kita tahu turunan dari fungsi posterior dan bisa menghitungnya secara numerik.
- Bayesian Optimization: Teknik optimasi global yang mencari nilai terbaik dari fungsi black-box (biasa digunakan dalam hyperparameter tuning).
- Markov Chain Monte Carlo (MCMC): Jika kita tidak bisa menemukan titik maksimum secara langsung, kita bisa mengambil sampel dari distribusi posterior untuk memahami bentuknya.
Dengan bantuan metode-metode ini, kita bisa tetap melakukan inferensi meskipun fungsi matematisnya tidak bisa dihitung secara tertutup. Ini yang membuat pendekatan Bayesian sangat kuat, bahkan untuk masalah yang sangat rumit.
Mengontrol dan mengoptimalkan dalam teorema Bayes bukan hanya soal memasukkan angka pada rumus. Ini adalah tentang membangun model yang kokoh dalam keyakinan awalnya, tetapi tetap terbuka untuk belajar dari data. Kita tidak hanya menebak, tetapi menimbang—menggabungkan hal yang sudah diketahui dengan hal-hal yang baru kita temukan dari data.
Algoritma Model Naive Bayes: Belajar dari Peluang
Apakah Anda pernah penasaran cara sistem email bisa otomatis memindahkan surat-surat “menyebalkan” ke folder spam atau cara ponsel bisa mengenali bahwa ulasan makanan itu bernada positif atau negatif?
Nah, Anda sedang melihat salah satu kekuatan dari Naive Bayes—sebuah algoritma klasifikasi yang sederhana, cepat, dan sering kali mengejutkan karena hasilnya yang efektif.
Model ini adalah salah satu algoritma paling klasik dalam dunia machine learning. Namanya terdengar sedikit merendahkan—“naive” artinya “naif” atau terlalu sederhana. Namun, jangan tertipu oleh namanya. Di balik kesederhanaannya, Naive Bayes sangat tangguh dan bahkan masih menjadi andalan dalam banyak tugas analisis teks hingga hari ini.
Konsep Dasar: Teorema Bayes + Asumsi Independen
Naive Bayes dibangun berdasarkan teorema Bayes, yaitu sebuah prinsip dalam statistik untuk menghitung peluang suatu hipotesis terjadi berdasarkan bukti yang diamati. Mari kita mulai dari rumus utama Naive Bayes.

Mari bahas mendalam rumus tersebut.
| P(C | x) disebut sebagai posterior probability yang menyatakan kemungkinan suatu data diklasifikasikan ke dalam kelas C setelah mempertimbangkan semua fitur yang dimiliki oleh data tersebut. Tujuan utama naive bayes adalah mencari nilai ini, yaitu seberapa besar kemungkinan data tertentu diklasifikasikan ke kelas tertentu, misalnya email spam dan bukan spam. |
| Di lain sisi, P(x | C) adalah likelihood yang menginformasikan seberapa besar kemungkinan fitur x muncul jika kita tahu data tersebut berasal dari kelas C. Lanjut, P(C) adalah prior probability, yaitu keyakinan awal terhadap kemungkinan sebuah data diklasifikasikan ke dalam kelas C, bahkan sebelum melihat isi atau fitur data tersebut. |
Terakhir, P(x) disebut juga evidence yang menyatakan probabilitas data x muncul secara umum, tanpa peduli data itu berasal dari kelas mana.
Mari buat penjelasannya lebih sederhana menggunakan sebuah studi kasus.
Deteksi Spam Email
Anda adalah seorang data science yang berencana membuat model machine learning yang bertujuan untuk mengklasifikasikan email ke dalam dua kelas:
- Spam
- Bukan Spam
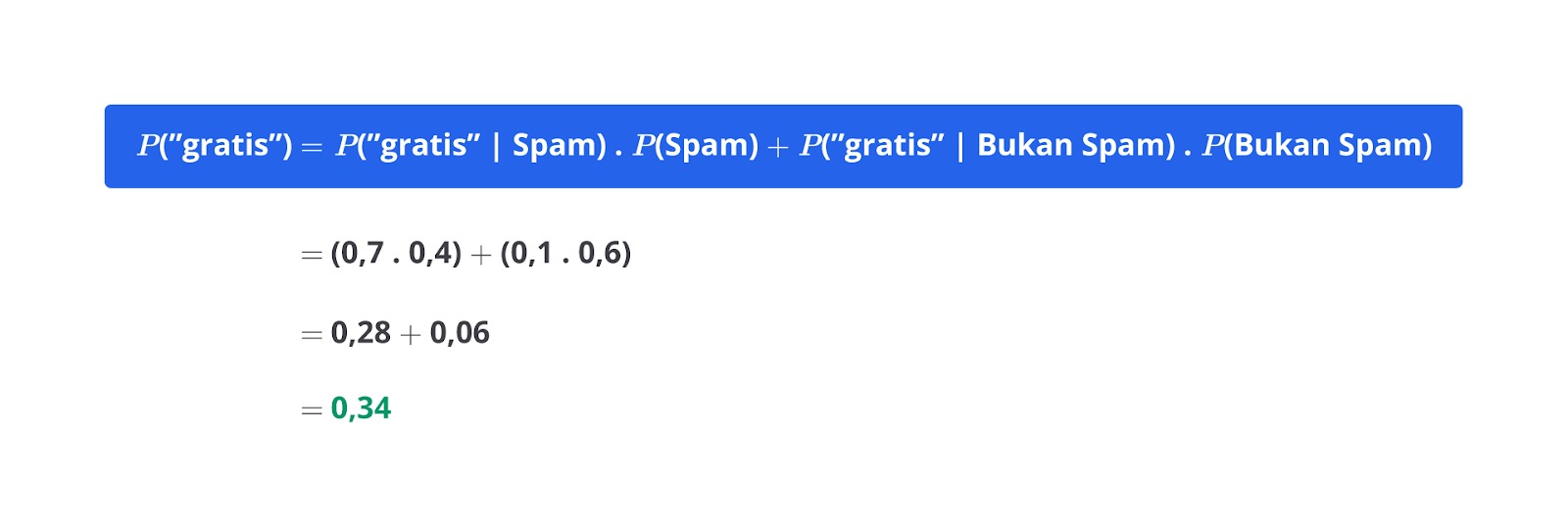
Sistem kamu menggunakan fitur berupa kata yang muncul di email tersebut. Misalnya, fitur yang diamati adalah email mengandung kata “gratis” atau tidak. Berikut adalah data yang Anda miliki.
| Kelas | Jumlah Email | Email yang mengandung kata “Gratis” |
|---|---|---|
| Spam | 40 | 28 |
| Bukan Spam | 60 | 6 |
Sekarang, Anda mendapati email yang baru masuk dan mengandung kata “gratis”. Apakah email tersebut spam atau bukan spam? Mari gunakan rumus Naive Bayes.
Ada tiga variabel yang harus ditemukan sebelum akhirnya rumus naive bayes bisa digunakan.
-
P(x C) yang merupakan likelihood. - P(C) yang merupakan prior probability.
- P(x) yang merupakan evidence.
Prior Probability – P(C)
Masih ingat dengan rumus probabilitas? Rumusnya adalah sebagai berikut.

Kita memiliki dua kelas spam dan bukan spam, sehingga perhitungan yang dilakukan adalah sebagai berikut.
- P(Spam) = 40/100 = 0.4
- P(Bukan Spam) = 60/100 = 0.6
Likelihood – P(x|C)
Sekarang, hitung bagian likelihood yang bertujuan mencari probabilitas kata “gratis” dikategorikan sebagai spam dan bukan spam.
-
P(“gratis” Spam) = 28/40 = 0.7 -
P(“gratis” Bukan Spam) = 6/60 = 0.1
Evidence – P(x)
Evidence adalah probabilitas data x yang muncul secara umum, tanpa peduli data itu berasal dari kelas mana. Sehingga, dalam studi kasus kita adalah melihat seluruh email yang mengandung kata “gratis”, baik dikategorikan spam atau pun bukan spam.
Evidence memiliki rumus sebagai berikut.
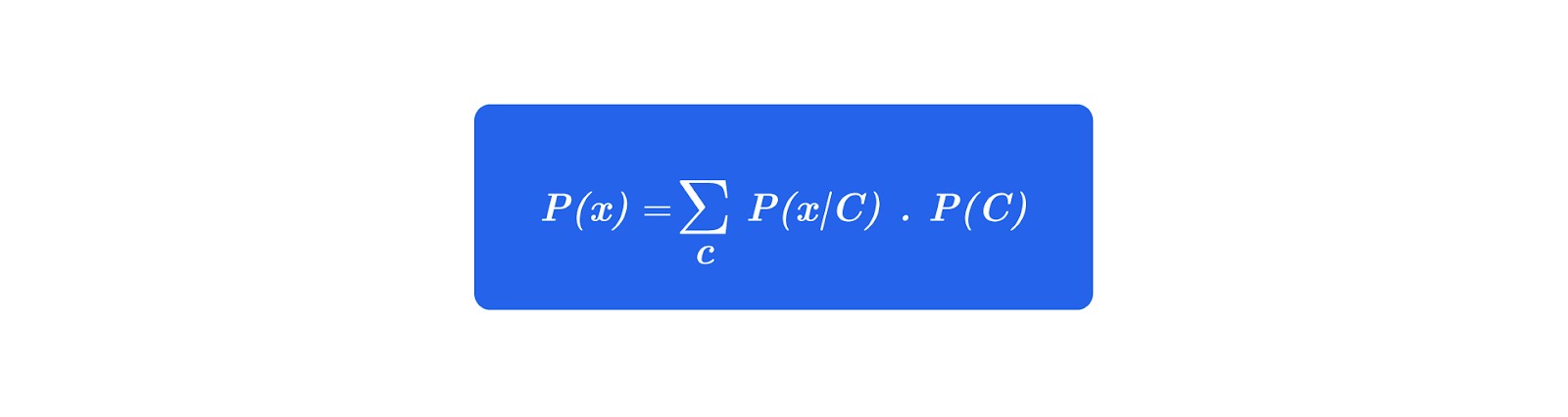
Di mana:
- x adalah fitur-fitur yang diamati (misalnya, kata “gratis” dalam email).
- C adalah semua kemungkinan kelas
- P(C) adalah prior probability.
-
P(x C) adalah likelihood.
Catatan:
Simbol notasi sigma (∑) menyatakan penjumlahan seluruh nilai dari ekspresi P(x|C) . P(C)
Sehingga, dalam kasus yang sedang kita amati, perhitungannya menjadi seperti berikut.
Posterior Probability – P(C|x)
Sekarang, semua variabel sudah disiapkan. Masukkan nilai-nilai tersebut ke dalam rumus naive bayes berdasarkan kelas yang ingin kita cari, yakni “Spam” dan “Not Spam”.

Didapat perhitungan detailnya seperti gambar di bawah ini.

Kesimpulan
Dari perhitungan tersebut, kita dapat melihat kalau nilai P(Spam | “gratis”) lebih besar dibandingkan P(Not Spam | “gratis”). Sehingga, dapat disimpulkan bahwa email terbaru diklasifikasikan sebagai SPAM.
Kata “Naive” dalam Naive Bayes
Dalam perhitungan yang sudah Anda pelajari, ada satu hal yang perlu diperhatikan, yakni Naive Bayes mengasumsikan setiap atribut dan kelas bersifat independen satu sama lain. Artinya, jika kita tahu bahwa sebuah email adalah spam, kehadiran kata “diskon” tidak mempengaruhi kemunculan kata “gratis”, walaupun di dunia nyata, dua kata ini sering muncul bersamaan.
Jika tidak menggunakan asumsi ini, perhitungan setiap atribut dan kelas akan menjadi sangat kompleks dan lebih sulit untuk dikalkulasikan.
Tipe Atribut
Selain itu, perhitungan yang Anda lakukan sangat bergantung pada jenis data yang digunakan. Pada contoh di atas, kita menggunakan data bertipe kategorikal dengan label spam dan bukan spam, yang memiliki nilai diskrit dan terbatas.
Namun, jika data Anda bertipe kontinu atau berupa angka diskrit dengan rentang luas, Anda perlu mengasumsikan nilai-nilai tersebut mengikuti distribusi tertentu misalnya distribusi Gaussian.
Catatan:
Kita akan membahas Distribusi Probabilitas pada modul berikutnya.
Mengapa demikian?
Karena untuk data kontinu atau diskrit dengan banyak kemungkinan nilai, kita tidak bisa menghitung probabilitas pasti untuk satu nilai tunggal (misalnya tepat pada 50 atau 50.4). Sebaliknya, kita menghitung probabilitas data berada dalam rentang tertentu, berdasarkan fungsi distribusi yang diasumsikan.
Contohnya, Probabilitas bahwa nilai atribut berada antara 40 hingga 50, dihitung dari kurva distribusi normal.
Penerapan Naives Bayes pada Kasus Lainnya
Mari kita lihat beberapa contoh aplikasi dari algoritma naives bayes di dunia nyata, seperti analisis sentimen dan klasifikasi topik dokumen.
Analisis Sentimen
Selain deteksi spam, Naive Bayes juga digunakan dalam analisis sentimen, yaitu proses mengidentifikasi emosi atau opini dalam sebuah teks. Contoh paling umum adalah menganalisis bahwa ulasan pelanggan terhadap produk bernada positif, negatif, atau netral.

Dalam hal ini, model dilatih dengan banyak data ulasan yang sudah diberi label. Kata-kata seperti “mantap”, “bagus banget”, “cepat sampai”, atau “sangat puas” cenderung sering muncul dalam ulasan yang positif. Sebaliknya, kata-kata seperti “mengecewakan”, “buruk”, atau “tidak sesuai” lebih sering muncul pada ulasan negatif.
Naive Bayes belajar dari pola-pola ini dan menghitung peluang suatu teks termasuk dalam kategori tertentu berdasarkan kemunculan kata-katanya. Karena pengolahan sentimen sering dilakukan pada data real-time (misalnya media sosial), kecepatan Naive Bayes sangat membantu dalam menyajikan hasil dengan cepat.
Klasifikasi Topik Dokumen
Aplikasi penting lainnya adalah dalam klasifikasi topik dokumen. Dalam tugas ini, kita ingin mengelompokkan dokumen, artikel, atau berita dalam beberapa kategori, yaitu “politik”, “olahraga”, “kesehatan”, “hiburan”, dan sebagainya.
Naive Bayes bekerja dengan mempelajari kata-kata yang sering muncul dalam masing-masing kategori. Misalnya, dokumen dengan kata-kata seperti “pemain”, “gol”, “lapangan”, “pertandingan” kemungkinan besar adalah artikel olahraga. Adapun dokumen dengan kata “pemilu”, “kebijakan”, “menteri”, atau “undang-undang” kemungkinan besar masuk kategori politik.
Model menghitung probabilitas setiap dokumen termasuk pada masing-masing kelas dan mengklasifikasikan dokumen dalam topik yang paling mungkin. Pendekatan ini sangat bermanfaat untuk sistem rekomendasi berita, pencarian konten, dan pengelompokan otomatis dokumen dalam sistem manajemen informasi.
Naive Bayes mungkin sederhana, tetapi kemampuannya untuk memahami pola-pola kata membuatnya sangat berguna dalam berbagai tugas klasifikasi teks. Ia bekerja cepat, dapat diinterpretasikan, dan cukup tangguh untuk digunakan dalam banyak aplikasi nyata. Hal yang paling menarik: kita bisa membangunnya hanya dengan logika probabilitas dan frekuensi kata!
Latihan Implementasi Algoritma Naive Bayes
Hebat! Anda sudah memahami sedikitnya cara kerja algoritma naive bayes pada studi kasus klasifikasi email spam dan bukan spam. Kali ini, kita akan menerapkan algoritma naive bayes dengan studi kasus yang berbeda dan mengimplementasikannya dengan Python.
Anda bisa menggunakan tools seperti Google Colab untuk mengikuti latihan ini. Silakan buat berkas notebook baru pada Drive Anda.
Langkah 1: Menyiapkan Data Pelatihan
Setiap perjalanan proyek data science dimulai dari data. Bayangkan Anda adalah seorang dokter yang memiliki tugas untuk mengklasifikasikan penyakit flu berdasarkan gejala yang dimiliki pasien.
Gejala-gejala tersebut adalah sebagai berikut.
- Chills (Panas Dingin).
- Runny nose (Pilek).
- Headache (Sakit Kepala).
- Fever (Demam).
Gejala-gejala tersebut mengarah pada asumsi seseorang dapat didiagnosa mengalami penyakit influenza (flu). Ini adalah data pelatihan yang akan digunakan dalam studi kasus kali ini.
Berikut adalah tampilan sekilas dari data pelatihan yang akan digunakan.
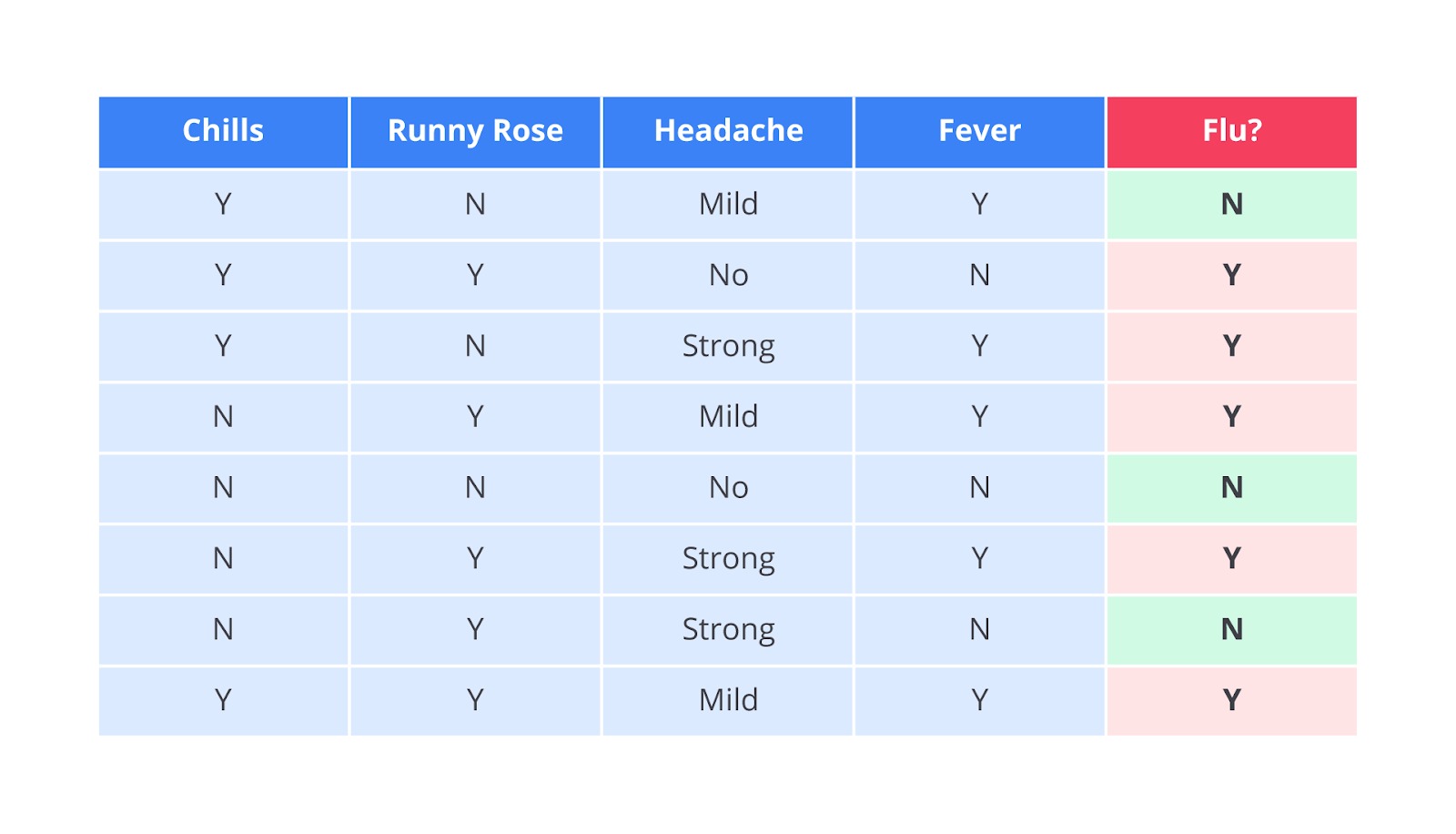
Dari delapan rekam medis ini, kita dapat mengidentifikasi dua kelas utama yang ingin kita prediksi: flu?=’Y’ (Ya, pasien ini memiliki flu) dan flu?=’N’ (Tidak, pasien ini tidak memiliki flu).
Langkah pertama yang dilakukan Naive Bayes adalah membentuk “keyakinan awal” atau prior probability terhadap setiap kelas. Ini adalah frekuensi kemunculan setiap kelas dalam seluruh data pelatihan.
- Kita menemukan ada lima pasien yang didiagnosis flu?=’Y’.
- Ada tiga pasien yang didiagnosis flu?=’N’.
- Total pasien adalah delapan.
Dengan demikian, prior probability yang kita dapatkan sebagai berikut.
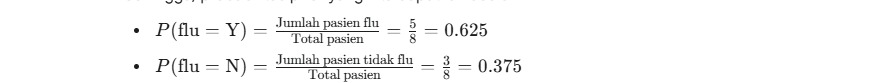
Angka-angka ini memberitahu kita bahwa berdasarkan pengalaman sebelumnya, flu cenderung lebih sering terjadi (62.5%) daripada tidak terjadi (37.5%). Inilah “pengetahuan awal” kita.
Jika membuat simulasi menggunakan bahasa pemrograman Python, kita perlu mendefinisikan data terlebih dahulu.
Salin dan tempel kode berikut pada Google Colab Anda.
import pandas as pd from collections import defaultdict
— 1. Data Pelatihan (dari Gambar) —
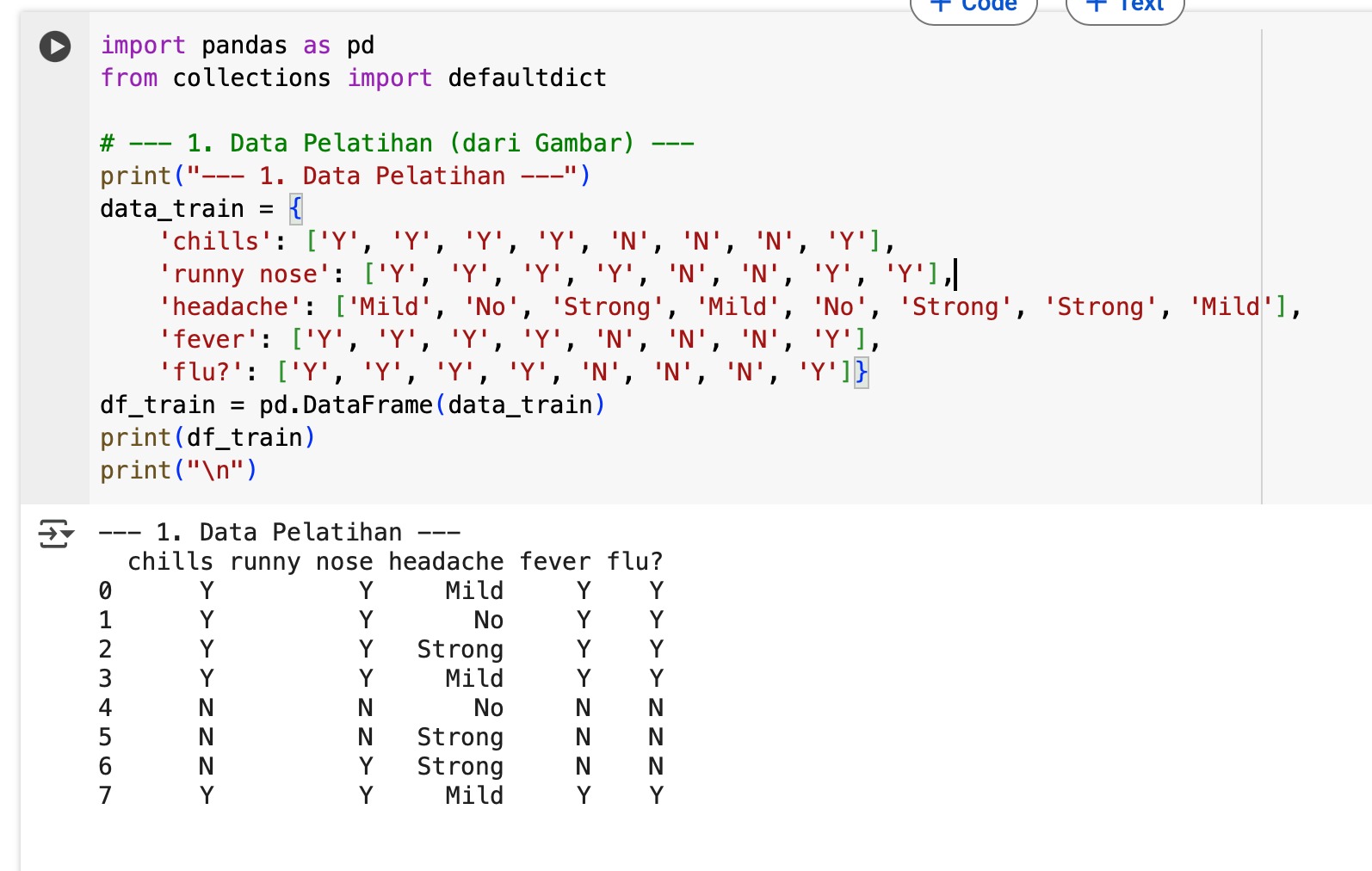
print(“— 1. Data Pelatihan —”) data_train = { ’chills’: [‘Y’, ’Y’, ’Y’, ’Y’, ’N’, ’N’, ’N’, ’Y’], ’runny nose’: [‘Y’, ’Y’, ’Y’, ’Y’, ’N’, ’N’, ’Y’, ’Y’], ’headache’: [‘Mild’, ’No’, ’Strong’, ’Mild’, ’No’, ’Strong’, ’Strong’, ’Mild’], ’fever’: [‘Y’, ’Y’, ’Y’, ’Y’, ’N’, ’N’, ’N’, ’Y’], ’flu?’: [‘Y’, ’Y’, ’Y’, ’Y’, ’N’, ’N’, ’N’, ’Y’]} df_train = pd.DataFrame(data_train) print(df_train) print(“\n”)
Jalankan kode tersebut dengan klik tombol Run cell yang ada tepat di sebelah kiri baris kode. Lalu, tampil sebuah tabel yang menunjukkan data pelatihan yang kita definisikan.
Langkah 2: Menghitung Probabilitas Prior
Setelah memiliki data latihnya, kita menghitung probabilitas prior dari flu?=Y dan flu?=N.
Klik tombol + Code pada tab bar, lalu salin baris kode di bawah ini.
# — Konfigurasi Naive Bayes — TARGET_VARIABLE = ’flu?’ FEATURES = [‘chills’, ’runny nose’, ’headache’, ’fever’] ALPHA = 1 # Untuk Laplace Smoothing
— 2. Hitung Probabilitas Prior P(Kelas) —
print(“— 2. Probabilitas Prior P(Kelas) —”) total_samples = len(df_train) class_counts = df_train[TARGET_VARIABLE].value_counts() classes = class_counts.index.tolist() # Mendapatkan nama kelas (Y, N)
priors = {} for cls in classes: priors[cls] = class_counts[cls] / total_samples print(f”P({TARGET_VARIABLE}={cls}) = {priors[cls]:.4f}”) print(“\n”)
Setelah dijalankan dengan klik kembali tombol Run cell di sebelah baris kode terbaru, tampilan pada Google Colab tampak seperti ini.
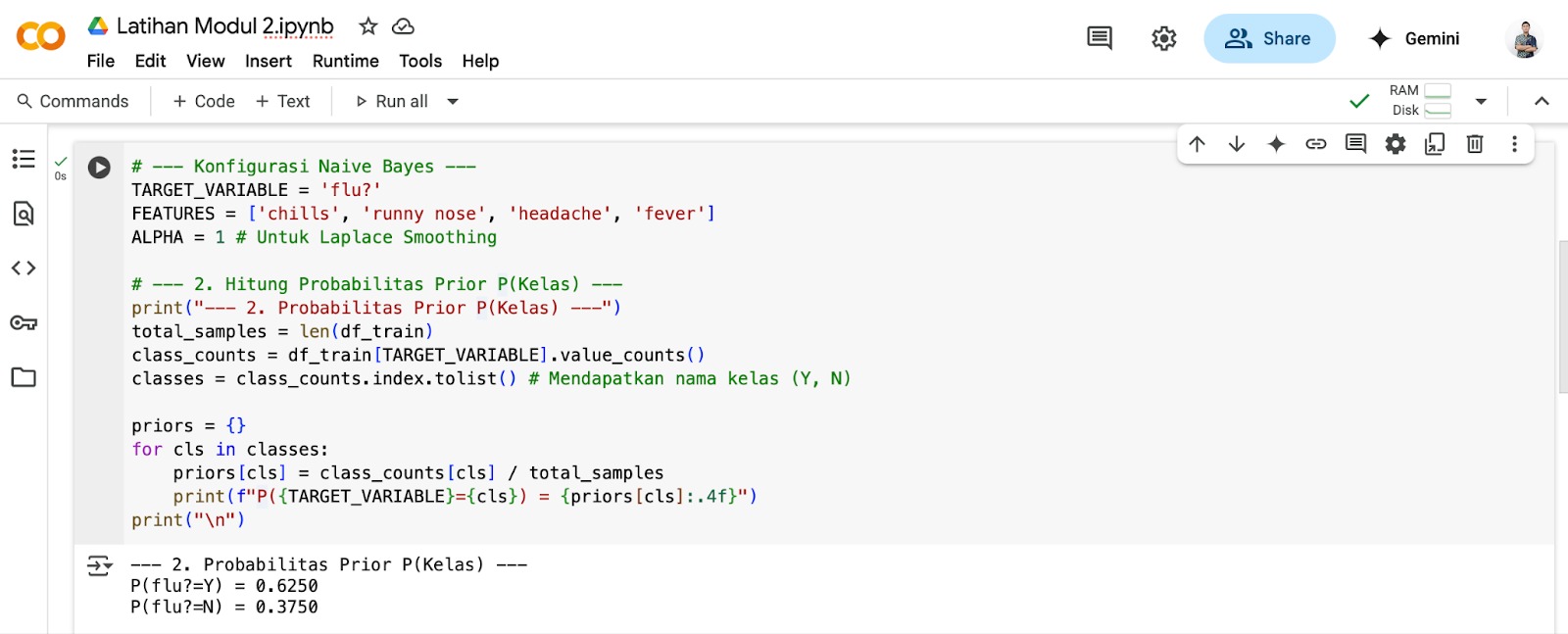
Probabilitas Prior P(Kelas) yang Anda lihat dalam Google Colab tersebut–P(flu?=Y) = 0.6250 dan P(flu?=N) = 0.3750–adalah hasil perhitungan langsung dari dataset.
Angka ini mencerminkan frekuensi relatif masing-masing kelas (flu atau tidak flu) dalam data pelatihan. Misalnya, 0.6250 berarti 62.50% dari total catatan data Anda adalah kasus flu. Hasil ini sesuai dengan perhitungan manual membuktikan bahwa ekstraksi informasi awal tentang proporsi kelas dari data Anda sudah benar. Ini adalah fondasi penting sebelum analisis lebih lanjut dalam modul probabilitas.


Langkah 3: Menghitung Probabilitas Kondisional
Setelah memiliki keyakinan awal tentang prevalensi flu, langkah selanjutnya adalah memahami cara setiap gejala spesifik (fitur) berkorelasi dengan kedua kelas (flu atau tidak flu). Inilah yang kita sebut probabilitas kondisional atau likelihood.
Sederhananya, kita ingin mengetahui seberapa besar kemungkinan suatu gejala muncul pada pasien yang sudah diketahui kelasnya (flu atau tidak flu). Misalnya, “Seberapa sering pasien flu mengalami chills=Y?” atau “Seberapa sering pasien tanpa flu mengalami headache=Mild?”
Di dunia nyata, kadang ada kombinasi fitur dan kelas yang tidak muncul sama sekali dalam data pelatihan. Kalau langsung dihitung, hasilnya bisa nol, dan ini bisa merusak prediksi Naive Bayes. Untuk mengatasi ini, kita gunakan teknik Laplace smoothing, yaitu menambahkan angka kecil (biasanya 1) pada setiap kemungkinan supaya tidak ada probabilitas nol.
Sekarang, kita akan menghitung probabilitas munculnya setiap nilai fitur (chills=’Y’, headache=’Mild’, dst) mengingat pasien tersebut termasuk dalam kelas ‘flu=Y’ atau ‘flu=N’. Proses ini diulang untuk setiap fitur dan setiap nilai unik dari fitur tersebut.
Silakan klik tombol + Code pada tab bar dan salin baris kode di bawah ini.
# — 3. Hitung Probabilitas Kondisional (P(Fitur | Kelas)) dengan Laplace Smoothing — print(“— 3. Probabilitas Kondisional P(Fitur | Kelas) (dengan Laplace Smoothing) —”) likelihoods = defaultdict(lambda: defaultdict(lambda: defaultdict(float)))
for feature in FEATURES: # Mendapatkan semua nilai unik untuk fitur ini dari data pelatihan unique_feature_values = df_train[feature].unique() num_unique_feature_values = len(unique_feature_values)
for cls in classes: subset_df = df_train[df_train[TARGET_VARIABLE] == cls] total_in_class = len(subset_df)
print(f” Untuk Kelas ‘{cls}’ (Jumlah sampel: {total_in_class}):”) for value in unique_feature_values: # Hitung frekuensi fitur di dalam subset kelas count_feature_in_class = (subset_df[feature] == value).sum()
# Terapkan Laplace Smoothing
# Rumus: (count + alpha) / (total_in_class + alpha * num_unique_feature_values)
likelihood = (count_feature_in_class + ALPHA) /
(total_in_class + ALPHA * num_unique_feature_values)
likelihoods[feature][value][cls] = likelihood print(f” P({feature}={value} | {TARGET_VARIABLE}={cls}) = ({count_feature_in_class} + {ALPHA}) / ({total_in_class} + {ALPHA}*{num_unique_feature_values}) = {likelihood:.4f}”) print(“\n”)
Inilah tampilan pada Google Colab setelah kode dijalankan.
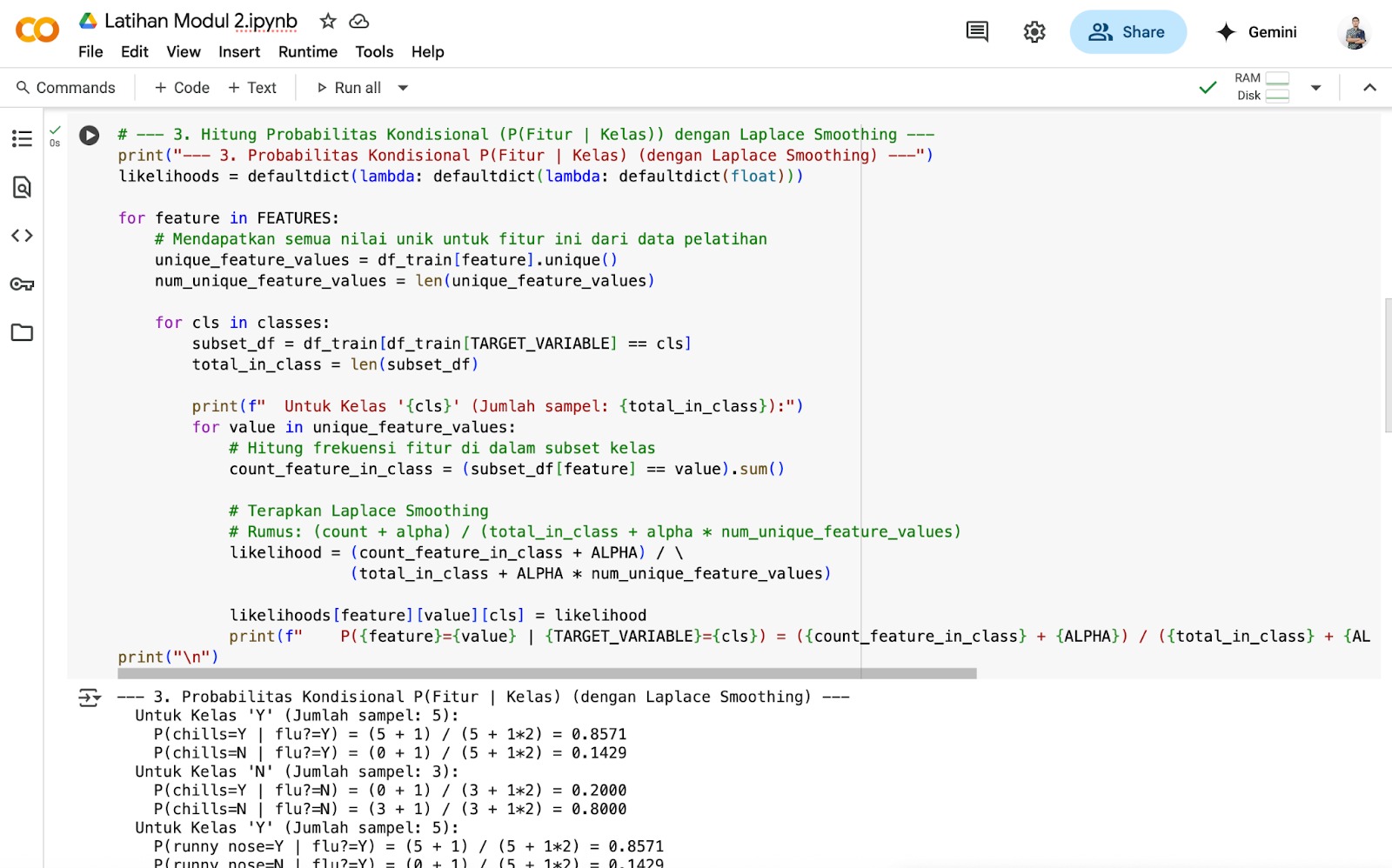
Berikut adalah penjelasan kode langkah demi langkah.
- Inisialisasi struktur penyimpanan
Kita membuatlikelihoods, yaitu dictionary bertingkat untuk menyimpan probabilitas setiap kombinasi fitur, nilai fitur, dan kelas. - Iterasi setiap fitur (gejala)
Kita ambil semua nama fitur yang ingin dianalisis (misal: chills, headache, dst). Untuk setiap fitur, kita cari tahu semua nilai unik yang pernah muncul dalam data pelatihan (misal: chills = Y atau T). - Iterasi setiap kelas (flu=Y atau flu=N)
Untuk setiap kelas, kita ambil subset data yang hanya berisi pasien dengan kelas tersebut. Misal, hanya data pasien flu saja. - Iterasi setiap nilai unik fitur
Untuk setiap kemungkinan nilai dari fitur itu (misal chills=Y), kita hitung seberapa banyak pasien pada subset tadi yang punya nilai fitur tersebut. -
Hitung probabilitas dengan Laplace smoothing
Rumus yang dipakai adalah berikut.(count + alpha) / (total_in_class + alpha * num_unique_feature_values)
Di sini,
alphaadalah angka kecil (biasanya 1) agar tidak ada probabilitas nol.
Hasilnya disimpan padalikelihoodsdan juga dicetak supaya kita bisa melihat proses perhitungannya. - Cetak hasil.
Setiap kombinasi fitur, nilai, dan kelas dicetak bersama dengan rumus dan hasil akhirnya.
Dengan proses ini, kita mendapatkan semua likelihood yang akan dipakai pada prediksi nanti. Semua probabilitas pasti lebih dari nol berkat Laplace smoothing.
Langkah ini bertujuan supaya model Naive Bayes tahu seberapa besar kemungkinan setiap gejala muncul pada pasien flu dan tidak flu, tanpa khawatir probabilitas nol yang bisa membuat model gagal memprediksi.
Langkah 4: Prediksi — Pertarungan Probabilitas Posterior
Kini tibalah saatnya untuk mempraktikkan semua pengetahuan yang telah kita kumpulkan. Katakanlah seorang pasien baru masuk dengan gejala: chills=’Y’, runny nose=’N’, headache=’Mild’, dan fever=’Y’. Pertanyaannya, apakah pasien ini memiliki flu?
Naive Bayes akan menghitung “skor” atau lebih tepatnya probabilitas posterior yang tidak dinormalisasi untuk kedua kemungkinan kelas (flu=Y dan flu=N). Kita akan membandingkan skor ini untuk menentukan mana yang lebih mungkin.
Silakan klik tombol + Code pada tab bar dan salin baris kode di bawah ini.
# — Data Pasien Baru untuk Prediksi — print(“— Data Pasien Baru —”)
Gejala Pasien: chills=Y, runny nose=N, headache=Mild, fever=Y
new_patient_features = { ’chills’: ’Y’, ’runny nose’: ’N’, ’headache’: ’Mild’, ’fever’: ’Y’ } print(f”Gejala Pasien Baru: {new_patient_features}”) print(“\n”)
— 4. Prediksi untuk Pasien Baru —
print(“— 4. Prediksi untuk Pasien Baru —”)
posterior_scores = {}
for cls in classes: # Mulai dengan probabilitas prior current_posterior = priors[cls] print(f”\n Menghitung untuk Kelas ‘{cls}’:”) print(f” P({TARGET_VARIABLE}={cls}) = {priors[cls]:.4f} (Prior)”)
# Kalikan dengan likelihoods dari setiap fitur pasien baru for feature in FEATURES: feature_value = new_patient_features[feature]
# Ambil likelihood. Pastikan nilai fitur dari pasien baru ada dalam likelihoods yang dihitung. # Jika nilai fitur tidak ada dalam data pelatihan, ini akan menghasilkan KeyError tanpa defaultdict. # Dengan defaultdict, ini akan menghasilkan 0.0 yang kemudian + alpha. # Karena kita sudah menghitung semua nilai unik, ini harusnya tidak menjadi masalah. likelihood = likelihoods[feature][feature_value][cls]
print(f” P({feature}={feature_value} | {TARGET_VARIABLE}={cls}) = {likelihood:.4f}”) current_posterior *= likelihood
posterior_scores[cls] = current_posterior print(f” Nilai Posterior (Proporsional) untuk ‘{cls}’: {current_posterior:.8f}”)
Inilah tampilan pada Google Colab setelah kode dijalankan.
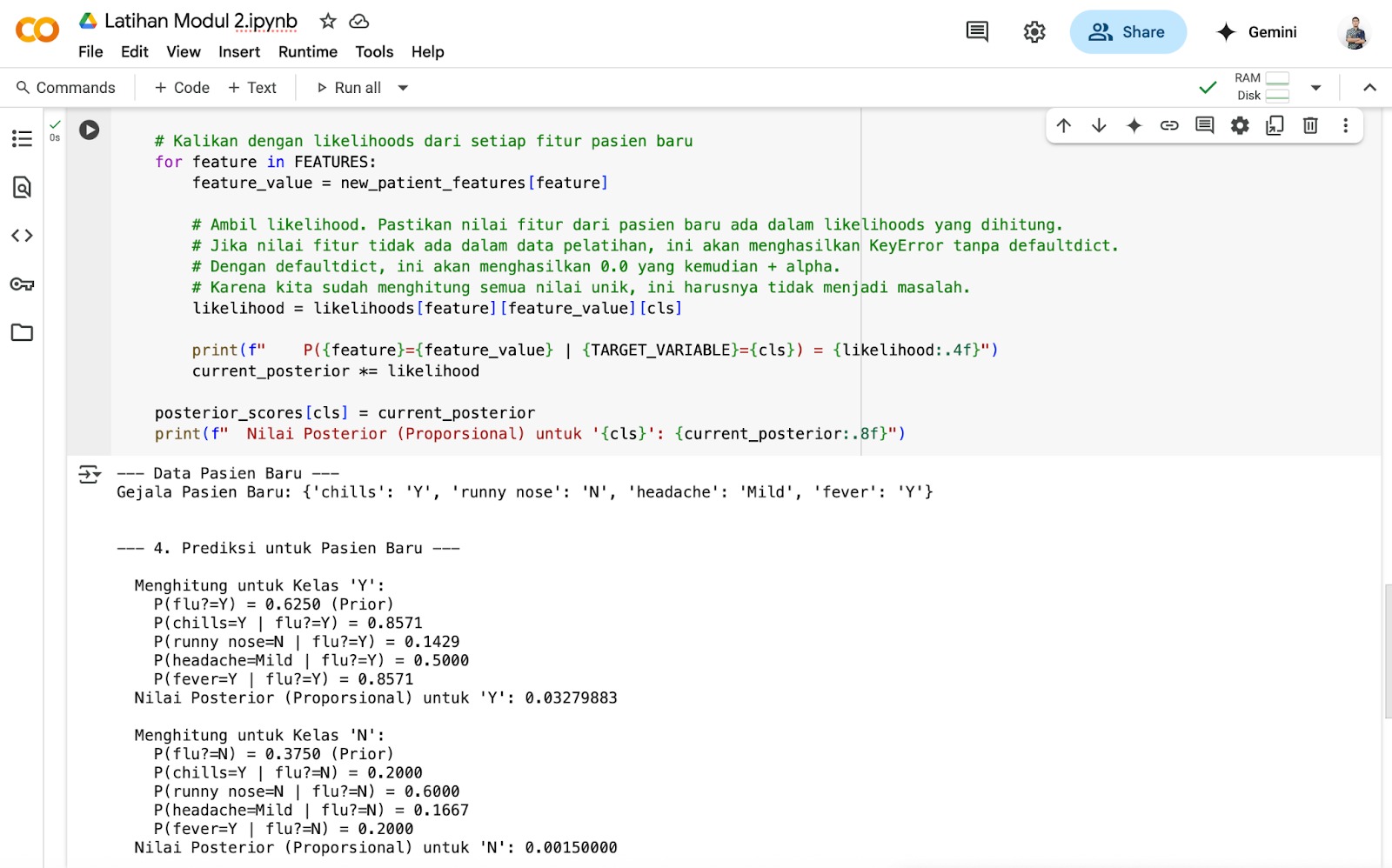
Berikut adalah penjelasan kode langkah demi langkah.
-
Menghitung Skor untuk ‘Flu=Y’
Kita mulai dengan probabilitas prior P(flu=Y) = 0.6250. Kemudian, kita kalikan dengan semua probabilitas kondisional dari gejala pasien baru jika pasien itu flu.P(flu=Y∣Gejala Baru) ∝ P(flu=Y) × P(chills=Y∣flu=Y) × P(runny nose=N∣flu=Y) × P(headache=Mild∣flu=Y) × P(fever=Y∣flu=Y)
Masukkan nilai-nilai yang telah kita hitung (dengan Laplace smoothing): P(flu = Y∣Gejala Baru) ∝ 0.6250 × 0.8571 × 0.1429 × 0.5000 × 0.8571 ≈ 0.0327
-
Menghitung Skor untuk ‘Flu=N’
Kita mulai dengan probabilitas prior P(flu=N) = 0.3750. Lalu, kita kalikan dengan semua probabilitas kondisional dari gejala pasien baru jika pasien itu tidak flu.P(flu=N∣Gejala Baru) ∝ P(flu=N) × P(chills=Y∣flu=N) × P(runny nose=N∣flu=N) × P(headache=Mild∣flu=N) × P(fever=Y∣flu=N)
Masukkan nilai-nilai yang telah kita hitung (dengan Laplace smoothing).
P(flu = N∣Gejala Baru) ∝ 0.3750 × 0.2000 × 0.6000 × 0.1667 × 0.2000 ≈ 0.0015
Langkah Terakhir: Diagnosis Berbasis Keyakinan Terbaru
Dengan kedua skor probabilitas posterior di tangan, kita siap membuat keputusan akhir.
- Skor untuk flu=Y: ≈ 0.0327
- Skor untuk flu=N: ≈ 0.0015
Silakan klik tombol + Code pada tab bar dan salin baris kode di bawah ini.
# — 5. Klasifikasi Akhir — print(“\n— 5. Klasifikasi Akhir —”) predicted_class = max(posterior_scores, key=posterior_scores.get) max_score = posterior_scores[predicted_class]
print(f”Skor untuk ‘flu? = Y’: {posterior_scores.get(‘Y’, 0):.8f}”) print(f”Skor untuk ‘flu? = N’: {posterior_scores.get(‘N’, 0):.8f}”) print(f”\nPasien baru ini kemungkinan besar memiliki flu: ‘{predicted_class}’ (dengan skor {max_score:.8f})”)
Inilah tampilan pada Google Colab setelah kode dijalankan.
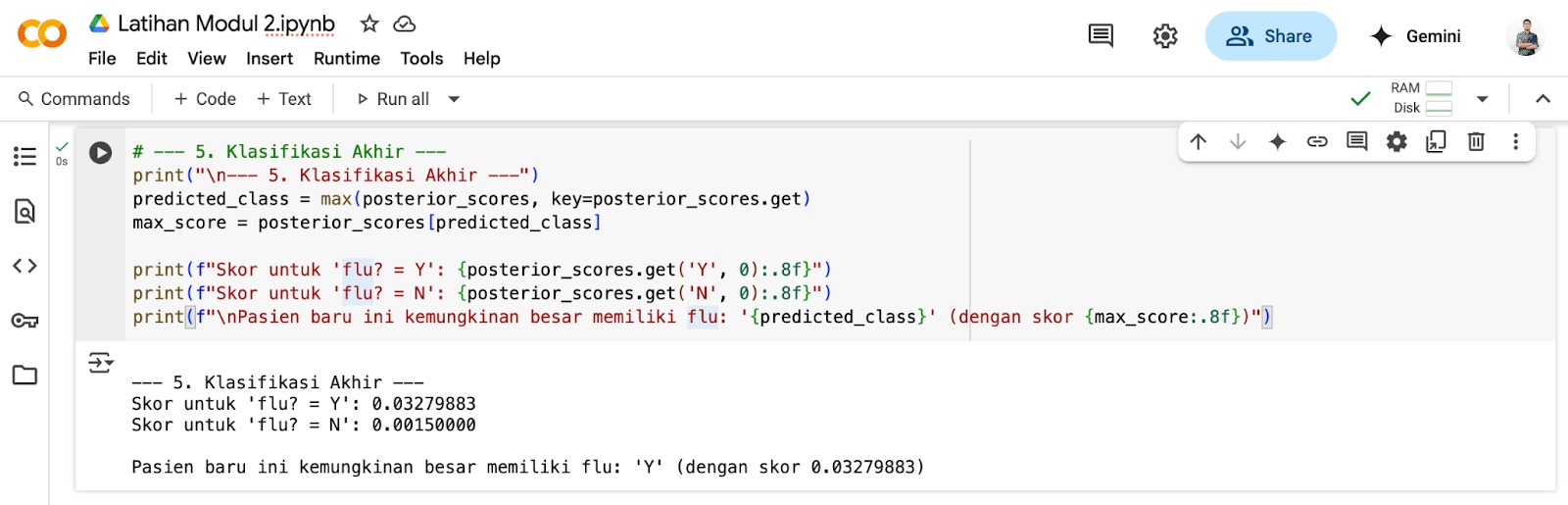
Karena skor untuk flu=Y jauh lebih tinggi daripada flu=N, algoritma Naive Bayes akan memprediksi bahwa pasien baru ini memiliki flu. Ini adalah “keyakinan terbaru” kita, yang diperbarui dari pengetahuan awal dengan bukti dari gejala spesifik pasien.
Untuk memahami kode latihan implementasi algoritma Naive Bayes dengan lebih detail, Anda bisa melihat pada link berikut: Latihan Modul 2
Rangkuman Dasar-Dasar Probabilitas
Akhirnya, kamu sudah mencapai akhir modul ini. Berikut adalah rangkuman dari modul Dasar-Dasar Probabilitas.
Apa itu Probabilitas?
Probabilitas adalah cabang matematika yang membantu kita mengukur ketidakpastian. Ia bukan sekadar tebakan, tetapi cara sistematis untuk memahami dan memperkirakan kemungkinan.
Secara sederhana, probabilitas adalah angka yang menunjukkan seberapa besar kemungkinan suatu kejadian akan terjadi. Probabilitas selalu bernilai di antara 0 dan 1, atau kalau dalam bentuk persen, antara 0% dan 100%.
Jika probabilitas suatu kejadian adalah 0, artinya kejadian itu tidak mungkin terjadi. Sebaliknya, jika probabilitasnya adalah 1, kejadian tersebut pasti akan terjadi. Nilai-nilai di antara 0 dan 1 menggambarkan tingkat ketidakpastian—semakin dekat ke 1, semakin besar kemungkinan kejadian itu benar-benar terjadi. Semakin dekat ke 0, semakin kecil kemungkinannya.
Aksioma: Aturan Dasar dalam Probabilitas
Aksioma dalam probabilitas adalah prinsip-prinsip yang harus selalu dipenuhi pada setiap sistem atau model probabilitas. Tanpa aksioma, kita akan kesulitan membangun logika probabilitas yang konsisten. Berikut adalah tiga aksioma dasar yang menjadi tiang penyangga dari seluruh teori probabilitas.
Aksioma Non-Negativitas
Setiap probabilitas suatu kejadian harus bernilai nol atau lebih, alias tidak boleh negatif. Secara matematis, kita bisa tulis sebagai berikut untuk setiap kejadian A.
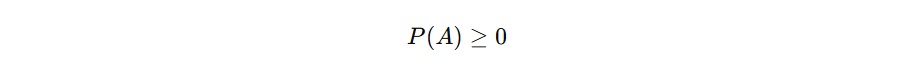
Aksioma Normalisasi
Jika kita mempertimbangkan semua kemungkinan hasil dari suatu percobaan, total probabilitasnya harus sama dengan 1. Secara matematis, pernyataan tersebut ditulis sebagai berikut.
P(S) = 1
S adalah ruang sampel, yaitu himpunan dari semua hasil yang mungkin.
Aksioma Adisi (Additivitas)
Kalau ada dua kejadian yang tidak bisa terjadi secara bersamaan (alias saling lepas), probabilitas gabungan dari keduanya adalah jumlah dari probabilitas masing-masing kejadian. Ini bisa ditulis sebagai berikut jika A∩B = ∅ (artinya A dan B tidak punya hasil yang sama).
P(A∪B) = P(A)+P(B)
Ruang Sampel: Semua Kemungkinan yang Bisa Terjadi
Secara sederhana, ruang sampel adalah kumpulan dari semua hasil yang mungkin terjadi saat kita melakukan suatu eksperimen atau percobaan acak. Dalam bahasa matematika, ruang sampel biasanya dilambangkan dengan huruf kapital S dan dituliskan dalam bentuk himpunan.
Untuk memahami konsep ini lebih baik, mari kita ambil beberapa contoh.
Bayangkan Anda sedang melempar sebuah dadu bersisi enam. Apa saja hasil yang bisa keluar? Jawabannya tentu saja: 1, 2, 3, 4, 5, atau 6. Tidak mungkin Anda mendapatkan angka tujuh atau nol dari dadu tersebut karena sisi dadu hanya ada enam.
Jadi, ruang sampel dari percobaan ini ditulis sebagai berikut.
S = {1,2,3,4,5,6}
Setiap angka dalam himpunan itu disebut sebagai anggota atau elemen dari ruang sampel dan masing-masing mewakili satu hasil yang mungkin terjadi. Dalam konteks ini, kita katakan bahwa ruang sampelnya adalah diskret karena hasil-hasil yang mungkin dapat dihitung satu per satu.
Kejadian: Fokus dari Perhitungan Probabilitas
Kalau ruang sampel adalah keseluruhan panggung pertunjukan, kejadian adalah adegan tertentu yang sedang kita soroti. Kejadian adalah bagian dari ruang sampel yang diperhatikan karena sesuai dengan pertanyaan atau fokus analisis kita.
Untuk memvisualisasikan hubungan antar kejadian dalam ruang sampel, Diagram Venn adalah cara sederhana dan kuat. Ia membantumu “melihat” bahwa kejadian-kejadian saling beririsan, saling lepas, atau bahkan saling melengkapi.
Jenis-Jenis Kejadian
Berikut adalah jenis-jenis kejadian.
Kejadian Sederhana
Kejadian sederhana adalah kejadian yang hanya terdiri dari satu hasil dalam ruang sampel. Misalnya, Anda melempar dadu dan ingin tahu peluang munculnya angka empat saja. Jadi, kejadian B adalah berikut.
B = {4}
Kejadian Majemuk (Compound Event)
Berbeda dengan kejadian sederhana, kejadian majemuk terdiri dari lebih dari satu hasil. Ini adalah jenis kejadian yang melibatkan gabungan dari beberapa kemungkinan. Misalnya, Anda ingin mengetahui peluang munculnya angka lebih dari dua, tetapi kurang dari lima saat melempar dadu. Kejadian tersebut adalah berikut.
C = {3,4}
Kejadian Mustahil dan Kejadian Pasti
Kadang-kadang, ada juga kejadian yang tidak mungkin terjadi, atau justru pasti terjadi. Ini dua kejadian ekstrem dari spektrum probabilitas.
-
Kejadian mustahil adalah kejadian yang tidak mengandung elemen sama sekali dari ruang sampel. Contoh: muncul angka delapan (8) saat melempar satu dadu enam sisi. Karena angka delapan tidak ada dalam ruang sampel {1,2,3,4,5,6}, kejadian ini adalah kejadian mustahil dan probabilitasnya sebagai berikut.
P = 0
-
Kejadian pasti adalah kejadian yang mencakup semua elemen dari ruang sampel. Contoh: “muncul angka antara 1 sampai 6” saat melempar dadu. Ini mencakup semua kemungkinan sehingga probabilitasnya berikut.
P = 1
Kejadian Saling Lepas: Tidak Bisa Terjadi Bersamaan
Salah satu hal penting yang perlu Anda pahami adalah konsep kejadian saling lepas atau dalam bahasa Inggris disebut mutually exclusive events. Dua kejadian dikatakan saling lepas jika tidak ada satu pun hasil yang bisa terjadi pada keduanya sekaligus.
Operasi pada Kejadian: Gabungan, Irisan, dan Komplemen
Berikut adalah beberapa operasi pada kejadian.
Gabungan (Union): A atau B
Bayangkan Anda sedang melempar dadu dan ingin tahu peluang munculnya angka lebih dari empat atau angka genap. Di sinilah Anda sedang bicara soal gabungan dua kejadian.
Secara definisi, gabungan dua kejadian A∪B adalah semua hasil dalam kejadian A, kejadian B, atau keduanya. Jadi, Anda tinggal menyatukan isi dari dua kejadian tersebut.
Misalnya berikut.
- A = {angka lebih dari 4} = {5, 6}
- B = {angka genap} = {2, 4, 6}
- Jadi, A ∪ B = {2,4,5,6}
Irisan (Intersection): A dan B
Kalau gabungan adalah “A atau B”, irisan adalah “A dan B”. Artinya, kita ingin tahu hasil yang muncul dalam kedua kejadian sekaligus.
Dalam notasi matematika, irisan ditulis sebagai A∩B, berarti kita hanya mengambil hasil pada A dan juga B.
Kita lanjutkan contoh sebelumnya.
- A = {angka lebih dari 4} = {5, 6}
- B = {angka genap} = {2, 4, 6}
- Jadi, A∩B={6}
Komplemen (Complement): Tidak A
Sekarang kita bahas operasi yang sering kali dilupakan, tetapi sangat berguna: komplemen. Komplemen dari suatu kejadian A adalah semua hasil dalam ruang sampel yang tidak termasuk pada A. Dalam simbol, ditulis sebagai A′.
Misalnya berikut.
- Ruang sampel S = {1, 2, 3, 4, 5, 6}
- A = {1, 2, 3}
- Jadi, komplemen A adalah berikut: A’ = { 4, 5, 6 }
Metode Penghitungan Probabilitas
Berikut adalah berbagai metode untuk menghitung probabilitas.
Aturan Perkalian: Probabilitas untuk Kejadian Majemuk
Aturan ini digunakan ketika Anda ingin mengetahui jumlah total kemungkinan dari dua atau lebih kejadian yang terjadi secara berurutan.
Misalnya, Anda punya opsi berikut.
- Tiga pilihan baju: A, B, C
- Dua pilihan celana: X, Y
Jadi, jumlah kombinasi pakaian yang bisa Anda pakai adalah berikut.
3 × 2 = 6 kombinasi
Permutasi: Urutan Itu Penting
Bayangkan Anda diminta menyusun tiga orang—A, B, dan C—dalam satu barisan. Anda mungkin berpikir, “Ya sudah, pilih satu-satu.” Namun, berapa banyak susunan yang berbeda bisa dibuat?
Jawabannya berikut.
ABC,ACB,BAC,BCA,CAB,CBA
Ada 6 susunan dan ini disebut sebagai permutasi.
Permutasi digunakan ketika Anda ingin menghitung banyaknya susunan berbeda dari sejumlah objek dan urutan menjadi hal yang penting.
Kombinasi: Urutan Tidak Penting
Kebalikan dari permutasi, kombinasi digunakan saat Anda hanya tertarik pada kelompok yang terbentuk, bukan urutannya.
Misalnya, dari sepuluh orang Anda ingin memilih lima orang untuk dijadikan tim. Anda tidak peduli siapa yang disebut duluan—yang penting siapa yang terpilih. Jadi, pasangan ABCDE sama saja dengan DEABC.
Aturan Penjumlahan: Salah Satu dari Beberapa Kejadian
Aturan penjumlahan digunakan saat kita ingin menghitung probabilitas salah satu dari beberapa kejadian yang bisa terjadi, tanpa terjadi bersamaan.
Misalnya berikut.
- Kejadian A: muncul angka 1 atau 2 dari satu dadu > P(A) = 2/6
- Kejadian B: muncul angka 5 > P(B) = 1/6
Karena A dan B tidak punya irisan (tidak bisa terjadi bersamaan), kita bisa gunakan aturan penjumlahan sebagai berikut.
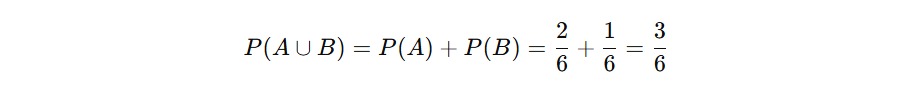
Kalau dua kejadian tidak saling lepas, Anda harus kurangi bagian irisan.
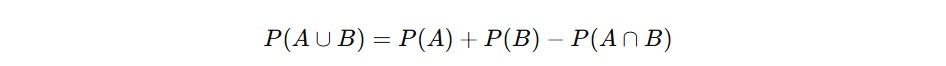
Prinsip Pigeonhole: Ketika Jumlah Tidak Cukup
Prinsip ini terdengar lucu, tetapi sangat berguna. Ia disebut prinsip pigeonhole atau dalam bahasa sederhana: prinsip kotak merpati.
Bayangkan Anda punya lima merpati dan empat kotak. Jika semua merpati harus masuk ke kotak, pasti ada setidaknya satu kotak yang berisi lebih dari satu merpati.
Secara umum, prinsip ini mengatakan hal berikut.
Jika n objek ditempatkan dalam k wadah, dan n>kn > kn>k, paling tidak ada satu wadah yang berisi lebih dari satu objek.
Dengan kata lain, jika kamu punya lebih banyak objek daripada wadah untuk menempatkannya, akan selalu ada wadah yang terisi ganda.
Probabilitas Bersyarat dan Teorema Bayes
Dalam bagian ini, telah dibahas materi mengenai probabilitas bersyarat dan teorema Bayes.
Probabilitas Bersyarat
Secara matematis, probabilitas bersyarat dari kejadian A yang terjadi jika diketahui kejadian B sudah terjadi, ditulis sebagai berikut.
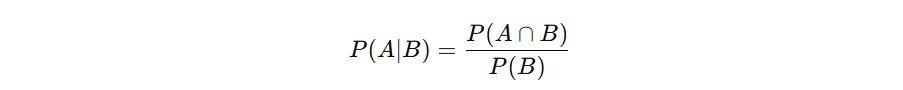
Artinya begini: dari semua kejadian saat B terjadi, kita ingin tahu seberapa besar bagian dari kejadian tersebut yang juga membuat A terjadi. Jadi, kita membatasi ruang pandang kita hanya pada kejadian B dan melihat berapa proporsi dari B yang juga termasuk A.
Teorema Bayes: Ketika Arah Sebab dan Akibat Dibalik
Secara matematis, teorema Bayes dituliskan sebagai berikut.
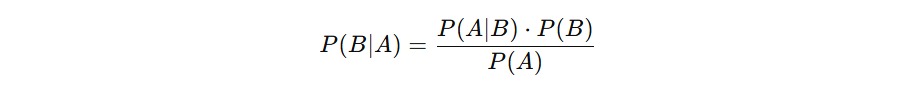
Kalau Anda belum familier dengan notasi ini, tenang dulu. Mari kita jabarkan secara perlahan.
- P(B∣A) adalah probabilitas bahwa B terjadi jika A sudah terjadi. Ini yang ingin kita cari.
- P(A∣B) adalah probabilitas bahwa A terjadi jika B benar. Biasanya ini informasi yang kita sudah tahu.
- P(B)) adalah probabilitas awal (prior) dari B terjadi, sebelum kita tahu apa-apa tentang A.
- P(A) adalah probabilitas total bahwa A terjadi dari semua kemungkinan yang bisa menyebabkannya.
Metode Bayes pada Machine Learning
Dalam dunia pemelajaran mesin (machine learning), teorema Bayes bukan hanya alat statistik, tetapi menjadi kerangka berpikir untuk menghadapi data yang terus berubah. Inti dari pendekatan Bayesian adalah memadukan pengetahuan awal (prior) dengan data yang baru ditemukan (evidence) untuk menghasilkan keyakinan terbaru (posterior). Ini membuat pendekatan Bayesian sangat fleksibel dan adaptif.
Salah satu contoh paling terkenal adalah algoritma Naive Bayes, yang banyak digunakan untuk klasifikasi teks, seperti deteksi spam, analisis sentimen, dan pengelompokan dokumen. Meskipun sederhana, Naive Bayes efektif karena ia menghitung peluang suatu kelas berdasarkan fitur (seperti kata-kata) yang muncul dalam data dengan asumsi bahwa fitur tersebut saling independen. Kecepatannya membuat algoritma Naive Bayes sangat berguna untuk dataset besar.
Kontrol Teorema Bayes
Salah satu kekuatan terbesar dari pendekatan Bayesian adalah kemampuannya untuk berpikir secara fleksibel di tengah ketidakpastian. Tidak hanya berhenti pada menghitung peluang, teorema Bayes juga membuka pintu bagi kita untuk menyusun keyakinan, memperbarui informasi secara bertahap, serta yang tidak kalah penting adalah mengontrol dan mengoptimalkan parameter dalam proses prediksi.
Dalam konteks dunia nyata, model probabilistik yang dibangun dengan pendekatan Bayesian sering kali tidak langsung memberikan jawaban. Kita harus merancang dan menyusun modelnya secara hati-hati: menentukan asal keyakinan awal, pengolahan data menjadi bukti, dan cara semua informasi itu disatukan untuk membentuk keyakinan akhir. Proses ini mencakup dua hal besar: kontrol parameter dan optimasi model.
Algoritma Model Naive Bayes: Belajar dari Peluang
Naive Bayes dibangun berdasarkan teorema Bayes, yaitu sebuah prinsip dalam statistik untuk menghitung peluang suatu hipotesis terjadi berdasarkan bukti yang diamati. Mari kita mulai dari bentuk dasar teorema Bayes.
Nah, yang membuat Naive Bayes “naive” adalah asumsi berikut: fitur-fitur dianggap independen satu sama lain jika diketahui kelasnya. Artinya, jika kita tahu bahwa sebuah email adalah spam, kehadiran kata “diskon” tidak memengaruhi kemunculan kata “gratis”—padahal dalam dunia nyata, tentu dua kata ini sering muncul bersamaan.
Namun, dengan asumsi ini, persamaan menjadi jauh lebih sederhana dan bisa dihitung dengan cepat.
Artinya, kita hanya perlu mengalikan probabilitas setiap fitur x muncul di kelas C, dikalikan dengan prior kelas C. Hasilnya adalah skor probabilitas relatif dan kita tinggal memilih kelas dengan skor tertinggi.
This file is located at: _chapters/991-belajar-matematika-untuk-data-science/020-dasar-dasar-probabilitas.md