lmvr-26
Bab 26: Pembelajaran Terfederasi dan LLM yang Menjaga Privasi
“Privasi bukan tentang menyembunyikan sesuatu; ini tentang melindungi identitas kita dan memastikan bahwa kita tetap memegang kendali atas data pribadi kita, bahkan di era AI.” — Andrew Trask
Catatan: Bab 26 dari LMVR memberikan eksplorasi mendalam tentang pembelajaran terfederasi (federated learning) dan teknik pelestarian privasi dalam konteks model bahasa besar (LLM). Bab ini dimulai dengan memperkenalkan konsep dasar pembelajaran terfederasi, menekankan pentingnya dalam pelatihan model terdesentralisasi dan pelestarian privasi data. Bab ini menggali metode penjagaan privasi seperti privasi diferensial (differential privacy) dan komputasi multipihak yang aman (secure multiparty computation), membahas peran kritis mereka dalam memastikan bahwa data sensitif tetap aman selama pelatihan LLM. Bab ini juga menyoroti keuntungan unik dari penerapan teknik-teknik ini menggunakan sistem yang efisien, dengan fokus pada performa, keamanan, dan fitur konkurensi. Terakhir, bab ini membahas tantangan saat ini dan arah masa depan dalam pembelajaran terfederasi dan metode pelestarian privasi, mendorong penelitian dan inovasi berkelanjutan untuk mengatasi keterbatasan yang ada.
26.1. Pembelajaran Terfederasi dan Teknik Pelestarian Privasi
Pembelajaran terfederasi (FL) mewakili pergeseran paradigma dalam cara model bahasa besar (LLM) dilatih dengan memungkinkan pelatihan terdesentralisasi di berbagai perangkat atau sumber data. Alih-alih mengumpulkan data di lokasi terpusat, FL memungkinkan setiap perangkat, seperti ponsel cerdas atau server lokal, untuk menghitung pembaruan model secara lokal pada datanya sendiri. Pembaruan ini, bukan data itu sendiri, kemudian diagregasikan untuk membentuk model global. Pendekatan ini meminimalkan transfer data, menjaga privasi pengguna, dan selaras dengan regulasi privasi data. Pembelajaran terfederasi sangat berharga bagi LLM yang perlu belajar dari sumber data terdistribusi—seperti perangkat pribadi—tanpa mengompromikan privasi data. Dikombinasikan dengan teknik pelestarian privasi, FL memungkinkan pengembangan LLM tangguh yang menghormati kerahasiaan pengguna, mematuhi persyaratan peraturan, dan menangani masalah etika seputar penggunaan data.
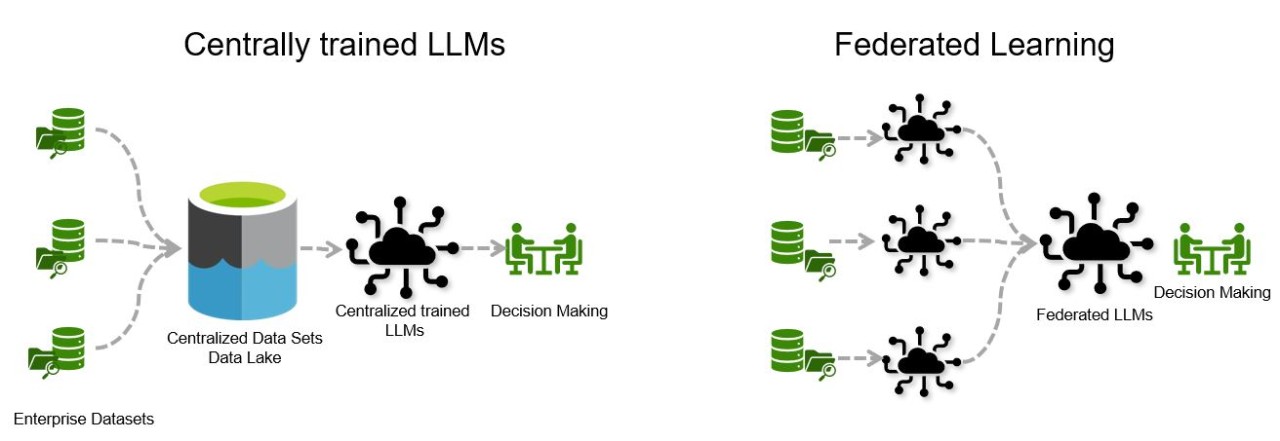 Gambar 1: Pengembangan LLM yang dilatih secara terpusat vs Pembelajaran Terfederasi.
Gambar 1: Pengembangan LLM yang dilatih secara terpusat vs Pembelajaran Terfederasi.
Teknik pelestarian privasi seperti privasi diferensial dan komputasi multipihak yang aman melengkapi pembelajaran terfederasi dengan memastikan bahwa pembaruan yang dikirimkan selama pelatihan mengungkapkan informasi minimal tentang data yang mendasarinya. Privasi diferensial mencapai hal ini dengan menambahkan noise yang terkalibrasi ke pembaruan, memastikan bahwa kontribusi individu tetap anonim dalam model agregat. Secara matematis, privasi diferensial beroperasi pada prinsip bahwa output algoritma tidak boleh berbeda secara signifikan baik saat data individu tertentu disertakan atau tidak. Misalnya, jika kita menunjukkan fungsi $f$ yang bertindak pada dataset $D$, privasi diferensial memastikan bahwa untuk dataset yang bertetangga $D$ dan $D’$ (berbeda satu data individu), distribusi probabilitas $P(f(D))$ kira-kira sama dengan $P(f(D’))$.
Komputasi multipihak yang aman (SMPC) melangkah lebih jauh dalam pelestarian privasi dengan memungkinkan banyak pihak untuk secara bersama-sama menghitung fungsi atas input mereka tanpa mengungkapkan input tersebut satu sama lain. SMPC sangat bermanfaat ketika pembaruan yang dikirimkan itu sendiri sensitif atau ketika kendala privasi tambahan perlu dipenuhi, seperti dalam pelatihan kolaboratif antar organisasi yang berbeda. Dalam SMPC, fungsi $f(x_1, x_2, \dots, x_n)$ dapat dihitung dengan memecahnya menjadi fungsi parsial $f_i(x_i)$ untuk setiap pihak $i$, yang kemudian hanya perlu membagikan hasil yang terenkripsi.
SMPC memungkinkan analisis kolaboratif data sensitif, seperti genom pasien dan dataset farmasi eksklusif, sambil memastikan bahwa hanya penyedia data asli yang dapat mengakses data mereka sendiri. Kemampuan ini memungkinkan pemangku kepentingan dalam biomedis—seperti institusi akademik, lab klinis, dan entitas komersial—untuk secara aman berbagi data sensitif untuk berbagai aplikasi biomedis, termasuk studi asosiasi genetik, prediksi target obat, dan profil metagenomik. MPC mencapai kolaborasi yang aman dengan mempartisi data sensitif ke dalam bagian-bagian terenkripsi (encrypted shares), yang kemudian didistribusikan ke beberapa pihak komputasi (seringkali penyedia data itu sendiri), menggunakan pendekatan kriptografi yang disebut secret sharing.
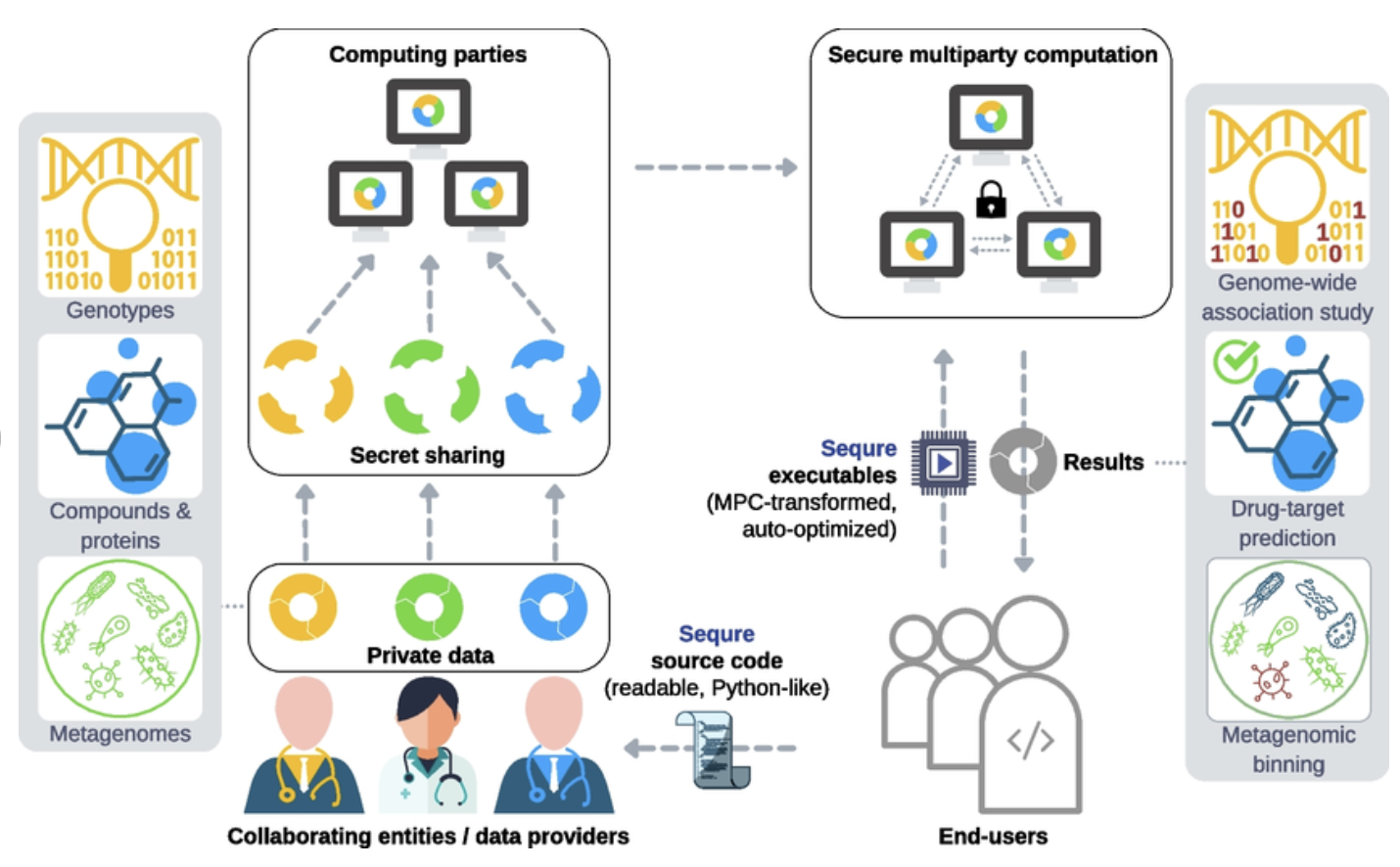 Gambar 2: Contoh kasus penggunaan SMPC di industri Layanan Kesehatan.
Gambar 2: Contoh kasus penggunaan SMPC di industri Layanan Kesehatan.
Pelatihan terdesentralisasi dalam FL berbeda secara signifikan dari pelatihan terpusat. Dalam pelatihan terpusat, semua data dikumpulkan dan disimpan di lokasi pusat, tempat pelatihan model terjadi. Pendekatan terpusat ini dapat menyebabkan risiko privasi yang signifikan, karena data yang dikumpulkan dari berbagai sumber dapat rentan terhadap pelanggaran. Sebaliknya, FL menghindari kerentanan tersebut dengan menjaga data tetap lokal. Hanya pembaruan model yang diagregasikan yang dikirimkan ke server pusat atau titik agregasi, yang secara drastis mengurangi paparan data sensitif.
Kebutuhan akan teknik pelestarian privasi dalam FL muncul tidak hanya dari pertimbangan etis tetapi juga dari mandat peraturan, seperti GDPR dan HIPAA, yang memerlukan perlindungan privasi data yang ketat. Di bidang kesehatan, misalnya, pembelajaran terfederasi dapat memungkinkan rumah sakit untuk secara kolaboratif melatih LLM pada data pasien tanpa membagikan data itu sendiri, mematuhi persyaratan privasi HIPAA.
Berikut adalah implementasi Python yang mensimulasikan sistem terfederasi dengan privasi diferensial sederhana menggunakan numpy dan multiprocessing.
Contoh Python: Simulasi Pembelajaran Terfederasi dengan Privasi Diferensial
import numpy as np
from multiprocessing import Pool
# Parameter privasi diferensial (Noise Scale)
EPSILON = 0.1
def train_local_model(data_subset):
"""Simulasi pelatihan lokal pada klien"""
# Menghitung bobot rata-rata sebagai model sederhana
local_weights = np.mean(data_subset, axis=0)
# Menambahkan noise Gaussian untuk Privasi Diferensial (DP)
noise = np.random.normal(0, EPSILON, local_weights.shape)
return local_weights + noise
def aggregate_models(updates):
"""Server pusat mengagregasi pembaruan dari klien"""
return np.mean(updates, axis=0)
def main():
# Simulasi data terdistribusi pada 4 klien
# Setiap klien memiliki 100 sampel dengan 5 fitur
data_clients = [np.random.rand(100, 5) for _ in range(4)]
print("Memulai Pelatihan Terfederasi...")
# Menggunakan Pool untuk mensimulasikan pelatihan paralel di perangkat klien
with Pool(processes=4) as pool:
local_updates = pool.map(train_local_model, data_clients)
# Agregasi di server pusat
global_model = aggregate_models(local_updates)
print("Model Global Berhasil Diperbarui:")
print(global_model)
if __name__ == "__main__":
main()
26.2. Dasar-dasar Pembelajaran Terfederasi
Pembelajaran terfederasi (FL) adalah pendekatan pembelajaran mesin terdesentralisasi yang dirancang untuk melatih model pada data yang didistribusikan di beberapa klien atau perangkat tanpa memusatkan data tersebut. Terdapat dua arsitektur utama dalam FL: model klien-server dan model peer-to-peer. Dalam model klien-server, masing-masing klien melatih model lokal dan mengirimkan pembaruan ke server pusat. Model peer-to-peer memungkinkan klien untuk berbagi pembaruan secara langsung satu sama lain.
Salah satu algoritma yang paling banyak digunakan dalam FL adalah Federated Averaging (FedAvg), yang diperkenalkan oleh McMahan et al. pada tahun 2017. FedAvg menggabungkan pembaruan model klien dengan merata-ratakan parameter mereka: $\theta = \frac{1}{N} \sum_{i=1}^N \theta_i$.
Konsep penting dalam FL adalah heterogenitas klien (client heterogeneity), yang mengacu pada perbedaan sumber daya klien, distribusi data, dan kondisi jaringan. Data dalam FL seringkali bersifat non-IID (non-independent and identically distributed). Misalnya, satu perangkat pengguna mungkin fokus pada istilah medis sementara yang lain pada istilah hukum. Hal ini dapat memperlambat konvergensi model.
Efisiensi komunikasi juga merupakan kunci skalabilitas. Teknik seperti kompresi model dan kuantisasi pembaruan umum digunakan untuk mengurangi jumlah data yang ditransmisikan. Selain itu, sistem harus mampu menangani client dropout (klien yang terputus) menggunakan teknik seperti mitigasi straggler.
Logika Pseudo-code: Sistem Pembelajaran Terfederasi
// Mendefinisikan Sistem Pembelajaran Terfederasi
SistemFL:
Klien: daftar perangkat yang berpartisipasi
Model_Global: model yang dibagikan
Metode latih_klien():
untuk setiap klien:
latih_model_lokal(klien.data)
kirim_update_terenkripsi_ke_server()
Metode agregasi_server():
kumpulkan parameter dari semua klien aktif
hitung rata-rata parameter: global = sum(params) / N
siarkan model_global_baru_ke_klien()
Metode tangani_non_IID():
sesuaikan bobot update berdasarkan varians data klien
26.3. Teknik Pelestarian Privasi dalam LLM
Privasi diferensial (DP) adalah standar emas untuk perlindungan data dalam LLM. Secara formal, DP didefinisikan dengan memastikan bahwa output algoritma secara statistik serupa terlepas dari apakah data individu tertentu disertakan. Hal ini diimplementasikan dengan menambahkan noise ke gradien selama pelatihan. Parameter $\epsilon$ (epsilon) mengontrol tingkat privasi; nilai yang lebih kecil berarti privasi lebih tinggi tetapi akurasi mungkin menurun.
Secure Multiparty Computation (SMPC) memungkinkan pelatihan kolaboratif tanpa berbagi data mentah. Jika pihak A memiliki $x$ dan pihak B memiliki $y$, protokol SMPC memungkinkan mereka menghitung $f(x, y)$ tanpa mengungkapkan $x$ atau $y$.
Homomorphic Encryption (HE) memungkinkan operasi dilakukan langsung pada data yang terenkripsi. Server dapat melakukan perhitungan pada bobot model tanpa pernah mendekripsinya, sehingga mengurangi risiko kebocoran data secara signifikan. Namun, tantangan utamanya adalah intensitas komputasi yang tinggi.
Logika Pseudo-code: Pelatihan LLM yang Menjaga Privasi
// Teknik Pelestarian Privasi
SistemPelatihanPrivat:
Metode apply_differential_privacy():
hitung gradien dari model
tambahkan noise Gaussian (terkalibrasi dengan epsilon)
update parameter model dengan gradien ber-noise
Metode perform_smpc():
bagi data menjadi 'shares' terenkripsi
hitung gradien pada masing-masing share di pihak berbeda
agregasikan share gradien tanpa dekripsi
dekripsi hasil akhir gradien global untuk update model
Berikut adalah simulasi pembagian rahasia sederhana (secret sharing) yang merupakan dasar dari SMPC di Python.
Contoh Python: Simulasi Secret Sharing Sederhana (SMPC)
import random
def create_shares(secret, num_shares=3):
"""Membagi sebuah nilai rahasia menjadi beberapa bagian"""
shares = [random.randint(0, 100) for _ in range(num_shares - 1)]
final_share = secret - sum(shares)
shares.append(final_share)
return shares
def reconstruct_secret(shares):
"""Menggabungkan kembali bagian-bagian menjadi nilai asli"""
return sum(shares)
def main():
# Misalkan bobot model adalah 42
weight = 42
print(f"Bobot asli: {weight}")
shares = create_shares(weight)
print(f"Bagian terenkripsi yang dikirim ke pihak berbeda: {shares}")
# Masing-masing pihak hanya melihat satu angka acak dan tidak tahu angka 42
result = reconstruct_secret(shares)
print(f"Bobot yang direkonstruksi (setelah agregasi): {result}")
if __name__ == "__main__":
main()
26.4. Pembelajaran Terfederasi dan Privasi dalam Ekosistem Rust
Meskipun buku aslinya menggunakan Rust, konsep ekosistemnya dapat dipahami melalui kebutuhan akan keamanan memori dan konkurensi. Model pemrograman asinkron sangat penting untuk mengelola komunikasi jaringan yang kompleks dalam FL. Sistem ini harus menangani ribuan pembaruan klien secara bersamaan tanpa degradasi performa.
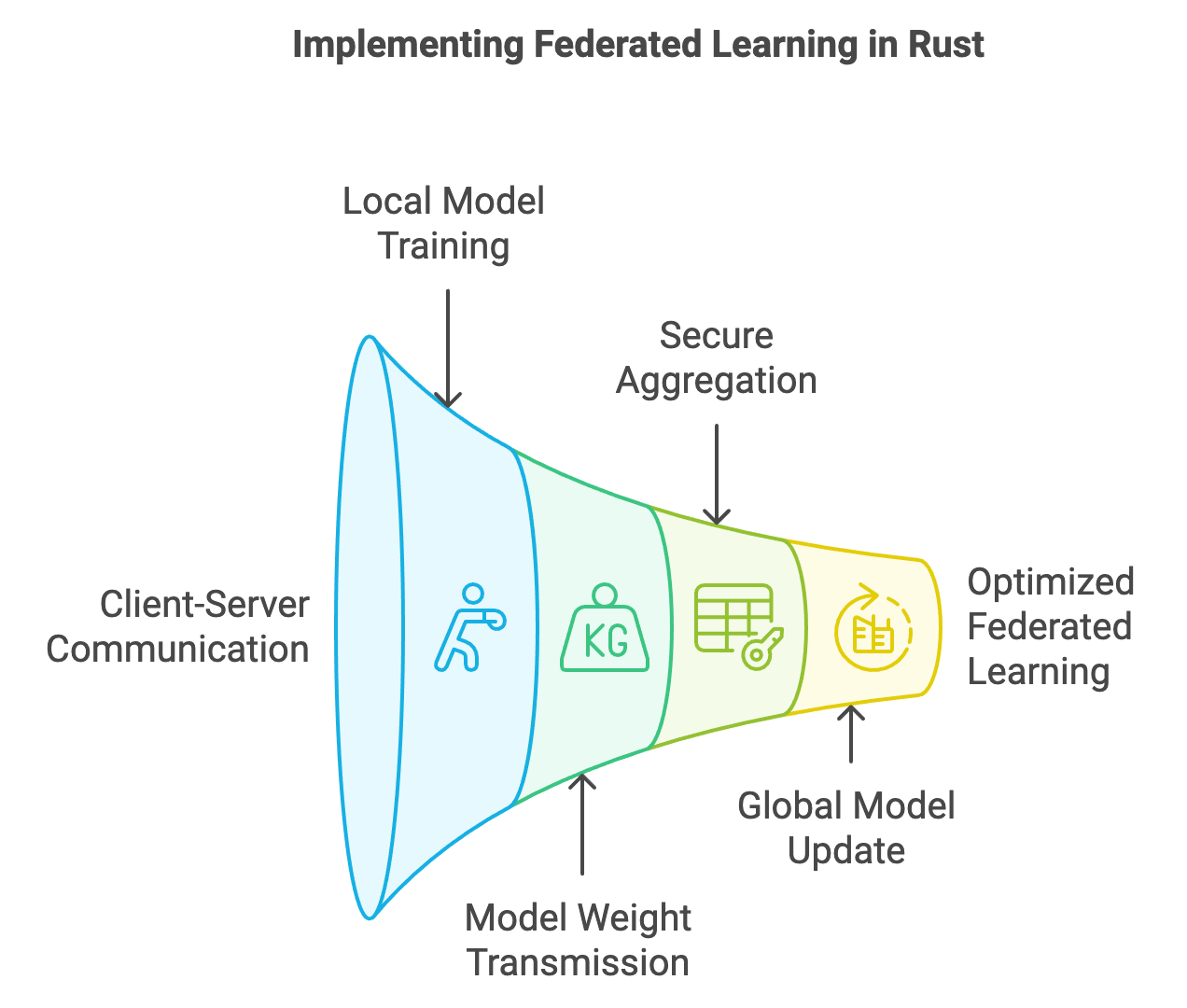 Gambar 4: Siklus implementasi pembelajaran terfederasi dalam sistem yang efisien.
Gambar 4: Siklus implementasi pembelajaran terfederasi dalam sistem yang efisien.
Perlindungan data memerlukan library kriptografi yang mendukung metode enkripsi yang efisien untuk transmisi. Penanganan memori yang ketat meminimalkan risiko kebocoran data yang tidak sah, yang sangat penting untuk kepatuhan terhadap regulasi seperti GDPR.
Berikut adalah simulasi Python dari proses FL asinkron menggunakan asyncio.
Contoh Python: Alur Kerja FL Asinkron
import asyncio
import json
async def client_update(client_id):
"""Simulasi pelatihan asinkron di klien"""
print(f"Klien {client_id} mulai melatih model...")
await asyncio.sleep(random.uniform(0.5, 2.0)) # Simulasi waktu pelatihan
update = {"client": client_id, "weights": [0.1, -0.2, 0.5]}
print(f"Klien {client_id} mengirimkan update.")
return json.dumps(update)
async def server_aggregation(num_clients):
"""Server mengumpulkan update secara asinkron"""
tasks = [client_update(i) for i in range(num_clients)]
# Menunggu semua update selesai (asinkron)
all_updates = await asyncio.gather(*tasks)
print(f"\nServer menerima {len(all_updates)} update. Memulai agregasi...")
# Logika agregasi ...
print("Model Global berhasil diperbarui.")
if __name__ == "__main__":
import random
# asyncio.run(server_aggregation(5))
26.5. Tantangan dan Arah Masa Depan
Tantangan utama FL meliputi kesulitan dalam mengagregasi data dari sejumlah besar klien yang memiliki kapasitas perangkat keras berbeda. Hal ini dapat memperlambat waktu pelatihan secara signifikan. Masalah lainnya adalah kerentanan terhadap serangan keamanan seperti model poisoning, di mana klien jahat mengirimkan pembaruan yang salah untuk merusak model global.
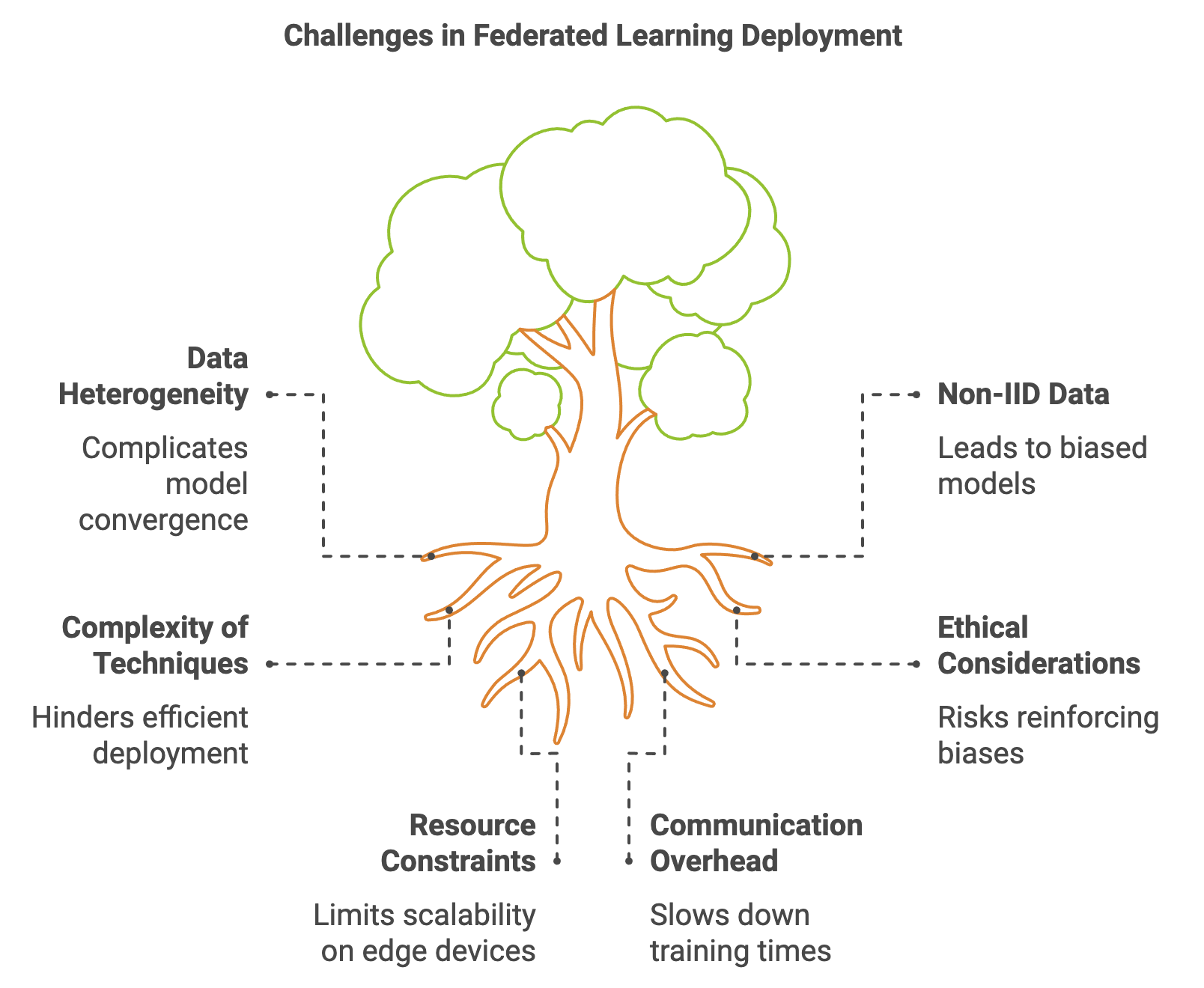 Gambar 5: Tantangan utama dalam penyebaran Pembelajaran Terfederasi.
Gambar 5: Tantangan utama dalam penyebaran Pembelajaran Terfederasi.
Pendekatan hibrida yang menggabungkan FL dengan teknik AI canggih seperti pembelajaran penguatan (reinforcement learning) dan model generatif menawarkan potensi untuk mengatasi tantangan ini. Model generatif dapat digunakan untuk menghasilkan data sintetis bagi klien yang kurang terwakili, meningkatkan keadilan model agregat.
Logika Pseudo-code: Sistem FL Tingkat Lanjut dengan Keamanan
// Sistem FL Lanjutan
AdvancedSistemFL:
Metode adaptive_client_training():
untuk setiap klien:
latih model lokal
adaptasi model dengan agen reinforcement learning
tambahkan noise DP
kirim ke server
Metode secure_aggregation():
kumpulkan update terenkripsi
verifikasi update dengan protokol poison_detection
agregasikan hanya update yang valid
Secara etis, pembelajaran terfederasi harus dievaluasi secara hati-hati agar tidak secara tidak sengaja memperkuat bias, terutama di bidang sensitif seperti keuangan dan hukum. Masa depan FL juga mengarah pada pemrosesan di perangkat edge seiring dengan meningkatnya kemampuan komputasi perangkat seluler dan IoT.
26.6. Kesimpulan
Bab 26 menggarisbawahi signifikansi pembelajaran terfederasi dan teknik pelestarian privasi sebagai alat penting untuk mengembangkan model bahasa besar yang etis dan aman. Dengan memanfaatkan sistem yang efisien, pengembang dapat menciptakan aplikasi yang tidak hanya menghormati privasi pengguna tetapi juga mempertahankan tingkat performa dan keamanan yang tinggi di dunia yang terdesentralisasi.
26.6.1. Pembelajaran Lebih Lanjut dengan GenAI
- Jelaskan perbedaan fundamental antara FL dan pelatihan terpusat tradisional.
- Diskusikan komponen kunci dari sistem FL (klien, server, protokol).
- Bagaimana algoritma Federated Averaging bekerja secara detail?
- Analisis dampak data non-IID terhadap konvergensi model.
- Jelajahi peran privasi diferensial dalam melindungi kontribusi data individu.
- Apa manfaat penggunaan SMPC dibandingkan enkripsi standar dalam ML?
- Diskusikan tantangan skalabilitas FL pada jutaan perangkat seluler.
- Bagaimana homomorphic encryption memungkinkan komputasi pada data terenkripsi?
- Analisis risiko keamanan seperti serangan model poisoning pada FL.
- Mengapa efisiensi sistem (seperti pada Rust) sangat penting untuk kriptografi dalam FL?
26.6.2. Latihan Praktis
Latihan Mandiri 26.1: Implementasi Federated Averaging
Tujuan: Mengembangkan algoritma FedAvg sederhana yang menangani update dari beberapa klien simulasi.
Latihan Mandiri 26.2: Privasi Diferensial dalam FL
Tujuan: Menambahkan noise Gaussian ke pembaruan model dan menganalisis trade-off antara tingkat privasi dan akurasi model.
Latihan Mandiri 26.3: Sistem SMPC Sederhana
Tujuan: Merancang skema pembagian rahasia di mana dua pihak dapat menghitung rata-rata tanpa mengetahui nilai satu sama lain.
Latihan Mandiri 26.4: Optimasi Efisiensi Komunikasi
Tujuan: Mengimplementasikan teknik kompresi pada update model klien untuk mengurangi penggunaan bandwidth jaringan.
Latihan Mandiri 26.5: Implementasi Enkripsi Homomorfik
Tujuan: Bereksperimen dengan operasi matematika (penjumlahan/perkalian) pada data yang terenkripsi dan membandingkan hasilnya dengan data asli.